Abstract
The rapid and accurate detection of Chinese flowering cabbage ripeness and the counting of Chinese flowering cabbage are fundamental for timely harvesting, yield prediction, and field management. The complexity of the existing model structures somewhat hinders the application of recognition models in harvesting machines. Therefore, this paper proposes the lightweight Cabbage-YOLO model. First, the YOLOv8-n feature pyramid structure is adjusted to effectively utilize the target’s spatial structure information as well as compress the model in size. Second, the RVB-EMA module is introduced as a necking optimization mechanism to mitigate the interference of shallow noise in the high-resolution sounding layer and at the same time to reduce the number of parameters in this model. In addition, the head uses an independently designed lightweight PCDetect detection head, which enhances the computational efficiency of the model. Subsequently, the neck utilizes a lightweight DySample upsampling operator to capture and preserve underlying semantic information. Finally, the attention mechanism SimAm is inserted before SPPF for an enhanced ability to capture foreground features. The improved Cabbage-YOLO is integrated with the Byte Tracker to track and count Chinese flowering cabbage in video sequences. The average detection accuracy of Cabbage-YOLO can reach 86.4%. Compared with the original model YOLOv8-n, its FLOPs, the its number of parameters, and the size of its weights are decreased by about 35.9%, 47.2%, and 45.2%, respectively, and its average detection precision is improved by 1.9% with an FPS of 107.8. In addition, the integrated Cabbage-YOLO with the Byte Tracker can also effectively track and count the detected objects. The Cabbage-YOLO model boasts higher accuracy, smaller size, and a clear advantage in lightweight deployment. Overall, the improved lightweight model can provide effective technical support for promoting intelligent management and harvesting decisions of Chinese flowering cabbage.
1. Introduction
Chinese flowering cabbage (Brassica rapa ssp. pekinensis) is a leafy vegetable widely cultivated in southern China and other Asian countries, with a high replanting index due to its nutritional value and crisp taste [1,2]. Its harvesting period is short, with early harvesting making it tender and low-yielding, and with late harvesting making it fibrous and poor in taste [3]; therefore, the rapid and accurate identification of its ripeness is the key to timely harvesting. The current assessment of Chinese flowering cabbage ripeness mainly relies on farmers to observe the degree of flower opening, but this method is subjective and limited. Dimensional measurements and chemical analysis are accurate but time-consuming and laborious [4,5]. Therefore, developing a non-destructive and lightweight online identification model of Chinese flowering cabbage ripeness is crucial for developing rational field management strategies and timely harvesting to ensure economic value [6]. The combination of image processing and machine vision applied to the accurate detection and counter-counting of Chinese flowering cabbage ripeness can provide the necessary support for the vision system of intelligent harvesting equipment, which is an important development direction for the intelligent harvesting of vegetables [7].
Currently, image-based detection methods are widely used for ripeness detection, disease detection, and quality inspection of fruits and vegetables [8,9,10]. Traditional machine learning technologies and deep learning technologies are mainly used [11]. Conventional algorithms mainly judge ripeness by manually designed features such as color, shape, texture, etc. Mohammadi et al. separated the red (R), green (G), and blue (B) constituents of a persimmon image to derive its ripeness thresholds, which enabled an accurate judgment of the ripeness of persimmons [12]. Zhang et al. used a specific hyperspectral dataset combining strawberry spectral and textural features to assess strawberry ripeness with a classification efficiency of more than 85% [13]. Goyal et al. manually extracted 13 features based on the defects and color intensity of tomatoes, and then used the Inception V3 model to obtain a large number of automated features and combined them with machine learning models such as SVM, DT, etc., to predict the ripeness index of tomatoes with an accuracy of 92%, a method that is an accurate but cumbersome [14]. Traditional image processing is limited by manual feature extraction, and in the face of complex environments, it is prone to poor anti-interference ability and low accuracy. In contrast, deep learning methods based on fruit and vegetable ripeness detection in complex environments are more advantageous [15]. The YOLO series, as a representative of deep learning networks, is widely used to detect and count fruits and vegetables [16]. Chen et al. presented a multi-task model for the simultaneous detection of clusters, fruit ripening, and cluster ripening in tomatoes based on YOLOv7, using scale-sensitive intersection in tandem (SIOU) instead of complete intersection (CIOU) to improve the detection accuracy in the model [17]. The mean accuracy of mAP is as high as 86.6%, but for small, densely distributed clusters, the recognition accuracy is below 68% [18]. Ren et al. proposed a “Yuluxiang” pear pollen stamen detection model based on YOLOv5n combined with the C3f module, PfAAMC3 module, and GhostConv module, and the mAP model’s accuracy reached up to 94.08%, but its detection efficiency was low with an FPS of 90.91 [19].
YOLO-based target detection algorithms in complex natural scenarios are effective but rely on high computational power and large storage resources, which limits the deployment and application of mature detection models for small mobile terminals [20]. To promote the practical application of detection algorithms, research on lightweight target detection networks has become a hotspot [21]. Liu et al. presented an enhanced YOLOv5x algorithm used for blueberry ripeness detection. The algorithm adopts the Little-CBAM lightweight structure, which has an average mAP accuracy of up to 78.3% on PC, but the real-time execution speed is 47 FPS, which is low [22]. Zeng et al. proposed the lightweight THYOLO algorithm for tomato fruit detection and ripeness classification in real time. With the introduction of the MobileNetV3 module through backbone networks and neck channel pruning, their model parameters were compressed by 78%, resulting in a size of 6.04 MB and a detection speed of only 26.5 FPS, and the model was weak in dense small target detection [23]. Based on the lightweight YOLOv5s, Zhang et al. proposed a multiscale features self-adaptive fusion model for complicated environments (MFAF-YOLO), which uses the K-means++ clustering algorithm, adjusts the anchoring boxes based on the morphological features of citrus varieties, reduces detection redundancy, and decreases the size of the model by 26.2% to 10.4 MB [24]. In summary, the YOLO model performs better in fruit and vegetable ripeness detection. However, due to the complexity of agricultural applications, although migration learning can provide better initialization parameters for model training, the detection of different crops still requires different models to be adapted, and for the ongoing research for ripeness detection of Chinese flowering cabbage [25]. It is important to study how to achieve accurate ripeness detection in Chinese flowering cabbage in a natural environment with limited computing power and storage space for the development of mobile vegetable and fruit harvesting robots. YOlOv8, as a generalized one-phase detection algorithm with advantages such as higher detection precision, smaller size, and faster inference, shows potential in the ripeness detection of Chinese flowering cabbage [26,27,28]. Therefore, this research is aimed at achieving lightweight, efficient, and accurate ripeness detection of Chinese flowering cabbage by optimizing the network structure and designing a lightweight detection head, as well as analyzing the characteristics of the dataset and improving the feature extraction and fusion methods, which can provide powerful support for the intelligent management of Chinese flowering cabbage fields. The primary contributions are as follows:
- By analyzing the characteristics of the research objects in the dataset, we adjusted the feature pyramid use strategy, thus changing the way feature extraction and fusion are performed, and improving the accuracy of Chinese flowering cabbage ripeness detection.
- Based on the working principle of PConv, PCDetect is designed as a lightweight detection head, which enhances the performance and reduces resource consumption.
- An improved up-sampling method and the addition of the SimAM attention mechanism were employed to enhance detection accuracy.
- The detection paradigm-based tracker was extended to simultaneously count and estimate Chinese flowering cabbage ripeness.
2. Materials and Methods
2.1. Chinese Flowering Cabbage Datasets
2.1.1. Dataset Acquisition
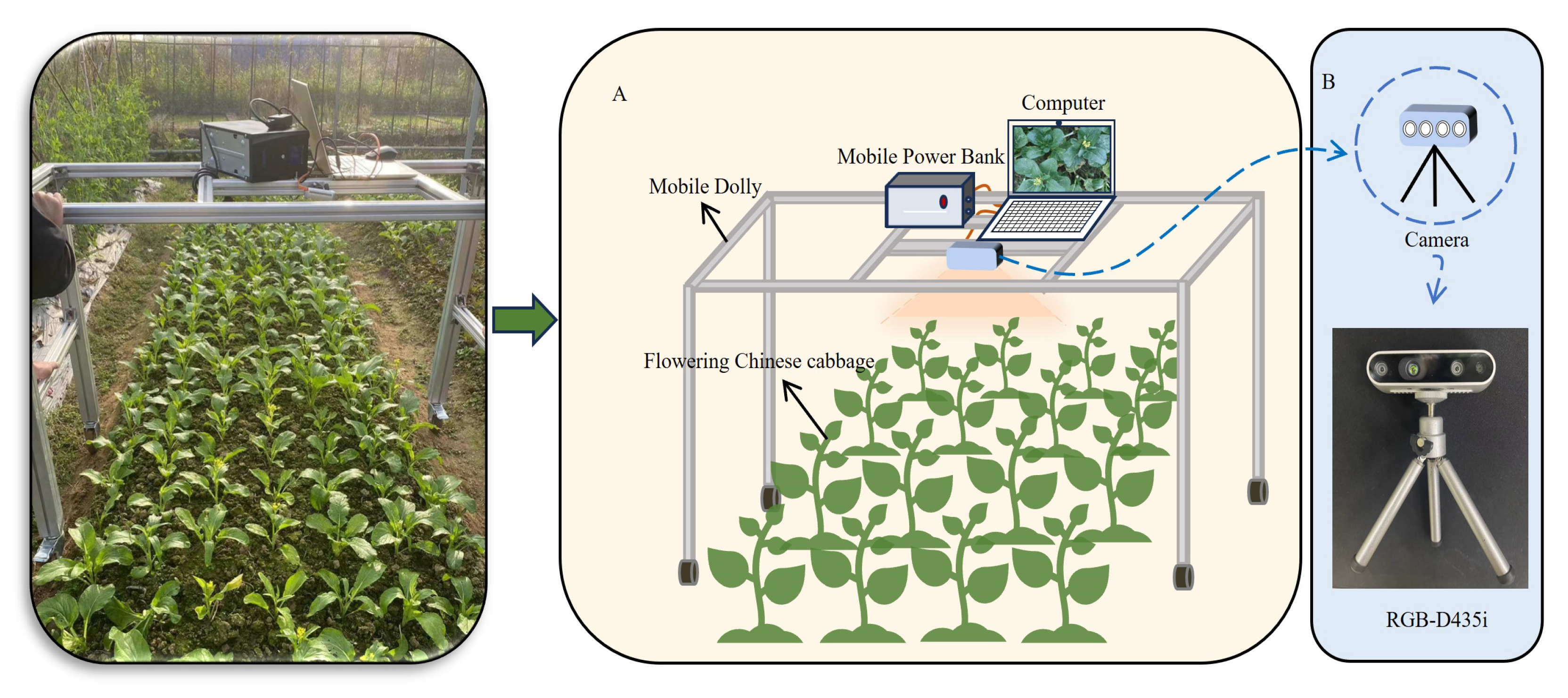
In this study, images and video data of Chinese flowering cabbage were collected from an outdoor experimental field at Qilin Farm, South China Agricultural University, Guangzhou, China (113.37° E, 23.17° N). The ridges in the Chinese flowering cabbage field within the experimental area were approximately 1.2 m wide and ranged from 6 to 7.5 m in length. To capture images, a self-designed data acquisition platform was utilized, continuously photographing Chinese flowering cabbage plants at the bud-break to flowering and fruiting stages. The platform was height-adjustable, with the camera positioned at a height from 0.9 to 1.25 m above the top of the Chinese flowering cabbage canopy. Figure 1 shows the real data collection scenario and a platform for data capture.
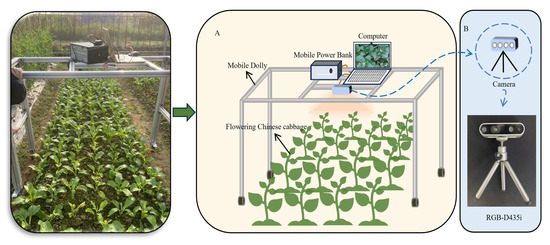
Figure 1.
Realistic acquisition scenarios. (A) Data collection platform. (B) Data acquisition camera.
All photography was conducted in natural environments, encompassing sunny and cloudy days with low light. Shooting time spanned from 9 a.m. to 6 p.m., with full coverage of a variety of natural lighting conditions from early morning softness to midday intensity to late evening oblique light. The data acquisition portion of the project was executed using a Redmi K40 smartphone (Redmi K40 is from Xiaomi Technology Co., Ltd., Beijing, China) for image capture, while the remainder of the project was conducted using an Intel D435i depth camera (Intel D435i depth camera is from Intel Corporation, Santa Clara, CA, USA). This camera was employed to move the acquisition platform at a constant speed of approximately 0.15 m/s, thereby acquiring the video stream from which a single frame of the images was extracted, as shown in Figure 1B. Following the screening process, a total of 1055 high-quality images were ultimately obtained.
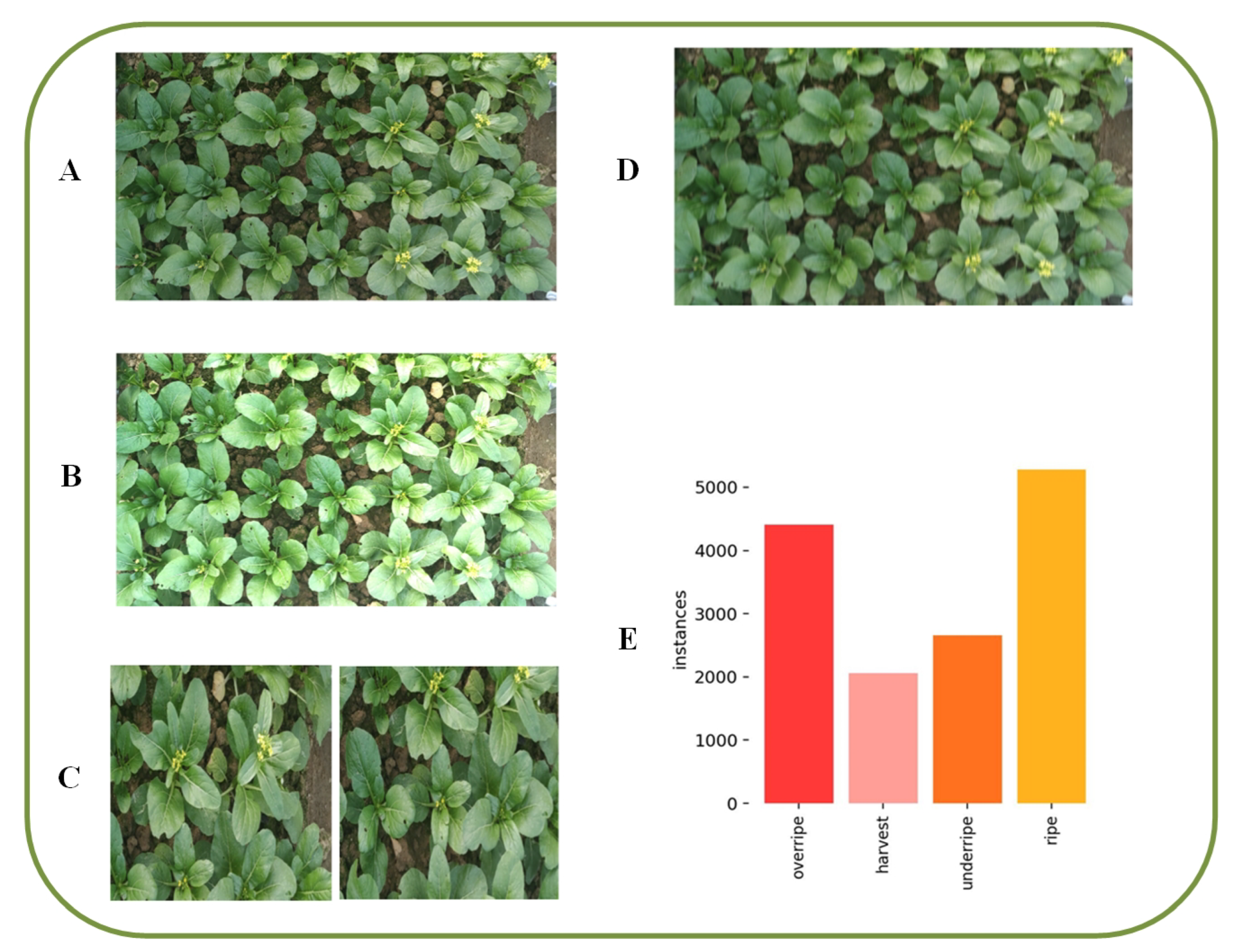
Based on agronomic standards and guidance from vegetable experts, the ripeness of Chinese flowering cabbage was classified into three categories: under-ripe, ripe, and over-ripe, and also had a harvested status [29]. Figure 2B shows in detail the characteristics of each category: under-ripe with dark green and tightly packed flower buds; ripe with yellowish flower buds that are partially open; and over-ripe with yellow and mostly bloomed flowers. For the harvested category, the main shoots were cut, leaving only the main stem and two to three cotyledons. Figure 2A shows the results using LabelImg markers. The size and number differences among the targets in the dataset are obvious and truly reflect the characteristics of the natural Chinese flowering cabbage distributions in the field, which can increase the generalization capability of the detection model.

Figure 2.
Dataset annotations and labeling categories. (A) Annotated image. (B) Example of a tag category.
2.1.2. Dataset Expansion
In the field environment and video streaming-based detection scenarios, Chinese flowering cabbage ripeness detection faces disturbances such as uneven illumination and motion blur. For this reason, this paper customizes the data enhancement strategy, including random cropping and scaling (Figure 3C), brightness adjustment (Figure 3B), and motion blur addition for camera shake (Figure 3D). The introduction of motion blur enhances the generalization ability of the model under motion shooting conditions. As a result, the dataset was expanded from 1055 to 4220 frames and divided into training, validation, and test sets in an 8:1:1 ratio. The enhanced data will be used for model training, as shown in Figure 3E, which demonstrates the distribution of labels in each category after data enhancement.
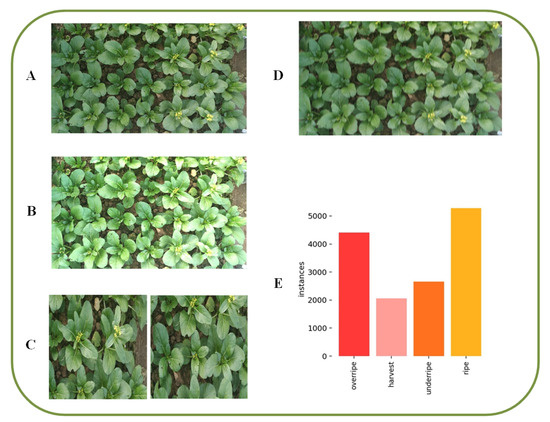
Figure 3.
Dataset expansion and label distribution visualization. (A) Original image. (B) Brightness adjustment. (C) Randomized cropping and scaling. (D) Add motion blur. (E) Visualization of the expanded label distribution.
2.2. Baseline Model
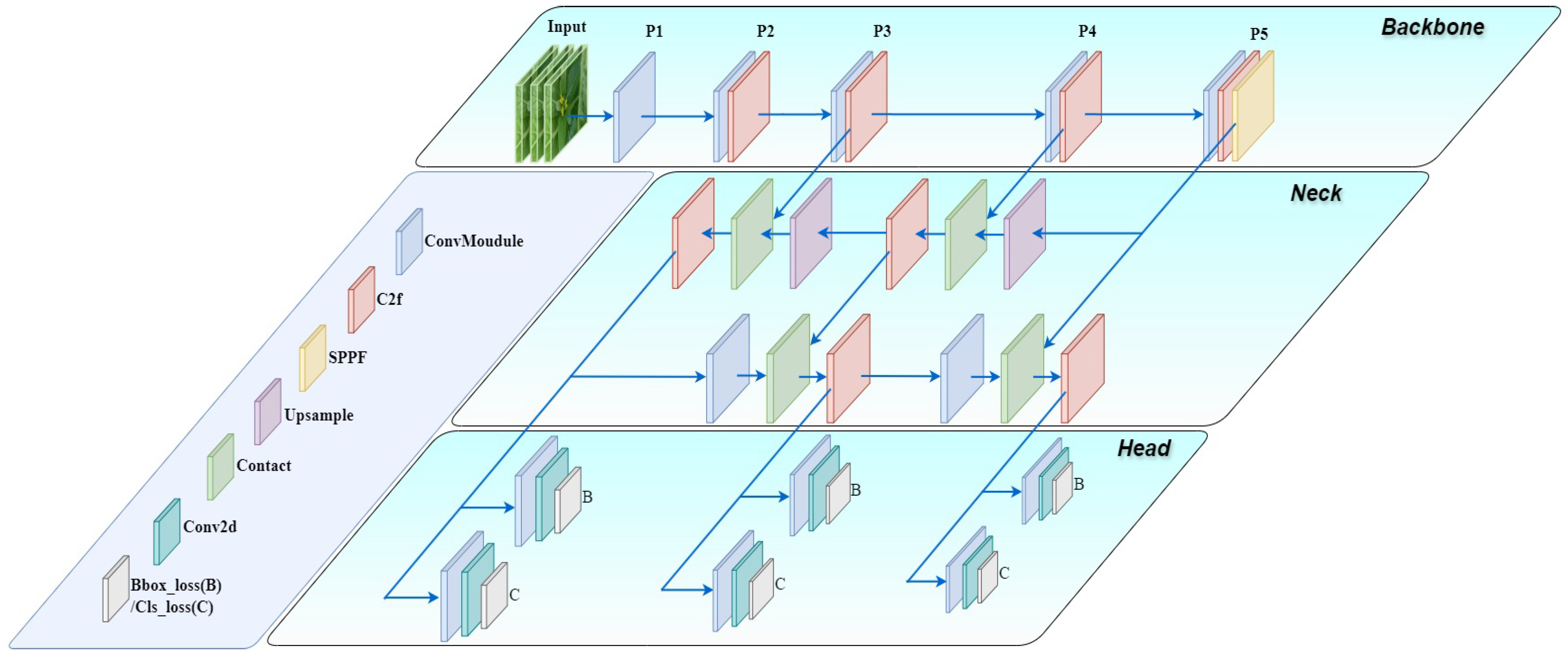
In this paper, of the YOLOv8 series (YOLOv8-n, YOLO-v8s, YOLOv8-m, YOLOv8-l, and YOLOv8-x), YOLOv8-n is used as the baseline network, taking into account the needs of accuracy and light weight. YOLOv8n is composed of three core components: the backbone, the neck network, and the detection head. The detailed structure is shown in Figure 4. The backbone network implements feature extraction through Conv, C2f (with ELAN attention mechanism), and SPPF modules. C2f utilizes lightweight ELAN to mitigate gradient vanishing and capture key features; SPPF unifies the feature map size. The neck network adopts the PANet structure to fuse FPN and PAN, integrating multi-scale information flow and realizing effective fusion of feature maps. Finally, the decoupled head structure is used to separate the regression and prediction branches, and the output feature maps of the neck network are directly exploited for predicting the bounding boxes and labels of the objects in the image, which improves feature mapping to the target boundary boxes and categories, but also brings about an increase in the amount of computation.
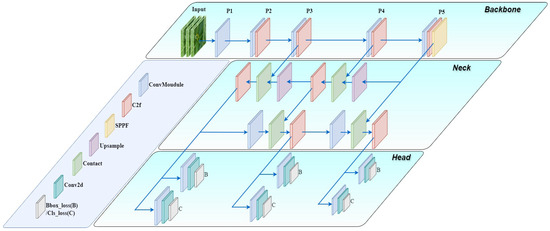
Figure 4.
Structure of the YOLOV8-n model.
After training, it was found that the original YOLOv8-n was not a perfect match for the ripeness detection of Chinese flowering cabbage, and there are the following problems: First, the YOLOv8-n model easily missed the detection of under-ripe stage in Chinese flowering cabbage due to its small size when detecting under-ripe class targets. Second, it was easy to confuse the under-ripe stage and ripe stage in Chinese flowering cabbage, which have more similar characteristics in some cases. More importantly, the purpose of this paper is to lighten the model to make it more suitable for low computing power environments such as mobile and embedded devices. At the same time, it was important to ensure that the lightweight design of the model did not lead to a reduction in detection accuracy. Therefore, in this paper, a lightweight model for detecting the ripeness of Chinese flowering cabbage, named Cabbage-YOLO, was designed with the YOLOv8-n model as the basis.
2.3. Cabbage-YOLO Model for Ripeness Detection in Chinese Flowering Cabbage
Based on the encountered issues and dataset characteristics of the YOLOV8-n model for detecting Chinese flowering cabbage ripeness, Cabbage-YOLO proposes the following improvements: focusing primarily on feature extraction, fusion, and model light weight. The specific enhancements are outlined as follows: (a) During feature extraction from the backbone network, the selection of feature maps is altered. Instead of utilizing the original P3, P4, and P5 outputs, P2, P3, and P4 are chosen to capture fine-grained details and underlying features of small targets, thereby concurrently reducing the weight of the backbone network. (b) Necking using RepViT Block after structural reparameterization to mitigate the computational cost. The EMA attention mechanism is embedded in the RepViT Block, smoothing the attention weights to mitigate the noise interference introduced by the improvement in (a) while improving the necking connection to optimize the target feature fusion. This results in the integration of the C2f-RVB-EMA module. (c) To minimize network complexity, a PCC module constructed using PConv lightweight convolution is employed to optimize the head network. (d) Cabbage-YOLO utilizes the efficient and lightweight DySample upsampling operator, which selectively preserves key points through differential sampling, thereby emphasizing the details of smaller targets during detection. (e) Before the SPPF layer, the SimAM attention mechanism, which introduces no additional parameters, is implemented to strengthen the model’s attention to critical foreground features and ultimately increase the differentiation of similar features. Figure 5 illustrates the structure of the enhanced Cabbage-YOLO model.
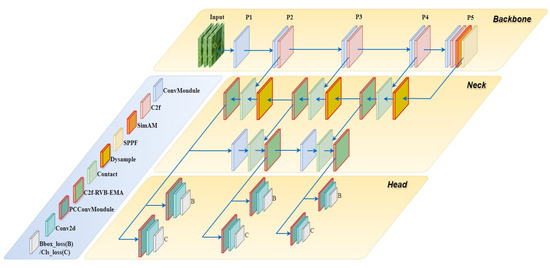
Figure 5.
Structure of the Cabbage-YOLO model.
2.4. Specific Improvements
2.4.1. Optimization of the Feature Pyramid Structure
The features at various levels of the YOLOv8-n model possess diverse resolutions and semantic information. In this study, we fused the feature information across different scales by modifying the output feature level of the backbone network. This modification renders the model more suited to the need for enhancing the accuracy of Chinese flowering cabbage detection tasks and promoting model lightweight design. Cabbage-YOLO refined the utilization of the feature pyramid, altered the manner of leveraging various layers of feature maps within the feature pyramid structure, and opted for the P2, P3, and P4 detection layers to substitute the original backbone network’s three outputs, P3, P4, and P5, as the input data for the neck feature extraction network. Such an enhancement diminishes the model’s parameters and weight size, and at the same time, improves the accuracy of target detection.
- Addition of a high-resolution detection layer module.The original YOLOv8 model has a large down-sampling factor, and the high-level feature maps do not easily capture small object features, leading to the degradation of fine-grained information in the original YOLOv8 model. However, the under-ripe stage in Chinese flowering cabbage, which occupies fewer pixels in the image, is easily ignored or misjudged. For this reason, this paper adds a high-resolution P2 detection layer to the original network to guide the network to pay more attention to the underlying features and fine-grained information of the target.
- Deletion of the low-resolution detection layer module.The P5 detection layer is suitable for detecting larger targets and having a deep feature map, but in Chinese flowering cabbage ripeness detection, shallow features are more important and the P5 layer becomes redundant. Eliminating the P5 detection layer simplifies the model’s architecture and enhances its efficiency during inference processes.
2.4.2. Neck Network Optimization RVB-EMA Module
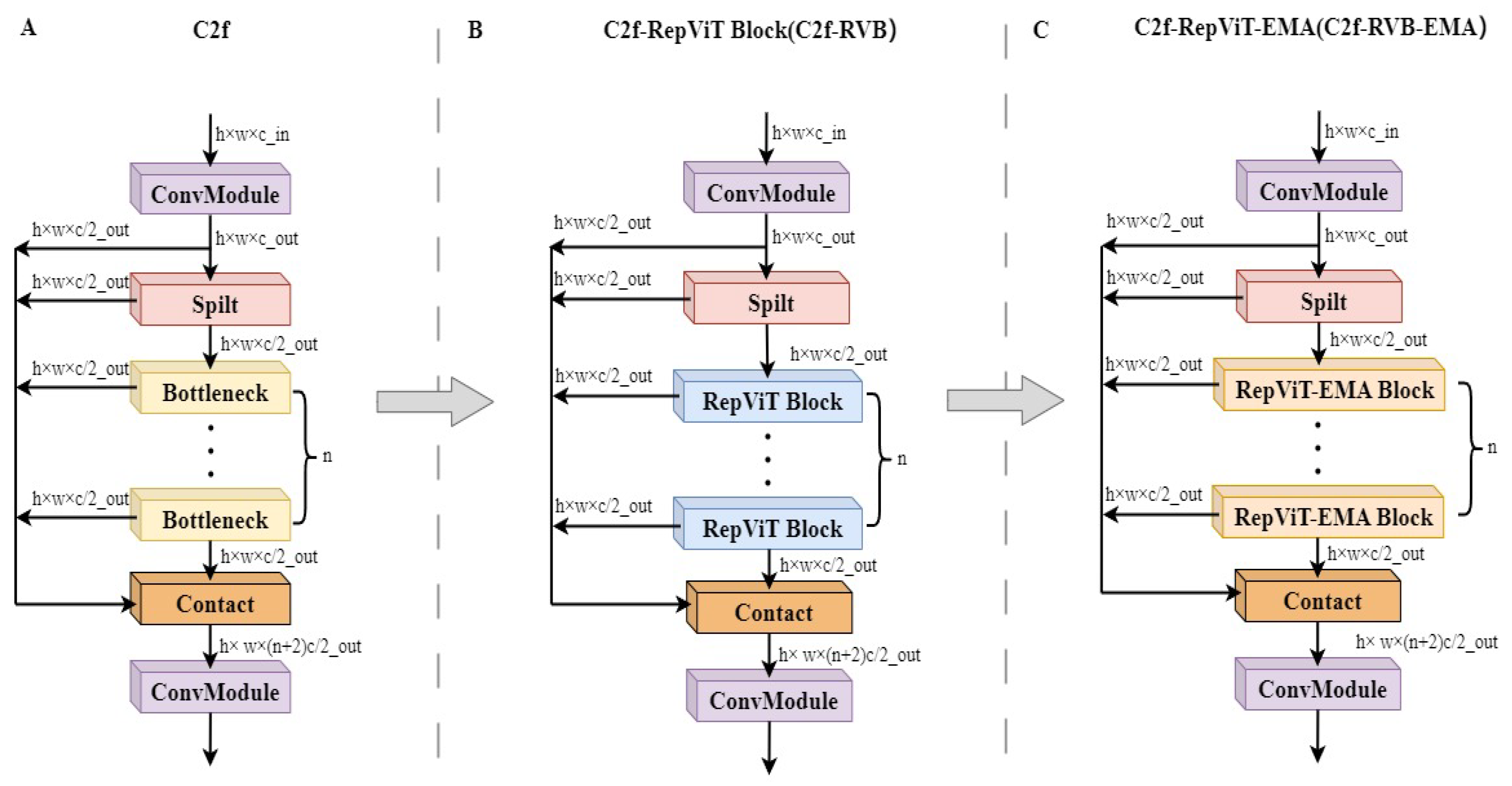
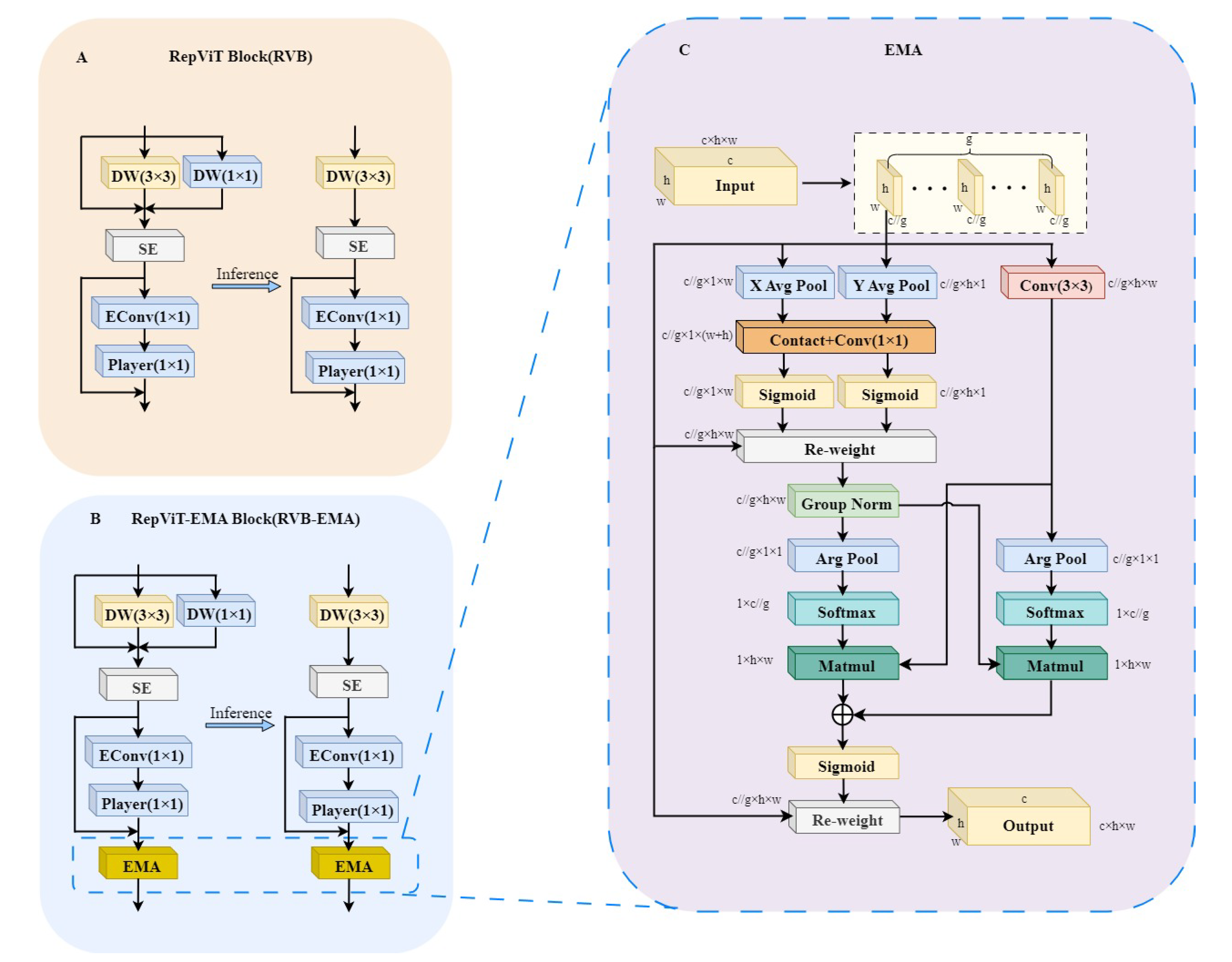
To reduce the neck network weight of the model to adapt to the deployment requirements, this paper replaces the Bottleneck in the C2f structure with the RepViT Block, which results in the C2f- RepViT Block (C2f-RVB) module [30], as shown in Figure 6A,B, where c is the number of channels, and w and h are the width and height of the image, respectively. The RepViT Block, as the core component of the RepViT model, is a lightweight and efficient model structure. As depicted in Figure 7A, this architecture incorporates a multi-pronged topology during the training stage by repositioning the 3 × 3 depth-wise (DW) convolution of the base MobileNetV3 module upwards, subsequently consolidating it into a unified-branch configuration during the evaluation phase. This transition not only allows the model to grasp more diverse feature representations but also mitigates the superfluous computational burden associated with the multi-branch approach, where squeeze-and-excitation denotes the squeeze excitation module. Next, 1 × 1 extended convolutional EConv and 1 × 1 projection layer Player (1 × 1) are used for inter-channel interaction (channel mixing), which further enhances the feature diversity and expressiveness.
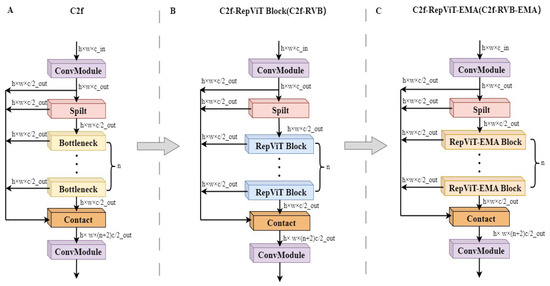
Figure 6.
Structure of the C2f- RepViT-EMA Block. (A) C2f module. (B) C2f- RepViT Block (C2f-RVB) module. (C) C2f- RepViT-EMA Block (C2f-RVB-EMA) module.
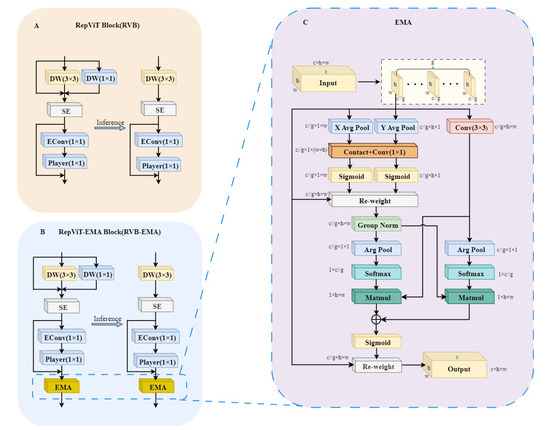
Figure 7.
C2f- Structure of the RepViT-EMA Block. (A) RepViT Block (RVB) module. (B) RepViT-EMA Block (RVB-EMA) module. (C) EMA attention mechanism.
In addition, the strategy for using the feature pyramid was adjusted according to Section 3.1. This strategy adds the P2 detection layer to remove the P5 detection layer; although it improves the accuracy of target location detection, the P2 layer is prone to introducing noise by processing shallow feature maps, and after removing the P5 layer, the model is more susceptible to background noise interference when dealing with targets of different sizes. The EMA attention mechanism enhances model robustness by applying an exponential moving average to historical data, effectively diminishing the impact of noise or outliers, thereby promoting stability within the model’s functioning without directly affecting its performance metrics [31]. To utilize the EMA module to smooth the feature weight function and reduce noise interference, we embed the EMA attention layer after the channel mixer of RepViT Block and integrate the RVB-EMA module, whose structure is shown in Figure 7B. Ultimately, this module not only retains the powerful feature extraction and representation capabilities of RepViT Block but also adjusts the importance weights of the feature maps through the EMA attention mechanism, so that the model can focus on the key information more accurately. This design effectively reduces the interference of noise while keeping the model lightweight.
2.4.3. PCDetect Lightweight Detection Header
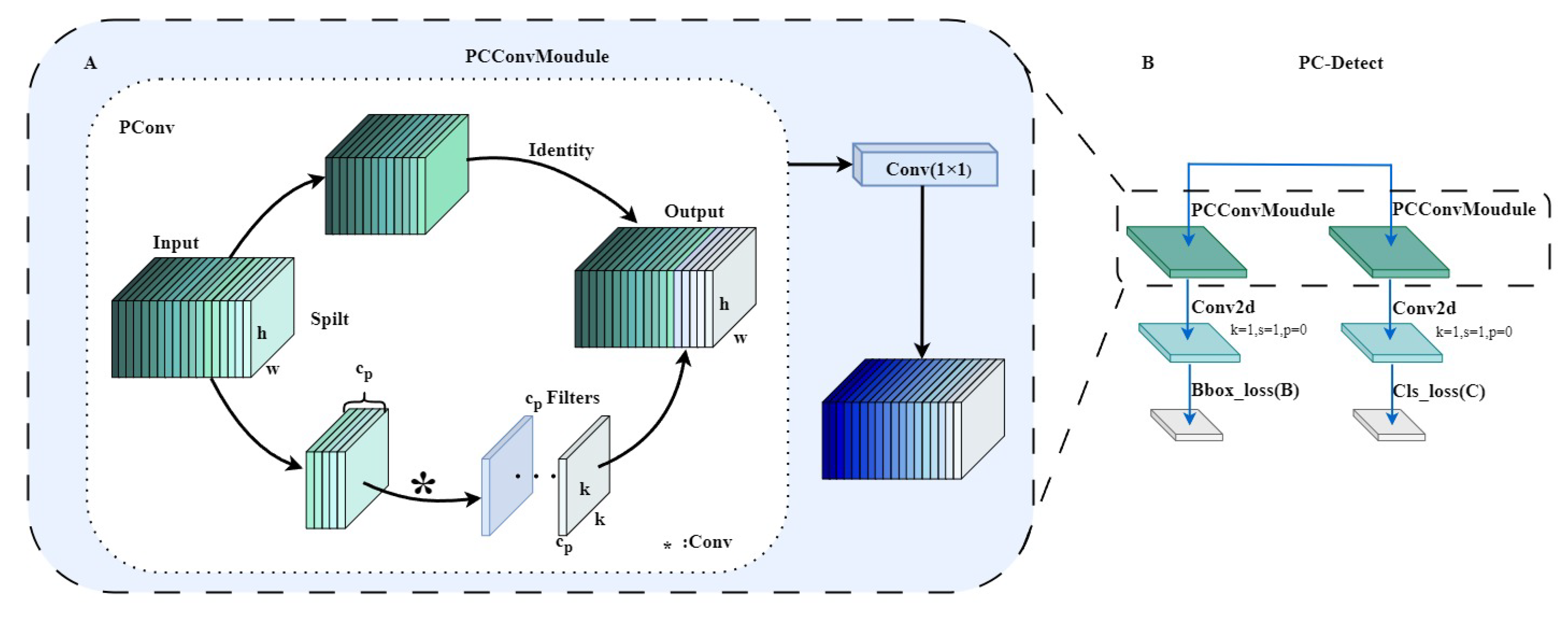
To reduce the computational effort of the detection head, this paper proposes a lightweight PCConv module based on the working principle of the lightweight convolutional module PConv, whose structure is shown in Figure 8A [32]. The PConv module performs convolution operations solely on a specified portion of the channels, preserving the remaining channels in their original state, unaltered. First, the PConv module splits the input feature map X into two parts, namely and , using an function scaled by r in the channel dimension. Subsequently, the part is a feature extracted by the convolution module, and the extracted features are spliced with the part to obtain the final feature map, which effectively reduces the computational complexity of the model. Subsequently, the part is a feature extracted by the convolution module, and the extracted features are spliced with the part to obtain the final feature map; therefore, the partial processing strategy effectively reduces the computational complexity of the model. The PCC module is based on PConv with the addition of a convolutional layer with a convolutional kernel size of 1 × 1. The enhancement bolsters the model’s capacity for integrating features and perceiving across channels, ultimately enhancing the model’s feature representational power notably, all while avoiding a substantial escalation in the parameter count. The process of obtaining the feature map Y by the PCC modules is shown in Equations (1) and (2), with representing the feature extraction using a convolutional module with convolutional kernel size i, and & denoting the splicing operation. The structure of the novel PCDetect detection module is depicted in Figure 8B, which starts with two lightweight PCC modules, and then each of them passes through a Conv2d module, and finally, the Cls loss and the Bbox loss are calculated, respectively.
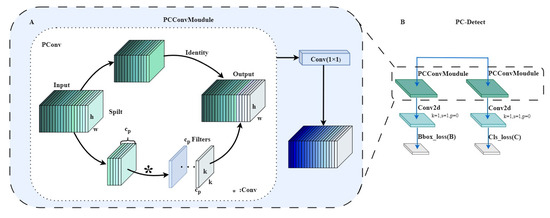
Figure 8.
Lightweight inspection head construction. (A) PCConv module (PCC). (B) PCDetect detection head.
2.4.4. DySample Up-Sampling
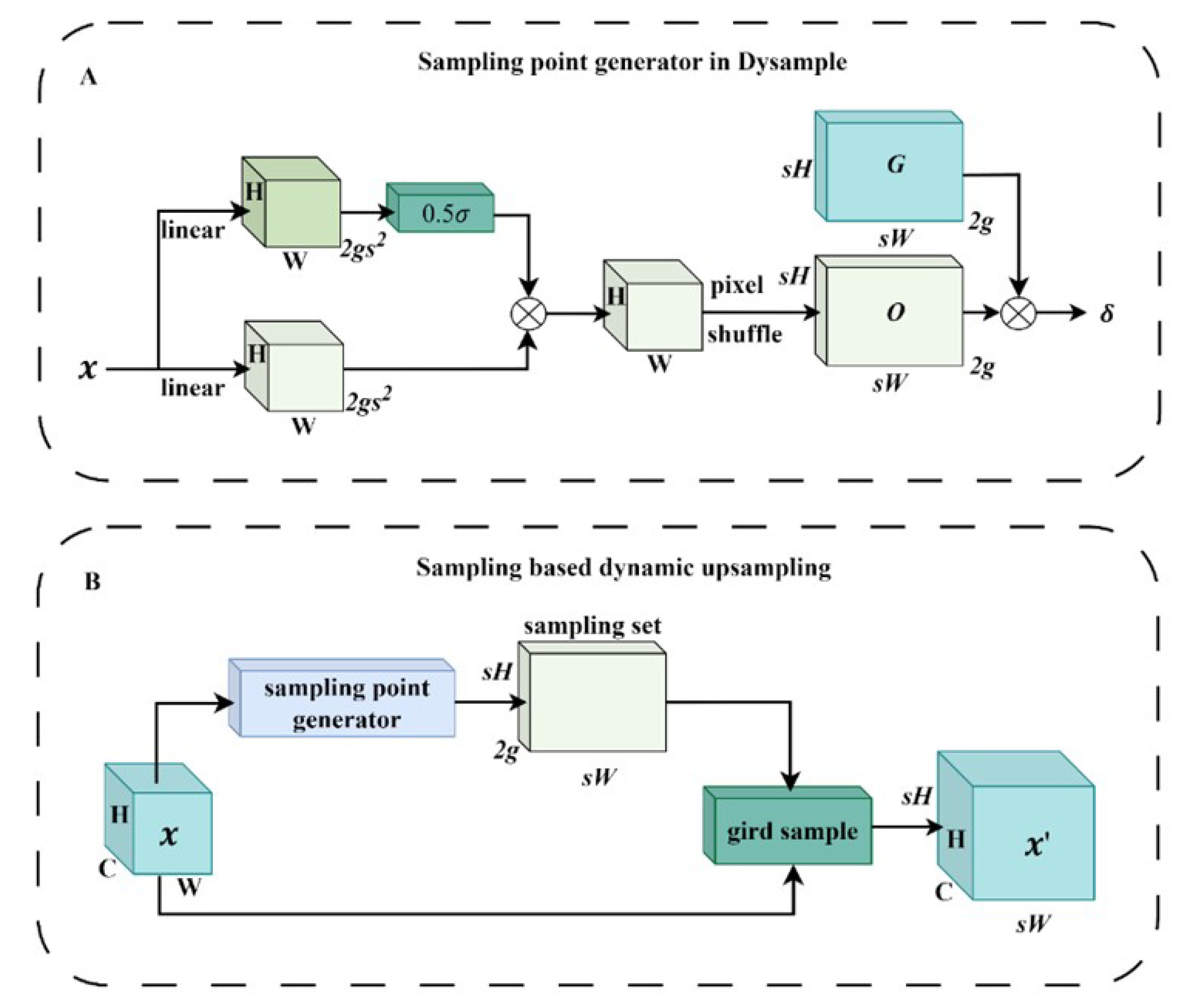
Up-sampling is used to improve the spatial resolution of feature maps and is important for pixel-level classification in semantic segmentation. However, YOLOV8-n up-sampling is prone to losing low-level details and semantic information. For this reason, lightweight dynamic up-sampling DySample is introduced to improve the model detection accuracy, and its algorithm structure is shown in Figure 9B [33]. The DySample up-sampling operator adopts the Pixel Shuffle (Pixel Shuffle) approach and utilizes its unique differential sampling method to better preserve the underlying semantic information of the under-ripe stage of Chinese flowering Chinese cabbage. In addition, DySample can achieve an increase in image resolution without adding too many parameters by generating only up-sampling locations and using a simple bilinear kernel.
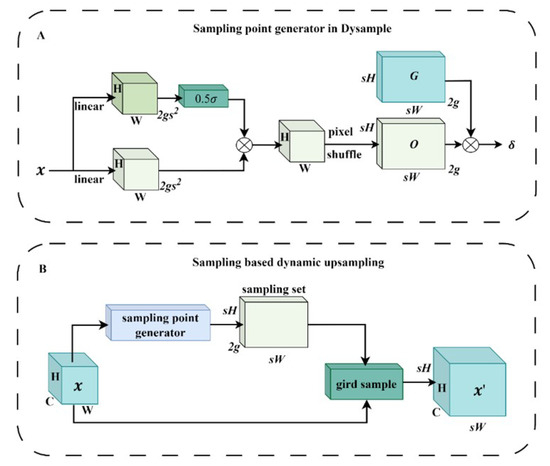
Figure 9.
Dynamic up-sampling of the structure of DySample. (A) A sample set generator with a dynamic range factor. (B) Sampling based Dynamic Upsampling.
Equations (3)–(5) define the process of sampling on the DySample with a dynamic range factor: first, a linear layer with input channels C and output channels 2 is used to map the input feature map X into a point-by-point placement bias O , as in Equation (4). A sample set generator with a dynamic range factor is used in this process, and the structure is shown in Figure 9A, where represents the sigmoid function. Next, it is reshaped to by the Pixel Shuffling function. Then, it is superimposed with the original grid point coordinates to obtain the new sampling location S, which is resampled by a grid sample at the new location. Finally, the feature map with rich semantic features is obtained.
2.4.5. SimAM Attention Mechanism
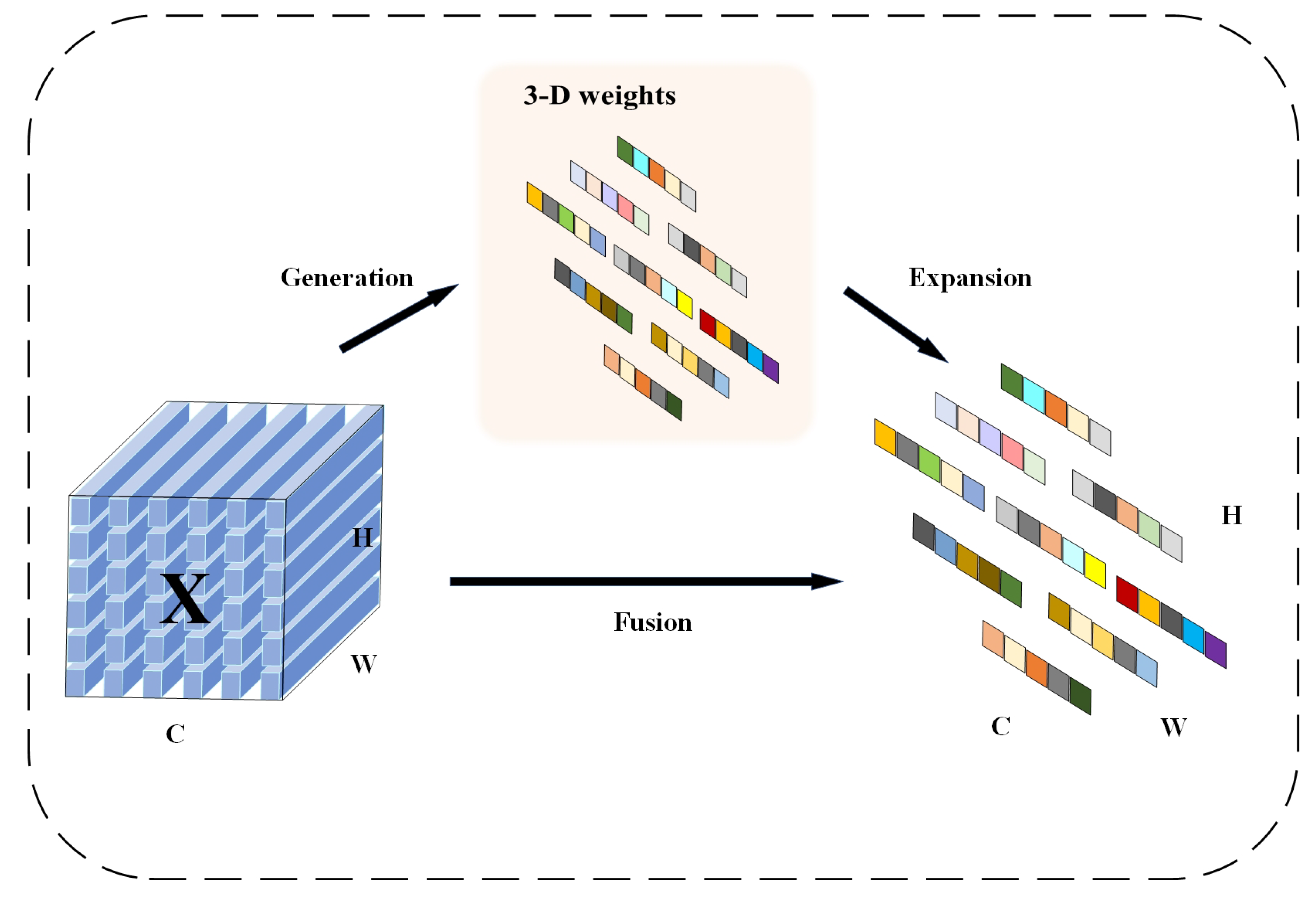
To address the similarity of Chinese flowering cabbage features between immature and mature stages in the detection target, this paper proposes to introduce the SimAM (Similarity-based Attention Module) attention mechanism without additional parameters before SPPF, which helps the model to pay more attention to the foreground features in the feature extraction stage, thus improving the differentiation of similar features. The SimAM attention mechanism weights spatial attention to feature maps by modeling neuronal activation patterns in neuroscience. The mechanism designs an optimized energy function (i.e., ) for assessing the importance of each neuron t (i.e., each position in the feature map) based on neuronal similarity differences. Specifically, the energy function quantifies the non-similarity between a neuron and neurons in its neighborhood, with a low energy value indicating that the neuron is more important in the feature representation, and therefore the weight of the neuron needs to be increased. SimAM generates a 3D weight map accordingly, and directly adjusts the activation strength of each neuron in the input feature map to make important features more prominent while suppressing minor features. Finally, the weights are smoothed and normalized by a nonlinear transformation of the sigmoid function to ensure that foreground features are prioritized and enhanced in the output feature map [34]. Moreover, in this paper, the SimAM attention mechanism is directly inserted before SPPF to optimize the original feature map, reducing the computational redundancy and effectively improving the FPS and model efficiency. Figure 10 shows the internal structure of the SimAM attention mechanism.
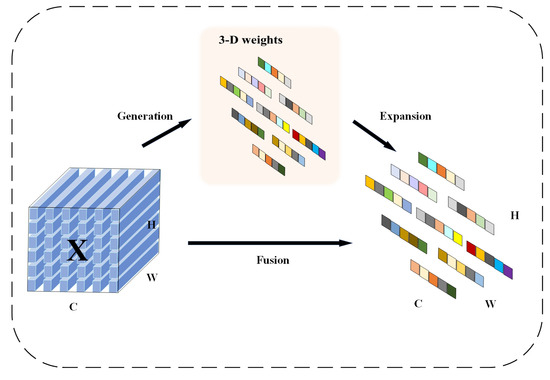
Figure 10.
SimAM attention mechanism.
SimAM defines an energy function based on the neuronal spatial inhibition phenomenon, as shown in Equation (6), which determines the mean and variance in the channel except for a specific neuron to evaluate the importance of the neuron. The importance of each neuron is computed by solving Equation (7) to generate the 3D weights of the feature map X. Then, this 3D weights module is utilized and the features are refined by scaling Equation (8), i.e., feature refinement, to obtain the refined feature map .
In the formula, X denotes the input feature map, E denotes the energy value of a single neuron, sigmoid is the activation function, and denotes the feature extraction.
2.5. Tracking, Counting
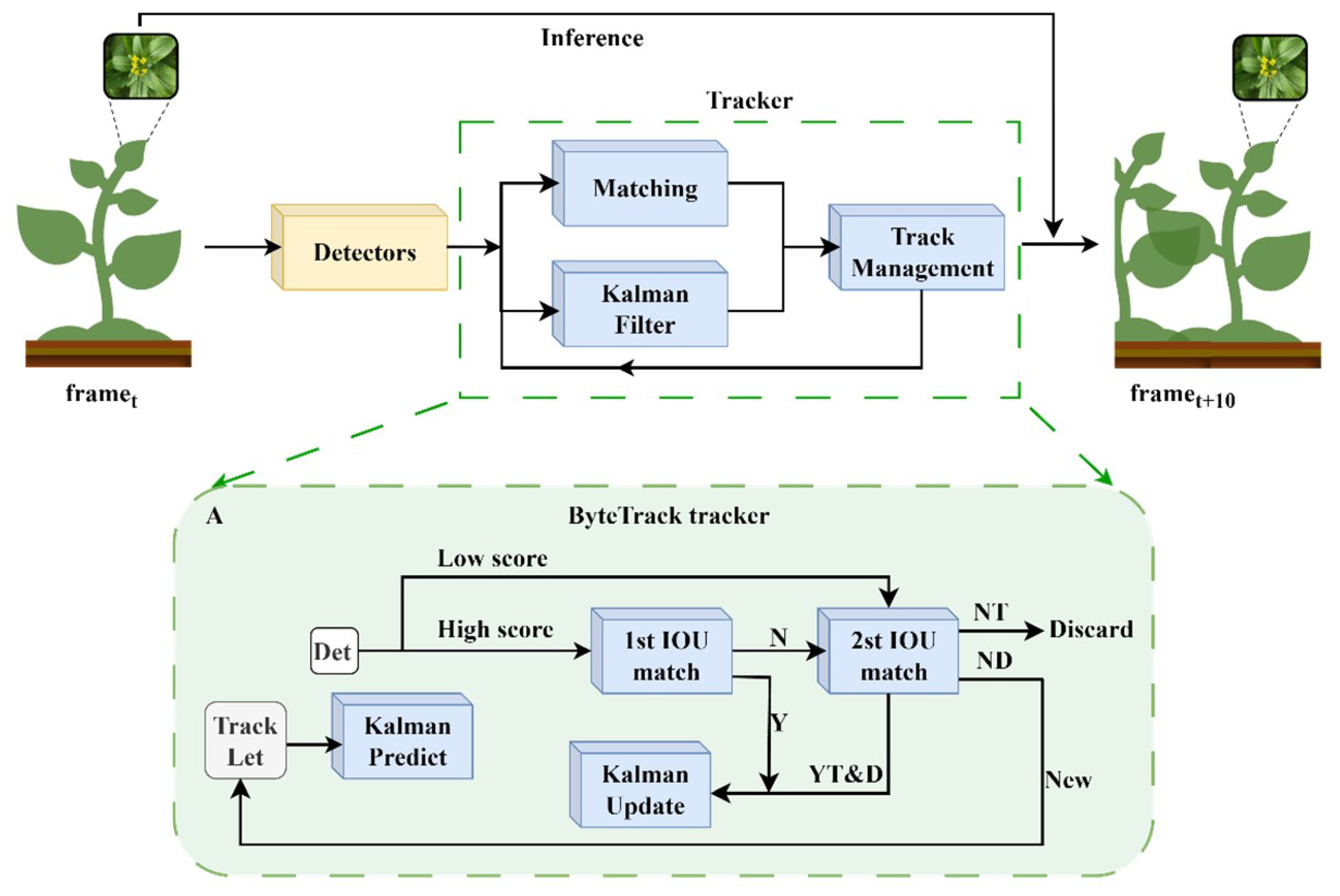
The main role of the detection network is to recognize the ripeness of the Chinese flowering cabbage and the target bounding box, while the tracking network achieves continuous detection of the same target by updating the position of the Chinese flowering cabbage in the video sequence. This paper chooses a tracking method that is based on a detection paradigm with two main core steps: target detection and re-identification [35]. Upon precise classification of Chinese flowering cabbage ripeness and establishment of the target bounding box, the Byte Tracker tracking module is employed to maintain the consistency of the identified outcomes. This methodology’s execution is illustrated in Figure 11.
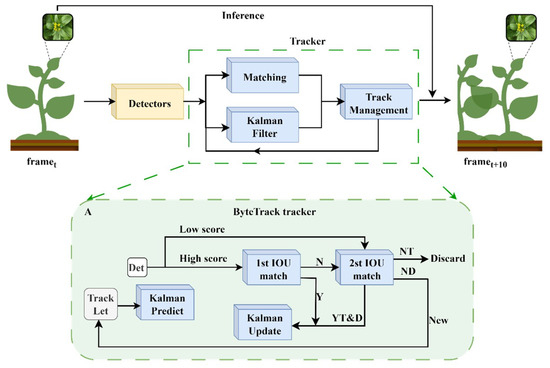
Figure 11.
Tracker operation process and Byte Tracker structure. (A) Byte Tracker internal operation logic.
Byte Tracker is a lightweight tracker in the field of multi-objective tracking (MOT), capable of running on resource-limited devices [36]. The tracking module mainly consists of a Hungarian matching algorithm, Kalman filtering, and tracking management for state updates. These components work together to enable Byte Tracker to realize the formation of trajectories by concatenating consecutive frames, and its detailed structure is shown in Figure 11A. During the tracking process, Kalman filtering provides predictions of the next position and velocity of the Chinese flowering cabbage, which is beneficial for maintaining the trajectory when the target temporarily disappears or is occluded. The Hungarian matching algorithm solves the cascade matching problem between consecutive frames and ensures the continuity of the Chinese flowering cabbage’s trajectory, while the state update’s tracking administration handles the updating of the Chinese flowering cabbage’s trajectory status in accordance with the freshly acquired detection outcomes. Meanwhile, using Byte Tracker in this process, the detection results with high confidence are directly used for trajectory updating, while the results with low confidence are re-associated with the entities, which effectively reduces the leakage detection.
3. Experimental Results and Discussion
3.1. Experimental Platform
The detection models constructed in this paper are all based on the Windows 11 operating system platform, and NVIDIA GeForce RTX 4060 Ti GPUs (NVIDIA GeForce RTX 4060 Ti GPUs is from NVIDIA Corporation, Santa Clara, CA, USA) and Intel 12th generation Core i5-12400F CPUs (Intel 12th generation Core i5-12400F CPUs is from Intel Corporation, Santa Clara, CA, USA) are used as the computing platforms, combined with Python 3.9 and CUDA 11.7 software environments for model training and testing. The input dimension of the images was configured as 640 × 640 pixels, with a total training duration of 150 epochs. Throughout the training phase, an adaptive learning rate adjustment was implemented via a gradient-based stochastic descent (SGD) approach, incorporating automated weight regularization and premature termination mechanisms to enhance the training efficacy. CPUs (Intel 12th generation Core i5-12400F is from Intel Corporation, Santa Clara, CA, USA) are used as the computing platforms, combined with Python 3.9 and CUDA 11.7 software environments for model training and testing. The input dimension of the images was configured as 640 × 640 pixels, with a total training duration of 150 epochs. Throughout the training phase, an adaptive learning rate adjustment was implemented via a gradient-based stochastic descent (SGD) approach, incorporating automated weight regularization and premature termination mechanisms to enhance the training efficacy.
3.2. Evaluation Metrics
In order to thoroughly assess the effectiveness of the enhancements presented herein, the ripeness detection experiment of Chinese flowering cabbage and the counting experiment of Chinese flowering cabbage were designed in this paper. In detection, model parameters (Params), frames per second (FPS) of processed images, model weight size, FLOPs, and mAP (average accuracy) (0.5) were selected to evaluate the complexity and accuracy of the detection model.For counting, the coefficient of determination () and root mean square error (RMSE) were chosen to evaluate the tracking counting performance. Intersection over Union (IoU), which quantitatively measures the extent of overlap between the predicted bounding box and the real bounding box, is realized by calculating the proportion of the merged area to the concatenation area of the two. The closer the IoU value is to 1, the higher the degree of overlap between the predicted and the real bounding box, i.e., the stronger the model’s localization accuracy to the target. In this study, an IoU threshold of 0.7 is set as the criterion for successful detection, i.e., when the IoU value between the detected target bounding box and the corresponding real bounding box exceeds this threshold, it is regarded as a valid detection and confirms its category attribution. The respective formulations for each evaluation criterion are detailed below:
In the given formula, TP (True Positives) signifies the count of positive instances accurately identified by the model, whereas FP (False Positives) denotes the quantity of instances that are falsely marked as positive by the model, and FN (False Negatives) indicates the number of negative samples incorrectly classified by the model. indicates the correlation between the model-predicted values and the actual observations, which is between 0 and 1. The closer the value of is to 1, the closer the trajectory is to the true trajectory. The mean value of error (RMSE) is the square root of the mean of the squares of the differences between the predicted values and the true values. where the smaller the RMSE, the higher the tracking accuracy.
3.3. Analysis of the Model Training Process
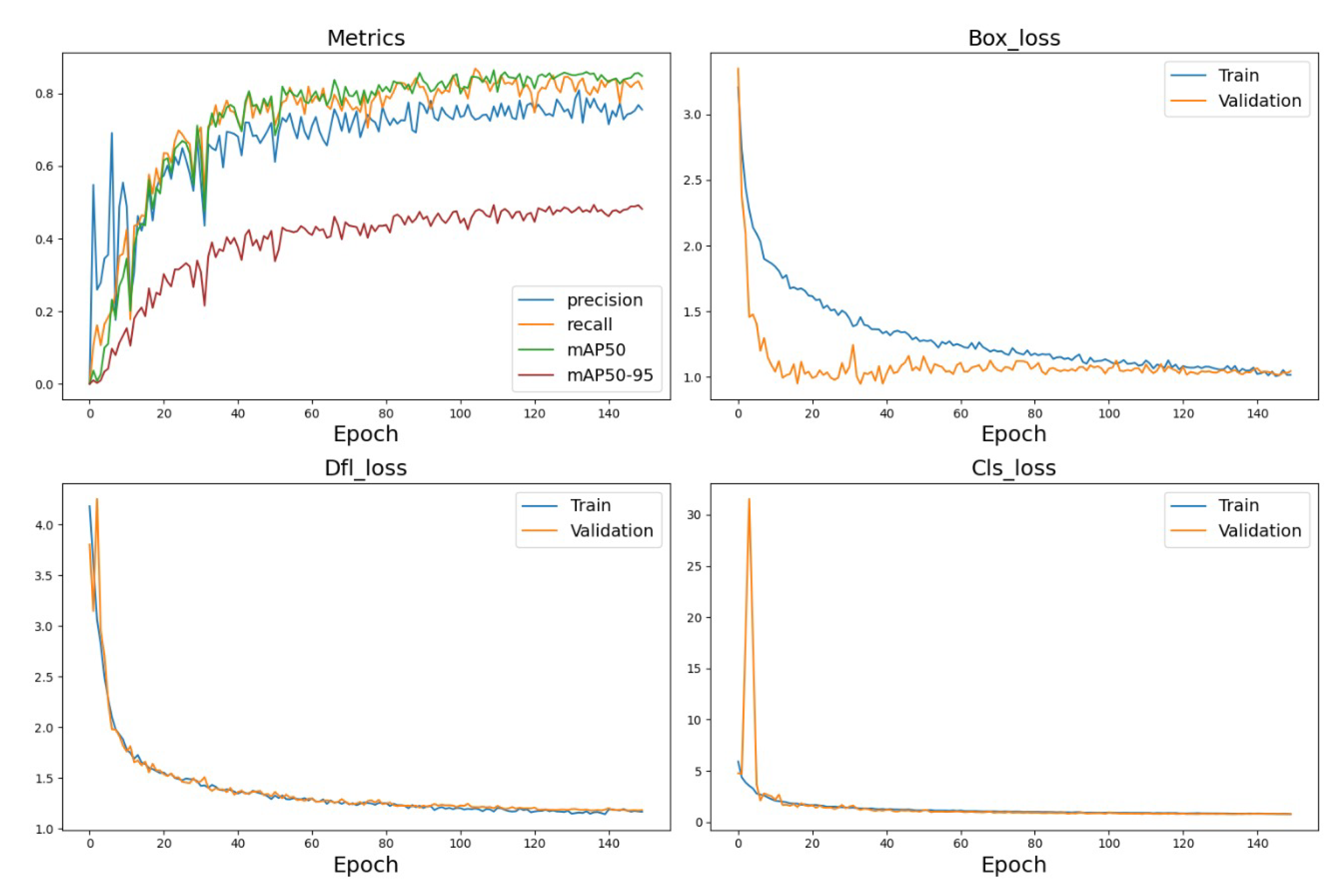
As shown in Figure 12, the curves of both training and validation metrics of the Cabbage-YOLO model show a significant and fast convergence trend from the 0th epoch to approximately the 20th epoch. In this phase, the Box_loss, classification loss (Cls_loss) and data fitting loss (Dfl_loss) on both the training and validation datasets are substantially reduced, while the model’s precision, recall, mAP@0.5, and mAP@0.5–0.95 metrics are significantly improved. As the quantity of training iterations escalates, particularly surpassing approximately the 50th epoch mark, the model’s progression across various performance metrics commences to stabilize and show diminishing returns. The model terminated the training process at the 150th epoch with a model mAP50 of 86.4%. In addition, the FPS of the model was tested to be 107.8, and the weight size was 3.4 M. The above training results further demonstrate the effectiveness of the improved model and verify that the model improves the detection accuracy while achieving light weight.
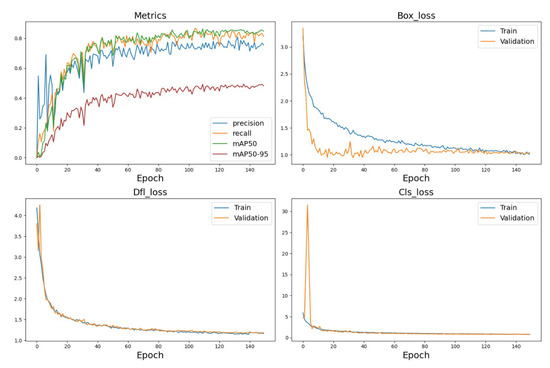
Figure 12.
Training results of the Cabbage-YOLO model.
3.4. Comparison with Other Target Detection Models
In this paper, the Cabbage-YOLO model is designed to effectively improve the detection accuracy and to achieve a light weight. To demonstrate the advantages of the proposed model, in this section, the performance of Cabbage-YOLO is compared with nine commonly used models in the field of target detection. These include not only YOLOv3-tiny, the lightweight versions of YOLOv5 to YOLOv8 [37], but also high-parameter models such as Faster-RCNN, SSD, YOLOv3, and YOLOv5-l [38,39]. The results of the comparison experiments are shown in Table 1. Compared with the lightweight model YOLOv5-n, which has the best comprehensive performance in the table, the number of Cabbage-YOLO parameters and weight size are 36.4% and 32% lower, and Cabbage-YOLO has higher detection accuracy and is more lightweight. Compared with the high-parameter model YOLOv3, which has the highest accuracy in the table, Cabbage-YOLO has only 1.5% of the number of parameters and 1.7% of the size, and its detection accuracy is only slightly lower than that of YOLOv3 by 0.6%. Regarding the model detection accuracy and model lightweight effect, they are originally better for the Cabbage-YOLO model than for other models in terms of the number of parameters and model size, as the number of parameters is only 1.591 M, the size of the model is 3.4 M, and the detection accuracy is up to 86.4%, which is an obvious advantage in its comprehensive performance compared with other models.

Table 1.
Experimental results for comparison with other target detection models.
By using five lightweight models to detect images of Chinese flowering Chinese cabbage at different ripening stages, we compared their detection results with Cabbage-YOLO. In the comparison graph (shown in Figure 13), the yellow diamond-shaped boxes represent missed detections, and the green circular boxes represent wrong detections. Among them, YOLOv3-tiny has the lowest detection accuracy, as seen in Figure 13A, and it has evident leakage detection for both immature and harvested targets with smaller sizes. As seen in Figure 13B, YOLOv5-n has a higher detection accuracy, but there is false detection for the under-ripe and ripe targets, which have more similar features. In Figure 13C through E, it is evident that YOLOv6-n, YOLOv7-n, and YOLOv8-n exhibit challenges in the form of inaccurate identifications or undetected instances stemming from the aforementioned dual factors. As can be seen from Figure 13F, the improved Cabbage-YOLO can effectively accomplish the task of detecting the ripening stage of Chinese flowering cabbage, which helps to realize the nondestructive detection of Chinese flowering cabbage ripeness.

Figure 13.
Five examples of lightweight algorithms for ripeness detection of Chinese flowering cabbage. (A) YOLOv3-tiny. (B) YOLOv5-n. (C) YOLOv6-n. (D)YOLOv7-n. (E) YOLOv8-n. (F) Cabbage-YOLO. The yellow diamond box in the figure indicates a missed detection, and the green circle indicates a misdiagnosis.
3.5. Ablation Experiments
In this section, an ablation experiment was designed to evaluate the utility of each improvement module in detail. The results of the ablation experiments are shown in Table 2, where “✓” indicates that the module is used and no “✓” indicates that the module is not used. First, the feature pyramid structure adjustment (FPA) was performed, and this improvement selected P2, P3, and P4 feature maps from the backbone network as the inputs to the feature pyramid, instead of the default P3, P4, and P5. This lead to a direct reduction in the initial model parameters by about 24.5%, a decrease in the model size from 6.2 M to 4.1 M, i.e., about 33.9%, and an increase in the detection accuracy by 3.6%, which suggests that this improvement effectively reduced the model complexity and improved the model accuracy. Due to the noise introduced by the previous improvement step, the improved C2f-RepVit-EMA (C2f-RA) lightweight module was used to replace the C2f module in the YOLOv8-n neck network. The model size was continuously reduced to 3.9 M, and the model parameters were reduced from 2.271 M to 1.872 M, resulting in an evident lightweight effect; meanwhile, the detection accuracy of the model at this time was decreased but still 2% higher than the baseline model. Second, the YOLOv8-n neck network up-sampling operator was replaced with the dynamic up-sampling operator DySample in its entirety, utilizing the effectiveness of DySample in capturing image details. At this point, the detection accuracy of the model was further improved to 87.2%, while the model size remained unchanged. Although the model parameters were slightly increased by 0.015 M, the slight increase in parameters is worthwhile relative to the improvement in detection accuracy. Then, in the YOLOv8-n header network, the newly constructed lightweight PCDetect was used to replace the original detection header, effectively reducing computational redundancy and memory access. At this point, based on the previous step, the number and size of model parameters were effectively reduced by 15.6% and 12.8%, respectively, and the FPS was improved by about 10.2. Finally, the introduction of the SimAM attention mechanism before the SPPF did not add any additional computation and improved the model’s ability to understand the forward features of immature Chinese flowering cabbage. At this point, the mAP of the model was improved to 86.4%, which was 1.9% higher than the mAP of the benchmark model YOLOv8-n.
Table 2.
Results of ablation experiments.
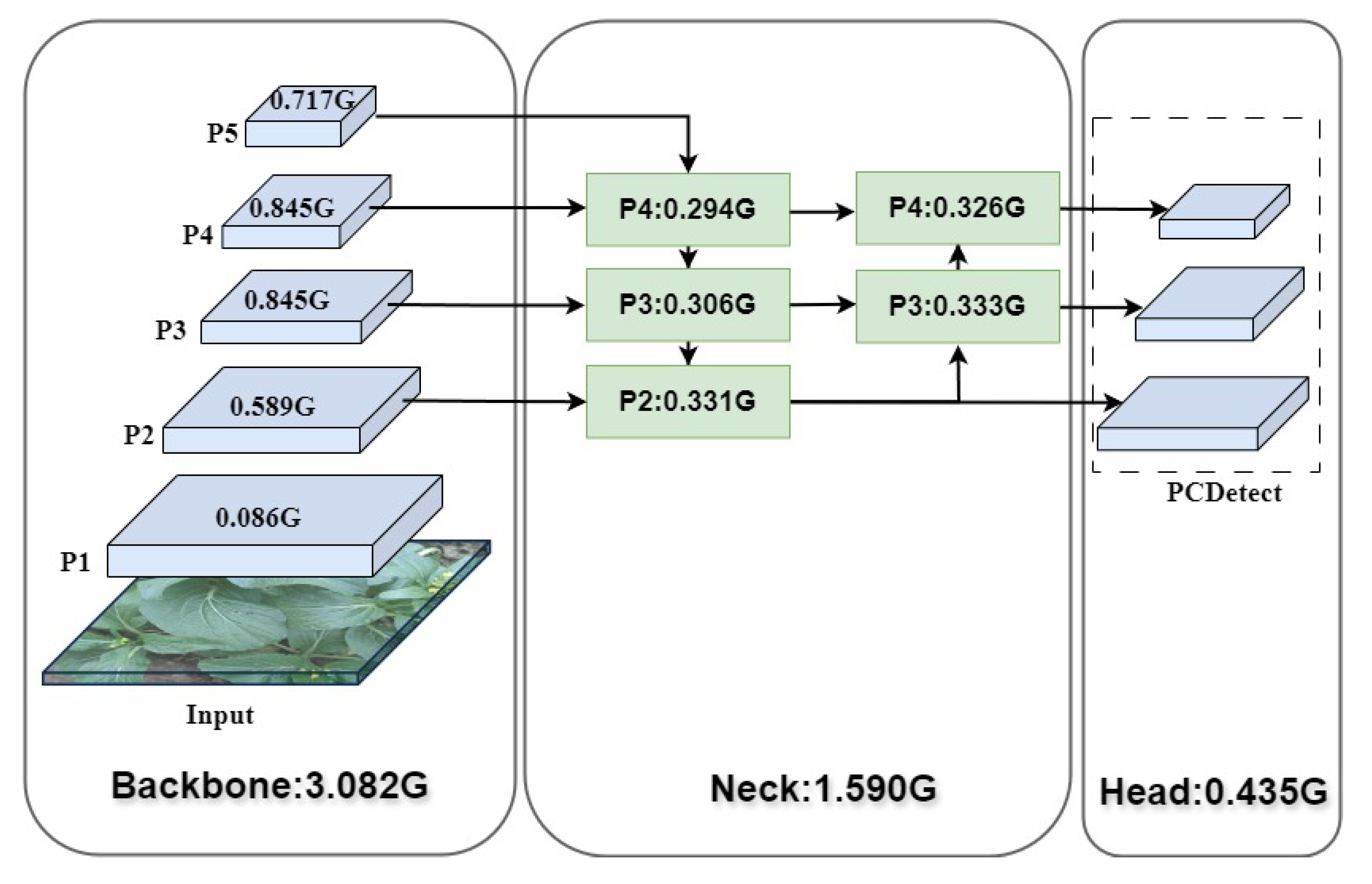
To further validate the effectiveness of the lightweight module used, this paper plots the size of FLOPs for each layer of Cabbage-YOLO to visualize the lightweight effect, as shown in Figure 14. The FLOPs of each part of the model, Backbone, Neck, and Head, are finally changed from the initial 3.082 G, 1.922 G, and 2.964 G to 3.082 G, 1.590 G, and 0.435 G. Among them, the FLOPs of the Neck and Head parts are reduced by 17.3% and 85.4%, respectively.
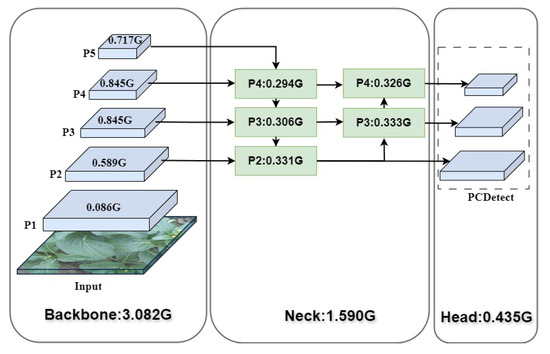
Figure 14.
FLOPs for each module of Cabbage-YOLO.
Overall, the Cabbage-YOLO model designed in this paper has a guaranteed improvement of 1.9% in model detection accuracy, and the number of parameters in the model decreases from the initial 3.011 M to 1.591 M. Meanwhile, there is a clear trend of decreasing the size of the model, which decreases all the way down from the initial 6.2 MB to 3.4 MB. Compared with the baseline model YOLOv8-n, the number of FLOPs, the number of parameters, and the weight size are reduced by about 35.9%, 47.1%, and 45.1%, respectively, with an FPS of 107.8. The outcomes of the aforementioned ablation experiments comprehensively demonstrate the efficacy and credibility of the proposed methodology in this paper in terms of enhancing both the model detection accuracy and its lightweight nature.
3.6. Tracking Count Results
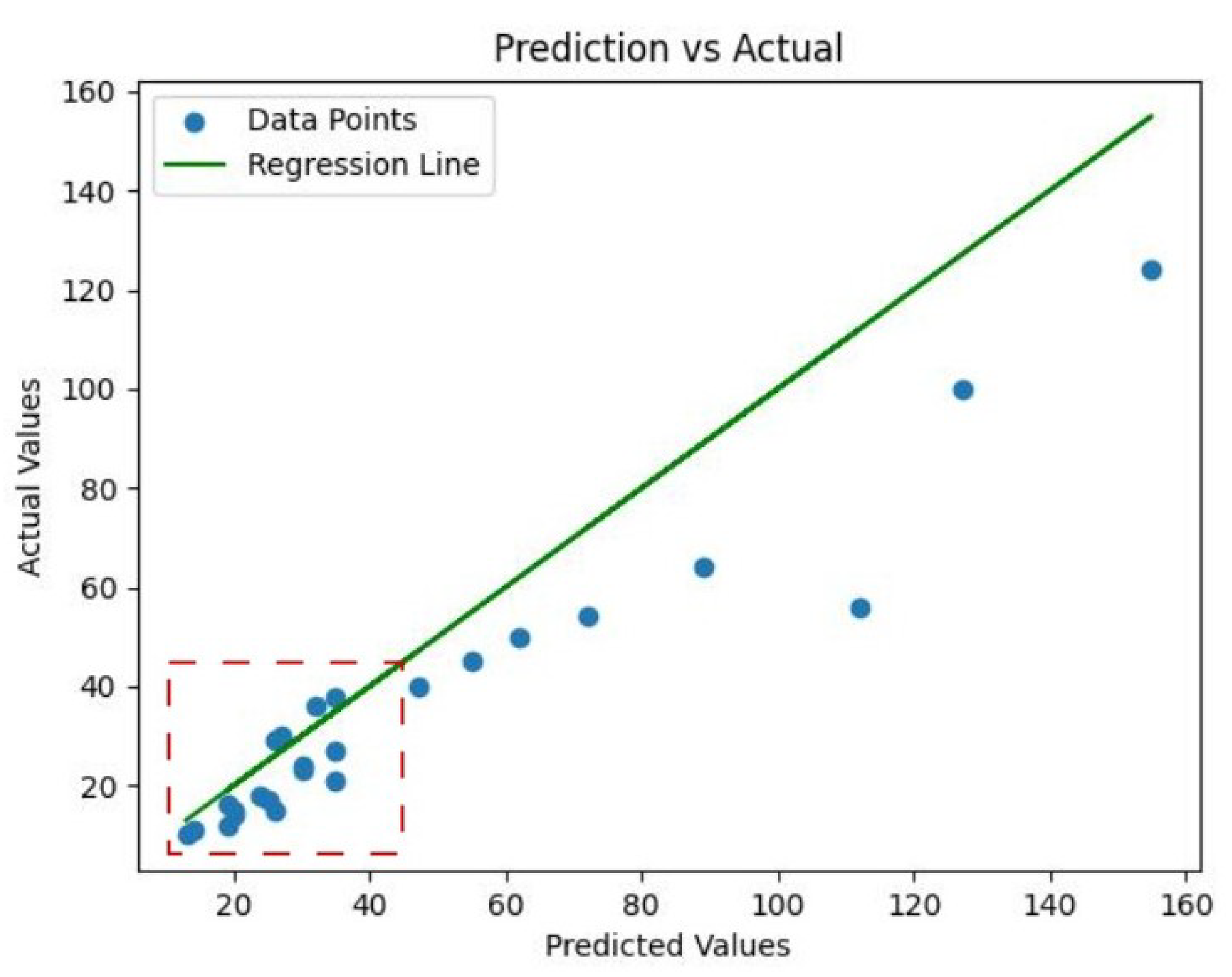
In this paper, we utilize Byte Tracker’s multi-target tracking function to assign a unique ID to each detected target, thus displaying the total number of current targets and the number of targets in each category in the upper left corner of the video in real time. To verify the validity of the tracking, Chinese flowering cabbage videos with different detection heights and growing days were detected and tracked. The tracking example is shown in Figure 15A–I. The Chinese flowering cabbage regions are all marked with colored rectangular boxes, with their IDs and categories displayed above the rectangular boxes, and the corresponding motion trajectories plotted by their central coordinates. Although the tracking algorithm can achieve continuous tracking of Chinese flowering cabbage regions in most cases, there are still cases of omission, as shown in the error examples in Figure 15F–I. The detection and tracking system was capable of precisely identifying and tracking regions of over-matured Chinese flowering cabbage exhibiting notable characteristics. Detection of counts performed better if the total number of Chinese flowering cabbage in the video was less than 30, with a tracker coefficient of determination of 0.76 and a mean error RMSE of 6.49. However, immature Chinese flowering cabbage and mature individuals show similarities in textural characteristics, which increases the difficulty of identification. As shown in Figure 16, such problems tend to be more prominent as the number of Chinese flowering cabbage counts increased to 50 and above. In this paper, the results of tracking counts are modeled against those of manual counts to evaluate their counting performance, as shown in Figure 16. The regression results reflect that the coefficient of determination of the tracker combined with Cabbage-YOLO and Byte Tracker is greater than 0.6, and the mean error RMSE is within 18, indicating that the proposed tracking method is reasonable and effective.

Figure 15.
(A–I) Example of tracking counts (the yellow diamond box in the figure indicates a missed detection).
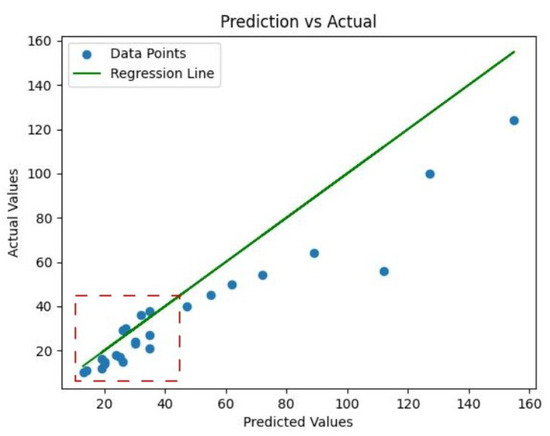
Figure 16.
Scatterplot of tracked predicted versus actual values. (The green regression line in the plot has a slope of 1 and an intercept of 0. The Red dotted frame highlights the scenario where the target quantity is 50).
4. Discussion
Although deep learning has been extensively utilized in the realm of fruit and vegetable detection, encompassing the recognition of green peppers [33], strawberries [34], grapes [35], and others, studies pertaining to cabbage maturity detection via deep learning are limited. This paper delves into the characteristics of cabbage maturity, categorizing it into four distinct stages, thereby facilitating the precise determination of cabbage maturity and enabling pertinent management decisions and yield projections. In comparison to alternative models, the enhanced Cabbage-YOLO model presented in this study attains an average detection accuracy of 86.4% for assessing the ripeness of Chinese flowering cabbage, with a minimal model size of 3.4 MB. When bench-marked against existing target detection methodologies, the proposed model achieves superior detection accuracy while maintaining a compact size. Additionally, to enable the monitoring and enumeration of cabbage in video sequences, the integration of Cabbage-YOLO with Byte Tracker was implemented. The experimental findings reveal that the tracker’s counting and tracking capabilities are effective, particularly when the total cabbage count is relatively low in a natural environment.
Although the proposed method effectively accomplished the task of detecting and enumerating Chinese flowering cabbage, similar to other studies, it has some shortcomings and limitations. (1) The average detection accuracy could be improved, especially for immature cabbage types. This is mainly due to the small pixel size of the features and the tendency of the critical bud features to be masked by young leaves. (2) In the case of dense Chinese flowering cabbages, Byte Tracker encountered challenges in tracking consecutive frames, resulting in duplicate counts and missed counts due to heavy occlusion. After analyzing the experimental results, the performance of the Cabbage-YOLO model in detecting and counting Chinese flowering cabbage ripeness can be improved by the following: (1) Increasing the size of the dataset for Chinese flowering cabbage categories that are prone to be missed or refining the maturity categorization, which can enable the model to better capture salient features. In addition, enhancing the model’s focus on shallow features of cabbages and minimizing the loss of potential semantic information can also improve its mAP. (2) Clarifying the region of interest to avoid reassigning IDs to emerging targets once a tracked target exits the field of view or is lost can minimize confusion with previous targets.
In addition, future work will prioritize the use of the depth information of the cabbage hearts already captured by the RGB-D camera to be aligned with the RGB images, which in turn will extract the 3D localization of the target and obtain the 3D coordinates of a single cabbage heart, in particular, to assist in agricultural work such as precision fertilizer application and targeted pesticide spraying.
In summary, the Cabbage-YOLO model offers an effective and lightweight resolution for detecting the ripeness of Chinese flowering cabbage and realizes the tracking and counting of Chinese flowering cabbage in video sequences, which provides an accurate ripeness judgment and management decision-making basis for harvesters.
5. Conclusions
Ripeness assessment and plant counting, essential aspects of cabbage cultivation, are currently reliant on labor-intensive manual operations. In this paper, a lightweight maturity detection and tracking model, Cabbage-YOLO, based on YOLOv8n, is studied, which helps to determine the maturity status of Chinese flowering cabbage in a timely manner and offer quantitative yield estimation, providing a capable assistant for farmers and managers. In terms of model lightness, the output layer of the backbone network is modified to strengthen the model’s concern for small targets while also reducing its complexity. Additionally, a lightweight feature extraction module, RVB-EMA, is introduced to minimize model parameters. Furthermore, the pconv lightweight convolutional network is employed to reconstruct the header network, achieving a more streamlined design. To boost the precision in detecting small targets, the lightweight DySample up-sampling operator is adopted, circumventing the semantic information loss associated with traditional up-sampling operators. Moreover, the SimAM attention mechanism, devoid of additional parameters, is integrated before the feature fusion module SPPF, augmenting foreground feature weights and significantly improving detection accuracy without changing the size of the model weights.Given the limited computational resources of field harvesting equipment, the smaller weight size and lower computational cost of the lightweight Cabbage-YOLO detection model make it more suitable for deployment in portable devices to help farmers monitor cabbage maturity and accurately estimate yield in real time. Finally, Cabbage-YOLO was integrated with Byte Tracker, facilitating the tracking and counting of Chinese flowering cabbage in video sequences. Under the aforementioned network optimizations, an improvement in ripeness detection accuracy for Chinese flowering cabbage by 1.9% is achieved. The FLOPs, number of parameters, and weight size of the model are scaled down by approximately 35.9%, 47.2%, and 45.2%, respectively. Additionally, the coefficient of determination and RMSE of the tracking and counting functionality are 0.64 and 16.41, respectively. The various experimental results show that the improved model in this paper has significant advantages in accuracy and model lightness compared with the existing model, and the results of tracking counts are valid, which can offer technical support for the ripeness status as well as quantitative yield estimation of Chinese flowering cabbage.
Author Contributions
M.W.: conceptualization, data analysis, software, writing—original draft, writing—review and editing, validation. K.Y.: conceptualization, data analysis, writing—review and editing, validation. Y.S.: data analysis, data acquisition, supervision. Q.W.: data acquisition, supervision, validation. Z.Z.: writing—review and editing, supervision, methodology, funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
The authors would like to acknowledge the support of this study from the State Key Research Program of China (Grant No. 2022YDF2001901-01), the Guangdong Provincial Department of Agriculture’s Modern Agricultural Innovation Team Program for Animal Husbandry Robotics (Grant No. 2019KJ129), and the Special Project of Guangdong Provincial Rural Revitalization Strategy in 2020 (YCN (2020) No. 39) (Fund No. 200-2018-XMZC-0001-107-0130).
Data Availability Statement
The original data of this article are available within reasonable requests.
Conflicts of Interest
The authors declare no competing interests.
Abbreviations
The following abbreviations are used in this manuscript:
| RGB-D | Red, Green, Blue, and Depth |
| FPA | Feature Pyramid Adjustment |
| Cls_loss | Classification Loss |
| RMSE | Root Mean Square Error |
| Dfl_loss | Data Fitting Loss |
| PCDetect | PConv Detect |
| FPS | Frames Per Second |
| Params | Parameters |
| RVB | RepViT Block |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
| P | Precision |
| R | Recall |
References
- Kong, X.; Chen, L.; Wei, T.; Zhou, H.; Bai, C.; Yan, X.; Miao, Z.; Xie, J.; Zhang, L. Transcriptome analysis of biological pathways associated with heterosis in Chinese cabbage. Genomics 2020, 112, 4732–4741. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Gu, A.; Feng, D.; Li, N.; Yang, R.; Zhang, X.; Luo, S.; Karamat, U.; Wang, Q.; Xuan, S.; et al. Fast tracking alien gene discovery by molecular markers in a late flowering Chinese cabbage-cabbage translocation line ‘AT7–4’. Hortic. Plant J. 2023, 9, 89–97. [Google Scholar] [CrossRef]
- Nugrahedi, P.; Dekker, M.; Widianarko, B.; Verkerk, R. Quality of cabbage during long term steaming; phytochemical, texture and colour evaluation. LWT-Food Sci. Technol. 2016, 65, 421–427. [Google Scholar] [CrossRef]
- Kleinhenz, M.D. A proposed tool for preharvest estimation of cabbage yield. HortTechnology 2003, 13, 182–185. [Google Scholar] [CrossRef]
- Li, F.; Wang, X.; Wang, F.; Wen, D.; Wu, Z.; Du, Y.; Du, R.; Robinson, B.H.; Zhao, P. A risk-based approach for the safety analysis of eight trace elements in Chinese flowering cabbage (Brassica parachinensis L.) in China. J. Sci. Food Agric. 2021, 101, 5583–5590. [Google Scholar] [CrossRef] [PubMed]
- Bhargava, A.; Bansal, A. Fruits and vegetables quality evaluation using computer vision: A review. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 243–257. [Google Scholar]
- Abbas, Q.; Ibrahim, M.E.; Jaffar, M.A. A comprehensive review of recent advances on deep vision systems. Artif. Intell. Rev. 2019, 52, 39–76. [Google Scholar]
- Liu, Q.; Fang, M.; Li, Y.; Gao, M. Deep learning based research on quality classification of shiitake mushrooms. LWT 2022, 168, 113902. [Google Scholar] [CrossRef]
- Parr, B.; Legg, M.; Alam, F. Grape yield estimation with a smartphone’s colour and depth cameras using machine learning and computer vision techniques. Comput. Electron. Agric. 2023, 213, 108174. [Google Scholar]
- Wang, X.; Liu, J. Vegetable disease detection using an improved YOLOv8 algorithm in the greenhouse plant environment. Sci. Rep. 2024, 14, 4261. [Google Scholar]
- Gupta, S.; Tripathi, A.K. Fruit and vegetable disease detection and classification: Recent trends, challenges, and future opportunities. Eng. Appl. Artif. Intell. 2024, 133, 108260. [Google Scholar]
- Mohammadi, V.; Kheiralipour, K.; Ghasemi-Varnamkhasti, M. Detecting maturity of persimmon fruit based on image processing technique. Sci. Hortic. 2015, 184, 123–128. [Google Scholar] [CrossRef]
- Guo, C.; Liu, F.; Kong, W.; He, Y.; Lou, B. Hyperspectral imaging analysis for ripeness evaluation of strawberry with support vector machine. J. Food Eng. 2016, 179, 11–18. [Google Scholar]
- Goyal, K.; Kumar, P.; Verma, K. Tomato ripeness and shelf-life prediction system using machine learning. J. Food Meas. Charact. 2024, 18, 2715–2730. [Google Scholar] [CrossRef]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Chen, W.; Liu, M.; Zhao, C.; Li, X.; Wang, Y. MTD-YOLO: Multi-task deep convolutional neural network for cherry tomato fruit bunch maturity detection. Comput. Electron. Agric. 2024, 216, 108533. [Google Scholar]
- Ren, R.; Sun, H.; Zhang, S.; Zhao, H.; Wang, L.; Su, M.; Sun, T. FPG-YOLO: A detection method for pollenable stamen in’Yuluxiang’pear under non-structural environments. Sci. Hortic. 2024, 328, 112941. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Xiao, F.; Wang, H.; Xu, Y.; Zhang, R. Fruit detection and recognition based on deep learning for automatic harvesting: An overview and review. Agronomy 2023, 13, 1625. [Google Scholar] [CrossRef]
- Liu, Y.; Zheng, H.; Zhang, Y.; Zhang, Q.; Chen, H.; Xu, X.; Wang, G. “Is this blueberry ripe?”: A blueberry ripeness detection algorithm for use on picking robots. Front. Plant Sci. 2023, 14, 1198650. [Google Scholar] [CrossRef] [PubMed]
- Zeng, T.; Li, S.; Song, Q.; Zhong, F.; Wei, X. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, L.; Chun, C.; Wen, Y.; Xu, G. Multi-scale feature adaptive fusion model for real-time detection in complex citrus orchard environments. Comput. Electron. Agric. 2024, 219, 108836. [Google Scholar]
- Sparrow, R.; Howard, M. Robots in agriculture: Prospects, impacts, ethics, and policy. Precis. Agric. 2021, 22, 818–833. [Google Scholar]
- Chen, X.; Liu, T.; Han, K.; Jin, X.; Wang, J.; Kong, X.; Yu, J. TSP-yolo-based deep learning method for monitoring cabbage seedling emergence. Eur. J. Agron. 2024, 157, 127191. [Google Scholar]
- Kazama, E.H.; Tedesco, D.; dos Santos Carreira, V.; Júnior, M.R.B.; de Oliveira, M.F.; Ferreira, F.M.; Junior, W.M.; da Silva, R.P. Monitoring coffee fruit maturity using an enhanced convolutional neural network under different image acquisition settings. Sci. Hortic. 2024, 328, 112957. [Google Scholar] [CrossRef]
- Qi, Z.; Zhang, W.; Yuan, T.; Rong, J.; Hua, W.; Zhang, Z.; Deng, X.; Zhang, J.; Li, W. An improved framework based on tracking-by-detection for simultaneous estimation of yield and maturity level in cherry tomatoes. Measurement 2024, 226, 114117. [Google Scholar] [CrossRef]
- Huang, Y.; Jiang, L.; Ruan, Y.; Shen, W.; Liu, C. An allotetraploid Brassica napus early-flowering mutant has BnaFLC 2-regulated flowering. J. Sci. Food Agric. 2013, 93, 3763–3768. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Lin, Z.; Han, J.; Ding, G. Repvit: Revisiting mobile cnn from vit perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle WA, USA, 17–21 June 2024; pp. 15909–15920. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Chen, J.; Kao, S.h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12021–12031. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6027–6037. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 1–21. [Google Scholar]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic bunch detection in white grape varieties using YOLOv3, YOLOv4, and YOLOv5 deep learning algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Lawal, O.M. YOLOMuskmelon: Quest for fruit detection speed and accuracy using deep learning. IEEE Access 2021, 9, 15221–15227. [Google Scholar] [CrossRef]
- Nan, Y.; Zhang, H.; Zeng, Y.; Zheng, J.; Ge, Y. Faster and accurate green pepper detection using NSGA-II-based pruned YOLOv5l in the field environment. Comput. Electron. Agric. 2023, 205, 107563. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).