1. Introduction
It is now widely acknowledged that climate change will produce significant effects on the hydrological cycle [
1,
2,
3,
4]. In recent decades, with outputs from climate models made available, hydrological impacts and responses amid a changing climate with respect to a number of river basins in the world have been studied [
5,
6,
7,
8].
Recently, climate-change impact studies have started to systematically consider associated uncertainties [
7], and rainfall–runoff modeling is recognized as one of the most important sources of uncertainty [
9]. It has been reported that the multi-model ensemble (MME) strategy is an efficient method to tackle the uncertainty of rainfall–runoff models [
10,
11].
All models are imperfect representations of real world processes. Different models have strengths in capturing different aspects of such processes. It is therefore highly desirable, in order to reduce the above-mentioned uncertainties and improve overall accuracy, that the best performing parts of various individual models are combined so that a prediction consensus can be reached. With a multi-model ensemble approach, more reliable runoff predictions can be made from multiple competing predictions made from a number of rainfall–runoff models [
11,
12]. This method was discussed and used in the pioneering works of [
13,
14,
15,
16] and others. Shamseldin et al. [
12] promoted the concept of combining outputs from various rainfall–runoff models to produce an overall combined output to be used as an alternative to the output of a single individual rainfall–runoff model. A recent application of this concept to future climate projections can be found in [
17,
18], where surface air temperature and precipitation are predicted.
The aim of this paper was to tackle the discrepancy of rainfall–runoff modeling in changing climate scenarios. This was done by combining three climate scenarios with eight carefully selected rainfall–runoff models. The final MME approaches were then applied to the Yellow River Basin (YRB) for two selected future target periods. The paper is organized as follows:
Section 2 describes the study area and the available data,
Section 3 presents the multi-model ensemble methods,
Section 4 briefs the selected rainfall–runoff models,
Section 5 provides the criteria to evaluate model performance,
Section 6 discusses the results, and
Section 7 presents the conclusions and the remarks.
3. Multi-Model Ensemble Methods
The concept of combining the forecasts obtained from different models or methods was discussed and used in the pioneering works of [
13,
14,
15,
16] and others. The essence of the concept of these methods is that each model output captures certain important aspects of the information available about the process being modeled, thereby providing a source of information that may be different from that of other models [
12]. Combining these various sources of information may enable the user to gain a merged, all-inclusive picture for a given study area. Furthermore, the judicious combination of outputs of different models may assist in understanding the underlying physical processes involved and thus in developing improved individual models. As such, it might be possible to develop a new individual model that can effectively utilize the different types of information reflected in the estimated outputs of each of the models included in the combination [
20].
Several methods of combining model outputs have been reported: the simple average method, the weighted average method [
12], the neural network method [
21] (which is based on a learning procedure through a black box), the first order Takagi–Sugeno method [
22] (which is based on a special class of fuzzy system), and the Bayesian model averaging method (BMA) [
11]. Compared with more traditional averaging methods, BMA is becoming popular due to its ability to optimize weights based on performance and thus providing a superior choice in modeling. In this paper, we are interested in comparing the results of a genetic-algorithm-based weighting average method with the results of Bayesian model averaging and simple average methods.
3.1. Genetic Algorithms
Genetic algorithms (GAs) are known as global search heuristics for finding exact or approximate solutions to optimization and search problems based on the evolutionary ideas of natural selection. They are often implemented in a computer simulation in which a population of abstract representations of candidate solutions to an optimization problem evolves toward improved solutions. The evolution starts from a population of randomly generated individuals and occurs in generations. In each generation, the fitness function of every individual in the population is evaluated, multiple individuals are stochastically selected from the current population (based on their fitness), and modified to form a new population through genetic operators of crossover (recombination) and mutation. For each new solution to be produced, a pair of “parent” solutions is selected from the pool for breeding. A new solution shares many of the characteristics of its “parents.” New parents are selected for each new child, and the process continues until a new population of solutions of appropriate size is generated. The new population is then used in the next iteration of the algorithm. The algorithm terminates when a termination condition has been reached, commonly a maximum number of generations has been produced [
23]. In this paper, a genetic algorithm based on [
23] is employed to optimize the set of weights for eight individual rainfall–runoff models.
3.2. Bayesian Model Averaging Scheme
Bayesian model averaging (BMA) is a statistical procedure that infers consensus predictions by weighing individual predictions based on their probabilistic likelihood measures, with the better performing predictions receiving higher weights than the worse performing predictions. Furthermore, BMA provides a description of the total predictive uncertainty that is more reliable than the original ensemble, leading to a sharper and better-calibrated probability density function for the probabilistic predictions [
10,
24]. A detailed description of BMA scheme implementation is given in [
11]. The same procedure from [
11] is employed in this study.
4. A Brief Description of the Selected Rainfall–Runoff Models
In climate-change-related hydrological modeling, monthly water balance models are becoming more popular thanks to their flexibility and ease of use [
25,
26,
27]. In favor of using conceptual water balance models instead of physically based models or black box models, the authors of [
26] stated that the detailed realism of a physically based model posed a different set of complications. First, the physically based models require a high resolution, in both space and time, of climatic input data that may not be available; second, it is possible that model parameters may need to change as climate evolves: soil structure may change, for example, as summers become drier, and, more importantly, the distribution and composition of catchment vegetation will probably alter. There are at present too many unknowns for detailed physically based models to be used in climate impact studies [
27].
Based on the above considerations, eight numerical models, including five lumped conceptual models, i.e., GR5M, AWBM, SIMHYD, TRPWB, VWBM, one local distributed model (the Yellow River Water Balance model, YRWBM), one physically based model (VIC), and one black-box model (the artificial neural network model, ANN), were employed in this study for comparison (see
Table 1 for details). A brief summary of these eight models is given in
Table 1. It should be pointed out that, being the only physically based model, the VIC’s performance might be affected due to the fact that only averaging parameters were used in the VIC on the sub-basin scale. The outputs of the eight different rainfall–runoff models were then combined using different BMA strategies to find the best fitted ensemble strategy for the YRB.
6. Results and Discussion
For optimal comparison results, all model simulations were performed with the same calibration, validation, and the simulation periods. The years from 1962 to 1980 was selected as the calibration period, while the years from 1981 to 2000 were used as the validation period. Two future target simulation periods were chosen: 2046–2065 and 2081–2100. The performance of the seven objective functions were then calculated for each of them and subsequently compared.
6.1. Model Performance during the Calibration Period (1962–1980)
Table 3 lists the performance results of the eight rainfall–runoff models referring to the seven criteria. It can be found that (1) the best benchmark values are achieved by the ANN, (2) all water balance (RE) values are less than 10%, with the best performance by the GR5M, and (3) six of the worst performance values belong to the VIC followed by the TRPW. It can also be noted that, for the Nash–Sutcliff criterion (NS), all models performed well, around or above 0.8, except for the VIC (NS = 0.51).
The RMSD and the RE are two typical objective functions in validating rainfall–runoff model results.
Table 4 presents the RMSD and RE variations of the eight models for different seasons (spring, summer, autumn, and winter). It can be observed that, for both RMSD and RE, (1) the ANN performs well in summer, and the TRPW performs well in autumn; (2) the ANN and VIC respectively have the best RMSD and RE in spring, and the YRWB and ANN respectively have the best RMSD and RE in winter. Although the results among the models are scattered, it is clear that the ANN showed the overall best performance in terms of seasonal modeling.
6.2. Model Performance during the Validation Period (1981–2000)
Similar to the calibration period, the same comparison is done for the validation period. The results of the performance values are summarized in
Table 5. For easy comparison, the corresponding values from calibration (
Table 3) are displayed in the line below in parentheses. As can be seen in
Table 5, most of the model performance is similar to that of the calibration period, except NS values for ANN and VIC, which decreased slightly. The AWBM performed best in terms of the NS, RMSD, and RCOEF, while the ANN’s performance dropped remarkably. This fact indicates the risks of using individual models and the need for a multi-model approach.
Again, there is a need to compare RMSD and RE variations in the eight models for different seasons of the validation period. As displayed in
Table 6, the results of these two parameters show a spread pattern over the four different seasons. The best performers are the GR5M, the TRPW, the AWBM, and the YRWB for the spring, summer, autumn, and winter, respectively, which is clearly different compared to that of the calibration period.
6.3. The Performance of Multi-Model Ensemble
6.3.1. Model Performance
All models are imperfect. This is generally true and has been shown in particular by the above examples. It is therefore interesting to see whether the ensemble approach and/or any other averaging methods can improve the objective function. In the following section, we compare the best individual model with three different methods:—the simple average method (SAM), a genetic algorithm (GA), and Bayesian model averaging (BMA)—to investigate the differences between them.
Table 7 illustrates the results of the four approaches for the same calibration period, with the RMSD and RE broken down into four different seasons. From the table, it is apparent that the GA and BMA approaches outperformed the best individual model for NS. Furthermore, for the seasonal cases, GA and BMA results showed values that are clearly superior to those of the best individual model for the RMSD for all seasons. Water balance (RE) is the only value where the best individual model had some slightly improved results.
For the case of the validation period, the results are slightly different, as shown in
Table 8. In
Table 8, the best individual model value for NS (0.826) is from the AWBM, which is still the lowest compared to others. For the seasonal changes of the RMSD and RE, the GA showed the best results for spring and summer seasons. The best individual model showed slightly improved results compared with the others, indicating improved water balance estimation, especially for the winter.
It is worth pointing out that objective functions from the best individual models are weighted through genetic and Bayesian treatment in order to produce a complementary objective function with improved accuracy. The final weights are not lineally corresponding to the best single values based on individual models. In other words, a higher NS function of an individual model may not necessarily result in higher weights for the GA and BMA approaches.
6.3.2. Rainfall–Runoff Simulation and Prediction
Based on the previous sections, it is clear that the genetic algorithm (GA) approach has the best performance and accuracy within the comparison. The GA method was therefore selected to simulate the runoff for the study area.
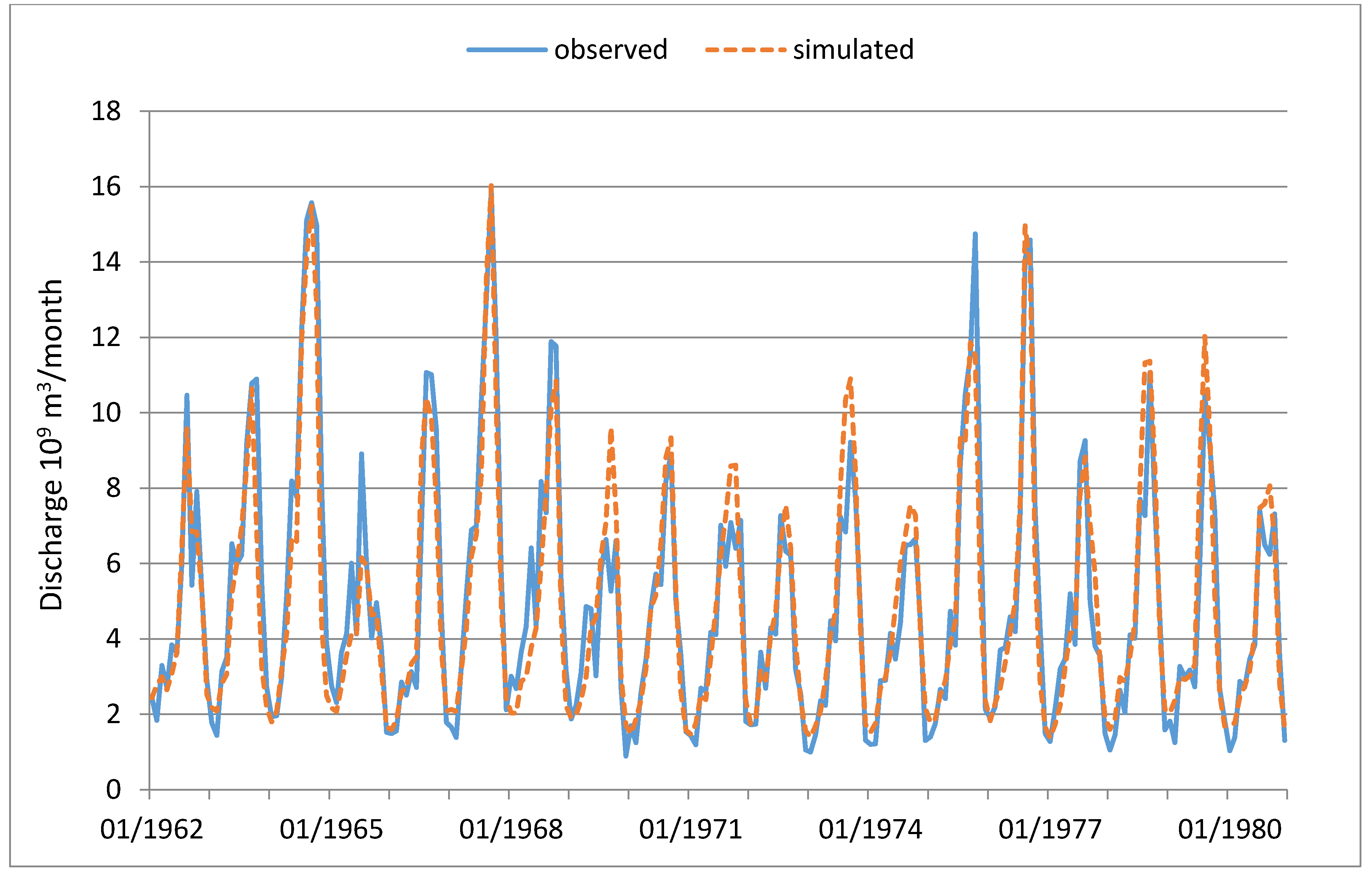
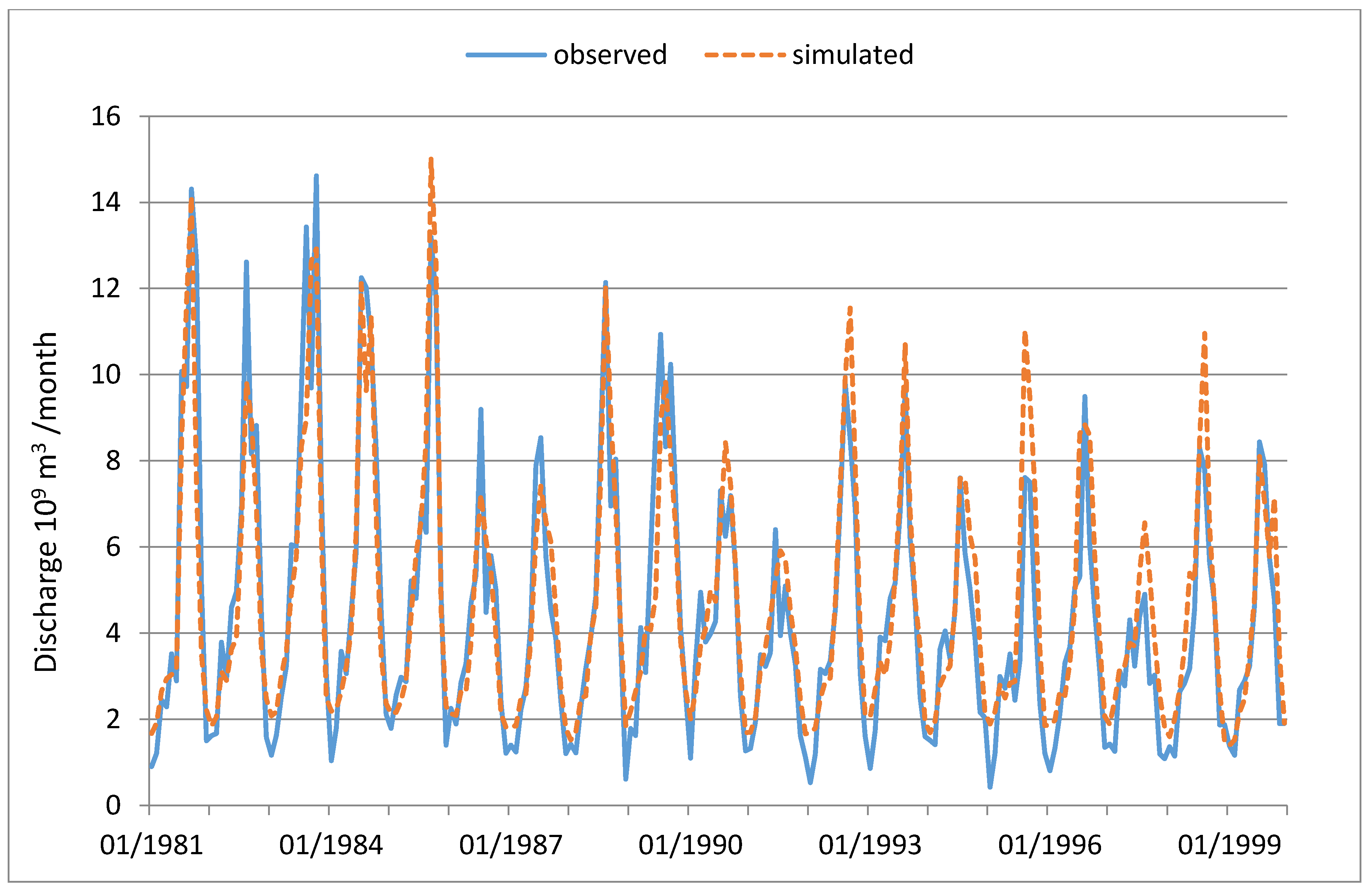
In
Figure 3 and
Figure 4, the simulation results of the GA method are plotted against the observed monthly runoff in calibration (1962–1980) and validation (1981–2000) periods, respectively, for the Huayuankou station (the lower reach of the entire YRB). As can be deduced from the figures, the simulation accuracy is satisfactory for most of the years in both periods (with NS = 891 and NS = 840, respectively).
6.4. Runoff Prediction under Varying Climate Scenarios
As described in
Section 2.2, future climate scenarios of A1B, A2, and B1 from the IPCC-SRES are used by the selected GCMs with downscaled outputs to produce the input for our eight rainfall–runoff models. The models are now furnished with the GA method for the best combination of objective functions.
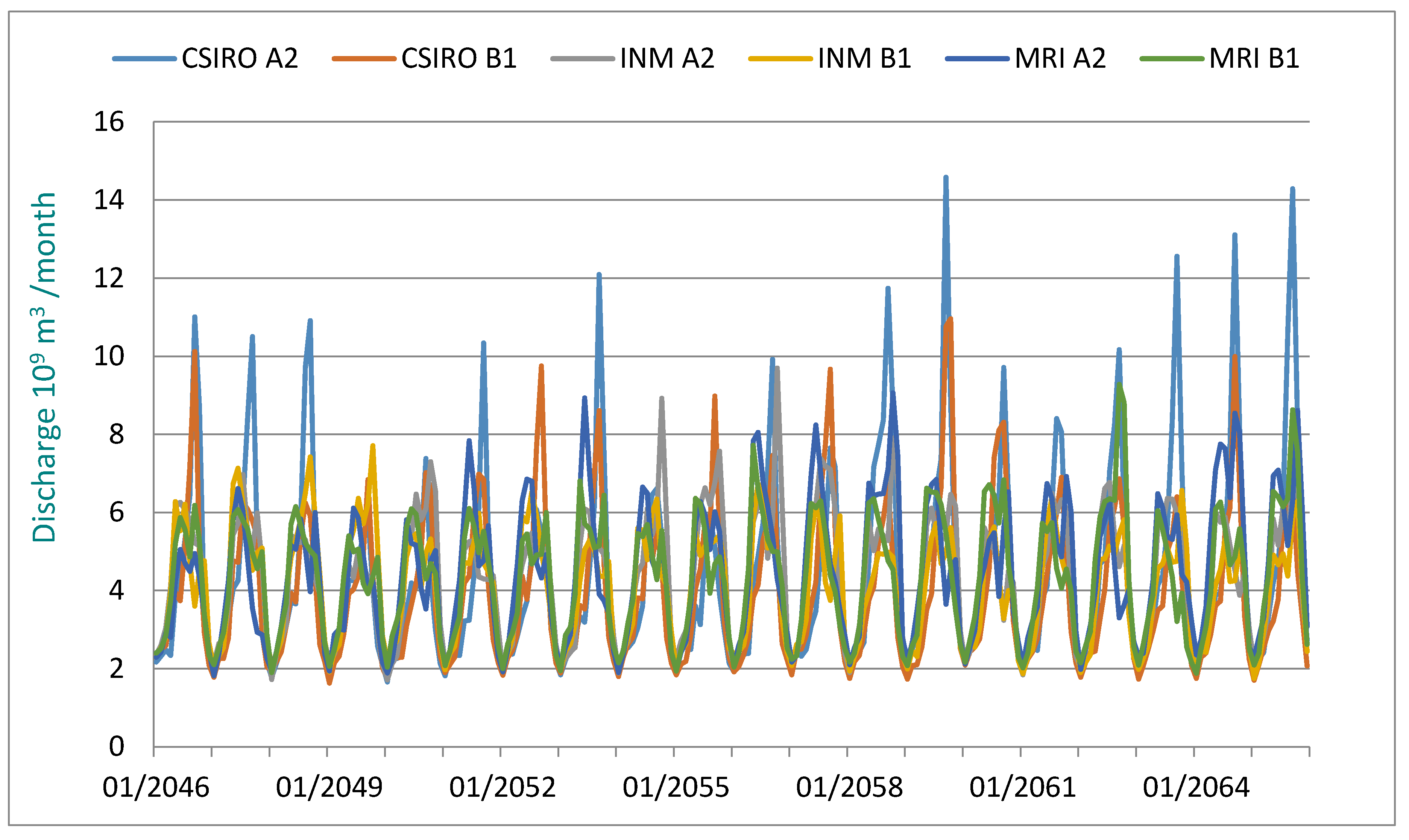
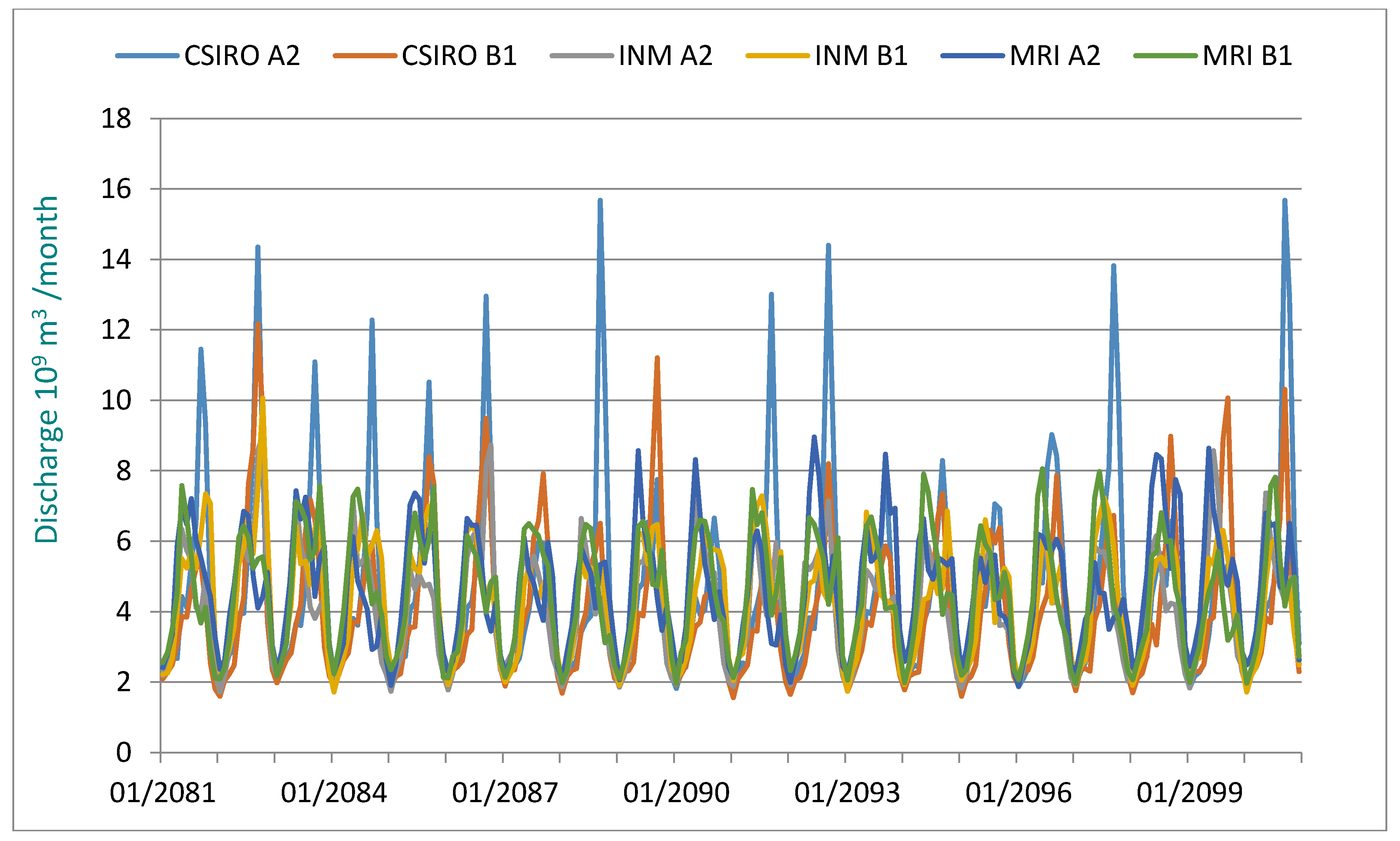
Figure 5 and
Figure 6 demonstrate the simulation results for the target periods of 2046–2065 and 2081–2100, respectively.
Mean values of the annual runoff in the periods of 2046–2065 and 2081–2100 are shown in
Table 9. With a baseline mean annual runoff of 56.7 billion m
3 (1961–2000), it is concluded that the greatest mean annual runoff scenario under climate change scenarios downscaled from MRI and A2 would be 53.1 billion m
3, while the smallest mean annual runoff driven by the CSIRO and B1 scenarios would be 47.21 billion m
3. In the period of 2081–2100, the greatest mean annual runoff scenario under climate change scenarios downscaled from MRI and A2 would be 55.3 billion m
3, while the smallest mean annual runoff driven by the CSIRO and B1 scenarios would be 47.02 billion m
3. It is interesting to note that the greatest and smallest runoff scenarios would be under the combined scenarios of MRI-A2 and CSIRO-B1 in both periods of 2046–2065 and 2081–2100.
The change rate of quantile and mean values for annual runoff in the periods of 2046–2065 and 2081–2100 compared with that in the baseline period of 1961–2000 is shown in
Table 10. Overall, it displays slight decreasing trends for runoff in the YRB in the simulated period. Average values of mean annual runoff in the periods of 2046–2065 and 2081–2100 are 50.86 and 51.65 billion m
3, which are remarkably smaller than runoff in the baseline period by 10.3 and 8.9%, respectively. Generally, runoff under the A2 scenario is greater than that under the B1 scenario.
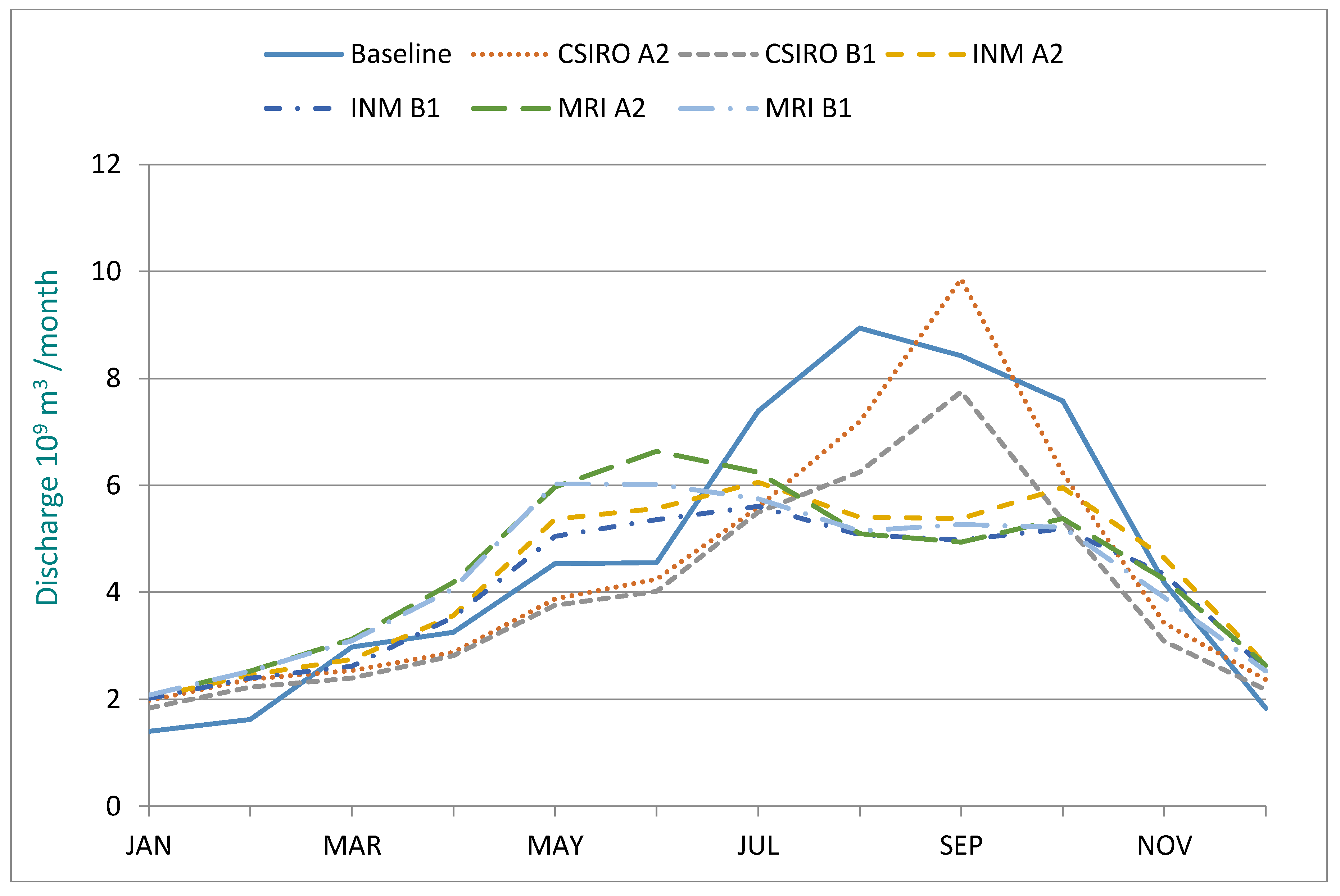
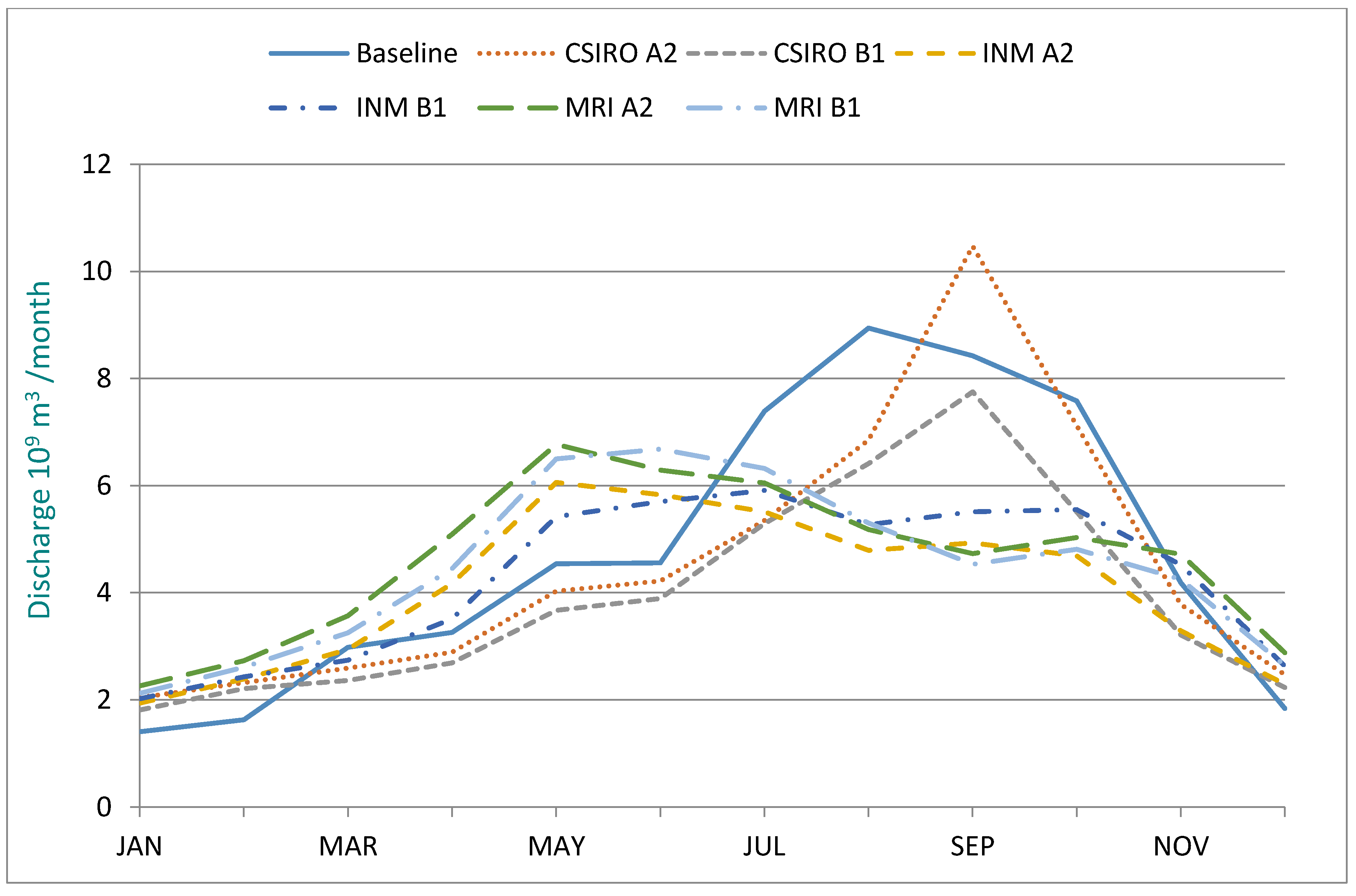
The distributions of the simulated monthly runoff over the year for the two targeted periods are plotted together with the baseline runoff in
Figure 7 and
Figure 8, respectively. For both periods, it is clear that the largest variations between climate scenarios are during May–June and August–October.
Compared to the baseline runoff, it is quantified that average spring, summer, autumn, and winter runoff of the Yellow River Basin would change −16.7–23.3%, −24.5–−13.9%, −28.7–−3.3%, and 28.4–49.0% for the 2046–2065 time span and change −19.1–43.2%, −25.4–−12.4%, −36.1–−5.8%, and 28.4–61.7% for the 2081–2100 time span.
7. Discussion and Conclusions
Three GCMs were employed to simulate future hydrological scenarios for the Yellow River Basin in climate scenarios A1B, A2, and B1 from the IPCC-SRES. The GCM outputs were then downscaled to a grid size of 0.5 × 0.5° for use with the eight rainfall–runoff models selected for this particular study. These runoff outputs were then combined using a multi-model ensemble (MME), which, compared with any individual model, can be expected to be more accurate and reliable. It should be noted that the choice of these three GCMs, among many others, might not be representative. It would be interesting to include other GCMs in a similar study in the future.
For regional scale modeling, GCMs involve high uncertainty due to the GCMs’ inter-model uncertainty as well as the coarse spatial resolution. One way to reduce this uncertainty might be to quantify the discrepancies by showing error bars for each case so that the inter-model uncertainty can be addressed more easily. Similar to the current study for hydrological outputs, another way to increase the reliability might be to employ an MME of GCM models, as described in [
50]. The performance of the VIC, the only distributed model, compared with other conceptual or black-box models, was worse in many cases. This is partly due to the lack of detailed distributed parameter inputs and partly due to the coarse averaging effects in the space and time domains. In a recent study, a long-term model with the VIC was successfully applied [
51]. One future step could be to incorporate the results of [
51] to an MME procedure so that the distributed model representation can be enhanced and inter-model uncertainty can thus be reduced.
For the calibration and validation periods of the YRB, it was confirmed that the MBA and GA approaches had an overall performance that was a substantial improvement in terms of rainfall–runoff outputs compared with the individual models and the simple average method (SAM). This indicates application potential for MME approaches in other areas. For example, more recent CMIP5 datasets could be used in the future to generate more reliable scenarios.
For cases of seasonal modeling, various individual models outperformed the MME approaches (
Table 7 and
Table 8). This might be because individual models are more sensitive to temporal variations than those of an MME, where temporal variations may be evened out.
Based on the combined predictions for the two target periods (
Figure 7 and
Figure 8), compared to the baseline, average annual runoff of the YRB will, for the 2046–2065 time span, decrease 5.6~7.8% in Scenario A2 and 8.1–16.1% in Scenario B1 and, for the 2081–2100 time span, decrease 1.7~13.2% in Scenario A2 and 4.9–16.4% in Scenario B1. This will threaten the water security in the YRB.
Relative to the baseline runoff, average spring, summer, autumn, and winter runoff of the YRB will change −16.7–23.3%, −24.5–−13.9%, −28.7–−3.3%, and 28.4–49.0% over the 2046−2065 period and, for the 2081–2100 period, change −19.1–43.2%, −25.4–−12.4%, −36.1–−5.8%, and 28.4–61.7% (
Figure 7 and
Figure 8). This means that, from January to June, the runoff in most of the simulated scenarios (4 of 6 cases) will be higher than the corresponding baseline period, while the opposite situation will appear for the second half of the year, implying increased severity in the water supply since the first half of the year is generally more vulnerable.
In summary, a multi-model ensemble (MME) using a genetic algorithm (GA) and a Bayesian model averaging method (BMA) is concluded to enhance rainfall–runoff predictions by providing a combined, better weighted parameter set compared to individual models. These results show that it is possible to reduce the uncertainty and thus improve the accuracy for future projections using MME-weighted models, because the MME approach will even out the bias and exploit the best performances of the individual models. Three future tasks are expected to be undertaken: one is the use of the same methodology in other river basins (e.g., the Yangtze River Basin) to confirm the usefulness; another is the optimization of choice of GCMs and of more recent climate change scenarios; a third is the optimization of the setup and composition of the rainfall–runoff models such that the balance between conceptual, black-box, and distributed models, as well as other models such as those reported by [
52,
53,
54], is improved.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}