1. Introduction
Water resources management is based on the study over time of meteorological and hydrological data trends. In order to evaluate resource availability and possible impacts, long records of continuous and reliable data are needed, but they are seldom available. Lack of records (gaps) or discontinuities in data series and quality issues are two of the main problems more often found in databases used for climate studies and water resources management [
1,
2,
3,
4,
5,
6], especially in mountain regions with limited meteorological monitoring and abundant precipitation often associated to extreme events [
7]. Flow data series from gauging stations are also affected by these problems. Unusual flood events may cause breakdowns and failures in the gauging stations which usually result in gaps in the daily flow data series, for instance. Moreover, even very short gaps may compromise the calculation of statistics and data utility [
8].
The problem of gaps in data series may be solved theoretically by completing daily flow records from existing data at gauging stations nearby, either upstream or downstream of the same watercourse (e.g., interpolation techniques), although the election of the donor station may be a critical factor affecting the results [
8]. Several methods have been used during the last decade for infilling missing data, including hydrodynamic modeling, remote sensing, or hydrological regionalization based on catchment geomorphological and meteorological data integration, resulting in general multivariate approaches (e.g., [
1,
3,
9]). Calibrated hydrological models for gap-filling streamflow data may perform adequately when estimating general annual trends [
10], but in many cases it is not possible to apply these procedures due to lack of data, or they do not provide the accuracy needed to generate daily flow series that reflect the particular characteristics or specificity of each streamflow regime [
6].
Approaches used in the past included physically-based rainfall-runoff models, conceptual models (knowledge-driven), or data-driven models [
11]. Data-driven, system-theoretical, or black-box models are purely empirical and do not consider the complex physical laws in the real world, but as they depend only on the information content in the hydrological data, they are usually easier to develop [
12]. Techniques applied to streamflow prediction or in-filling missing data encompass a great variety of statistical or artificial-intelligence procedures, linear and nonlinear: empirical regression, time series analysis, partitioning modeling, fuzzy rule-based systems, k-nearest neighbor algorithm techniques, pattern recognition, and artificial neural networks (e.g., [
9,
11,
13,
14,
15,
16,
17,
18,
19,
20]).
Artificial neural networks (ANN) have proven their value in many complex hydrological modeling problems [
6,
21,
22,
23], often improving results in comparison with other techniques [
17,
20,
24,
25,
26,
27,
28,
29]. By using historical data, it is possible to fit the ANN models to the patterns in the data [
23,
30,
31,
32]. They provide many advantages in the robust modeling of nonlinear systems [
21,
23], but Wu and Chau [
20] have pointed out that conclusions in the literature are very inconsistent. Some hybrid models that combine mechanistic and ANN models have also been proposed [
12,
33] to jointly account for linear and nonlinear trends [
34] or to aid with the configuration of ANN models (selection of inputs and/or outputs, e.g., correlograms for Joshi and Patel [
27], chaos theory in Elshorbagy et al. [
17], moving averages in Wu and Chau [
20] and Kashei and Bijari [
35]).
Problems most commonly found when working with ANNs are linked to the fact that most authors use variants of the back-propagation model, which architecture is set by trial and error [
17,
27,
36], running many models because they are sensitive to initial weights and have local minima issues. De Vos and Rientjes [
11] and Solaimani [
12] have dealt with modeling constraints and design aspects that affect model results and performance, and Kalteh [
36] has proposed useful approaches to understand the inner representations embedded in the net architecture.
In our study we intended to test the potential of a different ANN type, the cascade-correlation algorithm developed by Fahlman and Lebiere [
37] for completing discontinuous daily water flow records in a Mediterranean watershed, coupled with data preprocessing and a genetic algorithm [
38] for optimal selection of inputs, an approach used before by Alcazar et al. [
21] in environmental flow prediction. The advantage of this model is that its architecture needs not to be set by trial and error like in back-propagation, but optimal hidden layer dimension and net architecture are optimized during the training phase.
Our filling procedure was based on readily available variables, namely, Julian day and precipitation data from existing weather stations located within the watershed area, the usual most important variables to make streamflow predictions [
2,
23]. Our method could be classified as a single series approach according to the systematization done by Elshorbagy et al. [
16], where only one time series is available for the analysis, instead of using two correlated time series (bi-series approach). Nevertheless, an attempt at the identification of Elshorbagy et al.’s groups and modeling the intra-group structure was done through the use of data scenarios. It was expected that the high-variability characteristic of Mediterranean streams would pose more challenges to in-filling than other more stable environments and required considering changing intra (seasonal) and inter-annual flow conditions.
2. Materials and Methods
2.1. Study Area
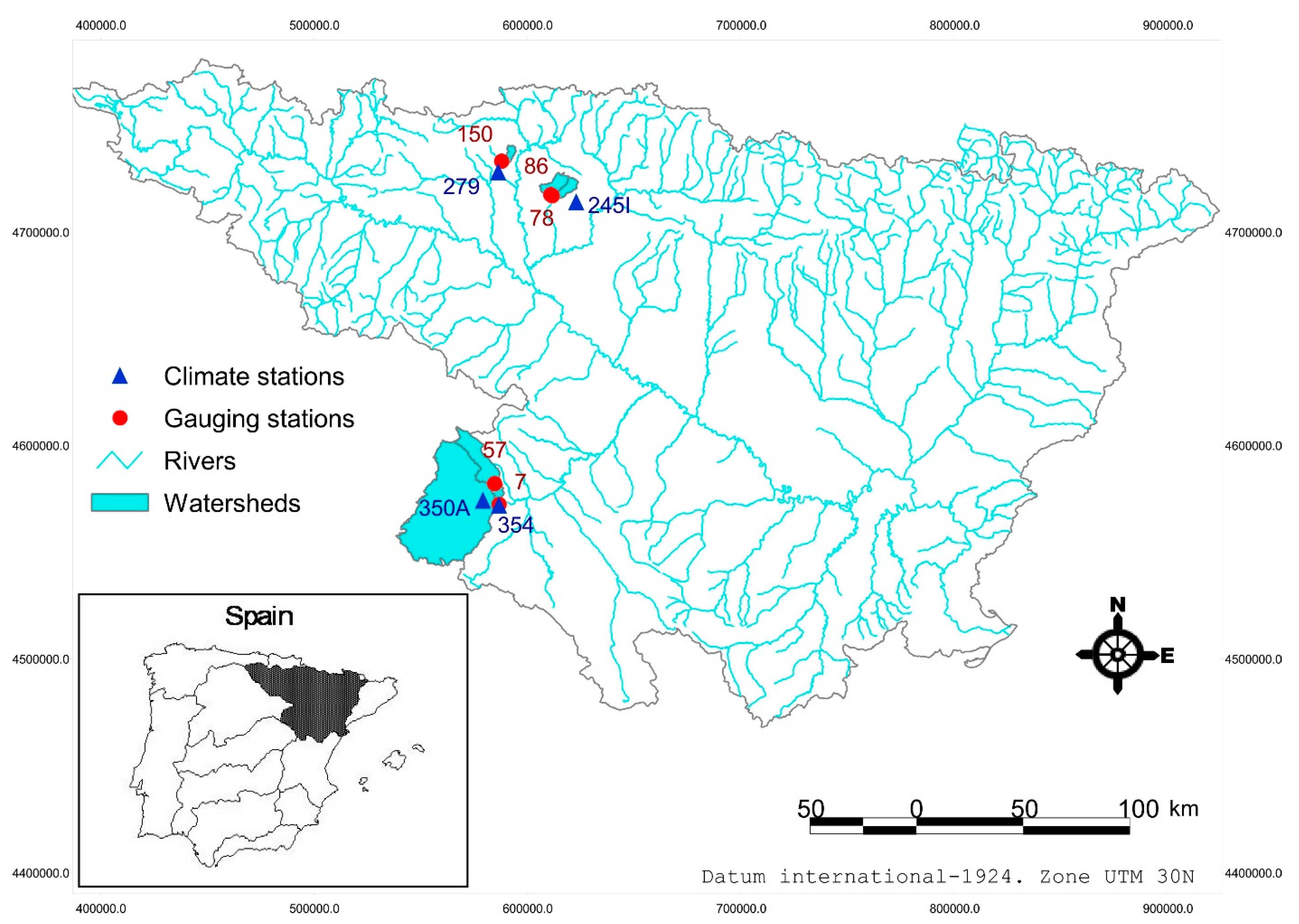
The domain of study was the Ebro river basin in Spain which is located in the northeast of the country (
Figure 1) and has an approximate area of 85,550 km
2 [
21]. It has a total length of 910 km, and it is the most important river in Spain in terms of flow, with an average water discharge of 430 m
3/s. The Ebro river is of major importance for ecological and human purposes, being subject to substantial demands from hydropower generation, irrigation of agricultural fields, and recreation and urban uses [
1].
2.2. Database
Five gauging stations (GS) out of the 240 existing within the watershed were selected for this study (
Figure 1,
Table 1). They were selected because all of them presented unimpaired, natural flow regimes with a reliable data range of 30 years (1976–2005) of daily weather and flow records (average daily water discharge in m
3/s), and no more than three gaps. In the context of this study, we define a gap as a discontinuity in the daily flow data series due to missing data of at least one or more consecutive days. The continuous period of years used for the study was selected based on data reliability and availability, but also to account for the variability of the Mediterranean climate in this area. The study period included dry spells in the 1980s and 1990s, but also periods in the 1970s and 2000s that were humid in Spain. The selected gauging stations showed a mainly rainfall-dominated hydrological regime.
Table 1 and
Figure 1 show the location and main characteristics of the weather and gauging stations.
The GS databases presented a total of 11 gaps (
Table 2) in flow records ranging from 6 to 272 days (nine months) out of a possible maximum of 11,950 records (30 years × 365 days). Missing daily flow data values for each gap would be modeled from meteorological data provided by four nearby weather stations. The variables used for completing gaps in the database were Julian day (JD), the precipitation (mm) on the day we had the missing value (PP), and the precipitation on the five days before the date of the missing value (PP-1 to PP-5). The calculated time of concentration using Kirpich’s equation [
39] for the different watersheds ranged from 1 to 9 h. Furthermore, from the analysis of the precipitation and streamflow data series, we found that the response of watersheds to rainfall events translates in the streamflow data series as peak flows always within a period of 5 days after the weather event. So, given the size of the watersheds and giving time enough for water from the watershed divide to reach the watershed outlet (time of concentration), a period of 5 days was considered appropriate for the particularities of shape, topography, vegetation, and soil characteristics of the watersheds studied.
2.3. ANN Models
Besides the fact that ANN models have proved highly accurate in many previous hydrological applications [
6,
21,
22,
23], in this case, the use of ANN had additional advantages since weather variables would be expected to be highly correlated spatially and temporally, violating assumptions required for traditional statistical model building [
21].
There are many types of artificial neural networks, but a specific multilayered feed-forward type of network was used in this study, the cascade-correlation model defined by Fahlman and Lebiere [
37] (CCANN). This algorithm was successfully used by Alcázar et al. [
21] for the estimation of environmental flows, and a similar model building procedure was followed here. This algorithm has the advantage of optimizing network architecture in the so-called ‘training’ or ‘learning’ process, so it does not rely on trial-and-error for final architecture like back-propagation.
Any net model was initially built with an input layer (with nodes for JD and PP variables) and an output layer (with one output node for mean daily flow), and no nodes in the hidden layer. Learning proceeded by testing nodes for the hidden layer, altering their weights iteratively, and adding these new nodes when they produced an improved net performance. We tested up to three new nodes (instead of just one) for addition at each step of the iterative process, until no improvement in performance was gained. An important difference with the previous environmental flow work (with only 46 training cases) was that in the current gaps problem the number of cases was on the order of magnitude of the thousands, so they did not limit network architecture and size. No constraints were imposed for restricting the number of weights in the model, though this algorithm was designed for optimal structure, and resulting models are usually parsimonious. As the number of weights (degrees of freedom) was not an issue, nodes of our models were always fully connected by weights in three layers (input-to-hidden, hidden-to-output, input-to-output).
We randomly split the databases for analysis in training (56%), test (24%), and validation (20%) groups, as usual in neural network modeling (e.g., [
12,
27]). To avoid effects of this type of hold-out method of cross-validation in model performance and testing [
40], the random splitting was repeated at least three times for each model, and 5 initial replicas were built with different sets of random weights for each group at the beginning of training. Convergence of the 15 trials for each model to a same or similar structure was considered a trait of robustness of the solution.
The iterative learning algorithm was based on an adaptative gradient learning rule [
37,
41], a variant of the general algorithm of back-propagation [
42,
43]. Training performance was set to optimize the Pearson product-moment correlation (
r, Equation (1)) between observed and predicted outcomes: the known flow values (average daily water discharge in m
3/s) and the output of the net. The test dataset was used to prevent overtraining; learning from the training set was periodically stopped to compute r for the test set and did not continue updating weights once test r started to decrease and diverge from training
r. Once training was concluded, the validation dataset was run through the network and its
r computed. Predictive model performance was evaluated based on balanced
r’s for the three datasets, as r is the best known quantitative measure of performance among the group of measures that preserve the pattern of data [
40]. Additional criteria used to evaluate the models were based on model residuals, or differences between observed and predicted mean daily flows, specifically the root mean square error (RMSE), mean absolute error (MAE), and absolute maximum error (AME) (Equations (1)–(4)) [
40].
where
is the mean of observed values (
observations) and
are the predicted values.
Several transformations were applied to the independent variables and tested through a genetic algorithm (GA, [
38,
44]) provided by Predict
® 3.24 software [
45] to determine the optimal inputs to the models, previously to model building. In this case, the GA evolved a population of variable sets that were selected, mated, and mutated for a maximum number of 50 generations (patience = 7) in order to find the fittest combination of independent variables for each network model. Reproduction parameters applied were: cross-over probability = 0.7, mutation = 1.0, and elitist fraction = 0.05. Fitness was evaluated by a logistic multiple regression function for each individual (or subset of the model’s input variables, between 2–30 transformed variables) in the population. Once a best model was obtained, a sensitivity analysis through partial derivatives [
45] of the variables included as inputs was used to rate their relative importance in the models [
21].
2.4. Scenarios
Six different approaches were defined to optimize the predictive models of daily water flow for all and each gap in any gauging station (
Table 3). They were required because the natural variability of flow regime (inter and intra-annual variability) is a key aspect in defining the functioning and structure of a river (e.g., [
46,
47,
48,
49]), especially in Mediterranean ecosystems. However, this high variability of the streamflow database could induce large errors when developing prediction models from large time spans (30 years, Scenario 1). Consequently, several scenarios were proposed to reduce errors induced by a high inter- and intra-annual daily flow variability while keeping the observations for model building representative (Scenarios 2, 3, 4, 6).
We also considered that the hydrological response of watersheds is influenced by the basin characteristics that regulate runoff, such as geomorphology, geology, and vegetation cover. Changes in land cover over time due to either natural causes or human activities may vary the hydrological behavior of the watershed, i.e., the relationship between precipitation and runoff. Then, the accuracy of streamflow prediction models based only on precipitation data over a long period of time may be lowered by errors related to vegetation cover changes, for instance. Scenario 5 tried to reduce this possible source of error by reducing the time span of the observations used for modeling to the short-term.
Consequently, we built models for each GA (5 GS models), for each gap in any GS (11 gap models), and for these six scenarios, which raised the number of models built, validated, and analyzed for best performance to 54, with 15 replicas each.
3. Results
Best models for each gauging station (GS), scenario, and gap are presented in
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8, if the models were judged robust and adequate according to the performance criteria (r and RMSE in tables, AME and MAE data not shown).
The most important results for the three gaps in GS-7
Jalón-Cetina can be examined in
Table 4. The results of GS-7 were based on climate stations 354 and 350A, but in some models one whole station’s variables were left out. Models for scenarios S1, S2, and S3 all had
r < 0.50, with S3 < 0.2. The scenario S2 was the best for the longer 88’ spring gap (87 days), but performance was not very good in the validation dataset, probably for the difficulty in modeling variable high water flows. The seasonal scenario S4 was best for the small 1991 summer gap (17 days). Best results were achieved for the 55-days gap in summer 1984 in which the short-term S5 model reached
r = 0.76 for the training dataset and
r = 0.82 for the test and validation datasets.
Station GS-57
Deza-Embid de Ariza was nearby and we used the same climate stations as for GS-7. Analysis of the water flow curves over all the years based on the average monthly volume showed no extreme years. No homogenous period within the year could be identified (heterogeneous data across all months), so scenarios S2, S3, S4, and S6 could not be applied. The other scenarios gave unsatisfying correlation values
r < 0.50 for all replicas. Best results can be seen in
Table 5.
Station GS-78
Cemborain-Garinoain water flow did not show any extreme years. The two existing gaps overlapped the periods with homogenous very low water flow and the period with high heterogeneous water flow so also here S2, S3, and S6 could not be applied. S1 and S4 gave low r values. The S5 model produced the best results for the 28-day 1992 winter gap with an
r = 0.60 for the trained dataset and an
r = 0.69 for the validation dataset (
Table 6). The 2004 spring-summer gap (134 days) was not successfully modeled under any of the scenarios.
GS-86
Zidacos-Barasoaínis shared climate station with GS-78. In this gauging station, all scenarios could be applied for modeling but none of them gave good results (
r values ≤ 0.50). The best model results can be seen in
Table 7, under S1.
GS-150
Salado-Estenozis was modeled with independent weather variables from climate station 279. S1 showed r values close to 0.56 for training, test, and validation data for all three gaps. S2, S3, and S6 could not be applied to the longer gaps (49-days and 77-days) because the gaps overlapped both high and low flow periods. Models for the gap in the high period (32-days) gave bad correlations in general (
r values ≤ 0.50), except for S5. S5 provided reasonably good results for all the gaps (
Table 8).
In most models, and in all best models, architectures were parsimonious and solutions converged to similar nets (
Table 9). The differences between the r values of the training, test, and validation datasets were well balanced (similar values for training, test, and validation groups) indicating good reliability in the best models, and RMSEs were low (metric in the same units as the flow data).
The sensitivity analysis of the variables in the best models allowed to identify the most relevant in predicting daily flows. Variables excluded from most models or with partial derivatives that did not indicate relevant contribution were usually the precipitation values 4 and 5 days before the gaps, but there were no clear trends across gauging stations. PP-3 was present in many models as quite influential. Julian day was always in the models, but usually not as the most influential variable.
4. Discussion
Natural and rainfall-dominated flow regime watersheds with a reliable data range of 30 years of daily weather and flow records were not abundant in the Ebro river watershed. These conditions were not easily met and consequently, the data used in this study was limited to five gauging stations and the period 1976–2005. Nevertheless, the selected gauging stations were located north and south of the main stream and include paired, nearby gauging stations. Models to fill eleven gaps representative of different conditions of inter and intra-annual flow variability were built.
The variables used to build the models were purposely few, because Julian day and precipitation data are considered the most important variables to make predictions on streamflow [
2,
23,
51] and they are usually available or easy to gather. Data availability is always an issue in this type of studies. Existing data at gauging stations nearby, either upstream or downstream of the same watercourse, are rarely available. Complex rainfall-runoff models can be built but they also require an abundance of data, and watershed characteristics (such as soil and vegetation influence on water cycle) are not always easily acquired.
Instead, we tested simple models based on generally available weather data and Julian day. In many instances the cascade-correlation network models further reduced the number of variables in order to improve training results; mainly precipitation values delayed 4 and 5 days from the gaps. This fact backed our assessment of the influence of the relatively small size of most of the watersheds and our selection of precipitation variables (previous 1–5 days) based on time of concentration and trends in the data flow series.
Like in other hydrological problems [
6,
21,
22,
23,
51], ANNs have proven their potential value for modeling complex hydrological processes with limited data (variables), but the variability of the Pearson r correlation values between observed and predicted outcomes under different scenarios and gauging stations indicate that procedures cannot be generalized. Not all CCANN models performed well enough for their intended in-filling gaps application, even with the advantages provided by this algorithm compared to backpropagation, and by the GA used for selecting the best combination of inputs as a preprocessing technique.
The results of the study suggested that there was not one single scenario suitable for filling up gaps in all gauging stations, but the short-term S5 (two years before and after the gap) gave the best results. Different scenarios would have to be tested, if applicable, but our approach seemed promising if seasonal variability is accounted for and short periods before and after the gap are considered. Using the full 30 years of data (S1) did not give satisfactory results which probably were related to changes in water flow over the years, with higher variability more likely within longer time spans. Gaps in low water flow periods apparently gave better modeling results, probably caused by a lower variability in the data typical of these periods. High heterogeneity in the water flow data negatively influenced the training of suitable models, like in case of GS-57 and GS-86 gauging stations, where suitable models were not found for any scenario or gap. Future work may have to look into neural network algorithms better suited to identify extreme values instead of general trends.




{kind=link}