
YOLOv11-HRS: An Improved Model for Strawberry Ripeness Detection


Abstract
:1. Introduction
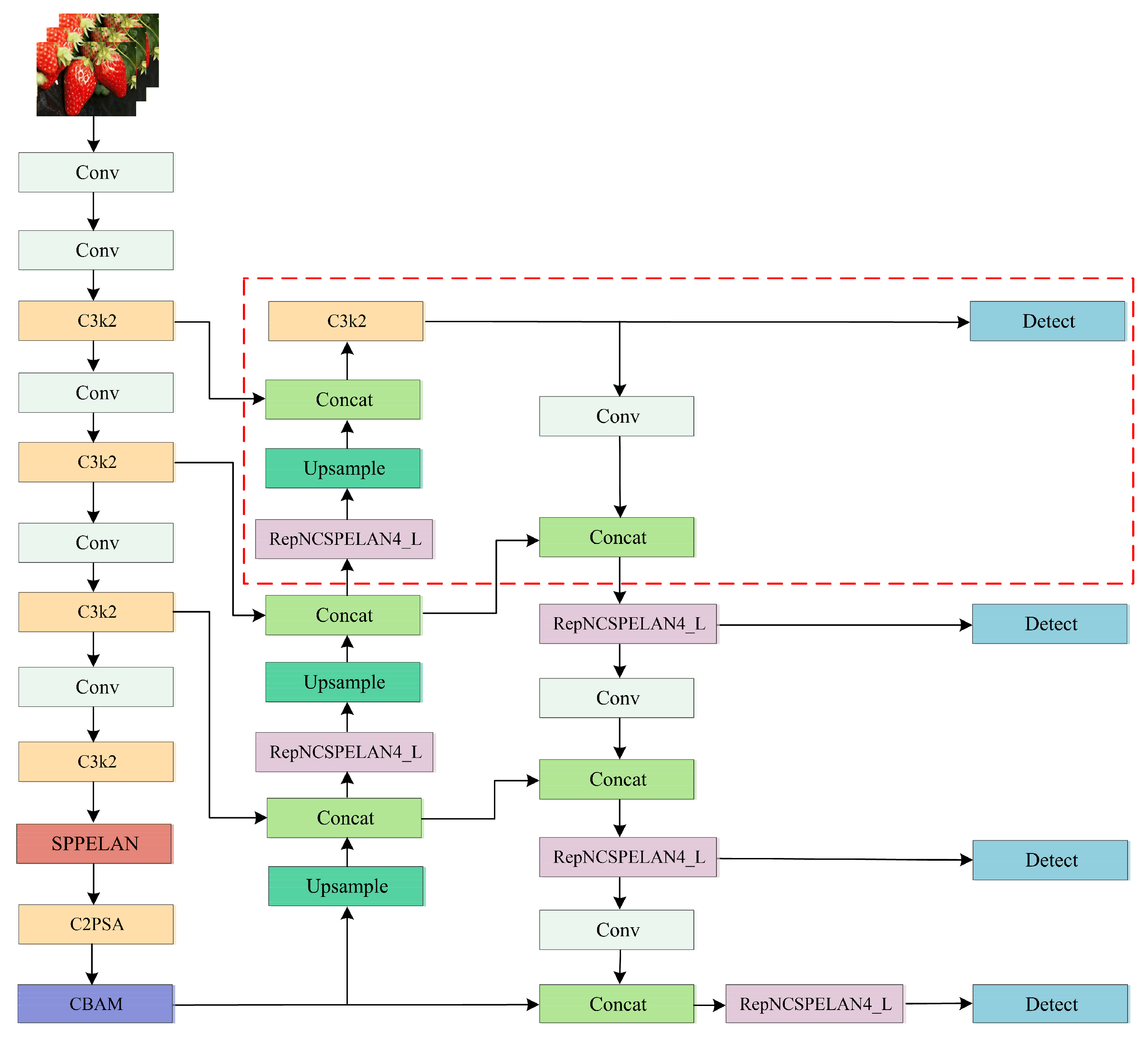
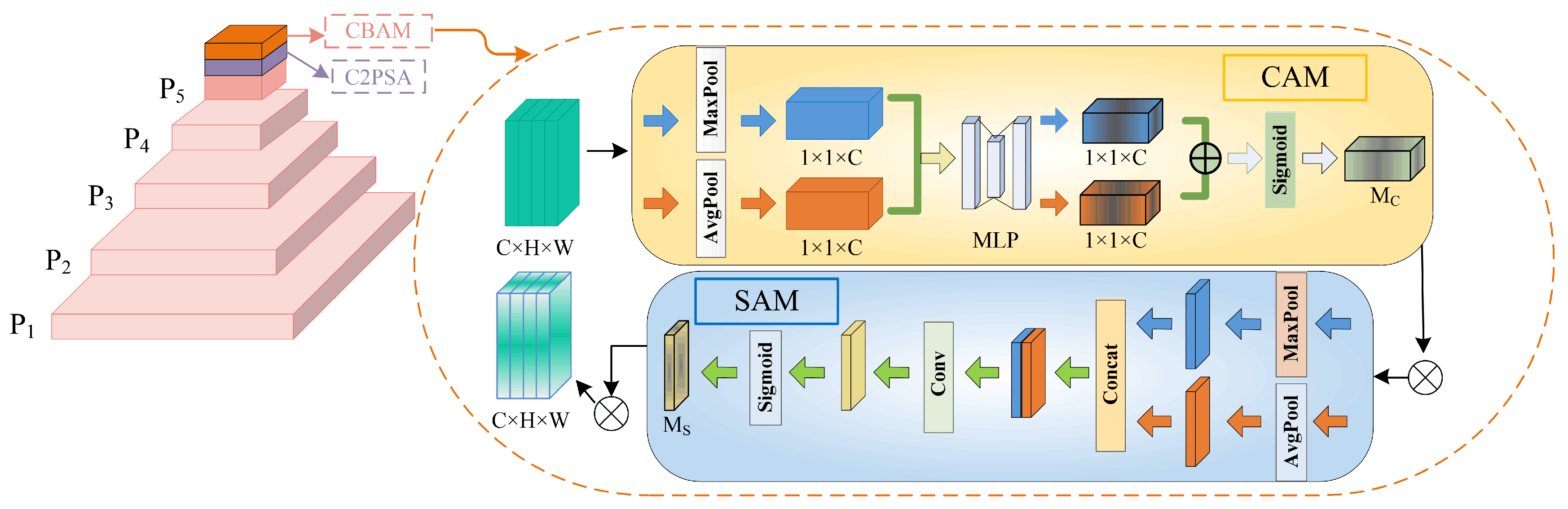
- The hybrid attention mechanism is introduced into the backbone network, which effectively mitigates interference in strawberry detection within complex backgrounds by assigning higher weights to key features, allowing the model to focus more on important target regions while minimizing the processing of irrelevant information.
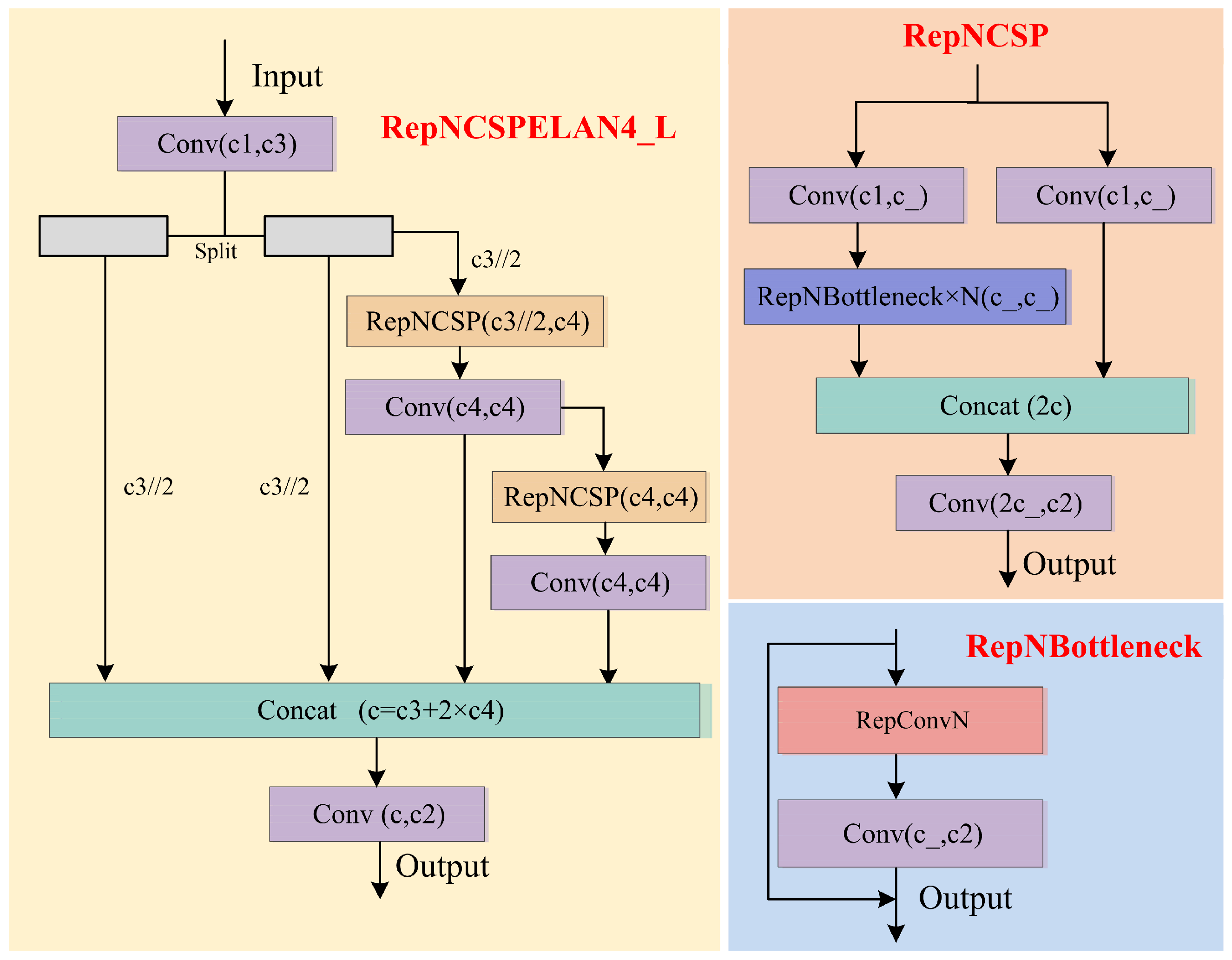
- To better extract feature information from multi-scale targets, the concepts of module splitting and reorganization are employed, combined with the hierarchical processing method of the Generalized Efficient Layer Aggregation Network (GELAN) [25], resulting in the development of the multi-branch, layer-hopping-connected feature extraction module, RepNCSPELAN4_L. This module simplifies the network structure, enhances feature fusion through optimized feature aggregation and layer-hopping connections, and significantly improves the recognition of multi-scale targets.
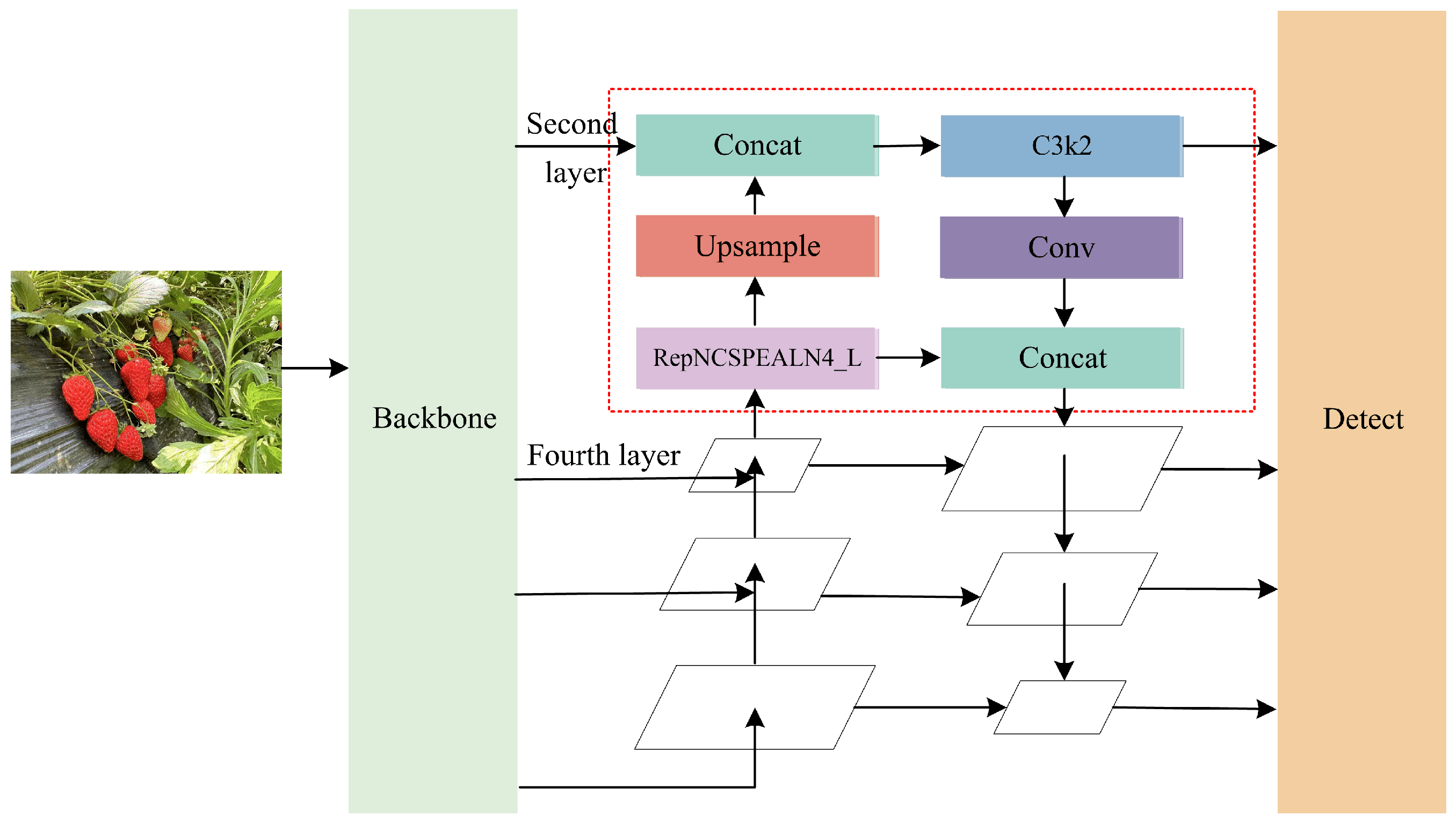
- A 160 × 160-pixel detection layer, specifically designed for small targets, is introduced to enhance the integration of deep and shallow semantic information. This design leads to a significant enhancement in the feature representation of small objects.
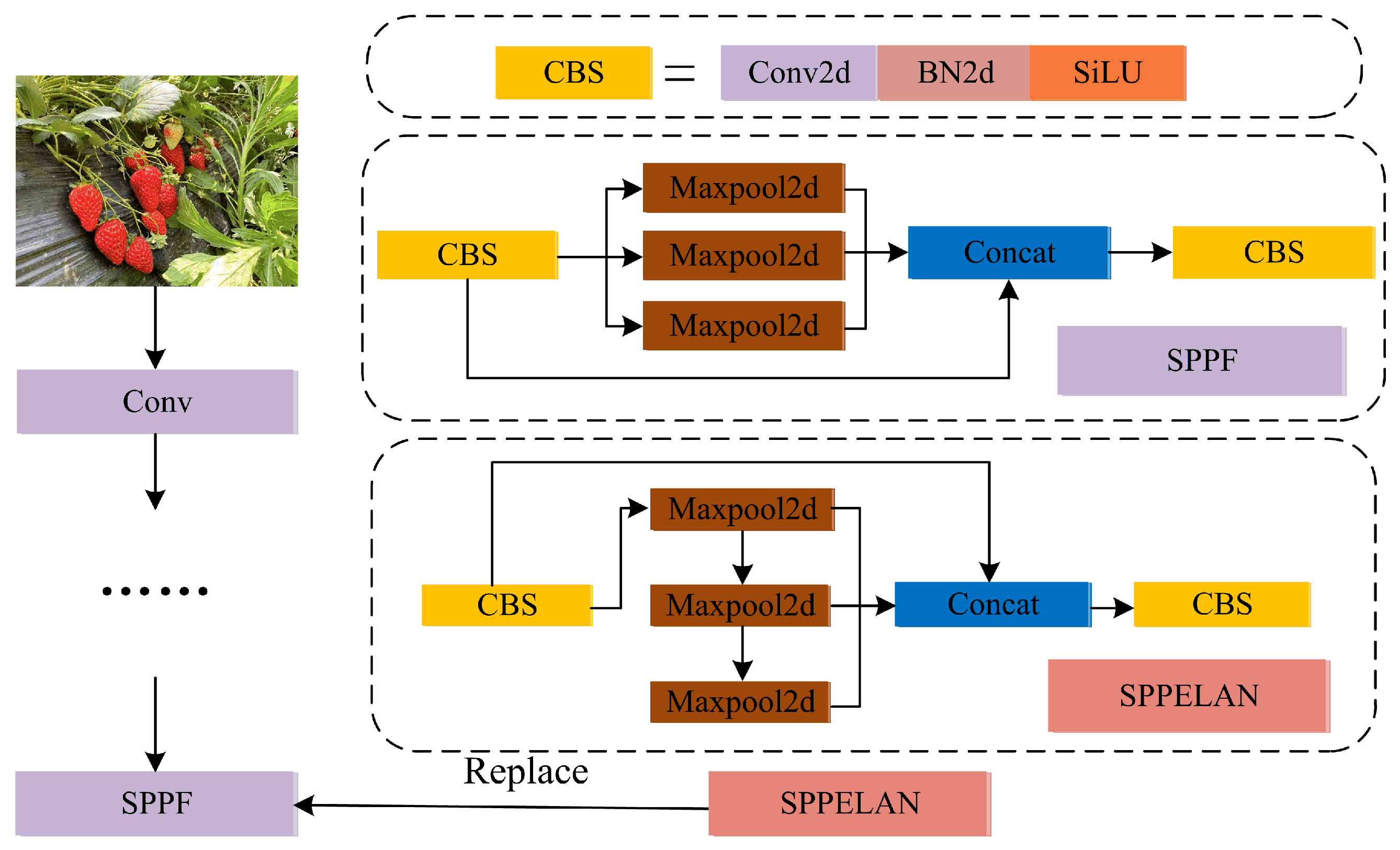
- A novel SPPELAN module is introduced to replace the traditional SPPF. It fully utilizes the spatial pyramid pooling capability of SPP and the efficient feature aggregation capability of ELAN, enhancing the detection performance without increasing the number of parameters and computational complexity.
2. Improved YOLOv11-HRS Model
2.1. Hybrid Attention Mechanism
2.2. RepNCSPELAN4_L Module
2.3. Small-Target Detection Head Module
2.4. SPPELAN Module
3. Experiment
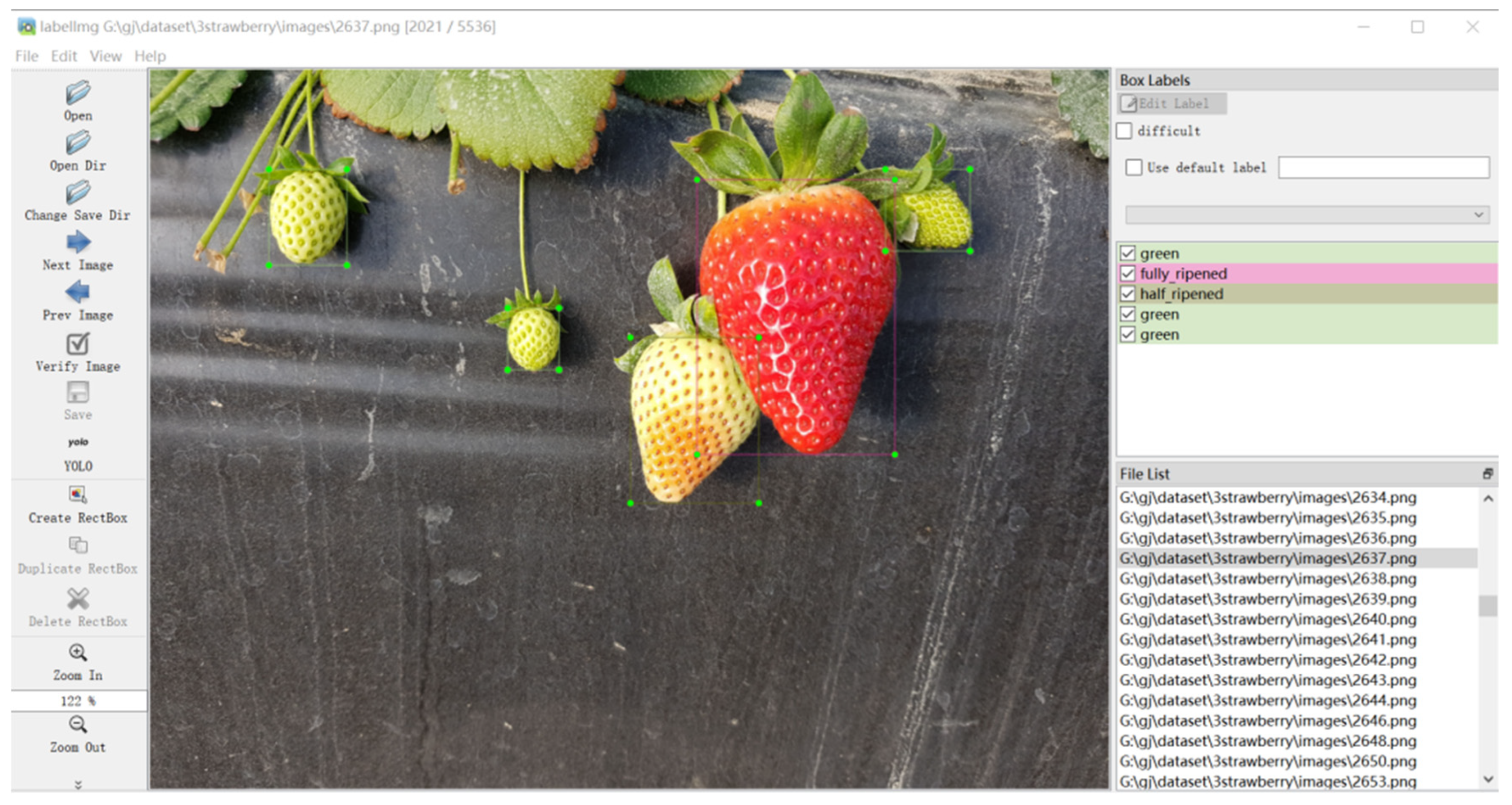
3.1. Construction of the Dataset
3.2. Experiment Environment and Evaluation Metrics
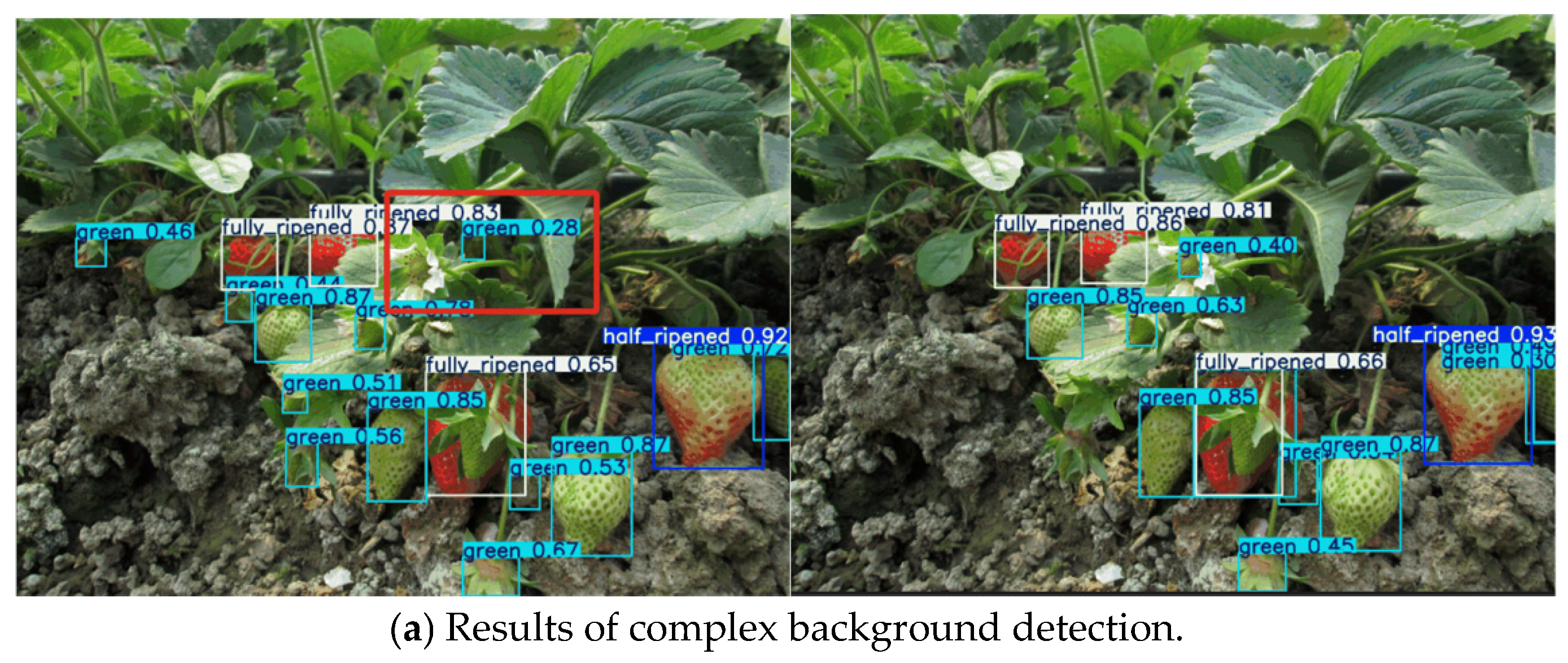
3.3. Visualization Results
3.4. Experimental Results and Analyses
3.4.1. Experiments on Attention Mechanisms
3.4.2. Small-Target Detection Head Improvement Experiments
3.4.3. Comparative Experiments of the RepNCSPELAN4_L Module
3.4.4. Comparative Experiments with the SPPELAN Module
3.4.5. Ablation Experiments
3.4.6. Comparative Analysis of Detection Performance Among Different Models
3.4.7. Model Generalization Experiments
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tian, H.; Wang, T.; Liu, Y.; Qiao, X.; Li, Y. Computer Vision Technology in Agricultural Automation—A Review. Inf. Process. Agric. 2020, 7, 1–19. [Google Scholar] [CrossRef]
- Han, X.; Chang, J.; Wang, K. You Only Look Once: Unified, Real-Time Object Detection. Procedia Comput. Sci. 2021, 183, 61–72. [Google Scholar] [CrossRef]
- Xiao, B.; Nguyen, M.; Yan, W.Q. Fruit Ripeness Identification Using YOLOv8 Model. Multimed. Tools Appl. 2024, 83, 28039–28056. [Google Scholar] [CrossRef]
- Ma, Y.; Zhang, S. YOLOv8-CBSE: An Enhanced Computer Vision Model for Detecting the Maturity of Chili Pepper in the Natural Environment. Agronomy 2025, 15, 537. [Google Scholar] [CrossRef]
- Xu, D.; Ren, R.; Zhao, H.; Zhang, S. Intelligent Detection of Muskmelon Ripeness in Greenhouse Environment Based on YOLO-RFEW. Agronomy 2024, 14, 1091. [Google Scholar] [CrossRef]
- Wang, C.; Han, Q.; Li, J.; Li, C.; Zou, X. YOLO-BLBE: A Novel Model for Identifying Blueberry Fruits with Different Maturities Using the I-MSRCR Method. Agronomy 2024, 14, 658. [Google Scholar] [CrossRef]
- Liu, Z.; Abeyrathna, R.R.D.; Sampurno, R.M.; Nakaguchi, V.M.; Ahamed, T. Faster-YOLO-AP: A Lightweight Apple Detection Algorithm Based on Improved YOLOv8 with a New Efficient PDWConv in Orchard. Comput. Electron. Agric. 2024, 223, 109118. [Google Scholar] [CrossRef]
- Ouhami, M.; Hafiane, A.; Es-Saady, Y.; El Hajji, M.; Canals, R. Computer Vision, IoT and Data Fusion for Crop Disease Detection Using Machine Learning: A Survey and Ongoing Research. Remote Sens. 2021, 13, 2486. [Google Scholar] [CrossRef]
- Wang, J.; Ma, S.; Wang, Z.; Ma, X.; Yang, C.; Chen, G.; Wang, Y. Improved Lightweight YOLOv8 Model for Rice Disease Detection in Multi-Scale Scenarios. Agronomy 2025, 15, 445. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, Y.; Zheng, Q.; Tao, R.; Liu, Y. SMC-YOLO: A High-Precision Maize Insect Pest-Detection Method. Agronomy 2025, 15, 195. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, Z.; Zhao, H.; Tang, C.; Liu, B.; Li, Z.; Wan, F.; Qian, W.; Qiao, X. YOLO-YSTs: An Improved YOLOv10n-Based Method for Real-Time Field Pest Detection. Agronomy 2025, 15, 575. [Google Scholar] [CrossRef]
- Qiao, Y.; Guo, Y.; He, D. Cattle Body Detection Based on YOLOv5-ASFF for Precision Livestock Farming. Comput. Electron. Agric. 2023, 204, 107579. [Google Scholar] [CrossRef]
- Xu, Z.; Li, J.; Meng, Y.; Zhang, X. CAP-YOLO: Channel Attention Based Pruning YOLO for Coal Mine Real-Time Intelligent Monitoring. Sensors 2022, 22, 4331. [Google Scholar] [CrossRef]
- Jia, Y.; Fu, K.; Lan, H.; Wang, X.; Su, Z. Maize Tassel Detection with CA-YOLO for UAV Images in Complex Field Environments. Comput. Electron. Agric. 2024, 217, 108562. [Google Scholar] [CrossRef]
- Soltani Firouz, M.; Sardari, H. Defect Detection in Fruit and Vegetables by Using Machine Vision Systems and Image Processing. Food Eng. Rev. 2022, 14, 353–379. [Google Scholar] [CrossRef]
- Liang, X.; Jia, X.; Huang, W.; He, X.; Li, L.; Fan, S.; Li, J.; Zhao, C.; Zhang, C. Real-Time Grading of Defect Apples Using Semantic Segmentation Combination with a Pruned YOLO V4 Network. Foods 2022, 11, 3150. [Google Scholar] [CrossRef]
- Moysiadis, V.; Siniosoglou, I.; Kokkonis, G.; Argyriou, V.; Lagkas, T.; Goudos, S.K.; Sarigiannidis, P. Cherry Tree Crown Extraction Using Machine Learning Based on Images from UAVs. Agriculture 2024, 14, 322. [Google Scholar] [CrossRef]
- Jiang, M.; Song, L.; Wang, Y.; Li, Z.; Song, H. Fusion of the YOLOv4 Network Model and Visual Attention Mechanism to Detect Low-Quality Young Apples in a Complex Environment. Precis. Agric. 2022, 23, 559–577. [Google Scholar] [CrossRef]
- Wang, C.; Wang, C.; Wang, L.; Wang, J.; Liao, J.; Li, Y.; Lan, Y. A Lightweight Cherry Tomato Maturity Real-Time Detection Algorithm Based on Improved YOLOV5n. Agronomy 2023, 13, 2106. [Google Scholar] [CrossRef]
- Fan, Y.; Zhang, S.; Feng, K.; Qian, K.; Wang, Y.; Qin, S. Strawberry Maturity Recognition Algorithm Combining Dark Channel Enhancement and YOLOv5. Sensors 2022, 22, 419. [Google Scholar] [CrossRef]
- Yang, S.; Wang, W.; Gao, S.; Deng, Z. Strawberry Ripeness Detection Based on YOLOv8 Algorithm Fused with LW-Swin Transformer. Comput. Electron. Agric. 2023, 215, 108360. [Google Scholar] [CrossRef]
- Wang, C.; Wang, H.; Han, Q.; Zhang, Z.; Kong, D.; Zou, X. Strawberry Detection and Ripeness Classification Using YOLOv8+ Model and Image Processing Method. Agriculture 2024, 14, 751. [Google Scholar] [CrossRef]
- Feng, W.; Liu, M.; Sun, Y.; Wang, S.; Wang, J. The Use of a Blueberry Ripeness Detection Model in Dense Occlusion Scenarios Based on the Improved YOLOv9. Agronomy 2024, 14, 1860. [Google Scholar] [CrossRef]
- Moysiadis, V.; Kokkonis, G.; Bibi, S.; Moscholios, I.; Maropoulos, N.; Sarigiannidis, P. Monitoring Mushroom Growth with Machine Learning. Agriculture 2023, 13, 223. [Google Scholar] [CrossRef]
- Chandra, N.; Vaidya, H.; Sawant, S.; Meena, S.R. A Novel Attention-Based Generalized Efficient Layer Aggregation Network for Landslide Detection from Satellite Data in the Higher Himalayas, Nepal. Remote Sens. 2024, 16, 2598. [Google Scholar] [CrossRef]
- Deng, T.; Liu, X.; Wang, L. Occluded Vehicle Detection via Multi-Scale Hybrid Attention Mechanism in the Road Scene. Electronics 2022, 11, 2709. [Google Scholar] [CrossRef]
- Samtani, J.B.; Rom, C.R.; Friedrich, H.; Fennimore, S.A.; Finn, C.E.; Petran, A.; Wallace, R.W.; Pritts, M.P.; Fernandez, G.; Chase, C.A.; et al. The Status and Future of the Strawberry Industry in the United States. HortTechnology 2019, 29, 11–24. [Google Scholar] [CrossRef]
- Mirhaji, H.; Soleymani, M.; Asakereh, A.; Mehdizadeh, S.A. Fruit Detection and Load Estimation of an Orange Orchard Using the YOLO Models through Simple Approaches in Different Imaging and Illumination Conditions. Comput. Electron. Agric. 2021, 191, 106533. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W. Biformer: Vision Transformer with Bi-Level Routing Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 10323–10333. [Google Scholar]
- Liu, Y.; Zheng, H.; Zhang, Y.; Zhang, Q.; Chen, H.; Xu, X.; Wang, G. “Is This Blueberry Ripe?”: A Blueberry Ripeness Detection Algorithm for Use on Picking Robots. Front. Plant Sci. 2023, 14, 1198650. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Girshick, R. Fast R-Cnn. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Varghese, R.; Sambath, M. Yolov8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Mark Liao, H.-Y. Yolov9: Learning What You Want to Learn Using Programmable Gradient Information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-Time End-to-End Object Detection. Adv. Neural Inf. Process. Syst. 2025, 37, 107984–108011. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Elhariri, E.; El-Bendary, N.; Saleh, S.M. Strawberry-DS: Dataset of Annotated Strawberry Fruits Images with Various Developmental Stages. Data Brief 2023, 48, 109165. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Images | Number of Bounding Box | ||
|---|---|---|---|---|
| Green | Half_Ripened | Fully_Ripened | ||
| Training Set | 5687 | 37,731 | 5656 | 9405 |
| Validation Set | 711 | 4772 | 756 | 1212 |
| Test Set | 711 | 4599 | 678 | 1092 |
| Sum | 7109 | 47,102 | 7090 | 11,709 |
| Settings | Parameters |
|---|---|
| CPU | 6 vCPU Intel(R) Xeon(R) Silver 4310 CPU @ 2.10 GHz |
| GPU | NVIDIA GeForce RTX 3090 |
| Operating System | Linux |
| Deep learning framework | PyTorch 2.4.1 |
| Language | Python 3.8.0 |
| Settings | Parameters |
|---|---|
| lr0 | 0.01 |
| Momentum | 0.9 |
| Optimizer | SGD |
| Epochs | 150 |
| Batch size | 32 |
| Model | mAP@0.5/% | mAP@0.5–0.9/% | Layer | GFLOPs |
|---|---|---|---|---|
| Baseline | 86.4 | 60.3 | 238 | 6.5 |
| YOLOv11 + ECA | 88.2 | 65.4 | 242 | 6.4 |
| YOLOv11 + GAM | 88.1 | 65.2 | 247 | 7.6 |
| YOLOv11 + Biformer | 88.6 | 65.7 | 244 | 8.9 |
| YOLOv11 + CBAM | 88.3 | 65.1 | 246 | 6.6 |
| Model | mAP@0.5/% | mAP@0.5–0.9/% | Precision/% | Recall/% | Params/MB | GFLOPs |
|---|---|---|---|---|---|---|
| YOLOv11 | 86.4 | 60.3 | 81.5 | 79.7 | 2.63 | 6.5 |
| +Head | 89.2 | 65.3 | 83.3 | 82.7 | 2.65 | 10.4 |
| +ECA + Head | 89.4 | 66.4 | 84.1 | 83.3 | 2.69 | 10.5 |
| +Biformer + Head | 89.2 | 66.2 | 83.5 | 81.6 | 2.67 | 12.8 |
| +CBAM + Head | 89.5 | 66.4 | 84.4 | 82.6 | 2.77 | 10.5 |
| Model | Precision/% | Recall/% | mAP@0.5/% | mAP@0.5–0.9/% |
|---|---|---|---|---|
| YOLOv11 + C3k2 | 81.5 | 79.7 | 86.4 | 60.3 |
| YOLOv11 + RepNCSPELAN4_L | 83.1 | 81.9 | 89.1 | 66 |
| Model | Precision/% | Recall/% | mAP@0.5/% | mAP@0.5–0.9/% |
|---|---|---|---|---|
| YOLOv11 + SPPF | 81.5 | 79.7 | 86.4 | 60.3 |
| YOLOv11 + SPPELAN | 83.5 | 82.2 | 88.7 | 65.7 |
| CBAM | Head | RepNCSPELAN4_L | SPPELAN | mAP@0.5/% | mAP@0.5–0.9/% | FPS | Params/MB | GFLOPs |
|---|---|---|---|---|---|---|---|---|
| 86.4 | 60.3 | 255.2 | 2.63 | 6.5 | ||||
| √ | 89.2 | 65.3 | 323.5 | 2.65 | 10.4 | |||
| √ | 88.3 | 65.1 | 360 | 2.68 | 6.6 | |||
| √ | √ | 89.5 | 66.4 | 310.1 | 2.77 | 10.5 |
| CBAM | Head | RepNCSPELAN4_L | SPPELAN | mAP@0.5/% | mAP@0.5–0.9/% | FPS | Params/MB | GFLOPs |
|---|---|---|---|---|---|---|---|---|
| √ | √ | 89.5 | 66.4 | 310.1 | 2.77 | 10.5 | ||
| √ | √ | √ | 89.4 | 66.3 | 249.6 | 2.51 | 9.9 | |
| √ | √ | √ | 89.6 | 66.4 | 305 | 2.69 | 10.5 | |
| √ | √ | √ | √ | 89.8 | 66.6 | 252.5 | 2.13 | 9.7 |
| Network | AP/% | mAP@0.5/% | mAP@0.5–0.9/% | GFLOPs | ||
|---|---|---|---|---|---|---|
| Half-Ripened | Green | Fully-Ripened | ||||
| SSD | 75.6 | 83.4 | 79.8 | 79.6 | 52.6 | 63.5 |
| YOLOv5n | 85.1 | 82.9 | 88.7 | 85.6 | 57.6 | 4.5 |
| YOLOv7-tiny | 85 | 85.2 | 89.3 | 86.6 | 58 | 13.2 |
| DETR | 72.9 | 71.7 | 81.9 | 75.5 | 41.9 | 100 |
| Faster R-CNN | 86.3 | 84.7 | 87.9 | 86.3 | 58.4 | 118.8 |
| EfficientDet-D1 | 86.7 | 85 | 87.8 | 86.5 | 58.4 | 6.1 |
| YOLOv8n | 86.8 | 84.2 | 89.4 | 86.8 | 61.2 | 8.7 |
| YOLOv9-t | 84 | 85.3 | 86.3 | 85.2 | 60.5 | 10.7 |
| YOLOv10n | 84.1 | 83 | 89.1 | 85.4 | 58.9 | 8.4 |
| YOLOv11n | 85.8 | 83.9 | 89.5 | 86.4 | 60.3 | 6.5 |
| YOLOv11-HRS | 91.5 | 88.2 | 89.5 | 89.8 | 66.6 | 9.7 |
| Network | Precision/% | Recall/% | mAP@0.5/% | mAP@0.5–0.9/% |
|---|---|---|---|---|
| YOLOv11 | 68.7 | 68.2 | 70.7 | 52.5 |
| YOLOv11-HRS | 72 | 68.3 | 74.2 | 55.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Guo, J.; Zhang, S. YOLOv11-HRS: An Improved Model for Strawberry Ripeness Detection. Agronomy 2025, 15, 1026. https://doi.org/10.3390/agronomy15051026
Liu J, Guo J, Zhang S. YOLOv11-HRS: An Improved Model for Strawberry Ripeness Detection. Agronomy. 2025; 15(5):1026. https://doi.org/10.3390/agronomy15051026
Chicago/Turabian StyleLiu, Jianhua, Jing Guo, and Suxin Zhang. 2025. "YOLOv11-HRS: An Improved Model for Strawberry Ripeness Detection" Agronomy 15, no. 5: 1026. https://doi.org/10.3390/agronomy15051026
APA StyleLiu, J., Guo, J., & Zhang, S. (2025). YOLOv11-HRS: An Improved Model for Strawberry Ripeness Detection. Agronomy, 15(5), 1026. https://doi.org/10.3390/agronomy15051026