1. Introduction
Drought is one of the most devastating natural catastrophes globally, causing the highest economic losses, and it happens when there is a shortage of precipitation compared to the long-term average precipitation [
1,
2]. On a worldwide scale, drought is responsible for 22% of the economic losses caused by calamities and 33% of the losses in terms of the number of people affected [
3,
4]. There are four types of droughts: meteorological, agricultural, socioeconomic, and hydrological [
5]. Drought is dependent on climatic variables such as rainfall and temperature. Additionally, there are a variety of drought indicators available, such as the Palmer drought severity index (PDSI), standardised precipitation evapotranspiration index (SPEI), effective drought index (EDI), reconnaissance drought index (RDI), and standardised precipitation index (SPI). SPI was introduced by McKee, et al. [
6], which is the most widely employed drought indicator and has been recommended by the World Meteorological Organisation [
7]. The SPI can be computed at various timescales to provide insight into various types of drought; for example, the short-to-medium timescale is appropriate for agricultural and meteorological droughts [
8].
Climate change is causing significant issues for the ecosystem, such as rainfall variation, which may lead to drought and desertification [
9,
10]. Additionally, the effect of global warming on temperature and precipitation in various areas of the world is uneven. The Arabian Peninsula, which has a mostly desert environment, is expected to face more rapid climate change due to global warming [
11].
Iraq, an arid country on the Arabian Peninsula, is one of the most affected by climate change in the world [
12,
13]. The Tigris and the Euphrates rivers are Iraq’s most important freshwater sources. As a result, many storage dams have been built along the paths of these rivers in Iraq [
14]. These rivers had severe water shortages from 2009 to 2014, which are predicted to increase due to climate change, leading to a rise in upstream water consumption (i.e., Turkey and Iran) [
14,
15]. Climate change has significant effects in Iraq, such as decreasing rainfall and increasing temperatures [
16]. Osman, et al. [
17] showed that most Iraqi areas are expected to experience decreased annual mean rainfall, particularly towards the end of the twenty-first century. Additionally, Salman, et al. [
11] deduced that yearly precipitation is decreasing at a rate of −1.0 to −5.0 mm/year in northwest Iraq. Furthermore, the temperature of Iraq is rising at a rate two to seven times more rapidly than the world average [
12]. As a result, these studies highlight the need for more research in drought forecasting in Iraq. It plays a significant role in providing decision-makers with helpful information that enables them to make appropriate decisions to alleviate the effects of drought [
18,
19].
Drought forecasting is essential for irrigated agriculture, water management, environmental monitoring, recreational tourism, and ecosystem health [
20]. Additionally, drought prediction and early warning are important for agricultural adaptability to climate change [
21]. Various machine learning (ML) technologies have shown remarkable performance in forecasting droughts due to their ability to manage the nonlinear correlation between meteorological factors and drought [
22,
23]. Traditional methods assume that the relationship between the predictors and the predictand is linear and may be unsuitable for solving real application problems [
24]. Owing to the nonlinear and complex character of the drought process, employing artificial intelligence (AI) techniques in drought forecasting has received significant attention [
25]. According to studies by Zhang, et al. [
3] and Belayneh, et al. [
26], AI models are superior to traditional models. These AI models that are employed to forecast drought are support vector machines (SVMs) [
27], adaptive neurofuzzy inference system (ANFIS) [
28], artificial neural network (ANN) [
29], and random forests [
30,
31].
The capability of the ANN model to simulate nonlinear and nonstationary time series data in water resources and hydrology issues makes it an attractive tool for predicting drought [
32], as proven in Dikshit, et al. [
33], Das, et al. [
34], and Bari Abarghouei, et al. [
35]. Additionally, the ANN was used in other hydrological fields and proved efficient in predicting accuracy, such as Apaydin, et al. [
36] and Ren, et al. [
37] for streamflow, Ömer Faruk [
38] and Seo, et al. [
39] for water quality, and Tiu, et al. [
40] for water level.
A hybrid model combines two or more methods, one working as the main model and the others as post-or preprocessing methods [
41]. Different methods and scenarios have been used to predict drought. The results have shown that the hybrid model outperforms the single model; therefore, most studies recommended employing the hybrid model to improve prediction accuracy, such as Zhang, et al. [
3], Khan, et al. [
42], and Adnan, et al. [
43].
To date, several studies confirmed the effectiveness of employing climatic variables and hybrid ANN models for forecasting drought, such as Banadkooki, et al. [
5], Nabipour, et al. [
25], Alawsi, et al. [
44], and Adnan, et al. [
43], additionally employing different data pretreatment approaches such as singular spectrum analysis (SSA) and utilising various preprocessing techniques for determining the best input model. Furthermore, hybrid models with nature-inspired optimisation algorithms are significantly encouraged.
Different optimisation algorithms have been used to solve issues in engineering fields. The optimisation techniques are designed to find the best values for the system’s parameters under various scenarios [
45]. Li, et al. [
46] introduced the slime mould algorithm (SMA), which has been used to solve optimisation problems, for example, water demand prediction [
47], spring design problem [
48], and photovoltaic models [
49]. In addition, the marine predators algorithm (MPA) was proposed by Faramarzi, et al. [
50]. It has been utilised in a variety of applications, including photovoltaic systems [
51], friction stir welding [
52], and power resources in distribution networks [
53].
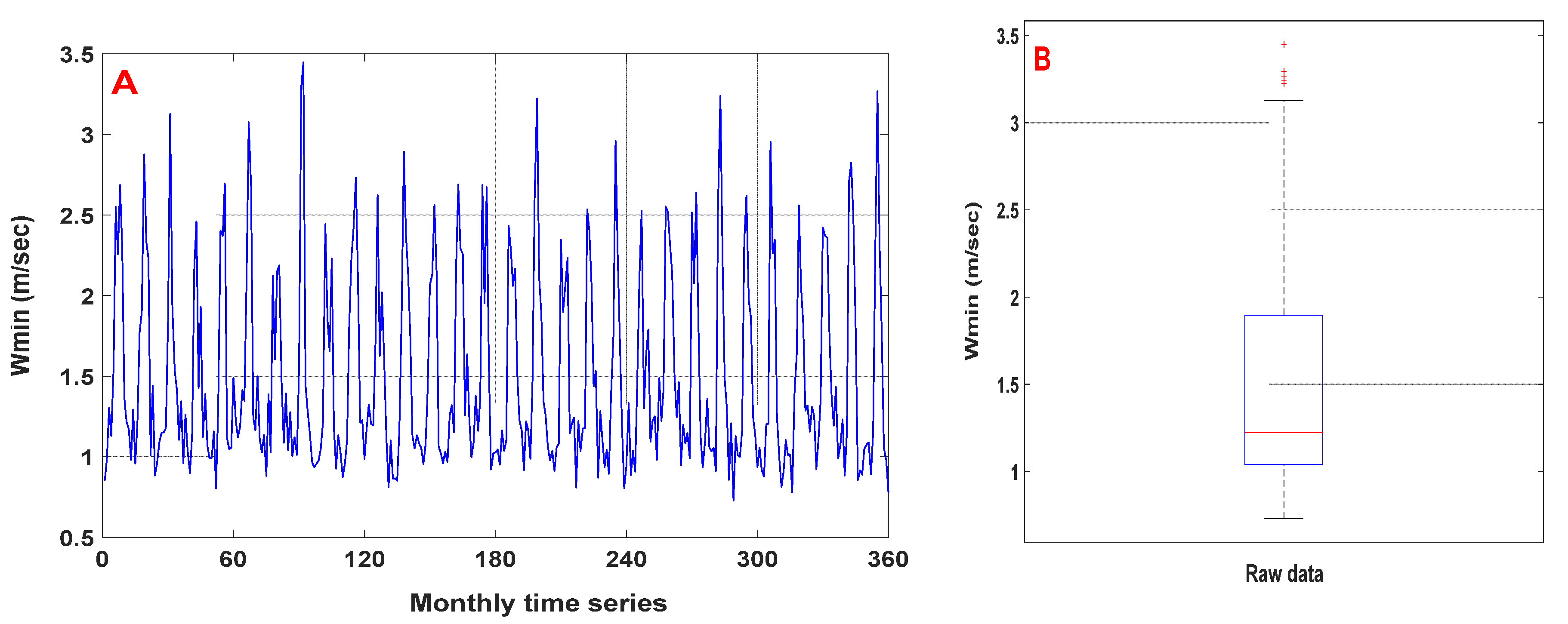
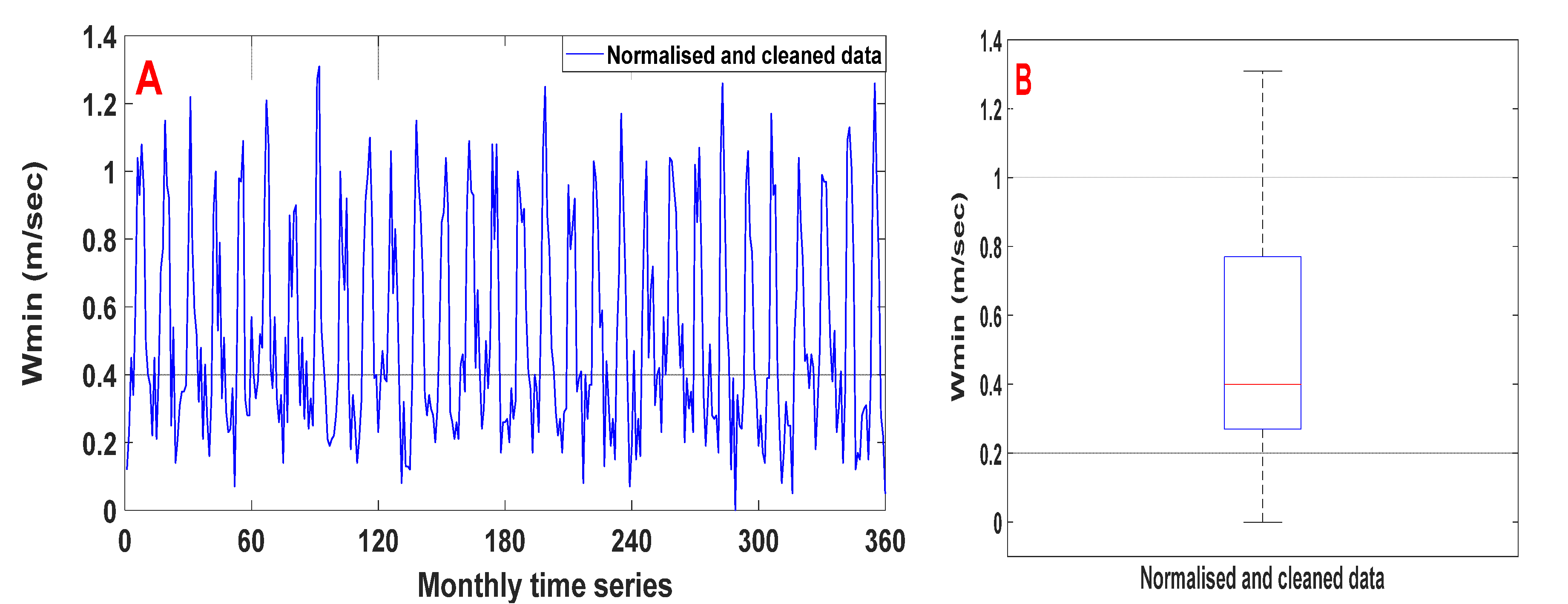
Additionally, data preprocessing techniques are necessary to improve prediction performance for hydrologic time series [
4,
54]. These techniques play a crucial role in ANNs by promoting high accuracy and minimising computing costs during the training phase since unreliable information and noise in data records negatively impact the learning phase and result in a flawed model [
9]. The primary goals of data preprocessing techniques are to enhance the quality of raw time series to determine the best predictors’ scenario [
41,
55].
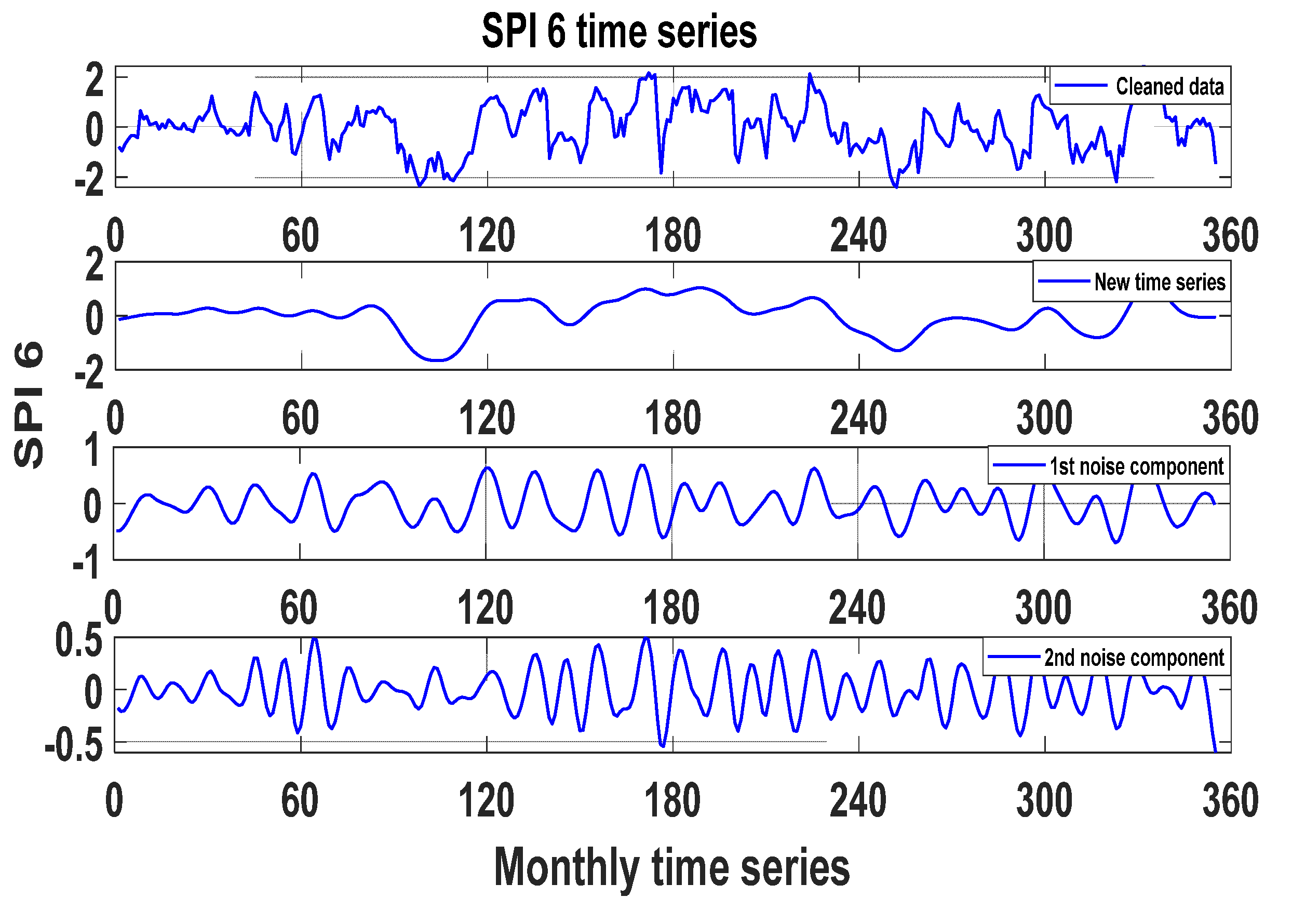
Recently, Alawsi, et al. [
44] reviewed drought forecasting articles that were published in the last several years and recommended:
Employing singular spectrum analysis (SSA) as a data pretreatment technique;
Using a multivariate strategy;
Applying the hybridisation of preprocessing-based with parameter optimisation-based hybrid models.
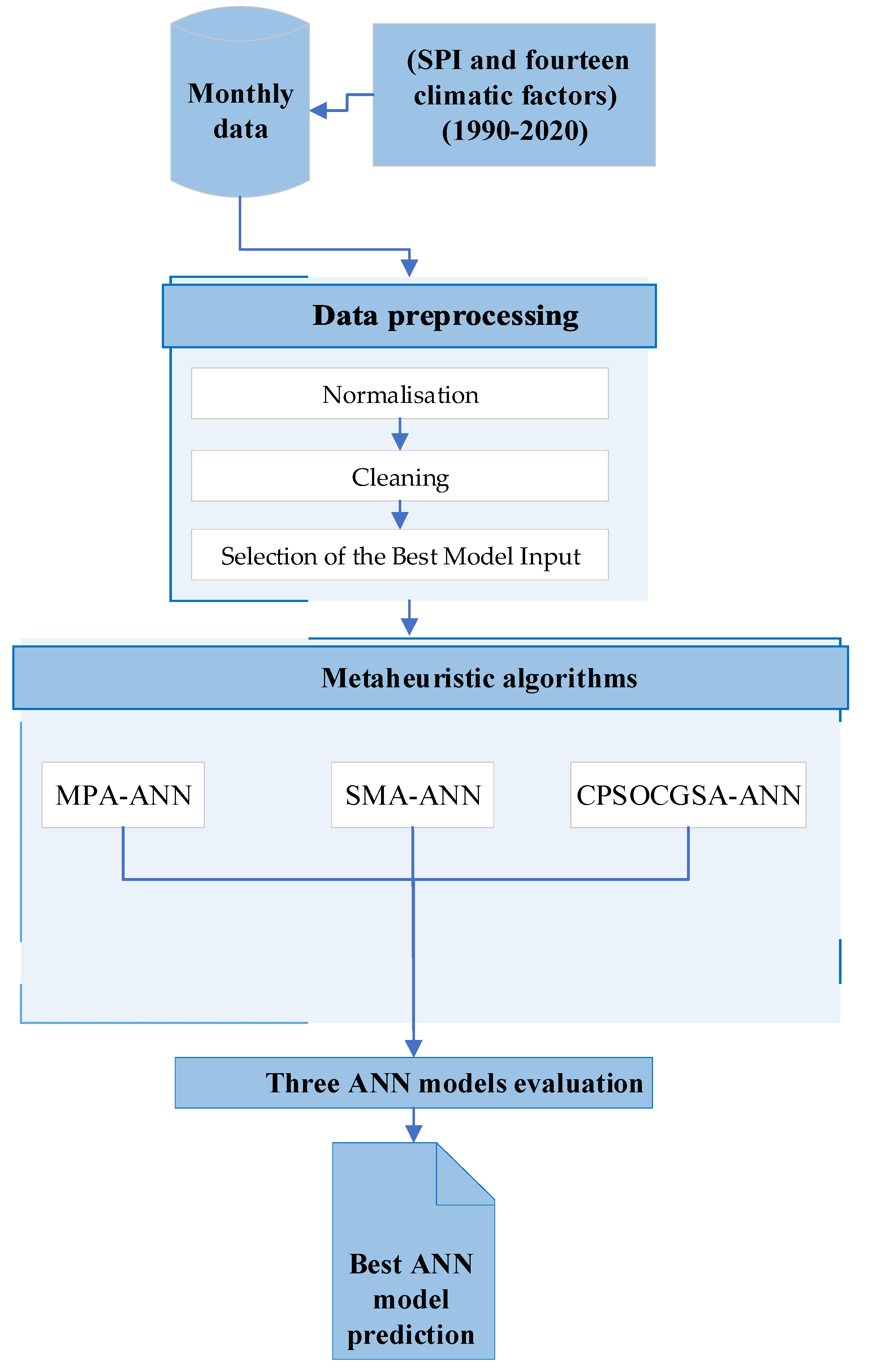
Accordingly, this study aims to evaluate a novel methodology (including data preprocessing techniques and an ANN model that integrates with different metaheuristic algorithms) to forecast the drought indices SPl 1, SPI 3, and SPI 6 for Al-Kut City, Iraq.
The primary objectives of this study are to:
Investigate 14 climate factors over thirty years to determine to what extent climate factors drive drought indices;
Enhance raw data quality and identify the optimal predictor scenario;
Integrate the ANN model with the recent CPSOCGSA algorithm to choose the optimal ANN hyperparameters;
Evaluate the CPSOCGSA-ANN technique’s performance by comparing it with the updated MPA-ANN and SMA-ANN algorithms;
Provide a scientific view of drought to the local stakeholders because this province has the highest production and marketing of wheat in Iraq.
Based on our knowledge, this is the first time to: (a) investigate this novel methodology for forecasting drought and (b) use Al-Kut City as a study area.
The organisation of the remaining sections of this paper follows:
Section 2 describes the study area and the data set employed in this study, together with the methodology utilised for constructing the prediction models. The results obtained in this study are presented in
Section 3.
Section 4 provides a discussion of the study’s findings. Finally, conclusions are stated in
Section 5.
4. Discussion
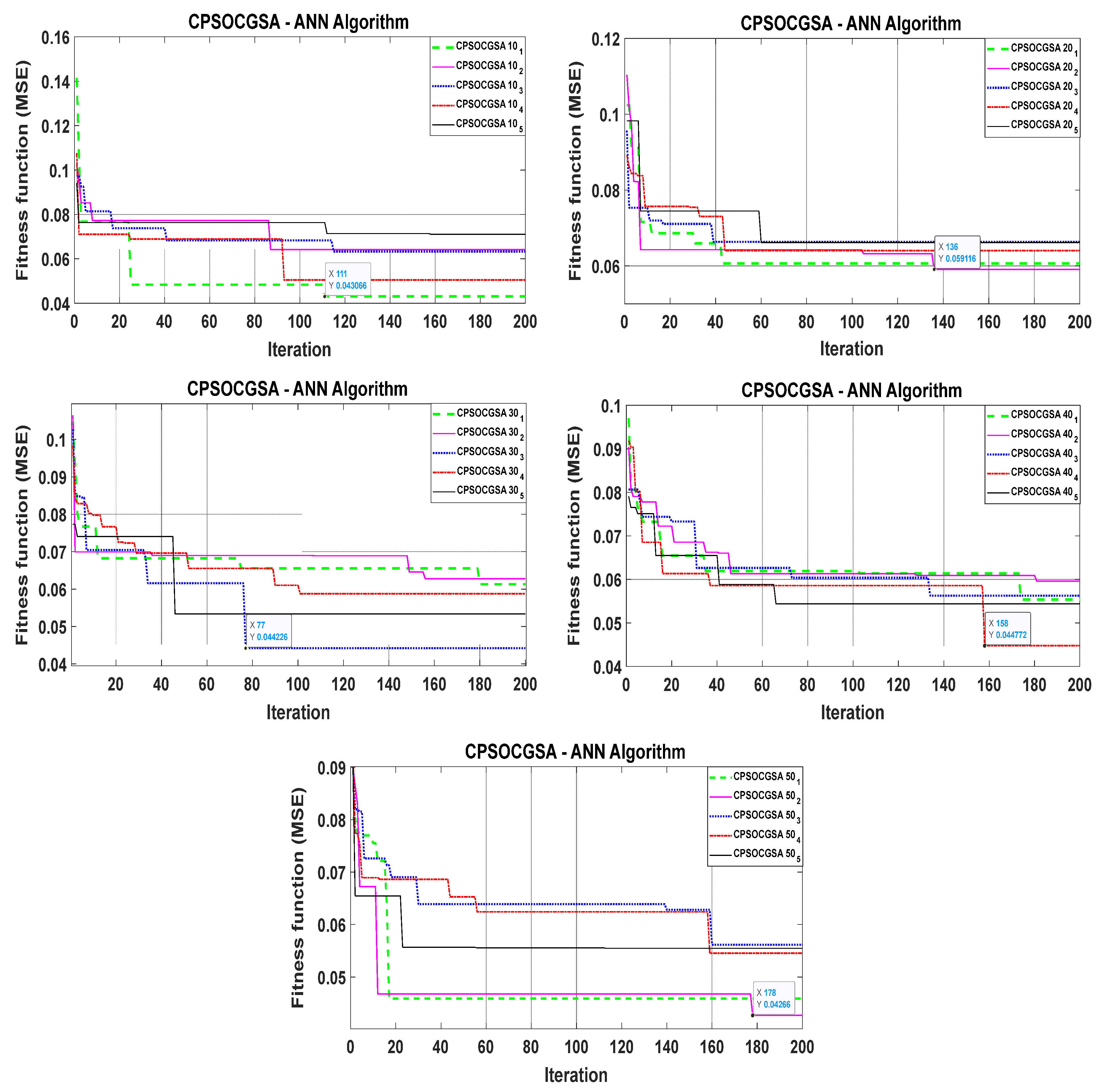
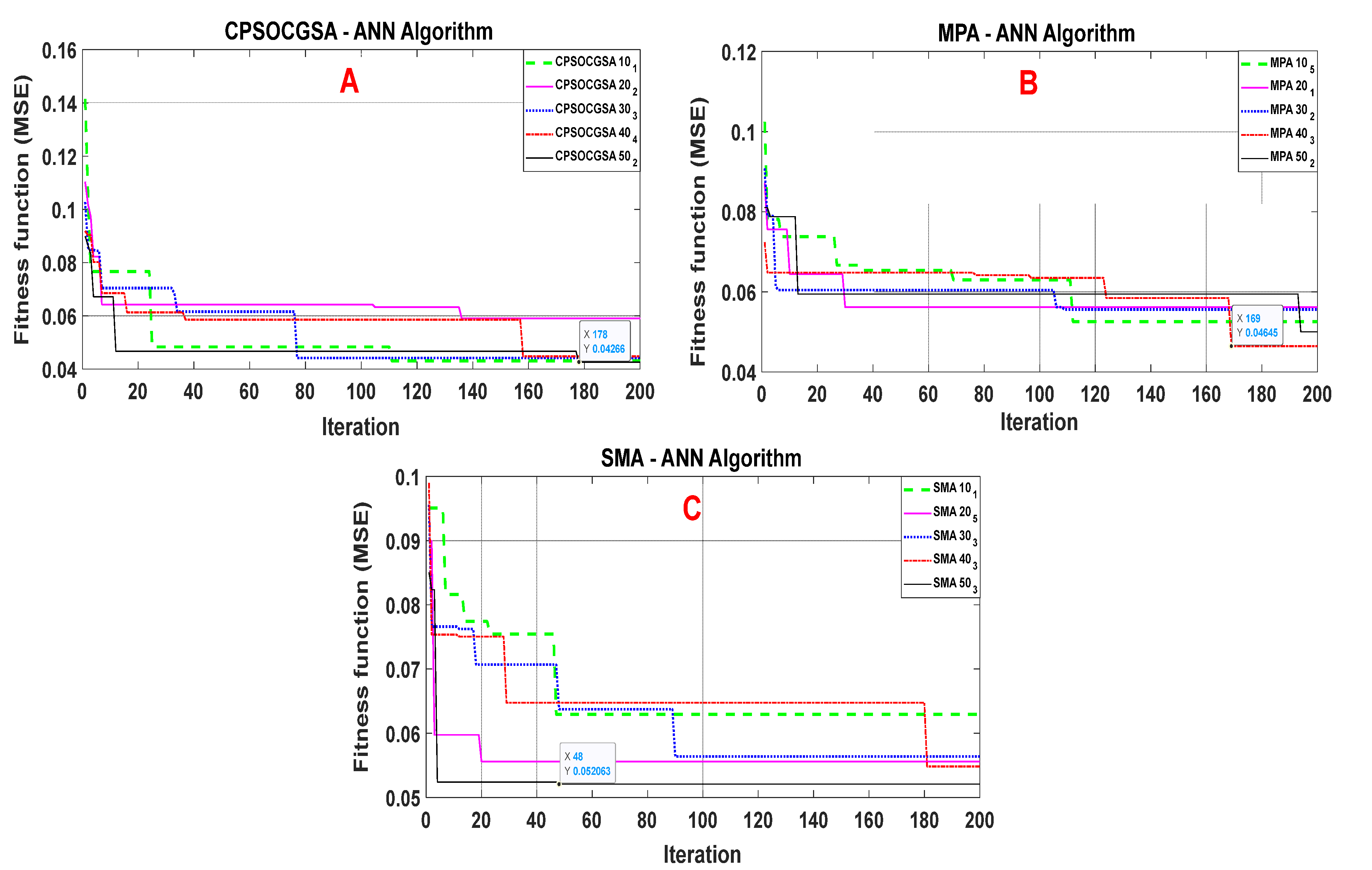
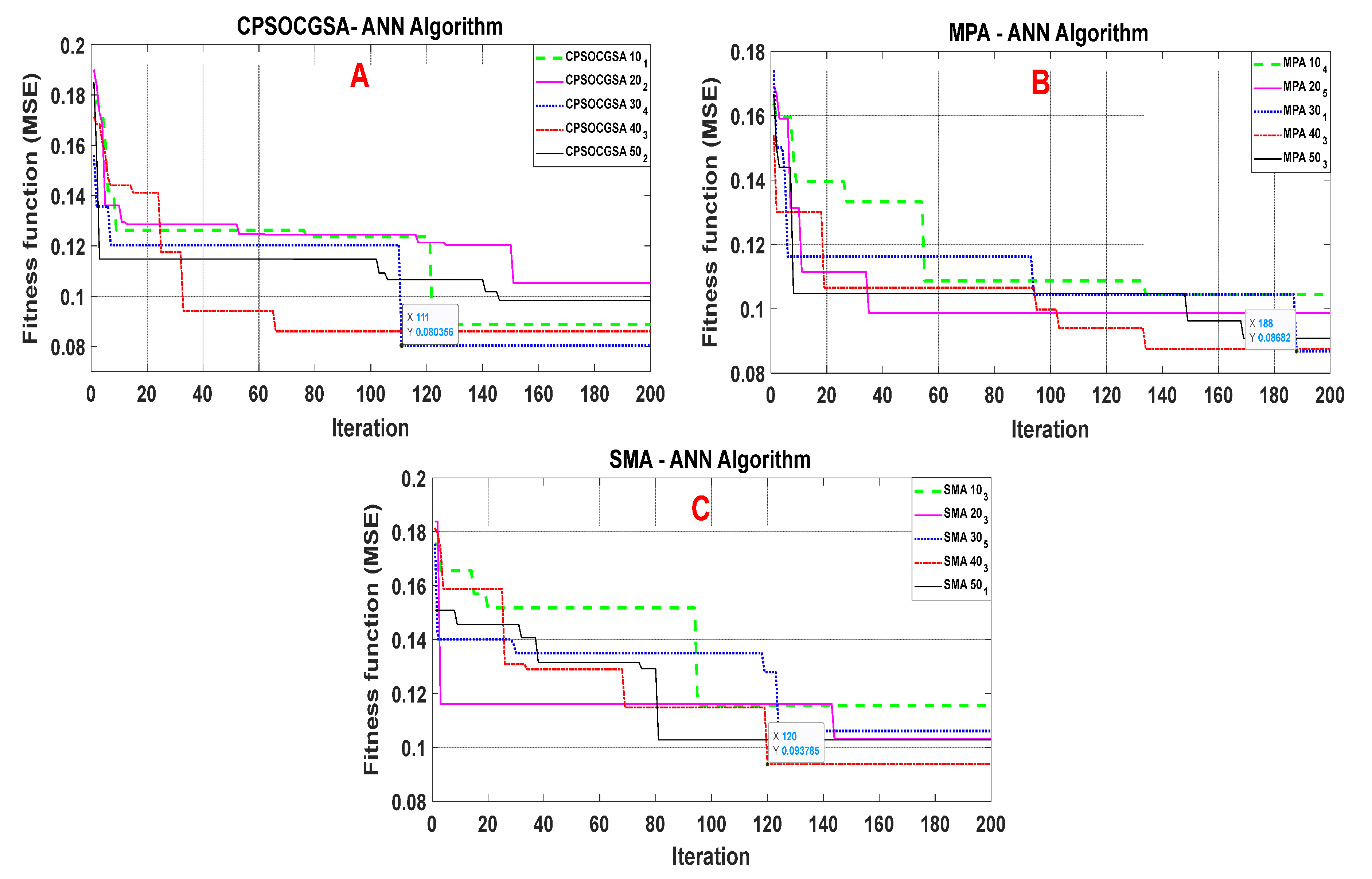
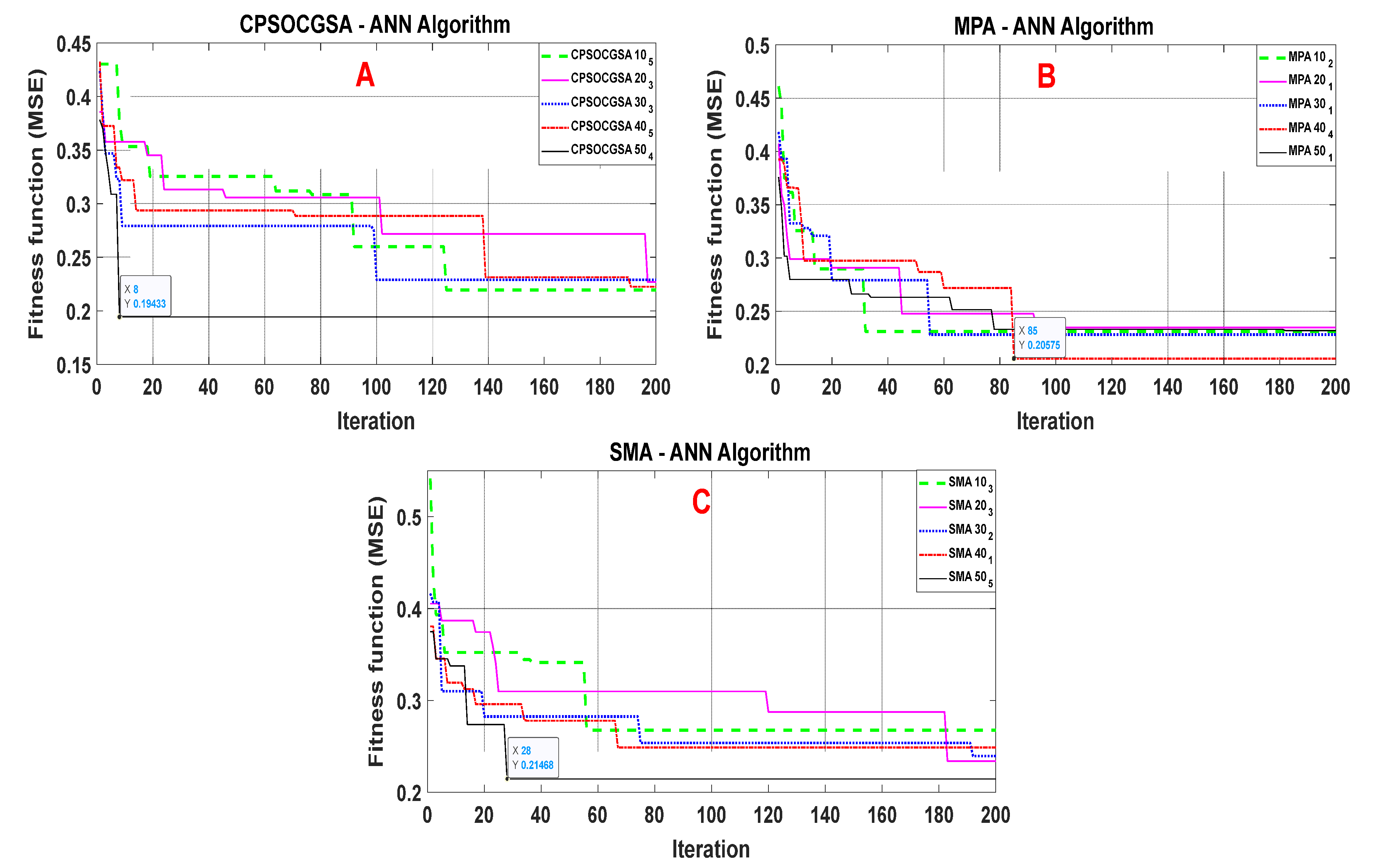
Droughts may have devastating consequences on socioeconomic and environmental conditions, but the agricultural sector is the most severely impacted by drought. Al-Kut is considered an agricultural area that is characterised by wheat production. Therefore, drought prediction is essential for mitigating the effects of droughts in the region. Based on our knowledge, no article has been published to predict droughts in the study area. As a result, the present study forecasts the standardised precipitation index using various machine learning techniques (CPSOCGSA-ANN, ANN-MPA, and ANN-SMA) with different time scales (SPI 1, SPI 3, and SPI 6).
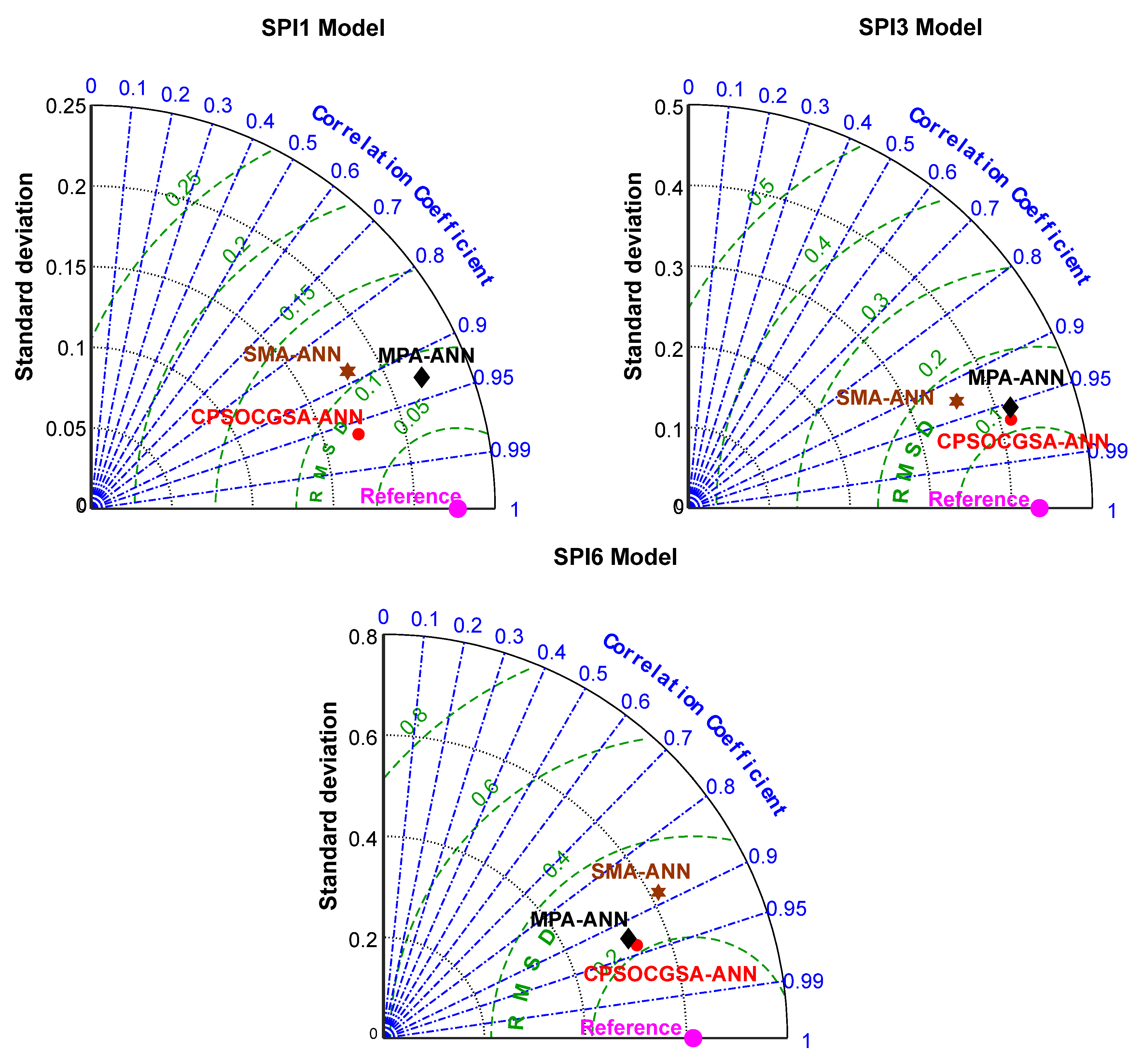
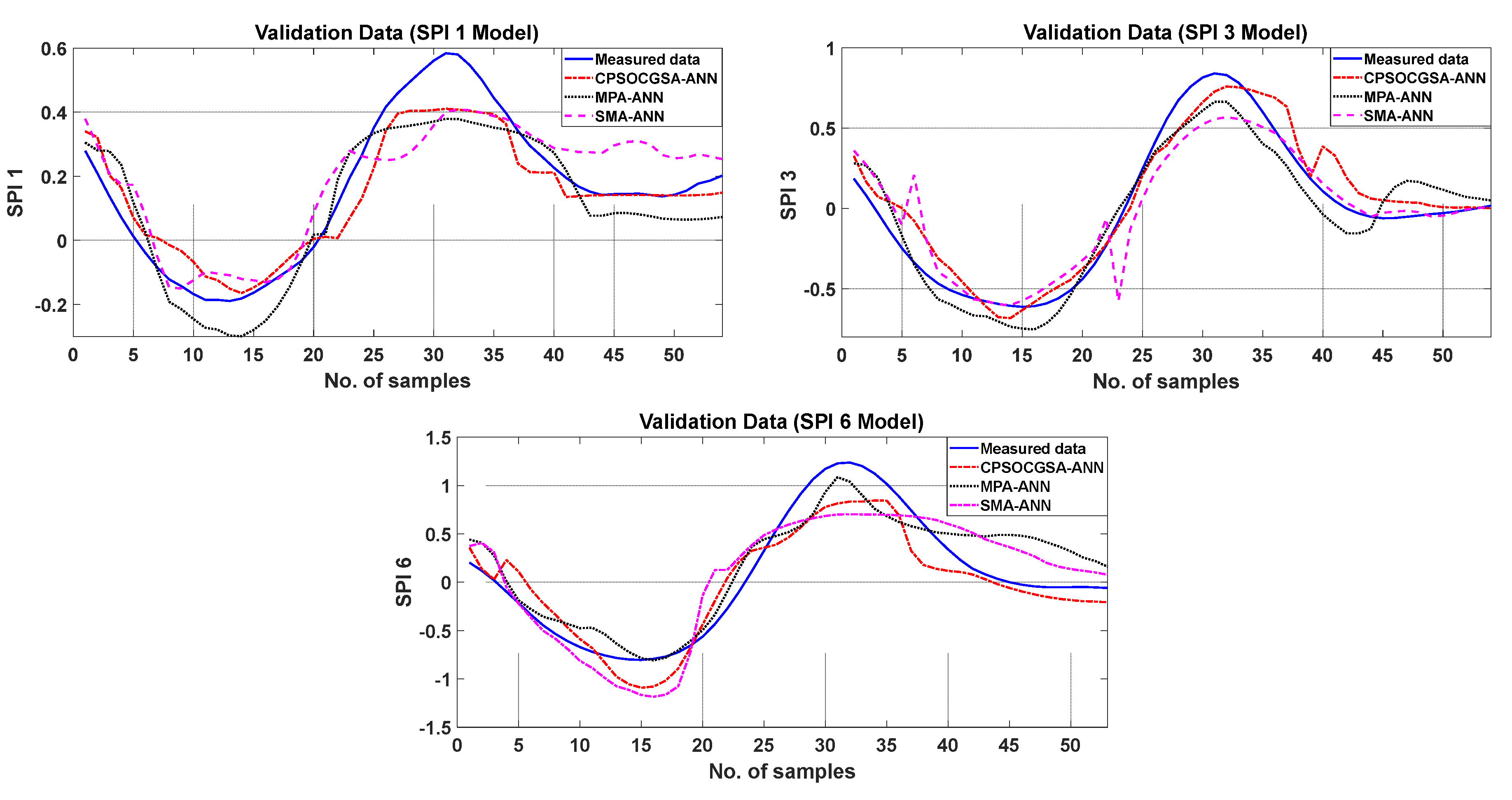
During the validation stage, the models with lowest RMSE, MAE, and greatest R2 are considered the best for predicting drought. This study reveals that predictions of SPI by using CPSOCGSA-ANN were the most accurate across all time scales (SPI 1, SPI 3, and SPI 6). This model can help the local authorities (managers and decision-makers) make intelligent decisions and improve effective irrigation system operation plans.
The artificial neural network (ANN) result was compared with support vector regression (SVR) to predict temporal drought occurrences in Australia. The findings showed that ANN outperformed SVR, with the former having the higher R
2 value of 0.86 compared to 0.75 for the latter [
33]. Despite the high ability of ANN in forecasting hydroclimate parameters (e.g., rainfall), this technique may show limitations in dealing with hydrological time series that are often nonstationary and cover a broad range of scales. As a result, data preprocessing may be a significant stage in overcoming defects and similar issues [
97]. Khan, et al. [
98] employed ANN and the hybrid ANN with wavelet (W-ANN) for predicting drought in Malaysia. The results show that the wavelet method achieved higher correlation coefficients (i.e., W-ANN outperforms the single ANN). The least-square support vector machine (LSSVM) and LSSVM-singular spectrum analysis (SSA-LSSVM) were used to predict the standardised precipitation index (SPI) for Taiwan. Prediction accuracy was higher for SSA-LSSVM than for LSSVM [
4]. Başakın, et al. [
28] evaluated the adaptive neurofuzzy inference system (ANFIS) and ANFIS with empirical mode decomposition (ANFIS-EMD) to predict drought. The statistical indicators MSE and NSE reveal that the combined EMD-ANFIS model is better than the ANFIS model when employed singularly. Bioinspired optimisation algorithms have been effectively utilised to improve model abilities by identifying the optimal hyperparameters of ML models [
5,
99]. Banadkooki, et al. [
5] utilised ANN models with three metaheuristic optimisation algorithms, namely particle swarm optimisation (PSO), the salp swarm algorithm (SSA), and the genetic algorithm (GA), to predict drought in the Yazd plain, Iran. The result reveals that SSA-ANN outperforms PSO-ANN and GA-ANN. Nabipour, et al. [
25] proposed a combined model of artificial neural networks (ANN) with different metaheuristic algorithms, including the salp swarm algorithm (SSA), grasshopper optimization algorithm (GOA), particle swarm optimization (PSO), and biogeography-based optimisation (BBO) for predicting short-term drought in Iran. According to the results, the combined model outperformed the single ANN.
The literature described above indicates that the hybridised version of the machine learning techniques is better than standalone models in forecasting drought. The present study shows that data preprocessing (i.e., normalisation, cleaning, and best model input) increased the correlation coefficient values between standardised precipitation indices (SPI 1, SPI 3, and SPI 6) and climatic variables (
Section 3.1). Moreover, this study showed that the hybrid ML model, specifically ANN-CPSOCGSA, was more accurate in drought prediction with different time scales (SPI 1, SPI 3, and SPI 6). Furthermore, the results of this study indicate that the drought simulation model may be installed as an early warning system in the Al-Kut region to mitigate the effects of drought.
5. Conclusions
The accuracy of future drought forecasting is critical for risk management, agriculture irrigation, and drought preparation. Climate variables play a significant role in drought forecasting. Drought is driven effectively by rainfall, temperature, wind speed, and relative humidity. Therefore, the effects of climate variables cannot be neglected in drought forecasting. This study suggested a novel hybrid methodology to simulate drought (SPI 1, SPI 3, and SPI 6) based on climatic factors over 30 years in Al-Kut City, Iraq. The methodology includes data preprocessing techniques and an ANN model integrated with the recent CPSOCGSA algorithm. Additionally, the MPA and SMA algorithms were applied to assess and validate the performance of the CPSOCGSA algorithm. The results reveal that the data preprocessing techniques (i.e., SSA and tolerance) effectively denoise time series and remove the redundant predictors leading to improving the data quality and selecting the best predictors scenario. The performance of CPSOCGSA-ANN outperforms both the MPA-ANN and SMA-ANN algorithms based on different statistical criteria (i.e., R2, MAE, and RMSE). The best models predicted SPI 1 with R2 = 0.93, MAE = 0.0635, and RMSE = 0.0791, SPI 3 with R2 = 0.93, MAE = 0.1020, and RMSE = 0.1270, and SPI 6 with R2 = 0.88, MAE = 0.2004, and RMSE = 0.2334. Additionally, the results indicate that the proposed model can be successfully applied in predicting drought for regions that suffer from variability in socioeconomic and climate variables. These findings can provide beneficial information to the local authorities (i.e., managers and decision-makers), helping the irrigation sector company to manage the irrigation system better, leading to improved service and management of resources in Al-Kut city. For future research, this study offers a framework for exploring and investigating innovative hybrid models that combine preprocessing and parameter optimisation. Further research using the same hybrid techniques to forecast different drought indices is needed for various regions.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}