
Narx Neural Networks Models for Prediction of Standardized Precipitation Index in Central Mexico

 ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
2.2. Standardized Precipitation Index
2.3. Cluster Analysis
2.4. Potential Evapotranspiration Index
2.5. Multivariate ENSO Index Data
2.6. Neural Network Forecasting
- (i)
- Features or variable selection.
- (ii)
- Neural network learning by training, test and validation.
- (iii)
- Varying the structure or architecture.
- (iv)
- Model confirmation and forecasting.
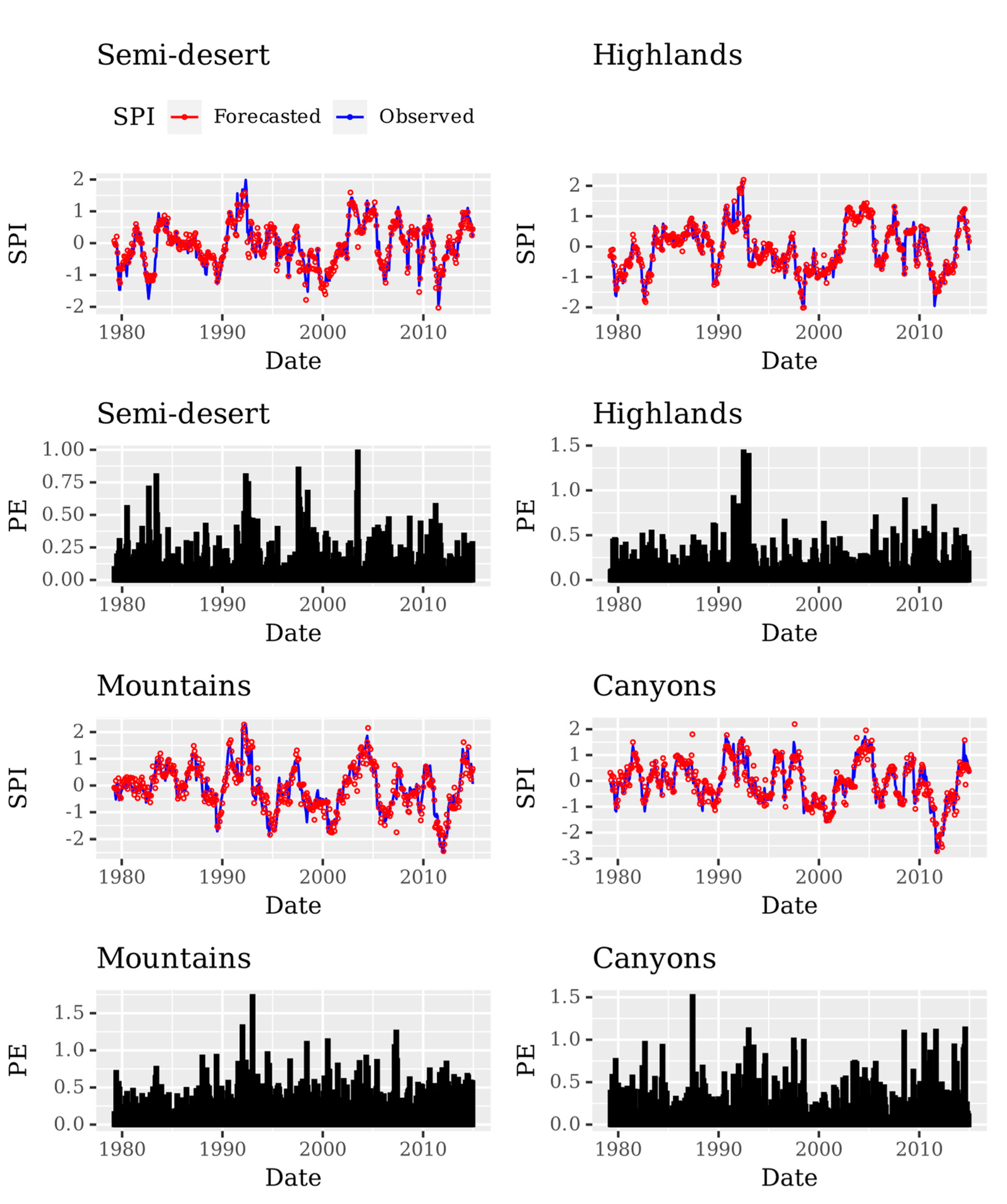
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kharin, V.V.; Zwiers, F.W.; Zhang, X.; Hegerl, G.C. Changes in Temperature and Precipitation Extremes in the IPCC Ensemble of Global Coupled Model Simulations. J. Clim. 2007, 20, 1419–1444. [Google Scholar] [CrossRef] [Green Version]
- Angheluţă, P.S.; Badea, C.G. The Water Resources in the Context of Climate Change Produced by the Greenhouse Gases. Ann. Univ. Oradea Fac. Econ. 2015, 1, 637–643. [Google Scholar]
- Choubin, B.; Malekian, A.; Gloshan, M. Application of several data-driven techniques to predict a standardized precipitation index. Atmósfera 2016, 29, 121–128. [Google Scholar] [CrossRef] [Green Version]
- Ali, Z.; Hussain, I.; Faisal, M.; Nazir, H.M.; Hussain, T.; Shad, M.Y.; Shoukry, A.M.; Gani, S.H. Forecasting Drought Using Multilayer Perceptron Artificial Neural Network Model. Adv. Meteorol. 2017, 2017, 5681308. [Google Scholar] [CrossRef]
- McKee, T.B.; Doesken, N.J.; Kleist, J. The relationship of drought frequency and duration to time scales. In Proceedings of the 8th Conference on Applied Climatology, American Meteorological Society, Boston, MA, USA, 17–22 January 1993; pp. 179–183. [Google Scholar]
- Naresh Kumar, M.; Murthy, C.S.; Sesha Sai, M.V.R.; Roy, P.S. On the use of Standardized Precipitation Index (SPI) for drought intensity assessment. Meteorol. Appl. 2009, 16, 381–389. [Google Scholar] [CrossRef] [Green Version]
- Mahfouz, P.; Mitri, G.; Jazi, M.; Karam, F. Investigating the Temporal Variability of the Standardized Precipitation Index in Lebanon. Climate 2016, 4, 27. [Google Scholar] [CrossRef] [Green Version]
- Giddings, L.; Soto, M.; Rutherford, B.; Maarouf, A. Standardized precipitation index zones for Mexico. Atmósfera 2005, 18, 33–56. [Google Scholar]
- Magallanes-Quintanar, R.; Blanco-Macías, F.; Galván-Tejada, E.C.; Galván-Tejada, J.I.; Márquez-Madrid, M.; Valdez-Cepeda, R.D. Negative regional Standardized Precipitation Index trends prevail in the Mexico’s state of Zacatecas. Rev. Terra Latinoam. 2019, 37, 487–499. [Google Scholar] [CrossRef] [Green Version]
- Poornima, S.; Pushpalatha, M. Drought prediction based on SPI and SPEI with varying timescales using LSTM recurrent neural network. Soft Comput. 2019, 23, 8399–8412. [Google Scholar] [CrossRef]
- Ozger, M.; Mishra, A.K.; Singh, V.P. Estimating Palmer Drought Severity Index using a wavelet fuzzy logic model based on meteorological variables. Int. J. Clim. 2010, 31, 2021–2032. [Google Scholar] [CrossRef]
- Belayneh, A.; Adamowski, J.; Khalil, B.; Ozga-Zielinski, B. Long-term SPI drought forecasting in the Awash River Basin in Ethiopia using wavelet neural network and wavelet support vector regression models. J. Hydrol. 2014, 508, 418–429. [Google Scholar] [CrossRef]
- Masinde, M. Artificial neural networks models for predicting effective drought index: Factoring effects of rainfall variability. Mitig. Adapt. Strat. Glob. Chang. 2013, 19, 1139–1162. [Google Scholar] [CrossRef]
- Deo, R.C.; Şahin, M. Application of the Artificial Neural Network model for prediction of monthly Standardized Precipitation and Evapotranspiration Index using hydrometeorological parameters and climate indices in eastern Australia. Atmos. Res. 2015, 161–162, 65–81. [Google Scholar] [CrossRef]
- Soh, Y.; Koo, C.; Huang, Y.; Fung, K. Application of artificial intelligence models for the prediction of standardized precipitation evapotranspiration index (SPEI) at Langat River Basin, Malaysia. Comput. Electron. Agric. 2018, 144, 164–173. [Google Scholar] [CrossRef]
- Thornthwaite, C.W. An Approach toward a Rational Classification of Climate. Geogr. Rev. 1948, 38, 55–94. [Google Scholar] [CrossRef]
- Koudahe, K.; Kayode, A.J.; Samson, A.O.; Adebola, A.A.; Djaman, K. Trend Analysis in Standardized Precipitation Index and Standardized Anomaly Index in the Context of Climate Change in Southern Togo. Atmos. Clim. Sci. 2017, 7, 401–423. [Google Scholar] [CrossRef] [Green Version]
- Caloiero, T. Drought analysis in New Zealand using the standardized precipitation index. Environ. Earth Sci. 2017, 76, 569. [Google Scholar] [CrossRef]
- Beguería, S.; Vicente-Serrano, S.M. SPEI: Calculation of the Standardized Precipitation-Evapotranspiration Index; R Package Version 1.7; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. Available online: https://www.cran.r-project.org/ (accessed on 30 May 2022).
- Unal, Y.; Kindap, T.; Karaca, M. Redefining the climate zones of Turkey using cluster analysis. Int. J. Clim. 2003, 23, 1045–1055. [Google Scholar] [CrossRef]
- Karmalkar, A.V.; Bradley, R.S.; Diaz, H.F. Climate change in Central America and Mexico: Regional climate model validation and climate change projections. Clim. Dyn. 2011, 37, 605–629. [Google Scholar] [CrossRef] [Green Version]
- Paradis, E.; Schliep, K. ape 5.0: An environment for modern phylogenetics and evolutionary analyses in R. Bioinformatics 2018, 35, 526–528. [Google Scholar] [CrossRef]
- Hanson, R.L. Evapotranspiration and Droughts. In National Water Summary 1988–89: Hydrologic Events and Floods and Droughts; US Geological Survey Water-Supply Paper 2375; US Government Printing Office: Washington, DC, USA, 1991; pp. 99–104. [Google Scholar]
- Vicente-Serrano, S.M.; Beguería, S.; López-Moreno, J.I. A multiscalar drought index sensitive to global warming: The standardized precipitation evapotranspiration index. J. Clim. 2010, 23, 1696–1718. [Google Scholar] [CrossRef] [Green Version]
- Wolter, K.; Timlin, M.S. El Niño/Southern Oscillation behaviour since 1871 as diagnosed in an extended multivariate ENSO index (MEI.ext). Int. J. Clim. 2011, 31, 1074–1087. [Google Scholar] [CrossRef]
- Wolter, K. The Southern Oscillation in surface circulation and climate over the tropical Atlantic, Eastern Pacific, and Indian Oceans as captured by cluster analysis. J. Appl. Meteorol. Climatol. 1987, 26, 540–558. [Google Scholar] [CrossRef] [Green Version]
- Wolter, K.; Timlin, M.S. Measuring the strength of ENSO events: How does 1997/98 rank? Weather 1998, 53, 315–324. [Google Scholar] [CrossRef]
- Mcculloch, W.S.; Pitts, W.H. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Wang, W.; Van Gelder, P.H.; Vrijling, J.; Ma, J. Forecasting daily streamflow using hybrid ANN models. J. Hydrol. 2006, 324, 383–399. [Google Scholar] [CrossRef]
- Farajzadeh, J.; Fard, A.F.; Lotfi, S. Modeling of monthly rainfall and runoff of Urmia lake basin using “feed-forward neural network” and “time series analysis” model. Water Resour. Ind. 2014, 7–8, 38–48. [Google Scholar] [CrossRef] [Green Version]
- Carbonera, L.F.B.; Bernardon, D.P.; Karnikowski, D.D.C.; Farret, F.A. The nonlinear autoregressive network with exogenous inputs (NARX) neural network to damp power system oscillations. Int. Trans. Electr. Energy Syst. 2020, 31, e12538. [Google Scholar] [CrossRef]
- Diaconescu, E. The use of NARX neural networks to predict chaotic time series. WSEAS Trans. Comput. Res. 2008, 3, 182–191. [Google Scholar]
- Liu, Q.; Chen, W.; Hu, H.; Zhu, Q.; Xie, Z. An Optimal NARX Neural Network Identification Model for a Magnetorheological Damper with Force-Distortion Behavior. Front. Mater. 2020, 7, 10. [Google Scholar] [CrossRef]
- The Mathworks. MATLAB. 2021. 9.7.0.1190202 (R2021b); The MathWorks Inc.: Natick, MA, USA, 2021. [Google Scholar]
- Chapra, S.C.; Canale, R.P. Numerical Methods for Engineers; McGraw-Hill Higher Education: Boston, MA, USA, 2006. [Google Scholar]
- Moustris, K.P.; Ziomas, I.C.; Paliatsos, A.G. 3-Day-Ahead Forecasting of Regional Pollution Index for the Pollutants NO2, CO, SO2, and O3 Using Artificial Neural Networks in Athens, Greece. Water Air Soil Pollut. 2009, 209, 29–43. [Google Scholar] [CrossRef]
- Moustris, K.P.; Larissi, I.K.; Nastos, P.T.; Paliatsos, A.G. Precipitation Forecast Using Artificial Neural Networks in Specific Regions of Greece. Water Resour. Manag. 2011, 25, 1979–1993. [Google Scholar] [CrossRef]
- Daliakopoulos, I.N.; Coulibaly, P.; Tsanis, I.K. Groundwater level forecasting using artificial neural networks. J. Hydrol. 2005, 309, 229–240. [Google Scholar] [CrossRef]
- Evkaya, O.O.; Kurnaz, F.S. Forecasting drought using neural network approaches with transformed time series data. J. Appl. Stat. 2020, 48, 2591–2606. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SPI Value | Class |
|---|---|
| ≥2.0 | Extremely wet |
| 1.5 to 1.99 | Severely wet |
| 1.0 to 1.49 | Moderately wet |
| −0.99 to 0.99 | Near normal |
| −1.49 to −0.99 | Moderately dry |
| −1.99 to −1.49 | Severely dry |
| ≤2.0 | Extremely dry |
| Region | ||||||
|---|---|---|---|---|---|---|
| Semi-Arid | SPI | PP (mm) | EVP (mm) | TMED (°C) | TMAX (°C) | PET (mm) |
| Min | −1.9577 | 0.0000 | 79.9297 | 10.1753 | 21.7807 | 24.6523 |
| µ | −0.0685 | 34.2184 | 163.9863 | 16.7953 | 29.3890 | 65.0969 |
| Max | 1.9913 | 282.3329 | 304.6525 | 22.4452 | 37.0236 | 116.3594 |
| σ | 0.6950 | 38.2306 | 47.1019 | 3.1163 | 2.6660 | 23.8464 |
| Highlands | SPI | PP (mm) | EVP (mm) | TMED (°C) | TMAX (°C) | PET (mm) |
| Min | −1.9803 | 0.0000 | 83.3820 | 10.1441 | 22.5070 | 20.2253 |
| µ | −0.0671 | 37.2929 | 172.0484 | 16.7851 | 29.4178 | 69.3710 |
| Max | 2.0847 | 263.7820 | 311.1621 | 25.2700 | 36.0990 | 121.6185 |
| σ | 0.7729 | 42.7967 | 51.0985 | 3.2487 | 2.7512 | 27.0455 |
| Mountains | SPI | PP (mm) | EVP (mm) | TMED (°C) | TMAX (°C) | PET (mm) |
| Min | −2.4941 | 0.0000 | 66.7167 | 12.0667 | 18.6623 | 24.7254 |
| µ | −0.0903 | 50.3055 | 172.1842 | 19.7793 | 32.7723 | 67.3928 |
| Max | 2.2986 | 294.1333 | 338.0667 | 26.5333 | 39.5000 | 271.1664 |
| σ | 0.8401 | 58.9066 | 57.1413 | 3.5075 | 3.1277 | 27.3713 |
| Canyons | SPI | PP (mm) | EVP (mm) | TMED (°C) | TMAX (°C) | PET (mm) |
| Min | −2.7563 | 0.0000 | 72.5509 | 10.1200 | 24.8750 | 20.2253 |
| µ | −0.0449 | 62.5014 | 153.5088 | 18.8842 | 31.6837 | 69.3710 |
| Max | 1.7283 | 350.5735 | 654.1389 | 24.8250 | 38.3750 | 121.6185 |
| σ | 0.8361 | 76.3667 | 57.7539 | 3.2312 | 2.8083 | 27.0455 |
| Region | MSE | R |
|---|---|---|
| Semi-desert | ||
| Training | 0.0813 | 0.9099 |
| Test | 0.1197 | 0.8936 |
| Highlands | ||
| Training | 0.0826 | 0.9341 |
| Test | 0.0486 | 0.9631 |
| Mountains | ||
| Training | 0.0889 | 0.9365 |
| Test | 0.0814 | 0.9514 |
| Canyons | ||
| Training | 0.0759 | 0.9426 |
| Test | 0.0991 | 0.9399 |
| Region | β0 | β1 | R2 | R |
|---|---|---|---|---|
| Semi-desert | −0.0099 | 0.8428 | 0.9076 | 0.9526 |
| Highlands | 0.0292 | 0.9417 | 0.7974 | 0.8930 |
| Mountains | −0.03158 | 0.9044 | 0.7767 | 0.8813 |
| Canyons | 0.0595 | 0.8738 | 0.7128 | 0.8443 |
| Region | PE < 0 | PE > 0 |
|---|---|---|
| Semi-desert | 0.4965 | 0.5035 |
| Highlands | 0.5058 | 0.4942 |
| Mountains | 0.5175 | 0.4825 |
| Canyons | 0.5858 | 0.4142 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Magallanes-Quintanar, R.; Galván-Tejada, C.E.; Galván-Tejada, J.I.; Méndez-Gallegos, S.d.J.; García-Domínguez, A.; Gamboa-Rosales, H. Narx Neural Networks Models for Prediction of Standardized Precipitation Index in Central Mexico. Atmosphere 2022, 13, 1254. https://doi.org/10.3390/atmos13081254
Magallanes-Quintanar R, Galván-Tejada CE, Galván-Tejada JI, Méndez-Gallegos SdJ, García-Domínguez A, Gamboa-Rosales H. Narx Neural Networks Models for Prediction of Standardized Precipitation Index in Central Mexico. Atmosphere. 2022; 13(8):1254. https://doi.org/10.3390/atmos13081254
Chicago/Turabian StyleMagallanes-Quintanar, Rafael, Carlos E. Galván-Tejada, Jorge I. Galván-Tejada, Santiago de Jesús Méndez-Gallegos, Antonio García-Domínguez, and Hamurabi Gamboa-Rosales. 2022. "Narx Neural Networks Models for Prediction of Standardized Precipitation Index in Central Mexico" Atmosphere 13, no. 8: 1254. https://doi.org/10.3390/atmos13081254
APA StyleMagallanes-Quintanar, R., Galván-Tejada, C. E., Galván-Tejada, J. I., Méndez-Gallegos, S. d. J., García-Domínguez, A., & Gamboa-Rosales, H. (2022). Narx Neural Networks Models for Prediction of Standardized Precipitation Index in Central Mexico. Atmosphere, 13(8), 1254. https://doi.org/10.3390/atmos13081254