
Summer Precipitation Forecast Using an Optimized Artificial Neural Network with a Genetic Algorithm for Yangtze-Huaihe River Basin, China


 ,
,  ,
, 
Abstract
:1. Introduction
2. Data and Model Construction
2.1. Data
2.2. Model Introduction
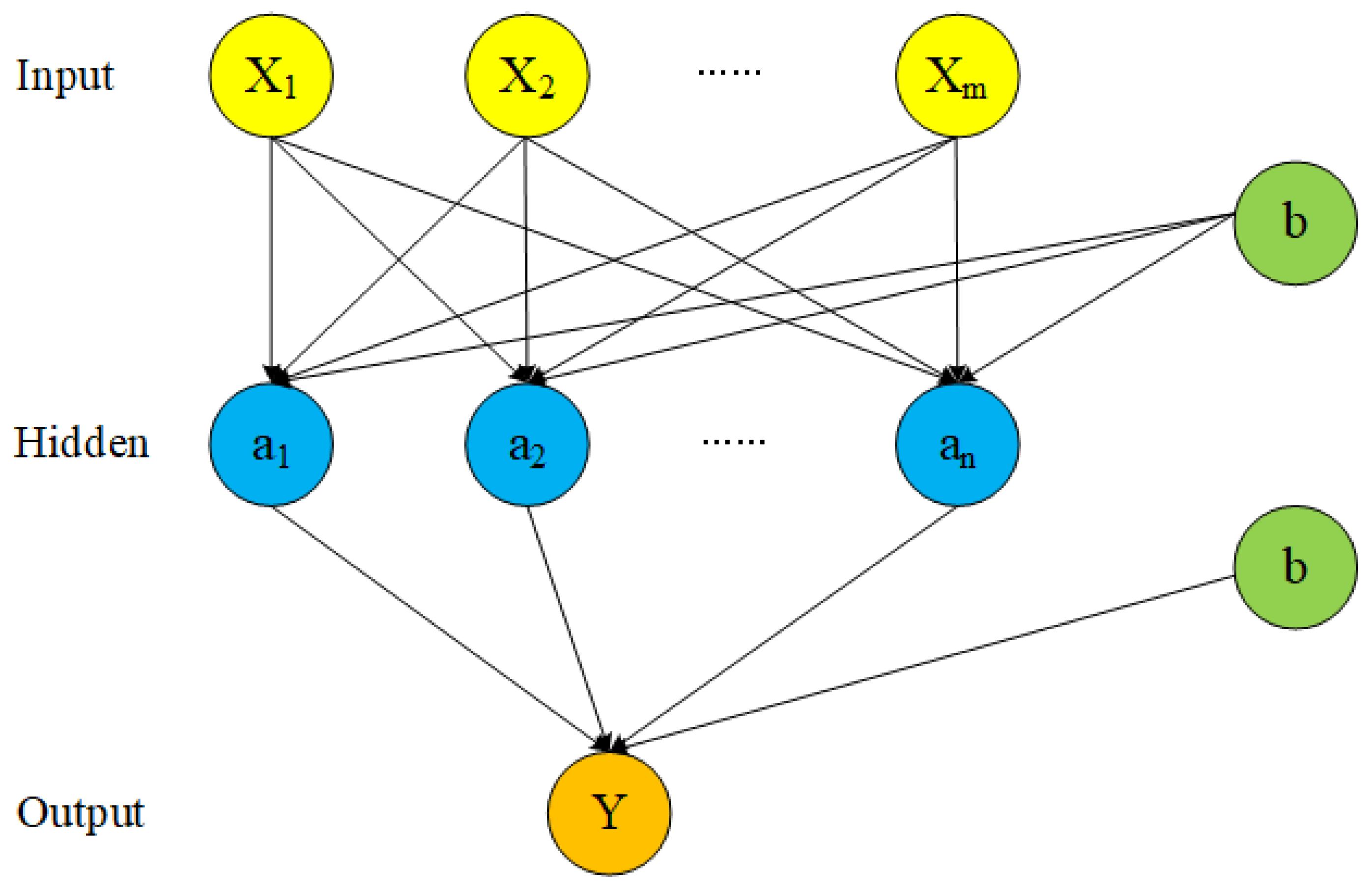
2.2.1. Backpropagation Neural Network
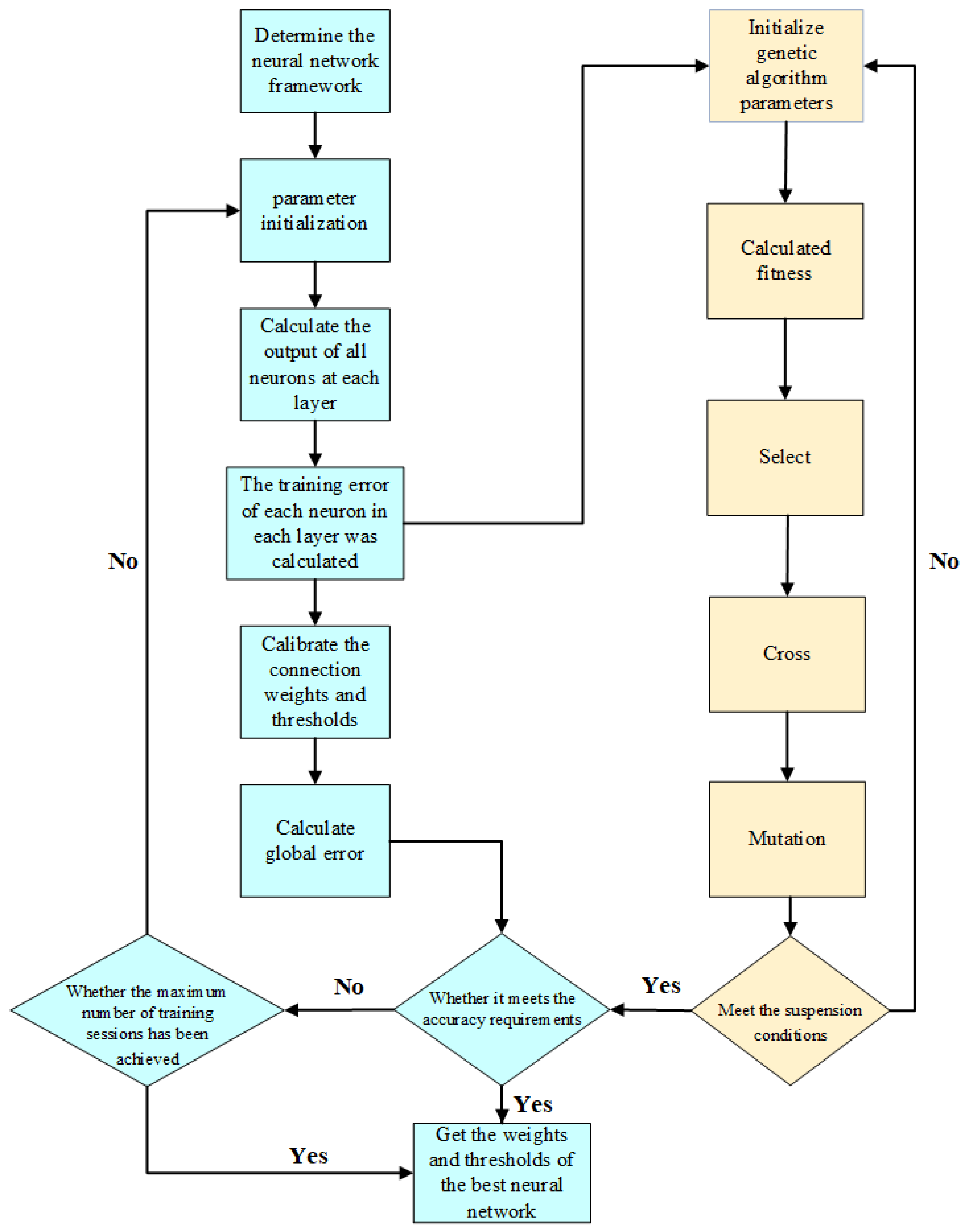
2.2.2. BPNN Optimized by Genetic Algorithm
2.2.3. Multiple Linear Regression
2.2.4. Support Vector Machine
2.3. Modeling Process
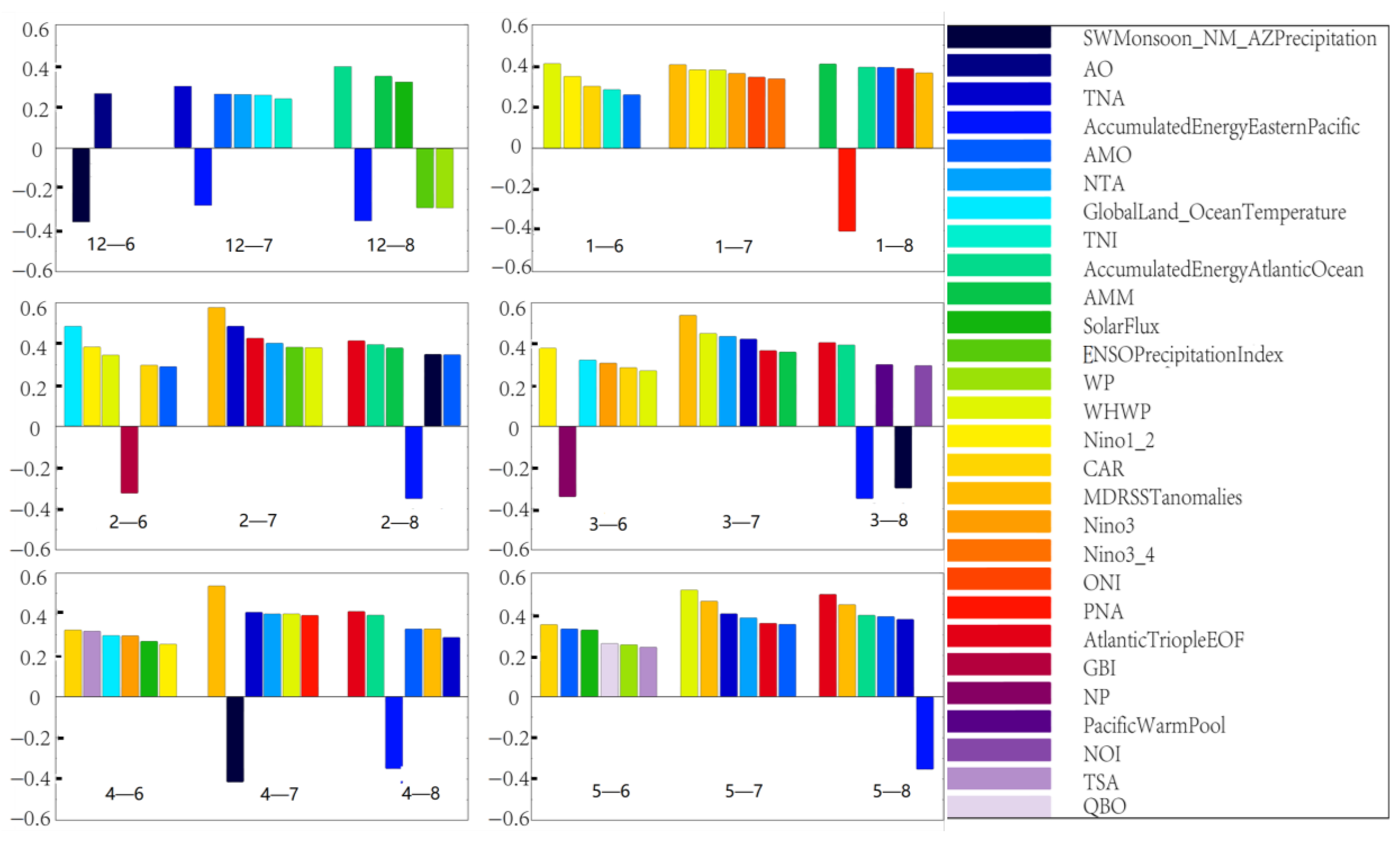
2.3.1. Factor Selection
2.3.2. Procedure of BPNN Forecasts
- (a)
- Standard BPNN modeling process
- (b)
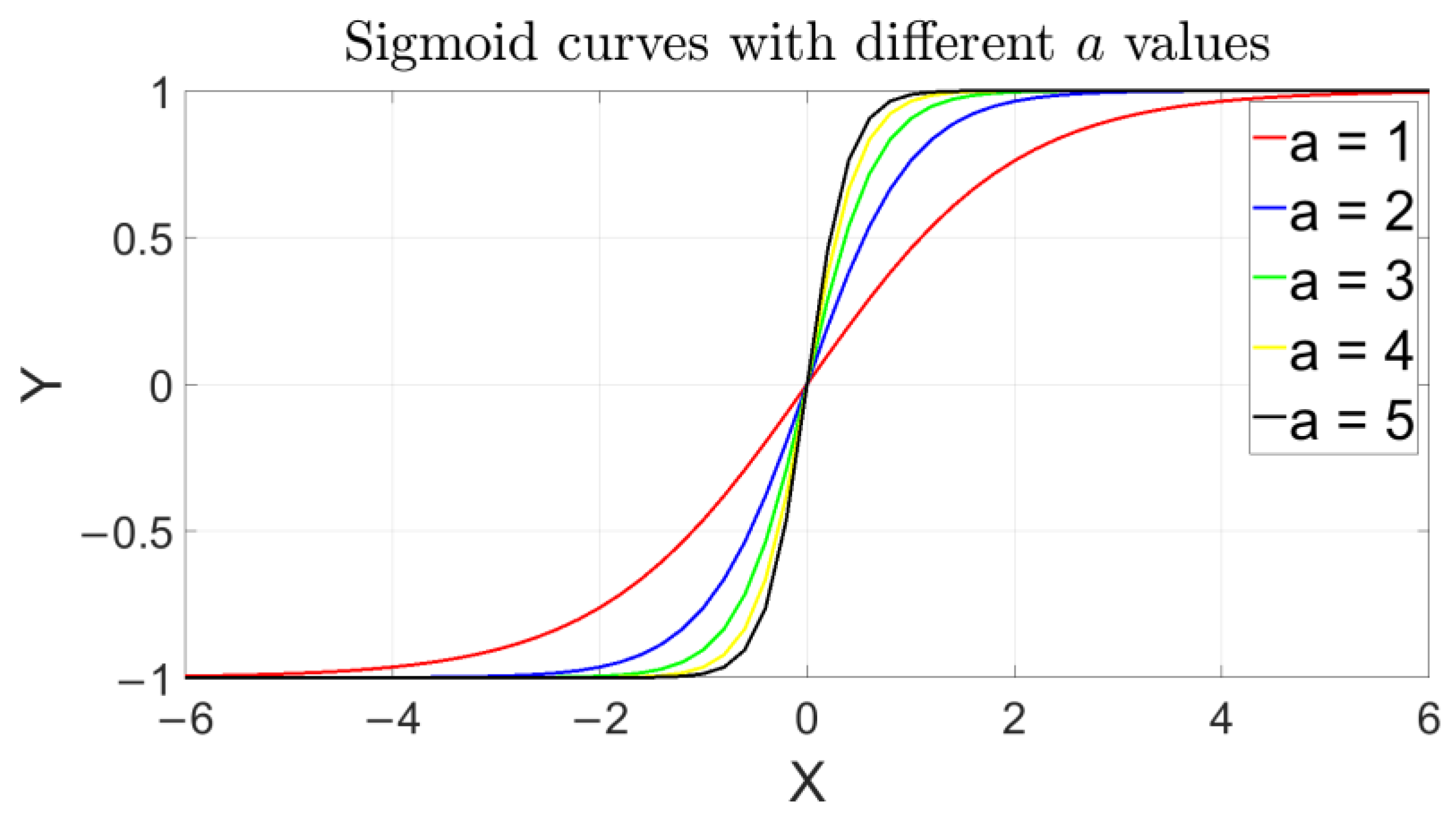
- Activation function selection and parameter tuning
2.3.3. GABP Calculation Process
2.3.4. Multiple Linear Regression Calculation Process
2.4. Model Evaluation Measures
3. Predicted Results
3.1. Comparison of Basin-Averaged Measures among the Four Methods
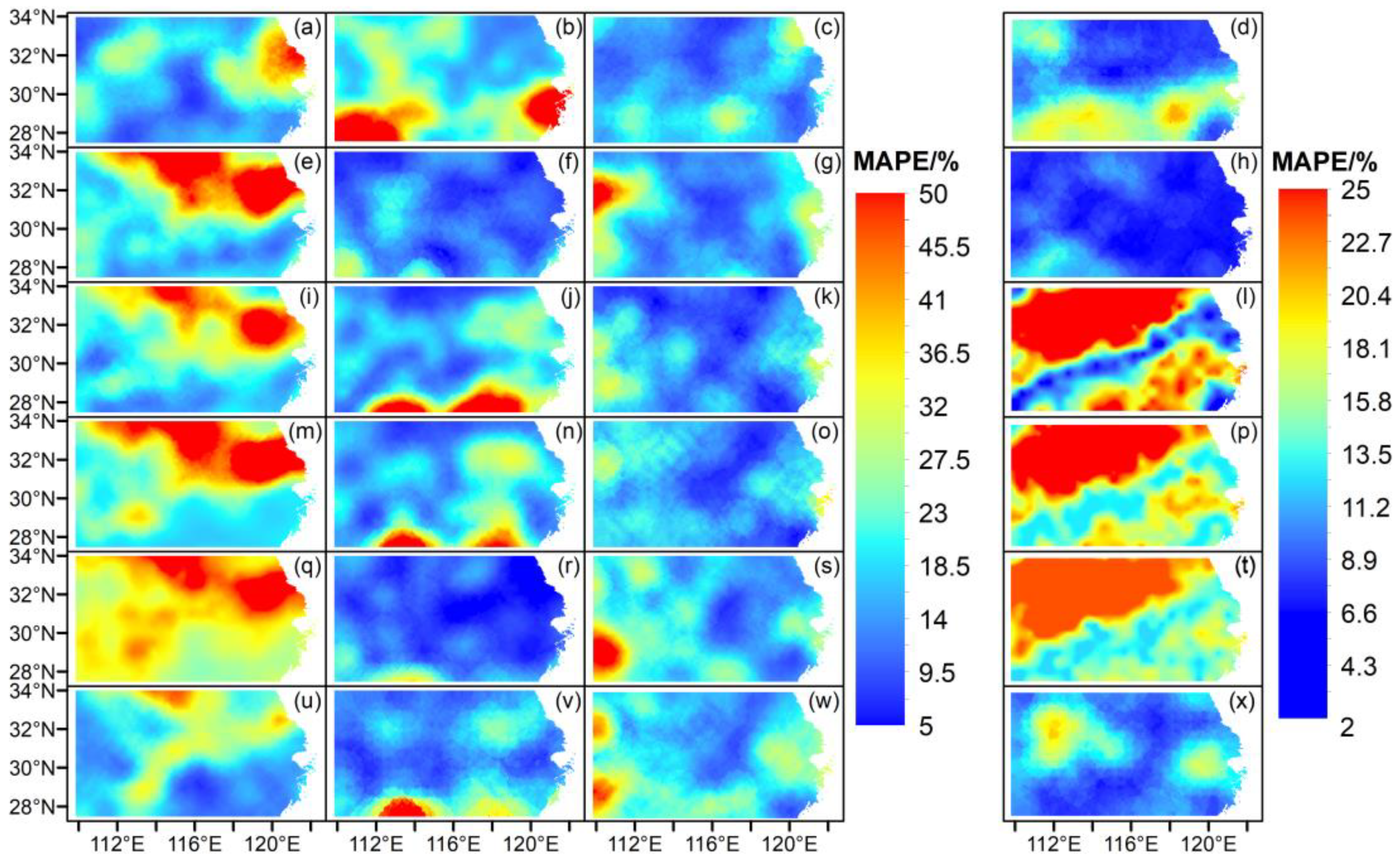
3.2. GABP-Produced Spatial Distributions of the Measures
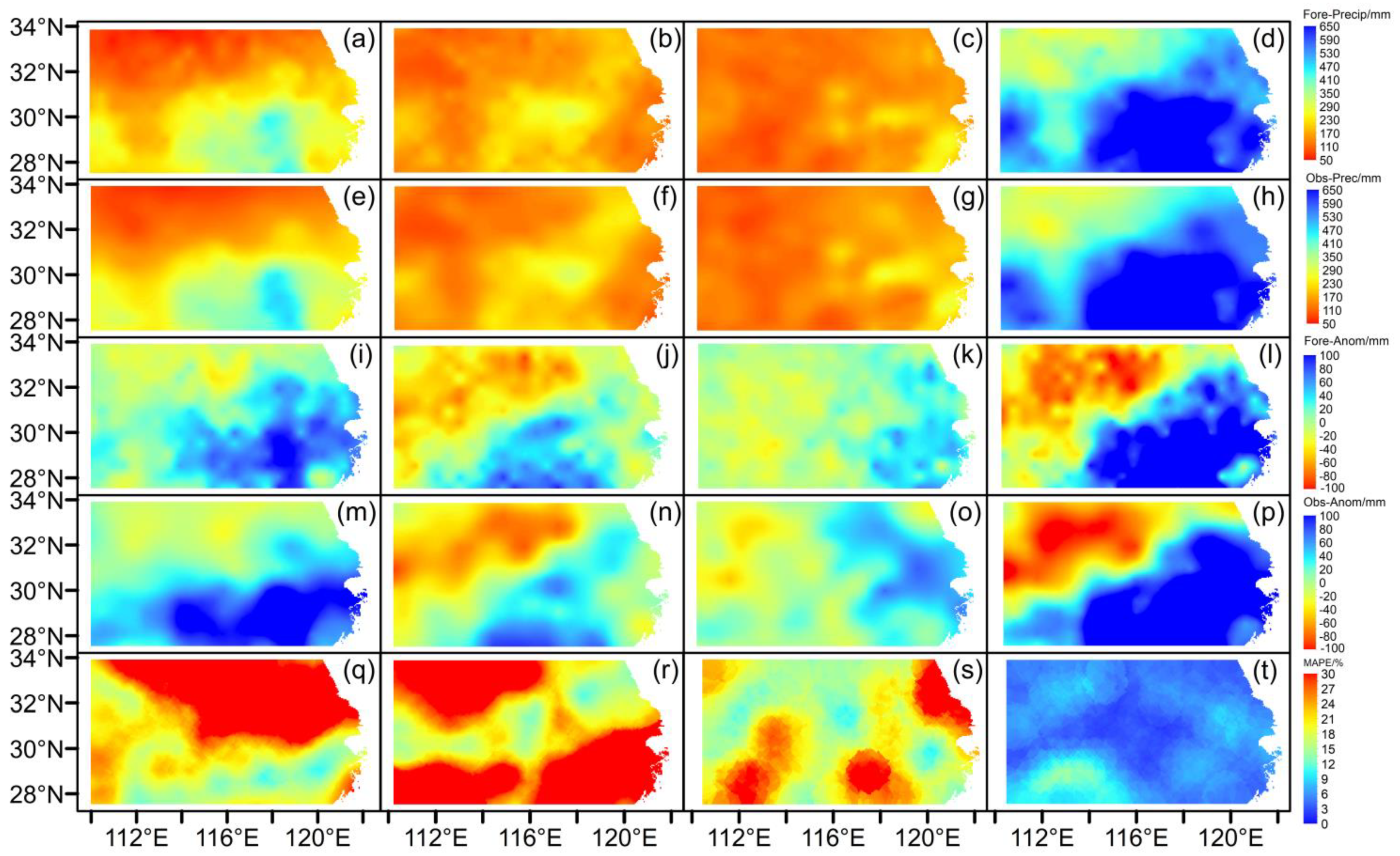
3.3. Spatial Distributions of Forecasted Summer Precipitation by the Best GABP Model
4. Concluding Remarks
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Predictors/Indices Used for Precipitation Forecast with Available Resources Listed
| SOI | Southern Oscillation Index; NOAA Climate Prediction Center (CPC) |
| PNA | Pacific North America Index; NOAA Climate Prediction Center (CPC) |
| NAO | North Atlantic Oscillation Index; NOAA Climate Prediction Center (CPC) |
| ONI | Ocean Nino Index; NOAA Climate Prediction Center (CPC) |
| NTA | Tropical North Atlantic Sea Temperature Index; ERSST V3b data set |
| CAR | Caribbean Sea Temperature Index; NOAA ERSST V3b data set |
| ENSO precipitation index | ENSO precipitation index; http://precip.gsfc.nasa.gov/ESPItable.html, accessed on 6 June 2021 |
| BEST | Bivariate ENSO time series; NOAA OI V2 SST data set |
| Nino3 | Tropical East Pacific Sea Temperature; NOAA ERSST V5 data set |
| Nino4 | Tropical Central Pacific Sea Temperature; NOAA ERSST V5 data set |
| Nino1+2 | Extreme eastern tropical Pacific sea temperature; NOAA ERSST V5 data set |
| Nino3+4 | The sea temperature of the tropical central and eastern Pacific Ocean; NOAA ERSST V5 |
| TNA | Tropical North Atlantic Index; HadISST and NOAA OI 1° × 1° data set |
| TSA | Tropical South Atlantic Index, from HadISST and NOAA OI 1° × 1° data set |
| Atlantic Tripole SST EOF | The first EOF mode of the tropical Atlantic SST |
| WP | Western Pacific Index; NOAA Climate Prediction Center (CPC) |
| QBO | Quasi-Biennial oscillation; zonal average of the equatorial 30mb zonal wind calculated by NCEP/NCAR reanalysis |
| WHWP | Monthly anomaly of the western hemisphere warm pool area above 28.5 degrees; HadISST and NOAA OI datasets |
| PDO | Pacific Interdecadal Oscillation; NOAA Climate Prediction Center (CPC) |
| NOI | Arctic Oscillation Index; NOAA Climate Prediction Center (CPC) |
| NP | North Pacific Oscillation; NOAA Climate Prediction Center (CPC) |
| EP | East Pacific Oscillation; NOAA Climate Prediction Center (CPC) |
| AAO | Antarctic Oscillation; NOAA Climate Prediction Center (CPC) |
| Pacific Warmpool SST EOF | first mode of Pacific Warmpool; NOAA OI 1° × 1° data set |
| Tropical Pacific SST EOF | Tropical Pacific SST EOF first mode; NOAA OI 1° × 1° data set |
| TNI | El-Niño Evolution Index; http://psl.noaa.gov/Pressure/Timeseries/TNI/, accessed on 6 June 2021 |
| AMO | Atlantic Multidecadal Oscillation long version; Kalplan sea surface temperature |
| AMM | Atlantic meridian model; NOAA Climate Prediction Center (CPC) |
| Indian | Rainfall Index in Central India; http://www.tropmet.res.in/, accessed on 6 June 2021 |
| Sahel | Sahel regional precipitation index; http://jisao.washington.edu/data_sets/sahel/Mitchell, accessed on 6 June 2021 |
| NAO | North Atlantic Oscillation; University of East Anglia Climatic Research Unit (CRU) |
| MEI | Multivariate ENSO Index; NOAA PSL data |
| AO | Arctic Oscillation; NOAA Climate Prediction Center (CPC) |
| Brazil | Precipitation anomalies in northeastern Brazil; http://jisao.washington.edu/data_sets/brazil/, accessed on 6 June 2021 |
| Solar Flux | from ftp://ftp.ngdc.noaa.gov/STP/space-weather/solar-data/, accessed on 6 June 2021 |
| Hurricane activity | Monthly Atlantic hurricanes and tropical storms; Colorado State University |
| Global Mean Land/Ocean Temperature | NASA Goddard Institute for Space Studies (GISS) |
| SW Monsoon Region rainfall | Average rainfall in Arizona and New Mexico; the climate department of NCDC |
| MDRSST | MDR minus tropical sea temperature observation anomalies, PSL from NOAA |
| AEEP | Accumulated Energy Eastern Pacific; NOAA Climate Prediction Center (CPC) |
| AEAO | Accumulated Energy Atlantic Ocean; NOAA Climate Prediction Center (CPC) |
| Atlantic Tripole EOF | The first EOF mode of tropical Pacific SST; NOAA Climate Prediction Center (CPC) |
References
- Wu, J.D.; Fu, Y.; Zhang, J.; Li, N. Analysis on the trend of meteorological disasters in China from 1949 to 2013. J. Nat. Resour. 2014, 29, 1520–1530. (In Chinese) [Google Scholar]
- Liu, Y.Y.; Ding, Y.H. Characteristics and possible causes for extreme Meiyu in 2020. Meteor. Mon. 2020, 46, 1483–1493. (In Chinese) [Google Scholar]
- Peng, Y.Z.; Wang, Q.; Yuan, C.; Lin, K.P. Review of Research on Data Mining in Application of Meteorological Forecasting. J. Arid Meteorol. 2015, 33, 19–27. (In Chinese) [Google Scholar]
- Li, C.Y. Climate Dynamics, 2nd ed.; Chapter 1; Meteorological Press: Beijing, China, 2000; pp. 2–3. [Google Scholar]
- Wang, X.; Song, L.C.; Wang, G.F.; Ren, H.L.; Wu, T.W.; Jia, X.L.; Wu, H.P.; Wu, J. Operational climate prediction in the era of big data in China: Reviews and prospects. J. Meteorol. Res. 2016, 30, 444–456. [Google Scholar] [CrossRef]
- Arcomano, T.; Szunyogh, I.; Pathak, J.; Wikner, A.; Hunt, B.R.; Ott, E. A machine learning-based global atmospheric forecast model. Geophys. Res. Lett. 2020, 47, e2020GL087776. [Google Scholar] [CrossRef]
- Bauer, P.; Thorpe, A.; Brunet, G. The quiet revolution of numerical weather prediction. Nature 2015, 525, 47–55. [Google Scholar] [CrossRef] [PubMed]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Gómez-Chova, L.; Tuia, D.; Moser, G.; Camps-Valls, G. Multimodal classification of remote sensing images: A review and future directions. Proc. IEEE 2015, 103, 1560–1584. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Tuia, D.; Bruzzone, L.; Benediktsson, J.A. Advances in hyperspectral image classification: Earth monitoring with statistical learning methods. IEEE Signal. Process. Mag. 2014, 31, 45–54. [Google Scholar] [CrossRef] [Green Version]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recogn. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Muhlbauer, A.; McCoy, I.L.; Wood, R. Climatology of stratocumulus cloud morphologies: Microphysical properties and radiative effects. Atmos. Chem. Phys. 2014, 14, 6695–6716. [Google Scholar] [CrossRef] [Green Version]
- Pan, B.; Hsu, K.; AghaKouchak, A.; Sorooshian, S. Improving precipitation estimation using convolutional neural network. Water Resour. Res. 2019, 55, 2301–2321. [Google Scholar] [CrossRef] [Green Version]
- Toms, B.A.; Barnes, E.A.; Ebert-Uphoff, I. Physically interpretable neural networks for the geosciences: Applications to Earth system variability. J. Adv. Modeling Earth Syst. 2020, 12, e2019MS002002. [Google Scholar] [CrossRef]
- Sharifi, E.; Saghafian, B.; Steinacker, R. Downscaling satellite precipitation estimates with multiple linear regression, artificial neural networks, and spline interpolation techniques. J. Geophys. Res. Atmos. 2019, 124, 789–805. [Google Scholar] [CrossRef] [Green Version]
- Nearing, G.S.; Kratzert, F.; Sampson, A.K.; Pelissier, C.S.; Klotz, D.; Frame, J.M.; Prieto, C.; Gupta, H.V. What role does hydrological science play in the age of machine learning? Water Resour. Res. 2021, 57, e2020WR028091. [Google Scholar] [CrossRef]
- Pham, Q.; Yang, T.-C.; Kuo, C.-M.; Tseng, H.-W.; Yu, P.-S. Combing Random Forest and Least Square Support Vector Regression for Improving Extreme Rainfall Downscaling. Water 2019, 11, 451. [Google Scholar] [CrossRef] [Green Version]
- Kang, J.; Wang, H.; Yuan, F.; Wang, Z.; Huang, J.; Qiu, T. Prediction of summer precipitation in China based on LSTM network. Clim. Change Res. 2020, 16, 263–275. [Google Scholar]
- He, C.; Wei, J.; Song, Y.; Luo, J.-J. Seasonal Prediction of Summer Precipitation in the Middle and Lower Reaches of the Yangtze River Valley: Comparison of Machine Learning and Climate Model Predictions. Water 2021, 13, 3294. [Google Scholar] [CrossRef]
- Gagne, D.J., II; McGovern, A.; Xue, M. Machine Learning Enhancement of Storm-Scale Ensemble Probabilistic Quantitative Precipitation Forecasts. Weather. Forecast. 2014, 29, 1024–1043. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Wang, X.; Guan, J. A Novel Multiple-Input Multiple-Output Recurrent Neural Network Based on Multimodal Fusion and Spatiotemporal Prediction for 0–4 h Precipitation Nowcasting. Atmosphere 2021, 12, 1596. [Google Scholar] [CrossRef]
- Kishtawal, C.M.; Basu, S.; Patadia, F.; Thapliyal, P.K. Forecasting summer rainfall over India using genetic algorithm. Geophys. Res. Lett. 2003, 30, 2203. [Google Scholar] [CrossRef]
- Feng, Y.; Zhang, W.F.; Sun, D.Z.; Zhang, L.Q. Ozone concentration forecast method based on genetic algorithm optimized back propagation neural networks and support vector machine data classification. Atmos. Environ. 2011, 45, 1979–1985. [Google Scholar] [CrossRef]
- Huang, X.Y.; Zhao, H.S.; Huang, Y.; Lin, K.P.; He, L. Application of genetic-neural network ensemble forecasting method to tropical cyclone precipitation forecast in Guangxi. J. Nat. Disasters 2017, 26, 184–196. [Google Scholar]
- Jin, L. Theory and Application of Neural Network Weather Forecast Modeling; China Meteorological Press: Beijing, China; pp. 41–45. (In Chinese)
- Jin, L.; Luo, Y.; Li, Y.H. Study on mixed prediction model of artificial neural for long range weather. J. Syst. Engi. 2003, 18, 331–336. (In Chinese) [Google Scholar]
- Zhao, J.L. Genetic algorithm for solving nonlinear optimization problems. Prog. Geophys. 1992, 7, 90–97. (In Chinese) [Google Scholar]
- Peng, Z.L. Research on China’s Seasonal Precipitation Forecast and Application Based on the Combination of Statistical Model and Dynamic Multi-Model; Dalian University of Technology: Dalian, China, 2014. (In Chinese) [Google Scholar]
- Wang, J.Z.; Liu, L.; Xu, J.Y. Daily flow forecast based on genetic algorithm and support vector machine. Hydropower Energy Sci. 2008, 26, 14–17. (In Chinese) [Google Scholar]
- Ghahramani, Z. Probabilistic machine learning and artificial intelligence. Nature 2015, 521, 452–459. [Google Scholar] [CrossRef]
- Liu, X.P.; Wang, H.J.; He, M.Y. Estimation of precipitation under future climate scenarios in the Yangtze-Huaihe region statistical downscaling. Adv. Water Sci. 2012, 23, 29–37. (In Chinese) [Google Scholar]
- Du, Y.; Long, K.H.; Wang, D.Y.; Wang, D.G. Prediction of annual precipitation in Anhui Province based on machine learning methods. Hydropower Energy Sci. 2020, 38, 5–7. (In Chinese) [Google Scholar]
- Sun, Y.X.; Feng, N. Application of Exhaustive Method in Programming. Comput. Times 2012, 8, 50–52. [Google Scholar]
- Shen, H.Y.; Wang, Z.X.; Qin, J. Determining the number of BP neural network hidden layer units. J. Tianjin Univ. Technol. 2008, 5, 13–15. (In Chinese) [Google Scholar]
- Zhen, Y.W.; Hao, M.; Lu, B.H.; Zuo, J.; Liu, H. Research of Medium and Long Term Precipitation Forecasting Model Based on Random Forest. Water Resour. Power 2015, 6, 6–10. [Google Scholar]
- Bai, H.; Gao, H.; Liu, C.Z. Assessment of Multi-model Downscaling Ensemble Prediction System for Monthly Temperature and Precipitation Prediction in Guizhou. J. Desert Oasis Meteorol. 2016, 10, 58–63. (In Chinese) [Google Scholar]
- Yao, S.B.; Jiang, D.B.; Fan, G.Z. Projection of precipitation seasonality over China. Chin. J. Atmos. Sci. 2018, 42, 1378–1392. (In Chinese) [Google Scholar]
- Yang, Y.; Dai, X.G.; Tang, H.W.; Zhang, B. CMIP5 Model Precipitation Bias-correction Methods and Projected China Precipitation for the Next 30 Years. Clim. Environ. Res. 2019, 24, 769–784. (In Chinese) [Google Scholar]
- Wang, H.; Ren, H.; Chen, H.; Jiehua, M.; Baoqiang, T.; Bo, S.; Yanyan, H.; Mingkeng, D.; Jun, W.; Lin, W. Highlights of climate prediction study and operation in China over the past decades. Acta Meteorol. Sin. 2020, 78, 317–331. (In Chinese) [Google Scholar]
- Ding, Y.; Chan, J.C.L. The East Asian summer monsoon: An overview. Meteor. Atmos. Phys. 2005, 89, 117–142. [Google Scholar]
- Zeng, X.M.; Wang, M.; Wang, N.; Yi, X.; Chen, C.H.; Zhou, Z.G.; Wang, G.L.; Zheng, Y.Q. Assessing simulated summer 10-m wind speed over China: Influencing processes and sensitivities to land surface schemes. Clim. Dyn. 2018, 50, 4189–4209. [Google Scholar] [CrossRef]
- Chen, C.; Georgakakos, A.P. Hydro-climatic forecasting using sea surface temperatures: Methodology and application for the southeast US. Clim. Dyn 2014, 42, 2955–2982. [Google Scholar] [CrossRef]
- Qian, S.N.; Chen, J.; Li, X.Q.; Xu, C.Y.; Guo, S.L.; Chen, H.; Wu, X.S. Seasonal rainfall forecasting for the Yangtze River basin using statistical and dynamical models. Int. J. Climatol. 2020, 40, 361–377. [Google Scholar] [CrossRef]
- Nitta, T. Convective activities in the tropical western Pacific and their impact on the Northern Hemisphere summer circulation. J. Meteor. Soc. Jpn. 1987, 64, 373–390. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Sumi, A.; Kimoto, M. Impact of El Niño on the East Asian monsoon. J. Meteor. Soc. Jpn. 1996, 74, 49–62. [Google Scholar] [CrossRef] [Green Version]
- Huang, R.; Gu, L.; Zhou, L.; Shangsen, L. Impact of the thermal state of the tropical western Pacific on onset date and process of the South China Sea summer monsoon. Adv. Atmos. Sci. 2006, 23, 909–924. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measure | Method | M12-6 | M12-7 | M12-8 | M1-6 | M1-7 | M1-8 | M2-6 | M2-7 | M2-8 |
|---|---|---|---|---|---|---|---|---|---|---|
| (M3-6) | (M3-7) | (M3-8) | (M4-6) | (M4-7) | (M4-8) | (M5-6) | (M5-7) | (M5-8) | ||
| MAPE/% | BPNN | 108.3 | 94.1 | 73.4 | 84.6 | 57.7 | 94.3 | 79.7 | 94 | 89 |
| (98.1) | (86.6) | (92.7) | (80.7) | (62.7) | (88.8) | (71.7) | (78.6) | (109.5) | ||
| GABP | 19.7 | 27.4 | 15.9 | 29.6 | 13.9 | 18.8 | 23.8 | 21.3 | 16 | |
| (31.5) | (19.9) | (17.1) | (27.6) | (12.9) | (20.4) | (31.3) | (18.3) | (20.6) | ||
| SVM | 43.8 | 58.6 | 32.3 | 51.3 | 61.9 | 39 | 51.5 | 45.4 | 41.5 | |
| (52.8) | (45.6) | (43.1) | (52) | (33.5) | (44.3) | (46.5) | (61.5) | (44.9) | ||
| MLR | 51.9 | 76.6 | 69.5 | 71.2 | 45.7 | 57.5 | 63.5 | 72 | 121 | |
| (98.6) | (160.1) | (87.7) | (60) | (171.8) | (63.9) | (81.3) | (79.9) | (214.3) | ||
| MAE/mm | BPNN | 130.3 | 115.7 | 100.4 | 122.4 | 112.7 | 108.2 | 107.7 | 132.2 | 109.7 |
| (136.3) | (127.9) | (106.2) | (123.9) | (112.4) | (107.4) | (104.4) | (116.8) | (121.7) | ||
| GABP | 25 | 31.6 | 20.2 | 38.6 | 23.3 | 21.4 | 31.8 | 29.4 | 18.8 | |
| (42.5) | (29.7) | (18.8) | (41.2) | (21.8) | (24.1) | (32.9) | (26.8) | (23.8) | ||
| SVM | 50.4 | 65.4 | 46.2 | 71.7 | 61.2 | 43.5 | 65.4 | 68.1 | 49.2 | |
| (80.4) | (66.3) | (47.4) | (78.3) | (60) | (52.8) | (69) | (62.1) | (53.4) | ||
| MLR | 66 | 100.8 | 88.4 | 134.9 | 80.6 | 79.9 | 83.3 | 123.3 | 143.8 | |
| (167.6) | (253.1) | (102.2) | (109.3) | (458.6) | (91.2) | (153.6) | (144.5) | (264.8) | ||
| RMSE/mm | BPNN | 169.4 | 140 | 120.5 | 154.9 | 137 | 126.8 | 131.6 | 152.6 | 130.7 |
| (169.5) | (150.8) | (128.9) | (148.4) | (136) | (126.3) | (130.6) | (138.3) | (142.1) | ||
| GABP | 30.9 | 38.8 | 24.6 | 47.2 | 28.7 | 26.1 | 38.5 | 35.5 | 23.1 | |
| (51.8) | (36.3) | (22.8) | (50.6) | (26.8) | (29.5) | (40.5) | (32.8) | (28.9) | ||
| SVM | 59.4 | 79.8 | 60.6 | 87 | 76.8 | 52.8 | 80.4 | 81 | 60.8 | |
| (97.5) | (81.0) | (58.2) | (96.3) | (73.8) | (65.4) | (85.5) | (77.4) | (66.0) | ||
| MLR | 81.9 | 132.8 | 113.8 | 202.7 | 99.2 | 99.0 | 103.6 | 156.2 | 202.1 | |
| (250.9) | (426.6) | (128.2) | (146.9) | (961.8) | (110.4) | (258.9) | (214.5) | (74.6) | ||
| AR/% | BPNN | 49.4 | 82.4 | 78.6 | 65.8 | 98.2 | 78.6 | 61.4 | 34.7 | 35.0 |
| (75.1) | (37.4) | (40.9) | (75.1) | (38.6) | (35.1) | (72.5) | (98.2) | (35.3) | ||
| GABP | 27.8 | 78.6 | 74.6 | 77.5 | 93.8 | 77.2 | 68.1 | 21.6 | 41.2 | |
| (81.6) | (21.7) | (48.5) | (81.6) | (34.5) | (41.5) | (81.6) | (92.1) | (41.8) | ||
| SVM | 35.3 | 74.5 | 49.7 | 61 | 82.9 | 62.6 | 54.6 | 55.3 | 44.2 | |
| (66.0) | (43.6) | (40.9) | (70.5) | (48.1) | (33.5) | (74.7) | (82.3) | (42.9) | ||
| MLR | 38.6 | 70.7 | 54.6 | 63.7 | 86.2 | 58.7 | 53.5 | 51.1 | 41.5 | |
| (62.0) | (41.8) | (39.2) | (67.1) | (52.0) | (36.8) | (70.5) | (86.8) | (45.3) |
| Measure | M12-S | M1-S | M2-S | M3-S | M4-S | M5-S |
|---|---|---|---|---|---|---|
| MAPE/% | 9.1 | 4.7 | 21.5 | 18.5 | 18.0 | 7.4 |
| AR/% | 74.0 | 88.3 | 37.7 | 51.5 | 57.9 | 78.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.-C.; Zeng, X.-M.; Li, G.; Lu, B.; Xiao, M.-Z.; Wang, B.-Z. Summer Precipitation Forecast Using an Optimized Artificial Neural Network with a Genetic Algorithm for Yangtze-Huaihe River Basin, China. Atmosphere 2022, 13, 929. https://doi.org/10.3390/atmos13060929
Zhang Z-C, Zeng X-M, Li G, Lu B, Xiao M-Z, Wang B-Z. Summer Precipitation Forecast Using an Optimized Artificial Neural Network with a Genetic Algorithm for Yangtze-Huaihe River Basin, China. Atmosphere. 2022; 13(6):929. https://doi.org/10.3390/atmos13060929
Chicago/Turabian StyleZhang, Zhi-Cheng, Xin-Min Zeng, Gen Li, Bo Lu, Ming-Zhong Xiao, and Bing-Zeng Wang. 2022. "Summer Precipitation Forecast Using an Optimized Artificial Neural Network with a Genetic Algorithm for Yangtze-Huaihe River Basin, China" Atmosphere 13, no. 6: 929. https://doi.org/10.3390/atmos13060929
APA StyleZhang, Z.-C., Zeng, X.-M., Li, G., Lu, B., Xiao, M.-Z., & Wang, B.-Z. (2022). Summer Precipitation Forecast Using an Optimized Artificial Neural Network with a Genetic Algorithm for Yangtze-Huaihe River Basin, China. Atmosphere, 13(6), 929. https://doi.org/10.3390/atmos13060929