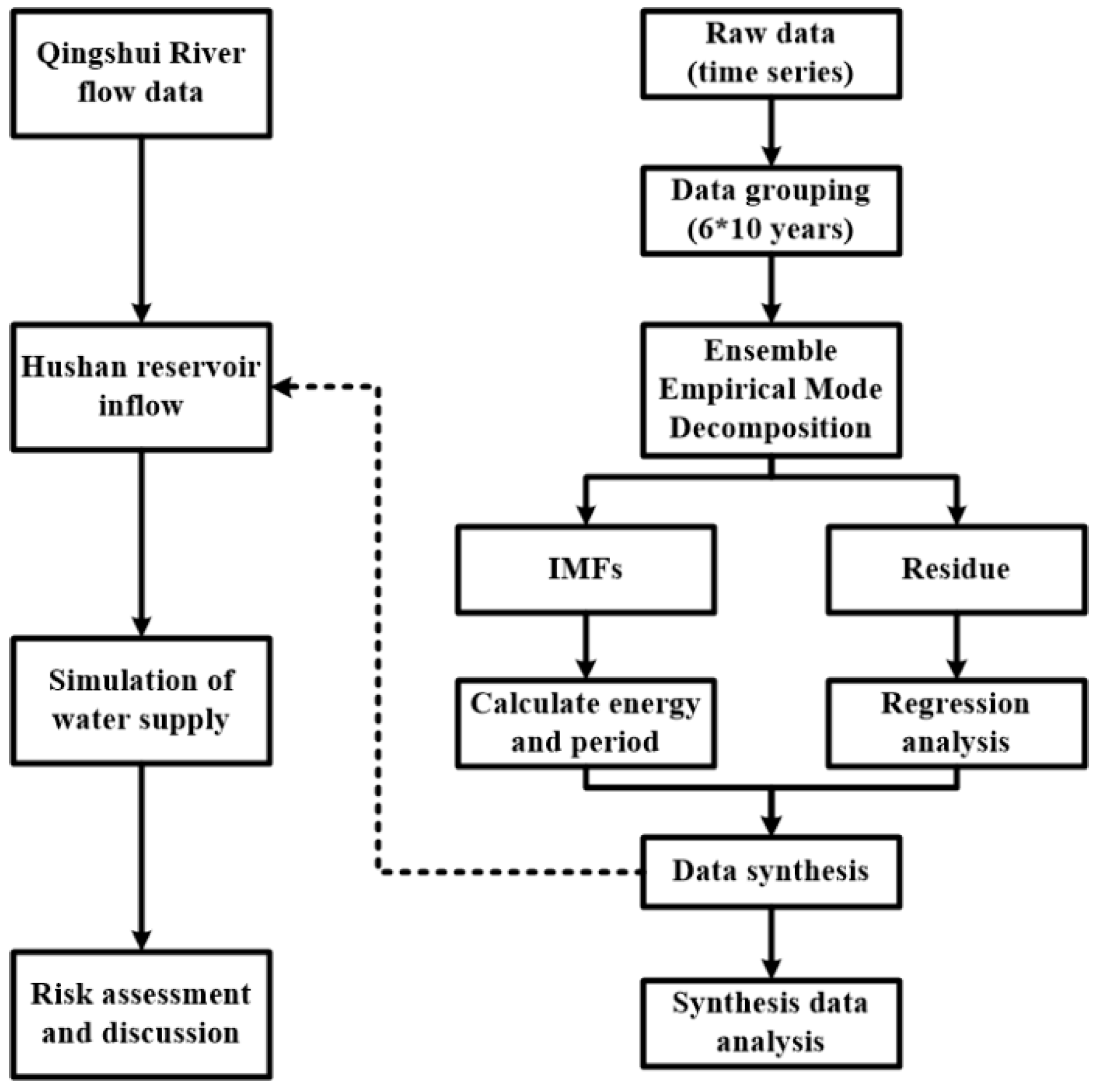
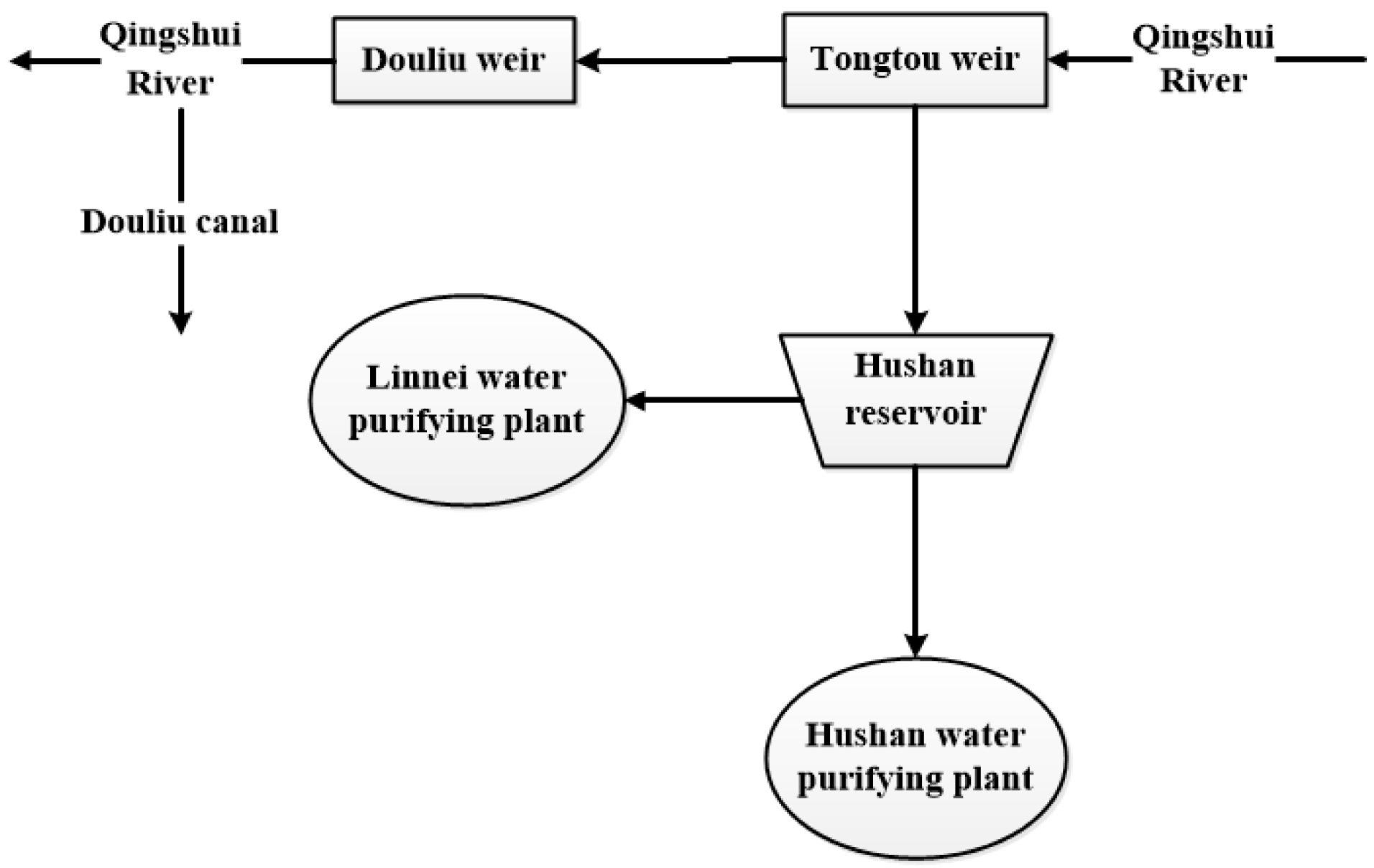
3.1. 60-Year Flow Data Analysis with EEMD
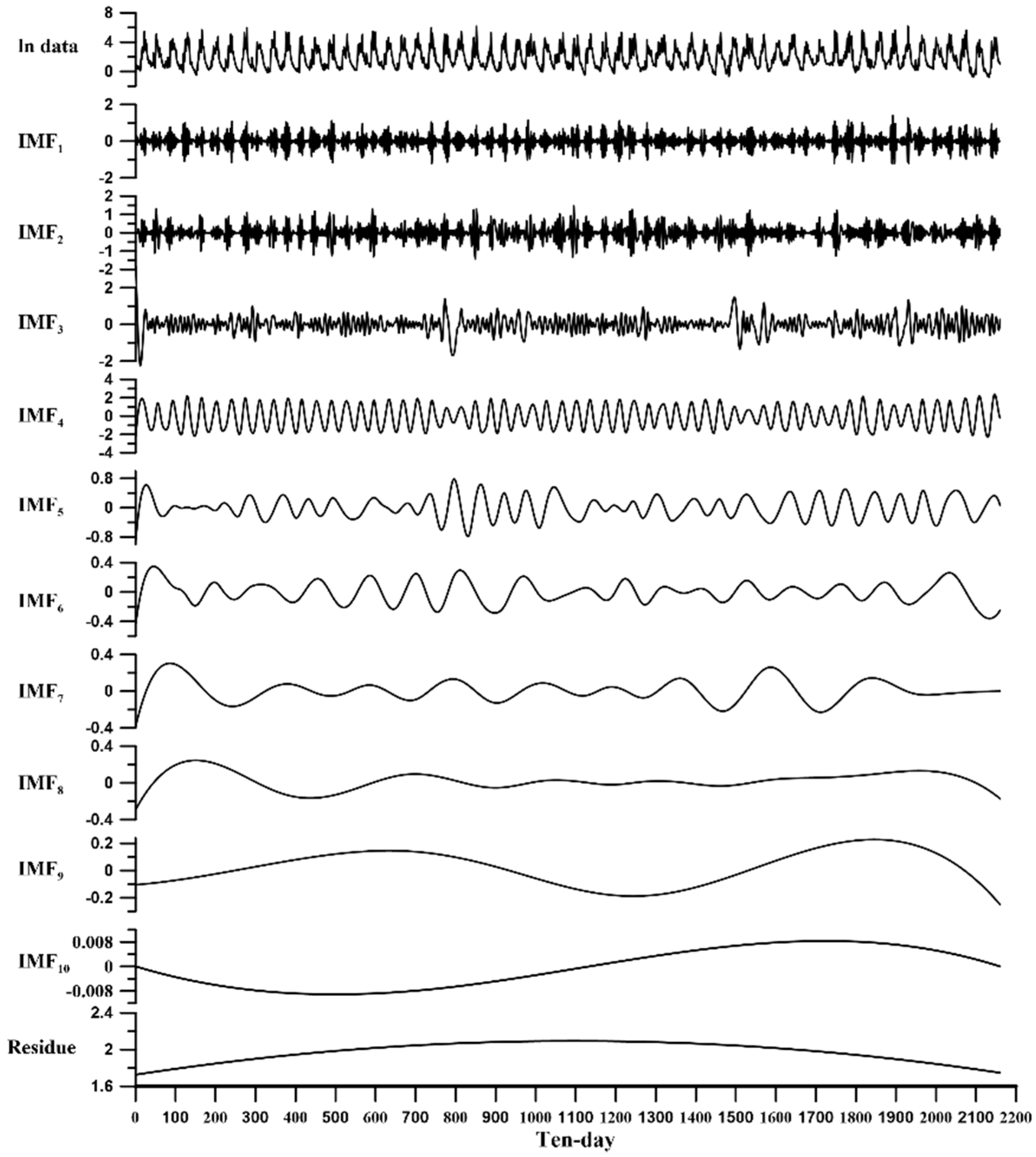
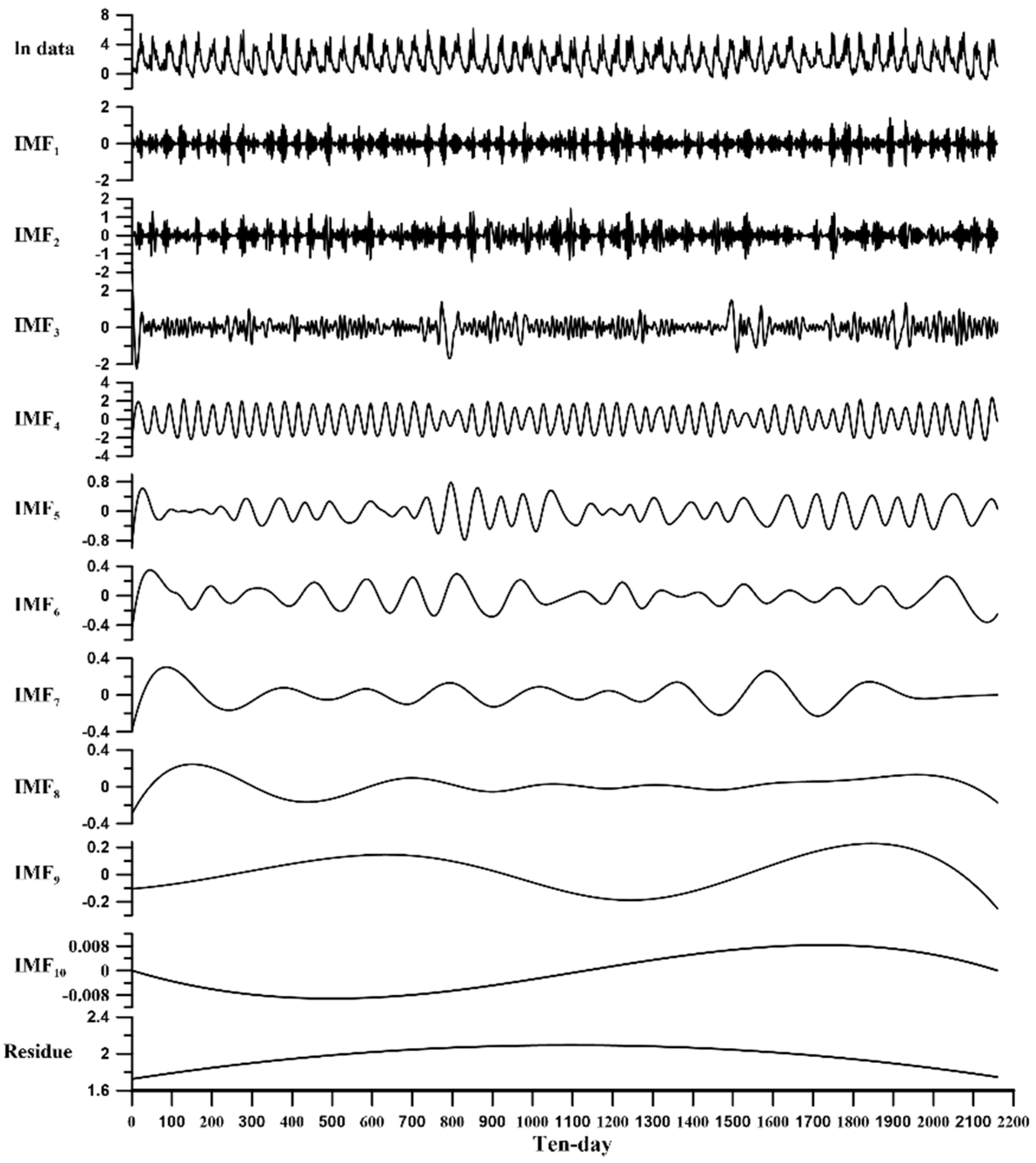
We analyze the historical flow data from 1956 to 2015 in this study. Because the skewness of flow data will affect the decomposition process, the historical flow data is taken nature log transformation before decomposing by the EEMD. The 60-year historical data is decomposed by the EEMD method, and the decomposed IMFs are shown in
Figure 8.
Figure 8 shows that there are 10 IMFs and 1 residue. The termination condition of the EEMD is according to following literatures: Wu and Huang [
14] show that the number of IMFs approaching
can be obtained by EEMD decomposition of the original data; in addition, Huang et al. [
27] also explained that the IMF obtained after the data is decomposed will be between
and
. Therefore, the result that deals with 60-year daily flow by EEMD will introduce 10 IMFs and 1 residue. Among them, the oscillation of IMF
1–IMF
10 gradually decrease from ± 3 to ± 0.008, but the range of the residue gradually increased from 1.73 to 2.09 and then decreased to 1.75, which is a monotonic function. From the decomposition, we can find that the residue part plays an important role, which often affects the trend of whole time series.
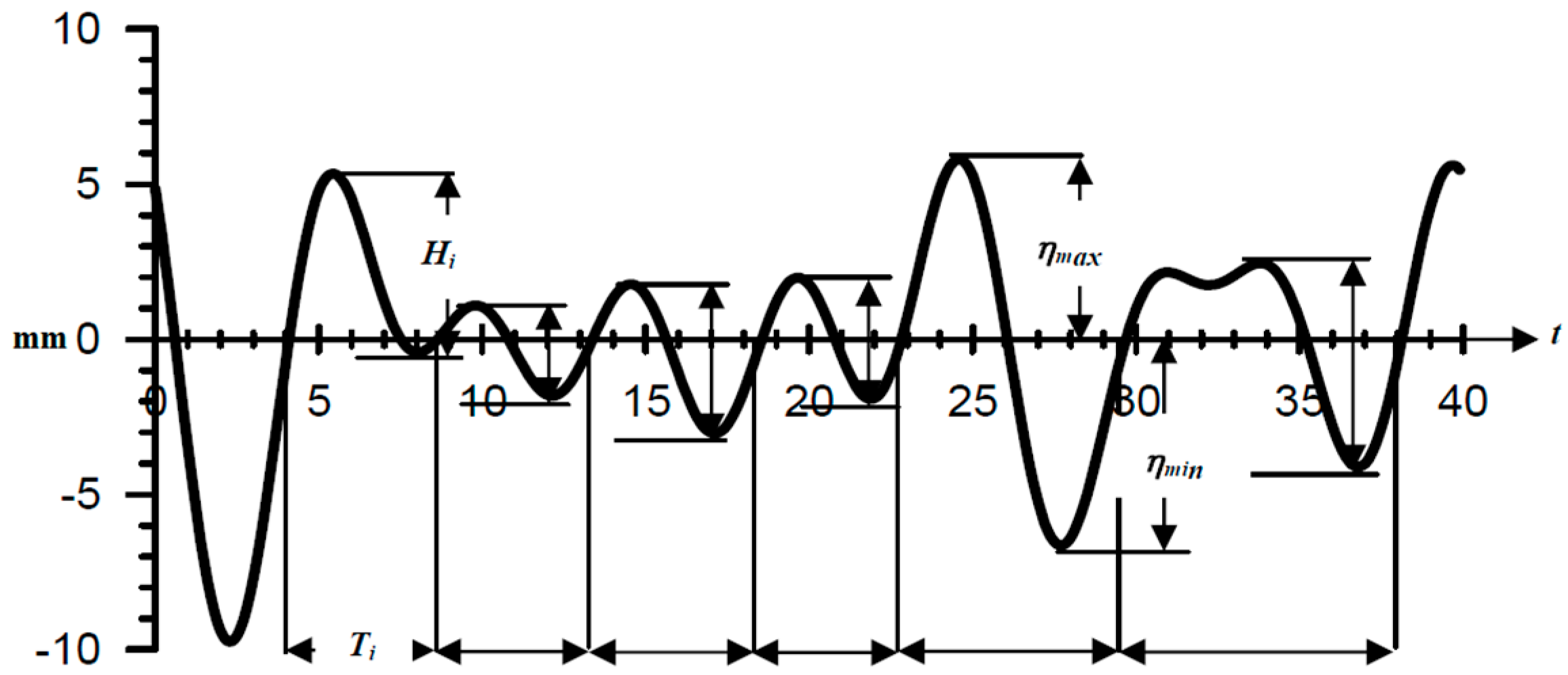
Historical flow data is regarded as a signal for a certain period of time. After decomposing the flow data through EEMD, the physical meaning of IMFs will be diagnosed. The period of each IMF is estimated according to zero up-cross analysis. However, the true energy value cannot be calculated, the square of the IMF value only be regarded as direct proportion with the true energy. In other words, the energy representation, the summation of square of each IMF, should be regarded as the ‘weight’ of oscillation for IMFs.
The values of the IMFs decomposed by the EEMD are squared and the sum is taken as the representative value of energy, as shown in
Figure 9 and
Table 3. After the zero up cross analysis method is used to average the IMF period of each group, the average period represented by the IMF can be obtained. IMF
10 is NAN because the period of the sequence cannot get after the zero up cross analysis method.
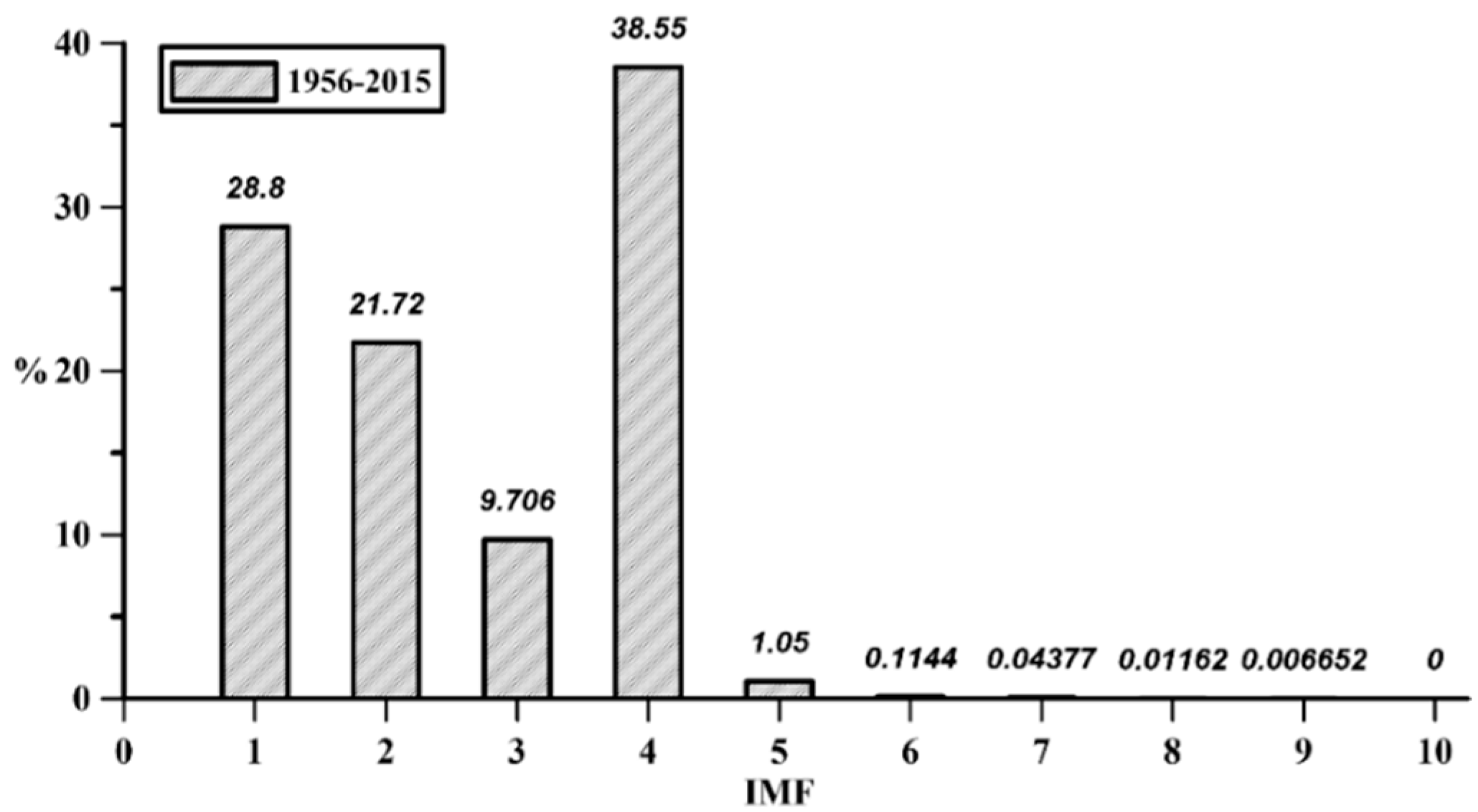
As can be seen from
Figure 9, the energy value is mostly concentrated in IMF
4, reaching 39% and the energy of IMF
4 is higher than that of other IMFs. Corresponding to IMF
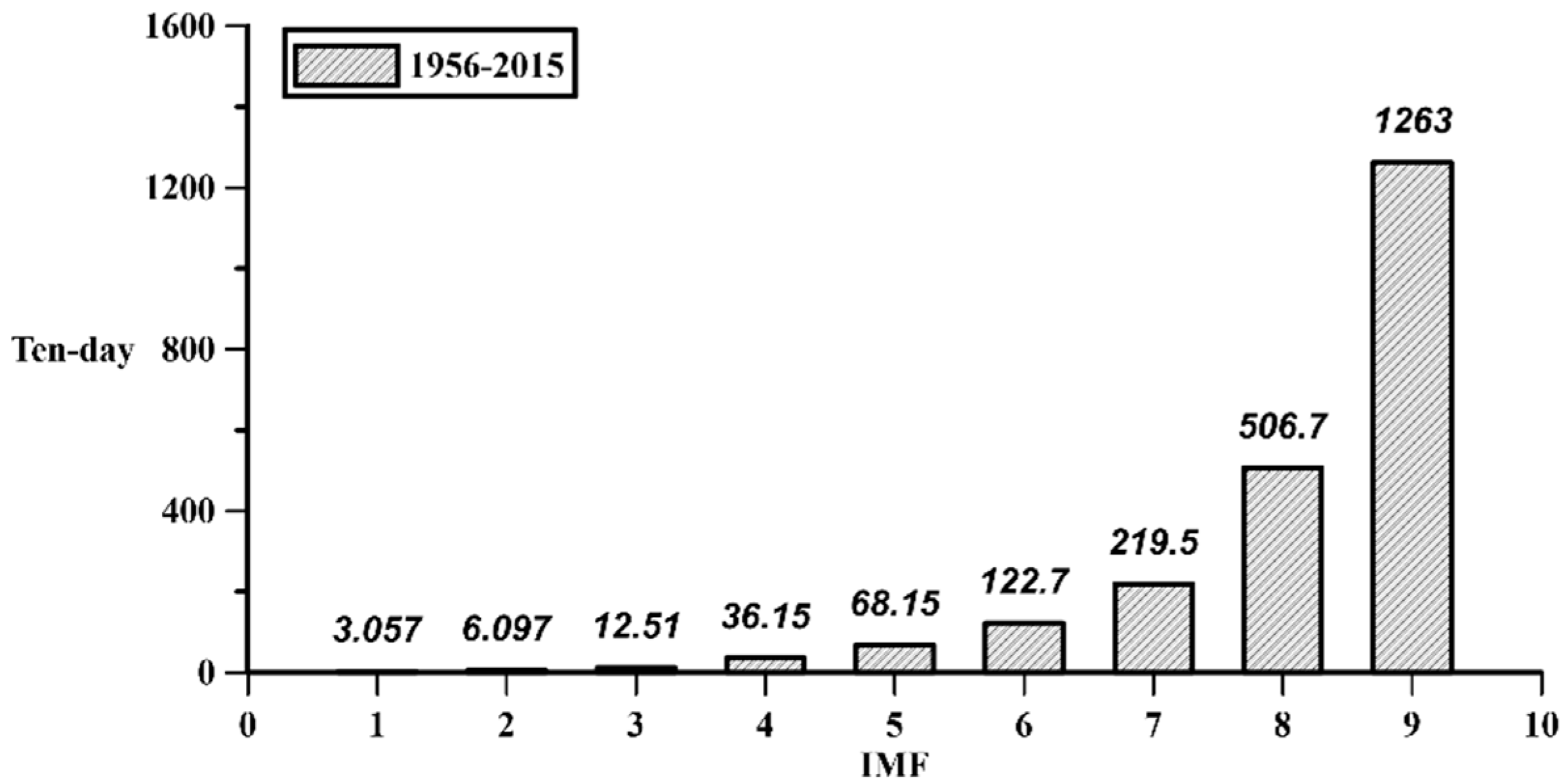
4 in
Figure 10, it can be found that the corresponding period is about 36 ten-day, which represents that the flow data has a strong annual (36 ten-day) period characteristic. In addition, the IMF
1 and IMF
2 still have a certain proportion of the energy percentage, which are 29% and 22% respectively, and their periods correspond to about 3 and 6 ten-day, respectively. Therefore, it can be seen that seasonal characteristics exists in the flow data.
3.3. Data Synthesis
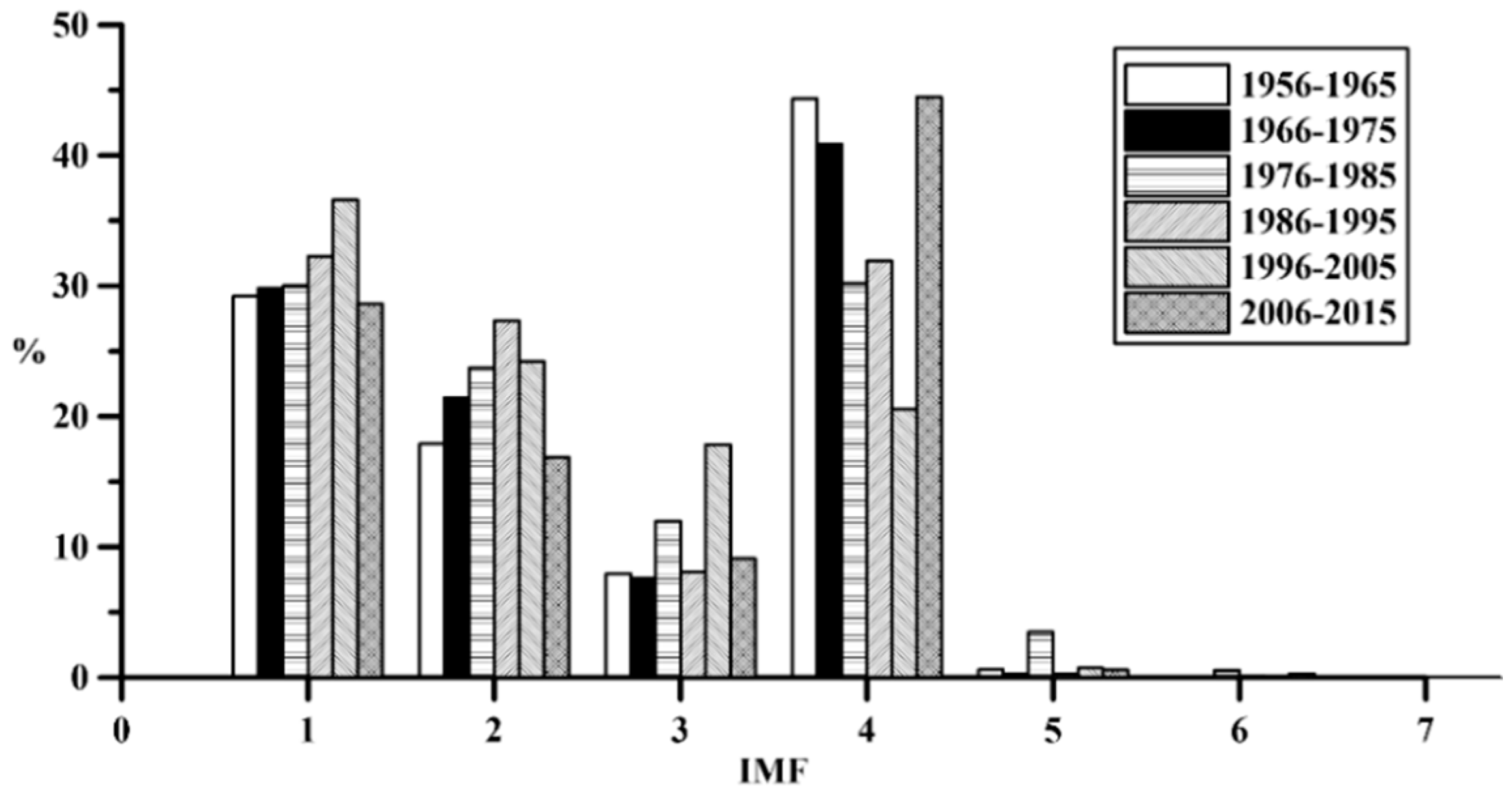
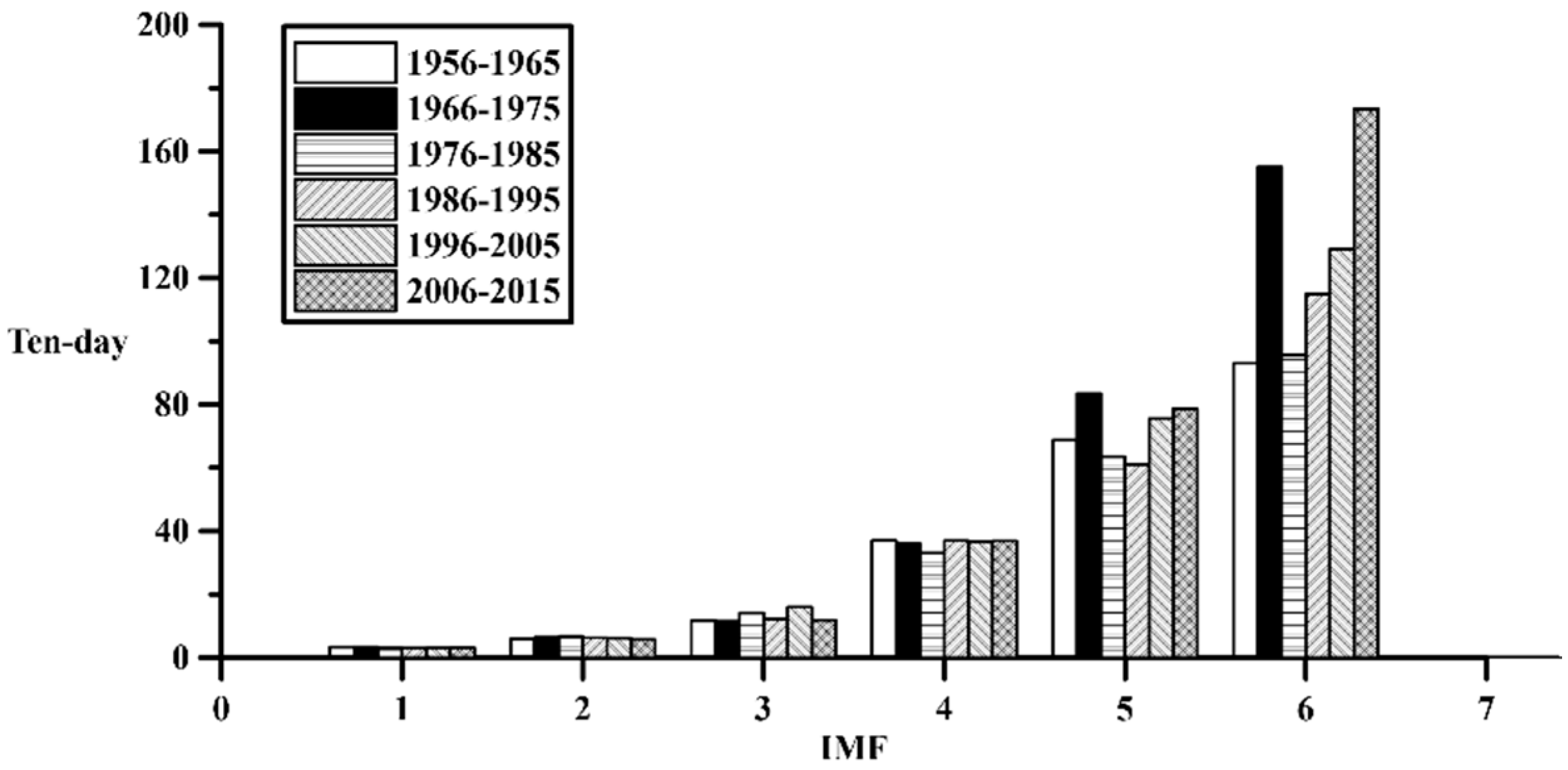
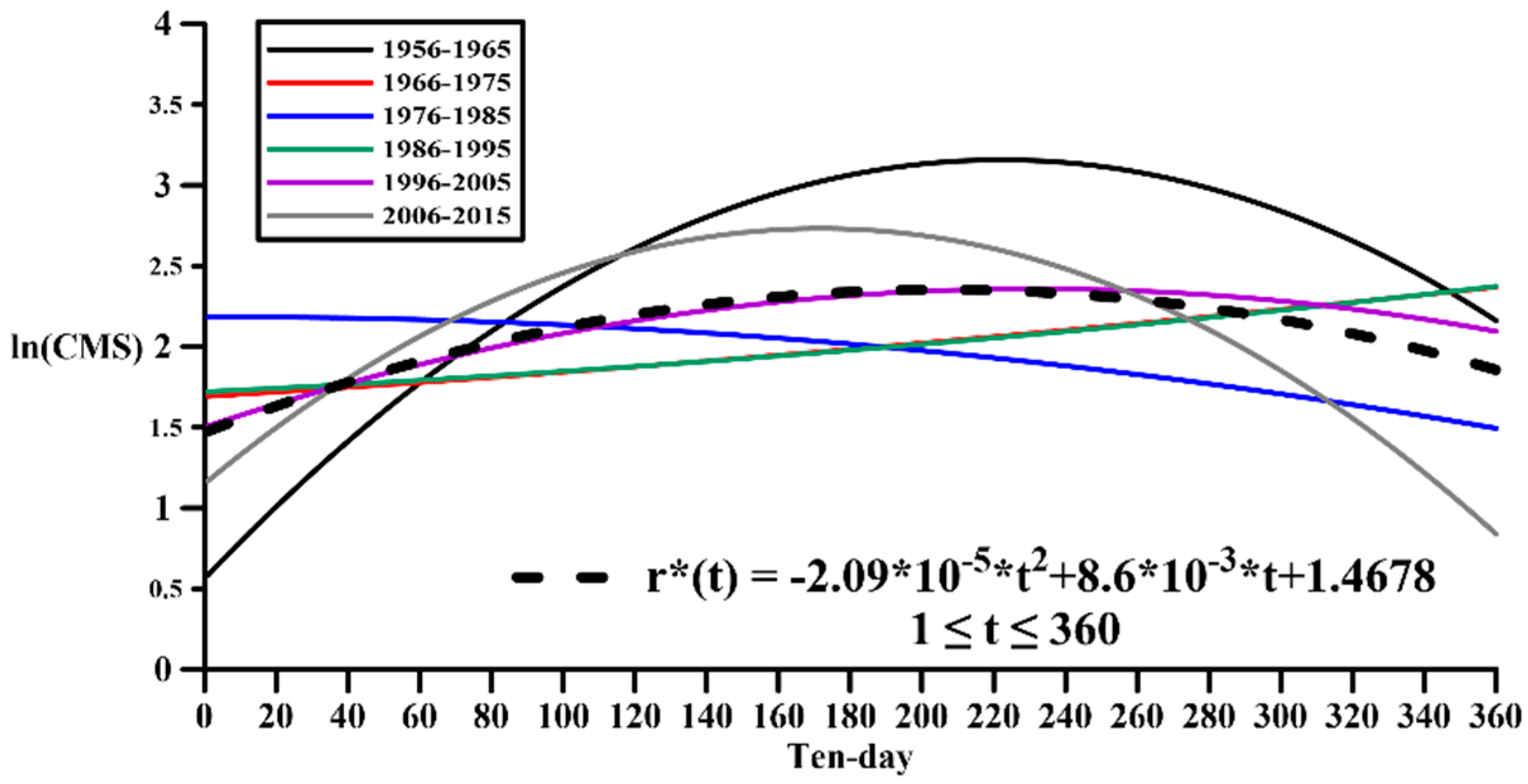
This section explains the synthesis of flow data. The historical flow data (1956–2015) is divided into six groups of 10-year segments in order. After decomposing through EEMD, multiple IMFs and residue corresponding to them can be obtained. The decadal residues are shown in
Figure 13. Regression analysis of different residue in each group is fitted to a new residue representing the value.
This study used two methods to synthesize new decadal flow data as the basis for simulation research. Method (I): first permutations and combinations all IMFs to get n
i (6
7 = 279,936) new IMF
set. Where n is the number of groups and i is the number of IMFs each group. After permutations and combinations of the IMFs, add a representative value of the residue, which is the regression of six residues. The representative value of the residue is shown in
Figure 13, the bold dashed line. Regression analysis fits the representative value of the residue, and then adds this residue to the IMF of the 279,936 group to obtain the synthesis flow data of the 279,936 group for 10 years. Method (II): all the IMFs and the residue in each group are permutations and combinations to obtain a total of n
i + 1 (6
7 + 1 = 1,679,616) new synthetic flow data. In the following, the new flow data synthesized from the two methods and historical flow data are compared with each other, and the differences are explored. In addition, this study will apply new flow data synthesized from two different methods to simulate Hushan reservoir water supply systems, and sequentially discuss the simulation results of different synthetic flow data in different water supply scenarios.
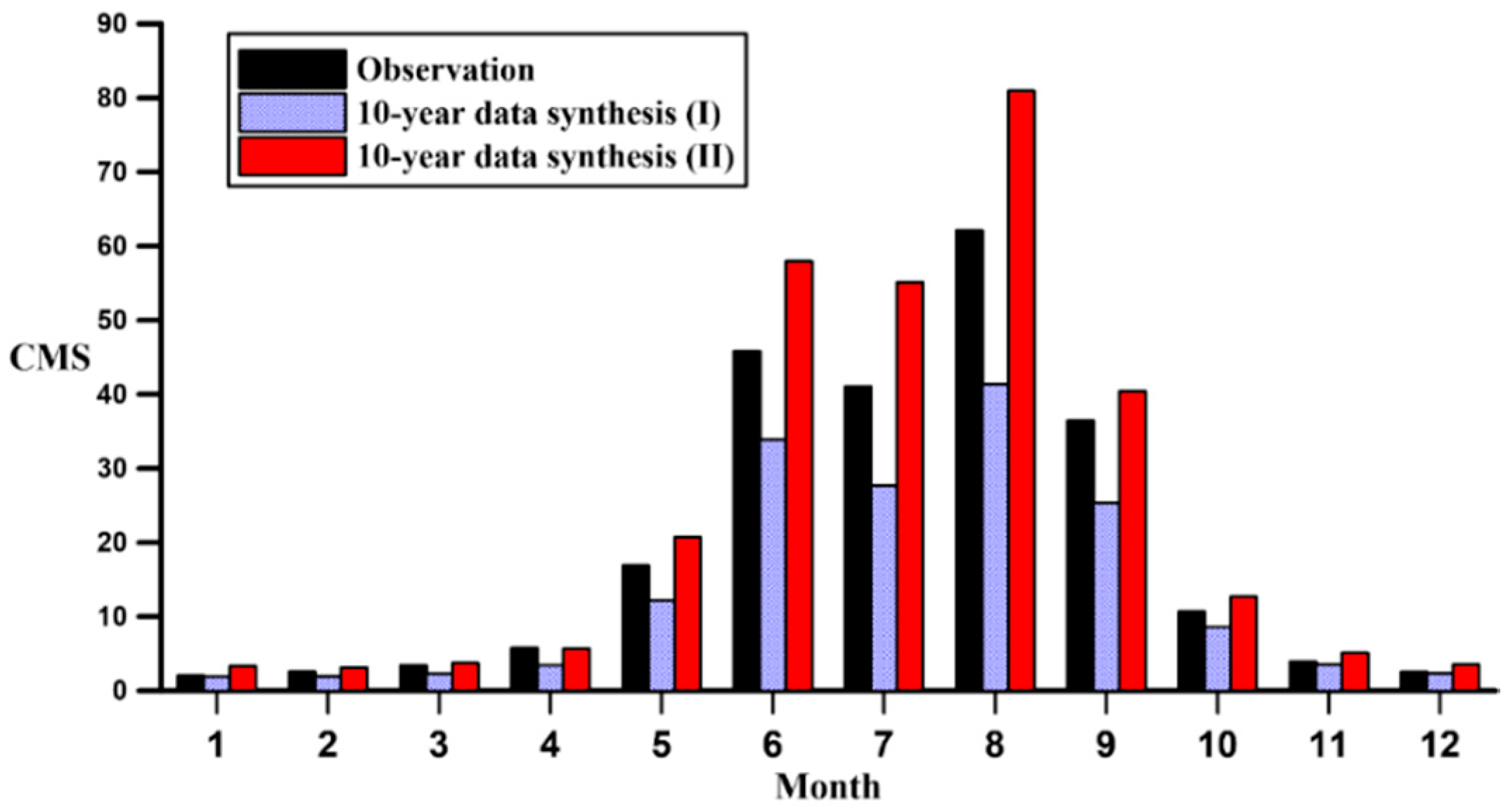
Result of comparing the synthetic data with historical data divided by 10 years is shown in
Table 5 and
Figure 14. For the historical data, the flow in Qingshui river is significantly different between the wet and dry season; the flow from wet season, May to October, is significantly higher than November to April. The ratio of wet/dry is about 9:1. The highest flow occurs in August (62.09 m
3/s) and the lowest flow occurs in January (2.05 m
3/s). Compared the historical with the synthetic flow, the monthly distribution is similar between both Method I and Method II. The synthetic flow is concentrated in May–October, and the highest flow always occurs in August, but the lowest flow occurs in the dry season in January and February. In terms of the overall flow during the wet season, the average synthesized by Method I is significantly less than the current situation; in contrast, the average synthesized by Method II is much higher. In the dry season, the average synthesized by Method I and Method II is not much different from the current.
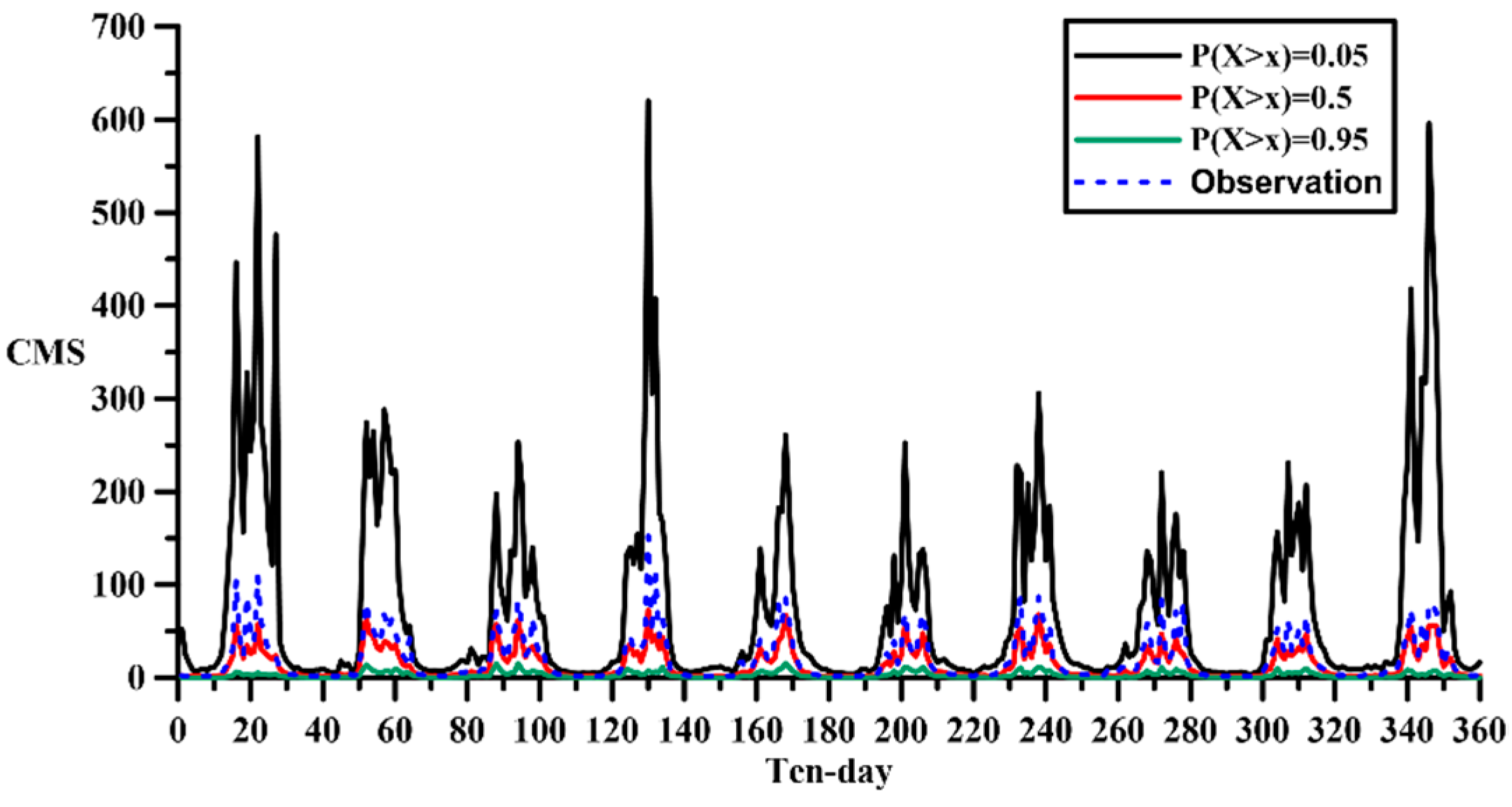
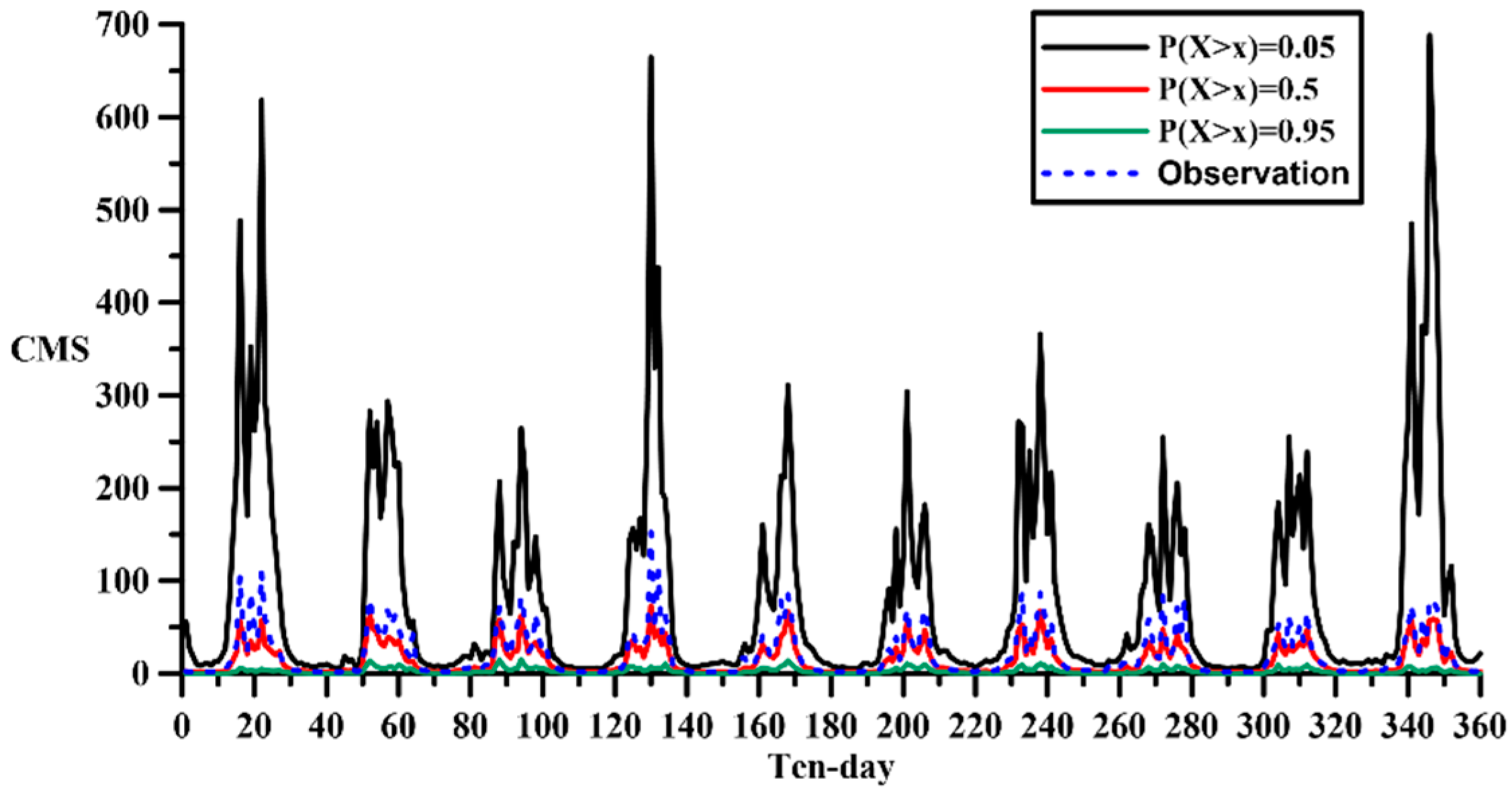
The distribution of the probability of exceedance is shown in the
Figure 15 and
Figure 16. For the 10-year synthesis, the overall time distribution is consistent with the historical one; furthermore, the synthesis keeps the distribution of wet and dry seasons as well. Through the probability of exceedance of 0.05, the extreme flow of Method II is greater than Method I. In contrast, while the probability of exceedance is 0.95, the flow data of Method II is much less than Method I. This will also lead to the opposite result of the average flow in the simulation of the water supply system.
Although the preceding says that, there are not much variance of the distribution trend between the 10-year flow data synthesized by these two different methods. However, the annual average between two synthesis methods is more significant. The flow data synthesized by Method II has an annual average flow of 24.34 m3/s, which is more than the annual average of Method I, 13.71 m3/s. The water supply system simulation will be based on these three flow sequences, historical data, Method I and Method II synthetic data, to simulate the water supply system of Hushan reservoir.
3.4. Application of Synthesis Data
Next, we apply the synthesized flow data to simulate the water supply system according to the given two demand scenarios. Using the historical flow data, Method I and the Method II synthetic flow data are used for simulation, and the simulation results are shown in the
Table 6 and
Figure 17.
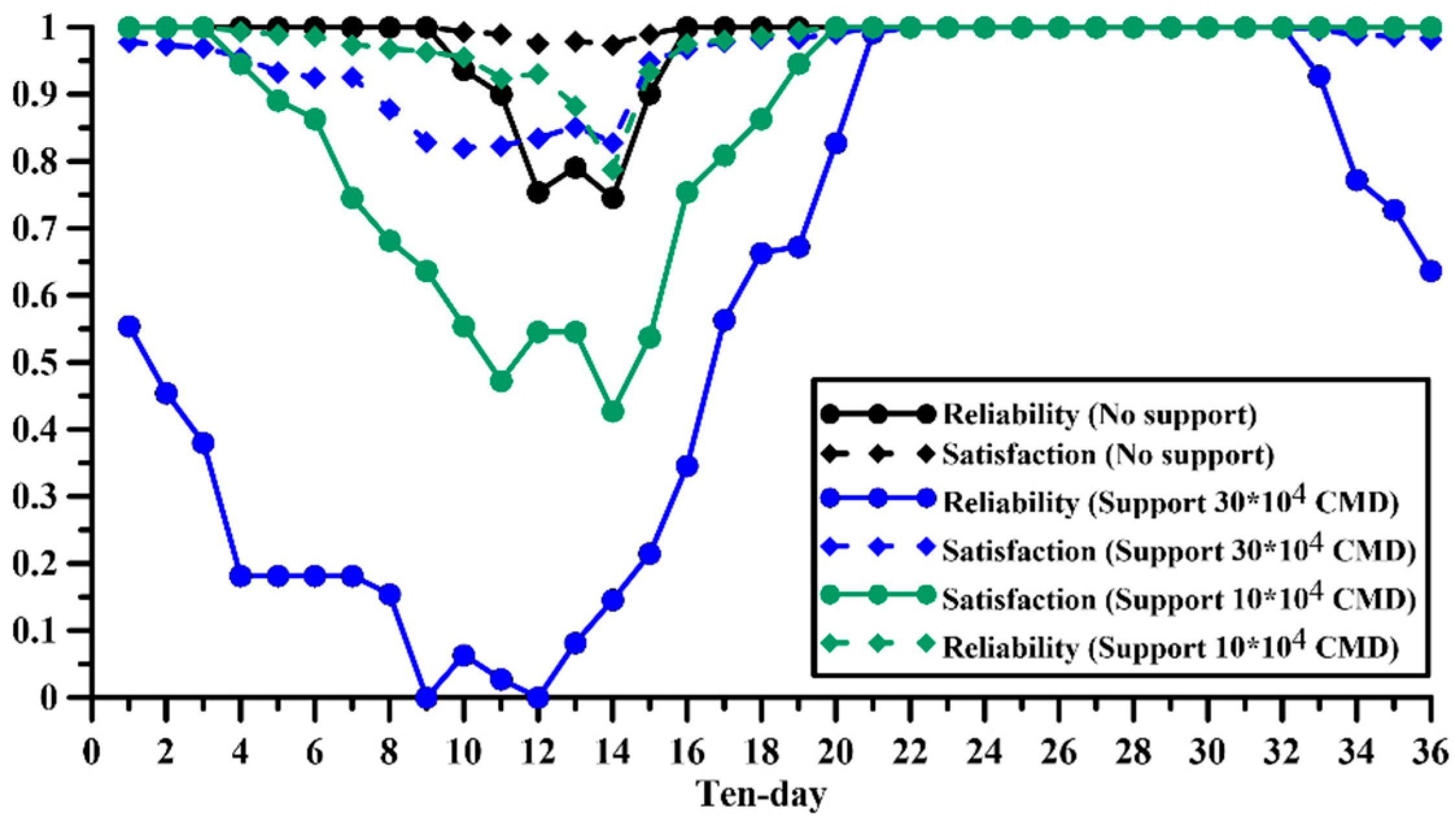
First, we apply the historical flow to simulate the water supply system. For the case of no supporting industrial water in Scenario I, the annual water supply and shortage are 101.93 × 10
6 m
3 and 0.27 × 10
6 m
3, respectively. The water shortage index (SI) is only 0.002. While the water shortage occurring, the average daily water shortage (ADWS) is only 0.03 × 10
6 m
3. The preceding indices show that if the Hushan reservoir only supplies water for domestic demand, the water supply situation will be very stable and shortage will not be easy to occur. In the case of supporting industrial water in Scenario II. If the daily support for industrial water is 300,000 m
3, the annual water supply will reach 165.14 × 10
6 m
3, and the annual water shortage will also increase significantly to 9.74 × 10
6 m
3. Although the SI only increases to 0.309, and the ADWS only increases to 0.06 × 10
6 m
3 while the water shortage occurred. The reliability of the water supply reaches 0 already at the 9th and 11th ten-day, as depicted in
Figure 17. The result show that the water supply risk in demand Scenario II is relatively severe than Scenario I.
Because the simulation of demand Scenario II indicates severe impact on domestic, we set the domestic SI = 0.1, and try to find the capability of industrial supporting for Hushan reservoir. We found that Hushan reservoir can support 100,000 m3/day of industrial water, and the annual water shortage has decreased to 2.18 × 106 m3. The number of average consecutive dry days (ACDD) for domestic has been greatly reduced to 45 days, and the reliability of the water supply is also raised to 0.4–0.5. In the following analyses, we recommend the daily supporting amount for industry from the Hushan reservoir should be 100,000 m3 as basis.
We simulate the water supply system with the historical flow as applied to method I (279,936 groups) and method II (1,679,616 groups) for newly synthesized flow data. The results are compared based on the ensemble average (as shown in
Table 7). Scenario I without considers supporting industrial water, the current annual water supply is 101.93 × 10
6 m
3, the annual water shortage is only 0.27 × 10
6 m
3, and the SI is only 0.002. While the water shortage occurring, the ADWS is only 0.03 × 10
6 m
3.
According to the water supply simulation results of 279,936 sets of flow data in Method I, the annual water supply slightly decreased to 98.25 × 10
6 m
3, the annual water shortage increased to 3.59 × 10
6 m
3, and the SI increased significantly to 0.668. While the water shortage occurring, the ADWS is increased slightly to 0.05 × 10
6 m
3. However,
Figure 18 shows that whether the reliability is lower than the current simulation result, they are still above 0.5, the lowest satisfaction is 0.87, which is generally acceptable.
According to the water supply simulation results of 1,679,616 sets of flow data in Method II. The annual water supply decreases to 95.52 × 10
6 m
3, the annual water shortage has increased significantly to 6.68 × 10
6 m
3. The SI increased significantly to 1.96 and the ADWS increased to 0.07 × 10
6 m
3 as well.
Figure 18 shows that the reliability is similar to the method I in dry season. However, Method II’s reliability is lower than method I value in the wet season. The satisfaction is generally lower than the current situation and the method I, but the minimum is still 0.84. The water supply situation of Method II is still acceptable. There is something odd: why the average annual flow of Method II is significantly more than the current situation and the average flow of Method I, but the simulation results are worse than the other cases? The main reason is that the extreme flow of the Method II often occurs; excessive flow cannot be used efficiently and there are many low flows during wet season. Therefore, the simulation result of Method II is the worst.
Finally, we simulate the water supply system using the historical flow with Method I and Method II’s synthesis flow data. The results are compared to the ensemble average (as shown in
Table 8). Under the condition of supporting 100,000 m
3 of industrial demand daily, the current annual water supply is 128.30 × 10
6 m
3, the annual water shortage is 2.18 × 10
6 m
3 and the SI is 0.1. While water shortage occurs, the average daily water shortage is 0.05 × 10
6 m
3.
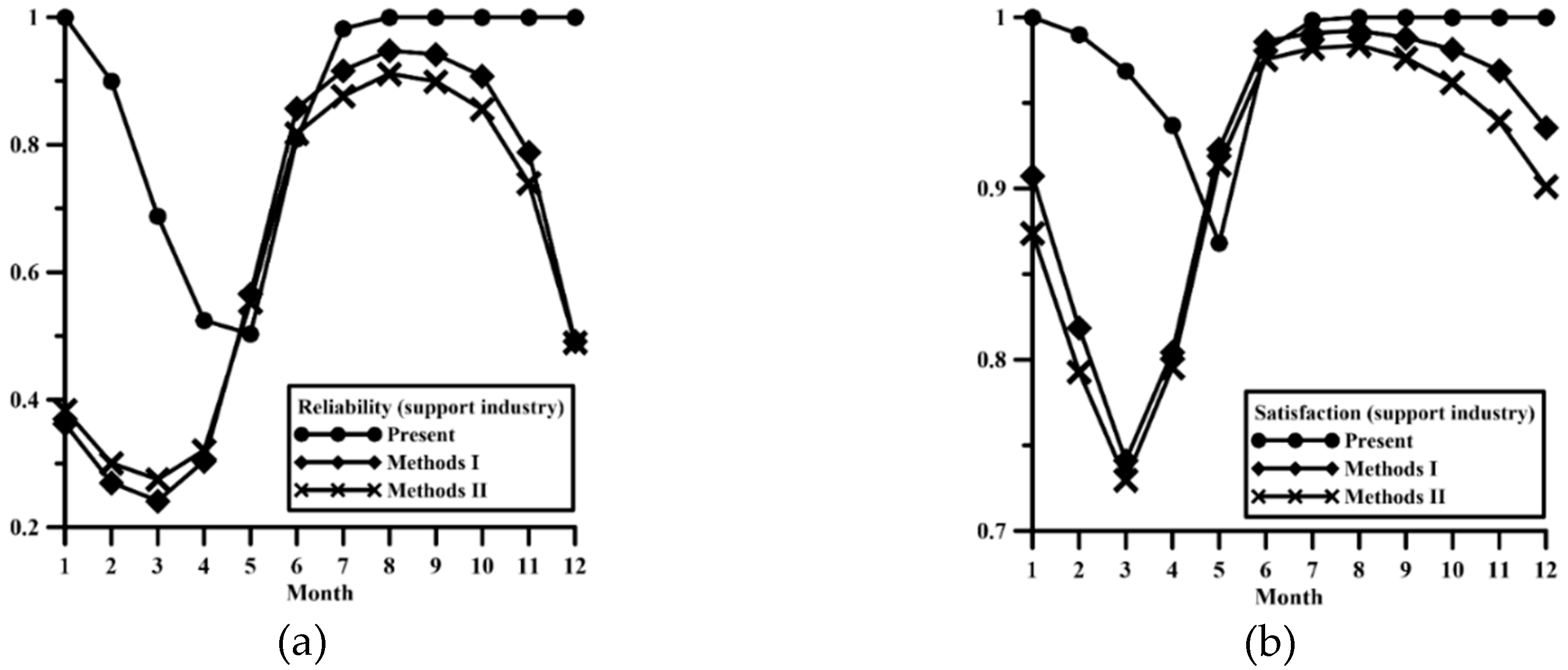
According to the simulation result of water supply in Method I, the annual water supply decreased slightly to 116.82 × 10
6 m
3, the annual water shortage increased to 11 × 10
6 m
3, and the SI increased significantly to 1.203. While the water shortage occurring, the ADWS is still maintained at 0.05 × 10
6 m
3.
Figure 19 shows that the reliability decrease more earlier than the current situation, the lowest monthly reliability reaches 0.24 in March, and recoveries in May. The lowest fulfillment of demand still occurs in March (0.74). In terms of dry season, the risk of water supply shortage is much worse than the current situation.
According to the simulation result of water supply in Method II, the annual water supply decreased to 113.82 × 10
6 m
3, the annual water shortage increased sharply to 13.46 × 10
6 m
3, and the SI increased significantly to 2.12. While occurs the water shortage event, the ADWS also increased to 0.07 × 10
6 m
3.
Figure 19 depicts that the reliability is similar to but lower than Method I in the dry season. Compared with the current situation, the water shortage occurs earlier, but it is lower than the Method I in the wet season. The satisfaction is generally lower than the current situation and the Method I, but similar to Method I. The satisfaction rises rapidly in May, which is higher than the current simulation results. However, the satisfaction is decreasing from August to October in wet season, it seems worse than the others.
In summary, no matter what kind of water supply scenario is applied, the current results are better than Method I and Method II. Although the simulation result of Method I is similar to Method II, the ensemble result of Method I is slightly better than the Method II. However, Method II synthesis annual average flow is significantly more than the current flow and the Method I flow, but the simulation results are worse than other cases. The main reason is that the extreme flow of the method II often occurs. Excessive flow cannot be used efficiently and there are many low flows in wet season. Therefore, the simulation result of Method II is the worst.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}