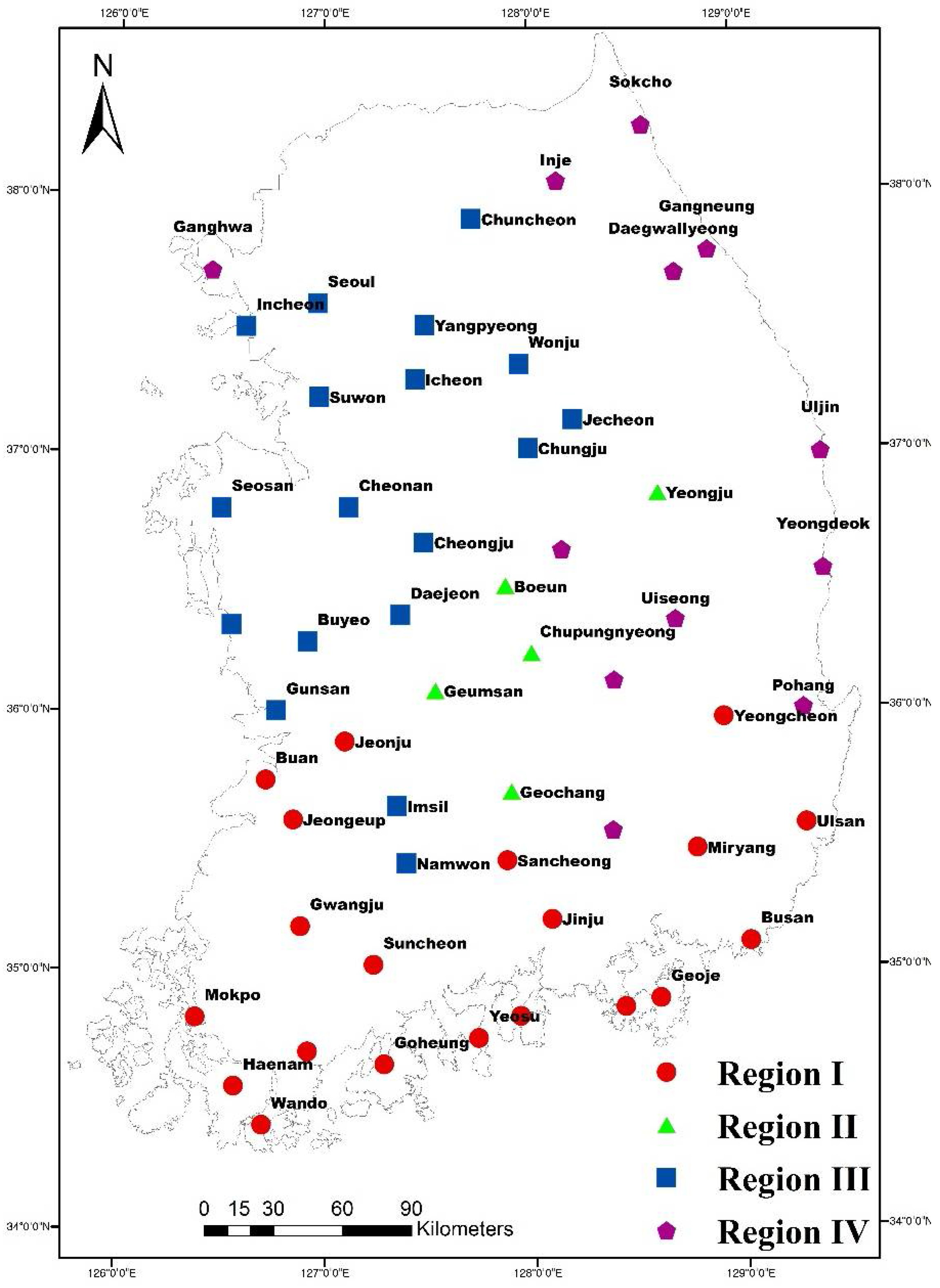
3.1. Bivariate Regionalization of Drought in South Korea
The HCPC algorithm was applied for the formation of initial regions, using topography and climate-based site characteristics of each station. However, regions obtained by the HCPC algorithm are not statistically homogeneous. Univariate and bivariate discordancy and homogeneity tests results showed that Tongyeong station in Region I, as well as the Ganghwa, Jeonju, and Boeun stations in Region III, were identified as discordant sites. Following methodology proposed by [
37], the stations shifted from one region to another, in order to improve the homogeneity of the regions. The spatial distribution of the final identified homogeneous regions is presented in
Figure 4. Region II, located at the mid-latitude inland of South Korea, is the smallest region compared to the others, as it contains only five stations. Moderate drought attributes observed in Region II may be because of its location away from the coastal areas, making it thus less affected by summer typhoons, which occur mostly at the coastal areas.
Table 2 showed that all the regions fulfill the criteria of homogeneity. The detailed results of the bivariate homogeneity tests are provided in [
32]. Since regional drought frequency analysis is based on the extreme values of drought variables (duration and severity), basic statistics such as mean, maximum, minimum, standard deviation, skewness, and kurtosis were computed for four homogeneous regions (
Table 3). The longest drought duration of 13 months was recorded at Jecheon station in Region I, and the highest severity of 22.30 was recorded at Yeongju station in Region II.
3.2. Identification of Regional Marginal Distribution
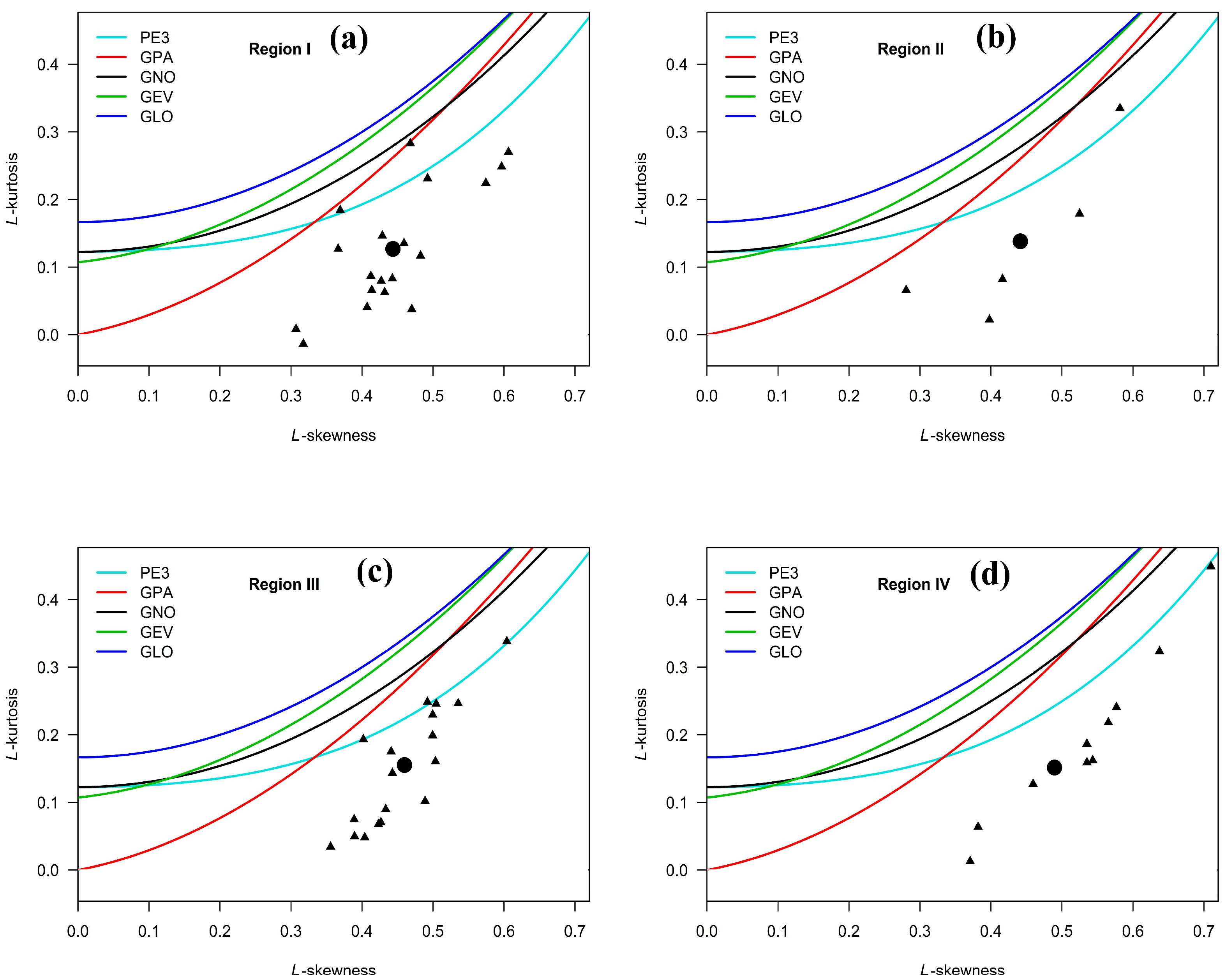
The L-moment ratio diagram, in the case of drought duration for the four identified homogeneous regions, is shown in
Figure 5. Among the five candidate probability distributions, the PE3 distribution line passed through the small portion of the observed data, in case of Regions I and III, and passed away from the observed data in the case of Regions II and IV. However, it is noted that the regional average point is always located away from the PE3 distribution line. The Z statistic value showed that none of the candidate probability distributions satisfied the criteria that
(
Table 4). This may be due to a large number of ties, especially with the short drought duration. Therefore, for drought duration, a more robust Kappa distribution was selected, as recommended by [
37,
46,
47,
48]. In the case of drought severity, the L-moment ratio diagram (
Figure 6) and Z statistics (
Table 4) showed that except for Region I, all other regions can be modeled with PE3 distribution. For Region I, a four-parameter Kappa distribution was selected.
The visual comparison between empirical and theoretical probability distribution functions (PDFs) and their corresponding cumulative distribution functions (CDFs) for the drought duration and severity of each region is presented in
Figure 7. CDFs and PDFs were computed using Kappa distribution for Regions I, II, III, and IV, in the case of drought duration, and for Region I in the case of drought severity. The drought severity of Regions II, III, and IV were computed using PE3 distribution. Here, the empirical cumulative probability was calculated by using plotting position formula
, proposed by Hosking [
49]. Here,
denotes the rank of the observations in ascending order, and
denotes sample size. The derived theoretical CDFs and PDFs show good agreement with the empirical ones, which indicates that these probability distributions perform well with the observed data. The CDFs of the final best-fitted probability distributions and their corresponding parameters are given in
Table 5.
The parameters of each distribution were estimated using the L-moment method. Before fitting the copula model, site-specific scaling factors were used to standardize the observations from the pooled sites [
50]. In this study
and
denote the site-specific scaling factor for drought duration and severity, respectively. This approach helped us to increase statistical reliability of the calculations, especially at the sites having small a length of records. The site-specific scaling factor for drought duration and severity of each region and the number of drought events recorded at each station are shown in
Table 6. The highest number of drought events (34) were recorded at Tongyeong station. This can be correlated with unusual precipitation patterns in southern coastal areas. This is because of the major contribution of typhoons to the seasonal (particularly summer) precipitation patterns and convective systems within the air mass in southern coastal areas [
51]. A study based on spatial patterns of trends in summer precipitation showed a significant increasing trend in amount and intensity of precipitation at southeast coastal areas [
20].
3.3. Application of Copulas
Prior to fitting the bivariate copulas, it is important to examine the dependence structure between the drought duration and severity. In this study, quantitative dependence was assessed using three correlation coefficient measures, such as Pearson’s linear correlation r, Spearman’s rank correlation ρ, and Kendall’s τ. The Student’s
t-test at the significance level of 0.05 was used to test the statistical significance of the correlation values. Since Pearson correlation coefficient can only indicate the linear dependence between the variables, it may not be useful for heavy-tailed variables and may be affected by the outliers. Therefore, Kendall’s τ was used to describe the wider class of dependencies and to cope with the outliers [
52]. Moreover, rank-based evaluation of the correlation between drought duration and severity was also presented in
Table 7. The three correlation coefficient test results showed that there is a statistically significant positive dependence between the drought variables for all regions.
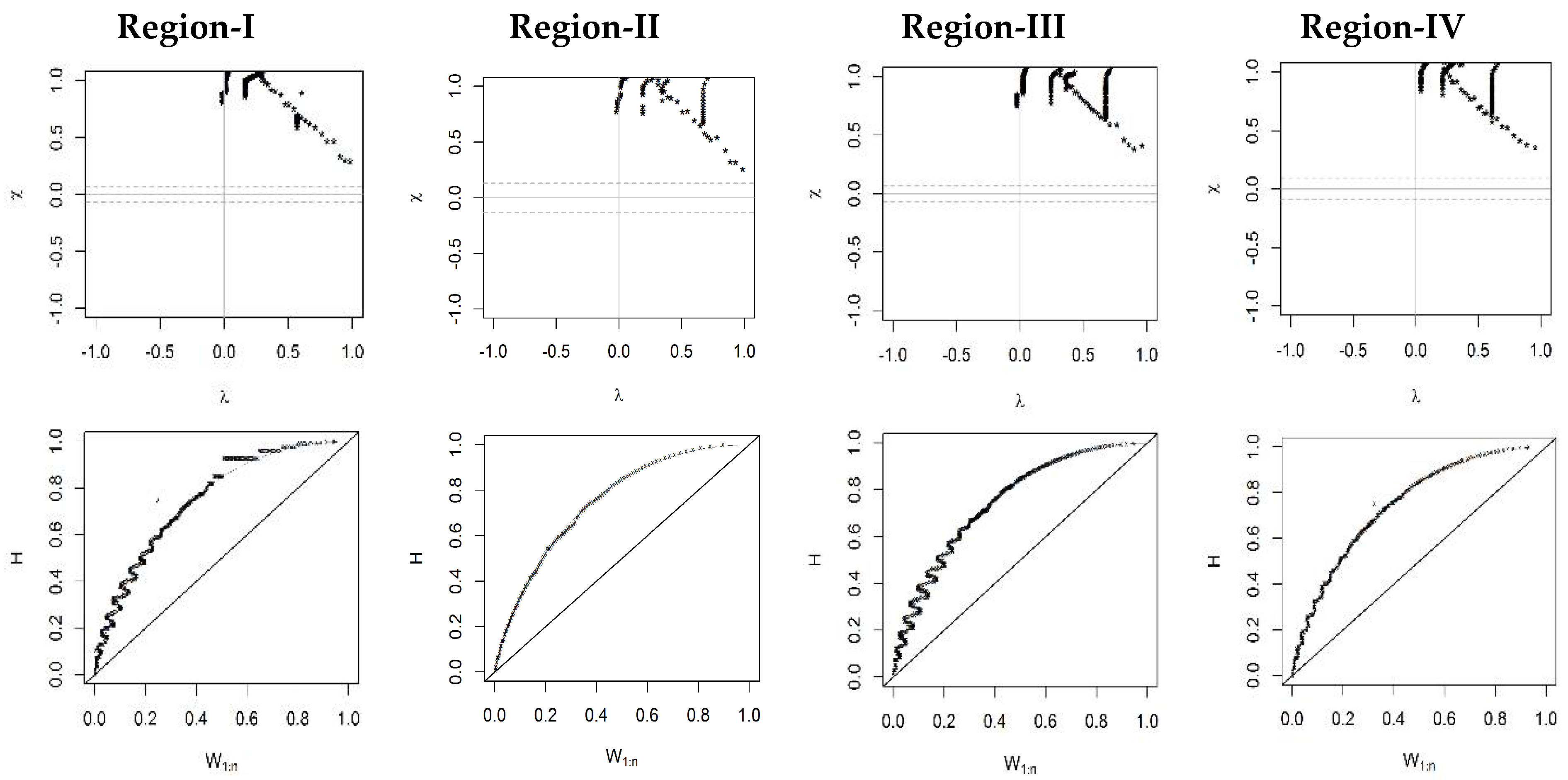
The qualitative dependence between drought variables were accomplished using graphical diagnostic tools. The pair-wise dependence pattern of drought variables, using Chi and Kendall plots for each region, is presented in
Figure 8. According to [
53,
54], the two variables could be considered as independent if the majority of the events lay within the confidence band of the Chi plots. In the case of the Chi plot, a strong deviation from the control point was observed for all regions. All the points fell near or away from the confidence band of the Chi plots. Furthermore, most of the drought event values were higher than the median value (positive lambda values). In the case of the Kendall plots, two variables could be considered as independent if the majority of the event lay on the diagonal line. Events above the diagonal line indicate positive dependence, and event below the diagonal line indicate the negative dependence. The results of the Kendall plots showed a strong deviation from the diagonal line for all regions. This indicates the presence of strong positive association between drought variables.
Since the qualitative and quantitative dependence measures indicated significant positive correlation between the drought variables, and goodness-of-fit tests indicated the best-fitted probability distributions, a copula can be employed to simulate the drought variables using joint distribution. Elliptical and Archimedean copula families, described in
Section 2.6, were fitted and compared to find the best-fitted copula. The Ali-Maikhail-Haq copula is also the part of Archimedean copula family, but was not considered in this study, because the application of this copula needs Kendall’s τ value to be within the range of [−0.1817, 0.333] [
38]. Furthermore, the six copula models were fitted using the MPL method, where the parameters were estimated using either Kappa or PE3 distribution. The performance of the copula families was compared using the Cramér–von Mises test (S
n). The test statistic S
n and its associated
p-value can be estimated using either parametric bootstrap [
39,
55] or by means of a multiplier approach [
56,
57].
The drawbacks of the parametric bootstrap are that it has very high computational cost, as each iteration requires both random number generation from the fitted copula and the estimation of copula parameters [
58]. Additionally, the parametric bootstrap method becomes prohibitive with an increase in the sample size. Therefore, a fast large-sample testing procedure based on the multiplier approach was preferred in this study. The S
n and
p-value were computed using the multiplier iteration of 10,000, with the sample length as the historical data (
Table 8). The S
n statistic was computed on the basis of the probability integral transformation of Rosenblatt [
59]. In addition to this, the AIC criteria as described in [
40] was also used to choose the appropriate copula model. Neither the Joe copula in Regions I, III, and IV nor the Gumbel copula in Region III was able to pass the S
n test at 90% significance level. Since the difference in the S
n statistic between the six copula values was very small, additional AIC statistics were also considered. Therefore, if the S
n statistics for the two copulas were the same, then the copula having a lower value of AIC was preferred. The Gaussian copula was identified as the best copula for Regions I and IV, and the Frank copula for Regions II and III are shown in
Table 8 (bold). Estimated parameters using the MPL approach for each copula family are also presented in
Table 8.
Overall, the AIC and S
n statistics indicate the different aspects of the model under study. The S
n statistic was used as the formal hypothesis test, as a criterion to rank the copulas according to a predefined significance level, whereas AIC is a relatively simple likelihood criteria-based method, where selection is only a matter of choosing the models with the lowest likelihood value. Results did not show any significant correlation between the two statistical tests; this may be because the numerical tests tend to narrowly focus on a particular aspect of the relationship between the empirical and theoretical copulas, and often try to compress the information into a single descriptive number (see e.g., [
60]). The second reason is that the test has been successfully applied to at-site frequency analysis, where the total sample size is very small compared to regional drought frequency analysis. Large sample sizes can affect the performance of an S
n goodness-of-fit test statistic, as described in [
39]. Comparing the method of computation, the
p-value in the S
n test statistic is complicated to implement and computationally intensive; however, the AIC has a relatively low computational cost.
Even though the AIC and S
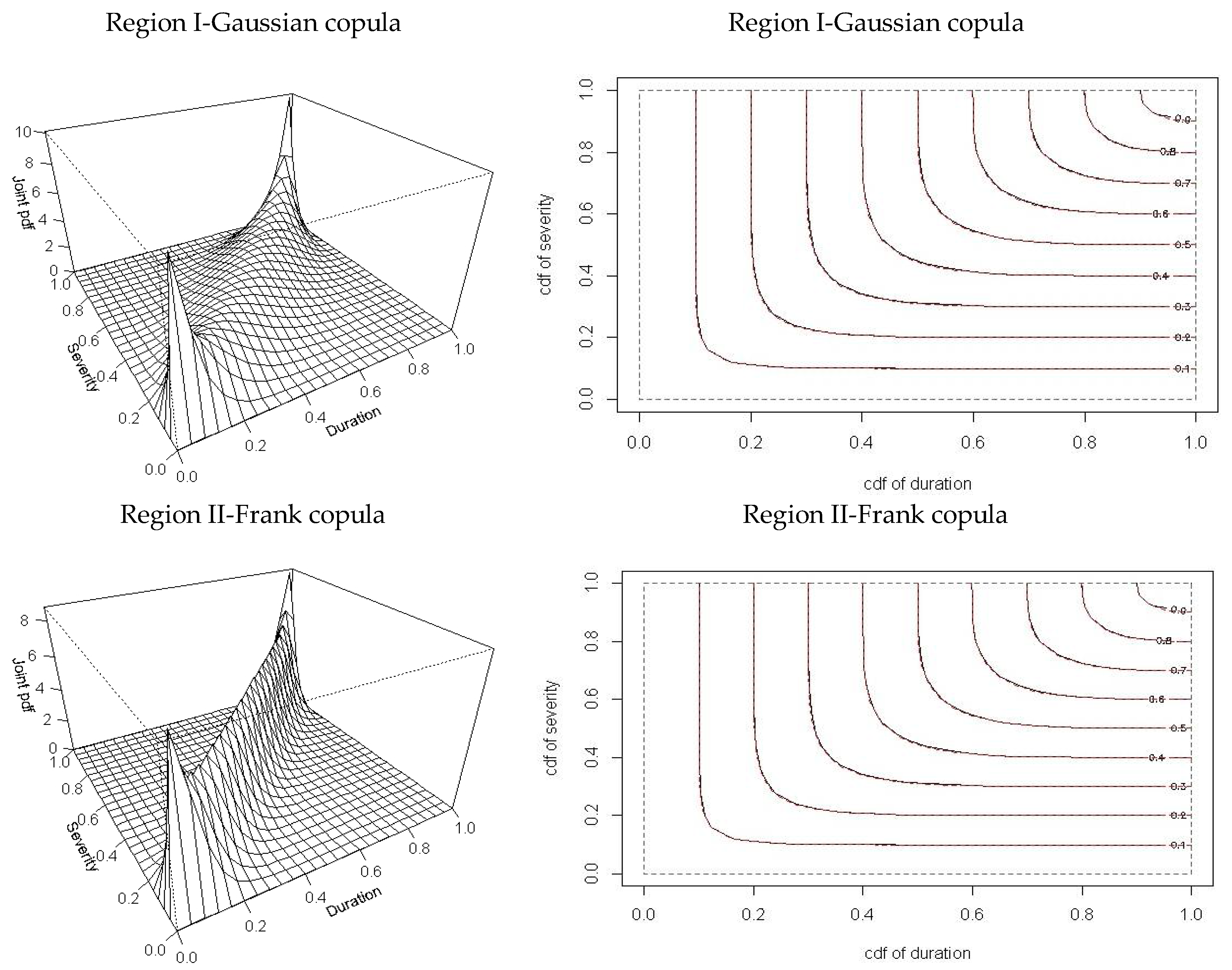
n goodness-of-fit test statistics accepted the commonly used copulas in drought studies, the graphical comparison of the empirical and theoretical copulas may not show good agreement. Therefore, joint CDFs and PDFs for drought duration and severity were estimated using the two best-fitted copulas (Gaussian and Frank) mentioned in
Table 8, and are shown in
Figure 9. Joint CDFs in
Figure 9 show the visual comparison between empirical and theoretical copula functions for drought duration and severity. The red dashed contour line shows the empirical copula obtained through
where
and
denote the ranks of the ordered sample. The solid contour line represents the theoretical copula. Results indicate that the Gaussian and Frank empirical copulas from the Regions I and II, respectively, matched well with the theoretical copulas.
However, the Frank and Gaussian empirical copulas from Regions III and IV, respectively, showed some deviations between the theoretical copulas, especially at low probability levels. This may be due to discrete characteristics of drought duration and the relative low accuracy of marginal distribution. Furthermore, the estimation of the probabilities of interest is affected by the majority of “ties” (i.e., identical pairs of drought duration and severity) at the lower probability level. It can be observed from
Figure 9 that at high probability levels, all regions showed good agreement between empirical and theoretical copula values. The upper and lower tail dependencies in the case of both the Gaussian and Frank copulas is 0.
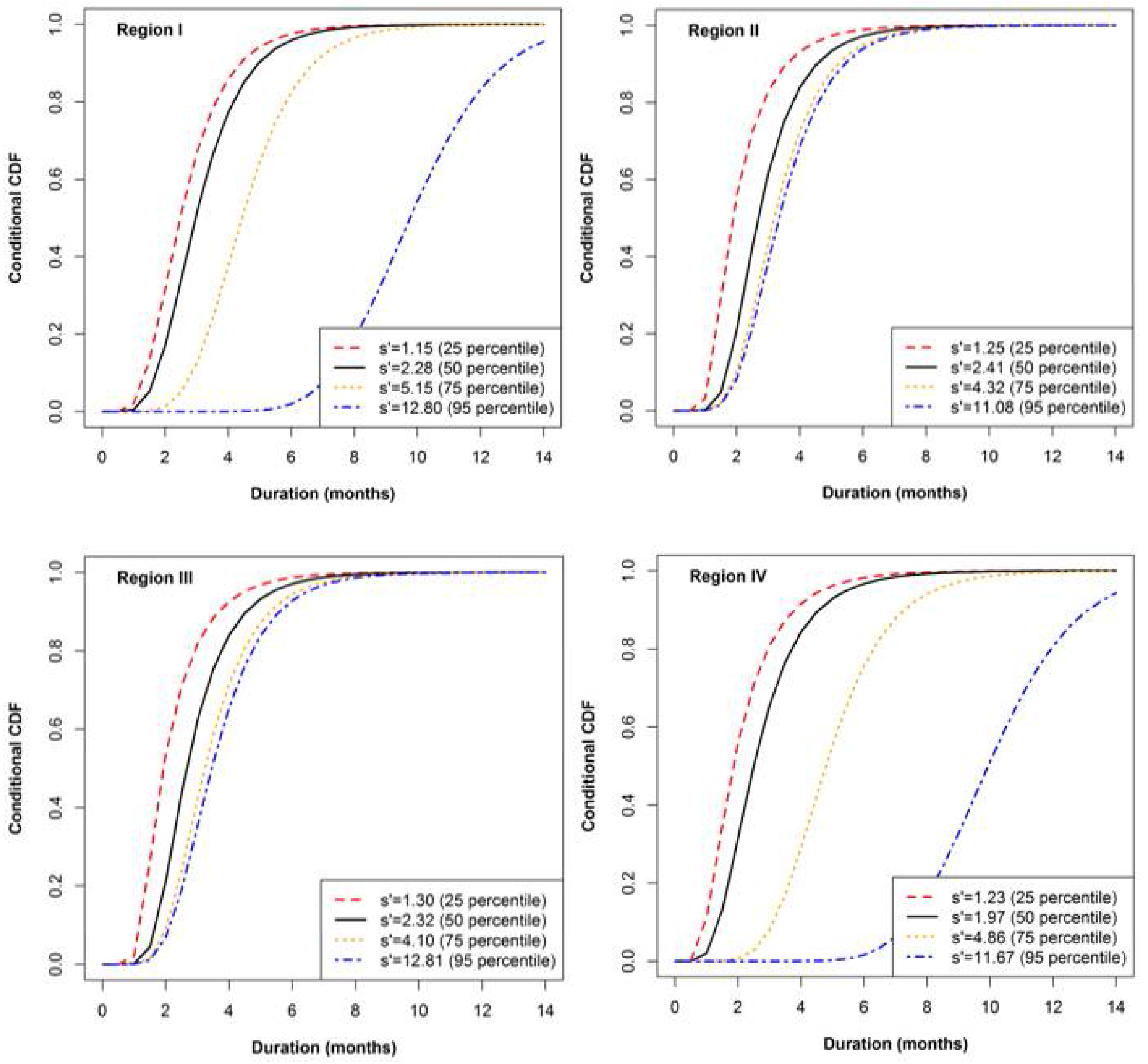
3.4. Conditional Probability
The copula-based joint distribution of drought duration and severity can provide very useful information for regional drought management. For illustration, the probability when drought duration and severity exceeds a threshold value, which can act as a special condition for a specific water demand and supply system, and may help to propose drought mitigation plan in the region. This probability can be easily derived with the help of copula-based joint distribution.
For example, if months and , as the threshold condition for water demand and the supply system of Region I, then the Kappa distribution would be and and the Gaussian copula would yield . Therefore, the probability that drought duration and severity exceeding three months and 2, respectively, will be equal to 0.20.
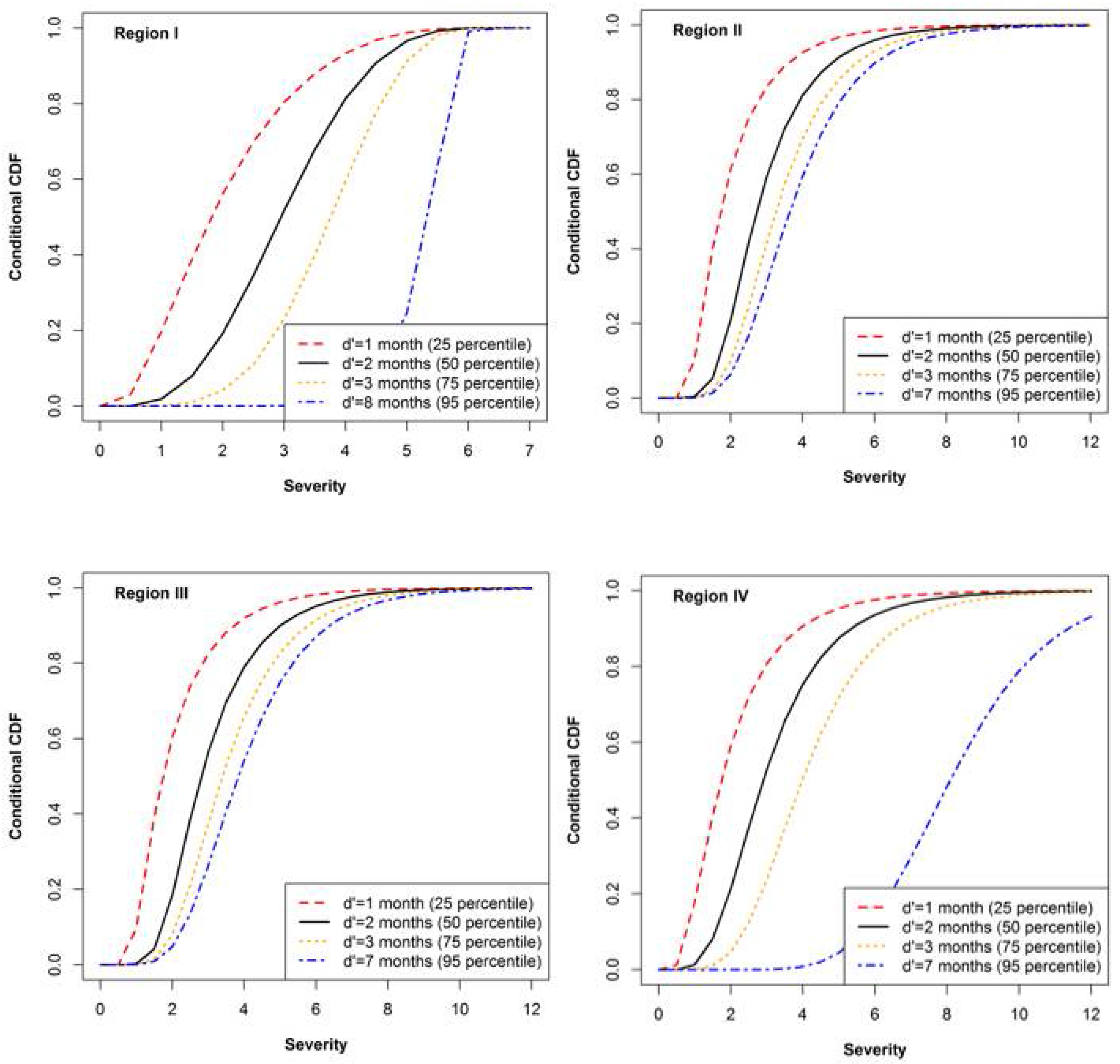
Water resource managers are interested to know about the conditional probability
of drought severity, given that drought durations exceeding the threshold values of
can be computed using Equation (4), and the conditional probability
of drought duration, given drought severity exceeding threshold values of
, can be computed using Equation (5). In this study,
and
took the threshold levels of the 25th, 50th, 75th, and 95th percentile, shown in
Figure 10 and
Figure 11. Both cases of conditional probability evaluated for the four regions (
) showed an increasing trend in the skewness of the conditional probability curves. Based on the computed conditional probability curves, water resource managers can extract useful information; for example, in the case of Region IV, the probabilities for a drought severity of less than 2 or 4, given a drought duration exceeding two months (50th percentile), will be equal to 0.235 and 0.785, respectively (
Figure 10). Similarly, the probabilities for a drought duration less than two or four months, given drought severity exceeding 1.97 (50th percentile), will be equal to 0.331 and 0. 853, respectively (
Figure 11).
Conditional probability curves also help us to evaluate and compare the drought risk between the regions. For example, for a drought severity of less than 3, given a drought duration exceeding three months (75th percentile), corresponding conditional probability ( values estimated for Regions I, II III, and IV are 0.532, 0.641, 0.612 and 0.596, respectively. This information can serve as basis to evaluate the capability of water demand and the supply system when considering different drought events, and can be used to trigger a drought contingency plan on regional scale.
3.5. Stochastic Simulation of Copulas and Bivariate Return Periods
The simulation of the copulas was performed using 5000 random samples generated from the Gaussian copula for Regions I and IV, and from the Frank copula for Regions II and III, as presented in
Figure 12. It can be observed that the simulated data (grey dots) for all regions fitted well with the observed data (red dots) of drought variables. A large number of “ties” (i.e., identical pairs of drought duration and severity) were observed at drought durations of one and two months, and the concentration of observed data decreased with an increase in drought duration. Simulated drought data also showed a similar trend, as it closely resembled that of the observed sample. Pearson’s r, Kendall’s τ, and Spearman’s rank ρ correlation coefficients of simulated drought data for Region I were 0.913, 0.748 and 0.916, respectively; for Region II they were 0.910, 0.839, and 0.967, respectively; for Region III, they were 0.925, 0.846, and 0.970, respectively; and for Region IV they were 0.914, 0.749, and 0.916, respectively. Among the three correlation coefficients, Kendall’s τ showed more variation from one region to another.
Figure 12 shows that the simulated data tend to concentrate along the main diagonal with the higher Kendall’s τ value (Regions II and III, with Kendall’s τ values of 0.839 and 0.846, respectively), and tend to disperse along the main diagonal with the lower Kendall’s τ value (Regions I and IV with Kendall’s τ values of 0.749 and 0.748 and, respectively). This shows that the behavior of a bivariate drought sample may change when the degree of association (e.g., Kendall’s τ) between the variables is considered. These results are in accordance with the findings of [
61] by using Frank and Gumbel copulas. The contour lines of joint return (standard) periods for 5, 10, 20, 50, 100, 200, and 500 years, computed using Equation (9), are shown in
Figure 12. Since the different combination of the correlated drought variables (duration and severity) can occur at the same time, the return periods are shown using contour lines, together with observed and simulated samples.
In drought frequency analysis, the droughts of longer duration and highest severities were always more important, because they can affect water resource planning and may pose a high risk to agriculture. Therefore, historical long-lasting drought events were identified for each region. In the case of Region I, the longest drought event recorded among 55 stations lasted for 13 months (
Table 3), at Jecheon station. It lasted from April 2008 to April 2009, with the corresponding severity of 16.04; the joint return period of this event is more than 1000 years. The second longest drought event was recorded at Suncheon and Miryang stations, with the duration of 10 months, from April 1988 to January 1989; their corresponding severities were 16.98 and 16.46, respectively, and the joint return period was closer to 500 years. Simultaneous occurrence of drought events was observed at both stations, and surrounding stations may have similar precipitation patterns.
In case of Region II, the two longest drought events had a duration of 12 months and 10 months, recorded at Yeongju station and Geochang station, respectively. The first lasted from March 1982 to February 1983, and the second from July 2008 to April 2009, and their corresponding severities were 22.30 and 21.50, respectively. In the case of Region III, the three longest drought events had an identical duration of 10 months, recorded at both Seoul and Incheon stations from March 2014 to December 2014, and at Buan station from April 1988 to January 1989; their corresponding severities were 15.44, 12.94, and 16.00, respectively, and their joint return periods were less than 500 years. Drought events at Seoul and Incheon stations occur simultaneously because of the possibility of having similar precipitation patterns at adjacent stations (
Figure 1). In the case of Region IV, the two longest drought events were recorded at Ganghwa and Mungyeong stations, from March 2014 to January 2015 and from March 1982 to December 1982, respectively, with the severities of 20.01 and 16.15, respectively; their joint return periods were nearly 200 and 500 years, respectively.
Since extreme drought events are more of a concern in drought frequency analysis, only droughts of the longest duration and highest severities were selected for spatial representation of drought risk maps. In this study, the drought events with
months and
were considered, being the droughts of longest duration and highest severities. This criterion was chosen because agriculture and surface water supplies are likely to be affected after six months. Additionally, this criteria was also recommend in previous studies [
62]. On the basis of the copula-based bivariate drought return period, the associated drought risk (R) can be computed using the equation
[
63], to impose the probability of extreme drought with a
year return period for N years of life span .
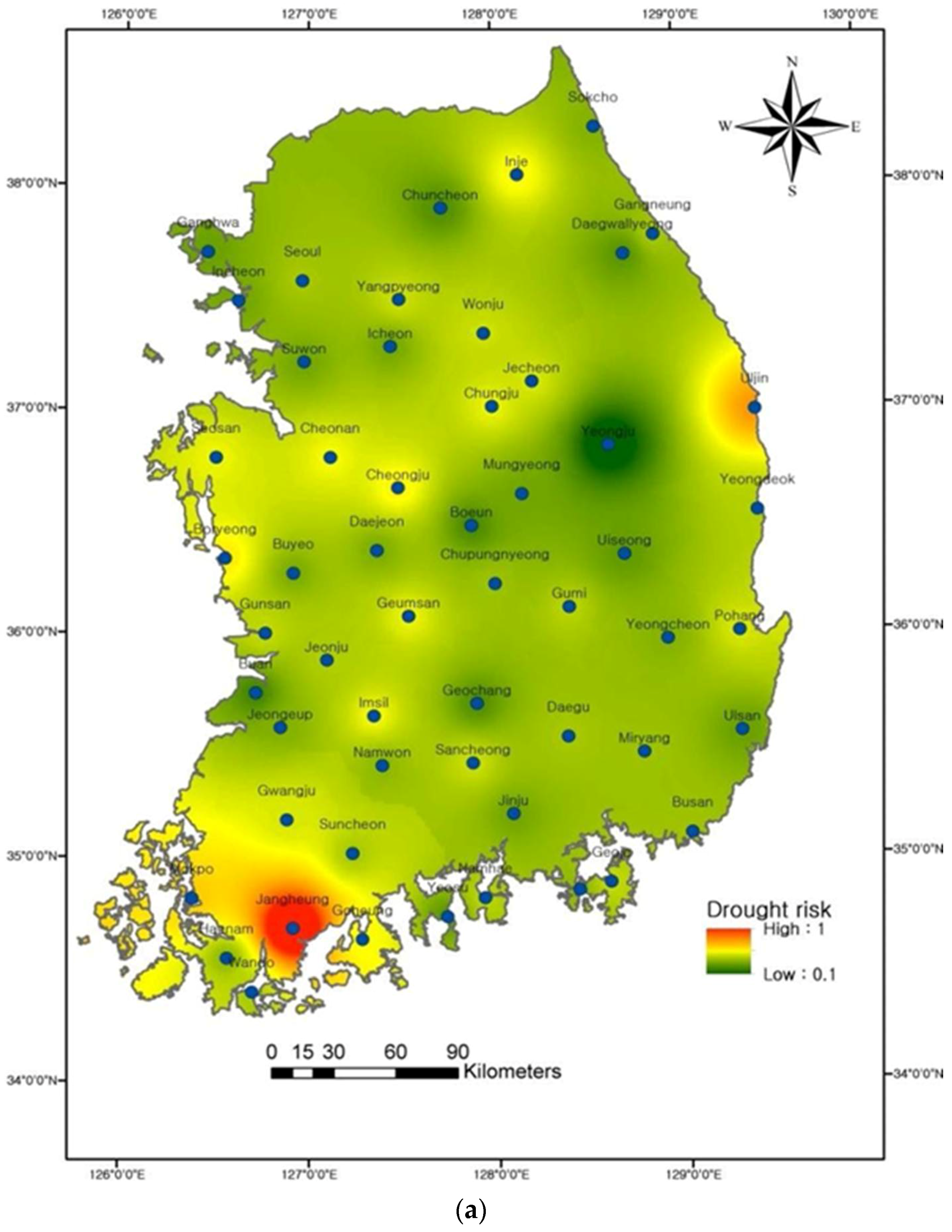
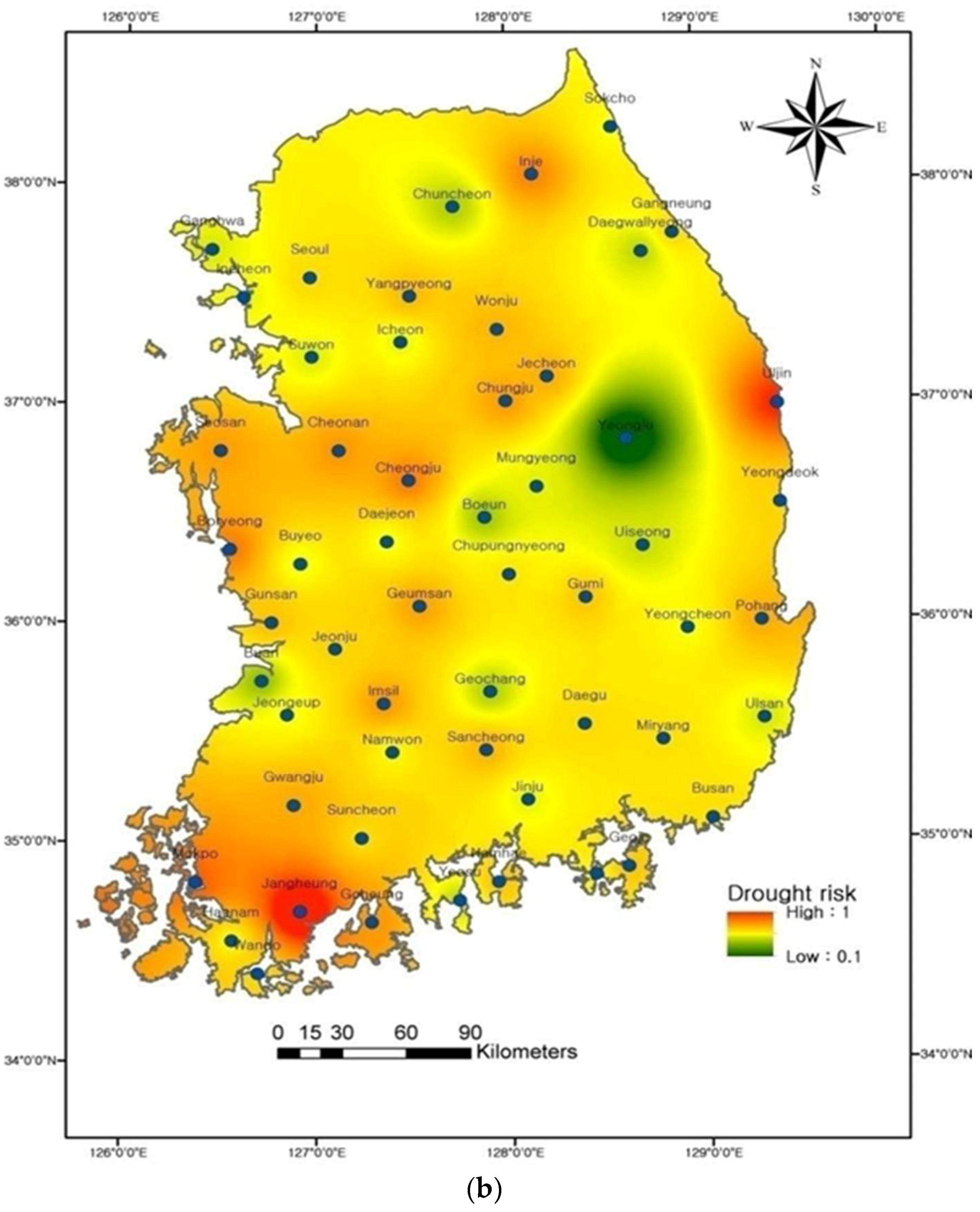
Figure 13 indicates spatial patterns of the regional drought risks, using the
observed at each site for the life spans of 10 and 50 years. In
Figure 13, green, yellow, and red colors indicate the areas of low, moderate, and high drought risks, respectively, and their values vary from 0 to 1. The drought risk map for N = 10 years shows low or nearly moderate drought risk, except on the southwestern coast (areas surrounding Jangheung, Goheung, Wando, and Mokpo stations) and the east coast (Uljin and Yeongdeok stations) of South Korea (
Figure 13a). In case when the N = 50 years, most of the areas fall under the category of moderate and high drought risk, except for the area surrounding Yeongju, Mungyeong, Ganghwa, and Chuncheon stations (
Figure 13b). Consequently, those regions which are located at the southern (Region I) and eastern coast (Region IV) of South Korea are under high drought risk, compared to other regions. This may be due to changes in precipitation patterns caused by the “Changma front”; thus, the rainy season becomes short, but the amount of the rainfall and the number of heavy rainfall days have increased at the southern and eastern coasts of South Korea [
20,
64]. Precipitation trend analysis showed the decline in annual mean precipitation on the southwest coast of South Korea [
21], which is therefore more vulnerable to drought risk. Kim et al. [
3] showed that extreme historical drought events mostly occurred in the central and southern regions of South Korea.
3.6. Comparison of the Bivariate Return Periods
Comparison of multivariate drought frequency analysis was performed using the best-fitted copulas for each region (
Table 9).
(“and”),
(“or”),
(Kendall’s), and
(conditional) joint return periods were computed for the duration of 2, 5, 10, 20, 50, 100, 200, 500, and 1000 years for the four regions, accounting for the bivariate drought properties (
Table 9).
,
,
,
, and
were computed using Equations (8)–(12), respectively. Since the primary, secondary, and conditional return periods explain the different situations, the preference of the return period may change, based on what type of drought risk needs to be evaluated for the area under study. The different levels of drought risks can be used to assess the malfunction of a specific water demand and supply system. For example, a particular water demand and supply system in Region I may be unable to supply water under a condition of drought severity exceeding 5.67, given a drought duration exceeding 4.41 months. The return period in this situation will be equal to 30.16 years, computed using Equation (12).
Table 9 shows the difference in the return period, according to the considered type of risk. For example, for Region I, at a univariate return period of 100 years, the values of drought duration and severities are 8.50 months and 9.65, respectively. However, joint bivariate return periods of drought variables show the return period being 9.95 years for
(D ≥ 8.50 and S ≥ 9.65) and 8.28 years for
(D ≥ 8.50 or S ≥ 9.65). Similarly, conditional and secondary return periods for
,
, and
are 96.04, 84.56, and 9.14 years, respectively. Furthermore,
Table 9 shows that Kendall return periods
are always greater than the
return periods and smaller than the
return periods.
is always smaller than
because the probability of occurrence of two cases simultaneously is always smaller than when only one of the two cases occur. The results match well with the finding of [
61]. Moreover, it is noticed that the difference between
and
increases with an increase in critical probability level t. Results showed that conditional return periods
and
are always greater than the primary and secondary return periods
,
, and
, and the conditional return period
was greater than
. However, direct comparison of different return periods is a difficult task, because each type of return period has a different physical meaning in drought risk analysis.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}