1. Introduction
Global warming is one of the largest threats facing human society, with an increase of ~0.99 °C in mean temperature compared with those in the pre-industrial period, and the mean temperature is predicted to rise further by 1–3 °C by the end of the 21st century [
1]. As a result, the increased severity and frequency of floods, hailstorms, droughts, changes in precipitation, and other disaster events have significant impacts on the livelihood capacity of residents especially in developing countries [
2,
3]. Bangladesh is a poor developing country with an agrarian economy located in the subtropical region of South Asia, and it is often hit by various natural disasters, including but not limited to floods, hurricanes, and droughts, and its agricultural production is extremely vulnerable to climate disasters. Currently, Bangladesh is listed as the seventh most affected country in the world by climate change according to the Global Climate Risk Index 2020 [
4], so there is an urgent need for high-resolution climate information to understand patterns and behaviors of climate change and then assess related risks and develop suitable mitigation strategies. However, the sparse and irregular distribution of meteorological stations in Bangladesh is far from enough to achieve this aim.
The emergence of statistical downscaling techniques has increased the possibility of obtaining high-resolution spatial data from low-resolution data [
5,
6]. Two-dimensional interpolation is the first tool used to downscale coarse-scale climate observation, but it ignores the impacts of topographic factors on climate, resulting in tat the obtained climate maps often containing unrealistic parallel structures [
7]. In order to overcome this limitation, the mature statistical downscaling model (SDSM) software uses multiple linear regression to convert the output of large-scale and low-resolution GCM outputs into small-scale and high-resolution regional climate information [
8,
9]. The SDSM is the most widely used mature tool for regional climate downscaling and forecasting [
10,
11]. However, large-scale atmospheric circulation always affects regional climate through a complex
nonlinear process, so although the SDSM uses a large number of GCM outputs, the downscaling performance by SDSM with multiple
linear regressions is not satisfactory [
12], especially Han et al. [
13] found that after inputting more than 20 large-scale atmospheric circulation factors, the accuracy of SDSM for downscaling temperature and precipitation in Bangladesh is still poor. The quantile mapping was developed to correct for any deviations in GCM simulation and downscaling process [
14,
15,
16], but this approach is highly dependent on the resolution of reanalysis data (e.g., NCEP gridded data with a resolution of 2.5° × 2.5°), leading to this difficult to produce high-resolution downscaled data. Alamgir et al. [
14] developed a prognostic statistical downscaling approach for Bangladesh by using CMIP5 outputs under future scenarios, but this approach is only suitable for gridded data and is computationally intensive. Therefore, the widely-used statistical downscaling techniques have limitations to meet high accuracy and high spatial resolution requirements.
Compared with statistical downscaling techniques, advanced data-driven learning techniques have shown excellent performance in handling complex nonlinear correlations between factors [
17]. Data-driven learning is used to establish various models through mining internal features and links inside observed data [
18]. Mainstream data-driven learning techniques include: the Support Vector Machine (SVM), which uses kernel functions to map complex data features into high-dimensional spaces in order to achieve the aim of accuracy prediction; Random Forest (RF) uses bagging or bootstrap aggregation to combine a series of small-scale decision trees for obtaining better prediction than that by any single tree; Gradient Boosting Regressor (GBR) is an ensemble regression tree, where a new tree is added to fit residuals and then reduce losses, finally obtaining higher prediction accuracy; the extreme gradient boosting (XGBoost) is an ensemble of gradient boosting decision trees. XGBoost supports parallel computing, leading to great improvements in the model training speed. These data-driven learning techniques have a wide range of applications in the field of environment and climate change. Zhang et al. [
19] used random forest to predict soil organic carbon in an intensively managed reclamation zone of eastern China. Li et al. [
20] compared the prediction effects of SVM and RF in icing severity. Nguyen et al. [
21] used RF models to predict the Normalized Difference Vegetation Index values to study the potential impact of climate change on vegetation growth. Trinh et al. [
22] used Logistic regression, SVM, and RF to generate landslide susceptibility mapping in the Ha Giang province of Vietnam. Eltazarov et al. [
23] used RF to downscale gridded precipitation data and then investigate the risk reduction potential of weather index insurance. Zhang et al. [
24] developed a data-driven wind turbine fault detection technique with the help of XGBoost. Li et al. [
25] proposed the use of the XGBoost model to quickly evaluate the severity of aircraft icing under different flight conditions.
Due to backward socio-economic development and its flat plain with low altitude, Bangladesh is widely recognized as one of the countries most affected by climate change. At the same time, Bangladesh has only very limited observations from irregularly distributed meteorological stations. In order to make reasonable planning to fight or mitigate the adverse effects of climate change and achieve agricultural sustainable development, Bangladesh urgently needs maps of high-resolution climate evolutions. Unfortunately, traditional climate modeling depending on high running costs and a huge amount of input parameters from observations cannot be utilized by poor Bangladesh. In this study, we developed a low-cost data-driven downscaling technique to generate finer spatially resolved temperature distribution maps for Bangladesh. After that, we explored the data-driven technique to generate a high-resolution temperature forecast map for 2025–2035. This whole article was organized as follows:
Section 2 describes climate and environmental conditions in Bangladesh and the sources of climate and topographic datasets used.
Section 3 introduces the structure and features of the main data-driven learning models.
Section 4 develops the data-driven downscaling technique and generates high-resolution temperature distribution maps of Bangladesh.
Section 5 explores the data-driven forecasting technique and generates high-resolution temperature forecast maps of Bangladesh. Finally,
Section 6 gives the conclusions and some discussion of the study.
2. Study Area and Data
Bangladesh is in the northeastern part of the South Asian subcontinent and is located in the alluvial delta of the Ganges and Brahmaputra rivers, bordering India on the east, west, and north, Myanmar to the southeast, and the Bay of Bengal to the south. Bangladesh is flat, the main terrain consists of floodplains and delta plains, with only some highlands in the north). Most of the country has a subtropical monsoonal climate, consisting of four seasons: winter (December to February), pre-monsoon summer (March to May), rainy season (June to September) and post-monsoon autumn (October to November) [
26]. The mean annual temperature in Bangladesh ranges from 25 to 30 °C, with winter being the most pleasant season of the year with a minimum temperature of 4 °C, and with summer highs usually ranging from 38 °C to about 41 °C, with April being the hottest month and January being the coldest. More than 80% of the precipitation occurs during the rainy season, with an average relative humidity of 80% and an annual precipitation of about 2428 mm, ranging from 1900 mm in the north-west and south-west regions to 3100 mm in the north-east region [
27].
The aim of our study is to develop a low-computation-cost and quick downscaling/forecast technique. Since Bangladesh has only limited irregular-distribution meteorological stations and limited computing resources, Bangladesh urgently needs such a downscaling/forecast technique. However, many environmental impact factors are poorly observed in Bangladesh, while topographic factors in Bangladesh are the only available factors observed in a high-resolution manner. At the same time, it is well-known that topographic factors have large impacts on temperature, e.g., a place with a high altitude has a low temperature; a place with a higher latitude has a low temperature. Therefore, we choose three topographic factors to support the generation of high-resolution temperature maps in Bangladesh.
Meteorological stations in Bangladesh are sparsely distributed and uneven (
Figure 1). The daily temperature data from 1989–2018 were collected from 34 meteorological stations of the Bangladesh Meteorological Department, and the longitude, latitude, and altitude data were extracted from the Global Multi-resolution Terrain Elevation Data 2010 (
Table 1) (
https://doi.org/10.5066/F7J38R2N, assessed at 1 December 2023). These data were used to generate high-resolution temperature distribution/forecast maps in
Section 4 and
Section 5.
3. Data-Driven Learning Models
Compared with statistical downscaling techniques, advanced statistical learning techniques have shown excellent performance in handling complex nonlinear correlations between variables [
18]. We used support vector machine (SVM), random forest (RF), gradient boosted regression (GBR), and eXtreme Gradient Boosting (XGBoost).
Support vector machine (SVM) is a non-parametric kernel-based supervised statistical learning model used to solve non-linear regression issues [
28]. SVM maps the input vectors into a high dimensional feature space using some nonlinear kernel functions and applies an optimum linear hyper-plane to separate data. For given
training data
, the SVM finds a regression function
such that
has at most
deviation from the actual value
, where
denotes a nonlinear transformation from
-dimensional space to a higher dimensional feature space,
is a weighting matrix, and
is a bias term. By minimizing the following regression risk:
subject to
. where
is a cost function and
is a constant which determines the tradeoff between minimizing training errors and minimizing the model complexity term
.
Random forest (RF) is an extension of regression trees (CART) to improve prediction accuracy. It combines the output of multiple decision trees to reach a single result [
29,
30]. Every tree is generated from a random vector that is sampled independently and has the same distribution for all trees in the forest. The divisions within each tree are determined by a subset of predictor variables randomly selected from all existing predictors. When the random forest model is applied for regression, the final output is the average of the results of all trees. In the random forest model, the number of trees in the forest (
), the number of variables used to grow each tree (
), and the minimum number of per terminal nodes (
nodesize) are the main parameters that affect the performance of random forest. The reliable estimates of the errors can be calculated by Out-of-Bag (OOB) data, which are a random subset of data that are not involved in the tree-building process. The mean square error (
) can be calculated:
where
is the number of observations,
is the measured value of the variable, and
is the average of all OOB predictions.
Gradient boosting regressor (GBR) is an ensemble learning algorithm that uses a boosting technique to minimize the loss of the model by adding weak learners in a stage-wise fashion. In each iterative step, a “weak” regression tree is fitted on a negative gradient (to reduce the loss) of the given loss function and added to the model. The final GBR output is the ensemble of all the regression trees [
31]. GBR is the application of gradient boosting and involves three elements: a loss function (which needs to be optimized), a weak learner (used for making predictions), and an additive model (to add weak learners to minimize the loss function). The main goal of this algorithm is to construct the new base-learners to be maximally correlated with the negative gradient of the loss function. Consider an additive model of this form [
32]:
where
are the basis functions, which are also called weak learners of boosting. Gradient boosting regressor builds the additive model in a forward stage-wise fashion:
At each stage, choosing the decision tree
to minimize the loss function
, given the current model
, and its fitting
.
The initial model is problem-specific; for least-squares regression, we chose the mean of the target values. For any given differentiable loss function , we started from an initial model, such as . then iterating until convergence was reached.
eXtreme gradient boosting (XGBoost) is an optimized-distributed gradient boosting library designed to be highly efficient, flexible, and portable [
33]. XGBoost is fundamentally the same as GBR since both of them are based on gradient-boosting implementations. Unlike GBR, XGBoost does regularization of the tree as well avoiding overfitting and it also deals with missing values efficiently.
4. High-Resolution Temperature Distribution Maps
We developed efficient downscaling models to generate high spatial-resolution temperature distribution maps, where the daily temperature data and longitude/latitude/altitude of the station were used as inputs to the statistical learning model. The output is a downscaled temperature product. Our downscaling model can largely compensate for the shortcomings of the multilinear-regression-based downscaling techniques (e.g., statistical downscaling models (SDSMs).
To demonstrate the accuracy and efficiency of our models with traditional MLR downscaling models, we generated high spatial-resolution temperature distribution maps directly from daily temperatures observed at 34 meteorological stations with irregular distribution. The correlation of determination (
R2), mean absolute error (
), and root mean square error (
) were used to assess the performance of different downscaling models. We adopted the 5-fold cross-validation [
34] in fairly comparing model performance. The main process during model training was to randomly divide all stations into five subsets. Each time, we took data on one subset of stations as the test set and data on the remaining four subsets of stations as the training set. The validation process was repeated five times and we finally took the average of five errors to measure model performance. All parameters of the model are automatically chosen by Scikit-Learn [
35]. Since the size of training data is not large, the proposed techniques can run very quickly on a regular laptop with the 12th Gen Intel
® Core™ i5-12500H.
Based on the daily temperature data and latitude/longitude/altitude data of Bangladesh from 1989 to 2018, we built downscaling models based on SVM, RF, and GBR algorithms, respectively, to obtain higher-resolution temperature data.
Table 2 compares the validation results of the three statistical learning downscaling models and one MLR downscaling model in simulating daily mean temperature values. Through 5-fold cross-validation, the downscaled temperatures obtained by the GBR were in best agreement with the original data, followed by RF and SVM, but all were significantly better than the traditional MLR model. The MLR can only extract the linear relationship between topographic factors and temperature variables, leading to that the accuracy by MLR being the worst. The GBR downscaling model produced the highest
(0.98) and the lowest
(0.06) and
(0.08).
Figure 2 shows the correlation between the downscaled temperature values and station-wise observations, where the GBR downscaled model fitted the best, followed by the RF, and the SVM with relatively poor results. A Taylor diagram is a visualization tool that compares the performance of different models by simultaneously displaying the correlation coefficients, standard deviations, and root mean square errors among multiple model simulations and station observations.
Figure 3 shows a Taylor diagram with observed and simulated temperature data. Clearly, GBR has the best performance of any of the three remaining models, RF and SVM have similar accuracy, and MLR has the poorest performance.
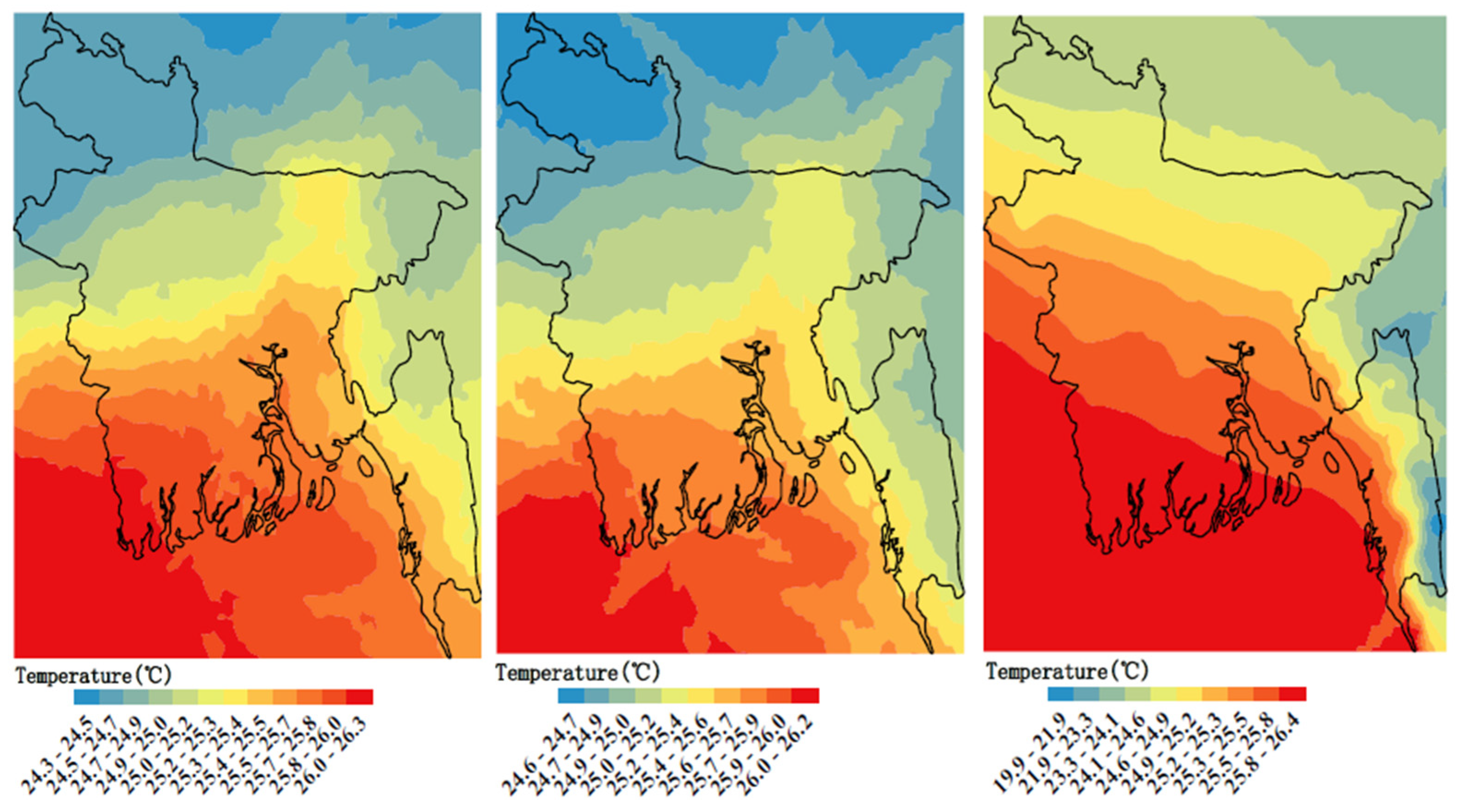
High-resolution mean annual temperature distribution maps are shown in
Figure 4. Two maps generated by GBR and RF are basically consistent, while the map by RF contained unrealistic parallel structures. Combining this with
Table 2, it means that the GBR downscaled model generated the high-resolution temperature distribution map with the best accuracy. From
Figure 4-left the mean annual temperature distribution of Bangladesh had relatively small regional variations, ranging from 24.3 °C to 26.3 °C. The temperature values gradually increased from the northeast to the southwest, reaching the highest in the southwest region.
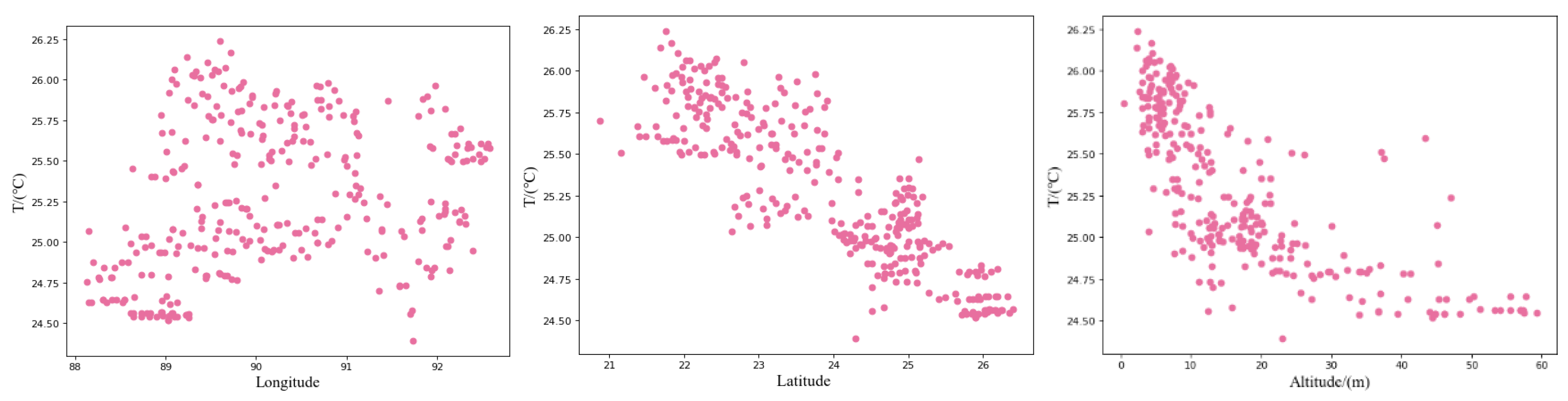
We further make a feature significance analysis of topographic factors (longitude, latitude, and altitude) for the spatial distribution of mean annual temperatures in Bangladesh (
Figure 5). It is very clear that latitude and altitude are closely linked with temperature. With the increasing latitude and altitude, the mean annual temperature demonstrates a significantly decreasing trend. However, longitude is not particularly linked with temperature.
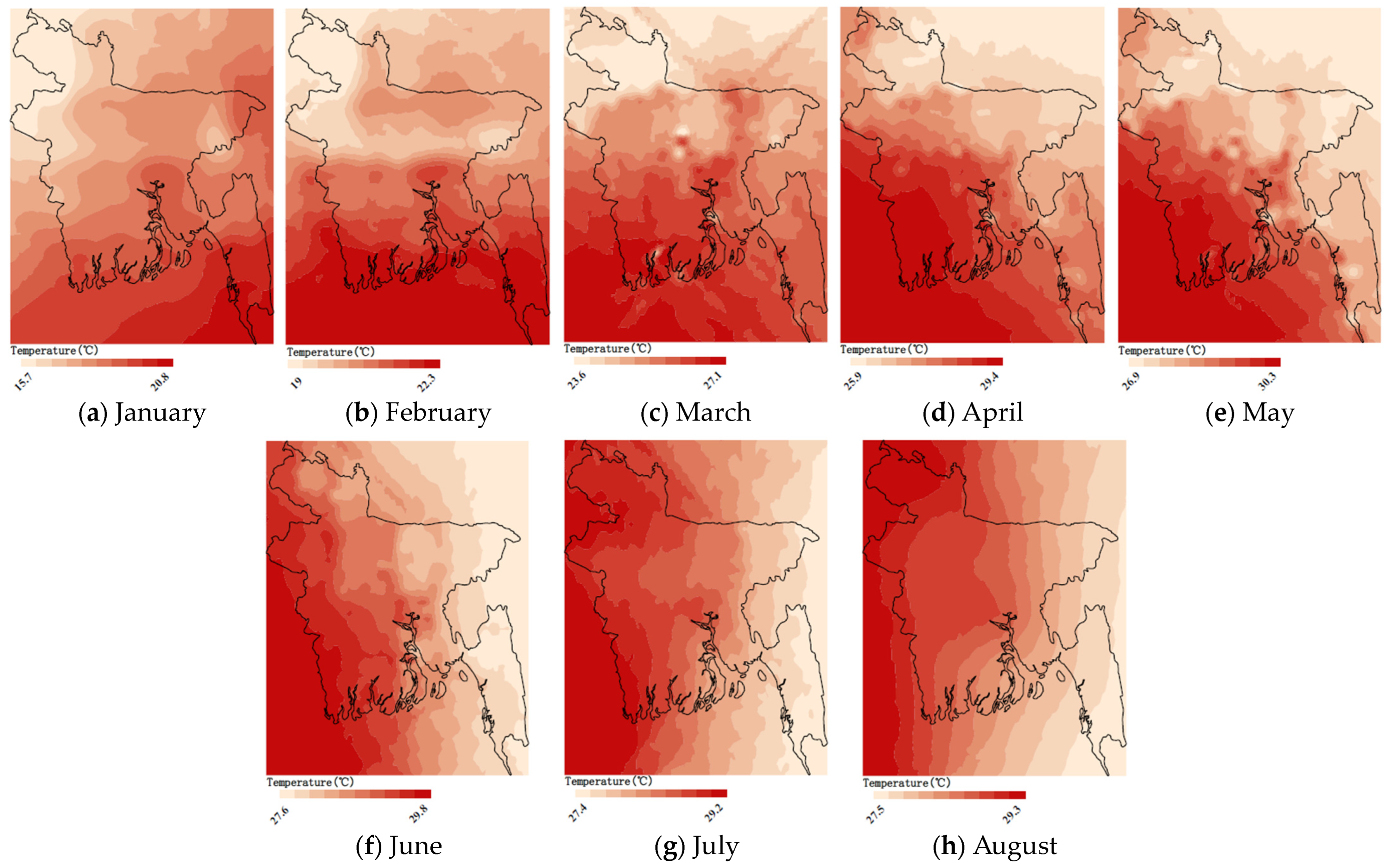
As the monthly variation in Bangladesh temperature is large,
Figure 6 shows the high-resolution monthly temperature distribution maps generated by the GBR downscaling model. It reveals a significant seasonal variation in the monthly mean temperature in Bangladesh, with the lowest monthly mean temperature of 15.7 °C (January) and the highest monthly mean temperature of 30.3 °C (May). The spatial patterns of mean temperatures during January–March (or October–December) are similar, with a gradual increase in temperature from the north to the south, peaking in coastal regions, and an overall cooler temperature in the northwestern region. In both April and May, high monthly temperatures are concentrated in the southwestern region, the central region spans a wide range of temperatures, and the northern, eastern, and southeastern regions have relatively low temperatures. The average temperatures in June–August gradually decrease from the west to the east, with a significant increase in the northern region compared with May. The variation of temperatures is relatively small in September, with a difference of no more than 1 °C in each region. Bangladesh demonstrates significant regional variations in the mean monthly temperatures.
5. High-Resolution Temperature Forecast Maps
Accurate climate prediction is of great value for Bangladesh to develop suitable plans for the mitigation of climate disasters and achieve sustainable development. Due to the high dimensionality, complexity, and uncertainty of the climate system, it is difficult to obtain good forecasts for future climate evolution. The known climate forecasts by CMIP6 models must depend on a huge amount of input parameters and high computing resources. Bangladesh does not have enough observations, computing resources, and financial support to run CMIP6 models. Moreover, the resolution of the CMIP6 model is just 1–2 degrees. In this study, we try to explore the low-cost data-driven climate forecast with high resolution (about 0.1 degrees) directly from limited climate observations. The forecast scenario adopted in this study is the “business as usual” scenario. Since the temperature forecast by CMIP6 models is based on RCP-SSP scenarios, we cannot compare our forecast with the low-resolution CMIP6 forecast.
As a set of gradient boosting decision trees, the XGBoost has a fast-training speed and high accuracy when dealing with complex nonlinear links and effectively avoids overfitting problems [
36,
37]. In this section, we use the XGBoost model to predict future temperature distribution under the business as usual (BAU) climate scenario. The input of the XGBoost model is the high-resolution downscaled historical temperature data in Bangladesh from 1989 to 2018, and the output is the forecast of future temperatures. In order to test the performance of our XGBoost-based forecast model, we selected the monthly temperature data from 1989 to 2015 to train the XGBoost-based prediction model, and then used the monthly average temperature data from 2016 to 2018 to test the prediction accuracy from three evaluation indicators: coefficient determination (
), root mean square error (
), and mean square error (
). The XGBoost-based prediction model demonstrated relatively high accuracy:
By comparison of predicted and observed monthly temperatures in Bangladesh (
Figure 7), the forecasted monthly temperature values were very close to the observed values.
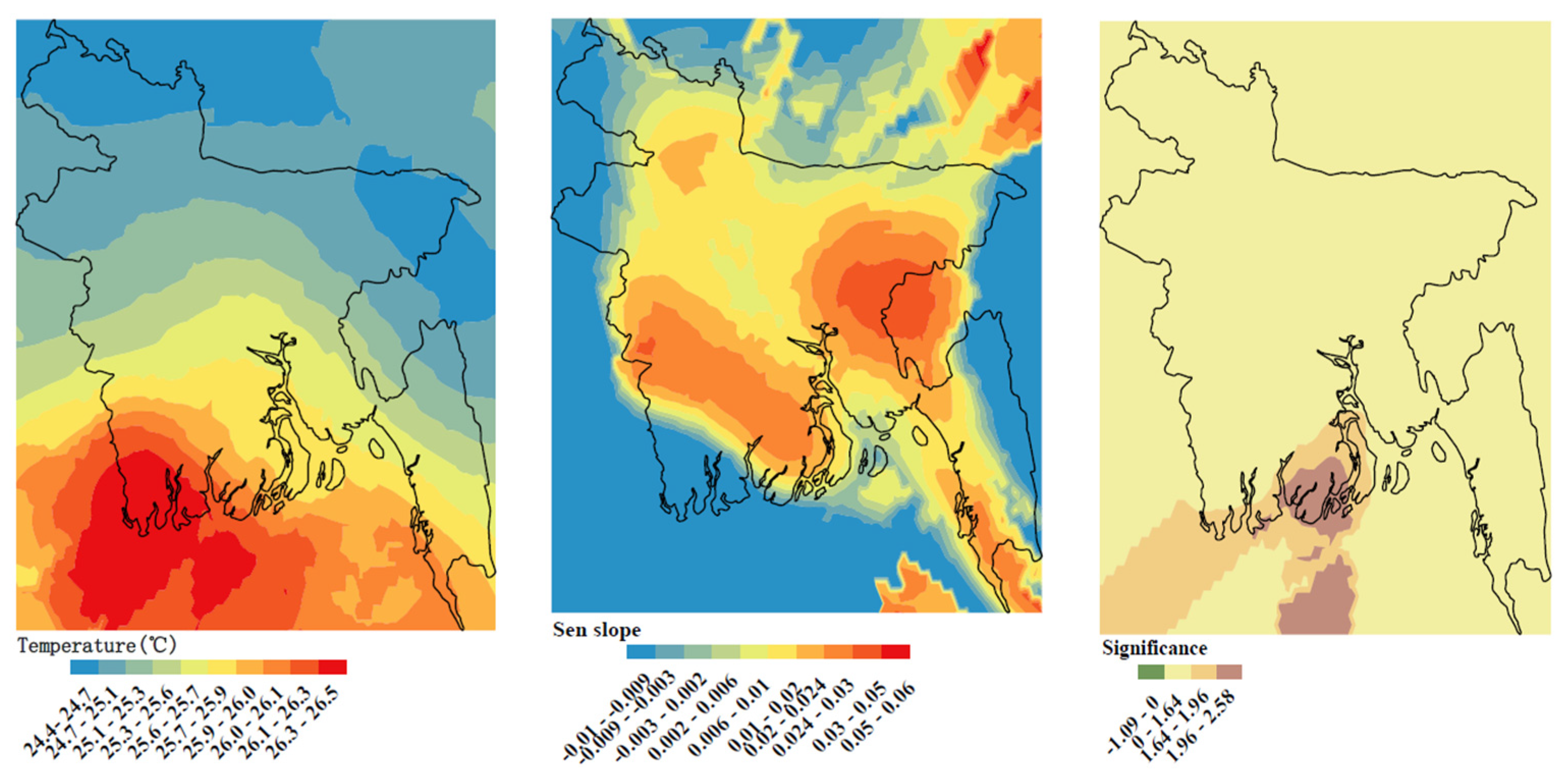
Finally, we used the high-resolution historical temperature data in Bangladesh during 1989–2018 as the input to the XGBoost-based forecast model to obtain high-resolution annual temperature forecast maps in Bangladesh during 2025–2035 (
Figure 8). The annual average temperature in 2025–2035 gradually increases from north to south, reaching a maximum temperature of 26.5 °C in the southwest, which is almost consistent with average temperature distribution during 1989–2018 (
Figure 8-left). Overall, the annual mean temperature is forecast to increase during 2025–2035, with at most 0.06 °C/year by Sen’s slope test (
Figure 8-middle). However, the increasing trends were not significant in most areas, except for the middle coastal regions (
Figure 8-right).
We performed the analysis of empirical orthogonal functions (EOF) analysis on annual mean temperature during 2025–2035 (
Table 3. The cumulative variance of the first three EOF modes reached 59% cumulatively, i.e., the first EOF mode explained 27%, the second EOF model explained 17%, and the third EOF model explained 15%, and all three EOF modes passed the North significance test.
The first EOF mode (
Figure 9, left) mainly showed double-phase features, with roughly a negative phase occurring northeast and southwest regions, and a positive phase occurring in the northwest region, central region, and middle coastal region. The associated time coefficient showed a downward trend (
Figure 10-left). The spatial distribution of the second EOF mode showed a significant multi-phase effect (
Figure 9, middle), where three positive phase peaks appeared in the northwest, east, and south regions, and the main negative phase peak appeared in the southeast region (
Figure 9, middle). The third EOF mode mainly showed the east–west reverse phase feature and the time coefficient associated with the second/third EOF mode showed an upward trend (
Figure 10).
6. Conclusions
Climate change has a serious impact on the agricultural production and economic development of Bangladesh. The generation of high-resolution temperature maps is a must for any poor countries like Bangladesh since these maps can reveal the climate patterns in observation blank regions in poor countries, and then help relevant departments to formulate policies to mitigate and adapt to climate change in a timely manner and support economic and agricultural development. Based on observed temperature data and longitude/latitude/altitude data of 34 meteorological observation stations in Bangladesh from 1989 to 2018, we developed an efficient data-driven downscaling technique to generate high spatial-resolution temperature distribution maps in Bangladesh directly from daily temperatures observed at 34 meteorological stations with irregular distribution. The main advantages of our method are: the input data are sparsely distributed, not gridded; there is no need to use a large number of GCM outputs, resulting in a very low computational cost; it makes full use of nonlinear links between topographic factors and climate factors.
The known climate forecasts by CMIP6 models must depend on a huge amount of input parameters and high computing resources. Many developing countries have not enough observations, computing resources, and financial support to run CMIP6 models. Moreover, the resolution of the CMIP6 model is just 1–2 degrees. In this study, we explore the data-driven high-resolution climate forecast directly from limited climate observations and generate a high-resolution temperature forecast map in Bangladesh during 2025–2035. This data-driven forecast technique is just at the beginning, more work needs to be undertaken in the future.
Although our study only focused on Bangladesh, the proposed data-driven downscaling and forecast techniques can be applied to any developing country with only irregularly distributed climate and environmental observations. Moreover, our techniques can also be used to generate high-resolution evolution maps for other climate and environmental factors, e.g., humidity, PM2.5, and wind speed. In the future, we will explore these aspects.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}