
Short-Term Intensive Rainfall Forecasting Model Based on a Hierarchical Dynamic Graph Network


Abstract
:1. Introduction
2. Background
2.1. Numerical Weather Prediction
2.2. Spatial–Temporal Sequence Prediction
2.3. Study Area and Data Sources
3. Methodology
3.1. Problem Description
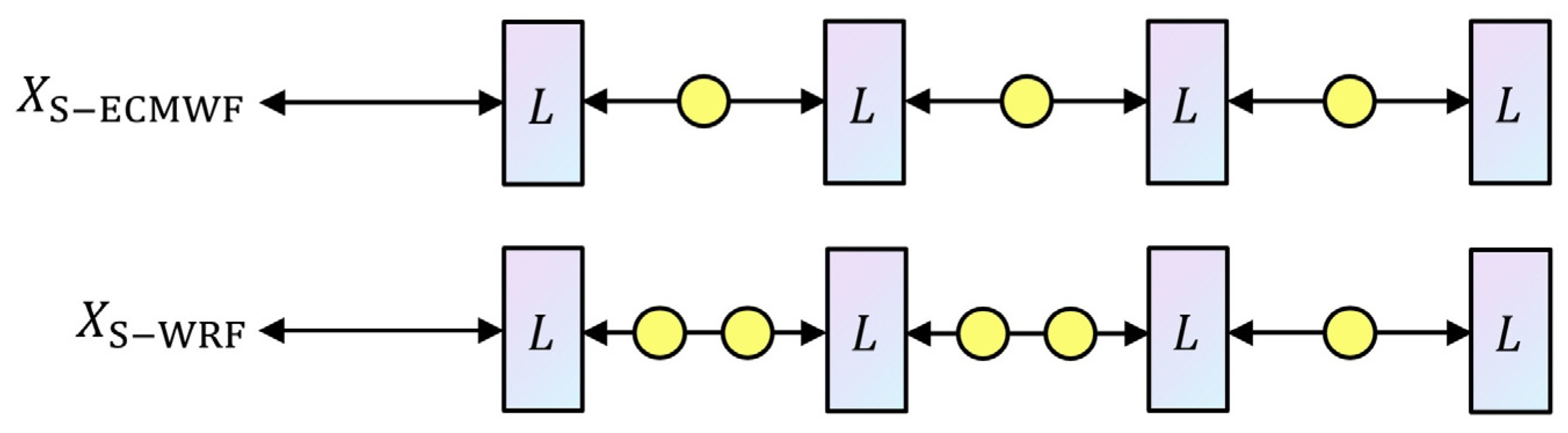
3.2. Data Preprocessing
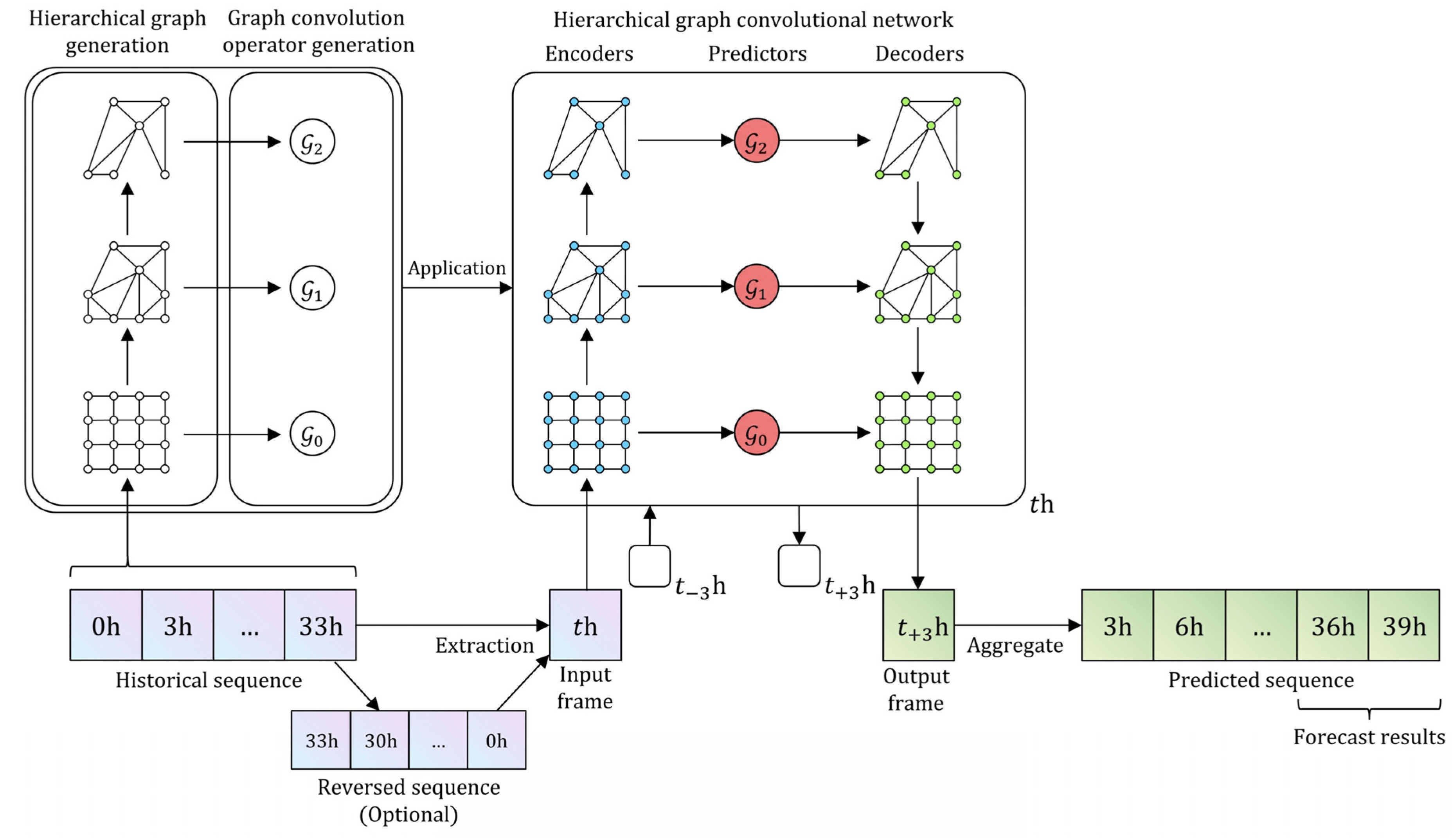
3.3. Hierarchical Dynamic Graph Network
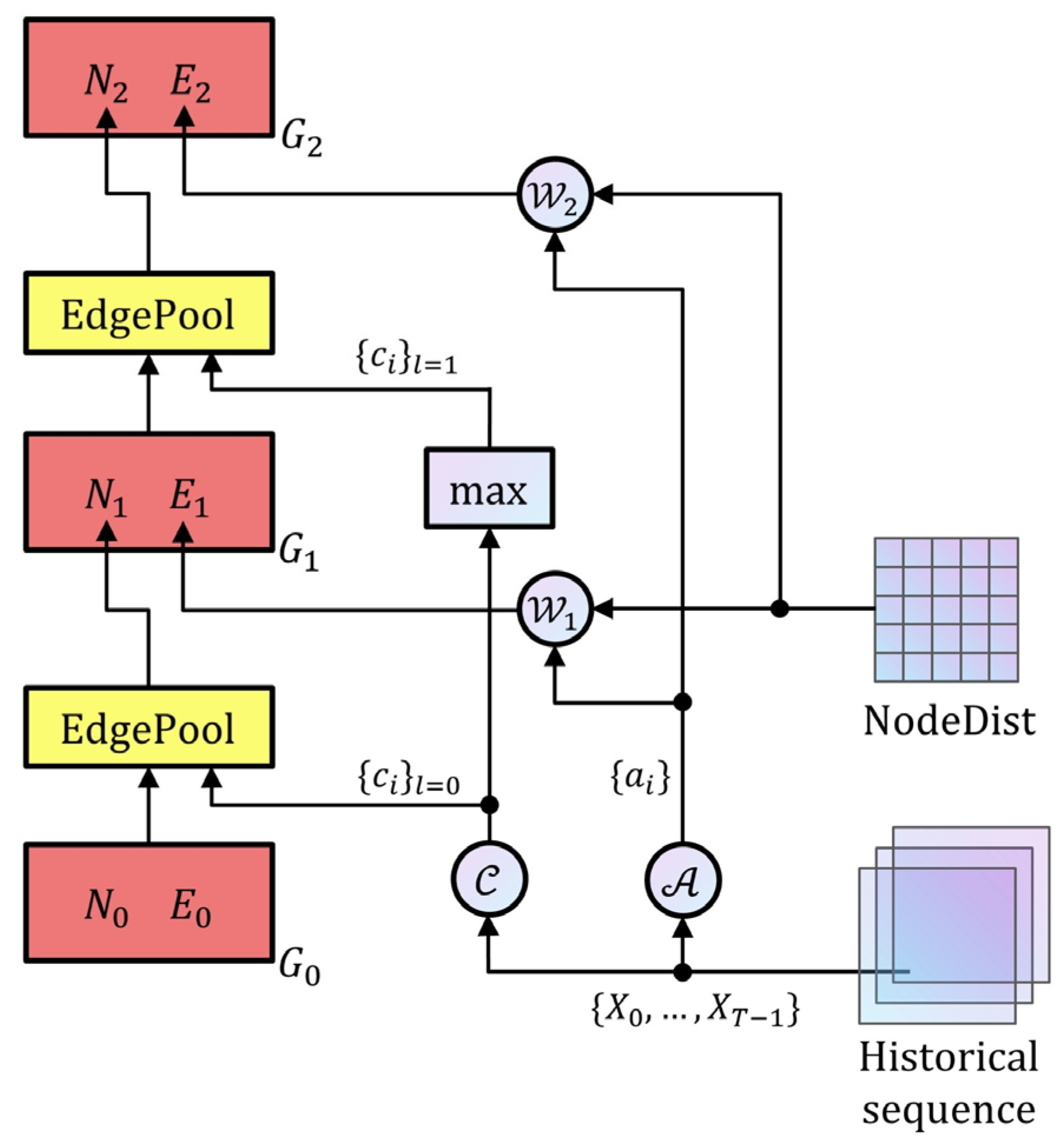
3.3.1. Hierarchical Graph Generation
3.3.2. Graph Convolution Operator Generation
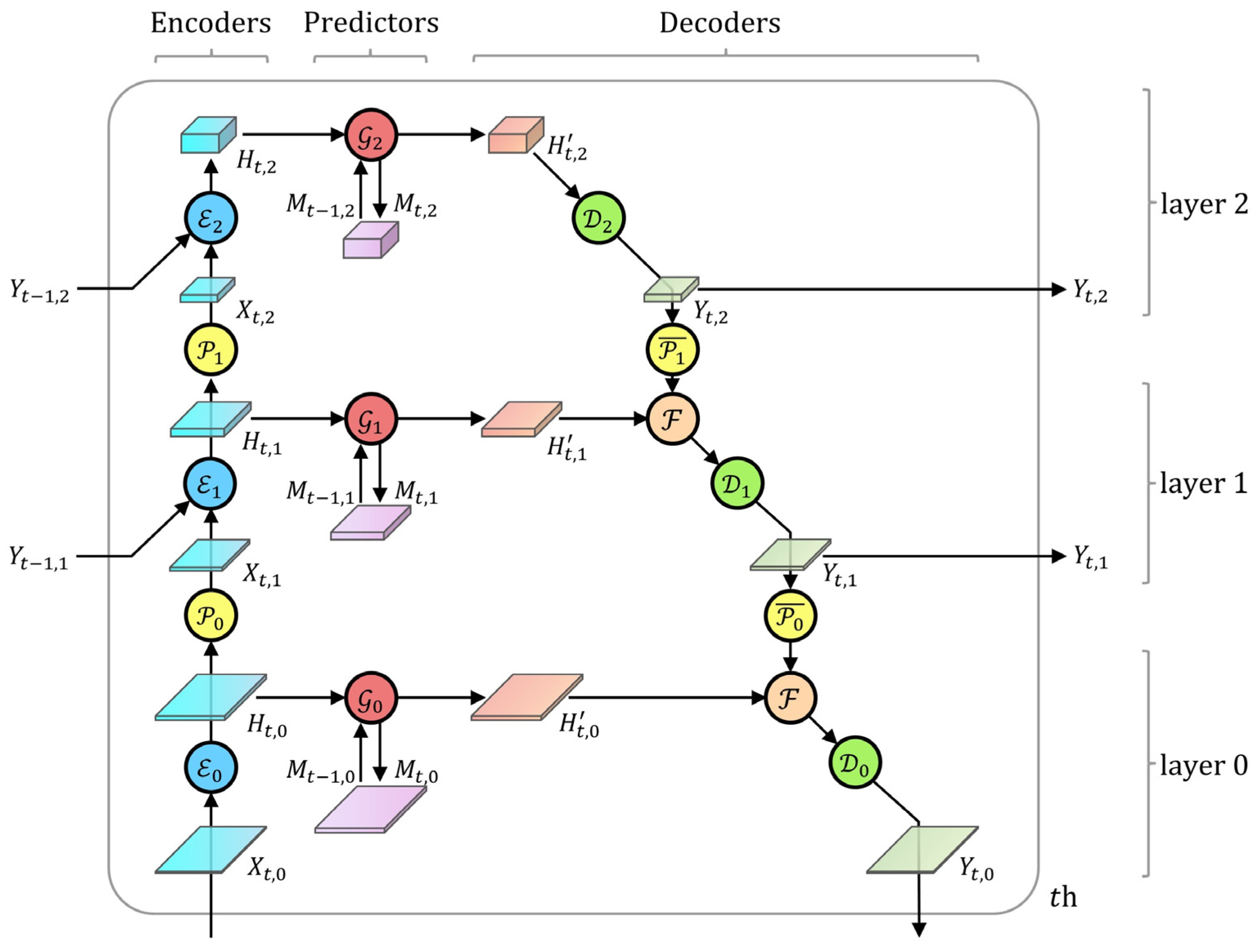
3.3.3. Hierarchical Graph Convolutional Network
3.3.4. Loss Function
4. Experimental Settings and Results
4.1. Experimental Settings
4.1.1. Model Configuration
4.1.2. Evaluation Index
4.2. Results
4.2.1. Comparison
4.2.2. Reversed Sequence Enhancement
4.2.3. Low-Rainfall Sequence Removal
4.2.4. Ablation Study of HDGN
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HDGN | Hierarchical Dynamic Graph Network |
| GCN | Graph Convolutional Network |
| LSTM | Long Short-Term Memory |
| DBN | Deep Belief Network |
| ConvLSTM | Convolutional LSTM |
| Seq2Seq | Sequence-to-Sequence |
| ASTGCN | Attention-based Spatial–Temporal Graph Convolutional Network |
| STGODE | Spatial–Temporal Graph Ordinary Differential Equation |
| GC-LSTM | Graph Convolution embedded LSTM |
| IDW | Inverse Distance Weight |
| DGCRN | Dynamic Graph Convolutional Recurrent Network |
| BDI | Box Difference Index |
| HGCN | Hierarchical Graph Convolutional Network |
| MLP | Multi-Layer Perceptron |
| HA | History Average |
References
- Xie, H.; Wu, L.; Xie, W.; Lin, Q.; Liu, M.; Lin, Y. Improving ECMWF short-term intensive rainfall forecasts using generative adversarial nets and deep belief networks. Atmos. Res. 2021, 249, 105281. [Google Scholar] [CrossRef]
- Liu, C.; Sun, J.; Yang, X.; Jin, S.; Fu, S. Evaluation of ECMWF precipitation predictions in China during 2015–2018. Weather Forecast. 2021, 36, 1043–1060. [Google Scholar] [CrossRef]
- Wang, T.; Liu, Y.; Dong, C.; Li, J. A summary of research on short-term precipitation forecast method and its application. Electron. World 2019, 41, 11–13. [Google Scholar] [CrossRef]
- Woo, W.; Wong, W. Operational Application of Optical Flow Techniques to Radar-Based Rainfall Nowcasting. Atmosphere 2017, 8, 48. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; He, L.; Zhao, H.; Wu, Y.; Huang, Y. Long-Term intelligent calculation and prediction model for heavy precipitation satellite cloud Images. In Proceedings of the 2018 4th International Conference on Advances in Energy Resources and Environment Engineering, ICAESEE 2018, Chengdu, China, 7–9 December 2018. [Google Scholar]
- Shi, E.; Li, Q.; Gu, D.; Zhao, Z. A Method of Weather Radar Echo Extrapolation Based on Convolutional Neural Networks. In Proceedings of the 24th International Conference on MultiMedia Modeling, MMM 2018, Bangkok, Thailand, 5–7 February 2018; pp. 16–28. [Google Scholar]
- Bouget, V.; Béréziat, D.; Brajard, J.; Charantonis, A.; Filoche, A. Fusion of Rain Radar Images and Wind Forecasts in a Deep Learning Model Applied to Rain Nowcasting. Remote Sens. 2021, 13, 246. [Google Scholar] [CrossRef]
- Boukabara, S.-A.; Krasnopolsky, V.; Stewart, J.Q.; Maddy, E.S.; Shahroudi, N.; Hoffman, R.N. Leveraging modern artificial intelligence for remote sensing and NWP: Benefits and challenges. Bull. Am. Meteorol. Soc. 2019, 100, ES473–ES491. [Google Scholar] [CrossRef]
- Zhou, K.; Zheng, Y.; Li, B.; Dong, W.; Zhang, X. Forecasting different types of convective weather: A deep learning approach. J. Meteorol. Res. 2019, 33, 797–809. [Google Scholar] [CrossRef]
- Qian, Z.; Zhou, Q.; Liu, L.; Feng, G. A preliminary study on the characteristics of quiet time and intrinsic dynamic mechanism of precipitation events in the rainy season in eastern China. Acta Meteorol. Sin. 2020, 78, 914. [Google Scholar] [CrossRef]
- Yin, S.; Ren, H. Performance verification of medium-range forecasting by T639, ECMWF and Japan models from September to November 2017. Meteorogical Mon. 2018, 44, 326–333. [Google Scholar]
- Yang, Q.; Dai, Q.; Han, D.; Chen, Y.; Zhang, S. Sensitivity analysis of raindrop size distribution parameterizations in WRF rainfall simulation. Atmos. Res. 2019, 228, 1–13. [Google Scholar] [CrossRef]
- Zhuo, S.; Zhang, J.; Yang, X.; Zi, L.; Qiu, H. Study on Comparison and Evaluation Index of Quantitative Rainfall Forecast Accuracy. J. Water Resour. Res. 2017, 6, 557–567. [Google Scholar] [CrossRef]
- Chen, M.; Yu, X.; Tan, X.; Wang, Y. A brief review on the development of nowcasting for convective storms. J. Appl. Meteorol. Sci. 2004, 15, 754–766. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Narejo, S.; Jawaid, M.M.; Talpur, S.; Baloch, R.; Pasero, E.G.A. Multi-step rainfall forecasting using deep learning approach. PeerJ Comput. Sci. 2021, 7, 1–23. [Google Scholar] [CrossRef]
- Shi, X.; Yeung, D.-Y. Machine learning for spatiotemporal sequence forecasting: A survey. arXiv 2018, arXiv:1808.06865. [Google Scholar]
- Liu, Y.; Racah, E.; Correa, J.; Khosrowshahi, A.; Lavers, D.; Kunkel, K.; Wehner, M.; Collins, W. Application of deep convolutional neural networks for detecting extreme weather in climate datasets. arXiv 2016, arXiv:1605.01156. [Google Scholar]
- Agrawal, S.; Barrington, L.; Bromberg, C.; Burge, J.; Gazen, C.; Hickey, J. Machine learning for precipitation nowcasting from radar images. arXiv 2019, arXiv:1912.12132. [Google Scholar]
- Zhang, C.; Wang, H.; Zeng, J.; Ma, L.; Guan, L. Tiny-RainNet: A deep convolutional neural network with bi-directional long short-term memory model for short-term rainfall prediction. Meteorol. Appl. 2020, 27, e1956. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems, NIPS 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Guen, V.L.; Thome, N. Disentangling physical dynamics from unknown factors for unsupervised video prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11474–11484. [Google Scholar]
- Lan, M.; Ning, S.; Li, Y.; Chen, Q.; Chen, X.; Han, X.; Cui, S. From single to multiple: Leveraging multi-level prediction spaces for video forecasting. arXiv 2021, arXiv:2107.10068. [Google Scholar]
- Su, J.; Byeon, W.; Kossaifi, J.; Huang, F.; Kautz, J.; Anandkumar, A. Convolutional tensor-train LSTM for spatio-temporal learning. In Proceedings of the 34th Conference on Neural Information Processing Systems, NeurIPS 2020, Virtual, Online, 6–12 December 2020. [Google Scholar]
- Seo, S.; Liu, Y. Differentiable physics-informed graph networks. arXiv arXiv:1902.02950, 2019.
- Wang, X.; Ma, Y.; Wang, Y.; Jin, W.; Wang, X.; Tang, J.; Jia, C.; Yu, J. Traffic flow prediction via spatial temporal graph neural network. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1082–1092. [Google Scholar]
- Zheng, C.; Fan, X.; Wang, C.; Qi, J. Gman: A graph multi-attention network for traffic prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 1234–1241. [Google Scholar]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 922–929. [Google Scholar]
- Fang, Z.; Long, Q.; Song, G.; Xie, K. Spatial-temporal graph ODE networks for traffic flow forecasting. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 364–373. [Google Scholar]
- Qi, Y.; Li, Q.; Karimian, H.; Liu, D. A hybrid model for spatiotemporal forecasting of PM2.5 based on graph convolutional neural network and long short-term memory. Sci. Total Environ. 2019, 664, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Feng, J.; Yan, H.; Jin, G.; Jin, D.; Li, Y. Dynamic graph convolutional recurrent network for traffic prediction: Benchmark and solution. arXiv 2021, arXiv:2104.14917. [Google Scholar]
- Lin, X.; Liu, A.; Lin, Y.; Xu, J. Technical Manual of Weather Forecast of Fujian Province; China Meteorological Press: Beijing, China, 2013. [Google Scholar]
- Xie, H.; Zhang, S.; Hou, S.; Zheng, X. Comparison research on rainfall interpolation methods for small sample areas. Res. Soil Water Conserv. 2018, 25, 117–121. [Google Scholar]
- Fu, B.; Peng, M.S.; Li, T.; Stevens, D.E. Developing versus nondeveloping disturbances for tropical cyclone formation. Part II: Western North Pacific. Mon. Weather Rev. 2012, 140, 1067–1080. [Google Scholar] [CrossRef] [Green Version]
- Diehl, F. Edge contraction pooling for graph neural networks. arXiv 2019, arXiv:1905.10990. [Google Scholar]
- Henaff, M.; Bruna, J.; LeCun, Y. Deep convolutional networks on graph-structured data. arXiv 2015, arXiv:1506.05163. [Google Scholar]
- Simonovsky, M.; Komodakis, N. Dynamic edge-conditioned filters in convolutional neural networks on graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3693–3702. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Processing Syst. 2019, 32, 8024–8035. [Google Scholar]
- Foresti, L.; Sideris, I.V.; Nerini, D.; Beusch, L.; Germann, U. Using a 10-year radar archive for nowcasting precipitation growth and decay: A probabilistic machine learning approach. Weather Forecast. 2019, 34, 1547–1569. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Stations | ECMWF250 | ECMWF125 | WRF |
|---|---|---|---|---|
| Horizontal range | 23.52°–28.37° N, 115.84°–120.67° E | 23.5°–28.5° N, 115.5°–121.0° E | 23.5°–28.45° N, 115.5°–120.99° E | |
| Time range | February 2015 to December 2018 | January 2017 to December 2018 | ||
| Time resolution | 3 h | 1 h | ||
| Number of stations/grid points | 2170 | 23 × 21 | 45 × 41 | 62 × 56 |
| Grid spacing | — | 0.25° × 0.25° | 0.125° × 0.125° | 0.09° × 0.09° |
| Number of available features | 3 | 113 | 26 | 24 |
| Starting time of the forecast | — | 08:00 and 20:00 (UTC + 8) | ||
| Data Source | Feature Name | Meaning |
|---|---|---|
| ECMWF125 | Q_850 | Specific humidity 850 kPa |
| Ki | k index | |
| Td_850 | Dew point temperature 850 kPa | |
| GH_1000 | Geopotential height 1000 kPa | |
| Tt_850 | Temperature 850 kPa | |
| ECMWF250 | TCWV | Atmospheric water vapor content |
| MSL | Sea-level pressure | |
| 2D | Dew point temperature 2 m | |
| WRF | TCDC | Total cloud cover |
| RH_850 | Relative humidity 850 kPa | |
| LCDC | Low cloud cover | |
| CR | Combined reflectance | |
| GUST | Wind gust | |
| CAPE | Convective avail pot energy | |
| REFD_1000 | Radar-derived reflectivity 1000 kPa | |
| MSLP | Mean sea-level pressure |
| Actual Class | Predicted Class | ||
|---|---|---|---|
| 0–1 mm | 1–30 mm | >30 mm | |
| 0–1 mm | |||
| 1–30 mm | |||
| >30 mm | |||
| Methods | Predict of First Frame | Predict of Second Frame | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CSI1 | ETS1 | FAR1 | CSI2 | ETS2 | FAR2 | CSI1 | ETS1 | FAR1 | CSI2 | ETS2 | FAR2 | |
| ECMWF | 0.205 | 0.159 | 0.722 | 0.0020 | 0.0018 | 0.9937 | — | — | — | — | — | — |
| HA | 0.102 | 0.086 | 0.578 | 0.0000 | 0.0000 | 1.0000 | 0.088 | 0.067 | 0.862 | 0.0000 | 0.0000 | 1.0000 |
| LSTM | 0.130 | 0.095 | 0.830 | 0.0043 | 0.0019 | 0.9963 | 0.110 | 0.073 | 0.867 | 0.0019 | 0.0008 | 0.9968 |
| ConvLSTM | 0.173 | 0.139 | 0.815 | 0.0059 | 0.0031 | 0.9940 | 0.163 | 0.131 | 0.814 | 0.0031 | 0.0016 | 0.9972 |
| DBN | 0.180 | 0.145 | 0.791 | 0.0069 | 0.0047 | 0.9923 | 0.165 | 0.131 | 0.805 | 0.0035 | 0.0022 | 0.9968 |
| ASTGCN | 0.157 | 0.074 | 0.841 | 0.0114 | 0.0105 | 0.9787 | 0.138 | 0.052 | 0.860 | 0.0051 | 0.0034 | 0.9913 |
| HDGN | 0.115 | 0.026 | 0.885 | 0.0211 | 0.0202 | 0.9576 | 0.107 | 0.018 | 0.892 | 0.0086 | 0.0068 | 0.9790 |
| Methods | Predict of First Frame | Predict of Second Frame | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CSI1 | ETS1 | FAR1 | CSI2 | ETS2 | FAR2 | CSI1 | ETS1 | FAR1 | CSI2 | ETS2 | FAR2 | |
| WRF | 0.143 | 0.076 | 0.839 | 0.0047 | 0.0037 | 0.9953 | — | — | — | — | — | — |
| HA | 0.174 | 0.143 | 0.513 | 0.0000 | 0.0000 | 1.0000 | 0.088 | 0.067 | 0.561 | 0.0000 | 0.0000 | 1.0000 |
| LSTM | 0.151 | 0.135 | 0.823 | 0.0057 | 0.0019 | 0.9944 | 0.124 | 0.110 | 0.853 | 0.0025 | 0.0008 | 0.9980 |
| ConvLSTM | 0.233 | 0.201 | 0.691 | 0.0088 | 0.0050 | 0.9851 | 0.217 | 0.188 | 0.722 | 0.0049 | 0.0027 | 0.9959 |
| DBN | 0.214 | 0.179 | 0.741 | 0.0090 | 0.0061 | 0.9805 | 0.195 | 0.164 | 0.763 | 0.0042 | 0.0029 | 0.9954 |
| ASTGCN | 0.146 | 0.052 | 0.851 | 0.0004 | 0.0004 | 0.9374 | 0.128 | 0.031 | 0.869 | 0.0002 | 0.0001 | 0.9762 |
| HDGN | 0.134 | 0.037 | 0.865 | 0.0343 | 0.0336 | 0.9219 | 0.123 | 0.025 | 0.876 | 0.0140 | 0.0003 | 0.9604 |
| Methods | S-ECMWF Predict of First Frame | S-WRF Predict of First Frame | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CSI1 | ETS1 | FAR1 | CSI2 | ETS2 | FAR2 | CSI1 | ETS1 | FAR1 | CSI2 | ETS2 | FAR2 | |
| ASTGCN | 0.157 | 0.074 | 0.841 | 0.0114 | 0.0105 | 0.9787 | 0.146 | 0.052 | 0.851 | 0.0004 | 0.0004 | 0.9374 |
| ASTGCN + reverse | 0.166 | 0.085 | 0.830 | 0.0153 | 0.0147 | 0.9714 | — | — | — | — | — | — |
| HDGN | 0.115 | 0.026 | 0.885 | 0.0211 | 0.0202 | 0.9576 | 0.134 | 0.037 | 0.865 | 0.0343 | 0.0336 | 0.9219 |
| HDGN + reverse | 0.123 | 0.035 | 0.877 | 0.0254 | 0.0252 | 0.9442 | 0.152 | 0.060 | 0.845 | 0.0401 | 0.0395 | 0.9457 |
| Settings | Data Proportion | S-ECMWF Predict of First Frame | ||||
|---|---|---|---|---|---|---|
| 1–30 mm | >30 mm | CSI1 | ETS1 | CSI2 | ETS2 | |
| del 0% | 0.1240 | 0.001399 | 0.113 | 0.024 | 0.0204 | 0.0196 |
| del 5% | 0.1239 | 0.001398 | 0.118 | 0.030 | 0.0202 | 0.0195 |
| del 10% | 0.1281 | 0.001544 | 0.115 | 0.026 | 0.0211 | 0.0202 |
| del 15% | 0.1246 | 0.001511 | 0.115 | 0.026 | 0.0202 | 0.0194 |
| del 20% | 0.1241 | 0.001495 | 0.115 | 0.027 | 0.0199 | 0.0191 |
| del 50% | 0.1196 | 0.001423 | 0.117 | 0.029 | 0.0179 | 0.0173 |
| Settings | S-ECMWF Predict of First Frame | S-WRF Predict of First Frame | ||||
|---|---|---|---|---|---|---|
| CSI2 | ETS2 | FAR2 | CSI2 | ETS2 | FAR2 | |
| 4 layers | 0.0211 | 0.0209 | 0.9576 | 0.0343 | 0.0341 | 0.9219 |
| 3 layers | 0.0186 | 0.0181 | 0.9631 | 0.0237 | 0.0229 | 0.9390 |
| 2 layers | 0.0007 | 0.0000 | 0.9976 | 0.0016 | 0.0011 | 0.9809 |
| 1 layer | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 1.0000 |
| Settings | S-ECMWF Predict of First Frame | S-WRF Predict of First Frame | ||||
|---|---|---|---|---|---|---|
| CSI2 | ETS2 | FAR2 | CSI2 | ETS2 | FAR2 | |
| HDGN | 0.0211 | 0.0209 | 0.9576 | 0.0343 | 0.0341 | 0.9219 |
| w/o multiplier | 0.0205 | 0.0203 | 0.9573 | 0.0088 | 0.0082 | 0.9647 |
| w/o dynamic graphs | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 1.0000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, H.; Zheng, R.; Lin, Q. Short-Term Intensive Rainfall Forecasting Model Based on a Hierarchical Dynamic Graph Network. Atmosphere 2022, 13, 703. https://doi.org/10.3390/atmos13050703
Xie H, Zheng R, Lin Q. Short-Term Intensive Rainfall Forecasting Model Based on a Hierarchical Dynamic Graph Network. Atmosphere. 2022; 13(5):703. https://doi.org/10.3390/atmos13050703
Chicago/Turabian StyleXie, Huosheng, Rongyao Zheng, and Qing Lin. 2022. "Short-Term Intensive Rainfall Forecasting Model Based on a Hierarchical Dynamic Graph Network" Atmosphere 13, no. 5: 703. https://doi.org/10.3390/atmos13050703