Abstract
DNA methylation change has been useful for cancer biomarker discovery, classification, and potential treatment development. So far, existing methods use either differentially methylated CpG sites or combined CpG sites, namely differentially methylated regions, that can be mapped to genes. However, such methylation signal mapping has limitations. To address these limitations, in this study, we introduced a combinatorial framework using linear regression, differential expression, deep learning method for accurate biological interpretation of DNA methylation through integrating DNA methylation data and corresponding TCGA gene expression data. We demonstrated it for uterine cervical cancer. First, we pre-filtered outliers from the data set and then determined the predicted gene expression value from the pre-filtered methylation data through linear regression. We identified differentially expressed genes (DEGs) by Empirical Bayes test using . Then we applied a deep learning method, “nnet” to classify the cervical cancer label of those DEGs to determine all classification metrics including accuracy and area under curve (AUC) through 10-fold cross validation. We applied our approach to uterine cervical cancer DNA methylation dataset (NCBI accession ID: GSE30760, 27,578 features covering 63 tumor and 152 matched normal samples). After linear regression and differential expression analysis, we obtained 6287 DEGs with false discovery rate (FDR) . After performing deep learning analysis, we obtained average classification accuracy () of the uterine cervical cancerous labels. This performance is better than that of other peer methods. We performed in-degree and out-degree hub gene network analysis using . We reported five top in-degree genes (, , , and ) and five top out-degree genes (, , , and ). After that, we performed KEGG pathway and Gene Ontology enrichment analysis of DEGs using tool WebGestalt(WEB-based Gene SeT AnaLysis Toolkit). In summary, our proposed framework that integrated linear regression, differential expression, deep learning provides a robust approach to better interpret DNA methylation analysis and gene expression data in disease study.
1. Introduction
DNA methylation has been found a promising biomarker in cancer detection and cancer classification. DNA methylation can be defined as a heritable epigenetic mark where a methyl group can transfer covalently to the C-5 position of the cytosine ring of DNA through DNA methyltransferases (DNMTs). DNA methylation is vital for normal development. It plays very important role in a number of key operations including genomic imprinting, inactivation of X-chromosome, repression of repetitive element transcription and transposition, and different diseases including cancer [1]. To biologically interpret the DNA methylation data, two kinds of analysis are available: (i) single differentially methylated genes (CpG sites) finding [2,3] and (ii) differentially methylated region (DMR) finding [4,5,6]. These two kinds of analysis are only specific to performing a single task. Therefore, it is important to incorporate different factors to correctly interpret DNA methylation data by which it can work as multi-functionalities from different directions such as prediction of gene expression using DNA methylation, differential expression analysis, cancer classification [7], hub gene finding, and others.
In practical scenarios, it is observed that DNA methylation normally reduces gene expression levels [8,9]. However, this opinion varies on different factors. There are different kinds of method to integrate DNA methylation and gene expression data. There are several shortcomings of those existing methods. Firstly, it is not easy to determine the directionality of the evaluated gene expression estimated from the DNA methylation. Normally, the suppression of gene expression is caused by hypermethylation in the promoter region, while the activation correlates the hypermethylation in the gene body. Therefore, the prediction of changing in gene expression based on simple DNA methylation results is difficult [10]. Secondly, an accurate measure of gene promoter methylation is difficult due to the variance in the size of canonical promoters as well as the presence of the distal augments, which initiates biases into the association of methylated regions with gene models [10]. Thirdly, the high probability of selecting a long gene due to the nearby differentially methylated CpGs or overlapping (or nested) with other genes [10]. Fourthly, some specific tools are required for reformatting the methylation data into the genomic region formats (e.g., BED) for some web-based methods such as GREAT [11], Galaxy [12]. It creates more complications in their usage [10].
Cervical cancer is a cancer which starts in the cervix, a hollow cylinder that connects the lower part of uterus to a woman’s vagina. Most of the cervical cancers grow in the cells on the outer surface of the cervix. Normally women are unable to realize this disease in the initial stage since the symptoms are more or less similar with the common conditions such as menstrual periods and urinary tract infections. The normal symptoms of the cervical cancer include abnormal bleeding during mensuration time or after having sex, pain in the pelvis, as well as pain during the urination [13]. Here, we used a DNA methylation dataset for uterine cervical cancer from NCBI (Accession ID: GSE30760) [14] which have two types of samples, one is normal sample and another one is uterine cervical cancer sample.
So far, there has been no method to integrate regression, differential expression and deep learning strategies for accurate interpretation of DNA methylation in a complex disease like cancer. To resolve the previously mentioned drawbacks, in this article, we provided an integrated framework using regression, differential expression and deep learning methods to correctly interpret biologically of the DNA methylation data through integrating that DNA methylation data and corresponding TCGA (The Cancer Genome Atlas) gene expression data for uterine cervical data (NCBI accession ID GSE30760) [14,15,16]. We pre-filtered the redundant CpG sites, eliminated outliers, and replaced missing values. Next, we predicted corresponding gene expression value from the pre-filtered DNA methylation data through linear regression algorithm where the impact between DNA methylation and TCGA gene expression has been determined. As a result, we obtained the predicted gene expression matrix for the preprocessed DNA methylation data. Through the entire analysis, we used ByMethyl R package [10]. Next, we identified differentially expressed genes (DEGs) using downstream analysis, Empirical Bayes test using [17,18,19]. After we applied a recently released deep learning method, “nnet” (feed-forward neural network based model) [20] to interpret those DEGs for determining the classification capacity of uterine cancer and normal groups, we then estimated all classification metrics (average accuracy, average sensitivity, average specificity, average precision, average overall error rate and area under curve (AUC)) using 10-fold cross validation. We trained our predicted DEG expression data using “nnet” with the default parameter settings (i) size (=number of units in hidden layer), (ii) rang (=initial random weights) while [−rang, rang], (iii) decay (=parameter for weight decay), (iv) maxit (=the maximum number of iterations or number of epochs), (v) MaxNWts (=the maximum allowable number of weights) and other default parameters. Remarkably, we obtained () as average classification accuracy of the uterine cervical cancer samples and normal samples by using DEG expression data. According to comparative study, the classification accuracy of our proposed method is higher than that of other state-of-the-art methods. We further performed in-degree and out-degree hub gene network analysis using [21]. We reported the five top in-degree genes (, , , and ) and the five top out-degree genes (, , , and ). After that, we performed Gene Set Enrichment Analysis (GESA) to determine enriched KEGG pathways and Gene Ontology (GO) terms including Biological Process (BP), Cellular Component (CC), and Molecular Function (MF) on the set of all DEGs having using WebGestalt (WEB-based Gene SeT AnaLysis Toolkit) [22]. Finally, our proposed integrated framework using linear regression, differential expression and deep learning method can interpret the DNA methylation data better than using single differential methylation analysis or differentially methylated region finding strategies for any kind of cancer.
2. Materials and Methods
The steps of our proposed framework are demonstrated as follows, as well as in Figure 1.
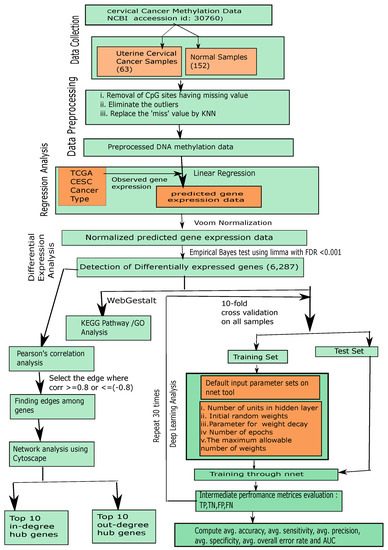
Figure 1.
Flowchart of the proposed framework.
2.1. Data Collection
In this study, we used a cervical cancer methylation dataset(NCBI accession ID: GSE30760) [14,15,16]. This dataset included 63 uterine cervical tumor samples and 152 matched normal samples. Of note, the initial analysis had 27,578 genes.
2.2. Preprocessing of Methylation Data
In this article, we provided an extensive analysis to integrate DNA methylation and corresponding TCGA gene expression data by utilization of regression, differential expression and deep learning. In this method, we have utilized different steps as below.
2.2.1. Data Preprocessing
First we eliminated the CpG sites that had missing values in more than half of the samples and then the remaining missing values would be imputed through integrating a new traditional quality control R package [23], which is widely useful in Illumina Human Methylation data analysis. The functions under the package are used to remove unwanted experimental noise and to improve accuracy and reproducibility of methylation measures. ENmix functions are very flexible and transparent. In our proposed method this quality control ‘ENmix’ was used in our methylation data to discard the outliers and to replace missing values using the popular k nearest neighbors (KNN) algorithm.
2.2.2. Computing Predicted Expression Scores of Gene through Linear Regression Analysis
In this step, we computed the predicted gene expression scores from the preprocessed of DNA methylation profiles and corresponding TCGA CESC cancer type through linear regression analysis along with corresponding pre-trained weight factor.
To do so, we utilized the linear regression algorithm to measure the impact between DNA methylation and gene expression for uterine cervical cancer on preprocessed DNA methylation and corresponding TCGA CESC cancer type [10]. In a statistical point of view, linear regression is a linear approach for molding the relationship between a scalar variable (or, dependent variable) and one or more explanatory variables (or independent variables). In regression analysis, gene expression () is the dependent variable and DNA methylation () is the independent variable. For an i-indexed gene denoted by , is the gene expression across n samples, and is the corresponding methylation matrix ( matrix here). Here, we chose those CpGs () whose beta values were correlated, i.e., Pearson’s correlation coefficient was greater than ) with gene expression label () for building the model, where is the beta value of -th CpG in sample n. The equation for the linear regression model was described as follows:
where denotes the linear regression intercepting factor, and refers to the coefficient vector. In our case, through this linear regression model, we generated the predicted gene expression matrix for the provided genes (CpG sites) using DNA methylation data. Then we applied 10-fold cross-validation to validate our model. That means, we need to check the quality of the gene expression inferred by the linear regression model. Basically, for each validation, to train the model we used 9/10 samples as training dataset. Then, we computed a gene expression profile for the rest 1/10 samples by integrating the DNA methylation data and trained model. After completion of 10-fold cross-validation, our further step was to merge test sample profiles to a gene expression profile containing all samples. For conducting downstream validation we compared the gene expression with the RNA-seq data.
2.2.3. Voom Normalization and Identifying Differentially Expressed Genes Using Limma
In this step normalization [24] was used and after that we applied [18,25]. After applying normalization tool, we detected DEGs from the predicted gene expression data for downstream analysis through [19]. According to benchmark methods the performance of is very good for any kind of data distributions for any sample size. The definition of the moderated t-statistic of is as follows [19]:
where denotes the sample size for diseased group and signifies the sample size for control group, and total sample size . , notify corresponding contrast estimator and posterior sample variance for the genes, respectively.
To find the false discovery rate (FDR) adjusted p-value using Empirical Bayes t-statistics, we used t-table or cumulative distribution function (cdf). FDR adjusted p-value less than 0.001 indicates the differentially expressed genes (DEGs) here. This p-value denotes the probability of observing a t-value which is either equal to or greater than the actually observed t-value in which the given null hypothesis is true.
Here, we applied the Empirical Bayes test using to compute t-score, p-value and FDR, where normal uterine samples group had 152 samples and uterine cervical cancer samples group included 63 samples. Finally, we selected those genes as differentially expressed genes whose . However, all the differentially expressed genes were considered as a single potential gene signature which could be verified at classification analysis through deep learning.
2.3. Disease Classification of DEGs through Deep Learning
Here, we used a latest deep learning method “nnet” (feed-forward neural network based model), [20]. We used this deep learning technique with 10-fold cross validation to examine the class-label (normal and Uterine Cervical cancer groups) of the differentially expressed genes with a repeat of thirty times. In the cross-validation, we divided the predicted gene expression data of the DEGs into 10 folds of samples of which nine folds of samples were used as training set, while remaining one fold of samples was utilized as the test set. From this sub step, we ran “nnet” tool using a certain number of epochs (termed as “maxit”) that means the deep learning method was internally repeated for that “maxit” times, and then computed the classification metrics at one time iteration of each fold. From this sub step, we obtained a confusion matrix consisting of True Positive (TP), False Negative (FN), False Positive (FP) and True Negative (TN). This sub procedure was repeated for each fold of samples (i.e., nine other fold samples). Then we added all these metrics for these 10 times internal repetition and then produced a final confusion matrix. Then we added all these metrics for these 10 internal repetitions and then produced a final confusion matrix. Thereafter, we repeated this entire procedure multiple times (30 times) here to obtain the average classification metric values (average accuracy, average sensitivity, average specificity, average precision, average overall error rate and area under curve (AUC)). Here, we used the test sample as a validation sample also. In this deep learning method, we used “nnet” with the default parameter settings (i) size (=number of units in hidden layer), (ii) rang (=initial random weights) while [−rang, rang], (iii) decay (=parameter for weight decay), (iv) maxit (=the maximum number of iterations or number of epochs), (v) MaxNWts (=the maximum allowable number of weights) and other default parameters also.
2.4. Hub Gene Finding
In this regard, we applied Pearson’s correlation analysis on the DEGs identified by our method for finding out the active edges among genes having correlation value ≥0.8 or ≤. After obtaining the set of active edges, we performed degree centrality analysis through online tool [21] and determined in-degree and out-degree scores of each DEG. We marked top 10 in-degree hub DEGs and top 10 out-degree hub DEGs.
2.5. Gene Set Enrichment Analysis
The potential function, biological significance, and disease relevance of a list of signature genes can be assessed by Gene Set Enrichment Analysis (GSEA). After identifying differentially expressed genes we used KEGG pathways and Gene Ontology (GO) annotations (three domains: Biological Process (BP), Cellular Component (CC), and Molecular Function (MF)) on a set of top differentially expressed genes by WebGestalt (WEB-based Gene SeT AnaLysis Toolkit) [22]. We obtained all KEGG pathways and Gene Ontology (GO) terms accompanied by number of genes in that pathway or GO-term, enriched p-value and FDR. We filtered out those KEGG pathways or GO terms whose FDR was greater than or equal to 0.05.
3. Results and Discussion
In this case study, we had 27,578 features and 215 samples including 152 normal samples and 63 uterine cervical cancer samples. After data preprocessing, linear regression and differential expression analysis, we obtained 6287 DEGs having by , in a list accompanied by computed t-score, p-value and FDR. Top 25 DEGs are shown in Table 1. For example, was the topmost DEG with minimum FDR (FDR = ). We provided the list of all DEGs obtained by differential expression analysis by Empirical Bayes test using with FDR corrected p-value in a Supplementary File, Additional file 1: Table S1. Furthermore, the predicted gene expression matrix of all DEGs computed from original pre-filtered uterine cervical cancer DNA methylation data through linear regression analysis was provided in another Supplementary File, Additional file 2: Table S2.

Table 1.
List of differentially expressed genes (false discovery rate (FDR) sorted).
After that, we applied the latest deep learning method “nnet” (feed-forward neural network based model), [20] on our computed DEG expression dataset which have 6287 features with 215 samples. We used this deep learning technique with 10-fold cross validation to examine the class-label (normal and uterine cervical cancer groups) of the differentially expressed genes with a repeat of 30 times. In the cross-validation, we divided all the samples of the predicted gene expression data of the DEGs into 10 folds of samples of which nine-fold of samples was used as training set, while the remaining one-fold of the samples was utilized as the test set. From this sub step, we ran “nnet” tool using maxit (number of epochs) equal to 100, that means the deep learning method was internally repeated for 100 times, and then computed the classification metrics at one time iteration of each fold. From this sub step, we obtained a confusion matrix consisting of True Positive (TP), False Negative (FN), False Positive (FP) and True Negative (TN). This sub procedure was repeated for each fold of samples (i.e., nine other folds). Then, we added all these metrics for these 10 times internal repetitions and produced a final confusion matrix. Thereafter, we repeated this entire procedure for multiple times (30 times) and obtained thirty confusion metrics. Using this, we obtained the average classification metric values (average accuracy, average sensitivity, average specificity, average precision, average overall error rate and area under curve (AUC)). Note that our deep learning method has already repeated 30,000 times () from which we computed the average accuracy, where every sample was used as a test set at least once (i.e., no sample was missing as a test sample). Here we used test sample as validation 163 sample. In this deep learning method, we used “nnet” with the default parameter settings (i) size (=number of units in hidden layer) (=2), (ii) rang (=initial random weights)(=0.1) while [−rang, rang], (iii) decay (=parameter for weight decay)(=), (iv) maxit (=the maximum number of iterations or number of epochs)(=100), (v) MaxNWts (=the maximum allowable number of weights)(=84,581) and other default parameters. As we used 10-fold cross validation, 9/10 of 215 samples (i.e., 194 or 193 samples) were considered as training set and 1/10 of 215 samples (i.e., 21 or 22 samples) were taken as test set. of which nine-fold of samples was used as a training set, while remaining one-fold of samples was utilized as a test set. Thus, each sample participated in each role, either in training sample or test sample, at least once. Here, we also used the test sample as the validation sample. We obtained () average classification accuracy and value of AUC was 0.858. For more details, see Table 2. We have plotted all metrics in Figure 2.
Table 2.
Values of disease classification metrics by proposed method.
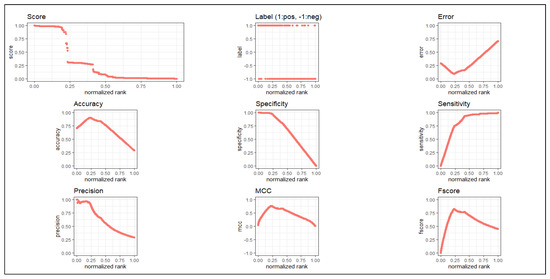
Figure 2.
ROC plots of all classification metrics for the proposed method.
We carried out a comparative study between proposed method and an existing method “RSNNS” (Stuttgart Neural Network Simulator (SNNS) based deep learning tool) with 10-fold cross validation with repeating 30 times. In case of “RSNNS” we also used same default parameter settings like (i) size (=number of units in hidden layer)(=2), (ii) maxit (=maximum number of iterations or number of epochs) (=100), among others. In both cases we have repeated entire procedure 30 times to to obtain a reliable classification. Our proposed method produced an average classification accuracy of () whereas existing method “RSNNS” had () as average classification accuracy (see Figure 3). We considered our framework had better performance than all other methods using deep learning tool.
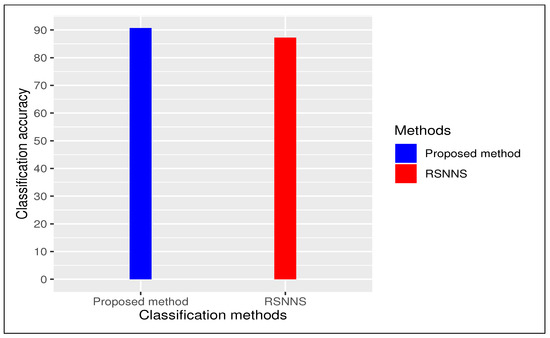
Figure 3.
Comparative bar plot: proposed method vs state-of-the-art method (RSNNS)).
Here, we applied Pearson’s correlation analysis on our DEGs for finding out edges among genes having correlation value greater than or equal to 0.8 or, less than or equal to (−0.8). Then, we also performed in-degree and out-degree hub gene network analysis using [21]. As an example the five top genes with highest in-degree values were namely , , , and , see Table 3. Similarly, the five top most out-degree genes were namely , , , and , see Table 4. We provided detail hub gene network structure in a Supplementary File, Additional file 7: Table S7.
Table 3.
Top 10 hub genes according to the in-degree centrality from our proposed method.
Table 4.
Top 10 hub genes according to the out-degree centrality from our proposed method.
In the corresponding literature survey, we found that most of the topmost hub genes detected by our method played an important role in the respective cancer. gene and cervical cancer were found to be associated by Berlanga et al. [26]. was utilized as the negatively regulator of p53 in tumorigenesis [27]. It had been also used as a potential bio-marker in DNA methylation at the time of treatment and risk assessment of cancer. Methylation of might be a protective factor in the development of tumor [28]. gene and cervical cancer were reported in the literature Broniarczyk et al. [29]. Similarly, gene is involved in cervical cancer, as reported in Sundaram et al. [30], while gene was associated with cervical cancer in Feron et al. [31]. Similarly, the topmost out-degree hub genes were mostly associated with cervical cancer through literature search. For example, the association between and cervical cancer were documented in Wen et al. [32], whereas was connected with the respective cervical cancer in Luo et al. [33]. In addition, and cervical cancer are reported in Liang et al. [34], while was found to be linked to cervical cancer in Zhang et al. [35].
These 6287 DEGs, which have , were taken for Gene Set Enrichment Analysis using WebGestalt (WEB-based Gene SeT AnaLysis Toolkit) [22]. We had applied WebGestalt (WEB-based Gene SeT AnaLysis Toolkit) database on our DEG set to obtain all KEGG pathways and Gene Ontology (GO) terms [Biological Process (BP), Cellular Component (CC) and Molecular Function (MF)], accompanied by number of genes in that pathway or GO-term, enriched p-value and FDR. Here, we took our input data set in the prescribed format of WebGestalt which was in a two-columns pattern, first one was gene name and second one was score. Here we used t-score as score. Significant pathways and GO-terms were described in below and also for more details see Table 5, Table 6, Table 7 and Table 8. For example, hsa05205:Proteoglycans in cancer was a top significant KEGG pathway which has minimum FDR value (). A total of 198 genes were associated in this pathway with enriched p-value . For the remaining top 10 significant KEGG pathways, see Table 5. We provided the list of all KEGG pathways in a Supplementary File, Additional file 3: Table S3. In addition, the volcano plot of the of normalized enrichment score of those FDR significant KEGG pathways is shown in Figure 4. Similarly, GO:0008283 cell proliferation was one of the top significant GO-BP terms with FDR value 0. A total of 1986 genes were associated with this GO-BP term, enriched p-value 0. For the remaining terms, see Table 6. We provided the list of all GO-BP terms in a Supplementary File, Additional file 4: Table S4. In such analysis, we found GO:0005783 endoplasmic reticulum as one of the top significant GO-CC terms with FDR value 0. A total of 1861 genes were associated with this GO-CC term, enriched p-value 0. For the rest, see Table 7. We provided the list of all GO-CC terms in a Supplementary File, Additional file 5: Table S5. Furthermore, GO:0042802 identical protein binding was one of the top significant GO-MF terms with minimum FDR value 0. A total of 1696 genes were associated with this GO-MF term having the enriched p-value 0. For details, see Table 8. We provided the list of all GO-MF terms in a Supplementary File, Additional file 6: Table S6.
Table 5.
Top significant KEGG Pathways (FDR sorted).
Table 6.
Top significant GO-BP term enriched (FDR sorted).
Table 7.
Top significant GO-CC term enriched (FDR sorted).
Table 8.
Top significant GO-MF term enriched (FDR sorted).
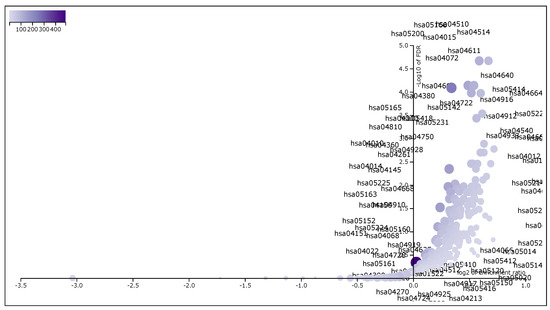
Figure 4.
The volcano plot of normalized enrichment score of the FDR significant KEGG pathways from GSEA analysis of DEGs.
4. Conclusions and Future Work
In this article, we provided a framework using linear regression, differential expression, and deep learning to provide correct biological interface for integrating DNA methylation and corresponding TCGA gene expression data to uterine cervical cancer. To develop the framework, first we eliminated outliers, then applied linear regression to determine predicted gene expression data from the preprocessed DNA methylation data by the use of TCGA gene expression data. Then we identified 6287 differentially expressed gene with FDR cut off less than 0.001 using downstream analysis through Empirical Bayes test using . After that, we applied “nnet” deep learning method to interpret differentially expressed genes with 10-fold cross validation and with the default parameter settings (i) size (=number of units in hidden layer), (ii) rang (=initial random weights) while [−rang, rang], (iii) decay (=parameter for weight decay), (iv) maxit (=the maximum number of iterations or number of epochs), (v) MaxNWts (=the maximum allowable number of weights) and other default parameters also. We obtained () as average classification accuracy of the uterine cervical cancer samples and normal samples for DEG expression data, which is more significant than other existing methods. So through the deep learning and comparative study, we can say that our obtained DEGs are strong and efficient in disease classification.
Here, we also performed in-degree and out-degree hub gene network analysis using [21]. We reported the five highest in-degree genes (, , , and ) and the five highest out-degree genes (, , , and ). Furthermore, we used pathway analysis on DEGs with using . Finally, our framework is useful for better biological interpretation of the DNA methylation data rather than single differential methylation analysis or differentially methylated region finding.
In our future study, we will extend our current work through integrating random forest ensemble method into deep learning strategy to obtain a better classification model in all prospective, and then apply that on big data (e.g., single cell RNA sequencing data or, other TCGA cancer tissue specific data) for cancer classification.
Supplementary Materials
The code is available online at https://drive.google.com/open?id=1LsYe3ypiweox2OSmnD5LDaYMJePeozDd, Table S1: List of all DEGs obtained by differential expression analysis by Empirical Bayes test using limma with FDR corrected p-value; Table S2: The predicted gene expression matrix of all DEGs computed from original prefiltered Uterine Cervical cancer DNA methylation data through linear regression analysis; Table S3: List of all KEGG pathways obtained by ; Table S4: List of all GO-BP terms obtained by ; Table S5: List of all GO-CC terms obtained by ; Table S6: List of all GO-MF obtained by ; Table S7: Image of hub-finding network by .
Author Contributions
Conceived and designed the experiments: S.M., S.S. and T.B. Execution of the experiments: S.M. and S.S. Data analysis: S.M. and S.S. Manuscript writing: S.M., S.S. and Z.Z. All authors have read and agreed to the published version of the manuscript.
Funding
Z.Z. was partially supported by Cancer Prevention and Research Institute of Texas (CPRIT RP170668 and RP180734). The funder had no role in the study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Conflicts of Interest
The authors have declared that no competing interests exist.
References
- Jin, B.; Li, Y.; Robertson, K.D. DNA Methylation: Superior or Subordinate in the Epigenetic Hierarchy? Genes Cancer 2011, 2, 607–617. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.H.; Karnovsky, A.; Mahavisno, V.; Weymouth, T.; Pande, M.; Dolinoy, D.C.; Rozek, L.S.; Sartor, M.A. LRpath analysis reveals common pathways dysregulated via DNA methylation across cancer types. BMC Genom. 2012, 13, 526. [Google Scholar] [CrossRef] [PubMed]
- Mallik, S.; Mukhopadhyay, A.; Maulik, U. Integrated Statistical and Rule-Mining Techniques for DNA Methylation and Gene Expression Data Analysis. JAISCR 2013, 3, 101–115. [Google Scholar] [CrossRef]
- Marsit, C.J.; Koestler, D.C.; Christensen, B.C.; Karagas, M.R.; Houseman, E.A.; Kelsey, K.T. DNA methylation array analysis identifies profiles of blood-derived DNA methylation associated with bladder cancer. J. Clin. Oncol. 2011, 29, 1133–1139. [Google Scholar] [CrossRef]
- Rijlaarsdam, M.A.; van der Zwan, Y.G.; Dorssers, L.C.J.; Looijenga, L.H.J. DMRforPairs: Identifying differentially methylated regions between unique samples using array based methylation profiles. BMC Bioinform. 2014, 15, 141. [Google Scholar] [CrossRef]
- Mallik, S.; Odom, G.J.; Gao, Z.; Gomez, L.; Chen, X.; Wang, L. An evaluation of supervised methods for identifying differentially methylated regions in Illumina methylation arrays. Briefings Bioinform. 2019, 20, 2224–2235. [Google Scholar] [CrossRef]
- Mallik, S.; Zhao, Z. Graph- and rule-based learning algorithms: A comprehensive review of their applications for cancer type classification and prognosis using genomic data. Briefings Bioinform. 2020, 21, 368–394. [Google Scholar] [CrossRef]
- Qin, G.; Mallik, S.; Mitra, R.; Li, A.; Jia, P.; Eischen, C.; Zhao, Z. MicroRNA and transcription factor co-regulatory networks and subtype classification of seminoma and non-seminoma in testicular germ cell tumors. Sci. Rep. 2020, 10, 852. [Google Scholar] [CrossRef]
- Mallik, S.; Qin, G.; Jia, P.; Zhao, Z. Molecular signatures identified by integrating gene expression and methylation in non-seminoma and seminoma of testicular germ cell tumors. Epigenetics 2020. [Google Scholar] [CrossRef]
- Wang, Y.; Franks, J.M.; Whitfield, M.L.; Cheng, C. BioMethyl: An R package for biological interpretation of DNA methylation data. Bioinformatics 2019, 35, 3635–3641. [Google Scholar] [CrossRef]
- McLean, C.Y.; Bristor, D.; Hiller, M.; Clarke, S.L.; Schaar, B.T.; Lowe, C.B.; Wenger, A.M.; Bejerano, G. GREAT improves functional interpretation of cis-regulatory regions. Nat. Biotechnol. 2010, 28, 495–501. [Google Scholar] [CrossRef] [PubMed]
- Goecks, J.; Nekrutenko, A.; Taylor, J.; Team, G. Galaxy: A comprehensive approach for supporting accessible, reproducible, and transparent computational research in the life sciences. Genome Biol. 2010, 11, R86. [Google Scholar] [CrossRef] [PubMed]
- Everything You Need to Know About Cervical Cancer. Available online: https://www.healthline.com/health/cervical-cancer (accessed on 17 March 2020).
- Zhuang, J.; Jones, A.; Lee, S.; Ng, E.; Fiegl, H.; Zikan, M.; Cibula, D.; Sargent, A.; Salvesen, H.B.; Jacobs, I.J.; et al. The dynamics and prognostic potential of DNA methylation changes at stem cell gene loci in women’s cancer. PLoS Genet. 2012, 8, e1002517. [Google Scholar] [CrossRef]
- Teschendorff, A.E.; Jones, A.; Fiegl, H.; Sargent, A.; Zhuang, J.J.; Kitchener, H.C.; Widschwendter, M. Epigenetic variability in cells of normal cytology is associated with the risk of future morphological transformation. Genome Med. 2012, 4, 24. [Google Scholar] [CrossRef]
- Teschendorff, A.E.; Jones, A.; Widschwendter, M. Stochastic epigenetic outliers can define field defects in cancer. BMC Bioinform. 2016, 17, 178. [Google Scholar] [CrossRef] [PubMed]
- Bandyopadhyay, S.; Mallik, S.; Mukhopadhyay, A. A survey and comparative study of statistical tests for identifying differential expression from microarray data. IEEE/ACM Trans. Comput. Biol. Bioinf. 2014, 11, 95–115. [Google Scholar] [CrossRef] [PubMed]
- Mallik, S.; Seth, S.; Bhadra, T.; Tomar, N.; Zhao, Z. A Multi-classifier Model to Identify Mitochondrial Respiratory Gene Signatures in Human Cancer. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 1928–1935. [Google Scholar]
- Mallik, S.; Mukhopadhyay, A.; Maulik, U. RANWAR: Rank-Based Weighted Association Rule Mining From Gene Expression and Methylation Data. IEEE Trans. NanoBiosci. 2015, 14, 59–66. [Google Scholar] [CrossRef]
- Venables, W.N.; Ripley, B.D. Feed-Forward Neural Networks and Multinomial Log-Linear Models (Package “nnet”). CRAN R Project Repository. 2020. Available online: http://www.stats.ox.ac.uk/pub/MASS4/ (accessed on 2 May 2020).
- Shannon, P.; Markiel, A.; Ozier, O.; Baliga, N.S.; Wang, J.T.; Ramage, D.; Amin, N.; Schwikowski, B.; Ideker, T. Cytoscape: A Software Environment for Integrated Models of Biomolecular Interaction Networks. Genome Res. 2003, 13, 2498–2504. [Google Scholar] [CrossRef]
- Liao, Y.; Wang, J.; Jaehnig, E.J.; Shi, Z.; Zhang, B. WebGestalt 2019: Gene set analysis toolkit with revamped UIs and APIs. Nucleic Acids Res. 2019, 47, W199–W205. [Google Scholar] [CrossRef]
- Xu, Z.; Niu, L.; Li, L.; Taylor, J.A. ENmix: A novel background correction method for Illumina HumanMethylation450 BeadChip. Nucleic Acids Res. 2016, 44, e20. [Google Scholar] [CrossRef]
- Law, C.W.; Chen, Y.; Shi, W.; Smyth, G.K. voom: Precision weights unlock linear model analysis tools for RNA-seq read counts. Genome Biol. 2014, 15, R29. [Google Scholar] [CrossRef] [PubMed]
- Ritchie, M.E.; Phipson, B.; Wu, D.; Hu, Y.; Law, C.W.; Shi, W.; Smyth, G.K. Limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 2015, 43, e47. [Google Scholar] [CrossRef] [PubMed]
- Berlanga1, J.J.; Baass, A.; Sonenberg, N. Regulation of poly(A) binding protein function in translation: Characterization of the Paip2 homolog, Paip2B. RNA 2006, 12, 1556–1568. [Google Scholar] [CrossRef] [PubMed]
- Kayama, K.; Watanabe, S.; Takafuji, T.; Tsuji, T.; Hironaka, K.; Matsumoto, M.; Nakayama, K.I.; Enari, M.; Kohno, T.; Shiraishi, K.; et al. GRWD1 negatively regulates p53 via the RPL11-MDM2 pathway and promotes tumorigenesis. EMBO Rep. 2017, 18, 123–137. [Google Scholar] [CrossRef]
- Gao, C.; Zhuang, J.; Li, H.; Liu, C.; Zhou, C.; Liu, L.; Sun, C. Exploration of methylation-driven genes for monitoring and prognosis of patients with lung adenocarcinoma. Cancer Cell Int. 2018, 18, 194. [Google Scholar] [CrossRef]
- Broniarczyk, J.; Pim, D.; Massimi, P.; Bergant, M.; Jozefiak, A.; Crump, C.; Banks, L. The VPS4 component of the ESCRT machinery plays an essential role in HPV infectious entry and capsid disassembly. Sci. Rep. 2017, 7, 45159. [Google Scholar] [CrossRef]
- Sundaram, M.K.; Raina, R.; Afroze, N.; Bajbouj, K.; Hamad, M.; Haque, S.; Hussain, A. Quercetin modulates signaling pathways and induces apoptosis in cervical cancer cells. Biosci. Rep. 2019, 39, BSR20190720. [Google Scholar] [CrossRef]
- Feron, O.; Boidot, R.; Branders, S.; Dupont, P.; Helleputte, T. Signature of Cycling Hypoxia and Use Thereof for the Prognosis of Cancer, International Application Published under the Patent Cooperation Treaty (PCT). WO 2015/015000 Al, 5 February 2015. Available online: https://patentimages.storage.googleapis.com/80/1a/3c/eac6d250b2943a/WO2015015000A1.pdf (accessed on 10 April 2020).
- Wen, H.; Chen, L.; He, J.; Lin, J. MicroRNA Expression Profiles and Networks in Placentas Complicated with Selective Intrauterine Growth Restriction. Mol. Med. Rep. 2017, 16, 6650–6673. [Google Scholar] [CrossRef]
- Luo, J.; Huang, Q.; Lin, X. STAT4 Expression Is Correlated with Clinicopathological Characteristics of Cervical Lesions. Available online: https://www.researchgate.net/publication/303787920_STAT4_expression_is_correlated_with_clinicopathological_characteristics_of_cervical_lesions/citations (accessed on 10 April 2020).
- Liang, W.S.; Aldrich, J.; Nasser, S. Simultaneous Characterization of Somatic Events and HPV-18 Integration in a Metastatic Cervical Carcinoma Patient Using DNA and RNA Sequencing. Int. J. Gynecol. Cancer 2014, 24, 329–338. [Google Scholar] [CrossRef]
- Zhang, C.; Liao, Y.; Liu, P.; Du, Q.; Liang, Y.; Ooi, S.; Qin, S.; He, S.; Yao, S.; Wang, W. FABP5 promotes lymph node metastasis in cervical cancer by reprogramming fatty acid metabolism. Theranostics 2020, 10, 6561–6580. [Google Scholar] [CrossRef]




© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).