1. Introduction
Agriculture is a strategic sector of economies worldwide. The use of new technologies has proven effective in increasing production and reducing costs [
1], specifically when applied in extensive cultivations, such as chickpeas (
Cicer arietinum L). In fact, chickpea is one of the most extended crops in the world, that grows in more than fifty countries on five continents [
2,
3]. Chickpea is cultivated on 13.98 million hectares (594,489 in Iran, where data collection of this research took place), and the approximate total amount of production is 13.74 million tons (261,616 tons in Iran). Some researchers have studied the genotypes of up to 90 chickpea varieties [
4], including wild varieties. There are five popular species of chickpeas in Iran: Adel, Arman, Azad, Bevanij and Hashem. Each type has a price and special applications in the food industry. However, the traditional method for detecting each variety of seeds is visual inspection by a human, which is a very tedious and time-consuming task [
5,
6].
Computer vision systems have a wide range of applications in agronomy and food industry such as irrigation, grading, harvesting, and automatic detection of different varieties of seeds as non-destructive assessment [
7,
8,
9,
10,
11]. Some research works have used machine vision systems for the classification of different seeds [
12]. For example, Aznan et al. [
13] used machine vision methods to classify cultivated rice seed variety, namely M263, and weedy rice seed variants. These variants included: close panicle; partly short awned-open panicle; close panicle; partly short awned-close panicle; and partly long awned-close panicle for the seed industry. For this purpose, 120 samples of each variant and 600 samples of M263 were prepared. They used different morphological features such as solidity and extend for use in a stepwise discriminant function analysis (DFA) to classify different types of rice. Classification accuracy for testing and training sets were 96% and 95.8%, respectively. In addition, Kurtulmus et al. [
14] proposed an algorithm for the classification of eight different varieties of pepper seeds based on machine vision combined with artificial neural networks (ANN). A total of 832 samples of these varieties were selected. After imaging, some color, shape and texture features were extracted from each sample. Then, these features were used as input to an ANN. The results showed that the accuracy of this classifier was 84.94%.
HemaChitra and Suguna [
15] presented a new method based on image analysis techniques to discriminate defective from normal samples of Indian pulse seeds. For this purpose, they extracted several color, shape and texture features. Then, these features used as input to an SVM for classification. The result shows that the accuracy of their method was 98.9%. More recently, Li et al. [
16] designed a system to discriminate different damaged types of corn. To do this, they used a database of images that included normal corn and six different damaged corns, such as blue eye mold-damaged and surface mold-damaged. The main techniques used are object segmentation, extraction of color and shape features, and a maximum likelihood classifier. In this case, the obtained classification accuracy was above 74% for all the classes.
As demonstrated in these papers, machine vision can be effectively used for seed classification, as an alternative to the traditional manual methods. They are able to increase accuracy and speed in packing and processing time. These systems use a classifier that is fed with features extracted from labelled data in order to learn the differences between distinct species or classes related to individual objects. On the other hand, there are several methods for selecting and classifying features, based on statistical and artificial intelligence methods, getting the latter more plausible results than the former due to non-sensitivity to the type of data distribution.
The main objective of the present research is to study and compare two different approaches in the selection of features in a particular task of fruit classification. The first method is based on a hybrid of artificial neural networks and the particle swarm optimization (PSO) metaheuristic algorithm. This method first extracts effective features from the data, by obtaining different color and texture information, in order to feed the classifier. The second approach can be referred to as a
featureless method, since there is not an explicit feature extraction phase, but image patches are directly introduced into the classifier. These patches are the input of a three-layered (input, hidden and output layer) ANN, based on the classic feed-forward backpropagation algorithm [
17].
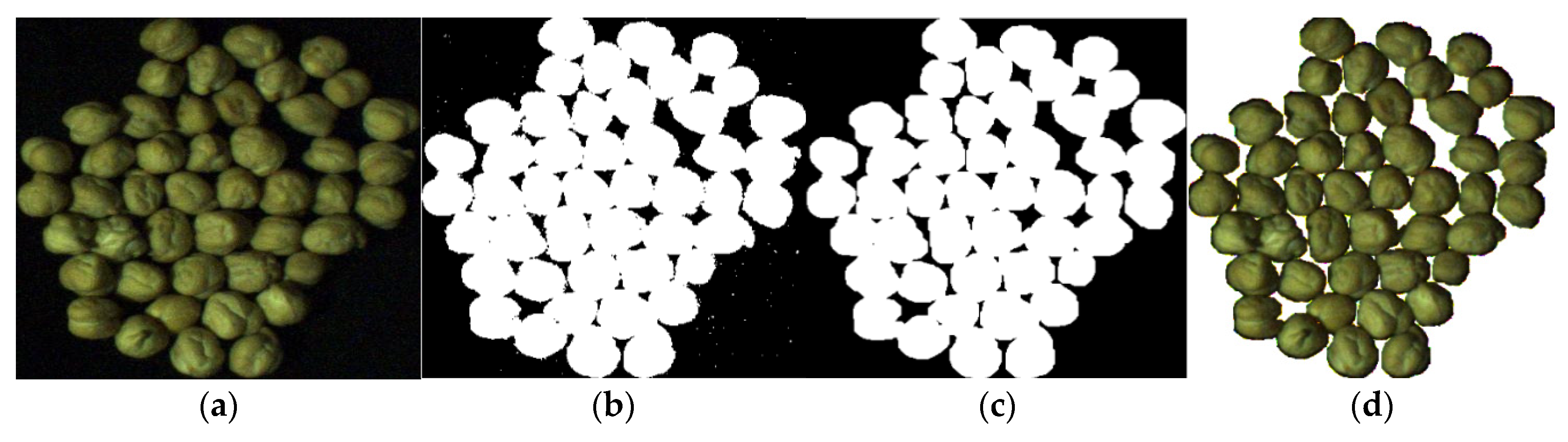
Specifically, in this paper, the problem of interest is the classification of the five most common varieties of chickpeas in Iran. The samples were obtained in an Iranian zone in Kermanshah, with a total of 1019 images, by using an industrial camera from a 10 cm fixed height above the samples. This setup simulates the conditions of an industrial automatic classification device in a fruit processing factory. Both approaches, using features and not using features, are compared using the same data.
4. Conclusions
In this paper, two different approaches have been compared for the problem of classifying chickpea varieties. The first method performs an explicit extraction of color and texture features, a selection of the optimal set of features, and classification using a hybrid of artificial neural networks and particle swarm optimization (ANN-PSO). The second approach avoids the explicit use of features by using color image patches directly as the input to a three-layered backpropagation artificial neural network. The results clearly prove that both methods are able to achieve a very high accuracy, defined by the Correct Classification Rate (CCR). A CCR of 98.04% and 99.35% were obtained by the ANN-PSO method and the backpropagation ANN, respectively.
Comparing sensitivity, accuracy and specificity measures, as well as CCR, the latter method also achieved the best results. In addition, it is more generic and could be applied to other fruit species, since it does not rely on predefined features. In any case, none of the methods produced a significant number of misclassifications. The first method had 6 / 306 (1.9% ICR) misclassified test samples, whereas the second only had 2 / 307 (0.65% ICR). Therefore, both classifiers could be effectively used in the agronomy industry with high accuracy.
The division factor applied for segmentation turned out to be of great importance in the featureless method. A well-chosen factor with the proper level of tolerated black percentage proved to have a significant impact on the final accuracy of the classifier.
Nonetheless, there are a few weaknesses associated with these methods. The feature-based method with hybrid ANN-PSO relies on statistical inferences based on a small group of features, which could be insufficient for less-controlled conditions. Regarding the featureless method with three-layered backpropagation ANN, it is fed exclusively by color pixels. While the available chickpeas can actually be distinguished by color, this method requires working with a data set where all the images have been taken on the same conditions in order to ensure color constancy. Some factors such as lighting color, white balance of the camera, brightness or other external conditions, could result in changes in the observed colors. In that case, grayscale images should be used to achieve a higher robustness.
Further studies could take these issues into account in order to make the predictive potential of the classifier independent from the conditions under which the images were obtained. Convolutional neural networks (CNN) and deep learning could be a recommended way to achieve this goal. For this purpose, a larger dataset of images taken under more varied conditions would be necessary.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}