1. Introduction
Precipitation is one of the major driving forces in the hydrological cycle that affects hydrological processes [
1,
2]. Nowadays, precipitation data are mainly acquired from rain gauges, weather radars, and satellites, while the first two are considered as the best data sources for catchment modeling [
3]. Even though there are measurement alternatives to rain gauges, the data acquired at in-situ measurements are still frequently used in many hydrological applications as they provide reliable and measured (not estimated) point information on the precipitation. However, before further use, the rain gauge data must be spatially interpolated, which might significantly affect the accuracy of the spatial precipitation field [
4]. The process of obtaining a reliable interpolated precipitation field is particularly challenging in mountainous environments. The spatial patterns of precipitation over these areas are mainly affected by the topography of the area and wind direction, which significantly affects runoff modeling in the catchment [
5]. Moreover, mountainous areas often face the problem of sparse rain gauge networks, which limits the accessibility of the data and affects the interpolation accuracy [
6].
The amount of precipitation measured by the rain gauge provides local information on the precipitation, not its areal variability [
7]. In hydrological applications, it is necessary to acquire the areal height of precipitation. Therefore, the rain gauge data is subject to spatial interpolation to reproduce its spatial variability. One of the main problems with spatial interpolation of rain gauge data is the small number of measurement points [
8], which is often insufficient to correctly reproduce areal precipitation, although the rainfall values measured at a given point are correct [
7]. An equal measurement of the precipitation height is expected within a distance of a few meters from each other, while at several hundred meters, this convergence is significantly reduced [
9].
Gridded datasets based on in-situ observations are mainly affected by station density and interpolation methodology [
10]. As for interpolation methodology, two aspects are crucial: the choice of the method and the resolution of the interpolation grid. Spatial interpolation techniques can be divided into deterministic and probabilistic methods. The first ones are based on deterministic interpolation algorithms, as a result of which a continuous or discontinuous precipitation field is created. The latter are based on algorithms in which it is assumed that the point information from measurement has a deterministic and a spatially correlated random component. Among the deterministic methods, the most commonly used techniques include inverse distance weighting (IDW), polynomial interpolation, and Thiessen polygons [
2,
11,
12]. As for the geostatistical methods that are the most used, the techniques are ordinary kriging and co-kriging [
13]. When the amount of available rain gauges is very limited, the geostatistical methods will not be effective [
14].
In many previous studies (e.g., [
6,
10,
15,
16]) assessments of interpolation methods were done in terms of statistical analysis like cross-validation or minimization of mean absolute error (MAE) or root mean square error (RMSE). However, when it comes to hydrological modeling, these statistical aspects of precipitation data are important, but their reliable values do not guarantee accurate discharge simulations using the rainfall-runoff model.
It’s frequently assumed that fully-distributed models are the best for investigation of the spatial variables (like precipitation) as they allow to provide input data in the grid cells and do not average values over larger areas like lumped and semi-distributed models do [
2]. However, the semi-distributed hydrological models are also sensitive to the spatial distribution of variables. That was the subject of an investigation by Cheng et al. [
1], where the authors analyzed the impact of three interpolation methods (Thiessen polygons, IDW, and co-kriging) and applied it to a semi-distributed model. Nonetheless, they omitted the aspects of grid resolution impact on interpolation outputs, as well as the impact of inverse distance power (IDP) value for IDW method. In another paper by Chen et al. [
4], three interpolation methods were also analyzed (regression-based scheme, IDW, and multiple linear method) and applied to a semi-distributed model. However, in their study, the authors set up the grid resolution to 500 × 500 m without any investigation. The impact of the IDP value in the IDW method for the purpose of hydrological modeling is also not sufficiently analyzed. There are some papers (e.g., [
17,
18,
19]) that investigated the effect of the IDP value on precipitation of the interpolation outputs, but the data were not applied to the hydrological model. Most frequently, the IDP value is set as equal to two, which seems to be a fine potency for hydrogeology applications [
20,
21]. As for hydrological applications, the IDP is also often assumed as two, but there is no strong evidence that it is the most optimal value.
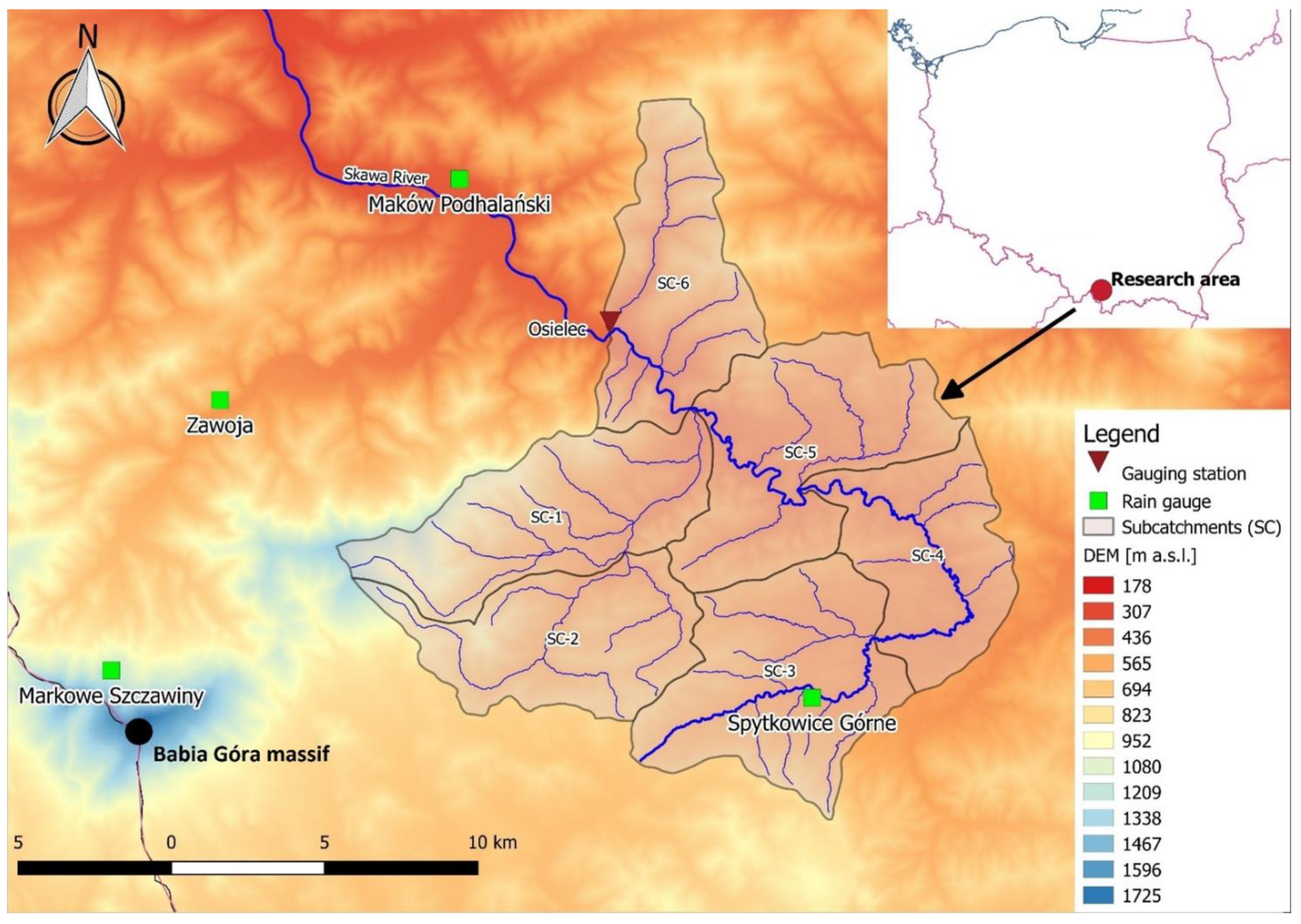
For hydrological modeling, there is a great need to interpolate precipitation data even when the number of measuring stations is too small to prevent the use of any geostatistical method. Taking into account that the grid size aspects are mostly neglected when interpolating precipitation, the main objective of this paper is to investigate both the impact of grid resolution and deterministic interpolation technique and evaluate them via rainfall-runoff simulations using the Hydrologic Engineering Center-Hydrologic Modelling System (HEC-HMS) semi-distributed hydrological model over a sparsely gauged mountainous catchment. Also, for the inverse distance weighting method, the impact of the IDP value on the hydrological simulation results was investigated. The simulations were performed using two interpolation methods (inverse distance weighting and first-degree polynomial interpolation) and 6 grid sizes (ranging from 250 m to 5000 m). The impact of IDP value in IDW interpolation and its impact on discharge simulation was also subject to investigation. As the study area, a sparsely rain-gauged mountainous catchment in southern Poland was chosen which frequently faces flooding events. The simulation results were evaluated using Nash-Sutcliffe efficiency (NSE), Kling-Gupta efficiency (KGE), and percent bias metrics. The KGE criterion is often considered as an alternative to NSE, and this paper tries to judge which of these two allows for better evaluation of the modeling results.
4. Summary and Conclusions
This paper presents a comprehensive investigation of the impact of deterministic interpolation methods of precipitation on rainfall-runoff modeling in a small mountainous catchment characterized by a quick time of response. When the number of rainfall stations is limited and too small to prevent the use of any geostatistical method, the deterministic methods are the only option. However, spatial interpolation of precipitation over a sparsely gauged mountainous catchment is particularly challenging. The performance of spatial interpolation of precipitation obtained using the inverse distance weighting and first-degree polynomial interpolation method was evaluated via the semi-distributed rainfall-runoff model. Furthermore, the impact of the grid resolution during the interpolation process was investigated for 6 grid sizes (ranging from 250 m to 5000 m). The impact of the IDP value in the IDW interpolation was also analyzed.
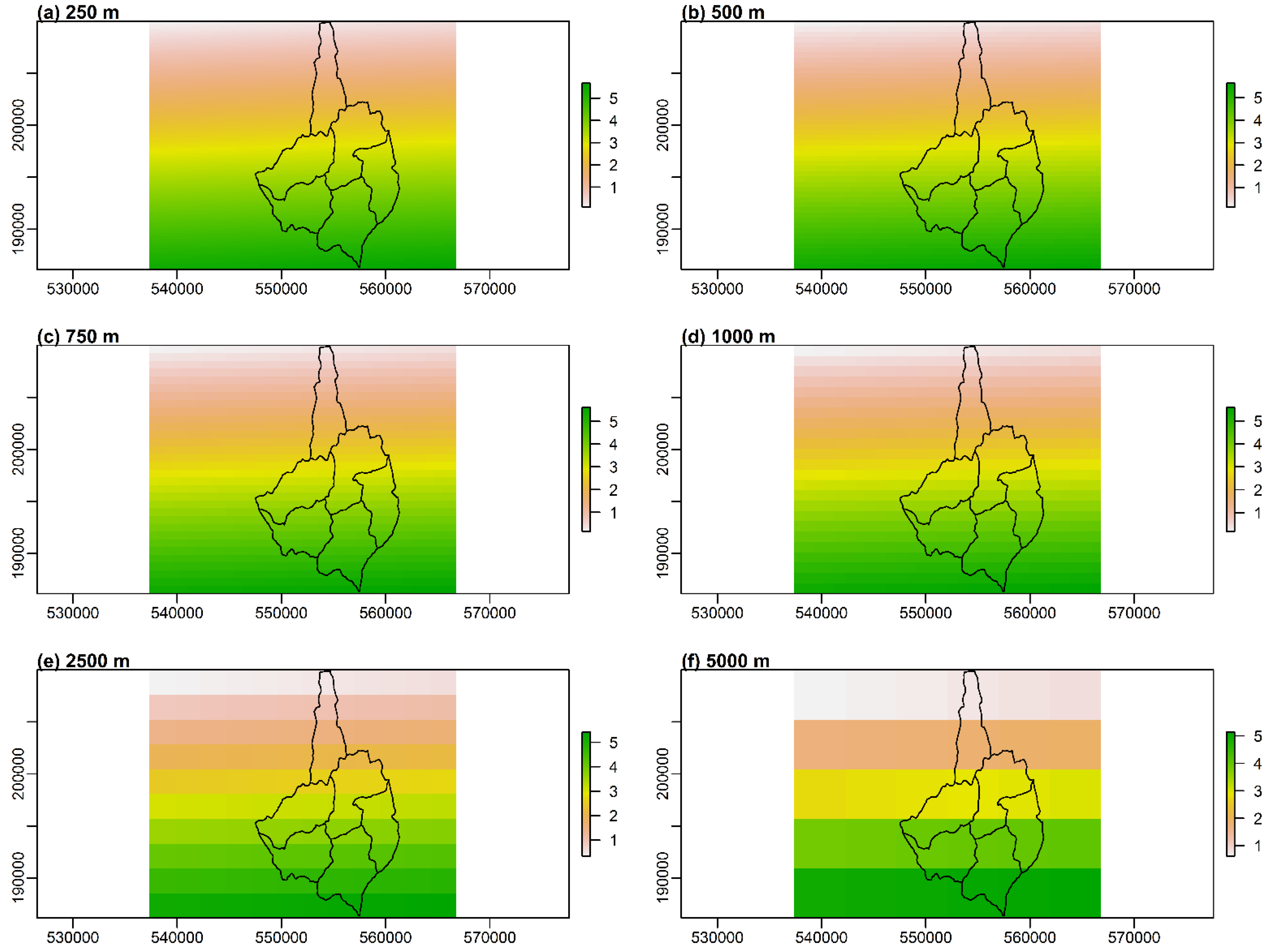
When using a semi-distributed hydrological model, the aspect of the grid resolution used for the preparation of precipitation data is often neglected. This study shows that for different interpolation methods, the grid resolutions have a significant impact on the outputs of hydrological modeling.
The following conclusions can be drawn from the analysis outcomes:
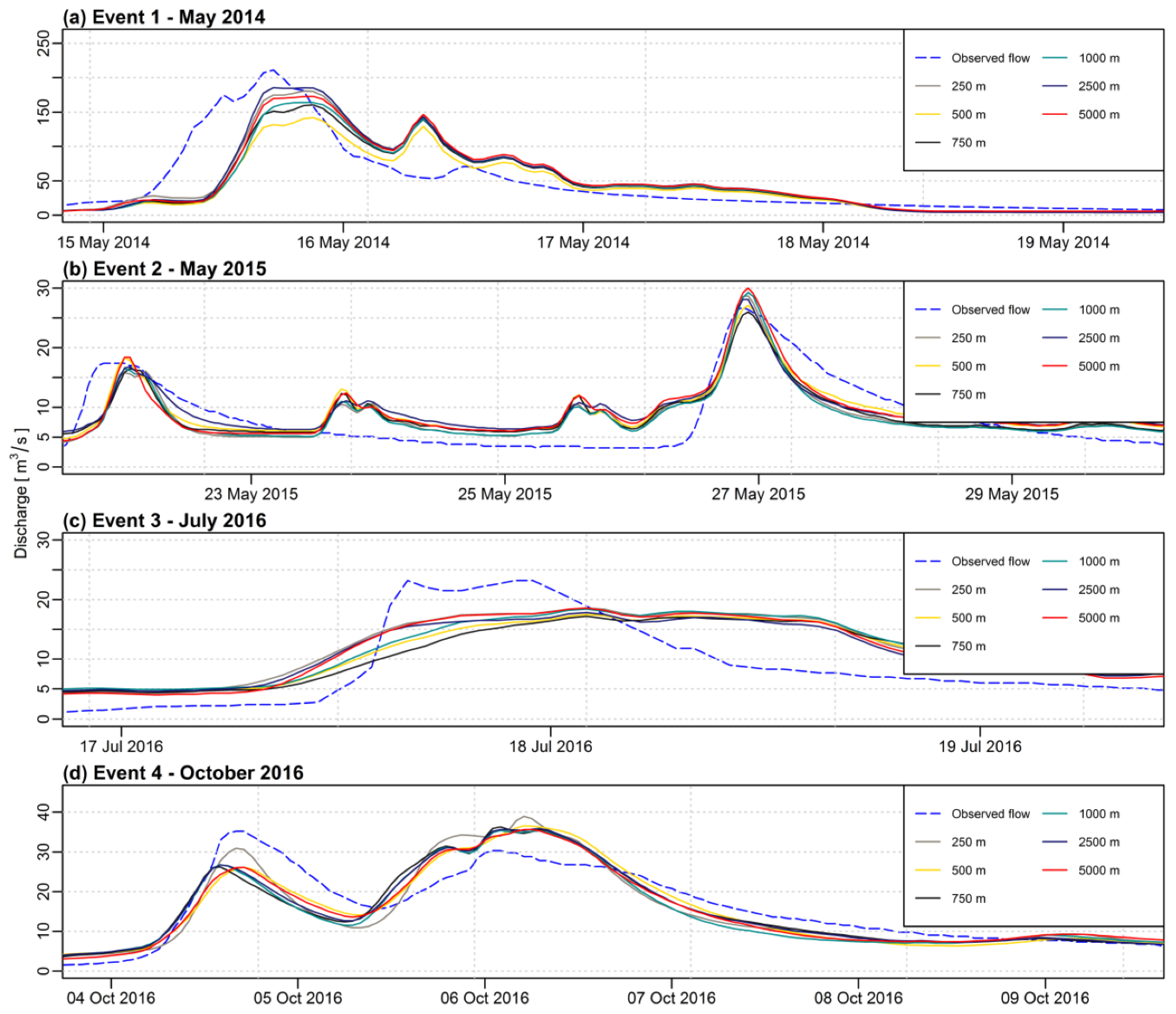
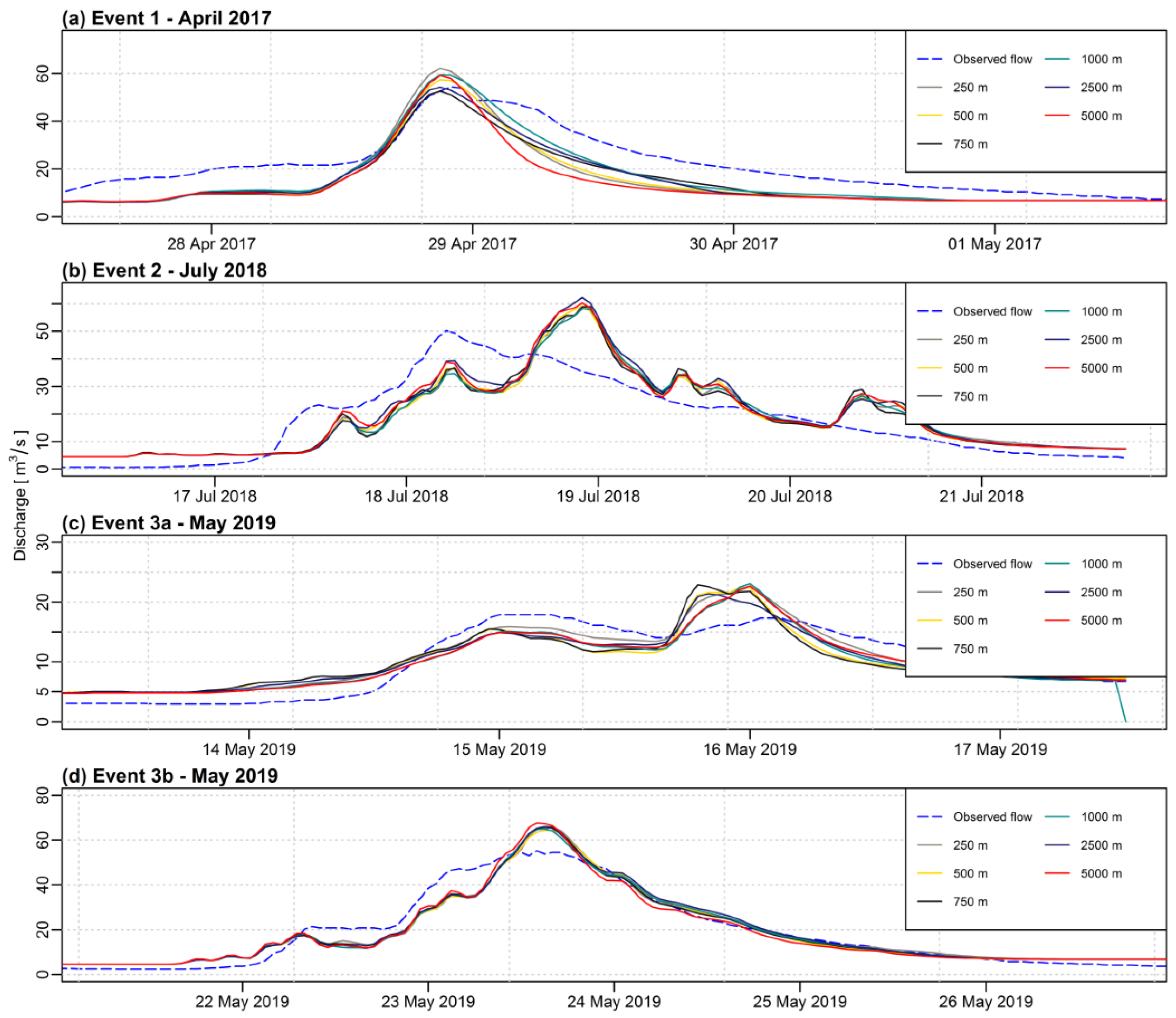
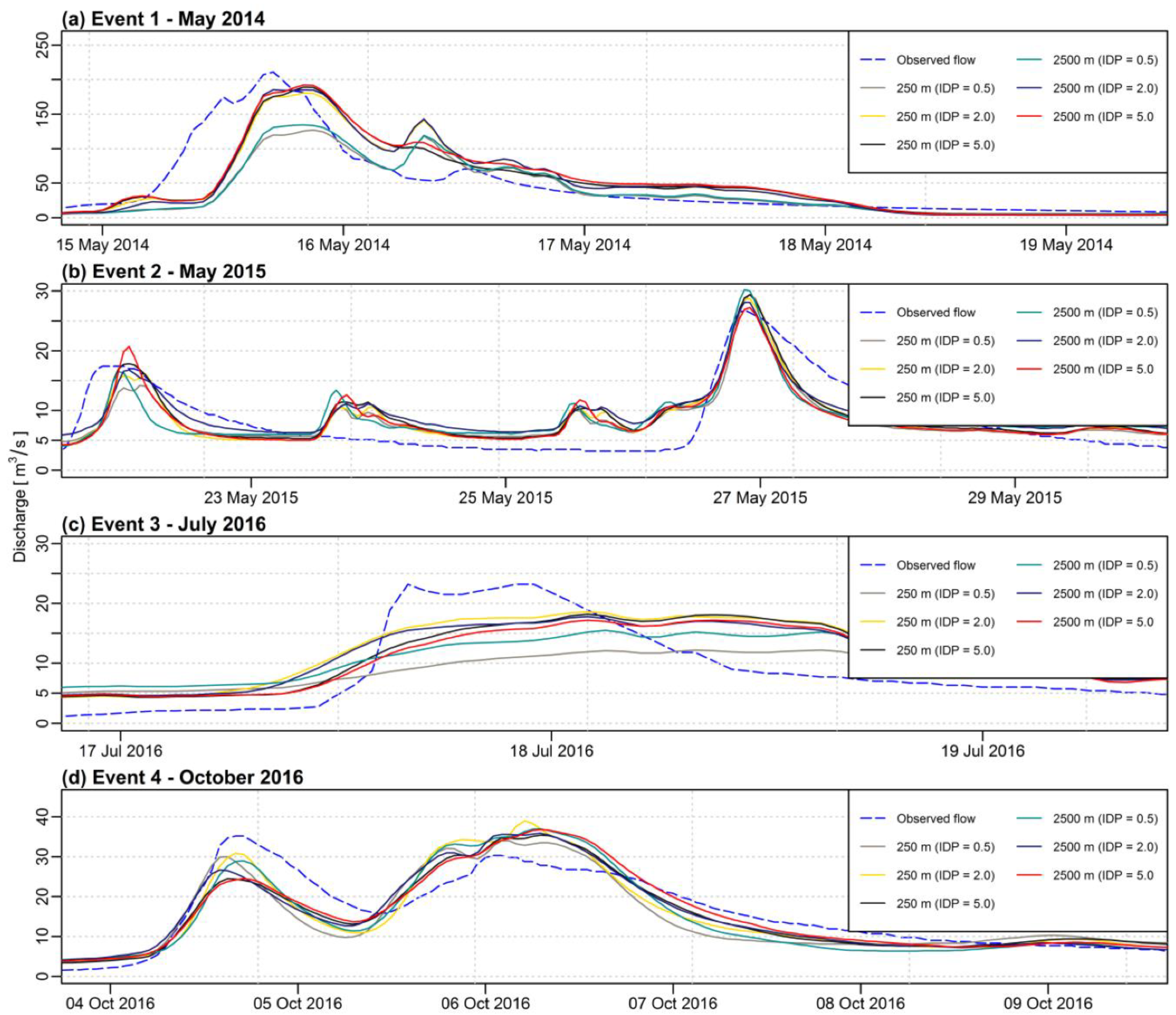
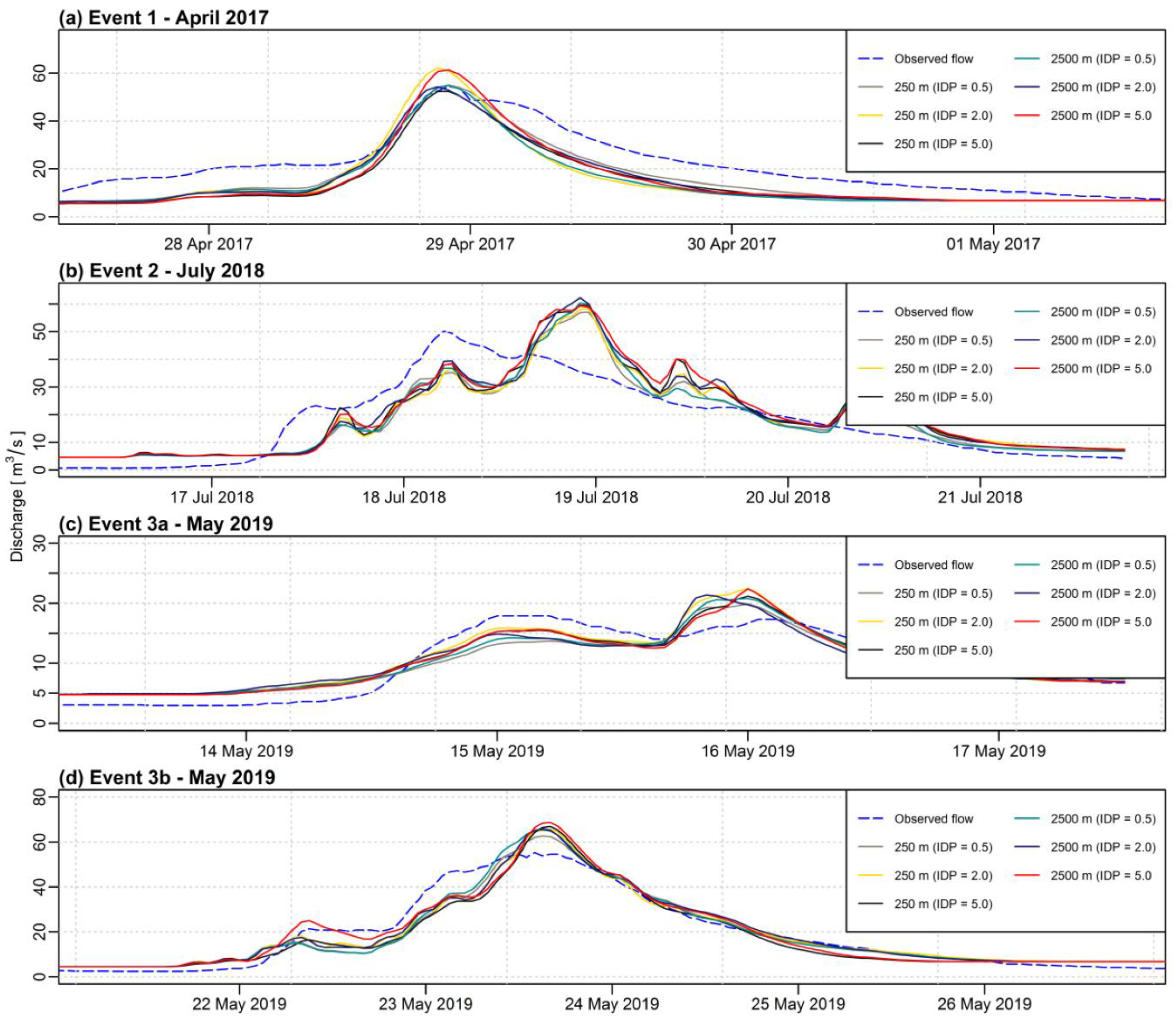
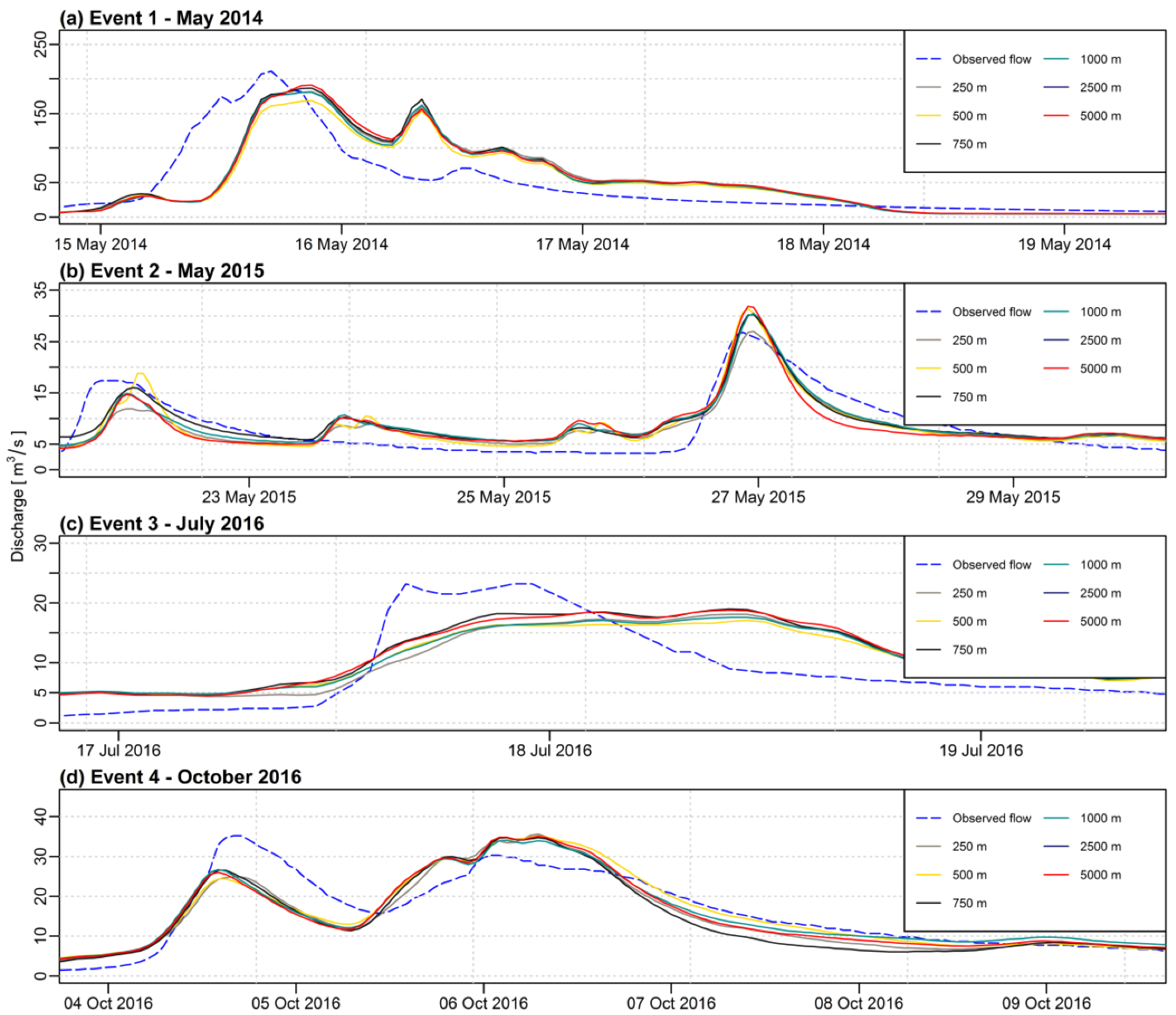
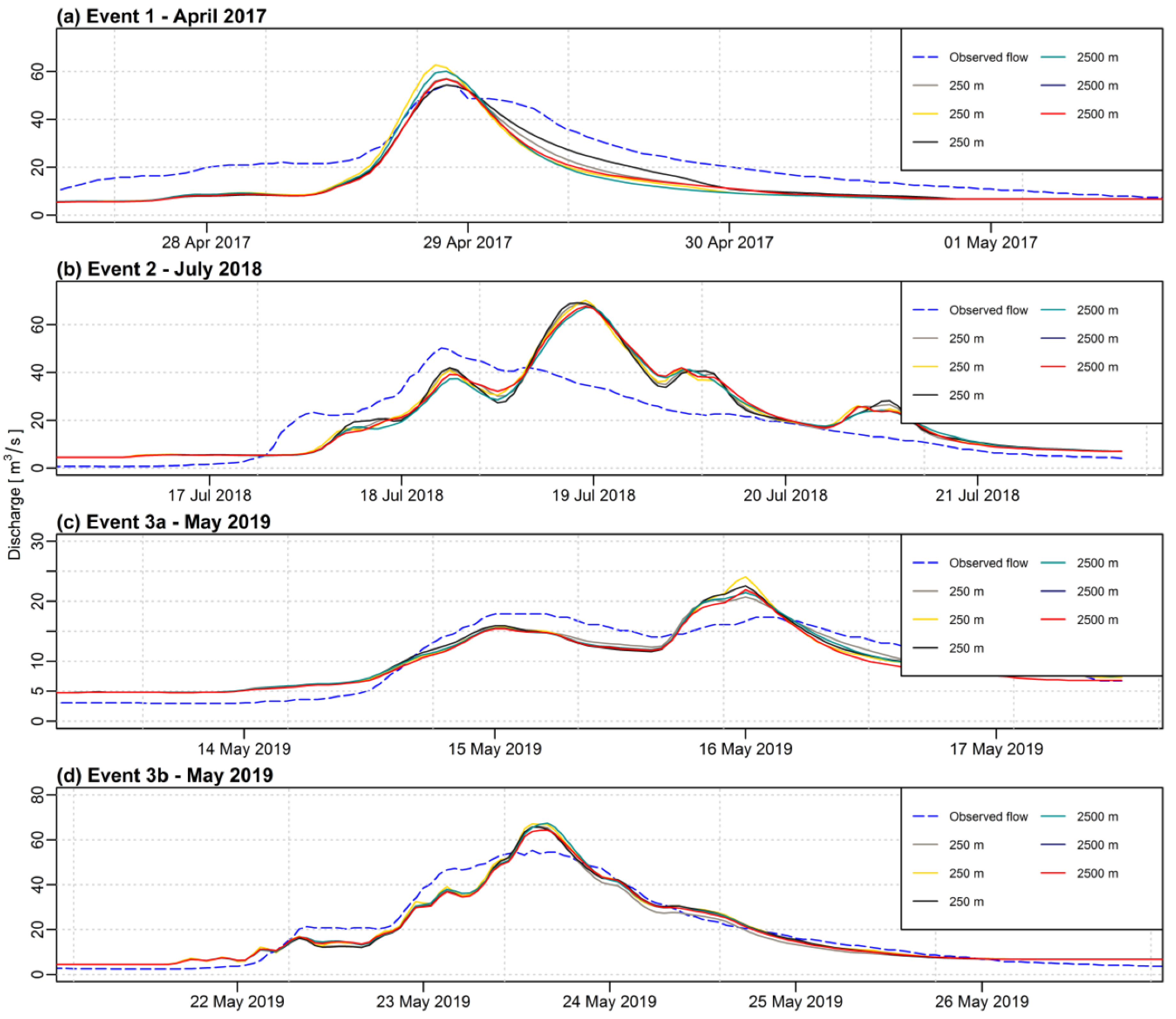
When analyzing
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8, it must be noticed that the curves for various sizes of the grid and different IDP values for the IDW method are very correlated when compared to the curve of the observed flow. Therefore, the choice of a different grid size (or IDP for the IDW method) does not change much the picture with respect to the observed discharge. However, when looking at the data more precisely with statistical analysis, some differences can be detected.
The impact of the grid resolution is more visible for the IDW method than for the first-degree polynomial interpolation. As for the IDW method, the maximum difference for the NSE criterion is 0.26 for both, calibration, and validation phases. For the first-degree polynomial method, the maximum differences for the NSE are 0.12 and 0.16, respectively. As the IDW method is frequently used in hydrological applications, the appropriate choice of the interpolation grid is of particular importance.
Among the analyzed grid resolutions, the best results for the IDW method were obtained for the grids of 250 m and 2500 m (average values of the NSE were 0.62 and 0.65 for the calibration and 0.74 and 0.76 for the validation respectively). For the first-degree polynomial method, higher grid resolutions (smaller or equal to 750 m) outperformed the lower ones (greater or equal to 1000 m). The mean value of the NSE for the calibration phase for grids up to 750 m was 0.63 and 0.67 for validation. As for the lower resolution grids, the results were 0.60 and 0.65 consecutively.
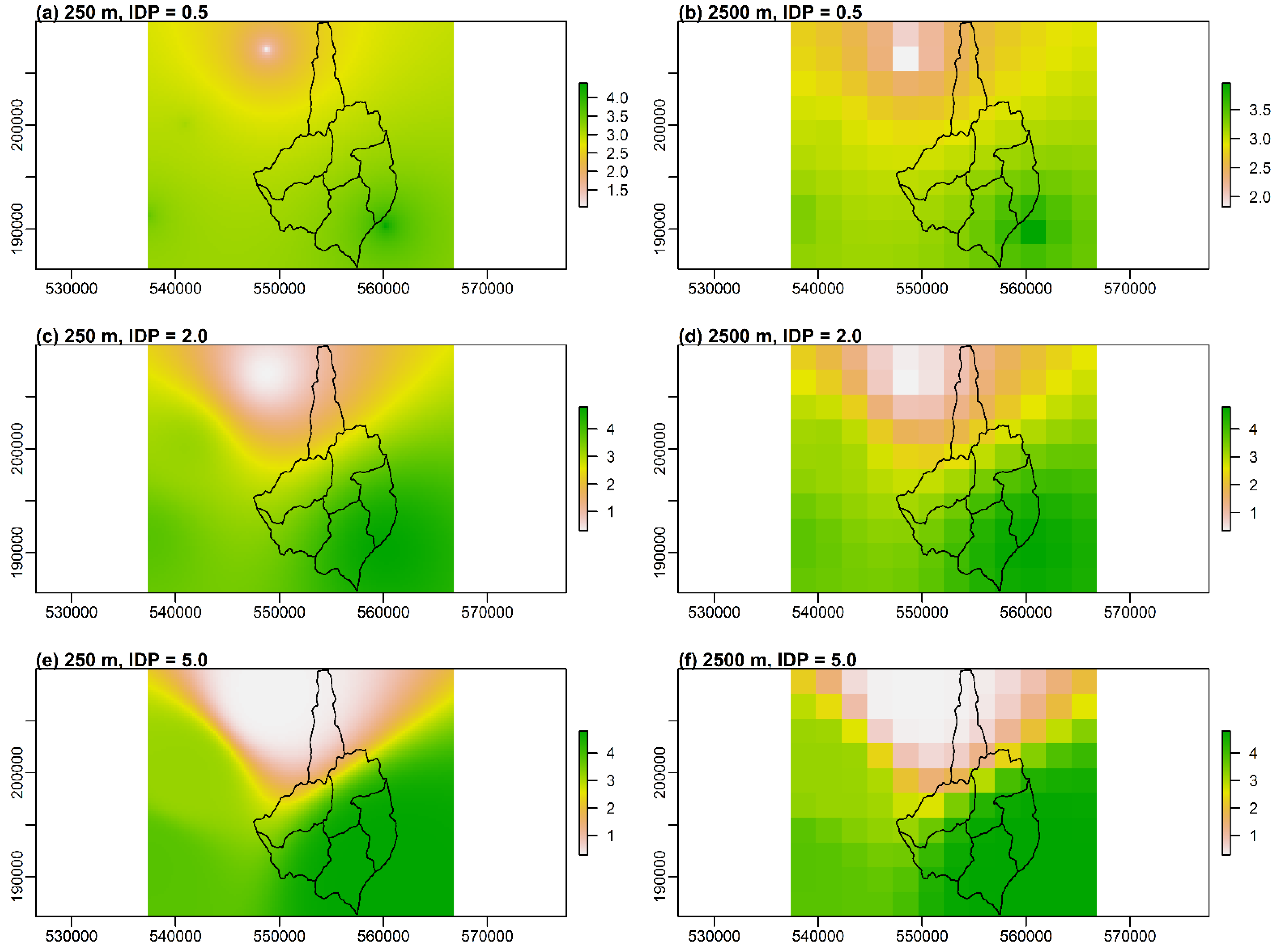
The applied value of the IDP in the IDW method has a significant impact on the outputs of hydrological modeling. In most of the cases, more accurate results were obtained using different values of IDP than traditionally applied value equal to 2.0. Therefore, the choice of the appropriate IDP value when using a semi-distributed hydrological model cannot be neglected and should be taken into account.
The IDP value in the IDW interpolation method has more impact on the simulation results than the grid size. That can be clearly seen when comparing the results presented in
Table 6.
Within the analyzed deterministic interpolation methods, slightly better results were obtained for the first-degree interpolation method than for the IDW interpolation considering the results of the evaluation criteria presented in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8. Tobin et al. [
39] reported that the IDW method tends to significantly underestimate rainfall volume, but this study shows that when using the right grid size and appropriate IDP value, this method can also be effective. It should also be noted (
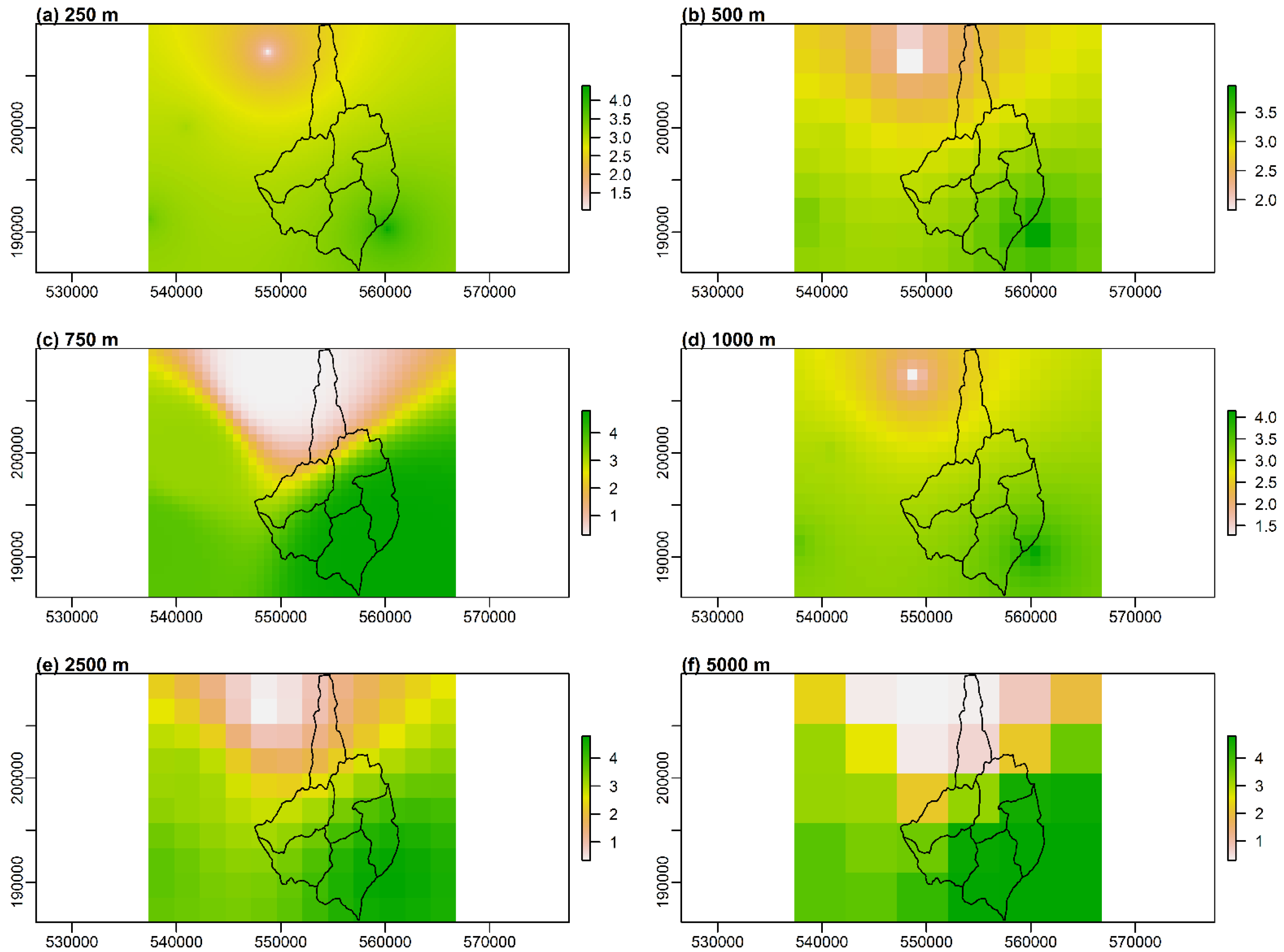
Figure A3) that the first-degree polynomial method can lead to significant underestimation of precipitation over relatively large areas (horizontal), especially when using low-resolution grids.
For small mountainous catchments, the best data source on the precipitation field would be rain gauge data interpolated using the first-degree interpolation method and grid size smaller or equal to 750 m. This method, unlike the IDW, is more straightforward in application, and does not require subjective investigation of the method’s parameters (the IDP value in the IDW interpolation method).
Kling-Gupta efficiency (KGE), which is considered as one of the alternatives to the Nash-Sutcliffe efficiency (NSE), generally tends to provide higher and less varied values, which makes it less useful for the evaluation of the results.
For future works, it will be interesting to investigate whether incorporating other environmental variables or covariates into the precipitation modeling process will lead to better simulation results when using a semi-distributed hydrological model. Apart from that, it would be worth considering other factors during the interpolation process, such as the density of meteorological stations or drainage area. Better simulation results might be obtained when performing validation of the precipitation field before its application into the hydrological model.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}