Machine Learning-Based Water Level Prediction in Lake Erie

Abstract
1. Introduction
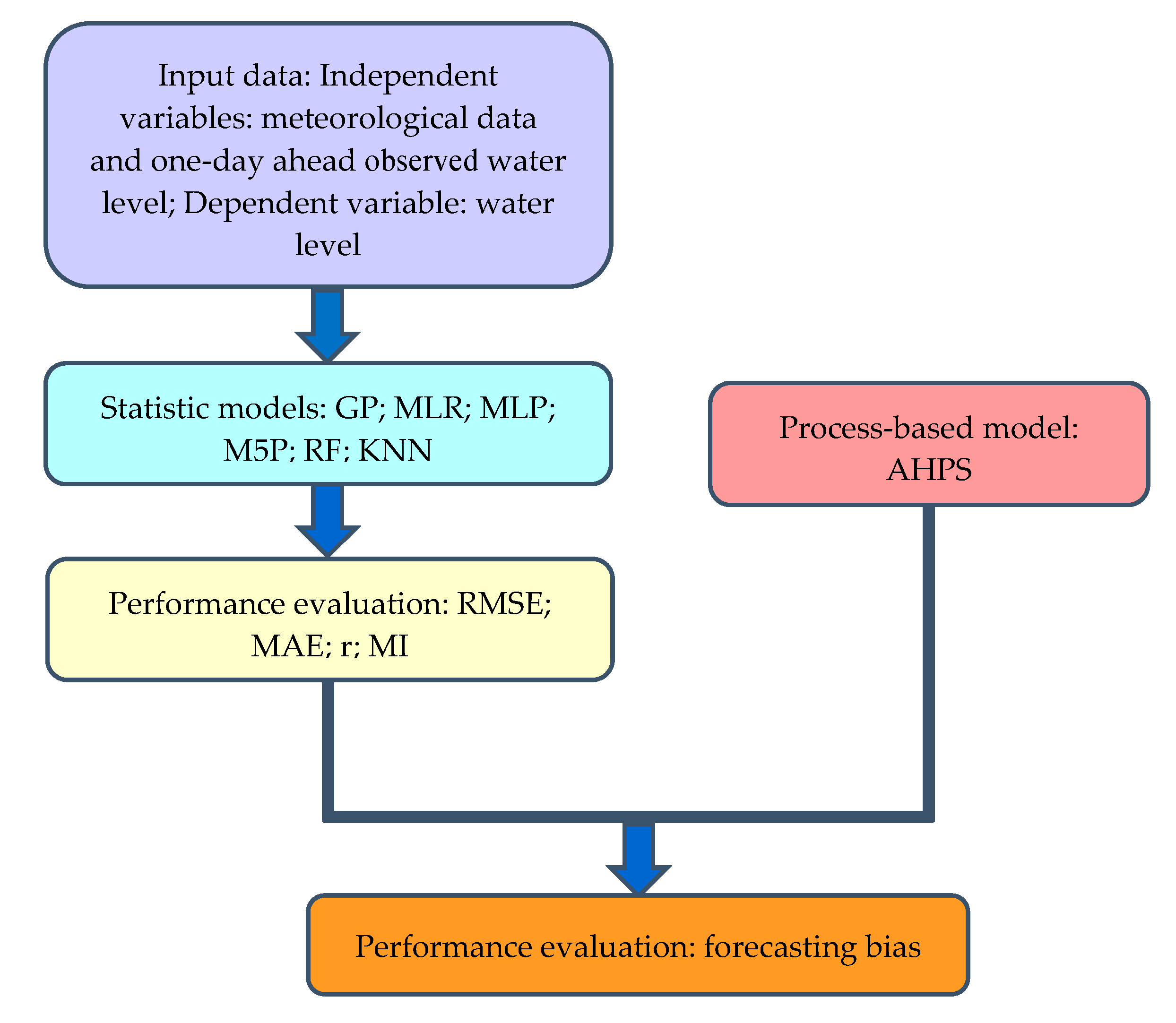
2. Materials and Methods
2.1. Study Area
2.2. Data Source
2.3. Machine Learning Algorithms
2.3.1. Gaussian Process
2.3.2. Multiple Linear Regression
2.3.3. Multilayer Perceptron
2.3.4. M5P Model Tree
2.3.5. Random Forest
2.3.6. K-Nearest Neighbor
2.4. Model Performance Evaluation
3. Results
3.1. Input Selection
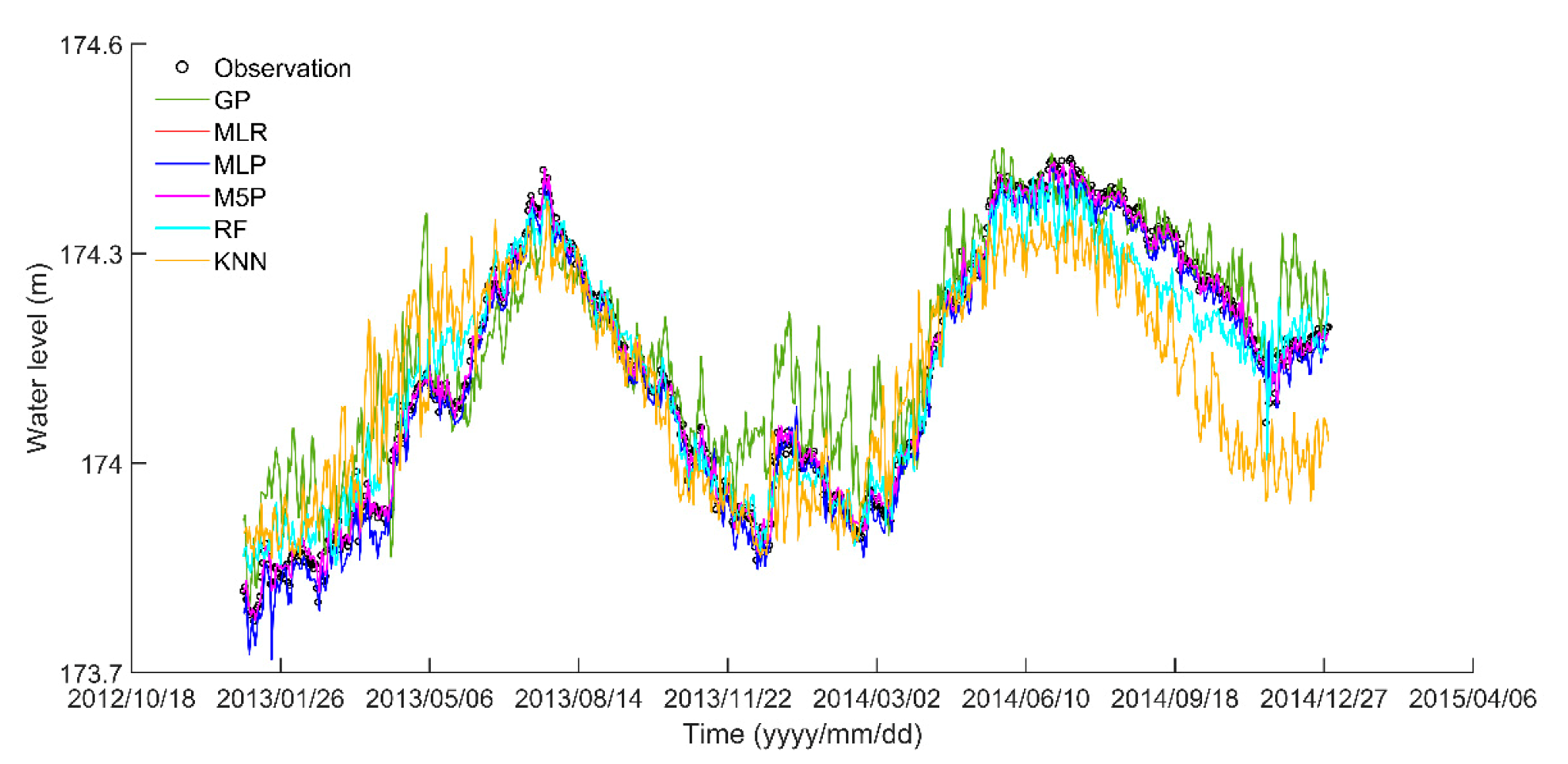
3.2. Model Performance Comparison
4. Discussion
4.1. Multiple ML Models Comparison
4.2. Comparison between ML Models and AHPS
4.3. Impact of Training and Testing Data Selection
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Håkanson, L.; Parparov, A.; Hambright, K. Modelling the impact of water level fluctuations on water quality (suspended particulate matter) in Lake Kinneret, Israel. Ecol. Model. 2000, 128, 101–125. [Google Scholar] [CrossRef]
- Oganesian, R.; Parparov, A. The problems of Lake Sevan and ways of solution. In Proceedings of the Symposium Biologica Hungarica, Conservation and Management of Lakes, Budapest, Hungary, 11–17 September 1989; Akademiai Kiado: Budapest, Hungary, 1989. [Google Scholar]
- Grima, A.; Wilson-Hodges, C. Regulation of Great Lakes water levels: The public speaks out. J. Great Lakes Res. 1977, 3, 240–257. [Google Scholar] [CrossRef]
- International Joint Commission. Living with the Lakes: Challenges and Opportunities-Annex G Public Information Program; International Joint Commission: Windsor, ON, Canada, 1989. [Google Scholar]
- International Joint Commission. Levels Reference Study: Great Lakes-St. Lawrence River Basin; The Board: Windsor, ON, Canada, 1993. [Google Scholar]
- Altunkaynak, A. Forecasting surface water level fluctuations of Lake Van by artificial neural networks. Water Resour. Manag. 2007, 21, 399–408. [Google Scholar] [CrossRef]
- Karimi, S.; Shiri, J.; Kisi, O.; Makarynskyy, O. Forecasting water level fluctuations of Urmieh Lake using gene expression programming and adaptive neuro-fuzzy inference system. IJOCS 2012, 3, 109–125. [Google Scholar] [CrossRef]
- Marchand, D.; Sanderson, M.; Howe, D.; Alpaugh, C. Climatic change and great lakes levels the impact on shipping. Clim. Chang. 1988, 12, 107–133. [Google Scholar] [CrossRef]
- Gronewold, A.D.; Clites, A.H.; Hunter, T.S.; Stow, C.A. An appraisal of the Great Lakes advanced hydrologic prediction system. J. Great Lakes Res. 2011, 37, 577–583. [Google Scholar] [CrossRef]
- Arhonditsis, G.B.; Brett, M.T. Evaluation of the current state of mechanistic aquatic biogeochemical modeling. Mar. Ecol. Prog. Ser. 2004, 271, 13–26. [Google Scholar] [CrossRef]
- Beck, M.B.; Ravetz, J.R.; Mulkey, L.; Barnwell, T.O. Hydraulics. On the problem of model validation for predictive exposure assessments. Stoch. Hydrol. Hydraul. 1997, 11, 229–254. [Google Scholar] [CrossRef]
- Yu, P.S.; Chen, S.T.; Chang, I.F. Support vector regression for real-time flood stage forecasting. J. Hydrol. 2006, 328, 704–716. [Google Scholar] [CrossRef]
- Yu, Z.; Lei, G.; Jiang, Z.; Liu, F. ARIMA modelling and forecasting of water level in the middle reach of the Yangtze River. In Proceedings of the 2017 4th International Conference on Transportation Information and Safety (ICTIS), Banff, AB, Canada, 8–10 August 2017. [Google Scholar]
- Alvisi, S.; Mascellani, G.; Franchini, M.; Bardossy, A. Water level forecasting through fuzzy logic and artificial neural network approaches. Hydrol. Earth Syst. Sci. 2006, 10, 1–17. [Google Scholar] [CrossRef]
- Ghorbani, M.A.; Khatibi, R.; Aytek, A.; Makarynskyy, O.; Shiri, J. Sea water level forecasting using genetic programming and comparing the performance with artificial neural networks. Comput. Geosci. 2010, 36, 620–627. [Google Scholar] [CrossRef]
- Khan, M.S.; Coulibaly, P. Application of support vector machine in lake water level prediction. J. Hydrol. Eng. 2006, 11, 199–205. [Google Scholar] [CrossRef]
- Buyukyildiz, M.; Tezel, G.; Yilmaz, V. Estimation of the change in lake water level by artificial intelligence methods. Water Resour. Manag. 2014, 28, 4747–4763. [Google Scholar] [CrossRef]
- Coulibaly, P. Reservoir computing approach to Great Lakes water level forecasting. J. Hydrol. 2010, 381, 76–88. [Google Scholar] [CrossRef]
- Meinshausen, M.; Smith, S.J.; Calvin, K.; Daniel, J.S.; Kainuma, M.L.T.; Lamarque, J.F.; Matsumoto, K.; Montzka, S.A.; Raper, S.C.B.; Riahi, K.; et al. The RCP greenhouse gas concentrations and their extensions from 1765 to 2300. Clim. Chang. 2011, 109, 213. [Google Scholar] [CrossRef]
- Bolsenga, S.J.; Herdendorf, C.E. Lake Erie and Lake St. Clair Handbook; Wayne State University Press: Detroit, MI, UAS, 1993. [Google Scholar]
- Boyce, F.M.; Chiocchio, F.; Eid, B.; Penicka, F.; Rosa, F. Hypolimnion flow between the central and eastern basins of Lake Erie during 1977 (interbasin hypolimnion flows). J. Great Lakes Res. 1980, 6, 290–306. [Google Scholar] [CrossRef]
- Conroy, J.D.; Boegman, L.; Zhang, H.; Edwards, W.J.; Culver, D.A. “Dead Zone” dynamics in Lake Erie: The importance of weather and sampling intensity for calculated hypolimnetic oxygen depletion rates. Aquat. Sci. 2011, 73, 289–304. [Google Scholar] [CrossRef]
- Bocaniov, S.A.; Scavia, D. Temporal and spatial dynamics of large lake hypoxia: Integrating statistical and three-dimensional dynamic models to enhance lake management criteria. Water Resour. Res. 2016, 52, 4247–4263. [Google Scholar] [CrossRef]
- Kisi, O.; Shiri, J.; Nikoofar, B. Forecasting daily lake levels using artificial intelligence approaches. Comput. Geosci. 2012, 41, 169–180. [Google Scholar] [CrossRef]
- Li, W. Mutual information functions versus correlation functions. J. Stat. Phys. 1990, 60, 823–837. [Google Scholar] [CrossRef]
- Ross, B.C. Mutual information between discrete and continuous data sets. PLoS ONE 2014, 9, e87357. [Google Scholar] [CrossRef] [PubMed]
- Grbić, R.; Slišković, D.; Kadlec, P. Adaptive soft sensor for online prediction and process monitoring based on a mixture of Gaussian process models. Comput Chem Eng. 2013, 58, 84–97. [Google Scholar] [CrossRef]
- Rasmussen, C.E. Gaussian processes in machine learning. In Proceedings of the Summer School on Machine Learning, Canberra, Australia, 2–14 February 2003; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Sun, A.Y.; Wang, D.; Xu, X. Monthly streamflow forecasting using Gaussian process regression. J. Hydrol. 2014, 511, 72–81. [Google Scholar] [CrossRef]
- Makridakis, S.; Wheelwright, S.C.; Hyndman, R.J. Forecasting Methods and Applications; John Wiley & Sons: Toronto, ON, Canada, 2008. [Google Scholar]
- Piasecki, A.; Jurasz, J.; Skowron, R. Forecasting surface water level fluctuations of lake Serwy (Northeastern Poland) by artificial neural networks and multiple linear regression. J. Environ. Eng. Landsc. Manag. 2017, 25, 379–388. [Google Scholar] [CrossRef]
- Kadam, A.K.; Wagh, V.M.; Muley, A.A.; Umrikar, B.N.; Sankhua, R.N. Environment. Prediction of water quality index using artificial neural network and multiple linear regression modelling approach in Shivganga River basin, India. Model Earth Syst. Environ. 2019, 5, 951–962. [Google Scholar] [CrossRef]
- Singh, A.; Imtiyaz, M.; Isaac, R.K.; Denis, D.M. Comparison of soil and water assessment tool (SWAT) and multilayer perceptron (MLP) artificial neural network for predicting sediment yield in the Nagwa agricultural watershed in Jharkhand, India. Agric. Water Manag. 2012, 104, 113–120. [Google Scholar] [CrossRef]
- Hertz, J.A. Introduction to the Theory of Neural Computation; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Lekkas, D.F.; Onof, C.; Lee, M.J.; Baltas, E.A. Application of artificial neural networks for flood forecasting. Glob. Nest J. 2004, 6, 205–211. [Google Scholar]
- Ghorbani, M.A.; Deo, R.C.; Karimi, V.; Kashani, M.H.; Ghorbani, S. Design and implementation of a hybrid MLP-GSA model with multi-layer perceptron-gravitational search algorithm for monthly lake water level forecasting. Stoch. Environ. Res. Risk Assess. 2019, 33, 125–147. [Google Scholar] [CrossRef]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Tasmania, 16–18 November 1992; World Scientific: Singapore, 1992. [Google Scholar]
- Solomatine, D.P.; Siek, M.B.L. Flexible and optimal M5 model trees with applications to flow predictions. In Proceedings of the 6th International Conference on Hydroinformatics, Singapore, 21–24 June 2004; World Scientific: Singapore, 2004. [Google Scholar]
- Solomatine, D.P.; Dulal, K.N. Model trees as an alternative to neural networks in rainfall—Runoff modelling. Hydrol. Sci. J. 2003, 48, 399–411. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Wang, X.; Liu, T.; Zheng, X.; Peng, H.; Xin, J.; Zhang, B. Short-term prediction of groundwater level using improved random forest regression with a combination of random features. Appl. Water Sci. 2018, 8, 125. [Google Scholar] [CrossRef]
- Bremner, D.; Demaine, E.; Erickson, J.; Iacono, J.; Langerman, S.; Morin, P.; Toussaint, G. Output-sensitive algorithms for computing nearest-neighbour decision boundaries. Discrete. Comput. Geom. 2005, 33, 593–604. [Google Scholar] [CrossRef]
- Atkeson, C.G.; Moore, A.W.; Schaal, S. Locally Weighted Learning; Springer: Dordrecht, The Netherlands, 1997; pp. 11–73. [Google Scholar]
- Poul, A.K.; Shourian, M.; Ebrahimi, H. A comparative study of MLR, KNN, ANN and ANFIS models with wavelet transform in monthly stream flow prediction. Water Resour. Manag. 2019, 33, 2907–2923. [Google Scholar] [CrossRef]
- Kinney, J.B.; Atwal, G.S. Equitability, mutual information, and the maximal information coefficient. Proc. Natl. Acad. Sci. USA 2014, 111, 3354–3359. [Google Scholar] [CrossRef]
- Choi, C.; Kim, J.; Han, H.; Han, D.; Kim, H.S. Development of Water Level Prediction Models Using Machine Learning in Wetlands: A Case Study of Upo Wetland in South Korea. Water 2020, 12, 93. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Machine learning basics. In Deep Learning; Kaiser, D.I., Weck, O.L.D., Eds.; MIT Press: Cambridge, MA, USA, 2016; Volume 1, pp. 98–164. [Google Scholar]
- Bazartseren, B.; Hildebrandt, G.; Holz, K.P. Short-term water level prediction using neural networks and neuro-fuzzy approach. Neurocomputing 2003, 55, 439–450. [Google Scholar] [CrossRef]
- Yoon, H.; Jun, S.C.; Hyun, Y.; Bae, G.O.; Lee, K.K. A comparative study of artificial neural networks and support vector machines for predicting groundwater levels in a coastal aquifer. J. Hydrol. 2011, 396, 128–138. [Google Scholar] [CrossRef]
- Nadkarni, P. Clinical Research Computing: A Practitioner’s Handbook; Academic Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Croley II, T. Using climate predictions in Great Lakes hydrologic forecasts. In Climate Variations, Climate Change, and Water Resources Engineering; Garbrecht, J.D., Piechota, T.C., Eds.; American Society of Civil Engineers: Arlington, VA, USA, 2006; pp. 166–187. [Google Scholar]
- Croley II, T.E.; Hartmann, H.C. Resolving thiessen polygons. J. Hydrol. 1985, 76, 363–379. [Google Scholar] [CrossRef]
- Deo, R.C.; Şahin, M. An extreme learning machine model for the simulation of monthly mean streamflow water level in eastern Queensland. Environ. Monit. Assess. 2016, 188, 90. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Source and Location | Frequency |
|---|---|---|
| Air temperature | US National Data Buoy Center (NDBC) buoys (western basin, station 45005); Environment and Climate Change Canada (ECCC) lake buoy data (central basin, Port Stanley 45132; eastern basin, Port Colborne 45142); Great Lakes Environmental Research Laboratory (GLERL) land stations (station THLO1); US NDBC land stations (stationGELO1, DBLN6) | Hourly |
| Wind speed | ||
| Longwave radiation | ||
| Shortwave radiation | ||
| Relative humidity | ||
| Precipitation | National Oceanic and Atmospheric Administration (NOAA) | Daily |
| Water level |
| Variable | Description | Variable | Description | Variable | Description | Variable | Description | Variable | Description | Variable | Description |
|---|---|---|---|---|---|---|---|---|---|---|---|
| X1 | Wind speed(daily ave.) | X2 | Air temperature (daily ave.) | X3 | Relative humidity (daily ave.) | X4 | Shortwave Radiation (daily ave.) | X5 | Longwave radiation (daily ave.) | X6 | Precipitation (daily ave.) |
| X7 | Wind speed (daily max) | X8 | Air temperature (daily max) | X9 | Relative humidity (daily max) | X10 | Shortwave Radiation (daily max) | X11 | Longwave radiation (daily max) | X12 | Wind speed (daily min) |
| X13 | Air temperature (daily min) | X14 | Relative humidity (daily min) | X15 | Shortwave Radiation (daily min) | X16 | Longwave radiation (daily min) | X17 | Wind speed (2-day ave.) | X18 | Air temperature (2-day ave.) |
| X19 | Relative humidity (2-day ave.) | X20 | Shortwave Radiation (2-day ave.) | X21 | Longwave radiation (2-day ave.) | X22 | Precipitation (2-day ave.) | X23 | Wind speed (2-day max) | X24 | Air temperature (2-day max) |
| X25 | Relative humidity (2-day max) | X26 | Shortwave Radiation (2-day max) | X27 | Longwave radiation (2-day max) | X28 | Wind speed (2-day min) | X29 | Air temperature (2-day min) | X30 | Relative humidity (2-day min) |
| X31 | Shortwave Radiation (2-day min) | X32 | Longwave radiation (2-day min) | X33 | Wind speed (3-day ave.) | X34 | Air temperature (3-day ave.) | X35 | Relative humidity (3-day ave.) | X36 | Shortwave Radiation (3-day ave.) |
| X37 | Longwave radiation (3-day ave.) | X38 | Precipitation (3-day ave.) | X39 | Wind speed (3-day max) | X40 | Air temperature (3-day max) | X41 | Relative humidity (3-day max) | X42 | Shortwave Radiation (3-day max) |
| X43 | Longwave radiation (3-day max) | X44 | Wind speed (3-day min) | X45 | Air temperature (3-day min) | X46 | Relative humidity (3-day min) | X47 | Shortwave Radiation (3-day min) | X48 | Longwave radiation (3-day min) |
| Model | MI | |||
|---|---|---|---|---|
| Gaussian process | 0.07 | 0.06 | 0.94 | 8.45 |
| Multiple linear regression | 0.02 | 0.01 | 0.99 | 8.54 |
| Multiple Perceptron | 0.03 | 0.02 | 0.99 | 8.57 |
| M5P Model Tree | 0.02 | 0.01 | 0.99 | 8.53 |
| Random Forest model tree | 0.05 | 0.04 | 0.97 | 8.43 |
| KNN | 0.10 | 0.09 | 0.83 | 8.25 |
| Method | Bias in Median Water Level Forecast (cm) | |
|---|---|---|
| 3-Month Forecast | 6-Month Forecast | |
| AHPS | −5.50 | −5.40 |
| Gaussian Process | 1.81 | 2.58 |
| Multiple Linear Regression | −2.05 | −3.31 |
| Multilayer Perceptron | −3.64 | −4.57 |
| M5P Model Tree | −2.05 | −3.31 |
| Random Forest Model Tree | −1.97 | −4.25 |
| KNN | −2.42 | −3.60 |
| Model | Train Time | Test Time |
|---|---|---|
| Gaussian Process | 156.0 s | 35.39 s |
| Multiple Linear Regression | 0.28 s | 0.61 s |
| Multilayer Perceptron | 53.78 s | 0.49 s |
| M5P Model Tree | 2.48 s | 0.51 s |
| Random Forest Model Tree | 5.83 s | 0.73 s |
| KNN | <0.1 s | 2.35 s |
| Model | MI | |||
|---|---|---|---|---|
| Gaussian process | 0.09 | 0.07 | 0.91 | 8.43 |
| Multiple linear regression | 0.02 | 0.01 | 0.99 | 8.52 |
| Multiple Perceptron | 0.03 | 0.02 | 0.99 | 8.52 |
| M5P Model Tree | 0.02 | 0.01 | 0.99 | 8.54 |
| Random Forest model tree | 0.06 | 0.05 | 0.95 | 8.42 |
| KNN | 0.10 | 0.08 | 0.83 | 8.17 |
| Model | MI | |||
|---|---|---|---|---|
| Gaussian process | 0.09 | 0.07 | 0.91 | 8.45 |
| Multiple linear regression | 0.02 | 0.01 | 0.99 | 8.42 |
| Multiple Perceptron | 0.02 | 0.01 | 0.99 | 8.59 |
| M5P Model Tree | 0.02 | 0.01 | 0.99 | 8.50 |
| Random Forest model tree | 0.06 | 0.05 | 0.95 | 8.41 |
| KNN | 0.11 | 0.09 | 0.80 | 8.21 |
| Model | MI | |||
|---|---|---|---|---|
| Gaussian process | 0.08 | 0.07 | 0.92 | 8.50 |
| Multiple linear regression | 0.02 | 0.01 | 0.99 | 8.52 |
| Multiple Perceptron | 0.02 | 0.02 | 0.99 | 8.56 |
| M5P Model Tree | 0.02 | 0.01 | 0.99 | 8.50 |
| Random Forest model tree | 0.05 | 0.04 | 0.96 | 8.44 |
| KNN | 0.11 | 0.09 | 0.81 | 8.19 |
| Model | MI | |||
|---|---|---|---|---|
| Gaussian process | 0.08 | 0.06 | 0.93 | 8.45 |
| Multiple linear regression | 0.02 | 0.01 | 0.99 | 8.53 |
| Multiple Perceptron | 0.03 | 0.02 | 0.99 | 8.57 |
| M5P Model Tree | 0.02 | 0.01 | 0.99 | 8.53 |
| Random Forest model tree | 0.06 | 0.05 | 0.95 | 8.39 |
| KNN | 0.11 | 0.09 | 0.79 | 8.21 |
| Model | MI | |||
|---|---|---|---|---|
| Gaussian process | 0.08 | 0.06 | 0.94 | 8.44 |
| Multiple linear regression | 0.02 | 0.01 | 0.99 | 8.54 |
| Multiple Perceptron | 0.03 | 0.02 | 0.99 | 8.57 |
| M5P Model Tree | 0.02 | 0.01 | 0.99 | 8.54 |
| Random Forest model tree | 0.06 | 0.04 | 0.96 | 8.39 |
| KNN | 0.10 | 0.09 | 0.82 | 8.19 |
| Model | MI | |||
|---|---|---|---|---|
| Gaussian process | 0.08 | 0.06 | 0.94 | 8.47 |
| Multiple linear regression | 0.02 | 0.01 | 0.99 | 8.53 |
| Multiple Perceptron | 0.02 | 0.01 | 0.99 | 8.56 |
| M5P Model Tree | 0.02 | 0.01 | 0.99 | 8.53 |
| Random Forest model tree | 0.05 | 0.04 | 0.97 | 8.44 |
| KNN | 0.10 | 0.08 | 0.84 | 8.26 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Wang, S. Machine Learning-Based Water Level Prediction in Lake Erie. Water 2020, 12, 2654. https://doi.org/10.3390/w12102654
Wang Q, Wang S. Machine Learning-Based Water Level Prediction in Lake Erie. Water. 2020; 12(10):2654. https://doi.org/10.3390/w12102654
Chicago/Turabian StyleWang, Qi, and Song Wang. 2020. "Machine Learning-Based Water Level Prediction in Lake Erie" Water 12, no. 10: 2654. https://doi.org/10.3390/w12102654
APA StyleWang, Q., & Wang, S. (2020). Machine Learning-Based Water Level Prediction in Lake Erie. Water, 12(10), 2654. https://doi.org/10.3390/w12102654