
Machine Learning Applications of Convolutional Neural Networks and Unet Architecture to Predict and Classify Demosponge Behavior

 ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Site, Video Imagery and Environmental Data Acquisition
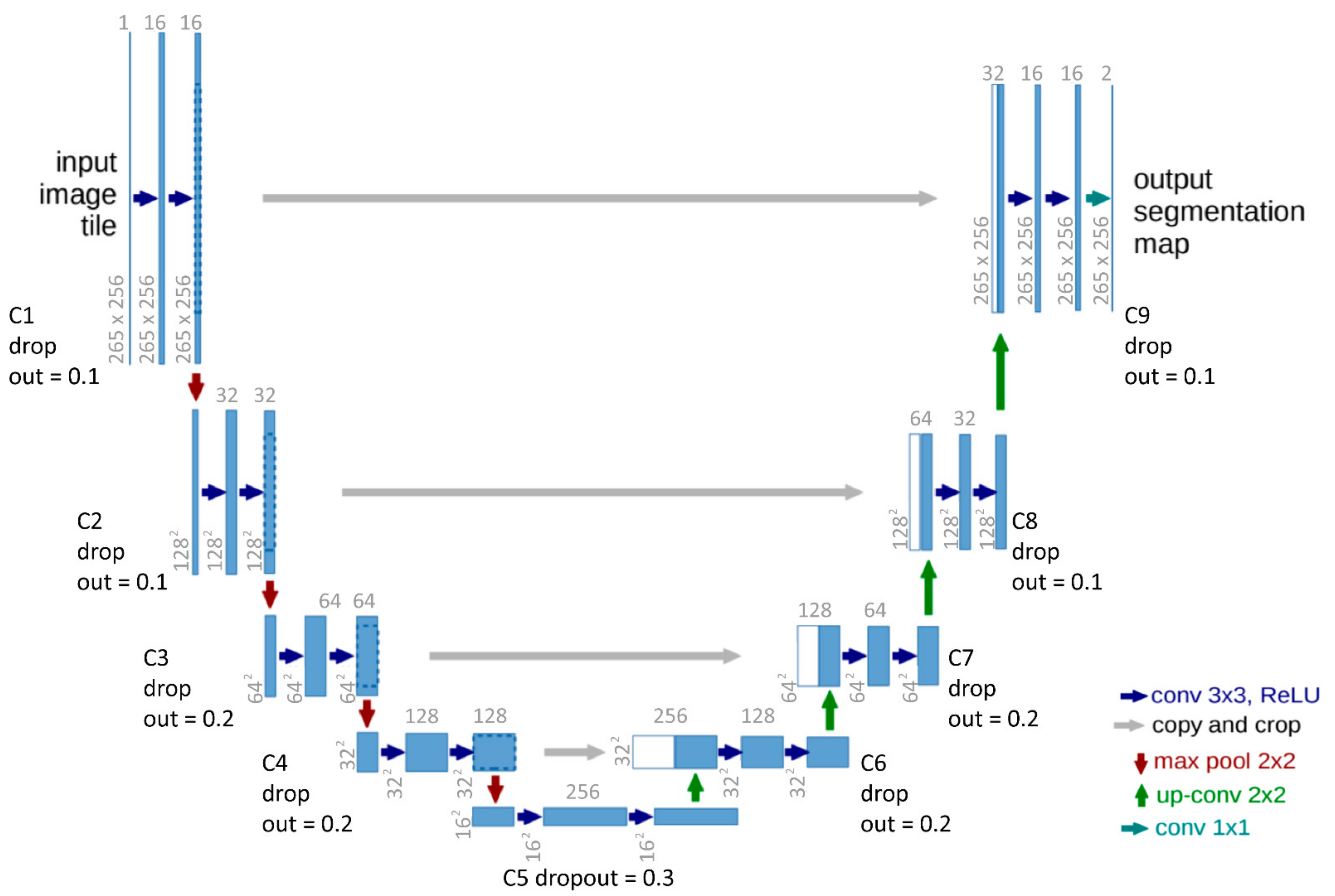
2.2. CNN and Unet Explanation
2.3. Running the Model
2.3.1. Preprocessing of Images
2.3.2. Processing: Unet Modification and the Steps to Running the Model
2.3.3. Post-Processing
3. Results
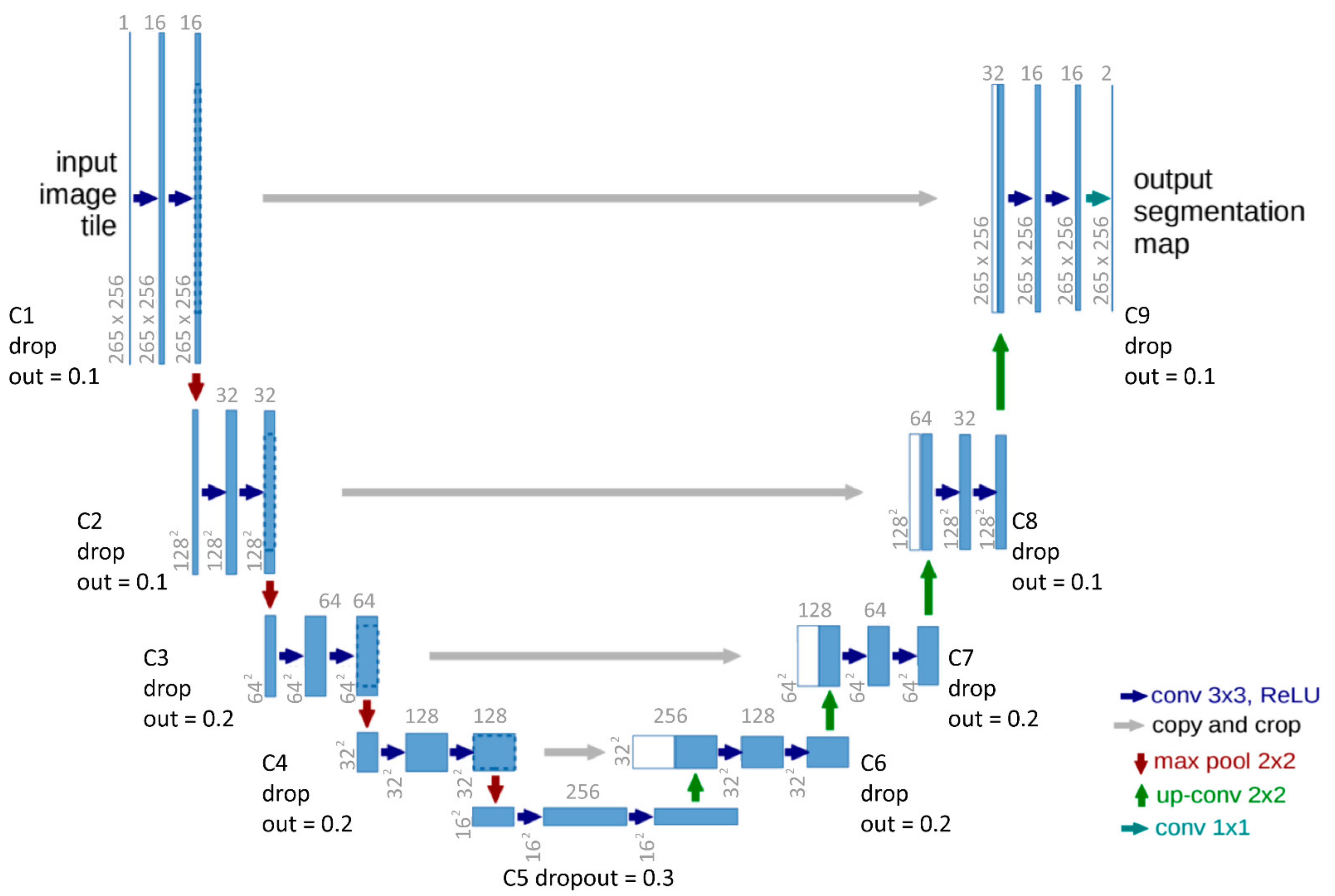
3.1. Model Architecture
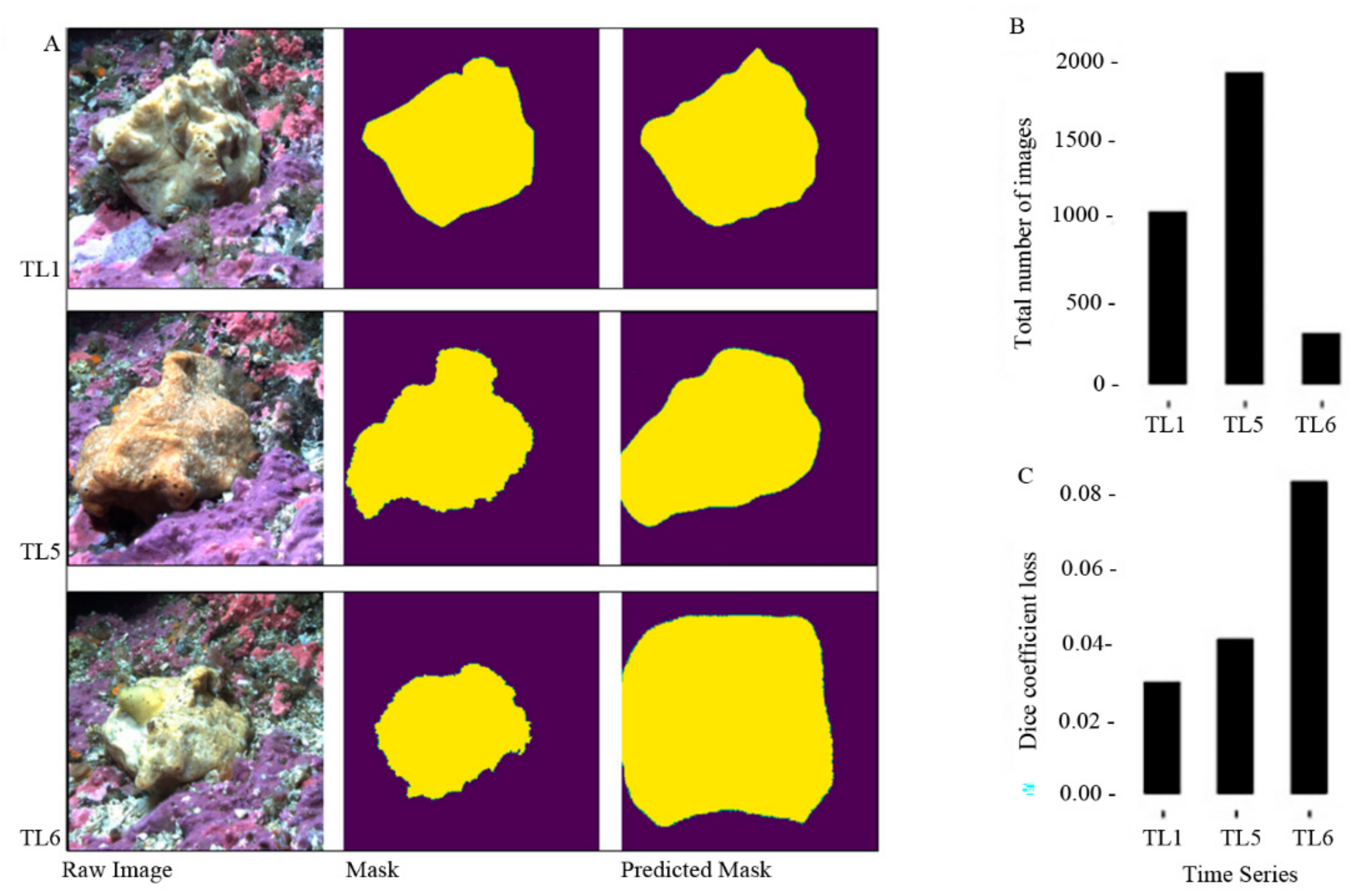
3.2. Data Summary
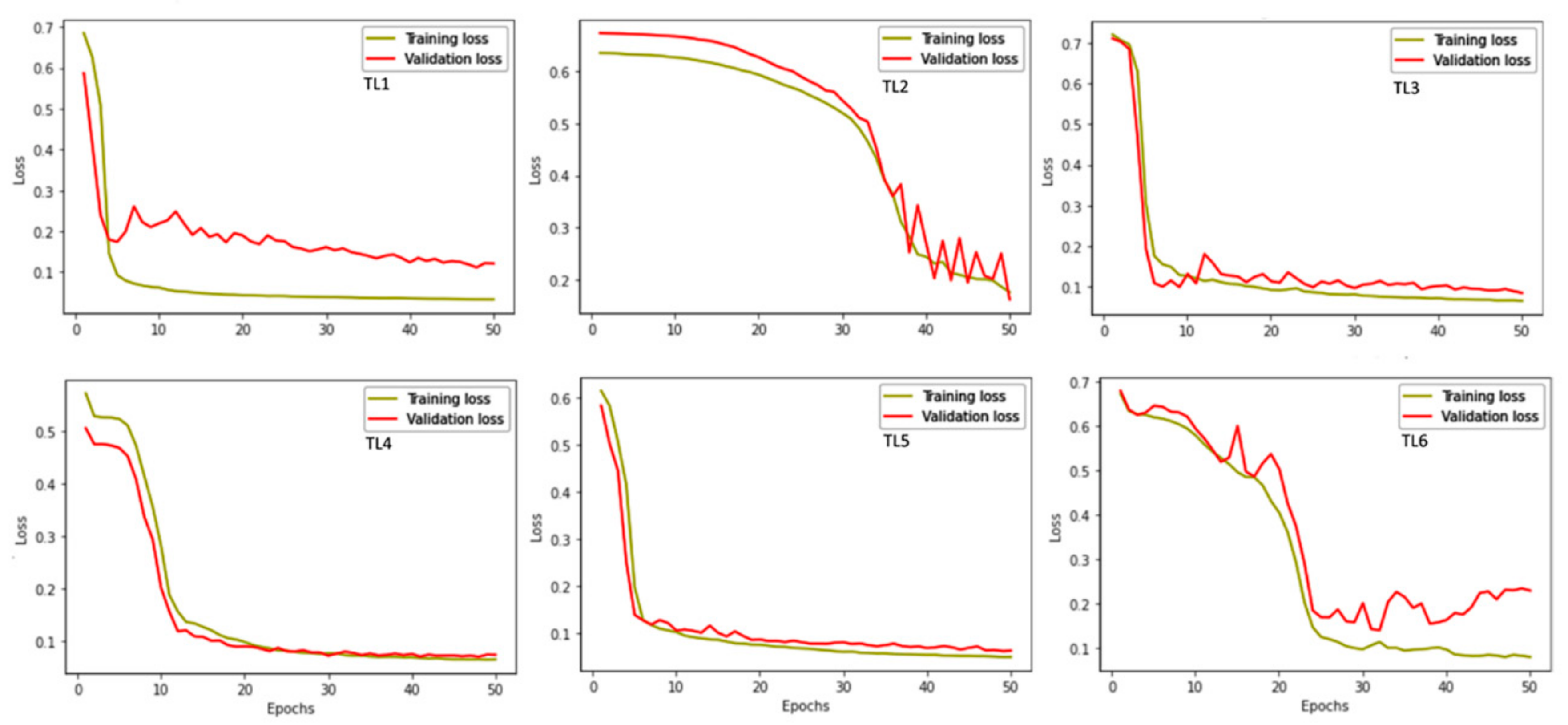
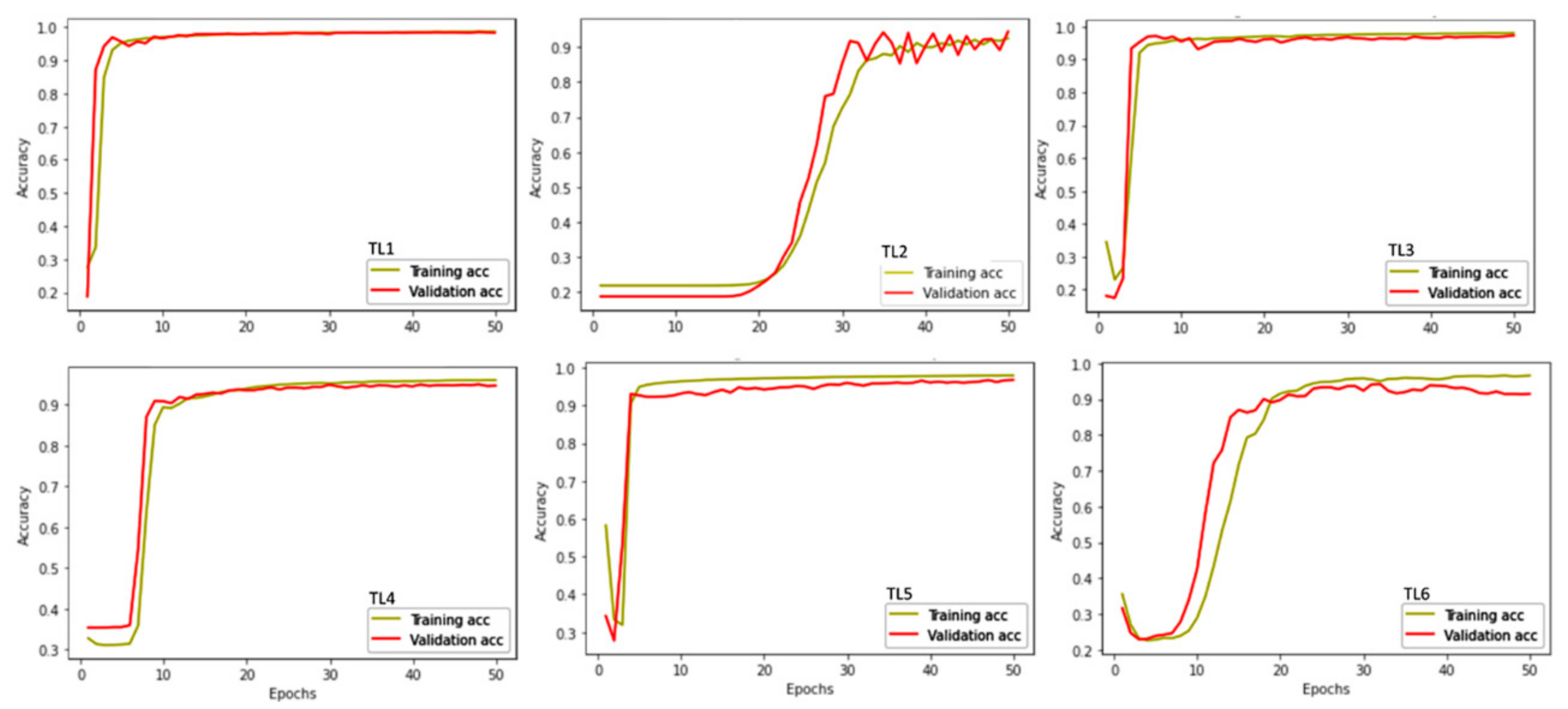
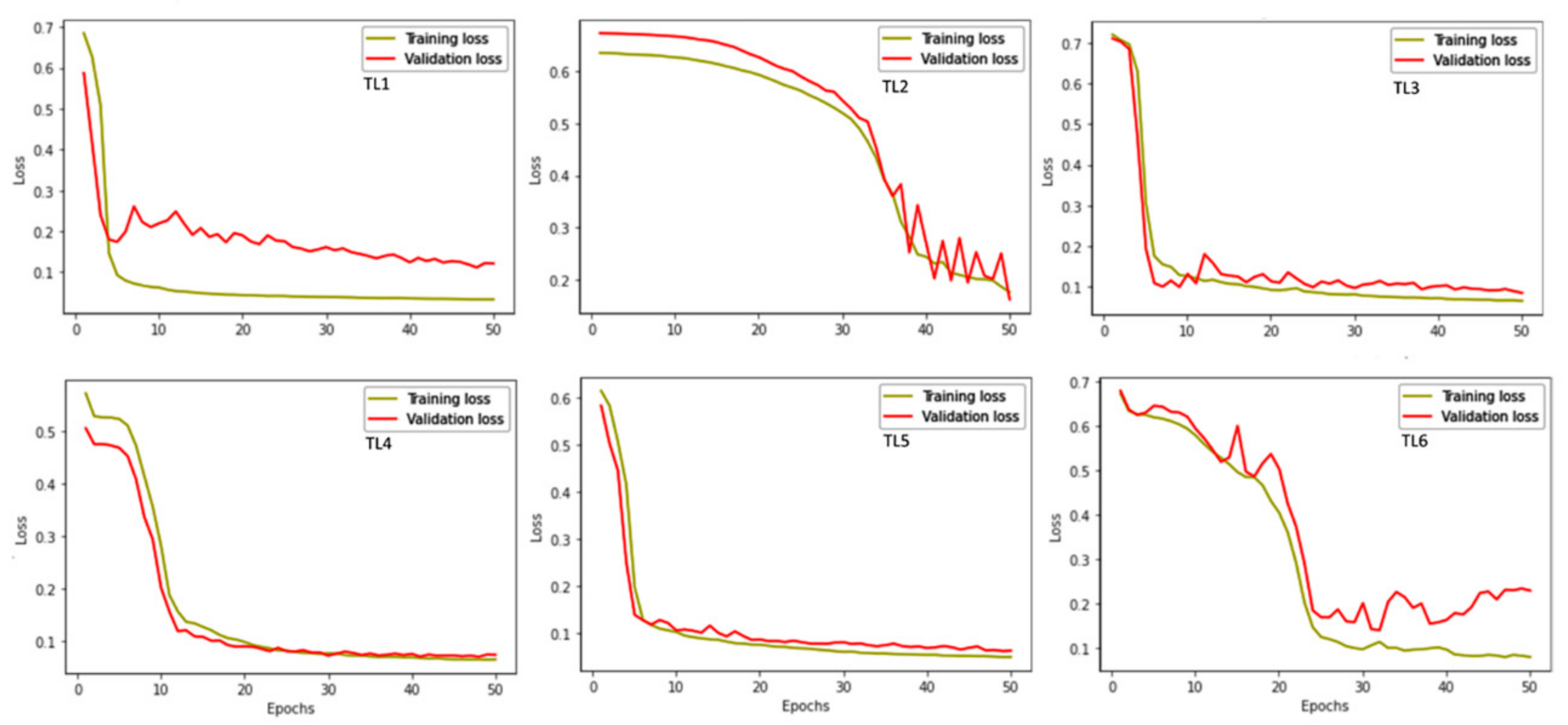
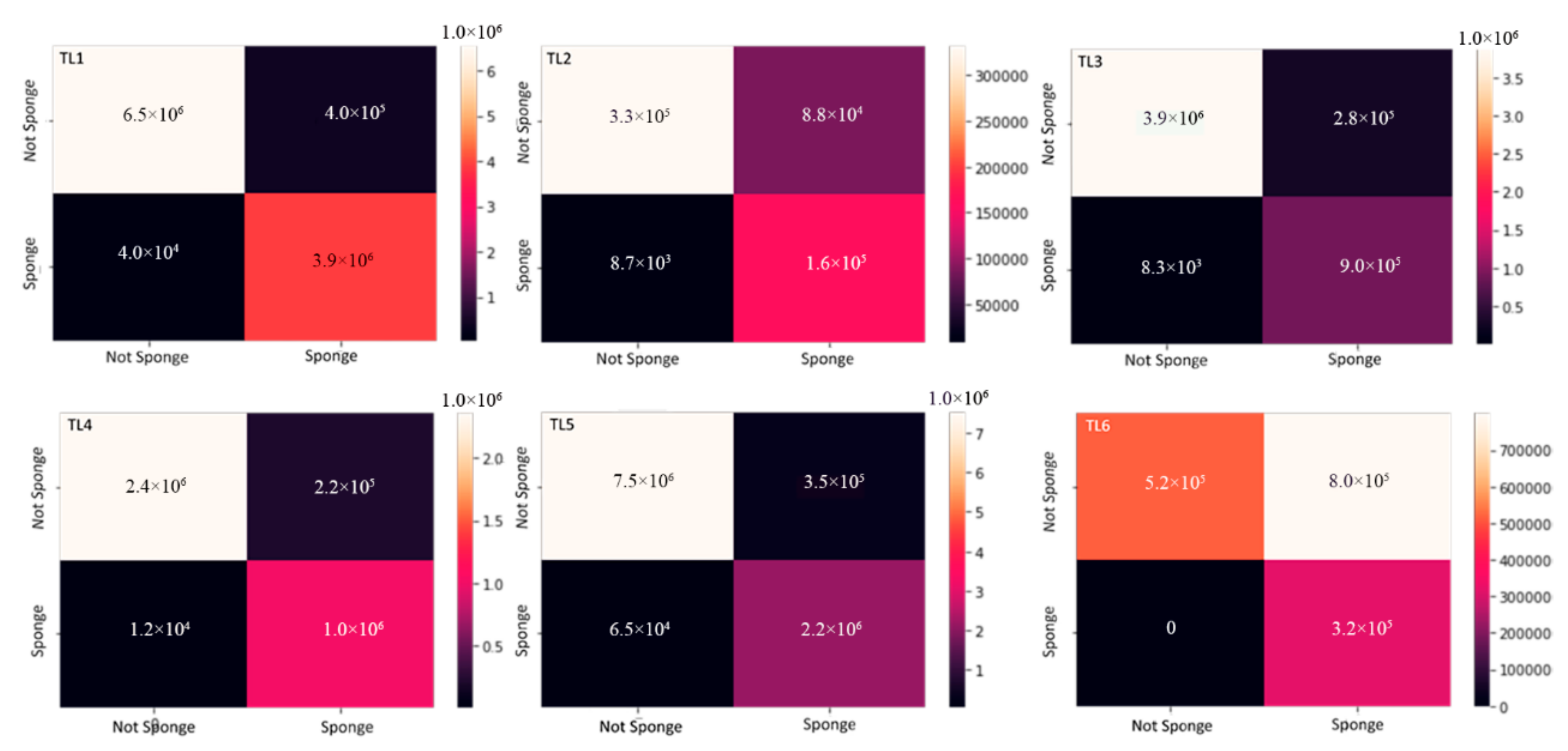
3.3. Model Performance
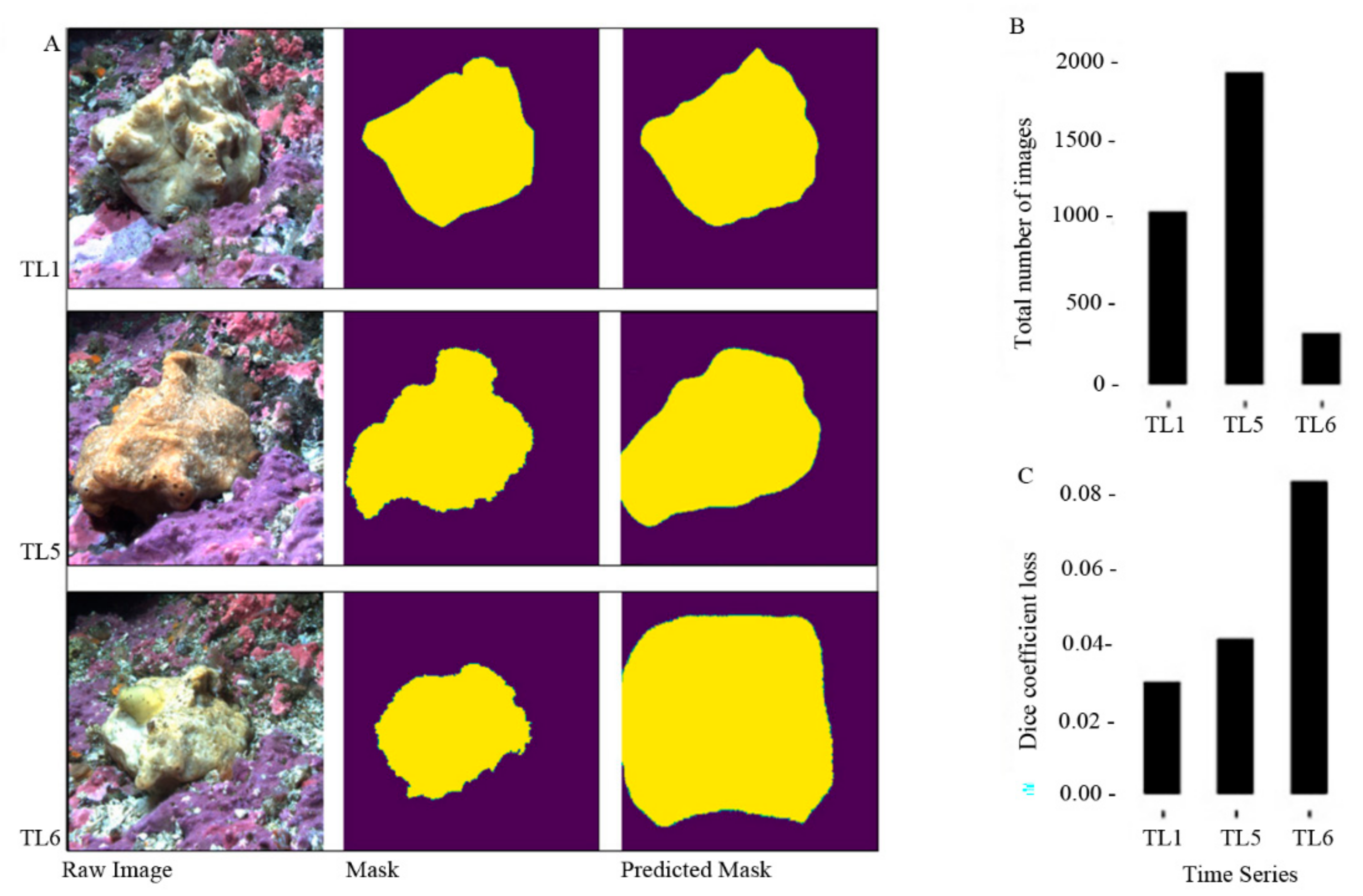
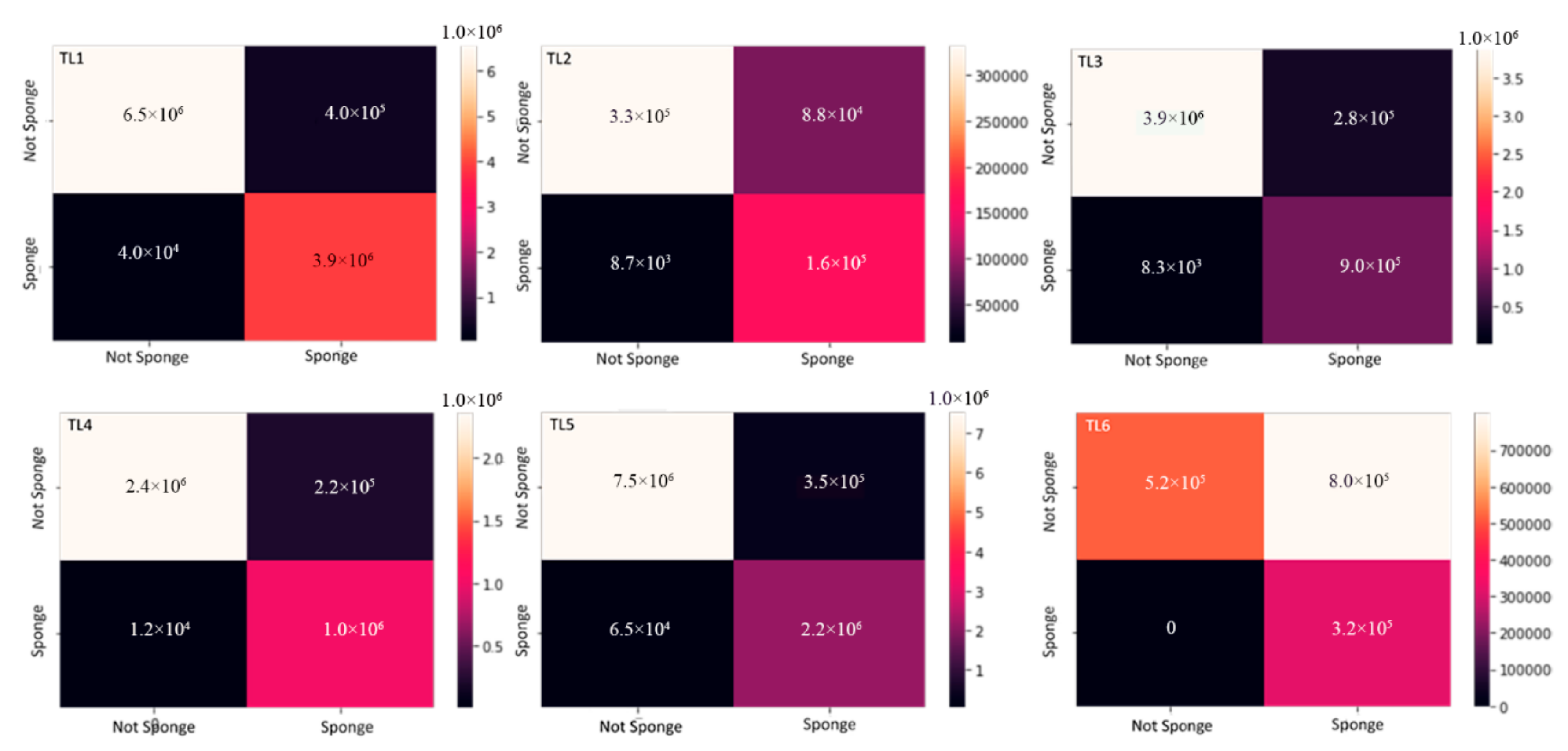
3.4. Validation of the Model
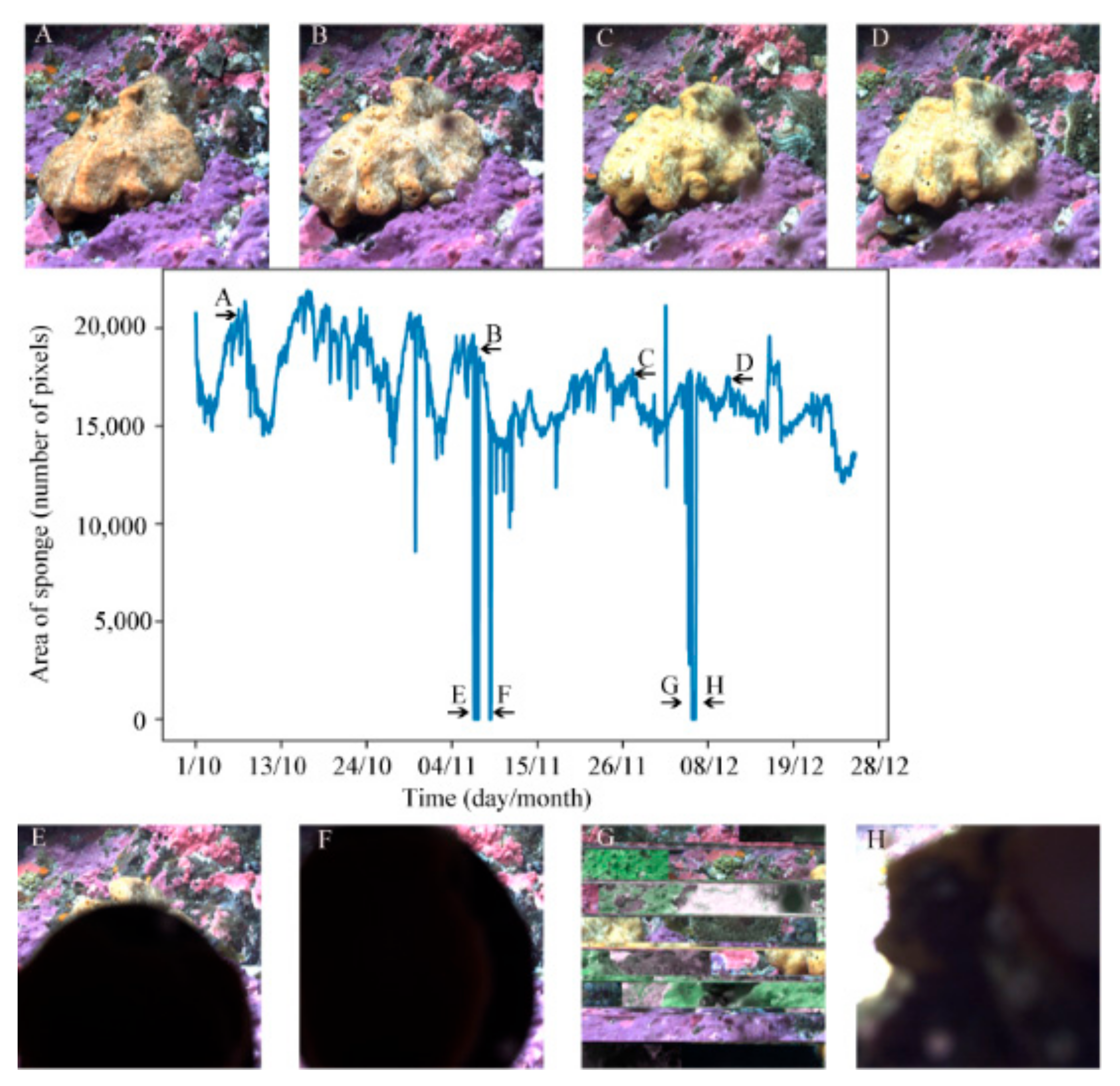
3.5. Area over Time
4. Discussion
4.1. Application of Biological Data Sets
4.2. Model Performance and Alterations
4.2.1. Masks
4.2.2. Architecture Alterations and Application to Other Data Sets
4.2.3. Model Success
4.3. Future Applications
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Finch, C.E. Hormones and the Physiological Architecture of Life History Evolution. Quaterly Rev. Biol. 1995, 70, 1–52. [Google Scholar] [CrossRef] [Green Version]
- Nylin, S.; Gotthard, K. Plasticity in Life-History Traits. Annu. Rev. Entomol. 1998, 43, 63–83. [Google Scholar] [CrossRef] [Green Version]
- Allen, R.M.; Metaxas, A.; Snelgrove, P.V.R. Applying Movement Ecology to Marine Animals with Complex Life Cycles. Ann. Rev. Mar. Sci. 2018, 10, 19–42. [Google Scholar] [CrossRef]
- Chénard, C.; Wijaya, W.; Vaulot, D.; Lopes dos Santos, A.; Martin, P.; Kaur, A.; Lauro, F.M. Temporal and Spatial Dynamics of Bacteria, Archaea and Protists in Equatorial Coastal Waters. Sci. Rep. 2019, 9, 1–13. [Google Scholar] [CrossRef] [Green Version]
- MacLeod, N.; Benfield, M.; Culverhouse, P. Time to Automate Identification. Nature 2010, 467, 154–155. [Google Scholar] [CrossRef] [PubMed]
- Malde, K.; Handegard, N.O.; Eikvil, L.; Salberg, A.B. Machine Intelligence and the Data-Driven Future of Marine Science. ICES J. Mar. Sci. 2020, 77, 1274–1285. [Google Scholar] [CrossRef]
- Guidi, L.; Guerra, A.F. Future Science Brief Big Data in Marine Science, 6th ed.; Heymans, S.J.J., Alexander, B., Piniella, Á.M., Kellett, P., Coopman, J., Eds.; Future Science Brief 6 of the European Marine Board: Ostend, Belgium, 2020; ISBN 9789492043931. [Google Scholar]
- Harmsen, B.J.; Foster, R.J.; Silver, S.; Ostro, L.; Doncaster, C.P. Differential Use of Trails by Forest Mammals and the Implications for Camera-Trap Studies: A Case Study from Belize. Biotropica 2010, 42, 126–133. [Google Scholar] [CrossRef]
- Ahumada, J.A.; Silva, C.E.F.; Gajapersad, K.; Hallam, C.; Hurtado, J.; Martin, E.; McWilliam, A.; Mugerwa, B.; O’Brien, T.; Rovero, F.; et al. Community Structure and Diversity of Tropical Forest Mammals: Data from a Global Camera Trap Network. Philos. Trans. R. Soc. B Biol. Sci. 2011, 366, 2703–2711. [Google Scholar] [CrossRef]
- Rovero, F.; Martin, E.; Rosa, M.; Ahumada, J.A.; Spitale, D. Estimating Species Richness and Modelling Habitat Preferences of Tropical Forest Mammals from Camera Trap Data. PLoS ONE 2014, 9, e103300. [Google Scholar] [CrossRef]
- Doya, C.; Aguzzi, J.; Pardo, M.; Matabos, M.; Company, J.B.; Costa, C.; Mihaly, S.; Canals, M. Diel Behavioral Rhythms in Sablefish (Anoplopoma Fimbria) and Other Benthic Species, as Recorded by the Deep-Sea Cabled Observatories in Barkley Canyon (NEPTUNE-Canada). J. Mar. Syst. 2014, 130, 69–78. [Google Scholar] [CrossRef]
- Lelièvre, Y.; Legendre, P.; Matabos, M.; Mihály, S.; Lee, R.W.; Sarradin, P.M.; Arango, C.P.; Sarrazin, J. Astronomical and Atmospheric Impacts on Deep-Sea Hydrothermal Vent Invertebrates. Proc. R. Soc. B Biol. Sci. 2017, 284, 20162123. [Google Scholar] [CrossRef]
- Aguzzi, J.; Bahamon, N.; Doyle, J.; Lordan, C.; Tuck, I.D.; Chiarini, M.; Martinelli, M.; Company, J.B. Burrow Emergence Rhythms of Nephrops Norvegicus by UWTV and Surveying Biases. Sci. Rep. 2021, 11, 1–13. [Google Scholar] [CrossRef]
- Chu, J.W.F.; Maldonado, M.; Yahel, G.; Leys, S.P. Glass Sponge Reefs as a Silicon Sink. Mar. Ecol. Prog. Ser. 2011, 441, 1–14. [Google Scholar] [CrossRef]
- Mcquaid, C.D.; Russell, B.D.; Smith, I.P.; Swearer, S.E.; Todd, P.A.; Rountree, R.A.; Aguzzi, J.; Marini, S.; Fanelli, E.; De Leo, F.C.; et al. Towards an optimal design for ecosystem-level ocean observatories. In Oceanography and Marine Biology; Taylor & Francis: Abingdon, UK, 2021; Volume 58. [Google Scholar]
- McIntosh, D.; Marques, T.P.; Albu, A.B.; Rountree, R.; De Leo, F. Movement Tracks for the Automatic Detection of Fish Behavior in Videos. arXiv 2020, arXiv:2011.14070. [Google Scholar]
- Pollak, D.J.; Feller, K.D.; Serbe, É.; Mircic, S.; Gage, G.J. An Electrophysiological Investigation of Power-Amplification in the Ballistic Mantis Shrimp Punch. J. Undergrad. Neurosci. Educ. 2019, 17, T12–T18. [Google Scholar] [PubMed]
- Laur, D.R.; Ebeling, A.W.; Reed, D.C. Experimental Evaluations of Substrate Types as Barriers to Sea Urchin (Strongylocentrotus Spp.) Movement. Mar. Biol. 1986, 93, 209–215. [Google Scholar] [CrossRef]
- Kahn, A.S.; Pennelly, C.W.; McGill, P.R.; Leys, S.P. Behaviors of Sessile Benthic Animals in the Abyssal Northeast Pacific Ocean. Deep. Res. Part II Top. Stud. Oceanogr. 2020, 173, 1–24. [Google Scholar] [CrossRef]
- Nickel, M. Kinetics and Rhythm of Body Contractions in the Sponge Tethya wilhelma (Porifera: Demospongiae). J. Exp. Biol. 2004, 207, 4515–4524. [Google Scholar] [CrossRef] [Green Version]
- Elliott, G.R.D.; Leys, S.P. Coordinated Contractions Effectively Expel Water from the Aquiferous System of a Freshwater Sponge. J. Exp. Biol. 2007, 210, 3736–3748. [Google Scholar] [CrossRef] [Green Version]
- Moeslund, T.B. Introduction to Video and Image Processing: Building Real Systems and Applications; Mackie, I., Ed.; Springer: Aalborg, Denmark, 2012; ISBN 9781447125020. [Google Scholar]
- Yao, R.; Lin, G.; Xia, S.; Zhao, J.; Zhou, Y. Video Object Segmentation and Tracking. ACM Trans. Intell. Syst. Technol. 2020, 11, 1743. [Google Scholar] [CrossRef]
- Zhang, A.B.; Hao, M.D.; Yang, C.Q.; Shi, Z.Y. BarcodingR: An Integrated r Package for Species Identification Using DNA Barcodes. Methods Ecol. Evol. 2017, 8, 627–634. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A Survey on Deep Learning Techniques for Image and Video Semantic Segmentation. Appl. Soft Comput. J. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Langenkämper, D.; Zurowietz, M.; Schoening, T.; Nattkemper, T.W. BIIGLE 2.0—Browsing and Annotating Large Marine Image Collections. Front. Mar. Sci. 2017, 4, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Marini, S.; Fanelli, E.; Sbragaglia, V.; Azzurro, E.; Del Rio Fernandez, J.; Aguzzi, J. Tracking Fish Abundance by Underwater Image Recognition. Sci. Rep. 2018, 8, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Tills, O.; Spicer, J.I.; Grimmer, A.; Marini, S.; Jie, V.W.; Tully, E.; Rundle, S.D. A High-Throughput and Open-Source Platform for Embryo Phenomics. PLoS Biol. 2018, 16, e3000074. [Google Scholar] [CrossRef]
- Yau, T.H.Y. Underwater Camera Calibration and 3D Reconstruction. Master’s Thesis, University of Alberta, Edmonton, AB, Canada, 2014. [Google Scholar]
- Leys, S.P.; Mah, J.L.; McGill, P.R.; Hamonic, L.; De Leo, F.C.; Kahn, A.S. Sponge Behavior and the Chemical Basis of Responses: A Post-Genomic View. Integr. Comp. Biol. 2019, 59, 751–764. [Google Scholar] [CrossRef] [PubMed]
- Harrison, D. Available online: https://github.com/domarom/Belinda-Unet-machine-learning (accessed on 5 June 2021).
- Ronneberger, O.; Fischer, P.; Bronx, T. UNet: Convolutional Networks for Biomedical Image Segmentation. IEEE Access 2015, 9, 16591–16603. [Google Scholar] [CrossRef]
- Alonso, I.; Cambra, A.; Muñoz, A.; Treibitz, T.; Murillo, A.C. Coral-Segmentation: Training Dense Labeling Models with Sparse Ground Truth. In Proceedings of the IEEE International Conference on Computer Vision Workshops 2017, Venice, Italy, 22–29 October 2017; Volume 2018, pp. 2874–2882. [Google Scholar]
- Torben, M. Tracking Sponge Size and Behaviour. In Pattern Recognition and Information Forensics; Zhang, Z., Suter, D., Tian, Y., Albu, A.B., Sidere, N., Escalante, H.J., Eds.; Springer: Beijing, China, 2019; Volume 1, pp. 45–54. ISBN 9783030057923. [Google Scholar]
- Matlab Compervision Tool Box: Image Labeller; Mathwork Inc.: Natick, MA, USA, 2010.
- He, P. Systematic Research to Reduce Unintentional Fishing-Related Mortality: Example of the Gulf of Maine Northern Shrimp Trawl Fishery. In Fisheries Bycatch: Global Issues and Creative Solutions; University of Alaska Fairbanks: Fairbanks, Alaska, 2015. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Ing, N.; Ma, Z.; Li, J.; Salemi, H.; Arnold, C.; Knudsen, B.S.; Gertych, A. Semantic segmentation for prostate cancer grading by convolutional neural networks. In Digital Pathology; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; p. 46. [Google Scholar] [CrossRef]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Siena, Italy, 27–29 October 2020. [Google Scholar] [CrossRef]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Kohavi, R. The Royal London Space Planning: An Integration of Space Analysis and Treatment Planning. Am. J. Orthod. Dentofac. Orthop. 1995, 118, 456–461. [Google Scholar] [CrossRef]
- Hughes, T.P.; Anderson, K.D.; Connolly, S.R.; Heron, S.F.; Kerry, J.T.; Lough, J.M.; Baird, A.H.; Baum, J.K.; Berumen, M.L.; Bridge, T.C.; et al. Spatial and Temporal Patterns of Mass Bleaching of Corals in the Anthropocene. Science (80-.) 2018, 359, 80–83. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, B.A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Series | Dates (DD/MM/YY) | Timeseries: Total Number of Images | Training Data: Number of Training Images and Masks | Testing Data: Number of Test Images |
|---|---|---|---|---|
| TL1 | 08/11/12–13/04/13 | 1072 | 428 | 644 |
| TL2 | 15/07/13–10/09/13 | 112 | 46 | 66 |
| TL3 | 20/10/13–15/12/13 | 968 | 387 | 581 |
| TL4 | 20/07/14–21/08/14 | 696 | 278 | 418 |
| TL5 | 01/10/14–31/01/15 | 1932 | 772 | 1160 |
| TL6 | 15/07/15–15/08/15 | 316 | 126 | 190 |
| Time Series | Loss | Dice-Coefficient Score | Accuracy | Validation Loss | Validation Dice-Coefficient Score | Validation Accuracy |
|---|---|---|---|---|---|---|
| TL1 | 0.0300 | 0.9700 | 0.9862 | 0.0505 | 0.9477 | 0.9619 |
| TL2 | 0.3417 | 0.6794 | 0.9176 | 0.2603 | 0.7397 | 0.8597 |
| TL3 | 0.0629 | 0.9375 | 0.9788 | 0.1328 | 0.8680 | 0.9473 |
| TL4 | 0.0575 | 0.9425 | 0.9627 | 0.0685 | 0.9309 | 0.9590 |
| TL5 | 0.0447 | 0.9553 | 0.9777 | 0.1140 | 0.8863 | 0.9429 |
| TL6 | 0.0779 | 0.9233 | 0.9646 | 0.6250 | 0.3696 | 0.3465 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Harrison, D.; De Leo, F.C.; Gallin, W.J.; Mir, F.; Marini, S.; Leys, S.P. Machine Learning Applications of Convolutional Neural Networks and Unet Architecture to Predict and Classify Demosponge Behavior. Water 2021, 13, 2512. https://doi.org/10.3390/w13182512
Harrison D, De Leo FC, Gallin WJ, Mir F, Marini S, Leys SP. Machine Learning Applications of Convolutional Neural Networks and Unet Architecture to Predict and Classify Demosponge Behavior. Water. 2021; 13(18):2512. https://doi.org/10.3390/w13182512
Chicago/Turabian StyleHarrison, Dominica, Fabio Cabrera De Leo, Warren J. Gallin, Farin Mir, Simone Marini, and Sally P. Leys. 2021. "Machine Learning Applications of Convolutional Neural Networks and Unet Architecture to Predict and Classify Demosponge Behavior" Water 13, no. 18: 2512. https://doi.org/10.3390/w13182512
APA StyleHarrison, D., De Leo, F. C., Gallin, W. J., Mir, F., Marini, S., & Leys, S. P. (2021). Machine Learning Applications of Convolutional Neural Networks and Unet Architecture to Predict and Classify Demosponge Behavior. Water, 13(18), 2512. https://doi.org/10.3390/w13182512