
Plausible Precipitation Trends over the Large River Basins of Pakistan in Twenty First Century


 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
2. Study Area and Data
2.1. Study Area
2.2. Climatology
2.3. APHRODITE Data
2.4. NEX-GDDP-GCMs-CMIP5 Data
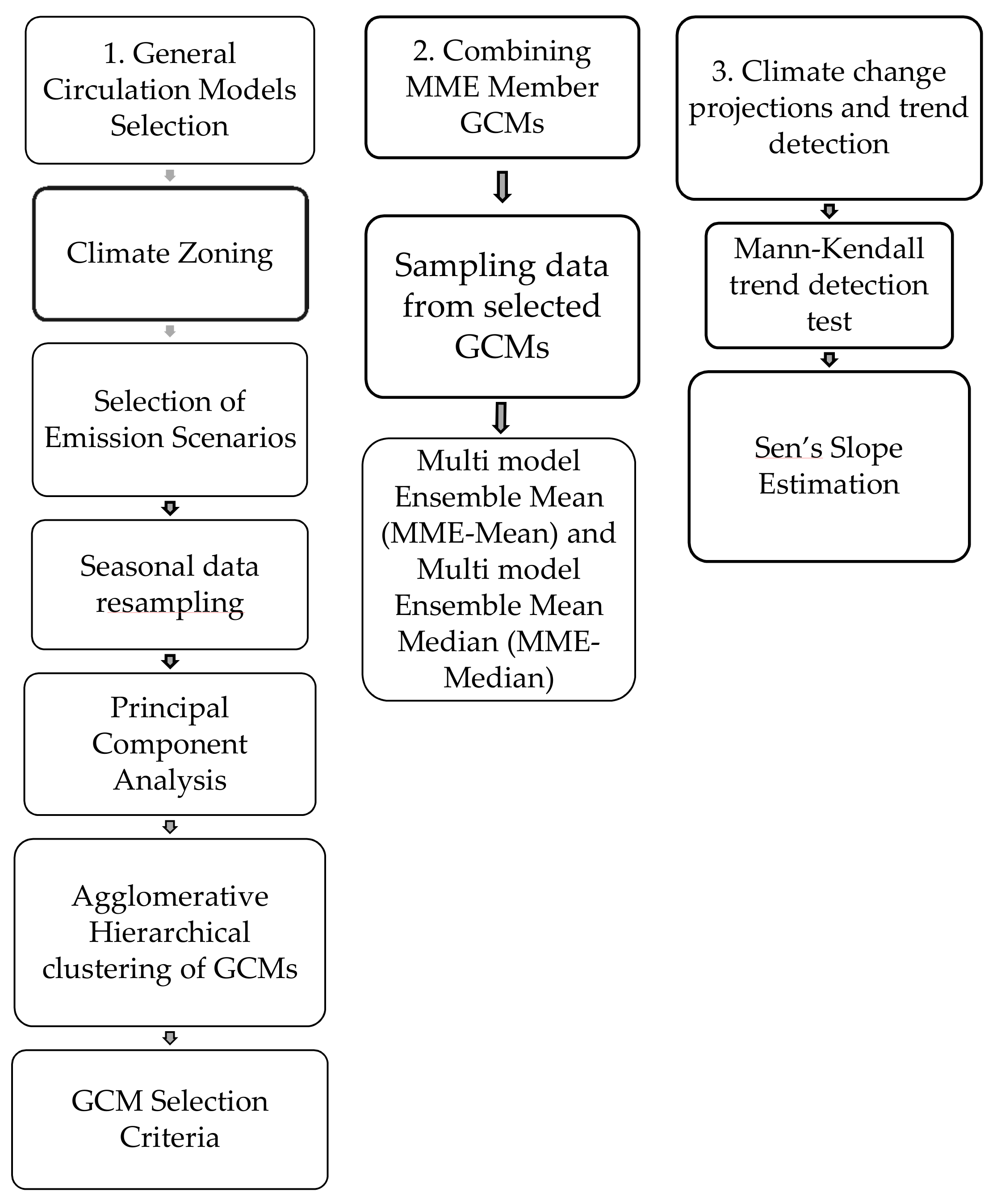
3. Methodology
3.1. Climate Zoning
3.1.1. Seasonal Data Resampling
3.1.2. Principal Component Analysis (PCA)
3.1.3. Agglomerative Hierarchical Clustering (AHC)
3.1.4. Formation of Climate Zones
3.1.5. Silhouette Score
3.2. GCM Selection in Climate Zones
- For the projected period, the precipitation data were sampled for two forcing scenarios, RCP 4.5 and RCP 8.5. The set of GCMs was selected using each of the forcing scenarios separately. It means that each climate zone would have two sets of selected GCMs, each corresponding to one forcing scenario. The idea was to incorporate every possible spread and diversity of climate signals to select GCMs, which is the basis of the envelope-based selection approach.
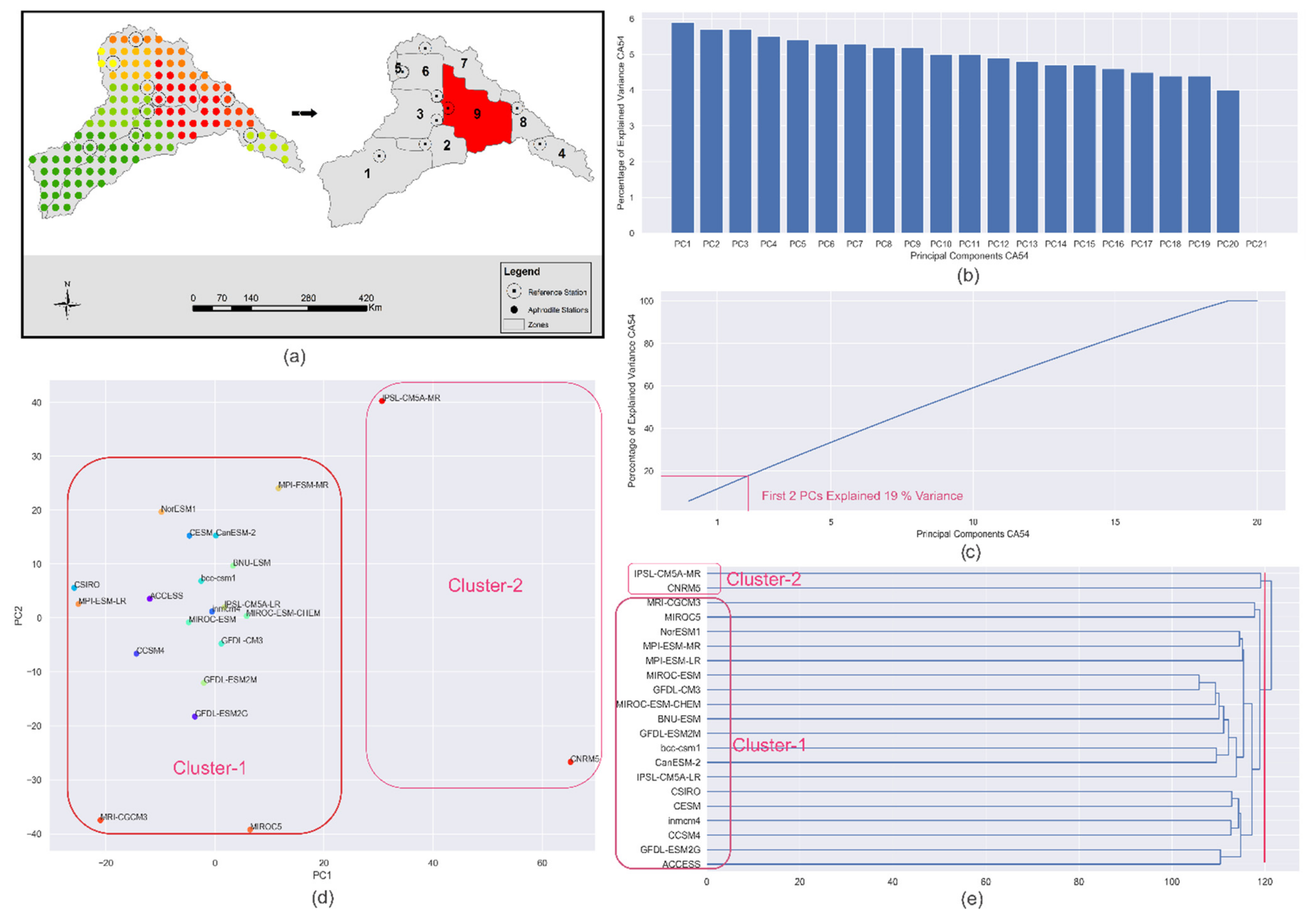
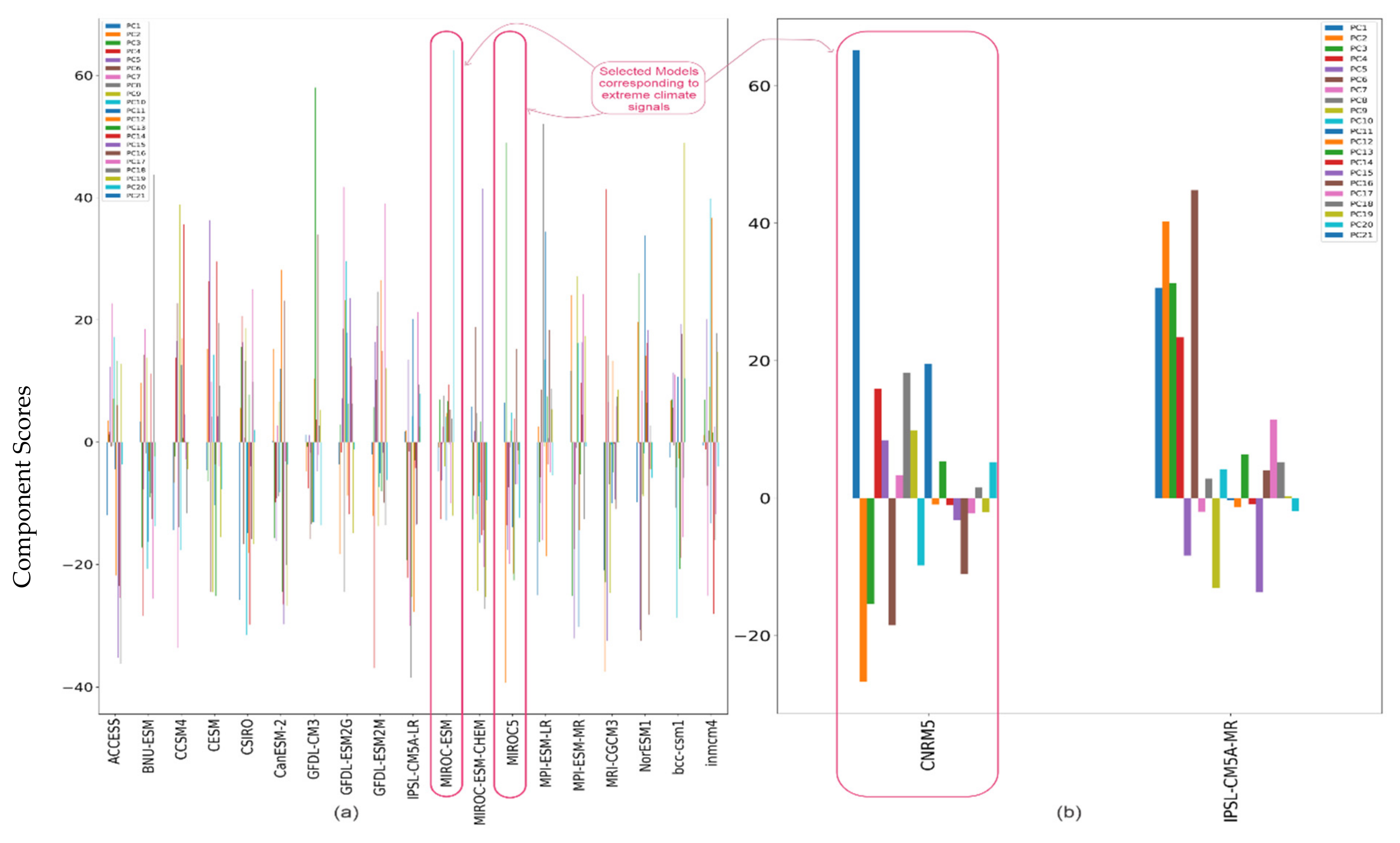
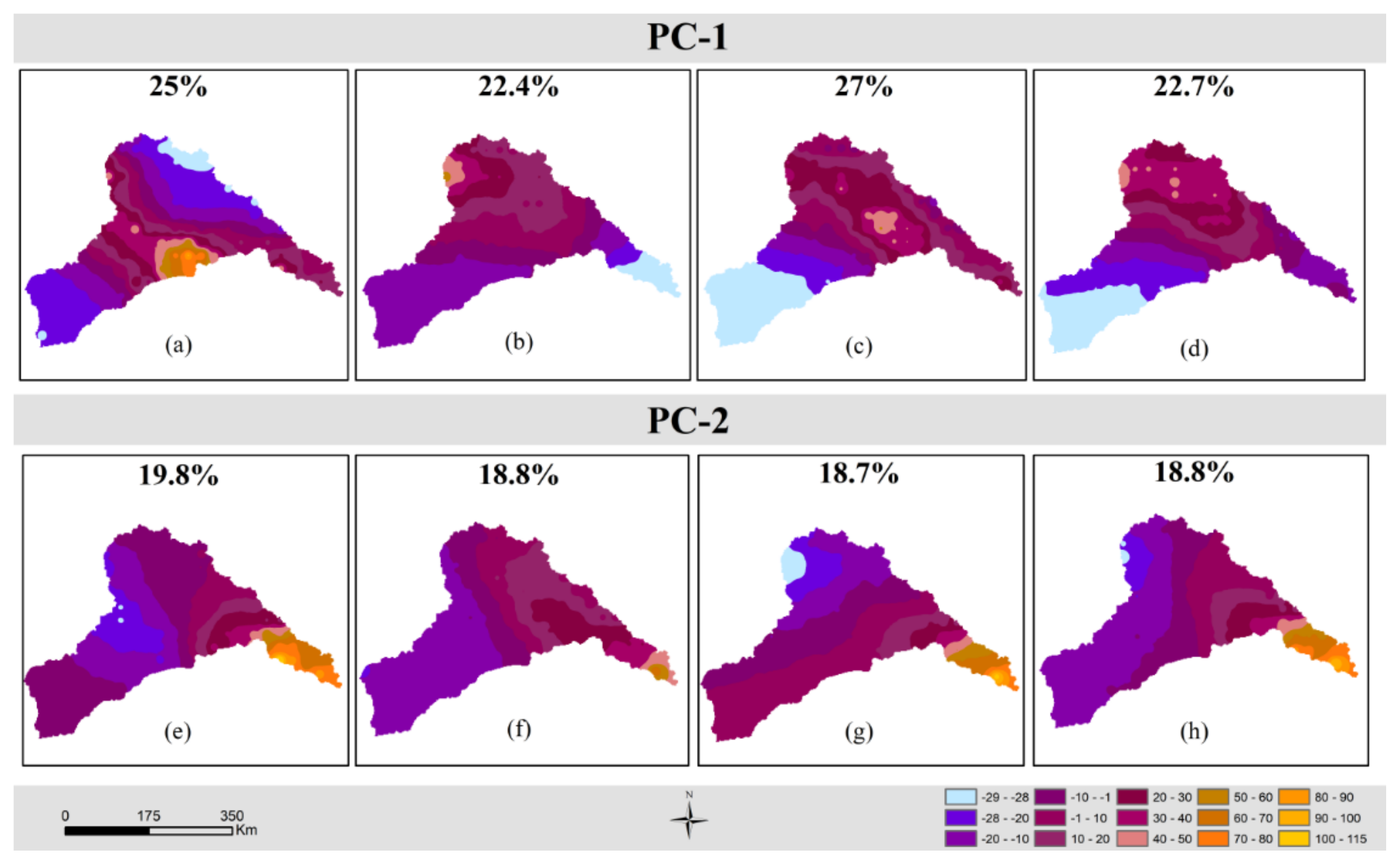
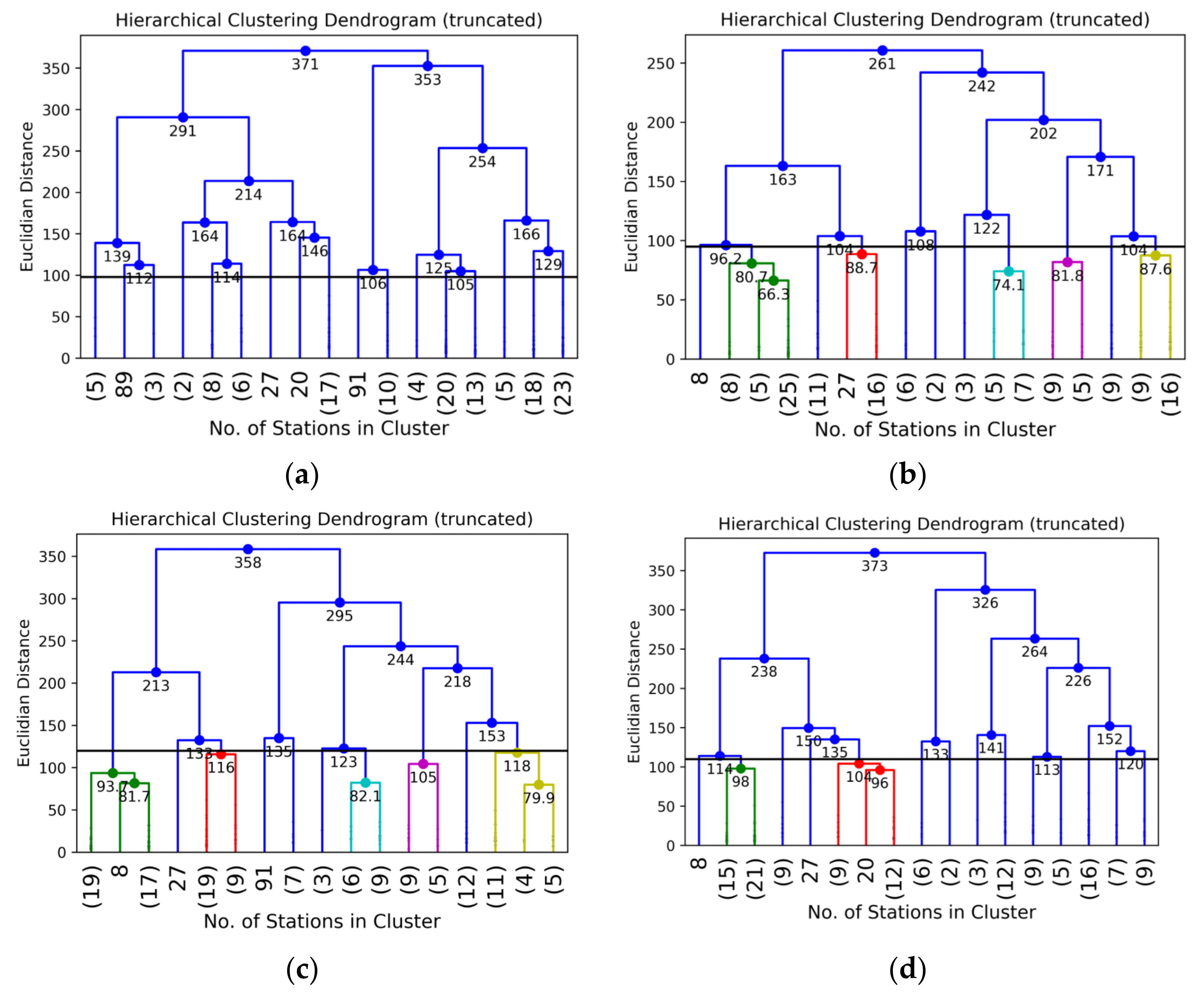
- After combining the data of 21 GCMs for the historical and projected periods for RCP 4.5 and RCP 8.5 for all the reference stations, Principal Component Analysis (PCA) was performed on 21 GCMs data at each of the reference stations. The objective was to reduce the dimensions of the large matrix of the daily time series of 129 years (base period: 1971–2004 and projected period: 2005–2099) for the reference stations in each of the climate zone of every season. In addition, to retain as much descriptive of the data as possible, PCA enabled us to reduce such a large matrix into a smaller-sized matrix. The Principal Components (PCs) were obtained using the data of 21 GCMs at each of the reference stations. The highly ranked PCs which explained maximum cumulative variance in the dataset were identified through the scree plot. The component scores are derived by eigenvectors and the eigenvalues for all the GCMs in each PC. These component scores represent climate change patterns/signals in that specific site and may be considered an alternative to the meteorological parameters, which are statistically independent [14,55]. Figure 3b,c are the scree plot showing the percentage of explained variance by individual GCM and the line plot representing the cumulative percentage of explained variance, respectively. The variance explained by the individual PCs as shown in Figure 3b ranges between 4 and 6%, which means that all the PCs are equally important in deciding the hierarchy of the clusters of the GCMs for this zone 9 of the cold dry season. The gradient of the line plot in Figure 3c depicts that 18 PCs have explained the cumulative variance of 90%. All principal components have been included for the agglomerative hierarchical clustering to accommodate the maximum variance of the data. Figure 3d presents the scatter of the component scores of all the GCMs for the first two PCs, which cumulatively explained 19% variance in the data at the reference station of climate zone 9. The dendrogram tree is presented in Figure 3e, which presents the agglomerative hierarchical clustering of the GCMs for this climate zone.
- The climate signals in the form of component scores were obtained for the PCs, which cumulatively explained 90% of the data variance. These component scores were then used in the Agglomerative Hierarchical clustering (AHC) of the GCM. AHC would result in the clusters of GCMs having similar descriptive statistics. Through this step, we were able to identify the clusters or groups of GCMs having similar climate signals. The method has been described in Section 3.1.2; the clustering of GCMs has been illustrated with the help of a dendrogram tree of GCMs shown in Figure 3e for the climate zone 9 of the cold dry season. The optimum number of clusters is based upon the Euclidian distance [59] between the clusters. The dendrogram tree presents the meaningful information of different clusters and the Euclidian distances between the clusters.
- The optimum number of clusters was determined with the help of a cluster validity index called the silhouette score (described in Section 3.1.5). The silhouette scores for different numbers of clusters have been shown in Table 1 for the climate zone 9 of the cold dry season. Two clusters are optimum for this case, as they produce the highest silhouette score. Euclidian distance of 120 has been evaluated, corresponding to the optimum number of clusters. The dendrogram tree was then truncated at a value of 120 Euclidian distance, as shown in Figure 3e, to obtain the number and identity of GCMs in each cluster.
3.3. Combining GCMs and Data Sampling
3.4. Climate Change Trends Projections
3.4.1. Mann-Kendall Test (MK Test)
3.4.2. Sen’s Slope Evaluation
4. Results and Discussion
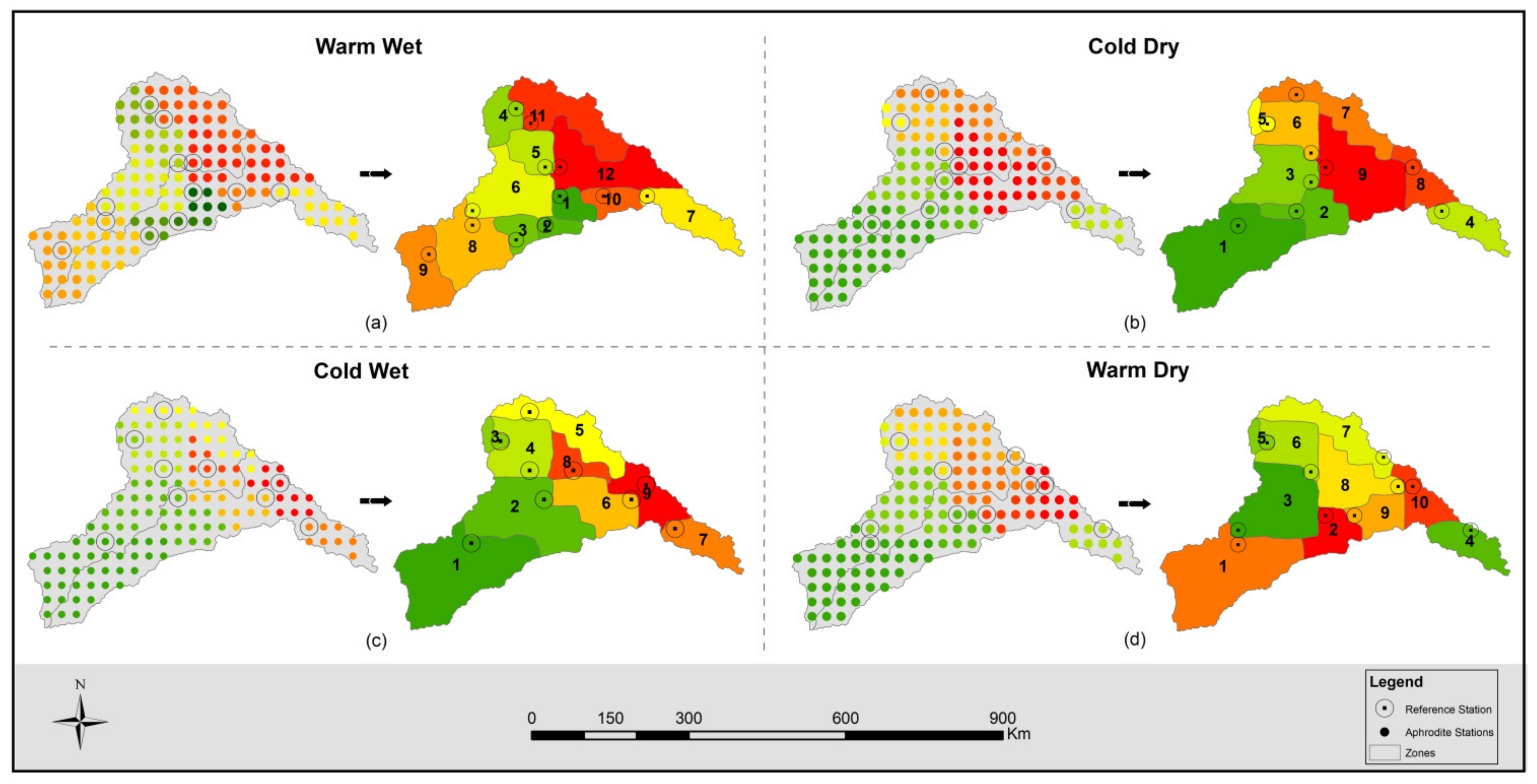
4.1. Formation of Climate Zones
4.1.1. Principal Component Analysis (PCA)
4.1.2. Agglomerative Hierarchical Clustering (AHC)
4.1.3. Climate Zones and Reference Site
4.2. GCM Selection
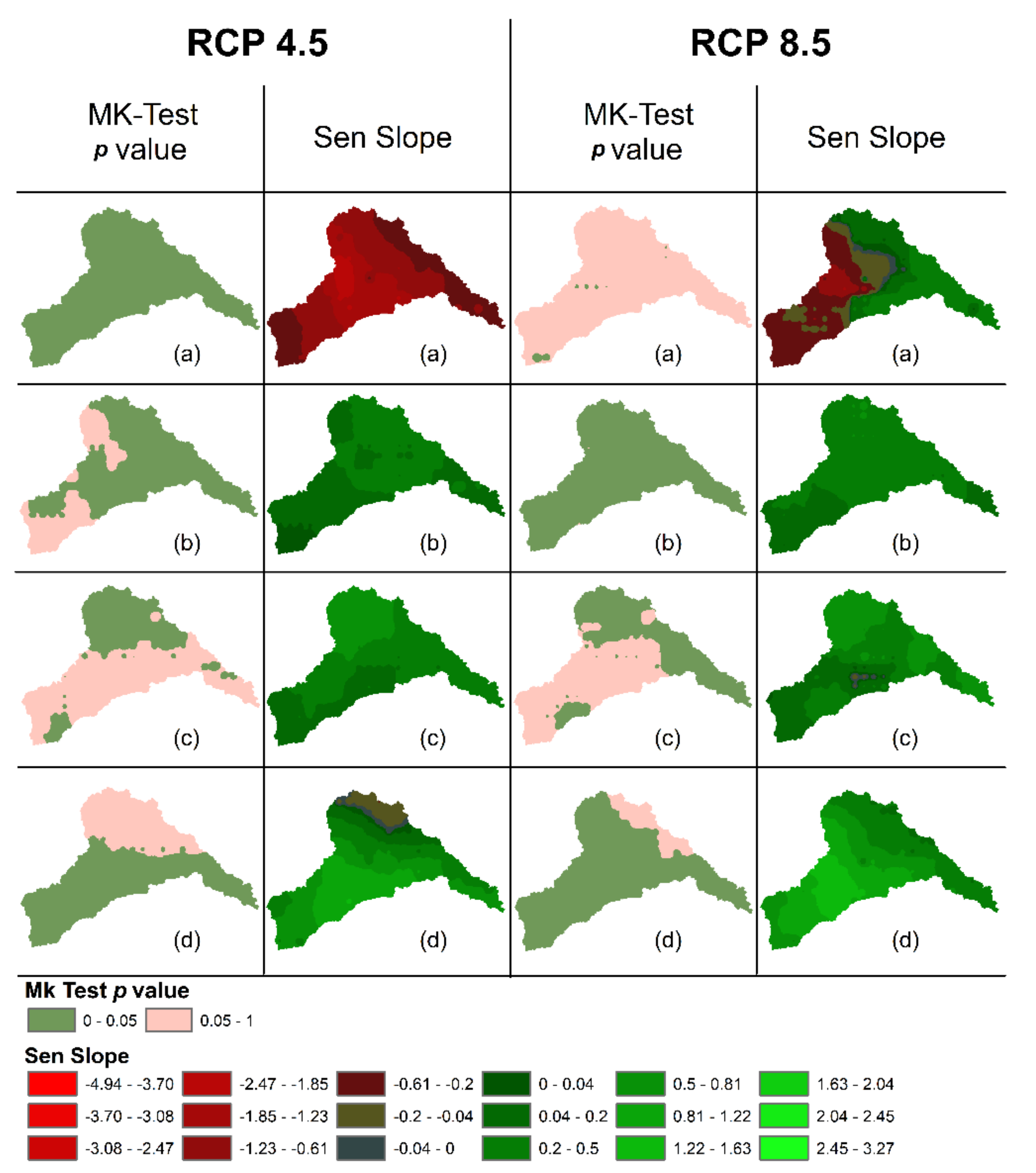
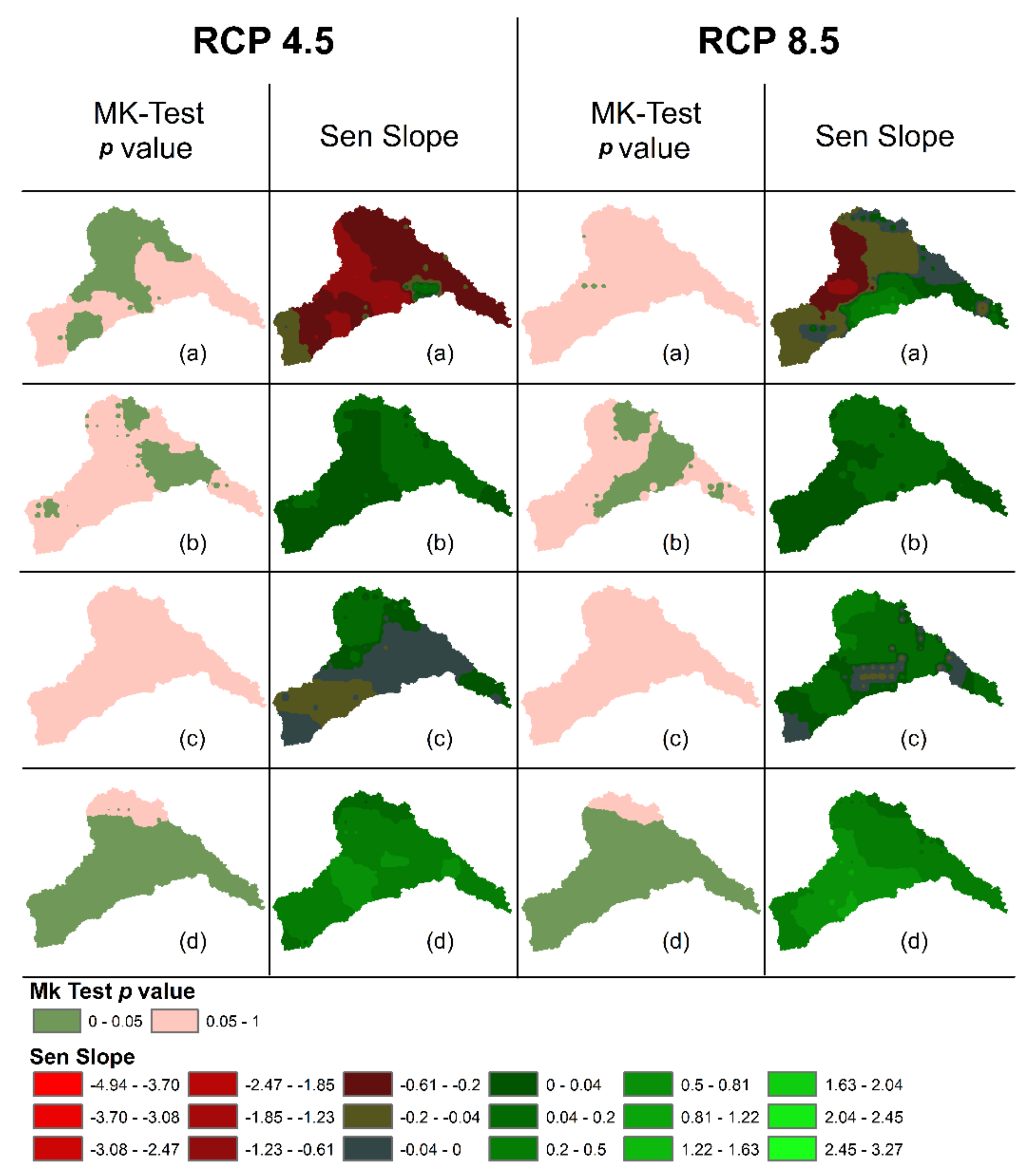
4.3. Seasonal Precipitation Trend Projection
4.3.1. For 2005–2040
4.3.2. For 2041–2070
4.3.3. For 2071–2099
4.3.4. For 2005–2099
5. Conclusions
- (1)
- The high variability in the climate in Pakistan poses a major challenge to the scientific community to project the plausible trends in climate, specifically precipitation change, which is considered to be the basic representative of climate and covariates. It was intended to select the suitable GCMs across the multiple homogeneous climate zones, which are representative of spatiotemporal variability of the climate in a region. The conventional method of using the spatiotemporal area average [13,31,77] of the climate data or various spatial metrics after analyzing the individual grid point data [66,78,79] is very common among the climate research community. However, the selected GCMs, through these methods, may not represent variability and range of climate signals in the region having spatially heterogeneous climate statistics, which poses uncertainty in projecting the climate data using these GCMs. Therefore, the entire study area was divided into 12, 9, 9, and 10 homogeneous precipitation regions for the warm wet, cold dry, cold wet, and warm dry season, respectively. The selection of GCMs was made in each homogeneous climate zone.
- (2)
- The precipitation trends were projected using the selected GCMs data on two forcing scenarios, RCP 4.5 and RCP 8.5, and two ensemble combinations; mean and median, thus making the total of four scenarios (RCP 4.5 Mean, RCP 4.5 Median, RCP 8.5 Mean, and RCP 8.5 Median). The trends projected using these scenarios provide the details of the range of trend variability of climate change in the region, with the knowledge of maximum increasing and decreasing trend quantification in the region seasonally, which is the purpose of envelope-based selection of GCMs.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shah, S.M.H.; Mustaffa, Z.; Teo, F.Y.; Imam, M.A.H.; Yusof, K.W.; Al-Qadami, E.H.H. A review of the flood hazard and risk management in the South Asian Region, particularly Pakistan. Sci. Afr. 2020, 10, e00651. [Google Scholar] [CrossRef]
- Tariq, M.A.U.R.; Van De Giesen, N. Floods and flood management in Pakistan. Phys. Chem. Earth Parts A/B/C 2012, 47, 11–20. [Google Scholar] [CrossRef]
- Ahmed, K.; Shahid, S.; Chung, E.-S.; Wang, X.; Harun, S.B. Climate Change Uncertainties in Seasonal Drought Severity-Area-Frequency Curves: Case of Arid Region of Pakistan. J. Hydrol. 2019, 570, 473–485. [Google Scholar] [CrossRef]
- Anjum, M.N.; Ding, Y.J.; Shangguan, D.H. Simulation of the projected climate change impacts on the river flow regimes under CMIP5 RCP scenarios in the westerlies dominated belt, northern Pakistan. Atmos. Res. 2019, 227, 233–248. [Google Scholar] [CrossRef]
- Bosshard, T.; Carambia, M.; Goergen, K.; Kotlarski, S.; Krahe, P.; Zappa, M.; Schär, C. Quantifying uncertainty sources in an ensemble of hydrological climate-impact projections. Water Resour. Res. 2013, 49, 1523–1536. [Google Scholar] [CrossRef] [Green Version]
- Sood, A.; Smakhtin, V. Global hydrological models: A review. Hydrol. Sci. J. 2015, 60, 549–565. [Google Scholar] [CrossRef]
- Pradhan, P.; Shrestha, S.; Sundaram, S.M.; Virdis, S.G.P. Evaluation of the CMIP5 general circulation models for simulating the precipitation and temperature of the Koshi River Basin in Nepal. J. Water Clim. Chang. 2021, 12, 3282–3296. [Google Scholar] [CrossRef]
- Almazroui, M.; Islam, M.N.; Saeed, F.; Saeed, S.; Ismail, M.; Ehsan, M.A.; Diallo, I.; O’Brien, E.; Ashfaq, M.; Martínez-Castro, D.; et al. Projected Changes in Temperature and Precipitation Over the United States, Central America, and the Caribbean in CMIP6 GCMs. Earth Syst. Environ. 2021, 5, 1–24. [Google Scholar] [CrossRef]
- Jang, D. An Application of ANN Ensemble for Estimating of Precipitation Using Regional Climate Models. Adv. Civ. Eng. 2021, 2021, 7363471. [Google Scholar] [CrossRef]
- Shiru, M.S.; Chung, E.-S. Performance evaluation of CMIP6 global climate models for selecting models for climate projection over Nigeria. Theor. Appl. Climatol. 2021, 146, 599–615. [Google Scholar] [CrossRef]
- Chen, J.; Brissette, F.P.; Poulin, A.; Leconte, R. Overall uncertainty study of the hydrological impacts of climate change for a Canadian watershed. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- IPCC. IPCC Expert Meeting on Emission Scenarios; IPCC: Washington, DC, USA, 2005. [Google Scholar]
- Lutz, A.F.; ter Maat, H.W.; Biemans, H.; Shrestha, A.B.; Wester, P.; Immerzeel, W.W. Selecting Representative Climate Models for Climate Change Impact Studies: An Advanced Envelope-Based Selection Approach. Int. J. Climatol. 2016, 36, 3988–4005. [Google Scholar] [CrossRef] [Green Version]
- Mendlik, T.; Gobiet, A. Selecting Climate Simulations for Impact Studies Based on Multivariate Patterns of Climate Change. Clim. Chang. 2016, 135, 381–393. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chhin, R.; Yoden, S. Ranking CMIP5 GCMs for Model Ensemble Selection on Regional Scale: Case Study of the Indochina Region. J. Geophys. Res. Atmos. 2018, 123, 8949–8974. [Google Scholar] [CrossRef]
- Azmat, M.; Qamar, M.U.; Huggel, C.; Hussain, E. Future Climate and Cryosphere Impacts on the Hydrology of a Scarcely Gauged Catchment on the Jhelum River Basin, Northern Pakistan. Sci. Total Environ. 2018, 639, 961–976. [Google Scholar] [CrossRef]
- Weigel, A.P.; Knutti, R.; Liniger, M.A.; Appenzeller, C. Risks of Model Weighting in Multimodel Climate Projections. J. Clim. 2010, 23, 4175–4191. [Google Scholar] [CrossRef]
- Knutti, R.; Furrer, R.; Tebaldi, C.; Cermak, J.; Meehl, G. Challenges in Combining Projections from Multiple Climate Models. J. Clim. 2010, 23, 2739–2758. [Google Scholar] [CrossRef] [Green Version]
- McSweeney, C.F.; Jones, R.G.; Lee, R.W.; Rowell, D.P. Selecting CMIP5 GCMs for downscaling over multiple regions. Clim. Dyn. 2015, 44, 3237–3260. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Huang, G.H.; Wang, D.; Zhang, X. Uncertainty assessment of climate change impacts on the hydrology of small prairie wetlands. J. Hydrol. 2011, 396, 94–103. [Google Scholar] [CrossRef] [Green Version]
- Cannon, A.J. Selecting GCM Scenarios that Span the Range of Changes in a Multimodel Ensemble: Application to CMIP5 Climate Extremes Indices. J. Clim. 2015, 28, 1260–1267. [Google Scholar] [CrossRef]
- Carter, T.R. General Guidelines on the Use of Scenario Data for Climate Impact and Adaptation Assessment, 2nd ed.; Task Group on Data and Scenario Support for Impact and Climate Assessment (TGICA); Intergovernmental Panel on Climate Change (IPCC): Helsinki, Finland, 2007; p. 66. [Google Scholar]
- Pennell, C.; Reichler, T. On the Effective Number of Climate Models. J. Clim. 2011, 24, 2358–2367. [Google Scholar] [CrossRef]
- Masson, D.; Knutti, R. Climate model genealogy. Geophys. Res. Lett. 2011, 38, 1–4. [Google Scholar] [CrossRef]
- Nusrat, A.; Gabriel, H.F.; Haider, S.; Ahmad, S.; Shahid, M.; Ahmed Jamal, S. Application of Machine Learning Techniques to Delineate Homogeneous Climate Zones in River Basins of Pakistan for Hydro-Climatic Change Impact Studies. Appl. Sci. 2020, 10, 6878. [Google Scholar] [CrossRef]
- Khan, F.; Pilz, J.; Ali, S. Evaluation of CMIP5 models and ensemble climate projections using a Bayesian approach: A case study of the Upper Indus Basin, Pakistan. Environ. Ecol. Stat. 2021, 28, 383–404. [Google Scholar] [CrossRef]
- Yaseen, M.; Ahmad, I.; Guo, J.L.; Azam, M.I.; Latif, Y. Spatiotemporal Variability in the Hydrometeorological Time-Series over Upper Indus River Basin of Pakistan. Adv. Meteorol. 2020, 2020. [Google Scholar] [CrossRef]
- Asmat, U.; Athar, H.; Nabeel, A.; Latif, M. An AOGCM based assessment of interseasonal variability in Pakistan. Clim. Dyn. 2018, 50, 349–373. [Google Scholar] [CrossRef]
- Azmat, M.; Wahab, A.; Huggel, C.; Qamar, M.U.; Hussain, E.; Ahmad, S.; Waheed, A. Climatic and hydrological projections to changing climate under CORDEX-South Asia experiments over the Karakoram-Hindukush-Himalayan water towers. Sci. Total Environ. 2020, 703, 135010. [Google Scholar] [CrossRef]
- Ahmad, M.; Chand, S.; Yaseen, M. High resolution bayesian spatio-temporal precipitation modelling in pakistan for the appraisal of trends. Pak. J. Agric. Sci. 2020, 57, 1669–1680. [Google Scholar] [CrossRef]
- Mahmood, R.; Jia, S.; Tripathi, N.K.; Shrestha, S. Precipitation Extended Linear Scaling Method for Correcting GCM Precipitation and Its Evaluation and Implication in the Transboundary Jhelum River Basin. Atmosphere 2018, 9, 160. [Google Scholar] [CrossRef] [Green Version]
- Ateequr, R.; Ghumman, A.R.; Ahmad, S.; Hashmi, H.N. Performance assessment of artificial neural networks and support vector regression models for stream flow predictions. Environ. Monit. Assess. 2018, 190. [Google Scholar] [CrossRef]
- Lenderink, G.; van Ulden, A.; van den Hurk, B.; Keller, F. A study on combining global and regional climate model results for generating climate scenarios of temperature and precipitation for the Netherlands. Clim. Dyn. 2007, 29, 157–176. [Google Scholar] [CrossRef] [Green Version]
- Wang, B. The Asian Monsoon; Springer Science & Business Media: Cham, Switzerland, 2006. [Google Scholar]
- Dimri, A.; Niyogi, D.; Barros, A.; Ridley, J.; Mohanty, U.; Yasunari, T.; Sikka, D. Western disturbances: A review. Rev. Geophys. 2015, 53, 225–246. [Google Scholar] [CrossRef]
- Khatri, W.D.; Xiefei, Z.; Ling, Z. Interannual and Interdecadal Variations in Tropical Cyclone Activity over the Arabian Sea and the Impacts over Pakistan. In High-Impact Weather Events over the SAARC Region; Springer: Berlin/Heidelberg, Germany, 2015; pp. 129–145. [Google Scholar]
- Rasul, G.; Chaudhry, Q. Review of advance in research on Asian summer monsoon. Pak. J. Meteorol. 2010, 6, 1–10. [Google Scholar]
- Parvaze, S.; Ahmad, D. Meteorological Drought Quantification with Standardized Precipitation Index for Jhelum Basin in Kashmir Valley. Int. J. Adv. Res. Comput. Sci. Manag. 2018, 7, 688–697. [Google Scholar]
- Mahmood, R.; Babel, M.S.; Jia, S. Assessment of temporal and spatial changes of future climate in the Jhelum river basin, Pakistan and India. Weather Clim. Extrem. 2015, 10, 40–55. [Google Scholar] [CrossRef] [Green Version]
- Rizwan, M.; Jamal, K.; Chen, Y.; Chauhdary, J.N.; Zheng, D.; Anjum, L.; Youhua, R.; Pan, X. Precipitation Variations under a Changing Climate from 1961-2015 in the Source Region of the Indus River. Water 2019, 11, 1366. [Google Scholar] [CrossRef] [Green Version]
- Immerzeel, W.W.; Wanders, N.; Lutz, A.F.; Shea, J.M.; Bierkens, M.F.P. Reconciling High-Altitude Precipitation in the Upper Indus Basin with Glacier Mass Balances and Runoff. Hydrol. Earth Syst. Sci. 2015, 19, 4673–4687. [Google Scholar] [CrossRef] [Green Version]
- Lutz, A.; Immerzeel, W.; Kraaijienbrink, P.D.A. Gridded Meteorological Datasets and Hydrological Modelling in the Upper Indus Basin; Future Water: Wageningen, The Netherlands, 2014; p. 83. [Google Scholar]
- Yatagai, A.; Kamiguchi, K.; Arakawa, O.; Hamada, A.; Yasutomi, N.; Kitoh, A. APHRODITE: Constructing a Long-Term Daily Gridded Precipitation Dataset for Asia Based on a Dense Network of Rain Gauges. Bull. Am. Meteor. Soc. 2012, 93, 1401–1415. [Google Scholar] [CrossRef]
- Lutz, A.; Immerzeel, W. Water Availability Analysis for the Upper Indus, Ganges and Brahmaputra River Basins; Future Water: Wageningen, The Netherlands, 2013; p. 85. [Google Scholar]
- Hersbach, H.; Bell, B.; Berrisford, P.; Biavati, G.; Horányi, A.; Muñoz Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Rozum, I.; et al. ERA5 Hourly Data on Single Levels from 1979 to Present. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels?tab=form (accessed on 2 November 2021).
- Department of Civil and Environmental Engineering Princeton University. Global Meteorological Forcing Dataset for Land Surface Modeling; Computational and Information Systems Laboratory, Research Data Archive at the National Center for Atmospheric Research: Boulder, CO, USA, 2006. [Google Scholar] [CrossRef]
- Chen, H.-P.; Sun, J.-Q.; Li, H.-X. Future changes in precipitation extremes over China using the NEX-GDDP high-resolution daily downscaled data-set. Atmos. Ocean. Sci. Lett. 2017, 10, 403–410. [Google Scholar] [CrossRef] [Green Version]
- Kumar, P.; Kumar, S.; Barat, A.; Sarthi, P.P.; Sinha, A.K. Evaluation of NASA’s NEX-GDDP-simulated summer monsoon rainfall over homogeneous monsoon regions of India. Theor. Appl. Climatol. 2020, 141, 525–536. [Google Scholar] [CrossRef]
- Taylor, E.K.; Ronald, S.; Meehl, G. An Overview of CMIP5 and the Experiment Design. Bull. Am. Meteor. Soc. 2011, 93, 485–498. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Asong, Z.E.; Khaliq, M.N.; Wheater, H.S. Regionalization of Precipitation Characteristics in the Canadian Prairie Provinces Using Large-scale Atmospheric Covariates and Geophysical Attributes. Stoch. Environ. Res. Risk Assess. 2015, 29, 875–892. [Google Scholar] [CrossRef]
- Liu, M.; Huang, Y.; Li, Z.; Tong, B.; Liu, Z.; Sun, M.; Jiang, F.; Zhang, H. The Applicability of LSTM-KNN Model for Real-Time Flood Forecasting in Different Climate Zones in China. Water 2020, 12, 440. [Google Scholar] [CrossRef] [Green Version]
- Zeraatpisheh, M.; Bakhshandeh, E.; Emadi, M.; Li, T.; Xu, M. Integration of PCA and Fuzzy Clustering for Delineation of Soil Management Zones and Cost-Efficiency Analysis in a Citrus Plantation. Sustainability 2020, 12, 5809. [Google Scholar] [CrossRef]
- Chen, Y.; Zheng, B.; Hu, Y. Mapping Local Climate Zones Using ArcGIS-Based Method and Exploring Land Surface Temperature Characteristics in Chenzhou, China. Sustainability 2020, 12, 2974. [Google Scholar] [CrossRef] [Green Version]
- Benestad, R.E.; Chen, D.; Mezghani, A.; Fan, L.; Parding, K. On Using Principal Components to Represent Stations in Empirical–Statistical Downscaling. Tellus A 2015, 67, 28326. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, C.; Li, H. Quality Assessment by Region and Land Cover of Sharpening Approaches Applied to GF-2 Imagery. Appl. Sci. 2020, 10, 3673. [Google Scholar] [CrossRef]
- Abbasi, F.; Bazgeer, S.; Kalehbasti, P.R.; Oskoue, E.A.; Haghighat, M.; Kalebasti, P.R. New climatic zones in Iran: A comparative study of different empirical methods and clustering technique. Theor. Appl. Climatol. 2021, 147, 47–61. [Google Scholar] [CrossRef]
- Sammour, M.; Othman, Z.A.; Muda, Z.; Ibrahim, R. An agglomerative hierarchical clustering with association rules for discovering climate change patterns. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 233–240. [Google Scholar] [CrossRef]
- Mimmack, G.M.; Mason, S.J.; Galpin, J.S. Choice of Distance Matrices in Cluster Analysis: Defining Regions. J. Clim. 2001, 14, 2790–2797. [Google Scholar] [CrossRef]
- Nam, W.; Shin, H.; Jung, Y.; Joo, K.; Heo, J.-H. Delineation of the Climatic Rainfall Regions of South Korea Based on a Multivariate Analysis and Regional Rainfall Frequency Analyses. Int. J. Climatol. 2015, 35, 777–793. [Google Scholar] [CrossRef]
- Carvalho, M.J.; Melo-Gonçalves, P.; Teixeira, J.C.; Rocha, A. Regionalization of Europe Based on a K-Means Cluster Analysis of the Climate Change of Temperatures and Precipitation. Phys. Chem. Earth Parts A/B/C 2016, 94, 22–28. [Google Scholar] [CrossRef] [Green Version]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Van Vuuren, D.P.; Edmonds, J.; Kainuma, M.; Riahi, K.; Thomson, A.; Hibbard, K.; Hurtt, G.C.; Kram, T.; Krey, V.; Lamarque, J.-F.; et al. The Representative Concentration Pathways: An Overview. Clim. Change 2011, 109, 5–31. [Google Scholar] [CrossRef]
- Rozante, J.; Moreira, D.; Godoy, R.C.M.; Fernandes, A. Multi-model ensemble: Technique and validation. Geosci. Model Dev. Discuss. 2014, 7, 2933–2959. [Google Scholar] [CrossRef] [Green Version]
- Stephenson, D.B.; Coelho, C.A.S.; Doblas-Reyes, F.J.; Balmaseda, M. Forecast assimilation: A unified framework for the combination of multi-model weather and climate predictions. Tellus A Dyn. Meteorol. Oceanogr. 2005, 57, 253–264. [Google Scholar] [CrossRef]
- Salman, S.A.; Shahid, S.; Ismail, T.; Ahmed, K.; Wang, X.-J. Selection of Climate Models for Projection of Spatiotemporal Changes in Temperature of Iraq with Uncertainties. Atmos. Res. 2018, 213, 509–522. [Google Scholar] [CrossRef]
- Sen, P.K. Estimates of the Regression Coefficient Based on Kendall’s Tau. J. Am. Stat. Assoc. 1968, 63, 1379–1389. [Google Scholar] [CrossRef]
- Mahmood, R.; Jia, S.F. Spatial and temporal hydro-climatic trends in the transboundary Jhelum River basin. J. Water Clim. Change 2017, 8, 423–440. [Google Scholar] [CrossRef] [Green Version]
- Jasrotia, A.S.; Baru, D.; Kour, R.; Ahmad, S.; Kour, K. Hydrological modeling to simulate stream flow under changing climate conditions in Jhelum catchment, western Himalaya. J. Hydrol. 2021, 593. [Google Scholar] [CrossRef]
- Dahri, Z.H.; Ludwig, F.; Moors, E.; Ahmad, S.; Ahmad, B.; Ahmad, S.; Riaz, M.; Kabat, P. Climate change and hydrological regime of the high-altitude Indus basin under extreme climate scenarios. Sci. Total Environ. 2021, 768, 144467. [Google Scholar] [CrossRef] [PubMed]
- McMahon, T.A.; Peel, M.C.; Karoly, D.J. Assessment of Precipitation and Temperature Data from CMIP3 Global Climate Models for Hydrologic Simulation. Hydrol. Earth Syst. Sci. 2015, 19, 361–377. [Google Scholar] [CrossRef] [Green Version]
- Smith, I.; Chandler, E. Refining Rainfall Projections for the Murray Darling Basin of South-East Australia—The Effect of Sampling Model Results Based on Performance. Clim. Chang. 2010, 102, 377–393. [Google Scholar] [CrossRef]
- Xu, C.-y.; Widén, E.; Halldin, S. Modelling Hydrological Consequences of Climate Change—Progress and Challenges. Adv. Atmos. Sci. 2005, 22, 789–797. [Google Scholar] [CrossRef]
- Kay, A.L.; Davies, H.N.; Bell, V.A.; Jones, R.G. Comparison of Uncertainty Sources for Climate Change Impacts: Flood Frequency in England. Clim. Change 2009, 92, 41–63. [Google Scholar] [CrossRef]
- Woldemeskel, F.M.; Sharma, A.; Sivakumar, B.; Mehrotra, R. An Error Estimation Method for Precipitation and Temperature Projections for Future Climates. J. Geophys. Res. 2012, 117, D22. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, Y.-P.; Fu, G. Uncertainties in SWAT Extreme Flow Simulation under Climate Change. J. Hydrol. 2014, 515, 205–222. [Google Scholar] [CrossRef]
- Latif, M.; Hannachi, A.; Syed, F.S. Analysis of Rainfall Trends over Indo-Pakistan Summer Monsoon and Related Dynamics Based on CMIP5 Climate Model Simulations. Int. J. Climatol. 2018, 38, e577–e595. [Google Scholar] [CrossRef]
- Srinivasa Raju, K.; Sonali, P.; Nagesh Kumar, D. Ranking of CMIP5-based global climate models for India using compromise programming. Theor. Appl. Climatol. 2017, 128, 563–574. [Google Scholar] [CrossRef]
- Khan, N.; Shahid, S.; Ahmed, K.; Ismail, T.; Nawaz, N.; Son, M. Performance Assessment of General Circulation Model in Simulating Daily Precipitation and Temperature Using Multiple Gridded Datasets. Water 2018, 10, 1793. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Clusters | Silhouette Score | Number of Clusters | Silhouette Score |
|---|---|---|---|
| 2 | 0.0279 | 6 | 0.0056 |
| 3 | 0.0249 | 7 | 0.0028 |
| 4 | 0.0184 | 8 | 0.0033 |
| 5 | 0.0171 | 9 | 0.0032 |
| Season | 5 PCs | 10 PCs | 15PCs | 20 PCs |
|---|---|---|---|---|
| Warm Wet | 78 | 88 | 93 | 95 |
| Cold Dry | 77 | 87 | 91 | 94 |
| Cold Wet | 77 | 88 | 92 | 95 |
| Warm Dry | 77 | 86 | 92 | 95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nusrat, A.; Gabriel, H.F.; e Habiba, U.; Rehman, H.U.; Haider, S.; Ahmad, S.; Shahid, M.; Ahmed Jamal, S.; Ali, J. Plausible Precipitation Trends over the Large River Basins of Pakistan in Twenty First Century. Atmosphere 2022, 13, 190. https://doi.org/10.3390/atmos13020190
Nusrat A, Gabriel HF, e Habiba U, Rehman HU, Haider S, Ahmad S, Shahid M, Ahmed Jamal S, Ali J. Plausible Precipitation Trends over the Large River Basins of Pakistan in Twenty First Century. Atmosphere. 2022; 13(2):190. https://doi.org/10.3390/atmos13020190
Chicago/Turabian StyleNusrat, Ammara, Hamza Farooq Gabriel, Umm e Habiba, Habib Ur Rehman, Sajjad Haider, Shakil Ahmad, Muhammad Shahid, Saad Ahmed Jamal, and Jahangir Ali. 2022. "Plausible Precipitation Trends over the Large River Basins of Pakistan in Twenty First Century" Atmosphere 13, no. 2: 190. https://doi.org/10.3390/atmos13020190
APA StyleNusrat, A., Gabriel, H. F., e Habiba, U., Rehman, H. U., Haider, S., Ahmad, S., Shahid, M., Ahmed Jamal, S., & Ali, J. (2022). Plausible Precipitation Trends over the Large River Basins of Pakistan in Twenty First Century. Atmosphere, 13(2), 190. https://doi.org/10.3390/atmos13020190