1. Introduction
Several methods are widely used for the objective of state estimation based on the weighted combination of different sources of information. The process of data assimilation (DA) refines forecasts by incorporating atmospheric observations and estimated errors in both observations and forecasts [
1,
2]. This leads to an optimal estimate of the initial state for numerical weather prediction (NWP) models, achieved through the combination of available information sources, including prior model forecasts and observations while considering uncertainties [
3]. To enhance the accuracy of forecasts, DA methodologies can play a pivotal role by combining the limited observations with the model’s first guess while accommodating uncertainties inherent in each information source.
The three-dimensional variational data assimilation (3D-VAR) DA systems include the Gridpoint Statistical Interpolation (GSI) developed by the National Centers for Environmental Prediction (NCEP), the Variational Analysis System by the European Centre for Medium-Range Weather Forecasts (ECMWF), and the Local Ensemble Transform Kalman Filter (LETKF) by the University of Maryland. In this spectrum, the WRF VAR system has a significant influence due to its versatile control variable (CV) options.
Optimal blending of observations with atmospheric model data results in an improved model initial state. This is particularly significant considering the relatively small amount of observations compared to the degrees of freedom of a forecast model’s initial state [
4]. The incorporation of surface observations into NWP models has demonstrated the potential to improve the model’s performance. Previous studies have aimed to refine simulations of weather parameters by assimilating both direct and modeled surface observations, including temperature, water vapor, mixing ratio, and wind [
5]. Additionally, assimilating data such as 2 m potential temperature, 2 m dew point temperature, and 10 m wind observations have been explored for determining planetary boundary layer (PBL) profiles [
6]. European Center for Medium-Range Weather Forecasts (ECMWF) pioneered the direct assimilation of high-resolution satellite data, including microwave radiance affected by precipitation [
7,
8,
9,
10]. Furthermore, studies have shown the possible improvement in rainfall forecasts from NWP models by assimilating radar reflectivity [
11,
12,
13] or radar-derived precipitation data [
14,
15]. However, it is crucial to validate remote sensing data against ground truth [
16]. Surface observations offer a valuable resource for simulating mesoscale weather phenomena [
17]. Notably, observations alone are inadequate for estimating background errors (BE) due to their scattered grid.
The effectiveness of the 3D-VAR DA systems relies on their operational mechanisms; part of them is the role of BE within variational schemes. In VAR schemes, BE provides information to balance the influence of the observations on the model forecasts in space and intensity. The accuracy of the DA solution depends highly on the representation of the observation error, which describes uncertainties in the numerical model forecasts prior to new observation incorporation.
Estimation of BE varies depending on the chosen methodology [
18]. One prevalent approach involves deriving BE covariances from innovation vectors, which are disparities between observed values and corresponding background state equivalents [
19]. This method operates with the assumption of known spatial structures of observation errors and considers dynamic balance assumptions between variables. Another common practice is using statistics of forecast differences as approximations for forecast error covariances, often referred to as the “NMC method” [
20]. Alternatively, the use of time-averaged covariances of an extended Kalman filter has been explored, although this demands more computational resources [
21]. Variants of Kalman filter-based techniques, such as the reduced rank Kalman filter and ensemble Kalman filter, offer means to attain synoptically dependent background error characteristics [
22]. Additionally, the maximum likelihood theory employs a covariance model fit to innovation vectors [
23]. Notably, the WRF model is frequently employed to calculate BE and perform DA experiments using model forecasts initialized at different times. Accurate estimation of BE is essential for the success of DA, as it ensures appropriate weighting to background information, implicitly considering observations [
24]. Additionally, BEs are spatially correlated, enabling the propagation of observational information in three dimensions. Moreover, these BEs for various meteorological variables demonstrate correlation, allowing multivariate adjustments that reflect atmospheric balance [
25,
26].
The utility of the WRF model is connected with the accuracy of initial and boundary conditions. The BEs are tied to the choice of control variables, which inherently influence the assimilation and, consequently, the prediction processes. For this reason, the latest version of the WRF model and WRF VAR is employed in the present study. As part of our methodological analysis, we employ detailed meteorological observations, only surface observations at this stage as a first attempt, which are processed, assimilated, and tested under various configurations, primarily focusing on three different control variable (CV) options under WRF DA, introducing differences in thermodynamic correlations of BE estimation. By comparing the outcomes from multiple 3D-VAR DA runs, the relative advantages and limitations of each CV choice are indicated, particularly at the near-surface layers, where the forecast differences are more evident due to the use of only surface observations. These CV options provide frameworks for atmospheric model state variable analysis, and their choice can influence the accuracy of model predictions at various spatial scales. The diverse nature of these CV options underlines the flexibility of the WRF VAR system, catering to various meteorological scenarios and scales. While each option has its strengths, their selection based on specific requirements can play a critical role in optimizing weather forecasts.
In an attempt to examine the aspect of different BE outcomes, a high-impact convective case, with characteristics of a supercell system, was selected that affected northern Greece. As far as the predictability of such phenomena, global models struggled to forecast this event accurately. On the other hand, mesoscale models, which are crucial for NWP, rely on global models for initial conditions. Analyzing control variable (CV) options’ impact on model predictions, especially in complex meteorological scenarios such as the present study, allows us to assess their accuracy and efficacy, particularly for extreme events like supercells.
With the increasing frequency and intensity of extreme weather events [
27,
28,
29,
30,
31], it is necessary to refine our meteorological models for more precise forecasts. The main goal is not just to understand the behavior of this specific event but also to distill insights that could enhance the operational reliability of the application of the WRF system in future events. The goal of this investigation is dual: firstly, to discern these variations, and secondly, to strive for the optimization of initial conditions in NWP results. This study aims mainly at exploring the effects of CVs in producing and assessing the different scales of the meteorological phenomena present in such a complex case study and hence providing the best initial conditions using at first only surface observations rather than reproducing or modeling the exact weather event in a model environment. It specifically highlights the best practice regarding the usage of CVs in extreme weather events where convective phenomena are present, especially considering areas with complex terrain, such as Greece. As a further outcome, it is to provide suggestions for introducing a best practice for future data assimilation of multi-site and multi-level observations, such as radar data, in order to reproduce the event having a more complete observational dataset.
The paper is structured as follows:
Section 2 provides an overview of BE and 3D-VAR data assimilation background necessary for the purposes of this paper. In
Section 3, the meteorological test case is presented.
Section 4 presents a concise description of the methodology and experiment design. The results of the DA experiments are analyzed and evaluated in
Section 5, and the findings are summarized in the concluding
Section 6.
5. Results
In this section, the steps of model applications and the corresponding DA efforts are outlined. An initial run is performed to establish a baseline configuration. Following this, the process and significance of modeling the BE covariance, commonly known as the B matrix, is explained, followed by the techniques and datasets utilized in our DA phase. The outcomes and deviations observed post DA are evaluated, as well as the impact and improvements over the initial runs.
5.1. Initial Run
An initial run for a period of two days was performed, which will serve as initial conditions for a warm start after data assimilation. The run is from 10.07.2019 00:00 UTC to 12.07.2019 00:00 UTC. Trying to overcome spin-up issues, the forecast of 06:00 UTC of 10.07.2019 was selected for DA purposes as a warm start, and the assimilated initial conditions are used for the runs of WRF after the DA of surface observation, performed for CV5, CV6, and CV7 configurations, starting from 10.07.2019 06:00 UTC to 12.07.2019 00:00 UTC.
5.2. Background Error Covariance Analysis
The BE covariance in 3D-VAR experiments is static and prescribed by the NMC method [
20]. It assumes homogeneous and isotropic correlations for a set of independent control variables derived from the forecast differences. In this study, the CV5, CV6, and CV7 options are used.
For the evaluation of BE, a 20-day period starting from 1.07.2018 to 20.07.2018 was selected. Forecasts of 12 h and 24 h WRF-ARW outputs, initialized both at 00:00 and at 12:00 UTC, were used. Thus, 40 pairs of perturbations are available to generate WRF-ARW BE. The test case examined refers to July of 2019, but the statistics refer to a year prior to the test case, based on the assumption that at the time when the event occurred, no statistical data were available. Thus, a climatological approach is to use the previous year’s data.
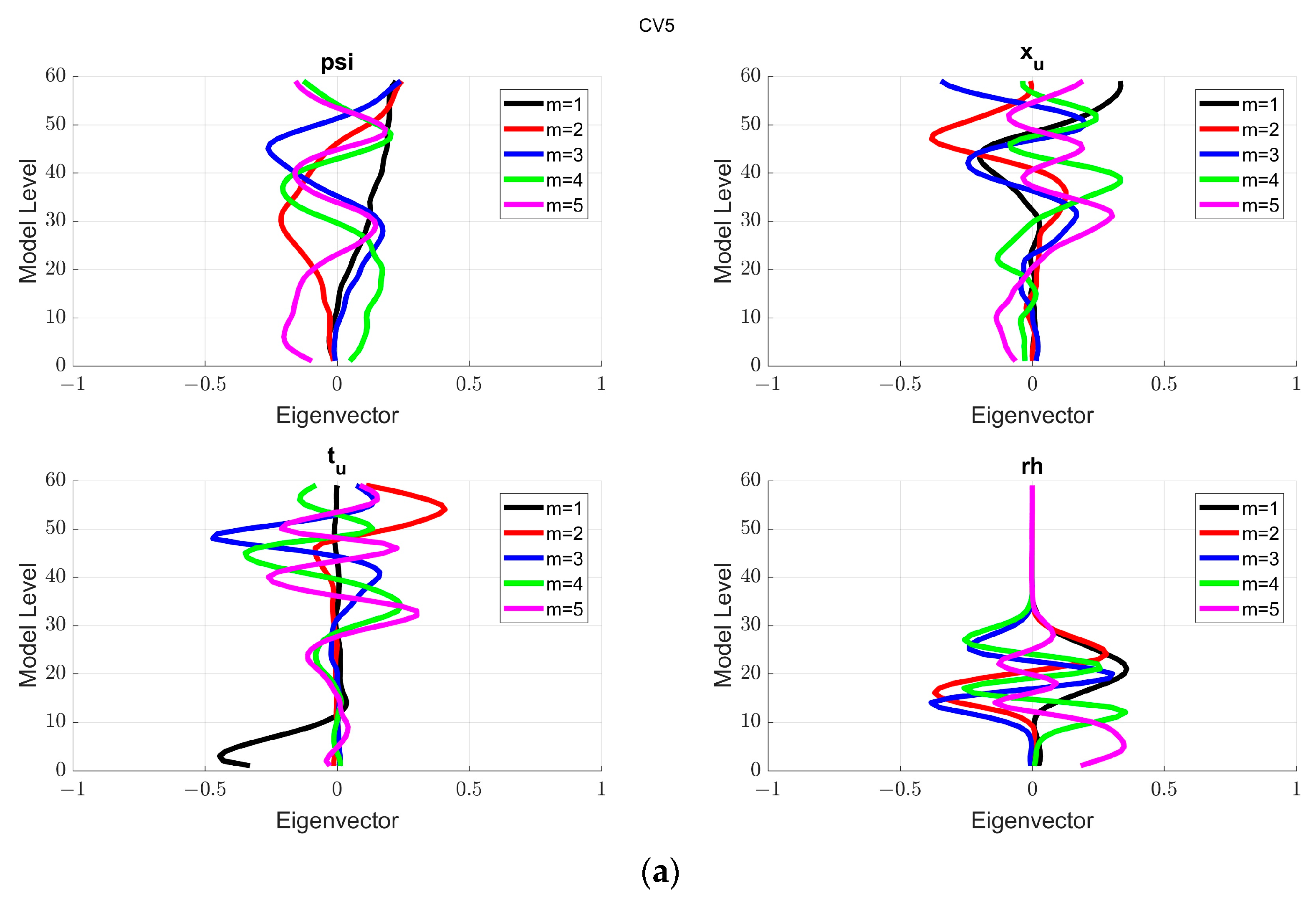
The reliability of DA significantly hinges on the accurate representation of the BE covariance B. Analyzing the eigenvectors corresponding to each configuration provides an enriched understanding of the role that various atmospheric variables play in influencing the overall error statistics.
For the CV5 configuration, the eigenstructure of the BE was analyzed across the five eigenvectors for each variable. As seen in
Figure 4a, the y axis represents the levels resolved by the model, and the x axis has the first five eigenvalues of each eigenvector. Regarding relative humidity (rh) at the first eigenvector, large-scale error structures associated become evident, exhibiting broad spatial structures across the model domain, potentially pointing to persistent atmospheric circulations or model biases. The values of streamfunction (ψ) in the first eigenvector reveal the interconnected nature of dynamic and thermodynamic processes in the atmosphere. Analyzing the rest of them, the atmospheric dynamics manifest in more complex patterns, indicating the intricate variability of streamfunction. The temperature (t
u) pattern suggests a growth in the lower levels, while the rh pattern suggests an interaction up to the intermediate levels. However, studying the rest of the eigenvectors, the relation grows more intricate, emphasizing the dynamic influence of temperature on the atmospheric structure.
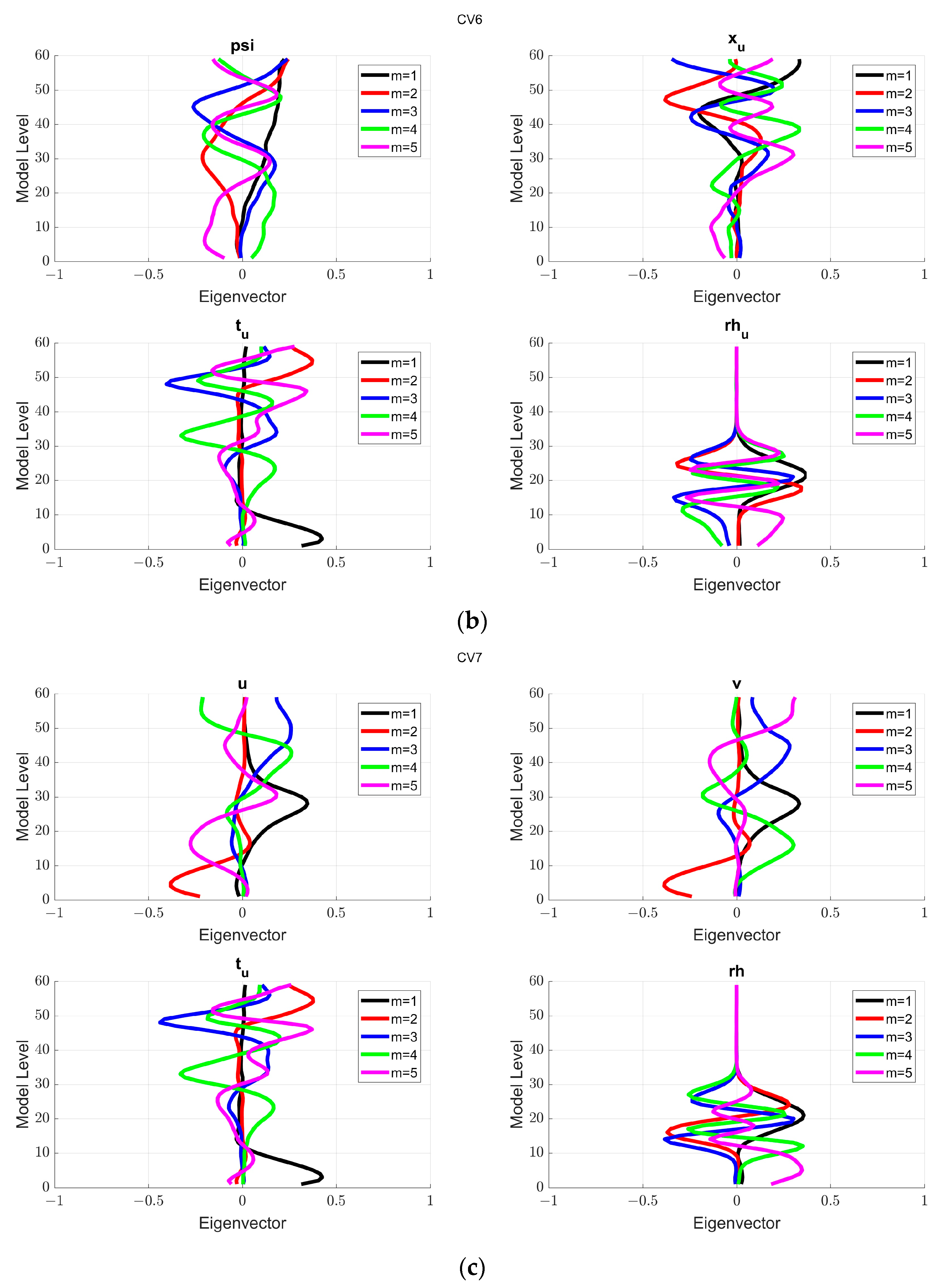
For the CV6 configuration (
Figure 4b), the eigenstructure was again dissected across the first five modes. The oscillatory patterns in rh grow more pronounced, suggesting a rich interplay at intermediate scales. The patterns in ψ and χ are the same as the CV5 configuration. The values of t
u highlight a dynamic equilibrium between temperature and other constituents, pivotal for the determination of moisture levels and circulation patterns.
For the CV7 configuration (
Figure 4c), the patterns in rh are the same as the CV5 configuration. The temperature patterns in CV7 also suggest variabilities like CV6 configuration.
5.3. Background Error Length Scales Analysis
A configuration overview regarding the control variable options follows; option CV5 consistently leans toward broader, synoptic scales across all the variables. This configuration is likely to be more relevant for large-scale weather events and phenomena, having a representation in the broader, synoptic scales. CV6, on the other hand, has been consistent in its representation of more localized mesoscale processes. It would be instrumental in understanding and predicting more localized weather events, especially in complex terrains or regions with significant land–sea interactions or convective events. CV7 is a transitional configuration and leans toward microscale phenomena, whereas its behavior is between synoptic-scale and mesoscale phenomena. The above length scales are derived from the BE covariance matrices for each CV configuration.
Analyzing ψ variable (available for CV5 and CV6 options), the length scales for CV5 start at broader values and tend to decrease steadily across levels, indicating a more synoptic behavior and representation. CV6 has generally smaller length scales compared to CV5, implying a more mesoscale and localized behavior.
Analyzing the χ variable (available for CV5 and CV6), the CV5 configuration exhibits larger spatial correlations with length scales showcasing steady declines across levels, reflecting the broader scales. For the CV6 configuration, as with ψ, a more localized behavior is displayed, with smaller length scales across levels.
Regarding the t variable (temperature for all configurations: CV5, CV6, and CV7) (
Figure 5), for the CV5 configuration, we encounter larger length scales to start with, gradually reducing across levels. This suggests broader spatial correlations in the beginning. CV6 exhibits smaller length scales throughout compared to CV5, showcasing its typical mesoscale behavior. CV7 displays a transitional behavior between CV5 and CV6, so we might expect length scales somewhere in between the two, striking a balance between synoptic and mesoscale characteristics. However, if CV7 leans more toward microscale representations, the length scales might be smaller than both CV5 and CV6.
Finally, for the rh variable (relative humidity), CV5 and CV7 options have the same length scales, while CV6 exhibits similar patterns.
Incorporating these insights can greatly optimize model utilization for specific weather prediction needs. For broader weather patterns, CV5 would be the most suitable. For more localized predictions, CV6 seems to be the most appropriate. Depending on the wind accuracy necessity, CV7 could be used for both mesoscale or synoptic area simulations, where the wind is the most important variable for assimilation.
5.4. Data Assimilation Using CV5, CV6, and CV7
DA of surface observation was performed for CV5, CV6, and CV7 BE. The variance scale parameter is carefully tuned to 3.0 rather than the default value of 1.0 to provide the best performance of the 3D-VAR among various experiments tested (not shown; this also improves the performance of 4D-VAR as compared to the default) [
3].
As stated in
Section 5.1, the initial conditions for DA and the new runs refer to 06:00 UTC of 10.07.2019. Three DA processes were performed for the three different BE configurations previously examined, using the same set of observations, as stated in 4.4. The process of DA for each control variable option is shown in
Figure 6.
The minimization of the cost function, as assessed using the conjugate gradient (CG) method, was performed across three different CV configurations: CV5, CV6, and CV7. All three configurations started from an identical cost function value of 2923.71. The initial gradients were different, with CV5, CV6, and CV7 showing initial gradients of 60.35, 55.10, and 87.87, respectively. This indicates that the CV7 setup had the steepest gradient, implying the most substantial deviation from the minimum.
CV5 took 12 iterations to converge to a cost function of 2379.51, showing a reduction of 544.2 from its initial value. CV6 converged in 10 iterations to a value of 2462.67, a decrease of 461.04. CV7 required the most iterations (16) to converge to a cost function of 1841.01, marking a significant reduction of 1082.7. As iterations progress, the gradient values for all configurations diminish. CV7 demonstrated the largest initial gradient, but it also showed the steepest decline, highlighting rapid convergence, especially in the first few iterations. For all configurations, the step sizes were not uniform, fluctuating based on the gradient magnitude and the curvature of the cost function.
Among the configurations, CV5 and CV6 required fewer iterations compared to CV7. However, CV7 achieved a more substantial reduction in the cost function value despite the necessity of more iterations. CV7 converged to the lowest cost function value of the three, indicating a better fit for the given problem.
The final J/(total number of observations) value for CV7 is also the lowest, suggesting that, on average, the misfit between observations and the model field is the smallest for CV7. However, CV7 required a few more iterations to converge compared to CV5 and CV6. The selection of the best option should consider other factors as well, such as computational efficiency and the physical interpretation of the results.
Table 2 details the computed outcomes of the objective function J for various CV configurations, namely CV5, CV6, and CV7. The final value of J is segmented into observational (J
o) and background (J
b) components. CV7 stands out with the lowest overall value of J, whereas CV6 stands out with the lowest value of J
b.
The calculation of the background term Jb, as well as the calculation of the observation term Jo, based on (Equation (2)), shows that CV6 has the lowest value of Jo, followed by CV5 and then CV7. Having as criteria the Jb value and not the J value, CV6 exhibited the best performance based on the results. The contribution of Jo in the final J value of CV6 is the biggest compared to CV5 and CV7, and this serves as observations that are well fitted to the analysis field much more efficiently than the other two CVs.
5.5. Runs and Analysis Post Data Assimilation
Three sets of new forecasts were available after the DA process. As the starting time was 06:00 UTC of 10.07.2019, the simulation of the WRF-ARW was performed for 42 h up to 00:00 UTC of 12.7.2019. The original run, which started at 00:00 UTC of 10.07.2019, will be referred to as ORIG, RCV5 for the run after CV5 option BE DA, RCV6 for the run after CV6 option BE DA, and RCV7 for the run after CV7 option BE DA.
Discrepancies are evident among these forecasts, necessitating detailed evaluation. This enhancement is sought through the exclusive use of one kind of observation (surface METAR), thereby enabling an assessment of the control variables. Given the sole reliance on surface observations, the contrasts among ORIG, RCV5, RCV6, and RCV7 manifest close to the surface of the model. This justifies the emphasis on near-surface and surface-layer discrepancies in our presentation.
In order to evaluate the results, a simple linear regression analysis between the surface observations and the CV results was performed, and the corresponding R
2, slope, and RMSE values were calculated. In particular, the verification was between the observational data and forecasts for each ORIG, RCV5, RCV6, and RCV7.
Table 3 illustrates the results for specific humidity parameters in periods with sufficient data available. The dates presented in
Table 3,
Table 4 and
Table 5 were chosen in order to have sufficient data samples for verification, as there were collection issues of archives where intermediate hours were faulty. The linear regression between the observations and the forecasts over the entire set of observations for the whole domain indicated that CV6 configuration forecasts (RCV6 run) had the best fit, as the higher values of the slope.
Table 4 further supports this outcome, showing the RCV6 runs to have the lowest RMSE among most of the runs.
CV6 configuration has a direct effect on representing humidity correlation, and this makes it the best configuration among these three for convective phenomena simulations. It is also noticeable that the ORIG run had the worst score compared with runs in which data assimilation was performed.
The above results are further supported when comparing IMERG and forecasted 24 h precipitation in an area that affected Greece the most, encompassing the Balkans (
Figure 7 Area A). The scattered diagrams between IMERG and forecast (not shown) indicate that there are both overestimation and underestimation of the observation. However, applying a simple regression analysis on these data, it is indicated that the slope and the R-square for RCV6 are the largest among the runs, and the RMSE has a minimum value for RCV5 (
Table 5).
Trying to support the result of the more accurate convective role of CV6 configuration, an area near Chalkidiki was selected to narrow down the results (
Figure 7—Area B). The same comparison was made between IMERG and forecasted 24 h precipitation, as shown in
Table 6, where the slope and the R-square of RCV6 are the biggest, and the RMSE has the lowest value among the runs as well.
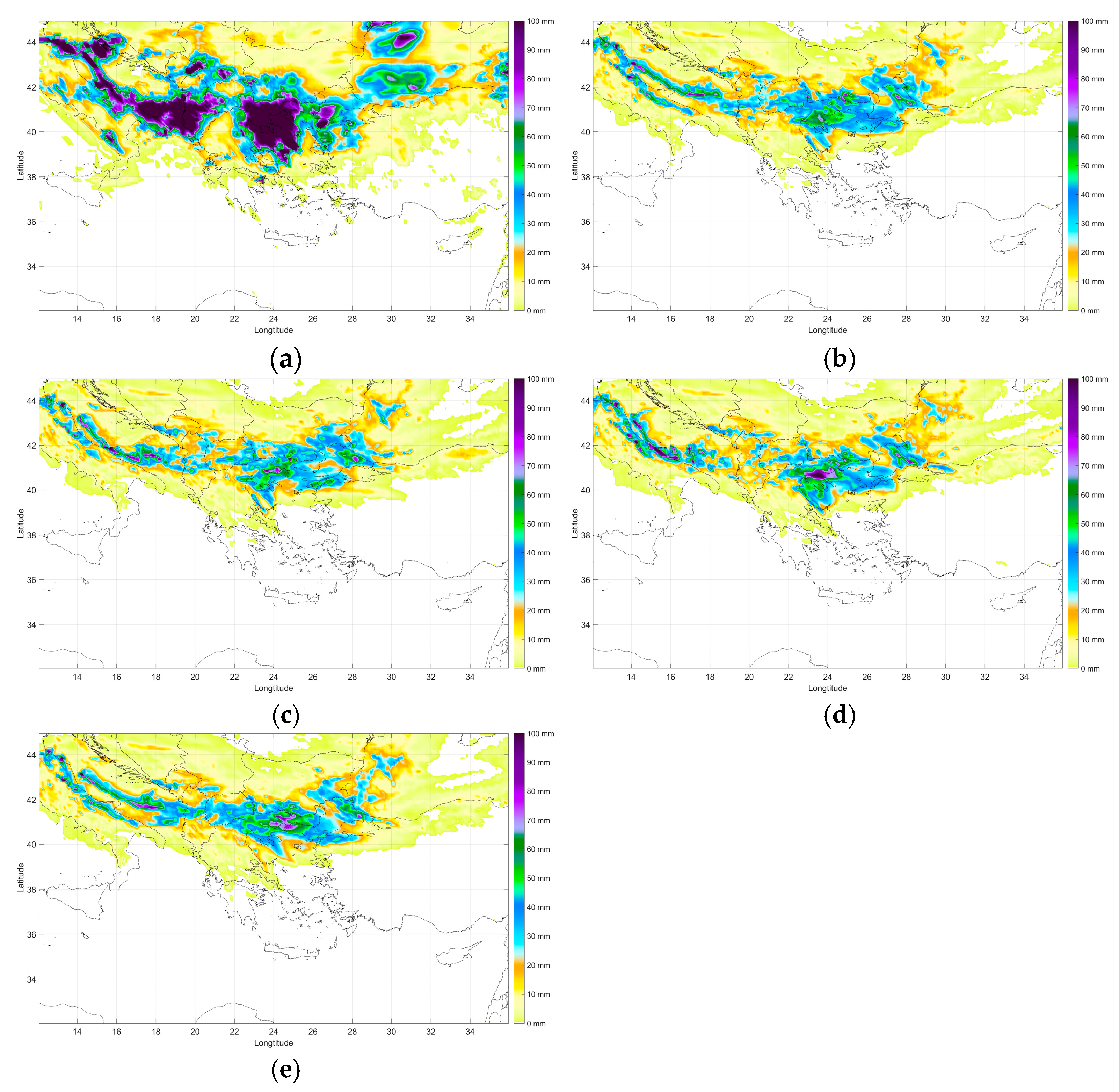
It is evident across all model outputs that the IMERG data (
Figure 8a) showcased higher precipitation values compared to the runs ORIG, RCV5, RCV6, and RCV7. This visual comparative analysis offers insights into how the assimilation of surface observations under different CV configurations affects model outcomes as well as the mathematical approach. Among all model runs, ORIG consistently demonstrated the least intensity of precipitation over the Chalkidiki area (
Figure 8b). This suggests the possibility that the initial conditions in ORIG might not capture certain atmospheric features or mechanisms driving precipitation over the region. The RCV5 run visualized in
Figure 8c reveals an increase in precipitation intensity over Chalkidiki compared to ORIG. However, this increase remains notably subdued when compared to the IMERG data and the other assimilation runs. The CV5 assimilation seems to have added some fidelity to the model over ORIG but is not as aggressive as CV6 in its precipitation forecast.
Figure 8d, showcasing the CV6 BE DA scenario, presents the most intense precipitation forecast over Chalkidiki among all runs. The amplification suggests that the assimilation of data in the CV6 scenario has a pronounced effect on the model’s prediction of mesoscale convective systems or similar rain-producing mechanisms over the region. The RCV7 run, illustrated in
Figure 8e, while showcasing a significant increase in precipitation, especially in the northern regions of Greece, places its intensity somewhere between CV5 and CV6 for the Chalkidiki area. This spatial variation indicates that CV7 may be capturing different atmospheric dynamics or processes that are more influential toward the northern parts of Greece as a local phenomenon due to wind direction increments.
In summary, while all model runs after the assimilation of surface observations (RCV5, RCV6, and RCV7) produced higher precipitation values than ORIG, they all remained conservative when compared to IMERG estimates, which serve as a reference for precipitation patterns in areas where rain gauge data are not available. This suggests that while DA can enhance the model’s accuracy, there is still a discrepancy between model forecasts and observed data, hinting at other influencing factors and the need for the inclusion of additional observational datasets. As stated before, the scope of this study is to underline the best practice regarding convection and probably capturing supercell intensity, such as this test case studied, especially when orography evidently plays a crucial role in forecasting regarding complex terrain. The findings underscore the value of DA in refining NWP model outputs. However, they also emphasize the necessity for continuous model evaluation and adjustment to better align with observational data.
6. Conclusions
In this study, surface data assimilation (DA) is implemented in WRF DA 3D-VAR and applied to a 9 km model configuration. We studied three control variable configurations, namely CV5, CV6, and CV7, to incorporate climatological background errors (Bes) utilizing the NMC method in WRF VAR. The DA fields were evaluated with a focus on understanding the impact of ΒΕ on convective weather evolution under complex terrain. Utilizing the WRF model, different BEs were calculated and compared to show their effects on the resulting weather forecasts.
The CVs were tested for simulating the convective weather conditions in a supercell case over a complex terrain configuration, a study which, to the knowledge of the authors, is the first time to be performed over Greece. In this way, insights are gained in their usage regarding the resolving space scales. The results suggest that the representation of BE plays a pivotal role in VAR DA. Specifically, the WRF runs demonstrate how different BE can influence weather evolution. It is clear that BE covariance calculation greatly influences the reliability of DA processes and, hence, the NWPs by influencing processes at different scales, such as cloud formation, vertical convective motions, and overall precipitation dynamics, especially regarding convection. Our findings illustrate that the CV6 configuration is a suitable approach for data assimilation regarding supercell thunderstorm forecasting, accommodating local-scale effects induced by orography as well as mesoscale characteristics.
Directly comparing the WRF runs of ORIG (no DA), RCV5, RCV6, and RCV7, it was evident that the latter three, post-DA runs, showcased an overall improvement in forecast accuracy over the Chalkidiki area regarding precipitation amounts. Among these, CV6 emerged as the standout, making the configuration CV6 an optimal choice for weather prediction in scenarios where localized phenomena develop, such as convective weather events. Configuration for CV6 had the minimum value of Jb, and the produced run, namely RCV6 forecasts, were enriched with the most rain gauge values while notably influencing the weather evolution, having the biggest amount of precipitation over the Chalkidiki region, and the highest score in the forecasts when validated to surface observations of humidity among RCV5, RCV7, and ORIG runs. Such an alignment of CV6 with localized mesoscale processes suggests that the representation of BE, especially those closely adhering to ground observations, can considerably affect the accuracy of NWP and DA mechanisms. This indicates that when our BE aligns closely with observations, our weather forecasting accuracy improves significantly, as shown by the minimization of the Jb term of Equation (2). Hence, CV6 seems to perform better in resolving the necessary scales associated with the extreme and complex convective event, producing more accurate precipitation forecasts, although only METAR observations were taken into account in the DA.
This study emphasizes how the selection of background error (BE) can notably improve humidity parameters, which are critical for convection phenomena. This fine tuning in data assimilation provides new insights into the significance of control variable configurations for enhancing the reliability of weather forecasting. The horizontal length scale was analyzed in order to describe to what extent the horizontal background covariance can spread the observation information. Given the limited availability of quality data in certain regions for DA, BE reliability is highly important. Furthermore, BE reliability becomes crucial, especially where the orography is quite complex and peculiarities of locally developed weather phenomena at any time in the year are often characterized by diversity and extremity, such as supercell thunderstorms. This study explores the novelty of the role of different control variable configurations in weather forecasting within the context of Greece’s notably complex terrain.
Different BE statistics experiments may be further applied for better fine tuning in the performance of WRFs’ forecasting ability, as in this study, the primary source of observational input for DA stemmed from surface METAR observations only. While surface observations are integral to refining the lower atmospheric layers and boundary conditions of the model, they have inherent limitations as they provide data on near-ground conditions and primarily influence the boundary layer conditions in model simulations. While they can provide valuable insights into atmospheric variables near the ground, they do not offer a holistic understanding of the entire atmospheric column. Therefore, incorporating upper-air observations, whether direct or indirect, could offer a more comprehensive depiction of atmospheric dynamics. Satellite-derived measurements, radiosonde data, and aircraft observations can provide insights into mid-tropospheric and upper-tropospheric conditions.
Having a more diverse observation dataset has the potential to improve forecasting skills using observations that are not only surface based but in the upper atmosphere layers as well. Radar data assimilation emerges as a promising solution for future research, as radar data offer high-resolution, three-dimensional insights into precipitation structures and dynamics. Integrating radar-derived observations could drastically enhance the accuracy of precipitation forecasts, especially for localized and intense meteorological events, influencing cloud dynamics and precipitation by diversifying the observational datasets integrated into the model—spanning from the surface to the upper atmosphere—where lies the potential for substantially improved and more accurate NWP outputs. Successful modeling of the BE covariance matrix is a prerequisite for further development of the NWP system in any regional NWP with DA.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}