
A Hybrid Synthetic Minority Oversampling Technique and Deep Neural Network Framework for Improving Rice Yield Estimation in an Open Environment


Abstract
1. Introduction
- A combination of rice yield estimation features was established using the Pearson correlation coefficient.
- SMOTE was introduced to address the issue of insufficient data samples, fully leveraging the advantages of machine learning algorithms and enhancing the accuracy of yield estimation.
- A hybrid SMOTE and DNN framework for rice yield estimation was established.
2. Materials and Methods
2.1. Study Area
2.2. UAV Image Collection
2.2.1. Multispectral Image
- Before data collection, reflectance calibration is carried out using a calibration plate, as shown in Figure 3.
- The flight is conducted under cloudless and well-lit conditions (from 10:00 to 14:00 Beijing time in China).
2.2.2. RGB Images
2.3. Yield Data Collection
2.4. Image Processing
2.5. Method
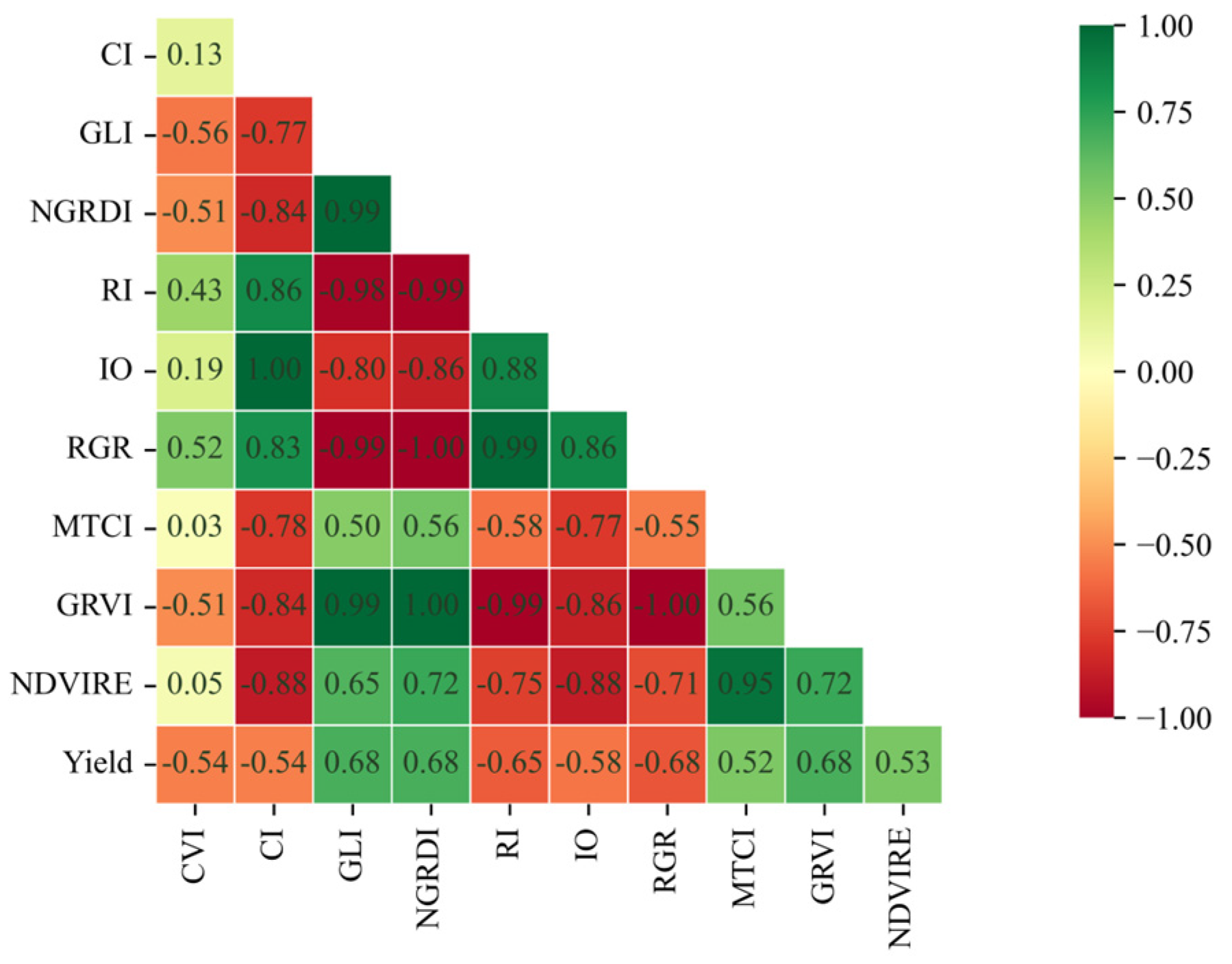
2.5.1. Selection of VIs
2.5.2. Data Augmentation
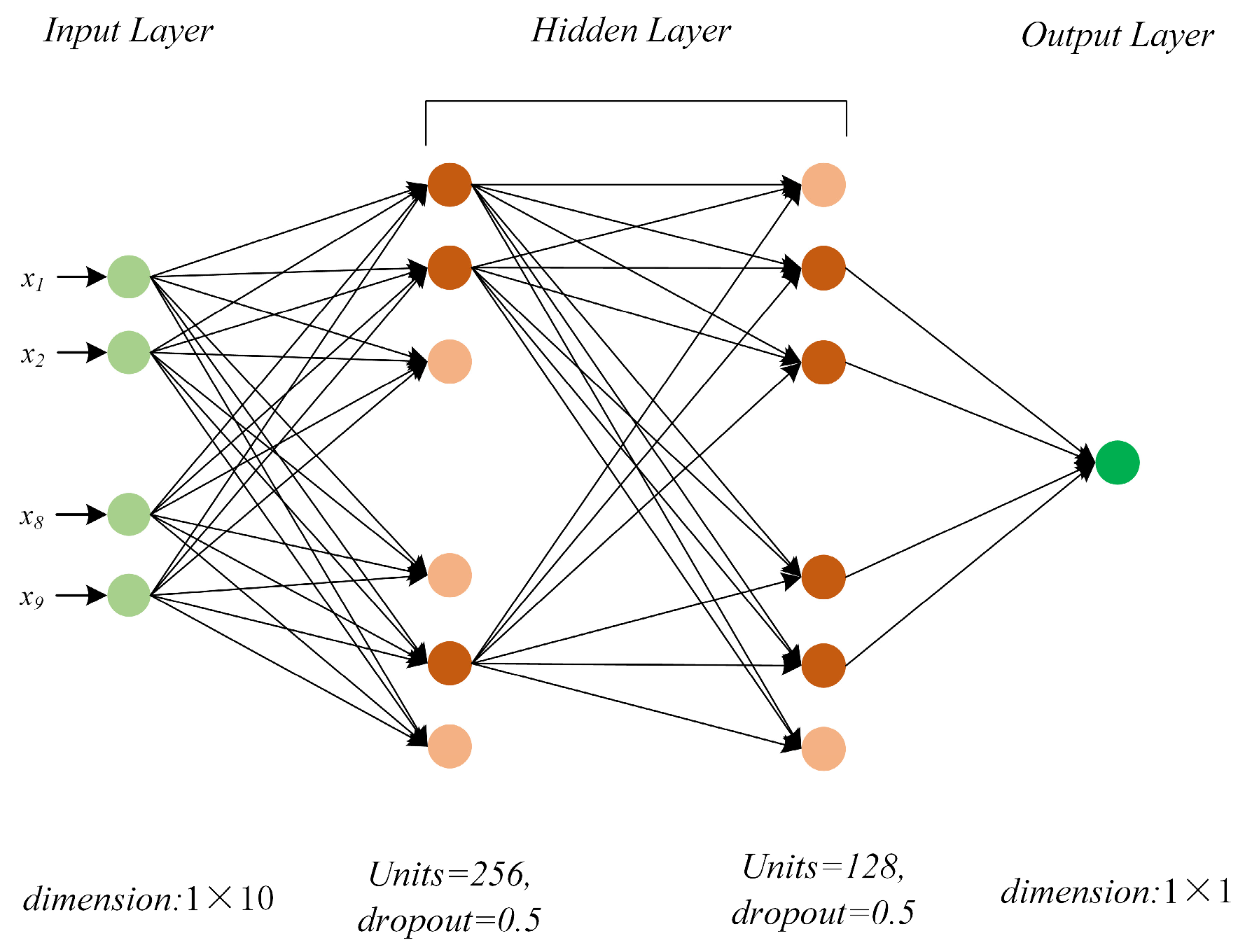
2.5.3. DNN Architecture
2.5.4. Model Evaluation Criteria
3. Results
3.1. Model Results
3.2. Oversampling Analysis
4. Discussion
4.1. The Impact of Feature Selection on Yield Estimation
4.2. The Impact of Data Augmentation on Yield Estimation
4.3. Study Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Vegetation Indices Extracted in This Paper

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Vegetation Index | Formula | Reference |
|---|---|---|---|
| 1 | ATSAVI (Adjusted Transformed Soil-adjusted Vegetation Index) | [33] | |
| 2 | ARVI2 (Atmospherically Resistant Vegetation Index2) | [33] | |
| 3 | BWDRVI (Blue-wide Dynamic Range Vegetation Index) | [34] | |
| 4 | CCCI (Canopy Chlorophyll Content Index) | [33] | |
| 5 | CIgreen (Chlorophyll Index Green) | [35] | |
| 6 | CIrededge (Chlorophyll Index RedEdge) | [35] | |
| 7 | CVI (Chlorophyll Vegetation Index) | [33] | |
| 8 | CI (Coloration Index) | [36] | |
| 9 | NDVI (Normalized Difference Vegetation Index) | [37] | |
| 10 | CTVI (Corrected Transformed Vegetation Index) | [38] | |
| 11 | GDVI (Difference NIR/Green Difference Vegetation Index) | [33] | |
| 12 | EVI (Enhanced Vegetation Index) | [39] | |
| 13 | EVI2 (2-band Enhanced Vegetation Index) | [40] | |
| 14 | GEMI (Global Environmental Monitoring Index) | [41] | |
| 15 | GARI (Green Atmospherically Resistant Vegetation Index) | [36] | |
| 16 | GLI (Greater or Less Ratio Index) | [42] | |
| 17 | GSAVI (Green Soil Adjusted Vegetation Index) | [33] | |
| 18 | GBNDVI (Green–Blue NDVI) | [36] | |
| 19 | GRNDVI (Green–Red NDVI) | [33] | |
| 20 | IPVI (Infrared Percentage Vegetation Index) | [33] | |
| 21 | MSRNir/Red (Modified Simple Ratio Nir/Red) | [33] | |
| 22 | MSAVI (Modified Soil Adjusted Vegetation Index) | [43] | |
| 23 | NGRDI (Normalized Green–red Difference Index) | [44] | |
| 24 | BNDVI (Normalized Difference NIR/Blue NDVI) | [36] | |
| 25 | GNDVI (Green NDVI) | [35] | |
| 26 | NDVIRE (Normalized Difference Vegetation Index Red edge) | [45] | |
| 27 | RI (Redness Index) | [33] | |
| 28 | NDVIrededge (Normalized Difference Rededge/Red Index) | [46] | |
| 29 | PNDVI (Pan NDVI) | [36] | |
| 30 | RBNDVI (Red–Blue NDVI) | [36] | |
| 31 | GRVI (Green–Red Vegetation Index) | [33] | |
| 32 | DVI (Difference Vegetation Index) | [47] | |
| 33 | RRI1 (Simple Ratio NIR/Rededge Rededge Ratio Index 1) | [33] | |
| 34 | IO (Simple Ratio Red/Blue Iron Oxide) | [36] | |
| 35 | RGR (Red Green Ratio Index) | [33] | |
| 36 | SRRed/Nir (Simple Ratio Red/NIR Ratio Vegetation Inde) | [33] | |
| 37 | RRI2 (Simple Ratio Rededge/Red Rededge Ratio Index2) | [36] | |
| 38 | TNDVI (Transformed NDVI) | [33] | |
| 39 | WDRVI (Wide Dynamic Range Vegetation Index) | [48] | |
| 40 | SAVI (Soil Adjusted Vegetation Index) | [49] | |
| 41 | OSAVI (Optimized Soil-adjusted Vegetation Index) | [50] | |
| 42 | RDVI (Renormalized Difference Vegetation Index) | [51] | |
| 43 | RVI (Ratio Vegetation Index) | [52] | |
| 44 | NLI (Non-Linear Index) | [47] | |
| 45 | MSR (Modified Simple Ratio) | [53] | |
| 46 | MNVI (Modified Nonlinear Vegetation Index) | [53] | |
| 47 | TVI (Triangular Vegetation Index) | [53] | |
| 48 | PPR (Plant Pigment Ratio) | [54] | |
| 49 | SIPI (Structure-Intensive Pigment Index) | [55] | |
| 50 | MCARI (Modified Chlorophyll Absorption Ratio Index) | [53] | |
| 51 | TCARI (Transformed Chlorophyll Absorption in Reflectance Index) | [56] | |
| 52 | MTVI2 (Modified Triangular Vegetation Index2) | [57] | |
| 53 | MTCI (Modified Triangular Chlorophyll Index) | [58] |
References
- De Wit, A.; Boogaard, H.; Fumagalli, D.; Janssen, S.; Knapen, R.; Van Kraalingen, D.; Supit, I.; Van Der Wijngaart, R.; Van Diepen, K. 25 years of the WOFOST cropping systems model. Agric. Syst. 2019, 168, 154–167. [Google Scholar] [CrossRef]
- Jones, J.W.; Hoogenboom, G.; Porter, C.H.; Boote, K.J.; Batchelor, W.D.; Hunt, L.A.; Wilkens, P.W.; Singh, U.; Gijsman, A.J.; Ritchie, J.T. The DSSAT cropping system model. Eur. J. Agron. 2003, 18, 235–265. [Google Scholar] [CrossRef]
- McCown, R.L.; Hammer, G.L.; Hargreaves, J.N.G.; Holzworth, D.P.; Freebairn, D.M. APSIM: A novel software system for model development, model testing and simulation in agricultural systems research. Agric. Syst. 1996, 50, 255–271. [Google Scholar] [CrossRef]
- Sibanda, M.; Mutanga, O.; Rouget, M.; Kumar, L. Estimating Biomass of Native Grass Grown under Complex Management Treatments Using WorldView-3 Spectral Derivatives. Remote Sens. 2017, 9, 55. [Google Scholar] [CrossRef]
- Wei, C.; Huang, J.; Mansaray, L.R.; Li, Z.; Liu, W.; Han, J. Estimation and Mapping of Winter Oilseed Rape LAI from High Spatial Resolution Satellite Data Based on a Hybrid Method. Remote Sens. 2017, 9, 488. [Google Scholar] [CrossRef]
- Yuan, L.; Pu, R.; Zhang, J.; Wang, J.; Yang, H. Using high spatial resolution satellite imagery for mapping powdery mildew at a regional scale. Precis. Agric. 2016, 17, 332–348. [Google Scholar] [CrossRef]
- Gómez, D.; Salvador, P.; Sanz, J.; Casanova, J. Modelling wheat yield with antecedent information, satellite and climate data using machine learning methods in Mexico. Agric. For. Meteorol. 2021, 300, 108317. [Google Scholar] [CrossRef]
- Zhuo, W.; Huang, J.; Li, L.; Zhang, X.; Ma, H.; Gao, X.; Huang, H.; Xu, B.; Xiao, X. Assimilating Soil Moisture Retrieved from Sentinel-1 and Sentinel-2 Data into WOFOST Model to Improve Winter Wheat Yield Estimation. Remote Sens. 2019, 11, 1618. [Google Scholar] [CrossRef]
- Xie, Y.; Wang, P.; Bai, X.; Khan, J.; Zhang, S.; Li, L.; Wang, L. Assimilation of the leaf area index and vegetation temperature condition index for winter wheat yield estimation using Landsat imagery and the CERES-Wheat model. Agric. For. Meteorol. 2017, 246, 194–206. [Google Scholar] [CrossRef]
- Zhang, C.; Marzougui, A.; Sankaran, S. High-resolution satellite imagery applications in crop phenotyping: An overview. Comput. Electron. Agric. 2020, 175, 105584. [Google Scholar] [CrossRef]
- Bu, H.; Sharma, L.K.; Denton, A.; Franzen, D.W. Comparison of Satellite Imagery and Ground-Based Active Optical Sensors as Yield Predictors in Sugar Beet, Spring Wheat, Corn, and Sunflower. Agron. J. 2017, 109, 299–308. [Google Scholar] [CrossRef]
- Stöcker, C.; Eltner, A.; Karrasch, P. Measuring gullies by synergetic application of UAV and close range photogrammetry—A case study from Andalusia, Spain. CATENA 2015, 132, 1–11. [Google Scholar] [CrossRef]
- Ammour, N.; Alhichri, H.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M. Deep Learning Approach for Car Detection in UAV Imagery. Remote Sens. 2017, 9, 312. [Google Scholar] [CrossRef]
- Kerkech, M.; Hafiane, A.; Canals, R. Vine disease detection in UAV multispectral images using optimized image registration and deep learning segmentation approach. Comput. Electron. Agric. 2020, 174, 105446. [Google Scholar] [CrossRef]
- Yang, W.; Nigon, T.; Hao, Z.; Dias Paiao, G.; Fernández, F.; Mulla, D.; Yang, C. Estimation of corn yield based on hyperspectral imagery and convolutional neural network. Comput. Electron. Agric. 2021, 184, 106092. [Google Scholar] [CrossRef]
- Tanaka, Y.; Watanabe, T.; Katsura, K.; Tsujimoto, Y.; Takai, T.; Tanaka, T.; Kawamura, K.; Saito, H.; Homma, K.; Mairoua, S.G.; et al. Deep Learning Enables Instant and Versatile Estimation of Rice Yield Using Ground-Based RGB Images. Plant Phenomics 2023, 5, 0073. [Google Scholar] [CrossRef]
- Fu, Z.; Jiang, J.; Gao, Y.; Krienke, B.; Wang, M.; Zhong, K.; Cao, Q.; Tian, Y.; Zhu, Y.; Cao, W.; et al. Wheat Growth Monitoring and Yield Estimation based on Multi-Rotor Unmanned Aerial Vehicle. Remote Sens. 2020, 12, 508. [Google Scholar] [CrossRef]
- Marques Ramos, A.P.; Prado Osco, L.; Elis Garcia Furuya, D.; Nunes Gonçalves, W.; Cordeiro Santana, D.; Pereira Ribeiro Teodoro, L.; Antonio da Silva Junior, C.; Fernando Capristo-Silva, G.; Li, J.; Henrique Rojo Baio, F.; et al. A random forest ranking approach to predict yield in maize with uav-based vegetation spectral indices. Comput. Electron. Agric. 2020, 178, 105791. [Google Scholar] [CrossRef]
- Pukrongta, N.; Taparugssanagorn, A.; Sangpradit, K. Enhancing Crop Yield Predictions with PEnsemble 4: IoT and ML-Driven for Precision Agriculture. Appl. Sci. 2024, 14, 3313. [Google Scholar] [CrossRef]
- Ma, J.; Liu, B.; Ji, L.; Zhu, Z.; Wu, Y.; Jiao, W. Field-scale yield prediction of winter wheat under different irrigation regimes based on dynamic fusion of multimodal UAV imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103292. [Google Scholar] [CrossRef]
- Mia, M.S.; Tanabe, R.; Habibi, L.N.; Hashimoto, N.; Homma, K.; Maki, M.; Matsui, T.; Tanaka, T. Multimodal Deep Learning for Rice Yield Prediction Using UAV-Based Multispectral Imagery and Weather Data. Remote Sens. 2023, 15, 2511. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Sreejith, S.; Nehemiah, H.K.; Kannan, A. Clinical data classification using an enhanced SMOTE and chaotic evolutionary feature selection. Comput. Biol. Med. 2020, 126, 103991. [Google Scholar] [CrossRef] [PubMed]
- Kourehpaz, P.; Hutt, C.M. Machine Learning for Enhanced Regional Seismic Risk Assessments. J. Struct. Eng. 2022, 148, 04022126. [Google Scholar] [CrossRef]
- Ke, H.; Gong, S.; He, J.; Zhang, L.; Mo, J. A hybrid XGBoost-SMOTE model for optimization of operational air quality numerical model forecasts. Front. Environ. Sci. 2022, 10, 1007530. [Google Scholar] [CrossRef]
- Shen, Y.; Yan, Z.; Yang, Y.; Tang, W.; Sun, J.; Zhang, Y. Application of UAV-Borne Visible-Infared Pushbroom Imaging Hyperspectral for Rice Yield Estimation Using Feature Selection Regression Methods. Sustainability 2024, 16, 632. [Google Scholar] [CrossRef]
- Jiang, J.; Wang, F.; Wang, Y.; Jiang, W.; Qiao, Y.; Bai, W.; Zheng, X. An Urban Road Risk Assessment Framework Based on Convolutional Neural Networks. Int. J. Disaster Risk Sci. 2023, 14, 475–487. [Google Scholar] [CrossRef]
- Wang, S.; Liu, S.; Zhang, J.; Che, X.; Yuan, Y.; Wang, Z.; Kong, D. A new method of diesel fuel brands identification: SMOTE oversampling combined with XGBoost ensemble learning. Fuel 2020, 282, 118848. [Google Scholar] [CrossRef]
- Nevavuori, P.; Narra, N.; Linna, P.; Lipping, T. Crop Yield Prediction Using Multitemporal UAV Data and Spatio-Temporal Deep Learning Models. Remote Sens. 2020, 12, 4000. [Google Scholar] [CrossRef]
- Yang, G.; Li, Y.; Yuan, S.; Zhou, C.; Xiang, H.; Zhao, Z.; Wei, Q.; Chen, Q.; Peng, S.; Xu, L. Enhancing direct-seeded rice yield prediction using UAV-derived features acquired during the reproductive phase. Precis. Agric. 2024, 25, 834–864. [Google Scholar] [CrossRef]
- Fan, J.; Zhou, J.; Wang, B.; Leon, N.; Kaeppler, S.; Lima, D.; Zhang, Z. Estimation of Maize Yield and Flowering Time Using Multi-Temporal UAV-Based Hyperspectral Data. Remote Sens. 2022, 14, 3052. [Google Scholar] [CrossRef]
- Sun, G.; Zhang, Y.; Chen, H.; Wang, L.; Li, M.; Sun, X.; Fei, S.; Xiao, S.; Yan, L.; Li, Y.; et al. Improving soybean yield prediction by integrating UAV nadir and cross-circling oblique imaging. Eur. J. Agron. 2024, 155, 127134. [Google Scholar] [CrossRef]
- Teodoro, P.E.; Teodoro, L.P.R.; Baio, F.H.R.; da Silva Junior, C.A.; dos Santos, R.G.; Ramos, A.P.M.; Pinheiro, M.M.F.; Osco, L.P.; Goncalves, W.N.; Carneiro, A.M.; et al. Predicting Days to Maturity, Plant Height, and Grain Yield in Soybean: A Machine and Deep Learning Approach Using Multispectral Data. Remote Sens. 2021, 13, 4632. [Google Scholar] [CrossRef]
- Hancock, D.W.; Dougherty, C.T. Relationships between Blue- and Red-based Vegetation Indices and Leaf Area and Yield of Alfalfa. Crop Sci. 2007, 47, 2547–2556. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Kaufman, Y.J.; Merzlyak, M.N. Use of a green channel in remote sensing of global vegetation from EOS-MODIS. Remote Sens. Environ. 1996, 58, 289–298. [Google Scholar] [CrossRef]
- Index DataBase—A Database for Remote Sensing Indices. Available online: https://www.indexdatabase.de/db/i.php (accessed on 23 July 2024).
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the Great Plains with ERTS. NASA Spec. Publ. 1974, 351, 309. [Google Scholar]
- Perry, C.R.; Lautenschlager, L.F. Functional equivalence of spectral vegetation indices. Remote Sens. Environ. 1984, 14, 169–182. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Jiang, Z.; Huete, A.; Didan, K.; Miura, T. Development of a two-band enhanced vegetation index without a blue band. Remote Sens. Environ. 2008, 112, 3833–3845. [Google Scholar] [CrossRef]
- Pinty, B.; Verstraete, M.M. GEMI: A Non-Linear Index to Monitor Global Vegetation from Satellites. Vegetatio 1992, 101, 15–20. [Google Scholar] [CrossRef]
- Louhaichi, M.; Borman, M.M.; Johnson, D.E. Spatially Located Platform and Aerial Photography for Documentation of Grazing Impacts on Wheat. Geocarto Int. 2001, 16, 65–70. [Google Scholar] [CrossRef]
- Qi, J.; Chehbouni, A.; Huete, A.R.; Kerr, Y.H.; Sorooshian, S. A modified soil adjusted vegetation index. Remote Sens. Environ. 1994, 48, 119–126. [Google Scholar] [CrossRef]
- Barrero, O.; Perdomo, S.A. RGB and multispectral UAV image fusion for Gramineae weed detection in rice fields. Precis. Agric. 2018, 19, 809–822. [Google Scholar] [CrossRef]
- Elsayed, S.; Rischbeck, P.; Schmidhalter, U. Comparing the performance of active and passive reflectance sensors to assess the normalized relative canopy temperature and grain yield of drought-stressed barley cultivars. Field Crops Res. 2015, 177, 148–160. [Google Scholar] [CrossRef]
- Robson, A.; Rahman, M.M.; Muir, J. Using Worldview Satellite Imagery to Map Yield in Avocado (Persea americana): A Case Study in Bundaberg, Australia. Remote Sens. 2017, 9, 1223. [Google Scholar] [CrossRef]
- Hadizadeh, M.; Rahnama, M.; Poor, H.A.; Behnam, H.; Mona, K. The comparison between remotely-sensed vegetation indices of Meteosat second generation satellite and temperature-based agrometeorological indices for monitoring of main crops in the northeast of Iran. Arab. J. Geosci. 2020, 13, 509. [Google Scholar] [CrossRef]
- Gitelson, A.A. Wide Dynamic Range Vegetation Index for Remote Quantification of Biophysical Characteristics of Vegetation. J. Plant Physiol. 2004, 161, 165–173. [Google Scholar] [CrossRef] [PubMed]
- Suárez, L.; Zarco-Tejada, P.J.; Sepulcre-Cantó, G.; Pérez-Priego, O.; Miller, J.R.; Jiménez-Muñoz, J.C.; Sobrino, J. Assessing canopy PRI for water stress detection with diurnal airborne imagery. Remote Sens. Environ. 2008, 112, 560–575. [Google Scholar] [CrossRef]
- Rondeaux, G.; Steven, M.; Baret, F. Optimization of soil-adjusted vegetation indices. Remote Sens. Environ. 1996, 55, 95–107. [Google Scholar] [CrossRef]
- Cao, Q.; Miao, Y.; Wang, H.; Huang, S.; Cheng, S.; Khosla, R.; Jiang, R. Non-destructive estimation of rice plant nitrogen status with Crop Circle multispectral active canopy sensor. Field Crops Res. 2013, 154, 133–144. [Google Scholar] [CrossRef]
- Jordan, C.F. Derivation of Leaf-Area Index from Quality of Light on the Forest Floor. Ecology 1969, 50, 663–666. [Google Scholar] [CrossRef]
- Chen, J.M. Evaluation of Vegetation Indices and a Modified Simple Ratio for Boreal Applications. Can. J. Remote Sens. 1996, 22, 229–242. [Google Scholar] [CrossRef]
- Metternicht, G. Vegetation indices derived from high-resolution airborne videography for precision crop management. Int. J. Remote Sens. 2003, 24, 2855–2877. [Google Scholar] [CrossRef]
- Akuraju, V.R.; Ryu, D.; George, B.J.G. Estimation of root-zone soil moisture using crop water stress index (CWSI) in agricultural fields. GIScience Remote Sens. 2021, 58, 340–353. [Google Scholar] [CrossRef]
- Haboudane, D.; Miller, J.R.; Tremblay, N.; Zarco-Tejada, P.; Dextraze, L. Integrated narrow-band vegetation indices for prediction of crop chlorophyll content for application to precision agriculture. Remote Sens. Environ. 2002, 81, 416–426. [Google Scholar] [CrossRef]
- Nguy-Robertson, A.L. The mathematical identity of two vegetation indices: MCARI2 and MTVI2. Int. J. Remote Sens. 2013, 34, 7504–7507. [Google Scholar] [CrossRef]
- Dash, J.; Curran, P.J. Evaluation of the MERIS terrestrial chlorophyll index. Adv. Space Res. 2006, 1, 100–104. [Google Scholar] [CrossRef]
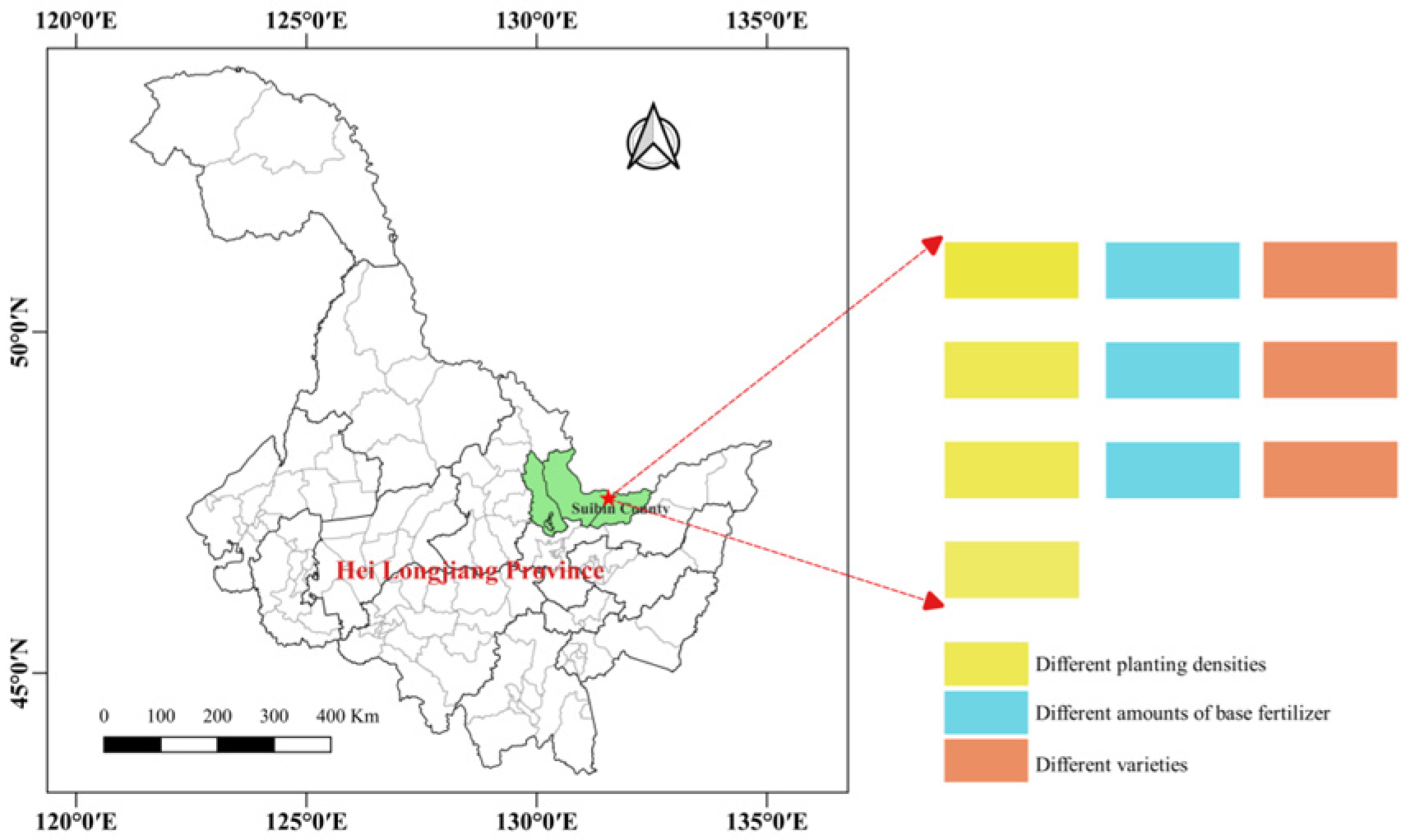





| Plot | Rice Varieties | Planting Density (cm) | Basal Fertilizer Amount (kg/ha) |
|---|---|---|---|
| 1 | Songjing 535 | 30 × 12 | 25 |
| 2 | Suijing 18 | ||
| 3 | Kendao 94 | ||
| 4 | Longjing 31 | 30 × 12 | 26.25 |
| 5 | 27.5 | ||
| 6 | 28.75 | ||
| 7 | Longjing 31 | 25 × 12 | 25 |
| 8 | 25 × 14 | ||
| 9 | 30 × 10 | ||
| 10 | 30 × 12 |
| Channel | Channel Name | Center Wavelength (nm) | Spectral Bandwidth (nm) |
|---|---|---|---|
| 1 | Blue | 450 | 35 |
| 2 | Green | 555 | 25 |
| 3 | Red | 660 | 20 |
| 4 | Red edge 1 | 720 | 10 |
| 5 | Red edge 2 | 750 | 15 |
| 6 | Near Infrared | 840 | 35 |
| Dataset | Category I Yield: 6000–8250 kg/ha | Category II Yield: 8250–10,500 kg/ha | Category III Yield: 10,500–12,750 kg/ha | Total |
|---|---|---|---|---|
| Original Data | 80 | 144 | 69 | 293 |
| Original Training Data | 64 | 115 | 55 | 234 |
| Original Test Data | 16 | 29 | 14 | 59 |
| Serial Number | VI | Formula |
|---|---|---|
| 1 | CVI (Chlorophyll Vegetation Index) | |
| 2 | CI (Coloration Index) | |
| 3 | GLI (Greater or Less Ratio Index) | |
| 4 | NGRDI (Normalized Green–Red Difference Index) | |
| 5 | NDVIRE (Normalized Difference Vegetation Index Red edge) | |
| 6 | RI (Redness Index) | |
| 7 | GRVI (Green–Red Vegetation Index) | |
| 8 | IO (Simple Ratio Red/Blue Iron Oxide) | |
| 9 | RGR (Red/Green Ratio Index) | |
| 10 | MTCI (Modified Triangular Chlorophyll Index) |
| Dataset | Data Components | Negative Samples I | Positive Samples | Negative Samples II | Total |
|---|---|---|---|---|---|
| Training Data | Original | 64 | 115 | 55 | 234 |
| Augmented | 48 | / | 57 | 105 | |
| Test Data | Original | 16 | 29 | 14 | 59 |
| Augmented | 12 | / | 14 | 26 | |
| Total | Original | 80 | 144 | 69 | 293 |
| Augmented | 60 | / | 71 | 131 | |
| Original + Augmented | 140 | 144 | 140 | 424 |
| Model | R2 | RMSE (t/ha) |
|---|---|---|
| PLSR | 0.514 | 1.07 |
| SVR | 0.503 | 1.08 |
| RF | 0.589 | 0.98 |
| DNN | 0.619 | 0.95 |
| Model | R2 | RMSE (t/ha) |
|---|---|---|
| PLSR | 0.641 | 0.92 |
| SVR | 0.671 | 0.89 |
| RF | 0.752 | 0.74 |
| DNN | 0.770 | 0.73 |
| Model | R2 | RMSE (t/ha) |
|---|---|---|
| PLSR | 0.529 | 1.05 |
| SVR | 0.524 | 1.06 |
| RF | 0.608 | 0.96 |
| DNN | 0.634 | 0.93 |
| Model | R2 | RMSE (t/ha) |
|---|---|---|
| PLSR | 0.688 | 0.89 |
| SVR | 0.700 | 0.87 |
| RF | 0.782 | 0.73 |
| DNN | 0.810 | 0.69 |
| Feature Selection Method | Data Augmentation | Training Data | Test Data | ||
|---|---|---|---|---|---|
| R2 | RMSE (t/ha) | R2 | RMSE (t/ha) | ||
| Pearson | No | 0.833 | 0.65 | 0.619 | 0.95 |
| Yes | 0.874 | 0.55 | 0.810 | 0.69 | |
| Feature Selection Method | Data Augmentation | R2 | RMSE (t/ha) |
|---|---|---|---|
| RF | No | 0.627 | 0.94 |
| Yes | 0.797 | 0.74 | |
| Pearson | No | 0.634 | 0.93 |
| Yes | 0.810 | 0.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, J.; Zheng, Z.; Chu, C.; Wang, W.; Guo, L. A Hybrid Synthetic Minority Oversampling Technique and Deep Neural Network Framework for Improving Rice Yield Estimation in an Open Environment. Agronomy 2024, 14, 1890. https://doi.org/10.3390/agronomy14091890
Yuan J, Zheng Z, Chu C, Wang W, Guo L. A Hybrid Synthetic Minority Oversampling Technique and Deep Neural Network Framework for Improving Rice Yield Estimation in an Open Environment. Agronomy. 2024; 14(9):1890. https://doi.org/10.3390/agronomy14091890
Chicago/Turabian StyleYuan, Jianghao, Zuojun Zheng, Changming Chu, Wensheng Wang, and Leifeng Guo. 2024. "A Hybrid Synthetic Minority Oversampling Technique and Deep Neural Network Framework for Improving Rice Yield Estimation in an Open Environment" Agronomy 14, no. 9: 1890. https://doi.org/10.3390/agronomy14091890
APA StyleYuan, J., Zheng, Z., Chu, C., Wang, W., & Guo, L. (2024). A Hybrid Synthetic Minority Oversampling Technique and Deep Neural Network Framework for Improving Rice Yield Estimation in an Open Environment. Agronomy, 14(9), 1890. https://doi.org/10.3390/agronomy14091890