1. Introduction
Models are used to investigate a single phenomenon or a whole system. Different models that are based on different concepts allow for looking at the physical truth from different angles, or to use contrasting approaches to prediction. Therefore, employing multiple models instead of only one has the potential for increasing system understanding and enhancing predictive power. However, each model has its own uncertainties, often classified as input, parameter, output uncertainties [
1,
2], or by other categories. Furthermore, when using multiple models, there is uncertainty in choosing between them. This is sometimes called conceptual uncertainty ([
3] and references therein).
Having a set of alternative models that share the same objective, e.g., predicting a specific quantity of interest (QoI), it often remains unclear how to optimally operate them as an ensemble. Attempts to solve this issue have yielded a plethora of what we suggest to call multi-model frameworks (MMF): methods that quantify conceptual uncertainty between models, rate them accordingly and allow us to operate them as weighted ensemble.
Typical examples for such model rating methods are information criteria like the Akaike IC (AIC [
4,
5]) or the Bayesian IC (BIC [
6]). Their results can be transferred into model weights that resemble the relative conceptual uncertainty between the models in the set. Based on these weights, a single model can be selected or a weighted ensemble can be obtained from the set. A popular BIC-type weighting method is Bayesian model averaging (BMA [
7,
8,
9]).
Bayesian statistics offer uniform and coherent principles for quantifying uncertainty [
10]. From a Bayesian perspective, uncertainty means lack of knowledge, and corresponding probability distributions—or probability density functions (PDFs)—express degree of belief in the available knowledge [
11]. In light of evidence like observed data, this knowledge changes and Bayesian distributions are updated from so-called priors to posteriors.
Model averaging under the Bayesian paradigm means averaging of probability distributions implied by the models. Honouring conceptual uncertainty, Bayesian multi-model frameworks (BMMFs) like BMA use model weights to average predictive distributions of multiple models to cover modelling uncertainty more broadly. Several other BMMFs for model averaging exist, but the meaning and purpose of model weights between them deviate tremendously (see [
12]). This complicates their use and often leads to misinterpretations.
We intend to clarify the reasons thereof and show how to ensure appropriate use of BMMFs. We focus on five popular methods: Bayesian model selection (BMS) and Bayesian model averaging (BMA), so-called Pseudo-BMS and Pseudo-BMA, and Bayesian Stacking (BS; e.g., [
13]), which recently attracted increased attention ([
14] and references therein).
In order to highlight similarities and differences between the BMMFs in model weighting, we use a modelling task and corresponding models that were already employed successfully in Bayesian multi-model inference by Schöniger et al. [
15]. We present consecutive work to Schöniger et al. [
15] that focused on model weighting via BMS and BMA as methods of choice for selecting the appropriate level of model complexity in applied modelling. Schöniger et al. [
15] demonstrated the suitability of BMS and BMA to accomplish this quest but also elicited limitations. We add Pseudo-BMS, Pseudo-BMA and Bayesian Stacking in order to contrast them to BMS and BMA. Additionally, we show under what circumstances and goals which of these methods is the most promising approach for model selection or averaging.
The remainder of this article is structured as follows: First, we present the theoretical underpinnings for all chosen methods, specifically putting the assumption into perspective of whether the allegedly true model, i.e., the data-generating process
, is part of the set of models under consideration
. Second, we revisit the work of Schöniger et al. [
15] as a basis for our comparison of BMMFs. Third, we analyse and contrast the evolution of model weights from all frameworks over growing data size in an applied modelling task. Thereby, we elicit differences and discuss proper use and caveats of each BMMF. It is our goal to foster broader application of the investigated methods. Hence, fourth and finally, we summarize key findings and conclude general rules for their employment.
2. Bayesian Multi-Model Frameworks
The Bayesian average of multiple models is a convex linear combination (
and
) of the model-wise posterior predictive distributions (see [
8,
15]):
with the individual posterior predictive distribution
of model
for the quantity of interest
given data
and corresponding posterior model weight
.
are measured observations, i.e.,
sampled instances of the QoI. All models are members of a finite set:
.
Note that the averaging does not occur on the level of model outputs themselves, but on their corresponding distributions. If actual model outputs were averaged, they would receive an own probability distribution that would differ from the above convex combination (see, e.g., [
12]).
2.1. BMS/BMA
The two popular methods Bayesian Model Selection and Bayesian Model Averaging (BMS/BMA [
7,
8,
9]) are different stages of the same BMMF—a fact often ignored as already pointed out by Minka [
16]. Selection or averaging simply refer to different levels of confidence, usually depending on the informativeness of the available data
. Until sufficient data are available for a reliable selection, weighted model averaging prevents a rash exclusion of alternatives. Given the currently available data
, the model weight
of model
is given by
Only in BMS/BMA can model weights also be interpreted as model probabilities:
and
are the posterior and prior model probabilities, respectively, that
is the true model
that generated
. The updating is based on the marginal likelihood a.k.a. Bayesian Model Evidence (BME), i.e., the prior predictive density for data
:
In the large-sample-limit of data, the weight of the allegedly true model is supposed to converge to 1, turning the weighted average of models (BMA) into a selection of the single best one (BMS)—“weights in BMA only reflect a statistical inability to distinguish the hypothesis based on limited data” [
16]. Ultimately, BMS seeks to identify
based on its prior predictive density for
. The ability of a selection procedure to converge to the true model (e.g., [
17]) is called “consistency”.
The consistency property results in a natural tendency towards simpler over more complex models of BMS/BMA (e.g., [
2]). Following the principle of parsimony (see [
18]), the best-rated model should always only be as complex as necessary and as simple as possible—just as the truth itself (see
Section 2.5).
Since the evaluation of the marginal likelihood according to Equation (
3) in BMS/BMA is typically a computationally challenging task, methods for its approximation are used. Among others, the most popular ones are the Kashyap (KIC) and the already mentioned Bayesian (BIC) information criteria [
19].
2.2. Pseudo-BMS/BMA
The classic way of estimating accuracy and precision of model predictions for yet unseen data is via cross-validation (CV; e.g., [
20]): Available observations
are split up into a part to train/calibrate the model and a remaining part for testing/validating the model afterwards. There are many variants of CV, a very popular but computationally expensive one is leave-one-out (LOO) CV: Over
iterations, one data point after another is held-out as testing data
, and the model is trained on the remaining data
. The model is then rated on the average performance over all iterations.
Pseudo-BMS and Pseudo-BMA refer to the Bayesian version of CV [
21,
22]—implying different stages of data availability, just as with BMS and BMA in
Section 2.1. Model weights are based on the so-called expected logarithmic predictive density
[
23], gained from LOO-CV:
Following the principle of LOO-CV, the
is the sum of the point-wise posterior predictive densities
over all held-out data points. This implies the assumption that all data points are independent and identically distributed (i.i.d.), which is a frequent point of criticism (see, e.g., invited and contributed Discussion in [
14]). Thereby,
is a marginalized likelihood, but, opposed to BMS/BMA, integrated over the posterior and not the prior parameter distribution:
In the large-sample-limit, the highest weight for one model does not imply that it is also the true model. Pseudo-BMS/BMA is one of so-called non-consistent (see, e.g., [
24]) model selection methods that lack the ability to converge to the true model since they implicitly assume that
is not part of
. They yield a rating of the best probabilistic accuracy-precision trade-off currently supported by the available data in approximating the true model. They do not test for model truth as BMS/BMA, but for posterior predictive skill.
This results in a natural tendency towards more complex models over simpler model approaches because it is assumed that more complex models with more functional features can approximate and predict the data-generating process more closely. Therefore, if a model in Pseudo-BMS/BMA receives highest model weight, this means two things: First, the winning model currently offers the best available trade-off between all model alternatives, and, second, another model with even more or new features could be added to the set. Potentially, this model of higher complexity is then able to approximate the data even better and strike a better trade-off between accuracy and precision. Pseudo-BMS/BMA implicitly expects that, as soon as more (informative) data are available, more and more complex models can be supported.
The famous AIC is an estimator for the expected logarithmic predictive density and hence the model weights in Equation (
4) are also often called Akaike weights [
25]. Based on different assumptions, further approximations exist, e.g., the Deviance (DIC) or Watanabe–Akaike (WAIC) information criteria [
19].
2.3. Bayesian Stacking
Opposed to BMS/BMA and Pseudo-BMS/BMA that both ultimately seek to select a single best model over growing data, Bayesian Stacking offers an alternative for averaging model predictive distributions as combination. Originally, stacking is an approach for averaging point estimators from deterministic models ([
14] and references therein). Le and Clarke [
26] provide a Bayesian generalization for averaging probabilistic models.
Model weights in Bayesian Stacking are also evaluated based on point-wise posterior predictive densities per model
. However, opposed to Pseudo-BMA/BMS, they are not based on individual model’s point-wise posterior predictive densities. In Bayesian Stacking, they are the result of a weight optimization to maximize the common point-wise posterior predictive density from all models in
as defined by (see [
14]):
Similar to Pseudo-BMS/BMA, Bayesian Stacking does not assume that one of the models in
is
. Hence, Bayesian Stacking seeks to optimize weights such that the common (rather than an individual) posterior predictive distribution yields the best probabilistic accuracy-precision trade-off. At the limit of growing data size, stable weights reflect constant model shares in the ensemble. Thus, the goal of Bayesian Stacking is to use the entire model set for best-possible linear combination in prediction. The optimized weights from Equation (
6) can be seen as a maximum predictive likelihood parameter choice of the mixed model implied by Equation (
1).
2.4. Bayesian Bootstrap
The model weights gained in both Pseudo-BMS/BMA and Bayesian Stacking use the held-out data points as proxies for the future data distribution [
14]. Furthermore, the model weights in Bayesian Stacking are the result of an optimization and are potentially unstable. Hence, it is questionable whether the available data are a sufficient proxy also for future data and whether the obtained weights are trustworthy.
An approach to counteract data scarcity and instability is so-called bootstrapping [
27]. It accounts for the uncertainty in definiteness of data
[
28]: Using re-sampling, the uncertainty of insufficient sampling from a distribution of interest [
29] becomes quantifiable. In particular, Bayesian Bootstrapping uses a Dirichlet distribution to generate a non-parametric approximation of the posterior distribution of each sample [
28].
Here, the distribution of interest is the data distribution coming from the data-generating process. Therefore, we look at the predictions of all models for each
by defining the logarithmic LOO predictive density as
. Over
b bootstrapping replications with
, posterior probabilities
for
are drawn from (see [
14]):
For each
b, marginalization over
yields the desired statistical moment [
28], here the mean [
14]:
Then, the expected bootstrapped model weights
are
By applying the Bayesian Bootstrap, extreme model weights like 0 or 1 are typically counteracted and model weights are stabilized [
14]. Bayesian Bootstrapping is inexpensive in terms of additional computational cost because required quantities have already been generated for evaluating the BMMFs in
Section 2.2 and
Section 2.3 and only need to be processed in one more step [
30].
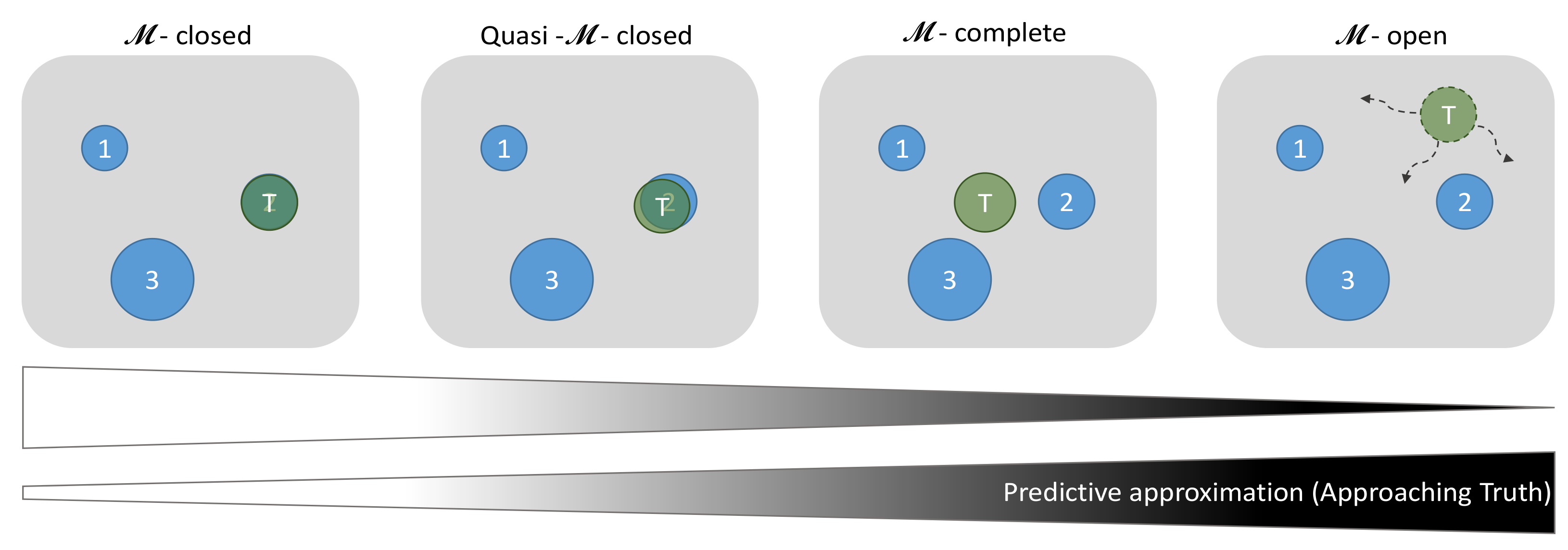
2.5. -Settings
The above methods react sensitively to the minute differences in how
(termed “true model”, “truth”, “data-generating process”, etc.) relates to the members of the model set
. For any modelling task at hand, these interrelations can be distinguished and interpreted by distinct
-settings adopted from Bernardo and Smith [
31]:
-closed,
-complete, and
-open. In addition, we specify a so-called Quasi-
-closed setting for applied modelling. The
-settings are depicted schematically in
Figure 1, and corresponding properties are summarized in
Table 1.
In a so-called
-closed setting, one of the models in
is in fact the data-generating true model
. Identifying
is often referred to as consistent model selection [
24,
32]. Therefore,
-closed is the only setting where model weights can actually express how likely it is for a particular model to be
. Among the presented BMMFs, only BMS/BMA supports this: Each model weight represents the probability of the particular model to be the true model that generated the observed data.
While the requirement of model weights to sum up to one in all convex linear combination methods can simply be seen as an unbiasedness constraint, in BMS/BMA, it resembles the axiom that the probability of all elements in an event space must sum up to one . Therefore, the enumeration to one hard-codes the assumption that contains , so that , and that the models are mutually exclusive possibilities.
In real world applications, it is unlikely that one model in the set is in fact the true model. Therefore, for application purposes, we suggest to relax the strict definition of the
-closed setting to a Quasi-
-closed setting [
12]: For example, mechanistic models might be developed to represent the true system up to the current state of physical knowledge, and modellers might be interested in isolating the one model with a prior predictive distribution being nearly identical to the true data distribution. We consider this a quasi-true model. Terming such a scenario a Quasi-
-closed setting allows us to apply BMS/BMA while acknowledging the unavailability of
-closed settings in applied sciences [
30]—yet with the restriction that model weights do not resemble probabilities.
In both other settings,
-complete and
-open, the true model is not a member of model set
. In
-complete, it is still hypothetically possible to conceptualize the true model because it has finite complexity. Thus, one could write it down in some (incomplete) fashion and at least come close to
.
-open is even more critical about the data-generating process. It can only be incompletely conceptualized and writing it down as a true model is impossible [
14], e.g., because it would be of infinite complexity. In both settings, model weights do not represent probabilities of being true because
and therefore
, so that
and a probabilistic interpretation would violate the axiom
.
In
-complete and
-open, BMMFs rather quantify the relative abilities of the calibrated ensemble members to approximate or imitate the truth. Hence, model rating is based on posterior (rather than prior) predictive densities. Modellers have two options: They can select a single best (but still wrong) model via Pseudo-BMS/BMA if operating only one model for predictions is desired. This could be the case if, e.g., model run times prohibit multiple model use or the one best model shall successively be enlarged with additional features [
23]—or, if multiple models shall be employed together, e.g., to obtain a better coverage of predictive uncertainty, Bayesian Stacking might be more promising. The combination of model distributions also cannot match the unknown truth but minimizes the risk of missing it by dropping model alternatives.
3. Modelling Task
As an application case for illustrating the above discussions, we take the modelling task from Schöniger et al. [
15] that is typical in hydrosystem modelling: Finding the best model for the spatial distribution of hydraulic conductivity
K to parameterize an aquifer. In the following, we provide an overview of the study which investigated the suitability of BMS/BMA to accomplish this task. For more details and further information, we refer to Schöniger et al. [
15].
3.1. System and Models Revisited
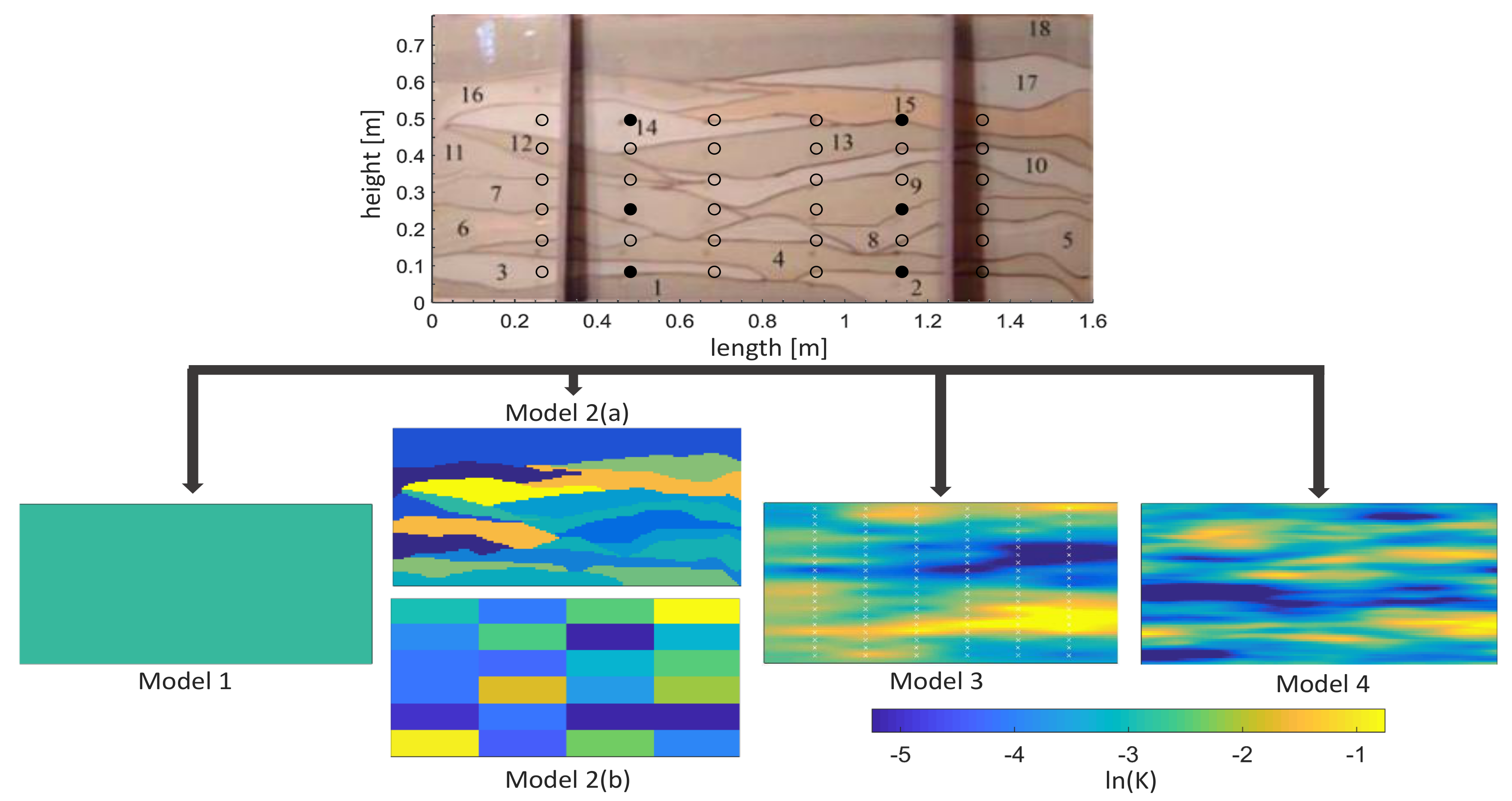
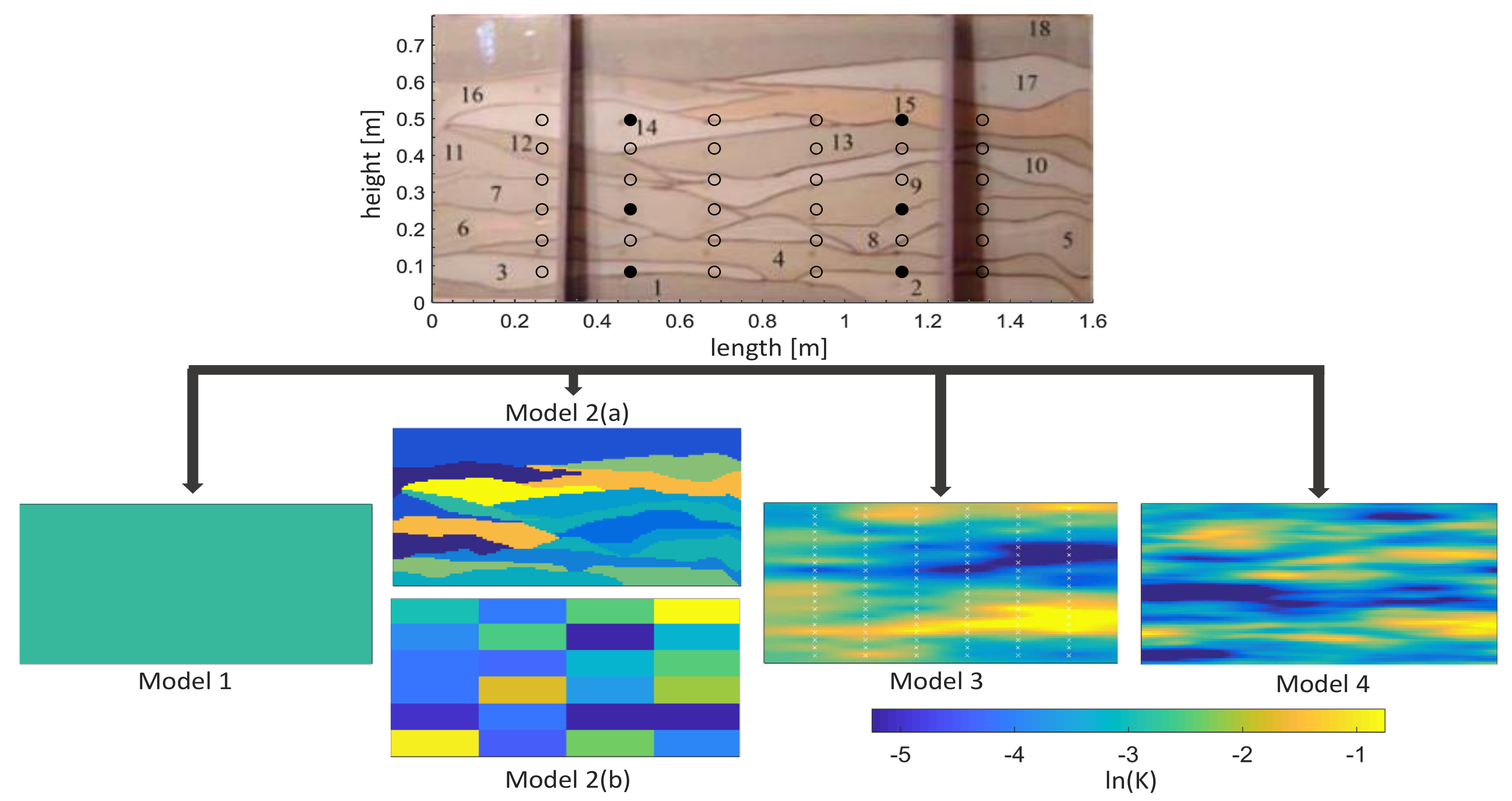
The modelled system was a synthetic laboratory-scale heterogeneous aquifer in a glass tank of 193.0 cm length, 82.6 cm height, and 10.2 cm depth that contained 18 different sand layers created by cyclic deposition of sediments [
33]. The sandbox aquifer and the derived models are shown in
Figure 2.
All models for this system are physics-based two-dimensional finite element models for fully saturated Darcy-flow. The models span a window of 160 cm length and 78 cm height as defined by Schöniger et al. [
15] as relevant domain. A spatial resolution of 1 cm in each direction yielded 12,480 elements. Hydraulic conductivity was assigned cell-wise according to common parameterization approaches of increasing complexity [
15]:
a homogeneous model with a single effective parameter (),
a zonated model
- (a)
with an informed zonation model based on the visible spatial distribution of sand layers (),
- (b)
with an uninformed zonation model that consists of unrealistic regular zones (),
a deterministic geostatistical model by Kriging based on stochastically parametrized pilot points for ln(K) (),
a stochastic geostatistical model generated from Fast Fourier Transform-based logarithmic multi-Gaussian random fields ( = 12,480).
Besides the plain number of parameters
that serves as measure for so-called parametric complexity, Schöniger et al. [
15] presented alternative metrics based on factor analysis for measuring model complexity. All measures confirmed the increasing order of complexity from models 1 to 4, although the relative differences from one model to the next more complex one varied between the metrics.
3.2. Data and Numerical Simulation
In the original experiment conducted by Illman et al. [
33], a regular grid of ports with 1.3 cm diameter granted access to the aquifer for measuring the hydraulic head during pumping tests. Over a number of sequential steady-state pumping tests (from which Schöniger et al. [
15] selected six), one alternating port served as pumping port and 35 others were used to observe hydraulic drawdown, yielding a total of 210 data points in six batches each of 35 observations. The standard deviation of measurement error was 2 cm.
For rating the alternative parameterization models within the BMS/BMA framework, it was assessed how successful each model is in reproducing the measured data. Therefore, pumping tests were simulated with each model approach for the same ports as in the experiment. Model-specific parameters were drawn from the respective prior parameter distribution. These were based on physical hydraulic properties of the synthetic aquifer that were measured during the installation of ports [
33]. Predictions from each statistical parameter sample were then obtained by plain forward model runs.
For Bayesian inference, an uncorrelated Gaussian likelihood function that represents the measurement error was used. Each model-specific marginalized likelihood (BME) was obtained by Monte Carlo integration over the entire prior parameter distribution. In accordance with rising model complexity, samples for the homogeneous model and samples for the other four approaches were drawn to assure convergence.
3.3. Former Results
Schöniger et al. [
15] investigated the ability and limitations of BMS/BMA to identify the allegedly true data-generating process under a growing amount of available observations. We want to highlight the two major findings:
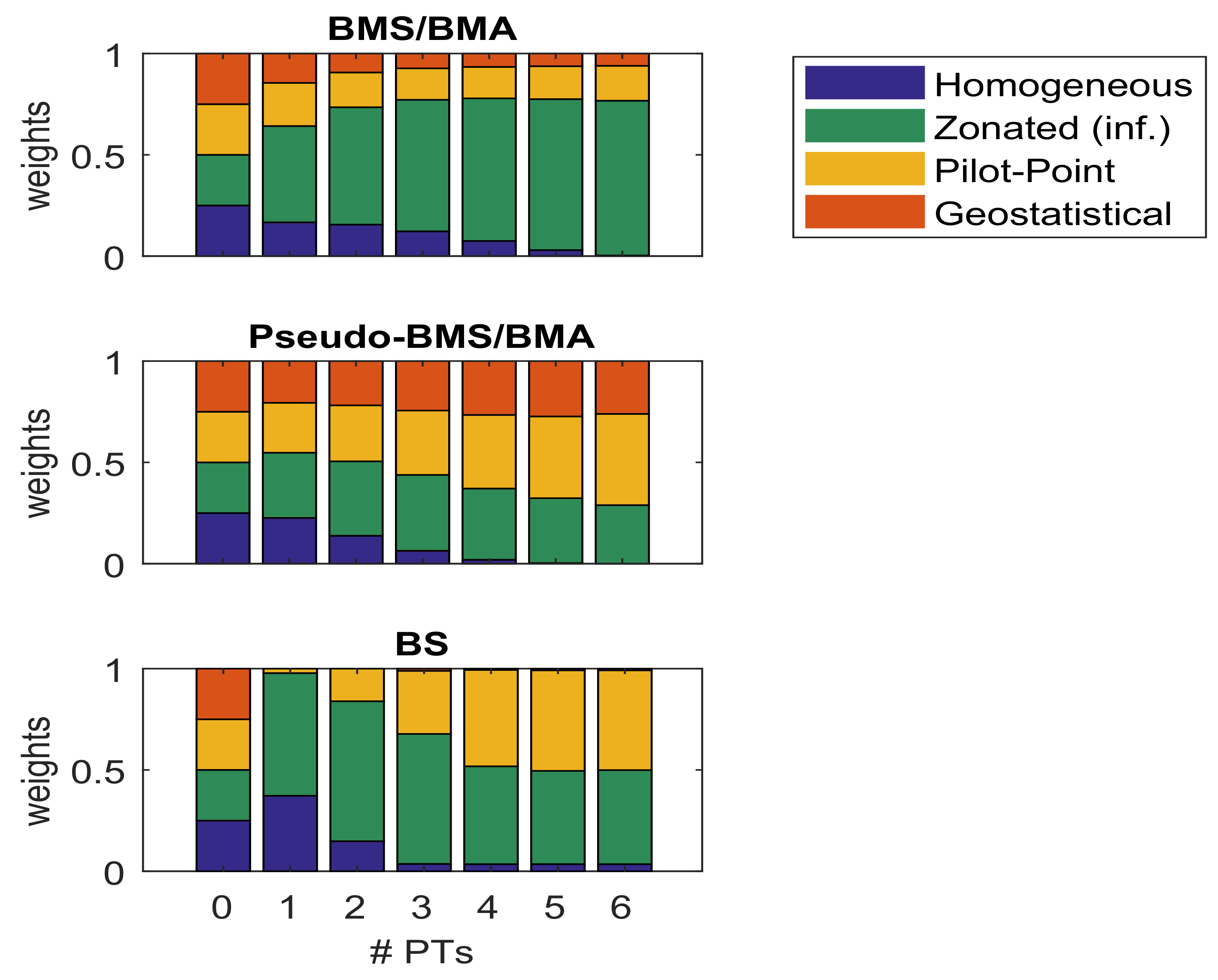
First, the evolution of model weights was analysed for two deviating model ensembles: One contained a visually close physical representation of the modelled system (informed zonated model 2a) and the other one an apparently wrong representation (uninformed zonated model 2b). For the first ensemble, BMS/BMA showed a clear convergence toward the (informed) zonated model. However, the uninformed zonated model was not prefered in the second ensemble, despite having a much lower model complexity than the geostatistical model alternatives.
Second, a model justifiability analysis based on a model confusion matrix was introduced. Using model (prior) predictions from all models in the first ensemble as synthetic observations, it was evaluated, first, how well BMS/BMA recognizes the data-generating model or another one as true model and, second, what the maximal model weights are that can be expected when only a limited subset of data are available. Given the limited amount of data (max. 210 observations), it was shown that, except for the simplest homogeneous model, none of the other models achieved a model weight of one even if actually being the data-generating model.
3.4. Study Extension
As extension to the investigation of Schöniger et al. [
15], we shift focus on contrasting the model weight evolution of alternative BMMFs by
We use the same data and also work with the numerical samples from each model’s prior parameter distribution to obtain marginal likelihoods. Exploiting the i.i.d. assumption for
and Bayes’ theorem, we then obtain the point-wise posterior predictive densities
via:
3.5. -Settings in Practise
The models and data are arranged in an
-closed, an Quasi-
-closed, and an
-complete setting as depicted in
Figure 3. An
-open setting is not considered because it is possible to fully conceptualize the controlled laboratory experiment by Illman et al. [
33]. For the considered
-settings, it is either the observed or the synthetically generated data that represents the data-generating process (DGP).
The -closed setting consists of the homogeneous (1), the informed zonated (2a), the pilot-point (3) and the stochastic geostatistical (4) models. The DGP is represented by the synthetic observations generated with the informed zonated model (2a) as presumably closest physical representation of the true system. Exchanging the synthetic data by actual observations and leaving the ensemble the same turns the setting into our proposed Quasi--closed case: unlike in typical field-scale experiments, the informed zonated model is a very accurate representation of the laboratory sandbox aquifer. However, it does not fully resolve the true system perfectly, e.g., the fringes between the different sand layers will be a mixture of sand grains that is not represented in the model. The difference between these two settings will indicate the strength of deviations one obtains when mistreating the assumption in real applications.
Finally, exchanging the informed zonated (2a) by the uninformed zonated (2b) model displays the -complete setting: it is only possible to incompletely conceptualize the true system with its zones, parameters, boundary conditions, etc. Hence, none of the ensemble members is an accurate representation of the true system. -complete refers to the rather typical situation in applied modelling that, even if we include everything we know about the observed system, we cannot fully resolve it but only approximate it, e.g., by matching statistical moments of its properties (as with models 3 and 4).
As synthetic data in the
-closed setting, we use model predictions from the justifiability analysis in Schöniger et al. [
15] for comparability. The model weights presented in
Section 4 are averages over 100 realizations. Since one of the ensemble members is in fact
(model 2a) and single model selection is a reasonable objective, we purposely focus only on the two BMMFs for model selection. Only in the Quasi-
-closed and
-complete settings, the actual observations are used, Bayesian Stacking is included and Bayesian Bootstrapping is applied to compensate for the limited amount of data as proxy for the true data distribution.
5. Summary and Conclusions
BMS/BMA and Pseudo-BMS/BMA are selection frameworks that rate models on their prior and posterior predictive density, respectively. Thereby, BMS/BMA shows a “play-it-safe” tendency to prefer simpler models and Pseudo-BMS/BMA tends toward models of growing complexity. BMS/BMA-based model choice might trigger using a sub-optimal model for further predictions because it measures performance of uncalibrated models that only contain prior knowledge. Contrarily, while Pseudo-BMS/BMA rates calibrated models for high predictive power, it lacks the consistency property to ultimately identify a (quasi-)true model in the set (if such a true model actually existed and was part of the model set).
Averaging in either of the two BMMFs is only a compromise to prevent rash model selection and therefore implies a trade-off: Explanatory or predictive power of the allegedly best model might be “diluted” by alternative models. In return, conceptual uncertainty is accounted for and predictive uncertainty is covered more broadly over multiple model alternatives until it ultimately diminishes at the large-data limit.
In Bayesian Stacking, model averaging rather than selection is the actual goal. No model is supposed to be employed alone but the whole weighted ensemble. The common posterior predictive density is maximized by optimal model weights. Since the true model is assumed not to be in the ensemble, the predictive distribution of every member has only a partial overlap with the true model. Bayesian Stacking reflects this conceptual uncertainty by stable model weights and provides a linear combination of model posterior predictive distributions accordingly.
In an obvious -closed setting, BMS/BMA is the method of choice due to its consistency property. However, usually, the -setting is unknown and the choice of a certain BMMF is not straight-forward. Hence, as general rules for employing the three analysed BMMFs, we suggest to use:
BMS if model selection shall have an implicit tendency to a preferably simple (parsimonious) model.
Pseudo-BMS if model selection shall tend towards the model of maximal complexity that is still supported by the given data.
BMA or Pseudo-BMA, respectively, if model averaging shall guard against rash selection of only one model until evidence clearly supports it.
Bayesian Stacking if averaging of distributions for broad coverage of predictive uncertainty is the goal and the whole weighted ensemble shall be used for predictions rather than only a single best model.
However, note that:
BMS/BMA is not supposed to select the model with best posterior (calibrated) predictive performance because the model rating is based on each model’s (uncalibrated) prior predictive performance.
Pseudo-BMS/BMA will select the model with best (calibrated) posterior predictive performance given the currently available data, but at the price of potential overfitting and lack of the consistency property.
Bayesian Stacking will yield a convex linear combination of model outputs’ posterior predictive distributions and not a combination of model outputs themselves. The latter obtained an own distribution that would be different from the former.
Typically, a modelling attempt is an iterative process. It might be challenging to develop a plausible first model for the task at hand. However, once it exists, there are usually various ideas about it being expanded, reduced or varied. This holds for both mechanistic models that are usually employed for process-understanding and system representation, or data-driven models that mimic the process of interest without knowledge of causality but extra-ordinary flexibility—and it also holds for the nuances of model types in-between these two extremes. Example applications of the three investigated BMMFs might therefore be:
BMS/BMA for eliciting which processes are relevant and need to be represented, refined, etc. in a mechanistic model.
Pseudo-BMS/BMA for restricting the amount of model parts and parameters in a data-driven model to the level that can still be constrained by the current data.
Bayesian Stacking for combining models of the above two or other model types in order to benefit from complementary strengths.
We believe that Bayesian methods for model ensembles are still used much too often below their full potential. We advise to include the inherent goals of each used BMMF and the assumed -setting of the modelling task at hand into the analysis. Then, the interpretation of model weights becomes more insightful and reliable, and consecutive model averaging might honor conceptual uncertainty in the intended way. Thereby, model-based process understanding and predictive power can be strengthened.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}