
An Atmospheric Visibility Grading Method Based on Ensemble Learning and Stochastic Weight Average

 ,
, 

Abstract
:1. Introduction
2. Materials and Methods
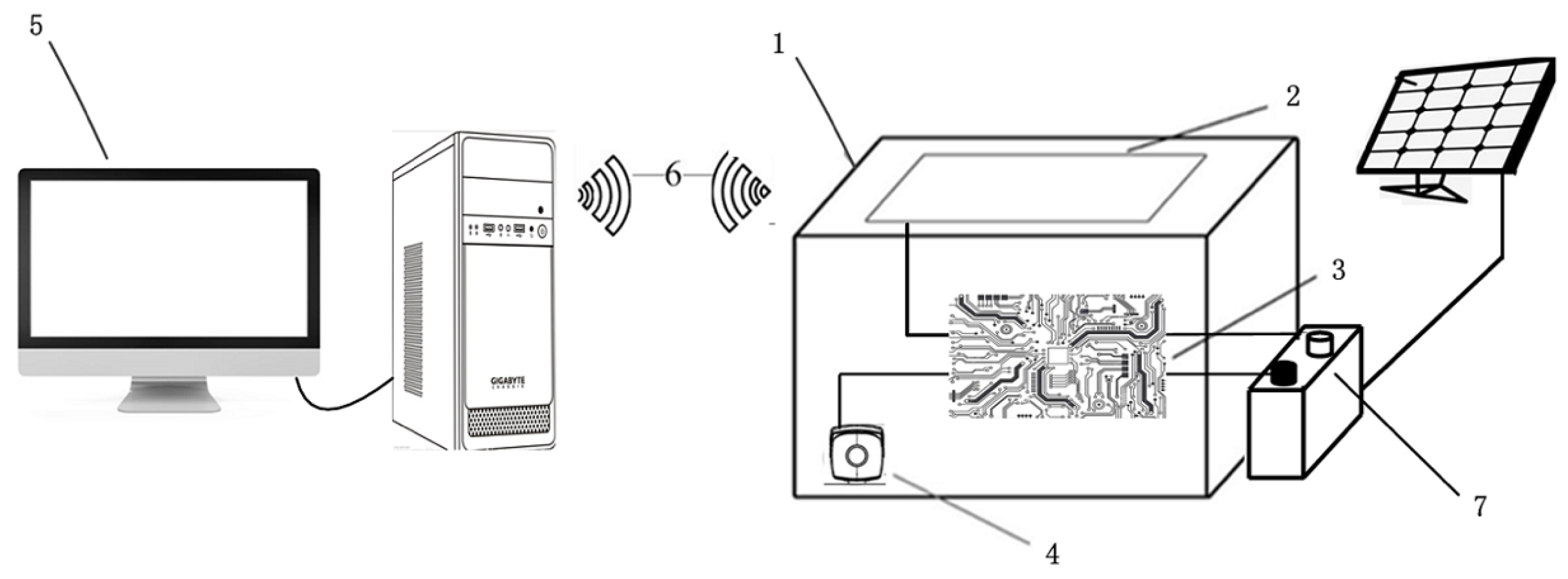
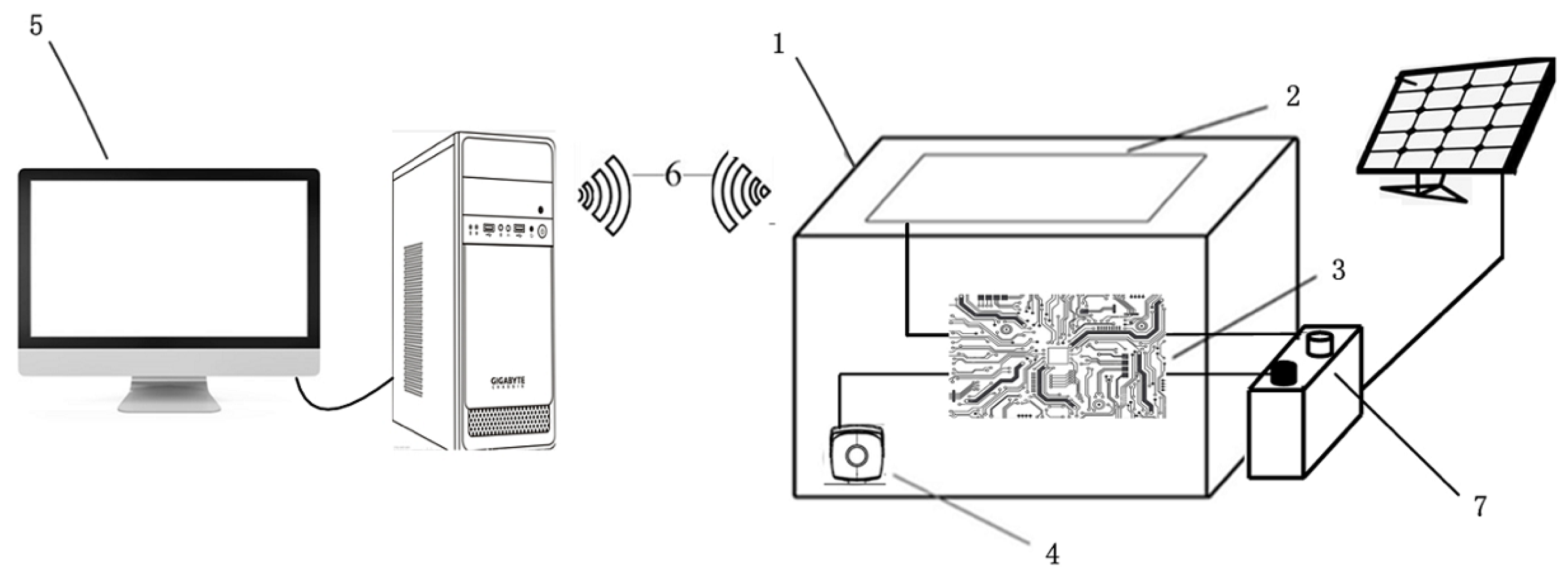
2.1. Materials
2.2. Visibility Level
2.3. The Method of Atmospheric Visibility Grading
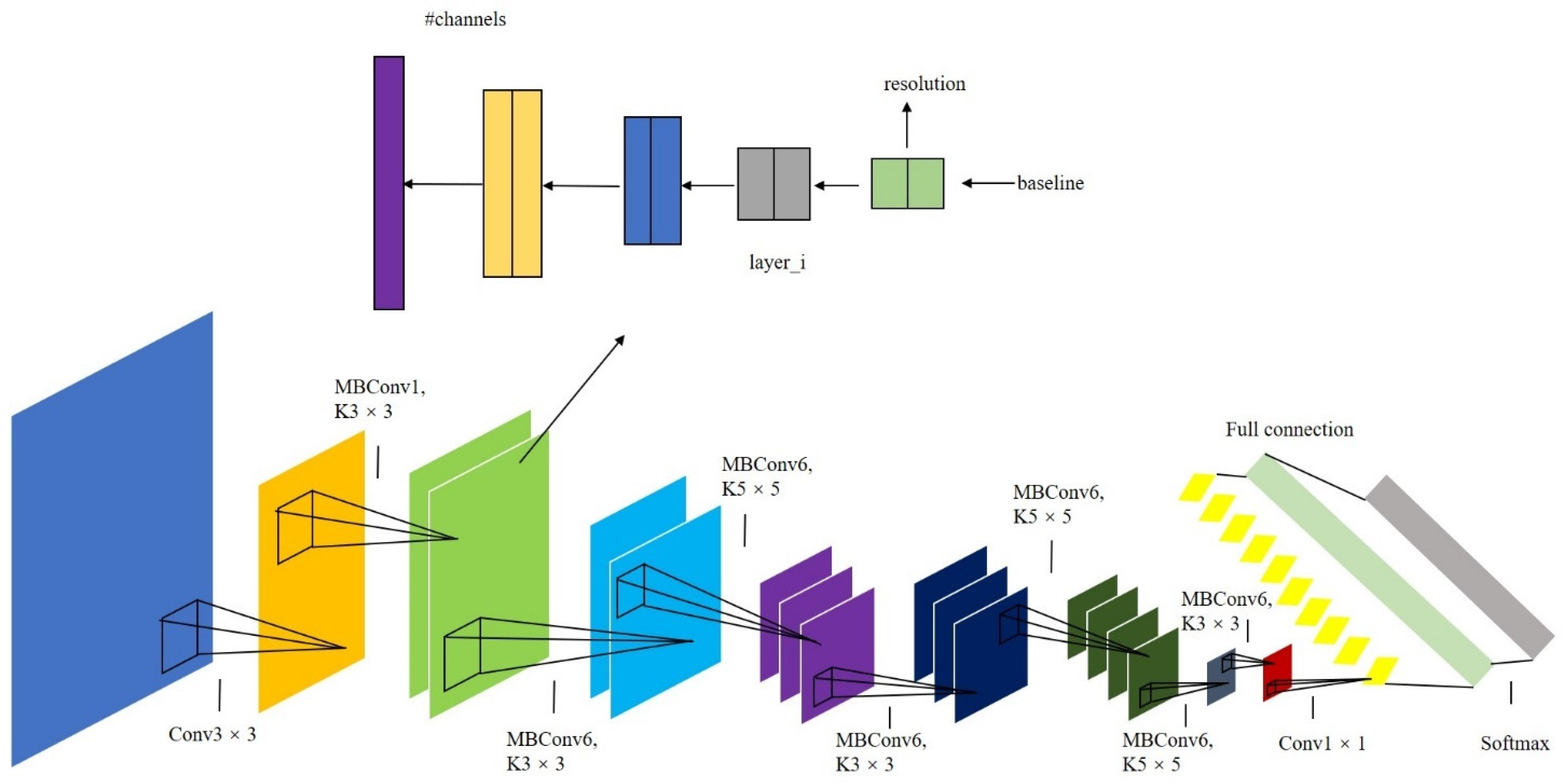
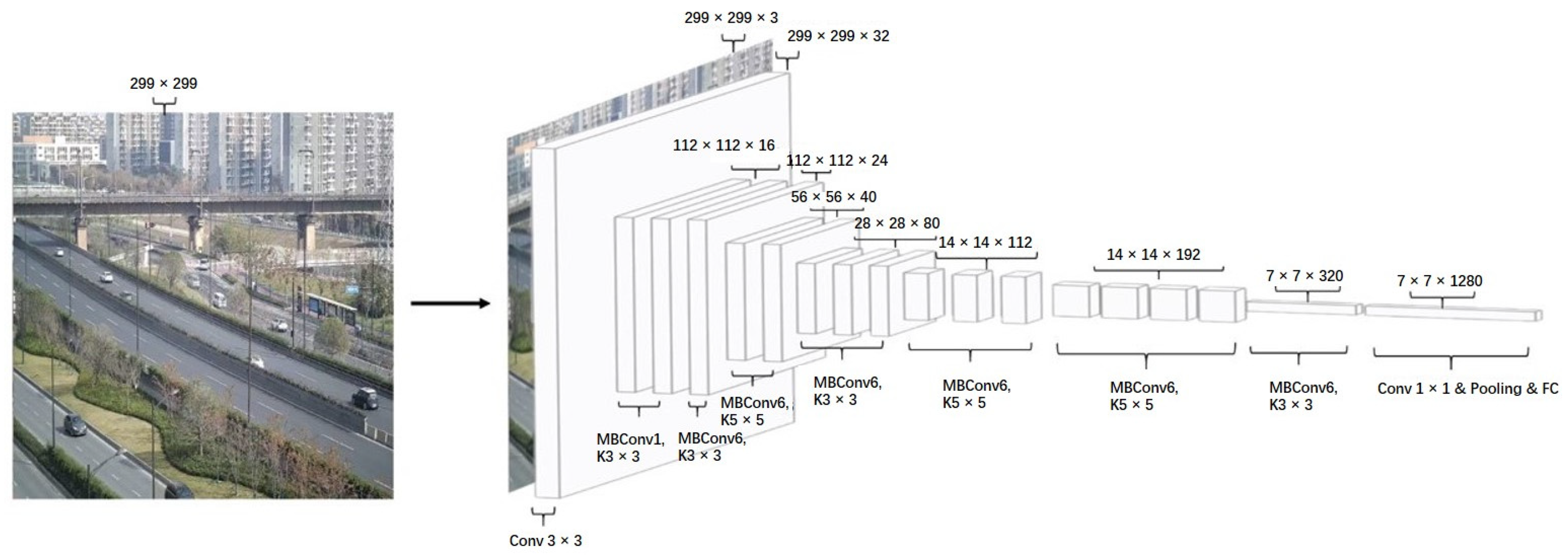
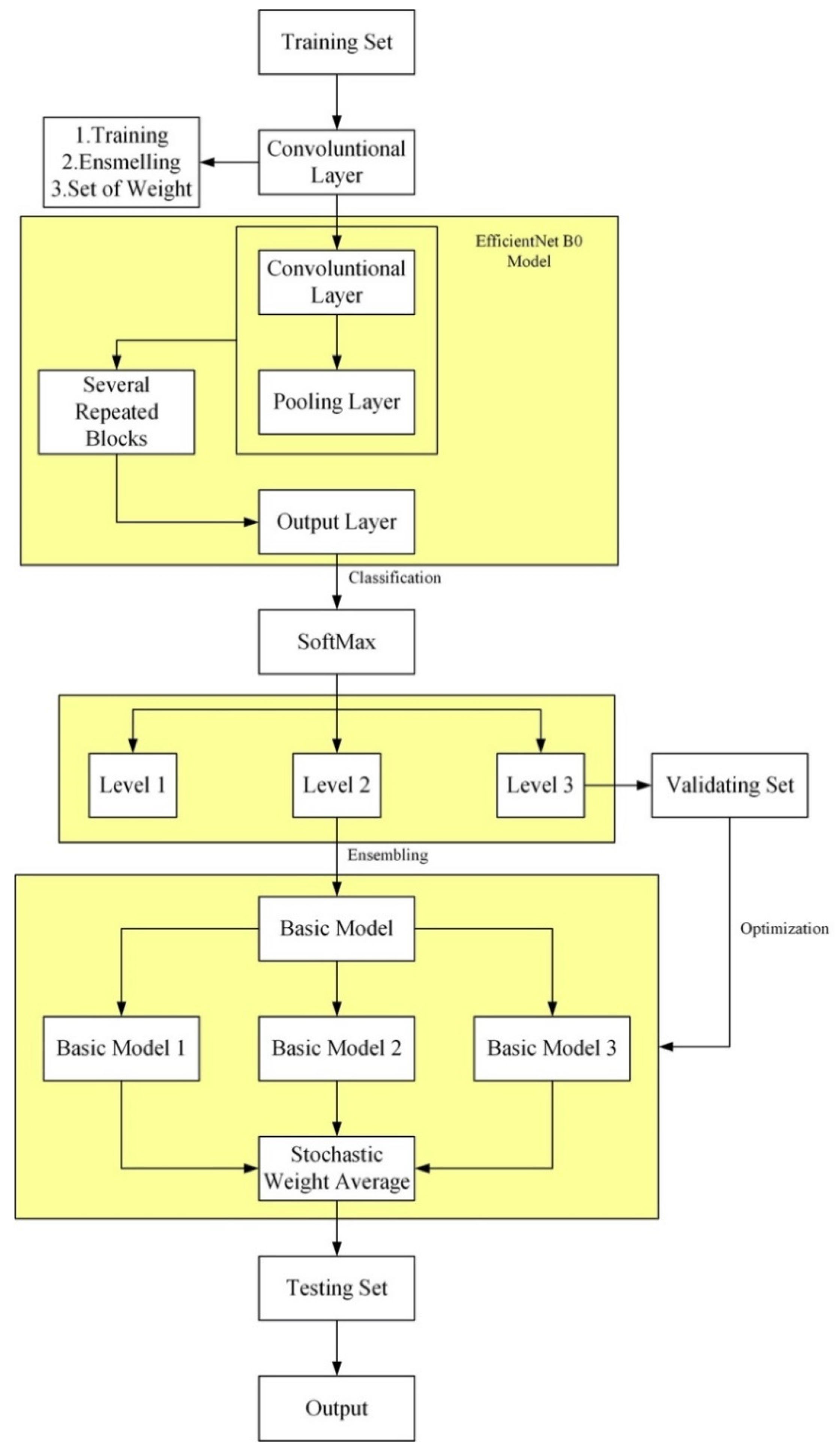
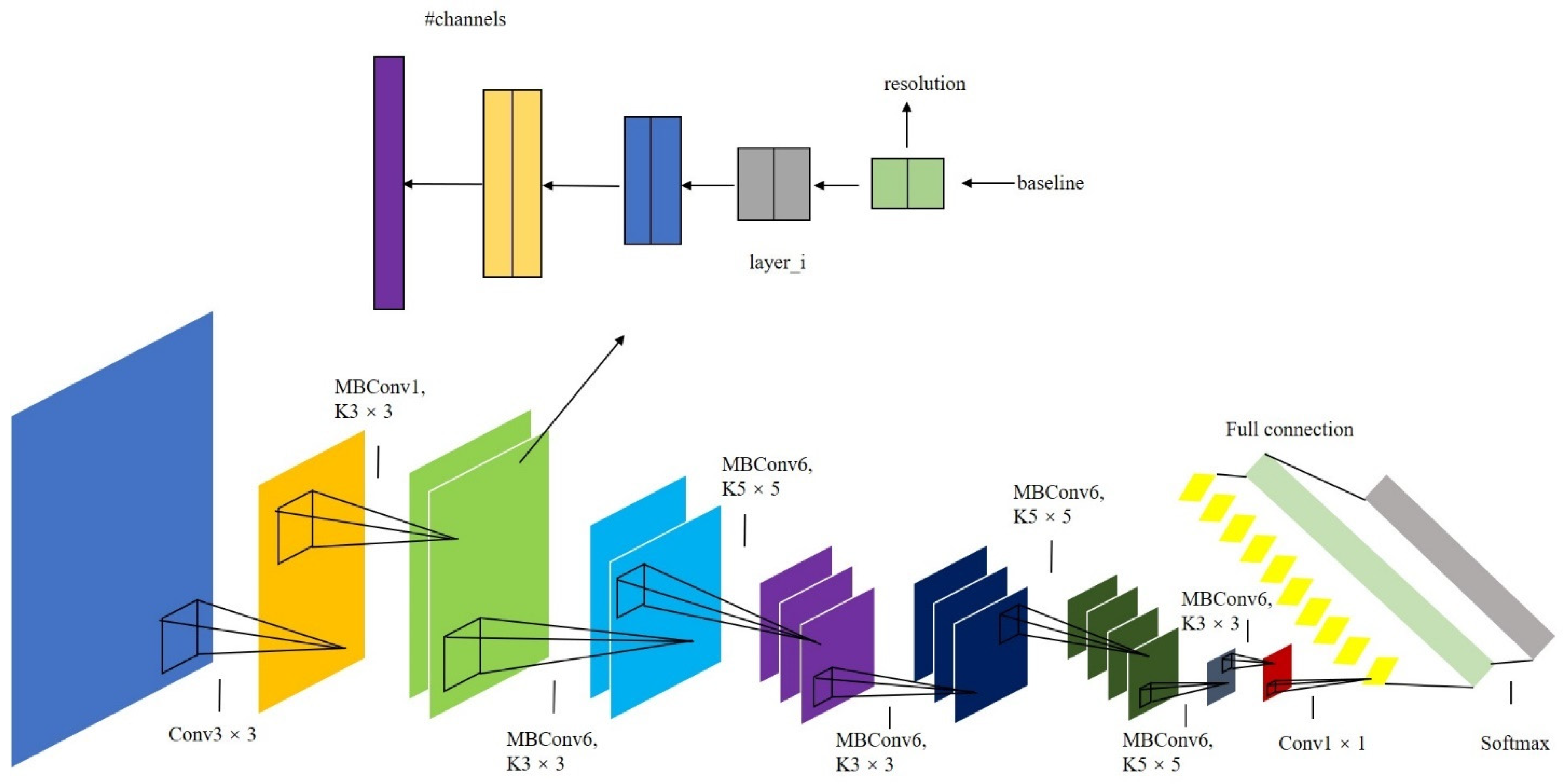
2.3.1. Application of EfficientNet
2.3.2. Training Based on Softmax Regression Model
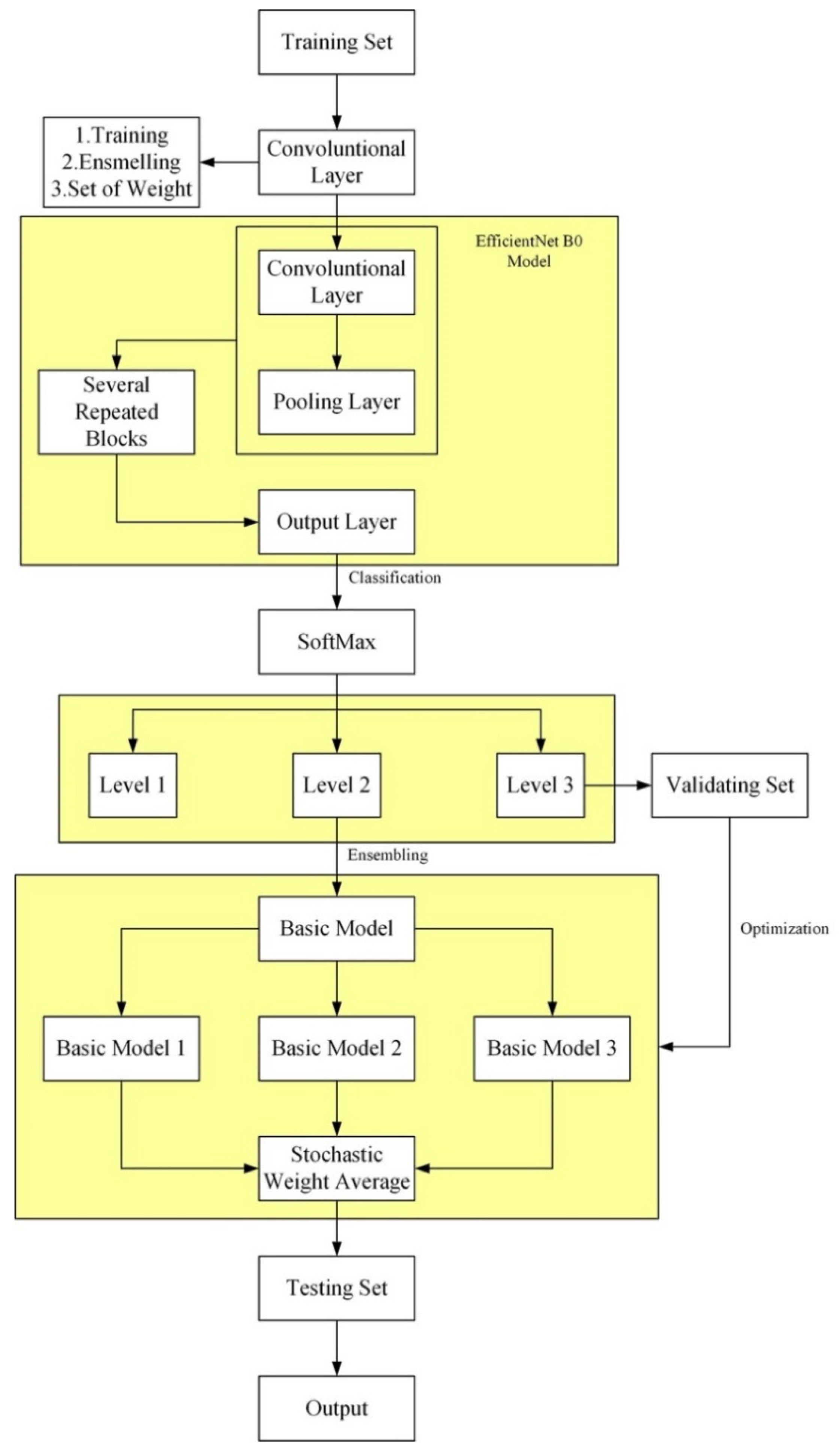
2.3.3. Ensemble Learning
2.3.4. Ensemble Method Based on Weight Space
3. Results and Discussion
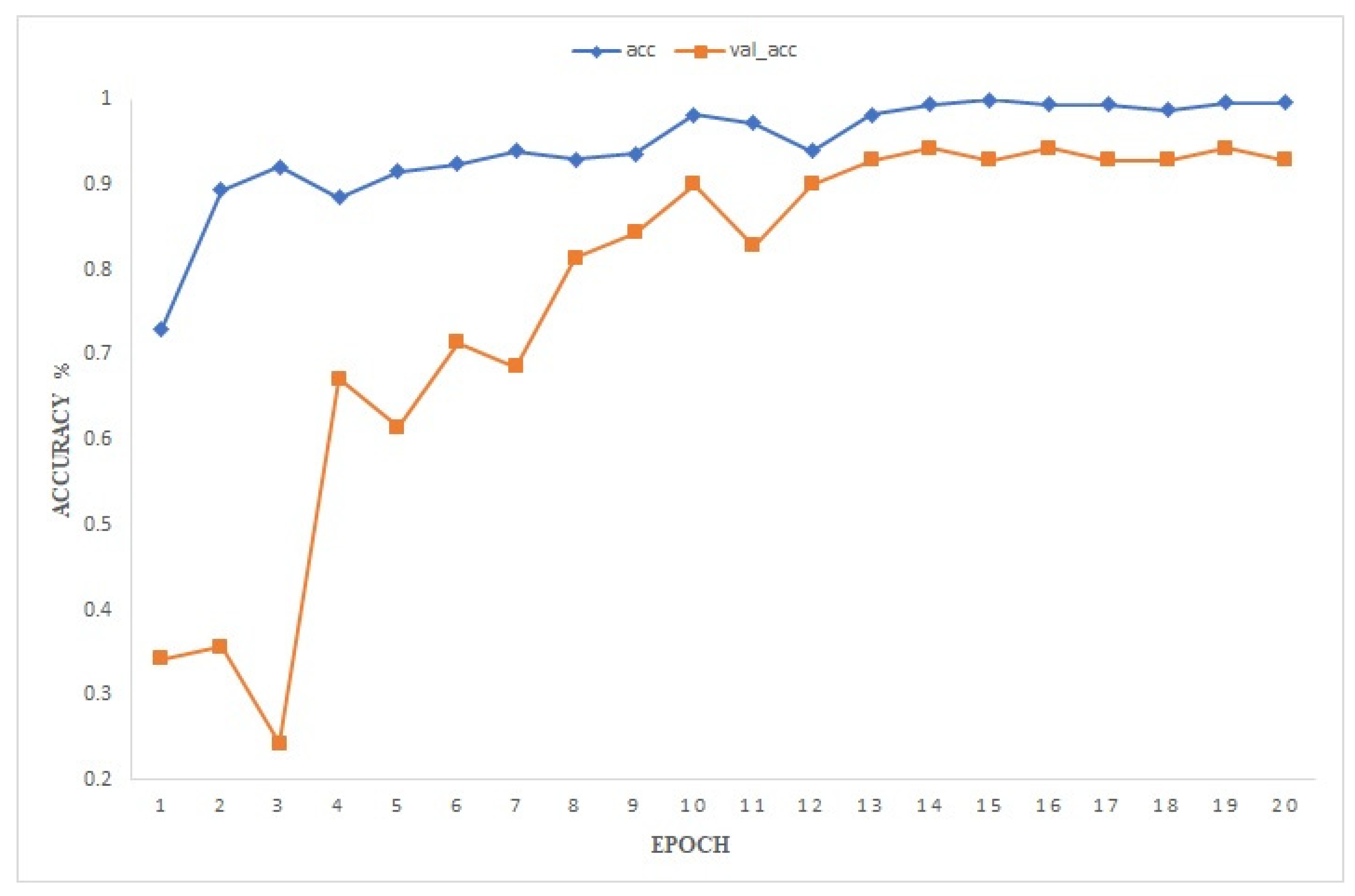
3.1. Experiment of Ensemble Learning Grading Based on SWA
3.2. Evaluation Indicator
- Convergence coefficient: When the model training process ceased, the model training curve is regarded to tend to be stable with the increase of training times, then the model is considered to have converged. The equation is expressed by:where, refers to the accuracy in the training process, and E is a custom threshold.
- Accuracy: There are many evaluation indicators to measure the model performance, and recognition accuracy is often used as the standard of model evaluation.where, TP represents a positive sample predicted by the model to be positive, TN represents a negative sample predicted by the model to be negative, FP represents a negative sample predicted by the model to be positive, and FN is a positive sample predicted by the model to be negative.
3.3. Experiment Analysis
- (1)
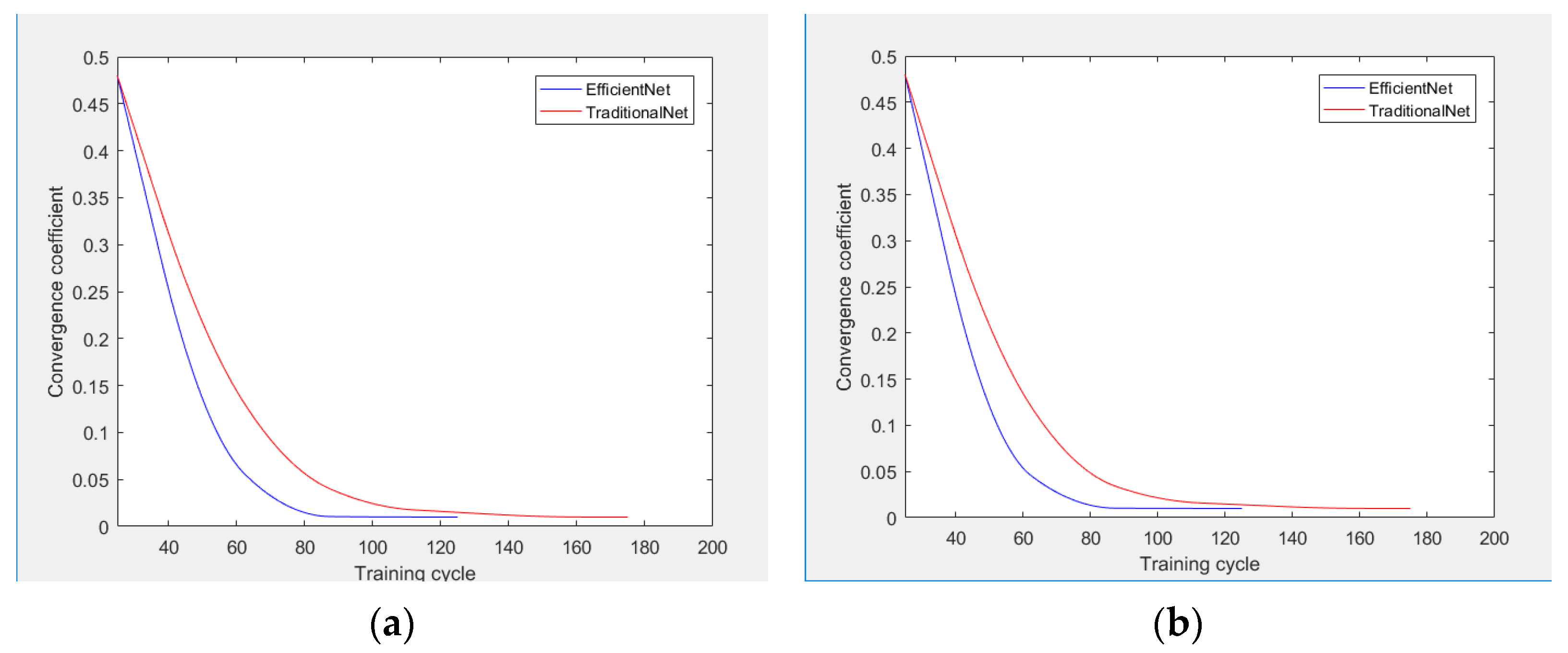
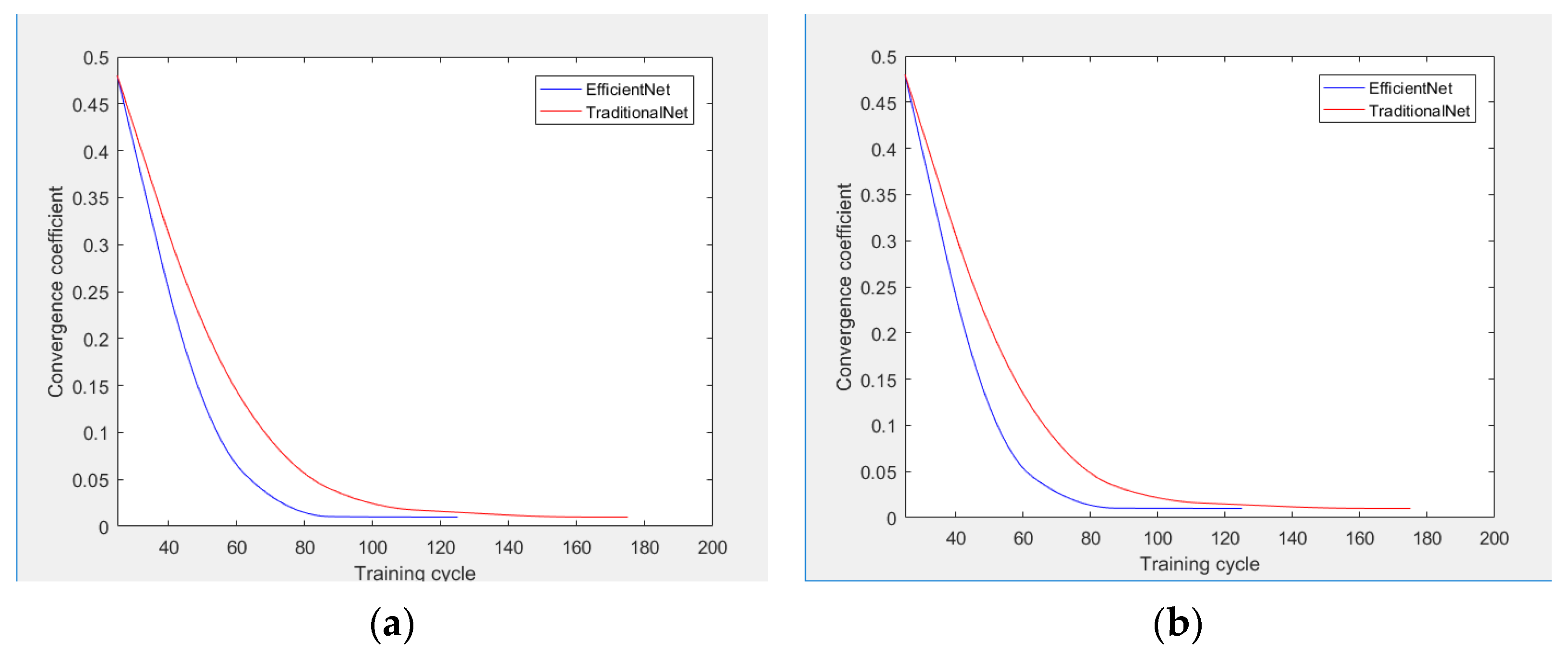
- The EfficientNet and the algorithm of the traditional neural networks were tested twice utilizing a visibility dataset, and the number of iteration periods of the two algorithms under convergence conditions was compared and analyzed.
- (2)
3.3.1. Convergence Analysis
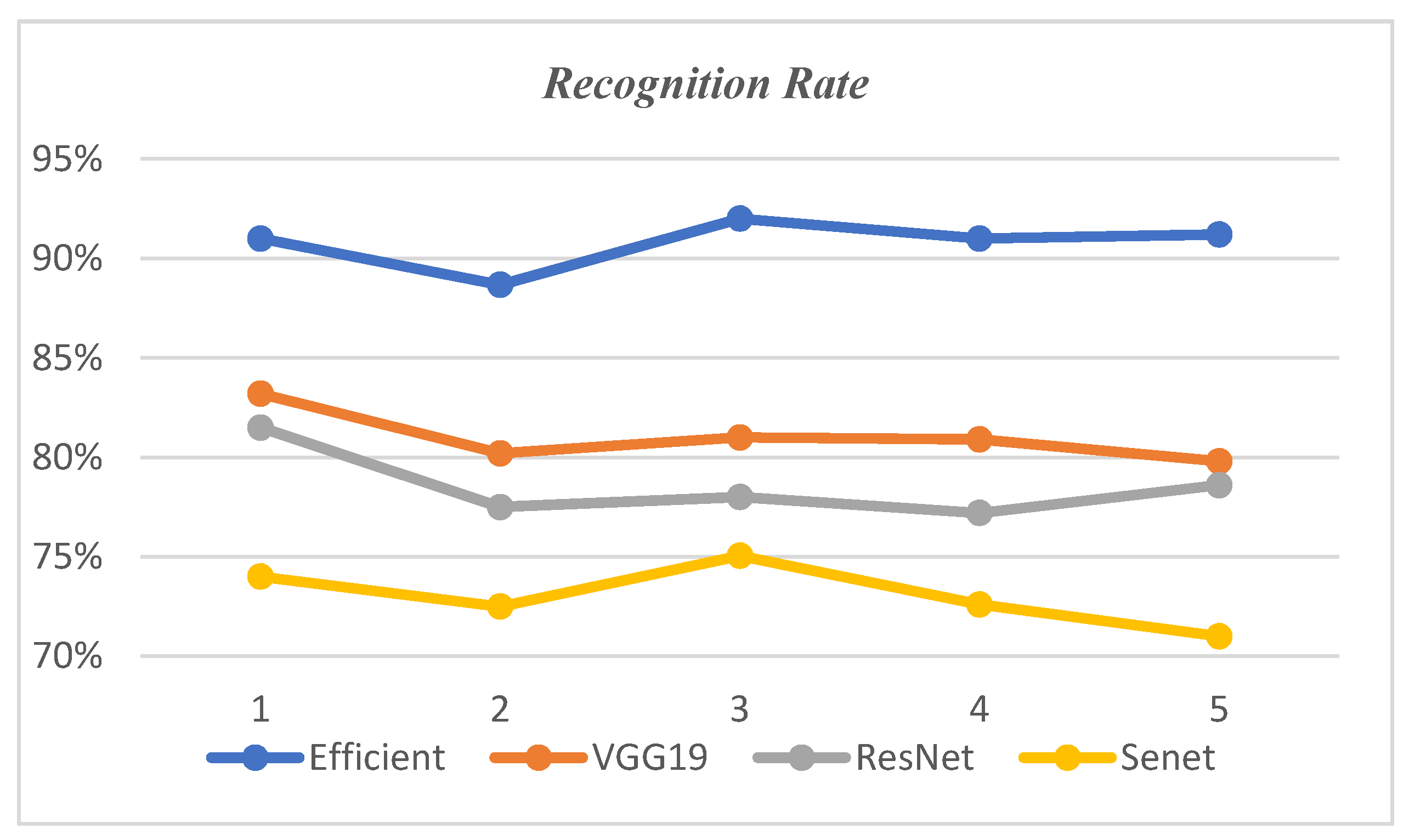
3.3.2. Overall Accuracy Analysis
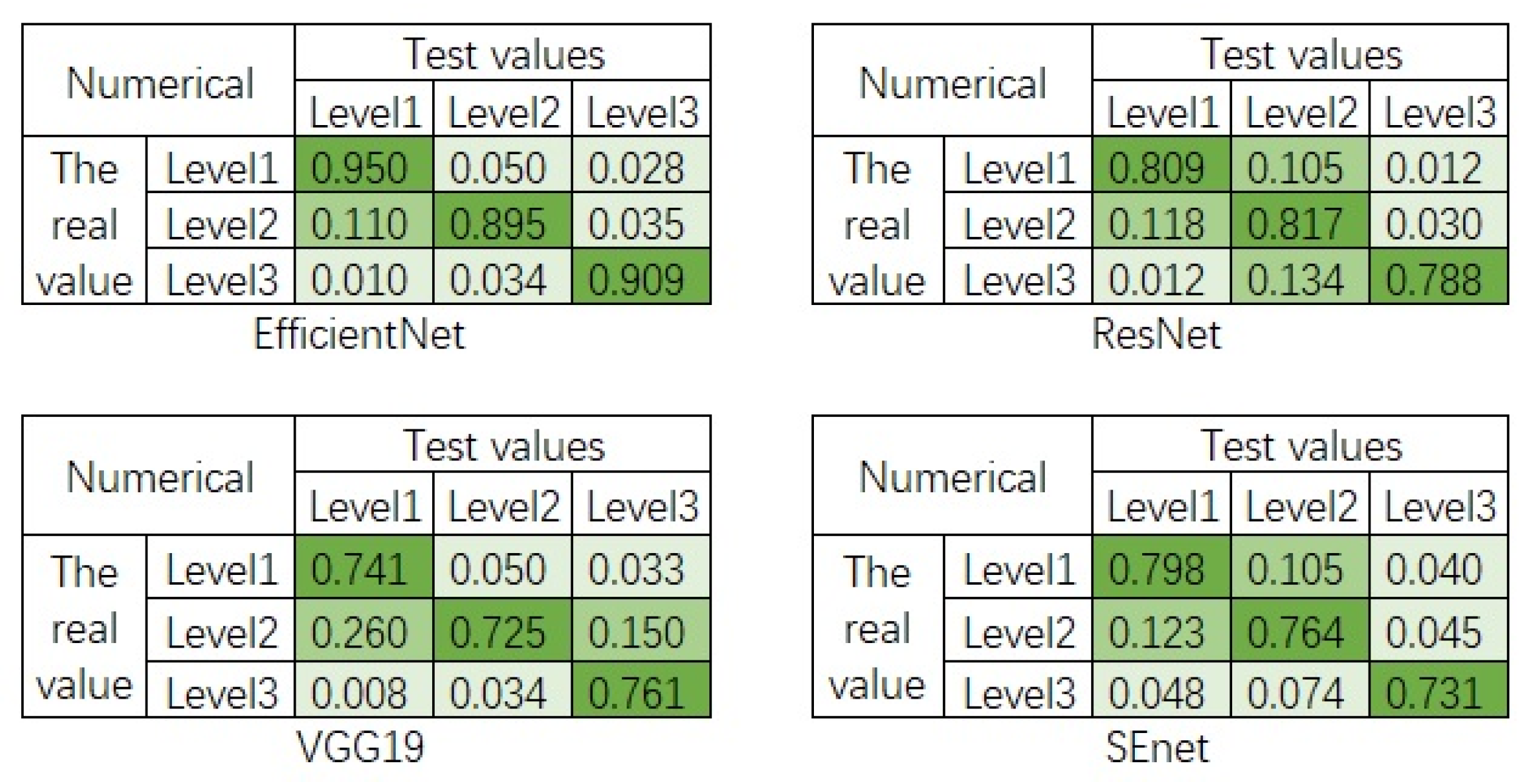
3.3.3. Analysis of Recognition Accuracy
4. Conclusions
- (1)
- At present, deep learning has been widely used in the field of image processing, and it is easy to operate and has considerably high accuracy among many methods, which has received extensive attention from researchers. Particularly, EfficientNet is a deep neural network model that can be applied to small datasets and maintain high accuracy. It has shown good performance on the image datasets we collected in the experiment.
- (2)
- The SWA method ensures that the model can converge faster during the training process. On the other hand, it achieves the self-ensemble of the deep learning model, that is, the deep neural network with the same model architecture, but different weights are ensembled. Therefore, the detection accuracy is significantly improved.
- (3)
- An atmospheric visibility detection model based on EfficientNet and ensemble learning has been built in this paper. Three atmospheric visibility levels can be detected and classified by training a deep learning model and integrating the obtained deep neural network with the same model architecture but different model weights. According to the performance of the model in the experiment, it can be concluded that the detection accuracy of the three atmospheric visibility levels of Level 1, Level 2, and Level 3 are 95.00%, 89.45%, and 90.91%, respectively, with an average detection rate of 91.79%. The model proposed in this paper can more accurately grade atmospheric visibility. In addition, the proposed method can only maintain high accuracy in an experimental environment with good light characteristics, and the experimental data set needs to be further improved.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Palvanov, A.; Cho, Y.I. Visnet: Deep convolutional neural networks for forecasting atmospheric visibility. Sensors 2019, 19, 1343. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, S.; Lee, D.H.; Kim, Y.G. In Development of a transmissometer for meteorological visibility measurement. In Proceedings of the 2015 Conference on Lasers and Electro-Optics Pacific Rim, Busan, Korea, 24–28 August 2015. [Google Scholar]
- Hautiére, N.; Babari, R.; Dumont, É.; Brémond, R.; Paparoditis, N. In Estimating meteorological visibility using cameras: A probabilistic model-driven approach. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010. [Google Scholar]
- Song, H.; Gao, Y.; Chen, Y. Traffic estimation based on camera calibration visibility dynamic. Chin. J. Comput. 2015, 38, 1172–1187. [Google Scholar]
- Chen, A.; Xia, J.; Chen, Y.; Tang, L. Research on visibility inversion technique based on digital photography. Comput. Simul. 2018, 35, 252–256. [Google Scholar]
- Tang, S.; Li, Q.; Hu, L.; Ma, Q.; Gu, D. A visibility detection method based on transfer learning. Comput. Eng. 2019, 45, 242–247. [Google Scholar]
- Bosse, S.; Maniry, D.; Muller, K.R.; Wiegand, T.; Samek, W. Deep neural networks for no-reference and full-reference image quality assessment. IEEE Trans. Image Process. 2018, 27, 206–219. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- You, Y.; Lu, C.; Wang, W.; Tang, C.K. Relative CNN-RNN: Learning relative atmospheric visibility from images. IEEE Trans. Image Process. 2019, 28, 45–55. [Google Scholar] [CrossRef] [PubMed]
- Graves, N.; Newsam, S. Camera-based visibility estimation: Incorporating multiple regions and unlabeled observations. Ecol. Inform. 2014, 23, 62–68. [Google Scholar] [CrossRef]
- Zheng, N.; Luo, M.; Zou, X.; Qiu, X.; Lu, J.; Han, J.; Wang, S.; Wei, Y.; Zhang, S.; Yao, H. A novel method for the recognition of air visibility level based on the optimal binary tree support vector machine. Atmosphere 2018, 9, 481. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q.V. In Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36 th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Chen, Y.; Kang, X.; Shi, Y.Q.; Wang, Z.J. A multi-purpose image forensic method using densely connected convolutional neural networks. J. Real-Time Image Process 2019, 16, 725–740. [Google Scholar] [CrossRef]
- Xiang, W.; Xiao, J.; Wang, C.; Liu, Y. In A new model for daytime visibility index estimation fused average Sobel gradient and dark channel ratio. In Proceedings of the 2013 3rd International Conference on Computer Science and Network Technology, Dalian, China, 12–13 October 2013. [Google Scholar]
- Chaabani, H.; Werghi, N.; Kamoun, F.; Taha, B.; Outay, F. Estimating meteorological visibility range under foggy weather conditions: A deep learning approach. Proced. Comput. Sci. 2018, 141, 478–483. [Google Scholar] [CrossRef]
- Yao, Y.; Wang, H. Optimal subsampling for softmax regression. Stat. Pap. 2019, 60, 235–249. [Google Scholar] [CrossRef]
- Cheng, X.; Yang, B.; Liu, G.; Olofsson, T.; Li, H. A total bounded variation approach to low visibility estimation on expressways. Sensors 2018, 18, 392. [Google Scholar]
- Alhichri, H.; Bazi, Y.; Alajlan, N.; Bin Jdira, B. Helping the visually impaired see via image multi-labeling based on squeezenet CNN. Appl. Sci. 2019, 9, 4656. [Google Scholar] [CrossRef] [Green Version]
- Lu, Z.; Xia, J.; Wang, M.; Nie, Q.; Ou, J. Short-term traffic flow forecasting via multi-regime modeling and ensemble learning. Appl. Sci. 2020, 10, 356. [Google Scholar] [CrossRef] [Green Version]
- Zheng, C.; Wang, C.; Jia, N. An ensemble model for multi-level speech emotion recognition. Appl. Sci. 2019, 10, 205. [Google Scholar] [CrossRef] [Green Version]
- Izmailov, P.; Podoprikhin, D.; Garipov, T.; Vetrov, D.; Wilson, A.G. In Averaging weights leads to wider optima and better generalization. In Proceedings of the 34th Conference on Uncertainty in Artificial Intelligence, Monterey, CA, USA, 6–10 August 2018. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. In Deep transfer learning with joint adaptation networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Wu, Z.; Shen, C.; Hengel, A.V.D. Wider or deeper: Revisiting the ResNet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. In Inception-v4, inception-ResNet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Software and Hardware | Model/Version |
|---|---|
| OS | Windows 10 |
| Camera | Hikvision |
| Software | Python 3.7 |
| CPU | i5-8500 |
| GPU graphics card | Nvidia RTX 2080 |
| Control host | DSP-DM642 |
| Air Quality | Visibility Level | Air Pollution Index | Range (m) |
|---|---|---|---|
| Good | Level 1 | 0–100 | Greater than 1000 |
| Moderate | Level 2 | 101–200 | 200–1000 |
| Poor | Level 3 | greater than 200 | below 200 |
| Epoch | Time | Loss | ACC | Val_loss | Val_acc |
|---|---|---|---|---|---|
| 1 | 35 s | 0.6187 | 0.7303 | 1.3687 | 0.3429 |
| 2 | 17 s | 0.3134 | 0.8939 | 6.2114 | 0.3571 |
| 3 | 19 s | 0.2673 | 0.9212 | 6.6086 | 0.2429 |
| 4 | 18 s | 0.3264 | 0.8848 | 0.0443 | 0.6714 |
| 5 | 19 s | 0.2055 | 0.9152 | 1.3207 | 0.6143 |
| 6 | 16 s | 0.2629 | 0.9242 | 0.2442 | 0.7143 |
| 7 | 16 s | 0.2156 | 0.9394 | 2.6681 | 0.6857 |
| 8 | 17 s | 0.1754 | 0.9303 | 1.4453 | 0.8143 |
| 9 | 17 s | 0.1637 | 0.9364 | 0.1460 | 0.8429 |
| 10 | 16 s | 0.0856 | 0.9818 | 1.0111 | 0.9000 |
| 11 | 16 s | 0.1101 | 0.9727 | 0.0911 | 0.8286 |
| 12 | 16 s | 0.1958 | 0.9394 | 1.6282 | 0.9000 |
| 13 | 16 s | 0.0811 | 0.9818 | 0.6060 | 0.9286 |
| 14 | 16 s | 0.0514 | 0.9939 | 0.0528 | 0.9429 |
| 15 | 16 s | 0.0416 | 1.0000 | 0.1663 | 0.9286 |
| 16 | 16 s | 0.0492 | 0.9939 | 0.0566 | 0.9429 |
| 17 | 16 s | 0.0447 | 0.9939 | 0.8719 | 0.9286 |
| 18 | 16 s | 0.0602 | 0.9879 | 0.4899 | 0.9286 |
| 19 | 16 s | 0.0456 | 0.9970 | 0.0461 | 0.9429 |
| 20 | 11 s | 0.0459 | 0.9970 | 0.4312 | 0.9286 |
| Visibility Level | Training Set | Test Set |
|---|---|---|
| Level 1 | 800 | 212 |
| Level 2 | 850 | 218 |
| Level 3 | 850 | 220 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, X.; Wu, J.; Cao, Z.; Qian, Y.; Zhang, S.; Han, L.; Liu, S.; Zhang, J.; Song, Y. An Atmospheric Visibility Grading Method Based on Ensemble Learning and Stochastic Weight Average. Atmosphere 2021, 12, 869. https://doi.org/10.3390/atmos12070869
Zou X, Wu J, Cao Z, Qian Y, Zhang S, Han L, Liu S, Zhang J, Song Y. An Atmospheric Visibility Grading Method Based on Ensemble Learning and Stochastic Weight Average. Atmosphere. 2021; 12(7):869. https://doi.org/10.3390/atmos12070869
Chicago/Turabian StyleZou, Xiuguo, Jiahong Wu, Zhibin Cao, Yan Qian, Shixiu Zhang, Lu Han, Shangkun Liu, Jie Zhang, and Yuanyuan Song. 2021. "An Atmospheric Visibility Grading Method Based on Ensemble Learning and Stochastic Weight Average" Atmosphere 12, no. 7: 869. https://doi.org/10.3390/atmos12070869
APA StyleZou, X., Wu, J., Cao, Z., Qian, Y., Zhang, S., Han, L., Liu, S., Zhang, J., & Song, Y. (2021). An Atmospheric Visibility Grading Method Based on Ensemble Learning and Stochastic Weight Average. Atmosphere, 12(7), 869. https://doi.org/10.3390/atmos12070869