Hourly Urban Water Demand Forecasting Using the Continuous Deep Belief Echo State Network

Abstract
:1. Introduction
2. Methodology
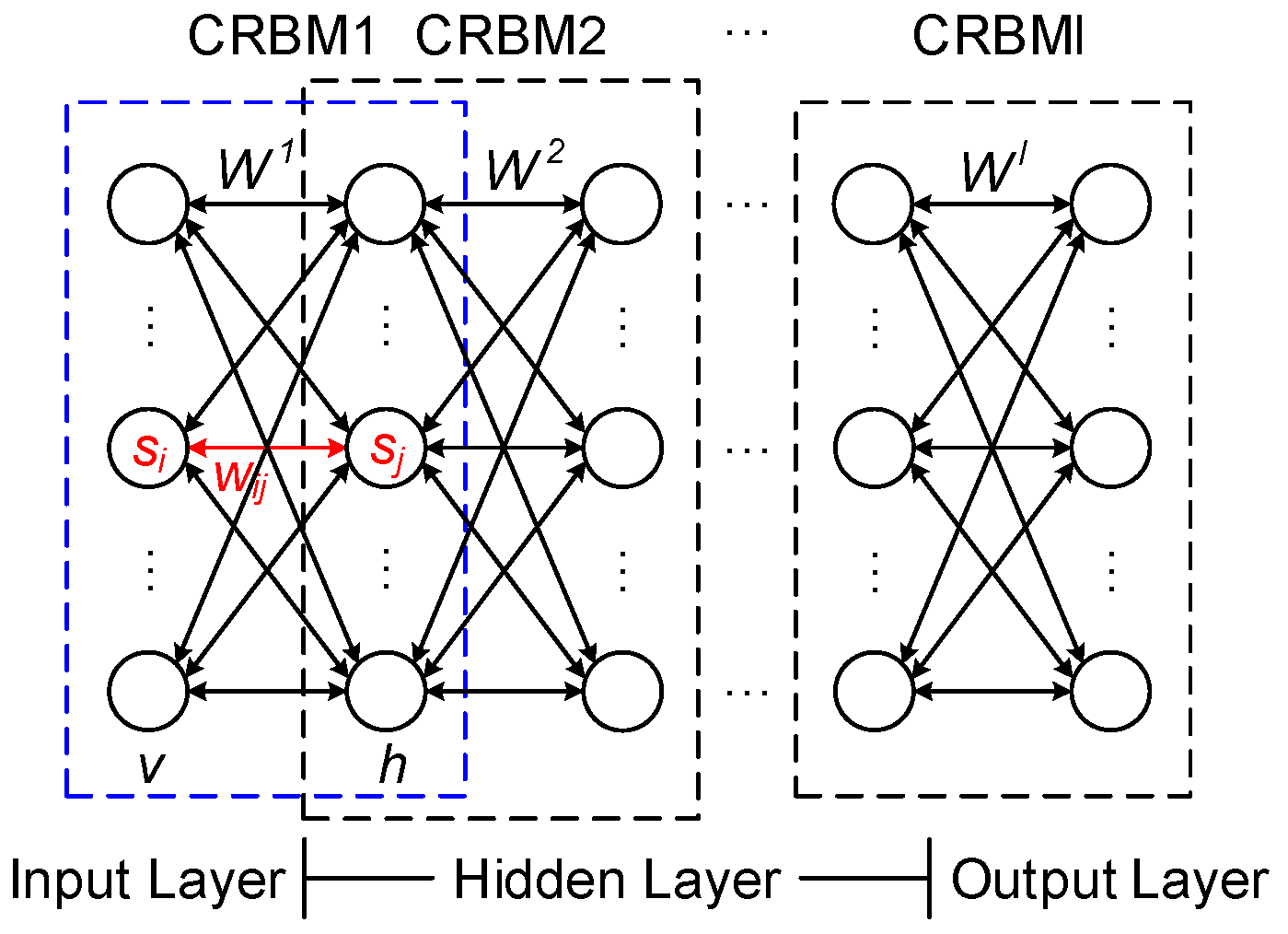
2.1. Continuous Deep Belief Network
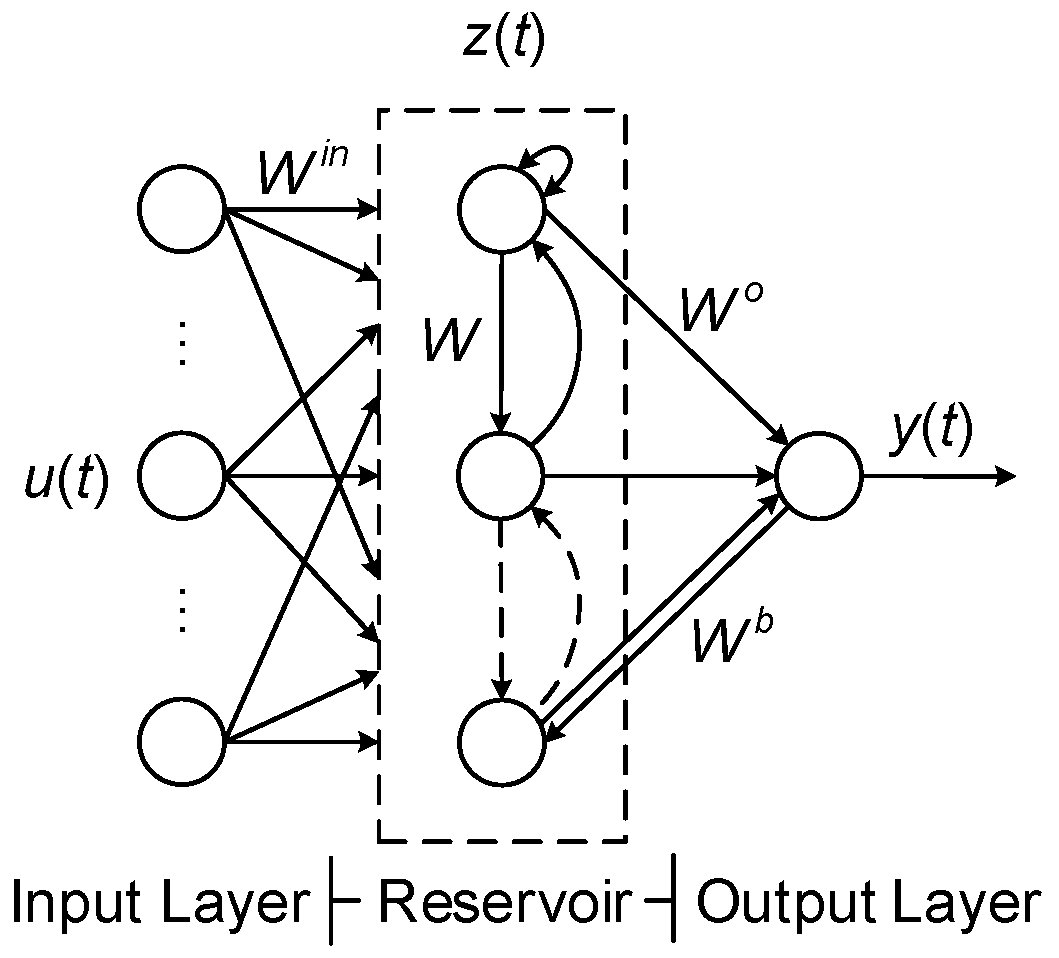
2.2. Echo State Network
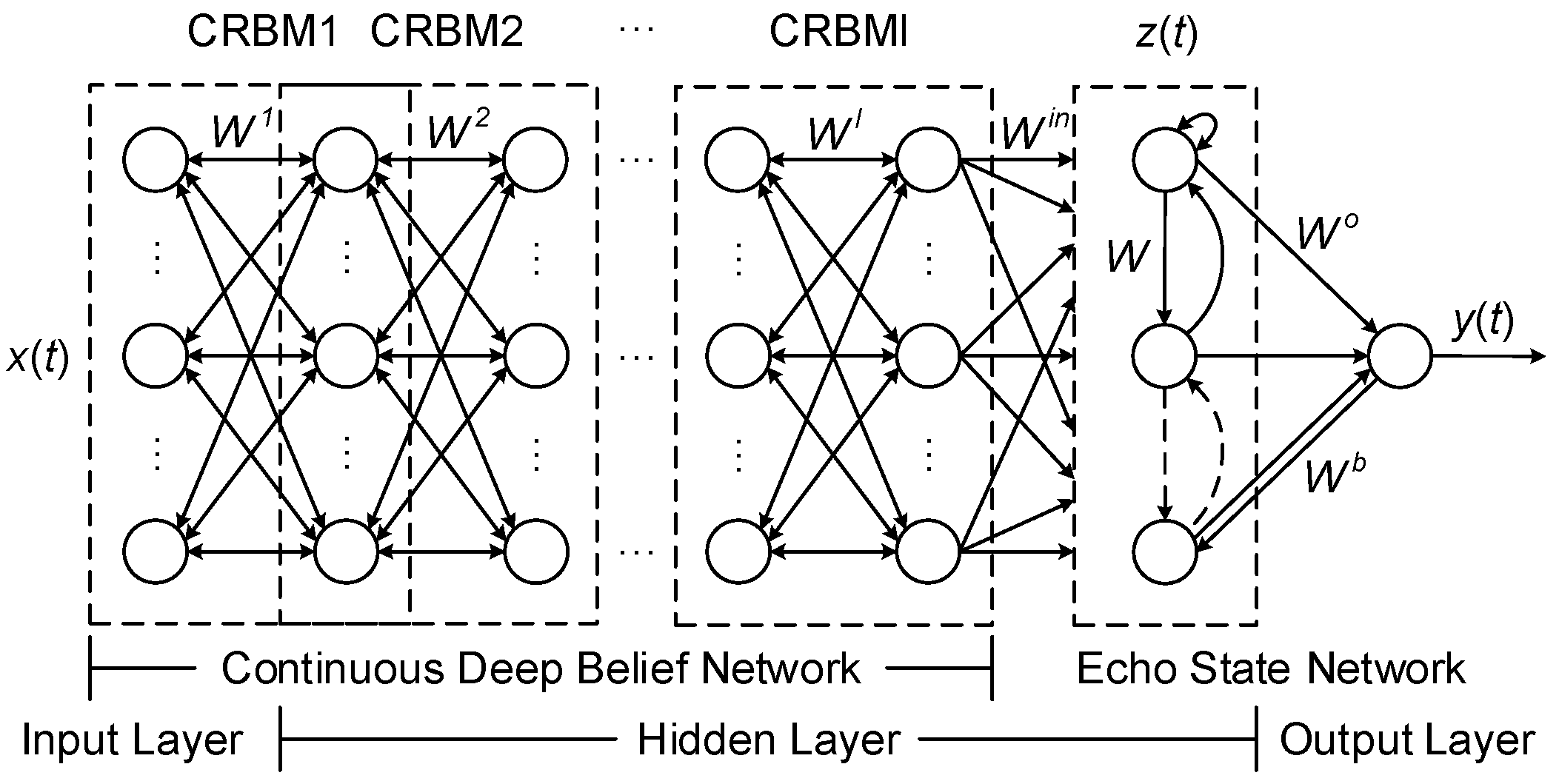
2.3. CDBESN Model
3. Application Example
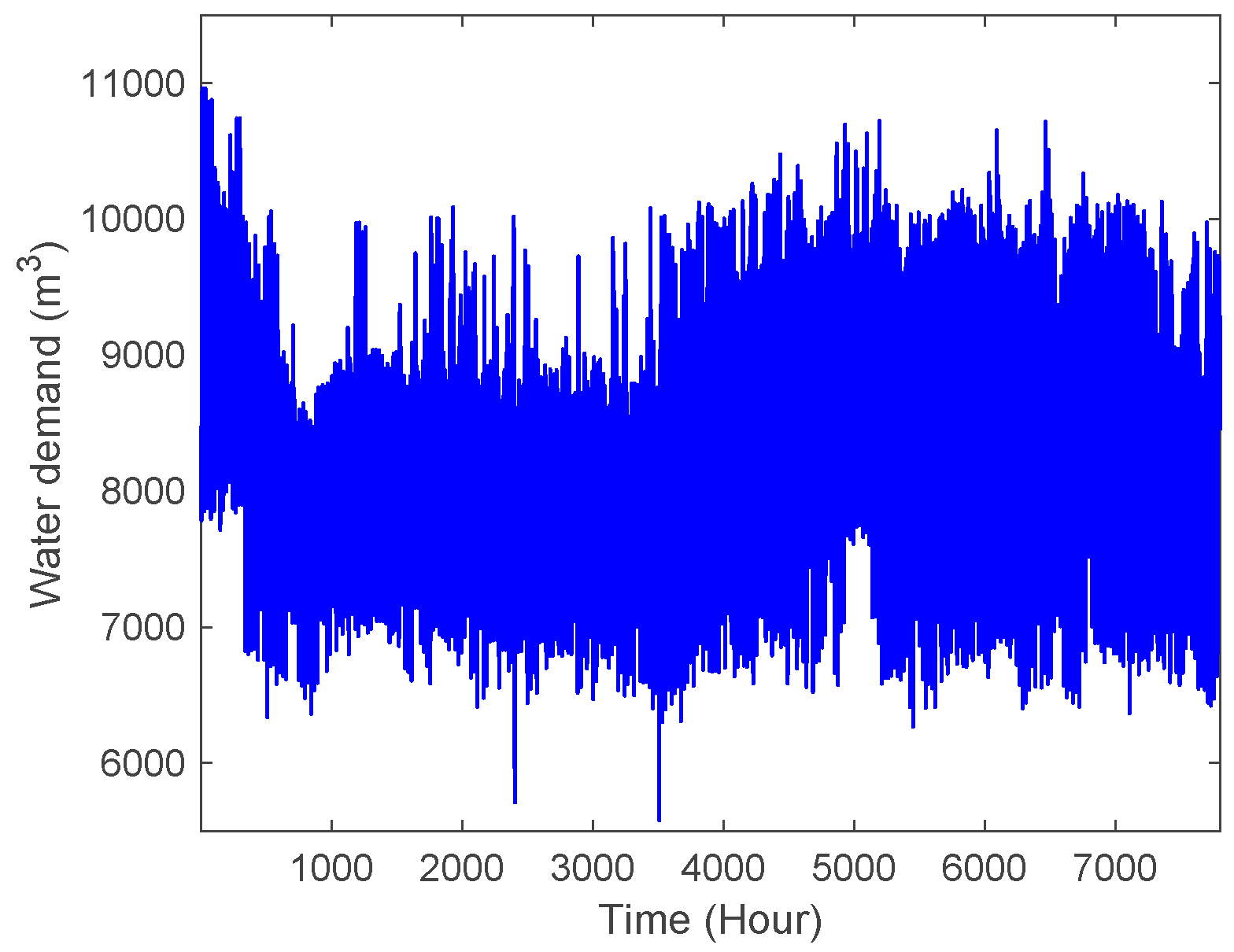
3.1. Study Area and Data Collection
3.2. Performance Index
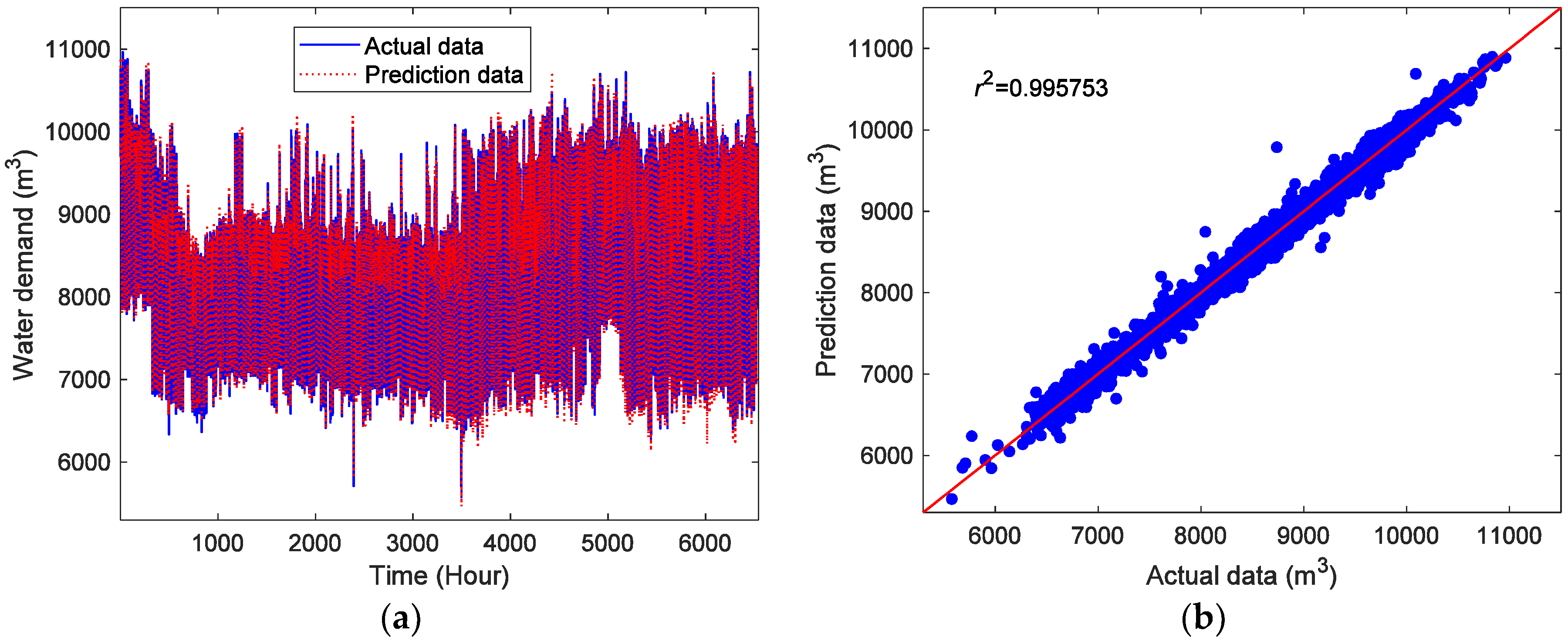
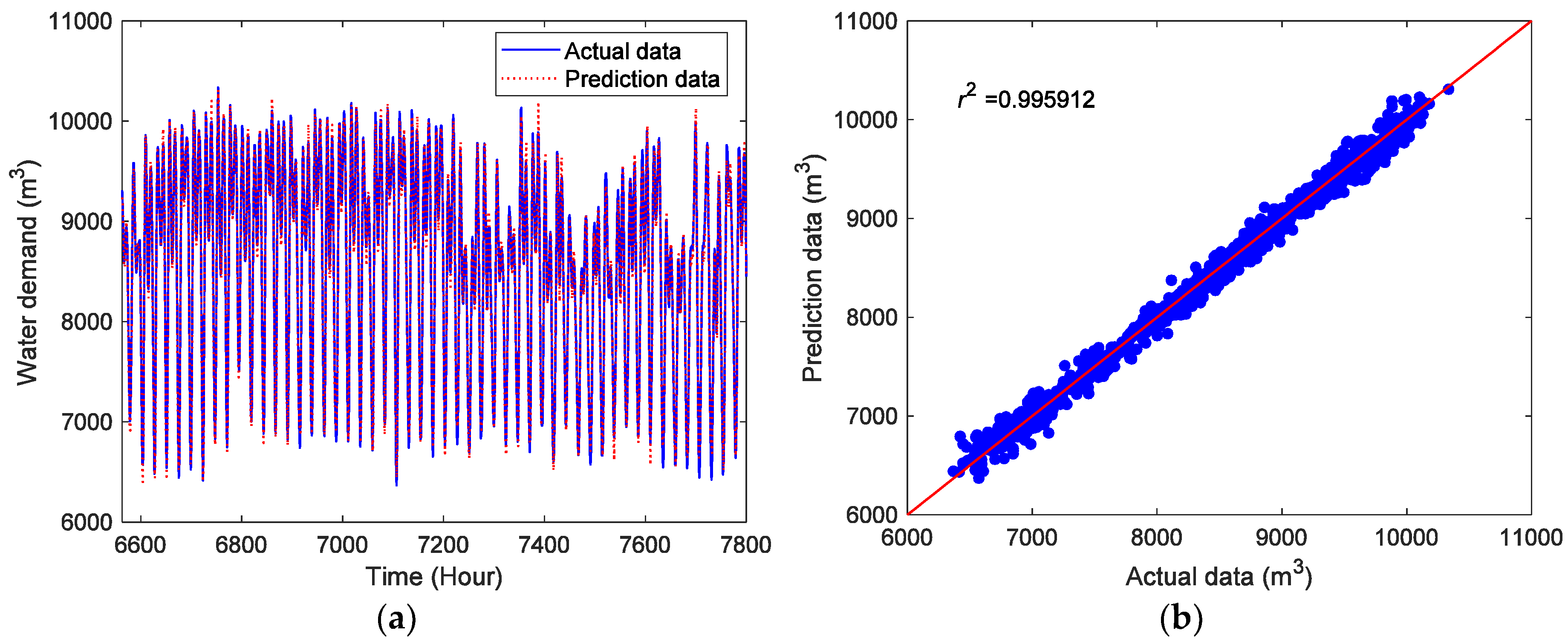
4. Results and Discussions
4.1. CDBESN Modeling
4.2. Prediction and Results
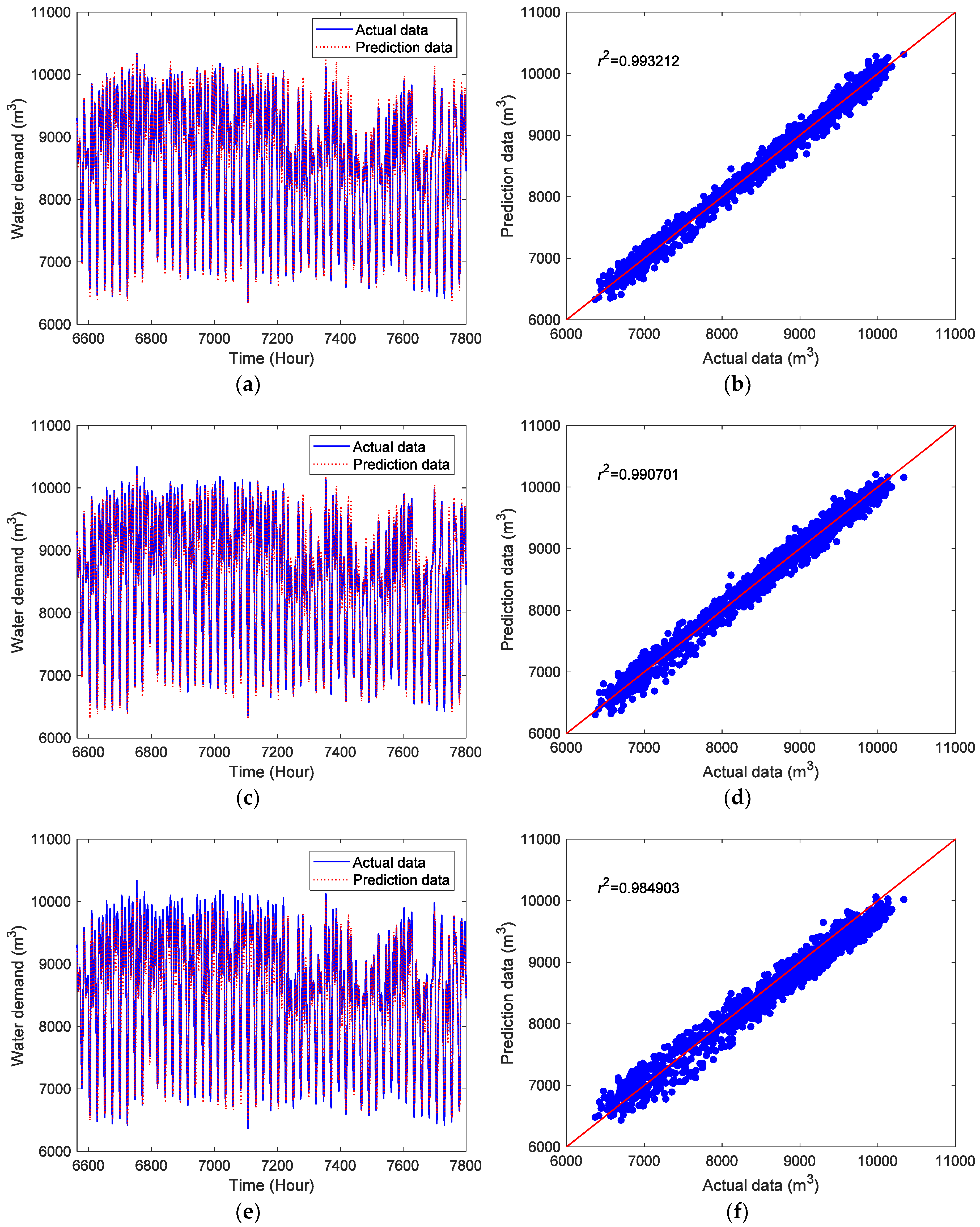
4.3. Comparison Experiment
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Msiza, I.S.; Nelwamondo, F.V.; Marwala, T. Artificial neural networks and support vector machines for water demand time series forecasting. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Montreal, QC, Canada, 7–10 October 2007; pp. 638–643. [Google Scholar]
- Candelieri, A.; Soldi, D.; Archetti, F. Short-term forecasting of hourly water consumption by using automatic metering readers data. Procedia Eng. 2015, 119, 844–853. [Google Scholar] [CrossRef]
- Chen, G.; Long, T.; Xiong, J.; Bai, Y. Multiple random forests modelling for urban water consumption forecasting. Water Resour. Manag. 2017, 31, 1–15. [Google Scholar] [CrossRef]
- Adamowski, J.; Karapataki, C. Comparison of multivariate regression and artificial neural networks for peak urban water-demand forecasting: Evaluation of different ann learning algorithms. J. Hydrol. Eng. 2010, 15, 729–743. [Google Scholar] [CrossRef]
- Gagliardi, F.; Alvisi, S.; Kapelan, Z.; Franchini, M. A probabilistic short-term water demand forecasting model based on the markov chain. Water 2017, 9, 507. [Google Scholar] [CrossRef]
- Bai, Y.; Wang, P.; Li, C.; Xie, J.; Wang, Y. A multi-scale relevance vector regression approach for daily urban water demand forecasting. J. Hydrol. 2014, 517, 236–245. [Google Scholar] [CrossRef]
- Candelieri, A. Clustering and support vector regression for water demand forecasting and anomaly detection. Water 2017, 9, 224. [Google Scholar] [CrossRef]
- Brentan, B.M.; Luvizotto, E., Jr.; Herrera, M.; Izquierdo, J.; Pérez-García, R. Hybrid regression model for near real-time urban water demand forecasting. J. Comput. Appl. Math. 2017, 309, 532–541. [Google Scholar] [CrossRef]
- Shabani, S.; Candelieri, A.; Archetti, F.; Naser, G. Gene expression programming coupled with unsupervised learning: A two-stage learning process in multi-scale, short-term water demand forecasts. Water 2018, 10, 142. [Google Scholar] [CrossRef]
- Donkor, E.A.; Mazzuchi, T.A.; Soyer, R.; Roberson, J.A. Urban water demand forecasting: Review of methods and models. J. Water Resour. Plan. Manag. 2014, 140, 146–159. [Google Scholar] [CrossRef]
- Jain, A.; Kumar Varshney, A.; Chandra Joshi, U. Short-term water demand forecast modelling at IIT Kanpur using artificial neural networks. Water Resour. Manag. 2001, 15, 299–321. [Google Scholar] [CrossRef]
- Adamowski, J.F. Peak daily water demand forecast modeling using artificial neural networks. J. Water Resour. Plan. Manag. 2008, 134, 119–128. [Google Scholar] [CrossRef]
- Bennett, C.; Stewart, R.A.; Beal, C.D. Ann-based residential water end-use demand forecasting model. Expert Syst. Appl. 2013, 40, 1014–1023. [Google Scholar] [CrossRef]
- Al-Zahrani, M.A.; Abo-Monasar, A. Urban residential water demand prediction based on artificial neural networks and time series models. Water Resour. Manag. 2015, 29, 3651–3662. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Sarikaya, R.; Hinton, G.E.; Deoras, A. Application of deep belief networks for natural language understanding. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 778–784. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–spatial classification of hyperspectral data based on deep belief network. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Zhao, Z.; Jiao, L.; Zhao, J.; Gu, J.; Zhao, J. Discriminant deep belief network for high-resolution sar image classification. Pattern Recognit. 2017, 61, 686–701. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Zhang, H.; Liang, T. Electric locomotive bearing fault diagnosis using novel convolutional deep belief network. IEEE Trans. Ind. Electron. 2017, 65, 2727–2736. [Google Scholar] [CrossRef]
- Zheng, J.; Fu, X.; Zhang, G. Research on exchange rate forecasting based on deep belief network. Neural Comput. Appl. 2017. [Google Scholar] [CrossRef]
- Fu, G. Deep belief network based ensemble approach for cooling load forecasting of air-conditioning system. Energy 2018, 148, 269–282. [Google Scholar] [CrossRef]
- Bai, Y.; Chen, Z.; Xie, J.; Li, C. Daily reservoir inflow forecasting using multiscale deep feature learning with hybrid models. J. Hydrol. 2016, 532, 193–206. [Google Scholar] [CrossRef]
- Bai, Y.; Sun, Z.; Zeng, B.; Deng, J.; Li, C. A multi-pattern deep fusion model for short-term bus passenger flow forecasting. Appl. Soft Comput. 2017, 58, 669–680. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, J.; Long, Z.; Chen, Y. A novel dual-scale deep belief network method for daily urban water demand forecasting. Energies 2018, 11, 1068. [Google Scholar] [CrossRef]
- Kuremoto, T.; Kimura, S.; Kobayashi, K.; Obayashi, M. Time series forecasting using a deep belief network with restricted boltzmann machines. Neurocomputing 2014, 137, 47–56. [Google Scholar] [CrossRef]
- Qin, M.; Li, Z.; Du, Z. Red tide time series forecasting by combining arima and deep belief network. Knowledge-Based Syst. 2017, 125, 39–52. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, J.; Long, Z.; Lv, M. Daily urban water demand forecasting based on chaotic theory and continuous deep belief neural network. Neural Process. Lett. 2018. [Google Scholar] [CrossRef]
- Ding, S.; Su, C.; Yu, J. An optimizing bp neural network algorithm based on genetic algorithm. Artif. Intell. Rev. 2011, 36, 153–162. [Google Scholar] [CrossRef]
- Sun, X.; Li, T.; Li, Q.; Huang, Y.; Li, Y. Deep belief echo-state network and its application to time series prediction. Knowledge-Based Syst. 2017, 130, 17–29. [Google Scholar] [CrossRef]
- Jaeger, H. The “Echo State” Approach to Analysing and Training Recurrent Neural Networks—With an Erratum Note; GMD Report 148; German National Research Center for Information Technology: Bonn, Germany, 2001. [Google Scholar]
- Jaeger, H. Short Term Memory in Echo State Networks; GMD Report 152; German National Research Center for Information Technology: Bonn, Germany, 2002. [Google Scholar]
- Jaeger, H.; Haas, H. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. Science 2004, 304, 78–80. [Google Scholar] [CrossRef]
- Jaeger, H.; Lukoševičius, M.; Popovici, D.; Siewert, U. Optimization and applications of echo state networks with leaky- integrator neurons. Neural Netw. 2007, 20, 335–352. [Google Scholar] [CrossRef]
- Lun, S.-X.; Yao, X.-S.; Qi, H.-Y.; Hu, H.-F. A novel model of leaky integrator echo state network for time-series prediction. Neurocomputing 2015, 159, 58–66. [Google Scholar] [CrossRef]
- Chouikhi, N.; Ammar, B.; Rokbani, N.; Alimi, A.M. Pso-based analysis of echo state network parameters for time series forecasting. Appl. Soft Comput. 2017, 55, 211–225. [Google Scholar] [CrossRef]
- Chen, H.; Murray, A. A continuous restricted Boltzmann machine with a hardware- amenable learning algorithm. In Proceedings of the 12th International Conference on Artificial Neural Networks, Madrid, Spain, 28–30 August 2002; pp. 358–363. [Google Scholar]
- Hinton, G.E. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | r2 | NRMSE | MAPE |
|---|---|---|---|
| CDBESN | 0.995912 | 0.027163 | 2.469419 |
| ESN | 0.993212 | 0.034783 | 3.300566 |
| CDBNN | 0.990701 | 0.040711 | 3.870726 |
| SVR | 0.984903 | 0.060430 | 5.683949 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Zhang, J.; Long, Z.; Tang, H.; Zhang, X. Hourly Urban Water Demand Forecasting Using the Continuous Deep Belief Echo State Network. Water 2019, 11, 351. https://doi.org/10.3390/w11020351
Xu Y, Zhang J, Long Z, Tang H, Zhang X. Hourly Urban Water Demand Forecasting Using the Continuous Deep Belief Echo State Network. Water. 2019; 11(2):351. https://doi.org/10.3390/w11020351
Chicago/Turabian StyleXu, Yuebing, Jing Zhang, Zuqiang Long, Hongzhong Tang, and Xiaogang Zhang. 2019. "Hourly Urban Water Demand Forecasting Using the Continuous Deep Belief Echo State Network" Water 11, no. 2: 351. https://doi.org/10.3390/w11020351
APA StyleXu, Y., Zhang, J., Long, Z., Tang, H., & Zhang, X. (2019). Hourly Urban Water Demand Forecasting Using the Continuous Deep Belief Echo State Network. Water, 11(2), 351. https://doi.org/10.3390/w11020351