1. Introduction
In recent years, the process of industrialization and urbanization has accelerated, injecting vitality into the global economy, bringing people a better life but causing serious damage to the ecological environment. Air quality issues have become a major concern for countries and individuals. Among them, atmospheric particulate matter (PM) is one of the main pollutants that causes air pollution, and fine particulate matter represented by PM2.5 has enveloped a layer of haze over most cities in the world. PM2.5 refers to the particulate matter with an aerodynamic equivalent diameter of 2.5 microns or less in the ambient air. The intuitive expression is that the atmosphere is in a turbid state. Although it has a small particle size, it has a large contact area with the air, is highly mobile, and can readily carry a large amount of toxic and harmful substances. If a large amount of PM2.5 is inhaled in the body, it will directly stimulate the bronchi, respiratory tract, cardiovascular system, and other parts of the body, and can easily cause various respiratory diseases such as cough, bronchitis, and asthma together with more severe maladies such as arrhythmia, nonfatal heart disease, and other cardiovascular diseases. It can even lead to embryonic deformities, directly endangering our next generation. Therefore, accurate PM2.5 concentration prediction has positive practical significance and far-reaching impacts on air quality detection, air pollution restoration, and human health.
At present, predicting PM2.5 mainly include numerical models, statistical modeling prediction, and machine learning methods. The numerical model prediction method mainly uses mathematical methods to establish the dilution and diffusion model of air pollution concentration, and dynamically predicts the changes of air quality and the concentration of main pollutants. Because the atmospheric process is too complex, the forecast cannot be accurate. Another shortcoming of this method is that the calculation is extensive and time-consuming. Most experts and scholars are conducting research on the latter two methods, taking into account factors that may affect PM2.5 concentration and establishing a combined model based on historical PM2.5 concentration data to predict the concentration of PM2.5 or other pollutants, which makes up for the uncertainty of the single numerical model prediction. The prediction of PM2.5 based on machine learning and deep learning forecasting methods has recently attracted relatively broad research attention. Among them, statistical modeling and forecasting mainly refer to traditional time series models such as the autoregressive integrated moving average model (ARIMA) and multiple linear regression (MLR). Machine learning techniques are divided into traditional machine learning models, such as the support vector machine (SVM) and the back propagation neural network (BPNN), and deep learning models that have emerged in recent years.
In terms of a single model, Wang et al. [
1] used the ARIMA model to predict PM
2.5 concentration, but ARIMA prediction usually only considers the PM
2.5 concentration sequence, without considering the variable factors that affect it, and the prediction accuracy is not ideal. Furthermore, Hui et al. [
2] used the autoregressive moving average with exogenous inputs (ARMAX) to predict the PM
2.5 concentration hourly by considering the impact of weather and other pollutants. The three evaluation indicators of R
2, MAE, and RMSE showed that ARMAX has a better fitting effect than the ARIMA model. Kanirajan et al. [
3] constructed a RBFNN model based on a radial basis function (RBF) neural network, which has a better prediction performance than the classic BPNN. Chen et al. [
4] first used a fuzzy granular time series and then used a SVM to predict PM
2.5 concentration that overcomes, to a certain extent, the instability of forecasts caused by the incomplete consideration of influencing factors. Among deep learning models, the most commonly used are the RNN and LSTM models. Biancofiore et al. [
5] established RNN models to predict PM
2.5 and PM
10. Evaluation indicators, including the correlation coefficient (R), fractional bias (FB), the normalized mean square error (NMSE), and factor of two (FA2), proved that its prediction performance is better than multiple linear regression models and the NN model without recursive structure. Considering that RNN has a short memory and gradient explosion problems, Tsai et al. [
6] established an improved LSTM model based on TensorFlow to predict air quality. The correlation coefficient, Spearman level, and mean square error of the LSTM model are better than those of the RNN. This proves that it is an air quality prediction model with higher accuracy and stronger generalization effect.
Due to the high complexity and randomness of the time series, and the PM
2.5 concentration is affected by multiple factors, a single model as described above does not fully explore the interaction between the multiple factors and the PM
2.5 concentration, and cannot make full use of the PM
2.5 forecast’s favorable factors, so most scholars study combined models to predict PM
2.5 concentration. Liu et al. [
7] jointly applied the SVM and particle swarm optimization (PSO) to establish a rolling forecast model, and the effect is better than a single radial basis neural network and multiple linear regression. Sun et al. [
8] combined principal component analysis (PCA) and least squares support vector regression (LSSVR) optimized by a cuckoo search algorithm to predict PM
2.5 daily. Because the traditional BPNN method cannot reflect the impact of data in the historical time window on the current prediction, Wenyi Zhao et al. [
9] established a weighted KNN-BP neural network model to predict PM
2.5 concentration. Xulin Liu et al. [
10] established CNN-Seq2seq to predict PM
2.5 concentration within an hour, and the effect was better than the combined Seq2seq model of a machine learning model and non-CNN extracting variable features. Kow et al. [
11] proposed that CNN-BP can adequately handle heterogeneous inputs with large time lags, cope with the curse of dimensionality, and achieve multiregion simultaneous multistep prediction of PM
2.5 concentration; the prediction performance is better than the BPNN, random forest, and LSTM models. To achieve a grid format prediction of PM
2.5 concentration, Guo et al. [
12] established a ConvLSTM deep neural network model using a convolution module to extract spatial features along with LSTM extracting time features. Yiwen et al. [
13] considered that the traditional RNN and LSTM using the same weight calculation for data at different moments did not conform to the brainlike design and proposed a PM
2.5 prediction method based on Adam’s attention mechanism. Through an experimental comparison, it was found that attention was added. The RNN and LSTM of the force mechanism are more accurate in predicting the concentration of PM
2.5 than those without this addition.
Most of these NN models give more attention to time series features. Common RNN and LSTM time series prediction models are not as sensitive to features as integrated learning models. Taking into account the time series characteristics of the data and the nonlinear characteristics of the data, this article proposes that an integrated learning model be combined with LSTM to establish a short-term prediction model of PM
2.5. In recent years, many scholars have begun to study forecasting models that combine ensemble learning and NNs, and then apply them to forecasts in economics, finance, power load and temperature forecasting, and sales. However, the ensemble model chosen by most scholars is extreme gradient boosting (XGBoost). Considering that LSTM has a better memory function than the RNN, LightGBM is much faster than XGBoost in model training, and the leafwise principle can reduce more errors and obtain better accuracy. A common combination model is to assign the same weight to each model and then add the predicted results. Weng et al. [
14] adopts the optimal weighting method to determine the weight of each model, which can effectively improve the advantages of a single model. This paper establishes a weighted combination model of LSTM and LightGBM through the optimal weighted combination method based on the residual of the verification set.
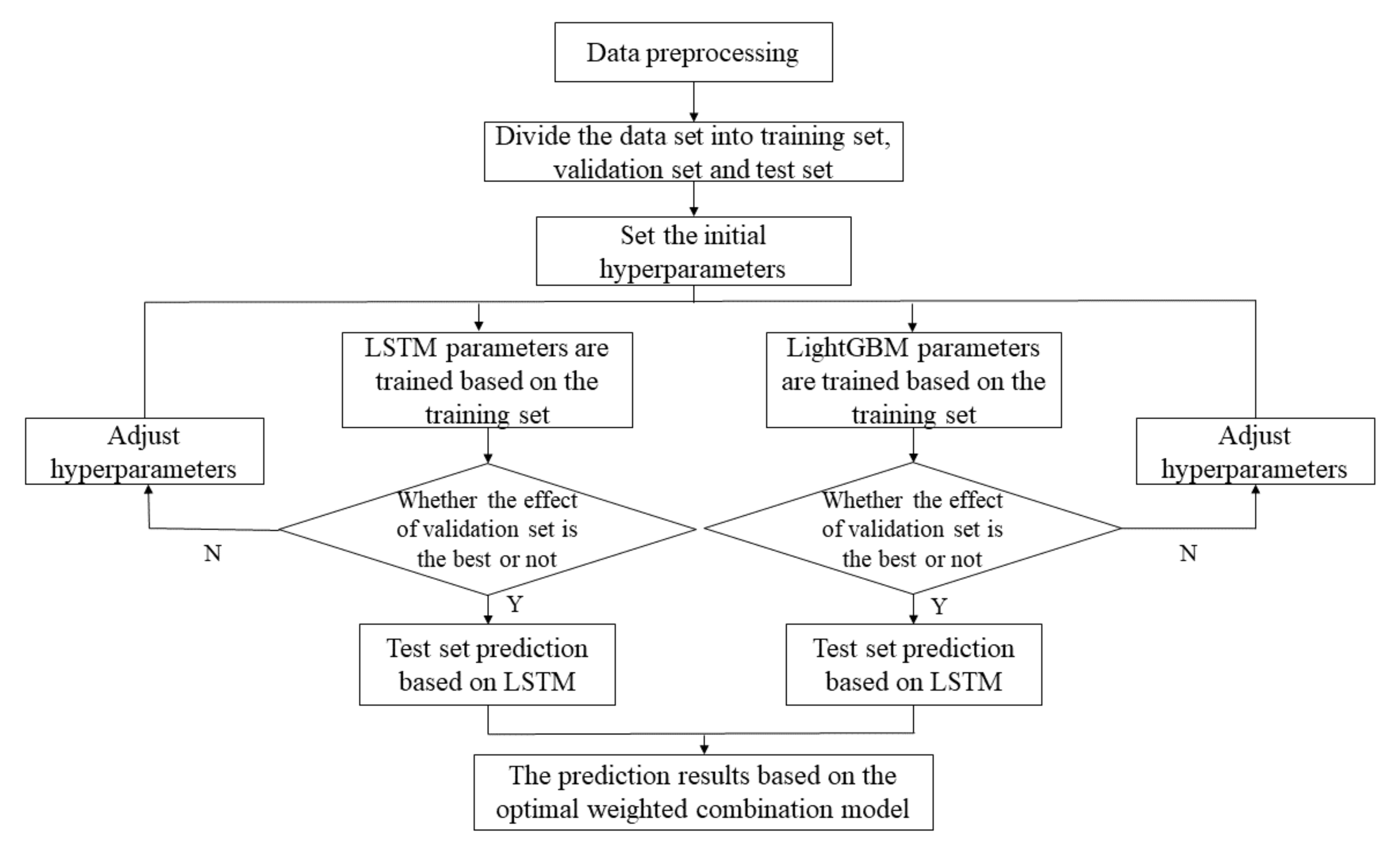
4. Model Construction and Evaluation
First, this section establishes the LSTM model and the TSLightGBM model, respectively. According to the performance on the verification set, the two models are weighted by the optimal weighted combination method, and the test set is then predicted. Finally, it is compared with LSTM, TSLightGBM, MLP, RNN, and RF.
4.1. LSTM Model
With the continuous accumulation or dissipation of air pollutants over a period of time, the PM2.5 in the air is constantly changing; that is, the PM2.5 in the current period is affected by the influencing factors of the previous N periods. This article conducts comparative experiments by setting different time windows T, where the time window refers to how many hours of historical data are used to predict the current PM2.5. In this paper, the size of the time window is set to 1, 3, 6, 9, 12, 15, 18, 21, and 24.
There are too many parameters affecting the performance of NN. Therefore, first, according to the previous experience, the activation function is determined as ReLU, and the optimization algorithm is determined as the Adam algorithm. Two hidden layers are set, the learning rate is set as the default parameter of 0.01, and some neurons are randomly deleted with a probability of 0.2. A pre-experiment is set to roughly adjust the secondary important parameters. In the pre-experiment, the batch size is set as 16, 32, and 64, the number of iterative training epochs is set to 100 and 200 to model the training samples, two hidden layers are set, the batch is set to 32, and the number of epochs is set to 100, which is more appropriate. At the same time, the MAE of the verification set has an upward trend in the last 50 trainings, so a mechanism (Early_Stopping) is set to prevent the model from overfitting. When the MAE of the verification set decreases by no more than 0.0005 for 15 consecutive times, model training is considered complete. According to the previous experience, the parameter settings completed by the pre-experiment are shown in
Table 2.
The formal experiment mainly adjusts the number of neurons contained in the two hidden layers. Under different time windows T, these two parameters must be continuously adjusted. The MAE is used as an evaluation index, and the parameter corresponding to the minimum MAE of the verification set in the current time window is selected. According to the length of the input sequence, the number of neurons in the hidden layer is obtained within the range of [50,400]. The optimal parameter settings obtained under each time window and the MAE and RMSE of the verification set are shown in
Table 3. Considering the authenticity of the results of the verification set, the MAE and RMSE in
Table 3 are calculated based on the index formula after restoring the predicted value of the verification set.
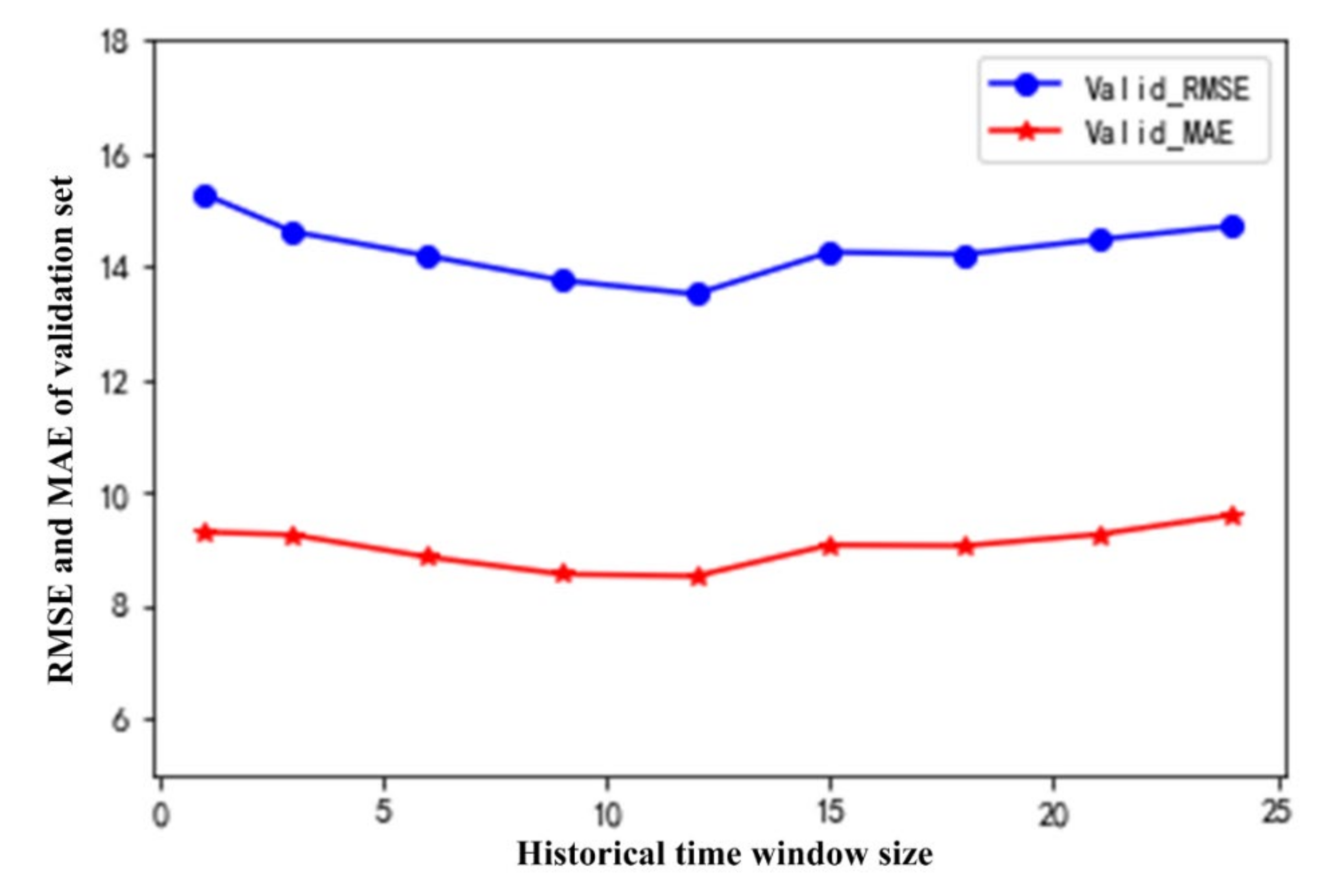
As shown in
Table 3, when T = 12, LSTM performs best on the validation set. The MAE and RMSE are 8.522 and 13.515, respectively. When T = 24, LSTM performs the worst on the validation set; MAE and RMSE are 9.604 and 14.724, respectively. In order to more intuitively judge the relationship between the prediction ability of LSTM and the size of T, the effect of the verification set of LSTM under each time window is presented in
Figure 9.
In
Table 3 and
Figure 9, as the time series increases, the overall performance of LSTM on the PM
2.5 value shows an upward trend and then a downward trend. The effect on the verification set is best when T = 12. The LSTM model has similar prediction performance for PM
2.5 within 3 h. For example, when T = 1 and T = 3, the MAE and RMSE are about 9.27 and 14.9, respectively; when T = 9 and T = 12, the MAE and RMSE are about 8.5 and 13.5, respectively; and when T = 15 and T = 18, the MAE and RMSE are about 9.05 and 14.2, respectively.
In summary, when the T is set to 12, LSTM performs best on the verification set. The specific parameters follow: the activation function is set to ReLU, the optimization algorithm is the Adam algorithm, the learning rate is the default parameter of 0.01, the batch size is 32, and the number of neurons in the first and second hidden layers is set to 320 and 160, respectively. During training, each hidden layer randomly discards some neurons with a probability of 0.2. If the MAE of the validation set drops less than 0.0005 for 15 consecutive times, training stops.
4.2. The TSLightGBM Model
When integrated models such as LightGBM and RF process time series, there is no time correlation between the input data. There are generally two ways to introduce time features: (1) One is to add basic feature variables, such as year, season, month, week, and hour. This model is denoted as TLightGBM. (2) The other uses T as a sliding window, and statistics such as the mean and standard deviation of each samples’ features are used as feature variables before T hours, so as to introduce the time characteristics to improve the training accuracy of the model. This model is denoted as TFLightGBM in this paper. However, these two methods do not make full use of the data in the time window T, and some information will be lost. In this section, when the time window size T is selected, the data of each T period are spliced into a one-dimensional shape as the explained variable of the PM
2.5 of the T + 1 period, so as to predict the PM
2.5 of the T + 1 h. In this paper, this model is denoted as TSLightGBM and compares it with the previous two methods that introduce temporal features. In order to ensure the fairness of the model comparison, the size of the selected sliding window and time window are the same as in
Section 4.1.
Considering that there are many parameters of the LightGBM model, the ensemble model of the tree is mainly affected by the number of trees, the maximum depth, and the learning rate. This section mainly adjusts the three main parameters of LightGBM as minimally as possible with the goal of verifying the set MAE. The number of trees (n_estimators) is adjusted within [100, 250, 500, 1000, 2000], the maximum tree depth (max_depth) is adjusted within [6, 8, 10, 12, 16], and the learning rate (learning_rate) is adjusted within [0.01, 0.05, 0.1]. The final adjustment results and the corresponding MAE and RMSE values are shown in
Table 4.
Table 4 shows the following: (1) The model with the best effect is TSLightGBM, and its RMSE and MAE are 8.153 and 13.266, respectively; (2) the second-best model is TLightGBM, and its RMSE and MAE are 12.496 and 19.570, respectively; and (3) the worst model is TFLightGBM, and its RMSE and MAE are 18.180 and 26.796, respectively. When LightGBM cannot provide the input data with a time correlation, the data in T are spliced into a one-dimensional shape as an explanatory variable to predict PM
2.5 in the T + 1 period, and the prediction performance of the model is better.
In summary, the feature construction method of TSLightGBM is selected, the number of trees is set to 1000, the maximum depth of the tree is 10, and the learning rate is 0.01. LightGBM performs best on the verification set.
4.3. LSTM-TSLightGBM Weighted Combination Model
Based on the verification set MAE of the optimal LSTM and the optimal LightGBM in
Section 4.1 and
Section 4.2, the ratio (0.42:0.58) of two models in the prediction is calculated according to the optimal weighted combination method.
In order to better evaluate the performance of the combined model, this section compares it with MLP, RNN, RF, LSTM, and TFLightGBM. These models all choose the parameters with the goal of the smaller MAE of the validation set. Among them, the input of MLP and RF is similar to that of TFLightGBM. Similar to other NNs, MLP is normalized when training the model. The RNN is constructed in the same way as LSTM. The real prediction performance of each model is shown in
Table 5.
Table 5 shows the following: (1) the weighted combination model LSTM-TSLightGBM has a better performance than any single model, and its MAE, RMSE, and SMAPE are the smallest, which are 11.873, 22.516, and 19.540%, respectively; (2) the second-best model is TSLightGBM, and its MAE, RMSE, and SMAPE are 12.278, 23.216, and 19.936%, respectively; (3) the third-best model is LSTM. Although the SMAPE of LSTM is 0.321% larger than that of RF, its MAE and RMSE are 12.918 and 23.501 respectively, which are 0.1 and 1.2 smaller than that of RF. Overall, LSTM is a better model than RF.
This paper assumes that if the difference between the prediction errors of the two models exceeds 10%, it is considered that there is a significant difference in the prediction performance of the two models. Compared with MLP and RNN models, MAE of LSTM-TSLightGBM decreased by 33.50% and 29.52%, respectively; RMSE decreased by 19.75% and 17.09% respectively; and SMAPE decreased by 47.15% and 44.94% respectively. On the whole, the prediction effect of LSTM-TSLightGBM on PM2.5 concentration is significantly improved.
To more intuitively judge the superiority of the LSTM-TSLightGBM performance, it is necessary to further combine graphics to judge its performance. Considering that the effect of graphic display is not obvious when the difference degree of MAE is within 1, this section only shows the comparison curve between the predicted value and the real value of LSTM-TSLightGBM model with the best performance and the MLP model with the worst performance. Due to the large sample size of the test set, all visualization will affect the judgment effect. Here, 100 samples are drawn from the first and second halves of the test set for comparison. The visualization results are shown in
Figure 10 and
Figure 11.
As shown in
Figure 10 and
Figure 11, compared with the LSTM-TSLightGBM model, the difference between the predicted value of MLP neural network and the actual value is more obvious. When PM
2.5 is in the range of 100 to 200, the predictive capabilities of LSTM-TSLightGBM and the MLP neural network are close. However, when PM
2.5 is close to 0 or greater than 350, the difference between the predicted value of MLP and the real value is clear, while the difference between the LSTM-TSLightGBM model and the real value is not. The reason why LSTM-TSLightGBM is better may be that LSTM has a “memory” function, and the variable inputs to the MLP are independent of each other. In addition, LSTM has gating rules and selectively filters variable information. At the same time, TSLightGBM also has the function of screening variables, which can reduce the influence of noise.
In terms of evaluation indicators and prediction results, LSTM-TSLightGBM combines the advantages of LSTM’s high sensitivity to time information and the advantages of LightGBM’s strong extraction of feature variables. Therefore, LSTM-TSLightGBM has superiority in the prediction of PM2.5.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}