We conducted several experiments to show that using only MSE and MAE measures to judge models in the context of the REE task is not enough, and our idea to improve the model’s ability of estimating unseen patterns, as well as the effectiveness of some IQA metrics in supporting the training process. We implemented the models with TensorFlow-GPU-1.8 and executed on NVIDIA Tesla P100 GPU (16GB) with the CUDA-9.0 library. All models were trained with the early-stopping strategy and settings in [
6] (maximum 200,000 iterations with batch-size 4). We set the learning rate at 0.0001 and decayed it after each 20,000 iterations with a rate of
. The pixel values of images were normalized to the range [0.0, 1.0] and all measures of comparison would be calculated on this range. Moreover, to avoid a possible “unlucky” random initialization, we trained each model several times and chose to report the best one here.
4.1. Evaluation of the Previous Work with IQA Metrics
We started by evaluating if a TrajGRU model constructed with the structure in [
6] can outperform ConvGRU and ConvLSTM models of the same structure in a viewpoint of CV. In this experiment, the models were trained with only MSE. We randomly selected 8000 samples from the
training set for training and used the remaining 2000 samples for validating (to provide the criterion of early stopping). We used all 4000 samples of Test A and Test B sets to form the
test set. This scenario is closest to the reality, in which a forecaster observes only the past data for predicting the future. Note that we did not use the Test A or Test B for validating as there was no information about their time periods. We present detail information of the models’ parameters and computing consumption in the training process in
Table A1 (
Appendix A). Here, we discuss the validating errors and testing measures in
Table 1, which interestingly shows different results from different angles. As all models outperformed the basic “last input” technique in all measures by large margins, we would not consider this common baseline again in the following comparisons and analyses.
Firstly, we evaluated the models purely by the MSE measure. On the test set, our results agreed with [
6] in that TrajGRU was the best model, with its percentages of advantage over ConvGRU and ConvLSTM were
and
, respectively. However, even though we found that TrajGRU was usually better in our different training executions (but not always), these margins were modest while the training process is more costly. Moreover, on the validating set, the errors of ConvGRU and ConvLSTM were much better than TrajGRU. This can be explained as the impact of the over-fitting problem was more severe with ConvGRU and ConvLSTM. When they were based on location-invariant filters, it appeared that they could learn well familiar patterns but were not strong in exploring unseen patterns. This explanation was not mentioned in [
6], but we believed that this is a critical point to consider when bringing these ConvRNNs models into practical uses. We argued that if the patterns in training and testing data are consistent, ConvGRU and ConvLSTM can be better than TrajGRU.
Secondly, in terms of the MAE measure and other IQA metrics, it is clear that TrajGRU was outperformed by ConvGRU and ConvLSTM. Particularly with SSIM, it was
and
worse than ConvGRU and ConvLSTM, respectively. With MAE, the advantages of ConvGRU and ConvLSTM were
and
, respectively. This means that TrajGRU is not better than the others in reflecting the local correlations and producing sharp edges of objects.
Figure 5 shows an example for demonstrating these findings. Intuitively, TrajGRU produced less accurate estimation of the local shape and resulted in more blurry images. We argued that the reason is because ConvGRU and ConvLSTM use location-invariant filters and hence are able to preserve the local shapes (from the previous step) better, while TrajGRU tends to break the local shapes and make a stronger assumption about global changes between two steps. That was why TrajGRU was better on the MSE measure, which is a global-orienting metric [
17]. This trade-off property is not discussed in [
6].
Finally, to synthetically compare each couple of models over these metrics, we averaged the percentages of advantage of a model over the other. By this way, ConvGRU and ConvLSTM were
and
better than TrajGRU, respectively, mainly thanks to their much better SSIM measure. Moreover, ConvGRU was
better than ConvLSTM, which confirmed the conclusion in [
6] that the two models may have similar performance even though the network size of ConvGRU is much smaller. This means that, from a CV perspective, ConvGRU can be the most effective ConvRNN model in the context of Shenzhen dataset. With this result, together with considering the significant higher resources and time consumption of TrajGRU (see
Table A1), we inferred that the performance of TrajGRU would not always be as outstanding as stated in [
6]. However, we argued that this situation is not advantageous to all the models, hence we altered the network structure as described in
Section 3.2 and were able to produce more reliable predictions in the next experiment.
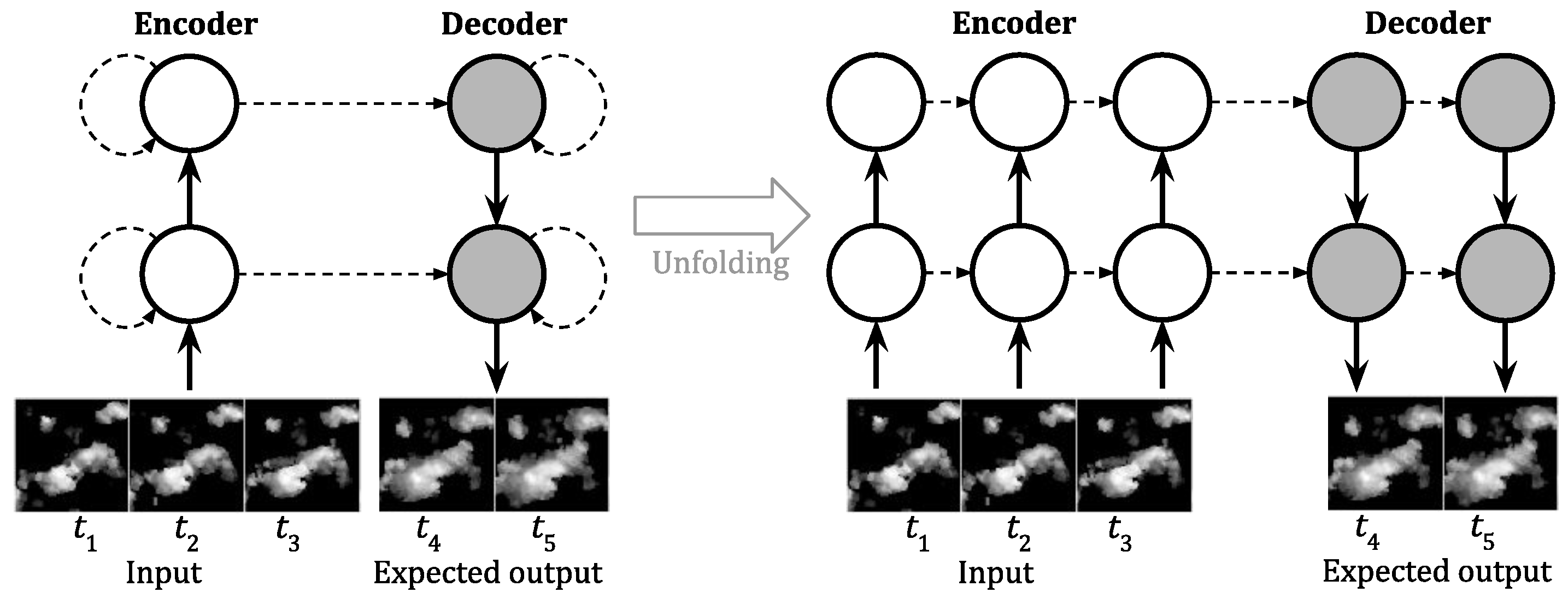
4.2. Evaluation of the dec-seq2seq Network Structure
We examined the behaviors of TrajGRU, ConvGRU and ConvLSTM models constructed with our proposed structure, and compared them with the above models. We named our models
dec-TrajGRU,
dec-ConvGRU and
dec-ConvLSTM and reused the above training settings.
Table 2 presents the validating and testing results, showing improvements of generalization by our design. On the test set, our models significantly improved over MSE, MS-SSIM and PCC. Especially with MSE, dec-TrajGRU, dec-ConvGRU and dec-ConvLSTM improved
,
and
from their previous versions, respectively. With MAE and SSIM, only dec-TrajGRU was able to improve, while dec-ConvGRU and dec-ConvLSTM got worse. Synthetic comparing, dec-TrajGRU was
and
better than dec-ConvGRU and dec-ConvLSTM, respectively, while dec-ConvGRU was
better than dec-ConvLSTM. In addition, our dec-TrajGRU was
better than ConvGRU, considered the best model in
Section 4.1. Interestingly, the validating error of all models significantly increased. This means that the dec-seq2seq structure was effective in reducing the over-fitting issue, especially for ConvGRU and TrajGRU. It is more impressive to note that our models are almost 3–4 times smaller than the previous ones (see
Table A1,
Appendix A).
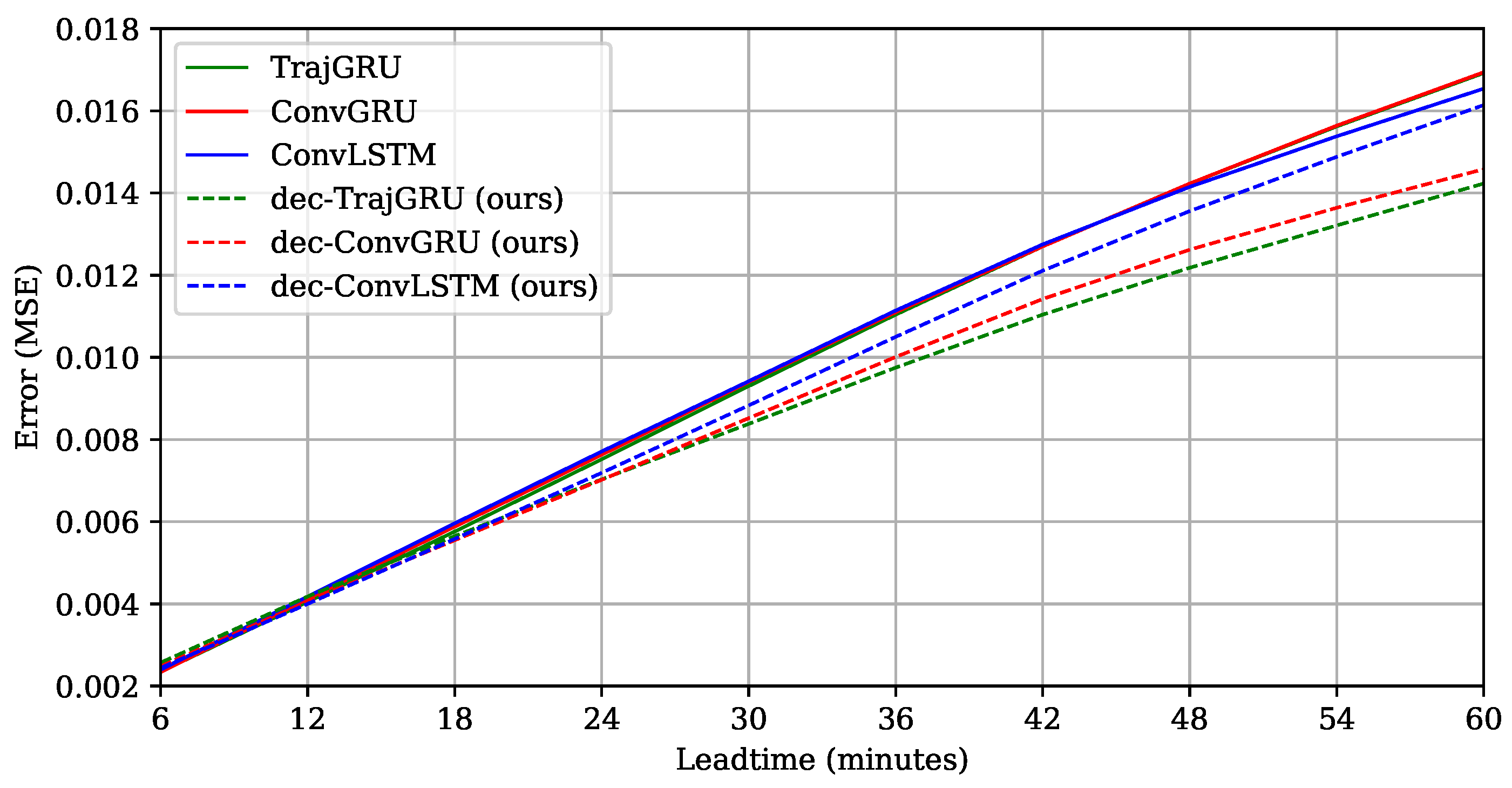
To view the results more clearly, we plotted the lead time errors of six models in
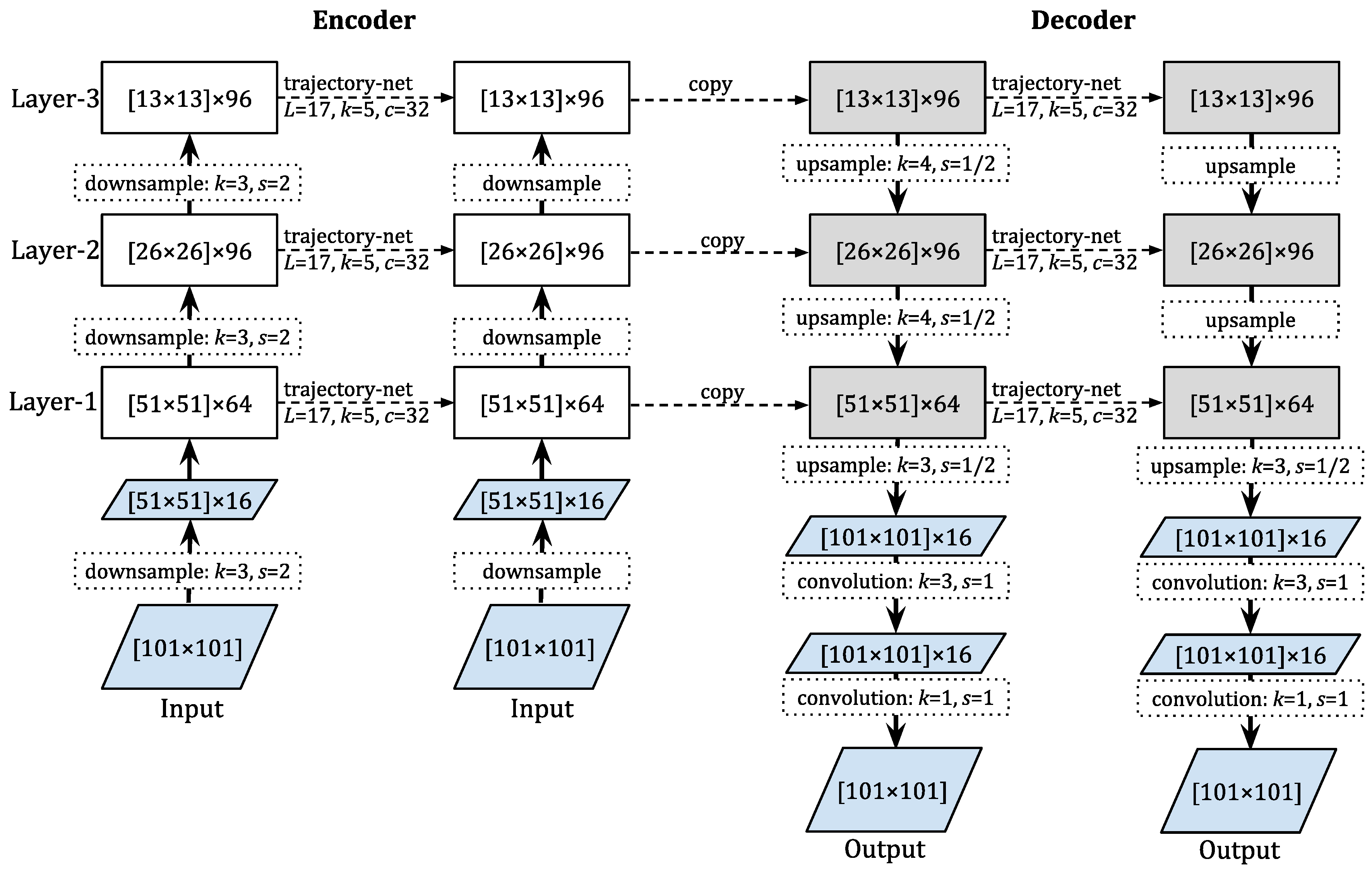
Figure 6. It is interesting that all models worked quite similarly on the first two or three steps, but our models significantly outperformed the previous models when going further into the future. This means that our proposed design was more tolerant to the high and increasing uncertainty in the context of Shenzhen dataset. As partly explained in
Section 3.2, because our models had less detailed information at the top and middle layers, they were more capable of escaping from familiar patterns (the possible local optimum in the training process) to estimate strange ones at global and intermediate scales better. Moreover, in this viewpoint, dec-TrajGRU is seen as the best model for longer time-step prediction, following by dec-ConvGRU. This means that our proposed design was particularly helpful for the TrajGRU architecture, leveraging its advanced properties successfully in this data context. To confirm this finding, we conducted an extensional experiment to compare TrajGRU and dec-TrajGRU with the MovingMNIST++ data, by generating several test sets with considerably different properties to the training set (see
Appendix B). The results were similar: when the uncertainty increased, both models got worse but dec-TrajGRU was less mistaken than TrajGRU.
However, we also observed the trade-off between the ability to estimate stronger changes of precipitation particles with the ability to generate sharp images. Intuitively, the dec-TrajGRU model produced more reasonable images than the others, but it also suffered more from the blurry effect (see
Figure 7). This can be explained by the fact that, in the context of high uncertainty, the top layers were not affected much by the patterns seen before and produced a reasonable abstract estimation of the overview of the image (presented as the cells’ outputted feature maps). These estimated feature maps are then upsampled and used to guide the lowest layer to estimate small local patches. The blurry effect appears mainly in these upsamling operations (because of having less detail information than the previous models), and is not solved well by the local estimating operations, as these operations are guided by MSE, a global-evaluating loss function. That was why we believed that adding other local-orienting loss functions can be a supplementary solution.
4.3. Evaluation of IQA-Based Loss Functions
In this experiment, we illustrated the effectiveness of several combined loss functions on the
dec-TrajGRU model in
Section 4.2. Firstly, we used the previous training settings and observed that using only MAE, SSIM or MS-SSIM as the loss function would significantly hurt the MSE-test performance, even though the overall performance could be slightly improved. This might lead to a poor estimation of the global changes in predicted images. Therefore, we focused on combining MSE with others to find the reasonably best function. To balance the magnitude of MSE and other measures in combined loss functions, we set
,
. Moreover, we also found that simply applying the previous early stopping technique on combined loss functions was not a good choice, because while some testing IQA metrics can be significantly improved, the MSE measure can be worsened. To deal with this issue, we trained the model with a combined loss function until the validating MSE got to an equal to or lower than the validation error in
Section 4.2 (which was
). Then, the early stopping technique was used to terminate the training process. This strategy is simple but very important and effective to keep reasonable testing MSE.
Table 3 shows the testing results of three single-measure loss functions and the most effective combined ones (some other combinations such as SSIM + MS-SSIM did not provide interesting results). It is clear that using single-measure functions would increase the testing result of that measure, but decrease the testing-MSE significantly. In general, the combinations with the presence of SSIM seemed to be better than others, and the best loss function in this context is MSE + MAE + SSIM. To our surprise, it even improved on testing-MSE and testing-MS-SSIM over the model trained with only MSE or MS-SSIM. Comparing to the three models following Shi et al. [
6], our best MSE measure was
better. Moreover, using only SSIM or MAE + SSIM also enhanced MAE and MS-SSIM significantly. As argued in
Section 4.2, our network tends to make strong assumptions about the global change rather than the local correlations, adding metrics which focus on local properties such as SSIM is a helpful compensation. Since it was able to produce more accurate predictions, other testing metrics could be improved too.
From the above results, we were able to confirm that using some common IQA metrics (and MAE) to train neural networks can produce less blurry images in the REE tasks than using only MSE. However, MSE still plays an important role to provide information about the global assumption. We illustrate these findings by the example in
Figure 8. It is also important to note that the calculation of these IQA metrics did not significantly increase the training time, thanks to the very fast GPU-based execution of TensorFlow. This means that using IQA metrics for training neural networks in the REE tasks is a very cheap but effective solution, not only for our proposed structure but any other network architectures. In addition, we also found that using MS-SSIM seemed to be ineffective. The main reason can be because MS-SSIM is a multi-scale estimation technique, which is similar to the network structure and hence can not compensate its weakness. This result is opposite to the conclusion in [
25] (about static image generation tasks). Using MAE only also seemed to be a poor choice. This means that the behaviors of IQA metrics can be different when being brought from CV tasks to the REE tasks, or more general the image processing applications in remote sensing.
To further confirm the meanings of our study findings in a closer view to an operational context, we compared the three best models in this part (chosen based-on the Overall Improvement) with the considered best one in [
6] (TrajGRU in
Section 4.1) in terms of Critical Success Index (CSI), False Alarm Rate (FAR), and Probability Of Detection (POD) metrics. We assumed that the dBZ values could be calculated by
. With this conversion, the dBZ range in the test set is
, and the proportions of dBZ thresholds 5, 20 and 40 are about
,
and
, respectively.
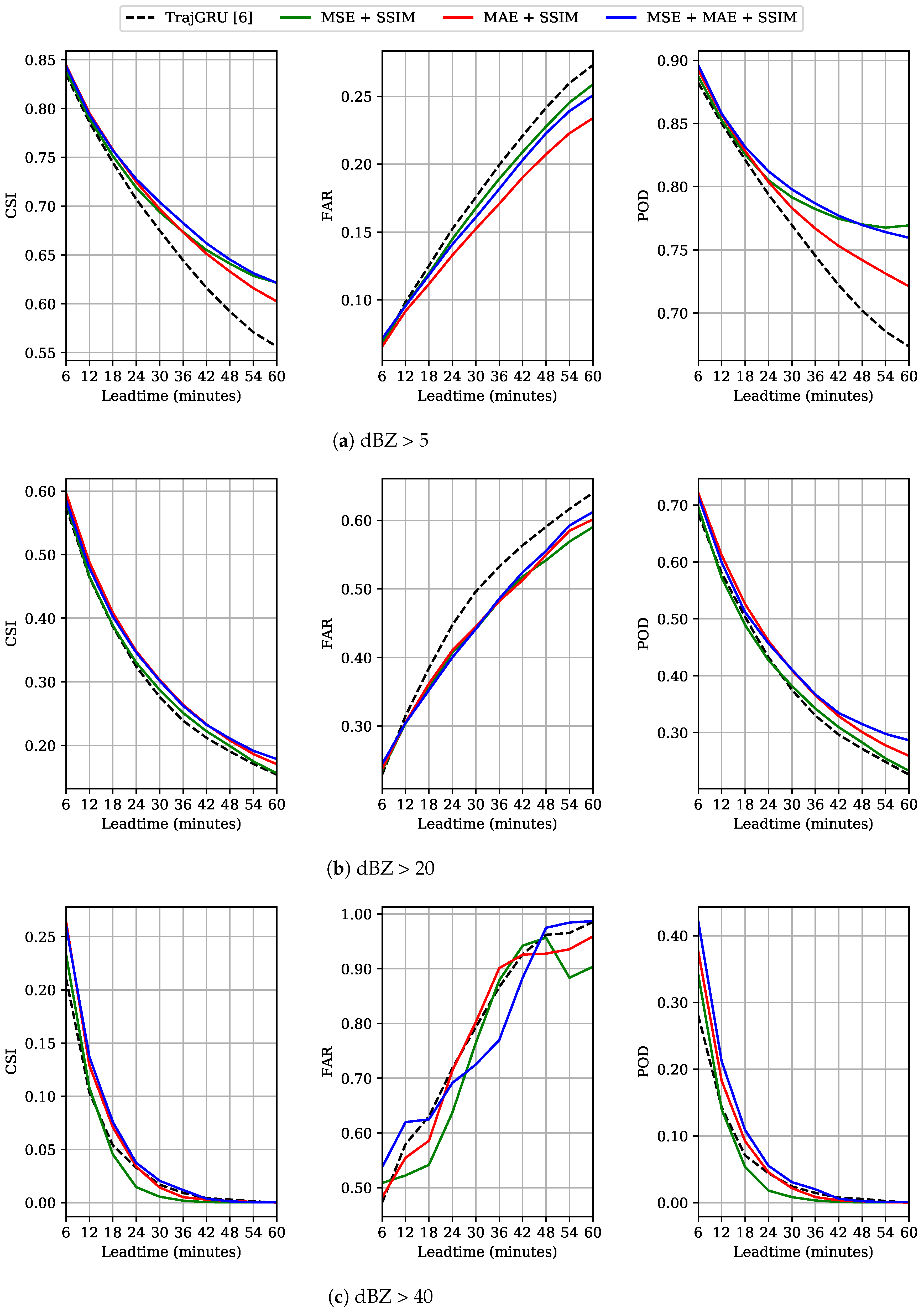
Table 4 provides an overall comparison over CSI, FAR and POD of these thresholds. While our model trained with MSE + SSIM was better than the previous best in seven among nine criteria, the two remaining models significantly outperformed that baseline in all criteria. Especially with heavier events, our models showed better overall predictions. We also tried other gains and offsets for the conversion and saw similar results. Hence, it can be concluded that the improvements in image quality are helpful for serving common operational expectations.
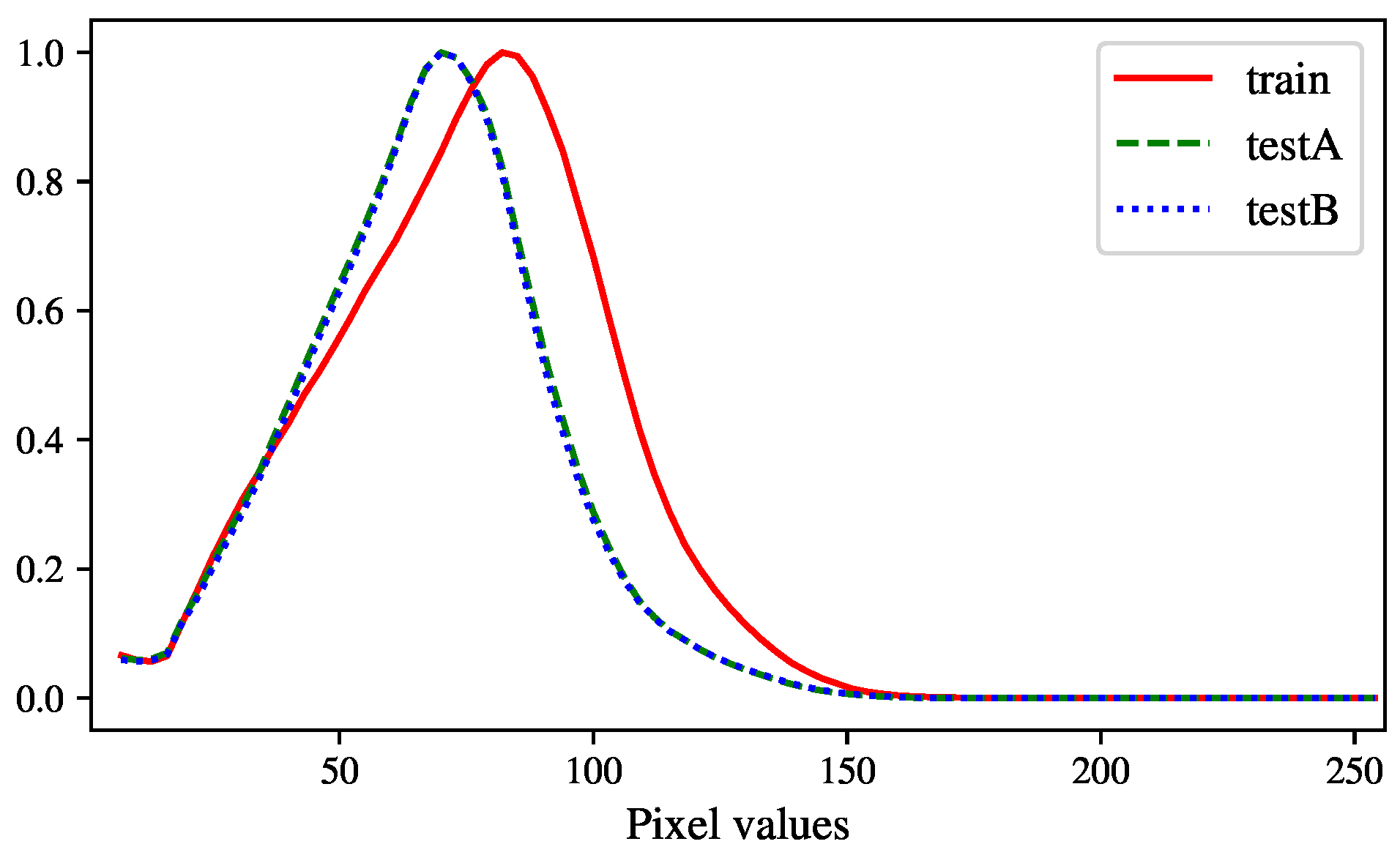
However, we realized that the models could work well with the dBZ thresholds 5 and 20 but were not stable with the dBZ threshold 40 (very low CSI but very high FAR). To analyze this issue more clearly, we plotted the frame-wise scores of these measures in
Figure 9. In the cases of dBZ > 5 and dBZ > 20, all models performed similarly for the first several steps, but our models were more accurate with the remaining ones. In the case of dBZ > 40, our models were often better for several starting steps (except for the MSE + SSIM model), but the quality of all models degraded rapidly, with the CSI and POD scores becoming nearly zero after 42 min. We argued that there could be several reasons. Firstly, the train and test data have high uncertainty and heavy rain rarely occurs (0.35%). As can be inferred from the results in
Figure 3, these events can be considered as outliers and are extremely difficult to model. This also made the evaluation vulnerable to noises (there are a number of white dots in the images, meaning very high rain-rate). Secondly, DL methods usually need big amount of data but the employed dataset is still considerably small in a DL context. The task is also more challenging with the test-size equals a half of the training-size. Thirdly, as limited by the fixed sequence length, we set a short input sequence and the models did not have enough information about the intensity change to estimate it well. Finally, our approach was driven to cope with the general precipitation rather than to focus on heavy rain. We believed that this issue can be solved by assigning higher weights on high rain rates (as in [
6]), and using a bigger dataset with longer input sequences.
Interestingly,
Figure 9c shows that the (MSE + SSIM) model degraded more rapidly than the others in terms of CSI and POD, but made the least wrong predictions in terms of FAR. We argued that using MSE for our models led to the fact that they did not make strong assumptions about the change of high intensity, and adding MAE was helpful. This argument agrees with the finding in [
6], i.e. using MAE is helpful for predicting heavier rain. This can be because MSE squares the distance between two values, and in the intensity range
, an error evaluation might become less and less important. On the other hand, MAE keeps the original distance of intensity to guide the training process. Because DL models usually produce low values in the initial training steps, and need the guidance from the loss functions to increase them, MAE could do better than MSE in this case. Moreover, SSIM might estimate the intensity well, but locally, and could not compensate MSE well enough. It should be noted that the FAR score of the MSE + SSIM model might fluctuate, as in
Figure 9c, because there are some high intensity particles suddenly appeared and decreased in some samples. However, we thought that it was hard to draw an adequate conclusion for this outlier case, and suggested this issue for the future work.
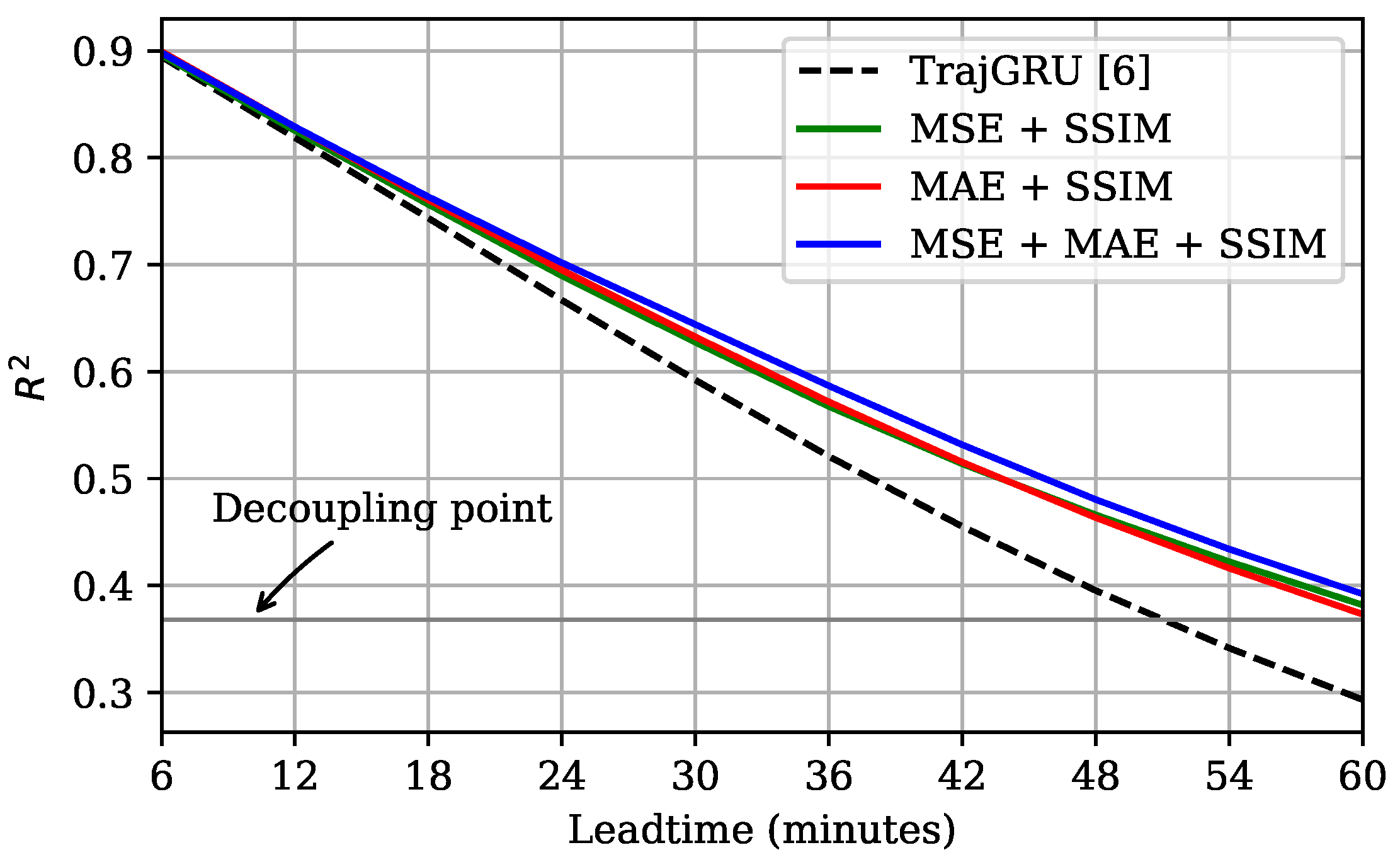
In general, we argued that the MSE + SSIM was still competitive with the MAE + SSIM and MSE + MAE + SSIM models, and outperformed the TrajGRU model. This is strongly supported by the evidence in
Figure 10, which shows that the coefficient of determination of our three models did not fall below the decoupling point in all 10 steps, but the TrajGRU model failed after Step 8 (48 min).



{kind=link}
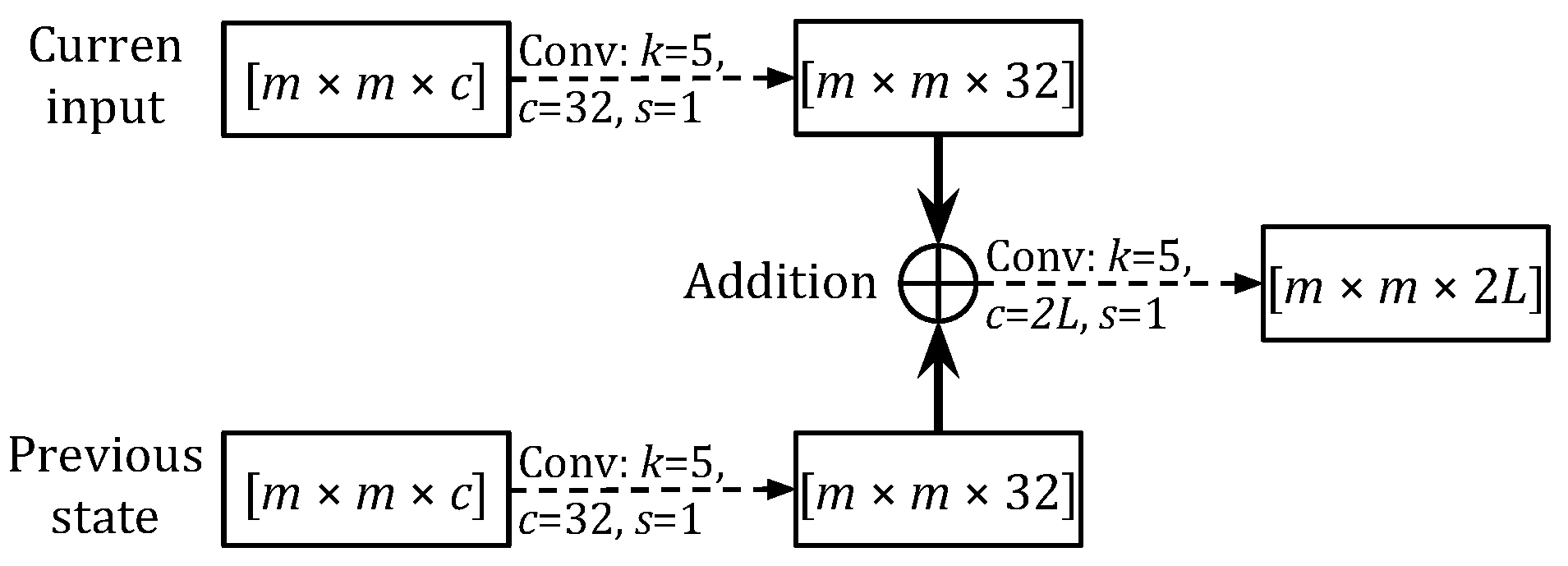{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










