4.1. Results of RBF-NN and SVR Scenario No. 1
Evaporation prediction was carried out by considering only the evaporation data as input variables for modeling. Three timescales (daily, weekly, and monthly) were used in training and testing the RBF-NN and SVR methods.
The evaluation metric values for the three different timescales (daily, weekly, and monthly) using the suggested methods (i.e.,
RBF-
NN and
SVR) are given in
Table 4. The results show that the best evaporation prediction with the daily data was attained by Model III using
SVR and
RBF-
NN techniques. It is remarkable that the prediction errors by the
RBF-
NN were less than those of the
SVR technique. The results revealed that the correlation between the predicted and actual evaporation data was high when employing
RBF-
NN compared with the other technique. Additionally, it can be seen that the relative error magnitude of the
RBF-
NN method was low compared with that attained by the
SVR technique.
For the weekly timescale, Model IV provided better results when predicting weekly evaporation compared with the other proposed models. The
RMSE and
MAE values obtained by
SVR and
RBF-
NN were relatively close. However, the correlation coefficient obtained by
RBF-
NN was obviously higher than that by the
SVR method.
Table 4 also presents the results obtained by the suggested techniques when using monthly data. The performance of the methods was improved when using two antecedent values of the evaporation data as input variables for modeling. The error indicator values (i.e.,
RMSE and
MAE) were more greatly improved when using
RBF-
NN compared with
SVR. Based on the results, the prediction accuracy of the
RBF-
NN approach was significantly better than the other models.
As shown in
Table 4, the performance of the suggested techniques was examined under several timescales. It is clear that the type of input variable and timescale had a significant effect on the results. According to four statistical indices, the daily timescale provided higher accuracy for the proposed methods. The
RBF-
NN method outperformed the other models using three input variables (i.e.,
E(t−1),
E(t−2), and
E(t−3)) within the daily timescale.
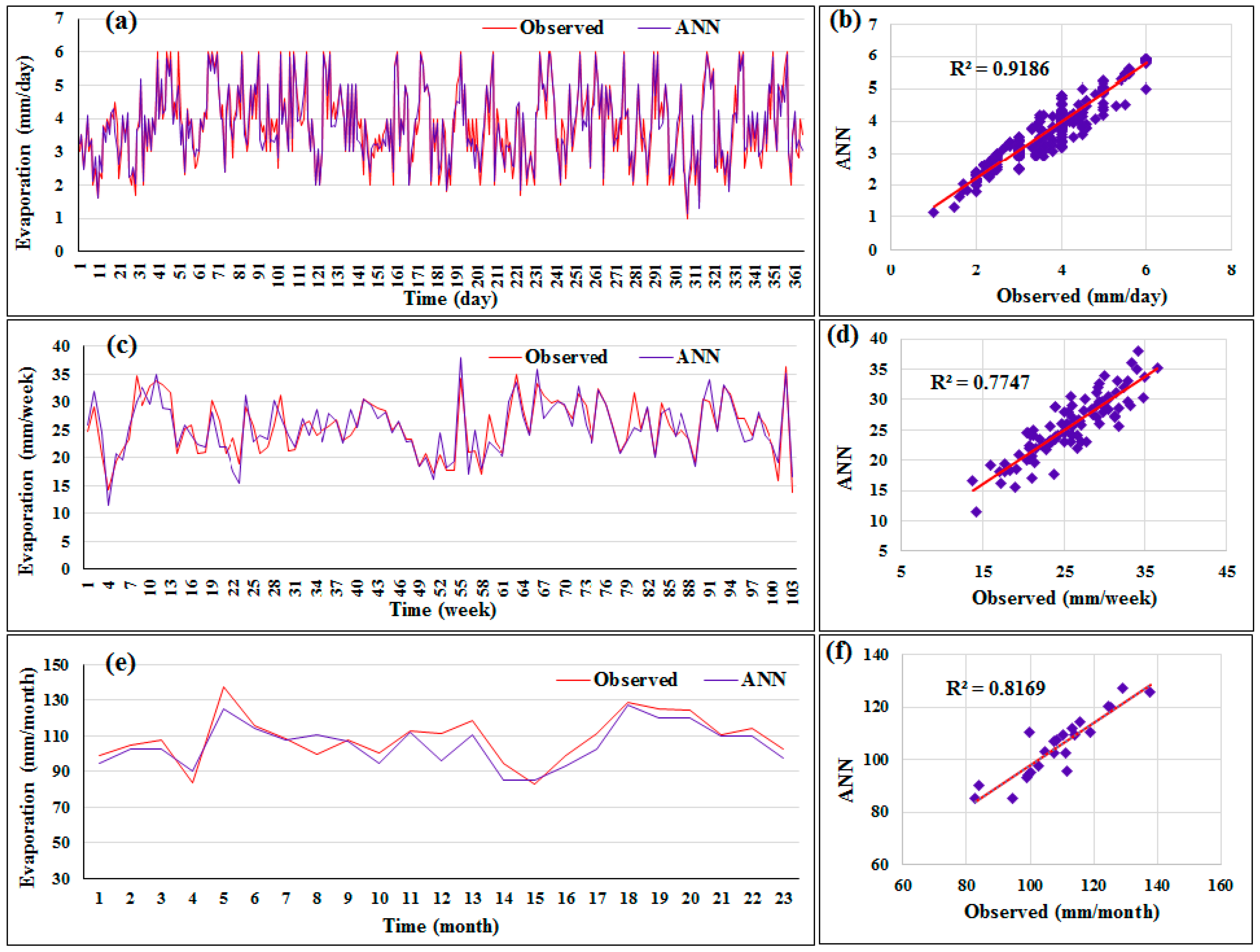
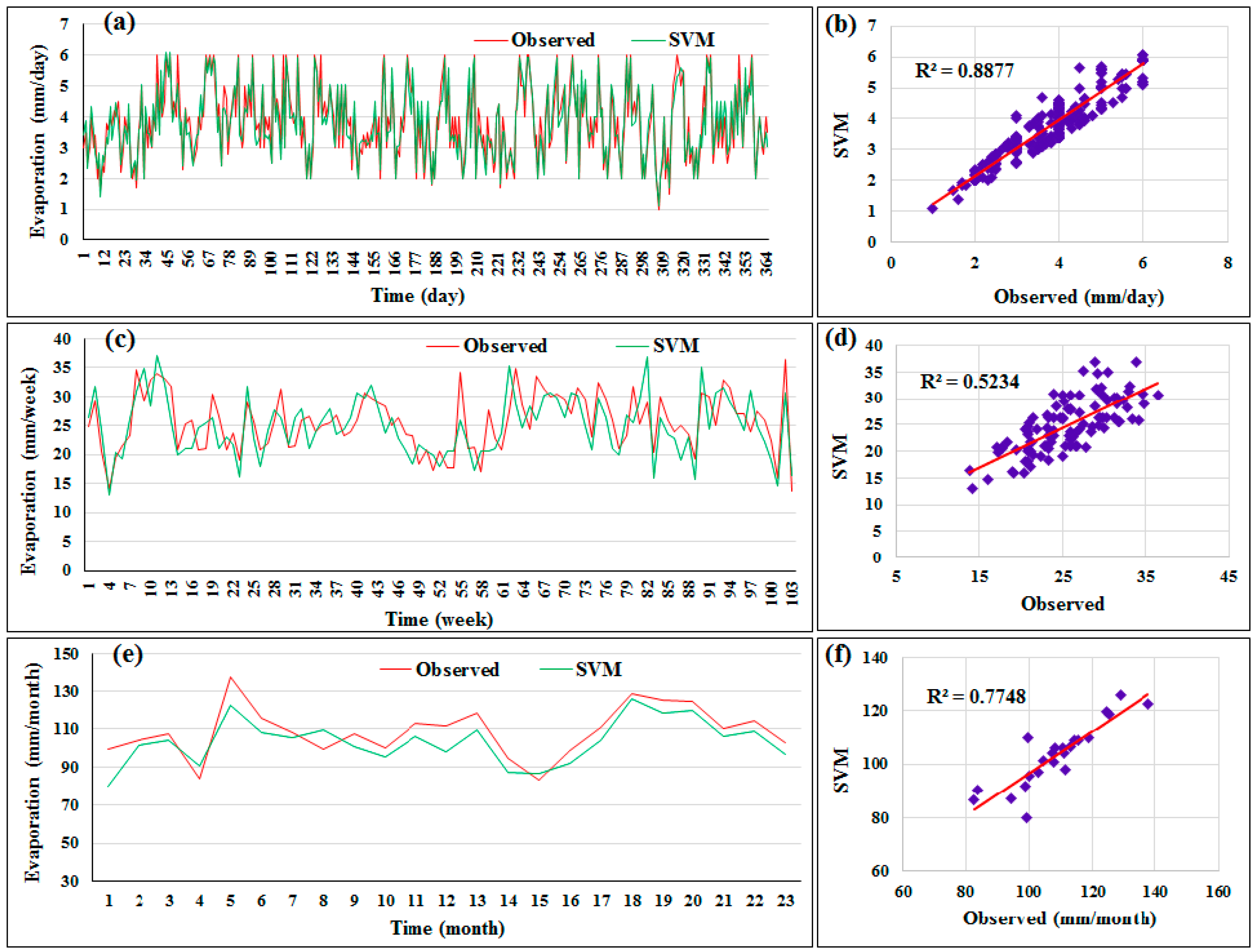
It is useful to present the distribution of the evaporation data which was predicted by the proposed models around a fit line. The pattern of the predicted data obtained by
SVR versus actual evaporation is presented in
Figure 4: (a) daily, (c) weekly, and (e) monthly. It can be seen that the suggested predictive model (i.e.,
SVR) was better with daily data at detecting the actual data than the other timescales. The scatterplots for the best models under the three timescales employing
SVR are also shown in
Figure 4. It is noticeable that the correlation between predicted and actual data with daily records was higher than the weekly and monthly timescales.
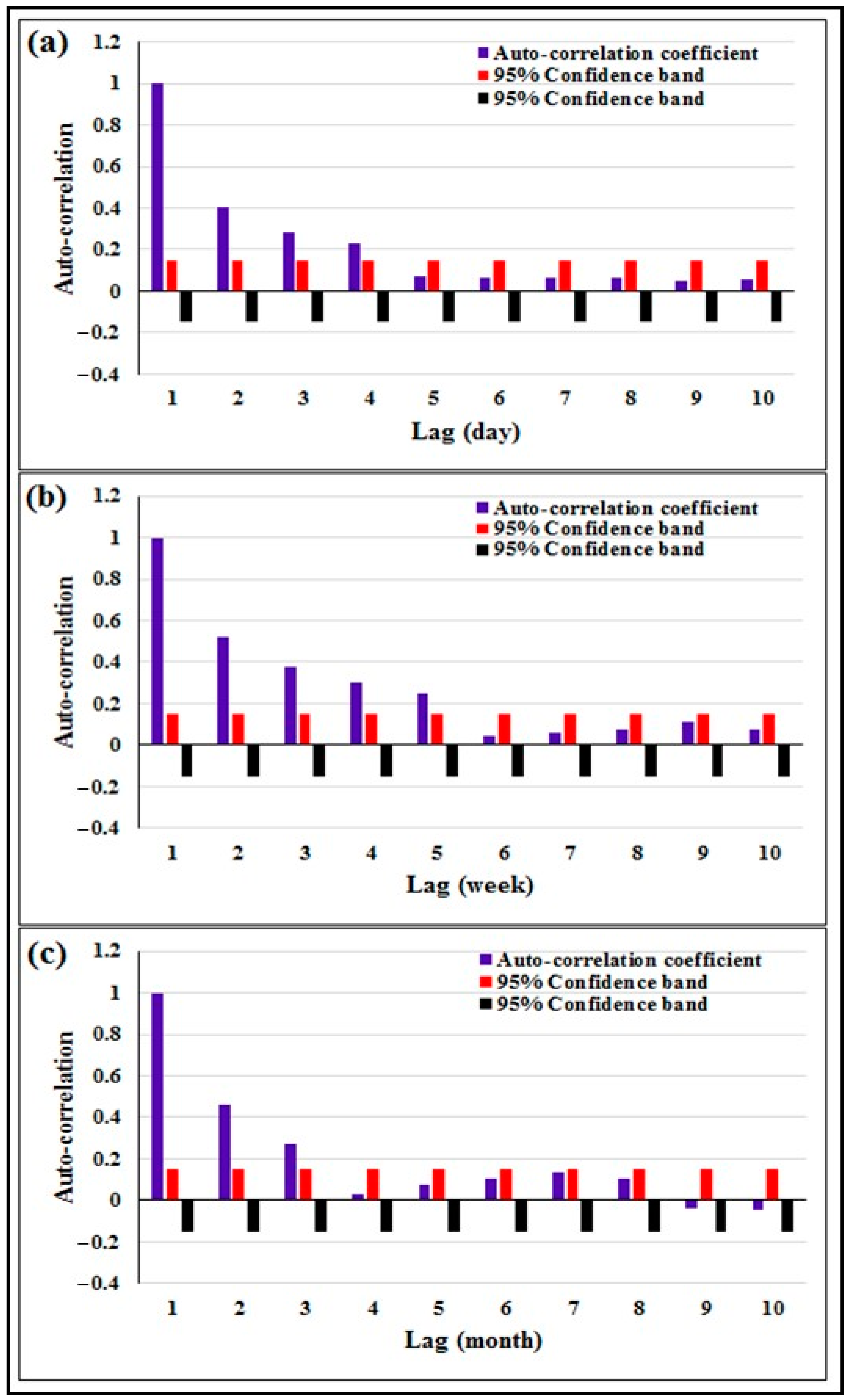
As the input variable(s) plays a significant role in the success of the model performance, it is essential as a first step to employ certain procedure to identify the proper input selection for the model for each time increment for the desired output. In this context, the model input selection variables were selected according to the autocorrelation procedure method. Mainly, the model is structured to consider three different time increments: daily, weekly and monthly. The autocorrelation procedure has been employed for all the time increment dataset. As a result, from the autocorrelation, for the case of daily time increment dataset, the output showed that there are four lags time has relatively strong correlation with the output. In this context, four different model input scenarios have been examined. While, for the weekly time increment, five lags time have correlation with the desired weekly output. Therefore, five different input scenarios have been applied in case weekly records. Finally, for the monthly time increment, only three lags have shown a strong correlation with the desired monthly output, and hence, only three different model scenarios have been applied for the monthly time increment. Consequently, the numbers of the examined models for each time increment are 4, 5 and 3 for daily, weekly and monthly time increment, respectively.
The RE% is a range falls between of the maximum experienced RE% for each model. The positive value of the RE% represents that the model is over-estimating the desired actual value of the output, while the negative value represents that the model is under-estimating the output.
Figure 5 illustrates the hydrographs of the evaporation data predicted by the
RBF-
NN method with the best input combination within several time records (i.e., daily, weekly, and monthly). Most of the time, the predictions of the predictive model were underestimated when using monthly records. The best model (i.e., daily timescale) could predict the maximum values with acceptable accuracy, while the predictive model could not provide data to match with the medium data over the testing period as desired (
Figure 5a). On the other hand, the scatterplots for the optimal model are shown in
Figure 5. The proposed method (
RBF-
NN) provided the worst correlation between actual and predicted data when using weekly records (
R2 = 0.774). Clearly, the agreement between the predicted and actual evaporation rate was significant with the daily timescale. Model III in daily scale has the best accuracy for both methods (
RBF-NN and
SVR) in all performance criteria. Where the best values of
R2 NSE and
KGE for SVR are (0.810, 0.781, and 0.795) respectively and for
RBF-NN are (0.918, 0.942 and 0.932) respectively. It can be seen that the performance of the predictive model using daily records was superior to weekly and monthly records. Additionally, the accuracy of the results within the monthly timescale was better than weekly. This indicates that increasing the timescale may or may not improve the accuracy of the predictive model. Hence, inspecting the performance of the suggested models under several timescales is crucial.
4.2. Results of RBF-NN and SVR Scenario No. 2
The mean temperature and evaporation values were the modeling input variables in this scenario. Three multiscale time-series data (i.e., daily, weekly, and monthly) were used to train and test the models. Several models were suggested to determine the suitable input combination. The evaluation of all of the proposed models was carried out by examining their performance when using different statistical metrics.
Table 5 shows the results of the five models for each predictive model (i.e.,
SVR and
RBF-
NN). Firstly, the
RMSE and
MAE indicators demonstrated the reliability of the second model when using daily records and the third model when using weekly and monthly evaporation data. It can be seen that the correlation between the predicted and actual data using those models (Models II and III) was high compared with the other models. To check for any significant effects of the input variables on the performance of the methods and to compare the suggested models, the relative error magnitude was calculated for each model. The relative error indicated the superiority of the methods that used two and three input variables (i.e., Models II and III).
The proposed model that employed two input parameters using daily data had the smallest
RMSE and
MAE and the highest
R2. This shows that the input combinations (
E(t−1),
E(t−2),
T(t−1),
T(t−2)) enhanced the performance of the predictive model. As seen in
Table 5, using weekly and monthly data provided poor predictions. Therefore, it is pertinent to consider the influence of the timescale on the accuracy of results. On the other hand, the
RBF-
NN outperformed the
SVR technique, according to the four indices (
RMSE = 0.281 mm/day;
MAE = 0.0201 mm/day;
RE% = +11, −12; and
R2 = 0.95). Model II in daily scale has the best accuracy for both methods (
RBF-NN and
SVR) where the best values of
R2 NSE and
KGE for
SVR are (0.887, 0.912, and 0.892) respectively and for
RBF-NN are (0.951, 0.968 and 0.935) respectively.
The patterns of the predicted data obtained by the architecture of the
SVM models which led to the best results using different timescales are shown in
Figure 6. These patterns demonstrate the flexibility and capability of
SVR for mapping and predicting linear or nonlinear functions when using daily data. The scatterplots of the best model under the three timescales are also presented in
Figure 6. It is observed that the
SVM provided poor matching between the predicted and actual evaporation data using weekly records. The suggested method (i.e.,
SVM) was highly capable of predicting the evaporation values, which were less than 4 mm/day (
Figure 6b). Finally, a high correlation magnitude was attained by employing daily evaporation data for modeling.
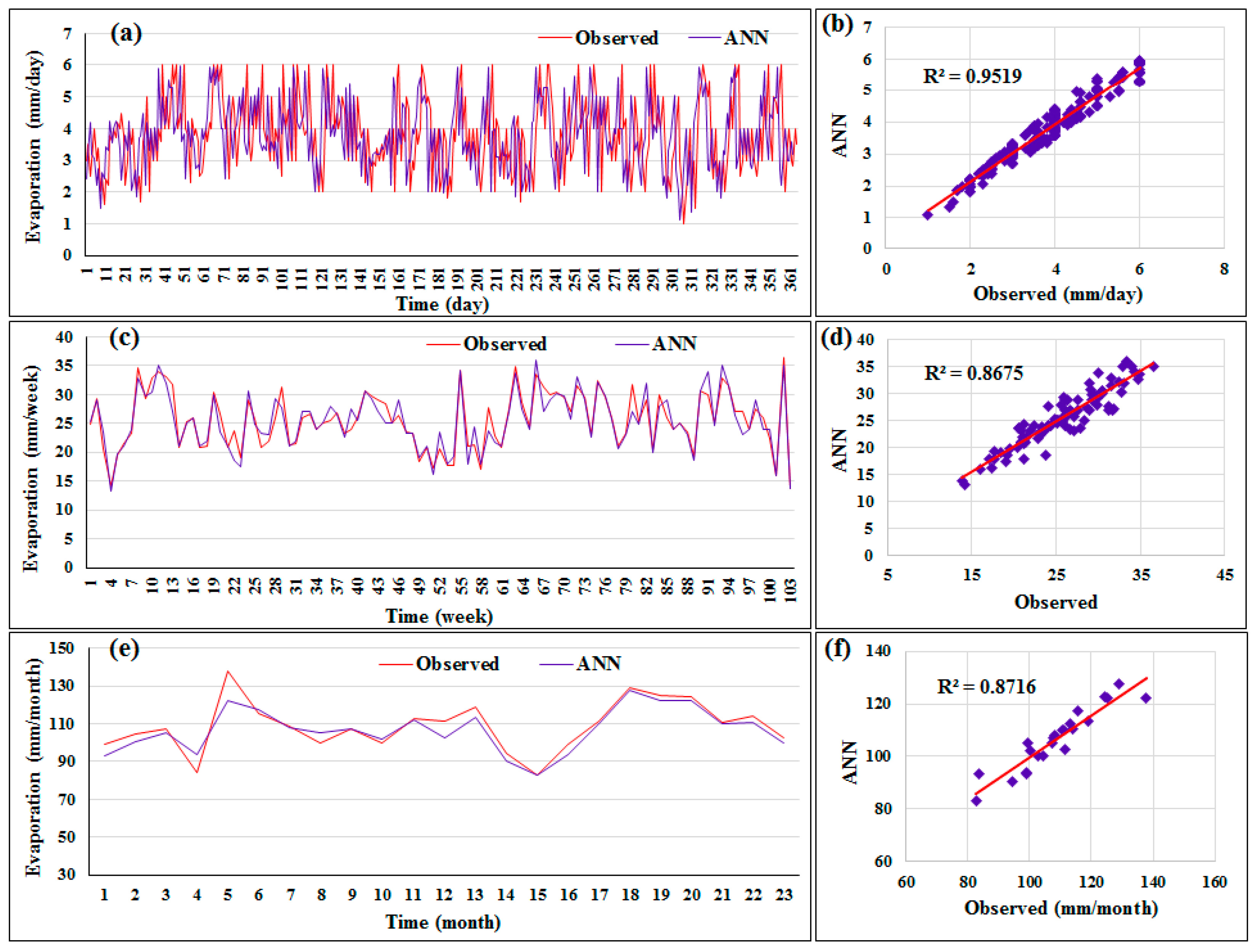
Figure 7 shows the distribution of the evaporation data predicted by the best model among all timescales (daily, weekly, and monthly). As seen in
Figure 7a, the predicted and actual evaporation data converged, with the exception of some peak values. The performance of the proposed method with monthly data was slightly better than with weekly records. It was found that the correlation coefficient by the
ANN method was 0.95. This magnitude of correlation was an adequate achievement in terms of the usability of the suggested model in predicting evaporation data in situations where indirect or direct methods cannot be used. The figures show that there was fairly good agreement between the predicted and actual data when using daily timescale data. Additionally, the improvement in the performance of the suggested method was attained with daily evaporation data. This demonstrates the ability of the
ANN method to detect patterns in time-series data when using a lower timescale.
4.3. Comparison of the Models
Ten-year evaporation and temperature data was used to predict the magnitude of evaporation from the reservoir in the future. A one-step prediction was attained for a one-year prediction period. To evaluate the performance of the suggested AI methods, two sceneries and three timescales were considered when predicting evaporation data. Noise reduction was not performed in the current study to investigate the performance of the method under hard conditions or with complex data. Therefore, the SVR and ANN techniques may provide greater accuracy than the current results when applied to noise-free evaporation data.
Four comparisons were carried out in this study: (i) comparing the optimal input combinations for the predictive model; (ii) comparing timescale suitability for modeling (iii) comparing two different input architectures (i.e., Scenario Nos. 1 and 2); and (iv) comparing the performances of the SVR and RBF-NN methods.
Firstly, the results in the first scenario revealed that three, four, and two input variables were the optimal input combinations for daily, weekly, and monthly timescales, respectively. In the second scenario, Model II for the daily basis and Model II for the weekly and monthly data were the best input variables for the predictive model.
In the light of the abovementioned results, the effect that the time increments had on the performance of the methods for evaporation prediction is clear.
Table 4 and
Table 5 show that using daily records increased the reliability of the
AI techniques more so than weekly and monthly evaporation data. The optimal input combination models attained a high correlation between the predicted and actual data when employing the daily timescale. In addition, the minimum prediction error was obtained with daily records with both methods.
It is known that the meteorological data have a considerable effect on evaporation magnitude estimations. Indeed, the records of one or more climate parameters might not be available in many study areas due to a lack of monitoring devices to measure such parameters. Therefore, the current study attempted to provide a predictive model that can still be highly accurate even with minimal climate parameters. The accuracy of the results was significantly improved in the second section compared with the first section of the research by both SVR and RBF-NN models over the test period. Clearly, prediction errors were reduced when considering the temperature values in the evaporation prediction.
Based on the aforementioned results, it should be pointed out that the RBF-NN presented in the current study is very useful for solving the evaporation prediction problem. It is quite clear that the RBF-NN method attained all the planned objectives along with some interesting findings. It can be seen that the more complicated SVR method did not perform better. The capability of the RBF-NN in predicting evaporation data was superior to the SVR method. Furthermore, the main advantage of using the RBF-NN method is that it does not need detailed information on the physical processes of the system, unlike other methods, while the SVR method can achieve high accuracy only when feeding the model most of the effecting variables.
The relative error is an important indicator for evaluating the performance of the suggested methods. Therefore, the evaluation ranking of all proposed models was carried out based on the magnitude of the relative error.
Table 6 illustrates the ranking of the models based on predicting monthly, weekly, and daily evaporation. The results showed that the
RBF-
NN (i.e., Model II, daily basis, under second scenario), with a relative error of 12%, was the best model for evaporation prediction in the current study. The second-best model was attained by feeding the
RBF-
NN with three input variables (i.e.,
E(
t−1),
E(
t−2), and
E(
t−3)). The
RBF-
NN with daily records employing
E(
t−1) and
T(
t−1) as input variables was the third-best model, followed by the same model but under Scenario No. 1 with an
REmax value of 19.5%. In fifth place was the
SVR method considering two input variables, daily data, and under the second scenario. The
SVR and
RBF-
NN methods were in sixth and seventh place when applying the
SVR with Model III and
RBF-
NN with Model II under the first scenario with daily data, for which the magnitude of the relative error was 20.2% and 20.8%, respectively. It could be observable that the daily records are more suitable for the prediction models to attain accurate results. It seems that the prediction of the evaporation using small time scale (i.e., daily) is more understandable for the
RBF-
NN and
SVR. The
RBF-
NN model was efficient even with minimum input variable. This indicates that the
RBF-
NN model could be better in case add some modifications for its procedure.
It can be seen from
Table 6 that the 33rd to 46th places were mostly under Scenario No. 1. Finally, the
RBF-
NN method which considered the effect of temperature data and daily records succeeded in predicting the amount of water loss in a reservoir by way of evaporation within a tropical environment.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}