Automatic Extraction of Supraglacial Lakes in Southwest Greenland during the 2014–2018 Melt Seasons Based on Convolutional Neural Network

 ,
,
Abstract
:1. Introduction
2. Study Region and Data
2.1. Study Region
2.2. Landsat 8 Imagery Collection and Pre-Processing
2.3. Sample Selection
3. Methods
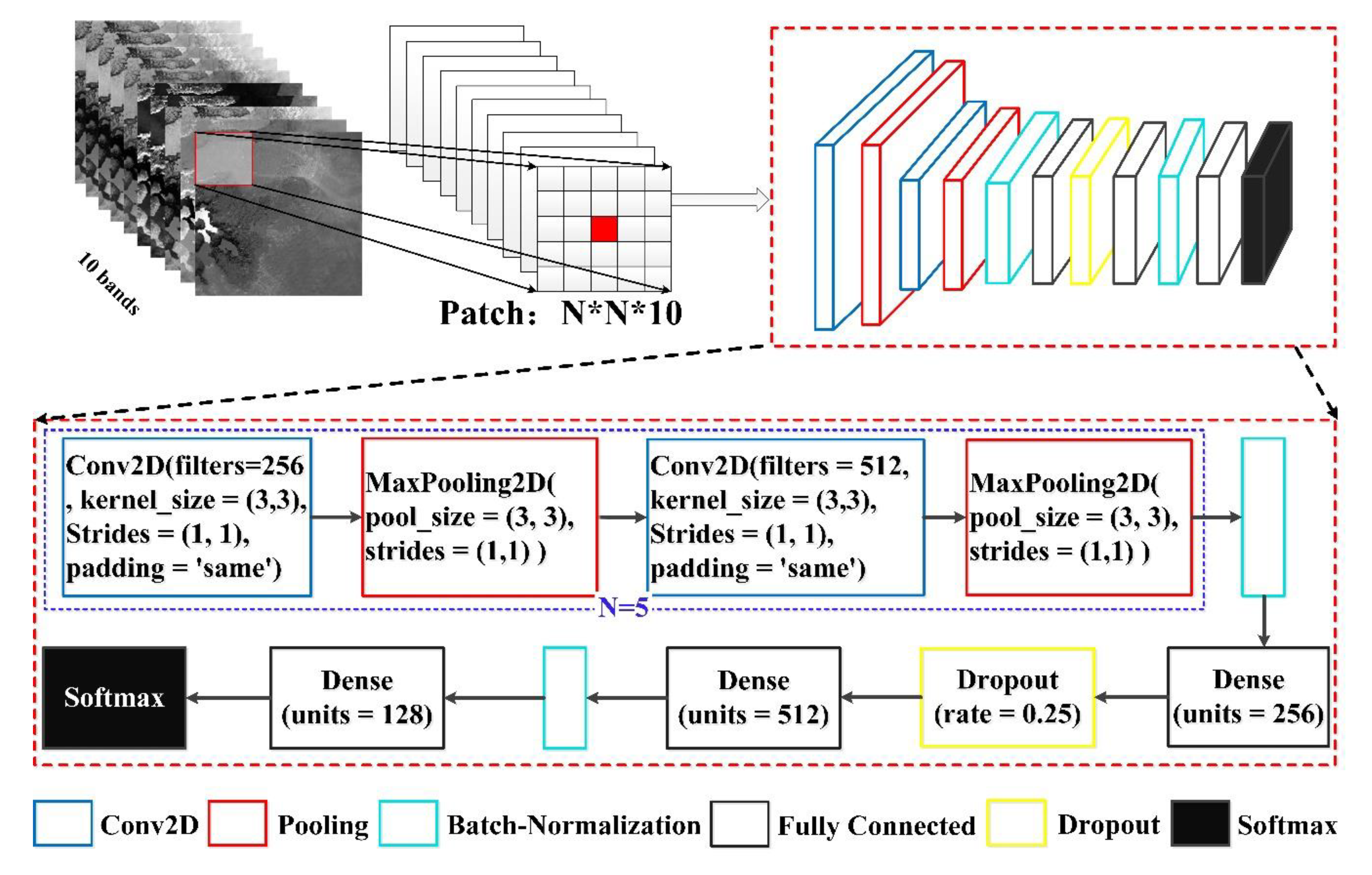
3.1. Water Identification Based on CNN
3.2. Accuracy Assessment for Water Identification
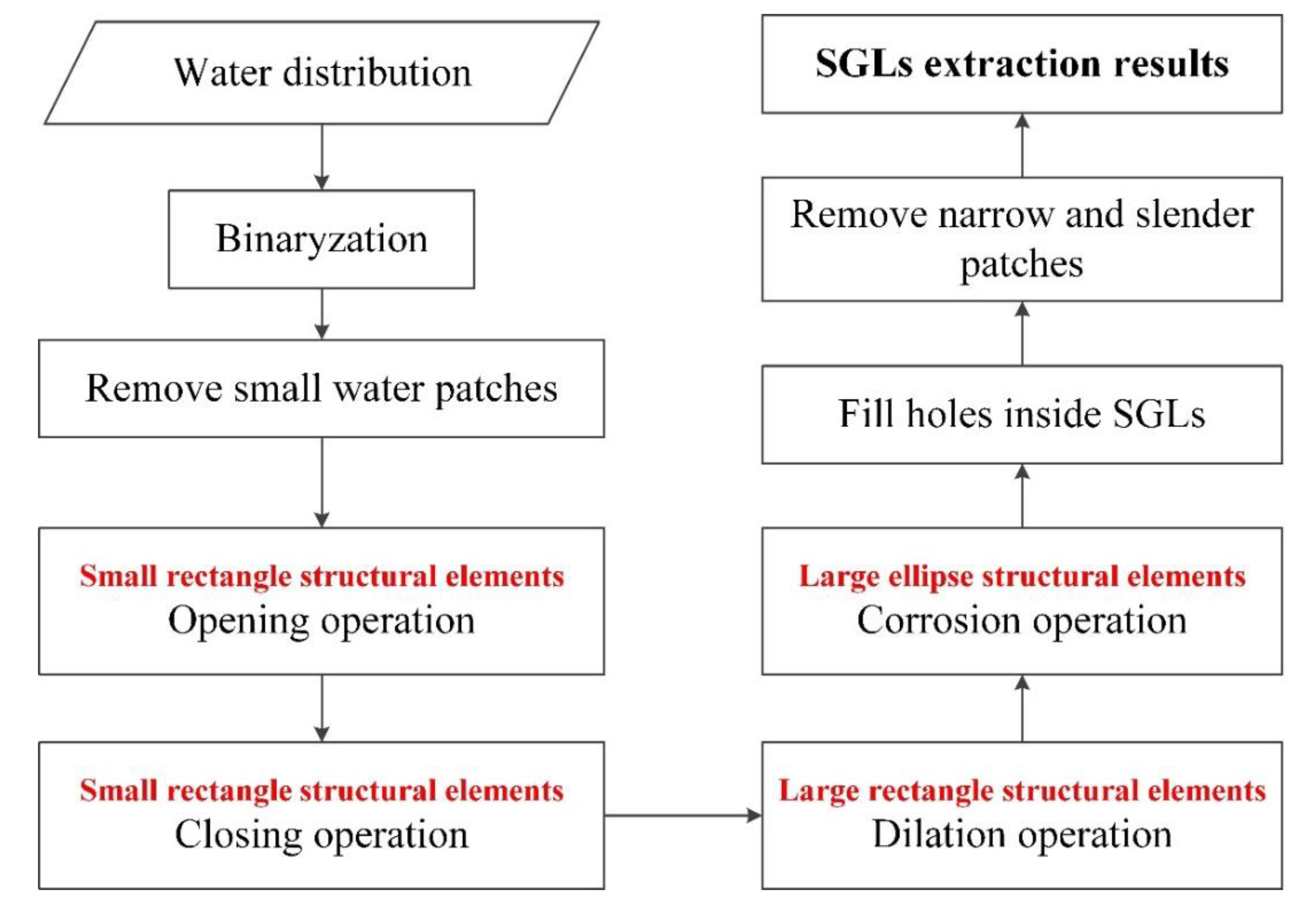
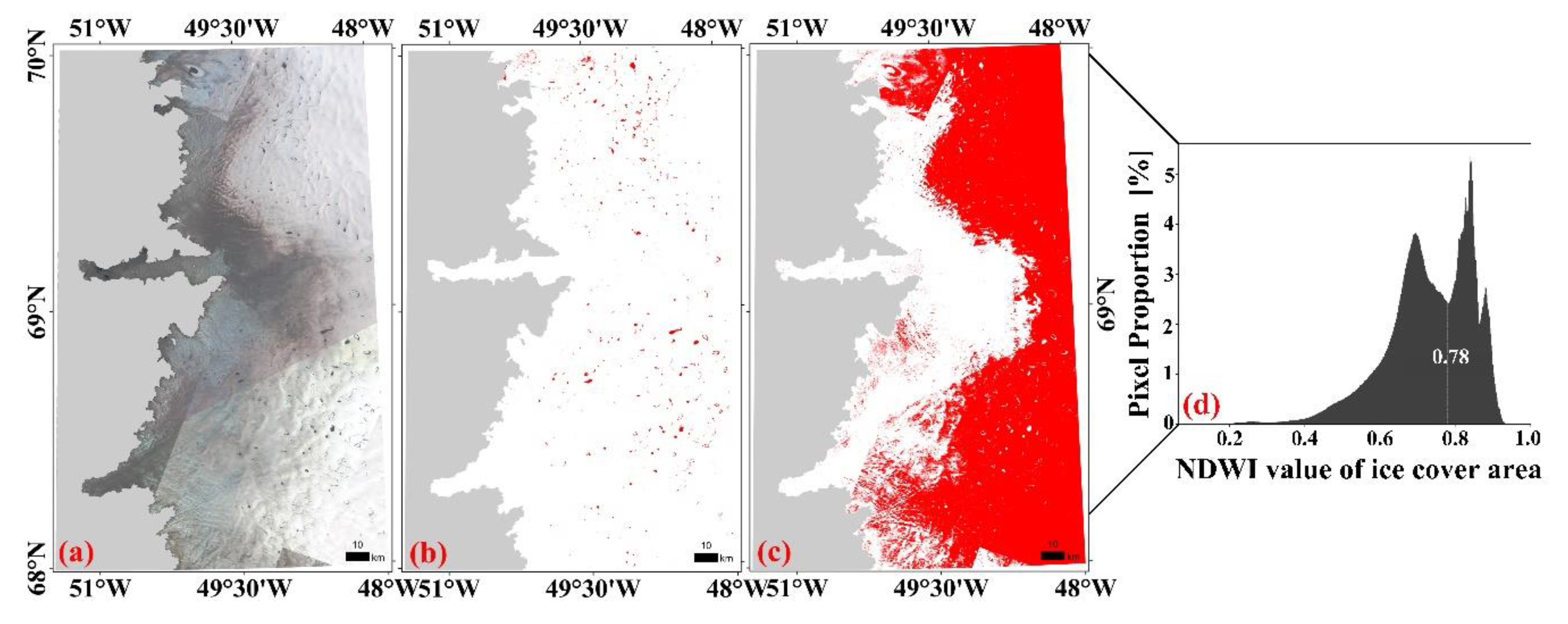
3.3. The Extraction of SGLs from Water
3.4. The Temporal–Spatial Change Detection of SGLs
3.5. Three Algorithms (Otsu, SVM, and RF) Used for Comparison with CNN
4. Results
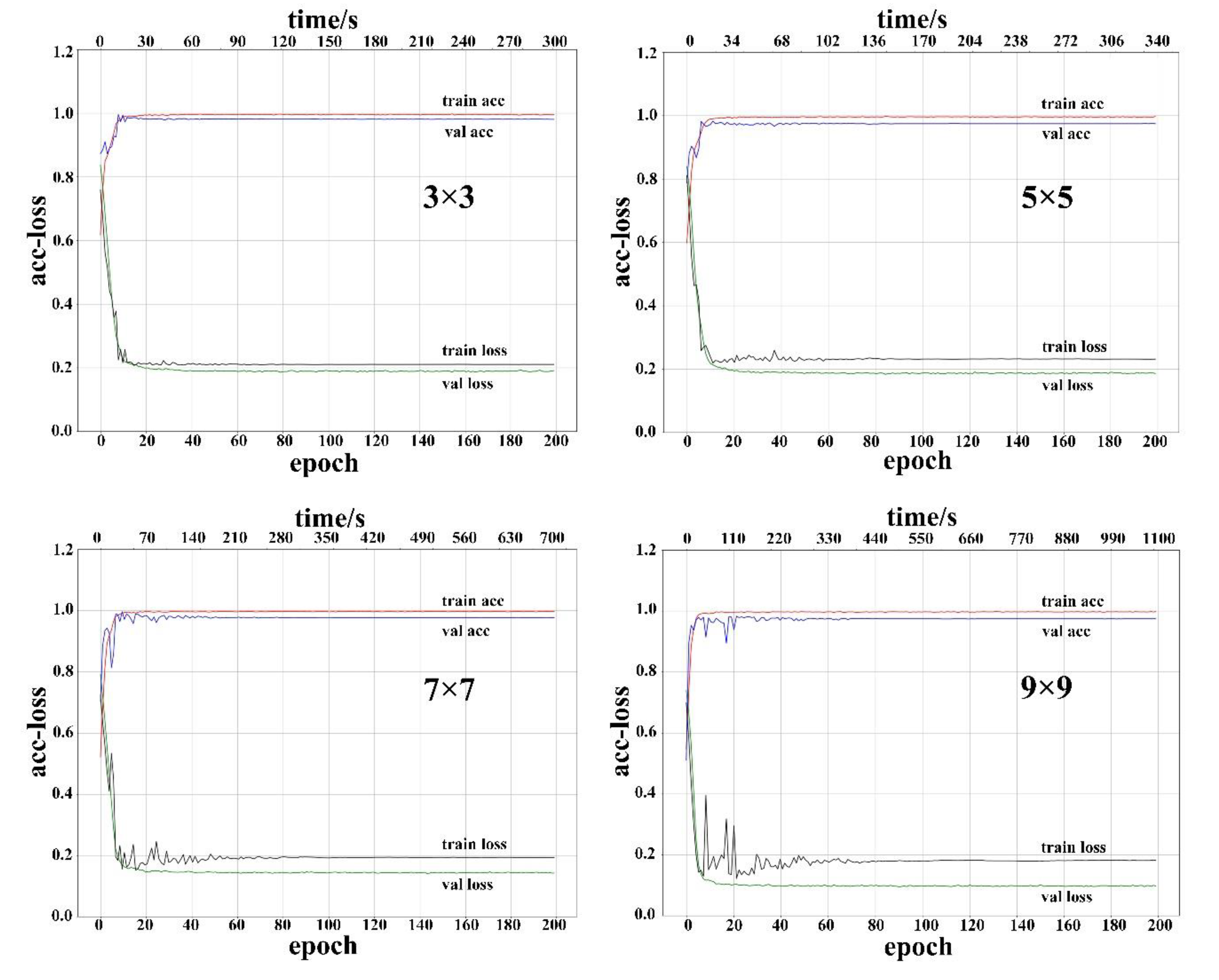
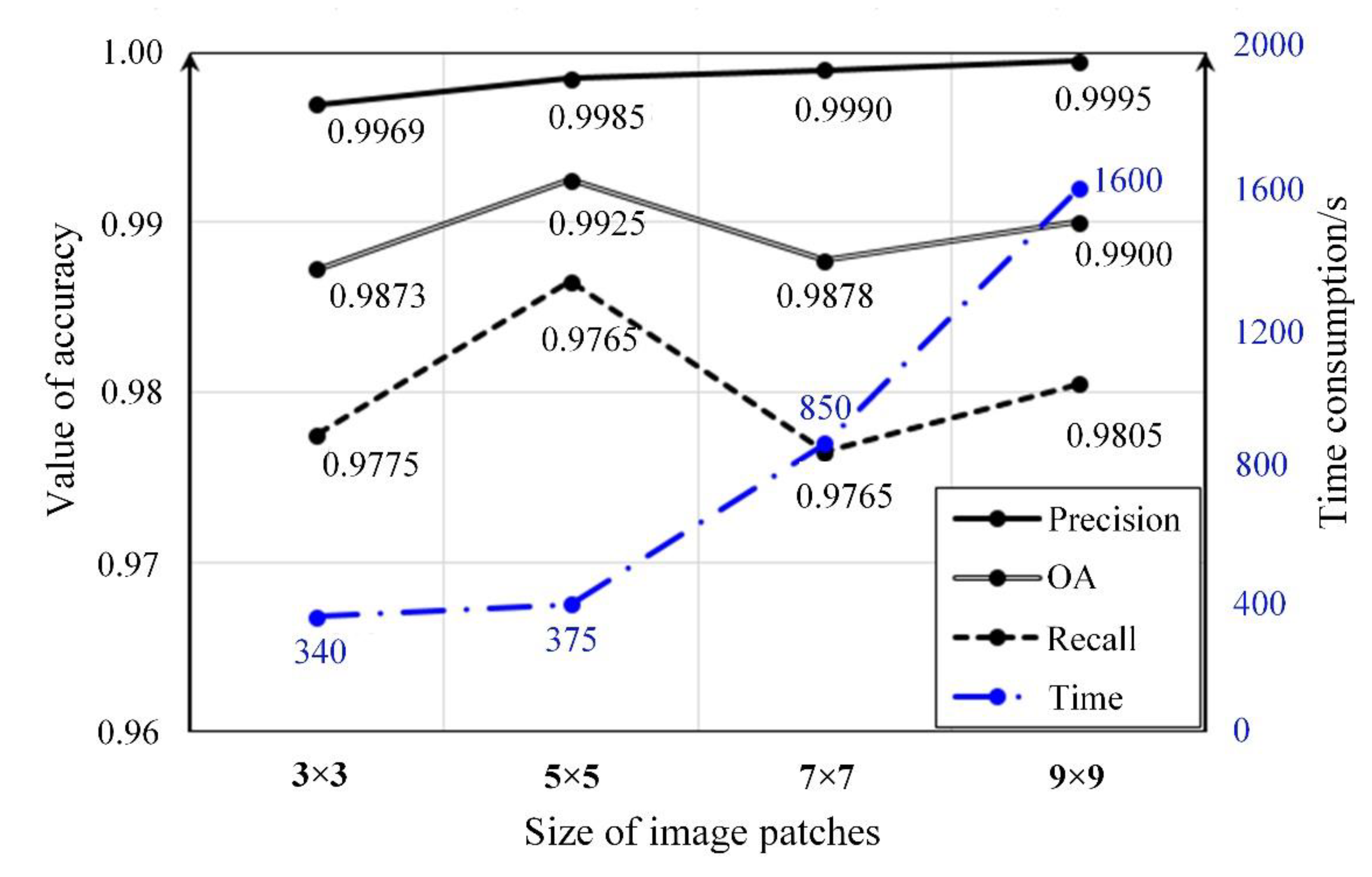
4.1. The Training and Testing Results of CNN
4.2. Accuracy Evaluation
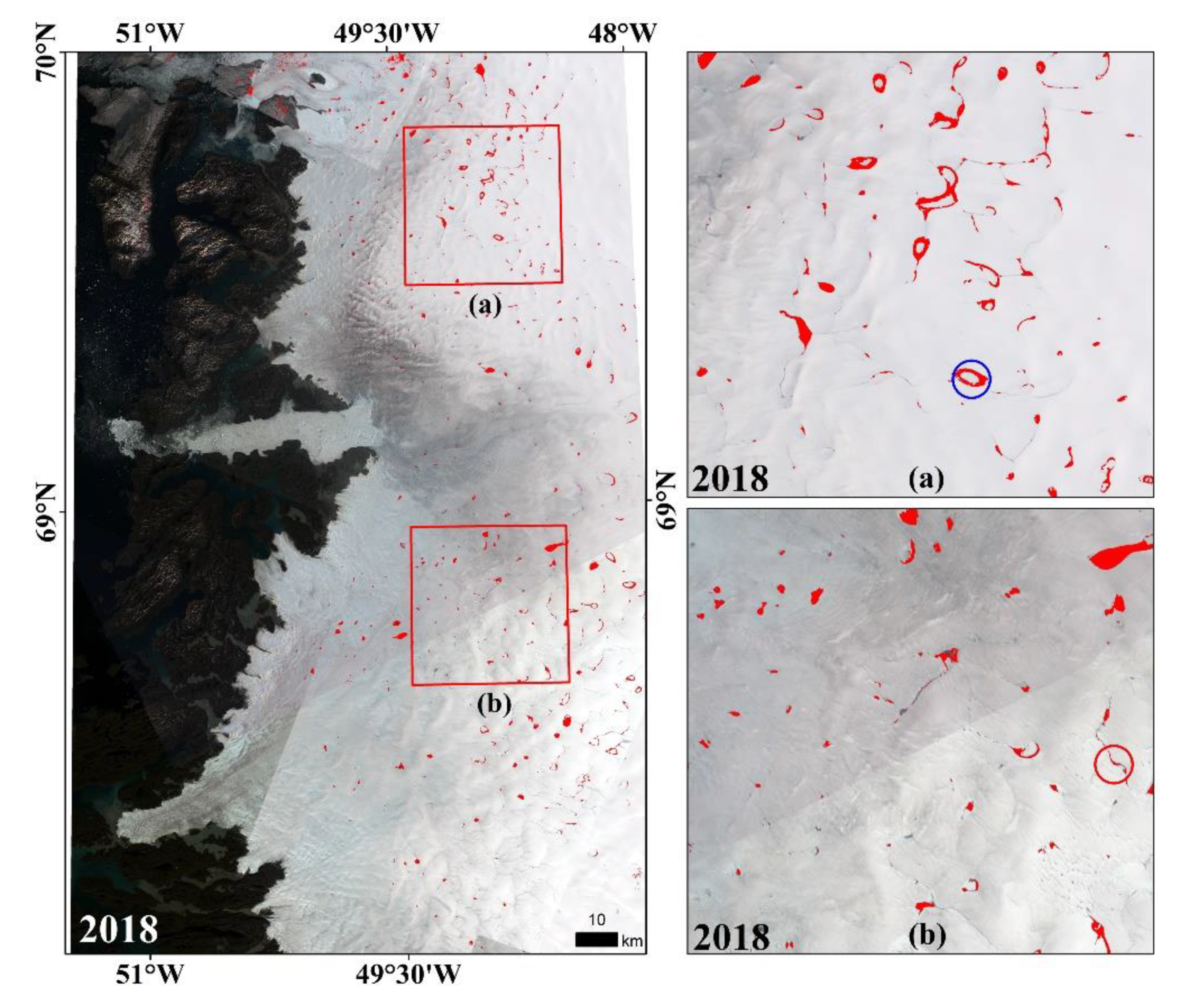
4.3. The Extraction Results of SGLs
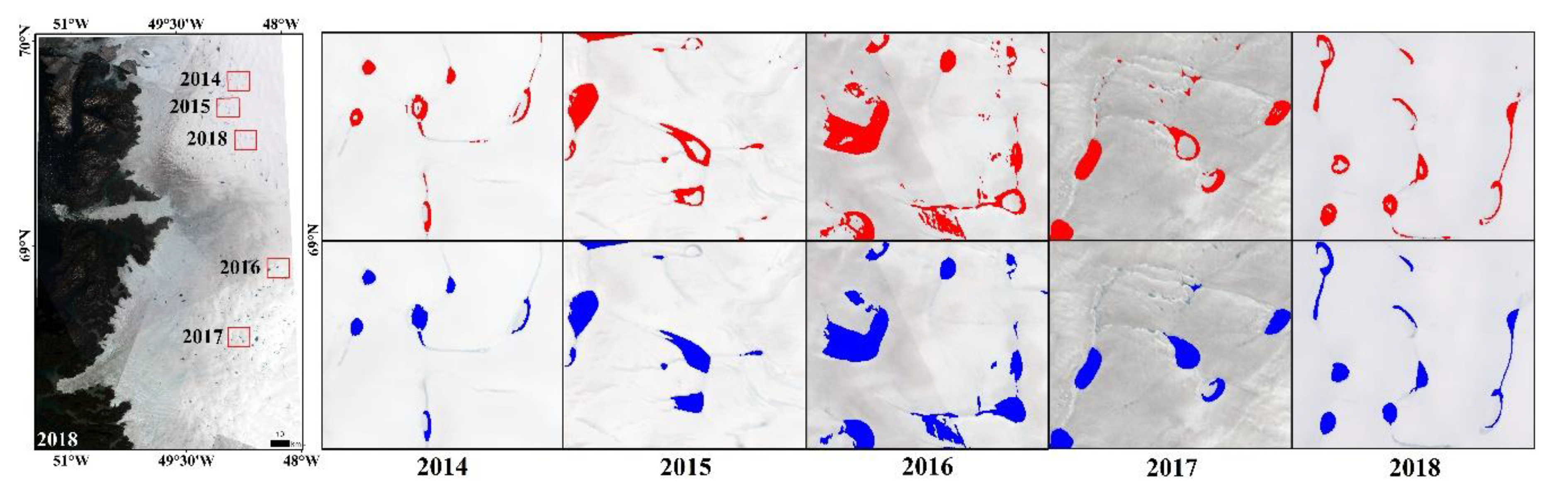
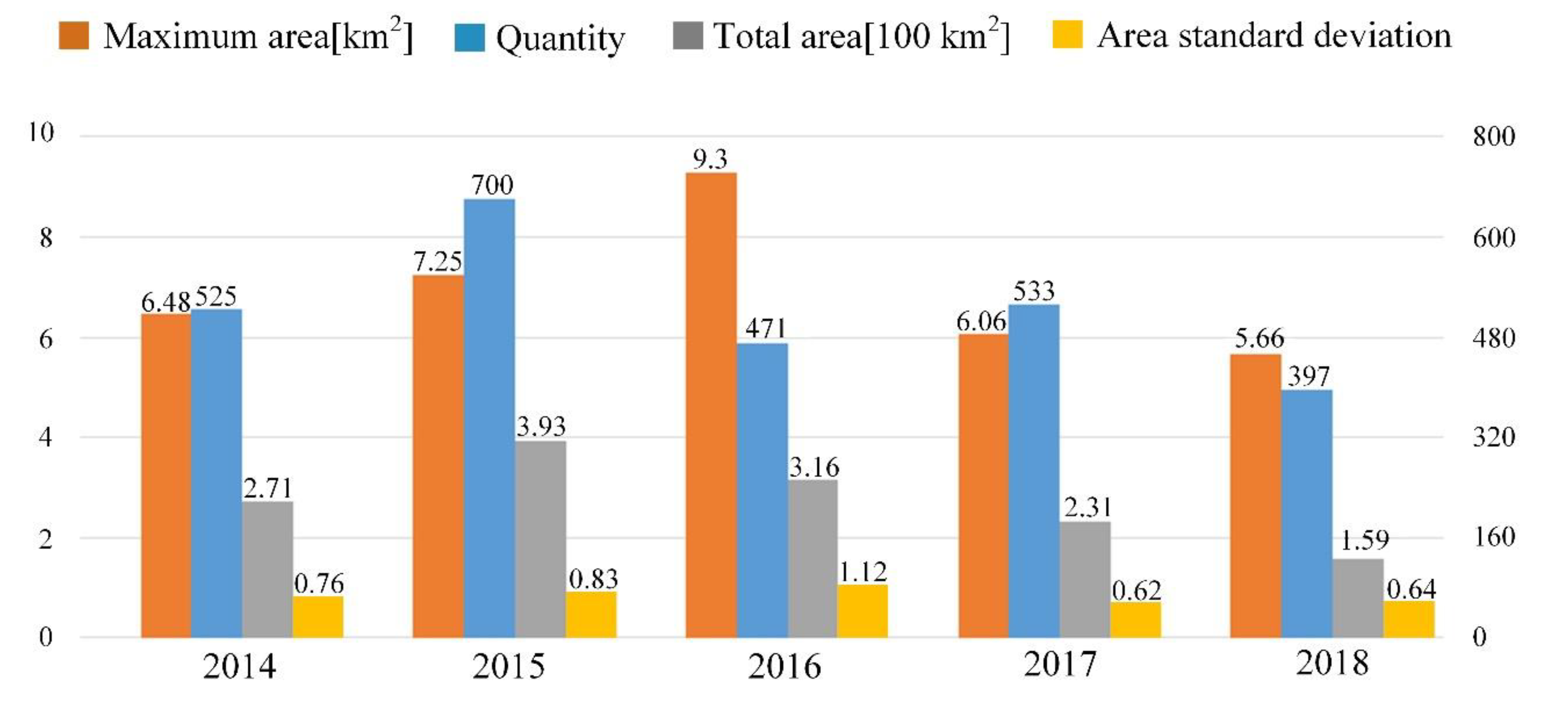
4.4. The Dynamic Changes of SGLs from 2014 to 2018
5. Discussion
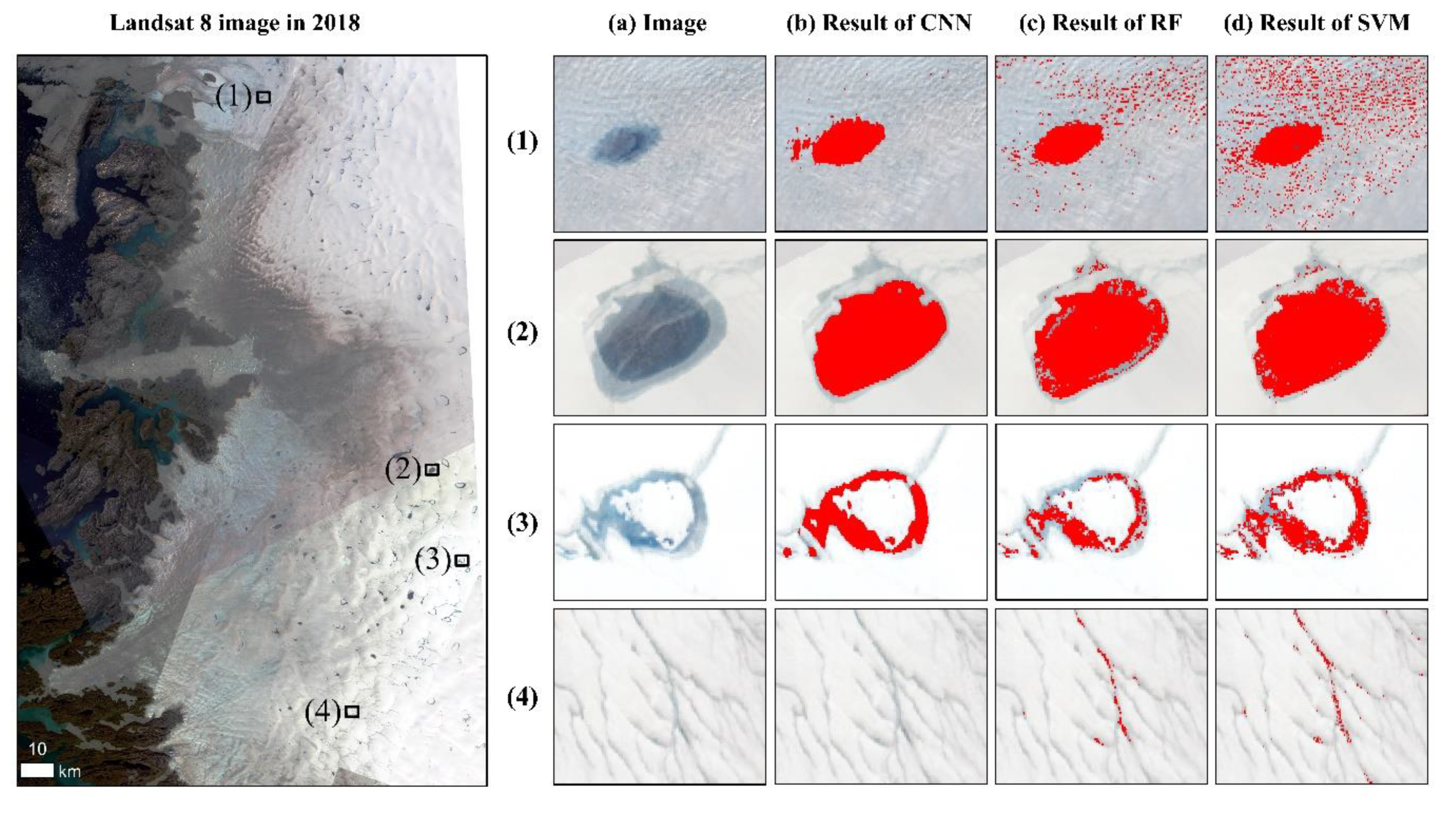
5.1. The Comparison of CNN and Otsu for Water Extraction
5.2. The Comparison of CNN, SVM, and RF for Water Extraction
5.3. The Comparison with the Related Study
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (type) | Output Shape | Number of Parameters | Number of Neurons |
|---|---|---|---|
| conv2d_1 (Conv2D) | (M, 5, 5, 128) | 11648 | 3200 |
| max_pooling2d_1 (MaxPooling2) | (M, 3, 3, 128) | 0 | 1152 |
| conv2d_2 (Conv2D) | (M, 3, 3, 256) | 295168 | 2304 |
| batch_normalization_1 (Batch) | (M, 3, 3, 256) | 1024 | 0 |
| max_pooling2d_2 (MaxPooling2) | (M, 1, 1, 256) | 0 | 256 |
| flatten_1 (Flatten) | (M, 256) | 0 | 256 |
| dense_1 (Dense) | (M, 128) | 32896 | 128 |
| dropout_1 (Dropout) | (M, 128) | 0 | 0 |
| dense_2 (Dense) | (M, 256) | 33024 | 256 |
| dense_3 (Dense) | (M, 256) | 65792 | 256 |
| dropout_2 (Dropout) | (M, 256) | 0 | 0 |
| dense_4 (Dense) | (M, 128) | 32896 | 128 |
| dense_5 (Dense) | (M, 64) | 8256 | 64 |
| dense_6 (Dense) | (M, 32) | 2080 | 32 |
| dense_7 (Dense) | (M, 2) | 66 | 2 |
References
- Gregory, J.M.; Huybrechts, P. Ice-sheet contributions to future sea-level change. Philos. Trans. Royal Soc. A Math. Phys. Eng. Sci. 2006, 364, 1709–1732. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cazenave, A.; Llovel, W. Contemporary sea level rise. Ann. Rev. Mar. Sci. 2010, 2, 145–173. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Chi, Z.; Zinglersen, K.; Tian, Y.; Wang, K.; Hui, F.; Cheng, X. A New Image Mosaic of Greenland Using Landsat-8 OLI Images. Science Bulletin 2020, 65. [Google Scholar] [CrossRef] [Green Version]
- van den Broeke, M.; Bamber, J.; Ettema, J.; Rignot, E.; Schrama, E.; van de Berg, W.J.; van Meijgaard, E.; Velicogna, I.; Wouters, B. Partitioning Recent Greenland Mass Loss. Science 2009, 326, 984–986. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mouginot, J.; Rignot, E.; Bjørk, A.A.; Van Den Broeke, M.; Millan, R.; Morlighem, M.; Noël, B.; Scheuchl, B.; Wood, M. Forty-six years of Greenland Ice Sheet mass balance from 1972 to 2018. Proc. Natl. Acad. Sci. USA 2019, 116, 9239–9244. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dowdeswell, J.A. ATMOSPHERIC SCIENCE: The Greenland Ice Sheet and Global Sea-Level Rise. Science 2006, 311, 963–964. [Google Scholar] [CrossRef]
- Nicholls, R.J.; Cazenave, A. Sea-Level Rise and Its Impact on Coastal Zones. Science 2010, 328, 1517–1520. [Google Scholar] [CrossRef]
- Shepherd, A.; Wingham, D. Recent Sea-Level Contributions of the Antarctic and Greenland Ice Sheets. Science 2007, 315, 1529–1532. [Google Scholar] [CrossRef] [Green Version]
- Enderlin, E.M.; Howat, I.M.; Jeong, S.; Noh, M.J.; van Angelen, J.H.; van den Broeke, M.R. An improved mass budget for the Greenland ice sheet. Geophys. Res. Lett. 2014, 41, 866–872. [Google Scholar] [CrossRef] [Green Version]
- Alley, R.B.; Fahnestock, M.; Joughin, I. Understanding Glacier Flow in Changing Times. Science 2008, 322, 1061–1062. [Google Scholar] [CrossRef]
- Yang, K.; Li, M.C. Greenland Ice Sheet surface melt: A review. Sci. Cold Arid Reg. 2014, 6, 99–106. [Google Scholar]
- Mclamb, W. An increase in crevasse extent, West Greenland: Hydrologic implications. Geophys. Res. Lett. 2011, 38, 113–120. [Google Scholar]
- Selmes, N.; Murray, T.; James, T.D. Fast draining lakes on the Greenland Ice Sheet. Geophys. Res. Lett. 2011, 38, 165–176. [Google Scholar] [CrossRef]
- Lüthje, M.; Pedersen, L.T.; Reeh, N.; Greuell, W. Modeling the evolution of supraglacial lakes on the West Greenland ice-sheet margin. J. Glaciol. 2006, 52, 608–618. [Google Scholar] [CrossRef] [Green Version]
- Tedesco, M.; Steiner, N. In-situ multispectral and bathymetric measurements over a supraglacial lake in western Greenland using a remotely controlled watercraft. Cryosphere 2011, 5, 445–452. [Google Scholar] [CrossRef] [Green Version]
- Tedesco, M.; Lüthje, M.; Steffen, K.; Steiner, N.; Fettweis, X.; Willis, I.; Bayou, N.; Banwell, A. Measurement and modeling of ablation of the bottom of supraglacial lakes in western Greenland. Geophys. Res. Lett. 2012, 39, 2502. [Google Scholar] [CrossRef]
- Zwally, H.J. Surface Melt-Induced Acceleration of Greenland Ice-Sheet Flow. Science 2002, 297, 218–222. [Google Scholar] [CrossRef]
- van de Wal, R.S.; Boot, W.; Van den Broeke, M.R.; Smeets, C.J.; Reijmer, C.H.; Donker, J.J.; Oerlemans, J. Large and Rapid Melt-Induced Velocity Changes in the Ablation Zone of the Greenland Ice Sheet. Science 2008, 321, 111–113. [Google Scholar] [CrossRef]
- Sundal, A.V.; Shepherd, A.; Nienow, P.; Hanna, E.; Palmer, S.; Huybrechts, P. Melt-induced speed-up of Greenland ice sheet offset by efficient subglacial drainage. Nature 2011, 469, 521–524. [Google Scholar] [CrossRef]
- Cowton, T.; Nienow, P.; Sole, A.; Wadham, J.; Lis, G.; Bartholomew, I.; Mair, D.; Chandler, D. Evolution of drainage system morphology at a land-terminating Greenlandic outlet glacier. J. Geophys. Res. Earth Surf. 2013, 118, 29–41. [Google Scholar] [CrossRef] [Green Version]
- Joughin, I.; Das, S.B.; Flowers, G.E.; Behn, M.D.; Alley, R.B.; King, M.A.; Smith, B.E.; Bamber, J.L.; van den Broeke, M.R.; Van Angelen, J.H. Influence of ice-sheet geometry and supraglacial lakes on seasonal ice-flow variability. Cryosphere 2013, 7, 1185–1192. [Google Scholar] [CrossRef] [Green Version]
- Andrews, L.C.; Catania, G.A.; Hoffman, M.J.; Gulley, J.D.; Lüthi, M.P.; Ryser, C.; Hawley, R.L.; Neumann, T.A. Direct observations of evolving subglacial drainage beneath the Greenland Ice Sheet. Nature 2014, 514, 80–83. [Google Scholar] [CrossRef] [PubMed]
- Bougamont, M.; Christoffersen, P.; AL, H.; Fitzpatrick, A.A.; Doyle, S.H.; Carter, S.P. Sensitive response of the Greenland Ice Sheet to surface melt drainage over a soft bed. Nat. Commun. 2014, 5, 5052. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dow, C.F.; Kulessa, B.; Rutt, I.C.; Tsai, V.C.; Pimentel, S.; Doyle, S.H.; van As, D.; Lindbäck, K.; Pettersson, R.; Jones, G.A.; et al. Modeling of subglacial hydrological development following rapid supraglacial lake drainage. J. Geophys. Res. Earth Surf. 2015, 120, 1127–1147. [Google Scholar] [CrossRef] [Green Version]
- Stevens, L.A.; Behn, M.D.; McGuire, J.J.; Das, S.B.; Joughin, I.; Herring, T.; Shean, D.E.; King, M.A. Greenland supraglacial lake drainages triggered by hydrologically induced basal slip. Nature 2015, 522, 73–76. [Google Scholar] [CrossRef]
- Davison, B.J.; Sole, A.J.; Livingstone, S.J.; Cowton, T.R.; Nienow, P.W. The Influence of Hydrology on the Dynamics of Land-Terminating Sectors of the Greenland Ice Sheet. Front. Earth Sci. 2019, 7. [Google Scholar] [CrossRef] [Green Version]
- Sundal, A.V.; Shepherd, A.; Nienow, P.; Hanna, E.; Palmer, S.; Huybrechts, P. Evolution of supra-glacial lakes across the Greenland Ice Sheet. Remote Sens. Environ. 2009, 113, 2164–2171. [Google Scholar] [CrossRef]
- Miles, K.E.; Willis, I.C.; Benedek, C.L.; Williamson, A.G.; Tedesco, M. Toward Monitoring Surface and Subsurface Lakes on the Greenland Ice Sheet Using Sentinel-1 SAR and Landsat-8 OLI Imagery. Front. Earth Sci. 2017, 5, 58. [Google Scholar] [CrossRef] [Green Version]
- Williamson, A.G.; Arnold, N.S.; Banwell, A.F.; Willis, I.C. A Fully Automated Supraglacial lake area and volume Tracking (“FAST”) algorithm: Development and application using MODIS imagery of West Greenland. Remote Sens. Environ. 2017, 196, 113–133. [Google Scholar] [CrossRef]
- Williamson, A.G.; Banwell, A.F.; Willis, I.C.; Arnold, N.S. Dual-satellite (Sentinel-2 and Landsat 8) remote sensing of supraglacial lakes in Greenland. Cryosphere 2018, 12, 3045–3065. [Google Scholar] [CrossRef] [Green Version]
- Schwatke, C.; Scherer, D.; Dettmering, D. Automated Extraction of Consistent Time-Variable Water Surfaces of Lakes and Reservoirs Based on Landsat and Sentinel-2. Remote Sens. 2019, 11, 1010. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Tang, H. Built-Up Area Extraction from Landsat 8 Images Using Convolutional Neural Networks with Massive Automatically Selected Samples. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV); Springer: Cham, Switzerland, 2018. [Google Scholar]
- Zhang, T.; Tang, H. Evaluating the generalization ability of convolutional neural networks for built-up area extraction in different cities of China. Optoelectron. Lett. 2020, 16, 52–58. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Poznanski, A.; Wolf, L. Cnn-n-gram for Handwriting Word Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2305–2314. [Google Scholar]
- He, R.; Wu, X.; Sun, Z.; Tan, T. Wasserstein CNN: Learning Invariant Features for NIR-VIS Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1761–1773. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Wang, Y.; Liu, Q.; Liu, X.; Wang, W. CNN Based Suburban Building Detection Using Monocular High Resolution Google Earth Images. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016. [Google Scholar]
- Liang, Y.L.; Colgan, W.; Lv, Q.; Steffen, K.; Abdalati, W.; Stroeve, J.; Gallaher, D.; Bayou, N. A decadal investigation of supraglacial lakes in West Greenland using a fully automatic detection and tracking algorithm. Remote Sens. Environ. 2012, 123, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- McFEETERS, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H.Q. A Study on Information Extraction of Water Body with the Modified Normalized Difference Water Index (MNDWI). J. Remote Sens. 2005, 5, 589–595. [Google Scholar]
- Zhang, T.; Tang, H. A Comprehensive Evaluation of Approaches for Built-Up Area Extraction from Landsat OLI Images Using Massive Samples. Remote Sens. 2018, 11, 2. [Google Scholar] [CrossRef] [Green Version]
- Hara, K.; Saito, D.; Shouno, H. Analysis of Function of Rectified Linear Unit Used in Deep Learning. In Proceedings of the International Joint Conference on Neural Networks, Killarney, Ireland, 12–16 July 2015. [Google Scholar]
- Yang, K.; Smith, L.C. Internally drained catchments dominate supraglacial hydrology of the southwest Greenland Ice Sheet. J. Geophys. Res. Earth Surf. 2016, 121, 1891–1910. [Google Scholar] [CrossRef]
- Wang, S.Y.; Liu, J.Y.; Zhang, Z.X.; Zhou, Q.B.; Zhao, X.L. Analysis on Spatial-Temporal Features of Land Use in China. Acta Geogr. Sin. 2001, 68, 631–639. [Google Scholar]
- Ewel, K.C. Appreciating tropical coastal wetlands from a landscape perspective. Front. Ecol. Environ. 2010, 8, 20–26. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 2007, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Tong, X.; Liu, S.; Luo, X.; Xie, H.; Li, C. Optimized Sample Selection in SVM Classification by Combining with DMSP-OLS, Landsat NDVI and GlobeLand30 Products for Extracting Urban Built-Up Areas. Remote Sens. 2017, 9, 236. [Google Scholar] [CrossRef] [Green Version]
- Goldblatt, R.; You, W.; Hanson, G.; Khandelwal, A.K. Detecting the Boundaries of Urban Areas in India: A Dataset for Pixel-Based Image Classification in Google Earth Engine. Remote Sens. 2016, 8, 634. [Google Scholar] [CrossRef] [Green Version]
- Morriss, B.F.; Hawley, R.L.; Chipman, J.W.; Andrews, L.C.; Catania, G.A.; Hoffman, M.J.; Lüthi, M.P. A ten-year record of supraglacial lake evolution and rapid drainage in West Greenland using an automated processing algorithm for multispectral imagery. Cryosphere 2010, 7, 1869–1877. [Google Scholar] [CrossRef] [Green Version]
- Leeson, A.A.; Shepherd, A.; Briggs, K.; Howat, I.; Fettweis, X.; Morlighem, M.; Rignot, E. Supraglacial lakes on the Greenland ice sheet advance inland under warming climate. Nat. Clim. Chang. 2014, 5, 51–55. [Google Scholar] [CrossRef] [Green Version]
- Cooley, S.; Christoffersen, P. Observation bias correction reveals more rapidly draining lakes on the Greenland Ice Sheet. J. Geophys. Res. Earth Surf. 2017, 122, 1867–1881. [Google Scholar] [CrossRef]















| Prediction | ||||
| Ground Truth | Background | Water | Sum | |
| Background | True Negative (TN) | False Positive (FP) | Actual Negative (TN + FP) | |
| Water | False Negative (FN) | True Positive (TP) | Actual Positive (FN + TP) | |
| Sum | Predicted Negative (TN + FN) | Predicted Positive (FP + TP) | TN + TP + FN + FP | |
| Algorithm | Abbreviation | Parameter Type | Parameter Name (sklearn) | Parameter Set |
|---|---|---|---|---|
| Support Vector Machine | SVM | kernel type | kernel | rbf |
| penalty coefficient | C | 10 | ||
| gamma | gamma | 100 | ||
| Random Forests | RF | base classifier | base_estimator | decision Tree |
| number of trees | n_estimators | 60 |
| Year | OA | Recall | Precision |
|---|---|---|---|
| 2014 | 0.9988 | 0.9975 | 1 |
| 2015 | 0.9988 | 1 | 0.9975 |
| 2016 | 0.9925 | 0.9875 | 0.9975 |
| 2017 | 0.9976 | 0.9887 | 0.9999 |
| 2018 | 0.9725 | 0.9475 | 0.9974 |
| Time Spans | 2014–2015 | 2015–2016 | 2016–2017 | 2017–2018 |
|---|---|---|---|---|
| CH (km2) | 122.45 | −76.97 | −85.81 | −71.85 |
| K (%) | 45.20 | −19.57 | −27.12 | −31.16 |
| Year | Mean Elevation (m) | Elevation of the Largest SGL(m) | 0–500 m (%) | 500–1000 m (%) | 1000–1500 m (%) | >1500 m (%) |
|---|---|---|---|---|---|---|
| 2014 | 1114 | 1337 | 2.51 | 28.43 | 67.31 | 1.74 |
| 2015 | 1110 | 1146 | 1.17 | 33.92 | 60.79 | 4.11 |
| 2016 | 1193 | 1197 | 2.69 | 22.42 | 66.37 | 8.52 |
| 2017 | 1082 | 1145 | 2.14 | 31.65 | 66.02 | 0.19 |
| 2018 | 1149 | 1210 | 1.31 | 28.72 | 67.36 | 2.61 |
| Index | Algorithm | 2014 | 2015 | 2016 | 2017 | 2018 |
|---|---|---|---|---|---|---|
| OA | CNN | 0.9988 | 0.9988 | 0.9925 | 0.9976 | 0.9725 |
| RF | 0.9938 | 0.9975 | 0.9863 | 0.9950 | 0.9900 | |
| SVM | 0.9975 | 0.9963 | 1.0 | 0.9988 | 0.9913 | |
| Recall | CNN | 0.9975 | 1.0 | 0.9875 | 0.9887 | 0.9475 |
| RF | 0.9875 | 0.9975 | 0.9850 | 0.9900 | 0.9875 | |
| SVM | 0.9950 | 0.9950 | 1.0 | 1.0 | 0.9900 | |
| Precision | CNN | 1.0 | 0.9975 | 0.9975 | 0.9999 | 0.9974 |
| RF | 1.0 | 0.9975 | 0.9875 | 1.0 | 0.9923 | |
| SVM | 1.0 | 0.9975 | 1.0 | 0.9975 | 0.9925 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, J.; Chi, Z.; Cheng, X.; Zhang, T.; Li, T.; Chen, Z. Automatic Extraction of Supraglacial Lakes in Southwest Greenland during the 2014–2018 Melt Seasons Based on Convolutional Neural Network. Water 2020, 12, 891. https://doi.org/10.3390/w12030891
Yuan J, Chi Z, Cheng X, Zhang T, Li T, Chen Z. Automatic Extraction of Supraglacial Lakes in Southwest Greenland during the 2014–2018 Melt Seasons Based on Convolutional Neural Network. Water. 2020; 12(3):891. https://doi.org/10.3390/w12030891
Chicago/Turabian StyleYuan, Jiawei, Zhaohui Chi, Xiao Cheng, Tao Zhang, Tian Li, and Zhuoqi Chen. 2020. "Automatic Extraction of Supraglacial Lakes in Southwest Greenland during the 2014–2018 Melt Seasons Based on Convolutional Neural Network" Water 12, no. 3: 891. https://doi.org/10.3390/w12030891
APA StyleYuan, J., Chi, Z., Cheng, X., Zhang, T., Li, T., & Chen, Z. (2020). Automatic Extraction of Supraglacial Lakes in Southwest Greenland during the 2014–2018 Melt Seasons Based on Convolutional Neural Network. Water, 12(3), 891. https://doi.org/10.3390/w12030891