


Forecasting the July Precipitation over the Middle-Lower Reaches of the Yangtze River with a Flexible Statistical Model

Abstract
1. Introduction
2. Data and Methods
2.1. The Input Data
2.2. Forecast Model and Experiments
3. Results
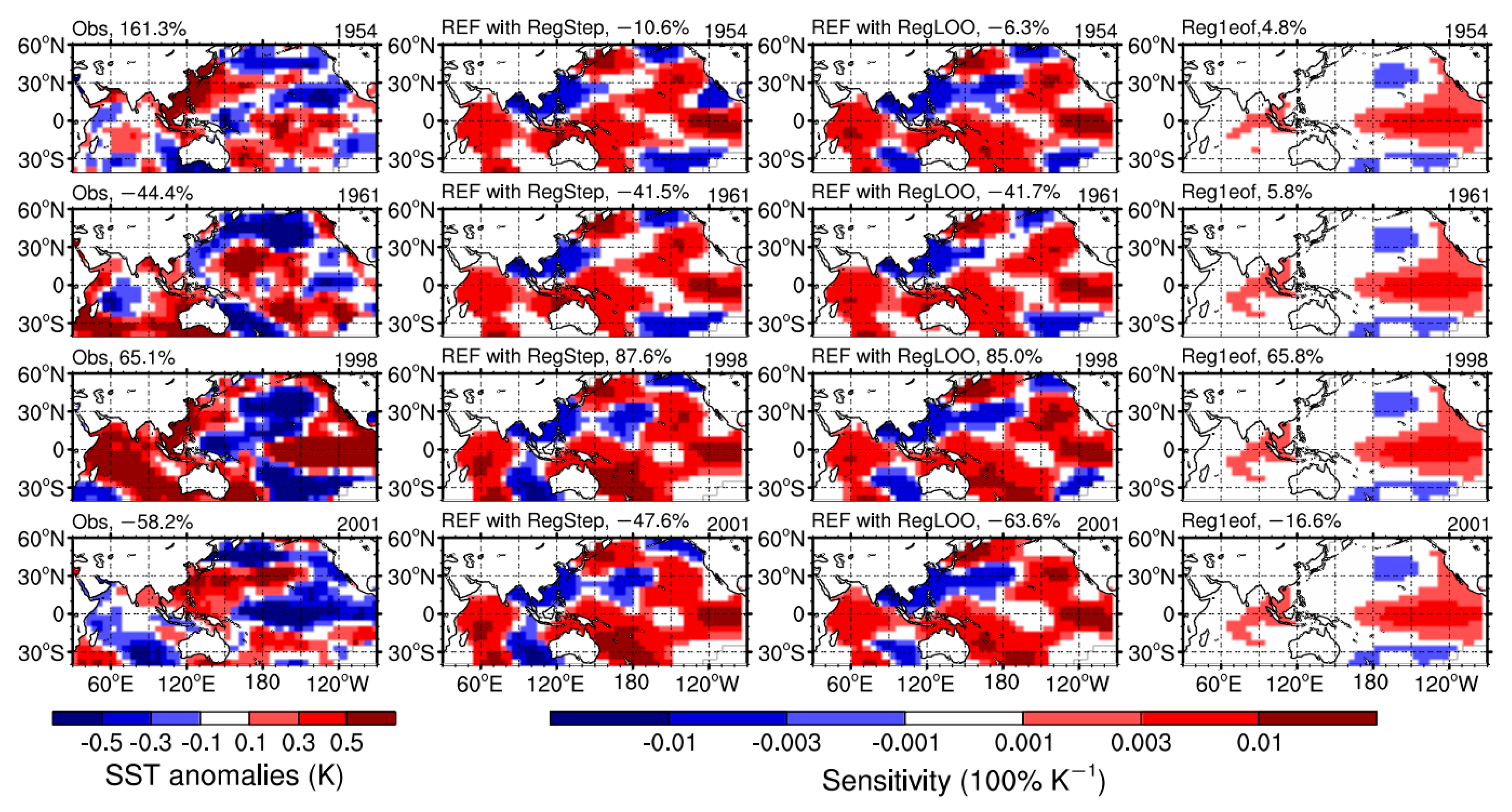
3.1. Performance and Forecast Skill
3.2. Effects of Special Treatments
3.3. Interpretability of the Forecast System
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, R.; Liu, S.C.; Cicerone, R.J.; Shiu, C.J.; Li, J.; Wang, J.L.; Zhang, Y.H. Trends of extreme precipitation in eastern China and their possible causes. Adv. Atmos. Sci. 2015, 32, 1027–1037. [Google Scholar] [CrossRef]
- Huang, R.H.; Xu, Y.H.; Zhou, L.T. The interdecadal variation of summer precipitation in China and the drought trend in north China. Plateau Meteorol. 1999, 4, 465–476. (In Chinese) [Google Scholar] [CrossRef]
- Zhang, R.H. Relations of Water Vapor Transport from Indian Monsoon with That over East Asia and the Summer Rainfall in China. Adv. Atmos. Sci. 2001, 18, 1005–1017. [Google Scholar] [CrossRef]
- Wang, Y.Q.; Li, Z. Observed trends in extreme precipitation events in China during 1961-2001 and the associated changes in large-scale circulation. Geophys. Res. Lett. 2005, 32, L09707. [Google Scholar] [CrossRef]
- Zong, Y.; Chen, X. The 1998 Flood on the Yangtze, China. Nat. Hazards 2000, 22, 165–184. [Google Scholar] [CrossRef]
- Li, J.; Wang, B. Predictability of summer extreme precipitation days over eastern China. Clim. Dyn. 2018, 51, 4543–4554. [Google Scholar] [CrossRef]
- Yim, S.Y.; Wang, B.; Xing, W. Prediction of early summer rainfall over South China by a physical-empirical model. Clim. Dyn. 2014, 43, 1883–1891. [Google Scholar] [CrossRef]
- Zhai, P.; Zhang, X.; Wan, H.; Pan, X. Trends in Total Precipitation and Frequency of Daily Precipitation Extremes over China. J. Clim. 2005, 18, 1096–1108. [Google Scholar] [CrossRef]
- Ning, L.; Liu, J.; Wang, B. How does the South Asian High influence extreme precipitation over eastern China? J. Geophys. Res. Atmos. 2017, 122, 4281–4298. [Google Scholar] [CrossRef]
- Yang, J.; Wang, B.; Bao, Q. Biweekly and 21–30-Day Variations of the Subtropical Summer Monsoon Rainfall over the Lower Reach of the Yangtze River Basin. J. Clim. 2010, 23, 1146–1159. [Google Scholar] [CrossRef]
- Xing, W.; Wang, B.; Yim, S. Long-Lead Seasonal Prediction of China Summer Rainfall Using an EOF–PLS Regression-Based Methodology. J. Clim. 2016, 29, 1783–1796. [Google Scholar] [CrossRef]
- Wei, W.; Yan, Z.; Jones, P.D. Potential Predictability of Seasonal Extreme Precipitation Accumulation in China. J. Hydrometeorol. 2017, 18, 1071–1080. [Google Scholar] [CrossRef]
- Wu, Z.W.; Wang, B.; Li, J.P.; Jin, F.F. An empirical seasonal prediction model of the East Asian summer monsoon using ENSO and NAO. J. Geophys. Res. 2009, 114, D18120. [Google Scholar] [CrossRef]
- Zhou, L.T.; Tam, C.Y.; Zhou, W.; Chan, J.C.L. Influence of South China Sea SST and the ENSO on winter rainfall over South China. Adv. Atmos. Sci. 2010, 27, 832–844. [Google Scholar] [CrossRef]
- Deng, Y.Y.; Gao, T.; Gao, H.W.; Yao, X.H.; Xie, L. Regional precipitation variability in East Asia related to climate and environmental factors during 1979–2012. Sci. Rep. 2014, 4, 5693. [Google Scholar] [CrossRef] [PubMed]
- Ying, K.; Zheng, X.; Quan, X.W.; Frederiksen, C.S. Predictable signals of seasonal precipitation in the Yangtze–Huaihe River Valley. Int. J. Climatol. 2013, 33, 3002–3015. [Google Scholar] [CrossRef]
- Wang, B.; Ding, Q.; Fu, X.; Kang, I.-S.; Jin, K.; Shukla, J.; Doblas-Reyes, F. Fundamental challenge in simulation and prediction of summer monsoon rainfall. Geophys. Res. Lett. 2005, 32, L15711. [Google Scholar] [CrossRef]
- Wang, H.J.; Fan, K.; Sun, J.; Li, S.; Lin, Z.; Zhou, G.; Chen, H.; Zhu, Y.; Li, F.; Zheng, F.; et al. A review of seasonal climate prediction research in China. Adv. Atmos. Sci. 2015, 32, 149–168. [Google Scholar] [CrossRef]
- Ding, Y.H. Advance in seasonal dynamical prediction operation. Acta Meteorol. Sin. 2004, 62, 598–612. (In Chinese) [Google Scholar] [CrossRef]
- Chen, H.P.; Sun, J.Q.; Wang, H.J. A Statistical Downscaling Model for Forecasting Summer Rainfall in China from DEMETER Hindcast Datasets. Weather Forecast. Rev. 2012, 27, 608–628. [Google Scholar] [CrossRef]
- Li, B.; Zhou, T. El Niño–Southern Oscillation–related principal interannual variability modes of early and late summer rainfall over East Asia in sea surface temperature-driven atmospheric general circulation model simulations. J. Geophys. Res. 2011, 116, D14118. [Google Scholar] [CrossRef]
- Su, Q.; Lu, R.Y.; Li, C.F. Large-scale circulation anomalies associated with interannual variation in monthly rainfall over South China from May to August. Adv. Atmos. Sci. 2014, 31, 273–282. [Google Scholar] [CrossRef]
- Oh, H.; Ha, K.J. Thermodynamic characteristics and responses to ENSO of dominant intraseasonal modes in the East Asian summer monsoon. Clim Dyn. 2015, 44, 1751–1766. [Google Scholar] [CrossRef]
- Peng, J.B.; Chen, L.T.; Zhang, Q.Y. The statistic prediction model and prediction experiments of the summer rain over China by multiple factors and multi-scale variations. Chin. J. Atmos. Sci 2006, 30, 596–608. (In Chinese) [Google Scholar] [CrossRef]
- Fan, K.; Wang, H.J.; Choi, Y.J. A physically based statistical forecast model for the middle-lower reaches of the Yangtze River valley summer rainfall. Chin. Sci. Bull. 2007, 53, 602–609. (In Chinese) [Google Scholar] [CrossRef]
- Li, J.; Wang, B. How predictable is the anomaly pattern of the Indian summer rainfall? Clim. Dyn. 2016, 46, 2847–2861. [Google Scholar] [CrossRef]
- Fang, K.; Gou, X.; Chen, F.; Cook, E.; Li, J.; Buckley, B.; D’Arrigo, R. Large-Scale Precipitation Variability over Northwest China Inferred from Tree Rings. J. Clim. 2011, 24, 3457–3468. [Google Scholar] [CrossRef]
- Lu, Z.; Guo, Y.; Zhu, J.; Kang, N. Seasonal Forecast of Early Summer Rainfall at Stations in South China Using a Statistical Downscaling Model. Weather Forecast. Rev. 2020, 35, 1633–1643. [Google Scholar] [CrossRef]
- Huang, P.; Huang, R.H. Relationship between the modes of winter tropical sea surface temperature anomalies in the pacific and the intraseasonal variations of the following summer rainfall anomalies in China. Atmos. Ocean. Sci. Lett. 2009, 2, 295–300. [Google Scholar] [CrossRef]
- Zhang, R.; Sumi, A.; Kimoto, M. A Diagnostic Study of the Impact of El Niño on the Precipitation in China. Adv. Atmos. Sci. 1999, 16, 229–241. [Google Scholar] [CrossRef]
- Kaplan, A.; Cane, M.A.; Kushnir, Y.; Clement, A.C.; Blumenthal, M.B.; Rajagopalan, B. Analyses of global sea surface temperature 1856–1991. J. Geophys. Res. 1998, 103, 18567–18589. [Google Scholar] [CrossRef]
- Wang, B.; Wu, R.; Fu, X. Pacific–East Asian Teleconnection: How Does ENSO Affect East Asian Climate? J. Clim. 2000, 13, 1517–1536. [Google Scholar] [CrossRef]
- Huang, R.H.; Wu, Y.F. The influence of ENSO on the summer climate change in China and its mechanism. Adv. Atmos. Sci. 1989, 6, 21–32. [Google Scholar] [CrossRef]
- Ulbrich, C.W.; Atlas, D. Extinction of Visible and Infrared Radiation in Rain: Comparison of Theory and Experiment. J. Atmos. Ocean. Technol. 1985, 2, 331–339. [Google Scholar] [CrossRef]
- Xing, W.; Wang, B. Predictability and prediction of summer rainfall in the arid and semi-arid regions of China. Clim. Dyn. 2017, 49, 419–431. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhou, W.; Chan, J.C.L.; Li, C.Y. Impacts of the basin-wide Indian Ocean SSTA on the South China Sea summer monsoon onset. Int. J. Climatol. 2008, 28, 1579–1587. [Google Scholar] [CrossRef]
- Annamalai, H.; Liu, P.; Xie, S.P. Southwest Indian Ocean SST variability: Its local effect and remote influence on Asian monsoons. J. Clim. 2005, 18, 4150–4167. [Google Scholar] [CrossRef]
- Zhang, R.H.; Min, Q.Y.; Su, J.Z. Impact of El Niño on atmospheric circulations over East Asia and rainfall in China: Role of the anomalous western North Pacific anticyclone. Sci. China Earth Sci. 2017, 60, 1124–1132. [Google Scholar] [CrossRef]
- Tetko, I.V.; Livingstone, D.J.; Luik, A.I. Neural network studies. 1. Comparison of Overfitting and Overtraining. J. Chem. Inf. Comput. Sci. 1995, 35, 826–833. [Google Scholar] [CrossRef]
- Wilks, D.S. Statistical Methods in the Atmospheric Sciences, 3rd ed.; Academic Press: London, UK, 2006; pp. 235–312. [Google Scholar] [CrossRef]
- Tan, H.; Mao, J.T.; Chen, H.H.; Chan, P.W.; Wu, D.; Li, F.; Deng, T. A Study of a Retrieval Method for Temperature and Humidity Profiles from Microwave Radiometer Observations Based on Principal Component Analysis and Stepwise Regression. J. Atmos. Ocean. Technol. 2011, 28, 378–389. [Google Scholar] [CrossRef]
- Elsner, J.B.; Schmertmann, C.P. Assessing forecast skill through cross validation. Wea. Forecasting Rev. 1994, 9, 619–624. [Google Scholar] [CrossRef]
- Michaelsen, J. Cross-Validation in Statistical Climate Forecast Models. J. Appl. Meteorol. Clim. 1987, 26, 1589–1600. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Anomaly Percentage (A, %) | Amplified Anomaly Percentage (Â, %) |
|---|---|
| A < −25% | Â = A − 25% |
| −25% < A < 25% | Â = A |
| A > 25% | Â = A + 25% |
| Experiments | Description |
|---|---|
| REF | Reference rolling forecast experiment. This experiment was run twice using RegStep and RegLOO, respectively. |
| Sensitivity experiments for the special treatments | |
| G-DOMAIN | Similar to REF but the MLYR domain was defined by traditional geographical concept (Figure 1). |
| FEWER-P | Similar to REF but only one/two SST principal components were used for establishing the regression equation. |
| NO-T-SAMPLE | Similar to REF but without theoretical samples. |
| NO-AMPLIFY | Similar to REF but the precipitations from abnormal years were not amplified. |
| Experiments | Cor | Succ | Bad | |
|---|---|---|---|---|
| REF | RegStep | 0.464 | 19/35 | 0/29 |
| RegLOO | 0.504 | 20/35 | 0/34 | |
| G-DOMAIN | RegStep | 0.445 | 18/37 | 2/34 |
| RegLOO | 0.393 | 16/37 | 2/37 | |
| FEWER-P | Reg1eof | 0.294 | 12/35 | 3/26 |
| Reg2eof | 0.402 | 13/35 | 2/26 | |
| NO-T-SAMPLE | RegStep | 0.374 | 11/35 | 1/15 |
| RegLOO | 0.362 | 13/35 | 1/23 | |
| NO-AMPLIFY | RegStep | 0.460 | 15/35 | 1/22 |
| RegLOO | 0.425 | 15/35 | 1/25 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Q.; Shi, X. Forecasting the July Precipitation over the Middle-Lower Reaches of the Yangtze River with a Flexible Statistical Model. Atmosphere 2023, 14, 152. https://doi.org/10.3390/atmos14010152
Jiang Q, Shi X. Forecasting the July Precipitation over the Middle-Lower Reaches of the Yangtze River with a Flexible Statistical Model. Atmosphere. 2023; 14(1):152. https://doi.org/10.3390/atmos14010152
Chicago/Turabian StyleJiang, Qixiao, and Xiangjun Shi. 2023. "Forecasting the July Precipitation over the Middle-Lower Reaches of the Yangtze River with a Flexible Statistical Model" Atmosphere 14, no. 1: 152. https://doi.org/10.3390/atmos14010152
APA StyleJiang, Q., & Shi, X. (2023). Forecasting the July Precipitation over the Middle-Lower Reaches of the Yangtze River with a Flexible Statistical Model. Atmosphere, 14(1), 152. https://doi.org/10.3390/atmos14010152