1. Introduction
Thousands of people’s lives could be influenced by torrential rain and higher city managements are required to facing these challenges. With climate change and the rapid process of urbanization in China, meteorological conditions have become more complex, diversified, and variable. Therefore, there is a great deal of uncertainty and ambiguity in the precipitation prediction process [
1]. Precipitation is a critical input for hydrologic simulation and prediction, and is widely used for agriculture, water resources management, and prediction of flood and drought, among other activities [
2]. Consequently, accurate precipitation prediction has been a difficult problem in current research. In hydrological processes, precipitation is any product of the condensation of atmospheric water vapor that falls under gravity and affected by many meteorological factors. So, how to analyze meteorological factors to predict the precipitation and improve the prediction accuracy is one of the key problems in the study of related disaster prevention.
With the development of information technology, especially information acquisition and storage technology, hydrometeorological data information has increased exponentially. Recently, there are many meteorologists studying the precipitation prediction model as well as other fields of meteorology by statistical prediction methods and machine learning techniques, such as the Autoregressive Moving Average model (ARMA), Multivariate Adaptive Regression Splines (MARS), Support Vector Machine (SVM), Artificial Neural Network (ANN), and other models [
3,
4,
5,
6]. Rahman et al. presented a comparative study of Autoregressive Integrated Moving Average model (ARIMA) and Adaptive Network-Based Fuzzy Inference System (ANFIS) models for forecasting the weather conditions in Dhaka, Bangladesh [
7]. Chen et al. proposed a machine learning method based on SVM that was presented to predict short-term precipitation occurrence by using FY2-G satellite imagery and ground in situ observation data [
8]. However, the statistical prediction methods assume that the data are stable, so the ability to capture unstable data is very limited, and statistical methods are only suitable for linear applications. These are considered the main disadvantages of using statistical methods when it comes to non-linear and unstable applications.
Recently, ANN is one of the most popular data-driven methods for precipitation prediction [
9,
10]. Nasseri developed ANN to simulate the rainfall field and used a so-called back-propagation (BP) algorithm coupled with a Genetic Algorithm (GA) to train and optimize the networks [
11]. Hosseini et al. formed a new rainfall-runoff model called SVR–GANN, in which a Support Vector Regression (SVR) model is combined with a geomorphologic-based ANN (GANN) model, and used this model in simulating the daily rainfall in a semi-arid region in Iran [
12]. However, the traditional artificial neural network often falls into the dilemma of the local minimum, and it cannot describe the relationship between the precipitation and the influencing factors and how they change over time. They predict future values only based on the observed values and the calculation of the previous step. So, its performance is relatively no better than other prediction methods.
Recent progress in deep learning has gained great success in the field of precipitation prediction. Deep learning is a particular kind of machine learning based on data representation learning. It usually consists of multiple layers, which usually combine simple models together and transfer data from one layer to another to build more complex models [
13,
14,
15]. Precipitation is always a kind of typical time-sequential data and varies greatly in time. Recurrent Neural Networks (RNNs) are some of the state-of-the-art deep learning methods in dealing with time series problems [
16]. There are many variants of RNNs, such as Long Short-Term Memory (LSTM), which are more stable. They have been used in the field of computer vision, speech recognition, sentiment analysis, finance, self-driving, and natural language processing [
17,
18,
19,
20,
21,
22]. There have been a number of researches that seek to explain the relationships between meteorological indices and precipitation using deep learning [
23,
24,
25,
26,
27,
28]. Concurrent relationships are typically quantified through deep neural networks analyses between precipitation and a range of meteorological indices such as North Atlantic Oscillation (NAO), East Atlantic (EA) Pattern, West Pacific (WP) Pattern, East Atlantic/West Russia Pattern (EA/WR), Polar/Eurasia Pattern (POL), Pacific Decadal Oscillation (PDO), and so on. For example, Yuan et al. predicted the summer precipitation using significantly correlated climate indices by an Artificial Neural Network (ANN) for the Yellow River Basin [
26]. Lee et al. developed a late spring–early summer rainfall forecasting model using an Artificial Neural Network (ANN) for the Geum River Basin in South Korea [
28]. Hartmann et al. used neural network techniques to predict summer rainfall in the Yangtze River basin. Input variables (predictors) for the neural network are the Southern Oscillation Index (SOI), the East Atlantic/Western Russia (EA/WR) pattern, the Scandinavia (SCA) pattern, the Polar/Eurasia (POL) pattern, and several indices calculated from sea surface temperatures (SST), sea level pressures (SLP), and snow data [
23]. However, the meteorological indices they used are global teleconnection patterns, and the approaches are applicable for long-time precipitation prediction and large-scale areas such as a country or a river basin. For a city or smaller area, the short-time precipitation may have a relatively weak relationship with the global teleconnection patterns, so other meteorological variables are needed to predict precipitation.
Some researchers have used the meteorological variables, such as Maximum Temperature, Minimum Temperature, Maximum Relative Humidity, Minimum Relative Humidity, Wind Speed, Sunshine, and so on, to predict the precipitation [
29,
30,
31,
32]. Gleason et al. designed the time series and case-crossover model to evaluate associations of precipitation and meteorological factors, such as temperature (daily minimum, maximum, and mean), dew point, relative humidity, sea level pressure, and wind speed (daily maximum and mean) [
29]. Poornima et al. presented an Intensified Long Short-Term Memory (Intensified LSTM) using Maximum Temperature, Minimum Temperature, Maximum Relative Humidity, Minimum Relative Humidity, Wind Speed, Sunshine, and Evapotranspiration to predict rainfall [
30]. Jinglin et al. applied deep belief networks in weather precipitation forecasting using atmospheric pressure, sea level pressure, wind direction, wind speed, relative humidity, and precipitation [
33]. However, they did not consider the contribution of the meteorological variables. The relationships between meteorological variables and precipitation vary with season and location. Not all the meteorological variables have a strong relationship with precipitation, and some of them may have a negative impact on the accuracy of the prediction. Therefore, meteorological variables selection is the key and difficult point to the application of precipitation prediction. However, little research has considered the contribution of the meteorological variables.
In meteorology, precipitation is any product of the condensation of atmospheric water vapor that falls under gravity. So, meteorological variables are potentially useful predictors of precipitation. The main contribution of this study is using the twice screening method to select effective meteorological variables and discard useless or counteractive indicators to predict precipitation by the LSTM model, according to different characteristics of each place. So, the objectives of this study are to: (1) propose a method of selecting available and effective variables to predict precipitation; (2) analyze whether the simulation performance can be improved by inputting refined meteorological variables; (3) compare the simulation capability of the LSTM model with other models (i.e., Autoregressive Moving Average model (ARMA) and Multivariate Adaptive Regression Splines (MARS) as the statistical algorithms and Back-Propagation Neural Network (BPNN), Support Vector Machine (SVM), Genetic Algorithm (GA), and traditional ANN models). The results of this study can provide better understandings of the potential of the LSTM in precipitation simulation applications. In this study, after one-hot encoding and normalizing the meteorological data, the possible candidate variables of meteorological variables are preliminarily determined by circular correlation analysis. Then, the candidate variables are used to construct the LSTM model, and the input variables with the greatest contribution are selected to reconstruct the LSTM model. Finally, the LSTM model with the final selected input variables is used to predict the precipitation and the performance is compared with other classical statistical algorithms and the machine learning algorithms. The result shows that the performance of the LSTM model with particular meteorological variables is better than the classical predictors and the time-consuming and laborious trial–error process is greatly reduced.
2. Overview of Study Area
Jingdezhen is a typical small- and medium-sized city in China, with rapid social and economic development, and the population of Jingdezhen is almost 1.67 million. It is located in the northeast of Jiangxi province, and it belongs to the transition zone between the extension of Huangshan Mountain, Huaiyu Mountain, and Poyang Lake Plain (as shown in
Figure 1). The city covers an area of 718.93 km
2, between 116°57′ E and 117°42′ E and 28°44′ N and 29°56′ N latitude.
Jingdezhen is characterized by a subtropical monsoon climate affected by the East Asian monsoon, with abundant sunshine and rainfall. It has long, humid, and very hot summers, and cool and drier winters with occasional cold snaps. The annual average temperature is 17.36 °C and extreme maximum temperatures of above 40 °C have been recorded, as have extreme minimums below −5 °C. The annual precipitation is 1763.5 mm, and the distributions of precipitation are quite uneven, with about 46% of precipitation occurring in the rainy season (from April to June). The average rainfall is about 200–350 mm in the rainy season, which is extremely prone to flooding. In 2016, the city’s 24-h average rainfall exceeded 300 mm with a return period of 20 years and the maximum flow of the Chengjiang River was 7090 m3/s. The flood caused by the extreme rainfall return period of the main stream of the Chengjiang River was 20 years, and some river sections were 50 years.
4. Results and Discussion
4.1. Experimental Setup
Because the distributions of precipitation in Jingdezhen are quite uneven, 46% of precipitation occurred in the rainy season (from April to June) and a great deal of observed precipitation is equal to zero in the non-rainy season. To balance the positive and negative data, the data from April to June every year, total 192,192 records, are selected to train, validate, and test the model by five-fold Cross-Validation.
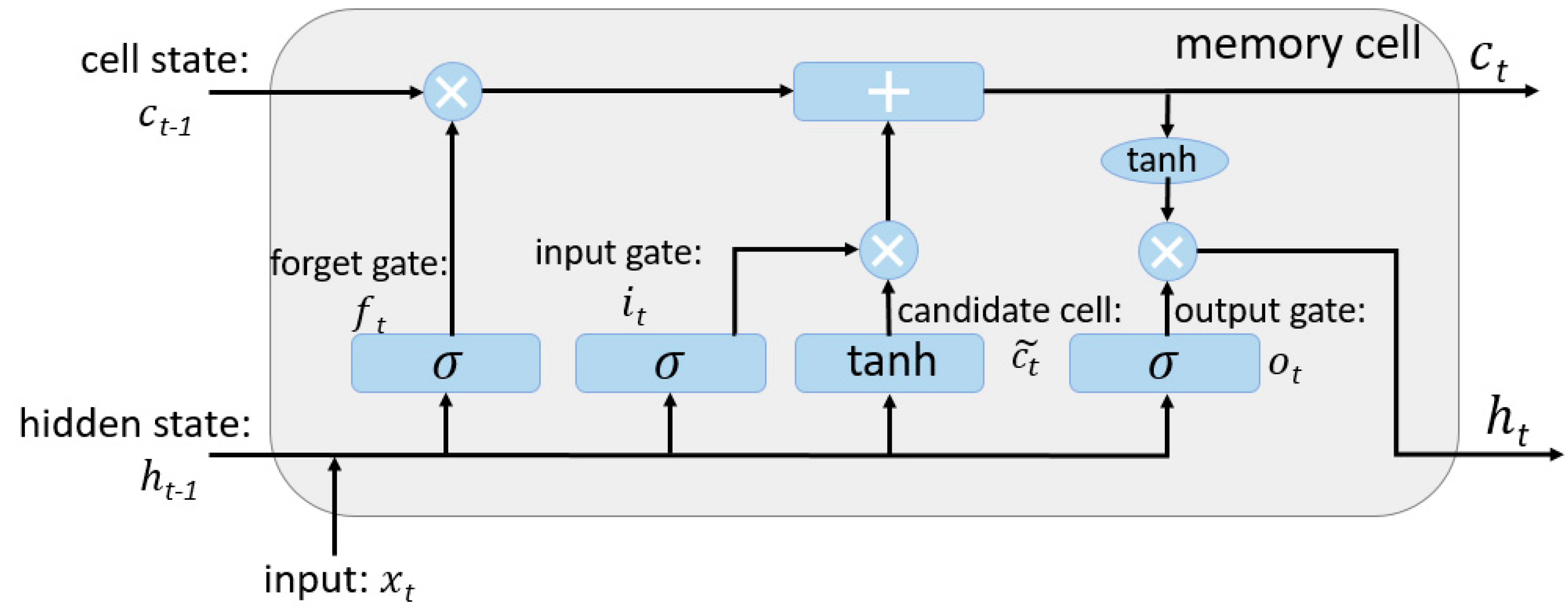
In this study, the interval of the meteorological data is 3 h. The data in the first 21 h are used to predict the data in the last three hours each day. The “many to one” LSTM model is used, so the size of the input is seven and the output length is one. The number of neurons affects the learning capacity of the network. Generally, more neurons would be able to learn more structure from the problem at the cost of longer training time. Then, we can objectively compare the impact of increasing the number of neurons while keeping all other network configurations fixed. We repeat each experiment 30 times and compare performance with the number of neurons ranging from 2 to 10.
The hyperparameters used to train this model were: epoch was 100, each epoch had 30 steps, a total of 3000 steps; the learning rate was 0.02; the batch size was 7, and every 50 steps, the loss value will be recorded once. We performed all the training and computation in the TensorFlow2.0 computational framework using an NVIDIA GeForce GTX 1070 and NVIDIA UNIX x86_64 Kernel Module 418 on a discrete server running a Linux system (Ubuntu18.04.3) (Canonical Group Limited, London, UK) with an Intel(R) Core(TM) i7-8700 CPU @ 3.20 GH (Intel Corporation, Santa Clara, CA, USA).
4.2. Meteorological Variables Analysis
According to the weather system, precipitation is a major component of the water cycle. Considering the actual situation of Jingdezhen, the precipitation predictor variables we choose are closely related to the water cycle. The predictor variables are temperature (T), dew point temperature (Td), minimum temperature (Tn), maximum temperature (Tx), atmospheric pressure (AP), pressure tendency (PT), relative humidity (RH), wind speed (WS), wind direction (WD), maximum wind speed (WSx), total cloud cover (TCC), height of the lowest clouds (HLC), and amount of clouds (AC). Because the distributions of precipitation in Jingdezhen are quite uneven, 46% of precipitation occurred in the rainy season (from April to June) and a great deal of observed precipitation is equal to zero in the non-rainy season. To balance the positive and negative data, the data from April to June every year are selected to train the model.
After one-hot encoding and normalizing the meteorological variables and historical precipitation data, the CCC between precipitation and each of the meteorological variables were calculated (see
Table 4). As shown from the results, it is evident that meteorological variables are potentially useful predictors of precipitation. A maximum negative correlation of -0.4768 was achieved for PT and a positive maximum correlation of 0.4475 is obtained for Td. However, the absolute value of CCC between precipitation and Tn, Tx, WD, and WSx is less than 0.1. So, Tn, Tx, WD, and WSx are ignored. The highly correlated nine meteorological variables, including T, Td, AP, PT, RH, WS, TCC, HLC, and AC, were selected as inputs for the LSTM model.
4.3. Preliminary LSTM Model for Precipitation Prediction
The optimal LSTM model structure with the selected nine input variables, was determined using the five-fold Cross-Validation procedure by varying the number of hidden neurons from 2 to 10. For each hidden neuron, five iterations of the training and validation were performed. The whole dataset of training and validation was used to train the selected models, and the weights for these trained structures were saved and the networks were evaluated for testing.
The average RMSE, SMAPE, and
TS scores between the actual precipitation and the predicted precipitation measured using the LSTM model with the selected nine input variables are presented in
Table 5. The results show that the performance of the model with different numbers of hidden neurons was not significantly different. The results also show that a larger number of hidden neurons did not always lead to better performance. In the training part, the SMAPE values ranged from 16.28% to 19.63%, and RMSE values ranged from 46.45 mm to 51.31 mm. In the validation part, the SMAPE values ranged from 18.01% to 20.64%, and RMSE values ranged from 49.61 mm to 54.26 mm. In the testing part, the SMAPE values ranged from 18.16% to 21.74%, and RMSE values ranged from 47.61 mm to 54.71 mm. The
TS1 score values ranged from 0.74 to 0.82, the
TS2 score values ranged from 0.55 to 0.61, and the
TS3 score values ranged from 0.66 to 0.71. The accuracy of the results is acceptable. Based on the minimum error in five-fold Cross-Validation, the structure with six hidden neurons in the LSTM model was considered the best, which are denoted as LSTM (9,6,1).
Compared with the average RMSE, SMAPE, and
TS score of the LSTM model with all 13 input variables (see
Table 6), only when the number of hidden neurons is three or eight, the average RMSE and SMAPE of the LSTM model with the selected nine input variables are worse. Except that the number of hidden neurons is three or eight, the average RMSE and SMAPE are better. The structure with eight hidden neurons in the LSTM model with all 13 input variables was considered the best, which are denoted as LSTM (13,8,1).
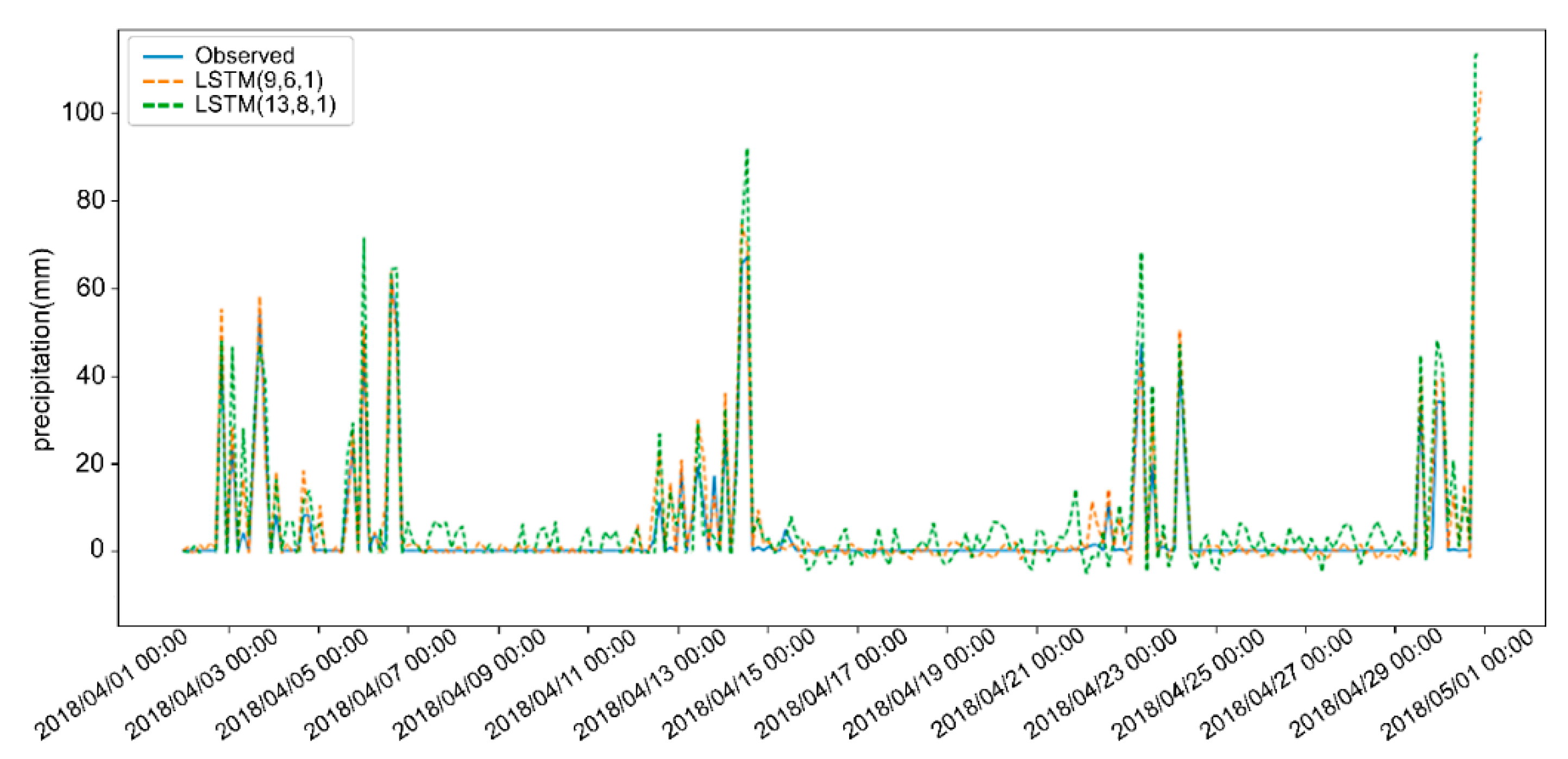
Figure 3 shows the precipitation prediction results for 3 h LSTM (9,6,1) and LSTM (13,8,1) in April 2018, which is the month with the largest precipitation in 2018. The predicted result LSTM (9,6,1) is better than LSTM (13,8,1). Therefore, after selecting meteorological variables by circular cross-correlation, the LSTM model with the selected nine input variables can perform better.
4.4. Quantification of Relative Importance of Input Variables
The relative contribution of input variables to the output value was quantified using the modified Garson’s weight method.
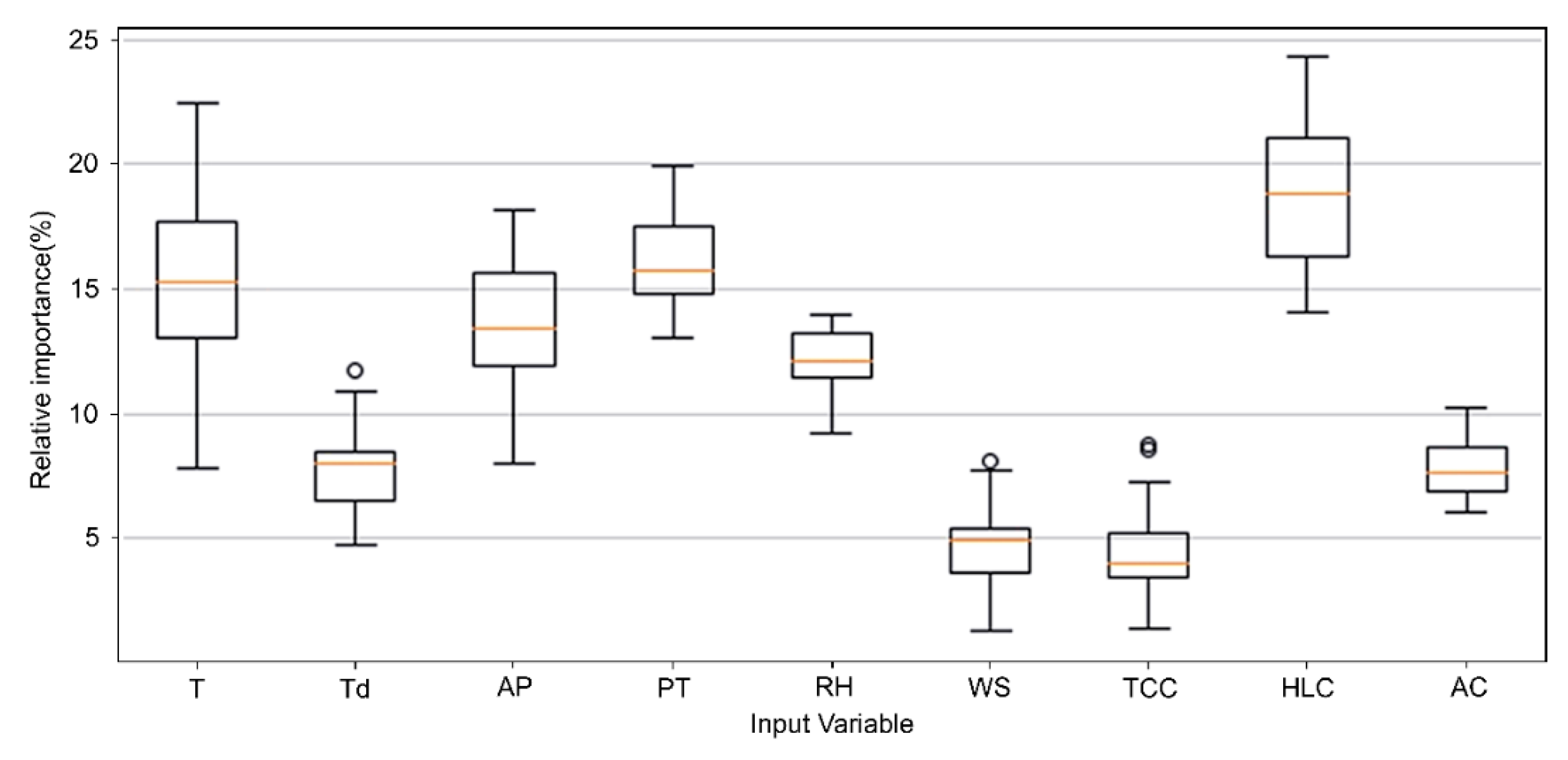
Figure 4 shows the relative importance of the nine variables obtained from Garson’s connection weights method in the form of a box plot. According to the different random initial weights, great changes in the importance values will be observed. Results show that in the LSTM (9,6,1) model, HLC shows the strongest relationship with predicted precipitation and its contribution of median value is 18.24%. TCC shows the weakest relationships; the contribution of the median value is less than 5%. There are several abnormal values, but the proportion is very low, so they are ignored. The top five important predictors are HLC, PT, T, AP, and RH.
We have talked about the general relative importance of input variables of the LSTM model in the above study. As we can see, HLC, PT, T, AP, and RH are the most important predictors, which always have a relative importance above 10%. WS and TCC are the least important predictors.
The urban heat island warms cities from 0.6 to 5.6 °C above surrounding suburbs and rural areas. This extra heat leads to greater upward motion, greater change of humidity, and atmospheric pressure, which can induce additional shower and thunderstorm activity [
44]. The study area, Jingdezhen City, is a fast-developing urbanized area situated at the transition zone between the Yellow Mountain, extension ranges of the Huaiyu Mountain, and the Poyang Lake Plain. The urban heat island also is a common phenomenon in Jingdezhen, and the local temperature, humidity, air convection, and other factors on the urban surface in Jingdezhen have changed. Therefore, local meteorology in Jingdezhen has been affected by urban heat island, the rates of precipitation have also been greatly affected. So, the height of the lowest clouds, temperature, atmospheric pressure, and humidity have a great impact on precipitation. However, Jingdezhen is surrounded by mountains, and the wind speed has a relatively small impact on precipitation. The quantification of the relative importance of input variables, analyzed by the LSTM model, is also good proof of this phenomenon. So, HLC, PT, T, AP, and H are selected to reconstruct the LSTM model.
4.5. Best LSTM Model for Precipitation Prediction
The optimal LSTM model structure with five input variables (HLC, PT, T, AP, and RH) was determined by varying the number of hidden neurons from 2 to 10.
Table 7 shows the training, validation, and testing results for the LSTM structures. As the number of hidden neurons increased, the trends of the change of the RMSE, SMAPE, and
TS score decreased generally and reached a minimum value when the number of hidden neurons was five, but after five hidden neurons they increased. In the training part, the SMAPE values ranged from 14.16% to 15.69%, and RMSE values ranged from 42.28 mm to 43.49 mm. In the validation part, the SMAPE values ranged from 14.28% to 15.83%, and RMSE values ranged from 42.03 mm to 43.27 mm. In the testing part, the SMAPE values ranged from 14.17% to 16.06%, and RMSE values ranged from 41.72 mm to 43.68mm. The
TS1 score values ranged from 0.82 to 0.89, the
TS2 score values ranged from 0.57 to 0.63, and the
TS3 score values ranged from 0.70 to 0.76. The prediction results are better than the LSTM model structure with the nine input variables. When the number of hidden neurons is five, the LSTM model structure with five input variables (HLC, PT, T, AP, and RH) performed the best, are denoted as LSTM (5,5,1).
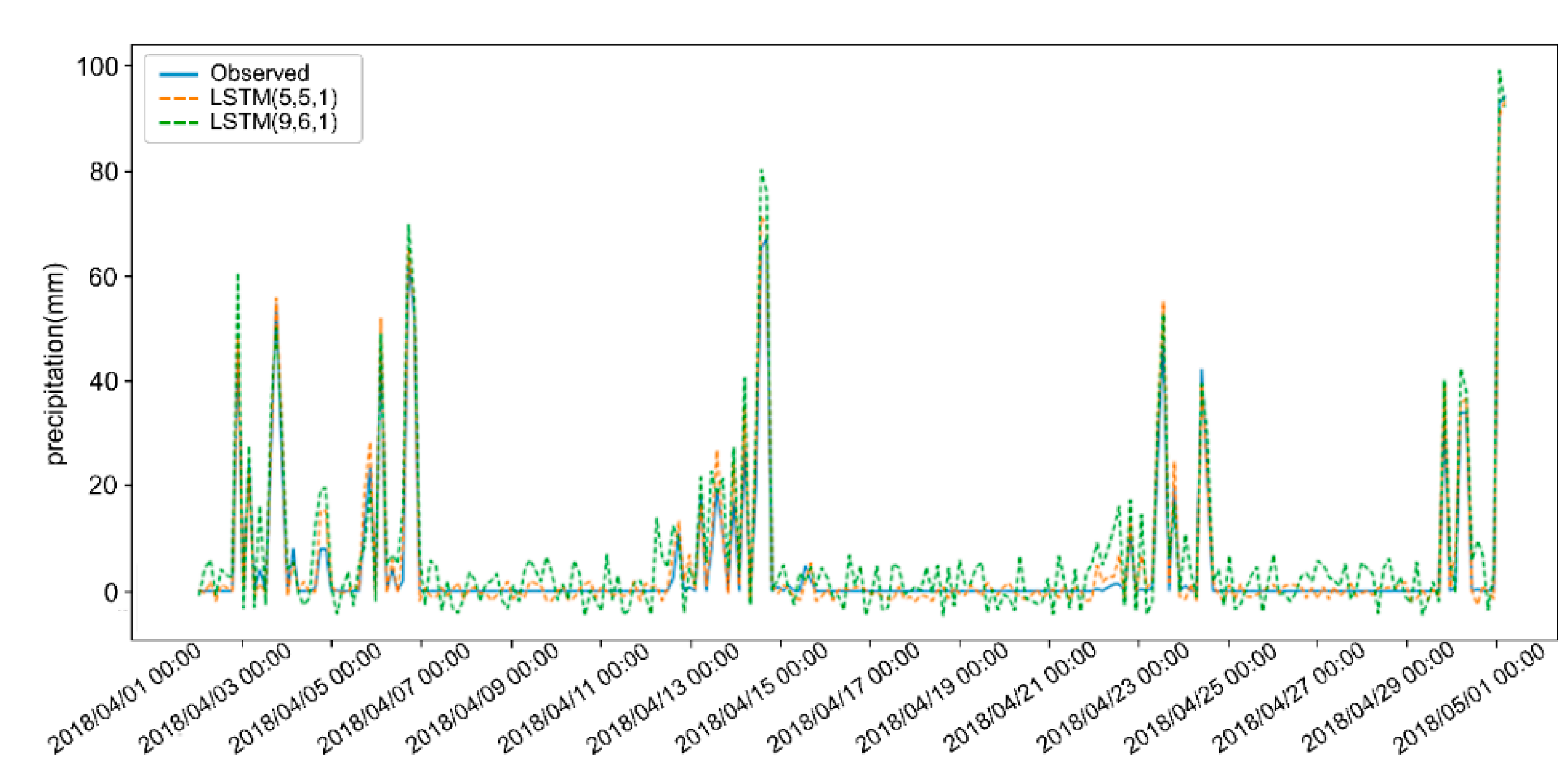
The precipitation prediction results by LSTM (5,5,1) and LSTM (9,6,1) for 3 h in April, 2018 are shown in
Figure 5. The predicted result LSTM (5,5,1) is evidently better than LSTM (9,6,1). Therefore, after further refining meteorological variables by the relative importance of input variables, the LSTM model can perform better.
In addition, we select the Autoregressive Moving Average model (ARMA) and Multivariate Adaptive Regression Splines (MARS) as the statistical algorithms and Back-Propagation Neural Network (BPNN), Support Vector Machine (SVM), and Genetic Algorithm (GA) as the machine learning algorithms for performance comparison. The test data set is from April to June 2018, which was a noted rainy season in 2018. The prediction performances are shown in
Table 8.
In comparison with the predictors, the performances of ARMA and MARS are evidently worse than BPNN, SVM, and GA. The performance of BPNN is better than SVM and GA, of which the performances are quite near. LSTM has better performance than the other classical machine learning models. It indicates that traditional statistics algorithms predict the precipitation only based on the previous meteorological data without taking the rapid changes caused by human activities and climate change into account. Classical machine learning algorithms take recent changes into account, but they make no discrimination between the long-term and short-term data. Therefore, they cannot predict the precipitation with great accuracy. However, LSTM can take advantage of all the historical data and recent changes, and it can balance the long-term and short-term data with larger weights for short-term data and less weight for long-term data. So, this study implies that with particular meteorological variables, LSTM could also outperform the statistics algorithms and classical machine learning predictors.
4.6. Scope of Application
Topography is one of the important factors affecting precipitation and its distribution. In mountainous environments, precipitation will change dramatically with the height of the mountain slopes over short distances. The meteorological parameters can change quickly over a short time and space scales in rough topography, among which the temperature changes most acutely [
45]. In cold climatic regions, atmospheric motions and thermodynamics also have a great impact on precipitation [
46]. So, rough topography and extreme climate have a great impact on the accuracy of the provided approach.
The approach provided in this study is mainly applicable to plains with a small area, where meteorological elements change gently. In mountainous environments such as Tibet or high latitude areas, because meteorological conditions change rapidly, this approach is not applicable at present. In a future study, the digital elevation model (DEM) will be considered as the main factor affecting precipitation intensity. More sensors need to be constructed to record more data. For every dataset recorded by the sensors, the provided approach can be used to predict the precipitation. The precipitation results can be distributed to different areas by the interpolation method to expand the prediction scale.
In recent years, the application of artificial intelligence (AI) in the field of meteorology has shown explosive growth and makes many achievements. However, the prediction quality of AI techniques is limited by the quality of input data. Most AI technologies are similar to “black box”, which works well under normal circumstances, but may fail in extreme situations. In order to achieve better results, it is necessary to strengthen the research and development of high-quality and long sequence meteorological training datasets, such as providing long history and consistent statistical characteristics of model data, sorting out and developing high-resolution observation, and analyzing data for training and testing.
5. Conclusions
In this study, five relative importance of input variables were selected to predict the precipitation by LSTM in Jingdezhen City, China. For this purpose, after identifying the circular cross-correlation coefficient between meteorological variables and precipitation amount in Jingdezhen, nine meteorological variables, which are T, Td, AP, PT, H, WS, TCC, HLC, and AC, were selected to construct the LSTM model. Then, the selected meteorological variables were refined by the relative importance of input variables. Finally, the LSTM model with HLC, PT, T, AP, and RH as input variables was used to predict the precipitation and the performance is compared with other classical statistical algorithms and the machine learning algorithms. The main conclusions are the following:
The quantification of the contribution of the variable relative importance was able to improve the accuracy of predicting precipitation by removing some input variables that show a weak correlation. The LSTM model can predict precipitation well with the help of the circular cross-correlation analysis and the quantification of variable importance.
The LSTM model’s performance with different numbers of hidden neurons was not significantly different. The results show that a large number of hidden neurons did not always lead to better performance. The best LSTM (5,5,1) model showed satisfactory prediction performance with RMSE values of 42.28 mm, 42.03 mm, and 41.72 mm, and SMAPE values of 14.19%, 14.28%, and 14.17% for the training, validation, and testing data sets, respectively.
HLC, PT, T, AP, and RH are the most important predictors for precipitation in Jingdezhen City. The optimal model predicted higher values of precipitation to be acceptable, but it needs enough meteorological data. Future studies need to be carried out to improve the models to predict the precipitation in rural areas where there is less data.
In comparison with the studies on precipitation prediction, the approach provided in this study can select different meteorological variables to optimize the precipitation prediction results according to the characteristics of different cities. In conclusion, this study revealed the possibility of precipitation predicting using LSTM and meteorological variables in advance for the study region. Good prediction of the precipitation amount could allow for the more flexible decision-making in Jingdezhen City and provide sufficient time to prepare strategies against potential flood damage. The LSTM model with particular input variables can be considered a data-driven tool to predict precipitation.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}