
Lightweight Wheat Spike Detection Method Based on Activation and Loss Function Enhancements for YOLOv5s


Abstract
1. Introduction
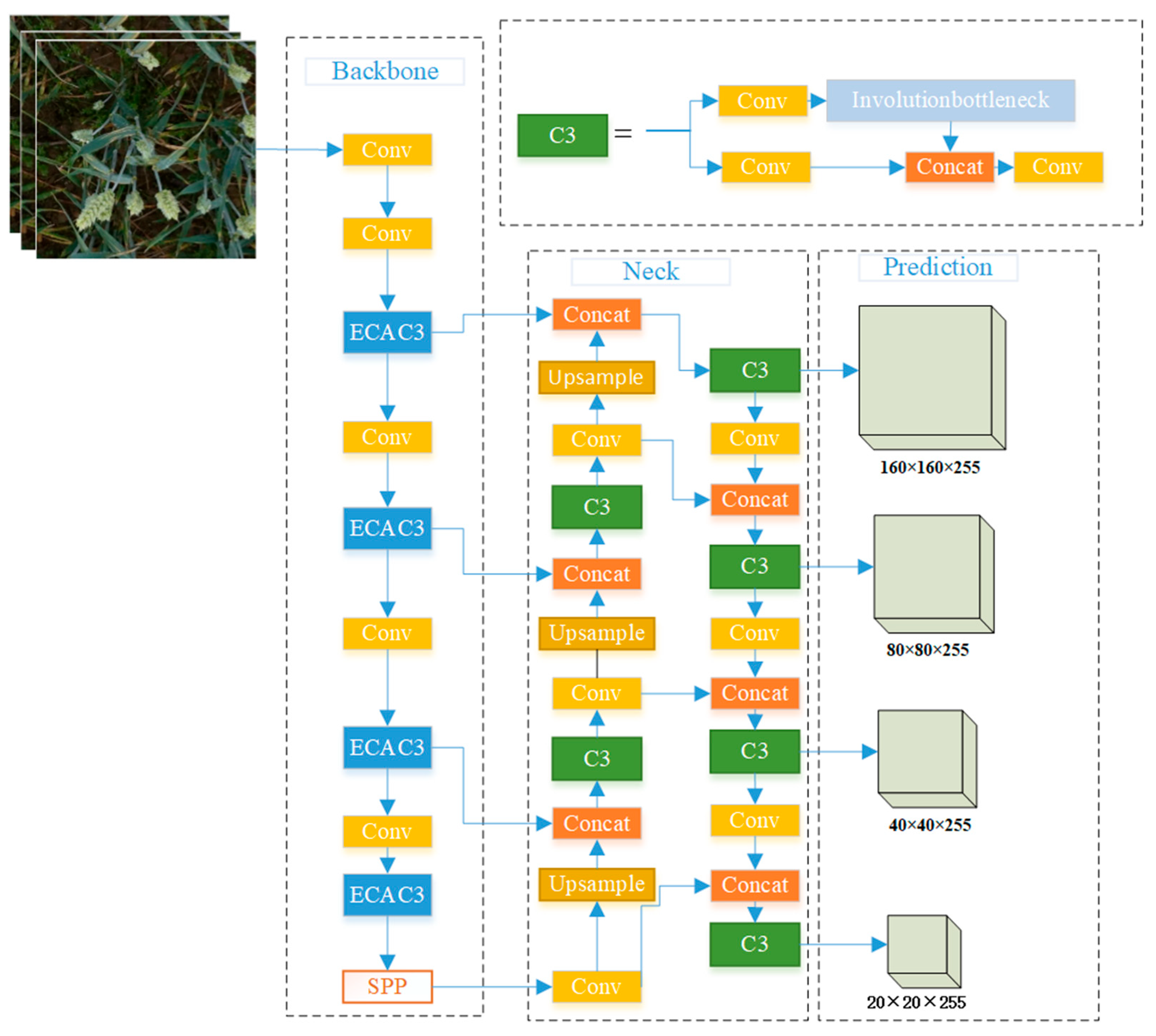
- The present study refines the original three-tiered detection scheme to a four-tiered one by incorporating an additional small-scale detection layer. This modification enables the YOLOv5s algorithm to more effectively leverage superficial information, thereby enhancing its detection capabilities for diminutive wheat spikes.
- Furthermore, improvements have been made to the backbone of the YOLOv5s algorithm by integrating the Efficient Channel Attention (ECA) attention mechanism into all CSP Bottleneck with three convolutions (C3) modules, which significantly boosts the network’s ability to extract features.
- To tackle the issue of current wheat spike detection algorithms being too cumbersome and having an excessive number of parameters, this study conducts a lightweight optimization of the enhanced YOLOv5s + 4 + ECAC3 algorithm. The GhostNet network architecture is initially utilized to perform lightweight modifications due to its innovative approach to feature map generation and efficient use of computational resources, effectively reducing its size and computational requirements.
- Thereafter, the network is further optimized with the Randomized Rectified Linear Unit (RReLU) activation function and the Efficient Intersection over Union (EIoU) loss function to elevate its detection efficacy for wheat spikes.
2. Related Works
3. Materials and Methods
3.1. Data Source and Preprocessing
3.2. Experimental Environment and Parameter Setting
3.3. Improvement of YOLOv5s
3.3.1. Addition of Additional Scale Layer
3.3.2. Addition of Attention Mechanism
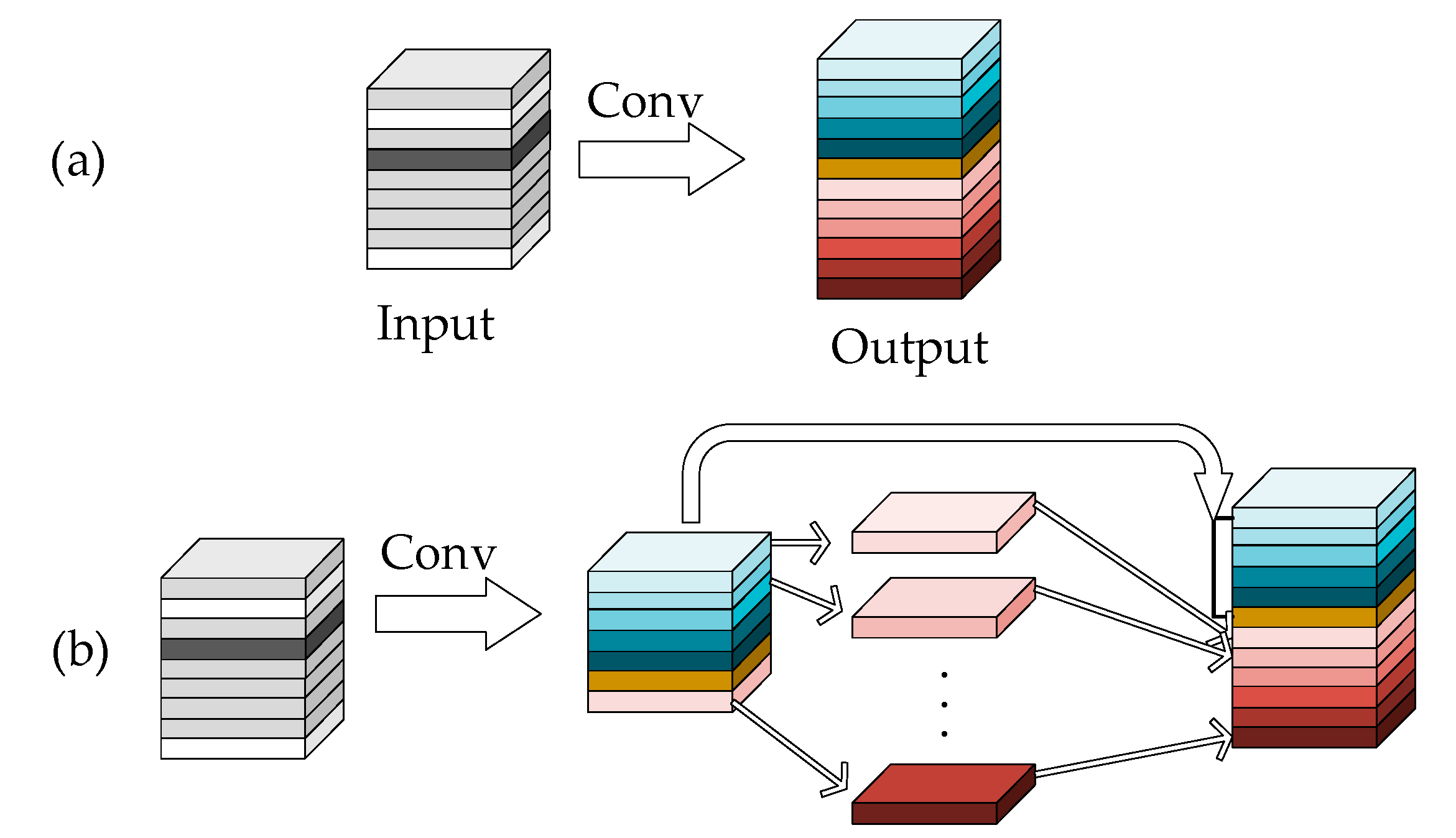
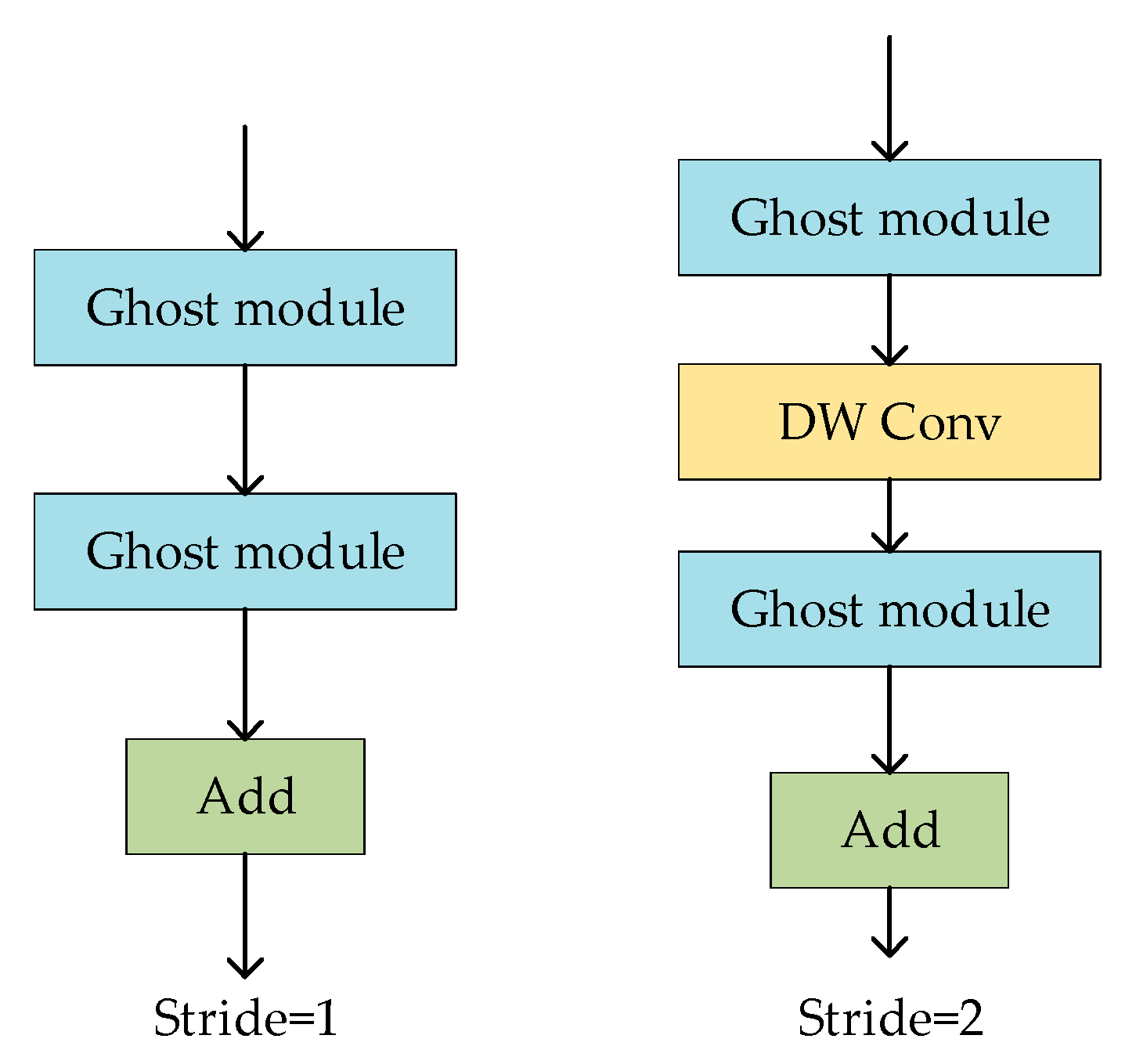
3.4. Model Lightweighting for YOLOv5s + 4 + ECAC3
3.4.1. Improvement of the YOLOv5s + 4 + ECAC3 Model Using GhostNet
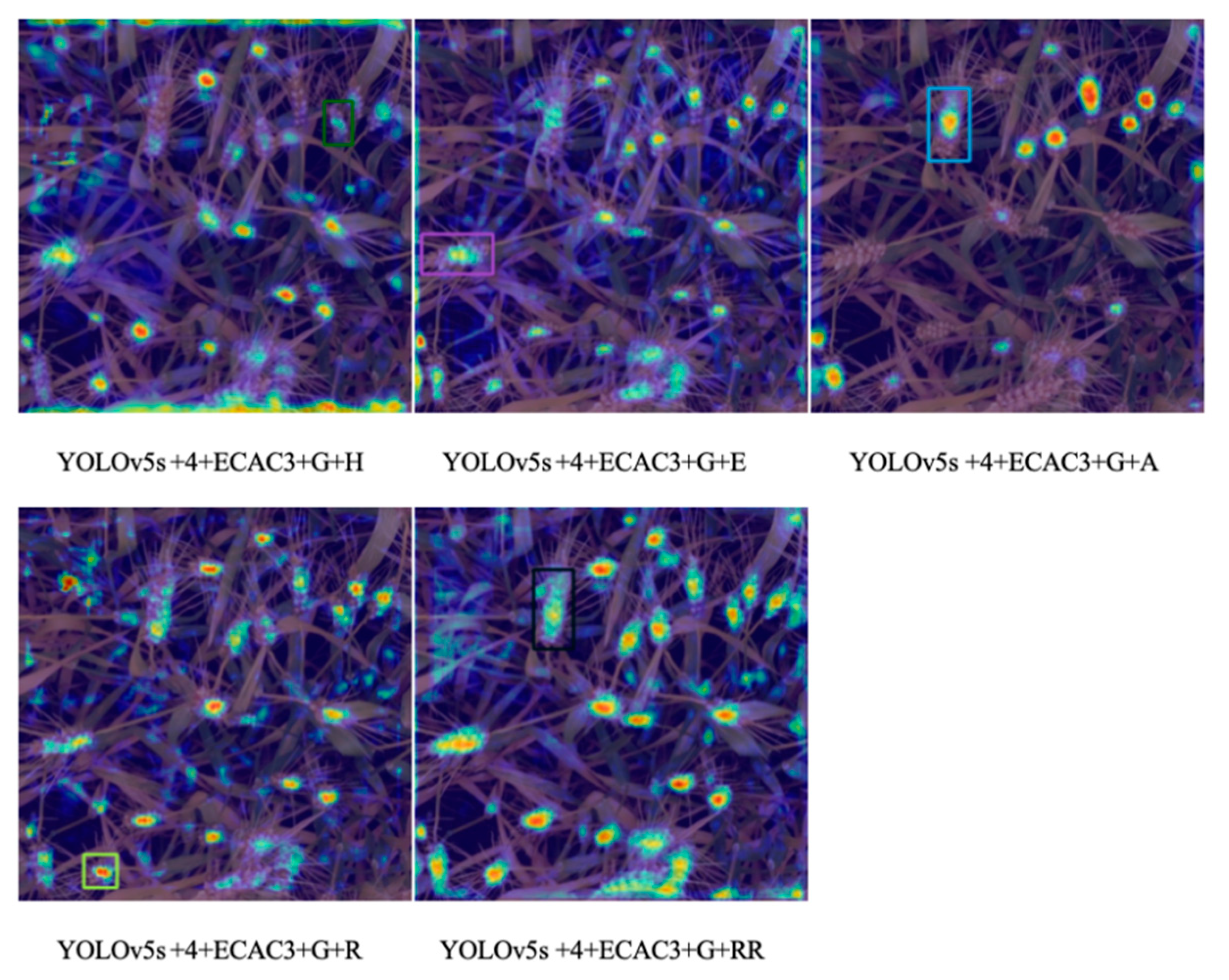
3.4.2. Improvement of Activation Function
3.4.3. Improvement of Loss Function
3.5. Evaluation Metrics
4. Results and Discussion
4.1. Evaluation of YOLOv5s + 4 + ECAC3
4.2. Lightweighting the YOLOv5s + 4 + ECAC3

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Para (M) | Size (MB) | GFlOPs | FPS | Acc (%) |
|---|---|---|---|---|---|
| YOLOv5s | 7.01 | 14.50 | 15.80 | 74.60 | 91.03 |
| YOLOv5s + 4 + ECAC3 | 7.50 | 16.10 | 21.40 | 49.50 | 93.97 |
| YOLOv5s + 4 + ECAC3 + G [23] | 5.10 | 11.60 | 14.30 | 51.80 | 89.84 |
| YOLOv5s + 4 + ECAC3 + S [28] | 3.50 | 7.40 | 2.60 | 71.40 | 78.52 |
| YOLOv5s + 4 + ECAC3 + M [29] | 3.50 | 7.50 | 6.20 | 80.60 | 86.80 |
4.3. Comparison of Activation Functions
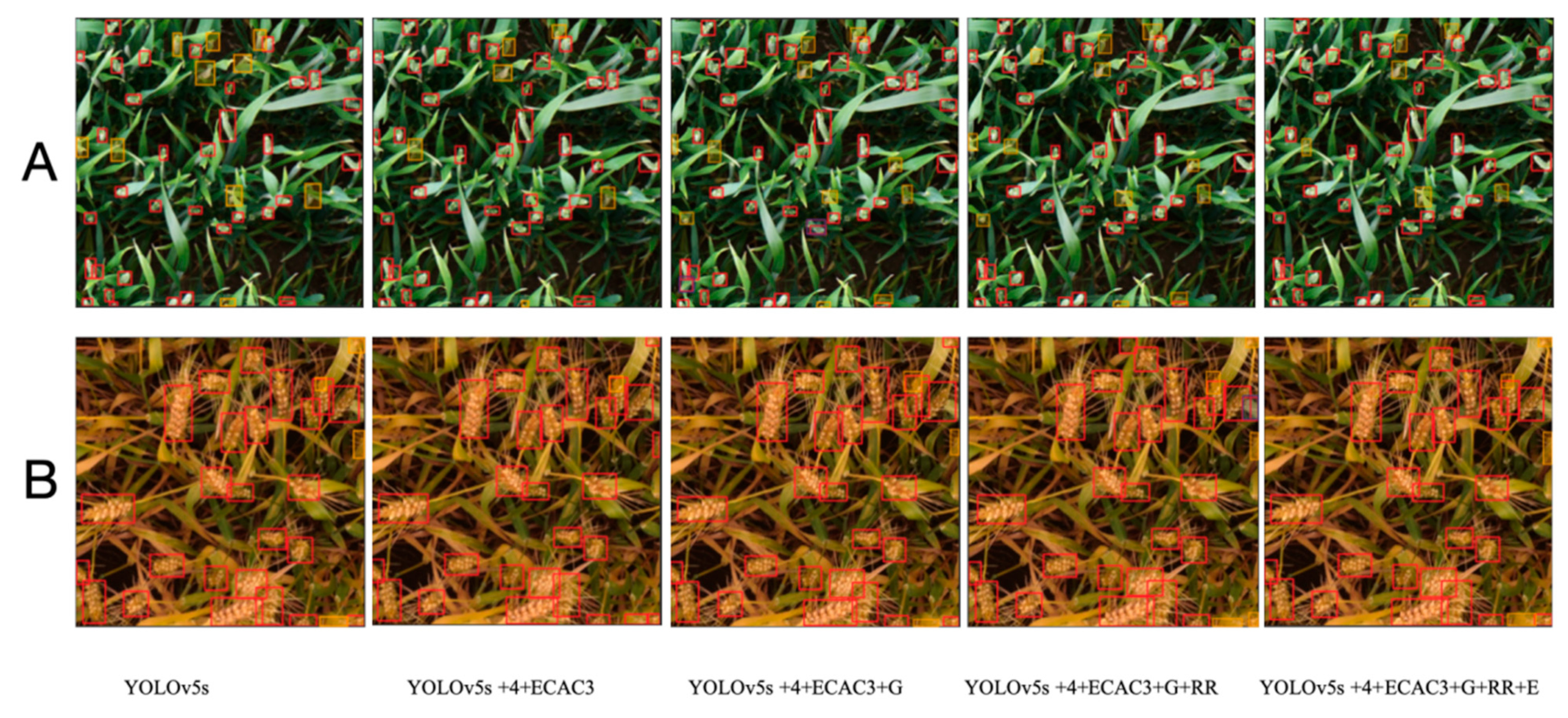
4.4. Comparison of Identification of Wheat Spikes for Different Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lv, Z.; Liu, X.; Cao, W.; Zhu, Y. Climate change impacts on regional winter wheat production in main wheat production regions of China. Agric. Forest Meteorol. 2013, 171, 234–248. [Google Scholar] [CrossRef]
- Zhao, J.; Du, S.; Huang, L. Monitoring wheat powdery mildew (Blumeria graminis f. sp. tritici) using multisource and multitemporal satellite images and support vector machine classifier. Smart Agric. 2022, 4, 17–28. [Google Scholar]
- Qiu, R.; He, Y.; Zhang, M. Automatic detection and counting of wheat spikelet using semi-automatic labeling and deep learning. Front. Plant Sci. 2022, 13, 872555. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Yan, J.; Xue, T.; Wang, S.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W.; Zhang, X. A deep learning method for oriented and small wheat spike detection (OSWSDet) in UAV images. Comput. Electron. Agric. 2022, 198, 107087. [Google Scholar] [CrossRef]
- Khaki, S.; Safaei, N.; Pham, H.; Wang, L. WheatNet: A lightweight convolutional neural network for high-throughput image-based wheat head detection and counting. Neurocomputing 2022, 489, 78–89. [Google Scholar] [CrossRef]
- Wiwart, M.; Suchowilska, E.; Lajszner, W.; Graban, Ł. Identification of hybrids of spelt and wheat and their parental forms using shape and color descriptors. Comput. Electron. Agric. 2012, 83, 68–76. [Google Scholar] [CrossRef]
- Pourreza, A.; Pourreza, H.; Abbaspour-Fard, M.H.; Sadrnia, H. Identification of nine Iranian wheat seed varieties by textural analysis with image processing. Comput. Electron. Agric. 2012, 83, 102–108. [Google Scholar] [CrossRef]
- Alharbi, N.; Zhou, J.; Wang, W. Automatic counting of wheat spikes from wheat growth images. In Proceedings of the 7th International Conference on Pattern Recognition Applications and Methods, Madeira, Portugal, 16–18 January 2018; SciTePress—Science and Technology Publications: Setúbal, Portugal, 2018; pp. 346–355. [Google Scholar]
- Madec, S.; Jin, X.; Lu, H.; De Solan, B.; Liu, S.; Duyme, F.; Heritier, E.; Baret, F. Ear density estimation from high resolution RGB imagery using deep learning technique. Agric. Forest Meteorol. 2019, 264, 225–234. [Google Scholar] [CrossRef]
- Artemenko, N.V.; Genaev, M.A.; Epifanov, R.U.; Komyshev, E.G.; Kruchinina, Y.V.; Koval, V.S.; Goncharov, N.P.; Afonnikov, D.A. Image-based classification of wheat spikes by glume pubescence using convolutional neural networks. Front. Plant Sci. 2024, 14, 1336192. [Google Scholar] [CrossRef]
- Yang, B.; Gao, Z.; Gao, Y.; Zhu, Y. Rapid detection and counting of wheat ears in the field using YOLOv4 with attention module. Agronomy 2021, 11, 1202. [Google Scholar] [CrossRef]
- Hong, Q.; Jiang, L.; Zhang, Z.; Ji, S.; Gu, C.; Mao, W.; Li, W.; Liu, T.; Li, B.; Tan, C. A lightweight model for wheat ear fusarium head blight detection based on RGB images. Remote Sens. 2022, 14, 3481. [Google Scholar] [CrossRef]
- Shen, R.; Zhen, T.; Li, Z. YOLOv5-based model integrating separable convolutions for detection of wheat head images. IEEE Access 2023, 11, 12059–12074. [Google Scholar] [CrossRef]
- David, E.; Serouart, M.; Smith, D.; Madec, S.; Velumani, K.; Liu, S.; Wang, X.; Pinto, F.; Shafiee, S.; Tahir, I.S.; et al. Global wheat head detection 2021: An improved dataset for benchmarking wheat head detection methods. Plant Phenomics 2021, 2021, 9846158. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, H.; Lu, F.; Tong, X.; Gao, X.; Wang, L.; Liao, Z. A model for detecting safety hazards in key electrical sites based on hybrid attention mechanisms and lightweight Mobilenet. Energy Rep. 2021, 7, 716–724. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, L. A new lightweight network based on MobileNetV3. KSII Trans. Internet Inform. Syst. 2022, 16, 1–15. [Google Scholar]
- Han, J.; Yang, Y. L-Net: Lightweight and fast object detector-based ShuffleNetV2. J. Real-Time Image Process. 2021, 18, 2527–2538. [Google Scholar] [CrossRef]
- Yin, J.; Guo, L.; Jiang, W.; Hong, S.; Yang, J. ShuffleNet-inspired lightweight neural network design for automatic modulation classification methods in ubiquitous IoT cyber–physical systems. Comput. Commun. 2021, 176, 249–257. [Google Scholar] [CrossRef]
- Li, H.; Qiu, W.; Zhang, L. Improved ShuffleNet V2 for lightweight crop disease identification. J. Comput. Eng. Appl. 2022, 58, 260. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Olorunshola, O.E.; Irhebhude, M.E.; Evwiekpaefe, A.E. A comparative study of YOLOv5 and YOLOv7 object detection algorithms. J. Comput. Soc. Inform. 2023, 2, 1–12. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–3 November 2019; pp. 1314–1324. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Dubey, S.R.; Singh, S.K.; Chaudhuri, B.B. Activation functions in deep learning: A comprehensive survey and benchmark. Neurocomputing 2022, 503, 92–108. [Google Scholar] [CrossRef]
- Xia, Y.; Zhang, J.; Gong, Z.; Jiang, T.; Yao, W. RBUE: A ReLU-based uncertainty estimation method for convolutional neural networks. Complex Intell. Syst. 2023, 9, 4735–4749. [Google Scholar] [CrossRef]
- Bhagat, S.; Kokare, M.; Haswani, V.; Hambarde, P.; Kamble, R. WheatNet-Lite: A novel light weight network for wheat head detection. In Proceedings of the 2021 IEEE CVF International Conference Computer Vision Workshop, ICCVW 2021, Montreal, BC, Canada, 11–17 October 2021; pp. 1332–1341. [Google Scholar]
- Wen, C.; Wu, J.; Chen, H.; Su, H.; Chen, X.; Li, Z.; Yang, C. Wheat spike detection and counting in the field based on SpikeRetinaNet. Front. Plant Sci. 2022, 13, 821717. [Google Scholar] [CrossRef]
- Zhang, G.; Wang, Z.; Liu, B.; Gu, L.; Zhen, W.; Yao, W. A density map-based method for counting wheat ears. Front. Plant Sci 2024, 15, 1354428. [Google Scholar] [CrossRef]

| Parameter | Value |
|---|---|
| Learning rate | 0.01 |
| Momentum coefficient | 0.937 |
| Weight decay | 0.005 |
| Batchsize | 16 |
| Epoch | 150 |
| Method | P/% | R/% | mAP@0.5/% | GFLOPs | Inference Speed (ms) |
|---|---|---|---|---|---|
| YOLOv5s | 92.6 | 89.7 | 94.2 | 15.8 | 13.4 |
| YOLOv5m | 93.4 | 89.1 | 94.2 | 47.9 | 21.4 |
| YOLOv5x | 93.1 | 89.8 | 94.2 | 203.8 | 27.4 |
| YOLOv5l | 92.2 | 90.3 | 94.4 | 47.9 | 20.8 |
| YOLOv7 | 94.0 | 96.0 | 93.6 | 105.1 | 45.1 |
| SSD [25] | 90.4 | 45.9 | 69.9 | 61.5 | 99.2 |
| YOLOv5s + 4 + ECAC3 | 92.8 | 89.8 | 94.6 | 21.4 | 20.2 |
| Method | Para (M) | Size (MB) | GFlOPs | FPS |
|---|---|---|---|---|
| YOLOv5s + 4 + ECAC3 + G | 5.10 | 11.60 | 14.30 | 89.84 |
| YOLOv5s + 4 + ECAC3 + G + H [30] | 5.10 | 11.60 | 14.30 | 89.90 |
| YOLOv5s + 4 + ECAC3 + G + E [31] | 5.10 | 11.60 | 14.30 | 86.70 |
| YOLOv5s + 4 + ECAC3 + G + A [32] | 5.10 | 11.60 | 14.30 | 88.52 |
| YOLOv5s + 4 + ECAC3 + G + R [24] | 5.10 | 11.60 | 14.30 | 89.23 |
| YOLOv5s + 4 + ECAC3 + G + RR | 5.10 | 11.60 | 14.30 | 90.94 |
| Method | Para (M) | Size (MB) | GFlOPs | FPS | Acc (%) |
|---|---|---|---|---|---|
| YOLOv5s | 7.01 | 14.50 | 15.80 | 74.60 | 91.03 |
| YOLOv5s + 4 + ECAC3 | 7.50 | 16.10 | 21.40 | 49.50 | 93.97 |
| YOLOv5s + 4 + ECAC3 + G | 5.10 | 11.60 | 14.30 | 51.80 | 89.84 |
| YOLOv5s + 4 + ECAC3 + G + RR | 5.10 | 11.60 | 14.30 | 51.80 | 90.94 |
| YOLOv5s + 4 + ECAC3 + G + RR + E | 5.10 | 11.60 | 14.30 | 51.30 | 91.80 |
| [35] | - | - | - | - | 91.30 |
| [36] | 92.62 | ||||
| [37] | - | - | - | - | 90.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Dai, F.; Qian, H.; Huang, L.; Zhao, J. Lightweight Wheat Spike Detection Method Based on Activation and Loss Function Enhancements for YOLOv5s. Agronomy 2024, 14, 2036. https://doi.org/10.3390/agronomy14092036
Li J, Dai F, Qian H, Huang L, Zhao J. Lightweight Wheat Spike Detection Method Based on Activation and Loss Function Enhancements for YOLOv5s. Agronomy. 2024; 14(9):2036. https://doi.org/10.3390/agronomy14092036
Chicago/Turabian StyleLi, Jingsong, Feijie Dai, Haiming Qian, Linsheng Huang, and Jinling Zhao. 2024. "Lightweight Wheat Spike Detection Method Based on Activation and Loss Function Enhancements for YOLOv5s" Agronomy 14, no. 9: 2036. https://doi.org/10.3390/agronomy14092036
APA StyleLi, J., Dai, F., Qian, H., Huang, L., & Zhao, J. (2024). Lightweight Wheat Spike Detection Method Based on Activation and Loss Function Enhancements for YOLOv5s. Agronomy, 14(9), 2036. https://doi.org/10.3390/agronomy14092036