Systematic analysis of each possible scenario, in theory, may be achieved using a completely deterministic simulation of predefined scenarios. However, the timing of the scenario’s predetermined adverse operating states (events) and determining whether events influence one another significantly complicates the analysis. To completely and deterministically analyze the full range of possible outcomes of a single scenario, all possible combinations of event timing and inflows should be considered. Consider an example scenario with three adverse operating states (events), A, B, and C, and 10,000 years of possible daily inflow values (this number of inflow-years is selected, in theory, to represent inflows up to and including a Probable Maximum Flood with an annual exceedance frequency of 1 in 10,000 years). There are a total of
possible inflow start days. Assuming the events can happen any time within a one-year window, there are a total of
possible combinations of event initiation times (the day in which the adverse operating state begins). This means
possibilities for a single scenario with three events occurring. This number considers only one set of possible impacts for event A, B, and C, which may have impacts (for example, outage lengths), that can significantly vary. Clearly, the number of combinations that must be analyzed to fully define the suite of potential outcomes for a single scenario is extremely large. Additionally, there may be a very large number of scenarios to be analyzed. For a relatively simple single-dam system with two gates, a low-level sluice, and two generating units, King et al. [
8] calculated that there were on the order of 10
27 possible scenarios if the system was represented in significant detail. Obviously, the analysis of each scenarios its possibilities becomes computationally prohibitive, even with state-of-the-art computing technology such as cluster computing.
3.1. System Dynamics Simulation Model Development
System dynamics emerged in the 1960s through the work of Forrester [
10] at the Massachusetts Institute of Technology. Forrester [
10] began developing system dynamics to analyze industrial and management systems and pioneered the earliest forms of system dynamics simulation software packages. He later extended the application of system dynamics simulation to model the social dynamics of cities, countries, and the world as a whole [
11,
12,
13]. System dynamics has since been applied across a variety of fields, including water resources engineering. Simonovic [
14] presents simulation techniques that deal with water resources in general, with a particular focus on system dynamics simulation as a tool for water resources engineering. In system dynamics, a stock-and-flow model can be used to represent the system structure through feedback loops and delays. These feedbacks and delays are the source of the system behaviour. Stock-and-flow diagrams are particularly suited to showing the complex interactions between different components of the system and facilitate easy modification of the system structure to experiment with various upgrades and operations strategies that may be considered to improve system performance. Stocks are represented as boxes and flows are represented as pipelines into or out of the stock controlled by spigots (with a “source” or “sink” that supplies or drains flows). Flows may be controlled or uncontrolled. Auxiliary variables and arrows make up the other major components and these represent constants or variables that change with time according to a mathematical equation or algorithm. The dynamics of the system behaviour are a consequence of the system structure. The process for developing a model of a dam system is described in the following paragraphs.
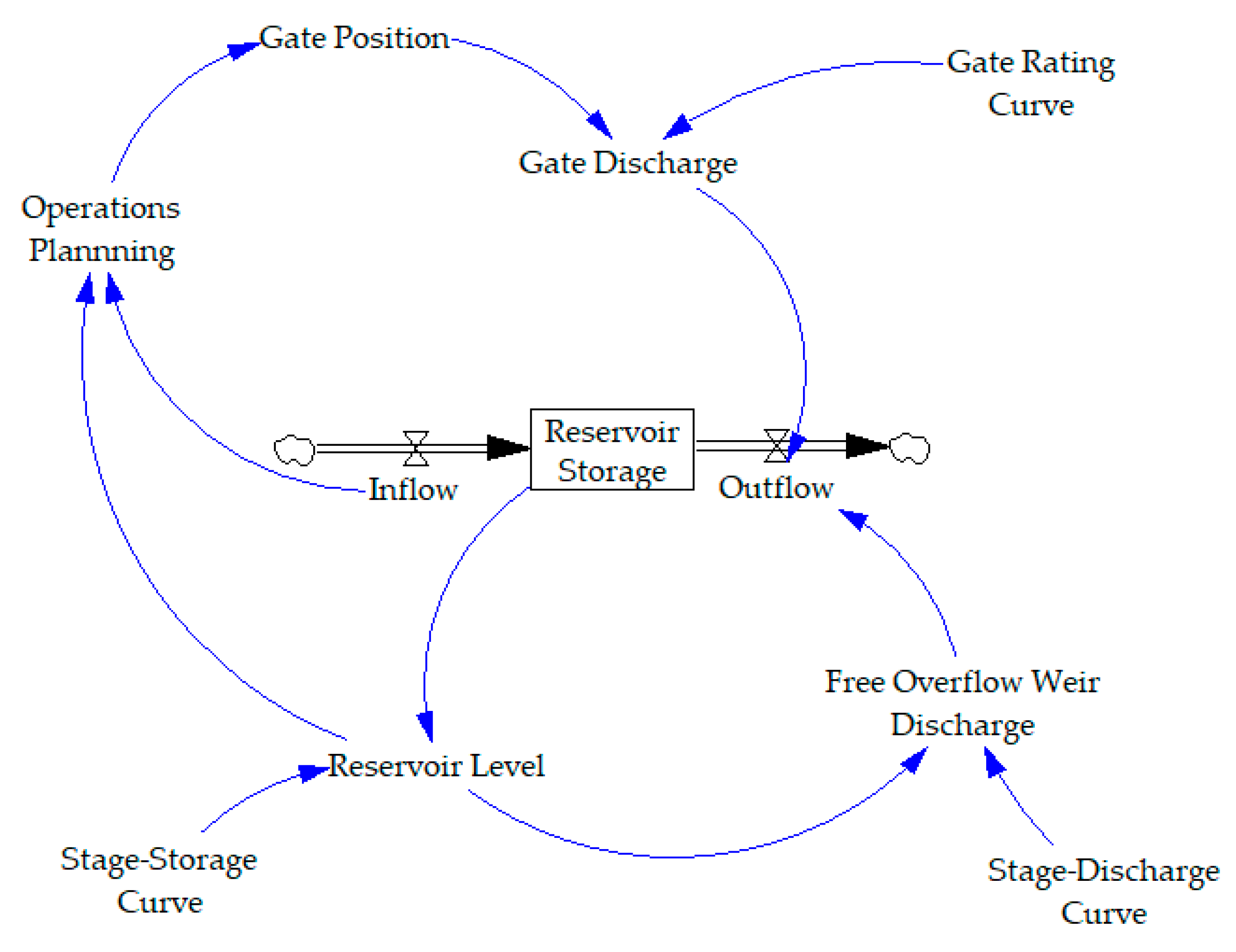
Consider a simple dam system, with a single reservoir and dam that is controlled by a free overflow weir and a gated spillway.
Figure 4 contains a representation of this system.
In
Figure 4, Reservoir Storage is represented as a stock with units m
3. Stocks are values that accumulate or deplete over time and can only be changed by flows. Flows have the same units as the stock over time. In this example, Inflow and Outflow are the stocks and have units of m
3/s. The change in Reservoir Storage can be computed as:
where
represents Reservoir Storage,
represents time,
represents Inflows, and
represents Outflows. System dynamics simulation tools use integration to calculate the value of the stock at each timestep. The Reservoir Level (
) value is a function of the Reservoir Storage as defined by the Stage–Storage Curve. The storage is expressed in units m
3/s × day, which significantly simplifies unit conversions when working with flow rates. It is valid for reservoir elevations from El. 352.42 m to El. 388.16 m. Similarly, Free Overflow Weir Discharge (
) is a function of the Reservoir Level, as defined by the Stage-Discharge Curve for the weir, which has a sill of El. 378.41 m. Equations presented here are representative of an example hydropower system.
where a = −35.75057, b = 40,896.27494, c = −15,593,240.06190, and d = 1,981,715,583.08889. Note that for “flashy” reservoirs with little storage in comparison to inflow volumes, the reservoir elevation may vary greatly throughout the day, so weir discharges may also vary hourly. For a model run on a daily timestep, it may be necessary to compute the Free Overflow Weir Discharge,
for a given day by iterating within the function over a 24-h period, taking into consideration fluctuations in the reservoir level. This will ensure weir discharges accurately reflect reality.
Inflows represent an external model input, which in this case, ranges from 5 to 25 m
3/s. Outflows are equal to the Free Overflow Weir Discharge:
The Gate Discharge (
) is a function of the Gate Position (
) and Reservoir Level (
RSE), as defined by the Gate Rating Curve. The gate rating curve can be used in a two-dimensional interpolation to determine what the corresponding flow is for a given reservoir elevation and gate position. In this example, the gate has a sill of El. 367.28 m.
Inflows may be calculated as shown in Equation (6). This inflow relationship has been selected to roughly mimic a seasonal variation.
Including some day-to-day variability in inflows for the simple system can be done using a random normally distributed variable (with a mean of 0 and a scale of 30 m3/s), which is added to the time-dependent sinusoidal inflow value. The value is then truncated, so that the minimum inflow value cannot be less than 2 m3/s. Note that this inflow variation was added for the sake of simple programming by the reader, and may not be representative of realistic variations in daily inflow values. Using historical inflows or synthetically generated inflows from the historic record are preferred for real case studies.
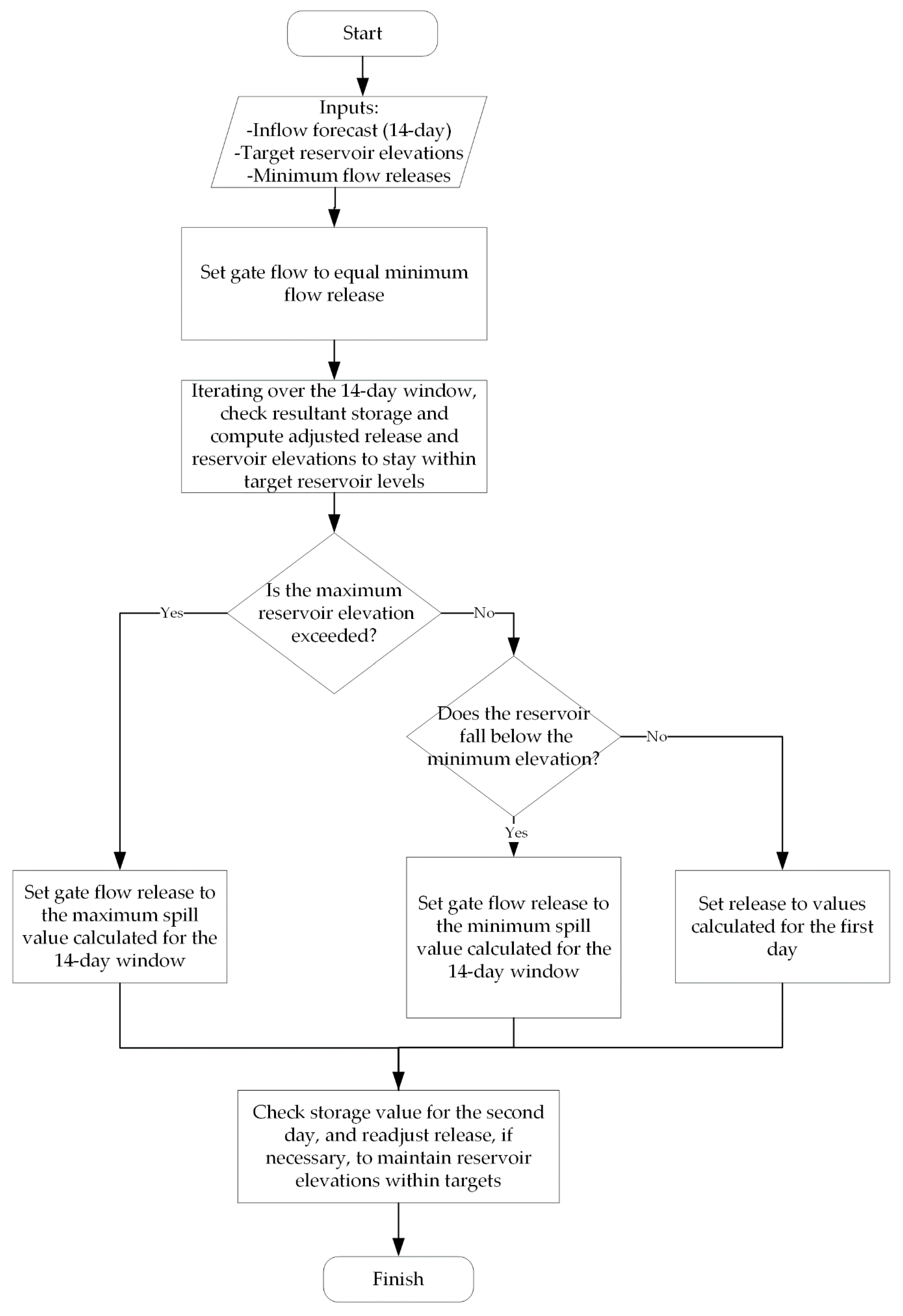
Operations planning is another key aspect of the model. Gate positions may be selected based on a number of inputs, including the inflow forecast, rule curves, target reservoir elevations, outflow constraints, and downstream impacts. Creating an algorithm to simulate operations planning is a more challenging aspect of model development, in particular in the case of cascading and parallel dam systems. Optimization is frequently cited in the literature [
15,
16,
17,
18,
19] and works well for balancing inflows, downstream effects, reservoir operational limits, and outflow constraints. However, optimization may significantly impede computational efficiency, which is an important consideration when running a simulation model a large number of times. For this simplified example based on a dam system with only a single gate, a simple if-then-else type algorithm has been developed for Operations Planning (see
Figure 5). The algorithm uses 14 days of inflow forecasting to determine the appropriate gate releases that will keep the reservoir level between target elevations (the normal maximum, NMax is El. 376.5 m). Inflow Forecast is based on the sinusoidal relationship described previously, with no random normal variable added. This means the operations planning algorithm has some indication of the average inflow to expect over the next 14 days but is not aware of any major deviations from the normal level due to the random normally distributed variable that is added. In a real dam system, operators may have more realistic expectations of inflow and can adjust the gate based on the hourly inflows to ensure reservoir elevations within target levels are maintained. The Operations Planning algorithm is detailed in
Figure 5. The output variable from Operations Planning for this simple example is gate flow, which can be transformed into a gate position instruction. The Gate Position is calculated using a reverse two-dimensional interpolation using the Operations Planning output (the desired gate flow) and the Reservoir Level, based on the Gate Rating Curve.
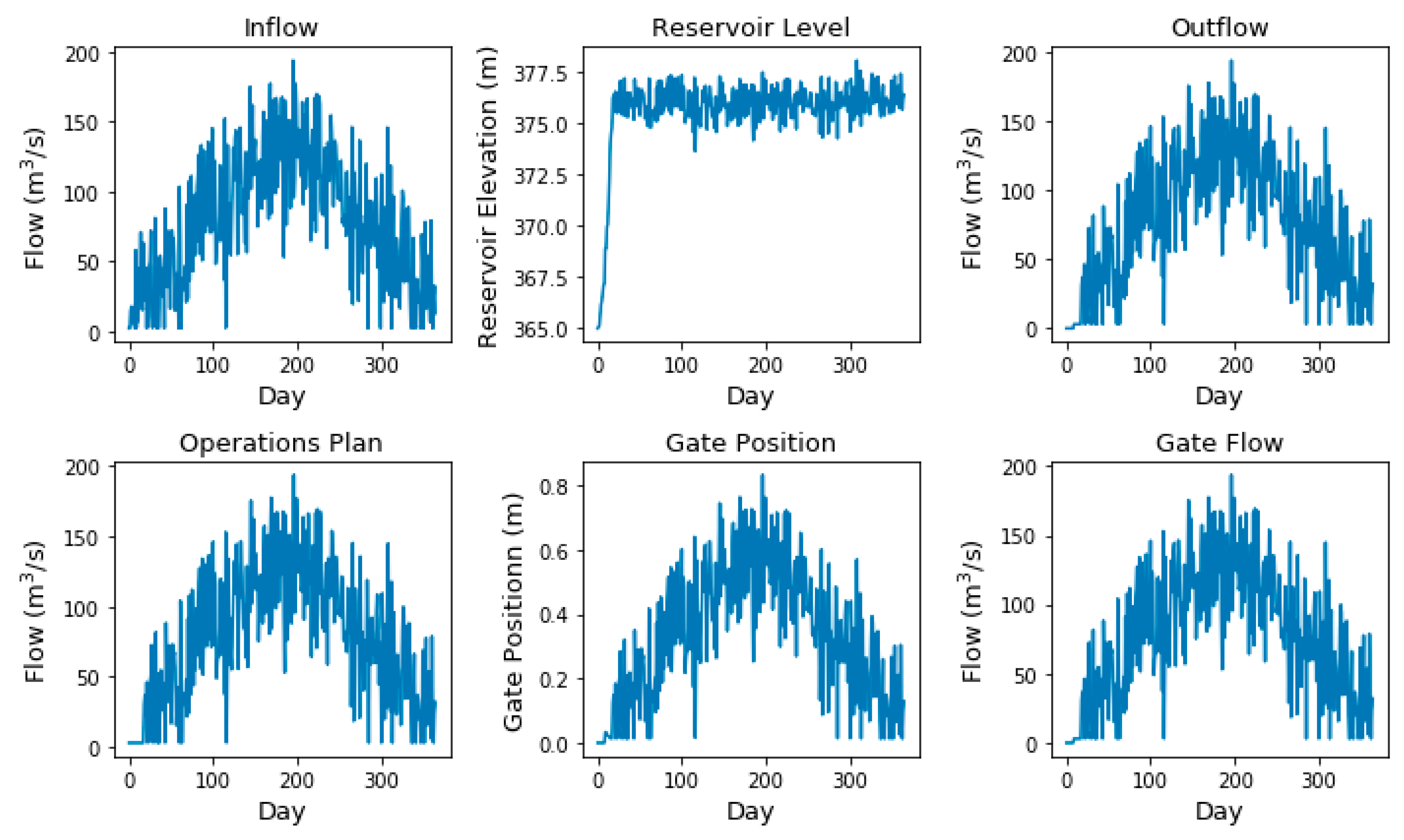
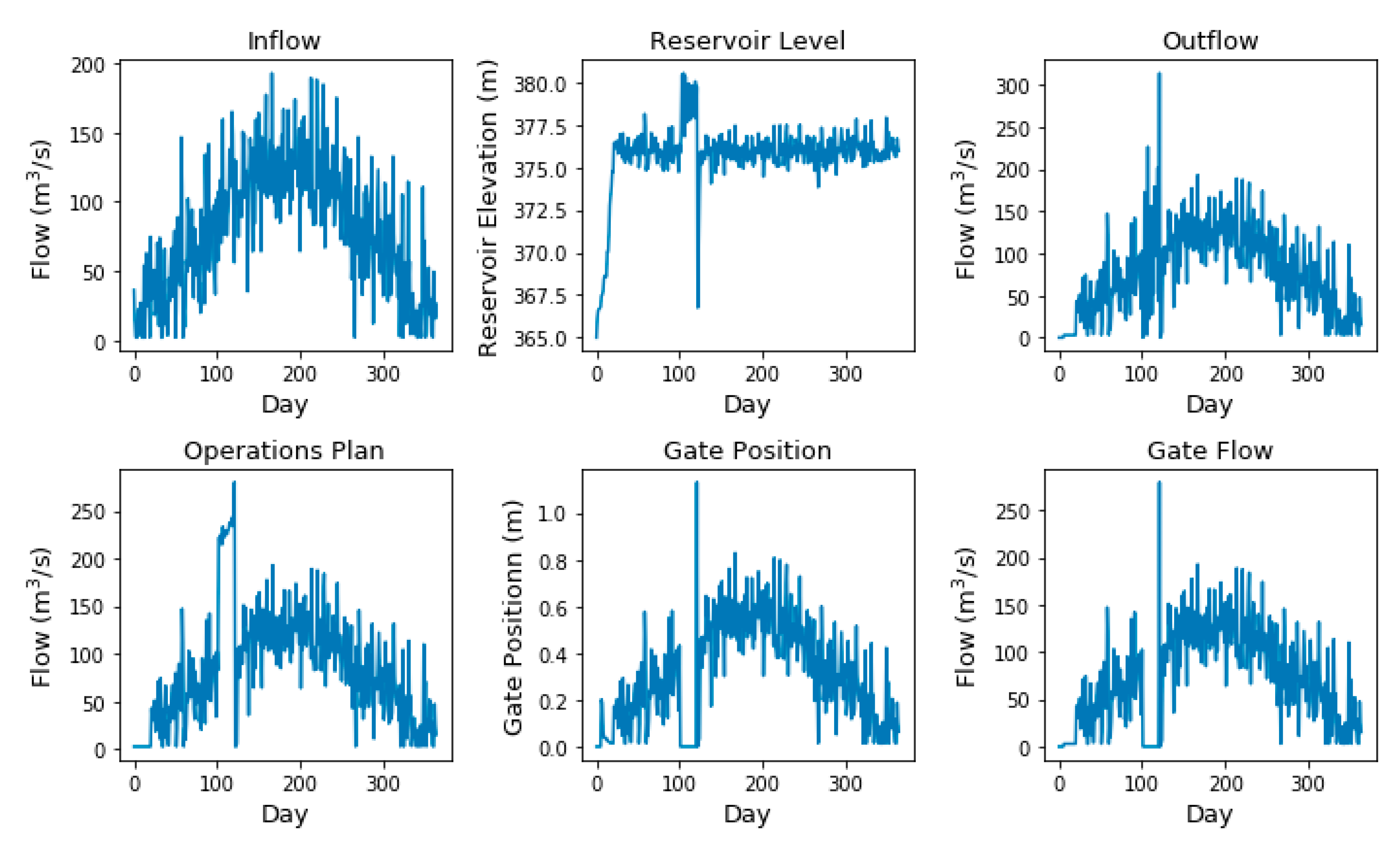
The simulation results for this simple example are shown in
Figure 6. The reservoir rises to the level of El 376.5 m (the Normal Maximum Reservoir Level), and hovers at that level or just above and below based on the deviations introduced by the random normal variable added to the inflow. Note that there are no power flow release facilities included in the model, so the algorithm keeps the reservoir level high because there is no reason to discharge more additional water than necessary to meet the maximum reservoir level target. In this example, there is no free overflow spill because the reservoir stays below El. 378.41 m which is the sill of the overflow spillway. As such, reservoir inflows are roughly equivalent to reservoir outflows, operations plan, and gate flow. They are also proportional to the gate position.
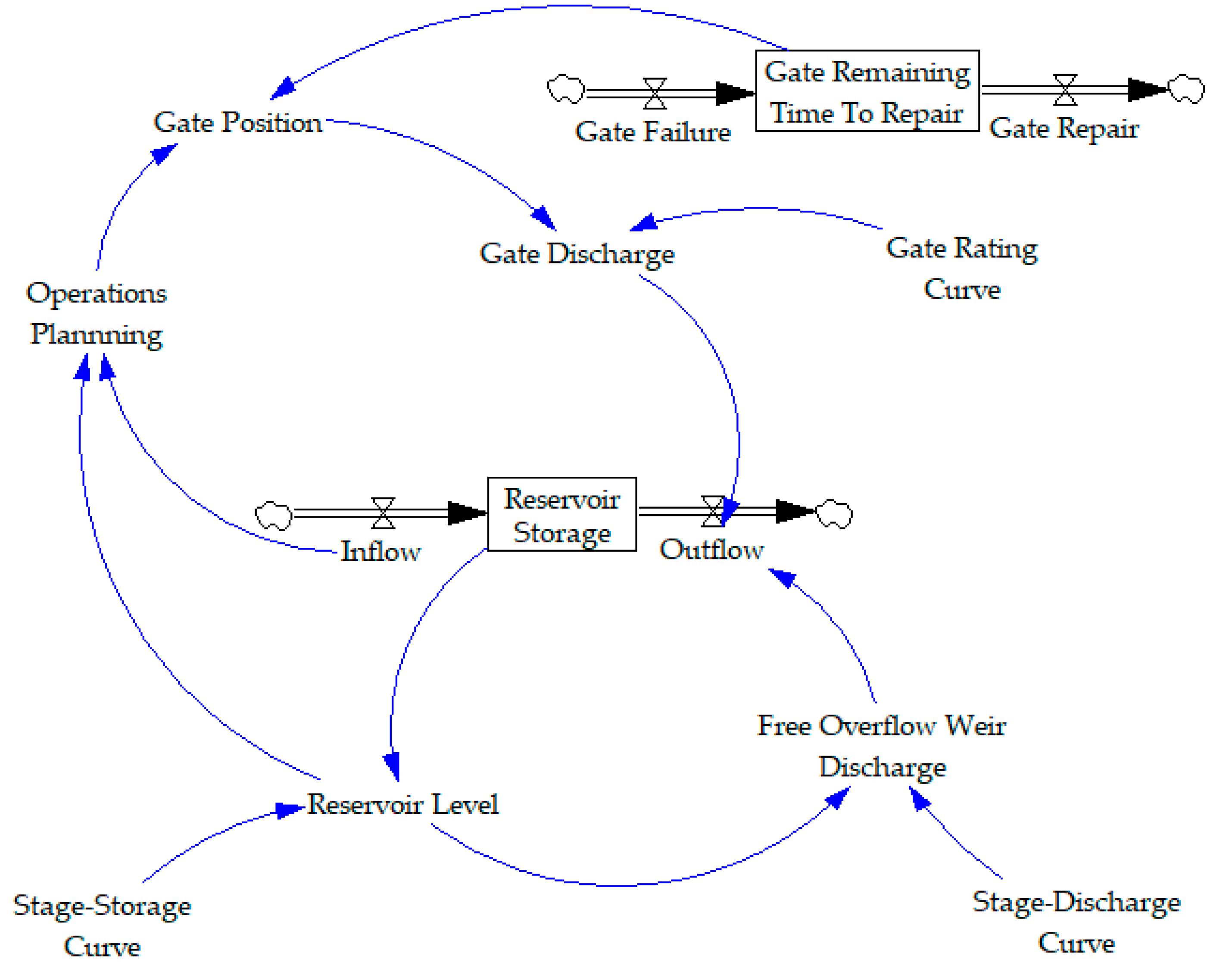
Another important feature of the simulation model within the context of this work is the ability to simulate component failures or outages. Considering the simple example developed, this can be added by creating a variable that tracks remaining time to repair following spillway operating gate failures, Gate Remaining Time to Repair,
. This is modelled as a stock, which receives a pulse of Gate Failure,
, when the gate fails. The stock drains with the value time when its value is positive, using the flow Gate Repair,
(note, gate repair is a flow out of the stock Gate Remaining Time To Repair, and has units time; gate failure is a flow into the stock and also has units time). The gate remaining time to repair can then be implemented in the model based on the impacts of a gate outage—in this simple example, the gate fails in the closed position. Gate failure causes an inflow to the stock of 20 days at time
, and the gate becomes stuck in the closed position for a 20-day period. The modified stock and flow diagram for this is shown in
Figure 7.
In this example, the gate remaining time to repair is calculated as:
This formula simply implies that the gate remaining time to repair is equal to the integral of gate failure (the stock’s flow in), and gate repair (the stock’s flow out). Gate Failure is calculated as:
Gate Repair is calculated as:
The Gate Position can then be calculated based on the gate availability:
where
represents the operations planning output, which is representative of the desired gate flow. Simulating this model yields the outcomes shown in
Figure 8.
The impacts of the gate failure can be seen in the image starting at day 100 of the simulation, where the gate position and gate flow drop to zero, and the reservoir elevation rises above the target elevation. Flow over the free overflow weir is observed during the gate outage (these are not shown but are the difference between Outflow and Gate Flow). Once the gate is back online, the gated spillway flow is increased significantly to reduce the reservoir elevation to within the target levels. The inflow on the day of the gate’s return to service is less than predicted, so the operator opens the gate more than is necessary and the reservoir drops to just above the gate sill elevation (El. 367.28 m). In reality, operators will have a relatively better idea with respect to the expected inflow. Dam operators would also be able to adjust the gate position within the 24-h period if the inflows are less than predicted to ensure rapid drawdown of the reservoir does not occur. This is one potential limitation of running the model on a 24-h timestep, though improved inflow prediction for the operations planning algorithm would avoid the issue. For less flashy reservoirs, a daily time step may be adequate.
As the simulation model becomes increasingly complex, the non-linearity of the problem becomes more obvious. Calculation of the reservoir level response becomes increasingly more complex as additional flow release components, variable gate positions, natural variability in inflows, outages, etc., are added to the simulation model. Simulation is necessary for quantifying the dynamics of the system response to various inputs. Events happening at a lower level in the system may influence the high-level system behaviour in unpredictable ways that can be assessed through simulation.
The system dynamics platform offers a particularly suitable modelling environment for complex, dynamic systems with interactions among components. The object-oriented building blocks help visualize the connections between the different components of the system. The general process for the development of a system dynamics simulation model for a dam system is described in
Figure 9. A variety of different outlets and multiple dams may be added to the model depending on the system of interest. It may also be possible to represent other physical processes provided the mathematical assumptions behind them are well understood. Potentially, physical processes could include pressure transients, cavitation, uplift, earth dam seepage, and stability thresholds, though a trade-off becomes apparent between the timestep and the computational effort, since many of these phenomena may occur within minutes or seconds. This is an important area for future work.
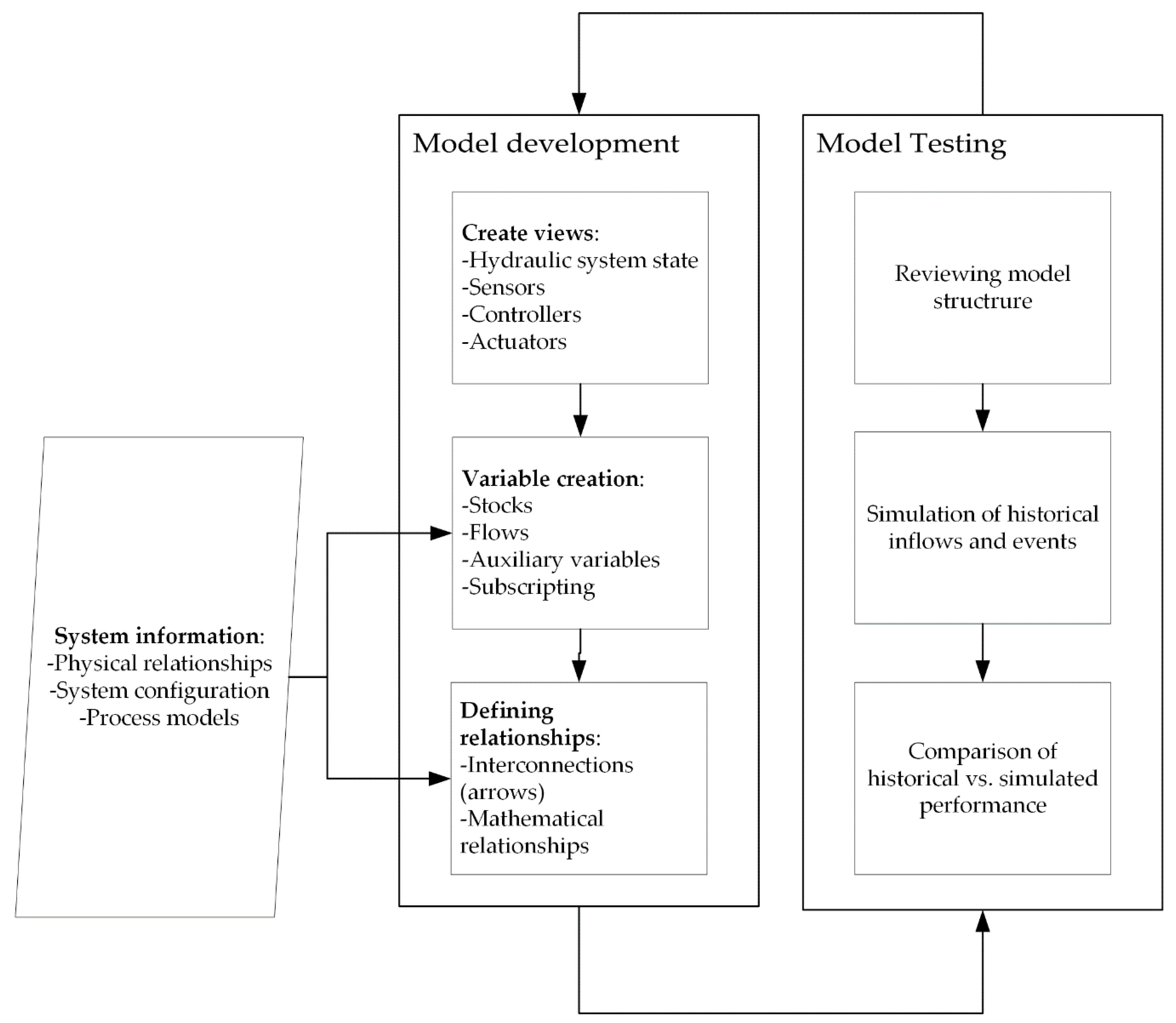
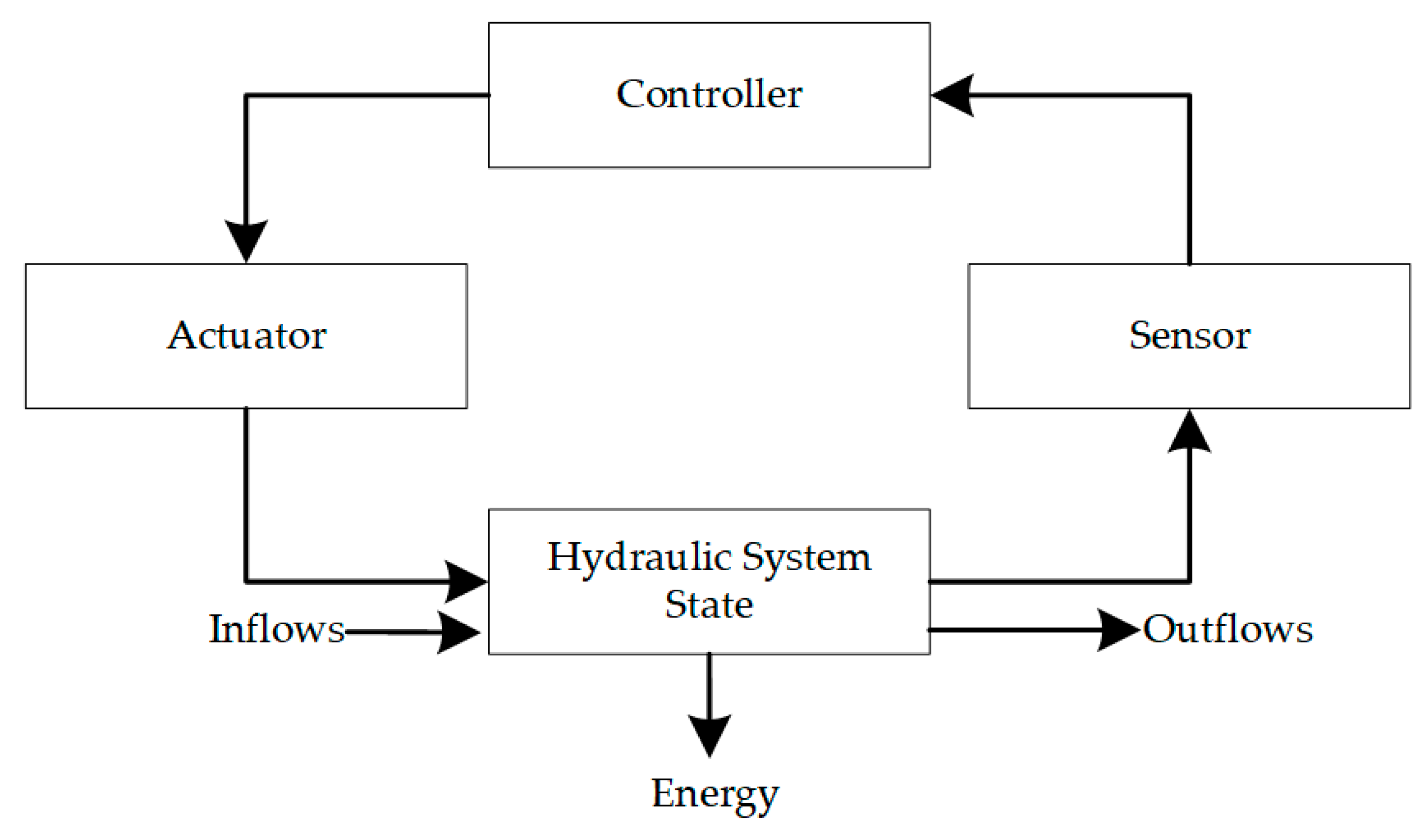
The process of model development is iterative; that is, model development is influenced by model testing, and development continues until the modeller is satisfied that the modelled system is an adequate representation of reality. The model is a description of physical and nonphysical relationships among system components. A significant amount of information about the system is required to define these relationships mathematically, and expert judgement is necessary in model development. Dividing the model into interconnected sub-systems shown in different views or sectors may be helpful. Sub-systems may be connected to each other by one or more variables. These sectors can follow a generic control loop (
Figure 10) as described by Leveson [
20] and adapted for a hydropower system, which includes: (1) A controller, who interprets information relating to the state of the system and produces a set of operating instructions; (2) actuators, the mechanical-electrical assemblies, which work to move gates in the controlled process; (3) a controlled process, representing the infrastructure being controlled or the hydraulic system state; (4) sensors, which relay information back to the controller; and (5) disturbances, which are not directly part of the control loop but may affect the functionality of any one of its features. This high-level system structure represents a hierarchical system of systems, with each box representing its own sub-system [
20]. The benefit of developing a detailed model of the system components is that low-level failures and events within the system can be initiated and the simulation model can determine the system-level impacts for a particular set of inflows and event parameters.
Selection of the variables that will be required to adequately represent the system is another important step. The variables represent states of the system, which the modeller is interested in over time, and there may also be a number of intermediate variables that transform information between the key variables of interest. Defining the relationships requires expert knowledge of the system, data, and programming capability. Some variables equations can be represented by simple if-then-else type formulae, while others may represent non-linear relationships or even complex algorithms with a number of processes occurring internally.
The model output is only as good as the modeller’s understanding of the interactions and relationships within the system being analyzed. Like all models, simulation models are abstractions of reality. Sterman [
21] argues that, because of this, all models are “wrong” and that simulation models can never be validated or verified in the traditional sense of the word. There are, however, a number of tests that can be done to gain confidence in the model performance. These tests should be done iteratively throughout the model development process. Analyzing the system structure and feedbacks to ensure all important variables are represented and their equations are grounded in reality is important. This includes checking the water balance, rating curves, and other physically derived variables. Checking the dimensions is another important model test. Historical records of system operation are also useful for testing and development of the model. A direct comparison between simulated and actual values provides information to the modeller about how well the system is mimicking reality in terms of normal operation. Comparison of historical vs. simulated reservoir levels and outflows can help the modeller adjust the system structure—this is particularly important during the development of operating rules. Once the model results are relatively close to reality, the model is ready for simulation.
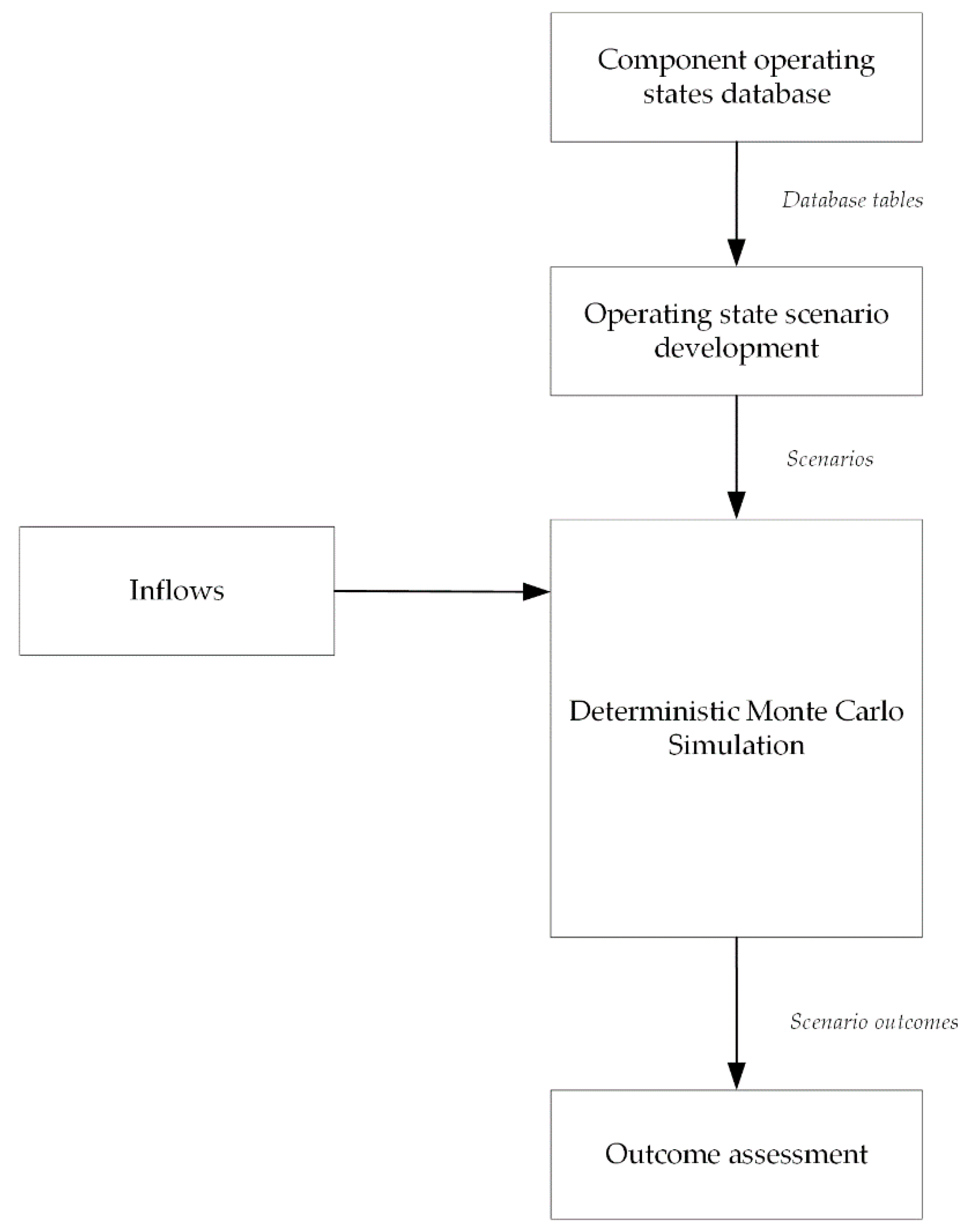
3.2. Monte-Carlo Variation of Scenario Parameters
The process of King et al. [
8] is used to generate scenarios, with each scenario representing a list of component operating states, which may be normal, erroneous, failed, etc., for each component in the dam system. An operating states database is presented, where the user first defines all components and their sub-components, and then their operating states, the operating state causal factors, and the operating state impacts. The database links each of the operating states to one or more causal factors and has a user-specified numeric range of impacts (minimum, maximum, and average) that can be expected should the operating state occur. Impacts may include outage length, error magnitude, or delay length. Causal factors vary depending on the system of interest and may include earthquakes, forest fires, lack of maintenance, human error, etc. The database information can be extracted in the form of tables, which contain each operating state-causal factor combination and the associated range of impacts. Linking the database information into the simulation model in a way that allows a wide range of potential outcomes to be explored for each scenario is a critical part of the implementation. An example of such a link was shown in the previous section. System dynamics modelling is inherently deterministic, so specific instructions for how to carry out the scenario must be given to the model before running. Monte-Carlo selection of simulation inputs is considered to be the most efficient way to cover as many outcomes for a single scenario as possible given computational constraints. Each scenario can be run many times, with varying simulation inputs to explore the system behavior as fully as possible without becoming computationally infeasible. This allows for some uncertainty in the outcomes to be investigated by looking at a range of potential implementations for each scenario.
Each operating state has varying impact magnitudes between minimum and maximum values specified in the database. In addition to this, the adverse operating states may be occurring within some temporal proximity to one another but not at the same time. Inflows may also significantly affect the way an operating state changes the system behaviour. While simulation facilitates the assessment of component interactions, feedbacks, and non-linear system behaviour, the Monte-Carlo variation of these important simulation inputs can help better capture a range of system behaviour that is possible as a result of a given scenario. The temporal proximity of the adverse operating states, the magnitude of impacts and the system inflows can all easily be varied using a Monte-Carlo simulation approach.
A wide range of hydrological conditions may be tested for each operating scenario, by selecting a random year and start date for each Monte-Carlo run of each scenario. The year and start date can be used to sample inflows from a synthetic inflow time series, which can be developed using a stochastic weather generator and a hydrologic model.
Operating state impacts may vary, and this is represented using minimum impact, maximum impact, and average impact (mode) as specified in the component operating states database in the operating states description. This information can be used to generate Monte-Carlo inputs with a triangular distribution [
22]:
where
represents a random variate from the uniform distribution between 0 and 1,
represents the minimum impact value specified in the database,
represents the maximum impact value specified in the database,
represents the average value specified in the database and
. A random impact for each operating state is generated in this way and used as the second Monte-Carlo input to the simulation model.
Timing of events may also vary within a scenario, and events can occur at the same time or within days, weeks, or even months of one another. The temporal proximity of events represents the third Monte-Carlo input to the simulation model. The causal factors for each operating state play a roll in determining operating state’s temporal proximity. The number of causal factors can be used to determine the number of time steps between adverse operating states arising from different causal factors. Operating states with the same causal factor (for example, an earthquake) are initiated at the same time. Operating states for subsequent causal factors are initiated at some value, in the future where and is equal to the number of causal factors less one (because the first causal factor is implemented at time t = 0 in the simulation). The ordering of causal factors is also varied so that the first operating state changes between Monte-Carlo inputs. For some causal factors, including lack of maintenance and aging, impact timing can be completely randomized if more than one component is affected; that is, failure of one component due to lack of maintenance may not occur at the same time as the failure of another component that has not been maintained. There may be a time limit within which these events can occur, as defined by the user for the system of interest. This is a parameter that helps increase the chance that the events are impacting one another so that the scenarios represented in the outputs are reflective of the input scenario (discussed further in the following section).
In addition to generating these randomized parameters for each scenario, it is necessary to program component-specific connections that link the database’s operating states to the specific point in the simulation model where the component failure, error, or delay occurs. An example of how this can be done was provided in the previous section. The timing and impact magnitude can be represented by variables that change with each Monte Carlo iteration. Inflow sequences can be selected from the historical record using the randomly generated day and year. Directing the impact towards the correct component and implementing it requires significant modelling effort. The implementation of these connections will differ from application to application and must be done at the front-end of the simulation model to ensure the scenario information is routed properly through the simulation model. Once the connections are made, simulation can proceed following
Figure 11 as discussed in the following section.
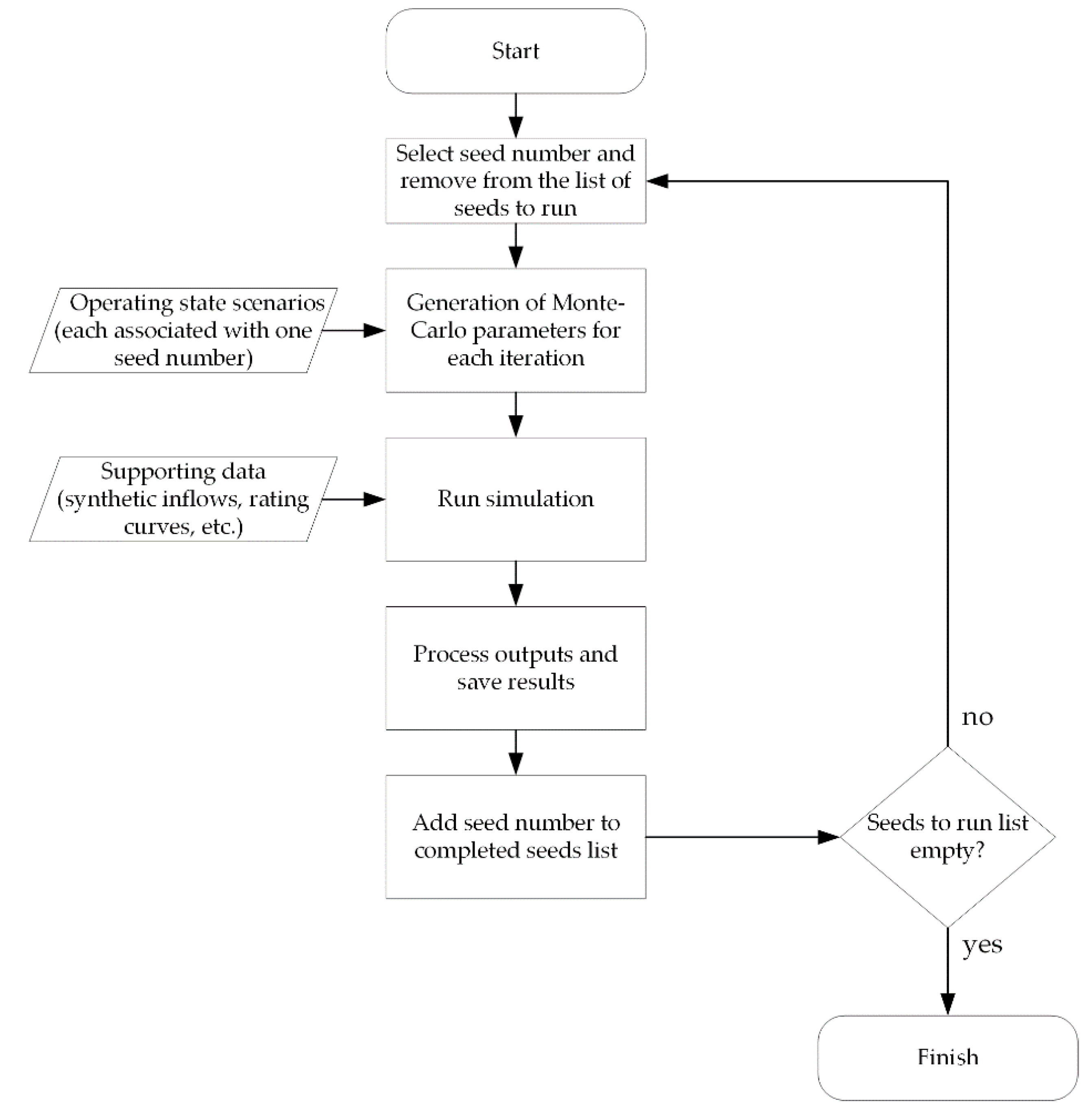
3.3. Deterministic Monte Carlo Simulation Process
Given a large number of automatically generated combinations of events (input scenarios), and a simulation model that is set up to use the operating states and their impact parameters as inputs, scenario simulation can proceed as shown in
Figure 11.
Each scenario in the scenario list (generated from the database using combinatorics) is given a unique simulation number (“seed number”) to identify it to the simulator. At the start of the simulation, a “seeds to run” list is developed. Each seed number corresponds to a line in a list of the scenarios, which contains a unique set of operating state combinations for the system. This is used to gather the information from the database tables (which contain the operating state impacts and their magnitudes) and set-up the Monte-Carlo parameters for each of the events in the scenario to be simulated. The Monte Carlo parameters are randomized inputs that vary within the bounds specified in the operating states database. This allows for a more complete exploration of the potential outcomes for a given scenario. Once the Monte Carlo input generation is completed based on the scenario of interest, the simulation of the scenario proceeds.
Following the simulation of each scenario iteration, timing considerations must be addressed, to ensure the results are accurately attributed to the scenario being represented. It is important to address the issue of whether preceding events are influencing the results of subsequent events. Such considerations arise when a component failure has been rectified, but the overall system remains in a “disturbed state”; that is, the system has not been restored to the state that it would have been in if the component failure had not occurred. The “system state deviation” needs to be considered along with the timing of component failures. This can be achieved by analyzing whether the reservoir level has returned to a predefined “normal” state following the initiation of an event. If not, there may be independent sub-scenarios within the simulation that should not count towards results of the scenario being analyzed. Consider the example shown in
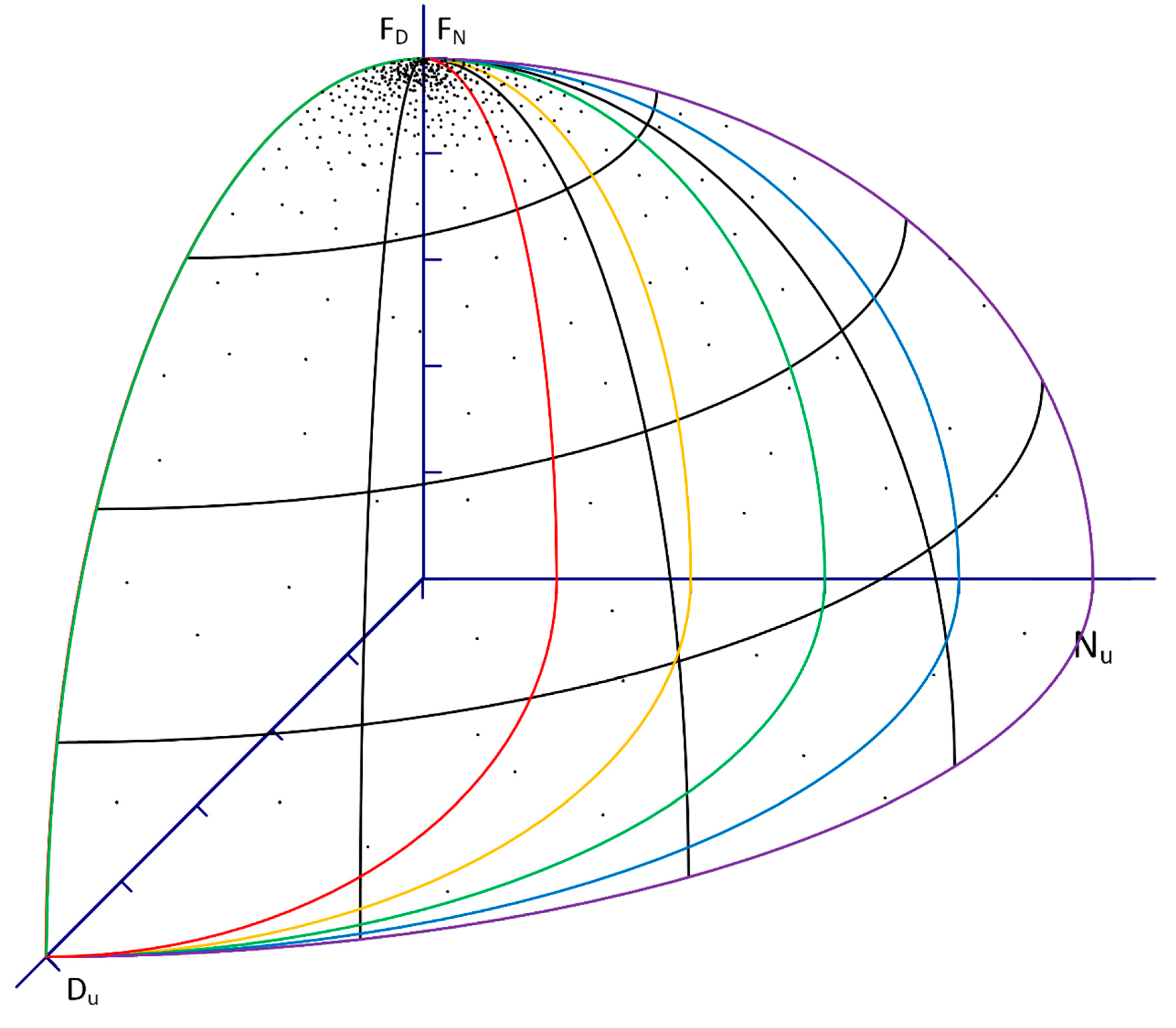
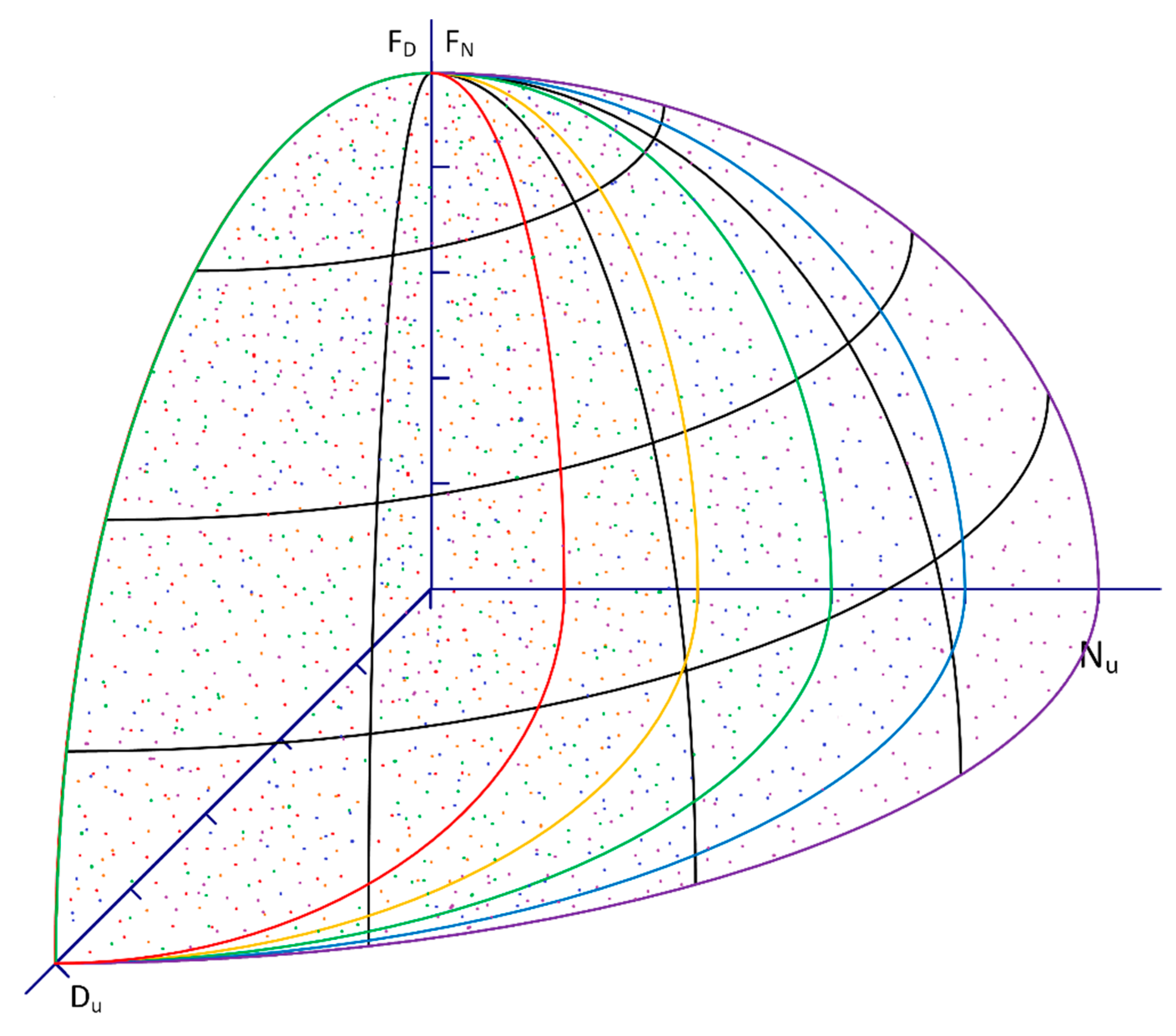
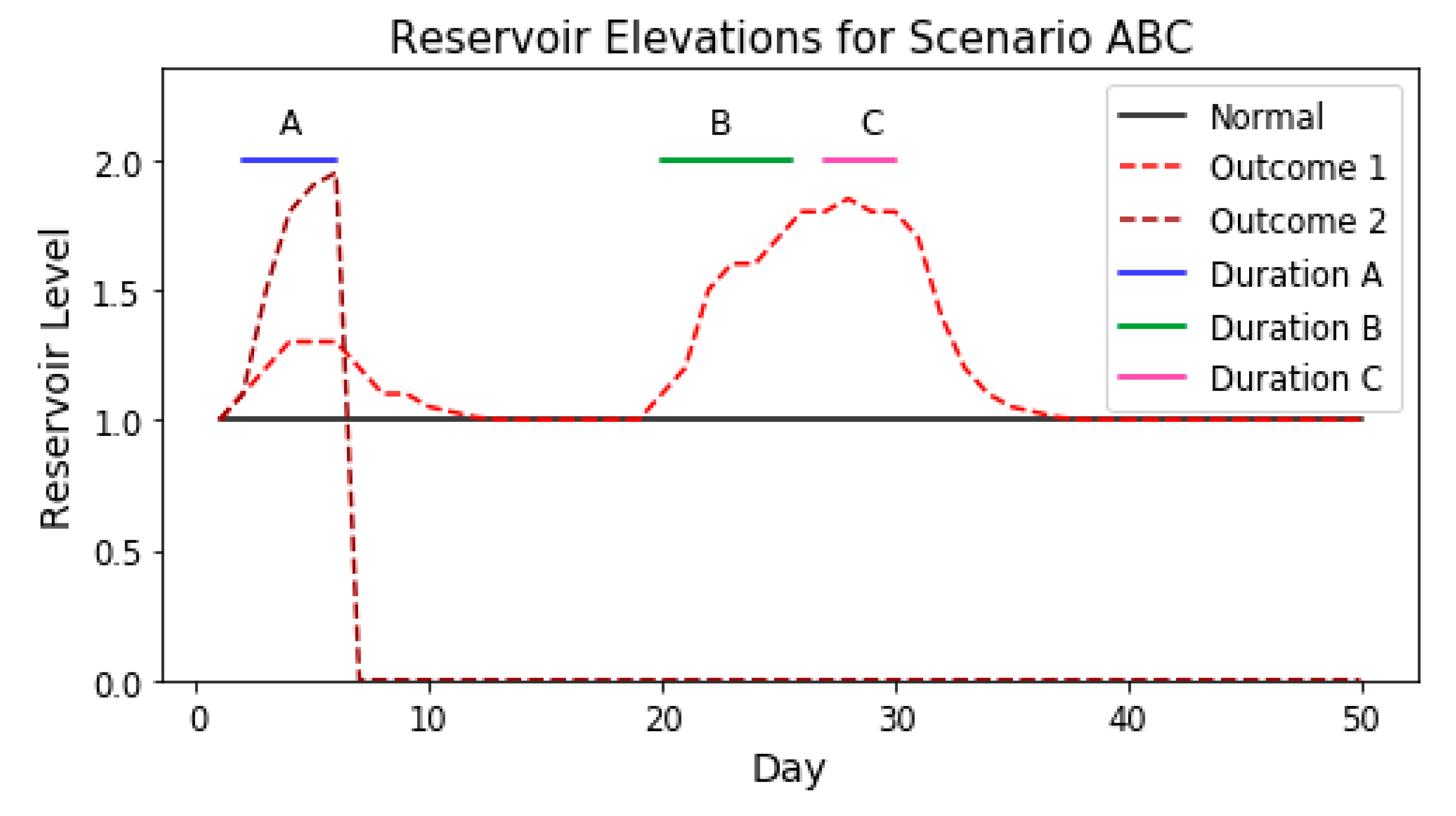
Figure 12, which has three events, A, B, and C occurring within some time of one another.
In the example, the reservoir has a constant elevation of 1 m under normal circumstances (everything being operational). For Outcome 1 (light red), Event A causes an increase to about 1.3 m and then the reservoir level returns to the normal elevation of 1 m prior to the initiation of Event B (this is determined by an operations planning algorithm within the simulation model). Event B causes in increase in reservoir elevation to about 1.8 m, after which Event C begins and increases the reservoir a further 0.1 m. After Event C, the reservoir returns to its normal elevation as a result of the operations planning decisions. In Outcome 1, Event A does not have any impact on the outcome of Events B and C, because the reservoir level has returned to a normal elevation. Event B, however, does impact Event C. Thus, for Outcome 1, two scenario results are shown: (1) The result of Event A, and (2) the combined result of Events B and C. In Outcome 2 (dark red), the reservoir rises to about 1.95 m following Event A, at which point dam breach is triggered and the reservoir drops to 0 m in elevation. In this case, the only real scenario being analyzed is Event A. This example shows that despite the simulation being intended to analyze the combined impacts of Events A, B, and C, they cannot be assumed to be influencing one another. Some analysis of each simulated outcome (the reservoir levels from each simulated Monte-Carlo iteration) is required to ensure simulation results are attributed to the actual scenarios being represented within the analysis.
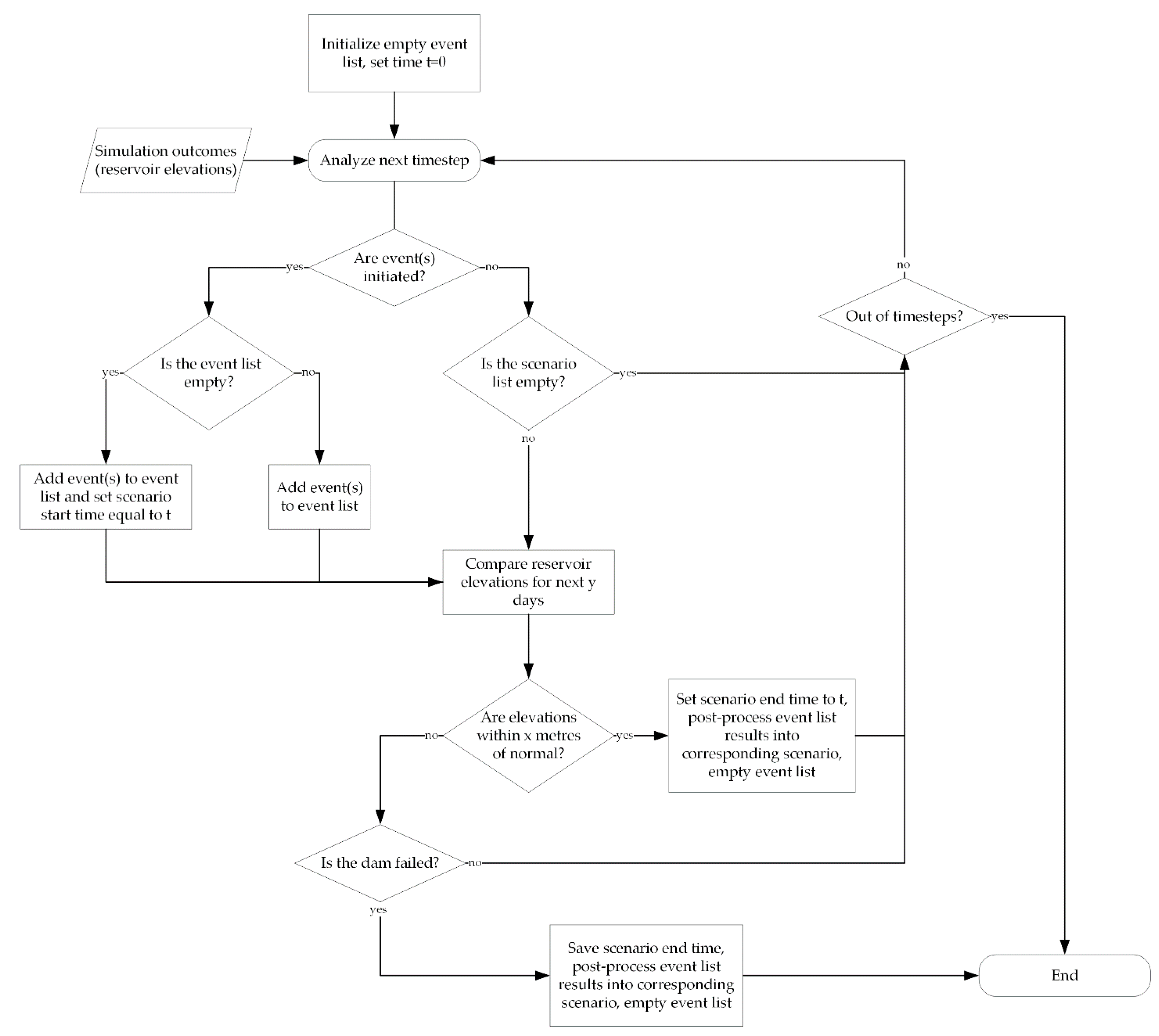
Assessing the event dependency can be done by analyzing the “system state deviance” to determine whether subsequent events are dependant on preceding events. An event dependency algorithm to analyze the outputs from each iteration is necessary in order to count the simulation results towards the scenarios that are truly represented within the output data. Given the time of occurrence of A, B, and C, the reservoir level under normal operations, and the resultant reservoir levels, a simple comparison can be used to determine whether events are influencing one another. The algorithm to analyze simulation outcomes from a single iteration is shown in
Figure 13.
First, an empty event list is created, and the time is set to . The analysis starts by first checking if a new event is initiated at the current time step (the event initiation time is determined through the Monte-Carlo sampling). If so, the event is added to the event list. If no previous events are in the list, time t represents the scenario start day. If there are events in the event list, a check is done to see whether the event impacts are over—this is a simple comparison of the following y days of simulated reservoir elevations with the previously expected reservoir elevations for that set of inflows. The choice of the number of subsequent days to be compared, y, depends on the system being modelled and may be shorter or longer depending on the storage relative to the inflows. If the elevations are within a certain threshold, , of the previously expected reservoir levels for all days within days of the current day, the scenario is considered to be over. The threshold is a small number that indicates the reservoir levels are basically the same—it may also vary depending on the reservoir being modelled and must be chosen by the analyst for the system of interest. Once the reservoir levels are restored to the previously expected values, the results for the scenario are saved, the event list is emptied, and the analysis proceeds to the next timestep. If the elevations are not yet matching, the analysis proceeds to the next time step, as long as the reservoir elevations have not risen to a sufficient level to fail the dam by overtopping. If the dam has failed, the results are processed and saved for the events in the list. The process continues through all of the timesteps, until either there are no more time steps to analyze or the dam has failed.
This process, when applied to Outcome 1 in
Figure 12, saves results for Scenario A and Scenario BC. For Outcome 2, it saves results for Scenario A only. This process could also be useful to analyze outcomes from fully stochastic simulation models, extracting more information than a singular probability of failure for the system being analyzed.
Once all iterations for a given scenario are analyzed, the scenario results are saved and the seed number is added to the completed seeds list. Then, a new scenario is chosen from the seeds to run list and executed. Simulation of the complete list of scenarios is a significant computational task, depending on the size of the scenario list and complexity of the simulation model. Linking of each individual component in the database to the corresponding system dynamics model component is required prior to the start of the simulation.
In using the Deterministic Monte Carlo approach, it is important to consider that the goal of the exercise is to analyze all scenarios (predefined combinations of operating states) as completely as possible given computational time constraints, to determine the criticality of these combinations. There should be enough data on each scenario to estimate the range of expected system performance and calculate the criticality parameters: Conditional failure frequencies, failure inflow thresholds, and conditional reservoir level exceedance frequencies. To ensure there is enough data collected for each scenario, it may be necessary to limit the time between events to ensure their collective impacts can be assessed. This limit may be determined as a function of the impact lengths for a given iteration (for example, by taking the sum of impact lengths). Whether the event initiation time limit should be greater than or less than the sum of the impact lengths requires experimenting with scenarios to determine how long the system typically takes to return to normal operation. For “flashy” reservoirs with relatively limited storage compared to inflows, the recovery time following a return to normal operations may be quite short—days or even hours. For reservoirs with large storage in comparison to inflows, this recovery time may be significantly longer. The recovery time may also be less than the sum of impact lengths, due to inflows that are less than the total capacity of the available flow conveyance facilities. The recovery time should influence the modellers decision regarding the appropriate time limit for event initiation. If the time limit for event initiation is too long, there may be two or more sub-scenarios within each scenario, and not enough data relating to the collective impact of the combination of events.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}