
Identification of an Unknown Stationary Emission Source in Urban Geometry Using Bayesian Inference
 ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Source–Receptor Relationship
2.2. Bayesian Inference
2.2.1. Likelihood Function
2.2.2. Prior Probability
2.2.3. Posterior Probability and Sampling Process
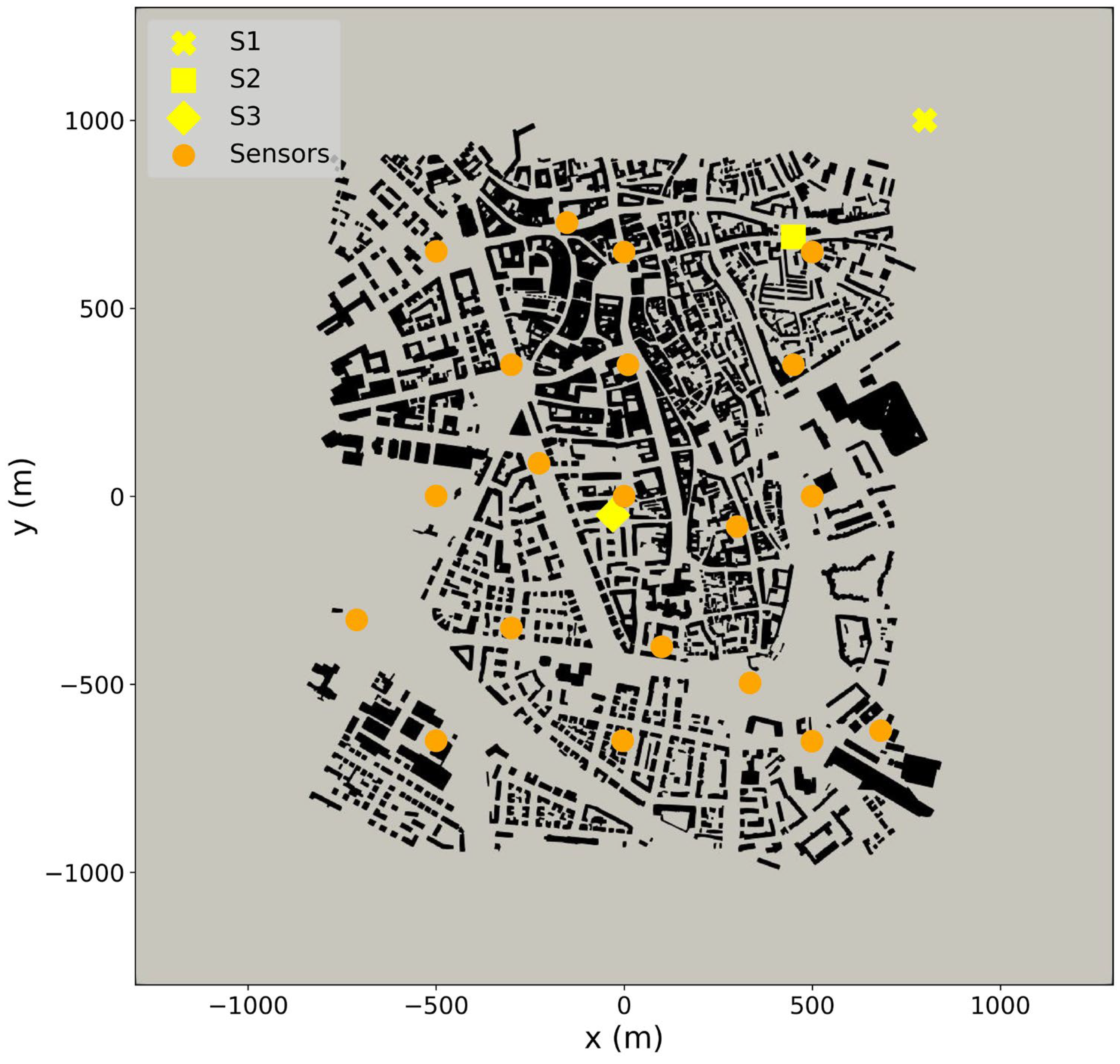
2.3. Case Description
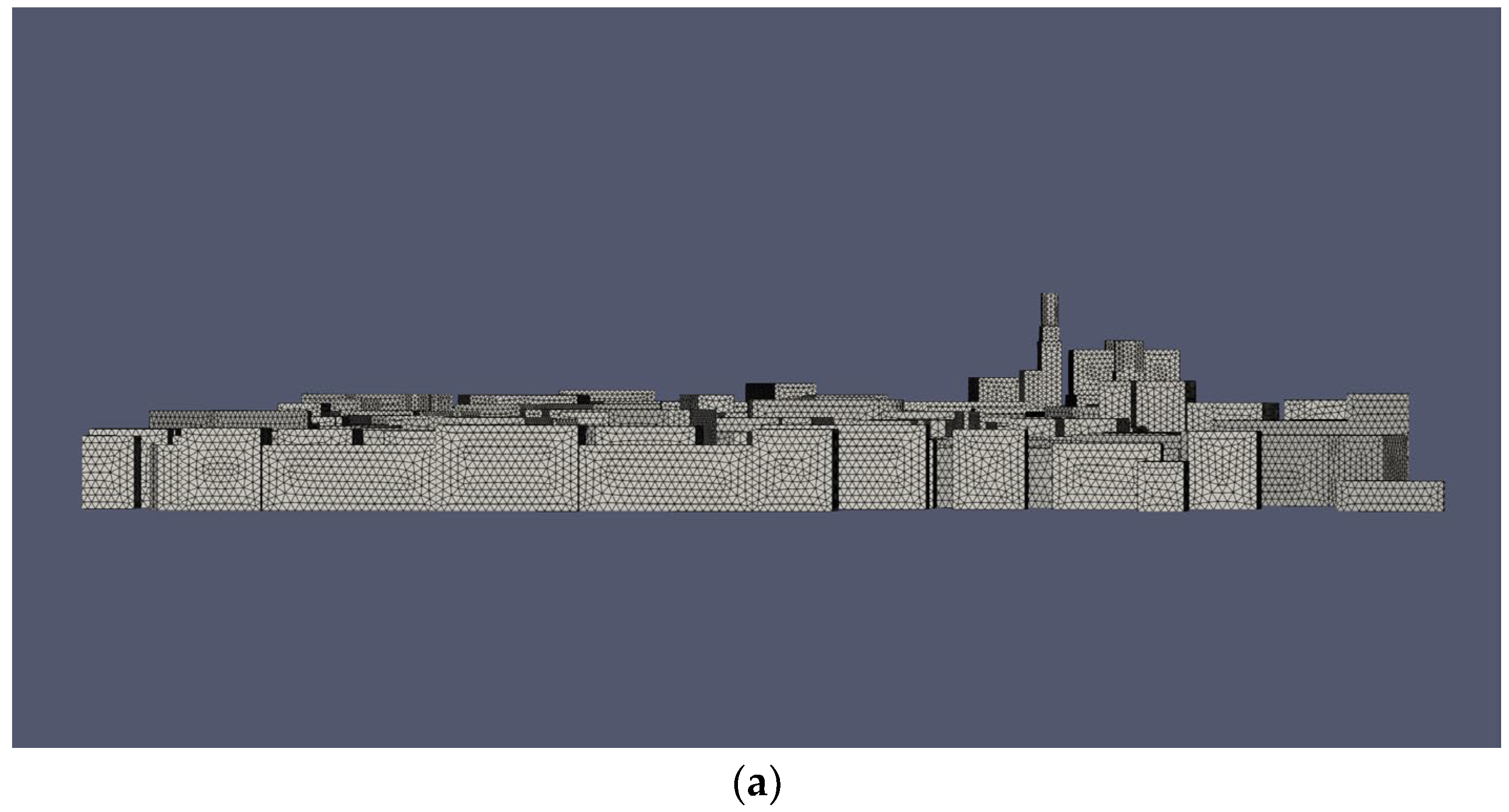
2.3.1. Computational Mesh
2.3.2. Release Scenarios—Datasets
2.4. Set Up
2.4.1. Numerical Simulations
2.4.2. Metropolis–Hastings MCMC
3. Results
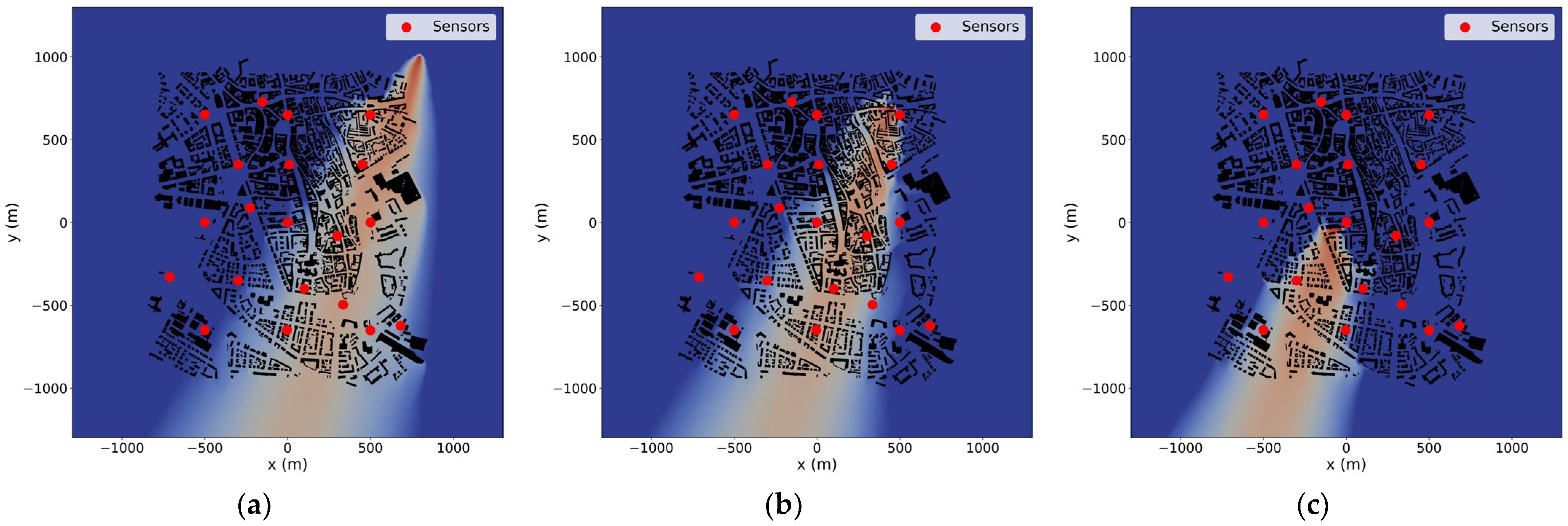
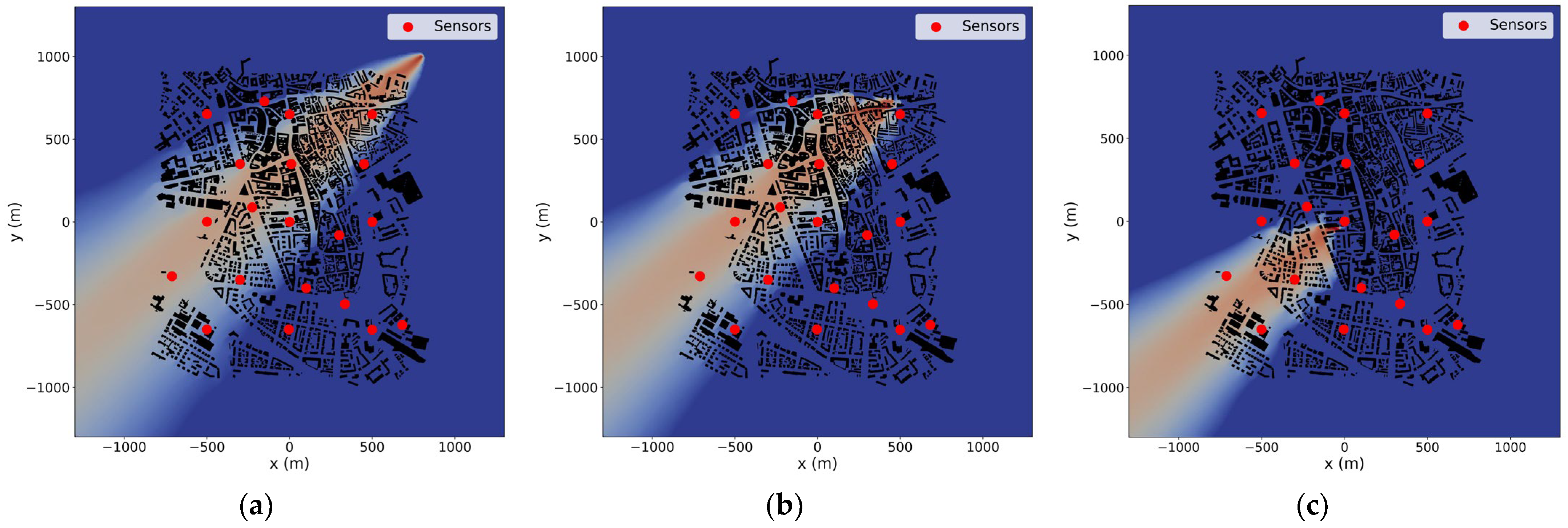
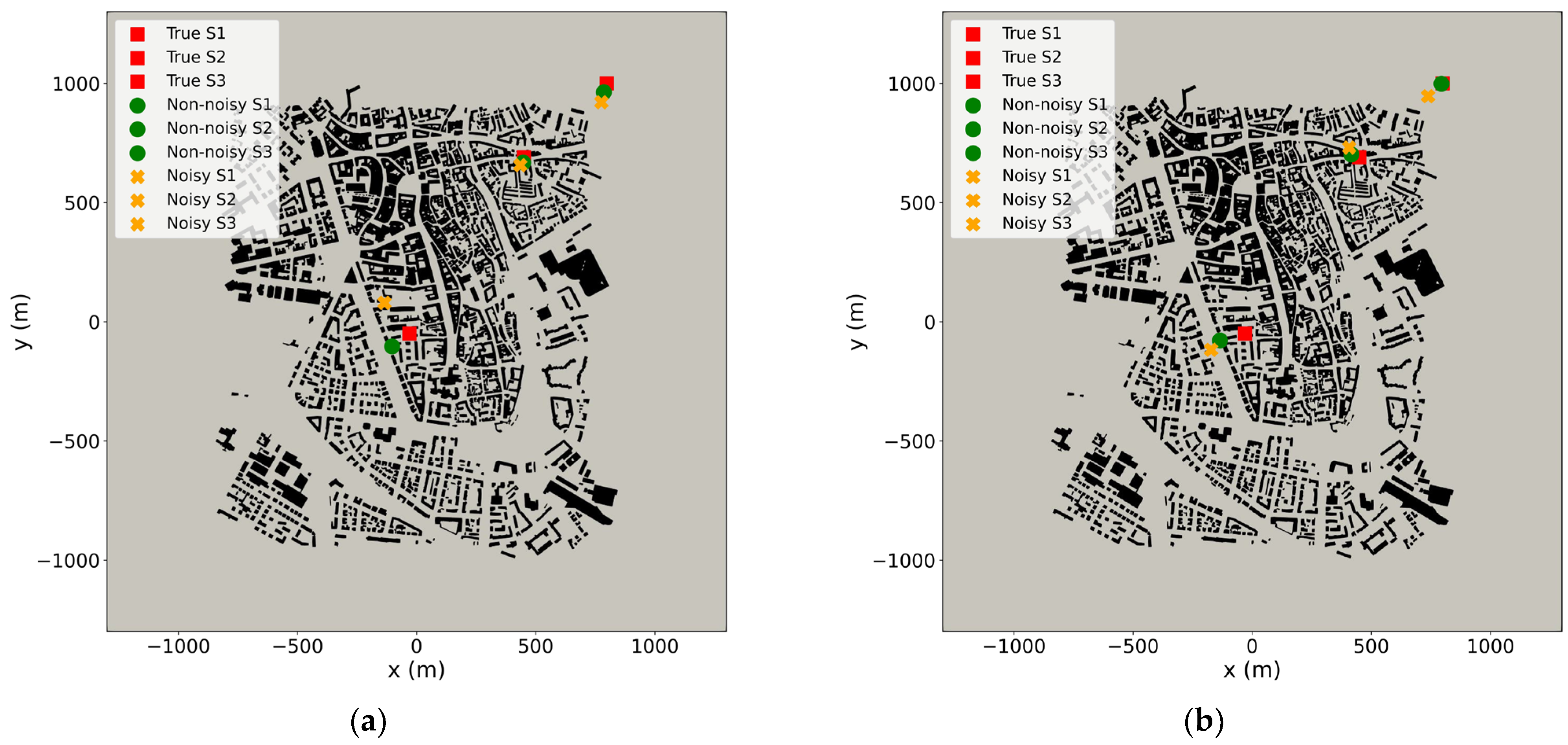
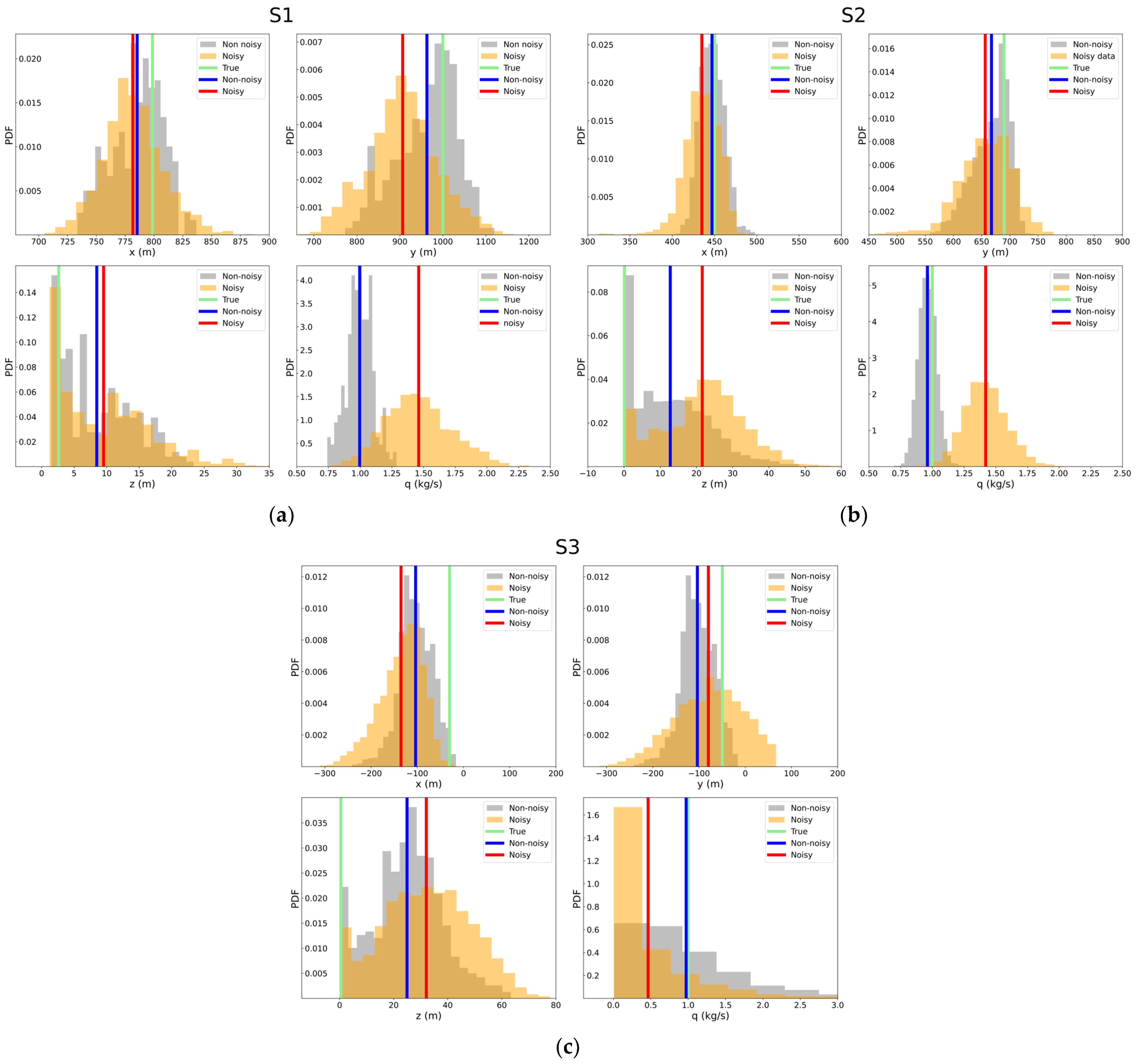
3.1. Synthetic Observations
3.2. Source Term Estimation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vlachokostas, C.; Achillas, C.; Slini, T.; Moussiopoulos, N.; Banias, G.; Dimitrakis, I. Willingness to Pay for Reducing the Risk of Premature Mortality Attributed to Air Pollution: A Contingent Valuation Study for Greece. Atmos. Pollut. Res. 2011, 2, 275–282. [Google Scholar] [CrossRef]
- Vlachokostas, C.; Banias, G.; Athanasiadis, A.; Achillas, C.; Akylas, V.; Moussiopoulos, N. Cense: A Tool to Assess Combined Exposure to Environmental Health Stressors in Urban Areas. Environ. Int. 2014, 63, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Anspaugh, L.R.; Catlin, R.J.; Goldman, M. The Global Impact of the Chernobyl Reactor Accident. Science 1988, 242, 1513–1519. [Google Scholar] [CrossRef] [PubMed]
- Ohtsuru, A.; Tanigawa, K.; Kumagai, A.; Niwa, O.; Takamura, N.; Midorikawa, S.; Nollet, K.; Yamashita, S.; Ohto, H.; Chhem, R.K.; et al. Nuclear Disasters and Health: Lessons Learned, Challenges, and Proposals. Lancet 2015, 386, 489–497. [Google Scholar] [CrossRef] [PubMed]
- Chouhan, T.R. The Unfolding of Bhopal Disaster. J. Loss Prev. Process Ind. 2005, 18, 205–208. [Google Scholar] [CrossRef]
- Pocchiari, F.; Silano, V.; Zampieri, A. Human Health Effects from Accidental Release of Tetrachlorodibenzo-p-Dioxin (tcdd) at Seveso, italy. Ann. N. Y. Acad. Sci. 1979, 320, 311–320. [Google Scholar] [PubMed]
- Okumura, T.; Takasu, N.; Ishimatsu, S.; Miyanoki, S.; Mitsuhashi, A.; Kumada, K.; Tanaka, K.; Hinohara, S. Report on 640 Victims of the Tokyo Subway Sarin Attack. Ann. Emerg. Med. 1996, 28, 129–135. [Google Scholar] [CrossRef] [PubMed]
- Pudykiewicz, J.A. Application of Adjoint Tracer Transport Equations for Evaluating Source Parameters. Atmos. Environ. 1998, 32, 3039–3050. [Google Scholar] [CrossRef]
- Allen, C.T.; Young, G.S.; Haupt, S.E. Improving Pollutant Source Characterization by Better Estimating Wind Direction with a Genetic Algorithm. Atmos. Environ. 2007, 41, 2283–2289. [Google Scholar] [CrossRef]
- Liu, Y.; Jiang, Y.; Zhang, X.; Pan, Y.; Qi, Y. Combined Grey Wolf Optimizer Algorithm and Corrected Gaussian Diffusion Model in Source Term Estimation. Processes 2022, 10, 1238. [Google Scholar] [CrossRef]
- Li, H.; Zhang, J.; Yi, J. Computational Source Term Estimation of the Gaussian Puff Dispersion. Soft Comput. 2019, 23, 59–75. [Google Scholar] [CrossRef]
- Park, M.; Ladosz, P.; Oh, H. Source Term Estimation Using Deep Reinforcement Learning With Gaussian Mixture Model Feature Extraction for Mobile Sensors. IEEE Robot. Autom. Lett. 2022, 7, 8323–8330. [Google Scholar] [CrossRef]
- Wade, D.; Senocak, I. Stochastic Reconstruction of Multiple Source Atmospheric Contaminant Dispersion Events. Atmos. Environ. 2013, 74, 45–51. [Google Scholar] [CrossRef]
- Efthimiou, G.C.; Kovalets, I.V.; Venetsanos, A.; Andronopoulos, S.; Argyropoulos, C.D.; Kakosimos, K. An Optimized Inverse Modelling Method for Determining the Location and Strength of a Point Source Releasing Airborne Material in Urban Environment. Atmos. Environ. 2017, 170, 118–129. [Google Scholar] [CrossRef]
- Efthimiou, G.C.; Kovalets, I.V.; Argyropoulos, C.D.; Venetsanos, A.; Andronopoulos, S.; Kakosimos, K.E. Evaluation of an Inverse Modelling Methodology for the Prediction of a Stationary Point Pollutant Source in Complex Urban Environments. Build. Environ. 2018, 143, 107–119. [Google Scholar] [CrossRef]
- Keats, A.; Yee, E.; Lien, F.-S. Bayesian Inference for Source Determination with Applications to a Complex Urban Environment. Atmos. Environ. 2007, 41, 465–479. [Google Scholar] [CrossRef]
- Kovalets, I.V.; Andronopoulos, S.; Venetsanos, A.G.; Bartzis, J.G. Identification of Strength and Location of Stationary Point Source of Atmospheric Pollutant in Urban Conditions Using Computational Fluid Dynamics Model. Math. Comput. Simul. 2011, 82, 244–257. [Google Scholar] [CrossRef]
- Xue, F.; Kikumoto, H.; Li, X.; Ooka, R. Bayesian Source Term Estimation of Atmospheric Releases in Urban Areas Using LES Approach. J. Hazard. Mater. 2018, 349, 68–78. [Google Scholar] [CrossRef] [PubMed]
- Xue, F.; Li, X.; Ooka, R.; Kikumoto, H.; Zhang, W. Turbulent Schmidt Number for Source Term Estimation Using Bayesian Inference. Build. Environ. 2017, 125, 414–422. [Google Scholar] [CrossRef]
- Jia, H.; Kikumoto, H. Source Term Estimation in Complex Urban Environments Based on Bayesian Inference and Unsteady Adjoint Equations Simulated via Large Eddy Simulation. Build. Environ. 2021, 193, 107669. [Google Scholar] [CrossRef]
- Rapkos, N.; Boikos, C.; Ioannidis, G.; Ntziachristos, L. Direct Deposition of Air Pollutants in the Wake of Container Vessels: The Missing Term in the Environmental Impact of Shipping. Atmos. Pollut. Res. 2024, 15, 102013. [Google Scholar] [CrossRef]
- Boikos, C.; Rapkos, N.; Ioannidis, G.; Oppo, S.; Armengaud, A.; Siamidis, P.; Tsegas, G.; Ntziachristos, L. Factors Affecting Pedestrian-Level Ship Pollution in Port Areas: CFD in the Service of Policy-Making. Build. Environ. 2024, 258, 111594. [Google Scholar] [CrossRef]
- Ioannidis, G.; Li, C.; Tremper, P.; Riedel, T.; Ntziachristos, L. Application of CFD Modelling for Pollutant Dispersion at an Urban Traffic Hotspot. Atmosphere 2024, 15, 113. [Google Scholar] [CrossRef]
- Rivas, E.; Santiago, J.L.; Lechón, Y.; Martín, F.; Ariño, A.; Pons, J.J.; Santamaría, J.M. CFD Modelling of Air Quality in Pamplona City (Spain): Assessment, Stations Spatial Representativeness and Health Impacts Valuation. Sci. Total Environ. 2019, 649, 1362–1380. [Google Scholar] [CrossRef] [PubMed]
- Rafael, S.; Vicente, B.; Rodrigues, V.; Miranda, A.I.; Borrego, C.; Lopes, M. Impacts of Green Infrastructures on Aerodynamic Flow and Air Quality in Porto’s Urban Area. Atmos. Environ. 2018, 190, 317–330. [Google Scholar] [CrossRef]
- Parra, M.A.; Santiago, J.L.; Martín, F.; Martilli, A.; Santamaría, J.M. A Methodology to Urban Air Quality Assessment during Large Time Periods of Winter Using Computational Fluid Dynamic Models. Atmos. Environ. 2010, 44, 2089–2097. [Google Scholar] [CrossRef]
- Santiago, J.L.; Borge, R.; Martin, F.; de la Paz, D.; Martilli, A.; Lumbreras, J.; Sanchez, B. Evaluation of a CFD-Based Approach to Estimate Pollutant Distribution within a Real Urban Canopy by Means of Passive Samplers. Sci. Total Environ. 2017, 576, 46–58. [Google Scholar] [CrossRef] [PubMed]
- Martín, F.; Janssen, S.; Rodrigues, V.; Sousa, J.; Santiago, J.L.; Rivas, E.; Stocker, J.; Jackson, R.; Russo, F.; Villani, M.G.; et al. Using Dispersion Models at Microscale to Assess Long-Term Air Pollution in Urban Hot Spots: A FAIRMODE Joint Intercomparison Exercise for a Case Study in Antwerp. Sci. Total Environ. 2024, 925, 171761. [Google Scholar] [CrossRef] [PubMed]
- Haupt, S.E.; Young, G.S.; Allen, C.T. Validation of a Receptor–Dispersion Model Coupled with a Genetic Algorithm Using Synthetic Data. J. Appl. Meteorol. Clim. 2006, 45, 476–490. [Google Scholar] [CrossRef]
- Allen, C.T.; Haupt, S.E.; Young, G.S. Source Characterization with a Genetic Algorithm–Coupled Dispersion–Backward Model Incorporating SCIPUFF. J. Appl. Meteorol. Clim. 2007, 46, 273–287. [Google Scholar] [CrossRef]
- Ma, D.; Tan, W.; Zhang, Z.; Hu, J. Parameter Identification for Continuous Point Emission Source Based on Tikhonov Regularization Method Coupled with Particle Swarm Optimization Algorithm. J. Hazard. Mater. 2017, 325, 239–250. [Google Scholar] [CrossRef] [PubMed]
- Thomson, L.C.; Hirst, B.; Gibson, G.; Gillespie, S.; Jonathan, P.; Skeldon, K.D.; Padgett, M.J. An Improved Algorithm for Locating a Gas Source Using Inverse Methods. Atmos. Environ. 2007, 41, 1128–1134. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, B.; Zhu, Z.; Wang, R.; Chen, F.; Zhao, Y.; Zhang, L. A Hybrid Strategy on Combining Different Optimization Algorithms for Hazardous Gas Source Term Estimation in Field Cases. Process Saf. Environ. Prot. 2020, 138, 27–38. [Google Scholar] [CrossRef]
- Ickowicz, A.; Septier, F.; Armand, P.; Delignon, Y. Adaptive Bayesian Algorithms for the Estimation of Source Term in A Complex Atmospheric Release. In Proceedings of the 15th International Conference on Harmonisation within Atmospheric Dispersion Modelling for Regulatory Purposes, Madrid, Spain, 6–9 May 2013. [Google Scholar]
- Jia, H.; Kikumoto, H. Line Source Estimation of Environmental Pollutants Using Super-Gaussian Geometry Model and Bayesian Inference. Environ. Res. 2021, 194, 110706. [Google Scholar] [CrossRef] [PubMed]
- Lane, R.O.; Briers, M.; Copsey, K. Approximate Bayesian Computation for Source Term Estimation. In Proceedings of the IMA Conference on Mathematics in Defence Cody Technology Park, Farnborough, Hampshire, UK, 19 November 2009. [Google Scholar]
- Wang, Y.; Huang, H.; Huang, L.; Ristic, B. Evaluation of Bayesian Source Estimation Methods with Prairie Grass Observations and Gaussian Plume Model: A Comparison of Likelihood Functions and Distance Measures. Atmos. Environ. 2017, 152, 519–530. [Google Scholar] [CrossRef]
- Yee, E.; Hoffman, I.; Ungar, K. Bayesian Inference for Source Reconstruction: A Real-World Application. Int. Sch. Res. Not. 2014, 2014, 507634. [Google Scholar] [CrossRef] [PubMed]
- Bieringer, P.E.; Young, G.S.; Rodriguez, L.M.; Annunzio, A.J.; Vandenberghe, F.; Haupt, S.E. Paradigms and Commonalities in Atmospheric Source Term Estimation Methods. Atmos. Environ. 2017, 156, 102–112. [Google Scholar] [CrossRef]
- Shankar Rao, K. Source Estimation Methods for Atmospheric Dispersion. Atmos. Environ. 2007, 41, 6964–6973. [Google Scholar] [CrossRef]
- Hutchinson, M.; Oh, H.; Chen, W.H. A Review of Source Term Estimation Methods for Atmospheric Dispersion Events Using Static or Mobile Sensors. Inf. Fusion 2017, 36, 130–148. [Google Scholar] [CrossRef]
- Gilks, W.R.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; CRC Press: Boca Raton, FL, USA, 1995. [Google Scholar]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of State Calculations by Fast Computing Machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef]
- Carlin, B.P.; Louis, T.A. Bayes and Empirical Bayes Methods for Data Analysis. Stat. Comput. 1997, 7, 153–154. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. Openstreetmap: User-Generated Street Maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Mooney, P.; Corcoran, P.; Winstanley, A.C. Towards Quality Metrics for OpenStreetMap. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 514–517. [Google Scholar]
- Haklay, M. How Good Is Volunteered Geographical Information? A Comparative Study of OpenStreetMap and Ordnance Survey Datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Neis, P.; Zielstra, D.; Zipf, A. The Street Network Evolution of Crowdsourced Maps: OpenStreetMap in Germany 2007–2011. Future Internet 2011, 4, 1–21. [Google Scholar] [CrossRef]
- Antoniou, A.; Ioannidis, G.; Ntziachristos, L. Realistic Simulation of Air Pollution in an Urban Area to Promote Environmental Policies. Environ. Model. Softw. 2024, 172, 105918. [Google Scholar] [CrossRef]
- Blocken, B. Computational Fluid Dynamics for Urban Physics: Importance, Scales, Possibilities, Limitations and Ten Tips and Tricks towards Accurate and Reliable Simulations. Build. Environ. 2015, 91, 219–245. [Google Scholar] [CrossRef]
- Ariff, M.; Salim, S.M.; Cheah, S.C. Wall Y+ Approach for Dealing with Turbulent Flows over a Surface Mounted Cube: Part 2—High Reynolds Number. In Proceedings of the Seventh International Conference on CFD in the Mineral and Process Industries, Melbourne, Australia, 9–11 December 2009. [Google Scholar]
- Henry, F.; Bonifacio, R.G.M.; Glasgow, L.A. Numerical Simulation of Transport of Particles Emitted from Ground-Level Area Source Using Aermod and CFD. Eng. Appl. Comput. Fluid. Mech. 2014, 8, 488–502. [Google Scholar] [CrossRef]
- Tominaga, Y.; Stathopoulos, T. Turbulent Schmidt Numbers for CFD Analysis with Various Types of Flowfield. Atmos. Environ. 2007, 41, 8091–8099. [Google Scholar] [CrossRef]
- Wang, X.; McNamara, K.F. Evaluation of CFD Simulation Using RANS Turbulence Models for Building Effects on Pollutant Dispersion. Environ. Fluid Mech. 2006, 6, 181–202. [Google Scholar] [CrossRef]
- Sanchez, B.; Santiago, J.L.; Martilli, A.; Martin, F.; Borge, R.; Quaassdorff, C.; de la Paz, D. Modelling NOX Concentrations through CFD-RANS in an Urban Hot-Spot Using High Resolution Traffic Emissions and Meteorology from a Mesoscale Model. Atmos. Environ. 2017, 163, 155–165. [Google Scholar] [CrossRef]
- Richards, P.J.; Hoxey, R.P. Appropriate Boundary Conditions for Computational Wind Engineering Models Using the K-ε Turbulence Model. Comput. Wind Eng. 1993, 1, 145–153. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wind Direction | Source | (m) | (m) | (-) | |||
|---|---|---|---|---|---|---|---|
| Non-Noisy | Noisy | Non-Noisy | Noisy | Non-Noisy | Noisy | ||
| 19 degrees | S1 | 39.37 | 82.65 | 5.85 | 5.55 | 1.00 | 1.08 |
| S2 | 22.70 | 36.90 | 12.66 | 21.50 | 1.04 | 1.42 | |
| S3 | 91.06 | 109.21 | 24.44 | 31.59 | 1.03 | 2.15 | |
| 50 degrees | S1 | 5.19 | 80.94 | 2.88 | 6.11 | 1.04 | 1.07 |
| S2 | 36.44 | 59.56 | 5.22 | 18.26 | 1.03 | 1.16 | |
| S3 | 109.15 | 157.92 | 28.01 | 57.53 | 1.46 | 2.20 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gkirmpas, P.; Tsegas, G.; Ioannidis, G.; Vlachokostas, C.; Moussiopoulos, N. Identification of an Unknown Stationary Emission Source in Urban Geometry Using Bayesian Inference. Atmosphere 2024, 15, 871. https://doi.org/10.3390/atmos15080871
Gkirmpas P, Tsegas G, Ioannidis G, Vlachokostas C, Moussiopoulos N. Identification of an Unknown Stationary Emission Source in Urban Geometry Using Bayesian Inference. Atmosphere. 2024; 15(8):871. https://doi.org/10.3390/atmos15080871
Chicago/Turabian StyleGkirmpas, Panagiotis, George Tsegas, Giannis Ioannidis, Christos Vlachokostas, and Nicolas Moussiopoulos. 2024. "Identification of an Unknown Stationary Emission Source in Urban Geometry Using Bayesian Inference" Atmosphere 15, no. 8: 871. https://doi.org/10.3390/atmos15080871