
Development of a CNN+LSTM Hybrid Neural Network for Daily PM2.5 Prediction



Abstract
:1. Introduction
2. Model Development
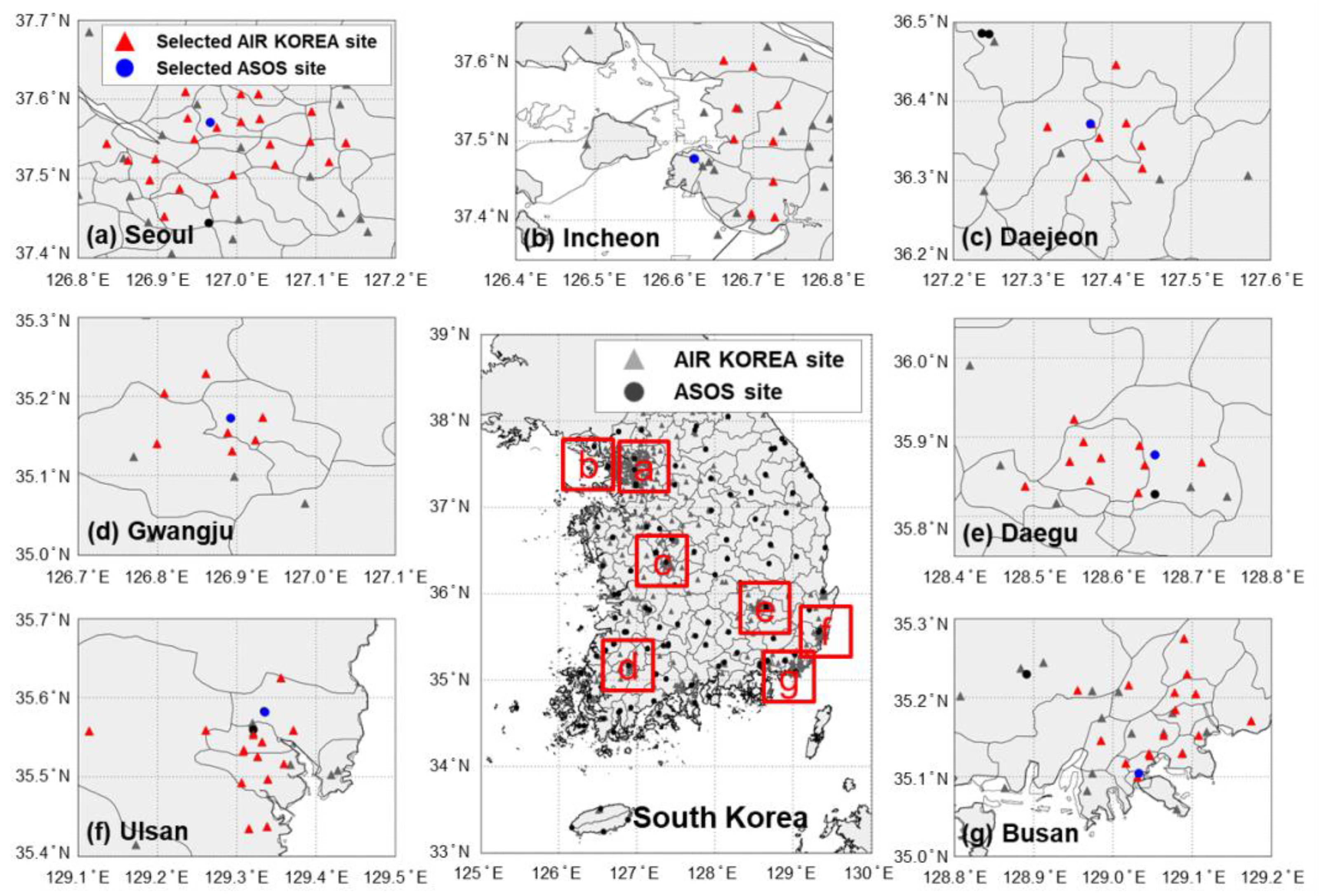
2.1. Dataset
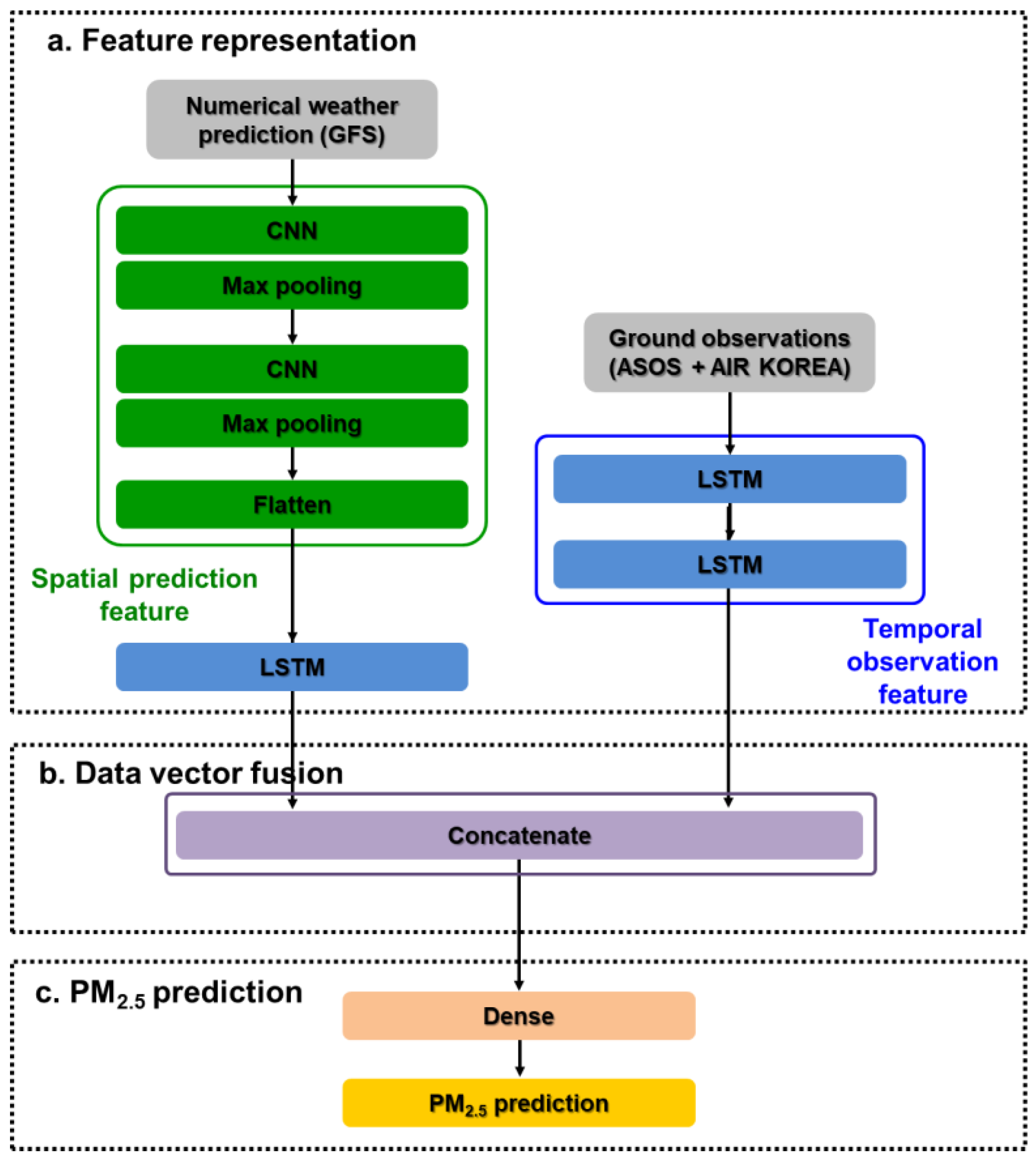
2.2. Model Construction
2.3. CNN+LSTM Optimization
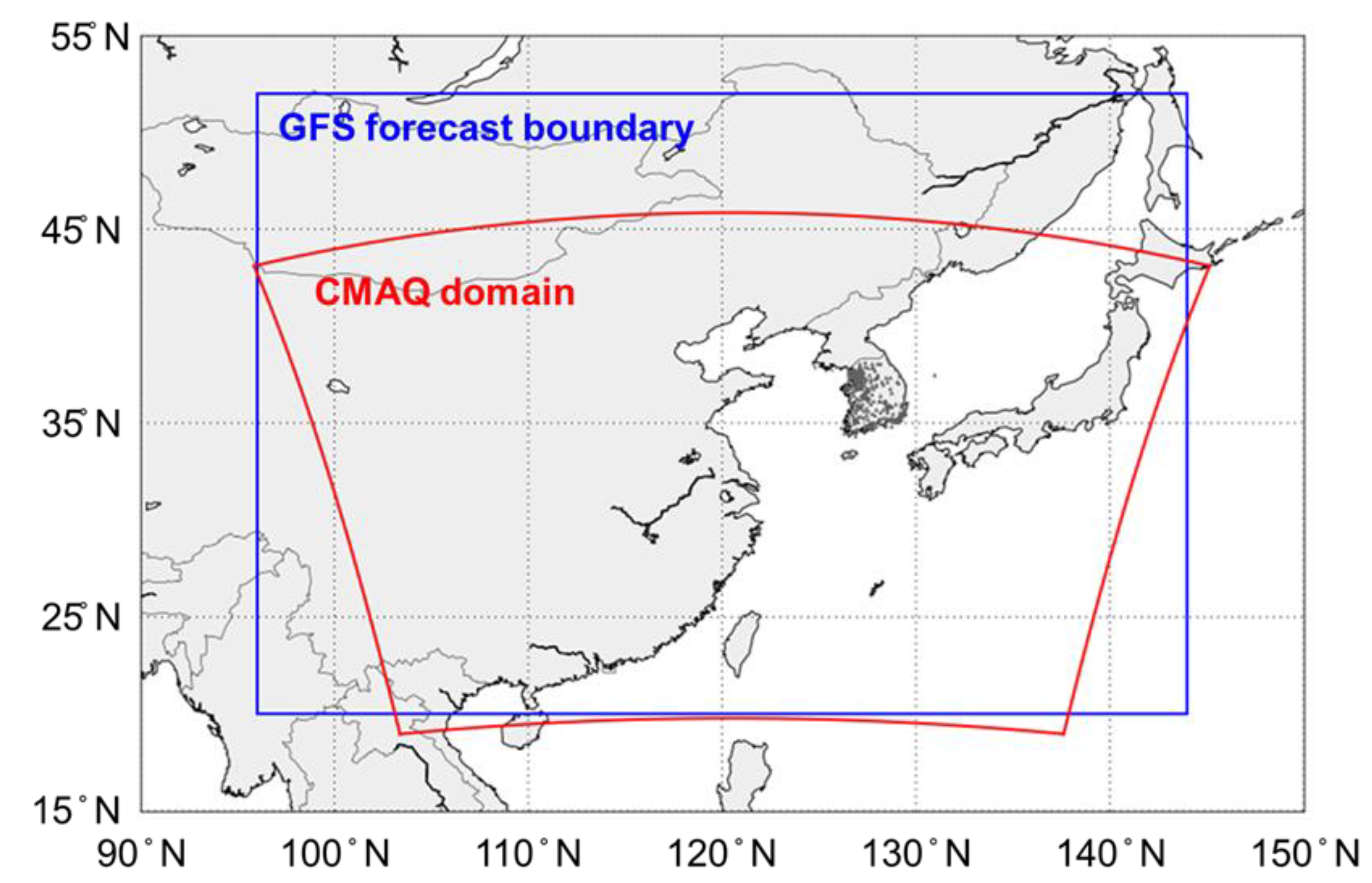
2.4. 3-D CTM-Based PM2.5 Prediction
2.5. Evaluation Metric
3. Results
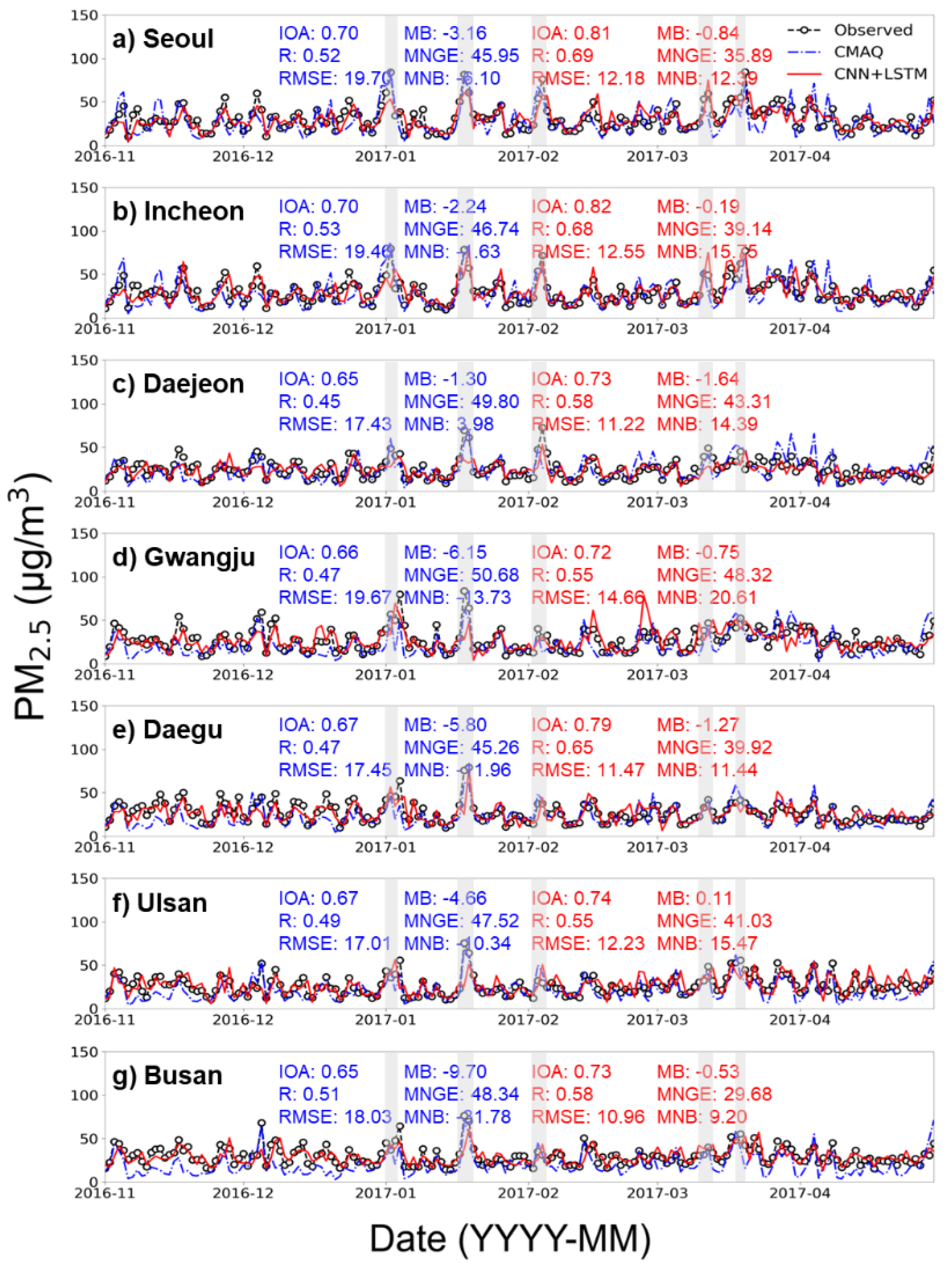
3.1. Model Evaluation
3.2. Importance of Input Features
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dorkery, D.W.; Schwartz, J.; Spengler, J.D. Air pollution and daily mortality: Associations with particles and acid aerosols. Environ. Res. 1992, 59, 362–373. [Google Scholar] [CrossRef] [PubMed]
- Pope III, C.A.; Dorkey, D.W. Health effects of fine particulate air pollution: Lines that connect. J. Air Waste Manag. Assoc. 2006, 56, 709–742. [Google Scholar] [CrossRef] [PubMed]
- Berge, E.; Huang, H.-C.; Chang, J.; Liu, T.-H. A study of the importance of initial conditions for photochemical oxidant modeling. J. Geophys. Res.-Atmos. 2001, 106, 1347–1363. [Google Scholar] [CrossRef]
- Liu, T.-H.; Jeng, F.-T.; Huang, H.-C.; Berger, E.; Chang, J.S. Influences of initial conditions and boundary conditions on regional and urban scale Eulerian air quality transport model simulations. Chem.-Glob. Change Sci. 2001, 3, 175–183. [Google Scholar] [CrossRef]
- Holloway, T.; Spak, S.N.; Barker, D.; Bretl, M.; Moberg, C.; Hayhoe, K.; van Dorn, J.; Wuebbles, D. Change in ozone air pollution over Chicago associated with global climate change. J. Geophys. Res.-Atmos. 2008, 113, D22306. [Google Scholar] [CrossRef] [Green Version]
- Han, K.M.; Lee, C.K.; Lee, J.; Kim, J.; Song, C.H. A comparison study between model-predicted and OMI-retrieved tropospheric NO2 columns over the Korean peninsula. Atmos. Environ. 2011, 45, 2962–2971. [Google Scholar] [CrossRef]
- Joharestani, Z.M.; Cao, C.; Ni, X.; Bashir, B.; Talebiesfandarani, S. PM2.5 prediction based on random forest, XGBoost, and deep learning using multisource remote sensing data. Atmosphere 2019, 10, 373. [Google Scholar] [CrossRef] [Green Version]
- Karimian, H.; Li, Q.; Wu, C.; Qi, Y.; Mo, Y.; Chen, G.; Zhang, X.; Sachdeva, S. Evaluation of different machine learning approaches to forecasting PM2.5 mass concentrations. Aerosol Air Qual. Res. 2019, 19, 1400–1410. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Hua, M.; Wu, X. A hybrid CNN-LSTM model for forecasting particulate matter (PM2.5). IEEE Access 2020, 8, 26933–26940. [Google Scholar] [CrossRef]
- Park, U.; Ma, J.; Ryu, U.; Ryom, K.; Juhyok, U.; Park, K.; Park, C. Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China. Sci. Total Environ. 2020, 699, 133561. [Google Scholar] [CrossRef]
- Al-Alawi, S.M.; Abdul-Wahab, S.A.; Bakheit, C.S. Combining principal component regression and artificial neural networks for more accurate predictions of ground-level ozone. Environ. Model. Softw. 2008, 23, 396–403. [Google Scholar] [CrossRef]
- Feng, y.; Zhang, W.; Sun, D.; Zhang, L. Ozone concentration forecast method based on genetic algorithm optimized back propagation neural networks and support vector machine data classification. Atmos. Environ. 2011, 45, 1979–1985. [Google Scholar] [CrossRef]
- Kim, H.S.; Park, I.; Song, C.H.; Lee, K.; Yun, J.W.; Kim, H.K.; Jeon, M.; Lee, J.; Han, K.M. Development of a daily PM10 and PM2.5 prediction system using a deep long short-term memory neural network model. Atmos. Chem. Phys. 2019, 19, 12935–12951. [Google Scholar] [CrossRef] [Green Version]
- Zhao, j.; Deng, F.; Cai, Y.; Chen, J. Long short-term memory—Fully connected (LSTM-FC) neural network for PM2.5 concentration prediction. Chemosphere 2019, 220, 486–492. [Google Scholar] [CrossRef] [PubMed]
- Chang-Hoi, H.; Park, I.; Oh, H.-R.; Gim, H.J.; Hur, S.K.; Kim, J.; Choi, D.-R. Development of a PM2.5 prediction model using a recurrent neural network algorithm for the Seoul metropolitan area, Republic of Korea. Atmos. Environ. 2021, 245, 118021. [Google Scholar] [CrossRef]
- Muruganandam, N.S.; Arumugam, U. Seminal stacked long short-term memory (SS-LSTM) model for forecasting particulate matter (PM2.5 and PM10). Atmosphere 2022, 13, 1726. [Google Scholar] [CrossRef]
- Eslami, E.; Choi, Y.; Lops, Y.; Sayeed, A. A real-time hourly ozone prediction system using deep convolutional neural network. Neural Comput. Appl. 2020, 32, 8783–8797. [Google Scholar] [CrossRef] [Green Version]
- Park, Y.; Kwon, B.; Heo, J.; Hu, X.; Liu, Y.; Moon, T. Estimating PM2.5 concentration of the conterminous United States via interpretable convolutional neural networks. Environ. Pollut. 2020, 256, 113395. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Wang, J.; Zeng, H.; Zhou, F. Prediction of air pollutant concentration based on one-dimensional multi-scale CNN-LSTM considering spatial-temporal characteristics: A case study of Xi’an, China. Atmosphere 2021, 12, 1626. [Google Scholar] [CrossRef]
- Connor, J.T.; Martin, R.D.; Atlas, L.E. Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 1994, 5, 240–254. [Google Scholar] [CrossRef]
- Sezer, O.B.; Gudelek, M.U.; Ozbayoglu, A.M. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Appl. Soft. Comput. 2020, 90, 106181. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1977, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin, Germany, 2012; Volume 385, pp. 37–45. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition. arXiv 2014, arXiv:1402.1128. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Kim, H.C.; Kim, E.; Bae, C.; Cho, J.H.; Kim, B.-U.; Kim, S. Regional contributions to particulate matter concentration in the Seoul metropolitan area, South Korea: Seasonal variation and sensitivity to meteorology and emissions inventory. Atmos. Chem. Phys. 2017, 17, 10315–10332. [Google Scholar] [CrossRef] [Green Version]
- Sayeed, A.; Lops, Y.; Choi, Y.; Jung, J.; Salman, A.K. Bias correcting and extending the PM forecast by CMAQ up to 7 days using deep convolutional neural networks. Atmos. Environ. 2021, 253, 118376. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Mass, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Kingma, D.; Ba, J. A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 3–8 May 2015. [Google Scholar]
- Mahsereci, M.; Ballers, L.; Lassner, C.; Henning, P. Early stopping without a validation set. arXiv 2017, arXiv:1703.09580. [Google Scholar]
- Woo, J.-H.; Kim, Y.; Kim, H.-K.; Choi, K.-C.; Eum, J.-H.; Lee, J.-B.; Lim, J.-H.; Kim, J.; Seong, M. Development of the CREATE Inventory in Support of Integrated Climate and Air Quality Modeling for Asia. Sustainability 2020, 12, 7930. [Google Scholar] [CrossRef]
- Guenther, A.; Karl, T.; Harley, P.; Wiedinmyer, C.; Palmer, P.I.; Geron, C. Estimates of global terrestrial isoprene emissions using MEGAN (Model of Emissions of Gases and Aerosols from Nature). Atmos. Chem. Phys. 2006, 6, 3181–3210. [Google Scholar] [CrossRef] [Green Version]
- Wiedinmyer, C.; Akagi, S.K.; Yokelson, R.J.; Emmons, L.K.; Al-Saadi, J.A.; Orlando, J.J.; Soja, A.J. The Fire INventory from NCAR (FINN): A high resolution global model to estimate the emissions from open burning. Geosci. Model Dev. 2011, 4, 625–641. [Google Scholar] [CrossRef] [Green Version]
- Emmons, L.K.; Walters, S.; Hess, P.G.; Lamarque, J.-F.; Pfister, G.G.; Fillmore, D.; Granier, C.; Guenther, A.; Kinnison, D.; Laepple, T.; et al. Description and evaluation of the Model for Ozone and Related chemical Tracers, version 4 (MOZART-4). Geosci. Model Dev. 2010, 3, 43–67. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Study Area | Period | Algorithm | RMSE (μg/m3) |
|---|---|---|---|---|
| Joharestani et al., 2019 [7] | Tehran, Iran | 2015–2018 | Random forest | 14.47 |
| XGBoost | 13.66 | |||
| MLP | 15.11 | |||
| Karimian et al., 2019 [8] | Tehran, Iran | 2013–2016 | MART | 13.19 |
| DFFN | 19.62 | |||
| LSTM | 9.42 | |||
| Li et al., 2020 [9] | Beijing, China | 2010–2014 | CNN+LSTM | 17.93 |
| LSTM | 18.08 | |||
| Park et al., 2020 [10] | Beijing, China | 2015–2017 | MLP | 37.79 |
| LSTM | 11.34 | |||
| CNN+LSTM | 5.357 |
| Data Type | Variable | Unit | Time Resolution | Feature Type |
|---|---|---|---|---|
| Observed meteorological variable | Temperature | K | 1 h | Temporal feature |
| Wind speed | m/s | |||
| Wind direction | ° | |||
| Relative humidity | % | |||
| Vapor pressure | hPa | |||
| Dew point | K | |||
| Pressure | hPa | |||
| Sea level pressure | hPa | |||
| Observed atmospheric environmental variable | SO2 | ppmv | 1 h | Temporal feature |
| CO | ppmv | |||
| O3 | ppmv | |||
| NO2 | ppmv | |||
| PM10 | μg/m3 | |||
| PM2.5 | μg/m3 | |||
| Predicted meteorological variable | Geopotential height * | gpm | 3 h | Spatial feature |
| Prediction Step | Structural Hyperparameter | Neural Network | |||||
|---|---|---|---|---|---|---|---|
| 1st CNN | 1st Max Polling | 2nd CNN | 2nd Max Polling | Flatten | LSTM | ||
| Feature representation for spatial features | Input shape | (None, 24, 128, 192, 1) | (None, 24, 128, 192, 32) | (None, 12, 64, 96, 32) | (None, 12, 64, 96, 24) | (None, 6, 32, 48, 24) | (None, 221184) |
| CNN kernels or hidden nodes | 32 | - | 24 | - | - | 512 | |
| Kernel size | (3, 3, 3) | - | (3, 3, 3) | - | - | - | |
| Activation | ReLU | - | ReLU | - | - | Tanh | |
| Pooling size | - | (2, 2, 2) | - | (2, 2, 2) | - | - | |
| Output shape | (None, 24, 128, 192, 32) | (None, 12, 64, 96, 32) | (None, 12, 64, 96, 24) | (None, 6, 32, 48, 24) | (None, 221184) | (None, 512) | |
| Feature representation for temporal features | 1st LSTM | 2nd LSTM | |||||
| Input shape | (None, 24, 14) | (None, 24, 512) | |||||
| Hidden nodes | 512 | 512 | |||||
| Activation | Tanh | Tanh | |||||
| Output shape | (None, 24, 512) | (None, 512) | |||||
| Data vector fusion | Concatenate layer | ||||||
| Input shape | [(None, 512), (None, 512)] | ||||||
| Output shape | (None, 1024) | ||||||
| PM2.5 prediction | Final dense layer | ||||||
| Input shape | (None, 1024) | ||||||
| Hidden nodes | 24 | ||||||
| Activation | Leaky-ReLU | ||||||
| Output shape | (None, 24) | ||||||
| City | Training | Validation | ||
|---|---|---|---|---|
| MSE | RMSE | MSE | RMSE | |
| Seoul | 131.85 | 11.48 | 152.81 | 12.36 |
| Incheon | 133.21 | 11.54 | 145.98 | 12.08 |
| Daejeon | 95.04 | 9.75 | 98.65 | 9.93 |
| Gwangju | 105.72 | 10.28 | 127.63 | 11.30 |
| Daegu | 87.57 | 9.36 | 96.20 | 9.81 |
| Ulsan | 101.60 | 10.08 | 112.51 | 10.61 |
| Busan | 124.09 | 11.14 | 140.84 | 11.87 |
| Model | City | Statistical Parameters | |||||
|---|---|---|---|---|---|---|---|
| IOA | R | RMSE | MB | MNGE | MNB | ||
| CMAQ | Seoul | 0.70 | 0.52 | 19.70 | −3.16 | 45.95 | −6.10 |
| Incheon | 0.70 | 0.53 | 19.46 | −2.24 | 46.74 | −1.63 | |
| Daejeon | 0.65 | 0.45 | 17.43 | −1.30 | 49.80 | 3.98 | |
| Gwangju | 0.66 | 0.47 | 19.67 | −6.15 | 50.68 | −13.73 | |
| Daegu | 0.67 | 0.47 | 17.45 | −5.80 | 45.26 | −11.96 | |
| Ulsan | 0.67 | 0.49 | 17.01 | −4.66 | 47.52 | −10.34 | |
| Busan | 0.65 | 0.51 | 18.03 | −9.70 | 48.34 | −31.78 | |
| CNN+LSTM | Seoul | 0.81 | 0.69 | 12.18 | −0.84 | 35.89 | 12.39 |
| Incheon | 0.82 | 0.68 | 12.55 | −0.19 | 39.14 | 15.75 | |
| Daejeon | 0.73 | 0.58 | 11.22 | −1.64 | 43.31 | 14.39 | |
| Gwangju | 0.72 | 0.55 | 14.66 | −0.75 | 48.32 | 20.61 | |
| Daegu | 0.79 | 0.65 | 11.47 | −1.27 | 39.92 | 11.44 | |
| Ulsan | 0.74 | 0.55 | 12.23 | 0.11 | 41.03 | 15.47 | |
| Busan | 0.73 | 0.58 | 10.96 | −0.53 | 29.68 | 9.20 | |
| Type | Input Feature | Feature Importance | ||||||
|---|---|---|---|---|---|---|---|---|
| Seoul | Incheon | Daejeon | Gwangju | Daegu | Ulsan | Busan | ||
| Meteorological variable | Geopotential height | 25.29 | 22.00 | 21.86 | 36.41 | 7.92 | 15.04 | 14.32 |
| Temperature | 12.87 | 12.54 | 9.82 | 9.71 | 4.70 | 3.10 | 5.95 | |
| Wind speed | 0.16 | 0.19 | 0.06 | 0.13 | 0.14 | 0.14 | 0.06 | |
| Wind direction | 1.86 | 3.90 | 0.30 | 2.22 | 2.71 | 1.29 | 0.48 | |
| Relative humidity | 1.86 | 1.84 | 7.40 | 7.88 | 3.65 | 7.79 | 3.65 | |
| Vapor pressure | 7.68 | 7.58 | 6.43 | 5.52 | 6.98 | 8.03 | 0.04 | |
| Dew point | 2.08 | 2.23 | 0.47 | 2.23 | 1.10 | 3.60 | 2.30 | |
| Pressure | 3.25 | 4.99 | 4.50 | 6.91 | 7.05 | 1.29 | 3.36 | |
| Sea level pressure | 2.60 | 2.37 | 2.61 | 7.26 | 7.29 | 2.56 | 3.00 | |
| Atmospheric environmental variable | SO2 | 2.67 | 1.87 | 1.86 | 6.22 | 7.93 | 2.91 | 2.36 |
| CO | 1.74 | 0.92 | 0.28 | 3.69 | 1.38 | 1.96 | 0.40 | |
| O3 | 8.06 | 3.33 | 10.44 | 15.73 | 6.79 | 8.87 | 3.66 | |
| NO2 | 2.26 | 0.94 | 1.71 | 3.79 | 3.43 | 3.84 | 0.33 | |
| PM10 | 0.96 | 1.64 | 5.08 | 0.77 | 1.20 | 2.36 | 4.58 | |
| PM2.5 | 38.80 | 38.24 | 34.93 | 41.82 | 37.17 | 34.79 | 31.67 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.S.; Han, K.M.; Yu, J.; Kim, J.; Kim, K.; Kim, H. Development of a CNN+LSTM Hybrid Neural Network for Daily PM2.5 Prediction. Atmosphere 2022, 13, 2124. https://doi.org/10.3390/atmos13122124
Kim HS, Han KM, Yu J, Kim J, Kim K, Kim H. Development of a CNN+LSTM Hybrid Neural Network for Daily PM2.5 Prediction. Atmosphere. 2022; 13(12):2124. https://doi.org/10.3390/atmos13122124
Chicago/Turabian StyleKim, Hyun S., Kyung M. Han, Jinhyeok Yu, Jeeho Kim, Kiyeon Kim, and Hyomin Kim. 2022. "Development of a CNN+LSTM Hybrid Neural Network for Daily PM2.5 Prediction" Atmosphere 13, no. 12: 2124. https://doi.org/10.3390/atmos13122124
APA StyleKim, H. S., Han, K. M., Yu, J., Kim, J., Kim, K., & Kim, H. (2022). Development of a CNN+LSTM Hybrid Neural Network for Daily PM2.5 Prediction. Atmosphere, 13(12), 2124. https://doi.org/10.3390/atmos13122124