Predicting the Trend of Dissolved Oxygen Based on the kPCA-RNN Model


Abstract
:1. Introduction
- Kernel Principal Component Analysis (kPCA) is implemented to reconstruct the input water quality data. Instead of feeding the water quality sensor data into the data-driven models directly, we pick up the top-ranked principal components as the new inputs. Meanwhile, the dropped principal components are expected to contain background noise. In this way, the reconstructed inputs only have useful information included.
- A recurrent neural network (RNN) is designed to capture the temporal variations within water quality variables and utilize the historical changing patterns as a guide for predicting water quality in the future.
2. Material and Methods
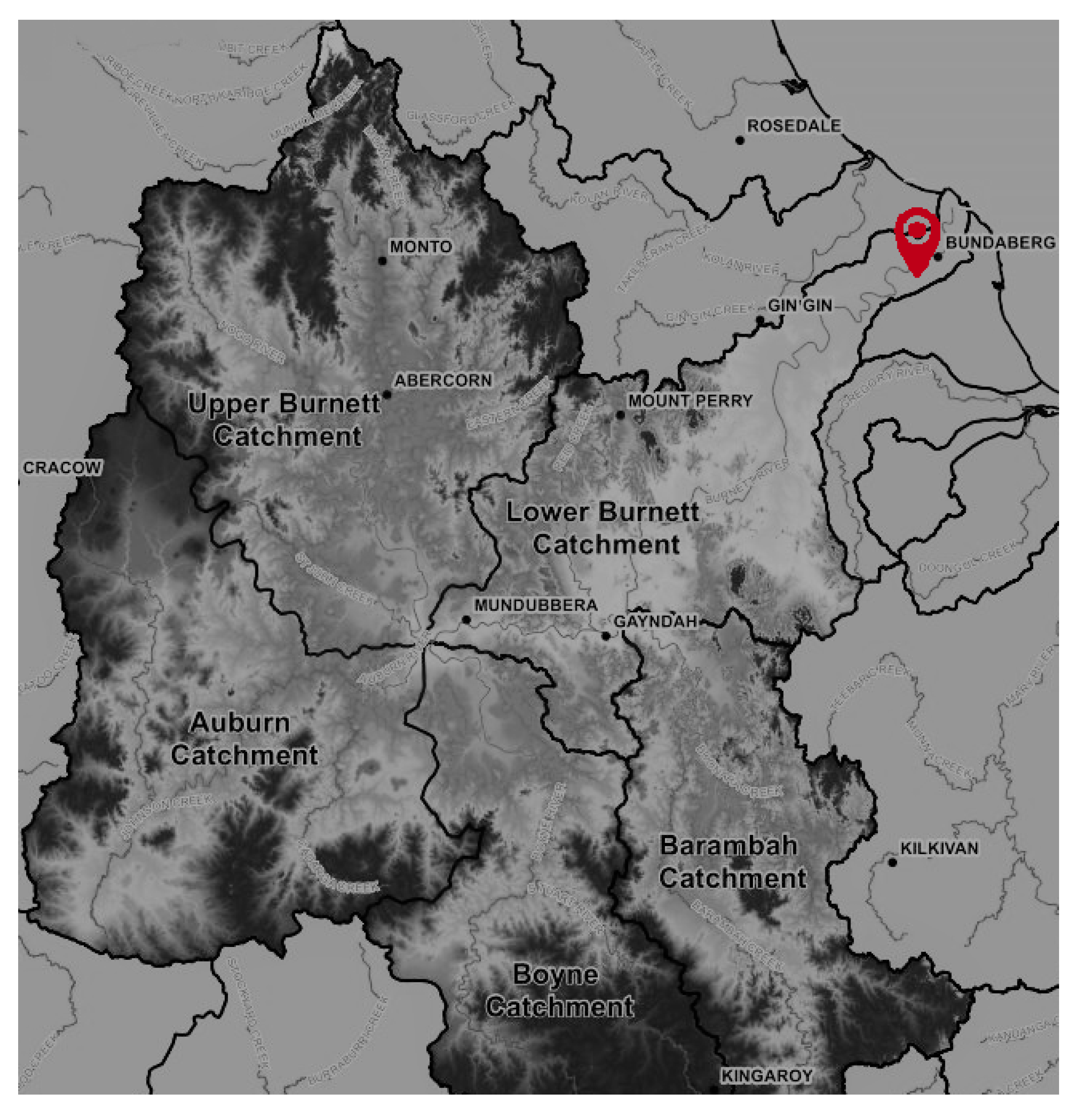
2.1. Study Area and Monitoring Data
2.1.1. Overview
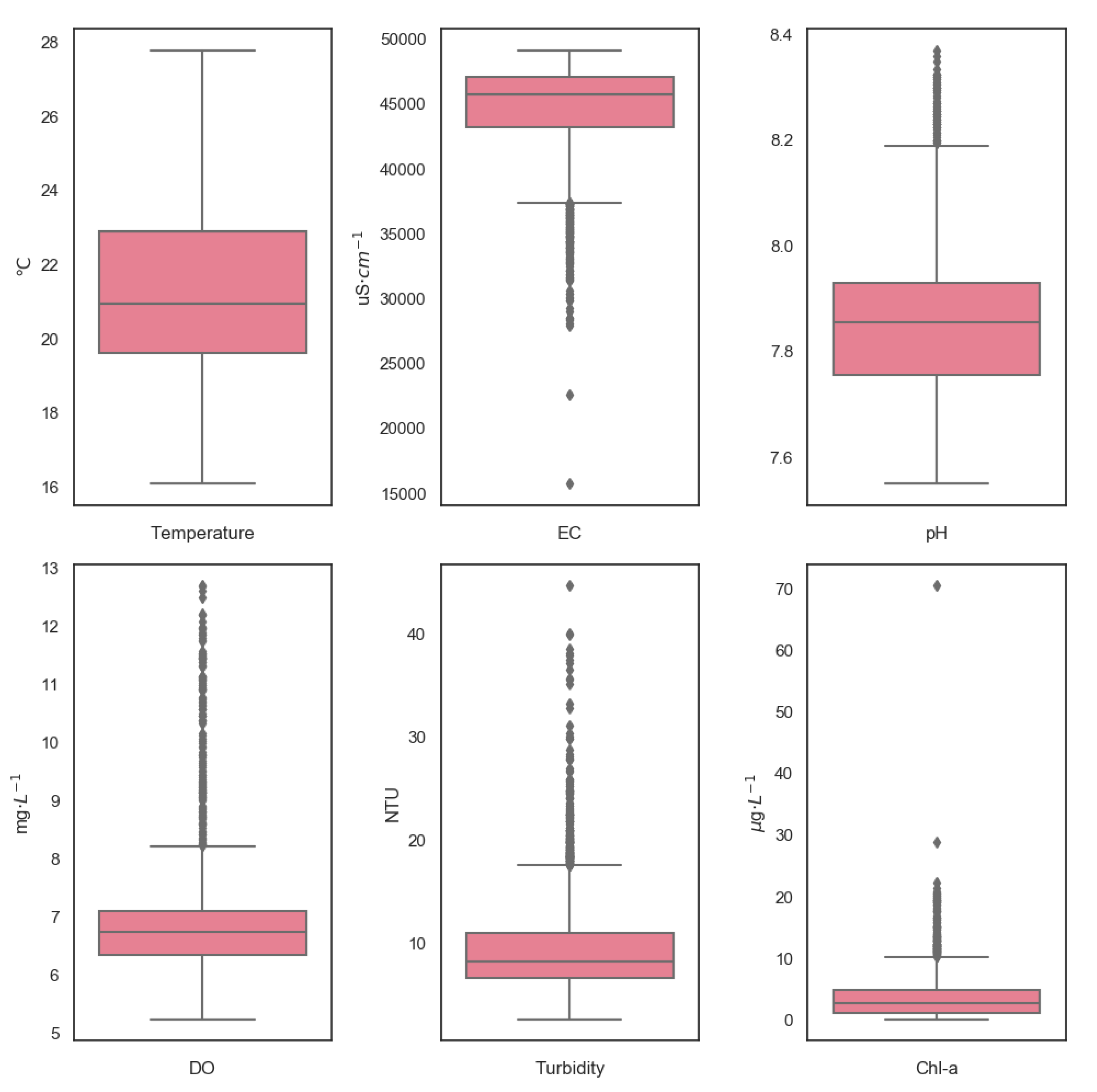
2.1.2. Water Quality Statistical Analysis
2.2. kPCA-RNN Model Description
2.2.1. Kernel PCA Based Input Abstraction
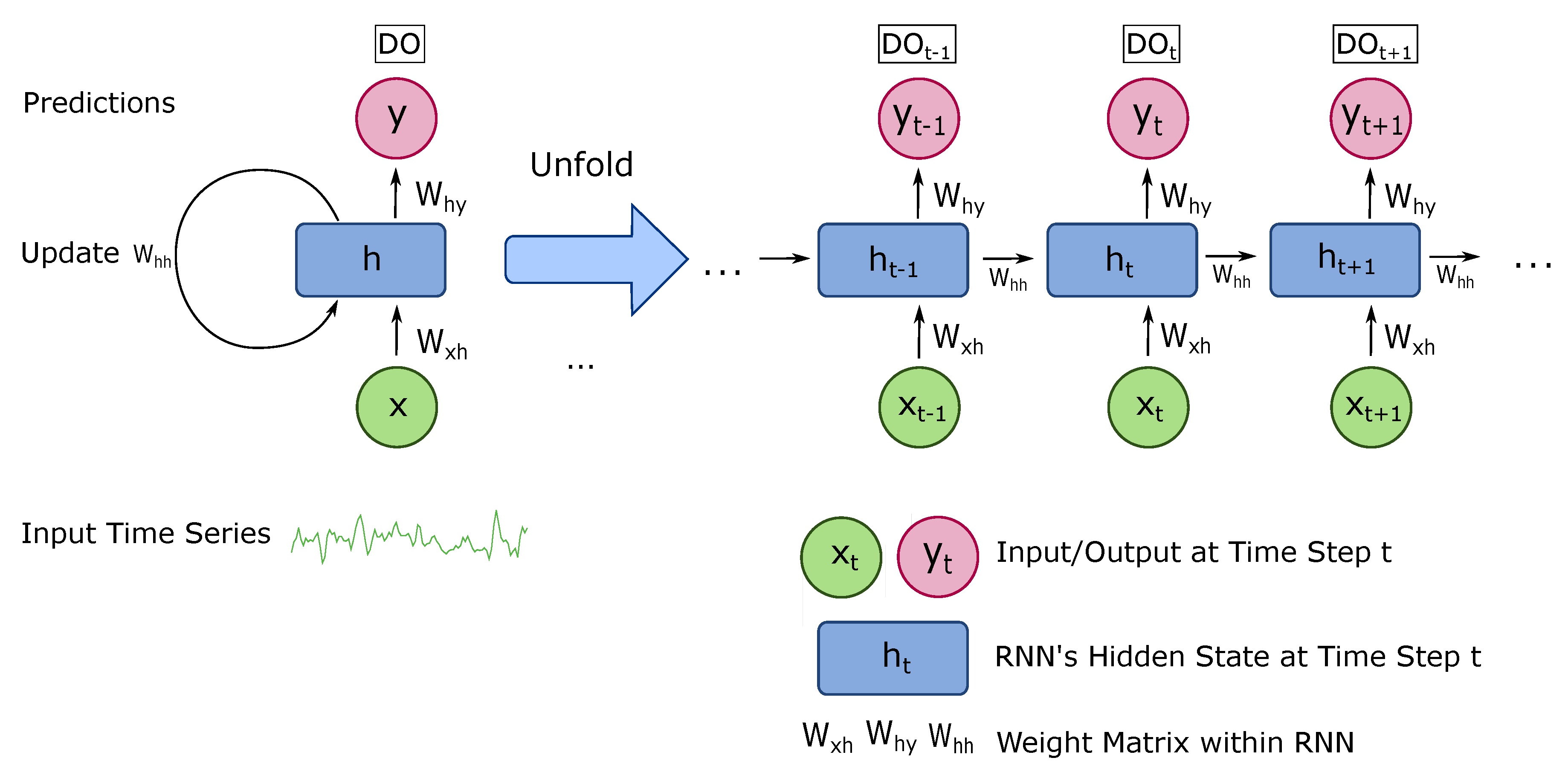
2.2.2. Recurrent Neural Network
2.3. Model Evaluation
- Feed-forward neural network (FFNN). FFNN has been broadly adopted for water quality analysis due to its capability in capturing nonlinear relationships within the short-term period [13].
- Support vector regression (SVR). SVR is a classic machine learning technique which can map inputs into higher dimensional space and interpret the problem as a linear regression [29].
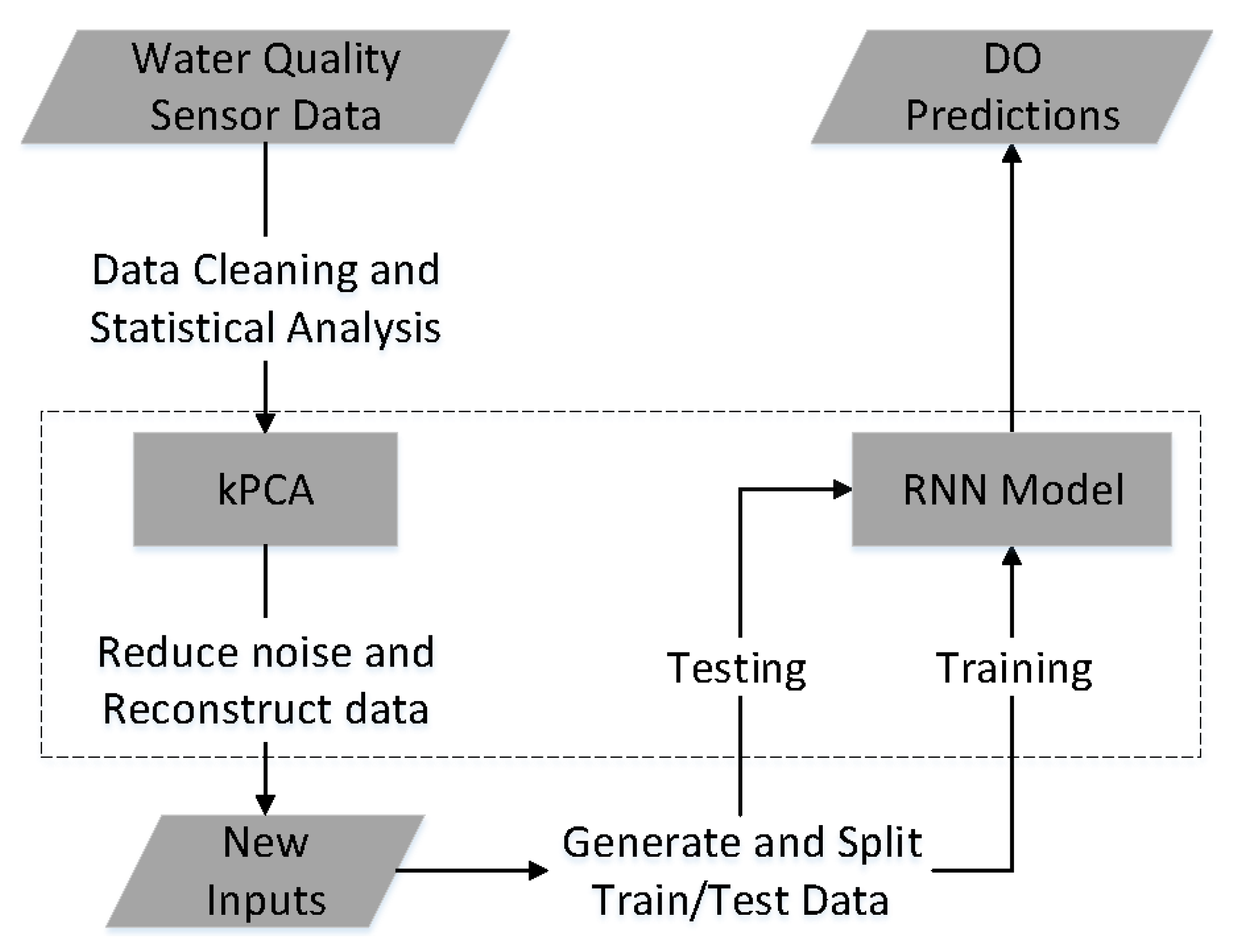
2.4. Workflow of Predicting DO
- Instead of using the sensor data directly, the kPCA method is implemented to the water quality sensor data to construct new inputs based on principal components. This step can help reduce the background noise and keep the most useful information for DO forecasting tasks.
- The recurrent neural network is applied to process the time series water quality data. The recurrent structure offers a powerful way of capturing the temporal patterns across a period of time, which is critical in forecasting the changing of DO concentration in the future.
3. Model Application
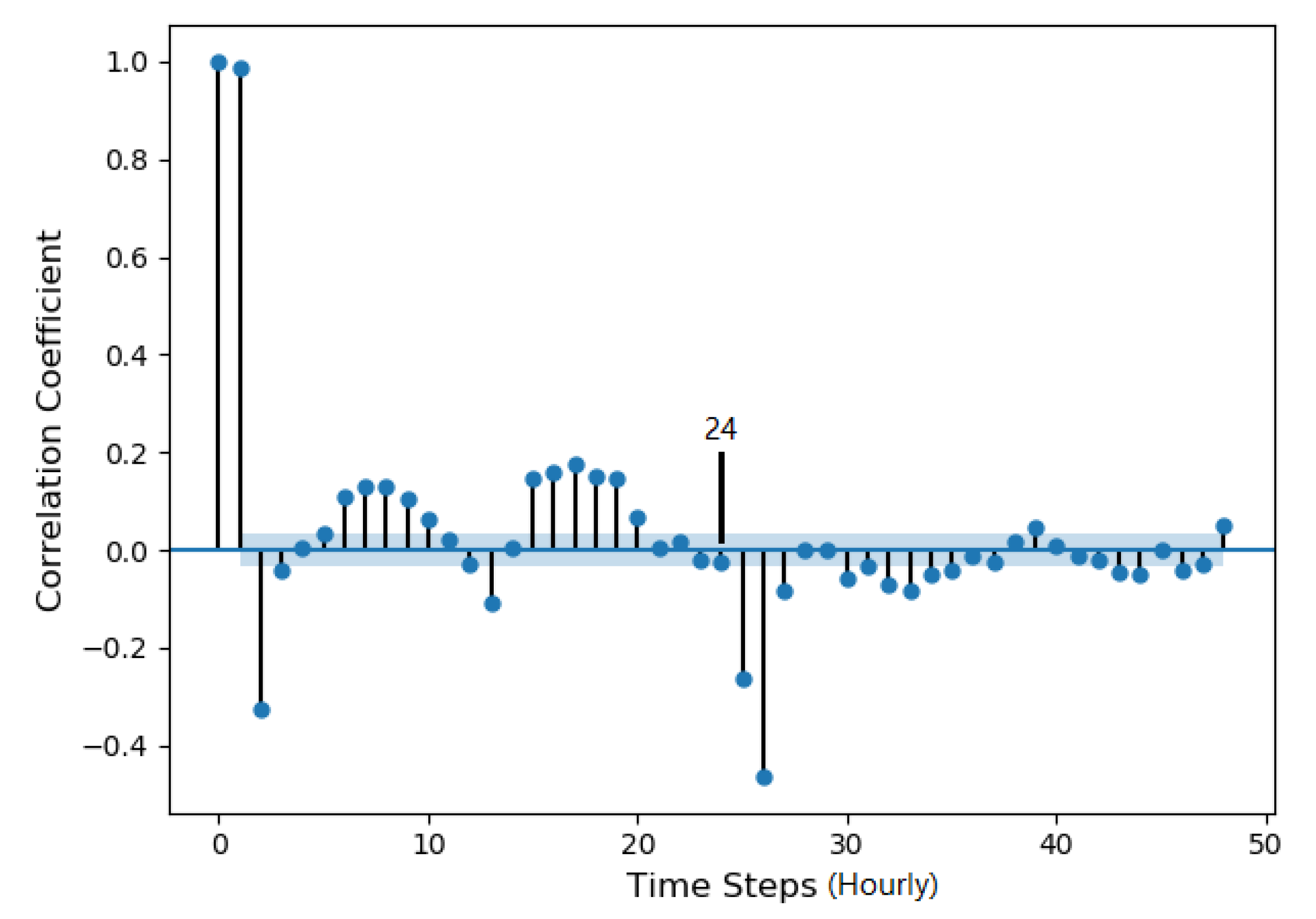
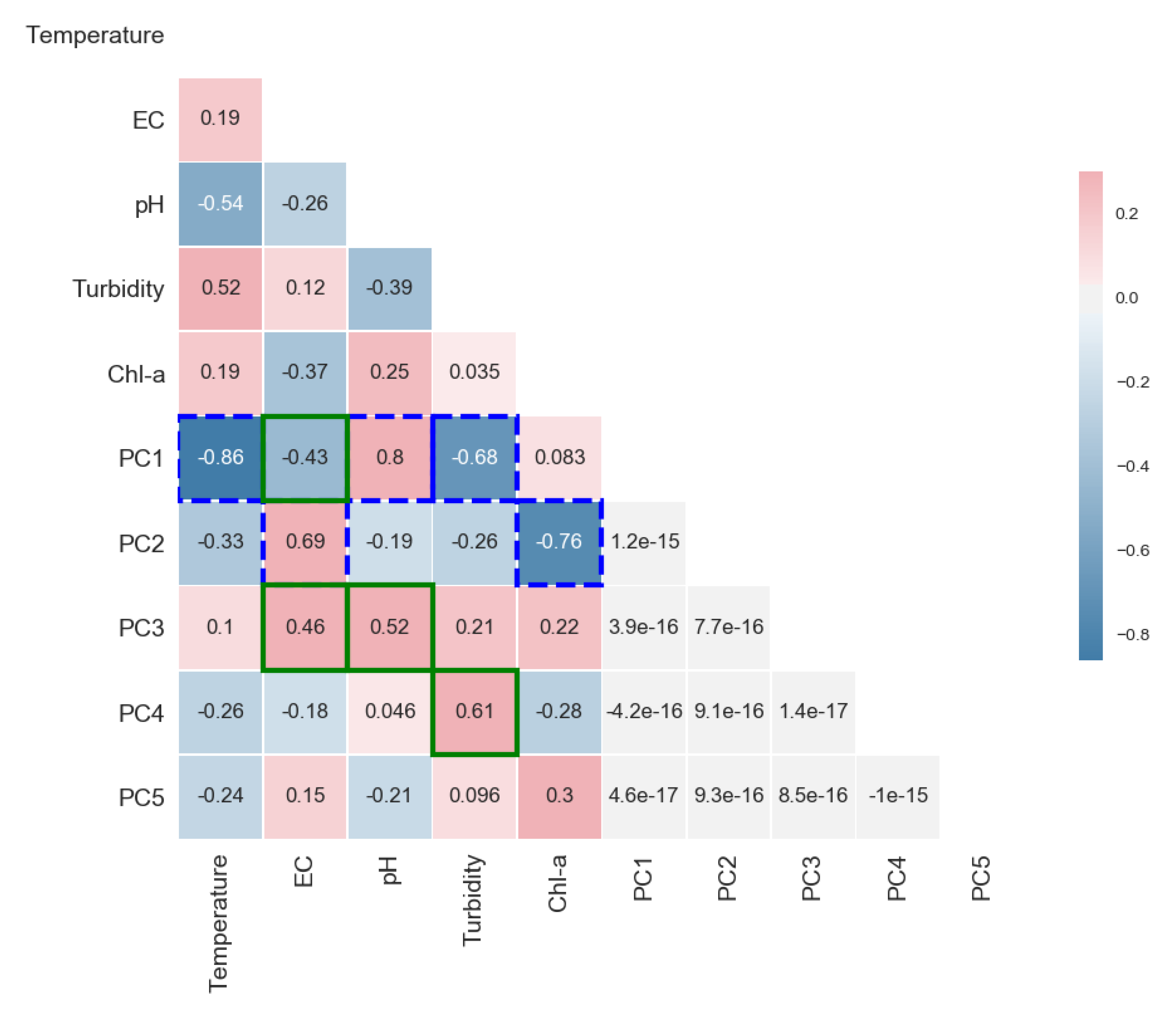
3.1. Applying kPCA on the Water Quality Data
3.2. RNN Hyperparameters Settings
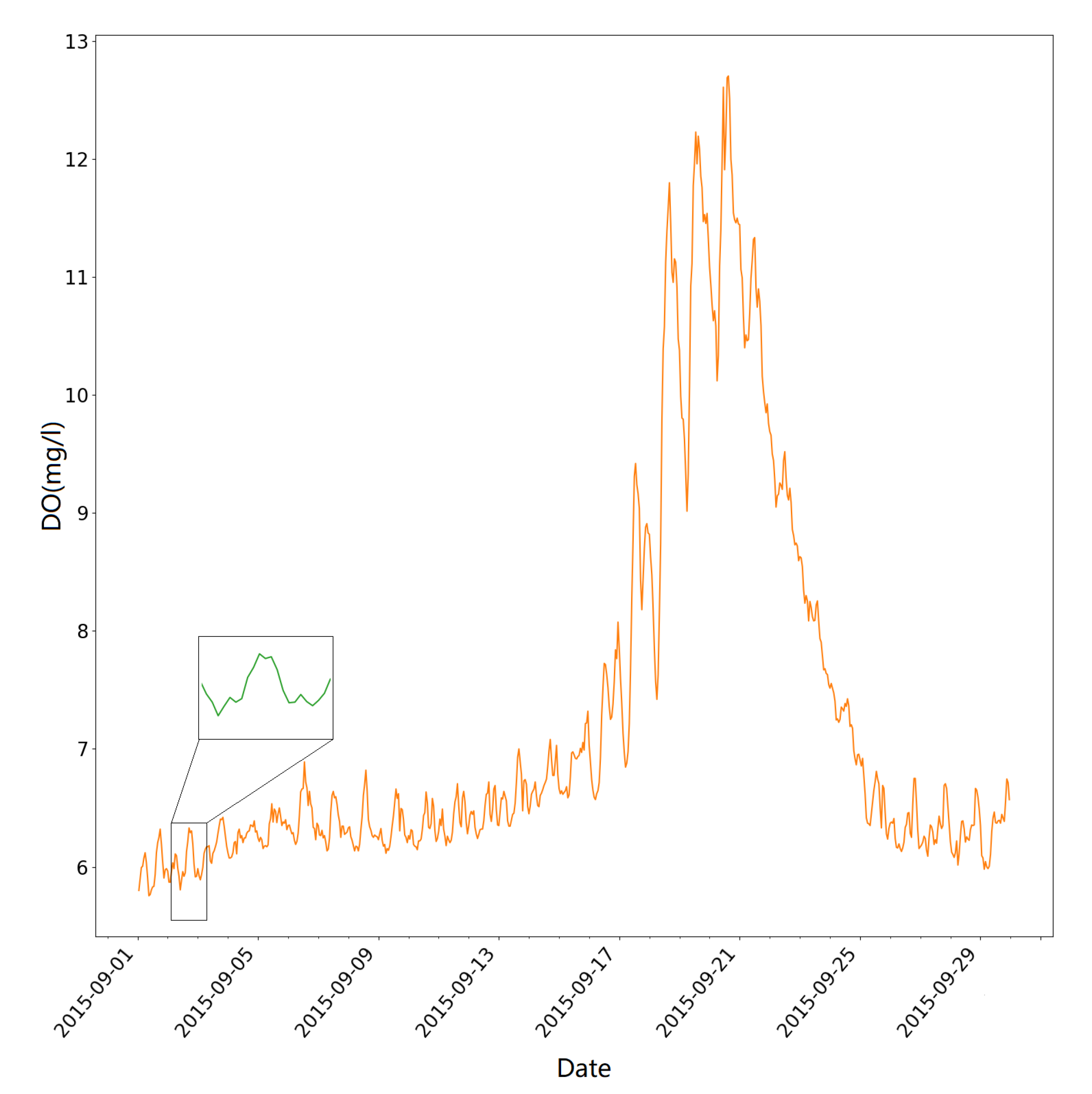
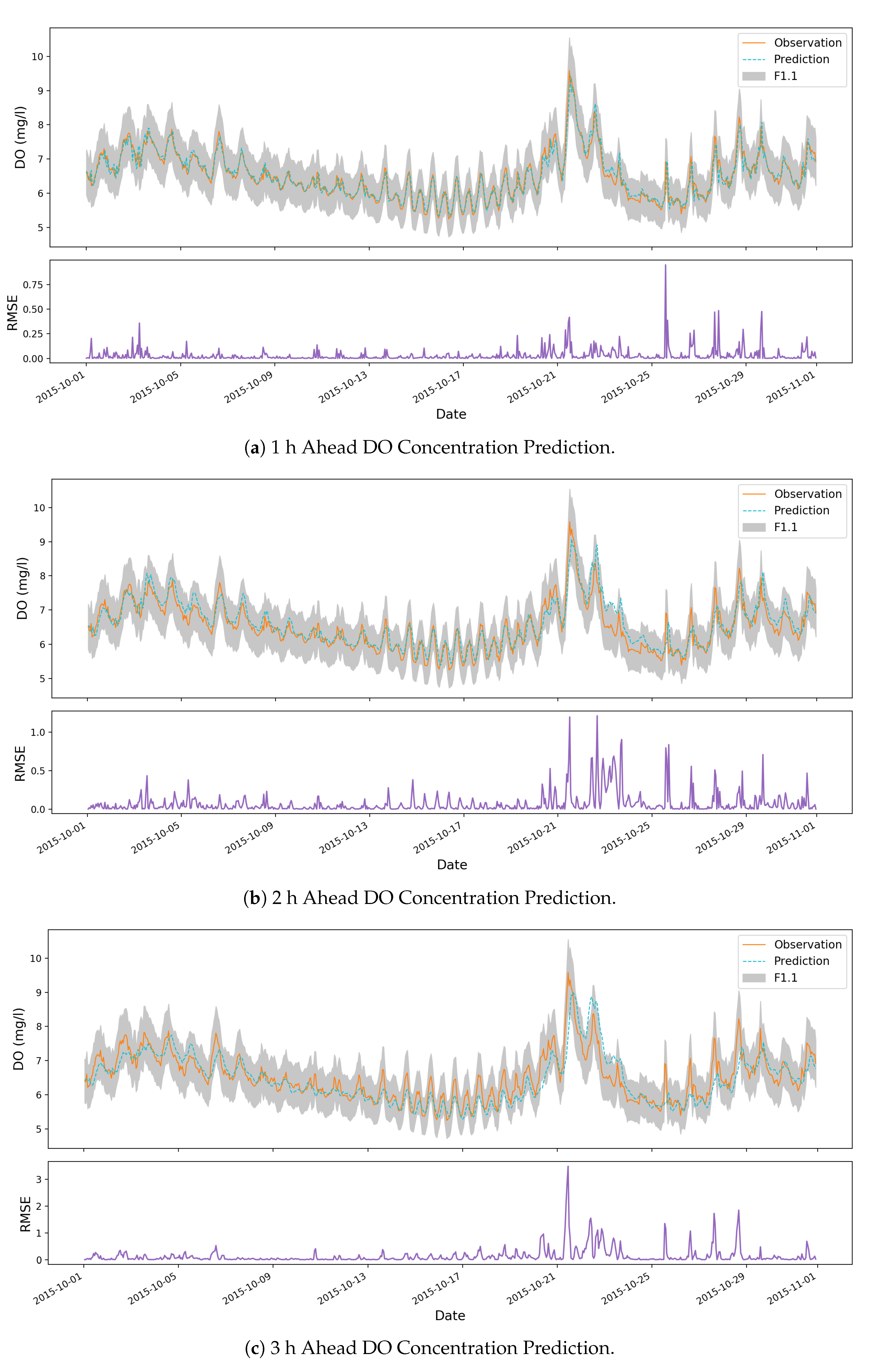
3.3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Barzegar, R.; Adamowski, J.; Moghaddam, A.A. Application of wavelet-artificial intelligence hybrid models for water quality prediction: A case study in Aji-Chay River, Iran. Stoch. Environ. Res. Risk Assess. 2016, 30, 1797–1819. [Google Scholar] [CrossRef]
- Hrachowitz, M.; Benettin, P.; van Breukelen, B.M.; Fovet, O.; Howden, N.J.; Ruiz, L.; van der Velde, Y.; Wade, A.J. Transit times-the link between hydrology and water quality at the catchment scale. Wiley Interdiscip. Rev. Water 2016, 3, 629–657. [Google Scholar] [CrossRef] [Green Version]
- Jin, T.; Cai, S.; Jiang, D.; Liu, J. A data-driven model for real-time water quality prediction and early warning by an integration method. Environ. Sci. Pollut. Res. 2019, 26, 30374–30385. [Google Scholar] [CrossRef] [PubMed]
- Tomić, A.Š.; Antanasijević, D.; Ristić, M.; Perić-Grujić, A.; Pocajt, V. A linear and nonlinear polynomial neural network modeling of dissolved oxygen content in surface water: Inter- and extrapolation performance with inputs’ significance analysis. Sci. Total. Environ. 2018, 610–611, 1038–1046. [Google Scholar] [CrossRef]
- King, A.J.; Tonkin, Z.; Lieshcke, J. Short-term effects of a prolonged blackwater event on aquatic fauna in the Murray River, Australia: Considerations for future events. Mar. Freshw. Res. 2012, 63, 576–586. [Google Scholar] [CrossRef]
- Zhang, Y.; Thorburn, P.J.; Fitch, P. Multi-Task Temporal Convolutional Network for Predicting Water Quality Sensor Data. In Proceedings of the 26th International Conference on Neural Information Processing (ICONIP2019), Sydney, Australia, 12–15 December 2019; Volume 1142, pp. 122–130. [Google Scholar]
- Hawkins, C.P.; Olson, J.R.; Hill, R.A. The reference condition: Predicting benchmarks for ecological and water-quality assessments. J. North Am. Benthol. Soc. 2010, 29, 312–343. [Google Scholar] [CrossRef] [Green Version]
- Marcomini, A.; Suter II, G.W.; Critto, A. Decision Support Systems for Risk-Based Management of Contaminated Sites; Springer Science & Business Media: New York, NY, USA, 2008; Volume 763. [Google Scholar]
- Chubarenko, I.; Tchepikova, I. Modelling of man-made contribution to salinity increase into the Vistula Lagoon (Baltic Sea). Ecol. Model. 2001, 138, 87–100. [Google Scholar] [CrossRef]
- Chapra, S.; Pelletier, G.; Tao, H. QUAL2K: A Modeling Framework for Simulating River and Stream Water Quality; Documentation and user manual; Tufts University: Medford, MA, USA, 2003. [Google Scholar]
- Ay, M.; Özgür, K. Estimation of dissolved oxygen by using neural networks and neuro fuzzy computing techniques. KSCE J. Civ. Eng. 2016, 21, 1631–1639. [Google Scholar] [CrossRef]
- Zhang, Y.; Thorburn, P.J.; Wei, X.; Fitch, P. SSIM -A Deep Learning Approach for Recovering Missing Time Series Sensor Data. IEEE Internet Things J. 2019, 6, 6618–6628. [Google Scholar] [CrossRef]
- Zhang, Y.; Fitch, P.; Vilas, M.P.; Thorburn, P.J. Applying Multi-Layer Artificial Neural Network and Mutual Information to the Prediction of Trends in Dissolved Oxygen. Front. Environ. Sci. 2019, 7, 46. [Google Scholar] [CrossRef]
- Antanasijević, D.; Pocajt, V.; Perić-Grujić, A.; Ristić, M. Modelling of dissolved oxygen in the Danube River using artificial neural networks and Monte Carlo Simulation uncertainty analysis. J. Hydrol. 2014, 519, 1895–1907. [Google Scholar] [CrossRef]
- Li, X.; Sha, J.; Wang, Z.l. A comparative study of multiple linear regression, artificial neural network and support vector machine for the prediction of dissolved oxygen. Hydrol. Res. 2017, 48, 1214–1225. [Google Scholar] [CrossRef]
- Sundermeyer, M.; Oparin, I.; Gauvain, J.L.; Freiberg, B.; Schlüter, R.; Ney, H. Comparison of feedforward and recurrent neural network language models. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8430–8434. [Google Scholar]
- Karami, J.; Alimohammadi, A.; Seifouri, T. Water quality analysis using a variable consistency dominance-based rough set approach. Comput. Environ. Urban Syst. 2014, 43, 25–33. [Google Scholar] [CrossRef]
- Liu, S.; Che, H.; Smith, K.; Chang, T. A real time method of contaminant classification using conventional water quality sensors. J. Environ. Manag. 2015, 154, 13–21. [Google Scholar] [CrossRef]
- Chuan Wang, W.; wing Chau, K.; Qiu, L.; bo Chen, Y. Improving forecasting accuracy of medium and long-term runoff using artificial neural network based on EEMD decomposition. Environ. Res. 2015, 139, 46–54. [Google Scholar] [CrossRef]
- Ambient Estuarine Water Quality Monitoring Data. Available online: https://data.qld.gov.au/dataset (accessed on 20 November 2017).
- Great Barrier Reef Catchment Loads Monitoring Program. Available online: https://www.reefplan.qld.gov.au/measuring-success/paddock-to-reef/catchment-loads/ (accessed on 1 June 2018).
- Macdonald, R.K.; Ridd, P.V.; Whinney, J.C.; Larcombe, P.; Neil, D.T. Towards environmental management of water turbidity within open coastal waters of the Great Barrier Reef. Mar. Pollut. Bull. 2013, 74, 82–94. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.R. Kernel principal component analysis. In Proceeedings of the Artificial Neural Networks—ICANN’97: 7th International Conference; Lausanne, Switzerland, 8–10 October 1997, Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 1997; pp. 583–588. [Google Scholar]
- Ince, H.; Trafalis, T.B. Kernel principal component analysis and support vector machines for stock price prediction. IIE Trans. 2007, 39, 629–637. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Specht, D.F. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [Green Version]
- Barzegar, R.; Moghaddam, A.A. Combining the advantages of neural networks using the concept of committee machine in the groundwater salinity prediction. Model. Earth Syst. Environ. 2016, 2, 26. [Google Scholar] [CrossRef] [Green Version]
- Granata, F.; Papirio, S.; Esposito, G.; Gargano, R.; de Marinis, G. Machine learning algorithms for the forecasting of wastewater quality indicators. Water 2017, 9, 105. [Google Scholar] [CrossRef] [Green Version]
- Roberts, W.; Williams, G.P.; Jackson, E.; Nelson, E.J.; Ames, D.P. Hydrostats: A Python package for characterizing errors between observed and predicted time series. Hydrology 2018, 5, 66. [Google Scholar] [CrossRef] [Green Version]
- Verbanck, M.; Josse, J.; Husson, F. Regularised PCA to denoise and visualise data. Stat. Comput. 2013, 25, 471–486. [Google Scholar] [CrossRef] [Green Version]
- Jaques, N.; Gu, S.; Turner, R.E.; Eck, D. Tuning recurrent neural networks with reinforcement learning. arXiv 2017, arXiv:1611.02796v3. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | No. of Data | Unit | Min | Max | Median | Mean | SD 1 | CV 2 (%) |
|---|---|---|---|---|---|---|---|---|
| Temperature | 3672 | C | 16.1 | 27.9 | 21.0 | 21.4 | 2.3 | 11 |
| EC | 3672 | uS·cm | 613.0 | 49,150.0 | 45,750.0 | 44,712.1 | 3566.8 | 8 |
| pH | 3672 | 7.5 | 8.4 | 7.9 | 7.8 | 0.1 | 2 | |
| DO | 3672 | mg·L | 5.2 | 13.0 | 6.8 | 6.9 | 0.9 | 13 |
| Turbidity | 3672 | NTU | 2.6 | 63.0 | 8.2 | 9.5 | 4.7 | 50 |
| Chl-a | 3672 | g·L | 0.1 | 137.6 | 2.6 | 3.5 | 3.6 | 102 |
| Principal Components | Eigenvalue | Cumulative Variance Proportion (%) |
|---|---|---|
| PC1 | 466.6 | 44.4 |
| PC2 | 285.3 | 71.5 |
| PC3 | 129.8 | 83.8 |
| PC4 | 114.8 | 94.8 |
| PC5 | 55.1 | 100.0 |
| Model Settings | Experimental Cases | ||
|---|---|---|---|
| 1 h Ahead | 2 h Ahead | 3 h Ahead | |
| No. of Hidden Layers | 1 | 2 | 3 |
| No. of Hidden Units | 40 | 30 | 20 |
| Recurrent Cell | LSTM 1 | LSTM 1 | LSTM 1 |
| Optimizer | Adam 2 | Adam 2 | Adam 2 |
| No. of Historical Time Steps | 24 | 24 | 24 |
| No. of Training Data | 2928 | 2928 | 2928 |
| No. of Testing Data | 744 | 744 | 744 |
| Predictive Models | Evaluation Criteria | |||
|---|---|---|---|---|
| MAE | RMSE | FA1.1 | ||
| 1 h Ahead Prediction | ||||
| kPCA-RNN Model | 0.149 | 0.908 | 0.208 | 0.995 |
| FFNN | 0.175 | 0.893 | 0.224 | 0.989 |
| SVR | 0.219 | 0.810 | 0.299 | 0.962 |
| GRNN | 0.263 | 0.727 | 0.355 | 0.944 |
| 2 h Ahead Prediction | ||||
| kPCA-RNN Model | 0.211 | 0.823 | 0.288 | 0.973 |
| FFNN | 0.258 | 0.757 | 0.338 | 0.958 |
| SVR | 0.314 | 0.594 | 0.437 | 0.890 |
| GRNN | 0.295 | 0.648 | 0.403 | 0.926 |
| 3 h Ahead Prediction | ||||
| kPCA-RNN Model | 0.303 | 0.671 | 0.394 | 0.926 |
| FFNN | 0.455 | 0.358 | 0.550 | 0.756 |
| SVR | 0.358 | 0.515 | 0.478 | 0.858 |
| GRNN | 0.320 | 0.562 | 0.450 | 0.910 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.-F.; Fitch, P.; Thorburn, P.J. Predicting the Trend of Dissolved Oxygen Based on the kPCA-RNN Model. Water 2020, 12, 585. https://doi.org/10.3390/w12020585
Zhang Y-F, Fitch P, Thorburn PJ. Predicting the Trend of Dissolved Oxygen Based on the kPCA-RNN Model. Water. 2020; 12(2):585. https://doi.org/10.3390/w12020585
Chicago/Turabian StyleZhang, Yi-Fan, Peter Fitch, and Peter J. Thorburn. 2020. "Predicting the Trend of Dissolved Oxygen Based on the kPCA-RNN Model" Water 12, no. 2: 585. https://doi.org/10.3390/w12020585
APA StyleZhang, Y. -F., Fitch, P., & Thorburn, P. J. (2020). Predicting the Trend of Dissolved Oxygen Based on the kPCA-RNN Model. Water, 12(2), 585. https://doi.org/10.3390/w12020585