
Current Situation and Prospect of Geospatial AI in Air Pollution Prediction





Abstract
1. Introduction
- It has an obvious space–time structure. First, the occurrence of earth science phenomena such as haze [32], volcanic eruption [33], and earthquake [34] has obvious time and space characteristics. Secondly, due to the great variability of the earth’s vegetation, rock strata, and climate in time and space, the input variables of earth science vary greatly in different locations.
- Estimating Difficult to Measure Variables: Artificial intelligence can use machine learning techniques to estimate Earth science variables that are difficult to measure. Relying on artificial intelligence algorithms, these previously difficult to measure geoscientific variables become precise.
- Detection of objects and events: AI tools can detect objects and events in Earth science through technologies such as image recognition and speech recognition. Li et al. [35] developed LOC-FLOW, a seismic detection and location workflow based on deep learning, to construct a high-precision microseismic catalog for the Xiluodu Reservoir area. This AI-generated catalog was then used in combination with conventional seismic array data to perform 3D velocity structure inversion and precise earthquake relocation. This AI-generated catalog containing 6595 earthquakes was integrated with conventional seismic array data to enhance ray coverage and improve the resolution of velocity structure imaging.
- Long-term prediction of geoscience variables: Artificial intelligence can predict the long-term trends and periodic changes in geoscience variables, such as precipitation, climate change, sea level rise, etc., through techniques such as time series analysis and deep learning. Jin, Weixin et al.’s study guided precipitation prediction based on deep learning models [36].
- Understand the interrelationships between different physical processes: Artificial intelligence can use techniques such as data mining and model analysis to understand the interrelationships between different physical processes.
2. Bibliometric Analysis
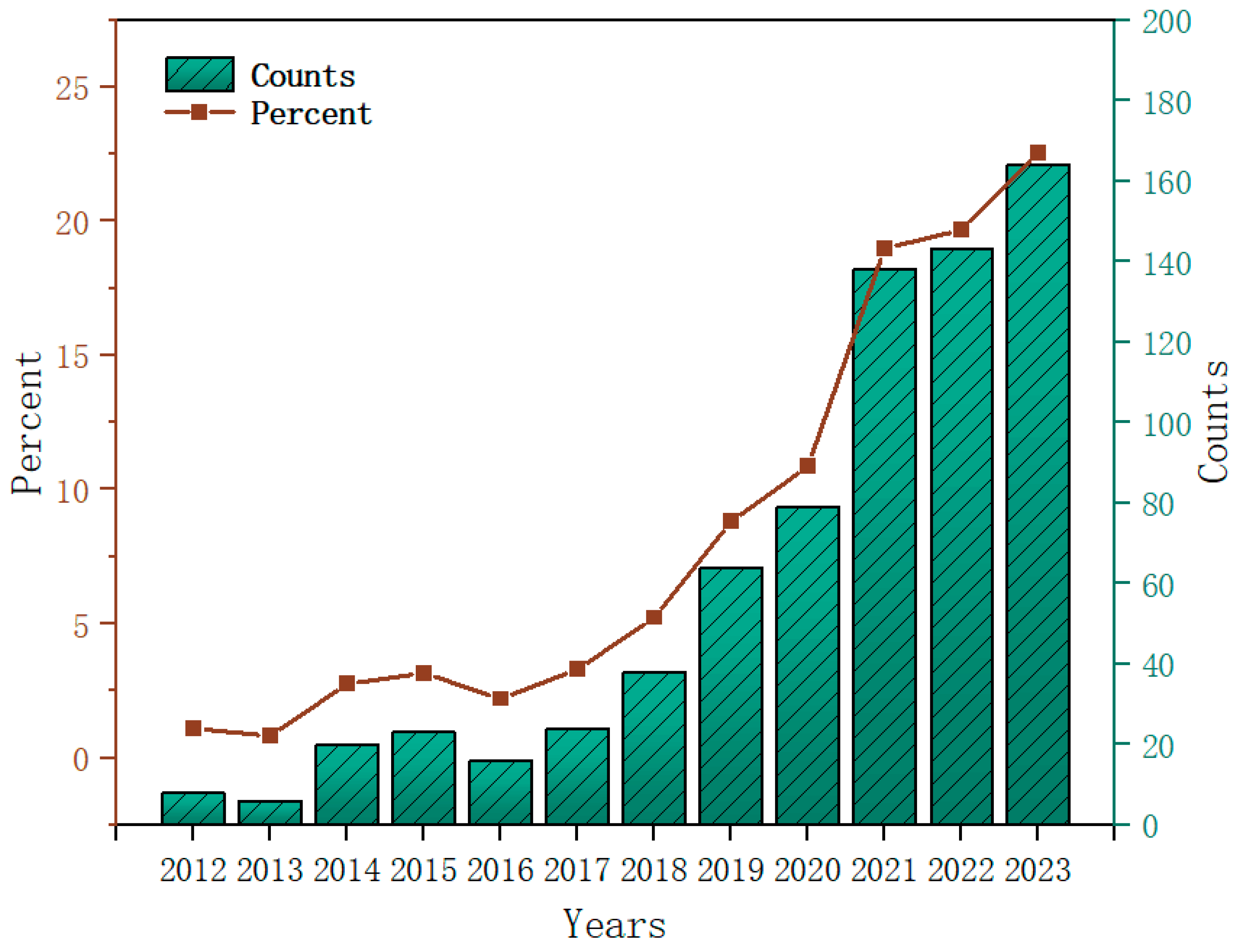
2.1. Literature Development Trend
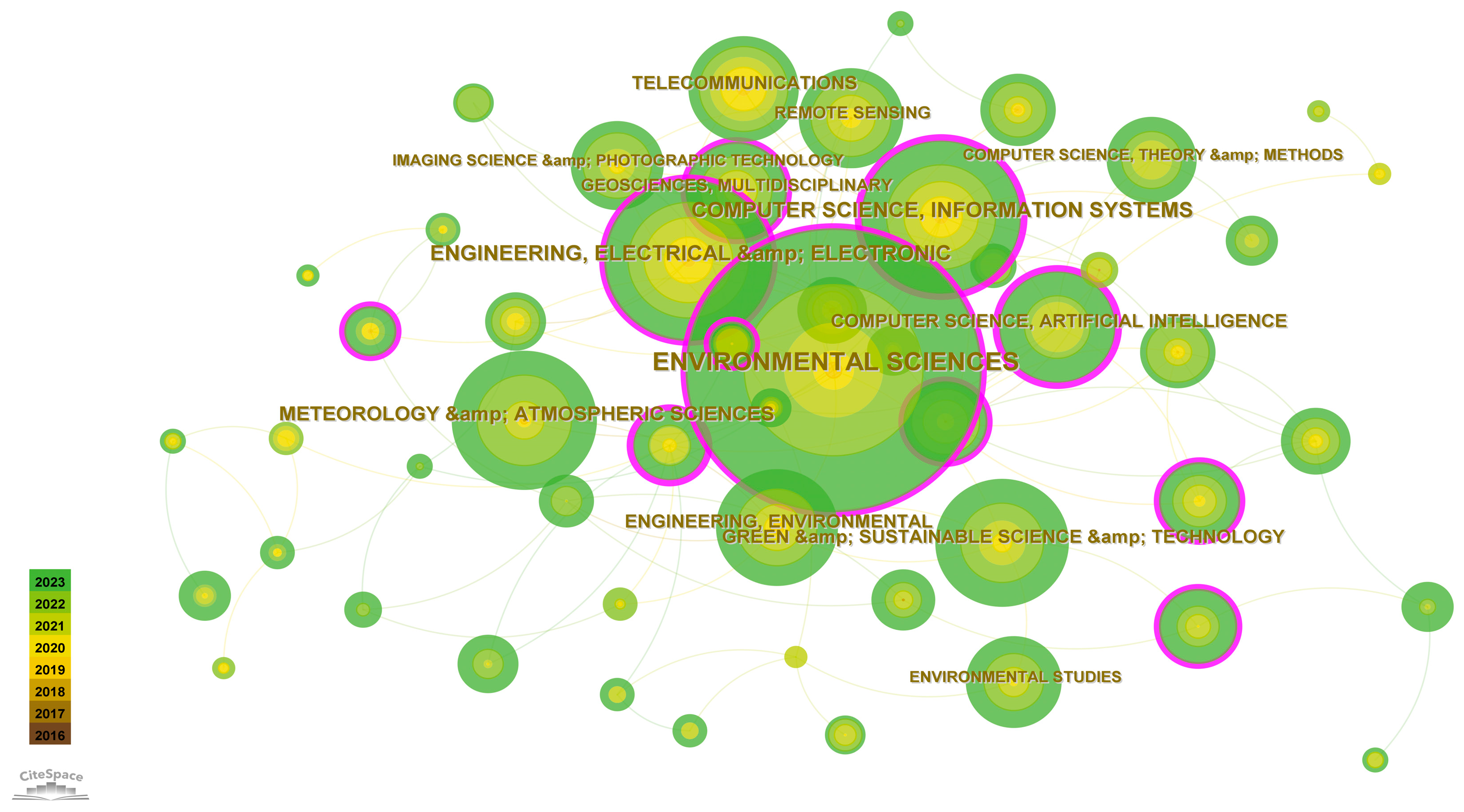
2.2. Cite Journals and Research Topics
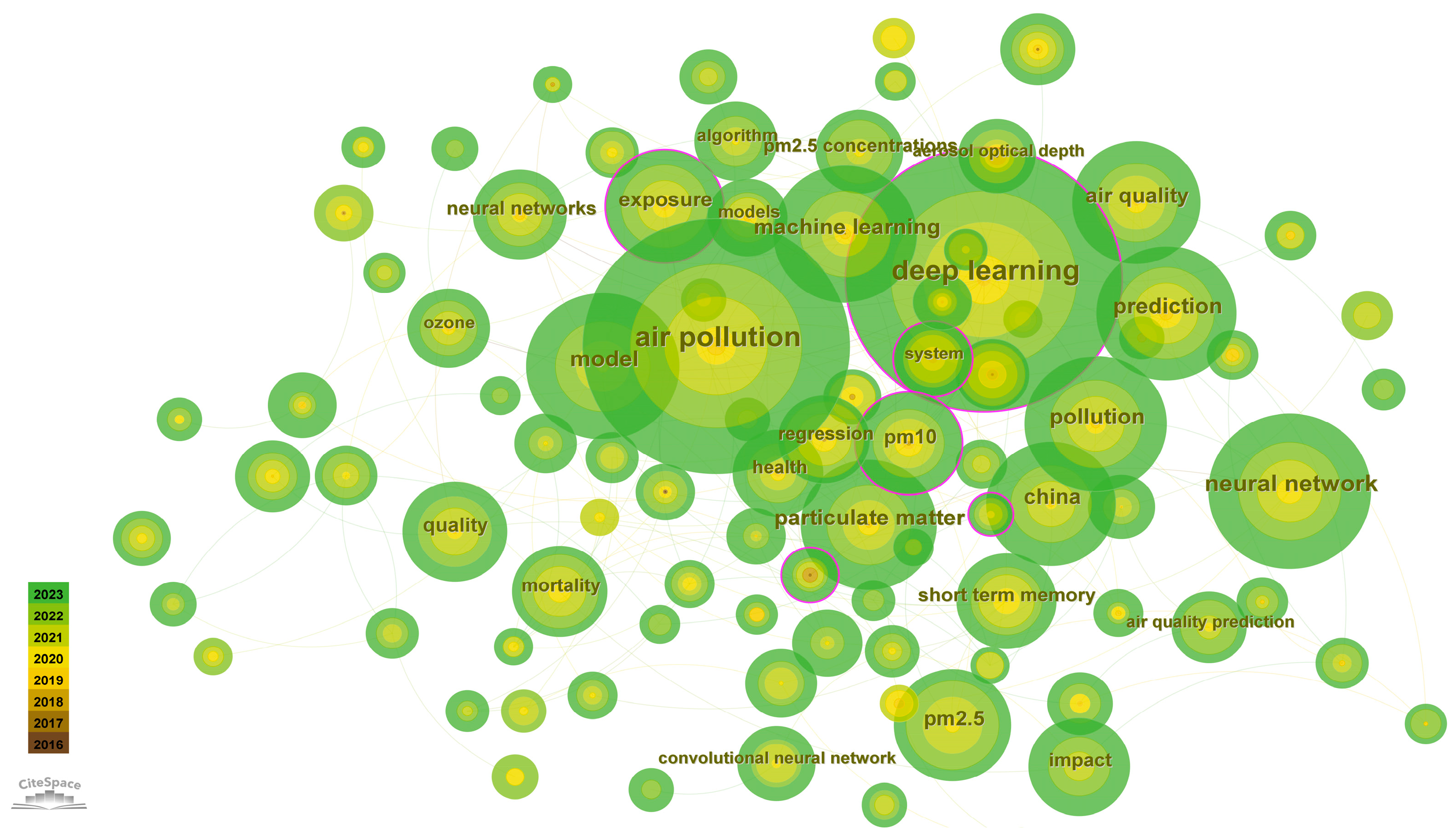
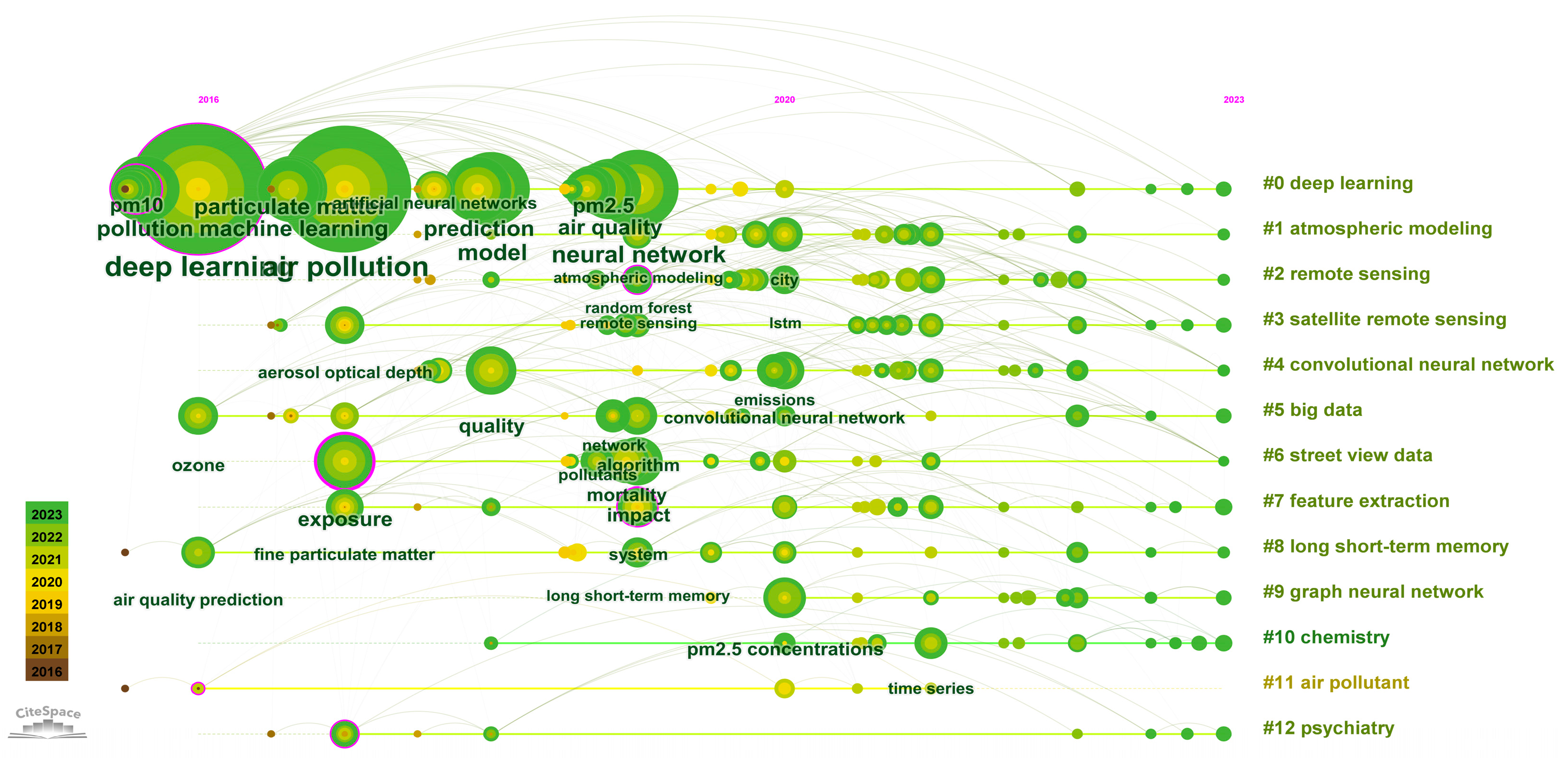
2.3. Keyword Co-Occurrence
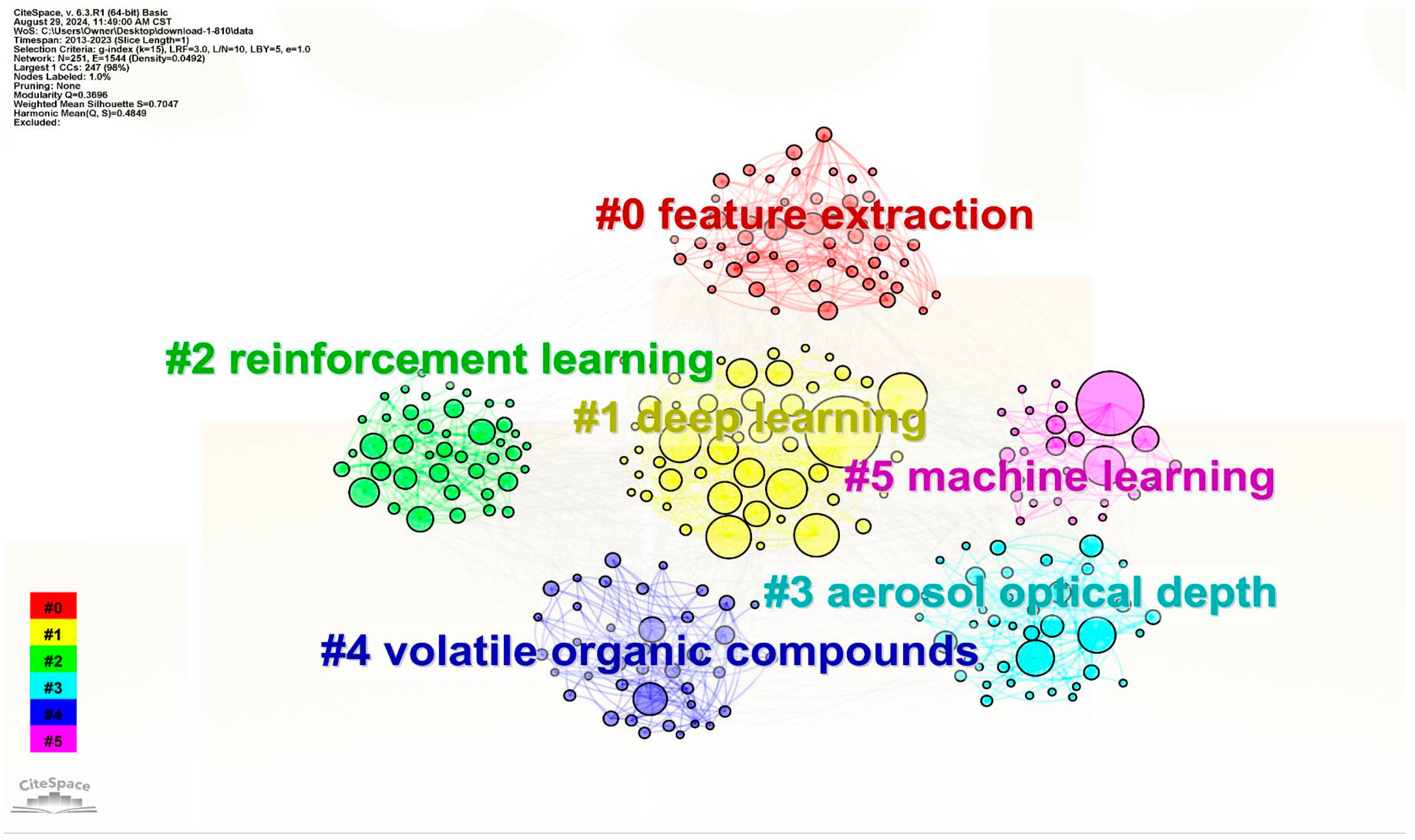
2.4. Cluster Analysis
3. Current Situation and Application
3.1. Air Quality Prediction
3.2. Statistical Model Combined with AI
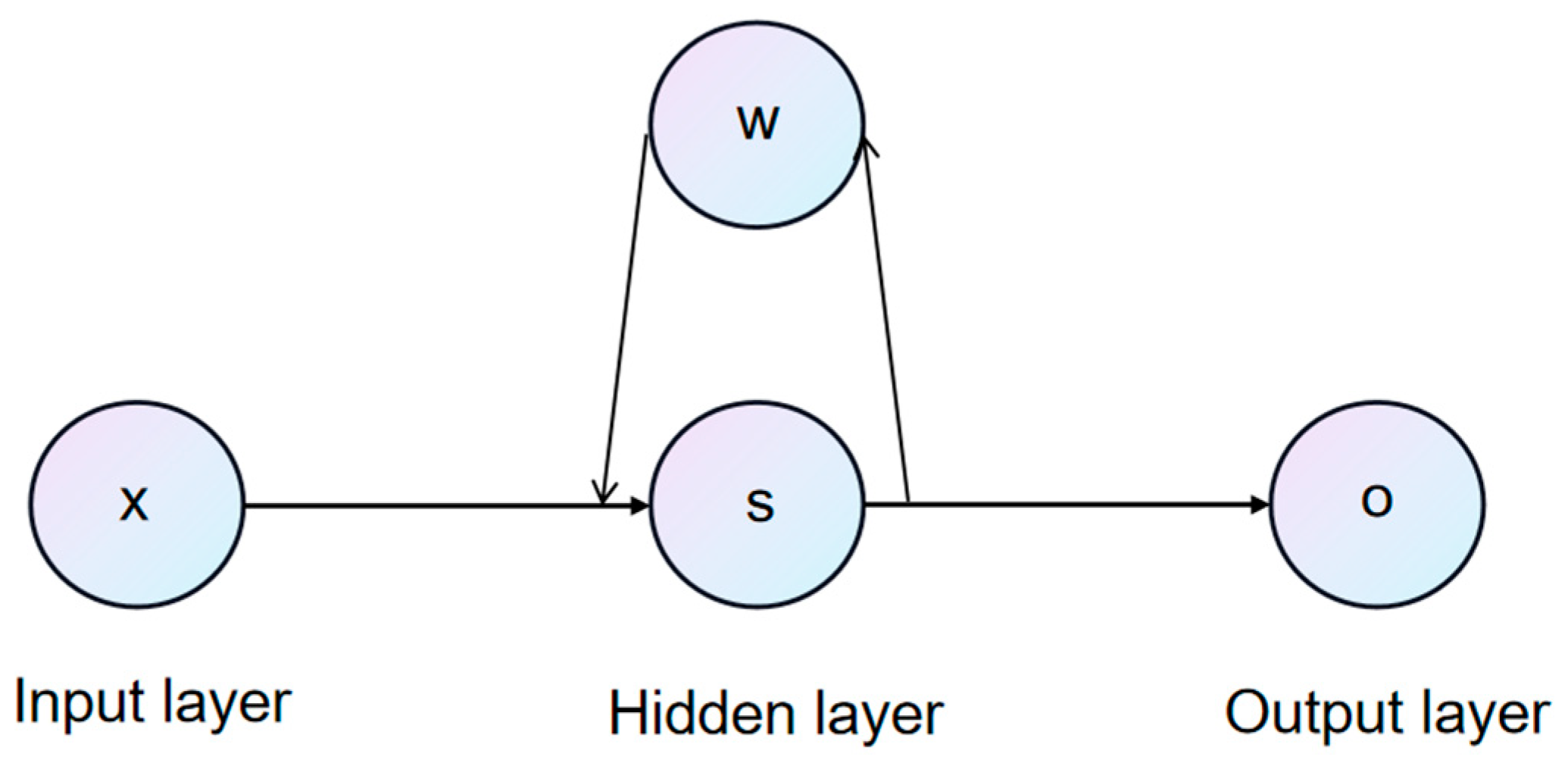
3.2.1. Artificial Neural Network (ANN)
- Identify problems: Identify the problems that need to be addressed, such as classification, regression, or clustering.
- Collect data: Collect data related to the problem, including training and testing data.
- Data preprocessing: Perform preprocessing operations such as cleaning, normalization, standardization, and feature extraction on the data to facilitate the training and testing of neural networks.
- Design network structure: Select the appropriate structure for the neural network, such as the network depth, the neuron number, etc.
- Initialization Weight: Randomly assign initial values and biases to the weight parameters of the neurons in the network.
- Training neural network: Use training data to iteratively adjust weights and biases through backpropagation algorithms, aiming to reduce the discrepancy between the network’s predictions and the real results.
- Test neural network: Use test data to test the trained neural network and evaluate its performance and accuracy.
- Application of neural network: apply the trained neural network to practical problems.
3.2.2. Recursive Neural Network (RNN)
3.2.3. Ensemble Model
4. Limitations and Future Directions
4.1. Issues and Improvement
4.1.1. The Curse of Dimension
4.1.2. The Interpretability of the Model
- Complexity: The relationship between a model’s sophistication and its transparency is often inverse. As models become more intricate, their inner workings become less clear. This is particularly evident in advanced architectures such as deep neural networks, where the sheer number of parameters—often in the millions—obscures the individual impact of each. Research by Eun Hun Lee and Hyeoncheol Kim [64] shed light on an interesting aspect of neural network training. They observed that effective learning involves not just the acquisition of repetitive units but also the development of complementary ones. These complementary units respond to identical inputs yet produce contrasting activation patterns. While this mechanism enhances the network’s capabilities, it introduces a layer of complexity when attempting to analyze the network’s decision-making process. The presence of these complementary elements can result in feature overlap, further complicating efforts to interpret the model’s behavior.
- Feature selection: Feature selection can effectively improve the interpretability and computational feasibility of learning models, which is the reason why it is gradually favored [65]. If the model uses too many or too few features, its interpretability could decline. For example, if the model uses a large number of highly correlated features, it is hard for the model to determine which features are the most important. The crux of addressing the feature selection challenge lies in modeling the parameter–response relationships effectively. The primary objective is to identify the most parsimonious set of feature combinations that adequately capture these relationships. Several approaches address this issue, including wrapper-based feature selection [66], sparse regularization model-based feature selection [67,68,69], and kernel feature selection methods [70,71].
- Data quality: Building and interpreting data visualization is critical to simplifying information access, improving data interpretability, and strengthening information literacy [72]. If there are errors or missing values in the training data, it may result in a reduction in the model’s interpretability.
- Black box algorithms: Some algorithms, such as ANN and SVM, are called black box algorithms. Deep neural networks are well-known for their capability to handle a wide variety of machine learning and artificial intelligence tasks effectively. However, because of their highly parameterized and opaque nature, understanding the prediction results of these deep models can be quite challenging [73].
- Data volume: If the training dataset is too small, it may lead to overfitting. When the dataset is too small, the model may try to remember the details of the training data without learning generalization rules, which can lead to poor performance on new data and may make it difficult for the model to explain. Much of the literature in recent years has expressed the importance of introducing additional data, such as topography, weather, and traffic, into the model. Canyang Guo et al. [60] conducted a detailed study on the relationship between humidity, air pressure, temperature, wind direction, and PM2.5 concentration, confirming that meteorological factors significantly influence air pollution levels.
4.1.3. The Utilization of the Internet of Things
4.2. Future Directions, Trends, Challenges
4.2.1. Using Smart Sensors
4.2.2. Adapt to Other Key Pollutants
4.2.3. Monitor the Concentration of Nanoparticles
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
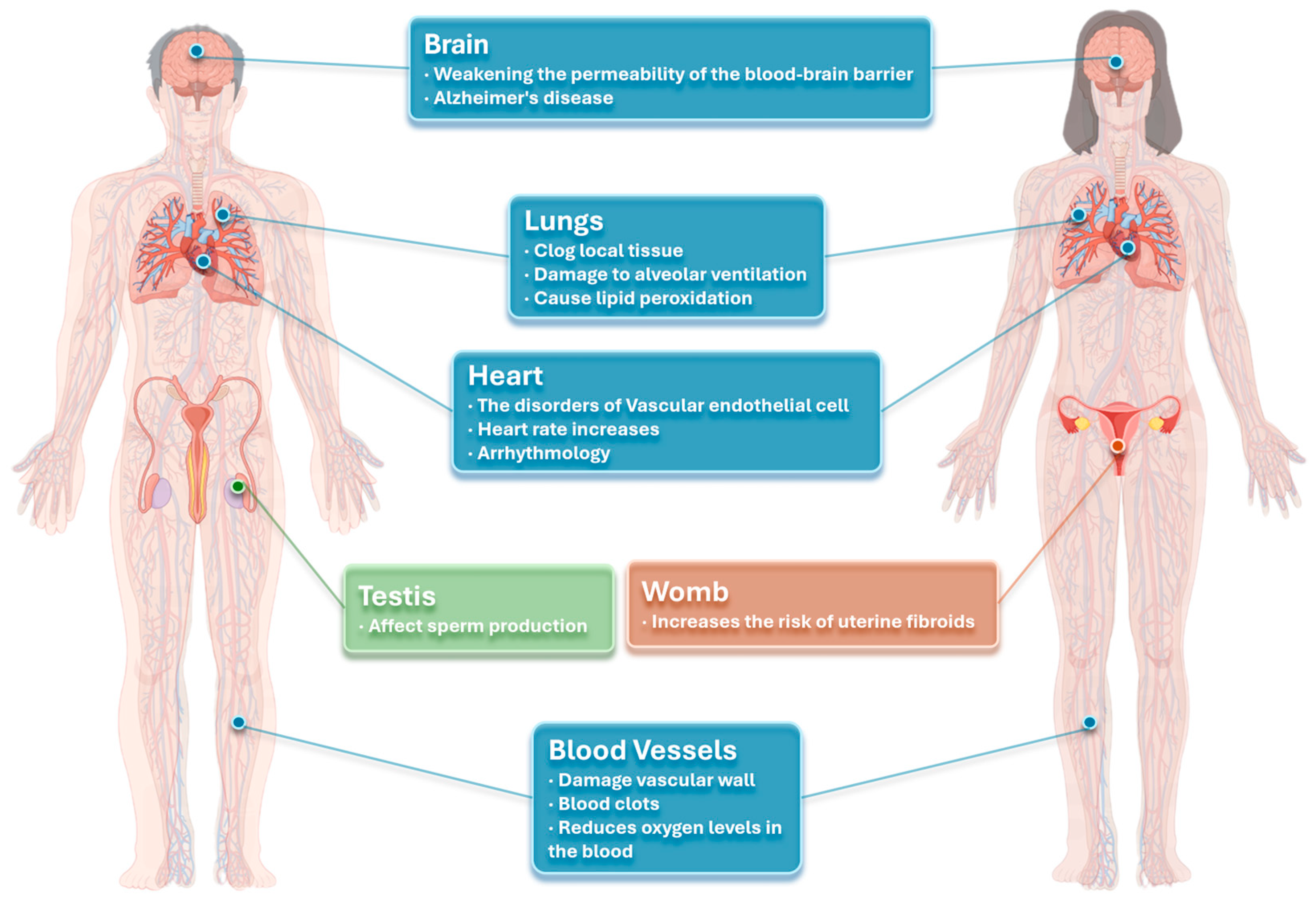
- Zheng, T.; Wang, Y.; Zhou, Z.; Chen, S.; Jiang, J.; Chen, S. PM2.5 Causes Increased Bacterial Invasion by Affecting HBD1 Expression in the Lung. J. Immunol. Res. 2024, 2024, 6622950. [Google Scholar] [CrossRef] [PubMed]
- Mokhtar, S.B.; Viljoen, J.; van der Kallen, C.J.; Berendschot, T.T.; Dagnelie, P.C.; Albers, J.D.; Soeterboek, J.; Scarpa, F.; Colonna, A.; van der Heide, F.C. Greater exposure to PM2.5 and PM10 was associated with lower corneal nerve measures: The Maastricht study-a cross-sectional study. Environ. Health 2024, 23, 70. [Google Scholar] [CrossRef] [PubMed]
- Min, K.B.; Min, J.Y. Association of Ambient Particulate Matter Exposure with the Incidence of Glaucoma in Childhood. Am. J. Ophthalmol. 2020, 211, 176–182. [Google Scholar] [CrossRef] [PubMed]
- Qiao, H.; Xue, W.T.; Li, L.; Fan, Y.; Xiao, L.; Guo, M.M. Atmospheric Particulate Matter 2.5 (PM2.5) Induces Cell Damage and Pruritus in Human Skin. Biomed. Environ. Sci. 2024, 37, 216–220. [Google Scholar]
- Li, M.; Tang, B.; Zheng, J.; Luo, W.; Xiong, S.; Ma, Y.; Ren, M.; Yu, Y.; Luo, X.; Mai, B. Typical organic contaminants in hair of adult residents between inland and coastal capital cities in China: Differences in levels and composition profiles, and potential impact factors. Sci. Total Environ. 2023, 869, 161559. [Google Scholar] [CrossRef]
- Paik, K.; Na, J.-I.; Huh, C.-H.; Shin, J.-W. Particulate Matter and Its Molecular Effects on Skin: Implications for Various Skin Diseases. Int. J. Mol. Sci. 2024, 25, 9888. [Google Scholar] [CrossRef]
- Gan, T.; Bambrick, H.; Tong, S.L.; Hu, W.B. Air pollution and liver cancer: A systematic review. J. Environ. Sci. 2023, 126, 817–826. [Google Scholar] [CrossRef]
- Jiang, R.; Qu, Q.; Wang, Z.; Luo, F.; Mou, S. Association between air pollution and bone mineral density: A Mendelian randomization study. Arch. Med. Sci. 2024, 20, 1334–1338. [Google Scholar] [CrossRef]
- Zhang, F.; Zhu, S.; Di, Y.; Pan, M.; Xie, W.; Li, X.; Zhu, W. Ambient PM2.5 components might exacerbate bone loss among middle-aged and elderly women: Evidence from a population-based cross-sectional study. Int. Arch. Occup. Environ. Health 2024, 97, 855–864. [Google Scholar] [CrossRef]
- Yang, Y.; Li, R.; Cai, M.; Wang, X.J.; Li, H.P.; Wu, Y.L.; Chen, L.; Zou, H.T.; Zhang, Z.L.; Li, H.T.; et al. Ambient air pollution, bone mineral density and osteoporosis: Results from a national population-based cohort study. Chemosphere 2023, 310, 8. [Google Scholar] [CrossRef]
- Park, S.Y.; Han, J.; Kim, S.H.; Suk, H.W.; Park, J.E.; Lee, D.Y. Impact of Long-Term Exposure to Air Pollution on Cognitive Decline in Older Adults Without Dementia. J. Alzheimers Dis. 2022, 86, 553–563. [Google Scholar] [CrossRef] [PubMed]
- Yadav, V.K.; Bijekar, S.; Gacem, A.; Alkahtani, A.M.; Yadav, K.K.; Alreshidi, M.A.; Kumar, P.; Ghosh, T.; Verma, R.K.; Mishra, S. The impact of fine particulate matters (PM10, PM2.5) from incense smokes on the various organ systems: A review of an invisible killer. Part. Part. Syst. Charact. 2024, 41, 2300157. [Google Scholar] [CrossRef]
- Liu, J.; Song, R.; Li, X.; Liu, L.; Wei, N.; Yuan, J.; Yi, W.; Pan, R.; Cheng, J.; Zhang, X. Effects of PM2.5 and Its Components on Disease Severity in Patients with Schizophrenia and the Mediating Role of Thyroid Hormones. Environ. Health 2024, 2, 290–300. [Google Scholar] [CrossRef]
- Ran, Z.; Yang, J.; Liu, L.; Wu, S.; An, Y.; Hou, W.; Cheng, T.; Zhang, Y.; Zhang, Y.; Huang, Y. Chronic PM2.5 Exposure Disrupts Intestinal Barrier Integrity via Microbial Dysbiosis-Triggered TLR2/5-MyD88-NLRP3 Inflammasome Activation. Environ. Res. 2024, 258, 119415. [Google Scholar] [CrossRef]
- Xu, J.; Wang, J.; He, Y.; Chen, R.; Meng, Q.L. acidophilus participates in intestinal inflammation induced by PM2.5 through affecting the Treg/Th17 balance. Environ. Pollut. 2024, 341, 122977. [Google Scholar] [CrossRef]
- Tamashiro, L.K.; Yariwake, V.Y.; Veras, M.M.; Bertolla, R.P.; Intasqui, P. Fine inhalable particulate matter (PM2.5) present in air pollution and its effects on male germ cells chromatin packaging. Fertil. Steril. 2023, 120, e213–e214. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, S.; Lu, Y.; Qi, J.; Li, X.; Gao, S.; Qi, X.; Tan, J. Association of ambient PM2.5 and its components with in vitro fertilization outcomes: The modifying role of maternal dietary patterns. Ecotoxicol. Environ. Saf. 2024, 282, 116685. [Google Scholar] [CrossRef]
- Tian, Y.; Ma, Y.; Wu, J.; Wu, Y.; Wu, T.; Hu, Y.; Wei, J. Ambient PM2.5 Chemical Composition and Cardiovascular Disease Hospitalizations in China. Environ. Sci. Technol. 2024, 58, 16327–16335. [Google Scholar] [CrossRef]
- Chanda, F.; Lin, K.-X.; Chaurembo, A.I.; Huang, J.-Y.; Zhang, H.-J.; Deng, W.-H.; Xu, Y.-J.; Li, Y.; Fu, L.-D.; Cui, H.-D. PM2.5-mediated cardiovascular disease in aging: Cardiometabolic risks, molecular mechanisms and potential interventions. Sci. Total Environ. 2024, 954, 176255. [Google Scholar] [CrossRef]
- Zhao, L.; Li, Z.; Qu, L. A novel machine learning-based artificial intelligence method for predicting the air pollution index PM2.5. J. Clean. Prod. 2024, 468, 143042. [Google Scholar] [CrossRef]
- Goodman, N.; Nematollahi, N.; Agosti, G.; Steinemann, A. Evaluating air quality with and without air fresheners. Air Qual. Atmos. Health 2020, 13, 1–4. [Google Scholar] [CrossRef]
- Lee, J.; Noh, J.H.; Noh, K.C.; Kim, Y.W.; Yook, S.J. Effect of a System Air Conditioner on Local Air Quality in a Four-bed Ward. Aerosol and Air Qual. Res. 2021, 21, 15. [Google Scholar] [CrossRef]
- Ma, Q.; Yuan, R.; Wang, S.; Sun, Y.; Zhang, Q.; Yuan, X.; Wang, Q.; Luo, C. Indigenized Characterization Factors for Health Damage Due to Ambient PM2.5 in Life Cycle Impact Assessment in China. Environ. Sci. Technol. 2024, 58, 17320–17333. [Google Scholar] [CrossRef] [PubMed]
- Braszus, B.; Rietbrock, A.; Haberland, C.; Ryberg, T. AI based 1-D P-and S-wave velocity models for the greater alpine region from local earthquake data. Geophys. J. Int. 2024, 237, 916–930. [Google Scholar] [CrossRef]
- Ro, S.H.; Gong, J. Scalable approach to create annotated disaster image database supporting AI-driven damage assessment. Nat. Hazards 2024, 120, 11693–11712. [Google Scholar] [CrossRef]
- Abegaz, R.; Wang, F.; Xu, J. History, causes, and trend of floods in the U.S.: A review. Nat. Hazards 2024. [Google Scholar] [CrossRef]
- Ghomi, S.M.M.M.; Bidhendi, G.R.N.; Amiri, M.J.; Kudahi, S.N. The Deployment Modeling of Low-Cost Sensors for Urban Particulate Matter Monitoring: A Case Study for PM2.5 Monitoring in Tehran City. Int. J. Environ. Res. 2024, 18, 111. [Google Scholar] [CrossRef]
- Jain, V.; Mukherjee, A.; Banerjee, S.; Madhwal, S.; Bergin, M.H.; Bhave, P.; Carlson, D.; Jiang, Z.; Zheng, T.; Rai, P. A hybrid approach for integrating micro-satellite images and sensors network-based ground measurements using deep learning for high-resolution prediction of fine particulate matter (PM2.5) over an Indian city, Lucknow. Atmos. Environ. 2024, 338, 120798. [Google Scholar] [CrossRef]
- Das, T.; Talukdar, S.; Naikoo, M.W.; Ahmed, I.A.; Rahman, A.; Islam, M.K.; Alam, E. Integration of fuzzy AHP and explainable AI for effective coastal risk management: A micro-scale risk analysis of tropical cyclones. Prog. Disaster Sci. 2024, 23, 100357. [Google Scholar] [CrossRef]
- Longo, R.; Lacanna, G.; Innocenti, L.; Ripepe, M. Artificial Intelligence and Machine Learning tools for improving Early Warning systems of volcanic eruptions: The case of Stromboli. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 7973–7982. [Google Scholar] [CrossRef]
- Demir, E.; Cavur, M.; Yu, Y.-T.; Duzgun, H.S. An Evaluation of AI Models’ Performance for Three Geothermal Sites. Energies 2024, 17, 3255. [Google Scholar] [CrossRef]
- Liu, N.; Zou, B.; Li, Y.; Zang, Z.; Xu, S.; Li, S.; Li, S.; Zhi, L.; Chen, J.; Zhao, F. An Accurate and Efficient Forecast Framework for Fine PM2.5 Maps Using Spatiotemporal Recurrent Neural Networks. J. Clean. Prod. 2024, 475, 143624. [Google Scholar] [CrossRef]
- Balcone-Boissard, H.; Boudon, G.; Zdanowicz, G.; Orsi, G.; Webster, J.D.; Civetta, L.; D’Antonio, M.; Arienzo, I. The space-time architecture variation of the shallow magmatic plumbing systems feeding the Campi Flegrei and Ischia volcanoes (Southern Italy) from halogen constraints. Am. Mineral. 2024, 109, 977–991. [Google Scholar] [CrossRef]
- Choiruddin, A.; Rahman, A.A.; Andreas, C. Algorithms for Fitting the Space-Time ETAS Model to Earthquake Catalog Data: A Comparative Study. J. Agric. Biol. Environ. Stat. 2024, 1–18. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, L.; Duan, M.; Zhao, C. Three-dimensional VP, VS, and VP/VS imaging based on AI microseismic detection reveals the mechanism of induced earthquakes in the Xiluodu Reservoir Area, China. J. Asian Earth Sci. 2024, 266, 106123. [Google Scholar] [CrossRef]
- Jin, W.X.; Luo, Y.; Wu, T.W.; Huang, X.M.; Xue, W.; Yu, C.Q. Deep Learning for Seasonal Precipitation Prediction over China. J. Meteorol. Res. 2022, 36, 271–281. [Google Scholar] [CrossRef]
- Pak, U.; Ma, J.; Ryu, U.; Ryom, K.; Juhyok, U.; Pak, K.; Pak, C. Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China. Sci. Total Environ. 2020, 699, 11. [Google Scholar] [CrossRef]
- Liu, D.R.; Lee, S.J.; Huang, Y.; Chiu, C.J. Air pollution forecasting based on attention-based LSTM neural network and ensemble learning. Expert. Syst. 2020, 37, 16. [Google Scholar] [CrossRef]
- Hu, J.L.; Li, X.; Huang, L.; Ying, Q.; Zhang, Q.; Zhao, B.; Wang, S.X.; Zhang, H.L. Ensemble prediction of air quality using the WRF/CMAQ model system for health effect studies in China. Atmos. Chem. Phys. 2017, 17, 13103–13118. [Google Scholar] [CrossRef]
- Liao, Q.; Zhu, M.M.; Wu, L.; Pan, X.L.; Tang, X.; Wang, Z.F. Deep Learning for Air Quality Forecasts: A Review. Curr. Pollut. Rep. 2020, 6, 399–409. [Google Scholar] [CrossRef]
- Hafiz, A.M.; Hassaballah, M.; Binbusayyis, A. Formula-Driven Supervised Learning in Computer Vision: A Literature Survey. Appl. Sci. 2023, 13, 15. [Google Scholar] [CrossRef]
- Kang, Y.; Cai, Z.; Tan, C.W.; Huang, Q.; Liu, H.F. Natural language processing (NLP) in management research: A literature review. J. Manag. Anal. 2020, 7, 139–172. [Google Scholar] [CrossRef]
- Bekkar, A.; Hssina, B.; Douzi, S.; Douzi, K. Air-pollution prediction in smart city, deep learning approach. J. Big Data 2021, 8, 21. [Google Scholar] [CrossRef] [PubMed]
- Uzun Ozsahin, D.; Duwa, B.B.; Ozsahin, I.; Uzun, B. Quantitative Forecasting of Malaria Parasite Using Machine Learning Models: MLR, ANN, ANFIS and Random Forest. Diagnostics. 2024, 14, 385. [Google Scholar] [CrossRef]
- Hoffman, S.; Filak, M.; Jasinski, R. Air Quality Modeling with the Use of Regression Neural Networks. Int. J. Environ. Res. Public Health 2022, 19, 33. [Google Scholar] [CrossRef]
- Biancofiore, F.; Busilacchio, M.; Verdecchia, M.; Tomassetti, B.; Aruffo, E.; Bianco, S.; Di Tommaso, S.; Colangeli, C.; Rosatelli, G.; Di Carlo, P. Recursive neural network model for analysis and forecast of PM10 and PM2.5. Atmos. Pollut. Res. 2017, 8, 652–659. [Google Scholar] [CrossRef]
- Petry, L.; Meiers, T.; Reuschenberg, D.; Mirzavand Borujeni, S.; Arndt, J.; Odenthal, L. Design and Results of an Ai-Based Forecasting of Air Pollutants for Smart Cities. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, VIII-4/W1-2021, 89–96. [Google Scholar]
- Menares, C.; Perez, P.; Parraguez, S.; Fleming, Z.L. Forecasting PM2.5 levels in Santiago de Chile using deep learning neural networks. Urban Clim. 2021, 38, 100906. [Google Scholar] [CrossRef]
- Kristiani, E.; Kuo, T.-Y.; Yang, C.-T.; Pai, K.-C.; Huang, C.-Y.; Nguyen, K.L.P. PM2.5 Forecasting Model Using a Combination of Deep Learning and Statistical Feature Selection. IEEE Access 2021, 9, 68573–68582. [Google Scholar] [CrossRef]
- Saab, S.; Fu, Y.W.; Ray, A.; Hauser, M. A Dynamically Stabilized Recurrent Neural Network. Neural Process. Lett. 2022, 54, 1195–1209. [Google Scholar] [CrossRef]
- Zhang, Z.; Zeng, Y.; Yan, K. A hybrid deep learning technology for PM2.5 air quality forecasting. Environ. Sci. Pollut. Res. Int. 2021, 28, 39409–39422. [Google Scholar] [CrossRef]
- Sun, Q.; Zhu, Y.; Chen, X.; Xu, A.; Peng, X. A hybrid deep learning model with multi-source data for PM2.5 concentration forecast. Air Qual. Atmos. Health 2020, 14, 503–513. [Google Scholar] [CrossRef]
- Wen, C.; Liu, S.; Yao, X.; Peng, L.; Li, X.; Hu, Y.; Chi, T. A novel spatiotemporal convolutional long short-term neural network for air pollution prediction. Sci. Total Environ. 2019, 654, 1091–1099. [Google Scholar] [CrossRef] [PubMed]
- Yeo, I.; Choi, Y.; Lops, Y.; Sayeed, A. Efficient PM2.5 forecasting using geographical correlation based on integrated deep learning algorithms. Neural Comput. Appl. 2021, 33, 15073–15089. [Google Scholar] [CrossRef]
- Faraji, M.; Nadi, S.; Ghaffarpasand, O.; Homayoni, S.; Downey, K. An integrated 3D CNN-GRU deep learning method for short-term prediction of PM2.5 concentration in urban environment. Sci. Total Environ. 2022, 834, 12. [Google Scholar] [CrossRef]
- Guo, Z.Y.; Yang, C.Y.; Wang, D.S.; Liu, H.B. A novel deep learning model integrating CNN and GRU to predict particulate matter concentrations. Process Saf. Environ. Protect. 2023, 173, 604–613. [Google Scholar] [CrossRef]
- Hu, J.T.; Chen, Y.Y.; Wang, W.; Zhang, S.C.; Cui, C.; Ding, W.K.; Fang, Y. An optimized hybrid deep learning model for PM2.5 and O-3 concentration prediction. Air Qual. Atmos. Health 2023, 16, 857–871. [Google Scholar] [CrossRef]
- Li, D.; Liu, J.P.; Zhao, Y.Y. Prediction of Multi-Site PM2.5 Concentrations in Beijing Using CNN-Bi LSTM with CBAM. Atmosphere 2022, 13, 19. [Google Scholar] [CrossRef]
- Tong, W.T.; Li, L.X.; Zhou, X.L.; Hamilton, A.; Zhang, K. Deep learning PM2.5 concentrations with bidirectional LSTM RNN. Air Qual. Atmos. Health 2019, 12, 411–423. [Google Scholar] [CrossRef]
- Guo, C.Y.; Liu, G.G.; Chen, C.H. Air Pollution Concentration Forecast Method Based on the Deep Ensemble Neural Network. Wirel. Commun. Mob. Comput. 2020, 2020, 13. [Google Scholar] [CrossRef]
- Wang, J.Y.; Li, J.Z.; Wang, X.X.; Wang, J.; Huang, M. Air quality prediction using CT-LSTM. Neural Comput. Appl. 2021, 33, 4779–4792. [Google Scholar] [CrossRef]
- Qiao, W.B.; Tian, W.C.; Tian, Y.; Yang, Q.; Wang, Y.N.; Zhang, J.Z. The Forecasting of PM2.5 Using a Hybrid Model Based on Wavelet Transform and an Improved Deep Learning Algorithm. IEEE Access 2019, 7, 142814–142825. [Google Scholar] [CrossRef]
- Choi, S.; Kim, B. Applying PCA to Deep Learning Forecasting Models for Predicting PM2.5. Sustainability 2021, 13, 3726. [Google Scholar] [CrossRef]
- Lee, E.H.; Kim, H. Feature-Based Interpretation of the Deep Neural Network. Electronics 2021, 10, 20. [Google Scholar] [CrossRef]
- Barraza, J.F.; Droguett, E.L.; Martins, M.R. Towards Interpretable Deep Learning: A Feature Selection Framework for Prognostics and Health Management Using Deep Neural Networks. Sensors 2021, 21, 30. [Google Scholar] [CrossRef] [PubMed]
- Kumar, R. Composition of Feature Selection for Time-Series Prediction with Deep Learning. Procedia Comput. Sci. 2024, 235, 1477–1488. [Google Scholar]
- Wu, W.-B.; Chen, S.-B.; Ding, C.; Luo, B. Non-linear Feature Selection Based on Convolution Neural Networks with Sparse Regularization. Cogn. Comput. 2024, 16, 654–670. [Google Scholar] [CrossRef]
- Sun, Z.; Chen, Z.; Liu, J.; Yu, Y. Multi-class feature selection via Sparse Softmax with a discriminative regularization. Int. J. Mach. Learn. Cybern. 2024, 1–14. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Wu, J.; Xie, M. Regularized Periodic Gaussian Process for Nonparametric Sparse Feature Extraction From Noisy Periodic Signals. IEEE Trans. Autom. Sci. Eng. 2024, 1–10. [Google Scholar] [CrossRef]
- Tang, Z.; Wang, S.; Li, Y. Dynamic NOX emission concentration prediction based on the combined feature selection algorithm and deep neural network. Energy 2024, 292, 130608. [Google Scholar] [CrossRef]
- Zheng, W.; Zhu, X.F.; Wen, G.Q.; Zhu, Y.H.; Yu, H.; Gan, J.Z. Unsupervised feature selection by self-paced learning regularization. Pattern Recognit. Lett. 2020, 132, 4–11. [Google Scholar] [CrossRef]
- de Foy, B.; Edwards, R.; Joy, K.S.; Zaman, S.U.; Salam, A.; Schauer, J.J. Interpretable machine learning tools to analyze PM2.5 sensor network data so as to quantify local source impacts and long-range transport. Atmos. Res. 2024, 311, 107656. [Google Scholar] [CrossRef]
- Rakholia, R.; Le, Q.; Vu, K.; Ho, B.Q.; Carbajo, R.S. Accurate PM2.5 urban air pollution forecasting using multivariate ensemble learning Accounting for evolving target distributions. Chemosphere 2024, 364, 143097. [Google Scholar] [CrossRef]
- Purnomo, A.; Badriah, S.; Andang, A.; Gunawan, M.R.; Maulana, D.I.; Sambas, A.; Madi, E.N. An Affordable Green IoT-Based System for Remote Sensing of PM1, PM2.5 and PM10 Particulate Matter. J. Adv. Res. Appl. Sci. Eng. Technol. 2024, 49, 134–148. [Google Scholar] [CrossRef]
- Kalajdjieski, J.; Zdravevski, E.; Corizzo, R.; Lameski, P.; Kalajdziski, S.; Pires, I.M.; Garcia, N.M.; Trajkovik, V. Air Pollution Prediction with Multi-Modal Data and Deep Neural Networks. Remote Sens. 2020, 12, 4142. [Google Scholar] [CrossRef]
- Raja, L.; Maheswaravenkatesh, P.; Shanthi, G.; Surya, G. Internet of things enabled automated air pollution monitoring using oppositional swallow swarm optimisation with deep learning model. J. Environ. Prot. Ecol. 2022, 23, 462–473. [Google Scholar]
- Hatta, M.; Han, H. Predicting indoor PM2.5/PM10 concentrations using simplified neural network models. J. Mech. Sci. Technol. 2021, 35, 3249–3257. [Google Scholar] [CrossRef]
- Banach, M.; Talaśka, T.; Dalecki, J.; Długosz, R. New technologies for smart cities—High-resolution air pollution maps based on intelligent sensors. Concurr. Comput. Pract. Exp. 2019, 32, e5179. [Google Scholar] [CrossRef]
- Tran, T.V.; Dang, N.T.; Chung, W.-Y. Battery-free smart-sensor system for real-time indoor air quality monitoring. Sens. Actuators B Chem. 2017, 248, 930–939. [Google Scholar] [CrossRef]
- Liu, B.C.; Binaykia, A.; Chang, P.C.; Tiwari, M.K.; Tsao, C.C. Urban air quality forecasting based on multi-dimensional collaborative Support Vector Regression (SVR): A case study of Beijing-Tianjin-Shijiazhuang. PLoS ONE 2017, 12, e0179763. [Google Scholar] [CrossRef]
- Nieto, P.J.; Anton, J.C.; Vilan, J.A.; Garcia-Gonzalo, E. Air quality modeling in the Oviedo urban area (NW Spain) by using multivariate adaptive regression splines. Environ. Sci. Pollut. Res. Int. 2015, 22, 6642–6659. [Google Scholar] [CrossRef]
- Philibert, A.; Loyce, C.; Makowski, D. Prediction of N2O emission from local information with Random Forest. Environ. Pollut. 2013, 177, 156–163. [Google Scholar] [CrossRef]
- Rybarczyk, Y.; Zalakeviciute, R. Machine Learning Approaches for Outdoor Air Quality Modelling: A Systematic Review. Appl. Sci. 2018, 8, 2570. [Google Scholar] [CrossRef]
- Yao, Q.; Shi, J.; Han, X.; Tian, S.; Huang, J.; Li, Y.; Ning, P. Emissions of polycyclic aromatic hydrocarbons in PM2.5 emitted from motor vehicles exhaust (PAHs-PM2.5-MVE) under the plateau with low oxygen content. Atmos. Environ. 2024, 321, 120364. [Google Scholar] [CrossRef]
- Al–Dabbous, A.N.; Kumar, P.; Khan, A.R. Prediction of airborne nanoparticles at roadside location using a feed–forward artificial neural network. Atmos. Pollut. Res. 2017, 8, 446–454. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number. | Journal | Counts | CiteScore | IF (2022) | Publishers |
|---|---|---|---|---|---|
| 1 | Atmosphere | 42 | 4.10 | 3.9 | MDPI |
| 2 | Atmospheric Pollution Research | 26 | 7.90 | 4.5 | TUNCAP |
| 3 | Atmospheric Environment | 25 | 10.30 | 5.755 | Elsevier |
| 4 | Sustainability | 22 | 5.80 | 3.889 | MDPI |
| 5 | Environmental Pollution | 17 | 14.90 | 9.888 | Elsevier |
| 5 | Environmental Science and Pollution Research | 17 | 7.90 | 5.19 | Springer Berlin Heidelberg |
| 5 | Science of The Total Environment | 17 | 16.80 | 9.8 | Elsevier |
| 8 | IEEE Access | 15 | 9.00 | 3.476 | IEEE |
| 8 | Urban Climate | 15 | 8.70 | 6.4 | Elsevier |
| 10 | Aerosol and Air Quality Research | 14 | 7.30 | 4 | AAGR Aerosol and Air Quality Research |
| Keywords | Year | Strength | Begin | End | 2012–2023 |
|---|---|---|---|---|---|
| Chemical Composition | 2012 | 4.7762 | 2015 | 2018 |  |
| Ambient Air | 2012 | 4.2621 | 2013 | 2019 |  |
| Particulate Air Pollution | 2012 | 4.0683 | 2012 | 2018 |  |
| YangtzeRiver Delta | 2012 | 4.0663 | 2015 | 2019 |  |
| Temporal Variation | 2012 | 3.8941 | 2014 | 2018 |  |
| Source Apportionment | 2012 | 3.5545 | 2013 | 2015 |  |
| Matter | 2012 | 3.5046 | 2017 | 2018 |  |
| Urban | 2012 | 3.2041 | 2015 | 2016 |  |
| Area | 2012 | 3.0398 | 2012 | 2016 |  |
| Particle | 2012 | 2.8987 | 2012 | 2013 |  |
| Seasonal Variation | 2012 | 2.878 | 2014 | 2018 |  |
| Aerosol | 2012 | 2.8742 | 2012 | 2018 |  |
| Asthma | 2012 | 2.647 | 2014 | 2016 |  |
| System | 2012 | 2.5919 | 2019 | 2021 |  |
| Modi | 2012 | 2.5647 | 2017 | 2018 |  |
| Pm2.5 | 2012 | 2.5153 | 2021 | 2023 |  |
| Trend | 2012 | 2.4823 | 2018 | 2019 |  |
| Cohort | 2012 | 2.3723 | 2014 | 2016 |  |
| Variability | 2012 | 2.204 | 2018 | 2019 |  |
| health | 2012 | 2.1927 | 2017 | 2018 |  |
| Model | Advantages | Disadvantages |
|---|---|---|
| VMD & BiLSTM [51] | In relation to current models, when evaluating the precision of forecasts and the capability to forecast tendencies accurately. | Not applicable to other prediction fields. |
| CNN & GRU [54] | Improve PM2.5 prediction accuracy. The average improvement is about 10%. | Only applicable to predicting the concentration of PM2.5 not applicable to other pollutants. |
| 3D CNN & GRU [55] | Compared with recent methods such as LSTM, ANN, and ARIMA, this model can yield promising outcomes with a lower RMSE and MAE in the PM2.5 prediction environment. | Data missing in the time series results in discontinuities in the data sequence and a decrease in long-term prediction ability. |
| RF & CNN & GRU [56] | In the case of incomplete raw data, it can effectively predict the concentration of PM2.5 in the indoor environment, reducing the RMSE by between 22.35% and 36.75%, and the R2 improved by between 10.88% and 29.31%. | The limited number of samples could potentially impact how well the model applies to more extensive data collection. |
| CNN & BiLSTM & GRU & DNN [57] | It is a promising method for predicting the performance of atmospheric and particulate pollutants. In the case of single-source data, for PM2.5, this model’s MAE decreased between 18.9 and 27.4%, and the RMSE decreased between 6.9 and 23.7%. The R2 increased between 0.8 and 3.6%. | Other factors, including traffic conditions and contaminants originating from pollution sources, are not considered and utilized. |
| CNN & LSTM [37] | Compared with multi-layer perception (MLP) and LSTM models, this method exhibits enhanced stability and prediction performance. This model (RMSE 2.997, MAE 2.21, MAPE 0.039) has an obvious improvement as compared to LSTM (RMSE 4.764, MAE 3.612, MAPE 0.068). | There was no attempt to limit the target site as the center method to the application scope of the target site itself or neighboring sites. |
| CNN&LSTM&DNN [52] | This model outperforms other models in predicting PM2.5 concentration. In the case of the multi-source data, the forecasting errors of the HDAQP model are lower than RMSE, MAE, and MAPE, which are 23.935, 12.252, and 23.541, respectively. | The HDAQP model’s forecasting accuracy tends to decline as it attempts to predict further into the future. |
| CBAM & CNN & BiLSTM [58] | Overcoming the shortcomings of CNN-LSTM and the long-term dependence of PM2.5 concentration, it has greater practical value. In single-step PM2.5 concentration prediction, this model reduces RMSE to 18.90, MAE to 11.20, improves R2 to 0.9397, and IA to 98.54%. | The study did not take into account vehicular movement, plant density, or foot traffic patterns. |
| LSTM & RNN [59] | Spatiotemporal interpolated data of air pollutant concentrations can be used. | They did not investigate the method of deploying the model onto a cluster computing framework to accelerate the process. |
| RNN & LSTM & GRU [60] | This model has better generalization ability and prediction ability. MAE and MAPE of this model were 8.58 and 24.73%, respectively, better than CGRU (8.56 and 20.50%) and other models. Compared with SGD, this model can effectively avoid local optima. | They lack research on the effects of human activities and terrain types on PM2.5. |
| CT & LSTM [61] | Has high prediction accuracy. The prediction accuracy of the new method is 93.70%, which is 8.22% higher than that of the BP neural network method (85.48%). | No research on multi-scale prediction in the spatial domain. |
| WT & SAE & LSTM [62] | Determine the optimal wavelet layer and order different samples. Improved the issue of LSTM gradient vanishing, resulting in better predictive performance than other models. The MAE of SAE-LSTM is between 0.1723 and 1.4574 lower than those of other models when applied to data from Xuchang. | Did not verify whether the algorithm in this study is applicable to other fields |
| Problem | Explain |
|---|---|
| Data sparsity | In high-dimensional space, the distance between data points becomes farther, resulting in sparse data. This means that in high-dimensional space, the similarity between data points becomes more blurred, posing challenges for the model to distinguish different data points accurately. |
| The predictive ability of the model has decreased. | As the number of spatial dimensions grows, the model’s complexity escalates correspondingly. This increased complexity raises the likelihood of overfitting, potentially compromising the prediction performance of the model. Moreover, the sparsity of data points in higher-dimensional spaces can lead to a decline in the model’s capacity to generalize effectively. |
| The demand for samples has increased. | In multi-dimensional environments, achieving model precision requires training samples to cover the feature space more comprehensively. Consequently, higher-dimensional problems demand larger datasets to effectively train and calibrate an accurate model. This phenomenon underscores the need for wider data sampling and processing in complex spatial prediction tasks. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Lu, S.; Tian, J.; Yin, L.; Wang, L.; Zheng, W. Current Situation and Prospect of Geospatial AI in Air Pollution Prediction. Atmosphere 2024, 15, 1411. https://doi.org/10.3390/atmos15121411
Wu C, Lu S, Tian J, Yin L, Wang L, Zheng W. Current Situation and Prospect of Geospatial AI in Air Pollution Prediction. Atmosphere. 2024; 15(12):1411. https://doi.org/10.3390/atmos15121411
Chicago/Turabian StyleWu, Chunlai, Siyu Lu, Jiawei Tian, Lirong Yin, Lei Wang, and Wenfeng Zheng. 2024. "Current Situation and Prospect of Geospatial AI in Air Pollution Prediction" Atmosphere 15, no. 12: 1411. https://doi.org/10.3390/atmos15121411
APA StyleWu, C., Lu, S., Tian, J., Yin, L., Wang, L., & Zheng, W. (2024). Current Situation and Prospect of Geospatial AI in Air Pollution Prediction. Atmosphere, 15(12), 1411. https://doi.org/10.3390/atmos15121411