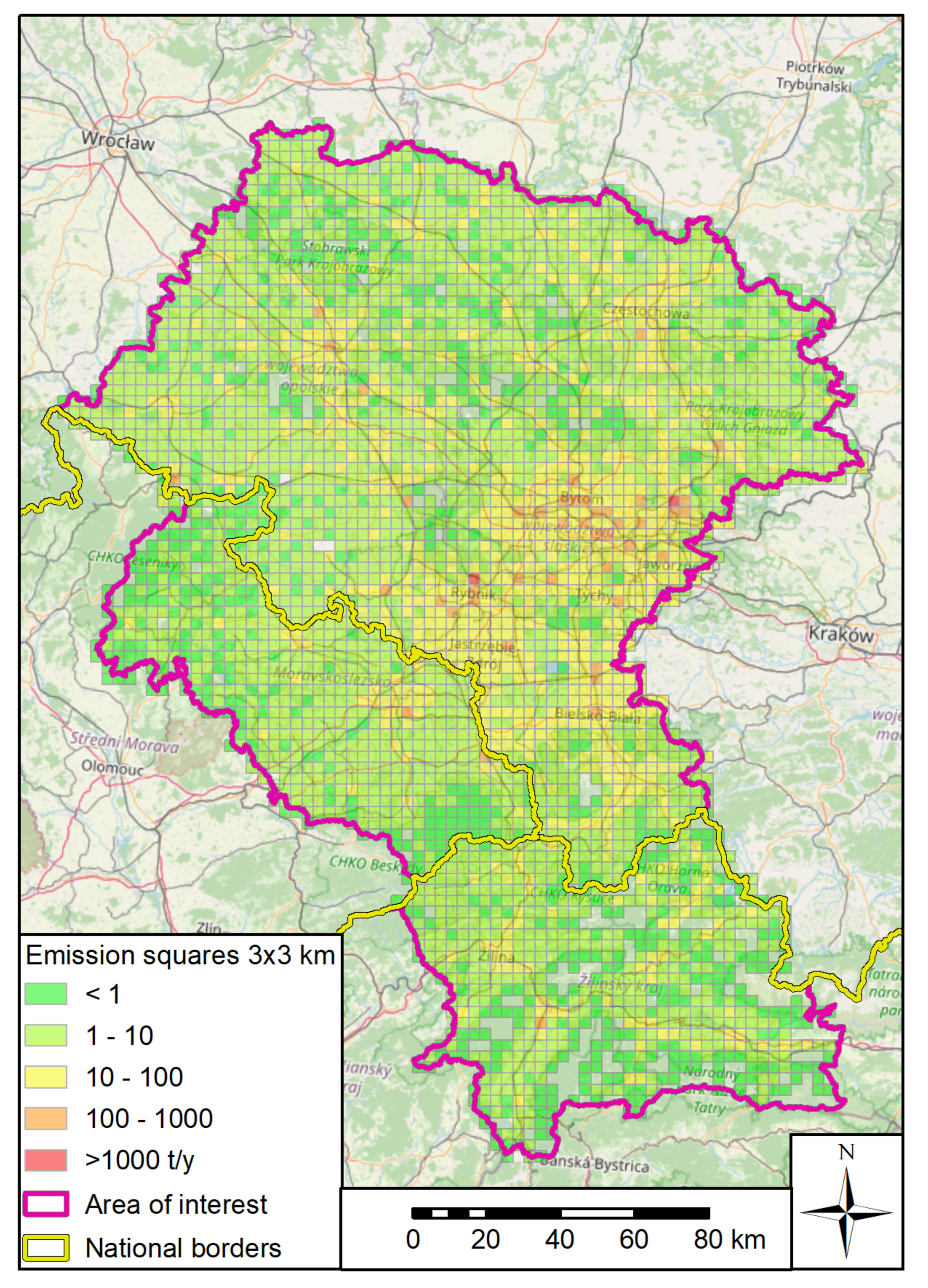
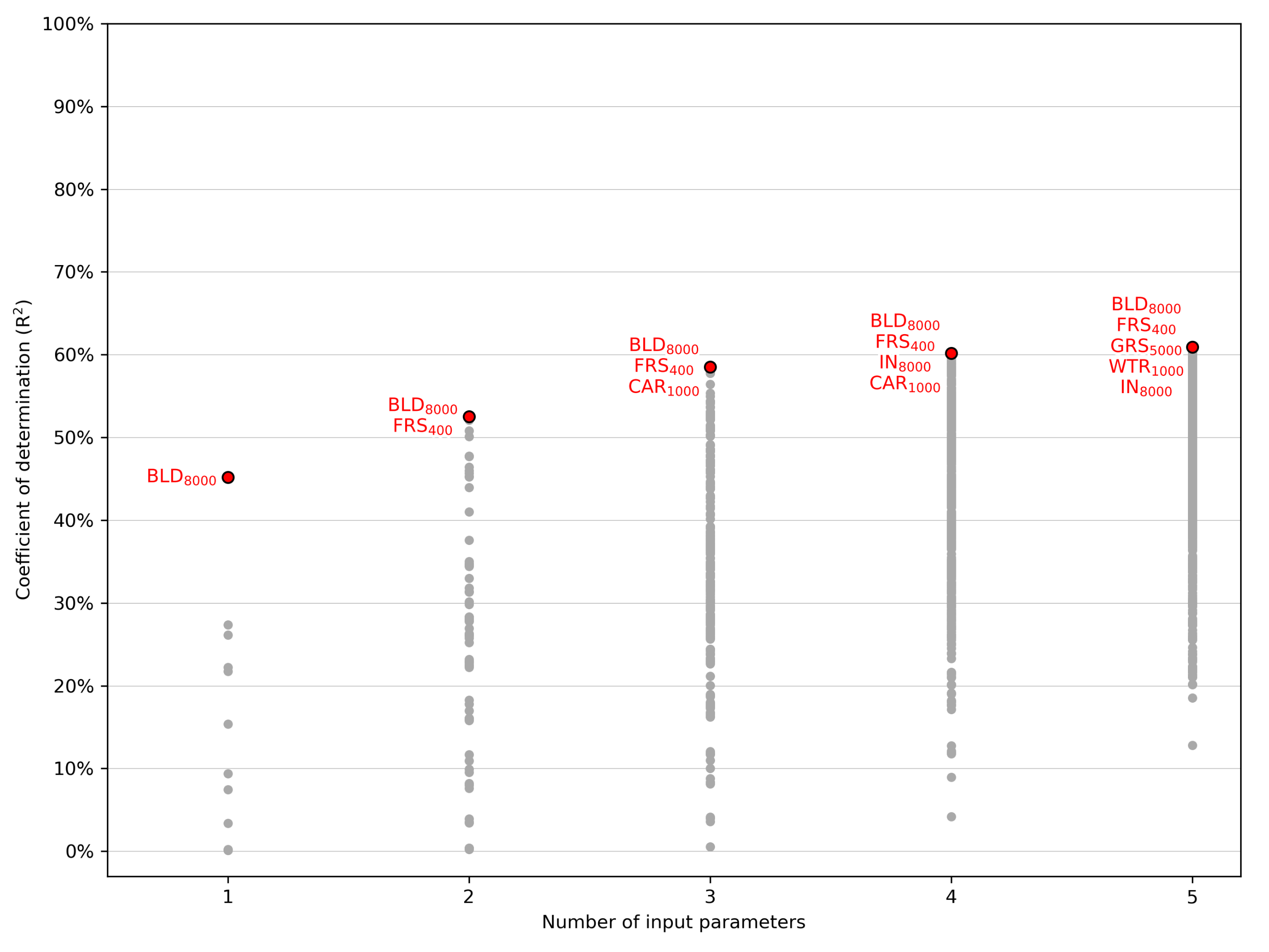
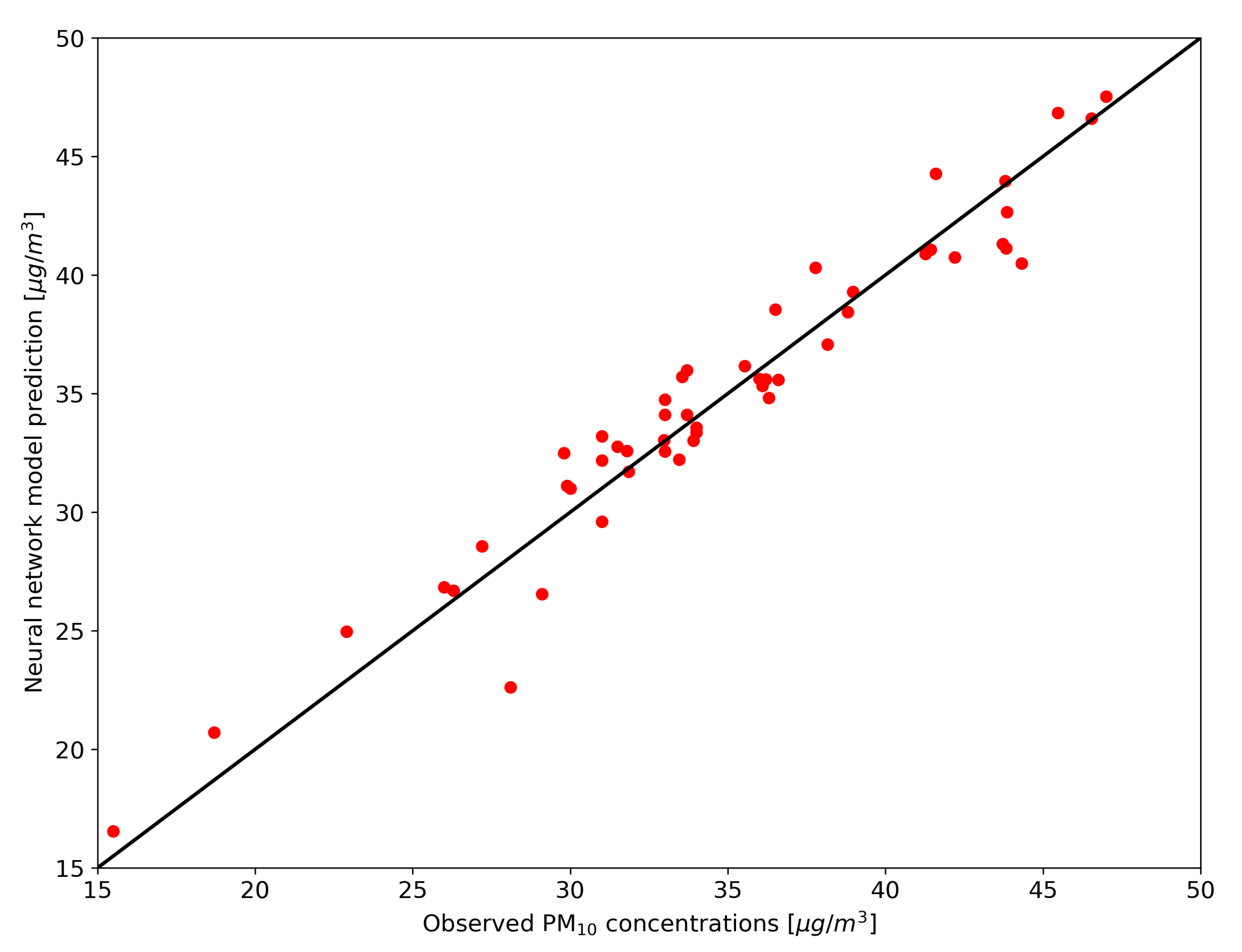
1.1. Air Pollution
Air pollution is an undesirable state of the environment caused by the emission of pollutants from various pollution sources to the air. A pollutant is defined as any substance that negatively affects human health, ecosystems or properties [
1,
2]. The overall imbalance in the environment has increased over the years. Sources of pollution can be classified as natural and anthropogenic. Concentrations emitted by natural sources appear as a natural background and are not influenced by human activities [
1]. Anthropogenic pollution is caused by human activities, and its origin is bound to human settlements. Anthropogenic pollution, unlike natural pollution, is influenceable. Common air pollution pollutants are particulate matter (PM
10 and PM
2.5), nitrogen oxides, carbon monoxide, sulphur dioxide, benzo[a]pyrene, persistent organic pollutants (POPs), etc., [
3]. This article deals with PM
10. PM
10 are solid or liquid (aerosol) particles of 10 μm or less in diameter, compound from various organics, sulfates, nitrates, ammoniac salts, soot, mineral particles, metals, bacteria, pollen and water [
1].
1.2. Air Pollution Modelling
Air pollution monitoring is a standard tool for the air pollution assessment. In the Czech Republic, it is supposed to be the main tool for air monitoring and research in accordance with Czech Act no. 201/2012 Coll. Air pollution concentrations are regulated in respect to both acute effects of pollution exposure (short-term averages) and the effects of chronic air pollution exposure represented by yearly averages. This approach was implemented from the EU Legislation Act on Ambient Air Quality and Cleaner Air for Europe [
4] and is universal for the EU countries. The given study focuses on the chronic part of the air pollution effect represented by yearly averages.
The disadvantage of pure air pollution monitoring is that measurements can provide information about concentrations only at specific measurement points. For effective air pollution management, it is better to have continuous information about the distribution in the study area. Mathematical air pollution dispersion modelling is a suitable method to acquire the concentration distribution of air pollution in the study area.
Mathematical models utilized in the air quality assessment and management can be classified by the model type as [
5]:
empirical models,
Gaussian models,
numerical models,
physical models.
Physical models are a smaller physical representation of a real situation that they represent and allow studying. Numerical models are a category of models based on general formulas and algorithms of computational fluid dynamics. These model categories are not considered in the study.
Empirical models are based on in situ measurements and observations. They use various data analysis techniques to create a model describing the phenomenon under study. Empirical models are usually much simpler, require less computational power, and are easier to work with. Their biggest disadvantage is that they are site and time specific. Their scope is limited by the data they are based on. A difference in data location or a time period results in different models constructed. Land Use Regression (LUR) models belong to the empirical model category.
1.3. Gaussian Models
Gaussian dispersion modelling is based on the assumption of continuous leakage of pollution from a pollution source and subsequent dispersion of pollutants in a constant homogeneous wind speed field without spatial limiting conditions. The dispersion of pollutants occurs in the wind direction due to convection and in the direction perpendicular to it due to diffusion, which is caused by atmospheric turbulence and expressed statistically using the (Gaussian) normal distribution [
6]. Spatial limiting conditions, such as the effect of terrain, are included in the calculation using coefficients [
7]. Input data of Gaussian models are terrain data, meteorological data, the characterization of pollution sources, and a mesh of reference points. Input data characterize an average situation during the modelled period [
8].
Gaussian models work with a reasonable degree of air pollution dispersion process abstraction. Therefore, it is possible to describe the relationship between the concentrations at the reference point and the source using an easily enumerable mathematical formula. Simultaneously, abstraction imposes smaller requirements on the input data and time consumption of evaluation. Therefore, Gaussian models are widely used for air pollution modelling in widespread areas. Among the Gaussian air pollution models preferred by the EPA are Industrial Source Complex (ISC) [
9], CALPUFF [
10], CALINE3 [
11], AERMOD [
12], and others. Gaussian models preferred by the Czech legislation are SYMOS’97 [
13], AEOLIUS [
14] and ATEM [
15]. These models provide steady-state results describing air pollution concentrations in the study area and time interval.
1.4. Land Use Regression
Models based on Land Use Regression belong to the category of empirical models. LUR can be treated as an independent air pollution modelling method. This kind of model is based on the principle that concentrations at a specific location depend on the characteristics of the surrounding environment, especially the characteristics that affect the intensity of emissions and rate of dispersion and deposition. Modelling itself is performed on the basis of the regression model describing the influence of relevant environmental and spatial characteristics, i.e.,
input factors [
16,
17]. The model is composed of regression equations that include the relationship between input factors and substance concentrations at monitoring sites. The resulting formula can be used to predict concentrations over the whole area represented by point measurements.
LUR models are not tied to any time or spatial resolution. They are used in a variety of time intervals from short-term campaigns to long-term averages at fixed pollution monitoring sites. The spatial resolution of LUR models can vary from hyper-local urban areas to regional or country level models.
Most LUR models deal with linear regression [
18]. Linear regression describes the relationship between the variables x and y, where the values of x (x can be a scalar or a vector representing a set of input values) are assumed to be independent variables and measured without errors. Linear regression consists of two variables connected by a linear function [
19]. The dependent random variable represents the value of y under investigation. It is assumed that the variable y is a linear function of x. The coefficient of determination (R
2) is used to evaluate the relationship between these variables [
20].
LUR itself is especially useful in areas that are difficult to monitor or have an unsatisfactory density of the monitoring station mesh. Therefore, LUR air pollution modelling is used for assessment all over the world, especially in Europe, America, Australia, and Asia.
Van den Bossche et al. [
21] used mobile monitoring to gather data at a high spatial resolution in order to build LUR models for the prediction of annual average concentrations of black carbon (BC). The overall prediction was low due to the input uncertainty and lack of predictive variables. The authors highlighted the use of independent data to validate and exclude those data during variable selection in the model building procedure and the importance of using an appropriate cross-validation scheme to estimate the predictive performance of the model. LASSO, the regularized linear model, performed slightly better than the classical supervised approach, and the nonlinear SVM technique did not show significant improvement over the linear model. The generalization of the LUR model to areas where no measurements were made was limited, especially when predicting absolute concentrations.
Lee et al. [
22] developed LUR models for particulate matter in the Taipei Metropolis with a high density of roads and strong activities of industry, commerce, and construction. It was possible to achieve R
2 values of 95% (PM
2.5), 96% (PM
2.5 absorbance), 87% (PM
10), and 65% (PM
coarse). Local traffic, construction, residential land use, and industrial sources were identified as the causes of PM
2.5 pollution. A variable representing the river vicinity decreased PM
2.5 pollution. PM
2.5 absorbance levels were boosted by local traffic, commercial and industrial land use. Increased concentrations of PM
coarse were caused by elevated motorways.
LUR input data have a spatial character. Geographic information systems are a suitable tool for processing and management, especially when using remote sensing data. Hsu et al. [
23] used GIS and remote sensing to develop ten regression models for the PM
2.5 bound compound concentration based on measurements of a six-year period. The regression models included NH
, SO
, NO
, OC, EC, Ba, Mn, Cu, Zn, and Sb. The authors managed to explain the variance (R
2) of the LUR models in the range between 0.60 and 0.92. In the course of the study, they were able to successfully estimate the fine spatial variability of PM
2.5 and its compounds in Taiwan. Traffic distribution, industrial areas, greenness, and culture-specific PM
2.5 sources, such as temples, were used as inputs. The main variables determined by the LUR model that affect PM
2.5-bound concentrations are traffic, industrial areas, and greenness.
The study Wu et al. [
24] assesses the influence of surrounding greenness on the concentrations caused by local culture-specific emission sources (Chinese restaurants and temples) within a city of Taipei using LUR modelling. Correlation analysis of the LUR PM
2.5 model was carried out. A strongly negative correlation (r: −0.71 to −0.77) between NDVI was detected. Temples (r: 0.52 to 0.66) and Chinese restaurants (r: 0.31 to 0.44) were positively correlated with PM
2.5 concentrations. The result was confirmed using a cross-validation test with the result R
2 of 0.90 and external validation R
2 of 0.83, and with the adjusted model R
2 of 0.89.
1.5. Artificial Neural Networks
Artificial neural networks (ANNs) are a mathematical abstraction of biological processes that constitute animal brains. An ANN consists of a set of nodes and neurons, which are interconnected. It loosely simulates the neurons of animal brains. Synapses are represented by these connections. Each neuron receives signals via connections, processes them, and signals further via connections. The signal is a real number. In each neuron, the input signals are summed and transformed using some nonlinear function (
activation function). The result is an output signal of the neuron. Each input connection has a weight set, which increases or decreases the importance of the signal. The neuron can also have a
bias property that represents the sensitivity of the neuron to the signal. The bias value is added to the input signal. Neurons are usually aggregated into layers. The layers can have different activation functions. In each neural network, the signal is propagated from the input receiving layer (input layer) to the output layer, which provides the output signal through one or more layers of neurons. The signal can be one-directional or contain loops McLachlan et al. [
25]. Neural networks can be trained via sets of examples consisting of pairs that combine inputs and desired results. From a mathematical point of view, training is an optimization process that optimizes the performance of the neural network. The performance is usually defined as the difference between the desired results and neural network outputs. Independent variables of the optimization are the weights and biases of the neural network. The adjustment of the weights and biases gives increasingly more accurate results. The training of the network is terminated after a sufficient number of adjustments. This process is called
supervised learning. There are also types of neural networks that are trained on data not containing the desired results. This process is called
unsupervised learning.
Network training is a time-consuming process demanding a lot of computational power. Once the training process is completed, the neural network is able to recall the output value when provided with an input dataset. Mathematically, this is an enumeration of an explicit mathematical formula, a quick and simple operation.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}