1. Introduction
From localized air-pollution caused by fireworks [
1], to seasonal changes in pollution caused by cars [
2], to planetary-scale dust transport from earth’s deserts [
3], particulate and gaseous hazardous matter can be dispersed throughout the environment from numerous natural and anthropogenic processes. One event which is important to public health and national security is the release of hazardous materials from nuclear weapons explosions, nuclear reactor breaches (such as Chernobyl or Fukushima), chemical spills, industrial accidents, and other toxic releases. These types of incidents happen suddenly and without warning, creating a plume of toxic material in the earth’s atmosphere or ocean which can threaten the well-being of living organisms and environments.
In such situations, it is crucial that politicians, policy makers, and first responders have adequate knowledge about how the toxic plume will disperse and deposit throughout the environment. This can be used to determine evacuation zones and how resources are deployed to minimize the loss of public health. For example, during the 2011 Fukushima Daiichi disaster, the United States Department of Energy, the United States Environmental Protection Agency, and other United States national agencies worked together to determine the effect of the radioactive release on international aviation routes, global food supply, and other crucial aspects of society [
4].
To predict how a toxic plume disperses and deposits throughout the environment, scientists typically run computer simulations. These dispersion simulations solve physical and chemical equations to produce evolving concentration and deposition fields, but many of the processes represented in the models are uncertain or not resolved at the scales of interest. These processes are represented by empirical or semi-empirical parameterizations, and no single set of parameterizations always performs best for every scenario. Picking and choosing different sets of parameterizations provides an estimate of uncertainty and is a necessary component of the prediction process. In addition, many detailed transport and dispersion models that are currently in use are very computationally expensive, sometimes requiring several hours to complete a single simulation. Since time is of the essence during emergencies, these long run-times can be detrimental to first-responder efforts.
Therefore, in the event of a toxic environmental release, the scientists making predictions with limited computing resources often face a dilemma: using a detailed model, they can make a small number of predictions quickly but have poor knowledge of the uncertainty of those predictions, or they can make a large number of predictions slowly but have better knowledge of the uncertainty of the predictions.
A machine learning or statistical method that emulates a transport and dispersion model provides the opportunity to minimize this uncertainty versus time dilemma. To do this, the scientists would vary the inputs to the traditional weather/dispersion model to create a small number of predictions. They would then train a statistical model to produce dispersion predictions given the original input values. Finally, the statistical model could be used to create predictions for the set of inputs that were not originally run with the traditional dispersion model. That is to say, the statistical model is an emulator of the original dispersion model.
In this paper, we introduce a statistical method that rapidly predicts spatial deposition of radioactive materials over a wide area. The deposition predictions we are emulating were originally produced using material releases in the FLEXible PARTicle dispersion model (FLEXPART) [
5] and meteorological fields generated from the Weather Research and Forecasting (WRF) [
6] model. We created two FLEXPART-WRF ensembles for training and testing—one simulating a continuous surface release from a hypothetical industrial accident and one simulating an instantaneous elevated cloud from a hypothetical nuclear detonation. Each ensemble contained 1196 members with different weather conditions. (Each ensemble initially contained 1200 runs, but four runs did not complete due to numerical stability issues). To create the ensembles, WRF physics parameterizations were varied (i.e., a multi-physics ensemble) and used as inputs for our statistical model. Multi-physics WRF ensembles are often used to estimate weather model uncertainty, and our statistical method is able to capture this uncertainty very efficiently without having to run the full ensemble. We use a hybrid statistical model consisting of a two-dimensional grid of linear and logistic regression models for predicting spatial deposition.
The paper is organized as follows:
Section 2 reviews the literature and the tools used.
Section 3 describes the details of the dataset.
Section 4 describes the statistical algorithm that is used as the emulator, and
Section 5 presents the performance of the algorithm. Finally,
Section 6 and
Section 7 discuss future work and summarize the current work, respectively.
3. Dataset
We trained our statistical model on two sets of FLEXPART dispersion simulations. Both sets release the radioactive particulate material cesium-137 (Cs-137), which has a half-life of 30.17 years, is highly soluble, and is subject to removal from the atmosphere by rainout and wet and dry deposition. Both sets of FLEXPART simulations use 1196 different weather conditions generated by a WRF multi-physics ensemble, as described below. The first set contains the results for a hypothetical continuous release of Cs-137 from the surface of the earth at an industrial facility representing a large-scale radiological accident. This set of simulations is referred to as the “surface release” case or the “surface” case. The second set contains simulations of a hypothetical instantaneous release of Cs-137 in the form of a mushroom cloud similar to how contaminants are created from a nuclear detonation. This set of simulations is referred to here as the “elevated release” case or “elevated” case. Any mathematical notation from this point forward can be generalized to either case unless otherwise specified.
Within a case, each ensemble member k consists of an input vector and an target deposition map , where M and N are the number of grid boxes in latitudinal and longitudinal directions, respectively. (The dimensionality of the input vector will be explained later in this section). The vector contains the physics parameterizations used by WRF and is the input to our statistical model. The deposition map is the output of FLEXPART-WRF given and is used as the target data for training our statistical model. The input vectors are identical between the surface release case and the elevated release case because they are based on the same WRF ensemble, i.e., = .
The FLEXPART settings remain constant for every ensemble member within a given case. Consequently, they are not included as inputs to our statistical model. Each FLEXPART simulation was set to begin at 12:00Z on 24 April 2018 and end 48 h later. An adaptive timestep was used for the sampling rate of the output, but the nominal value was 180 s. Subgrid terrain effects and turbulence were included, and land-use data were taken from WRF. Two million Lagrangian particles were released, and the total mass for the surface and elevated cases was 1 kg and 0.28 g, respectively. We used the default precipitation scavenging coefficients for Cs-137.
Table 1 shows the Cs-137 particle size distributions and masses as a function of altitude for the elevated release case, as further described in Norment [
30]. Further information about the release scenarios can be found in Lucas et al. [
31] and Lucas et al. [
32].
While the FLEXPART settings of each ensemble member remain constant within the case, the set of physics options in WRF is different for every ensemble member. We vary the following five categories of physics parameterizations within WRF: planetary boundary layer physics (PBL), land surface model (LSM), cumulus physics (CU), microphysics (MP), and radiation (RA). Any remaining parameterizations or options remain fixed. To run WRF, one parameterization must be chosen from each physics category. While each category has several different parameterization options available, yielding well over 100,000 possible combinations of parameterizations, we selected a subset of 1200 possibilities expected to simulate the weather, as determined by expert judgment. The ensemble members were roughly chosen to maximize diversity in physics parameterizations.
In a real-world scenario, these 1200 possibilities would be forecasts, i.e., plausible scenarios for the time evolution of the weather and plumes over a two-day period given initial weather conditions that are known at the beginning of the forecast. Therefore, we assume that each ensemble member is equally likely and do not attempt to “prune" the ensemble while it is running because it is a short-term forecast. The 1200-member ensemble therefore provides an estimate of weather model uncertainty in forecasting the deposition from the hypothetical Cs-137 release events. Because we used data from 2018, we were able to verify the meteorological forecasts. In work not presented here, we ran simulations using data assimilation to produce analysis-observational fields. The ensemble simulations provide a reasonable spread around the nudged fields [
32], which gives us confidence that our machine learning model can perform in realistic scenarios. Furthermore, for our short-term forecasts of two days, the WRF parameterization uncertainty is expected to dominate the variability. Very short term forecasts (e.g., 1 h) would not have a lot of variability, while longer forecasts (e.g., 7 days) have errors dominated by initial conditions, and the machine learning task would be much more difficult.
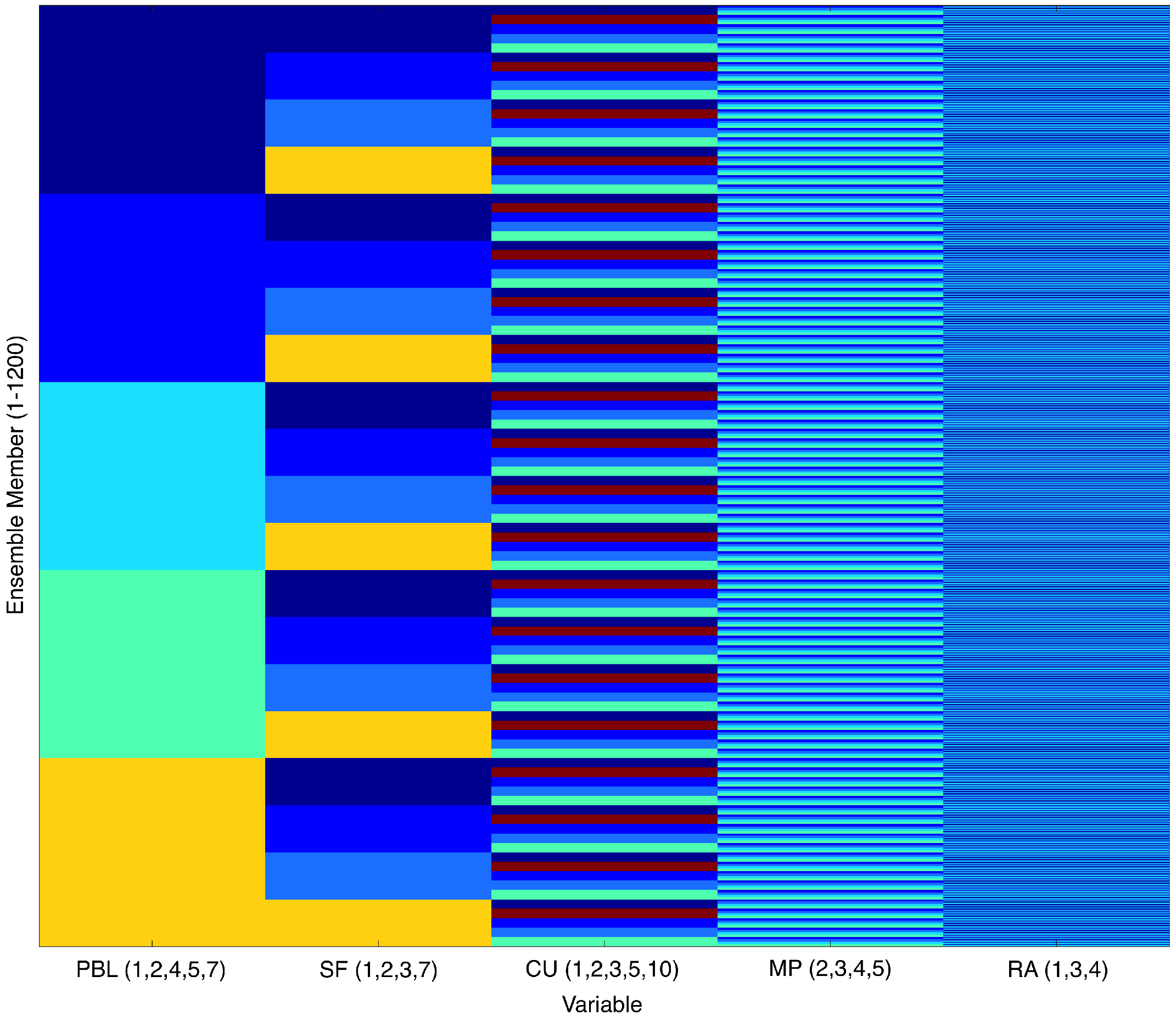
Ultimately, we selected five parameterizations for PBL, four for LSM, five for CU, four for MP, and three for RA. The specific parameterizations are shown in
Table 2. This results in
different combinations of the WRF parameterizations. However, 4 of the 1200 combinations caused numerical issues in WRF, which failed to run to completion, so there are only 1196 members in the final multi-physics weather dataset. The 1196 input vectors
are vertically concatenated to create a
input matrix
. The 1196 output matrices
are concatenated in the third dimension to make the
output matrix
. The ordering of the parameterization combinations in the ensemble is shown in
Figure 1.
The individual physics parameterizations are nominal categorical variables represented as numbers in WRF. In other words, the parameterizations are not ordinal—PBL parameterization 2, which represents the MYJ scheme, is not greater than PBL parameterization 1, which represents the YSU scheme. To prevent our statistical model from treating a higher numbered parameterization differently than a lower numbered parameterization, we transformed the input WRF parameterization vector using one-hot encoding [
28]. This turns the five categorical variables for the parameterizations into sixteen boolean variables, which is why
has shape
. For example, the LSM parameterization has four options: LSM 1, LSM 2, LSM 3, and LSM 7. When one-hot encoding, LSM 1 is represented by the vector
, LSM 2 is represented by the vector
, LSM 3 is represented by the vector
, and LSM 7 is represented by the vector
. The vectors for each parametrization are concatenated together. (For example, the ensemble member run with PBL 2, LSM 1, CU 5, MP 4, and RA 4 has a one-hot encoded input vector
).
The output matrix consists of 1196 simulations produced by FLEXPART-WRF. Each ensemble member is an map of the surface deposition of Cs-137 from either the surface release or the elevated release. For the surface release case, each map contains a total of 160,000 grid cells, with 400 cells in the latitudinal direction and 400 cells in longitudinal direction using a spatial resolution of about 1.7 km per cell. For the elevated release case, each map contains 600 grid cells by 600 grid cells with a resolution of about 1.2 km. Both deposition domains range from to in the latitudinal direction and to in the longitudinal direction. The height of the surface release domain was 3000 m resolved using 11 vertical layers, and the height of the elevated release domain was 4500 m resolved using 14 layers. The latitude and longitude of the location of the surface release were and , respectively. The latitude and longitude of the location of the elevated release were and , respectively. This domain is centered on the southwest corner of the US state North Carolina and has many different land types, including the Appalachian Mountains and the Atlantic Ocean.
The surface deposition output of FLEXPART-WRF accounts for both wet and dry removal of Cs-137 from the atmosphere and is reported in units of Bq/m
using a specific activity for Cs-137 of 3.215 Bq/nanogram. We also filtered out data less than 0.01 Bq/m
in our analysis, as deposition values below this level are comparable to background levels from global fallout [
33] and do not pose much risk to public health.
All FLEXPART-WRF runs were completed on Lawrence Livermore National Laboratory’s Quartz supercomputer which has 36 compute cores, 128 GB of RAM per node, and 3018 nodes total. A single WRF run costs about 150 core-hours, and a single FLEXPART run costs about 20 core-hours. The total ensemble cost was about 180,000 core-hours. The speedup between the full ensemble and the machine learning training set cost depends on the training size, which is discussed in
Section 5. For a training size of 50, the total cost would be 7500 core-hours, which is a speedup of 24 times (or a savings of 172,500 core-hours).
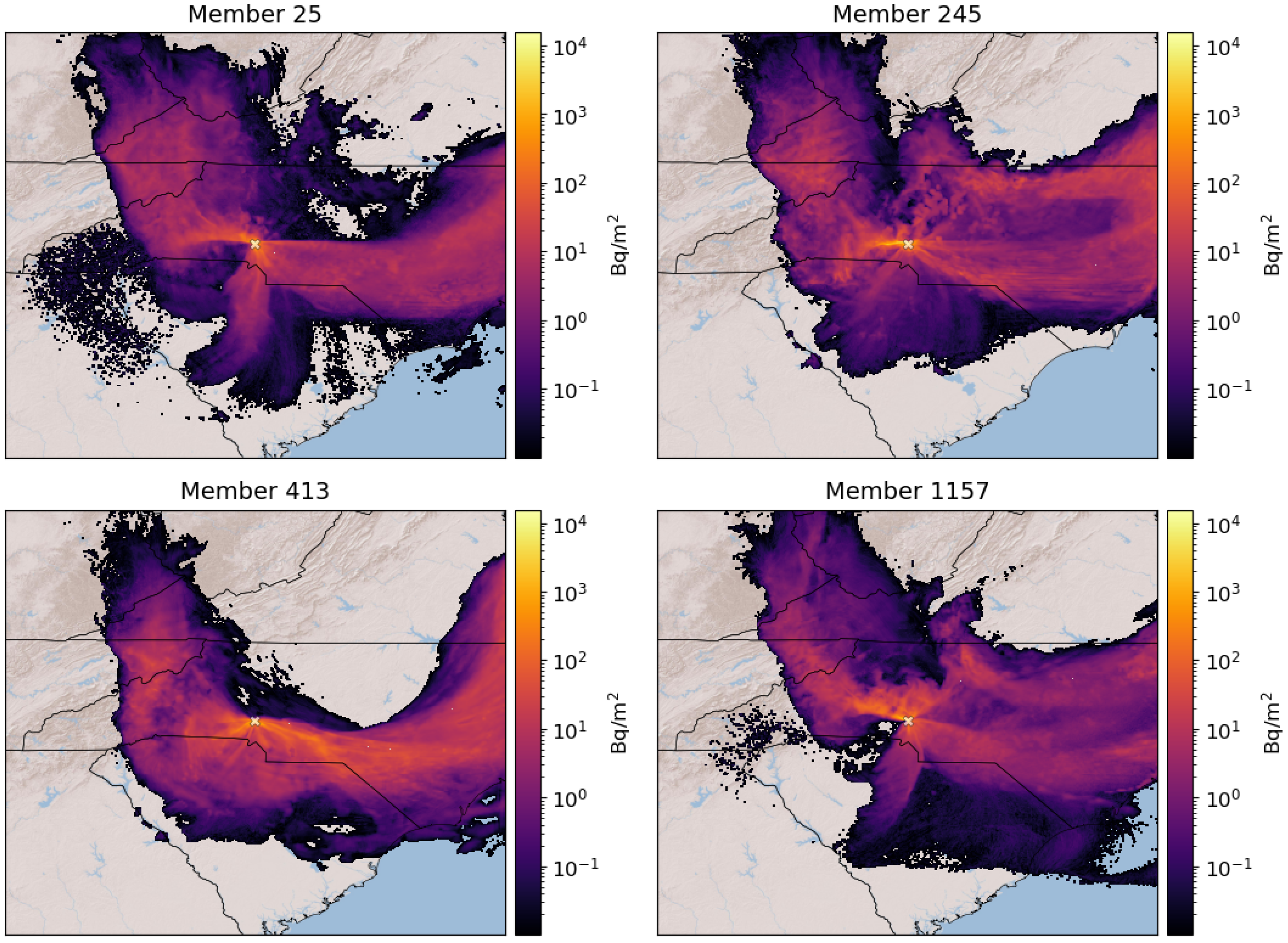
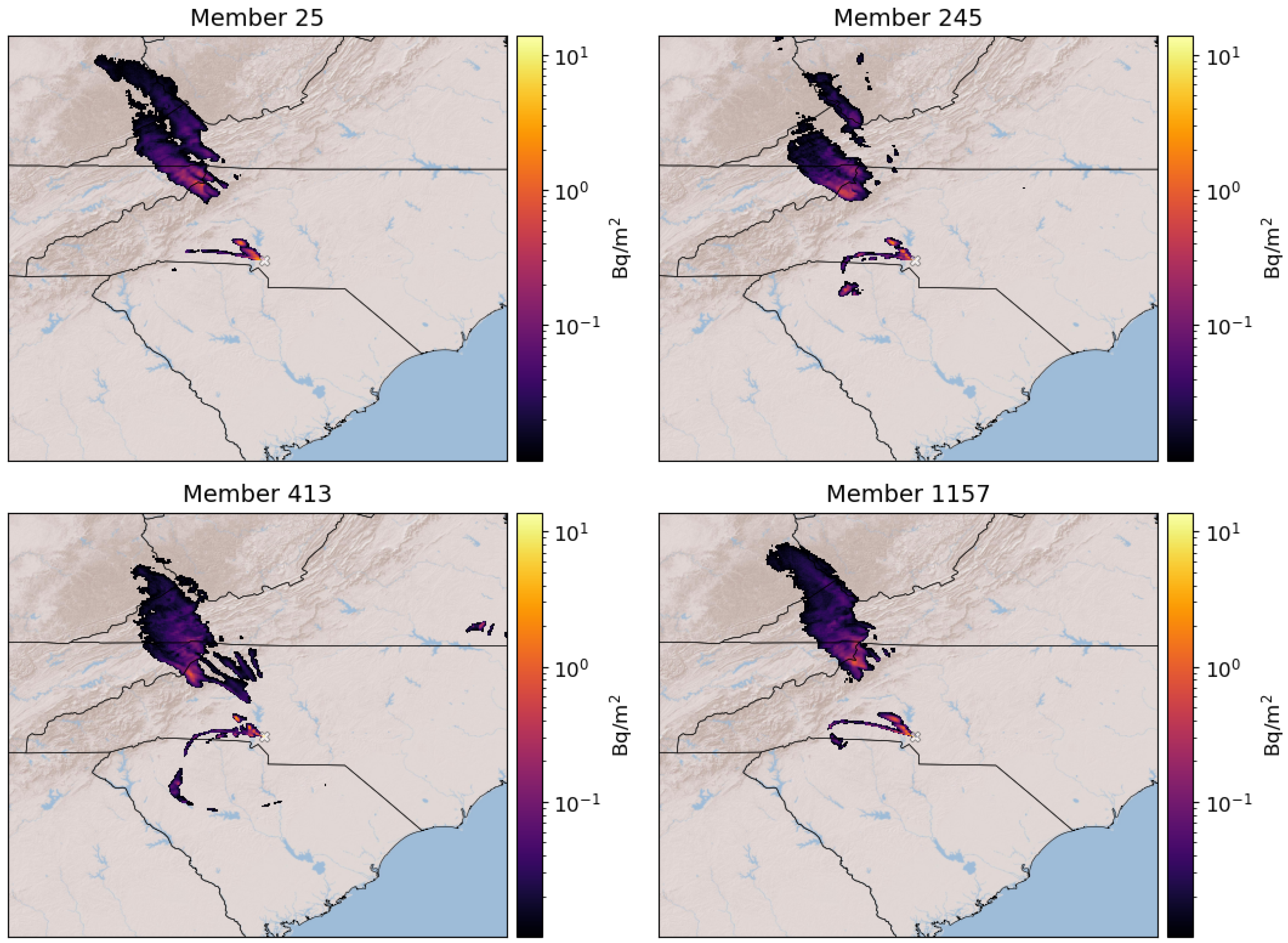
Figure 2 and
Figure 3 show selected examples of ensemble members from the surface case and elevated case, respectively. The members were chosen to highlight the diversity of the ensemble. The examples in the figures used PBL, LSM, CU, MP, and RA parameterization combinations (1, 1, 2, 3, 4) for member 25, (2, 1, 1, 3, 4) for member 245, (2, 3, 5, 3, 4) for member 413, and (7, 7, 10, 3, 4) for member 1157.
Table 2.
WRF parameterizations used to create dataset, referred to here by their standard option number (between parentheses), name, and corresponding citation.
Table 2.
WRF parameterizations used to create dataset, referred to here by their standard option number (between parentheses), name, and corresponding citation.
| PBL | LSM | CU | MP | RA |
|---|
| (1) YSU [34] | (1) Thermal Diffusion [35] | (1) Kain-Fritsch [36] | (2) Lin (Purdue) [37] | (1) RRTM [38] |
| (2) MYJ [39] | (2) Noah [40] | (2) Betts-Miller-Janjic [39] | (3) WSM3 [41] | (3) CAM [42] |
| (4) QNSE [43] | (3) RUC [44] | (3) Grell-Devenyi [45] | (4) WSM5 [41] | (4) RRTMG [46] |
| (5) MYNN2 [47] | (7) Pleim-Xu [48] | (5) Grell-3 [49] | (5) Eta (Ferrier) [50] | |
| (7) ACM2 [51] | | (10) CuP [52] | | |
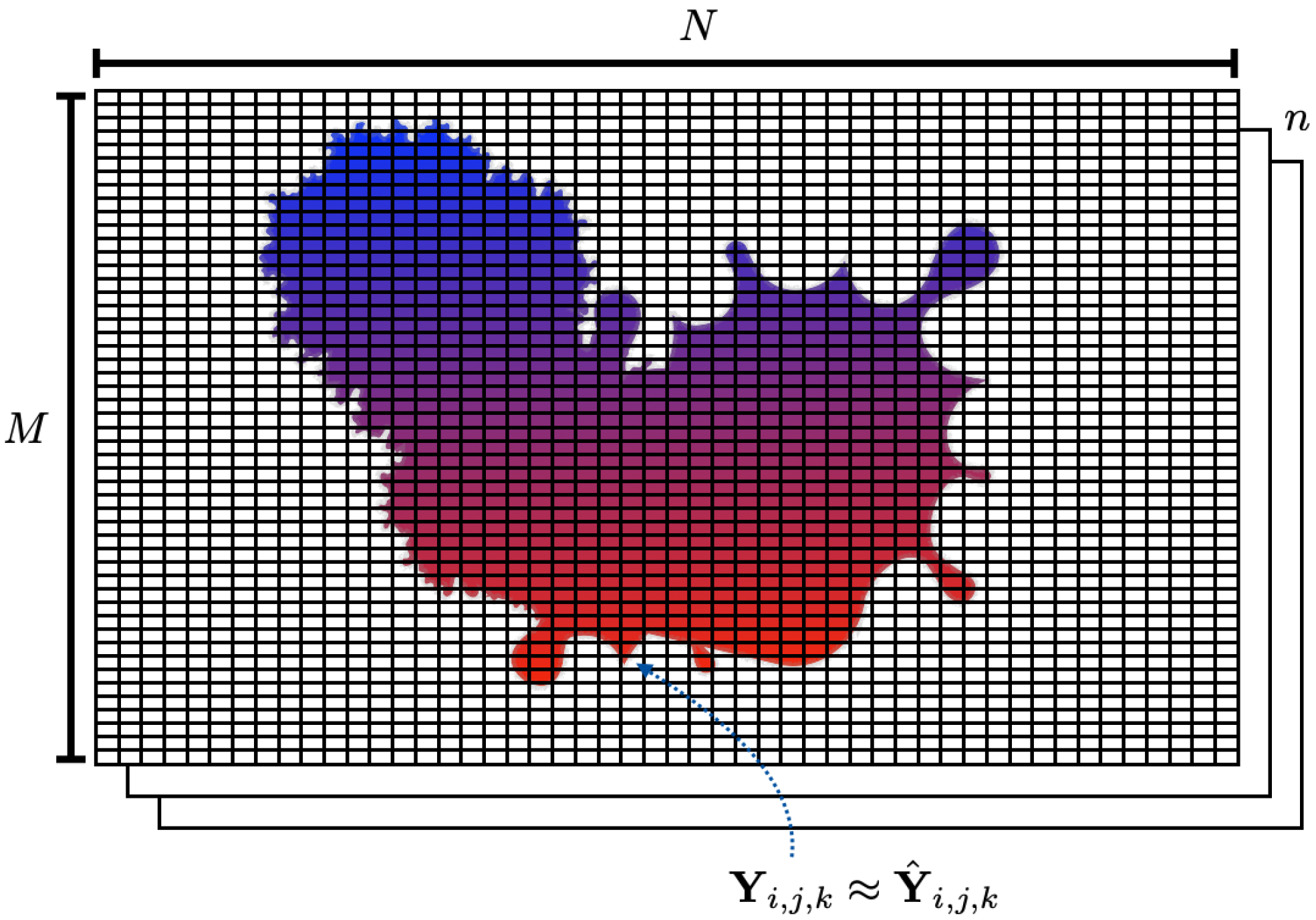
4. Spatial Prediction Algorithm
The algorithm we use to emulate physics package changes in WRF is straightforward. A conceptual schematic can be seen in
Figure 4. We start by creating an
grid
to represent the prediction of a given FLEXPART-WRF map
. Each grid cell
is the combined output of an independent linear regression and logistic regression model. The inputs to every linear and logistic regression model in the grid are the same: a
vector
of one-hot-encoded WRF physics categorical variables, as described in
Section 3. For each grid cell, the associated logistic regression model determines the probability that the location will experience surface contamination from the hypothetical release event. If the probability at that location is greater than a pre-determined threshold value, the corresponding linear regression model determines the magnitude of the deposition. Mathematically, the value of a given grid cell
is given by Equations (
1) and (
2). The
and
terms represent the vector of regression coefficients for the logistic and linear regression models, respectively. The coefficients in Equation (
2) are exponentiated because the linear regression is trained on the logarithm of the deposition. This linearizes the deposition values which allows the regression model to be fit; however, the logarithm is also useful for analyzing the data in general since the deposition values span many orders of magnitude.
The full dataset can be split into an training set and an testing set . The linear regression models are trained on the logarithm of the deposition values, while the logistic regression models are trained on a binary indicator determining whether a grid cell has deposition or not.
We implemented our model in Python 3 using Numpy [
53]. We used the linear regression and the logistic regression implementations from Scikit-Learn [
54]. The logistic regression implementation in Scikit-Learn was run with the “liblinear“ solver and L2 regularization with
. L2 regularization is necessary to obtain accurate results and ensure convergence. With 50 training examples, training regression models for every grid cell in the domain took approximately 1–1.5 min on a modern desktop computer. Making predictions for 1146 full maps took 5–6 min on the same computer, but that was achieved by re-implementing the Scikit-Learn “predict” functions using the Python just-in-time compiler Numba [
55]. At approximately 315 ms per prediction on one core, the machine learning model offers an approximately two million times speedup for a single run. Some researchers have found similar speedups using ML on scientific codes [
56]. Large scale experiments where the training and testing cycles had to occur thousands of times (e.g., determining training size convergence curves) were completed on Lawrence Livermore National Laboratory’s Quartz Supercomputer and could take up to a few hours.
5. Results and Analysis
To test the effectiveness of our statistical model, we ran a suite of tests and derived performance statistics from the results. For these tests, we trained and evaluated our statistical model for eight different training sizes, with 100 runs with varying random seeds for each training size. The eight different training sizes we used were , , , , , , , and ensemble members. This corresponds to 2.09%, 4.18%, 6.27%, 8.36%, 20.90%, 41.81%, 62.71%, and 83.61% of our 1196-member ensemble dataset, respectively. Varying the random seed allowed each of the 100 runs for a given training size to have different members in the training set, which allowed us to see how much performance varied by training set member selection. The members of the test set for a given training size and random seed can be used in the training set for a different random seed. In other words, for a given training size and random seed, we had a training set and a testing set, but looking at all the random seeds for a given training size together was similar to k-fold cross validation. Since we used all 1196 members for this process, we did not have any truly held out test set that was not part of the 1196-member ensemble.
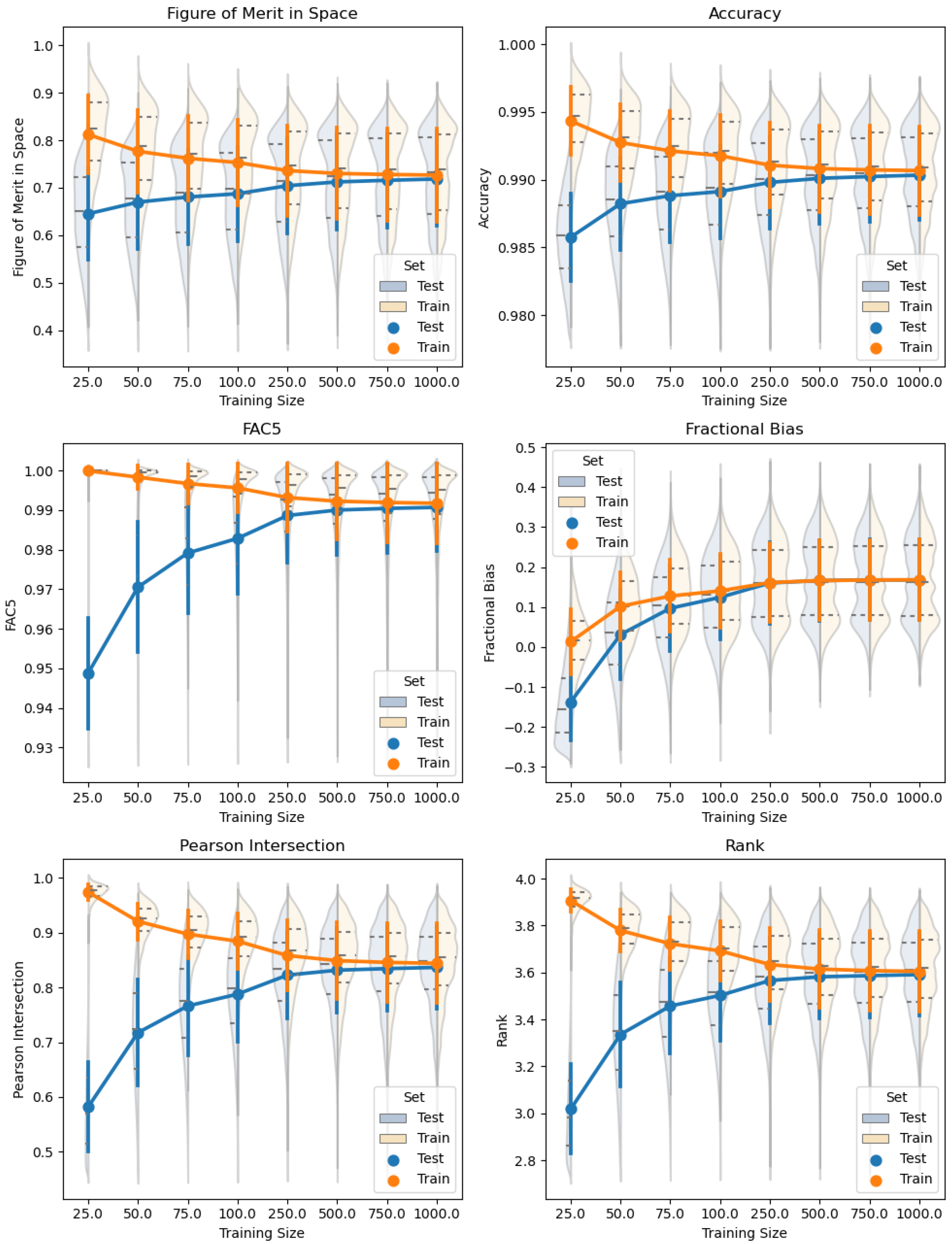
Figures that do not show training size variability (
Figure 5,
Figure 6 and
Figure 7) show the results from a 50-member training set with the same fixed random seed. The number 50 is somewhat arbitrary but shows the minimum amount of training examples that produces accurate predictions. At 50 training examples, the predictions are qualitatively good, and one starts to see significant overlap between the training and testing performance metric distributions.
Figure 8,
Figure 9 and
Figure 10 all show results from the cross-validation tests.
The following subsections summarize the statistical and numerical performance of the algorithm. Some subsections present summary statistics, while some subsections present individual member predictions. In subsections where individual predictions are present, the training size is also presented.
5.1. Decision Threshold
Before showing summary statistics, it is important to understand how the output of our model is a probabilistic prediction.
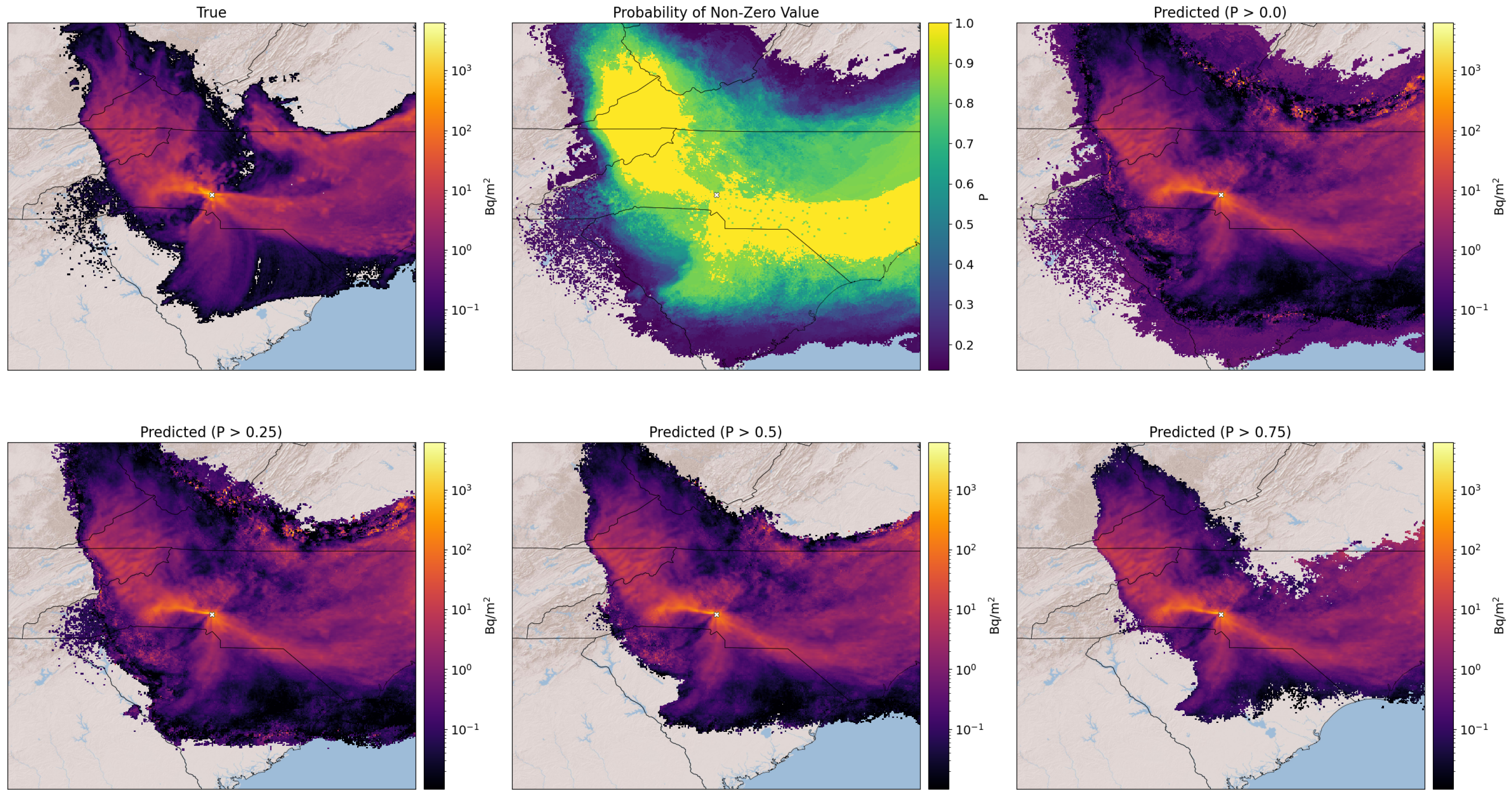
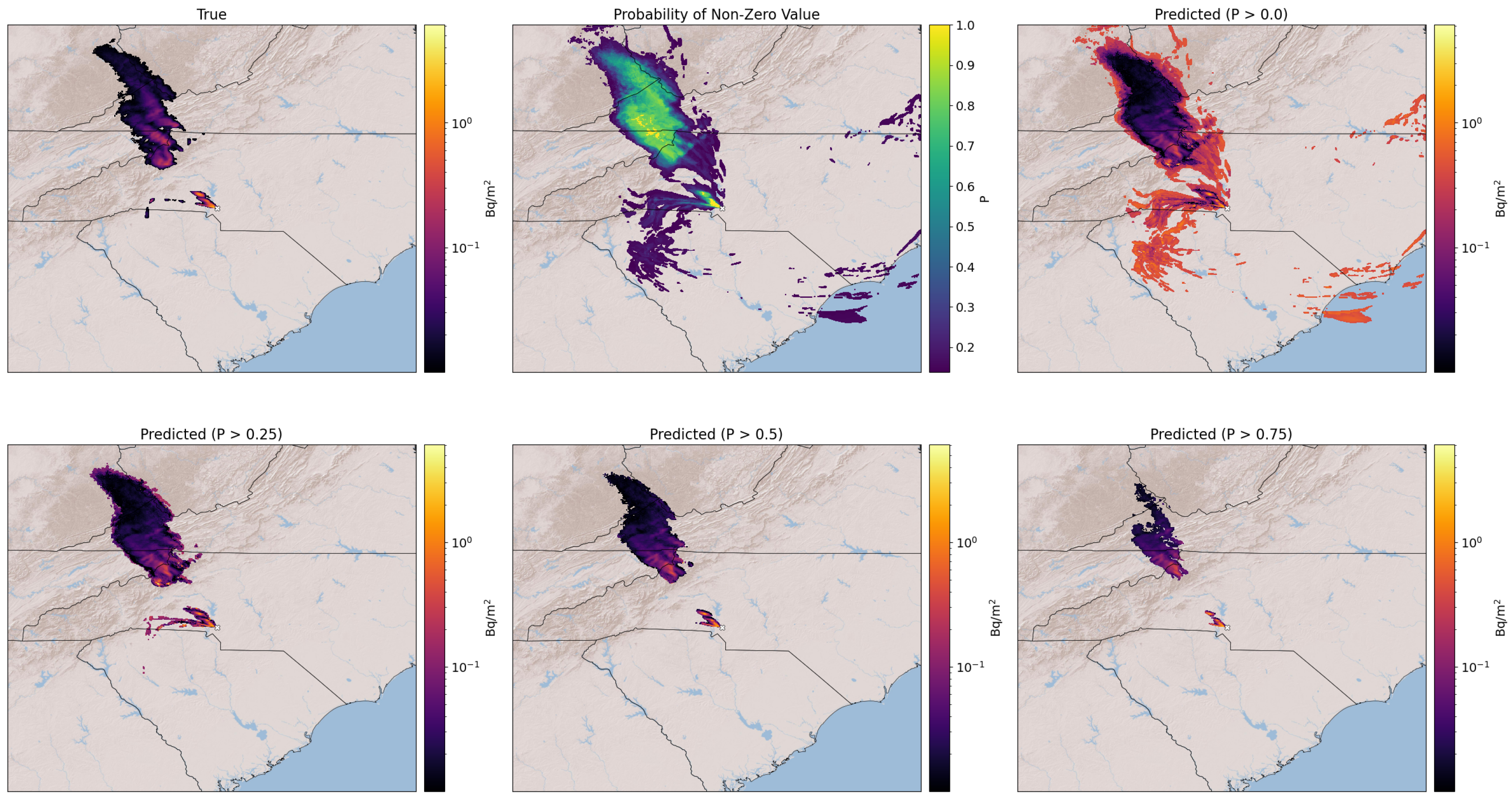
Figure 5 and
Figure 6 both have six subplots. The top left plot shows the true output by FLEXPART-WRF for a selected ensemble member. The top middle plot shows the probability map produced by the grid of logistic regression models. The color at each pixel represents the probability that the pixel has a non-zero deposition value. The areas of this subplot that are not colored are excluded from prediction because the corresponding grid cells in the training data contain no deposition. The remaining areas use the combination of logistic and linear regressions for making predictions.
The output of the logistic regression models is used in conjunction with a user-defined decision threshold value to produce deposition predictions. As determined from the training data, grid cells with probabilities greater than the threshold are predicted to have deposition, while those less than it are not. If conservative estimates are desired, a low threshold value can be used to include low probability, but still likely, areas of contamination in the prediction. The top-right and entire bottom row of
Figure 5 and
Figure 6 show the predictions at different decision thresholds. The decision threshold can also be thought of as a probability cutoff value. The term “decision threshold” is synonymous with “decision boundary”, which is referred to in the literature when classifying positive and negative outcomes [
28].
Through a qualitative assessment, we determined that a decision threshold of 0.5 appears to be optimal. With values larger than 0.5, the plume shape starts becoming distorted and leaves important sections out. With values less than 0.5, noisy values at the edges of the plume are included, which are typically not accurate. These noisy values occur in grid cells where there are not many examples of deposition in the training data, and they are eliminated as more examples are included when the training size increases (see
Section 5.2). These values can be seen in the bottom left subplot of
Figure 5 on the northern edge of the plume. Anomalously large prediction values skew the performance statistics and are removed from the metrics if they exceed the maximum deposition value present in the training examples.
5.2. Training Size Variability
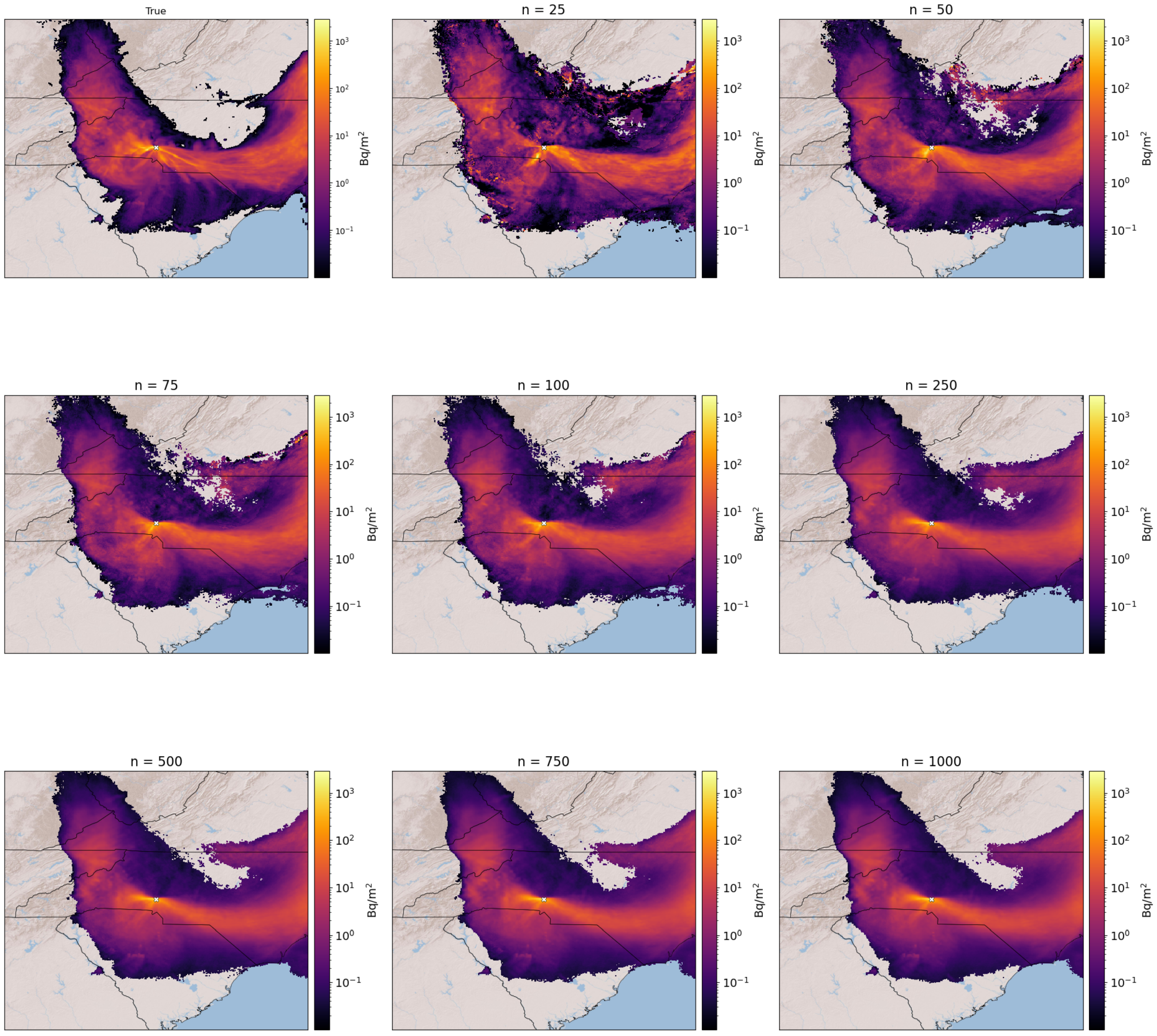
As with all statistical methods, the size of the training set affects the model performance.
Figure 7 shows the plume prediction for ensemble member 296 as the training size increases. The members of the training set at a given size are also all included in the training set at the next largest size (i.e., the
training set is a proper subset of the
training set). The decision threshold is set to 0.5 for each training size. It is evident from the figure that as the training size increases, the deposition values and the plume boundary become less noisy. A quantitative assessment of how the predictions change with increasing training size is shown in
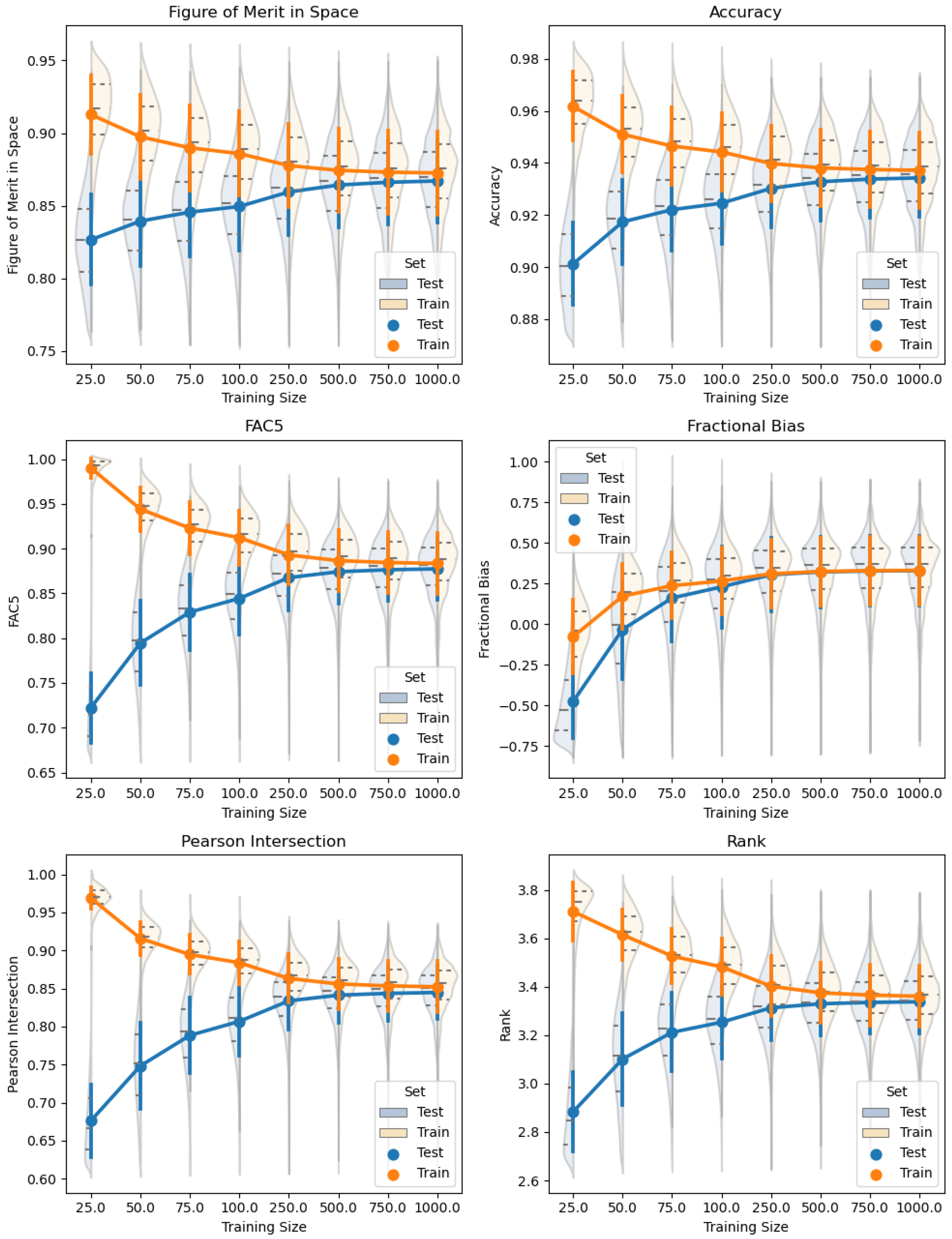
Figure 8 and
Figure 9 for the surface case and elevated case, respectively.
These two figures show different statistical measures for predicting the members of training and testing sets as a function of training size. Because the selection of members is random and can affect the prediction performance, the experiment is repeated 100 times using different random seeds. Therefore, each “violin” in the plots displays the statistical variation stemming from member selection differences. For a given training size n, the orange training distributions are estimated from predictions, while the blue test distributions are derived from predictions.
The following error metrics are used to assess the predictive performance of the regression system. Two of the metrics target the logistic regressions (figure of merit in space and accuracy), three are for the linear regressions (fraction within a factor of 5, R, and fractional bias), and an aggregated metric (rank) is used to gauge the overall performance. Many other metrics are available to judge regression and classification performance (e.g., mean squared error, F1), but we wanted to use metrics that were commonly used in the atmospheric science community [
57,
58].
Figure of Merit in Space (FMS): A spatial error metric which is defined as the intersection of the area of the predicted and actual plumes divided by the union of area of the predicted and actual plumes [
57]. Outside of atmospheric science this is also known as the Jaccard index. This metric depends only on the absence or presence of deposition, not the magnitude, and so directly assesses the logistic regressions. This metric varies between 0 and 1, and values of 0.8 and above are generally considered good for atmospheric models.
Fraction within a Factor 5 (FAC5): The fraction of the predicted values within a factor of 5 of the actual values is an effective metric for assessing the linear regressions. Generalized, this is defined as
[
57]. We present the FAC5 value for the intersection of the predicted and actual plume locations. This metric can range from 0 to 1, with values above 0.85 generally being considered good values for atmospheric models.
Pearson’s R: Pearson’s correlation coefficient R measures the linear relationship between the predicted and actual magnitudes of deposition in a log space. We present R calculated for the natural log of the intersection of the predicted and actual plume locations. This metric can range from −1 to 1, with values further away from 0 being good. (A Pearson’s R value of −1 implies perfect anticorrelation, which is still useful).
Accuracy: This is the standard classification accuracy as explained in Swets [
59]. It is defined as the ratio of the sum of true positives and true negatives to all classifications considered (i.e.,
). In a logistic regression case such as ours, a grid cell is classified as positive or negative by whether it has deposition above or below a certain threshold value. As described in
Section 3, a deposition threshold of 0.01 Bq/m
was used. This metric can range from 0 to 1, with values closer to 1 being considered good.
Fractional Bias (FB): Fractional bias is defined as
, where
and
are the mean observed values and mean predicted values, respectively. It is a normalized indicator of model bias and essentially describes the difference in means in terms of the average mean. This metric ranges from −2 to +2 and has an ideal value of 0. In
Figure 8 and
Figure 9, the fractional bias plot has a different shape from all the others. One reason for this is the fractional bias range is different, and the ideal value is in the center of the range. However, even if the absolute value of the fractional bias was taken, the shape would still be different. In this case, as the training set size increases, the fractional bias statistic converges to the inherent bias that exists between our statistical model and FLEXPART-WRF, just as the others do. However, in this case, it is shown that the training size that produces the least fractional bias is
. This does not mean that
is the best sample size overall, as other metrics improve with increasing sample size. Like the other metrics, the fractional bias training and test curves converge with increasing training size, though they seem to converge much faster than the others.
Rank: Described in Maurer et al. [
58], the rank score is a metric that combines several statistics into a single number used to assess the overall performance of an atmospheric model. It is defined as
.
is the coefficient of determination, and FB is the fractional bias. Each term in the equation ranges from 0 to 1, with 1 being best, which means the rank score ranges from 0 to 4, with 4 being best. The models studied in Maurer et al. [
58] had a mean rank score of 2.06, which means our model looks very good in comparison. However, the models studied were time series models applied to individual stations, so they cannot be directly compared to our model.
In both the surface and elevated release cases, increasing the training size leads to, on average, an increase in performance on the test set and a decrease in performance on the training set. Nevertheless, as expected, the training set performance is better than the testing set performance. There is no immediately distinguishable difference in performance between the surface case and the elevated case; on some metrics the surface case performs better and on others the elevated case performs better. However, the distribution of error metrics for the elevated case is often bimodal, whereas the surface case is more unimodal. This makes intuitive sense since the elevated case often has two separate deposition patterns with different shapes, while the surface case typically only has one large pattern.
Figure 7 and
Figure 8 highlight one of the most important conclusions from this work. Very few training samples are needed to make reasonable predictions. Even a prediction using 50 training samples, or
of the total dataset, is capable of accurately predicting deposition values in over 100,000 grid cells. Because there is significant overlap between the training and test distributions in
Figure 8, these predictions are also robust to the 50 training samples selected from the full set.
5.3. Predictability of Individual Ensemble Members
The previous subsection described how training size affected the statistical model performance for the entire ensemble. In this section, we show how the predictions vary with training size for selected individual ensemble members. The purpose of this test is to show that some FLEXPART-WRF members are easier to predict than others, regardless of the amount of training members.
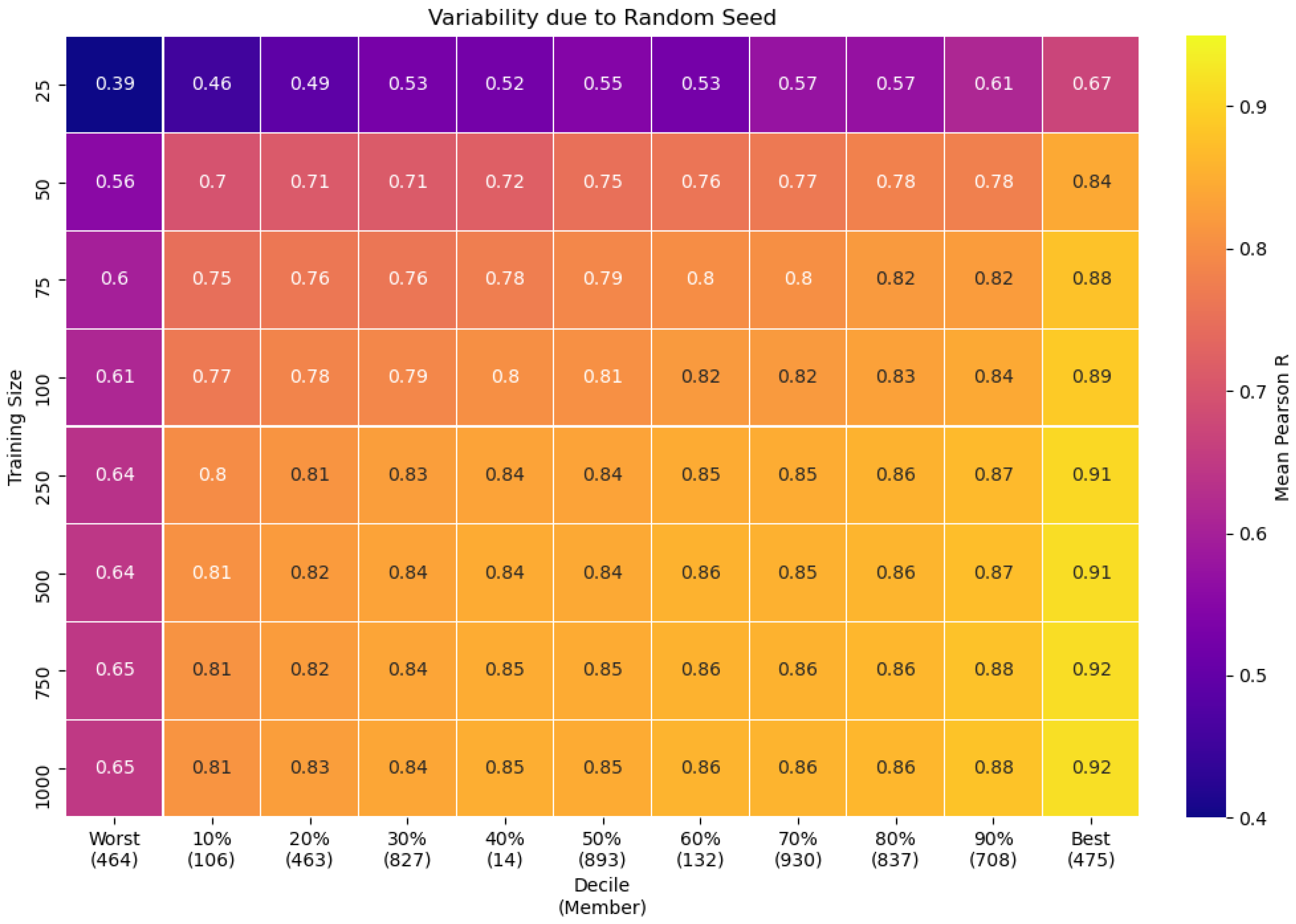
Figure 10 shows the mean Pearson’s R score by training size and member number for the surface release case for selected members of the test set. The members are selected by their decile average performance. We only show the members that are closest to the decile average performance because showing all 1196 members results in a visualization that is difficult to read.
For example, take the square marked by “60% (132)” on the x-axis and “250” on the y-axis. This square represents the mean Pearson’s R score for member 132 calculated from every statistical model (out of 100) where member 132 was contained in the test set. Member 132 is the member that is closest to the 60th percentile mean Pearson’s R score averaged over all training sizes.
As already demonstrated, the general performance of the model increases as the training set size increases; however, the relative individual performance does not generally change. Part of this can be explained statistically. Our statistical model essentially fits a hyperplane in the WRF-parameter/deposition space. A hyperplane is one of the simplest possible models, and there is noise in the dataset. Some data points will be far away from the hyperplane, and increasing the training size does not move the hyperplane enough to successfully fit those points. This highlights the importance of the fact that physics-based modeling-machine learning is not able to capture all of the variation present in the dataset, even with very large training sizes. While we analyzed the WRF inputs associated with well and poorly performing members, we found no consistent pattern associated with poor predictions and WRF parameterizations. Hypothetically, if there was a relationship between WRF inputs and poorly performing members, the information could be used by WRF developers to improve accuracy for certain parameterizations. This figure also shows that low amounts of training data start producing accurate predictions. A similar analysis can be done for the elevated case but is not included here.
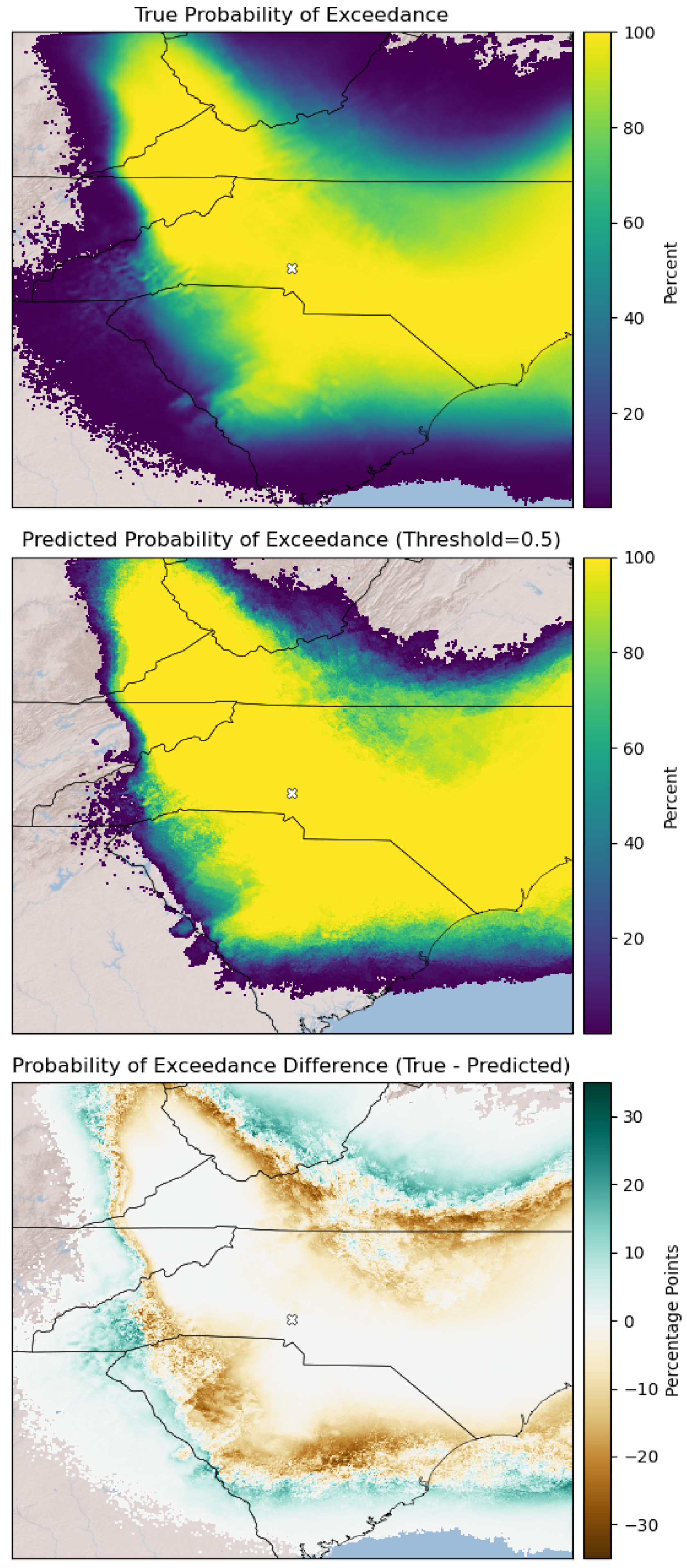
5.4. Ensemble Probability of Exceedance
One of the main goals of emulating Cs-137 spatial deposition is to account for the variability in the ensemble from weather uncertainty, so we use probability of exceedance plots to compare the variability of the predicted and true ensemble in
Figure 11. The topmost and center subplots of
Figure 11 show the percentage of members in the ensemble that have deposition values that exceed a threshold of 0.01 Bq/m
at every location. For example, if 598 ensemble members have deposition above 0.01 Bq/m
at grid cell (200, 200), the percentage for that cell is
. Yellow colors indicate areas where many, if not all ensemble members report above-threshold deposition values. Dark purple colors indicate areas where very few ensemble members report above-threshold deposition values. Generally, the probability of exceedance drops as one moves further away from the release location. The predictions are based on 50 training samples, and both ensembles used for this plot contain all 1196 members, meaning the training and testing predictions are included for the predicted percentages.
The topmost subplot shows the probability of exceedance of the true ensemble. As expected, the outside of the shape is made up of low percentage grid cells, as only outlier plumes make up those locations. The center subplot shows the probability of exceedance of the predicted ensemble. The predicted probability of exceedance takes up less area than the true ensemble because the outliers around the edge are challenging for the regressions to predict.
Despite the vast differences in computational resources needed to produce them, the probability of exceedance in the true and predicted ensembles appears similar. To highlight the differences, we created the bottom-most subplot of
Figure 11, which shows the difference between the true ensemble percentages and the predicted ensemble percentages. Positive values, in teal, show areas where the population of members in the true ensemble is higher than the predicted ensemble. Negative values, in brown, show areas with higher predicted population than true population. Comparing the plot to
Figure 12, one notices that the boundary between brown and teal happens approximately where the number of samples per pixel drops below 17, which is where the linear regression becomes underdefined. The conclusion we have drawn is that the regressions tend to overpredict values where there are sufficient samples (with some exceptions, such as in the center right of the plot) and underpredict where there are not sufficient samples.
5.5. Spatial Coefficient Analysis
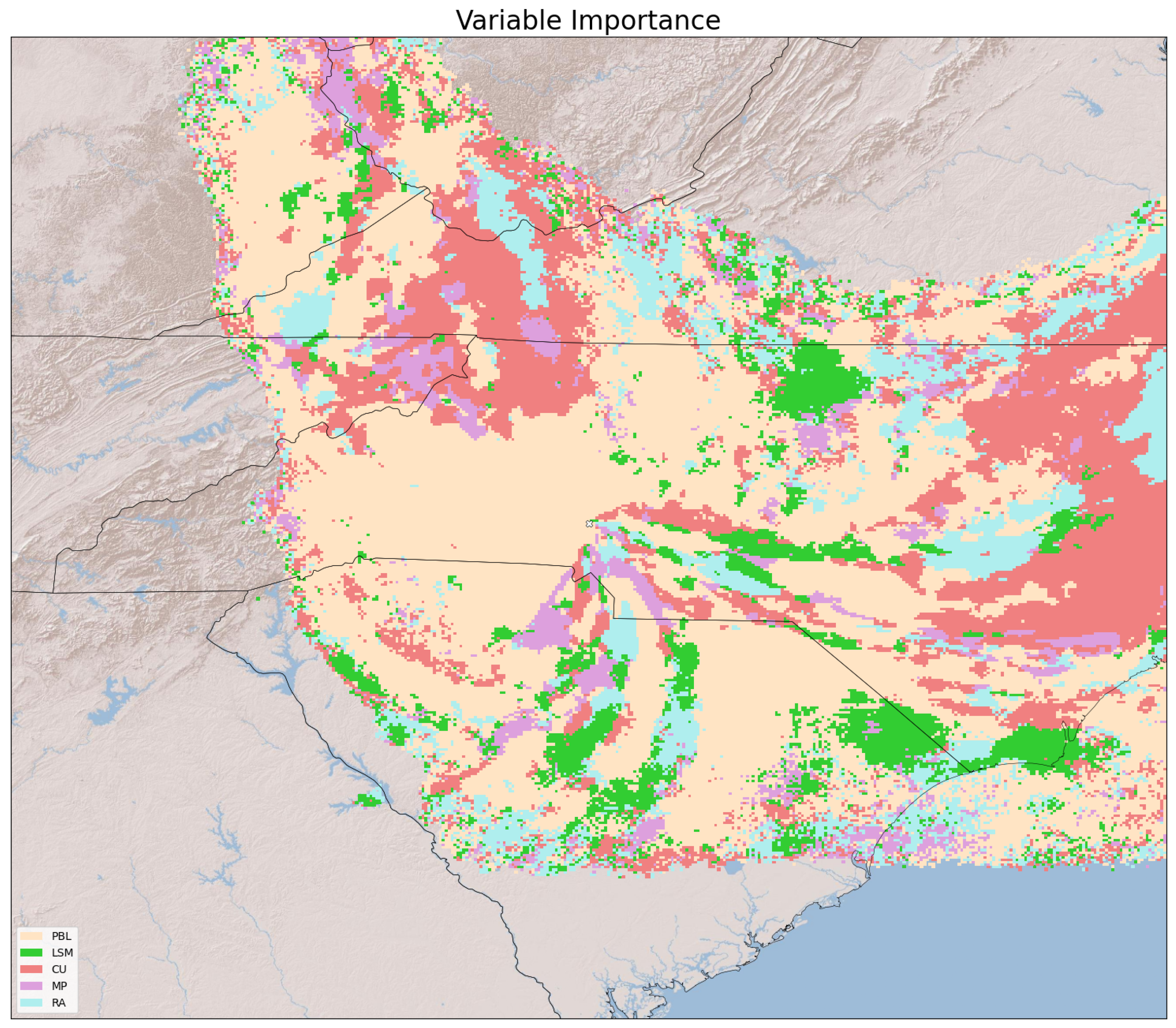
One advantage our regression method holds over other machine learning models is the potential for interpretability. In this subsection we highlight one aspect of this interpretability. Our predictions are made using thousands of individual regression models, each of which has coefficients that transform the WRF parameterization input variables into a deposition value. In traditional regression approaches with non-categorical inputs, the units of all the input variables can be standardized so that the magnitude of a coefficient is related to the effect of its corresponding variable. That is, the larger the value of a coefficient, the more important the corresponding predictor is to the output. However, our WRF variables are one-hot-encoded as binary inputs, so determining their importance is not as straightforward as standard regression. Each of the regression models in our method has seventeen input terms—one for the intercept and sixteen binary encoded variables that represent five different WRF physics parameterizations. Out of these sixteen non-intercept coefficients, the first four represent the five PBL schemes, the next three represent the four LSM schemes, the next four represent the five CU schemes, the next three represent the four MP schemes, and the final two coefficients represent the three RA schemes. Taking the mean of the absolute value of a WRF physics package’s coefficients gives an estimate of the importance of that variable. In other words, represents the importance of PBL, represents the importance of LSM, and so on.
Once the mean coefficient magnitudes are calculated, the argmax is used to find the WRF parameterization which is most important at a given grid cell. These results can be plotted to see which parameterizations are most important for a given area, as seen in
Figure 12 for the surface release case.
Figure 12 was created using models trained on 50 ensemble members and only includes grid cells that have greater than 17 samples. The intercept is not considered when determining importance. It is important to remember that with our process, the “most important variable” is not the same as “only important variable.” Combinations of WRF parameterization changes can be important, resulting in the many coefficients that have a similar mean magnitude. In other words, the second most important WRF parameterization can still be very important because it has a mean coefficient magnitude slightly smaller than the most important WRF parameterization. Regardless, this analysis provides an interesting consequence of using regression models to interpret WRF physics.
Figure 12 shows that PBL variations tend to dominate other WRF parameterizations, as captured by the large areas in beige. This result is not surprising, as changing the PBL scheme in WRF is known to greatly influence atmospheric turbulence and mixing near the surface. The variable importance map also shows other interesting features, including the red areas highlighting the relatively elevated importance of cumulus convection variations over coastal and mountainous areas where precipitation occurs during the release events. Similarly, magenta areas where microphysics is important occur near areas where cumulus convection is also important, which is consistent with the correlation of these physical processes in the model. The overall spatial complexity in
Figure 12 illustrates one final critical point. No single WRF parameterization is most important everywhere, so multi-physics WRF ensembles that vary a range of physical parameterizations are needed to capture weather model uncertainty.
6. Future Work
The regression prediction method we have described has some drawbacks and unknowns, which means there are several avenues for further exploration. The most significant drawback is that it does not exploit spatial correlations of nearby locations in the domain. Since each grid cell is treated as completely independent from the other grid cells, spatial correlations are not used to improve the overall prediction. This means that any predicted plume is limited to the envelope of the union of all of the training plumes, as our model cannot predict in areas that do not have any training data. However, this trait can be viewed as a positive feature of our algorithm; it will not poorly extrapolate in areas where there are no training data. To overcome this problem, spatial data can be incorporated into the overall model. Including spatial correlation information in our model may lead to a more parsimonious model or one that produces improved predictions. Including spatial correlations can also potentially be done using dimensional reduction techniques such as PCA or autoencoders. For example, the model we describe could be used to produce an initial map, and then an alternate model based off radial basis functions, multitask learning, or even linear regression can be used to refine it.
Another drawback is the subjective nature of picking a decision threshold in the logistic regression component. We used a value of 0.5 for all the calculations presented here, which is a reasonable value to use, but that is the result of qualitative analysis. Implementing an optimization routine to determine the best to use would increase the objectivity and may improve the performance of our model. The tuned threshold could also be applied at a grid-cell level, which may increase performance in the boundary regions.
As mentioned in
Section 5.1, we remove outlier deposition values which are predicted to be larger than any deposition value present in the training set. This is a simple way to remove outliers and is easily implemented operationally. However, it is a naive outlier removal method. A more complex outlier removal method may be beneficial to help differentiate false extreme values from true extreme values, the latter of which can pose a large risk to public health.
When we create training sets for our method we sample randomly from the entire population of predictions. By using methods from adaptive sampling, it may be possible to dynamically produce a training set that is more representative of the population than a random sample, leading to higher performance for the trained model with fewer expensive computer simulations. In an emergency situation, this would be very useful.
The individual models that predict hazardous deposition in each grid cell do not necessarily have to be linear or logistic regression models. They can be produced by other regression and classification models such as random forests or artificial neural networks. The biggest hurdle in implementing more complex grid cell-level models is the training time. During our testing on a desktop computer, the training time for a single grid cell took between 1 and 10 ms, and training a full spatial map was on the order of minutes. Changing to a more complicated model could potentially increase training time by an order of magnitude.
Finally, this regression method should be tested with more FLEXPART-WRF simulations. It should be tested with different hazardous releases in different locations from FLEXPART-WRF, but it could also be tested on completely different physical models. More terms could also be added to the regression model to account for larger initial condition errors present in longer forecast simulations. There is nothing about our method that is inherently specific to FLEXPART-WRF, and we think this method could work for simulations that are unrelated to deposition.
7. Conclusions
In this paper, we presented a statistical method that can be used to quickly emulate complex, spatially varying radiological deposition patterns produced by the meteorological and dispersion tools WRF and FLEXPART. FLEXPART-WRF is slow to run, and a single simulation from it may have significant uncertainty due to model imperfections. To estimate uncertainty, researchers can run FLEXPART-WRF hundreds of times by varying representations of physical processes in the models, but that can take crucial hours. Instead of running FLEXPART-WRF hundreds of times, researchers can run it dozens of times, use the results to train our emulator, and then use the emulator to produce the remaining results.
Our emulator is represented by an grid where the value at each grid cell is determined by the output of independent linear regression and logistic regression models. The logistic regression determines whether hazardous deposition is present at that location, and the linear regression determines the magnitude of the deposition. Since all the grid cells are independent from one another, our model can accurately predict subsets of locations.
We used two datasets for training, testing, and predicting. One was a simulated continuous surface contaminant release representing a large-scale industrial accident, and the other was a simulated instantaneous elevated contaminant release from a hypothetical nuclear explosion. For each of the two cases, there were 1196 different simulations, all representing variations in the WRF parameterizations. The WRF parameterizations were treated as categorical variables that were binary encoded and used as the inputs to the linear and logistic regression models used in our emulator.
We conducted several tests to evaluate the performance of our emulator. We found that the emulator performs well, even with only 50 samples out of the 1196-member population. While the deposition patterns have variance, they are not drastically different shapes, which is why 50 samples is sufficient to make reasonable predictions. This is promising since in an emergency situation, the amount of computationally expensive runs should be minimized. As with many machine learning models, the prediction performance on the test set increases with increasing training size. We also found that for each case there are some members that perform better than others, regardless of the training size.
In general, we think that the emulator that we have presented here is successful in predicting complex spatial patterns produced by FLEXPART-WRF with relatively few training samples. We think there are several areas that can be explored to improve our emulator, and we hope to complete some of them in the future.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











