
Time-Series Data-Driven PM2.5 Forecasting: From Theoretical Framework to Empirical Analysis

 ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
2. Bibliometric Analysis
2.1. Literature Trends
2.2. Geographic Distribution of Research
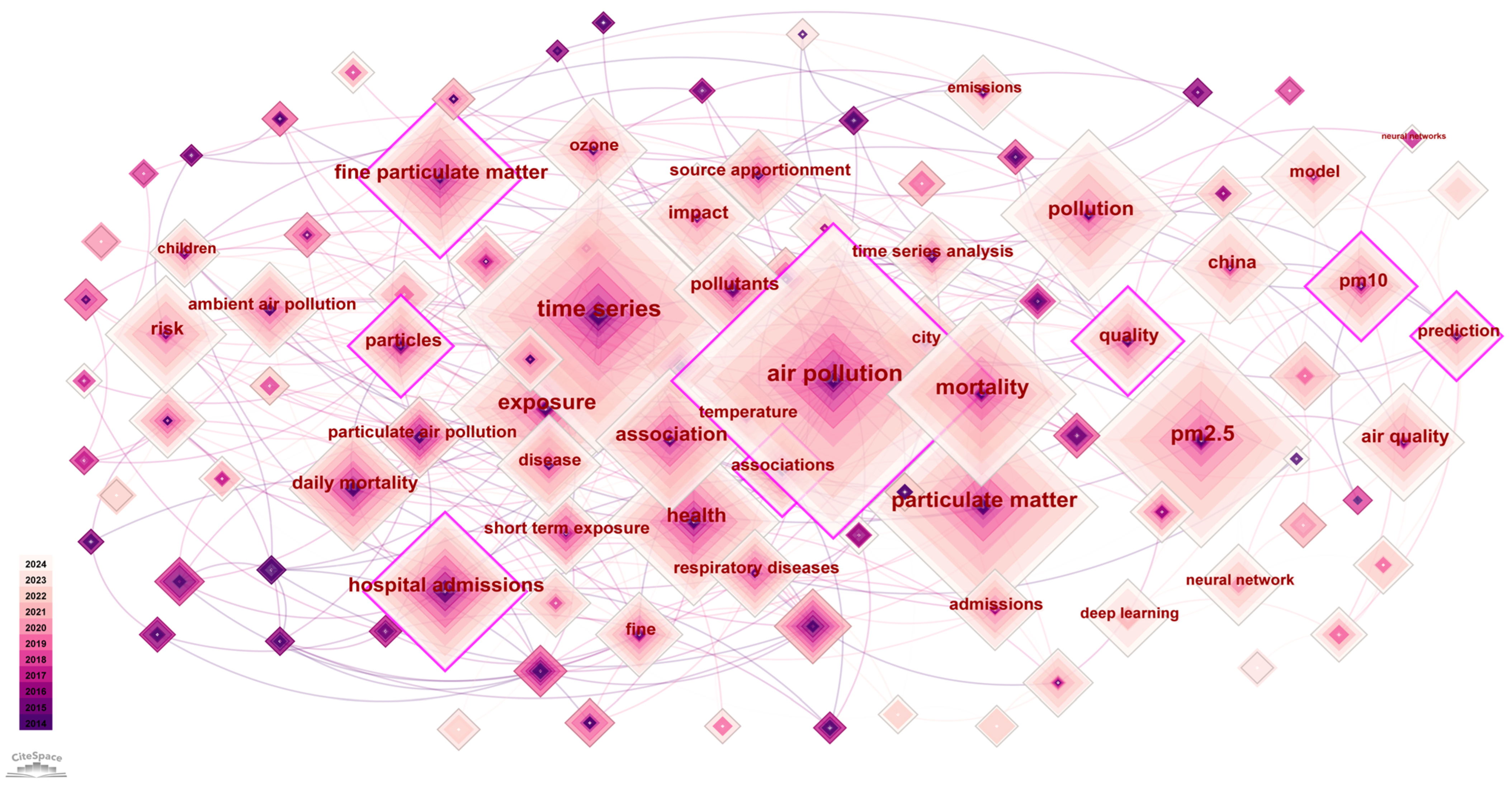
2.3. Keyword Co-Occurrence Analysis
2.4. Mutant Terms
2.5. Clustering Timeline Mapping
3. Fundamentals of PM2.5 Forecasting and Data Characteristics
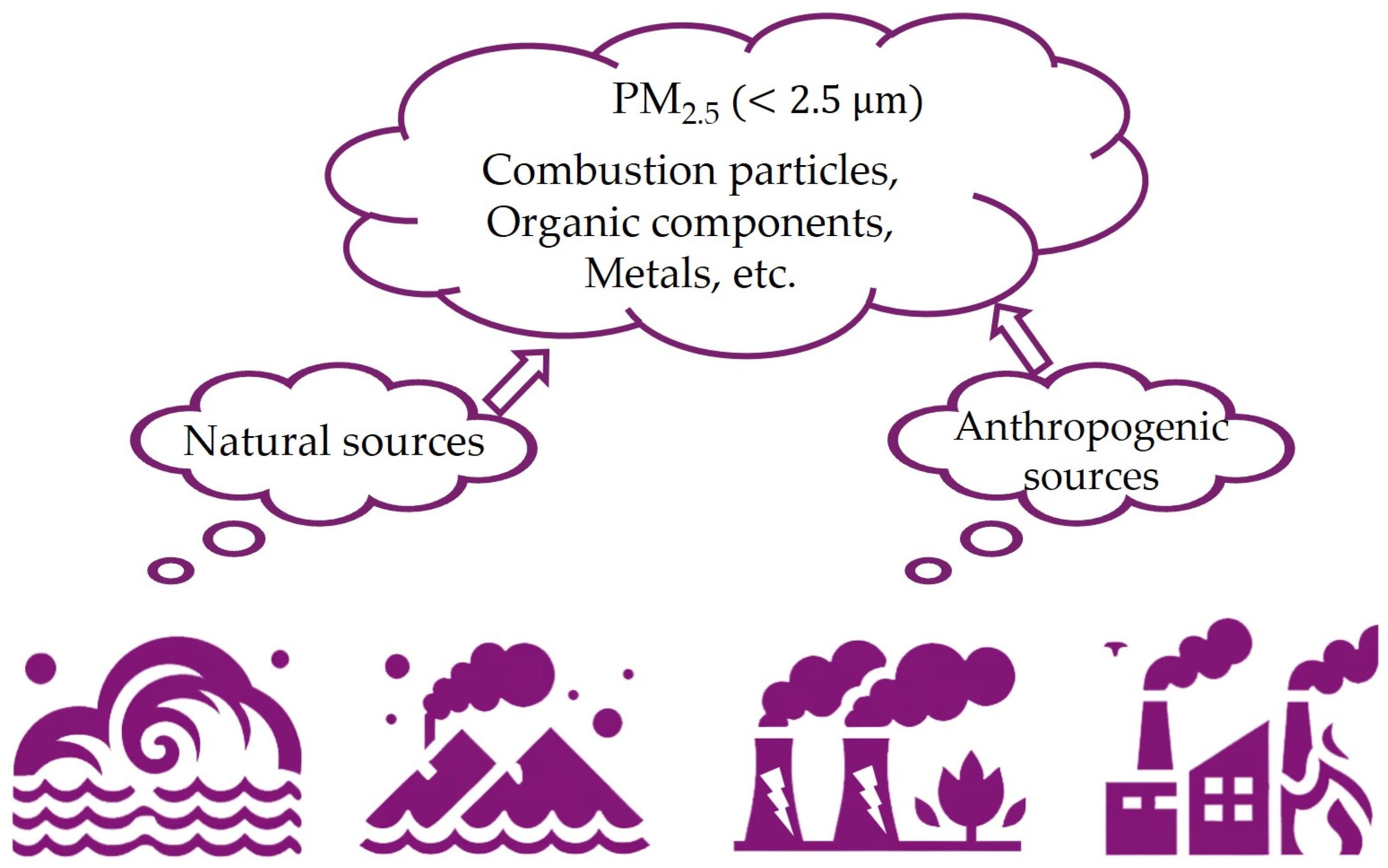
3.1. Physical and Chemical Properties and Formation Mechanism of PM2.5
3.2. Data Types and Sources
3.2.1. Ground-Based Monitoring Data
- China
- United States
- Australia
- Republic of Korea
- Italy
3.2.2. Meteorological Data
- China
- United States
- Australia
- Republic of Korea
- Italy
3.2.3. Reanalysis Data
- ERA5 (European Centre for Medium-Range Weather Forecasts, ECMWF)
- MERRA-2 (NASA)
- JRA-55 (Japan Meteorological Agency)
- NCEP/NCAR Reanalysis and CFSR (NOAA)
3.2.4. Remote Sensing Data
- NASA and U.S.-Based Platforms
- European Platforms and ESA
- NOAA and Other International Platforms
- Google Earth Engine
3.2.5. Socioeconomic and Anthropogenic Activity Data
- Traffic Data
- Industrial Emissions and Energy Consumption
- Population and Land Use/Land Cover Data
3.3. Data Quality and Preprocessing
3.3.1. Missing Data Imputation
3.3.2. Outlier and Noise Detection
3.3.3. Denoising and Stationarity Transformation
3.3.4. Feature Engineering and Normalization
3.4. Common Evaluation Metrics in Prediction Tasks
- Mean Squared Error
- 2.
- Root Mean Squared Error
- 3.
- Mean Absolute Error
- 4.
- Mean Absolute Percentage Error
- 5.
- Coefficient of Determination ()
4. Deep Learning for PM2.5 Time Series Forecasting
4.1. RNN and Its Improvements (LSTM, GRU)
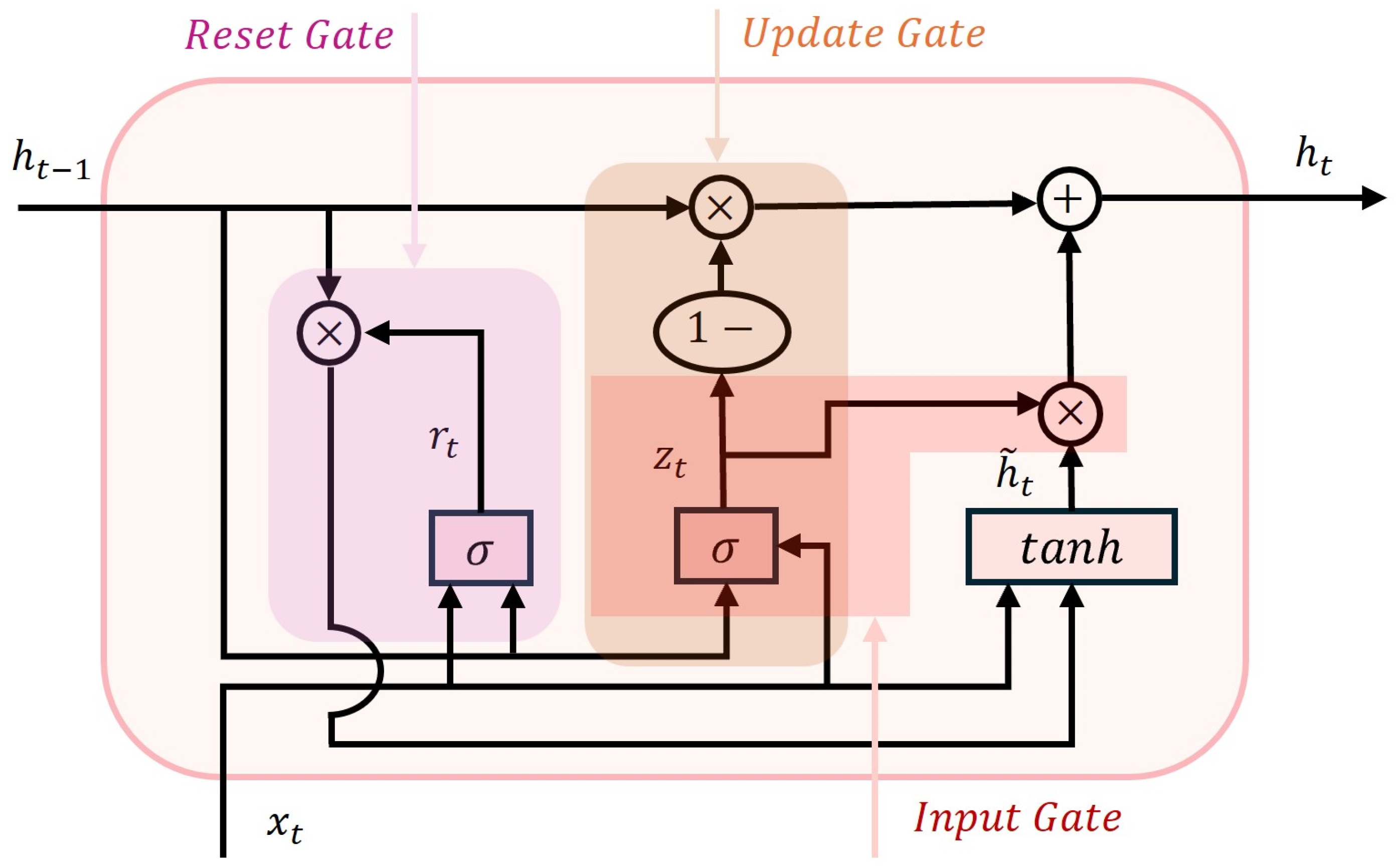
4.1.1. Model Structure and Principle Description (RNN, LSTM, and GRU)
4.1.2. Research Cases (RNN, LSTM, and GRU)
4.2. CNN and Their Hybrid Structures
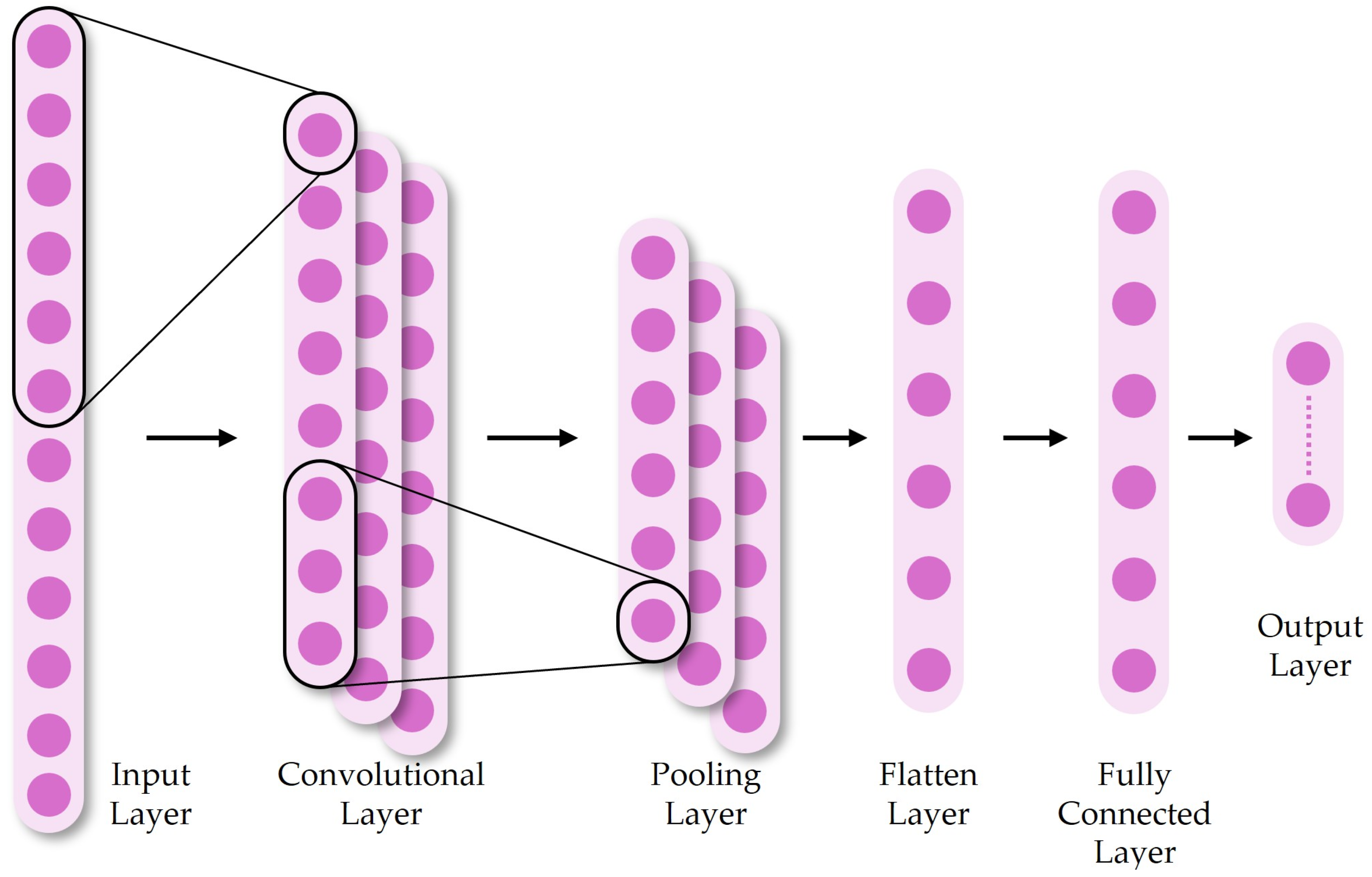
4.2.1. Model Structure and Principle Description (CNN)
4.2.2. Research Cases (CNN and Their Hybrid Structures)
4.3. Temporal Convolutional Network (TCN)
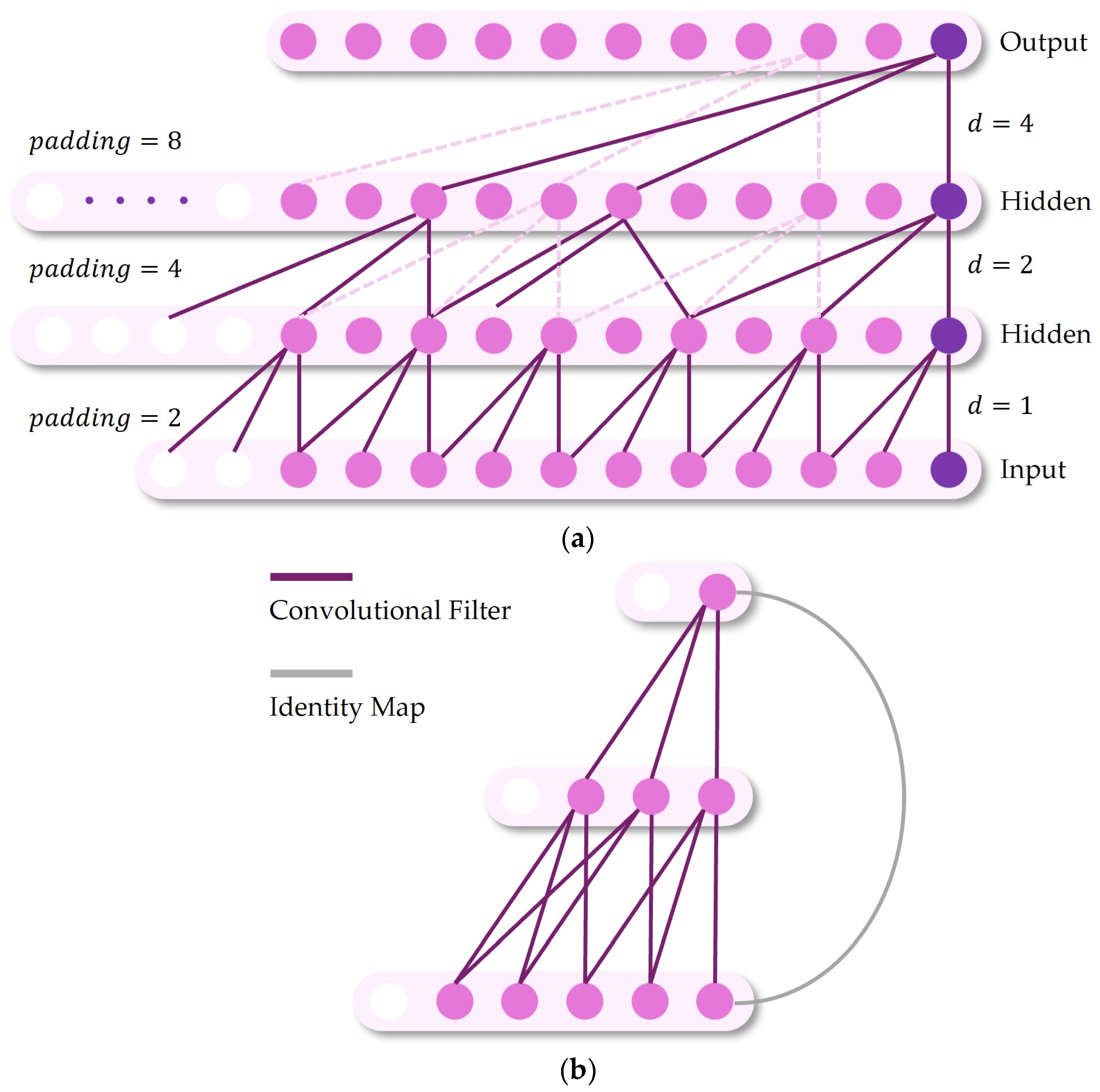
4.3.1. Model Structure and Principle Description (TCN)
4.3.2. Specific Research Cases (TCN)
4.4. Transformer and Attention Mechanism
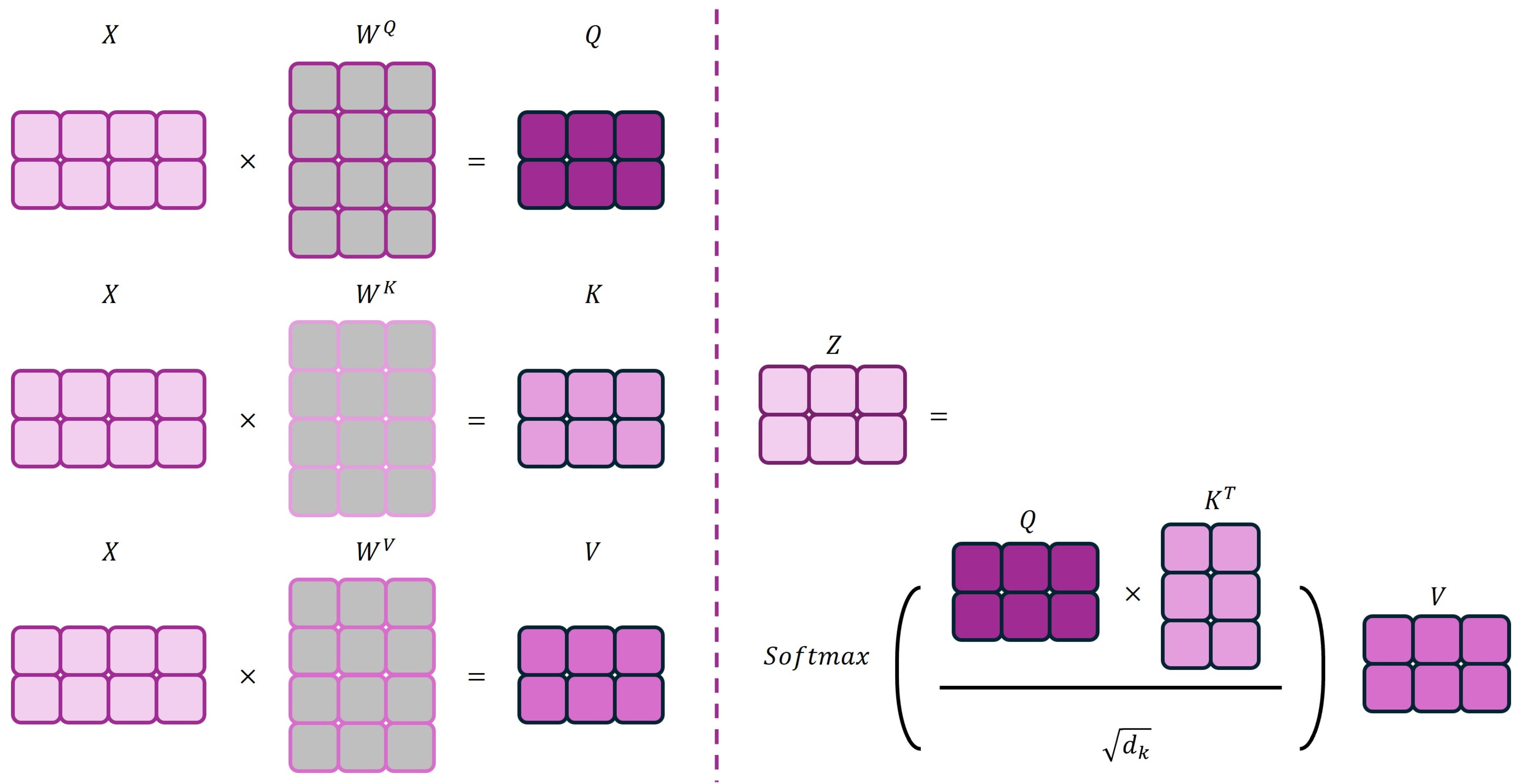
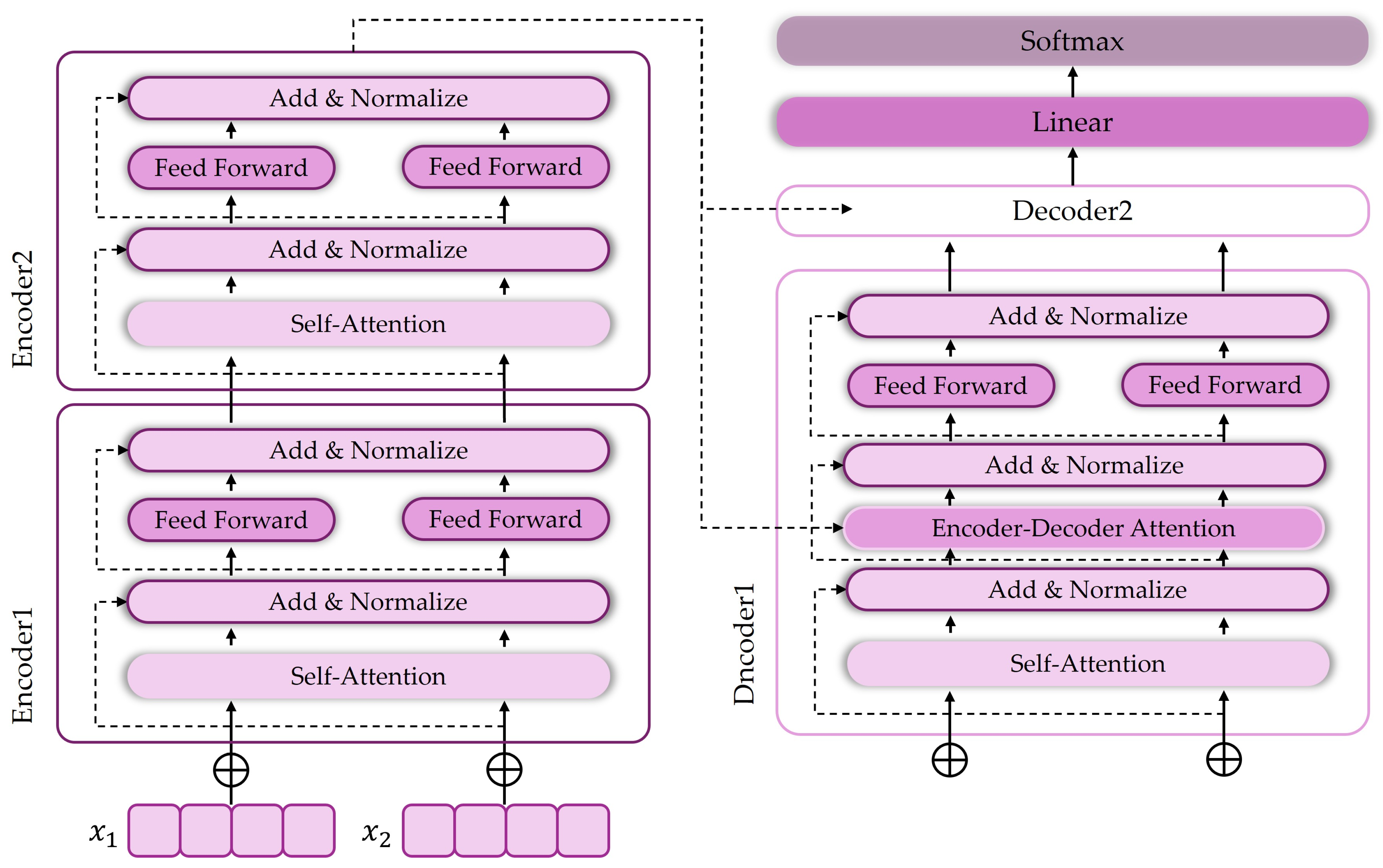
4.4.1. Model Structure and Principle Description (Transformer)
4.4.2. Research Cases (Transformer)
5. Discussion and Future Directions
5.1. Research Status and Main Findings
5.2. Existing Problems and Limitations
5.3. Future Research Directions and Development Trends
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mokhtar, S.B.; Viljoen, J.; van der Kallen, C.J.; Berendschot, T.T.; Dagnelie, P.C.; Albers, J.D.; Soeterboek, J.; Scarpa, F.; Colonna, A.; van der Heide, F.C. Greater exposure to PM2.5 and PM10 was associated with lower corneal nerve measures: The Maastricht study-a cross-sectional study. Environ. Health 2024, 23, 70. [Google Scholar] [CrossRef] [PubMed]
- Zheng, T.; Wang, Y.; Zhou, Z.; Chen, S.; Jiang, J.; Chen, S. PM2.5 Causes Increased Bacterial Invasion by Affecting HBD1 Expression in the Lung. J. Immunol. Res. 2024, 2024, 6622950. [Google Scholar] [CrossRef]
- Qiao, H.; Xue, W.T.; Li, L.; Fan, Y.; Xiao, L.; Guo, M.M. Atmospheric Particulate Matter 2.5 (PM2.5) Induces Cell Damage and Pruritus in Human Skin. Biomed. Environ. Sci. 2024, 37, 216–220. [Google Scholar]
- Li, M.; Tang, B.; Zheng, J.; Luo, W.; Xiong, S.; Ma, Y.; Ren, M.; Yu, Y.; Luo, X.; Mai, B. Typical organic contaminants in hair of adult residents between inland and coastal capital cities in China: Differences in levels and composition profiles, and potential impact factors. Sci. Total Environ. 2023, 869, 161559. [Google Scholar] [CrossRef] [PubMed]
- Min, K.B.; Min, J.Y. Association of Ambient Particulate Matter Exposure with the Incidence of Glaucoma in Childhood. Am. J. Ophthalmol. 2020, 211, 176–182. [Google Scholar] [CrossRef] [PubMed]
- Gan, T.; Bambrick, H.; Tong, S.L.; Hu, W.B. Air pollution and liver cancer: A systematic review. J. Environ. Sci. 2023, 126, 817–826. [Google Scholar] [CrossRef]
- Paik, K.; Na, J.-I.; Huh, C.-H.; Shin, J.-W. Particulate Matter and Its Molecular Effects on Skin: Implications for Various Skin Diseases. Int. J. Mol. Sci. 2024, 25, 9888. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Zhu, S.; Di, Y.; Pan, M.; Xie, W.; Li, X.; Zhu, W. Ambient PM2.5 components might exacerbate bone loss among middle-aged and elderly women: Evidence from a population-based cross-sectional study. Int. Arch. Occup. Environ. Health 2024, 97, 855–864. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Li, R.; Cai, M.; Wang, X.J.; Li, H.P.; Wu, Y.L.; Chen, L.; Zou, H.T.; Zhang, Z.L.; Li, H.T.; et al. Ambient air pollution, bone mineral density and osteoporosis: Results from a national population-based cohort study. Chemosphere 2023, 310, 8. [Google Scholar] [CrossRef]
- Jiang, R.; Qu, Q.; Wang, Z.; Luo, F.; Mou, S. Association between air pollution and bone mineral density: A Mendelian randomization study. Arch. Med. Sci. 2024, 20, 1334–1338. [Google Scholar] [CrossRef]
- Zhao, L.; Li, Z.; Qu, L. A novel machine learning-based artificial intelligence method for predicting the air pollution index PM2.5. J. Clean. Prod. 2024, 468, 143042. [Google Scholar] [CrossRef]
- Xiao, Y.-j.; Wang, X.-k.; Wang, J.-q.; Zhang, H.-y. An adaptive decomposition and ensemble model for short-term air pollutant concentration forecast using ICEEMDAN-ICA. Technol. Forecast. Soc. Change 2021, 166, 120655. [Google Scholar] [CrossRef]
- Liao, K.; Huang, X.; Dang, H.; Ren, Y.; Zuo, S.; Duan, C. Statistical Approaches for Forecasting Primary Air Pollutants: A Review. Atmosphere 2021, 12, 686. [Google Scholar] [CrossRef]
- Zhang, B.; Rong, Y.; Yong, R.; Qin, D.; Li, M.; Zou, G.; Pan, J. Deep learning for air pollutant concentration prediction: A review. Atmos. Environ. 2022, 290, 119347. [Google Scholar] [CrossRef]
- Su, J.G.; Meng, Y.-Y.; Chen, X.; Molitor, J.; Yue, D.; Jerrett, M. Predicting differential improvements in annual pollutant concentrations and exposures for regulatory policy assessment. Environ. Int. 2020, 143, 105942. [Google Scholar] [CrossRef] [PubMed]
- Wen, Q.; Zhang, T. Economic policy uncertainty and industrial pollution: The role of environmental supervision by local governments. China Econ. Rev. 2022, 71, 101723. [Google Scholar] [CrossRef]
- Yang, W.; Wang, J.; Zhang, K.; Hao, Y. A novel air pollution forecasting, health effects, and economic cost assessment system for environmental management: From a new perspective of the district-level. J. Clean. Prod. 2023, 417, 138027. [Google Scholar] [CrossRef]
- Wong, K.-S.; Chew, Y.J.; Ooi, S.Y.; Pang, Y.H. Toward forecasting future day air pollutant index in Malaysia. J. Supercomput. 2021, 77, 4813–4830. [Google Scholar] [CrossRef]
- Li, H.; Xu, X.-L.; Dai, D.-W.; Huang, Z.-Y.; Ma, Z.; Guan, Y.-J. Air pollution and temperature are associated with increased COVID-19 incidence: A time series study. Int. J. Infect. Dis. 2020, 97, 278–282. [Google Scholar] [CrossRef]
- Gu, J.; Shi, Y.; Zhu, Y.; Chen, N.; Wang, H.; Zhang, Z.; Chen, T. Ambient air pollution and cause-specific risk of hospital admission in China: A nationwide time-series study. PLoS Med. 2020, 17, e1003188. [Google Scholar] [CrossRef] [PubMed]
- Moshammer, H.; Poteser, M.; Hutter, H.-P. COVID-19 and air pollution in Vienna—A time series approach. Wien. Klin. Wochenschr. 2021, 133, 951–957. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Lee, J.-T. Inter-mortality displacement hypothesis and short-term effect of ambient air pollution on mortality in seven major cities of South Korea: A time-series analysis. Int. J. Epidemiol. 2020, 49, 1802–1812. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; Liu, P.; Zhao, X.; He, X.; Liu, J.; Mu, Y. Responses of surface O3 and PM2.5 trends to changes of anthropogenic emissions in summer over Beijing during 2014–2019: A study based on multiple linear regression and WRF-Chem. Sci. Total Environ. 2022, 807, 150792. [Google Scholar] [CrossRef]
- Wong, P.-Y.; Lee, H.-Y.; Chen, Y.-C.; Zeng, Y.-T.; Chern, Y.-R.; Chen, N.-T.; Candice Lung, S.-C.; Su, H.-J.; Wu, C.-D. Using a land use regression model with machine learning to estimate ground level PM2.5. Environ. Pollut. 2021, 277, 116846. [Google Scholar] [CrossRef] [PubMed]
- Kumar, V.; Sahu, M. Evaluation of nine machine learning regression algorithms for calibration of low-cost PM2.5 sensor. J. Aerosol Sci. 2021, 157, 105809. [Google Scholar] [CrossRef]
- Zhang, P.; Ma, W.; Wen, F.; Liu, L.; Yang, L.; Song, J.; Wang, N.; Liu, Q. Estimating PM2.5 concentration using the machine learning GA-SVM method to improve the land use regression model in Shaanxi, China. Ecotoxicol. Environ. Saf. 2021, 225, 112772. [Google Scholar] [CrossRef]
- Ibrir, A.; Kerchich, Y.; Hadidi, N.; Merabet, H.; Hentabli, M. Prediction of the concentrations of PM1, PM2.5, PM4, and PM10 by using the hybrid dragonfly-SVM algorithm. Air Qual. Atmos. Health 2021, 14, 313–323. [Google Scholar] [CrossRef]
- Lai, X.; Li, H.; Pan, Y. A combined model based on feature selection and support vector machine for PM2.5 prediction. J. Intell. Fuzzy Syst. 2021, 40, 10099–10113. [Google Scholar] [CrossRef]
- Sethi, J.K.; Mittal, M. Efficient weighted naive bayes classifiers to predict air quality index. Earth Sci. Inform. 2022, 15, 541–552. [Google Scholar] [CrossRef]
- Apriani, N.F.; Salampessy, J.E.B.; Kusumadewi, S.; Rizky, R.R.; Siagian, A.H.A.M.; Siahaan, F.B.; Riyanto, S.; Sriyadi; Irfiani, E. Classification and Forecasting Air Pollution Using Naive Bayes and Prophet: A Use Case of Air Quality Index in Jakarta. In Proceedings of the 2024 International Conference on Computer, Control, Informatics and its Applications (IC3INA), Bandung, Indonesia, 9–10 October 2024; pp. 279–284. [Google Scholar]
- Merdani, A. Comparative Machine Learning Analysis of PM25 and PM10 Forecasting in Albania. In Proceedings of the 2024 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Croatia, Balkans, 26–28 September 2024; pp. 1–7. [Google Scholar]
- Guo, B.; Zhang, D.; Pei, L.; Su, Y.; Wang, X.; Bian, Y.; Zhang, D.; Yao, W.; Zhou, Z.; Guo, L. Estimating PM2.5 concentrations via random forest method using satellite, auxiliary, and ground-level station dataset at multiple temporal scales across China in 2017. Sci. Total Environ. 2021, 778, 146288. [Google Scholar] [CrossRef]
- Su, Z.; Lin, L.; Chen, Y.; Hu, H. Understanding the distribution and drivers of PM2.5 concentrations in the Yangtze River Delta from 2015 to 2020 using Random Forest Regression. Environ. Monit. Assess. 2022, 194, 284. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhai, S.; Huang, J.; Li, X.; Wang, W.; Zhang, T.; Yin, F.; Ma, Y. Estimating high-resolution PM2.5 concentration in the Sichuan Basin using a random forest model with data-driven spatial autocorrelation terms. J. Clean. Prod. 2022, 380, 134890. [Google Scholar] [CrossRef]
- Zhang, T.; He, W.; Zheng, H.; Cui, Y.; Song, H.; Fu, S. Satellite-based ground PM2.5 estimation using a gradient boosting decision tree. Chemosphere 2021, 268, 128801. [Google Scholar] [CrossRef]
- Liu, M.; Chen, H.; Wei, D.; Wu, Y.; Li, C. Nonlinear relationship between urban form and street-level PM2.5 and CO based on mobile measurements and gradient boosting decision tree models. Build. Environ. 2021, 205, 108265. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, X.; Wu, Y. A spatiotemporal XGBoost model for PM2.5 concentration prediction and its application in Shanghai. Heliyon 2023, 9, e22569. [Google Scholar] [CrossRef]
- Jeong, J.I.; Park, R.J.; Yeh, S.-W.; Roh, J.-W. Statistical predictability of wintertime PM2.5 concentrations over East Asia using simple linear regression. Sci. Total Environ. 2021, 776, 146059. [Google Scholar] [CrossRef]
- Gong, H.; Guo, J.; Mu, Y.; Guo, Y.; Hu, T.; Li, S.; Luo, T.; Sun, Y. Atmospheric PM2.5 Prediction Model Based on Principal Component Analysis and SSA–SVM. Sustainability 2024, 16, 832. [Google Scholar] [CrossRef]
- Tella, A.; Balogun, A.-L.; Adebisi, N.; Abdullah, S. Spatial assessment of PM10 hotspots using Random Forest, K-Nearest Neighbour and Naïve Bayes. Atmos. Pollut. Res. 2021, 12, 101202. [Google Scholar] [CrossRef]
- Chen, C.-C.; Wang, Y.-R.; Yeh, H.-Y.; Lin, T.-H.; Huang, C.-S.; Wu, C.-F. Estimating monthly PM2.5 concentrations from satellite remote sensing data, meteorological variables, and land use data using ensemble statistical modeling and a random forest approach. Environ. Pollut. 2021, 291, 118159. [Google Scholar] [CrossRef]
- He, W.; Meng, H.; Han, J.; Zhou, G.; Zheng, H.; Zhang, S. Spatiotemporal PM2.5 estimations in China from 2015 to 2020 using an improved gradient boosting decision tree. Chemosphere 2022, 296, 134003. [Google Scholar] [CrossRef] [PubMed]
- Unik, M.; Sitanggang, I.S.; Syaufina, L.; Jaya, I.N.S. PM2.5 estimation using machine learning models and satellite data: A literature review. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 359–370. [Google Scholar] [CrossRef]
- Torres, J.F.; Hadjout, D.; Sebaa, A.; Martínez-Álvarez, F.; Troncoso, A. Deep Learning for Time Series Forecasting: A Survey. Big Data 2020, 9, 3–21. [Google Scholar] [CrossRef]
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A 2021, 379, 20200209. [Google Scholar] [CrossRef]
- Park, Y.; Kwon, B.; Heo, J.; Hu, X.; Liu, Y.; Moon, T. Estimating PM2.5 concentration of the conterminous United States via interpretable convolutional neural networks. Environ. Pollut. 2020, 256, 113395. [Google Scholar] [CrossRef] [PubMed]
- Xia, S.; Zhang, R.; Zhang, L.; Wang, T.; Wang, W. Multi-dimensional distribution prediction of PM2.5 concentration in urban residential areas based on CNN. Build. Environ. 2025, 267, 112167. [Google Scholar] [CrossRef]
- Kow, P.-Y.; Wang, Y.-S.; Zhou, Y.; Kao, I.F.; Issermann, M.; Chang, L.-C.; Chang, F.-J. Seamless integration of convolutional and back-propagation neural networks for regional multi-step-ahead PM2.5 forecasting. J. Clean. Prod. 2020, 261, 121285. [Google Scholar] [CrossRef]
- Dai, X.; Liu, J.; Li, Y. A recurrent neural network using historical data to predict time series indoor PM2.5 concentrations for residential buildings. Indoor Air 2021, 31, 1228–1237. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Yan, S.; Li, J.; Li, Y.; Lang, J.; Qu, G. A Spatiotemporal Recurrent Neural Network for Prediction of Atmospheric PM2.5: A Case Study of Beijing. IEEE Trans. Comput. Soc. Syst. 2021, 8, 578–588. [Google Scholar] [CrossRef]
- Xie, N.; Li, B. PM2.5 Monitoring and Prediction Based on IOT and RNN Neural Network. In Proceedings of the Artificial Intelligence Security and Privacy, Singapore, 6–7 December 2024; pp. 241–253. [Google Scholar]
- Gao, X.; Li, W. A graph-based LSTM model for PM2.5 forecasting. Atmos. Pollut. Res. 2021, 12, 101150. [Google Scholar] [CrossRef]
- Kristiani, E.; Lin, H.; Lin, J.-R.; Chuang, Y.-H.; Huang, C.-Y.; Yang, C.-T. Short-Term Prediction of PM2.5 Using LSTM Deep Learning Methods. Sustainability 2022, 14, 2068. [Google Scholar] [CrossRef]
- Lin, M.-D.; Liu, P.-Y.; Huang, C.-W.; Lin, Y.-H. The application of strategy based on LSTM for the short-term prediction of PM2.5 in city. Sci. Total Environ. 2024, 906, 167892. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Li, X.; Zhang, B.; Ren, J. PM2.5 concentration forecasting at surface monitoring sites using GRU neural network based on empirical mode decomposition. Sci. Total Environ. 2021, 768, 144516. [Google Scholar] [CrossRef] [PubMed]
- Qing, L. PM2.5 Concentration Prediction Using GRA-GRU Network in Air Monitoring. Sustainability 2023, 15, 1973. [Google Scholar] [CrossRef]
- Jiang, W.; Li, S.; Xie, Z.; Chen, W.; Zhan, C. Short-term PM2.5 Forecasting with a Hybrid Model Based on Ensemble GRU Neural Network. In Proceedings of the 2020 IEEE 18th International Conference on Industrial Informatics (INDIN), Warwick, UK, 20–23 July 2020; pp. 729–733. [Google Scholar]
- Yu, M.; Masrur, A.; Blaszczak-Boxe, C. Predicting hourly PM2.5 concentrations in wildfire-prone areas using a SpatioTemporal Transformer model. Sci. Total Environ. 2023, 860, 160446. [Google Scholar] [CrossRef]
- Cui, B.; Liu, M.; Li, S.; Jin, Z.; Zeng, Y.; Lin, X. Deep learning methods for atmospheric PM2.5 prediction: A comparative study of transformer and CNN-LSTM-attention. Atmos. Pollut. Res. 2023, 14, 101833. [Google Scholar] [CrossRef]
- Dai, Z.; Ren, G.; Jin, Y.; Zhang, J. Research on PM2.5 concentration prediction based on transformer. J. Phys. Conf. Ser. 2024, 2813, 012023. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, H.; Qin, Z.; Zhang, G. A novel hybrid-Garch model based on ARIMA and SVM for PM2.5 concentrations forecasting. Atmos. Pollut. Res. 2017, 8, 850–860. [Google Scholar] [CrossRef]
- Pakrooh, P.; Pishbahar, E. Forecasting Air Pollution Concentrations in Iran, Using a Hybrid Model. Pollution 2019, 5, 739–747. [Google Scholar] [CrossRef]
- Liu, B.; Jin, Y.; Li, C. Analysis and prediction of air quality in Nanjing from autumn 2018 to summer 2019 using PCR–SVR–ARMA combined model. Sci. Rep. 2021, 11, 348. [Google Scholar] [CrossRef] [PubMed]
- Shahriar, S.A.; Kayes, I.; Hasan, K.; Hasan, M.; Islam, R.; Awang, N.R.; Hamzah, Z.; Rak, A.E.; Salam, M.A. Potential of ARIMA-ANN, ARIMA-SVM, DT and CatBoost for Atmospheric PM2.5 Forecasting in Bangladesh. Atmosphere 2021, 12, 100. [Google Scholar] [CrossRef]
- Chen, C. CiteSpace: A Practical Guide for Mapping Scientific Literature; Nova Science Publishers: Hauppauge, NY, USA, 2016. [Google Scholar]
- Tucker, W.G. An overview of PM2.5 sources and control strategies. Fuel Process. Technol. 2000, 65–66, 379–392. [Google Scholar] [CrossRef]
- Lim, C.-H.; Ryu, J.; Choi, Y.; Jeon, S.W.; Lee, W.-K. Understanding global PM2.5 concentrations and their drivers in recent decades (1998–2016). Environ. Int. 2020, 144, 106011. [Google Scholar] [CrossRef]
- Burke, M.; Childs, M.L.; de la Cuesta, B.; Qiu, M.; Li, J.; Gould, C.F.; Heft-Neal, S.; Wara, M. The contribution of wildfire to PM2.5 trends in the USA. Nature 2023, 622, 761–766. [Google Scholar] [CrossRef] [PubMed]
- Geng, G.; Xiao, Q.; Liu, S.; Liu, X.; Cheng, J.; Zheng, Y.; Xue, T.; Tong, D.; Zheng, B.; Peng, Y.; et al. Tracking Air Pollution in China: Near Real-Time PM2.5 Retrievals from Multisource Data Fusion. Environ. Sci. Technol. 2021, 55, 12106–12115. [Google Scholar] [CrossRef]
- Pan, S.; Qiu, Y.; Li, M.; Yang, Z.; Liang, D. Recent Developments in the Determination of PM2.5 Chemical Composition. Bull. Environ. Contam. Toxicol. 2022, 108, 819–823. [Google Scholar] [CrossRef]
- Alves, C.; Evtyugina, M.; Vicente, E.; Vicente, A.; Rienda, I.C.; de la Campa, A.S.; Tomé, M.; Duarte, I. PM2.5 chemical composition and health risks by inhalation near a chemical complex. J. Environ. Sci. 2023, 124, 860–874. [Google Scholar] [CrossRef] [PubMed]
- Sidwell, A.; Smith, S.C.; Roper, C. A comparison of fine particulate matter (PM2.5) in vivo exposure studies incorporating chemical analysis. J. Toxicol. Environ. Health Part B 2022, 25, 422–444. [Google Scholar] [CrossRef]
- Kim, N.K.; Kim, Y.P.; Ghim, Y.S.; Song, M.J.; Kim, C.H.; Jang, K.S.; Lee, K.Y.; Shin, H.J.; Jung, J.S.; Wu, Z.; et al. Spatial distribution of PM2.5 chemical components during winter at five sites in Northeast Asia: High temporal resolution measurement study. Atmos. Environ. 2022, 290, 119359. [Google Scholar] [CrossRef]
- Xie, Y.; Zhou, M.; Hunt, K.M.R.; Mauzerall, D.L. Recent PM2.5 air quality improvements in India benefited from meteorological variation. Nat. Sustain. 2024, 7, 983–993. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, H.; Liang, D. Spatiotemporal variations and connections of single and multiple meteorological factors on PM2.5 concentrations in Xi’an, China. Atmos. Environ. 2022, 275, 119015. [Google Scholar] [CrossRef]
- Lu, X.; Yuan, D.; Chen, Y.; Fung, J.C.H. Impacts of urbanization and long-term meteorological variations on global PM2.5 and its associated health burden. Environ. Pollut. 2021, 270, 116003. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Dong, X.; Kong, Z.; Dong, K. Does national air quality monitoring reduce local air pollution? The case of PM2.5 for China. J. Environ. Manag. 2021, 296, 113232. [Google Scholar] [CrossRef]
- Liu, S.; Geng, G.; Xiao, Q.; Zheng, Y.; Liu, X.; Cheng, J.; Zhang, Q. Tracking Daily Concentrations of PM2.5 Chemical Composition in China since 2000. Environ. Sci. Technol. 2022, 56, 16517–16527. [Google Scholar] [CrossRef]
- Zhang, Q.; Zheng, Y.; Tong, D.; Shao, M.; Wang, S.; Zhang, Y.; Xu, X.; Wang, J.; He, H.; Liu, W.; et al. Drivers of improved PM2.5 air quality in China from 2013 to 2017. Proc. Natl. Acad. Sci. USA 2019, 116, 24463–24469. [Google Scholar] [CrossRef] [PubMed]
- Solomon, P.A.; Crumpler, D.; Flanagan, J.B.; Jayanty, R.K.M.; Rickman, E.E.; McDade, C.E. U.S. National PM2.5 Chemical Speciation Monitoring Networks—CSN and IMPROVE: Description of networks. J. Air Waste Manag. Assoc. 2014, 64, 1410–1438. [Google Scholar] [CrossRef]
- Heo, J.; Adams, P.J.; Gao, H.O. Public Health Costs of Primary PM2.5 and Inorganic PM2.5 Precursor Emissions in the United States. Environ. Sci. Technol. 2016, 50, 6061–6070. [Google Scholar] [CrossRef]
- Nazarenko, Y.; Pal, D.; Ariya, P.A. Air quality standards for the concentration of particulate matter 2.5, global descriptive analysis. Bull World Health Organ 2021, 99, 125–137d. [Google Scholar] [CrossRef] [PubMed]
- Bailie, C.R.; Ghosh, J.K.C.; Kirk, M.D.; Sullivan, S.G. Effect of ambient PM2.5 on healthcare utilisation for acute respiratory illness, Melbourne, Victoria, Australia, 2014-2019. J. Air Waste Manag. Assoc. 2023, 73, 120–132. [Google Scholar] [CrossRef]
- Chang, L.T.-C.; Scorgie, Y.; Duc, H.N.; Monk, K.; Fuchs, D.; Trieu, T. Major Source Contributions to Ambient PM2.5 and Exposures within the New South Wales Greater Metropolitan Region. Atmosphere 2019, 10, 138. [Google Scholar] [CrossRef]
- Danesi, N.; Jain, M.; Lee, Y.H.; Dev, S. Predicting Ground-based PM2.5 Concentration in Queensland, Australia. In Proceedings of the 2021 Photonics & Electromagnetics Research Symposium (PIERS), Hangzhou, China, 21–25 November 2021; pp. 1183–1190. [Google Scholar]
- Dong, T.T.T.; Stock, W.D.; Callan, A.C.; Strandberg, B.; Hinwood, A.L. Emission factors and composition of PM2.5 from laboratory combustion of five Western Australian vegetation types. Sci. Total Environ. 2020, 703, 134796. [Google Scholar] [CrossRef]
- Johnston, F.H.; Borchers-Arriagada, N.; Morgan, G.G.; Jalaludin, B.; Palmer, A.J.; Williamson, G.J.; Bowman, D.M.J.S. Unprecedented health costs of smoke-related PM2.5 from the 2019–2020 Australian megafires. Nat. Sustain. 2021, 4, 42–47. [Google Scholar] [CrossRef]
- Kumar, N.; Park, R.J.; Jeong, J.I.; Woo, J.-H.; Kim, Y.; Johnson, J.; Yarwood, G.; Kang, S.; Chun, S.; Knipping, E. Contributions of international sources to PM2.5 in South Korea. Atmos. Environ. 2021, 261, 118542. [Google Scholar] [CrossRef]
- Kumar, N.; Johnson, J.; Yarwood, G.; Woo, J.-H.; Kim, Y.; Park, R.J.; Jeong, J.I.; Kang, S.; Chun, S.; Knipping, E. Contributions of domestic sources to PM2.5 in South Korea. Atmos. Environ. 2022, 287, 119273. [Google Scholar] [CrossRef]
- Lee, H.-M.; Kim, N.K.; Ahn, J.; Park, S.-M.; Lee, J.Y.; Kim, Y.P. When and why PM2.5 is high in Seoul, South Korea: Interpreting long-term (2015–2021) ground observations using machine learning and a chemical transport model. Sci. Total Environ. 2024, 920, 170822. [Google Scholar] [CrossRef]
- Cesari, D.; De Benedetto, G.E.; Bonasoni, P.; Busetto, M.; Dinoi, A.; Merico, E.; Chirizzi, D.; Cristofanelli, P.; Donateo, A.; Grasso, F.M.; et al. Seasonal variability of PM2.5 and PM10 composition and sources in an urban background site in Southern Italy. Sci. Total Environ. 2018, 612, 202–213. [Google Scholar] [CrossRef]
- Ciucci, A.; D’Elia, I.; Wagner, F.; Sander, R.; Ciancarella, L.; Zanini, G.; Schöpp, W. Cost-effective reductions of PM2.5 concentrations and exposure in Italy. Atmos. Environ. 2016, 140, 84–93. [Google Scholar] [CrossRef]
- Stafoggia, M.; Bellander, T.; Bucci, S.; Davoli, M.; de Hoogh, K.; de’ Donato, F.; Gariazzo, C.; Lyapustin, A.; Michelozzi, P.; Renzi, M.; et al. Estimation of daily PM10 and PM2.5 concentrations in Italy, 2013–2015, using a spatiotemporal land-use random-forest model. Environ. Int. 2019, 124, 170–179. [Google Scholar] [CrossRef]
- Peng, S.; Ding, Y.; Liu, W.; Li, Z. 1 km monthly temperature and precipitation dataset for China from 1901 to 2017. Earth Syst. Sci. Data 2019, 11, 1931–1946. [Google Scholar] [CrossRef]
- He, J.; Yang, K.; Tang, W.; Lu, H.; Qin, J.; Chen, Y.; Li, X. The first high-resolution meteorological forcing dataset for land process studies over China. Sci. Data 2020, 7, 25. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Xu, X.; Ding, Y.; Liu, Y.; Zhang, H.; Wang, Y.; Zhong, J. The impact of meteorological changes from 2013 to 2017 on PM2.5 mass reduction in key regions in China. Sci. China Earth Sci. 2019, 62, 1885–1902. [Google Scholar] [CrossRef]
- Banzon, V.; Smith, T.M.; Chin, T.M.; Liu, C.; Hankins, W. A long-term record of blended satellite and in situ sea-surface temperature for climate monitoring, modeling and environmental studies. Earth Syst. Sci. Data 2016, 8, 165–176. [Google Scholar] [CrossRef]
- Young, A.M.; Skelly, K.T.; Cordeira, J.M. High-impact hydrologic events and atmospheric rivers in California: An investigation using the NCEI Storm Events Database. Geophys. Res. Lett. 2017, 44, 3393–3401. [Google Scholar] [CrossRef]
- Brewer, M.J.; Hollingshead, A.; Dissen, J.; Jones, N.; Webster, L.F. User Needs for Weather and Climate Information: 2019 NCEI Users’ Conference. Bull. Am. Meteorol. Soc. 2020, 101, E645–E649. [Google Scholar] [CrossRef]
- Su, C.H.; Eizenberg, N.; Steinle, P.; Jakob, D.; Fox-Hughes, P.; White, C.J.; Rennie, S.; Franklin, C.; Dharssi, I.; Zhu, H. BARRA v1.0: The Bureau of Meteorology Atmospheric high-resolution Regional Reanalysis for Australia. Geosci. Model Dev. 2019, 12, 2049–2068. [Google Scholar] [CrossRef]
- Hudson, D.; Alves, O.; Hendon, H.H.; Lim, E.-P.; Liu, G.; Luo, J.-J.; MacLachlan, C.; Marshall, A.G.; Shi, L.; Wang, G.; et al. ACCESS-S1 The new Bureau of Meteorology multi-week to seasonal prediction system. J. South. Hemisph. Earth Syst. Sci. 2017, 67, 132–159. [Google Scholar] [CrossRef]
- Park, M.S.; Park, S.H.; Chae, J.H.; Choi, M.H.; Song, Y.; Kang, M.; Roh, J.W. High-resolution urban observation network for user-specific meteorological information service in the Seoul Metropolitan Area, South Korea. Atmos. Meas. Tech. 2017, 10, 1575–1594. [Google Scholar] [CrossRef]
- Park, M.-S. Overview of Meteorological Surface Variables and Boundary-layer Structures in the Seoul Metropolitan Area during the MAPS-Seoul Campaign. Aerosol Air Qual. Res. 2018, 18, 2157–2172. [Google Scholar] [CrossRef]
- Hong, S.-Y.; Kwon, Y.C.; Kim, T.-H.; Esther Kim, J.-E.; Choi, S.-J.; Kwon, I.-H.; Kim, J.; Lee, E.-H.; Park, R.-S.; Kim, D.-I. The Korean Integrated Model (KIM) System for Global Weather Forecasting. Asia-Pac. J. Atmos. Sci. 2018, 54, 267–292. [Google Scholar] [CrossRef]
- Panagos, P.; Ballabio, C.; Borrelli, P.; Meusburger, K.; Klik, A.; Rousseva, S.; Tadić, M.P.; Michaelides, S.; Hrabalíková, M.; Olsen, P.; et al. Rainfall erosivity in Europe. Sci. Total Environ. 2015, 511, 801–814. [Google Scholar] [CrossRef] [PubMed]
- Fratianni, S.; Acquaotta, F. The Climate of Italy. In Landscapes and Landforms of Italy, Soldati, M., Marchetti, M., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 29–38. [Google Scholar]
- Squizzato, S.; Masiol, M. Application of meteorology-based methods to determine local and external contributions to particulate matter pollution: A case study in Venice (Italy). Atmos. Environ. 2015, 119, 69–81. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Soci, C.; Hersbach, H.; Simmons, A.; Poli, P.; Bell, B.; Berrisford, P.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Radu, R.; et al. The ERA5 global reanalysis from 1940 to 2022. Q. J. R. Meteorol. Soc. 2024, 150, 4014–4048. [Google Scholar] [CrossRef]
- Crossett, C.C.; Betts, A.K.; Dupigny-Giroux, L.-A.L.; Bomblies, A. Evaluation of Daily Precipitation from the ERA5 Global Reanalysis against GHCN Observations in the Northeastern United States. Climate 2020, 8, 148. [Google Scholar] [CrossRef]
- Gelaro, R.; McCarty, W.; Suárez, M.J.; Todling, R.; Molod, A.; Takacs, L.; Randles, C.A.; Darmenov, A.; Bosilovich, M.G.; Reichle, R.; et al. The Modern-Era Retrospective Analysis for Research and Applications, Version 2 (MERRA-2). J. Clim. 2017, 30, 5419–5454. [Google Scholar] [CrossRef]
- Draper, C.; Reichle, R.H. Assimilation of Satellite Soil Moisture for Improved Atmospheric Reanalyses. Mon. Weather Rev. 2019, 147, 2163–2188. [Google Scholar] [CrossRef]
- Cullather, R.I.; Nowicki, S.M.J. Greenland Ice Sheet Surface Melt and Its Relation to Daily Atmospheric Conditions. J. Clim. 2018, 31, 1897–1919. [Google Scholar] [CrossRef]
- Kobayashi, S.; Ota, Y.; Harada, Y.; Ebita, A.; Moriya, M.; Onoda, H.; Onogi, K.; Kamahori, H.; Kobayashi, C.; Endo, H.; et al. The JRA-55 Reanalysis: General Specifications and Basic Characteristics. J. Meteorol. Soc. Japan. Ser. II 2015, 93, 5–48. [Google Scholar] [CrossRef]
- Harada, Y.; Kamahori, H.; Kobayashi, C.; Endo, H.; Kobayashi, S.; Ota, Y.; Onoda, H.; Onogi, K.; Miyaoka, K.; Takahashi, K. The JRA-55 Reanalysis: Representation of Atmospheric Circulation and Climate Variability. J. Meteorol. Soc. Jpn. Ser. II 2016, 94, 269–302. [Google Scholar] [CrossRef]
- Kobayashi, C.; Iwasaki, T. Brewer-Dobson circulation diagnosed from JRA-55. J. Geophys. Res. Atmos. 2016, 121, 1493–1510. [Google Scholar] [CrossRef]
- Kalnay, E.; Kanamitsu, M.; Kistler, R.; Collins, W.; Deaven, D.; Gandin, L.; Iredell, M.; Saha, S.; White, G.; Woollen, J.; et al. The NCEP/NCAR 40-Year Reanalysis Project. Bull. Am. Meteorol. Soc. 1996, 77, 437–472. [Google Scholar] [CrossRef]
- Decker, M.; Brunke, M.A.; Wang, Z.; Sakaguchi, K.; Zeng, X.; Bosilovich, M.G. Evaluation of the Reanalysis Products from GSFC, NCEP, and ECMWF Using Flux Tower Observations. J. Clim. 2012, 25, 1916–1944. [Google Scholar] [CrossRef]
- Sharp, E.; Dodds, P.; Barrett, M.; Spataru, C. Evaluating the accuracy of CFSR reanalysis hourly wind speed forecasts for the UK, using in situ measurements and geographical information. Renew. Energy 2015, 77, 527–538. [Google Scholar] [CrossRef]
- Román, M.O.; Justice, C.; Paynter, I.; Boucher, P.B.; Devadiga, S.; Endsley, A.; Erb, A.; Friedl, M.; Gao, H.; Giglio, L.; et al. Continuity between NASA MODIS Collection 6.1 and VIIRS Collection 2 land products. Remote Sens. Environ. 2024, 302, 113963. [Google Scholar] [CrossRef]
- Levy, R.C.; Mattoo, S.; Sawyer, V.; Shi, Y.; Colarco, P.R.; Lyapustin, A.I.; Wang, Y.; Remer, L.A. Exploring systematic offsets between aerosol products from the two MODIS sensors. Atmos. Meas. Tech. 2018, 11, 4073–4092. [Google Scholar] [CrossRef]
- He, J.; Zha, Y.; Zhang, J.; Gao, J.; Wang, Q. Synergetic retrieval of terrestrial AOD from MODIS images of twin satellites Terra and Aqua. Adv. Space Res. 2014, 53, 1337–1346. [Google Scholar] [CrossRef]
- Wu, J.; Yao, F.; Li, W.; Si, M. VIIRS-based remote sensing estimation of ground-level PM2.5 concentrations in Beijing–Tianjin–Hebei: A spatiotemporal statistical model. Remote Sens. Environ. 2016, 184, 316–328. [Google Scholar] [CrossRef]
- Chen, Q.-X.; Han, X.-L.; Gu, Y.; Yuan, Y.; Jiang, J.H.; Yang, X.-B.; Liou, K.-N.; Tan, H.-P. Evaluation of MODIS, MISR, and VIIRS daily level-3 aerosol optical depth products over land. Atmos. Res. 2022, 265, 105810. [Google Scholar] [CrossRef]
- Yao, F.; Si, M.; Li, W.; Wu, J. A multidimensional comparison between MODIS and VIIRS AOD in estimating ground-level PM2.5 concentrations over a heavily polluted region in China. Sci. Total Environ. 2018, 618, 819–828. [Google Scholar] [CrossRef] [PubMed]
- Tariq, S.; Ali, M. Spatio–temporal distribution of absorbing aerosols over Pakistan retrieved from OMI onboard Aura satellite. Atmos. Pollut. Res. 2015, 6, 254–266. [Google Scholar] [CrossRef]
- Choi, S.; Joiner, J.; Choi, Y.; Duncan, B.N.; Vasilkov, A.; Krotkov, N.; Bucsela, E. First estimates of global free-tropospheric NO2 abundances derived using a cloud-slicing technique applied to satellite observations from the Aura Ozone Monitoring Instrument (OMI). Atmos. Chem. Phys. 2014, 14, 10565–10588. [Google Scholar] [CrossRef]
- Krotkov, N.A.; McLinden, C.A.; Li, C.; Lamsal, L.N.; Celarier, E.A.; Marchenko, S.V.; Swartz, W.H.; Bucsela, E.J.; Joiner, J.; Duncan, B.N.; et al. Aura OMI observations of regional SO2 and NO2 pollution changes from 2005 to 2015. Atmos. Chem. Phys. 2016, 16, 4605–4629. [Google Scholar] [CrossRef]
- Clerc, S.; Donlon, C.; Borde, F.; Lamquin, N.; Hunt, S.E.; Smith, D.; McMillan, M.; Mittaz, J.; Woolliams, E.; Hammond, M.; et al. Benefits and Lessons Learned from the Sentinel-3 Tandem Phase. Remote Sens. 2020, 12, 2668. [Google Scholar] [CrossRef]
- Quartly, G.D.; Nencioli, F.; Raynal, M.; Bonnefond, P.; Nilo Garcia, P.; Garcia-Mondéjar, A.; Flores de la Cruz, A.; Crétaux, J.-F.; Taburet, N.; Frery, M.-L.; et al. The Roles of the S3MPC: Monitoring, Validation and Evolution of Sentinel-3 Altimetry Observations. Remote Sens. 2020, 12, 1763. [Google Scholar] [CrossRef]
- Zheng, Z.; Yang, Z.; Wu, Z.; Marinello, F. Spatial Variation of NO2 and Its Impact Factors in China: An Application of Sentinel-5P Products. Remote Sens. 2019, 11, 1939. [Google Scholar] [CrossRef]
- Bodah, B.W.; Neckel, A.; Stolfo Maculan, L.; Milanes, C.B.; Korcelski, C.; Ramírez, O.; Mendez-Espinosa, J.F.; Bodah, E.T.; Oliveira, M.L.S. Sentinel-5P TROPOMI satellite application for NO2 and CO studies aiming at environmental valuation. J. Clean. Prod. 2022, 357, 131960. [Google Scholar] [CrossRef]
- Reshi, A.R.; Pichuka, S.; Tripathi, A. Applications of Sentinel-5P TROPOMI Satellite Sensor: A Review. IEEE Sens. J. 2024, 24, 20312–20321. [Google Scholar] [CrossRef]
- Peuch, V.-H.; Engelen, R.; Rixen, M.; Dee, D.; Flemming, J.; Suttie, M.; Ades, M.; Agustí-Panareda, A.; Ananasso, C.; Andersson, E.; et al. The Copernicus Atmosphere Monitoring Service: From Research to Operations. Bull. Am. Meteorol. Soc. 2022, 103, E2650–E2668. [Google Scholar] [CrossRef]
- Plummer, S.; Lecomte, P.; Doherty, M. The ESA Climate Change Initiative (CCI): A European contribution to the generation of the Global Climate Observing System. Remote Sens. Environ. 2017, 203, 2–8. [Google Scholar] [CrossRef]
- Klaes, K.D. A status update on EUMETSAT programmes and plans. Proc. SPIE 2017, 10402, 1040202. [Google Scholar]
- Hager, L.; Lemieux, P. Data Stewardship Maturity Report for NOAA JPSS Ozone Mapping and Profile Suite (OMPS) Nadir Total Column Science Sensor Data Record (SDR) from IDPS; National Oceanic and Atmospheric Administration: Washington, DC, USA, 2021. [Google Scholar] [CrossRef]
- Requia, W.J.; Higgins, C.D.; Adams, M.D.; Mohamed, M.; Koutrakis, P. The health impacts of weekday traffic: A health risk assessment of PM2.5 emissions during congested periods. Environ. Int. 2018, 111, 164–176. [Google Scholar] [CrossRef] [PubMed]
- Askariyeh, M.H.; Zietsman, J.; Autenrieth, R. Traffic contribution to PM2.5 increment in the near-road environment. Atmos. Environ. 2020, 224, 117113. [Google Scholar] [CrossRef]
- Chen, S.; Cui, K.; Yu, T.-Y.; Chao, H.-R.; Hsu, Y.-C.; Lu, I.C.; Arcega, R.D.; Tsai, M.-H.; Lin, S.-L.; Chao, W.-C.; et al. A Big Data Analysis of PM2.5 and PM10 from Low Cost Air Quality Sensors near Traffic Areas. Aerosol Air Qual. Res. 2019, 19, 1721–1733. [Google Scholar] [CrossRef]
- Mailloux, N.A.; Abel, D.W.; Holloway, T.; Patz, J.A. Nationwide and Regional PM2.5-Related Air Quality Health Benefits From the Removal of Energy-Related Emissions in the United States. GeoHealth 2022, 6, e2022GH000603. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, S.; Yao, J. Impacts of deregulation reform on PM2.5 concentrations: A case study of business registration reform in China. J. Clean. Prod. 2019, 235, 1138–1152. [Google Scholar] [CrossRef]
- Hendryx, M.; Islam, M.S.; Dong, G.-H.; Paul, G. Air Pollution Emissions 2008–2018 from Australian Coal Mining: Implications for Public and Occupational Health. Int. J. Environ. Res. Public Health 2020, 17, 1570. [Google Scholar] [CrossRef]
- Lee, S.-J.; Lee, H.-Y.; Kim, S.-J.; Kim, N.-K.; Jo, M.; Song, C.-K.; Kim, H.; Kang, H.-J.; Seo, Y.-K.; Shin, H.-J.; et al. Mapping the spatial distribution of primary and secondary PM2.5 in a multi-industrial city by combining monitoring and modeling results. Environ. Pollut. 2024, 348, 123774. [Google Scholar] [CrossRef] [PubMed]
- Perrino, C.; Gilardoni, S.; Landi, T.; Abita, A.; Ferrara, I.; Oliverio, S.; Busetto, M.; Calzolari, F.; Catrambone, M.; Cristofanelli, P.; et al. Air Quality Characterization at Three Industrial Areas in Southern Italy. Front. Environ. Sci. 2020, 7, e1700300. [Google Scholar] [CrossRef]
- Shen, H.; Tao, S.; Chen, Y.; Ciais, P.; Güneralp, B.; Ru, M.; Zhong, Q.; Yun, X.; Zhu, X.; Huang, T.; et al. Urbanization-induced population migration has reduced ambient PM2.5 concentrations in China. Sci. Adv. 2017, 3, e1700300. [Google Scholar] [CrossRef] [PubMed]
- Han, L.; Zhou, W.; Pickett, S.T.A.; Li, W.; Li, L. An optimum city size? The scaling relationship for urban population and fine particulate (PM2.5) concentration. Environ. Pollut. 2016, 208, 96–101. [Google Scholar] [CrossRef]
- Wang, L.; Wang, H.; Liu, J.; Gao, Z.; Yang, Y.; Zhang, X.; Li, Y.; Huang, M. Impacts of the near-surface urban boundary layer structure on PM2.5 concentrations in Beijing during winter. Sci. Total Environ. 2019, 669, 493–504. [Google Scholar] [CrossRef]
- Yang, H.; Chen, W.; Liang, Z. Impact of Land Use on PM2.5 Pollution in a Representative City of Middle China. Int. J. Environ. Res. Public Health 2017, 14, 462. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Liu, H.; Zhou, J.; Xia, M. GIS-Based Urban Afforestation Spatial Patterns and a Strategy for PM2.5 Removal. Forests 2019, 10, 875. [Google Scholar] [CrossRef]
- Guo, L.; Luo, J.; Yuan, M.; Huang, Y.; Shen, H.; Li, T. The influence of urban planning factors on PM2.5 pollution exposure and implications: A case study in China based on remote sensing, LBS, and GIS data. Sci. Total Environ. 2019, 659, 1585–1596. [Google Scholar] [CrossRef]
- Hadeed, S.J.; O’Rourke, M.K.; Burgess, J.L.; Harris, R.B.; Canales, R.A. Imputation methods for addressing missing data in short-term monitoring of air pollutants. Sci. Total Environ. 2020, 730, 139140. [Google Scholar] [CrossRef] [PubMed]
- Belachsen, I.; Broday, D.M. Imputation of Missing PM2.5 Observations in a Network of Air Quality Monitoring Stations by a New kNN Method. Atmosphere 2022, 13, 1934. [Google Scholar] [CrossRef]
- Yuan, H.; Xu, G.; Yao, Z.; Jia, J.; Zhang, Y. Imputation of Missing Data in Time Series for Air Pollutants Using Long Short-Term Memory Recurrent Neural Networks. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 1293–1300. [Google Scholar]
- Aslan, M.E.; Onut, S. Detection of Outliers and Extreme Events of Ground Level Particulate Matter Using DBSCAN Algorithm with Local Parameters. Water Air Soil Pollut. 2022, 233, 203. [Google Scholar] [CrossRef]
- Yin, Z.; Fang, X. An Outlier-Robust Point and Interval Forecasting System for Daily PM2.5 Concentration. Front. Environ. Sci. 2021, 9, 747101. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, H.; Zhu, J.; Ding, Z. Daily PM2.5 and PM10 forecasting using linear and nonlinear modeling framework based on robust local mean decomposition and moving window ensemble strategy. Appl. Soft Comput. 2022, 114, 108110. [Google Scholar] [CrossRef]
- Xing, G.; Zhao, E.-l.; Zhang, C.; Wu, J. A Decomposition-Ensemble Approach with Denoising Strategy for PM2.5 Concentration Forecasting. Discret. Dyn. Nat. Soc. 2021, 2021, 5577041. [Google Scholar] [CrossRef]
- Dong, L.; Hua, P.; Gui, D.; Zhang, J. Extraction of multi-scale features enhances the deep learning-based daily PM2.5 forecasting in cities. Chemosphere 2022, 308, 136252. [Google Scholar] [CrossRef] [PubMed]
- Kristiani, E.; Kuo, T.Y.; Yang, C.T.; Pai, K.C.; Huang, C.Y.; Nguyen, K.L.P. PM2.5 Forecasting Model Using a Combination of Deep Learning and Statistical Feature Selection. IEEE Access 2021, 9, 68573–68582. [Google Scholar] [CrossRef]
- Wang, J.; Wang, R.; Li, Z. A combined forecasting system based on multi-objective optimization and feature extraction strategy for hourly PM2.5 concentration. Appl. Soft Comput. 2022, 114, 108034. [Google Scholar] [CrossRef]
- Lee, Y.S.; Choi, E.; Park, M.; Jo, H.; Park, M.; Nam, E.; Kim, D.G.; Yi, S.-M.; Kim, J.Y. Feature extraction and prediction of fine particulate matter (PM2.5) chemical constituents using four machine learning models. Expert Syst. Appl. 2023, 221, 119696. [Google Scholar] [CrossRef]
- Luo, G.; Zhang, L.; Hu, X.; Qiu, R. Quantifying public health benefits of PM2.5 reduction and spatial distribution analysis in China. Sci. Total Environ. 2020, 719, 137445. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Wang, W.; Zhu, L.; Qiao, Q.; Kang, Y. Deep-learning architecture for PM2.5 concentration prediction: A review. Environ. Sci. Ecotechnol. 2024, 21, 100400. [Google Scholar] [CrossRef]
- Yin, L.; Wang, L.; Huang, W.; Tian, J.; Liu, S.; Yang, B.; Zheng, W. Haze Grading Using the Convolutional Neural Networks. Atmosphere 2022, 13, 522. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, J.; Zheng, W.; Yin, L. Spatial and temporal distribution characteristics of haze and pollution particles in China based on spatial statistics. Urban Clim. 2022, 41, 101031. [Google Scholar] [CrossRef]
- Chen, X.; Yin, L.; Fan, Y.; Song, L.; Ji, T.; Liu, Y.; Tian, J.; Zheng, W. Temporal evolution characteristics of PM2.5 concentration based on continuous wavelet transform. Sci. Total Environ. 2020, 699, 134244. [Google Scholar] [CrossRef]
- Tian, J.; Liu, Y.; Zheng, W.; Yin, L. Smog prediction based on the deep belief—BP neural network model (DBN-BP). Urban Clim. 2022, 41, 101078. [Google Scholar] [CrossRef]
- Wu, C.; Lu, S.; Tian, J.; Yin, L.; Wang, L.; Zheng, W. Current Situation and Prospect of Geospatial AI in Air Pollution Prediction. Atmosphere 2024, 15, 1411. [Google Scholar] [CrossRef]
- Chang-Hoi, H.; Park, I.; Oh, H.-R.; Gim, H.-J.; Hur, S.-K.; Kim, J.; Choi, D.-R. Development of a PM2.5 prediction model using a recurrent neural network algorithm for the Seoul metropolitan area, Republic of Korea. Atmos. Environ. 2021, 245, 118021. [Google Scholar] [CrossRef]
- Tsai, Y.T.; Zeng, Y.R.; Chang, Y.S. Air Pollution Forecasting Using RNN with LSTM. In Proceedings of the 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress(DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; pp. 1074–1079. [Google Scholar]
- Wu, X.; Liu, Z.; Yin, L.; Zheng, W.; Song, L.; Tian, J.; Yang, B.; Liu, S. A Haze Prediction Model in Chengdu Based on LSTM. Atmosphere 2021, 12, 1479. [Google Scholar] [CrossRef]
- Ho, C.-H.; Park, I.; Kim, J.; Lee, J.-B. PM2.5 Forecast in Korea using the Long Short-Term Memory (LSTM) Model. Asia-Pac. J. Atmos. Sci. 2023, 59, 563–576. [Google Scholar] [CrossRef]
- Huang, H.; Qian, C. Modeling PM2.5 forecast using a self-weighted ensemble GRU network: Method optimization and evaluation. Ecol. Indic. 2023, 156, 111138. [Google Scholar] [CrossRef]
- Zhang, Z.; Tian, J.; Huang, W.; Yin, L.; Zheng, W.; Liu, S. A Haze Prediction Method Based on One-Dimensional Convolutional Neural Network. Atmosphere 2021, 12, 1327. [Google Scholar] [CrossRef]
- Zheng, T.; Bergin, M.; Wang, G.; Carlson, D. Local PM2.5 Hotspot Detector at 300 m Resolution: A Random Forest–Convolutional Neural Network Joint Model Jointly Trained on Satellite Images and Meteorology. Remote Sens. 2021, 13, 1356. [Google Scholar] [CrossRef]
- Faraji, M.; Nadi, S.; Ghaffarpasand, O.; Homayoni, S.; Downey, K. An integrated 3D CNN-GRU deep learning method for short-term prediction of PM2.5 concentration in urban environment. Sci. Total Environ. 2022, 834, 155324. [Google Scholar] [CrossRef]
- Kow, P.-Y.; Chang, L.-C.; Lin, C.-Y.; Chou, C.C.K.; Chang, F.-J. Deep neural networks for spatiotemporal PM2.5 forecasts based on atmospheric chemical transport model output and monitoring data. Environ. Pollut. 2022, 306, 119348. [Google Scholar] [CrossRef] [PubMed]
- Zhu, M.; Xie, J. Investigation of nearby monitoring station for hourly PM2.5 forecasting using parallel multi-input 1D-CNN-biLSTM. Expert Syst. Appl. 2023, 211, 118707. [Google Scholar] [CrossRef]
- Li, D.; Liu, J.; Zhao, Y. Prediction of Multi-Site PM2.5 Concentrations in Beijing Using CNN-Bi LSTM with CBAM. Atmosphere 2022, 13, 1719. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Jiang, F.; Zhang, C.; Sun, S.; Sun, J. Forecasting hourly PM2.5 based on deep temporal convolutional neural network and decomposition method. Appl. Soft Comput. 2021, 113, 107988. [Google Scholar] [CrossRef]
- Tan, J.; Liu, H.; Li, Y.; Yin, S.; Yu, C. A new ensemble spatio-temporal PM2.5 prediction method based on graph attention recursive networks and reinforcement learning. Chaos Solitons Fractals 2022, 162, 112405. [Google Scholar] [CrossRef]
- Fei, L.; Xuan, Z.; Yuning, Y. PM2.5 concentration prediction based on temporal convolutional network. In Proceedings of the International Conference on Cloud Computing, Performance Computing, and Deep Learning (CCPCDL 2022), Wuhan, China, 11–13 March 2022; p. 122871W. [Google Scholar]
- Ren, Y.; Wang, S.; Xia, B. Deep learning coupled model based on TCN-LSTM for particulate matter concentration prediction. Atmos. Pollut. Res. 2023, 14, 101703. [Google Scholar] [CrossRef]
- Samal, K.K.R. Auto imputation enabled deep Temporal Convolutional Network (TCN) model for pm2.5 forecasting. EAI Endorsed Trans. Scalable Inf. Syst. 2024, 12, 1–15. [Google Scholar] [CrossRef]
- Chen, W.; Bai, X.; Zhang, N.; Cao, X. An improved GCN–TCN–AR model for PM2.5 predictions in the arid areas of Xinjiang, China. J. Arid Land 2024, 17, 93–111. [Google Scholar] [CrossRef]
- Hu, J.; Jia, Y.; Jia, Z.-H.; He, C.-B.; Shi, F.; Huang, X.-H. Prediction of PM2.5 Concentration Based on Deep Learning for High-Dimensional Time Series. Appl. Sci. 2024, 14, 8745. [Google Scholar] [CrossRef]
- Zeng, Q.; Wang, L.; Zhu, S.; Gao, Y.; Qiu, X.; Chen, L. Long-term PM2.5 concentrations forecasting using CEEMDAN and deep Transformer neural network. Atmos. Pollut. Res. 2023, 14, 101839. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Wu, R. MSAFormer: A Transformer-Based Model for PM2.5 Prediction Leveraging Sparse Autoencoding of Multi-Site Meteorological Features in Urban Areas. Atmosphere 2023, 14, 1294. [Google Scholar] [CrossRef]
- Kim, H.S.; Han, K.M.; Yu, J.; Youn, N.; Choi, T. Development of a Hybrid Attention Transformer for Daily PM2.5 Predictions in Seoul. Atmosphere 2025, 16, 37. [Google Scholar] [CrossRef]
- Al-qaness, M.A.A.; Dahou, A.; Ewees, A.A.; Abualigah, L.; Huai, J.; Abd Elaziz, M.; Helmi, A.M. ResInformer: Residual Transformer-Based Artificial Time-Series Forecasting Model for PM2.5 Concentration in Three Major Chinese Cities. Mathematics 2023, 11, 476. [Google Scholar] [CrossRef]
- Zou, R.; Huang, H.; Lu, X.; Zeng, F.; Ren, C.; Wang, W.; Zhou, L.; Dai, X. PD-LL-Transformer: An Hourly PM2.5 Forecasting Method over the Yangtze River Delta Urban Agglomeration, China. Remote Sens. 2024, 16, 1915. [Google Scholar] [CrossRef]
- Tong, W.; Limperis, J.; Hamza-Lup, F.; Xu, Y.; Li, L. Robust Transformer-based model for spatiotemporal PM2.5 prediction in California. Earth Sci. Inform. 2024, 17, 315–328. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, S. Modeling air quality PM2.5 forecasting using deep sparse attention-based transformer networks. Int. J. Environ. Sci. Technol. 2023, 20, 13535–13550. [Google Scholar] [CrossRef]
- Kim, D.-Y.; Jin, D.-Y.; Suk, H.-I. Spatiotemporal graph neural networks for predicting mid-to-long-term PM2.5 concentrations. J. Clean. Prod. 2023, 425, 138880. [Google Scholar] [CrossRef]
- Mandal, S.; Thakur, M. A city-based PM2.5 forecasting framework using Spatially Attentive Cluster-based Graph Neural Network model. J. Clean. Prod. 2023, 405, 137036. [Google Scholar] [CrossRef]
- Zhao, G.; He, H.; Huang, Y.; Ren, J. Near-surface PM2.5 prediction combining the complex network characterization and graph convolution neural network. Neural Comput. Appl. 2021, 33, 17081–17101. [Google Scholar] [CrossRef]
- An, Y.; Xia, T.; You, R.; Lai, D.; Liu, J.; Chen, C. A reinforcement learning approach for control of window behavior to reduce indoor PM2.5 concentrations in naturally ventilated buildings. Build. Environ. 2021, 200, 107978. [Google Scholar] [CrossRef]
- An, Y.; Chen, C. Energy-efficient control of indoor PM2.5 and thermal comfort in a real room using deep reinforcement learning. Energy Build. 2023, 295, 113340. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, Z. An attention-based domain spatial-temporal meta-learning (ADST-ML) approach for PM2.5 concentration dynamics prediction. Urban Clim. 2023, 47, 101363. [Google Scholar] [CrossRef]
- Yadav, K.; Arora, V.; Kumar, M.; Tripathi, S.N.; Motghare, V.M.; Rajput, K.A. Few-Shot Calibration of Low-Cost Air Pollution (PM2.5) Sensors Using Meta Learning. IEEE Sens. Lett. 2022, 6, 113340. [Google Scholar] [CrossRef]
- Wang, J.; Wei, Y.D.; Lin, B. How social media affects PM2.5 levels in urban China? Geogr. Rev. 2023, 113, 48–71. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Keywords | Year | Strength | Begin | End | 2014–2024 * |
|---|---|---|---|---|---|
| fine particles | 2014 | 13.6 | 2014 | 2018 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| coarse particles | 2014 | 12.74 | 2014 | 2019 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| matter | 2014 | 11.9 | 2014 | 2018 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| case-crossover analysis | 2014 | 9.41 | 2014 | 2017 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| chemical composition | 2014 | 9 | 2014 | 2018 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| particulate air pollution | 2014 | 8.53 | 2014 | 2018 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| long-term exposure | 2014 | 7.35 | 2014 | 2018 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| United States | 2015 | 11.46 | 2015 | 2019 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| hospital admissions | 2014 | 11.36 | 2015 | 2017 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| chemical constituents | 2015 | 6.95 | 2015 | 2017 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| short term exposure | 2014 | 10.87 | 2017 | 2020 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| inflammation | 2014 | 8.99 | 2017 | 2019 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| cardiovascular mortality | 2015 | 10.68 | 2018 | 2020 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| burden | 2019 | 7.24 | 2019 | 2021 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| algorithm | 2020 | 10.46 | 2020 | 2021 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| models | 2019 | 7.42 | 2021 | 2022 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| machine learning | 2022 | 11.85 | 2022 | 2024 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| air pollutants | 2016 | 11.8 | 2022 | 2024 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| prevalence | 2022 | 9.37 | 2022 | 2024 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| neural network | 2020 | 8.5 | 2022 | 2024 | ▃▃▃▃▃▃▃▃▃▃▃▃ |
| State | Data Source |
|---|---|
| Victoria | https://www.epa.vic.gov.au/for-community/airwatch (accessed on 8 January 2025) |
| New South Wales | https://www.airquality.nsw.gov.au/air-quality-in-my-area/concentration-data (accessed on 8 January 2025) |
| Queensland | https://apps.des.qld.gov.au/air-quality/ (accessed on 8 January 2025) |
| Western Australia | https://www.wa.gov.au/service/environment/environment-information-services/air-quality (accessed on 8 January 2025) |
| South Australia | https://www.epa.sa.gov.au/environmental_info/air_quality/new-air-quality-monitoring (accessed on 8 January 2025) |
| Parameter | Definition | Description |
|---|---|---|
| Weight matrix from the previous hidden state to the current hidden state | Maps the previous hidden state to the current time step | |
| Weight matrix from the input to the current hidden state | Projects the input to the hidden representation | |
| Weight matrix from the hidden state to the output layer | Maps the hidden state to the output space | |
| Bias vector for the hidden state | Shifts the output of the activation function | |
| Bias vector for the output layer | Adjusts the result at the output layer | |
| Activation function at the hidden layer | Commonly or , enhances nonlinear representation | |
| Activation function at the output layer | Typically, sigmoid or for output computations |
| Parameter | Definition | Description |
|---|---|---|
| Input-to-gate and candidate weight matrices | ) | |
| Hidden-to-gate and candidate weight matrices | to current gates or candidate | |
| Bias vectors for gates and candidate | Adjust values for forget gate, input gate, output gate, and candidate | |
| Sigmoid activation function | Controls gate opening, range [0, 1] | |
| Hyperbolic tangent activation function | Maps values to range [−1, 1]; enhances nonlinearity | |
| Element-wise multiplication (Hadamard product) | Used for gate control and state updates |
| Parameter | Definition | Description |
|---|---|---|
| Weight matrices for update gate, reset gate, and candidate hidden state | Used to transform into corresponding gate values or the candidate state | |
| Bias vectors for update gate, reset gate, and candidate hidden state | , | |
| Activation functions | Sigmoid for gate control ([0, 1]); | |
| Hyperbolic tangent for nonlinearity ([−1, 1]) | ||
| Element-wise multiplication (Hadamard product) | Used in reset gate and hidden state update |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Wang, R.; Lu, S.; Tian, J.; Yin, L.; Wang, L.; Zheng, W. Time-Series Data-Driven PM2.5 Forecasting: From Theoretical Framework to Empirical Analysis. Atmosphere 2025, 16, 292. https://doi.org/10.3390/atmos16030292
Wu C, Wang R, Lu S, Tian J, Yin L, Wang L, Zheng W. Time-Series Data-Driven PM2.5 Forecasting: From Theoretical Framework to Empirical Analysis. Atmosphere. 2025; 16(3):292. https://doi.org/10.3390/atmos16030292
Chicago/Turabian StyleWu, Chunlai, Ruiyang Wang, Siyu Lu, Jiawei Tian, Lirong Yin, Lei Wang, and Wenfeng Zheng. 2025. "Time-Series Data-Driven PM2.5 Forecasting: From Theoretical Framework to Empirical Analysis" Atmosphere 16, no. 3: 292. https://doi.org/10.3390/atmos16030292
APA StyleWu, C., Wang, R., Lu, S., Tian, J., Yin, L., Wang, L., & Zheng, W. (2025). Time-Series Data-Driven PM2.5 Forecasting: From Theoretical Framework to Empirical Analysis. Atmosphere, 16(3), 292. https://doi.org/10.3390/atmos16030292