1. Introduction
Air pollutants pose significant threats to public health, especially the toxicity and diseases caused by atmospheric fine particulate matter [
1]. According to a survey, air pollution kills approximately 4.2 million people every year [
2]. Therefore, air quality is still an issue of concern in recent years. Environmental researchers mine air quality data to uncover potential value and information, which captures user behavior [
3], estimates influenza diseases [
4], explores greenhouse gas emissions [
5], investigates personal actions to reduce greenhouse gas emissions [
6], and so on, to advise the related policy makers. However, due to problems of instrument malfunction, communication noise, and/or other unknown reasons [
7], data are frequently missing. Moreover, although most air quality monitoring data are time series data, processing extensive time series environmental data with missing values is usually laborious and difficult, and sometimes unexpected failures are not detected until data are processed. Consequently, environmental databases frequently have some gaps caused by missing data [
8]. It is the gap that not only seriously affects the accuracy and availability of data, but also affects the subsequent work of in-depth analysis and data mining [
9]. Therefore, it is worthwhile to understand the types of data with missing values and propose an effective and robust strategy to fill time series air quality data with missing values.
In terms of the research of Rubin et al. [
10], there are three types of data with missing values: Missing Completely at Random (MCAR), Missing at Random (MAR), and Not Missing at Random (NMAR). When data are MCAR, the fact that the data are missing is independent of the observed and unobserved data [
10,
11]. When data are MAR, the fact that the data are missing is systematically related to the observed but not the unobserved data [
10,
12]. When data are NMAR, the fact that the data are missing is systematically related to the unobserved data, that is, the missingness is related to events or factors that are not measured by the researcher [
10,
13]. Following these three categories, there are some efficient strategies to coordinate data with missing values, appropriately known as “imputation methods” [
14]. Mean imputation and Median imputation are two common missing value imputation methods when data are MCAR. They are used as benchmark methods for imputing missing values in air quality datasets in many studies, such as [
15,
16,
17,
18,
19]. They substitute the mean or median of the corresponding observed attribute’s values for the missing values of that attribute in a dataset, respectively [
20]. However, these two simple imputation strategies lose sight of the correlation between the missing value’s own attribute and other attributes in the data points.
k-nearest neighbor imputation [
21] and random forest imputation [
22] are two typical missing value imputation methods when data are MAR. They take into account the dependencies among different attributes of data points, and the missing value of a data point can be obtained according to other data points with complete values. In the
k-nearest neighbor imputation method, the missing attribute values in a data point are replaced by the average of the corresponding attribute values of
k nearest neighbors of the data point [
21,
23]. It has been proven that
k-nearest neighbor has good imputation performance for air quality data in the literature [
15,
16]. Researchers [
24] have proven that the imputation performance of random forest outperforms
k-nearest neighbor due to its being a combination of tree predictors, where each tree depends on a random data point sampled independently [
22,
25]. However, an air quality monitor runs as a time series and can generate large amounts of missing data sometimes. The missing data mechanism of air quality data is generally random (MAR—missing at random) [
19]. The above methods are most capable in datasets with a low missing rate, but they may provide a poor performance on a large number of discrete datasets with a relatively high missing rate [
26]. Moreover, without considering that the timeliness among data points also affects data quality in a dataset, these methods may be not suitable for time series data. When processing time series datasets, these methods usually require a large number of training data points to establish a low imputation error model, because they ignore the fact that time series data points are correlated with each other over continuous time intervals, namely, the data differ less in value in short time intervals since the time corresponding to the data point is continuous. Therefore, to solve the issues of missing values in time series air quality data, it is necessary to further explore a more suitable imputation method for time series air quality data with missing values, which not only can train a higher imputation performance model with fewer air quality data, but also can achieve more efficient imputation for relatively high-missing-rate time series air quality datasets with discrete missing values.
In this paper, to achieve more efficient imputation of discrete missing values in time series air quality data, we raise a new single imputation method [
18,
27] called “First five last three logistic regression imputation (FTLRI)”. This method combines the traditional logistic regression with a presented “first Five & last Three” model, which can explain relationships between/among disparate attributes and extract the data points that are extremely relevant, both in terms of time and attributes, to the data point with missing values, respectively.
Since timeliness of data points in a dataset in an important factor affecting data quality [
28], FTLRI uses a model of “first Five & last Three (FT)” to address that issue based on the sliding window, where “F” refers to the five data points with complete values immediately before the data point with missing values, and “T” refers to the three data points with complete values immediately after the data point with missing values in a time series dataset. Selecting the first five and the last three data points next to the data point with missing values ensures commonality of experience between data points, and the eight data points are most closely related in time to the missing value. In addition, to fully consider the correlation between different attributes in the data points, FT selects the attributes extremely related to the attribute with missing values based on the Pearson correlation. Therefore, FT emerges as a time-dependent and attribute-related model, which chooses the most appropriate, minimal amount of data to set the basis for the subsequent, most efficient missing data imputation.
To further fully use correlation between continuous time and the different attributes of data points in air quality data, these eight data points with complete values selected by FT are employed in logistic regression to train a model to fill missing values effectively. Logistic regression has been widely studied recently, such as parameter estimation [
29], credit scoring [
30], visual detectability prediction [
31], and so on, but few studies have examined the application of logistic regression to missing data, let alone its application to fill time series air quality data. Although Akbar et al. [
32] indicated that random forest is more accurate than traditional logistic regression imputation for data with missing values, they did not make a detailed analysis of the two approaches. As an imputation method under the category MAR, logistic regression imputation warrants further investigation in time series air quality data with missing values for the declarative reasons. One is that logistic regression is used to explain the relationship between one dependent attribute and one or more independent attributes by estimating probabilities using a logistic regression equation in the description and analysis of data [
33]. There is an interaction among the six main pollutants in the air quality data points. For example, the concentration of PM
2.5 may be affected by the concentration of the other pollutants, such as SO
2, CO, and NO
2 [
34]. The second is that logistic regression does not require high computing power, and low-performance equipment can complete the calculation [
35].
To investigate the performance of FTLRI, this paper compares the three assessment indexes of FTLRI with five other classical imputation methods and a new dynamic imputation method [
36] using a neural network with missing rates of 5%, 10%, 20%, and 40%, respectively, and demonstrates that the performance of FTLRI is superior to the others. Overall, the main advantages of FTLRI are as follows.
- (1)
FTLRI is an effective time series air quality data imputation model that not only considers correlation, both in terms of time and attributes of the data points, but also legitimately utilizes logistic regression to deal with such correlation.
- (2)
FTLRI relies on fewer training data points for each data point with missing values, including eight data points extremely relevant to the data point with missing values, to achieve a lower imputation error model compared with the other classical imputation methods.
- (3)
FTLRI realizes accurate imputation of short-term/long-term time series air quality datasets with different missing rates by extracting the data points that are extremely relevant, both in terms of time and attributes, to the data point with missing values.
2. Materials and Methods
This section will illustrate the imputation method FTLRI proposed in this paper and the indicators to evaluate the performance of FTLRI.
2.1. A Developed FT Based on Pearson Correlation and Sliding Window
Time series air quality data are time-dependent and attribute-related. To better understand how to extract the data that are highly relevant to missing data through “first Five & last Three (FT)” in time series datasets, this subsection elaborates the developed model FT covering the Pearson correlation and a sliding window.
The Pearson correlation is employed to reveal the attributes that are highly relevant to the attribute with missing values in a time series dataset in this paper. The Pearson correlation coefficient indicates a linear relation between two attributes in a dataset, and it ranges from −1 to +1. The greater the absolute value of the correlation coefficient is, the higher the correlation degree of the two attributes in a dataset will be [
37]. In this study, if the Pearson correlation coefficient between an attribute and the attribute with missing values is greater than or equal to 0.6, then the attribute is regarded as a target attribute of the attribute with missing values. It is assumed that the concentration of one pollutant at a certain time is
p and the concentration of another pollutant at the same time is
q in a time series air quality dataset containing
n data points; then, the Pearson correlation coefficient
r of the two pollutants can be expressed as Equation (1). The process of filtering the target attributes of the attribute with missing values through the Pearson correlation coefficients is first done through FT, that is, the selected target attributes through FT first are the attributes that are extremely related to the attribute with missing values.
A sliding window is employed to seek out the data points that are highly relevant in time to the data point with missing values in a time series dataset in this paper. As shown in
Figure 1, assuming that the concentration of one pollutant measured at time
t is
X(
t), a sliding window refers to a window with size
w that is used to slide from the starting point of a time series air quality dataset to the end with a step length of
l, and the values in the window are recorded for subsequent research when the window moves forward. The missing data in a time series dataset may lead to incomplete data in the sliding window. The proposed model FT focuses on the imputation of the missing data through the complete data in the sliding window, which are closest in time. Through the sliding window, the “first Five” data points and the “last Three” data points with complete values closest in time to the data point with missing values are found, which is required for the second step of the model FT.
Instead of depending on all the other complete data like other methods to fill missing values, FT screens out the data that are highly correlated with the missing data, both in terms of attributes and time, in a time series air quality dataset to ensure a more effective imputation later. The basic steps of FT are as follows.
Step 1. If the Pearson correlation coefficient between an attribute and the attribute with a missing value is greater than or equal to 0.6, then this attribute is a target attribute.
Step 2. Find the “first Five (F)” data points and the “last Three (T)” data points close in time to the data point with missing values by a sliding window based on the first step, if and only if F and T are the data points with complete values composed of target attributes and attributes with missing values in a time series air quality dataset.
In Step 2, if a data point with missing values is followed by another data point with missing values for the corresponding attribute, then the search continues until the eight data points with complete values are discovered. Thus, there are two cases for the step length
l and size
w of the sliding window. The first one is that the step length
l and size
w of the sliding window are fixed, in which the sliding window size is 9. To test the performance of the imputation method proposed in this paper under different missing rates, the step length
l of the sliding window is calculated according to the number of the data points and self-defined missing rate in a time series dataset. Assuming that there are
n data points in a time series air quality dataset, and the self-defined missing rate is
R, the step length can be expressed as Equation (2). The second case is that the step length
l and size
w of the sliding window are unfixed. When one of the three data points immediately behind the data point with missing values in time has a missing value for the corresponding attribute, it will continue to look for a data point with complete values. This is the reason the size
w and the step length
l of the window will increase by one. Therefore, we can obtain eight data points with complete values highly relevant to the data point with missing values in time through FT, which will alter as the data point with missing values alters in a time series air quality dataset.
The data selected through FT are extremely attributively and temporally related to each missing data point. In other words, for each data point with missing values, we search for the eight highly correlated data points through FT, which is more targeted and offers the possibility for more effective imputation in the follow-up.
By training an imputation model with the eight data points from FT for each data point with missing values, we not only can overcome the obstacle of other methods that demand large volumes of training data points to build a highly effective model, but also can save the time of training, especially for low-missing-rate datasets with discrete missing values. Thus, it is worth adopting FT into the imputation of time series air quality data with discrete missing values.
2.2. Logistic Regression Imputation
Since there exists a certain relationship between missing values and complete values in data points, this section will first introduce the idea of logistic regression and then describe how logistic regression is used to fill the missing values by employing this relationship.
Logistic regression includes three steps: finding a prediction function, constructing a loss function, and finding regression parameters that minimize a loss function [
38,
39]. The objective function of logistic regression is expressed as Equation (3).
where
θ is an unknown vector of parameters to be determined,
x = (
x1,
x2, …
xd), and
d denotes data point
x has
d attributes. The loss function reflects the degree of model prediction error. Suppose there are
n data points, then the average log-likelihood loss will be Equation (4).
where
y is a return variable with a value of 0 or 1. The regression parameter
θ minimizes the loss function, which can be obtained by Gradient Descent [
40] and Newton’s method [
41] and so on. Newton’s method is adopted in this study. Newton’s method takes the second-order Taylor Formula of the function near the existing estimate of the minimum point and then finds the next estimate of the minimum point. Assuming
θk is an estimate of the current minimum, then there will be Equation (5).
Supposing
φ′ (
θ) = 0, there will be Equation (6).
where
k is the number of iterations. Equation (6) is the iterative updated equation. From Equations (5) and (6), we can see this study requires the objective function
J(
θ) to be second-order continuously differentiable.
This paper applies logistic regression to the imputation domain of missing values. For each data point with missing values in a time series air quality dataset, we rely on an objective regression equation to build a specific imputation model using eight corresponding highly relevant data points from FT. However, it is worth noticing that this study needs to convert the complete data of a missing attribute from continuous type into integer type since logistic regression is frequently employed to cope with classification. For example, when there are missing values in the concentration of PM2.5, we need to convert the complete values in PM2.5 into integer data before we use logistic regression to train an imputation model. That is, when using logistic regression to train an imputation model to impute continuous data, we need to preprocess the complete data of the missing attribute by scaling the complete continuous data up to a multiple of 10 to the nth power, or by other methods, to obtain integer data. Further, the integer data processed can be inputted into logistic regression to train an imputation model. Accordingly, for the missing values of the continuous attribute converted into integer type, after the imputed values are obtained through logistic regression, it is necessary to be restored to continuous type. It is the restored data that constitute the final imputation concentration values of this study.
2.3. FTLRI Based on FT and Logistic Regression
“First five last three logistic regression imputation (FTLRI)” integrates the FT proposed in
Section 2.1 and the logistic regression introduced in
Section 2.2 to fill the discrete missing values in a time series air quality dataset. FTLRI is inspired by the following two considerations, which are clearly shown in
Figure 2. The first point is that time series data have the characteristic of autocorrelation; in other words, the attribute values of a data point are closely related to the corresponding attribute values of the other data points in a time interval. For example, the concentration value of PM
2.5 is closely related to the concentration values before and after it, namely, it is not independent. The second point is that there exists a kind of cross-influence relationship among air pollutants. For example, the concentration of PM
2.5 can be extremely correlated with the concentration of the other pollutants at the same time, such as CO and PM
10. Exploiting highly correlated relationships to fill discrete missing values in time series air quality datasets offers higher accuracy. Instead of depending on all the other complete data like other methods to fill missing values, FTLRI depends on these two correlations to utilize FT to extract the data points that are highly relevant to each data point with missing values. FTLRI also makes full use of logistic regression to train a suitable imputation model for each data point with missing values.
The detailed procedure of FTLRI to impute data points with missing values is outlined in Algorithm 1. The process of FTLRI starts with an incomplete time series air quality dataset, and it takes no input parameters. By calculating the Pearson correlation coefficient, Step 1 can easily access the attributes highly relevant to the missing value attributes. Step 2 is based on Step 1 to search for the first five data points and the last three data points that are strongly related to the missing value in time by FT firstly. By finding the first five data points and the last three data points, then, we rely on logistic regression to train an imputer fitted to them. Finally, the missing values can be obtained by this imputer.
| Algorithm 1 First five last three logistic regression imputation (FTLRI) |
![Atmosphere 13 01044 i001]()
Output Ym |
Figure 3 illustrates the process of the imputation approach for a data point with missing values in more detail. We present only the attributes that are highly correlated with PM
2.5 in this figure, including CO and PM
10. In
Figure 3, the missing value for the concentration of PM
2.5 is finally filled with “24”. First of all, by detecting the data point with a missing value and accessing its Pearson correlation coefficient, we can discovery the corresponding “first Five” and “last Three” of the data point, which are represented on the brownish-yellow background and blue-green background colors in the figure, respectively. Next, the “first Five” and the “last Three” are employed to train a model by logistic regression, and this model is applied to obtain the missing concentration values of PM
2.5 last; then, “24” is obtained.
From the detailed explanation of the process in
Figure 3, we can see that, in the process of training and filling through the model, it is the corresponding “first Five” and the “last Three” adjacent to each data point with missing values that simplify the training process of the imputation model and save training time.
Instead of depending on all the other complete data points like other methods, we select these eight data points highly relevant, both in terms of time and attributes, to each data point with missing values to fill missing values, which is the key of FTLRI to train a model with lower imputation errors through logistic regression under different missing rates.
2.4. Assessment Indexes
To evaluate the performance of FTLRI, three assessment indexes are used: Mean absolute error (
MAE), Root-mean-square of error (
RMSE) and Mean absolute percentage error (
MAPE) [
42,
43,
44], which are shown in the following Equations (7)–(9), respectively:
where
r and
f are real and imputation values, respectively, and
n denotes the number of a dataset with missing values.







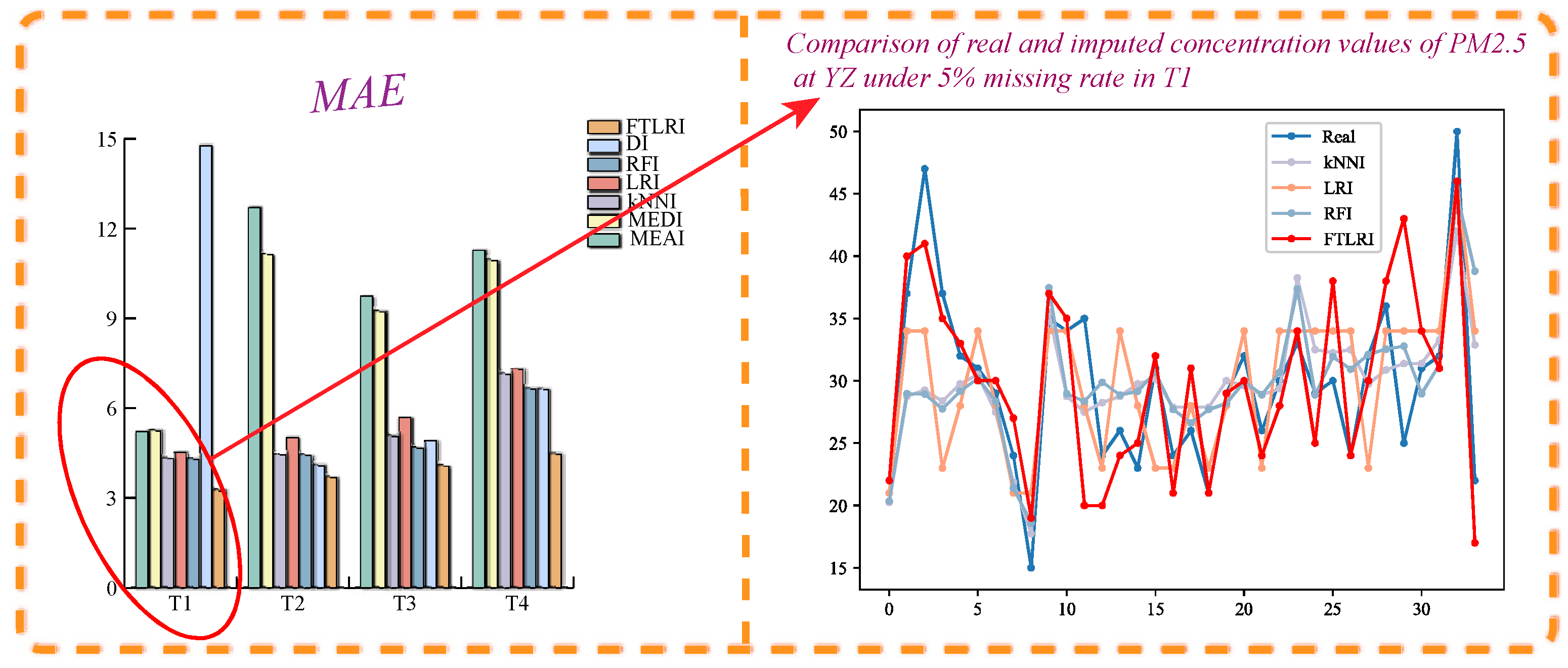






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}