Hybrid Models Combining EMD/EEMD and ARIMA for Long-Term Streamflow Forecasting



Abstract
:1. Introduction
2. Methodology
2.1. Empirical Mode Decomposition (EMD)
- 1.
- Let { ∈ X: t = 1, 2, …, N} denote the original average ten-day hydrological time series. All the local extremes of are identified and all the maxima and minima are connected by a cubic spline line [48] to form the upper envelope and lower envelope . However, the spline fitting method has a serious problem at the end point where the cubic spline can have a wide swing. In order to deal with this problem, Huang et al. [37] extended the original time series by adding characteristic waves at the ends which are defined by the two consecutive extrema for both their frequency and amplitude of the added waves. This method has been proved to be able to confine the large swings successfully. In this study, we choose the ‘wave’ boundary condition to extend the time series based on the EMD package in software R.
- 2.
- The mean of the upper envelope and lower envelope is calculated by Equation (1),
- 3.
- Subtract from the original time series to obtain the component as shown in Equation (2).
2.2. Ensemble Empirical Mode Decomposition (EEMD)
- Set the ensemble number and amplitude of white noise added sequence.
- Add a set of white noise to the original data with the determinate amplitude.
- Decompose the time sequence with the added white noise in the ensemble into IMFs by EMD.
- Repeat steps 2 and 3 until all the time series in the ensemble have been decomposed. Every time a new white noise sequence is added, the final mean of the corresponding IMFs in the ensemble are the true IMFs.
2.3. Autoregressive Integrated Moving Average (ARIMA) Model
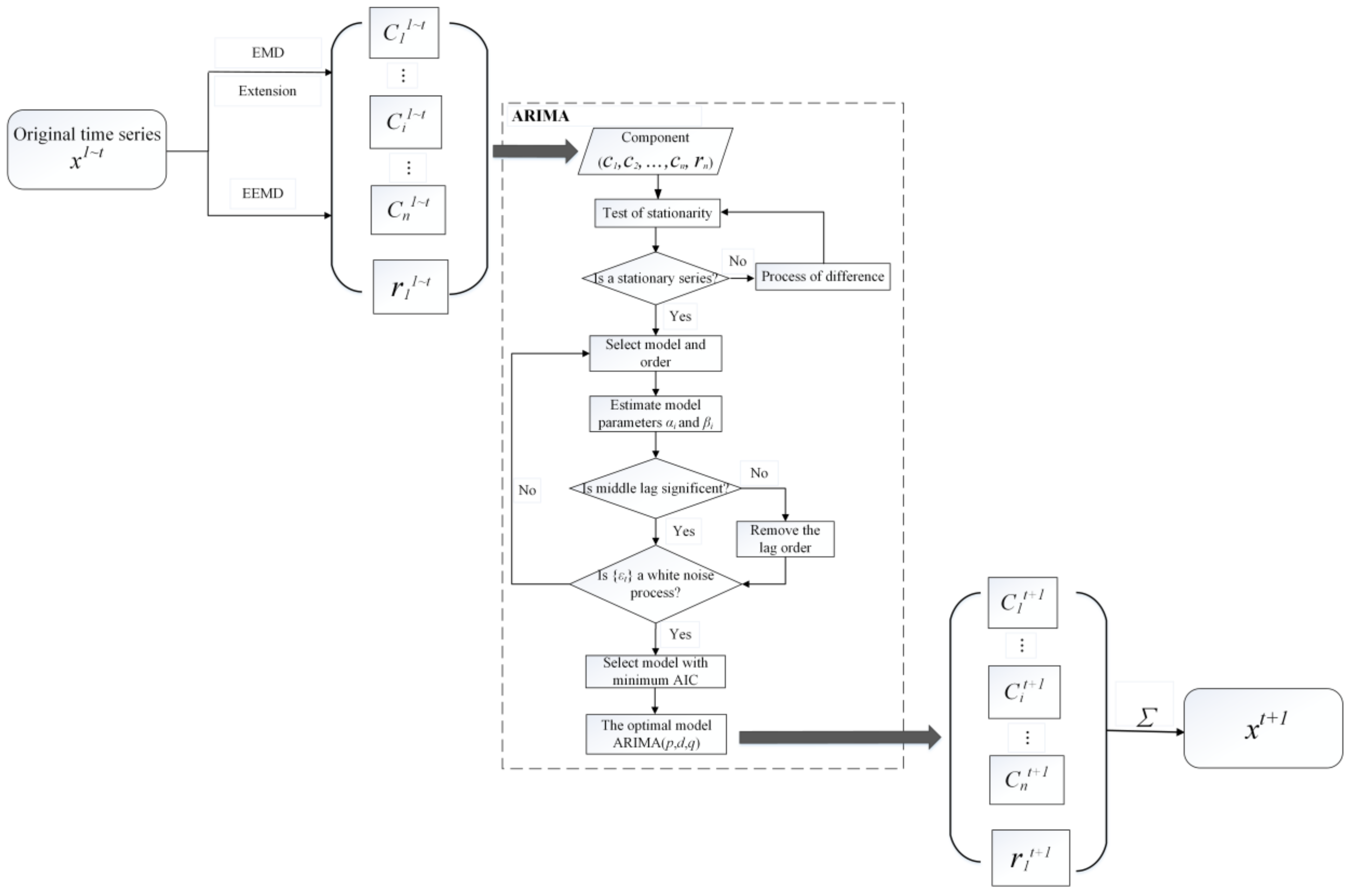
2.4. EMD/EEMD-ARIMA Hybrid Prediction Model
- 1.
- Let { ∈ X: t = 1, 2, …, N} denote the original average ten-day hydrological time series.
- 2.
- Divide the time series into calibration datasets { ∈ X: t = 1, 2, …, k} and validation datasets { ∈ X: t = k, k + 1, …, n}.
- 3.
- Decompose the time series by EMD and EEMD to obtain IMFs and residual .
- 4.
- Establish appropriate ARIMA models with appropriate parameters for each IMF and residual. Box and Jenkins [50] set the standard for modeling stationary time series by using ARIMA model. The detailed modeling process of ARIMA model mainly includes: ① Let { ∈ Z: t = 1, 2, …, N} denotes the time series that need to be modeled; ② Check whether satisfies the condition of stationary time series by the unit root test. If the time series is a non-stationary time series, that means there are unit roots in the time series, and the original time series needs to be differentiated to obtain a stationary time series ; ③ Select appropriate models (AR model, MA model or ARMA model), and the lag order can be based on an autocorrelation (AC) function and the partial correlation (PAC) function of the stationary time series ; ④ Estimate the parameters in the model. If some of the parameters in the middle lag are too small, the parameters are not significant (the significance level used in this study is 5%); these lag orders need to be removed from the model; ⑤ Residuals of the model are determined to be white noise or not; if residual sequences are white noise, the autocorrelation coefficients of non-zero lag are all zero. This can be tested by the Q statistic (shown in Equation (13)) proposed by Box et al. [51] and Ljung et al. [52].where is the sample’s autocorrelation coefficient, and if the sample size is large enough, . The Q-statistic approximately obeys a distribution and the degree of freedom is s. If the residual sequence is not white noise, then the model needs to be improved; ⑥ The model with the minimum AIC (Akaike Information Criterion) [53] is chosen as the optimal model from many models which satisfy the conditions in steps ②–⑤).
- 5.
- Use the candidate models ARIMA (p, d, q) to compute one-time step ahead forecast across all the components of EMD/EEMD which would result in component forecasts (). The prediction of one time step ahead is the sum of each component prediction (shown in Equation (11)).In order to be fairly compared with the ARIMA model, the prediction of the hybrid model is also carried out at one-time step ahead every time.
- 6.
- Record observed data for one-time step ahead. Add these data to and decompose the updated calibration datasets. Repeat steps 3–5 until obtain all components are forecast for the complete original time series.
2.5. Verification Strategy
3. Case Study
3.1. Study Case
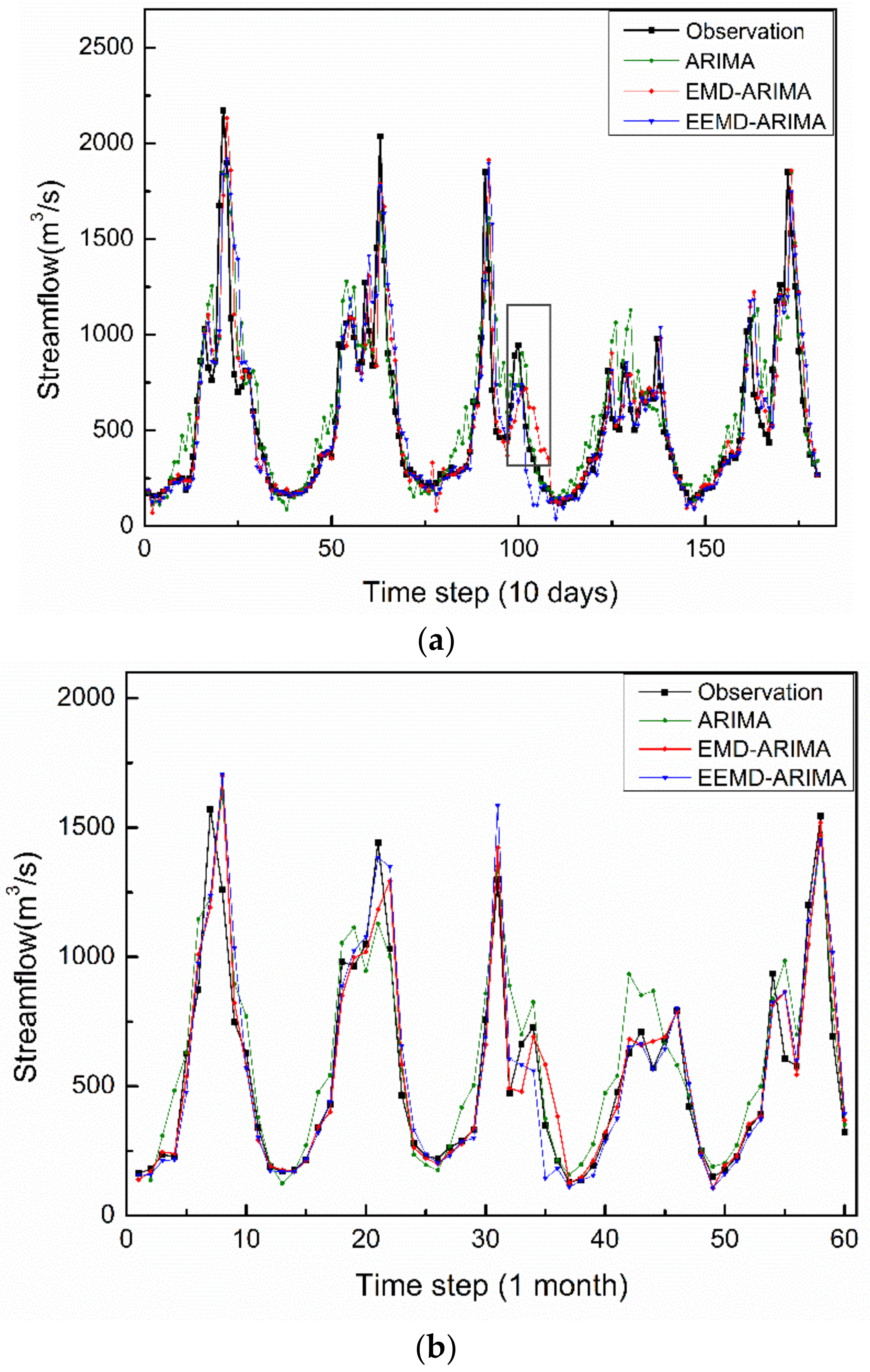
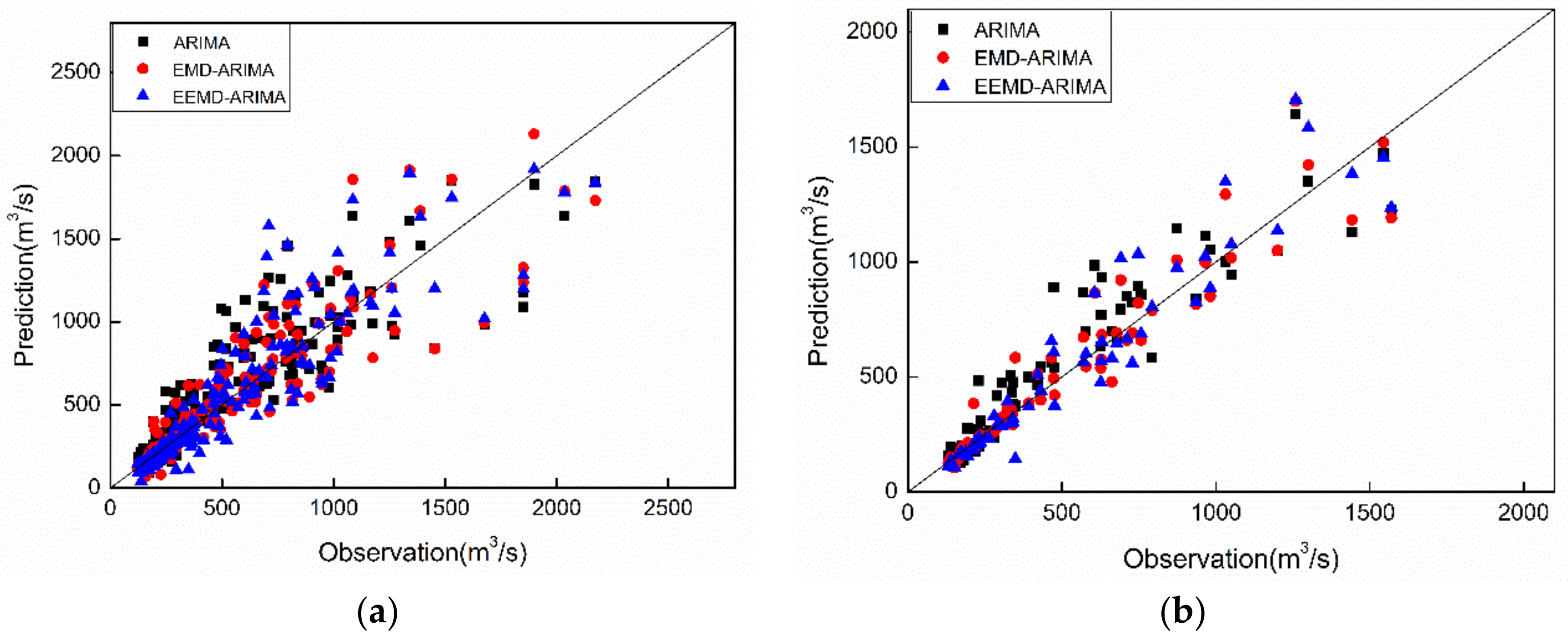
3.2. Results
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yang, L.; Tian, F.; Sun, Y.; Yuan, X.; Hu, H. Attribution of hydrologic forecast uncertainty within scalable forecast windows. Hydrol. Earth Syst. Sci. 2014, 18, 775–786. [Google Scholar] [CrossRef] [Green Version]
- Seo, Y.; Kim, S.; Kisi, O.; Singh, V.P. Daily water level forecasting using wavelet decomposition and artificial intelligence techniques. J. Hydrol. 2015, 520, 224–243. [Google Scholar] [CrossRef]
- He, Z.; Wen, X.; Liu, H.; Du, J. A comparative study of artificial neural network, adaptive neuro fuzzy inference system and support vector machine for forecasting river flow in the semiarid mountain region. J. Hydrol. 2014, 509, 379–386. [Google Scholar] [CrossRef]
- Borga, M.; Stoffel, M.; Marchi, L.; Marra, F.; Jakob, M. Hydrogeomorphic response to extreme rainfall in headwater systems: Flash floods and debris flows. J. Hydrol. 2014, 518, 194–205. [Google Scholar] [CrossRef]
- Strauch, M.; Bernhofer, C.; Koide, S.; Volk, M.; Lorz, C.; Makeschin, F. Using precipitation data ensemble for uncertainty analysis in SWAT streamflow simulation. J. Hydrol. 2012, 414, 413–424. [Google Scholar] [CrossRef]
- Ralph, F.M.; Coleman, T.; Neiman, P.J.; Zamora, R.J.; Dettinger, M.D. Observed impacts of duration and seasonality of atmospheric-river landfalls on soil moisture and runoff in coastal Northern California. J. Hydrometeorol. 2013, 14, 443–459. [Google Scholar] [CrossRef]
- Hanna, E.; Jones, J.M.; Cappelen, J.; Mernild, S.H.; Wood, L.; Steffen, K.; Huybrechts, P. The influence of North Atlantic atmospheric and oceanic forcing effects on 1900–2010 Greenland summer climate and ice melt/runoff. Int. J. Climatol. 2013, 33, 862–880. [Google Scholar] [CrossRef]
- Rosenberg, E.A.; Clark, E.A.; Steinemann, A.C.; Lettenmaier, D.P. On the contribution of groundwater storage to interannual streamflow anomalies in the Colorado River basin. Hydrol. Earth Syst. Sci. 2013, 17. [Google Scholar] [CrossRef]
- Sinha, T.; Sankarasubramanian, A.; Mazrooei, A. Decomposition of sources of errors in monthly to seasonal streamflow forecasts in a rainfall-runoff regime. J. Hydrometeorol. 2014, 15, 2470–2483. [Google Scholar] [CrossRef]
- Aqil, M.; Kita, I.; Yano, A.; Nishiyama, S. A comparative study of artificial neural networks and neuro-fuzzy in continuous modeling of the daily and hourly behaviour of runoff. J. Hydrol. 2007, 337, 22–34. [Google Scholar] [CrossRef]
- Kalra, A.; Miller, W.P.; Lamb, K.W.; Ahmad, S.; Piechota, T. Using large-scale climatic patterns for improving long lead time streamflow forecasts for Gunnison and San Juan River Basins. Hydrol. Process. 2013, 27, 1543–1559. [Google Scholar] [CrossRef]
- Verkade, J.S.; Brown, J.D.; Reggiani, P.; Weerts, A.H. Post-processing ECMWF precipitation and temperature ensemble reforecasts for operational hydrologic forecasting at various spatial scales. J. Hydrol. 2013, 501, 73–91. [Google Scholar] [CrossRef]
- Aubert, A.H.; Tavenard, R.; Emonet, R.; de Lavenne, A.; Malinowski, S.; Guyet, T.; Quiniou, R.; Odobez, J.M.; Merot, P.; Gascuel-Odoux, C. Clustering flood events from water quality time series using Latent Dirichlet Allocation model. Water Resour. Res. 2013, 49, 8187–8199. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.C.; Chau, K.W.; Qiu, L.; Chen, Y.B. Improving forecasting accuracy of medium and long-term runoff using artificial neural network based on EEMD decomposition. Environ. Res. 2015, 139, 46–54. [Google Scholar] [CrossRef] [PubMed]
- Gulhane, P.; Menezes, B.; Reddy, T.; Shah, K.; Soman, S.A. Forecasting using decomposition and combinations of experts. In Proceedings of the 2005 International Conference on Artificial Intelligence (ICAI ‘05), Las Vegas, NV, USA, 27–30 June 2005; Arabnia, H.R., Joshua, R., Eds.; CSREA Press: Athens, Greece, 2005; pp. 67–73. ISBN 1-932415-68-8. [Google Scholar]
- Kalteh, A.M. Monthly river flow forecasting using artificial neural network and support vector regression models coupled with wavelet transform. Comput. Geosci. 2013, 54, 1–8. [Google Scholar] [CrossRef]
- Dehghani, M.; Saghafian, B.; Saleh, F.N.; Farokhnia, A.; Noori, R. Uncertainty analysis of streamflow drought forecast using artificial neural networks and Monte-Carlo simulation. Int. J. Climatol. 2014, 34, 1169–1180. [Google Scholar] [CrossRef]
- Dariane, A.B.; Azimi, S. Forecasting streamflow by combination of a genetic input selection algorithm and wavelet transforms using ANFIS models. Hydrol. Sci. J. 2016, 61, 585–600. [Google Scholar] [CrossRef]
- Shi, B.; Hu, C.H.; Yu, X.H.; Hu, X.X. New fuzzy neural network-Markov model and application in mid- to long-term runoff forecast. Hydrol. Sci. J. 2016, 61, 1157–1169. [Google Scholar] [CrossRef]
- Lohani, A.K.; Kumar, R.; Singh, R.D. Hydrological time series modeling: A comparison between adaptive neuro-fuzzy, neural network and autoregressive techniques. J. Hydrol. 2012, 442, 23–35. [Google Scholar] [CrossRef]
- Dong, S.; Chi, K.; Zhang, Q.Y.; Zhang, X.D. The application of a Grey Markov Model to forecasting annual maximum water levels at hydrological stations. J. Ocean Univ. China 2012, 11, 13–17. [Google Scholar] [CrossRef]
- Wu, J.S.; Han, J.; Annambhotla, S.; Bryant, S. Artificial neural networks for forecasting watershed runoff and stream flows. J. Hydrol. Eng. 2005, 10, 216–222. [Google Scholar] [CrossRef]
- Chang, F.J.; Chiang, Y.M.; Chang, L.C. Multi-step-ahead neural networks for flood forecasting. Hydrol. Sci. J. 2007, 52, 114–130. [Google Scholar] [CrossRef] [Green Version]
- Sudheer, C.; Maheswaran, R.; Panigrahi, B.K.; Mathur, S. A hybrid SVM-PSO model for forecasting monthly streamflow. Neural Comput. Appl. 2013, 24, 1381–1389. [Google Scholar] [CrossRef]
- Nanda, T.; Sahoo, B.; Beria, H.; Chatterjee, C. A wavelet-based non-linear autoregressive with exogenous inputs (WNARX) dynamic neural network model for real-time flood forecasting using satellite-based rainfall products. J. Hydrol. 2016, 539, 57–73. [Google Scholar] [CrossRef]
- Armstrong, J.S. Combing forecast—The end of the beginning or the beginning of the end. Int. J. Forecast. 1989, 5, 585–588. [Google Scholar] [CrossRef]
- Temraz, H.K.; Salama, M.M.A.; Quintana, V.H. Application of the decomposition technique for forecasting the load of a large electric power network. IEE Proc. Gener. Transm. Distrib. 1996, 143, 13–18. [Google Scholar] [CrossRef]
- Zou, H.; Yang, Y.H. Combining time series models for forecasting. Int. J. Forecast. 2004, 20, 69–84. [Google Scholar] [CrossRef] [Green Version]
- Hibon, M.; Evgeniou, T. To combine or not to combine: Selecting among forecasts and their combinations. Int. J. Forecast. 2005, 21, 15–24. [Google Scholar] [CrossRef]
- Wu, C.L.; Chau, K.W.; Fan, C. Prediction of rainfall time series using modular artificial neural networks coupled with data-preprocessing techniques. J. Hydrol. 2010, 389, 146–167. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.S.; Chiu, S.H.; Lin, T.Y. Empirical mode decomposition-based least squares support vector regression for foreign exchange rate forecasting. Econ. Model. 2012, 29, 2583–2590. [Google Scholar] [CrossRef]
- Nourani, V.; Hosseini Baghanam, A.; Adamowski, J.; Kisi, O. Applications of hybrid wavelet–Artificial Intelligence models in hydrology: A review. J. Hydrol. 2014, 514, 358–377. [Google Scholar] [CrossRef]
- Nourani, V.; Komasi, M.; Alami, M.T. Hybrid wavelet–genetic programming approach to optimize ANN modeling of rainfall–runoff process. J. Hydrol. Eng. 2012, 17, 724–741. [Google Scholar] [CrossRef]
- Badrzadeh, H.; Sarukkalige, R.; Jayawardena, A.W. Improving ANN-based short-term and long-term seasonal river flow forecasting with signal processing techniques. River Res. Appl. 2016, 32, 245–256. [Google Scholar] [CrossRef]
- Liu, Y.Q.; Brown, J.; Demargne, J.; Seo, D.J. A wavelet-based approach to assessing timing errors in hydrologic predictions. J. Hydrol. 2011, 397, 210–224. [Google Scholar] [CrossRef]
- Maheswaran, R.; Khosa, R. Comparative study of different wavelets for hydrologic forecasting. Comput. Geosci. 2012, 46, 284–295. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.L.C.; Shih, H.H.; Zheng, Q.N.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Huang, N.E.; Wu, Z. A review on Hilbert-Huang transform: Method and its applications to geophysical studies. Rev. Geophys. 2008, 46. [Google Scholar] [CrossRef] [Green Version]
- Lee, T.; Ouarda, T.B.M.J. Long-term prediction of precipitation and hydrologic extremes with nonstationary oscillation processes. J. Geophys. Res. 2010, 115. [Google Scholar] [CrossRef] [Green Version]
- Zhu, S.; Zhou, J.; Ye, L.; Meng, C. Streamflow estimation by support vector machine coupled with different methods of time series decomposition in the upper reaches of Yangtze River, China. Environ. Earth Sci. 2016, 75. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. Theory Appl. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Chiew, F.H.S.; Peel, M.C.; Amirthanathan, G.E.; Pegram, G.G.S. Identification of oscillations in historical global streamflow data using empirical mode decomposition. In Regional Hydrological Impacts of Climatic Change—Hydroclimatic Variability; Franks, S., Wagener, T., Bogh, E., Gupta, H.V., Bastidas, L., Nobre, C., Galvao, C.D.O., Eds.; International Association Hydrological Sciences: Wallingford, UK, 2005; Volume 296, pp. 53–62. ISBN 978-1-901502-13-8. [Google Scholar]
- Zhang, H.; Singh, V.P.; Wang, B.; Yu, Y. CEREF: A hybrid data-driven model for forecasting annual streamflow from a socio-hydrological system. J. Hydrol. 2016, 540, 246–256. [Google Scholar] [CrossRef]
- Zhang, X.; Peng, Y.; Zhang, C.; Wang, B. Are hybrid models integrated with data preprocessing techniques suitable for monthly streamflow forecasting? Some experiment evidences. J. Hydrol. 2015, 530, 137–152. [Google Scholar] [CrossRef]
- Kisi, O.; Latifoğlu, L.; Latifoğlu, F. Investigation of empirical mode decomposition in forecasting of hydrological time series. Water Res. Manag. 2014, 28, 4045–4057. [Google Scholar] [CrossRef]
- Di, C.L.; Yang, X.H.; Wang, X.C. A four-stage hybrid model for hydrological time series forecasting. PLoS ONE 2014, 9, e104663. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Chen, X. Auto regressive and ensemble empirical mode decomposition hybrid model for annual runoff forecasting. Water Res. Manag. 2015, 29, 2913–2926. [Google Scholar] [CrossRef]
- Hou, H.S.; Andrews, H.C. Cubic-splines for image interpolation and digital filtering. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 508–517. [Google Scholar]
- Valipour, M.; Banihabib, M.E.; Behbahani, S.M.R. Comparison of the ARMA, ARIMA, and the autoregressive artificial neural network models in forecasting the monthly inflow of Dez dam reservoir. J. Hydrol. 2013, 476, 433–441. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G. Time series analysis, forecasting and control. In Time Series Analysis, Forecasting and Control; INSPEC:209917; Holden-Day: San Francisco, CA, USA, 1970; pp. 19–553. [Google Scholar]
- Box, G.E.P.; Pierce, D.A. Distribution of residual autocorrelations in autoregressive-integrated moving average time series models. J. Am. Stat. Assoc. 1970, 65, 1509–1526. [Google Scholar] [CrossRef]
- Ljung, G.M.; Box, G.E.P. Measure of lack of fit in time-series models. Biometrika 1978, 65, 297–303. [Google Scholar] [CrossRef]
- Akaike, H. Bayesian-analysis of minimum AIC procedure. Ann. Inst. Stat. Math. 1978, 30, 9–14. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Ten-Day Prediction | Monthly Prediction | ||||||
|---|---|---|---|---|---|---|---|---|
| MAPE | RMSE (m3/s) | MAE (m3/s) | R | MAPE | RMSE (m3/s) | MAE (m3/s) | R | |
| ARIMA | 0.284 | 214.75 | 143.67 | 0.870 | 0.232 | 153.21 | 111.60 | 0.930 |
| EMD-ARIMA | 0.186 | 182.00 | 109.40 | 0.903 | 0.127 | 121.260 | 74.77 | 0.950 |
| EEMD-ARIMA | 0.194 | 196.44 | 117.71 | 0.894 | 0.137 | 129.28 | 80.90 | 0.950 |
| Model | Ten-Day Prediction | Monthly Prediction |
|---|---|---|
| Skill Score | Skill Score | |
| EMD-ARIMA | 0.239 | 0.330 |
| EEMD-ARIMA | 0.181 | 0.275 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.-Y.; Qiu, J.; Li, F.-F. Hybrid Models Combining EMD/EEMD and ARIMA for Long-Term Streamflow Forecasting. Water 2018, 10, 853. https://doi.org/10.3390/w10070853
Wang Z-Y, Qiu J, Li F-F. Hybrid Models Combining EMD/EEMD and ARIMA for Long-Term Streamflow Forecasting. Water. 2018; 10(7):853. https://doi.org/10.3390/w10070853
Chicago/Turabian StyleWang, Zhi-Yu, Jun Qiu, and Fang-Fang Li. 2018. "Hybrid Models Combining EMD/EEMD and ARIMA for Long-Term Streamflow Forecasting" Water 10, no. 7: 853. https://doi.org/10.3390/w10070853
APA StyleWang, Z.-Y., Qiu, J., & Li, F.-F. (2018). Hybrid Models Combining EMD/EEMD and ARIMA for Long-Term Streamflow Forecasting. Water, 10(7), 853. https://doi.org/10.3390/w10070853