1. Introduction
According to the United Nations report, 60% of the global population is projected to live in cities by 2030 [
1]. The welfare and safety of residents depends on high-performance technical infrastructure, including power distribution and water supply networks, gas grids, heat distribution networks, telecommunication networks, as well as road networks [
2]. The major objectives of this infrastructure involve the supply of specific utilities to consumers. In the case of water supply infrastructure, a reliable supply of water in the right quantity, at the required pressure, and of adequate quality should be ensured. The reliability assessment of the supply covering all aspects has become a key issue in urban governance [
3]. However, it turns out that this is not an easy task. Urban development has led to increased city size and higher urban infrastructure complexity. Utility network layout is specific for a given city. The large number of factors influencing the arrangement of infrastructure links gives a quasi-random character to the thus-formed geometric set. All these factors have prevented the development of a universal method for assessing the reliability of utility services supply via urban infrastructure networks. To date, undertakings in this respect have focused on two main aspects [
4,
5,
6]: the assessment of the efficient operation of the existing networks, and the assessment of the reliability of utilities supply via networks at the network design stage.
In the first group of undertakings, the reliability theory has been employed. The assessment is based on collected performance data, mainly including the number and types of failures, and times of their occurrence and repair [
7]. This allows a variety of reliability indicators related to specific components of the examined infrastructure to be identified, such as the efficiency probability of the selected network components. Additional information, such as the age of specific fragments of the examined infrastructure, the manufacturing materials, service load, structural load, weather conditions etc., allows different methods to be implemented for anticipating the potential time and area/site of a failure, estimating the risk of possible failure occurrence, limiting the overall operational costs, or the costs incurred through the repairs of network failures [
8,
9,
10,
11,
12,
13]. Here, the layout of the examined networks is considered to be of secondary importance. This layout can be considered by using, for example, the method of minimum efficiency paths, but then determining the probability of water supply from the source to a given recipient requires the knowledge of the efficiency probability of the particular components of the network [
14,
15].
The undertakings related to assessing the reliability of utilities supply while designing the infrastructure are more complex. In the absence of performance data, the probable reliability of individual components of the infrastructure is assessed using the data found in the literature [
16]. The assessment of the reliability of utilities supply at subsequent stages may be conducted as in the case of the first group of undertakings. However, it is worth remembering that the use of the efficiency path method leads most often to neglecting the role of the flow resistance, of the discharge capacity, or of the demand distribution. In recent years, however, other approximate assessment methods have appeared that are primarily based on the analysis of the (geometric) layout of infrastructure networks. They assume the occurrence of one of three cases [
6]: failures affecting links only, nodes only, or links and nodes at the same time. In any of the above cases, the main objective is to define the minimum efficiency or inefficiency paths (minimal cut set) between the source (s—source) and each consumer (t—sink node). A number of algorithms based on graph theory [
5,
14,
17,
18] have been developed to solve this problem. Zhibin [
19] suggested the development of these methods. His method provides for determining/identifying efficiency paths, assuming that failures are likely to occur in both the nodes and links of a network. However, he has only tested his method on a model network made of four nodes and seven links. Yeh [
18] developed an algorithm considering the stochastic flow via s–t network, but he limited himself to a single source network. Due to calculation limitations appearing in the above-mentioned algorithms, Kansal and Devi [
20] have proposed that the reliability of utility supply be assessed only by determining the number of minimum efficiency or inefficiency paths. They tested their algorithm on a system containing 18 nodes, assuming that failures are likely to occur only along links connecting the nodes.
Another approach to an approximate assessment of water supply certainty was proposed by Yazdani and Jeffrey [
21] based on two indicators characterizing network topology: the average node degree ratio (ANDr) and meshedness coefficient ratio (MCr). Based on these indicators, Jung and Kim [
22] proposed an optimization method aiming at the system design to minimize costs and maximize topic and hydraulic reliability. This task was carried out based on a model network containing 6 × 6 nodes. Maiolo et al. [
23] proposed a method of evaluation using the vulnerability measure. This task was tested, among others, at the network proposed by Ozger and Mays [
24] (2 reservoirs, 13 nodes, and 21 pipes).
It should be noted, however, that the existing urban infrastructure networks have numerous nodes and links. This makes the assessment rather labor-intensive and relatively unreliable. Proper interpretation of the obtained results also poses a problem. In view of the above, it is necessary to search for new methods for assessing the reliability of utilities supply via the infrastructure networks. The paper presents two self-originated methods for assessing an approximate reliability of utilities supply via complex infrastructure networks, using the number of efficiency paths linking the source and reference service points, and the relationship between the number of paths and the fractal dimension of the geometric layout of the network. The presentation is based on a selected model and the existing water supply networks.
2. Materials and Methods
As specified in the study objectives, the paper presents two authors’ methods for assessing the reliability of water delivery to consumers via a water supply network: the reference service point method, and the method based on the fractal dimension of network layouts. The proposed methods relate only to one element of water supply reliability—supply of water, ignoring the aspects of its pressure and quality. In both methods, the assessment was based on checking the possibility of water supply from a single source to a selected customer—the most unfavorably located one in relation to the source. The assessment considered the geometrical structure of the existing links in the analyzed networks, ignoring the problems involving the resistance head in water and flow capacity.
The efficiency path method was used in the calculations. Therefore, it was necessary to know the probability of the efficiency of the links connecting the network nodes. The adopted value of probable efficiency of individual links was 0.99 [
16]. In the calculations, we assumed that failures occur only in the links of the analyzed networks.
This study examined water supply networks. The layout of municipal water supply networks is very intricate (i.e., branched, looped, and mixed systems). As in the case of any other type of urban infrastructure, the layout is city-specific, and since it is additionally influenced by numerous factors, the spatial arrangement of the networks is also quasi-random [
25]. The authors examined 22 model and 7 existing networks found in real cities. Model networks included:
- -
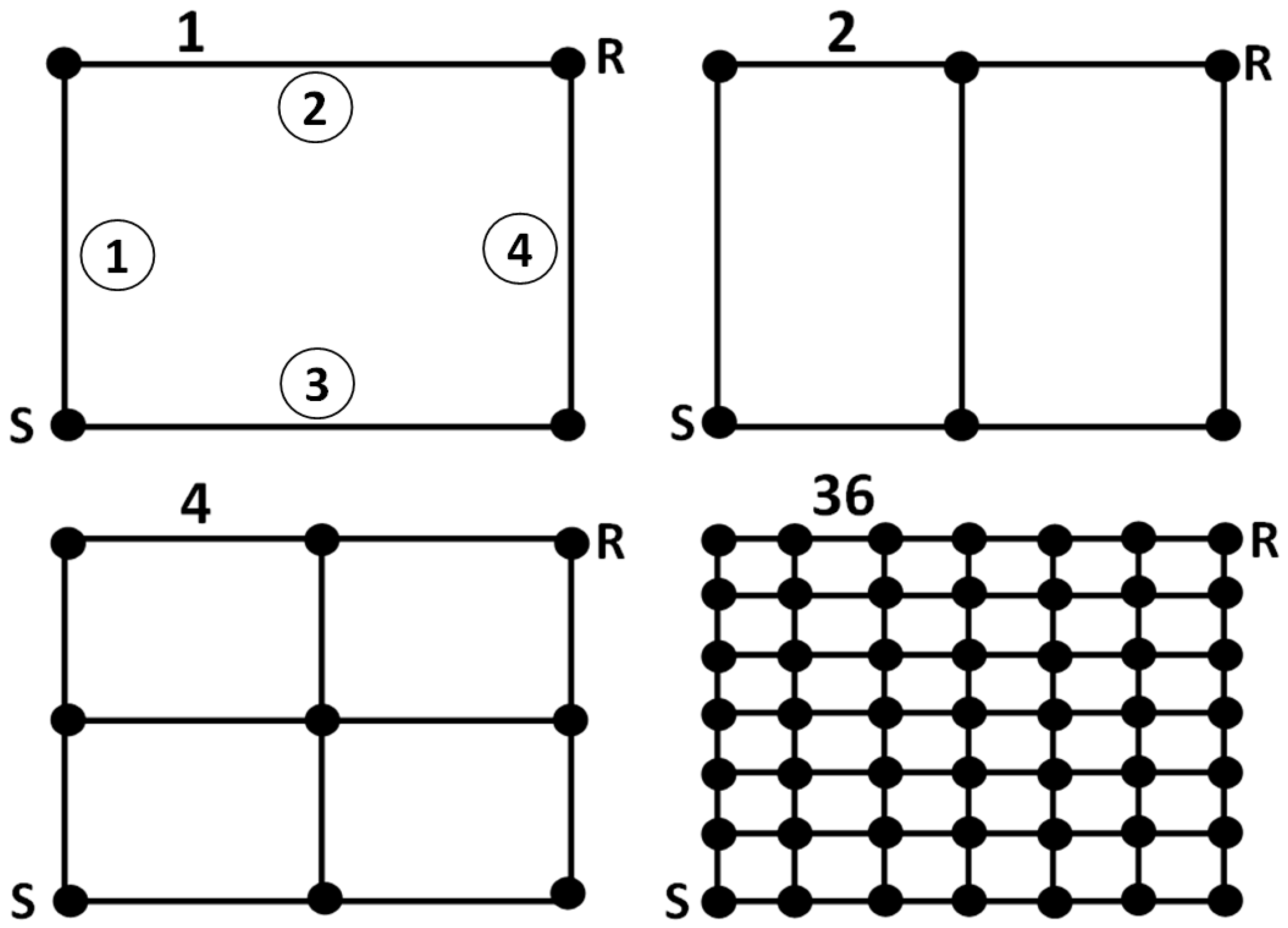
A linear network, made of four nodes and three links (
Figure 1), where water can flow in only one direction;
- -
A looped network made of 1–36 loops, containing from 4 to 49 nodes and from 4 to 84 links (
Figure 2), where water can flow via individual links in different directions. This network was also defined by the number of nodes in a row and column (
Table 1).
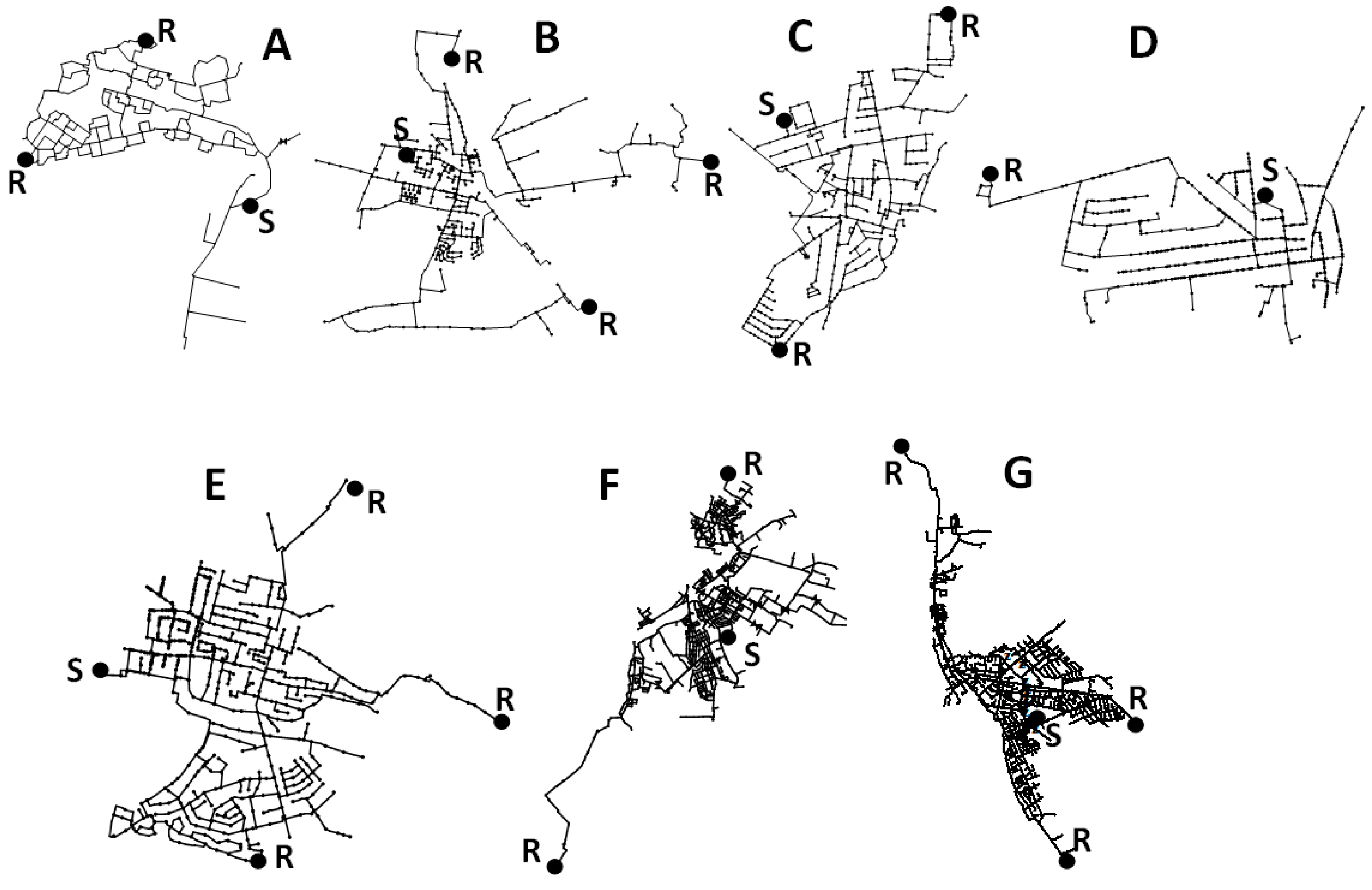
Basic data describing the layouts of the analyzed networks operating in the selected cities are collected in
Table 2.
The data presented in the table demonstrate no strict dependence between the number of nodes and links and the number of residents supplied with water via specific networks. This confirms previous statements about the case-specific and quasi-random nature of water supply network layouts. The layouts are presented in
Figure 3.
All examined water supply networks were mixed systems, containing numerous loops and many branches. In addition, all analyzed networks had a single source of water supply.
2.1. Reference Service Point Method
The method is based on the above-presented algorithms for determining efficiency paths linking the water source and its supply terminals. The probable efficiency of an efficiency path in time
t may be determined using the formula [
6,
15,
16]:
where
Pj(
t) is the probable efficiency of path
j,
Pi(
t) is the probable efficiency of the link being a component of a determined efficiency path,
j is the number of an efficiency path,
i is the reference number of the link being a component of path
j, and
n is the number of links included in an efficiency path.
The reliability of water supply via an examined network can be calculated as the probable efficiency of at least one path from among the defined efficiency paths, using the formula [
6,
15,
16]:
where
Ps(
t) is the probable efficiency of at least one of the fixed efficiency paths in time
t, and
k is the number of defined efficiency paths.
Table 3 presents a calculation example of the efficiency path method used to determine the probability of water delivery from point S to point R, for model network no. 1 (
Figure 1).
In more complex network structures, the efficiency paths were defined using graph theory. The calculations were based on DFS (depth-first search) [
26]. After importing the layouts of the examined networks into the program, the following objects were created: Graph, Node, and Edge. In order to avoid cycles, and consequently infinite loops of searching graph data structures, each encountered node could be used only once. The Graph object stored information about edge duplicates detected in the input file, and the number of defined paths once the calculations were made. During the run of graph searching algorithm, the currently used nodes and the total number of traversals between the nodes were recorded. The algorithm was additionally expected to validate the imported data, create an object-based representation of the graph based on the read out data, connect the nodes as neighbors, and recurrently traverse the graph from the determined starting node to the target node. The Node class allows the nodes to be presented as objects, whereas the Edge class represents graph edge components. Edges were used to collect information about neighboring nodes. Additionally, due to duplicates that may be found in the input file, the set of imported edges was validated for repetitions (e.g., two edges having different names determining the same neighbor relationship).
The software based on the above-presented algorithm was created using the Python 3.6 language, and
Qt library [
27,
28], adapted to apps written in this language.
In order to reduce labor intensity and to facilitate the interpretation of the obtained results, the authors proposed to make calculations only for selected reference service points, instead of all water supply terminals as suggested—among others—by Yeh [
18], Zhibin [
19], or Kansal and Devie [
20]. Such terminals should be located in the worst-case conditions in relation to the water source. In the case of model networks (
Figure 1 and
Figure 2), these are the terminals most distant from the source. While considering the existing networks, the authors propose to determine from one to three reference points (
Figure 3). The most wanted solution is then the lowest value of probability calculated using Formula (2), defined for each reference point in a given network.
The use of the number of defined efficiency paths as an independent indicator is a modification of the above method. Unlike in Kansal and Devi’s method [
20], instead of considering all possible links between network nodes, we suggest limiting the analysis to the paths linking water sources and reference points. As previously, the proposed solution is to adopt the lowest of the defined values for each reference point.
2.2. Method Based on Fractal Dimension
As already mentioned, the layouts formed by urban infrastructure networks, including water supply networks, are of very specific, semi-random nature. Based on the studies by Mandelbrot [
29] and Falconer [
30], it was found that these structures can be described using fractal geometry [
25]. The degree of complexity of a given layout can therefore be defined using the fractal dimension, calculated using the formula [
31]:
where dim
BF is the value of the fractal dimension, and
Nδ is the number of squares with sides of length
δ covering a given geometric set.
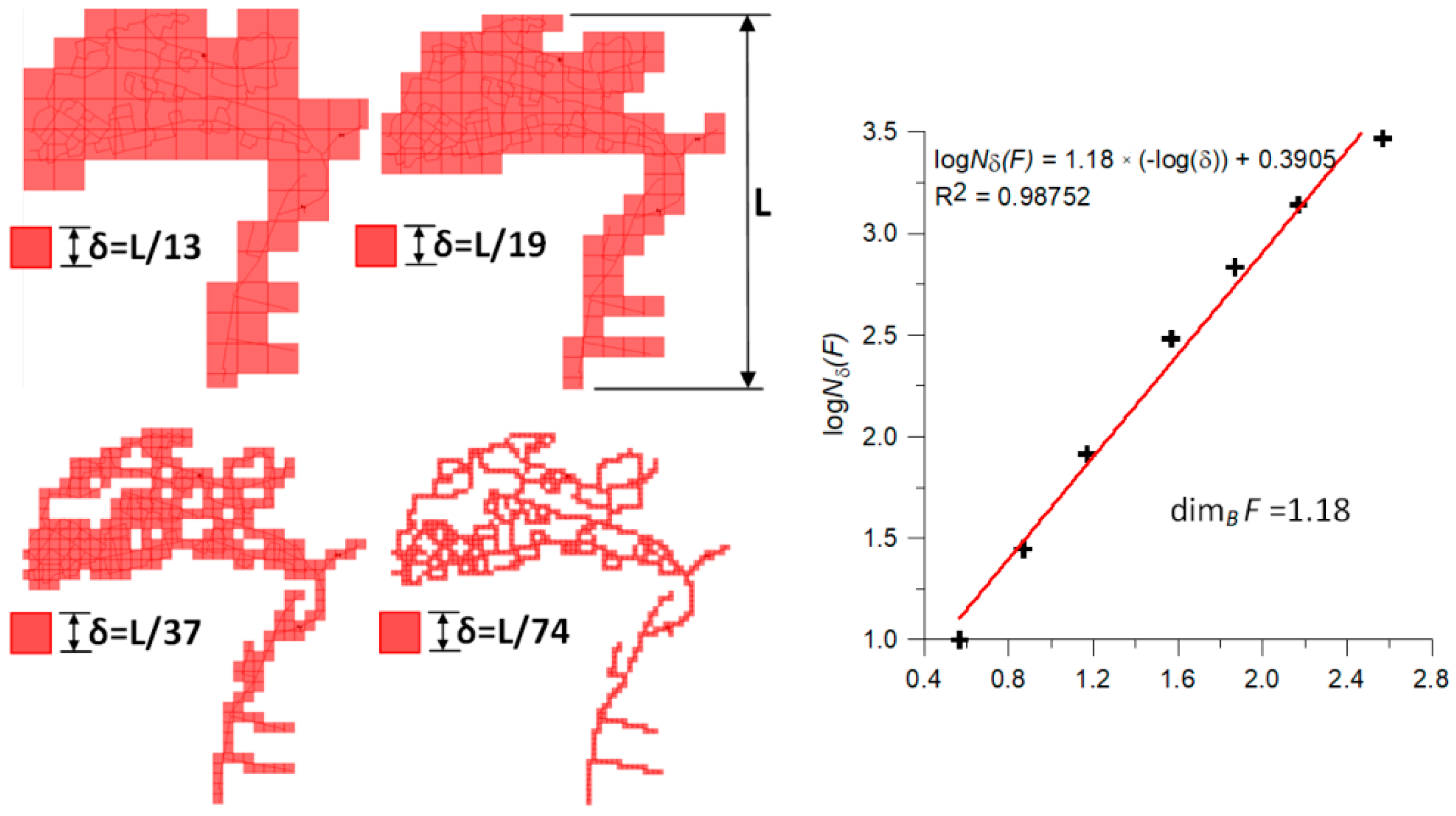
In practical issues to determine the fractal dimension, it is more convenient to use the so-called box counting method [
31]. It consists of covering the considered geometric structure with squares (boxes) with increasingly smaller size and counting the minimum number of these squares necessary to cover the analyzed network structure. Subsequently, a graph of dependence on log
Nδ(
F)–log
δ is made. The directional coefficient of the regression line described on this compound corresponds to the value of the fractal dimension (
Figure 4).
For each—model and existing—network examined in this study, the value of the fractal dimension was determined using the box-counting method [
30,
31] using the program Statistica 12.1 [
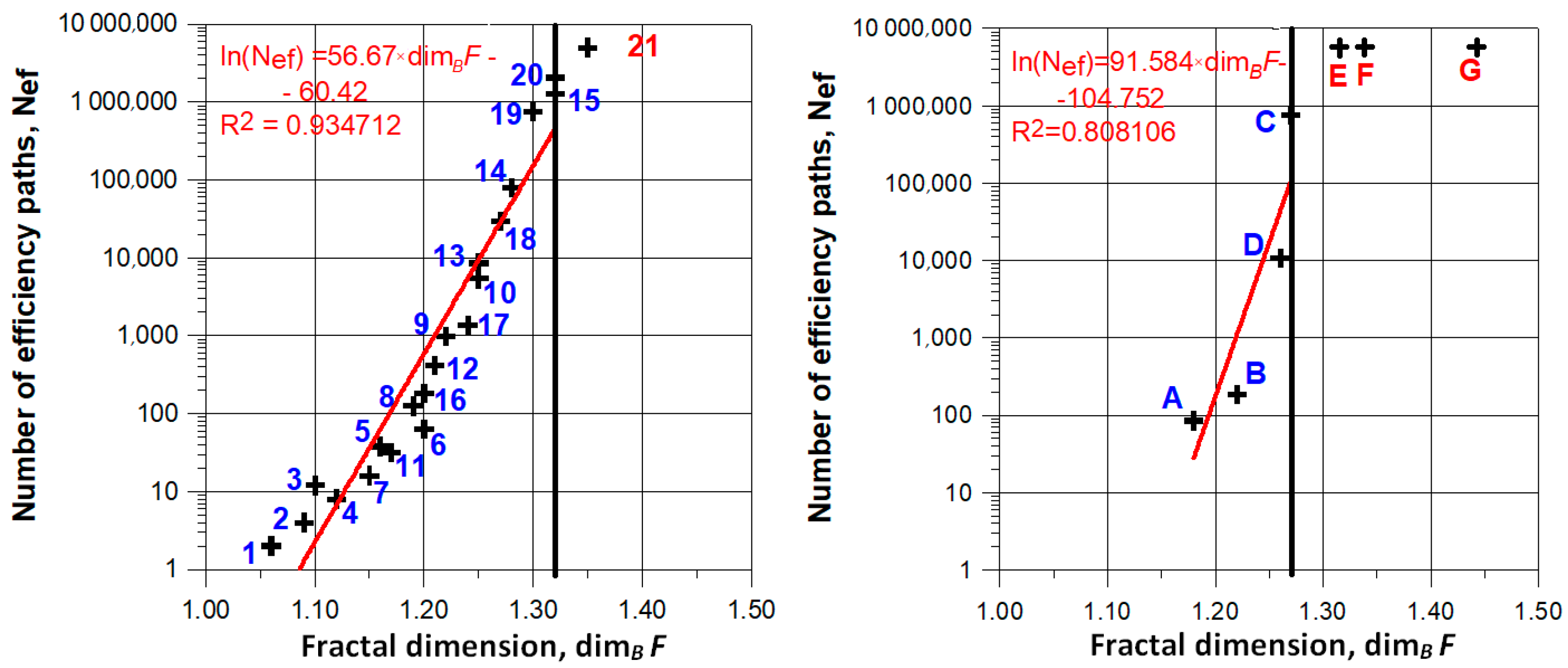
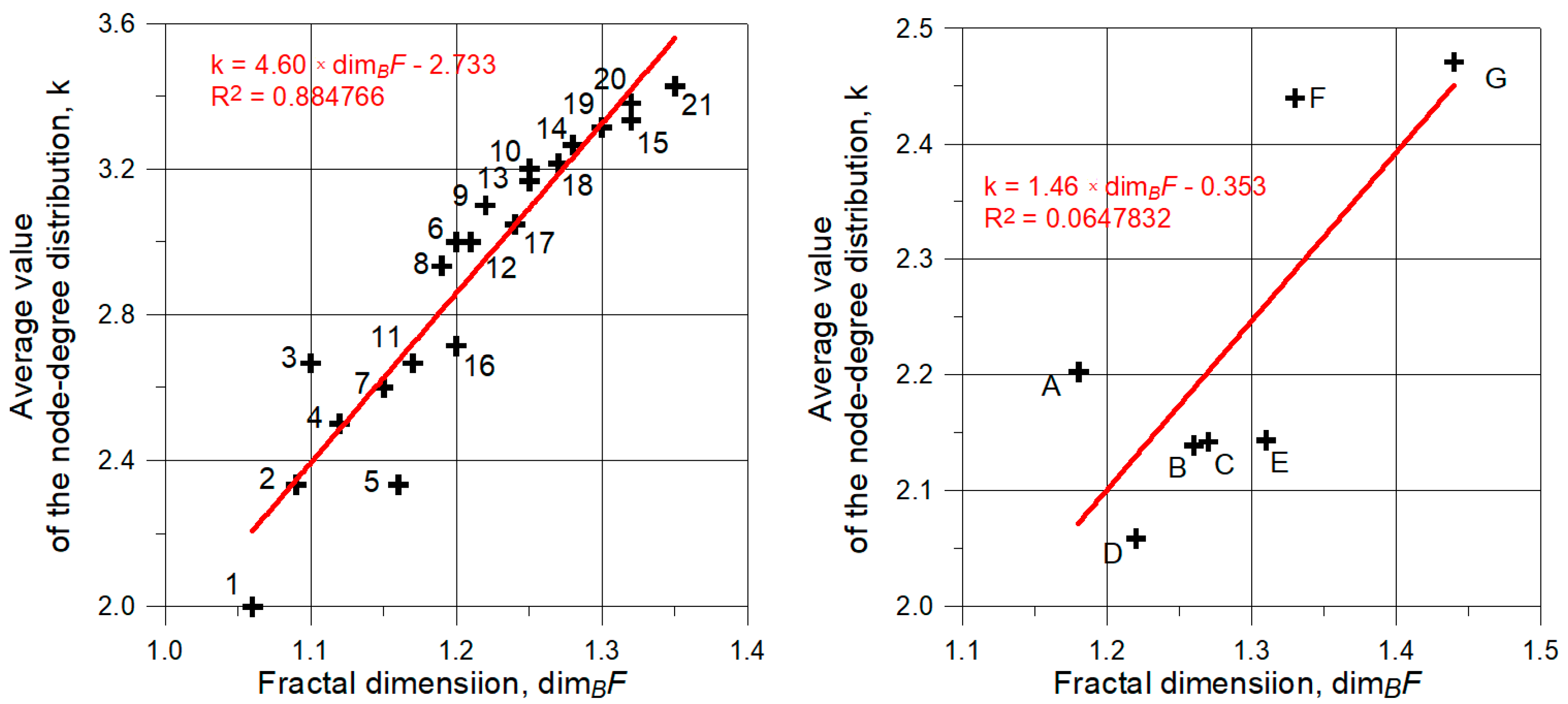
32]. Then, this value was compared with the number of efficiency paths defined using the reference service point method. The study was expected to show whether the fractal dimension can constitute an independent indicator allowing the reliability of water supply via the analyzed networks to be assessed.
The obtained fractal dimension values were compared with another indicator characterizing the topology of water supply networks (i.e., the average value of the node-degree distribution). This indicator was calculated using the formula provided below [
33], which was also employed, among others, by Yazdani and Jefffry [
21] and Maiolo et al. [
24] in its modified form:
where
m is the number of links,
n number of junctions in the analyzed water supply network.
Similar to the case of fractal dimension calculations, the complexity of a network does not condition the possibility of determining the average value of the node-degree distribution. It is relatively easy to calculate. In the model and existing networks presented above, the “Project Summary” option available in the EPANET 2.0 [
34] software was used for that purpose.
4. Conclusions
The method of reference points based on determining the certainty of water supply from the source to the most unfavorably located recipient proposed in the paper may be employed for networks comprising up to six loops. The computations carried out for the model and existing water supply networks indicate that the calculated probability always equals 1.0 if this value is exceeded.
Using the number of efficiency paths as the sole indicator for estimating the certainty of water supply from the source to the most unfavorably located recipient turned out to be an efficient method for the networks comprising up to 36 loops.
The conducted calculations indicated that there is a relationship between the number of efficiency paths and fractal dimension. This relationship was confirmed for the maximum fractal dimension values of 1.32 and 1.27 for the model and existing networks, respectively.
Fractal dimension can be treated as a topological indicator of an approximate assessment of water supply reliability. The network complexity does not influence the possibility of its determination.
The conducted analysis of fractal dimension value with average value of the node-degree distribution indicates the existence of a linear relation between these indicators in the considered model networks. However, this relation was not confirmed in the case of the existing networks.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}