1. Introduction
Reliable low-flow estimates are necessary to provide information for water supply planning, reservoir storage design, water quantity and quality preservation, irrigation, hydropower production, and pollution load dispersion [
1,
2,
3,
4]. In the case of insufficient or no streamflow records, several approaches can be used to obtain low-flow estimates. For example, regression models, including linear methods, can be applied with explanatory variables that are determined by physiographical and meteorological characteristics. Additionally, several studies with nonlinear models have been conducted to provide more reliable low-flow estimates [
5,
6,
7].
The drainage area ratio method is a linear model between the drainage area and discharge and has been popular for the estimation of low-flow with a 10/365 non-exceedance probability [
8]. A number of studies have applied the drainage area ratio method. Wiche et al. [
9] examined historic streamflow data by focusing on the James River in North Dakota and South Dakota, USA and performed record extension based on different techniques, such as the drainage area ratio method. Guenthner et al. [
10] and Emerson and Dressler [
11] studied monthly gauged and estimated streamflow for the Red River, USA and used the drainage area ratio approach to develop streamflow records. Cho et al. [
12] investigated low-flows during a dry season in South Korea to obtain low-flow estimates at ungauged sites based on three approaches, including the drainage area ratio method.
The regional frequency analysis (RFA) method has been widely used to assess hydrological characteristics at locations with little or no data available. The hydrological estimations that are derived from RFA are of prime significance in the design of hydraulic structures such as dams and reservoirs. In RFA, two principal steps are required: (a) the identification of groups of basins (homogenous regions) that are hydrologically similar to a target basin and (b) model application for regional estimation within the homogenous regions. These regions have been traditionally defined using geographical and administrative boundaries considering hydrological features [
13,
14]. The region of influence approach, which pools a certain number of river basins based on proximity in a catchment feature space, has also been utilized to define homogenous regions with objective functions [
15,
16,
17]. In recent studies, the canonical correlation analysis (CCA) was recommended and used to determine hydrologically similar regions by creating a canonical space and providing the optimal number of stations in the regions [
18].
As a common nonlinear regression approach, artificial neural networks (ANNs) have been broadly adopted for a wide range of hydrological problems. Luk et al. [
19] performed rainfall forecasting using an ANN over an urban catchment in Australia. Shu and Burn [
20] and Dawson et al. [
21] used an ANN for indexing floods and flood quantile estimation based on catchments in the United Kingdom (UK) by improving a hydrological prediction model. Seidou et al. [
22] also applied an ANN for the regional estimation of lake ice thickness at ungauged locations in Canada. Shu and Ouarda [
23] used regional frequency analysis based on ANN models to obtain flood quantile estimations for 151 river networks in the province of Quebec, Canada. Ouarda and Shu [
3] conducted a regional low-flow frequency analysis using an ANN model with low-flow quantiles of the summer and winter seasons based on selected river basins in Canada.
The main objectives of the present study are to develop an advanced method of obtaining low-flow estimates in ungauged basins and to identify the relationships between physiographical/meteorological variables and hydrological variables in South Korea. A regional low-flow estimation approach based on CCA and ANNs for RFA is proposed and compared with the drainage area ratio method. CCA is used to identify the canonical space that is the transformed space to obtain continuous hydrologic variables. In this space, the prediction performance of the original data is preserved and redundant information is excluded to improve the estimates. CCA also identifies projections of high correlations between the two sets of multivariate variables by providing canonical variables that are linear combinations of the variables. ANNs are then used to establish the nonlinear relationships between the canonical variables and hydrological variables to be estimated. We will provide more details about these processes in the methodology section.
The remainder of the paper is organized as follows. In
Section 2, the data set that was used in the present study is described.
Section 3 presents the methodologies that were used in the analysis to obtain low-flow estimates with assessments based on the proposed models. The results and discussion are given in
Section 4. Finally, conclusions are summarized in
Section 5.
2. Data Set
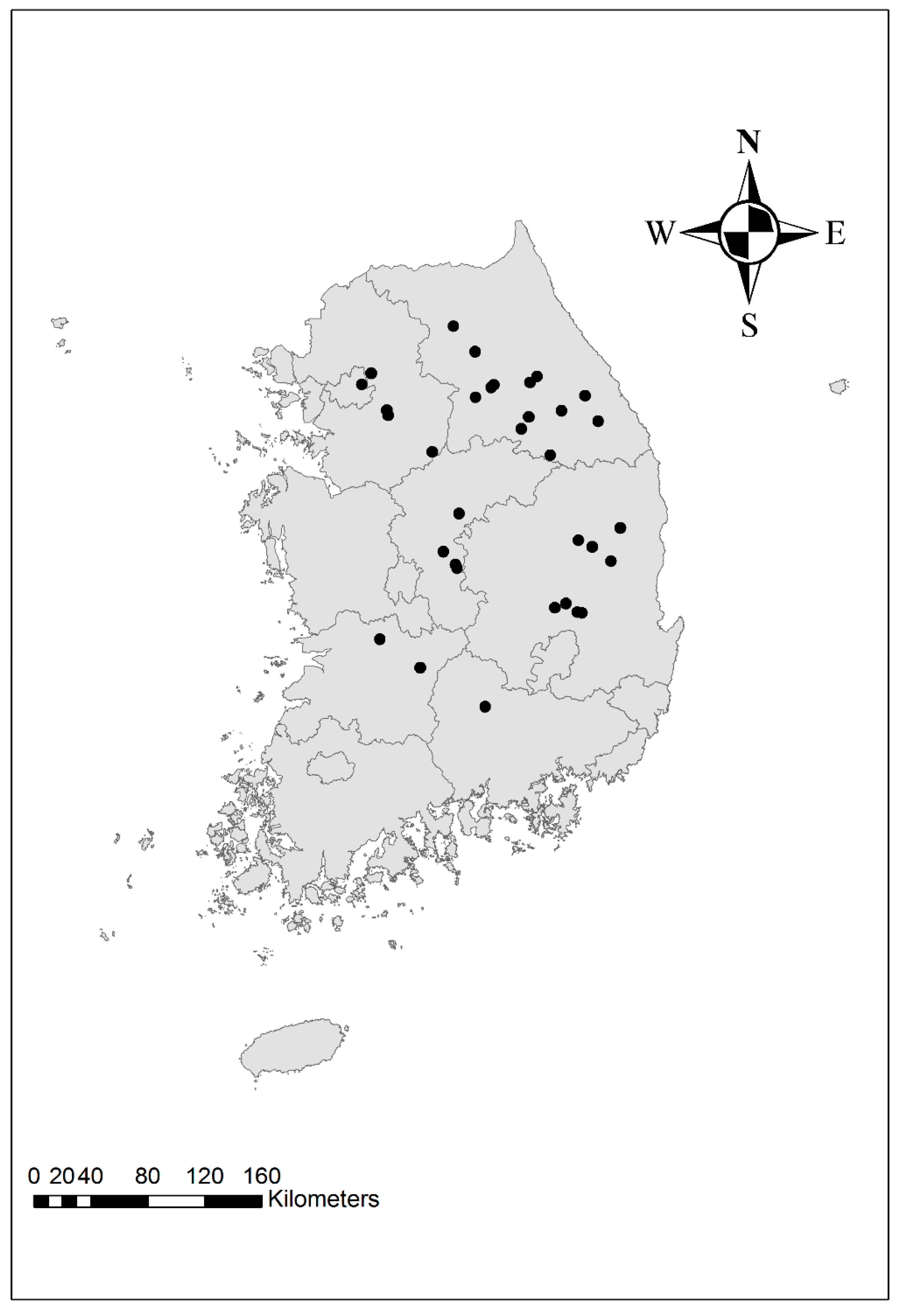
A data set of 33 river basins in South Korea was created to estimate the low-flow values in ungauged basins. The variables of the river basins that were used for this study are shown in
Table 1.
Figure 1 shows the outlet of each basin selected in the present study based on the following criteria.
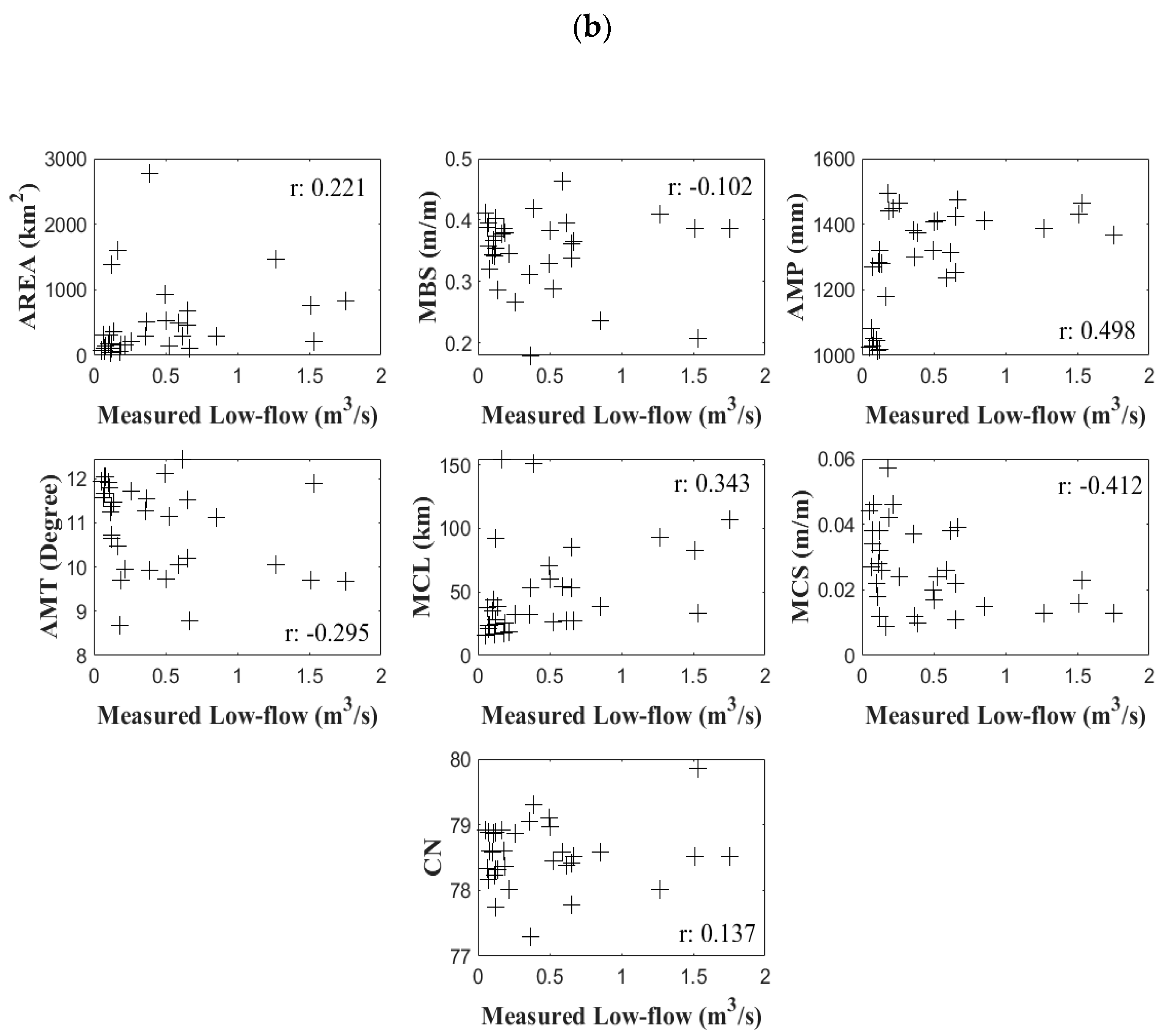
To conduct RFA, several variables representing the physiographical and meteorological features were obtained for the river networks in South Korea. In this study, we set seven variables that have generally been used in previous studies with RFA [
3,
18,
23,
26]. These variables include the drainage area (AREA), mean basin slope (MBS), annual mean precipitation (AMP), annual mean temperature (AMT), length of the main channel (MCL), slope of the main channel (MCS), and curve number (CN). A brief description with statistics for all the variables that were used in the analysis is given in
Table 2.
For the hydrological variables that are related to low-flows in the present work, the specific quantiles, such as the two-year and five-year quantiles, are calculated based on the flow records from all the gauged sites in the study area. Cho et al. [
12] investigated the low-flows in South Korea to select an appropriate statistical distribution and found that the Gamma distribution was the most feasible for the analysis of the low-flows. Thus, we used the Gamma distribution to estimate the two-year and five-year quantiles. Additionally, to compare the results based on different statistical distributions, we investigated several distributions, including the generalized extreme value (GEV), two-parameter lognormal (LN2), and Weibull (W2) distributions, which are commonly applied for hydrological analysis [
3,
23,
27,
28].
3. Methodology
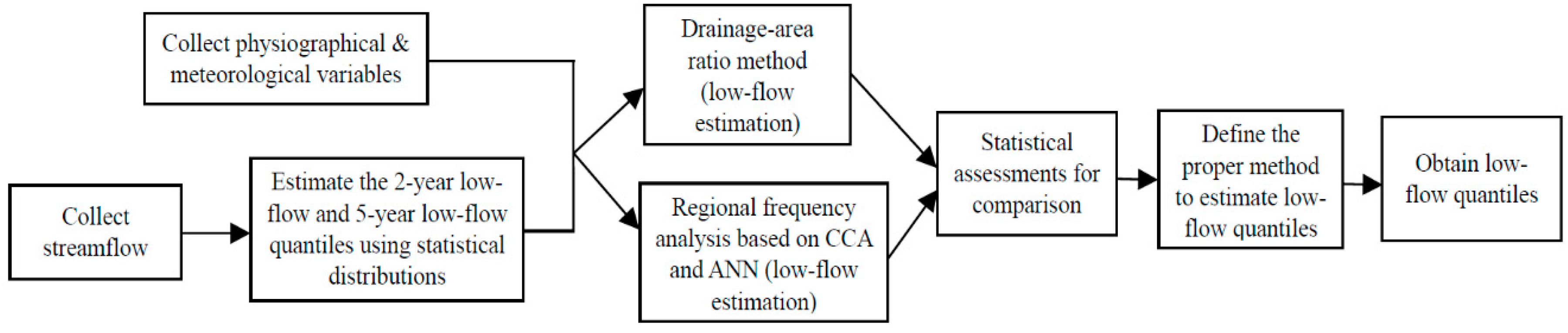
After all the variables that were used to estimate the low-flows were obtained, two methodologies, including the drainage area ratio and RFA, were applied to enhance the low-flow estimations at ungauged sites in South Korea. The drainage area ratio method uses the drainage area and low-flow quantiles. We describe this method in detail in
Section 3.1. In RFA, the appropriate data preprocessing steps are required before performing the analysis. In the preprocessing stage, the physiographical, meteorological, and hydrological variables were standardized. Then, we obtained the standardized database that has a mean of zero and standard deviation of one, and asymmetry in the variables could then be assessed. With the database, RFA using CCA and ANNs were performed to estimate the low-flow quantiles in ungauged basins. We specifically describe the RFA application process and provide a diagram of the procedures that were used to obtain the low-flow estimates in
Section 3.2. The overall processes that were applied in the present study are shown with a simple diagram in
Figure 2.
3.1. Drainage Area Ratio Method
The drainage area ratio approach is based on the assumption that the streamflow at a location of interest can be estimated by multiplying the ratio of the drainage area corresponding to a streamflow at ungauged stations and the drainage area corresponding to a streamflow at gauged stations. The drainage area ratio approach is commonly used to estimate low-flows at ungauged locations because of its simplicity [
12,
29,
30,
31]. This method is relatively effective if the streams have similar hydrological features [
32]. The method that was used in the present study is given as follows:
where
denotes the estimated low-flows in the river basin of interest,
is the basin area of the river basin of interest,
is the basin area of the river basin with the streamflow records, and m is the exponent of
. In the simplest drainage ratio method, it is assumed that m equals 1 and the equation is unbiased, indicating that the expected value of the estimated low-flows tends to equal the value of the observed low-flows.
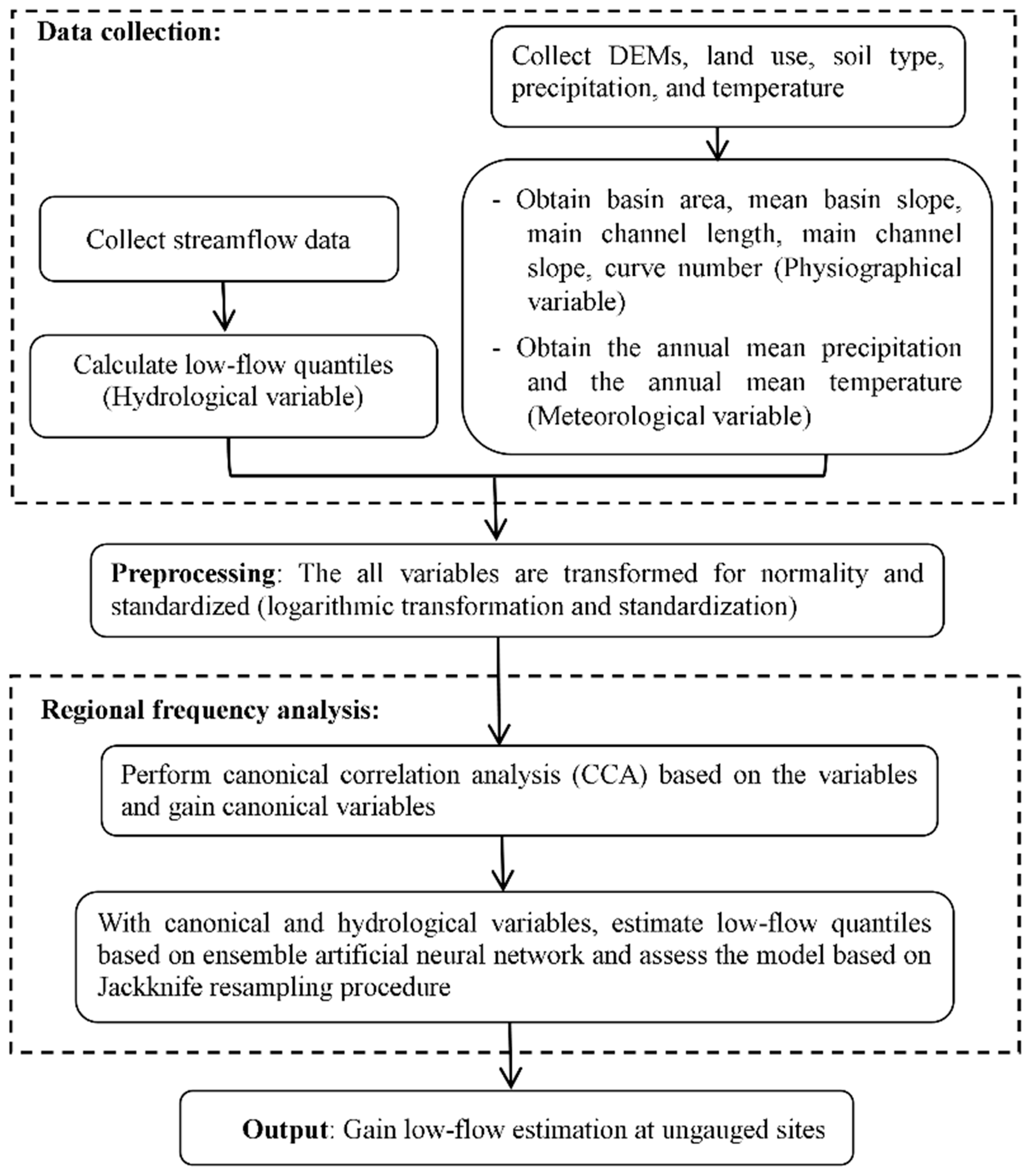
3.2. Ensemble ANN for RFA
The ANNs that were used to conduct the RFA have been applied to estimate extreme events in several studies. For example, Shu and Ouarda [
23] used an ensemble ANN with a CCA to improve the flood quantile estimation for extremely high flow events based on 151 catchments with ungauged sites and Ouarda and Shu [
3] analyzed the low-flow quantiles of extreme events using an ensemble ANN based on more than 100 river basins in Canada. In the present study, the RFA method that was implemented to estimate the low-flows at ungauged sites in South Korea was based on the CCA and ANN methods. Using the CCA, we could construct the physiographical space as a canonical space to interpolate the hydrological variables of interest in the space, estimate the hydrological variables at ungauged sites, and create canonical variables. The canonical variables that were obtained from CCA were then fed to the ANN models to generate hydrological variable estimates in the physiographical domain. In
Figure 3, a simple diagram shows the processes that were used to estimate hydrological variables such as low-flow quantiles using the CCA and ANN models.
The CCA method is a statistical multivariate analysis method that reflects the relationship between two sets of random variables by omitting nonessential data and preserving the original characteristics of the variables [
33,
34]. Given that we have a set of physiographical and meteorological variables, X, and a set of hydrological variables, Y, CCA was used to link the two sets based on vectors of canonical variables. If W and V are linear combinations of X and Y, we have
where W represents the canonical physiographical and meteorological variables and V represents the canonical hydrological variables. The correlation between W and V is estimated as follows.
In the CCA processes, we identified vectors
and
by maximizing the correlation
as discussed in previous studies [
18,
23]. After the first pair of canonical variables were obtained, other pairs of canonical variables were calculated based on the correlation subject to the constraint of the unit variance for normalization.
The CCA in the RFA was used to construct a transformed space (canonical space) which was determined by the physiographical and meteorological characteristics of the variables and a canonical space in which the hydrological variables that are continuous can be obtained [
35]. The hydrological variables can be indirectly estimated in space by establishing a functional relationship between the physiographical and meteorological variables and the hydrological variables. The physiographical and meteorological variables that are generally available at ungauged locations can provide information to calculate the hydrological variables at the ungauged sites. Thus, we can estimate hydrological variables by locating an ungauged site of interest in the canonical space defined by the variables. Additional detailed theoretical information about the application of CCAs for RFAs can be found in the study of Ouarda et al. [
18]. Note that the study of Ouarda et al. [
18] proposed a theoretical framework for the application of the CCA for RFAs. In the present study, the CCA was used to estimate low-flow quantiles for ungauged locations based on the ANN-based model. Also, the DAR method was applied to the study region and the results of the DAR were compared with the results of the ANN model to determine a better approach for low-flow estimation in South Korea.
In this study, ANN models were applied in canonical space to estimate the hydrological variables, such as low-flow quantiles, for ungauged basins in South Korea. Based on the CCA, the canonical variables W and V can be obtained as the linear combination of the set of physiographical and meteorological variables and the set of hydrological variables. After we obtained the canonical variable W, the ANN models were used to approximate the functional relationship between W and the hydrological variable Y. With these variables, multilayer perceptrons (MLPs), which are also known as multilayer feed-forward networks, were used to train the hydrological variables in the ANN procedure. The MLPs consist of an input layer, with one or more hidden layers, and an output layer that are interconnected. The MLP input layer receives values of the input variables and the hidden layers between the input and output layers play significant roles in transferring information between these layers. The transfer functions of the hidden layers affect the behavior of the ANN model. The output layer then provides an ANN prediction and represents the model output, which is the low-flow estimate in the present study.
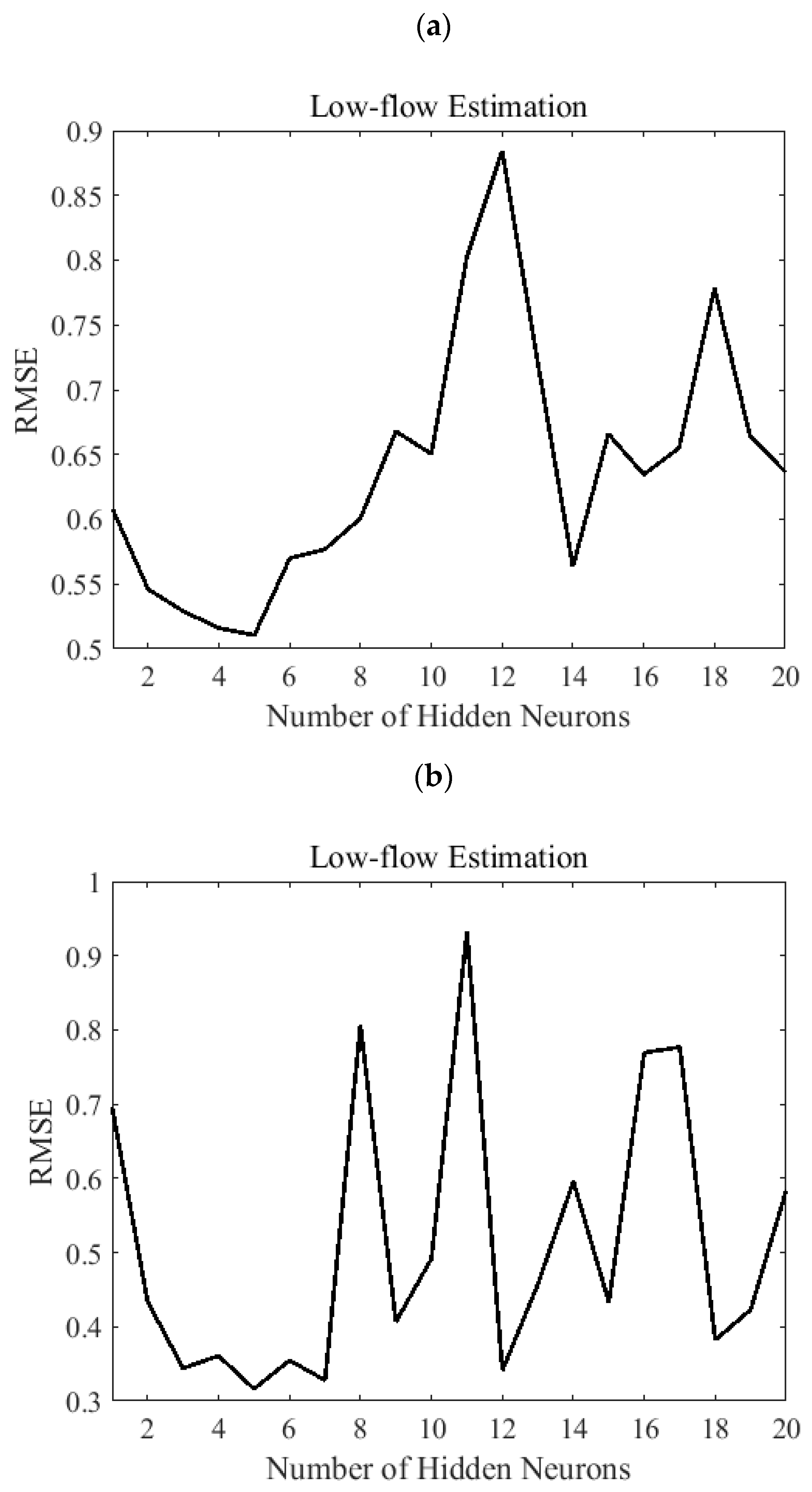
The ANNs should be trained in the estimation phase using the samples from the gauged locations. During the training process of ANNs, network parameters such as the number of neurons in the hidden layer and learning rate must be optimized until the estimation error of the network is minimized and the network reaches the specified level of accuracy for the ANN model. After a network is trained and tested, the new input information can be provided to produce the model output. The training algorithm that was used in this study is the Levenberg-Marquardt (LM) algorithm. This algorithm is faster than other algorithms, such as the gradient descent method, in finding optimal solutions [
36,
37,
38]. In the LM algorithm, an appropriate value of the scalar parameter
should be selected [
39]. A large
value forces the LM algorithm to follow the gradient descent method with a small sized step, whereas a small
value leads to the Guess-Newton method, which is accurate near a minimum error solution. The initial value was given as 0.005, and the value of
changed during the ANN training process until the performance of the ANN was satisfactory. In the process, when the training epoch decreases the function of the performance, the μ value is multiplied by 0.1, whereas when the training epoch increases the function of the performance, the μ value is multiplied by 10. The maximum μ value is 10
6, at which point the training algorithm stops. In the analysis of the ANN with the scalar parameter, an early stopping criterion was used to avoid overfitting (overtraining) during ANN training as described by Bishop [
40].
To improve the generalizability and stability of the ANN, an ensemble ANN model was used in the present study. The ensemble ANN model consisted of a set of ANNs that were trained for the same task and produced the output of the model. The bagging method was applied for the ensemble ANN model to provide component networks by averaging the resulting networks. In the bagging method, each member ANN of the ensemble was trained with a subset of the training set and the subset was drawn from the original training set with replacement. This approach assists in enhancing the accuracy of the predictions and the model generalization ability in regression and classification problems [
41,
42,
43]. Selecting the size of an ensemble plays an important role in obtaining satisfactory output from ANN models. The improvement of the generalizability is not apparent if the ensemble size is too small and the training time and ensemble creation will have time costs if this value is too large. Different ensemble sizes ranging from two to 20 were considered for the study area to determine the ideal number, as demonstrated in a previous study [
23]. The ensemble size of 14 was chosen in this study based on the characteristics of the ensemble and hydrological variables.
3.3. Evaluation Criteria
To assess the proposed methods in the present work, we used the following indices: the R-squared (R
2), mean bias (BIAS), and root mean squared error (RMSE) indices. These indices were calculated based on the following equations:
where RSS is the residual sum of squares, TSS is the total sum of squares, n is the total number of sites,
is the at-site estimate for site i, and
is the estimate that was derived from the models for site i.
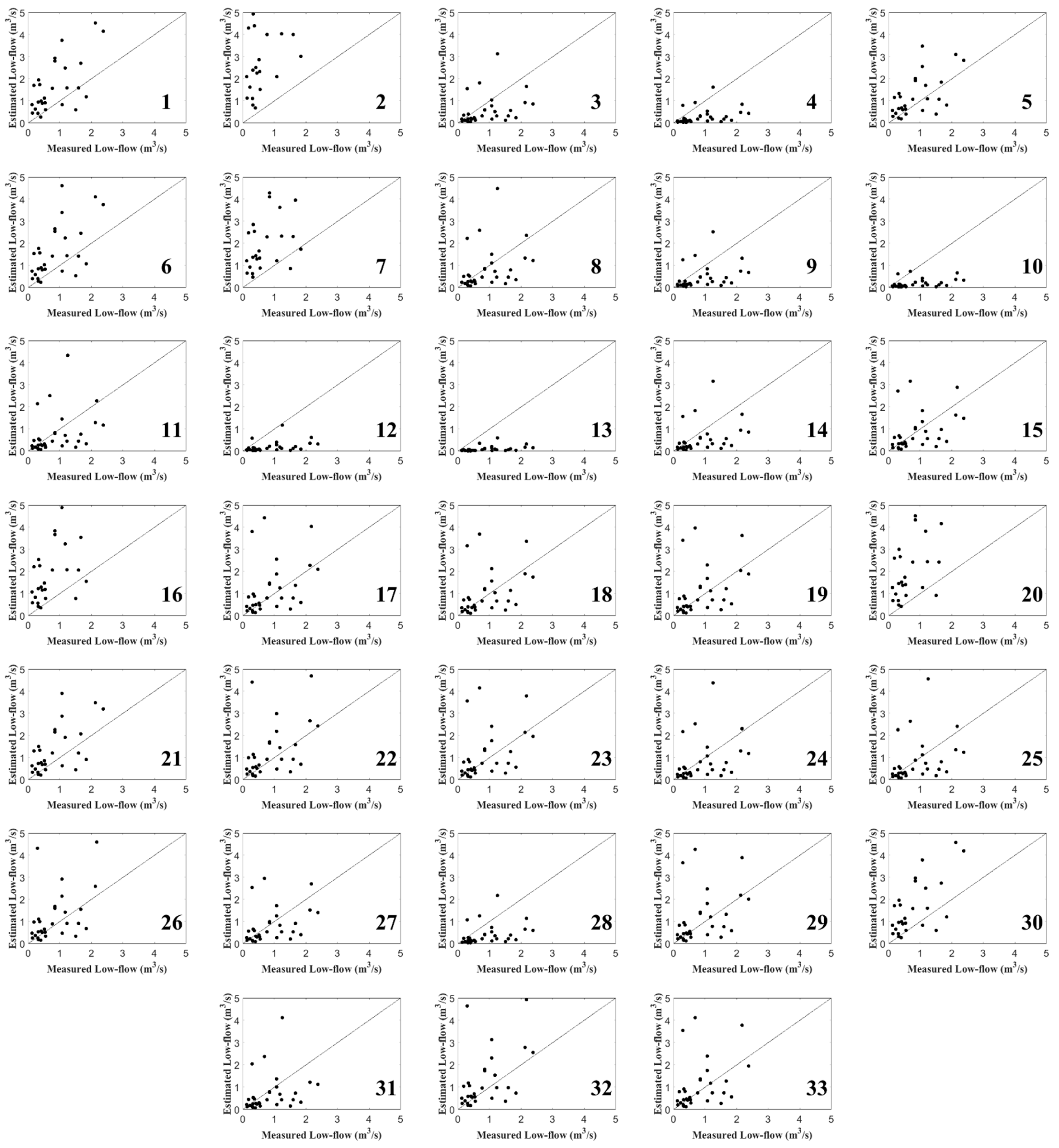
In the evaluation procedure, we use the jackknife resampling technique to compare the relative performance of each model that was used to estimate the low-flow quantiles at ungauged locations. In this procedure, the low-flow records in each drainage basin were temporarily removed from the database to assume that the site represented an ungauged location. Each model was calibrated using the data from the remaining sites. Then, regional estimates could be obtained for the ungauged river basins based on the calibrated models that were proposed in the study, and these estimates were compared to the at-site estimates, which were also called local estimates.
5. Conclusions
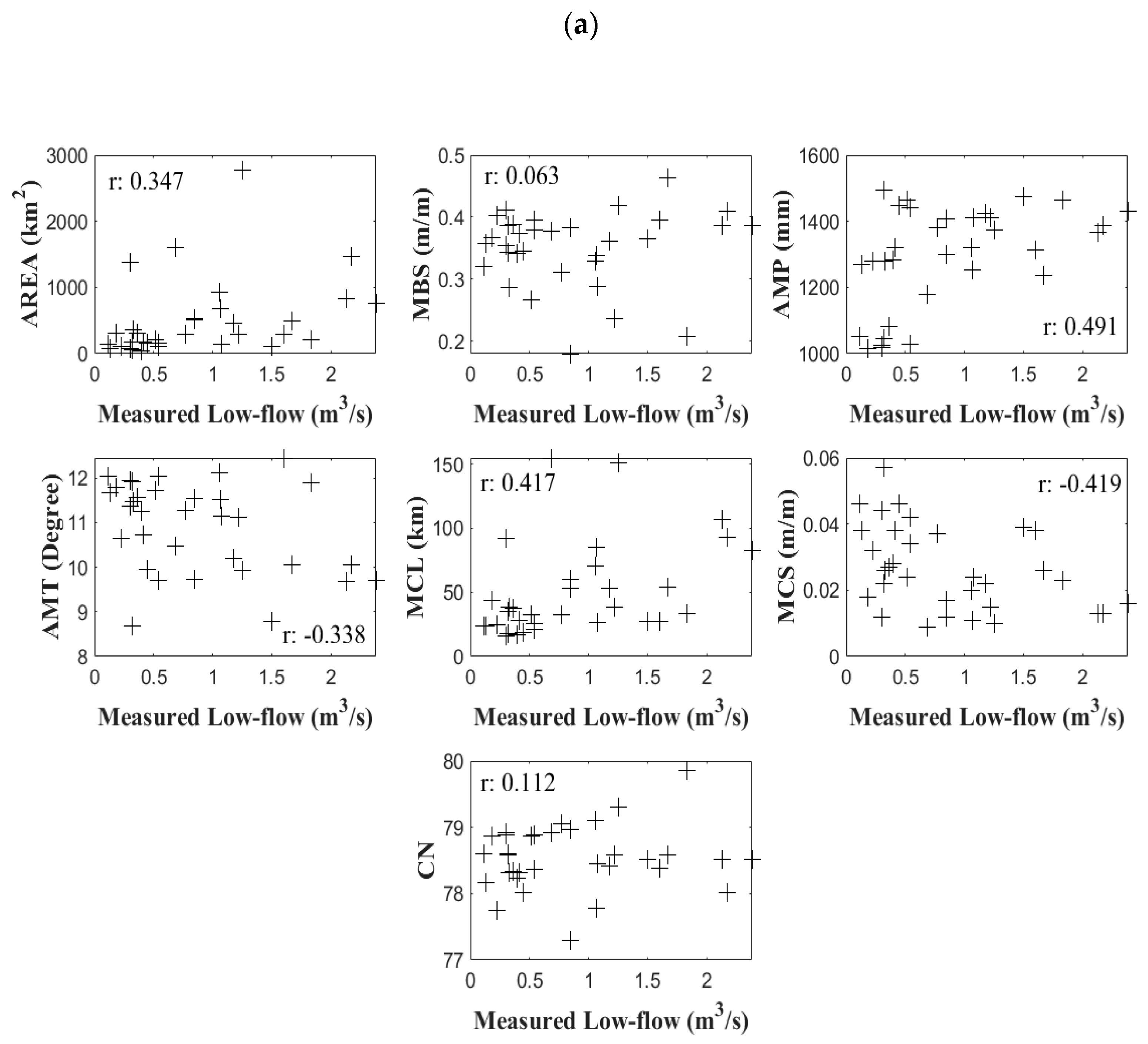
We examined the correlations between the physiographical/meteorological variables and the hydrological variables to better understand the characteristics of low-flows. Among the variables representing the physiographical and climatic features, we found that AREA, AMP, MCL, and MCS are positively correlated with low-flows based on a significance test. Additionally, MBS, AMT, and CN are not significantly correlated with low-flows, but are correlated with other variables that may influence the RFA results. In addition, when we used CCA to generate the canonical correlation coefficients of the variables, the correlations between the physiographical/meteorological variables and low-flows were improved.
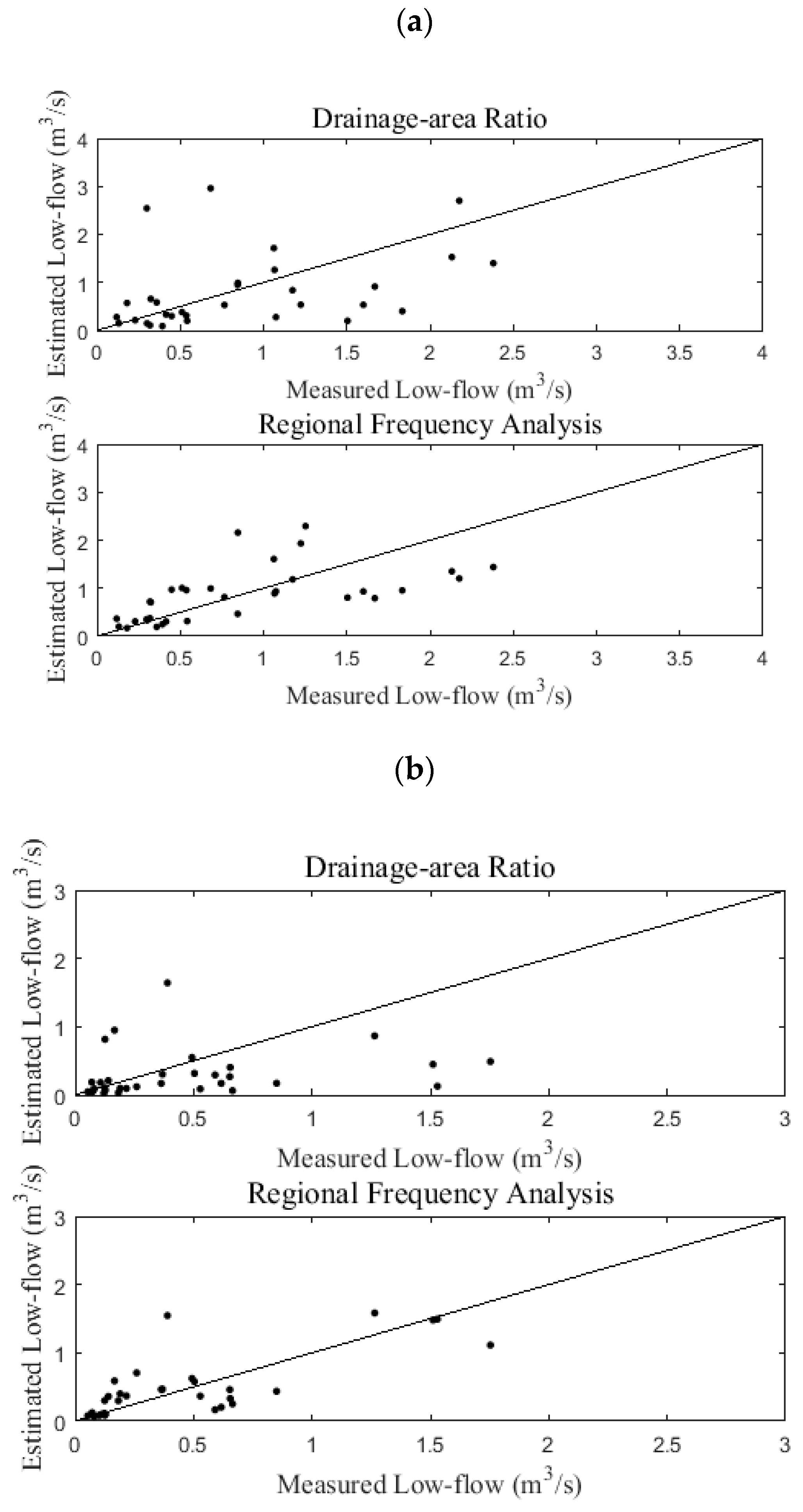
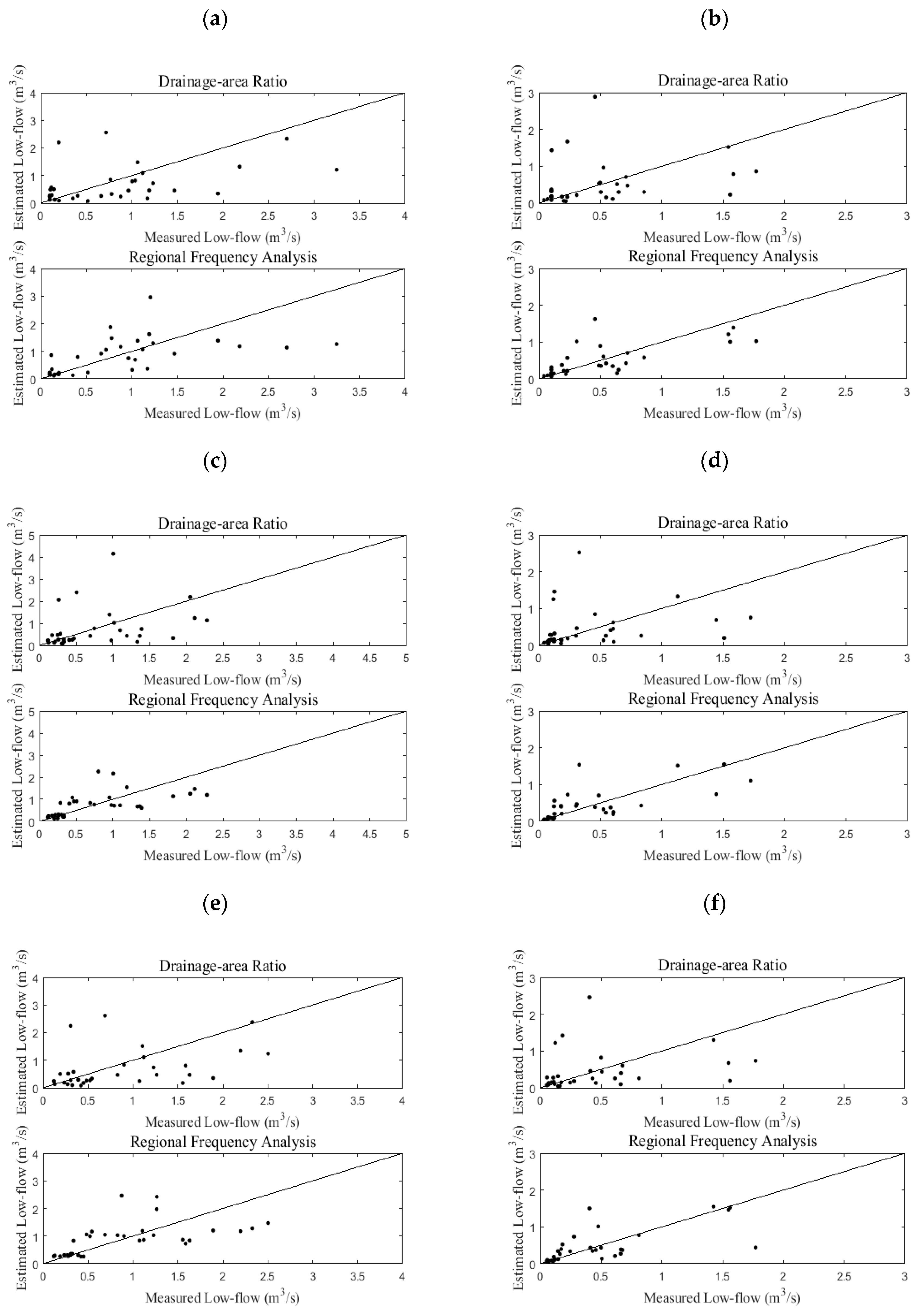
The drainage area ratio method was used to estimate the low-flows at ungauged sites. With this method, one river basin was considered a gauged basin and the other basins were considered ungauged basins. Using the basin area ratio, the method was assessed based on the BIAS, RMSE, and R2. The average values of BIAS, RMSE, and R2 were −0.703, 2.097, and 0.121 for the two-year quantile and −0.297, 1.111, and 0.050 for the five-year quantile, respectively. To compare the results of the drainage area ratio method and RFA, several basins that exhibited good performance were selected. The ranges of the BIAS, RMSE, and R2 values of the Misung, Tanbugyo, Chungmi, and Hwachon basins were −0.042~0.095, 0.924~1.042, and 0.109~0.120 for the two-year quantile and −0.011~0.166, 0.536~0.631, and 0.042~0.049 for the five-year quantile, respectively. Additionally, if the selected basin was too small or too large, the estimated quantiles were biased. Based on the results of this study, the estimates seem to be relatively overestimated when the basin area is smaller than 150 km2 and relatively underestimated when the basin area is larger than 1000 km2.
Compared with the drainage area ratio approach, RFA using CCA-based ANNs was applied for the 33 river basins. In this assessment, we used jackknife validation with statistical indices, such as BIAS, RMSE, and R2. The indices based on the RFA were 0.013, 0.511, and 0.408 for the two-year quantile and −0.018, 0.316, and 0.573 for the five-year quantile. Based on the indices, we found that the RFA method that was proposed in this paper performs better than the drainage area ratio method based on the results for the 33 river basins. We determine that the ensemble ANN method, as a nonlinear model, seems to outperform the drainage area ratio approach, a linear model, in obtaining low-flow estimates at ungauged sites in South Korea. Although the ensemble ANN did not show such improvements, we found that the nonlinear model has the potential to enhance low-flow estimations in the study region.
Other statistical distributions, such as GEV, LN2, and W2, were used to obtain the two-year and five-year low-flow quantiles and to assess the low-flow estimates at ungauged basins. When these distributions are used in RFA and the drainage area ratio method, RFA based on CCA and ANNs outperforms the drainage area ratio approach, and the Gamma distribution provides the best results. The BIAS, RMSE, and R2 values are also used for model assessment based on the distributions. W2 exhibits the best performance for BIAS and the Gamma distribution displays the best performance for RMSE and R2. In this paper, we found that the machine learning-based nonlinear model provides relatively reliable estimates of low-flow quantiles for ungauged basins in South Korea compared to the estimates by the linear model. The results point to the use of the machine learning model to enhance estimates of low-flow quantiles in areas characterized by nonlinearity. Additionally, the explicit correlations between the quantiles and the sets of physiographical and meteorological covariates can be determined to improve the quality of regional quantile estimates in ungauged basins.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}