
The Economic Loss Prediction of Flooding Based on Machine Learning and the Input-Output Model


Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data
2.2.1. Meteorological Data
2.2.2. Socio-Economic Data
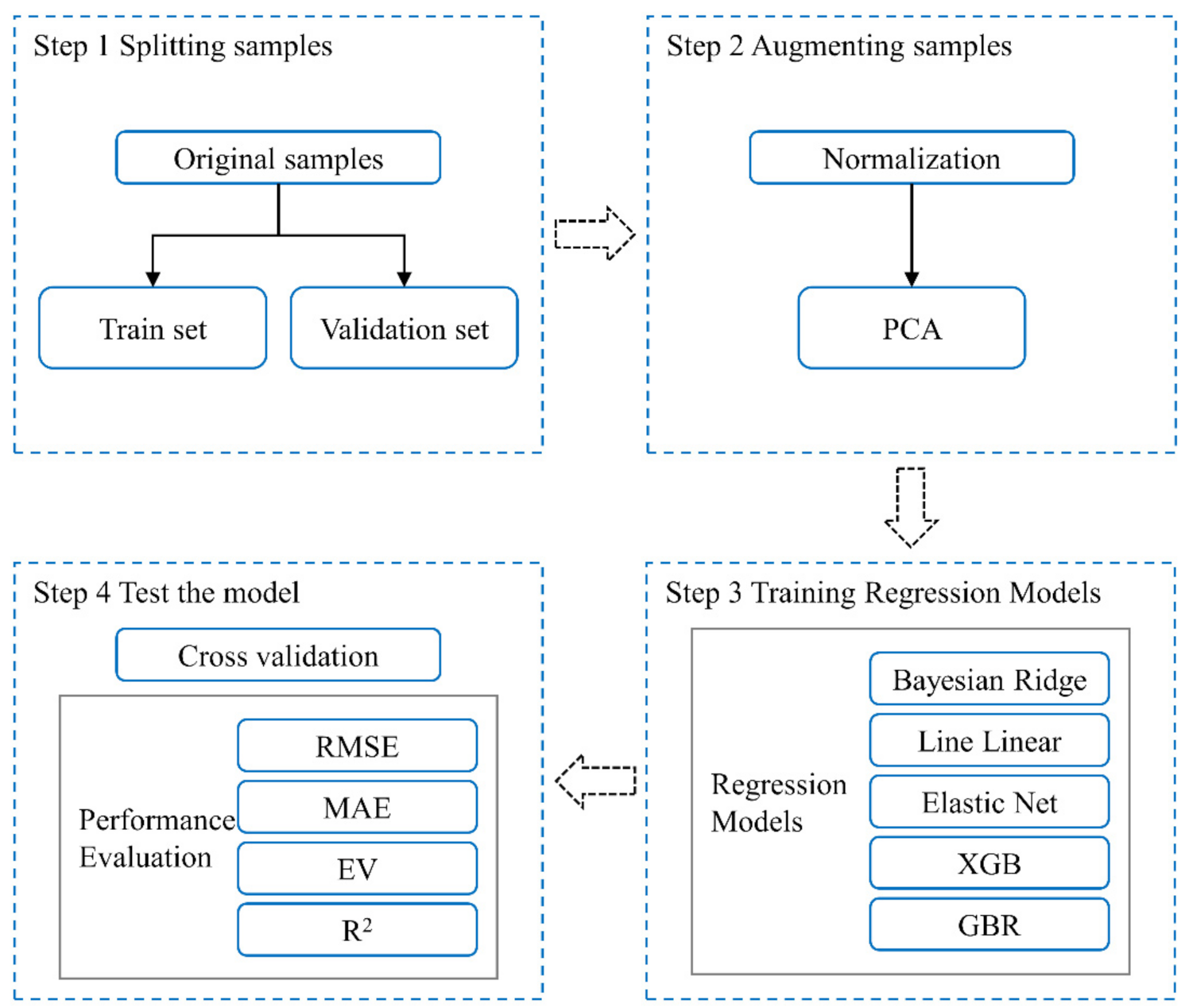
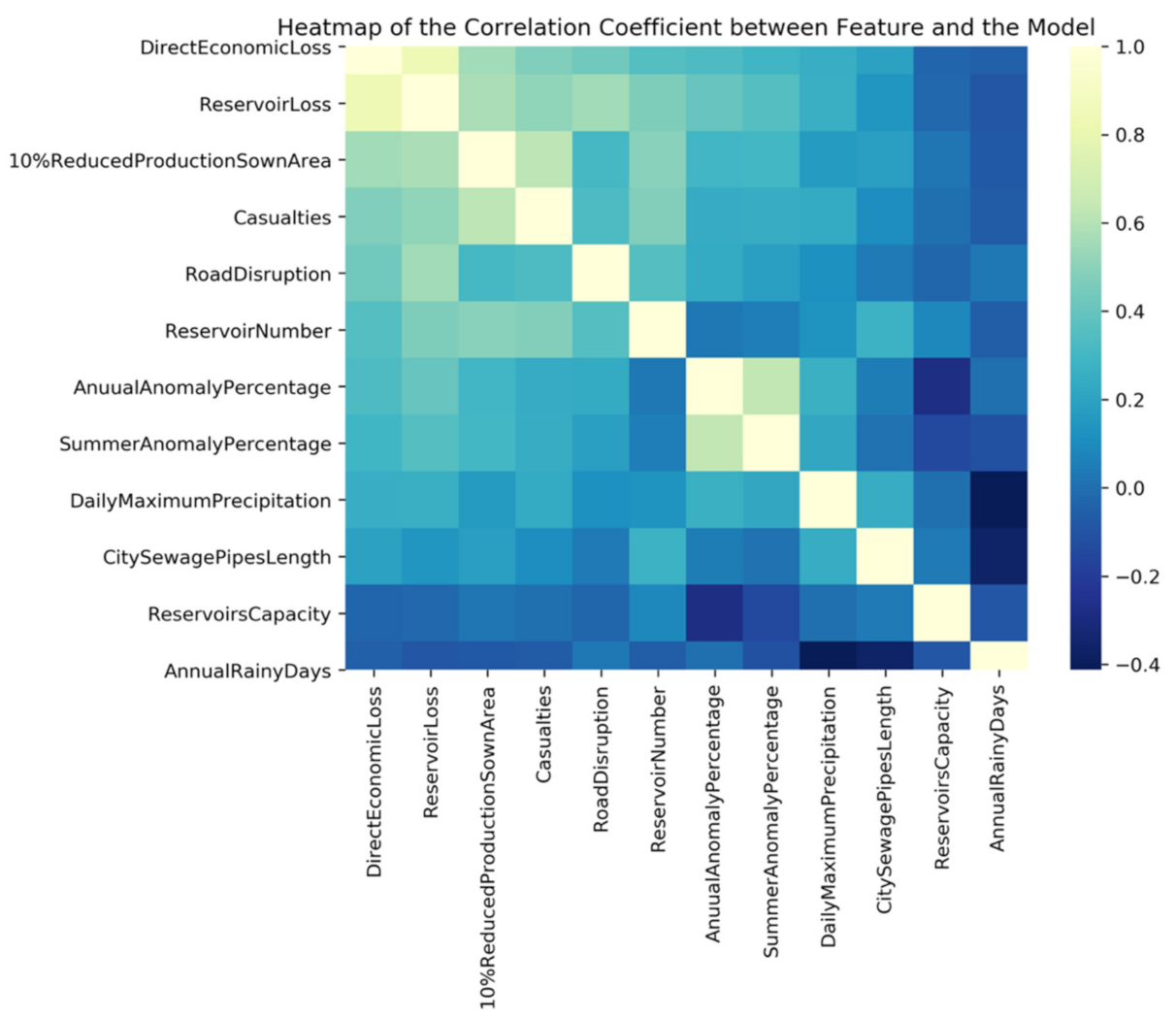
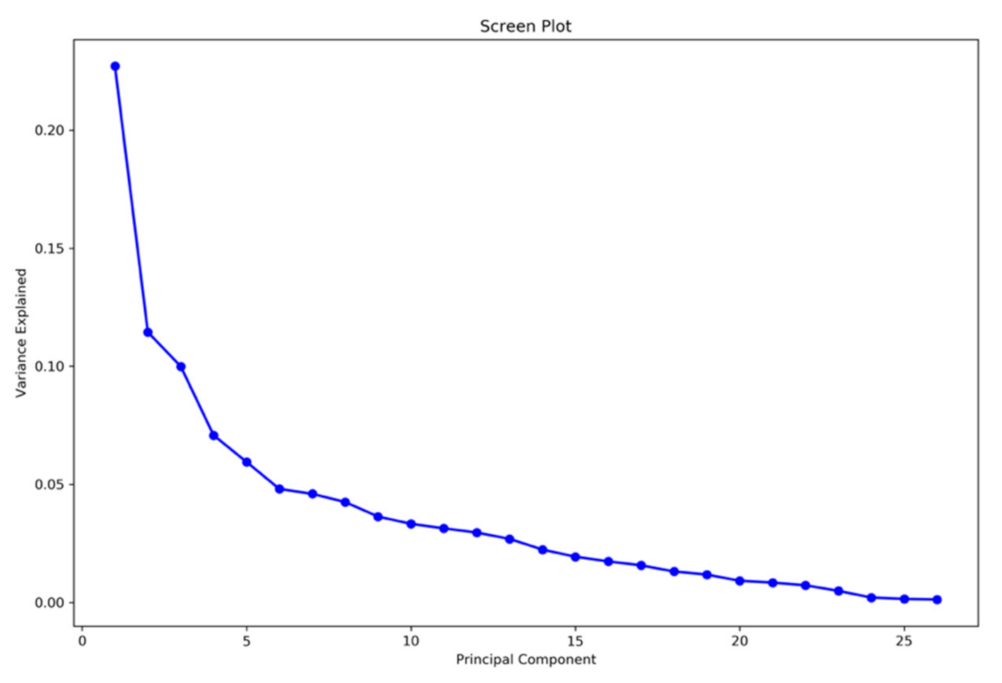
2.2.3. Data Processing
2.3. Methods
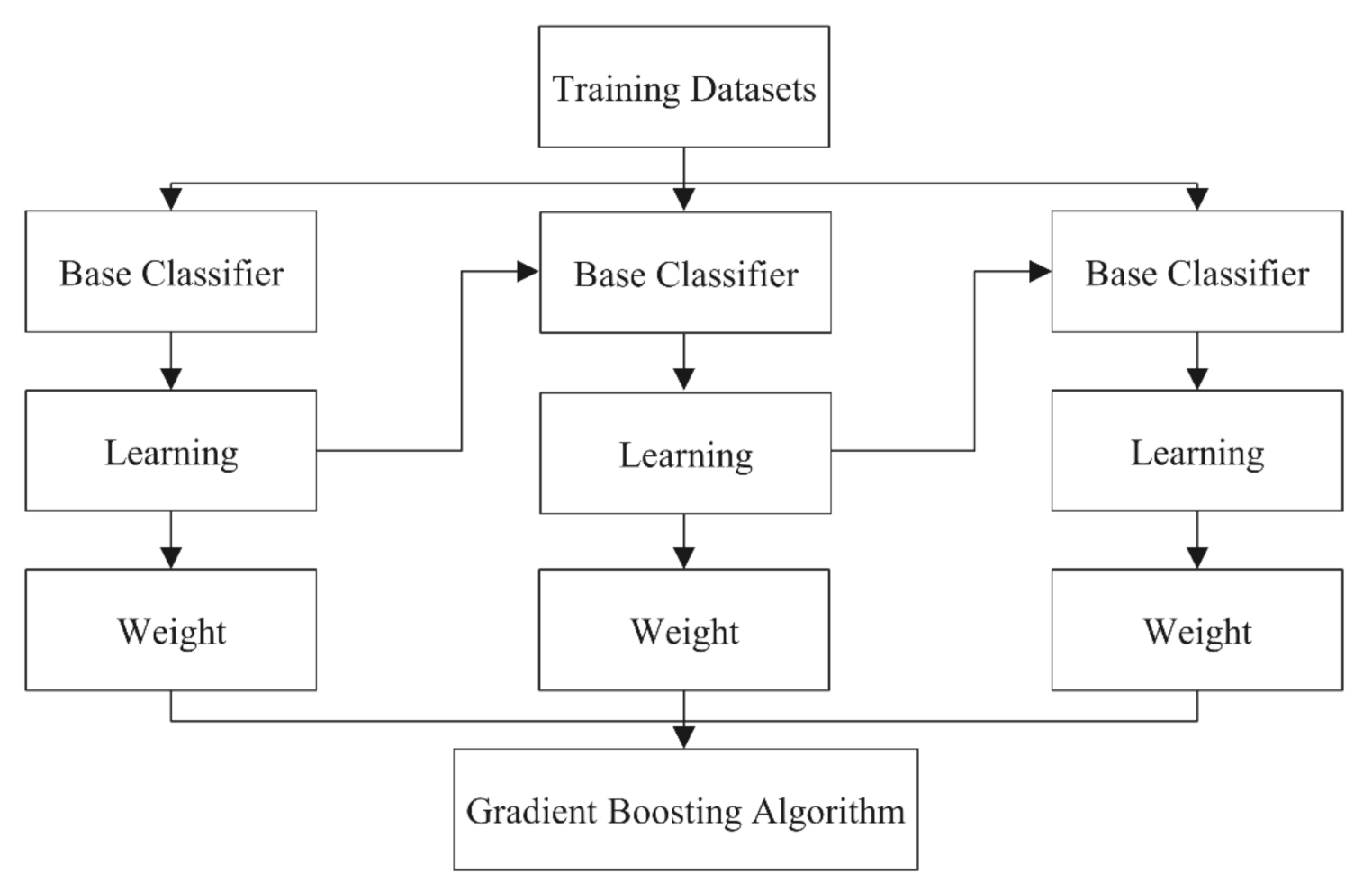
2.3.1. Gradient Boosting Regression Trees (GBR)
- Initialize the parameters in the learning machine with the following equation:
- 2.
- A regression tree is generated with J leaf nodes, described as follows:where refers to a regression tree with J leaf nodes, TNT refers to terminal node tree.
- 3.
- Estimating the value of the leaf nodes in the regression tree. The value can be estimated by the following equation:where refers to the value of the leaf nodes in the regression tree.
- 4.
- The learning machine of this iteration can be obtained, as shown in the following:
- 5.
- After iterations, the final regression model can be shown as follows:
2.3.2. Input-Output (IO) Model
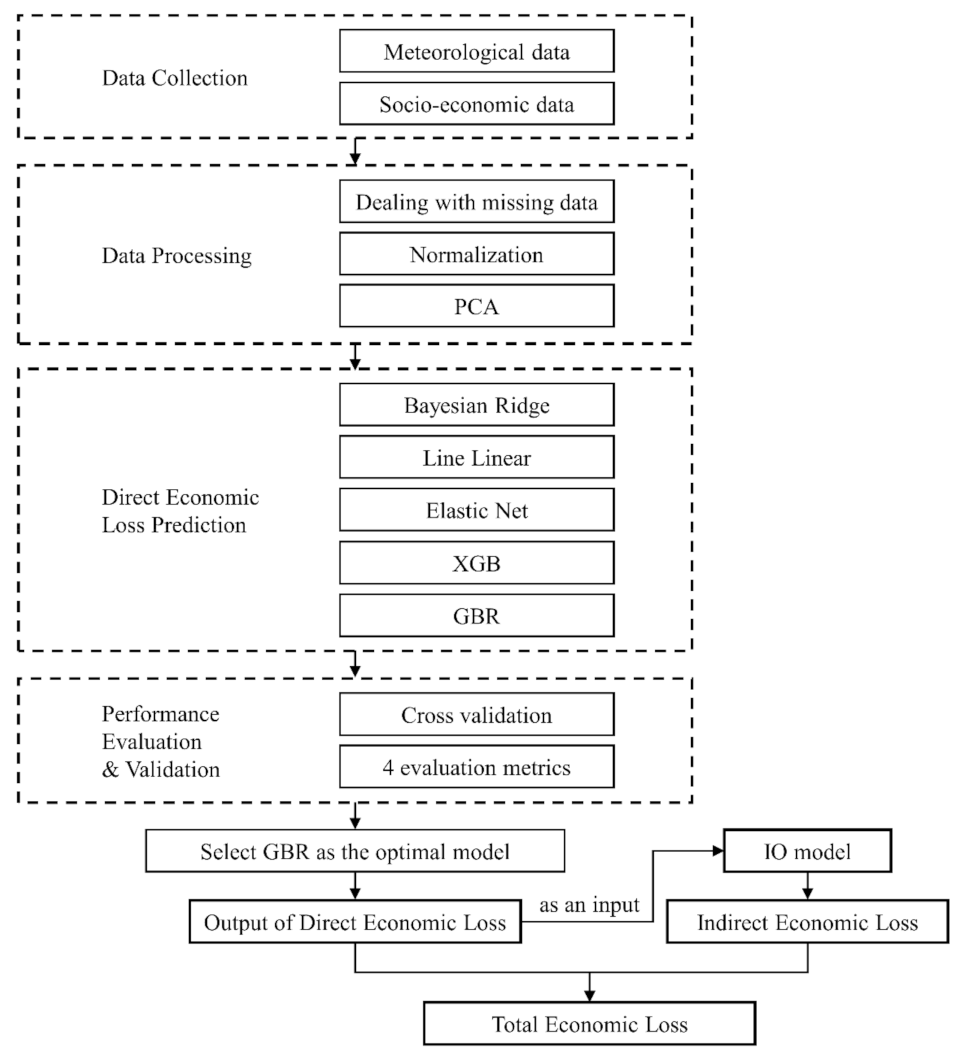
2.3.3. The Pre-Disaster Prediction System
3. Results & Discussion
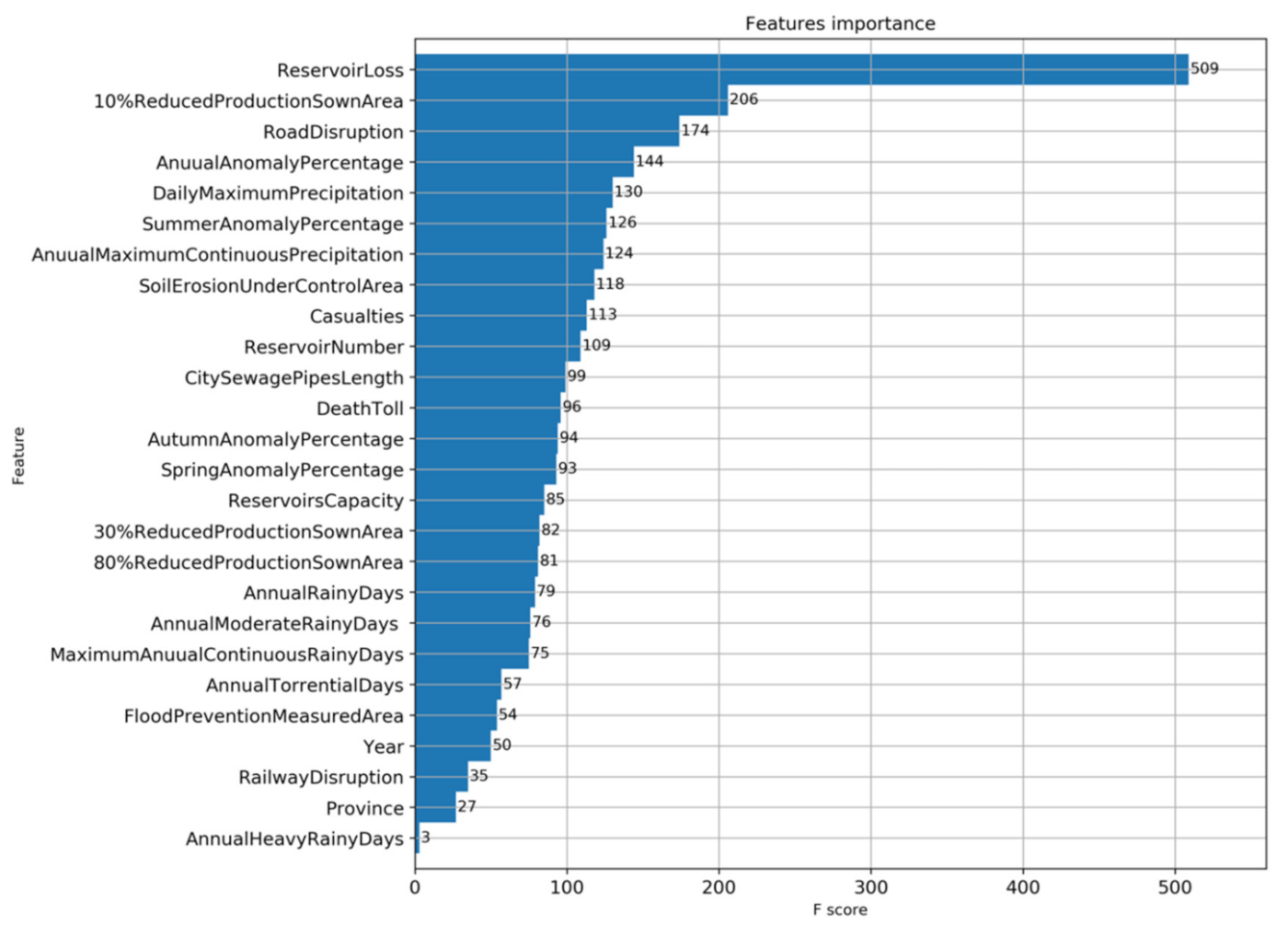
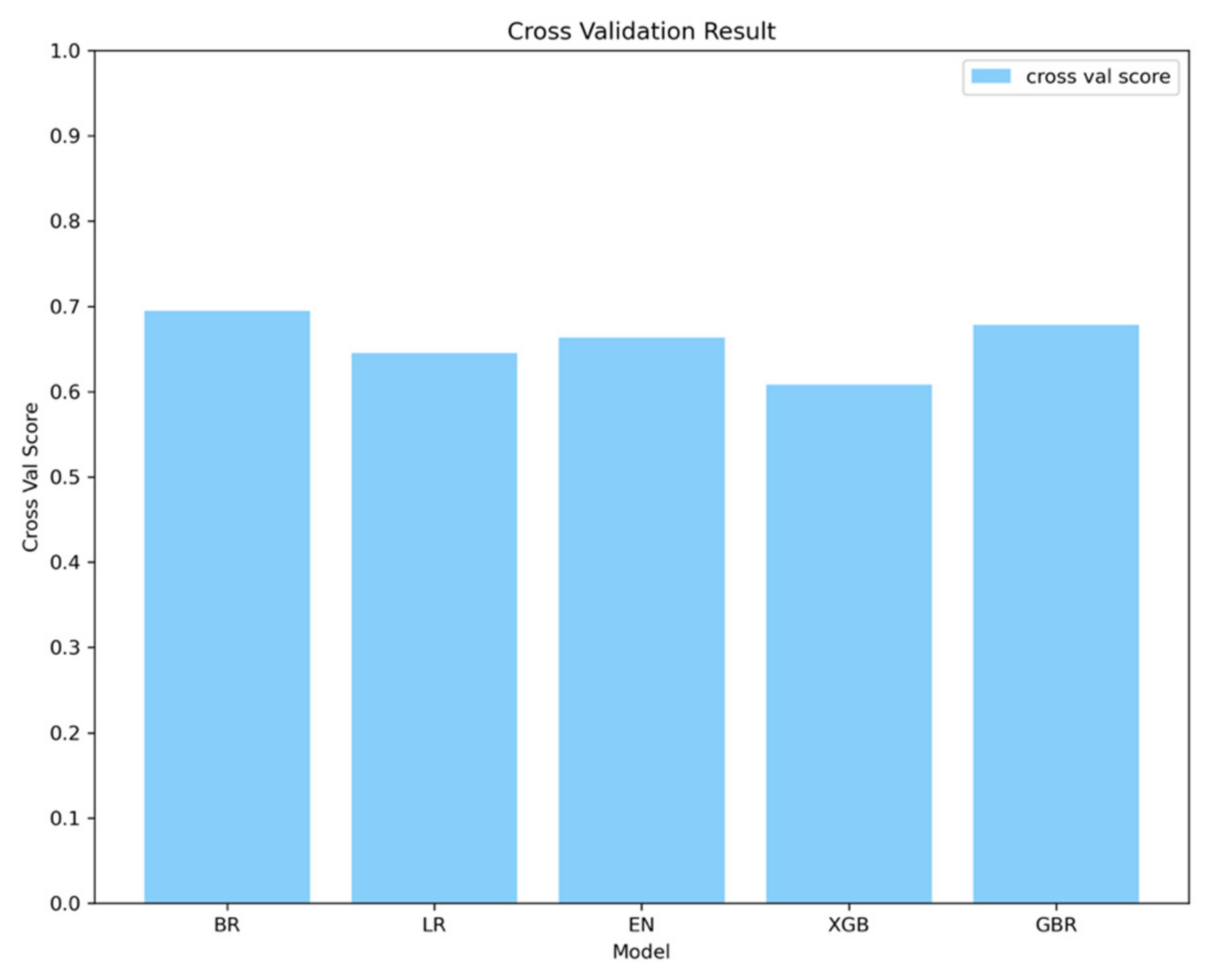
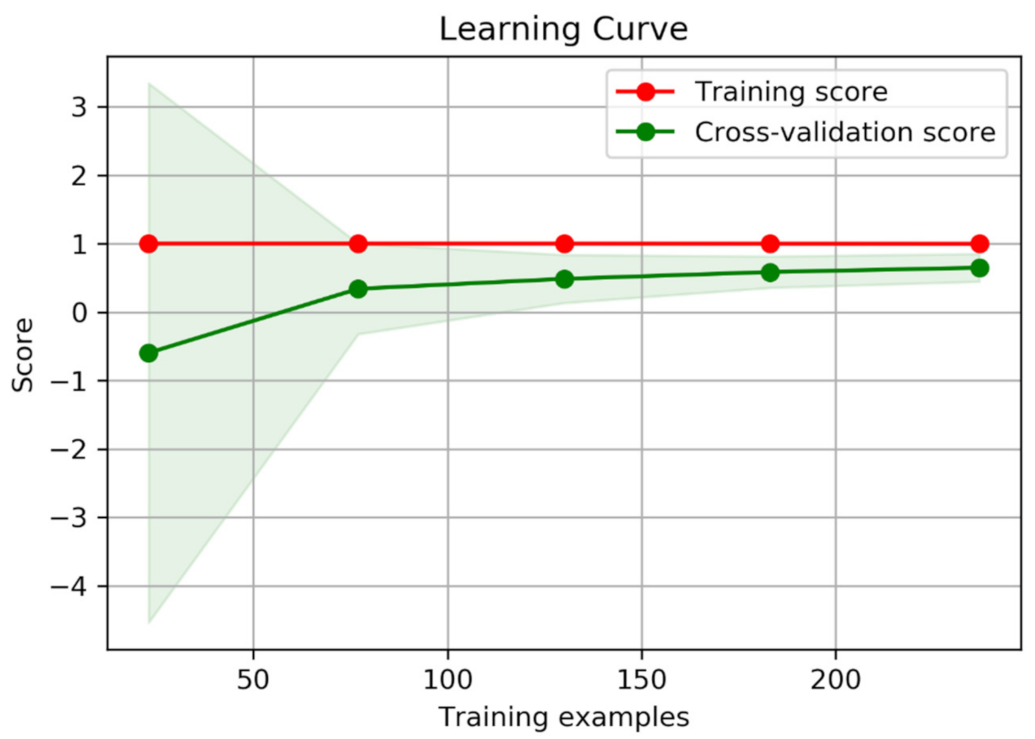
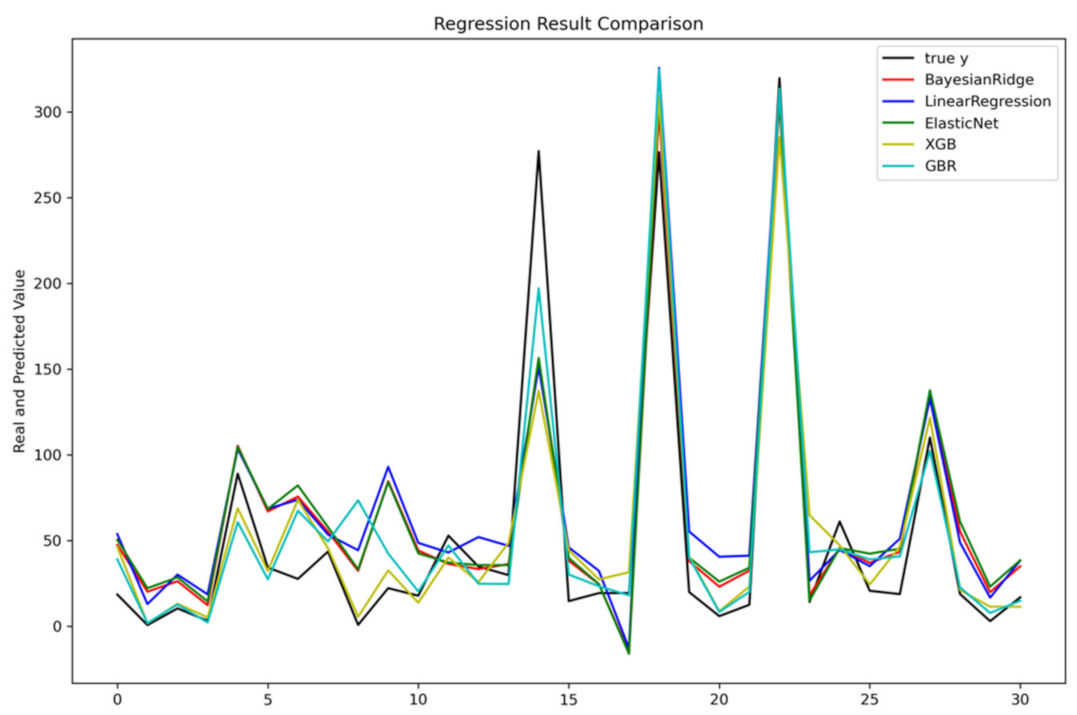
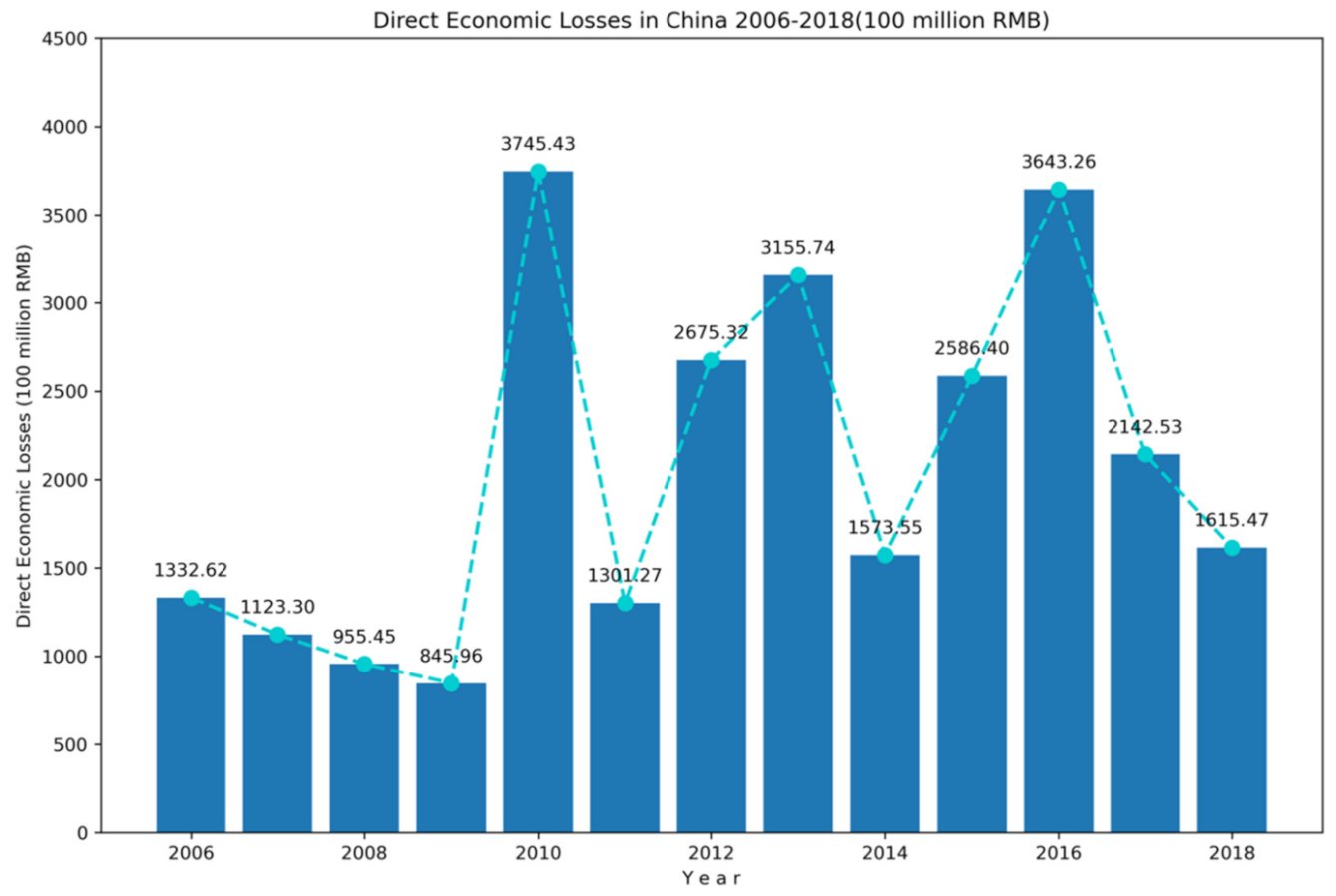
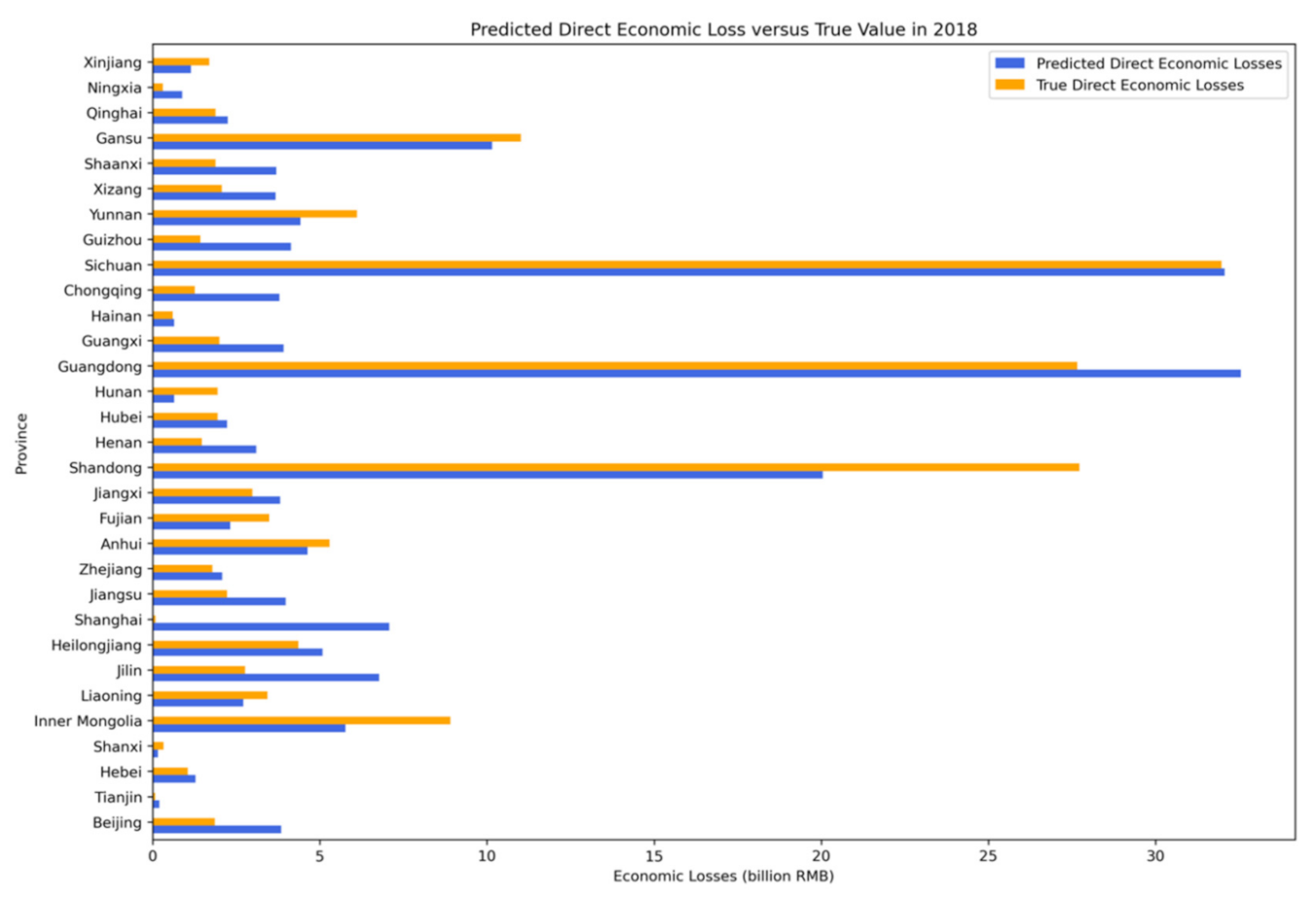
3.1. Direct Economic Loss Prediction
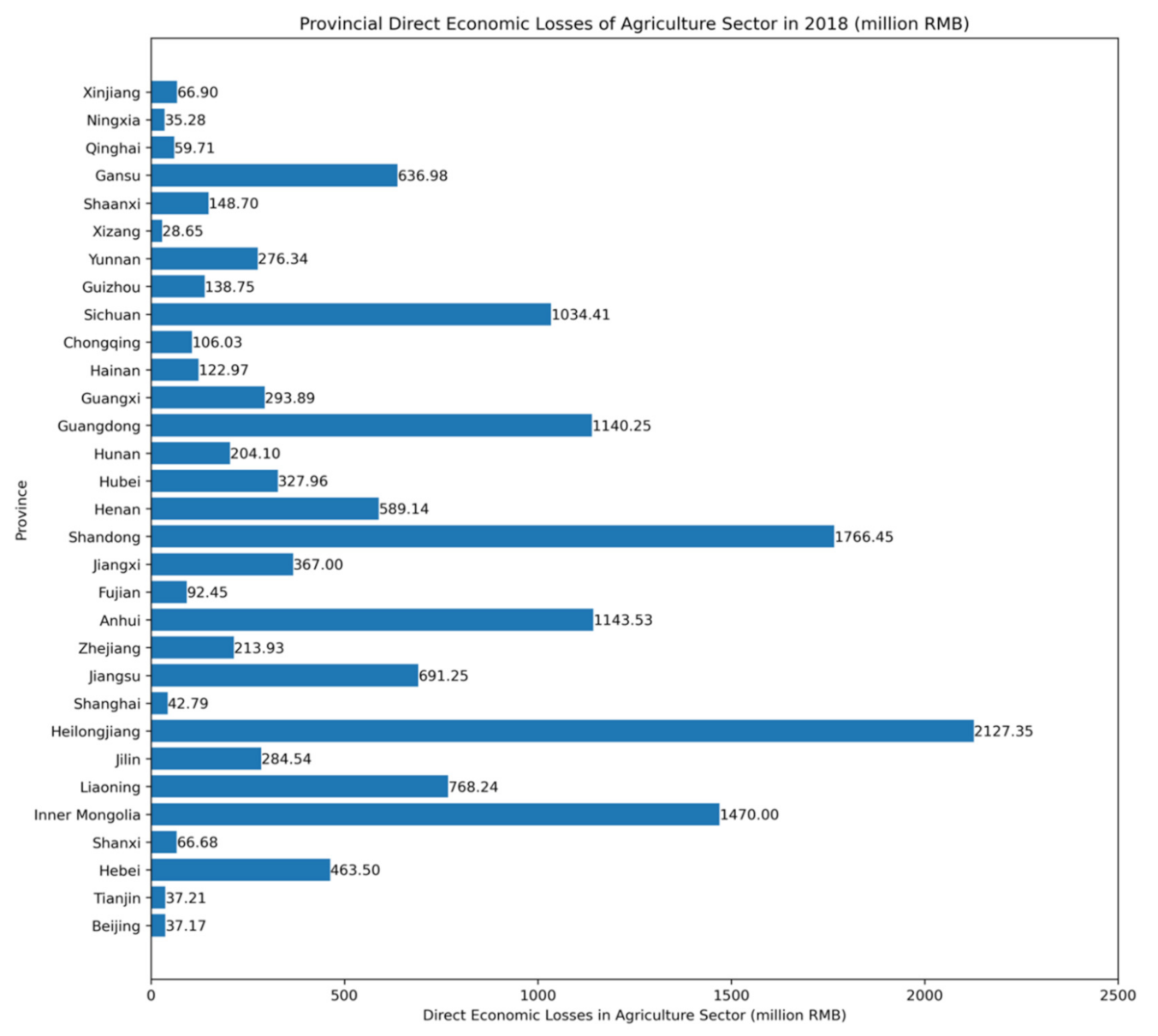
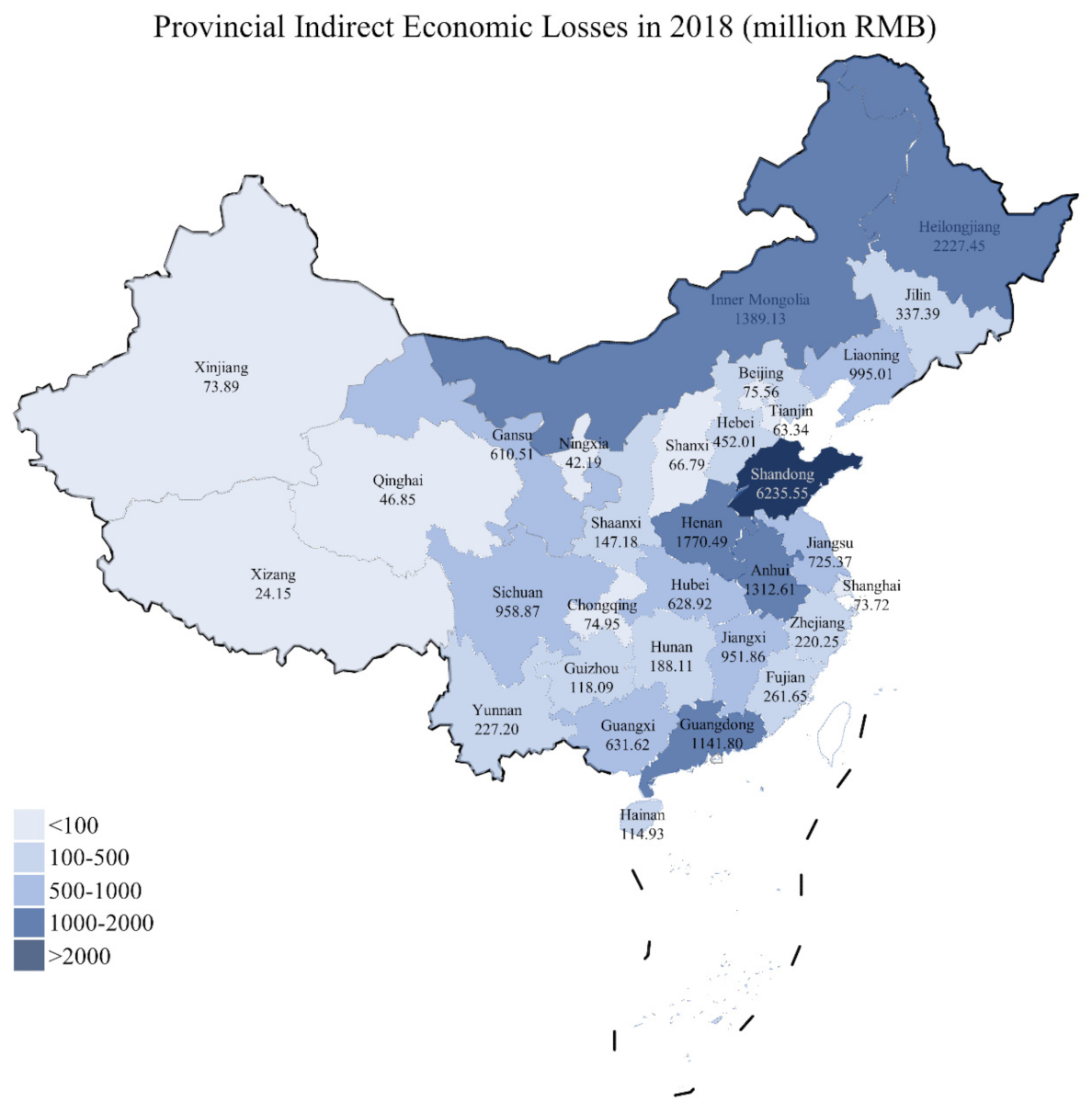
3.2. Indirect Economic Loss Prediction
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Climate Change Widespread, Rapid, and Intensifying—IPCC. Available online: https://public.wmo.int/en/media/press-release/climate-change-widespread-rapid-and-intensifying-%E2%80%93-ipcc (accessed on 26 August 2021).
- Huang, X.; Tan, H.; Zhou, J.; Yang, T.; Benjamin, A.; Wen, S.W.; Li, S.; Liu, A.; Li, X.; Fen, S. Flood hazard in Hunan province of China: An economic loss analysis. Nat. Hazards 2008, 47, 65–73. [Google Scholar] [CrossRef]
- Wu, X.; Guo, J. A new economic loss assessment system for urban severe rainfall and flooding disasters based on big data fusion. In Economic Impacts and Emergency Management of Disasters in China; Springer: Berlin/Heidelberg, Germany, 2021; pp. 259–287. [Google Scholar]
- Wang, D.; Huang, C.; Mai, B. To Facilitate the Advance of Risk Analysis and Crisis Response in China. Environ. Res. 2016, 148, 547–549. [Google Scholar] [CrossRef]
- Kreimer, A. Social and economic impacts of natural disasters. Int. Geol. Rev. 2001, 43, 401–405. [Google Scholar] [CrossRef]
- Das, S.; Lee, R. A nontraditional methodology for flood stage-damage calculations 1. JAWRA J. Am. Water Resour. Assoc. 1988, 24, 1263–1272. [Google Scholar] [CrossRef]
- Krzysztofowicz, R.; Davis, D.R. Category-unit loss functions for flood forecast-response system evaluation. Water Resour. Res. 1983, 19, 1476–1480. [Google Scholar] [CrossRef]
- Huabin, W.; Gangjun, L.; Weiya, X.; Gonghui, W. GIS-based landslide hazard assessment: An overview. Prog. Phys. Geogr. 2005, 29, 548–567. [Google Scholar] [CrossRef]
- Sanders, B.F.; Schubert, J.E.; Detwiler, R.L. ParBreZo: A parallel, unstructured grid, Godunov-type, shallow-water code for high-resolution flood inundation modeling at the regional scale. Adv. Water Resour. 2010, 33, 1456–1467. [Google Scholar] [CrossRef]
- Koç, G.; Natho, S.; Thieken, A.H. Estimating direct economic impacts of severe flood events in Turkey (2015–2020). Int. J. Disaster Risk Reduct. 2021, 58, 102222. [Google Scholar] [CrossRef]
- Sun, H.; Wang, J.; Ye, W. A data augmentation-based evaluation system for regional direct economic losses of storm surge disasters. Int. J. Environ. Res. Public Health 2021, 18, 2918. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Tian, W.; Wu, J.; Cui, H.; Hu, T. Drought Prediction Based on Feature-Based Transfer Learning and Time Series Imaging. IEEE Access 2021, 9, 101454–101468. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Li, J.; Crawford-Brown, D.; Syddall, M.; Guan, D. Modeling imbalanced economic recovery following a natural disaster using input-output analysis. Risk Anal. 2013, 33, 1908–1923. [Google Scholar] [CrossRef] [PubMed]
- Narayan, P.K. Macroeconomic impact of natural disasters on a small island economy: Evidence from a CGE model. Appl. Econ. Lett. 2003, 10, 721–723. [Google Scholar] [CrossRef]
- Rose, A. Input-output economics and computable general equilibrium models. Struct. Chang. Econ. Dyn. 1995, 6, 295–304. [Google Scholar] [CrossRef]
- You, S.; Wang, H.; Zhang, M.; Song, H.; Xu, X.; Lai, Y. Assessment of monthly economic losses in Wuhan under the lockdown against COVID-19. Humanit. Soc. Sci. Commun. 2020, 7, 1–12. [Google Scholar] [CrossRef]
- Organisation, W.M. Heavy Rains and Flooding Hit Large Parts of Asia. Available online: https://public.wmo.int/en/media/news/heavy-rains-and-flooding-hit-large-parts-of-asia (accessed on 18 September 2021).
- Dutta, D.; Herath, S. Trend of floods in Asia and flood risk management with integrated river basin approach. In Proceedings of the 2nd international conference of Asia-Pacific hydrology and water resources Association, Singapore, 5–9 June 2004; pp. 55–63. [Google Scholar]
- Death Toll from Floods in China's Henan Province Rises to 302. Available online: https://www.reuters.com/world/china/death-toll-flooding-chinas-henan-province-rises-302-2021-08-02/ (accessed on 30 August 2021).
- The Input and Output Table with 42 Sectors. 2017. Available online: https://data.stats.gov.cn/ifnormal.htm?u=/files/html/quickSearch/trcc/trcc01.html&h=740 (accessed on 18 September 2021).
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Mason, L.; Baxter, J.; Bartlett, P.; Frean, M. Boosting algorithms as gradient descent in function space. Proc. NIPS 1999, 12, 512–518. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: Oxfordshire, UK, 2017. [Google Scholar]
- Prasad, A.M.; Iverson, L.R.; Liaw, A. Newer classification and regression tree techniques: Bagging and random forests for ecological prediction. Ecosystems 2006, 9, 181–199. [Google Scholar] [CrossRef]
- Ding, C.; Wu, X.; Yu, G.; Wang, Y. A gradient boosting logit model to investigate driver’s stop-or-run behavior at signalized intersections using high-resolution traffic data. Transp. Res. Part C Emerg. Technol. 2016, 72, 225–238. [Google Scholar] [CrossRef]
- Li, H.; Sun, J.; Wu, J. Predicting business failure using classification and regression tree: An empirical comparison with popular classical statistical methods and top classification mining methods. Expert Syst. Appl. 2010, 37, 5895–5904. [Google Scholar] [CrossRef]
- Sun, R.; Gong, Z.; Gao, G.; Shah, A.A. Comparative analysis of Multi-Criteria Decision-Making methods for flood disaster risk in the Yangtze River Delta. Int. J. Disaster Risk Reduct. 2020, 51, 101768. [Google Scholar] [CrossRef]
- Doan, T.; Kalita, J. Selecting machine learning algorithms using regression models. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 1498–1505. [Google Scholar]
- Halko, N.; Martinsson, P.-G.; Tropp, J.A. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM Rev. 2011, 53, 217–288. [Google Scholar] [CrossRef]
- Perlich, C.; Provost, F.; Simonoff, J. Tree Induction vs. Logistic Regression: A learning-Curve Analysis. J. Mach. Learn. Res. 2003, 4, 211–255. [Google Scholar]
- China Flooding Causes Worst Death Toll in Decade. Available online: https://www.theguardian.com/world/2010/jul/21/china-flooding-worst-decade (accessed on 18 September 2021).
- China's Historic Floods Are among the Earth's Most Costly Weather-Related Disasters. Available online: https://www.climatesignals.org/events/china-floods-june-july-2016 (accessed on 19 September 2021).
- Wang, H.; Wang, Z.; Dong, Y.; Chang, R.; Xu, C.; Yu, X.; Zhang, S.; Tsamlag, L.; Shang, M.; Huang, J. Phase-adjusted estimation of the number of coronavirus disease 2019 cases in Wuhan, China. Cell Discov. 2020, 6, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Bulletin of Flood and Drought Disasters in China (2006–2019). Available online: http://www.mwr.gov.cn/sj/tjgb/zgshzhgb/ (accessed on 19 September 2021).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Indicators | Variables |
|---|---|---|
| Disaster-inducing factors | Year | X1 |
| Daily Maximum Precipitation | X2 | |
| Precipitation Anomaly Percentage | X3 | |
| Precipitation Anomaly Percentage in Spring | X4 | |
| Precipitation Anomaly Percentage in Summer | X5 | |
| Precipitation Anomaly Percentage in Autumn | X6 | |
| Precipitation Days | X7 | |
| Moderate Rainy Days | X8 | |
| Heavy Rainy Days | X9 | |
| Torrential Rainy Days | X10 | |
| Maximum Continuous Precipitation | X11 | |
| Maximum Annual Rainfall | X12 | |
| Maximum Annual Continuous Rainy Days | X13 | |
| Disaster-affected bodies | Casualties | X14 |
| Death Toll | X15 | |
| Sown Area with 10% Reduced Production | X16 | |
| Sown Area with 30% reduced production | X17 | |
| Sown Area with 80% reduced production | X18 | |
| Railway Disruption | X19 | |
| Road Disruption | X20 | |
| Reservoir Loss | X21 | |
| Province | X22 | |
| Disaster Prevention Capabilities | Number of Reservoirs | X19 |
| Capacity of Reservoirs | X20 | |
| Area with Flood Prevention Measures | X21 | |
| Areas with Soil Erosion under Control | X22 | |
| City Sewage Pipes Length | X23 |
| RMSE | MAE | EV | R2 | |
|---|---|---|---|---|
| Bayesian Ridge | 32.80 | 24.61 | 0.86 | 0.84 |
| Linear Regression | 36.66 | 28.97 | 0.84 | 0.80 |
| Elastic Net | 34.03 | 26.06 | 0.85 | 0.82 |
| XGB | 31.76 | 18.64 | 0.85 | 0.85 |
| GBR | 25.57 | 16.49 | 0.90 | 0.90 |
| Province | Predicted Direct Economic Losses (PDEL, billion RMB) | PDEL/ Provincial GDP (‰) | Province | Predicted Direct Economic Losses (PDEL, billion RMB) | PDEL/ Provincial GDP (‰) |
|---|---|---|---|---|---|
| Beijing | 3.84 | 0.02 | Hubei | 2.23 | 0.15 |
| Tianjin | 0.2 | 0.05 | Hunan | 0.64 | 0.05 |
| Hebei | 1.28 | 0.14 | Guangdong | 32.55 | 0.11 |
| Shanxi | 0.16 | 0.04 | Guangxi | 3.92 | 0.32 |
| Inner Mongolia | 5.77 | 0.86 | Hainan | 0.64 | 0.23 |
| Liaoning | 2.71 | 0.42 | Chongqing | 3.79 | 0.03 |
| Jilin | 6.77 | 0.3 | Sichuan | 32.07 | 0.22 |
| Heilongjiang | 5.08 | 1.73 | Guizhou | 4.14 | 0.08 |
| Shanghai | 7.08 | 0.02 | Yunnan | 4.42 | 0.11 |
| Jiangsu | 3.98 | 0.08 | Xizang | 3.68 | 0.16 |
| Zhejiang | 2.08 | 0.04 | Shaanxi | 3.7 | 0.06 |
| Anhui | 4.63 | 0.39 | Gansu | 10.15 | 0.75 |
| Fujian | 2.32 | 0.07 | Qinghai | 2.25 | 0.17 |
| Jiangxi | 3.81 | 0.42 | Ningxia | 0.88 | 0.12 |
| Shandong | 20.04 | 0.94 | Xinjiang | 1.15 | 0.06 |
| Henan | 3.1 | 0.35 |
| Sector | Agriculture Forestry Animal Husbandry and Fishery | Food and Tobacco Processing | Manufacture of Chemical Products | Smelting and Processing of Metals | Repair of Metal Products, Machinery and Equipment | Wholesale and Retail Trades | Real Estate | |
|---|---|---|---|---|---|---|---|---|
| Province | ||||||||
| Beijing | 0.28 | 0.28 | 0.23 | 0.13 | 0.18 | 0.11 | 0.22 | |
| Tianjin | 0.24 | 0.26 | 0.20 | 0.06 | 0.06 | 0.14 | 0.07 | |
| Hebei | 0.19 | 0.19 | 0.11 | 0.02 | 0.05 | 0.06 | 0.02 | |
| Shanxi | 0.16 | 0.06 | 0.20 | 0.03 | 0.04 | 0.04 | 0.01 | |
| Inner Mongolia | 0.22 | 0.12 | 0.13 | 0.02 | 0.04 | 0.09 | 0.03 | |
| Liaoning | 0.33 | 0.18 | 0.21 | 0.04 | 0.05 | 0.05 | 0.02 | |
| Jilin | 0.30 | 0.18 | 0.15 | 0.05 | 0.03 | 0.06 | 0.04 | |
| Heilongjiang | 0.32 | 0.10 | 0.13 | 0.01 | 0.03 | 0.05 | 0.02 | |
| Shanghai | 0.24 | 0.21 | 0.25 | 0.04 | 0.06 | 0.14 | 0.10 | |
| Jiangsu | 0.20 | 0.13 | 0.19 | 0.04 | 0.04 | 0.06 | 0.03 | |
| Zhejiang | 0.09 | 0.11 | 0.22 | 0.03 | 0.08 | 0.07 | 0.02 | |
| Anhui | 0.23 | 0.16 | 0.18 | 0.04 | 0.04 | 0.05 | 0.04 | |
| Fujian | 0.03 | 0.02 | 0.22 | 0.00 | 0.03 | 0.00 | 0.01 | |
| Jiangxi | 0.04 | 0.02 | 0.35 | 0.00 | 0.02 | 0.02 | 0.02 | |
| Shandong | 0.03 | 0.06 | 0.21 | 0.05 | 0.11 | 0.18 | 0.05 | |
| Henan | 0.03 | 0.01 | 0.29 | 0.03 | 0.05 | 0.06 | 0.02 | |
| Hubei | 0.02 | 0.01 | 0.08 | 0.07 | 0.04 | 0.05 | 0.02 | |
| Hunan | 0.22 | 0.18 | 0.17 | 0.02 | 0.04 | 0.04 | 0.02 | |
| Guangdong | 0.21 | 0.26 | 0.13 | 0.04 | 0.05 | 0.04 | 0.02 | |
| Guangxi | 0.02 | 0.00 | 0.09 | 0.00 | 0.01 | 0.00 | 0.01 | |
| Hainan | 0.10 | 0.12 | 0.20 | 0.01 | 0.02 | 0.10 | 0.05 | |
| Chongqing | 0.09 | 0.09 | 0.10 | 0.02 | 0.05 | 0.04 | 0.03 | |
| Sichuan | 0.22 | 0.14 | 0.20 | 0.02 | 0.02 | 0.04 | 0.02 | |
| Guizhou | 0.20 | 0.04 | 0.16 | 0.02 | 0.05 | 0.08 | 0.01 | |
| Yunnan | 0.21 | 0.07 | 0.15 | 0.02 | 0.04 | 0.04 | 0.03 | |
| Xizang | 0.25 | 0.17 | 0.15 | 0.01 | 0.03 | 0.05 | 0.02 | |
| Shaanxi | 0.17 | 0.11 | 0.21 | 0.04 | 0.03 | 0.05 | 0.03 | |
| Gansu | 0.19 | 0.06 | 0.17 | 0.02 | 0.06 | 0.06 | 0.02 | |
| Qinghai | 0.16 | 0.14 | 0.14 | 0.02 | 0.07 | 0.05 | 0.01 | |
| Ningxia | 0.20 | 0.14 | 0.19 | 0.02 | 0.09 | 0.09 | 0.03 | |
| Xinjiang | 0.27 | 0.09 | 0.29 | 0.01 | 0.03 | 0.07 | 0.01 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, A.; You, S.; Li, J.; Liu, H. The Economic Loss Prediction of Flooding Based on Machine Learning and the Input-Output Model. Atmosphere 2021, 12, 1448. https://doi.org/10.3390/atmos12111448
Chen A, You S, Li J, Liu H. The Economic Loss Prediction of Flooding Based on Machine Learning and the Input-Output Model. Atmosphere. 2021; 12(11):1448. https://doi.org/10.3390/atmos12111448
Chicago/Turabian StyleChen, Anqi, Shibing You, Jiahao Li, and Huan Liu. 2021. "The Economic Loss Prediction of Flooding Based on Machine Learning and the Input-Output Model" Atmosphere 12, no. 11: 1448. https://doi.org/10.3390/atmos12111448
APA StyleChen, A., You, S., Li, J., & Liu, H. (2021). The Economic Loss Prediction of Flooding Based on Machine Learning and the Input-Output Model. Atmosphere, 12(11), 1448. https://doi.org/10.3390/atmos12111448