
Flood Risk Mapping by Remote Sensing Data and Random Forest Technique



Abstract
:1. Introduction
2. Overview of Case Study and Data
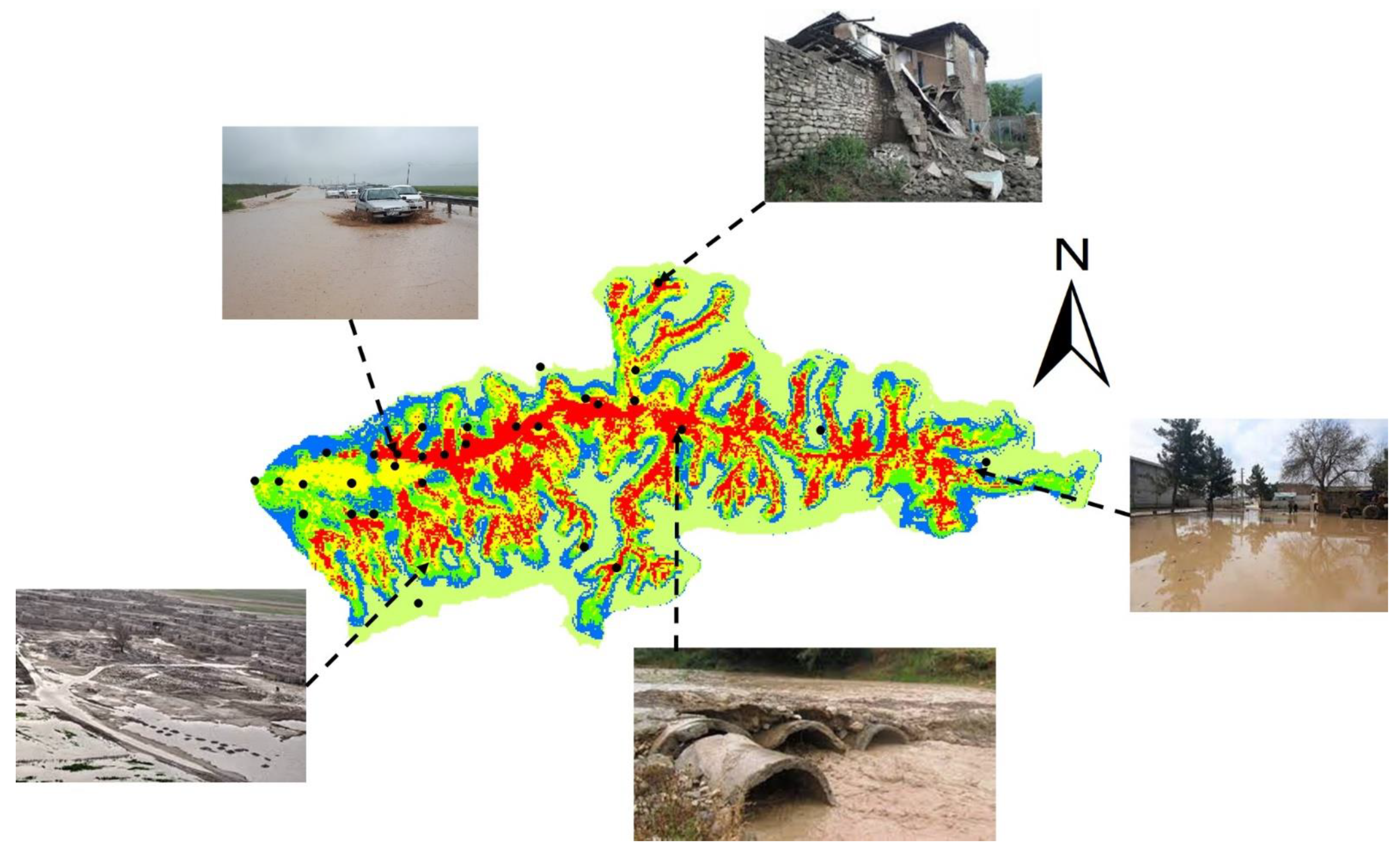
2.1. Research Case Study
2.2. Data
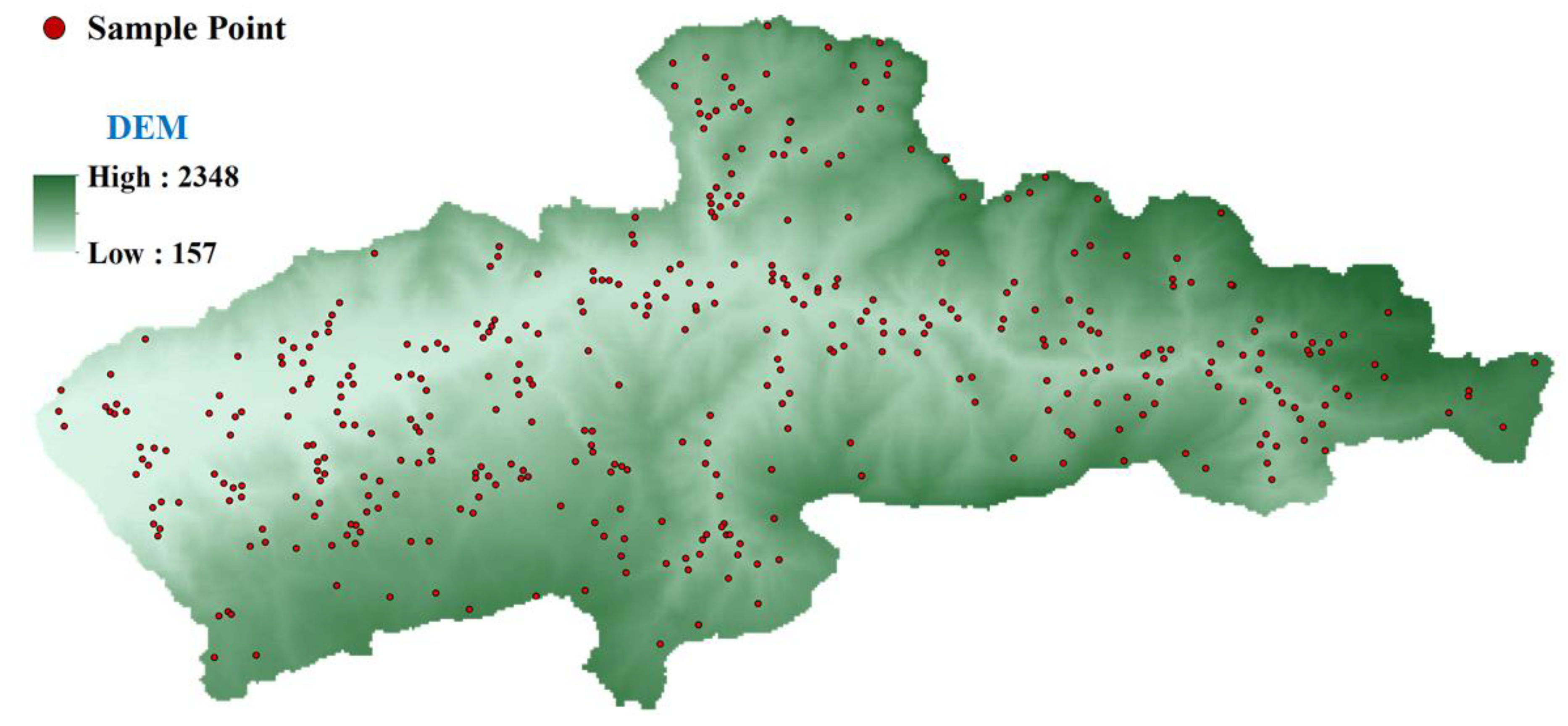
2.2.1. SRTM DEM
2.2.2. Landsat 8 Satellite
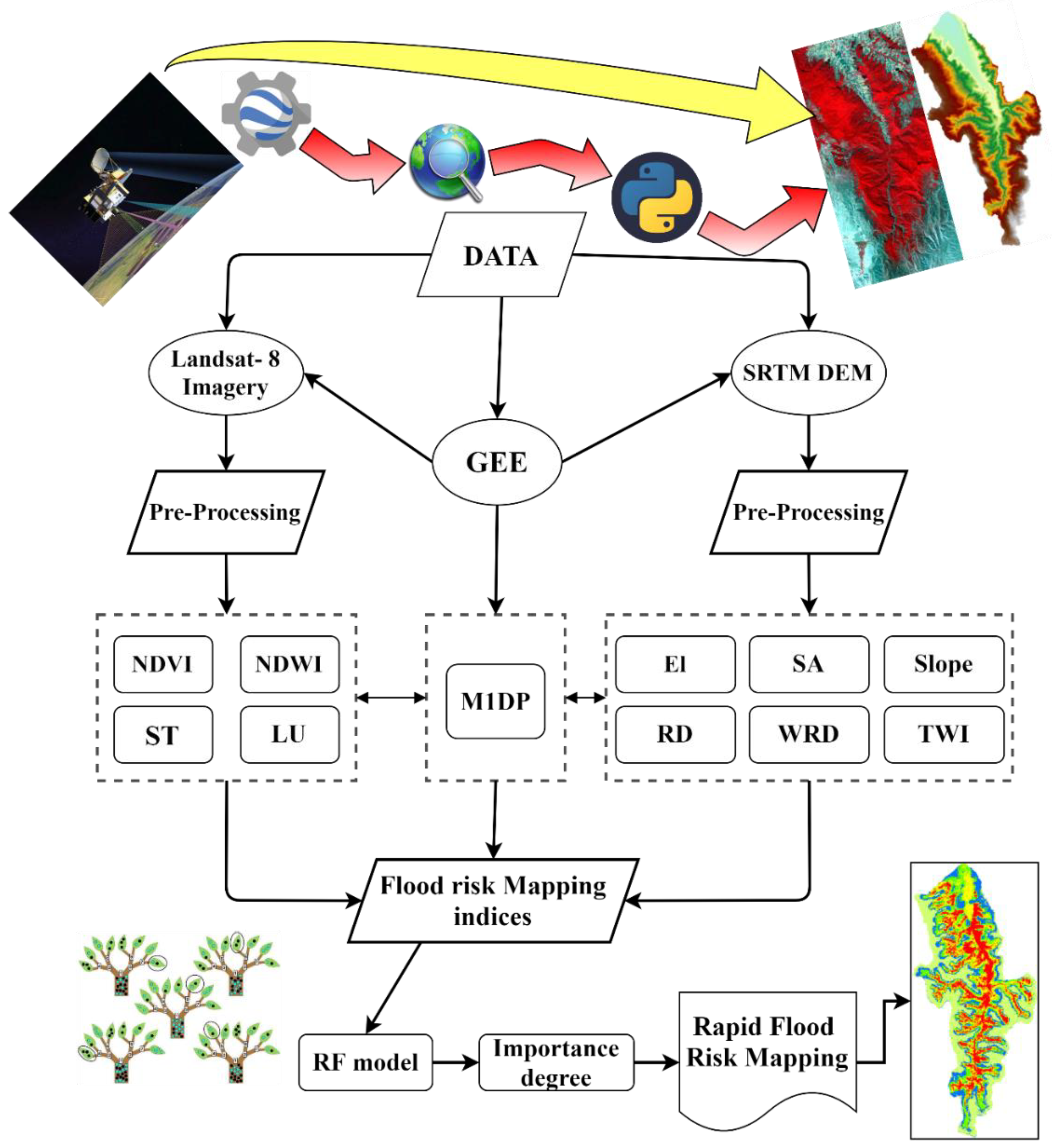
3. Methodology of the Research
3.1. Definition of Indices
3.1.1. Elevation
3.1.2. Slope
3.1.3. Slope Aspect
3.1.4. Land Use
3.1.5. Normalized Differential Vegetation Index
3.1.6. Normalized Difference Water Index
3.1.7. Topographic Wetness Index
3.1.8. River Distance
3.1.9. Waterway and River Distance
3.1.10. Soil Texture
3.1.11. Maximum One-Day Precipitation
3.2. Collection of Training Data
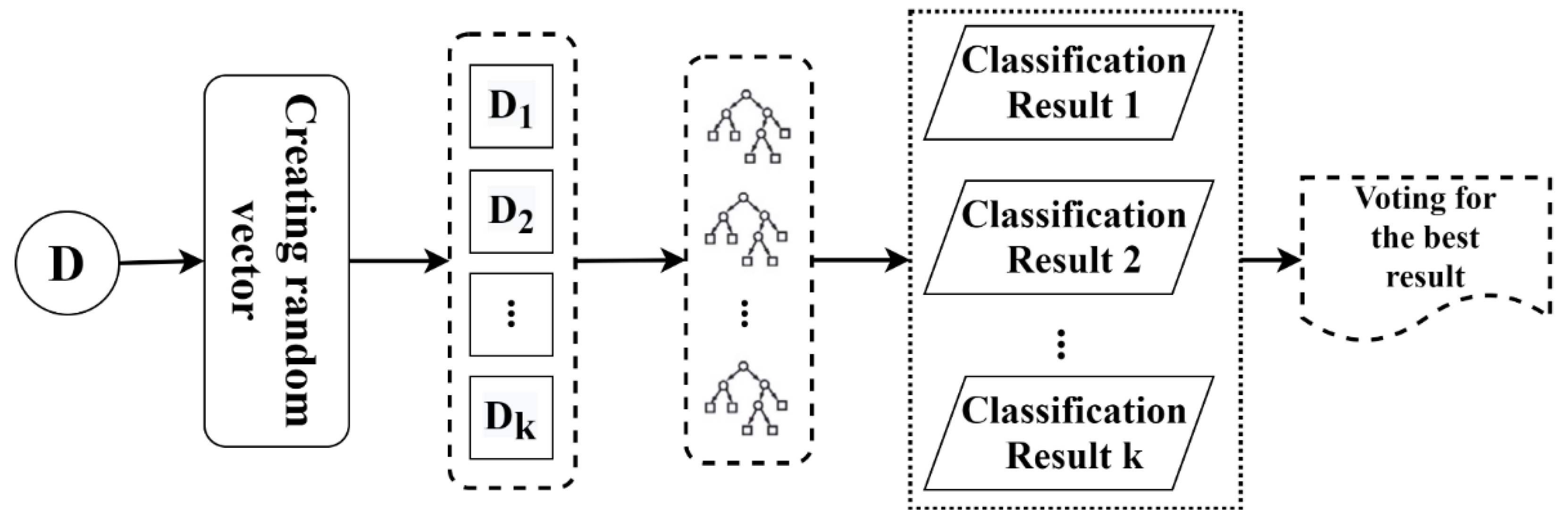
3.3. Implementation of Random Forest
3.4. Flood Risk Mapping and Risk Assessment
3.5. Definition of Error and Index Importance Degree
3.6. Evaluation of the Proposed Model
4. Result and Discussions
4.1. Results of Risk Indices
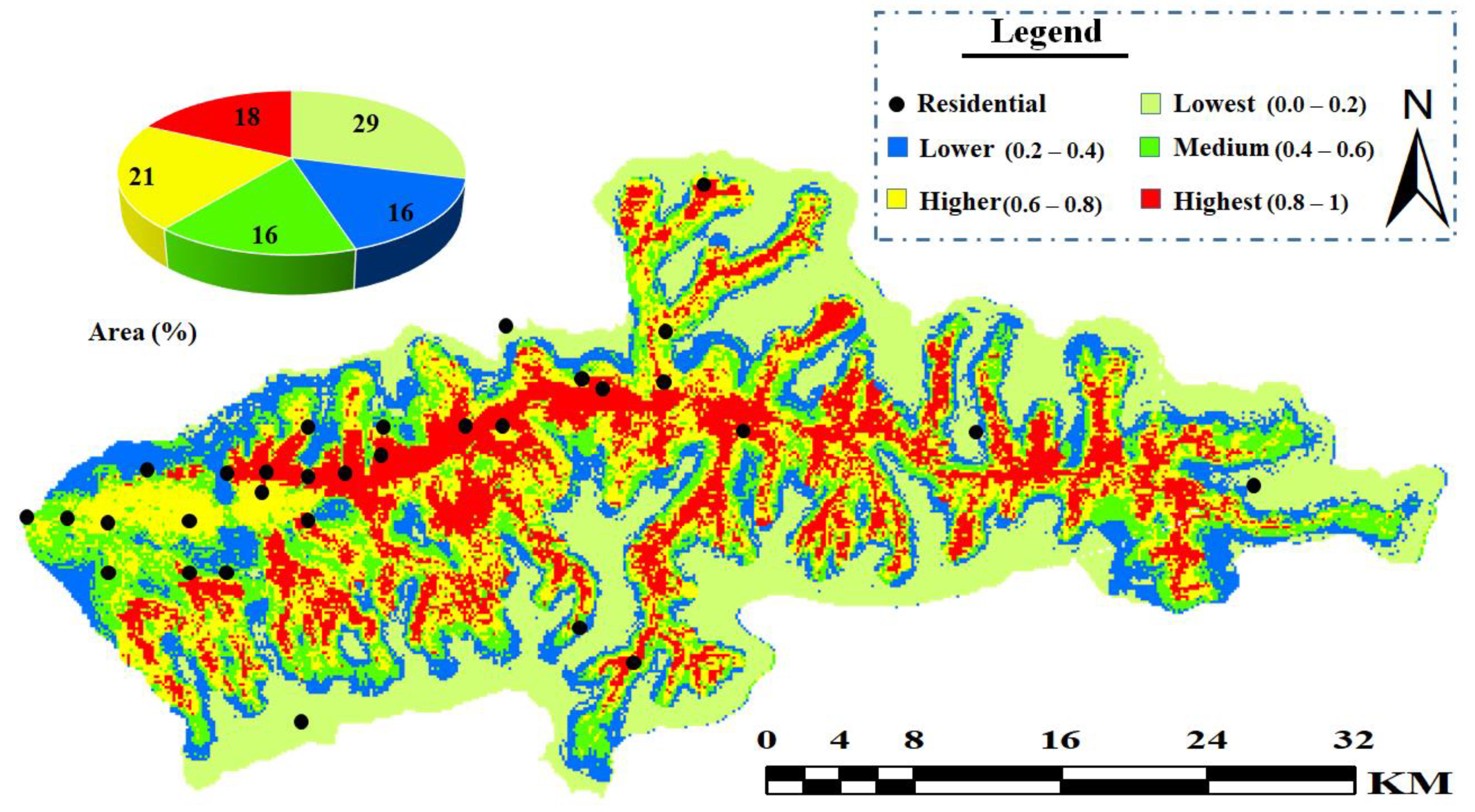
4.2. Flood Risk Mapping
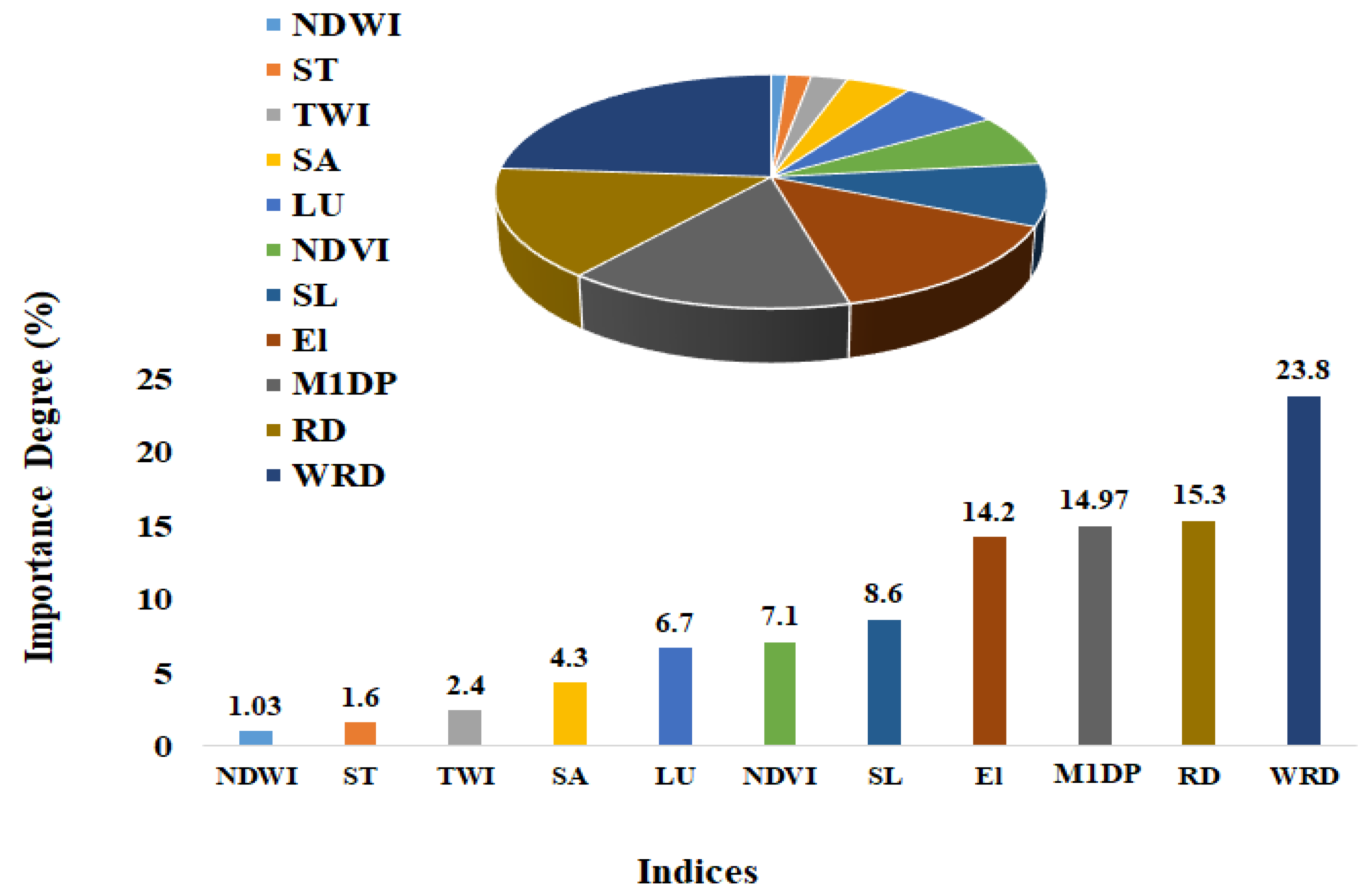
4.3. Index Importance Degree Analysis
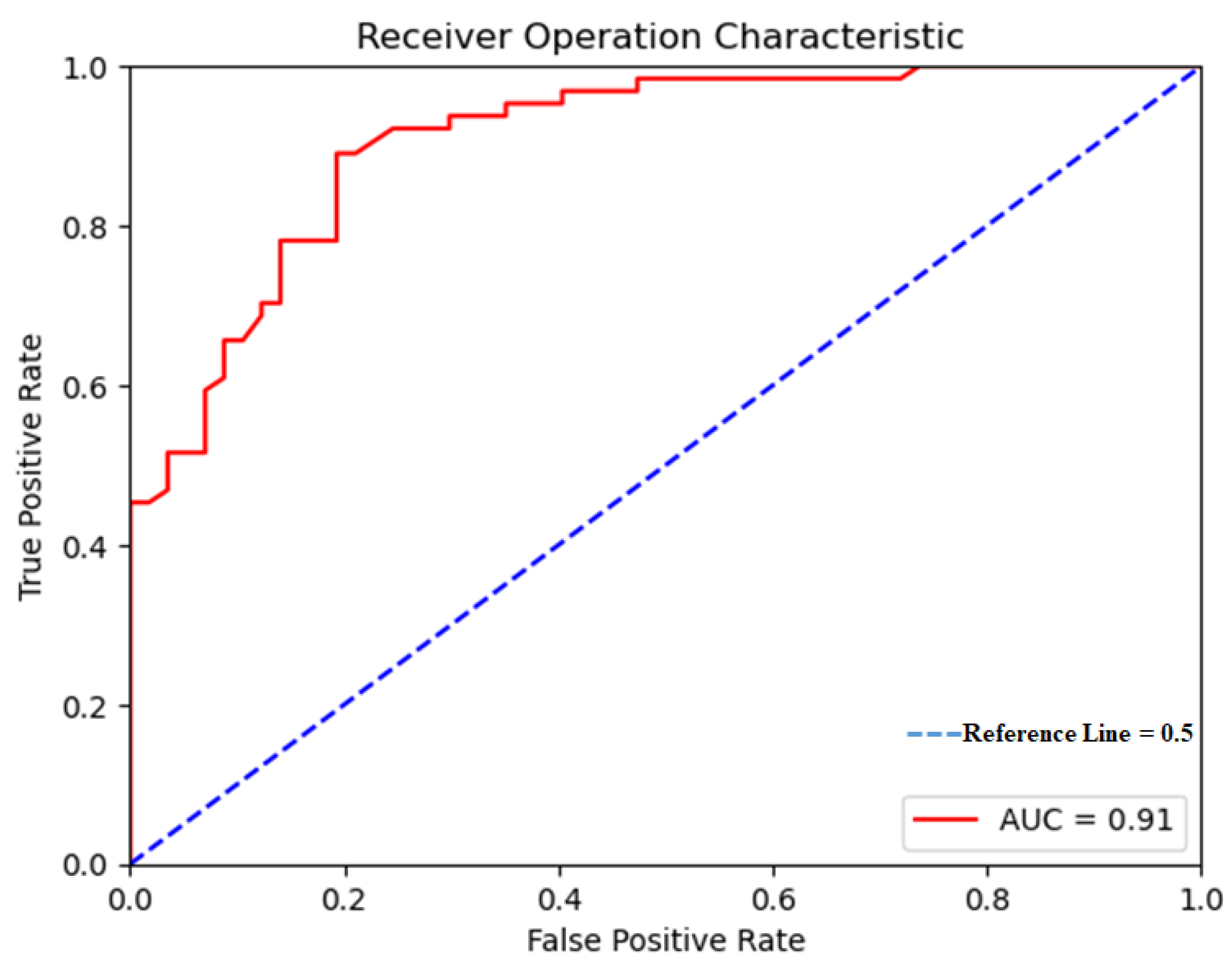
4.4. Assessment of RF Performance
4.5. Comparison of Results with Previous Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Stefanidis, S.; Stathis, D. Assessment of flood hazard based on natural and anthropogenic factors using analytic hierarchy process (AHP). Nat. Hazards 2013, 68, 569–585. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, C.; Xu, K.; Watanabe, M. Flood disaster monitoring and evaluation in China. Glob. Environ. Chang. Part B Environ. Hazards 2002, 4, 33–43. [Google Scholar] [CrossRef]
- Ok, A.O.; Akar, O.; Gungor, O. Evaluation of random forest method for agricultural crop classification. Eur. J. Remote Sens. 2012, 45, 421–432. [Google Scholar] [CrossRef]
- Hallegatte, S.; Green, C.; Nicholls, R.J.; Corfee-Morlot, J. Future flood losses in major coastal cities. Nat. Clim. Chang. 2013, 3, 802–806. [Google Scholar] [CrossRef]
- Costabile, P.; Costanzo, C. A 2D-SWEs framework for efficient catchment-scale simulations: Hydrodynamic scaling properties of river networks and implications for non-uniform grids generation. J. Hydrol. 2021, 599, 126306. [Google Scholar] [CrossRef]
- Afshari, S.; Tavakoly, A.A.; Rajib, M.A.; Zheng, X.; Follum, M.L.; Omranian, E.; Fekete, B.M. Comparison of new generation low-complexity flood inundation mapping tools with a hydrodynamic model. J. Hydrol. 2018, 556, 539–556. [Google Scholar] [CrossRef]
- Papaioannou, G.; Loukas, A.; Vasiliades, L.; Aronica, G.T. Flood inundation mapping sensitivity to riverine spatial resolution and modelling approach. Nat. Hazards 2016, 83, 117–132. [Google Scholar] [CrossRef]
- Petroselli, A.; Vojtek, M.; Vojtekova, J. Flood mapping in small ungauged basins: A comparison of different approaches for two case studies in Slovakia. Hydrol. Res. 2019, 50, 379–392. [Google Scholar] [CrossRef] [Green Version]
- Costabile, P.; Costanzo, C.; Lorenzo, G.D.; Santis, R.D.; Penna, N.; Macchione, F. Terrestrial and airborne laser scanning and 2-D modelling for 3-D flood hazard maps in urban areas: New opportunities and perspectives. Environ. Model. Softw. 2021, 135, 104889. [Google Scholar] [CrossRef]
- Liu, G.; Tong, F.; Tian, B.; Gong, J. Finite element analysis of flood discharge atomization based on water–air two-phase flow. Appl. Math. Model. 2021, 81, 473–486. [Google Scholar] [CrossRef]
- Woodruff, J.L.; Dietrich, J.C.; Wirasaet, D.; Kennedy, A.B.; Bolster, D.; Silver, Z.; Meldin, S.D.; Kolar, R.L. Subgrid corrections in finite-element modeling of storm-driven coastal flooding. Ocean Model. 2021, 167, 101887. [Google Scholar] [CrossRef]
- Dewan, A.M.; Islam, M.M.; Kumamoto, T.; Nishigaki, M. Evaluating flood hazard for land-use planning in Greater Dhaka of Bangladesh using remote sensing and GIS techniques. Water Resour. Manag. 2007, 21, 1601–1612. [Google Scholar] [CrossRef]
- Ji, L.; Zhang, L.; Wylie, B. Analysis of Dynamic Thresholds for the Normalized Difference Water Index. Photogramm. Eng. Remote Sens. 2009, 75, 1307–1317. [Google Scholar] [CrossRef]
- Proud, S.R.; Fensholt, R.; Rasmussen, L.V.; Sandholt, I. Rapid response flood detection using the MSG geostationary satellite. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 536–544. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Xu, L. Assessment of urban flood susceptibility using semi-supervised machine learning model. Sci. Total. Environ. 2019, 659, 940–949. [Google Scholar] [CrossRef]
- Dodangeh, E.; Choubin, B.; Eigdir, A.N.; Nabipour, N.; Panahi, M.; Shamshirband, S.; Mosavi, A. Integrated machine learning methods with resampling algorithms for flood susceptibility prediction. Sci. Total Environ. 2020, 705, 135983. [Google Scholar] [CrossRef]
- Baig, M.A.; Xiong, D.; Rahman, M.; Islam, M.M.; Elbeltagi, A.; Yigez, B.; Rai, D.K.; Tayab, M.; Dewan, A. How Do Multiple Kernel Functions in Machine Learning Algorithms Improve Precision in Flood Probability Mapping? Research Square: Durham, NC, USA, 2021. [Google Scholar] [CrossRef]
- Bourenane, H.; Bouhadad, Y.; Guettouche, M.S. Flood hazard mapping in urban area using the hydrogeomorphological approach: Case study of the Boumerzoug and Rhumel alluvial plains (Constantine city, NE Algeria). J. Afr. Earth Sci. 2019, 160, 103602. [Google Scholar] [CrossRef]
- Bui, D.T.; Hoang, N.-D.; Martínez-Álvarez, F.; Ngo, P.-T.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A novel deep learning neural network approach for predicting flash flood susceptibility: A case study at a high frequency tropical storm area. Sci. Total Environ. 2020, 701, 134413. [Google Scholar]
- Guo, E.; Zhang, J.; Ren, X.; Zhang, Q.; Sun, Z. Integrated risk assessment of flood disaster based on improved set pair analysis and the variable fuzzy set theory in central Liaoning Province, China. Nat. Hazards 2014, 74, 947–965. [Google Scholar] [CrossRef]
- Ogato, G.S.; Bantider, A.; Abebe, K.; Geneletti, D. Geographic information system (GIS)-Based multicriteria analysis of flooding hazard and risk in Ambo Town and its watershed, West shoa zone, oromia regional State, Ethiopia. J. Hydrol. Reg. Stud. 2020, 27, 100659. [Google Scholar] [CrossRef]
- Seejata, K.; Yodying, A.; Wongthadam, T.; Mahavik, N.; Tantanee, S. Assessment of flood hazard areas using analytical hierarchy process over the Lower Yom Basin, Sukhothai Province. Procedia Eng. 2018, 212, 340–347. [Google Scholar] [CrossRef]
- Soltani, K.; Ebtehaj, I.; Amiri, A.; Azari, A.; Gharabaghi, B.; Bonakdari, H. Mapping the spatial and temporal variability of flood susceptibility using remotely sensed normalized difference vegetation index and the forecasting changes in the future. Sci. Total Environ. 2021, 770, 145288. [Google Scholar] [CrossRef]
- Chakraborty, R.; Rahmoune, R.; Ferrazzoli, P. Use of passive microwave signatures to detect and monitor flooding events in Sundarban Delta. In 2011 IEEE International Geoscience and Remote Sensing Symposium; IEEE: Piscataway, NJ, USA, 2011; pp. 3066–3069. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Huntington, J.L.; Hegewisch, K.C.; Daudert, B.; Morton, C.G.; Abatzoglou, J.T.; McEvoy, D.J.; Erickson, T. Climate Engine: Cloud Computing and Visualization of Climate and Remote Sensing Data for Advanced Natural Resource Monitoring and Process Understanding. Bull. Am. Meteorol. Soc. 2017, 98, 2397–2410. [Google Scholar] [CrossRef]
- Kumar, L.; Mutanga, O. Google Earth Engine Applications, 1st ed.; MDPI: Basel, Switzerland, 2019. [Google Scholar]
- Wang, J.; Yi, S.; Li, M.; Wang, L.; Song, C. Effects of sea level rise, land subsidence, bathymetric change and typhoon tracks on storm flooding in the coastal areas of Shanghai. Sci. Total Environ. 2018, 621, 228–234. [Google Scholar] [CrossRef] [PubMed]
- Kumar, L.; Mutanga, O. Google Earth Engine Applications Since Inception: Usage, Trends, and Potential. Remote Sens. 2018, 10, 1509. [Google Scholar] [CrossRef] [Green Version]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Homayouni, S.; Gill, E. The First Wetland Inventory Map of Newfoundland at a Spatial Resolution of 10 m Using Sentinel-1 and Sentinel-2 Data on the Google Earth Engine Cloud Computing Platform. Remote Sens. 2018, 11, 43. [Google Scholar] [CrossRef] [Green Version]
- Tamiminia, H.; Salehi, B.; Mahdianpari, M.; Quackenbush, L.; Adeli, S.; Brisco, B. Google Earth Engine for geo-big data applications: A meta-analysis and systematic review. ISPRS J. Photogramm. Remote Sens. 2020, 164, 152–170. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Rezaie Farhadabad, A.; Kerle, N. Post-disaster recovery monitoring with google earth engine. Appl. Sci. 2020, 10, 4574. [Google Scholar] [CrossRef]
- Chung, H.W.; Liu, C.C.; Cheng, I.F.; Lee, Y.R.; Shieh, M.C. Rapid response to a typhoon-induced flood with an SAR-derived map of inundated areas: Case study and validation. Remote Sens. 2015, 7, 11954–11973. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.-C.; Shieh, M.-C.; Ke, M.-S.; Wang, K.-H. Flood Prevention and Emergency Response System Powered by Google Earth Engine. Remote. Sens. 2018, 10, 1283. [Google Scholar] [CrossRef] [Green Version]
- Fernández, D.; Lutz, M. Urban flood hazard zoning in Tucumán Province, Argentina, using GIS and multicriteria decision analysis. Eng. Geol. 2010, 111, 90–98. [Google Scholar] [CrossRef]
- Yang, X.L.; Ding, J.H.; Hou, H. Application of a triangular fuzzy AHP approach for flood risk evaluation and response measures analysis. Nat. Hazards 2013, 68, 657–674. [Google Scholar] [CrossRef]
- Guerriero, L.; Ruzza, G.; Guadagno, F.M.; Revellino, P. Flood hazard mapping incorporating multiple probability models. J. Hydrol. 2020, 587, 125020. [Google Scholar] [CrossRef]
- Eini, M.; Kaboli, H.S.; Rashidian, M.; Hedayat, H. Hazard and vulnerability in urban flood risk mapping: Machine learning techniques and considering the role of urban districts. Int. J. Disaster Risk Reduct. 2020, 50, 101687. [Google Scholar] [CrossRef]
- Li, X.; Yeh, A.G.-O. Neural-network-based cellular automata for simulating multiple land use changes using GIS. Int. J. Geogr. Inf. Sci. 2002, 16, 323–343. [Google Scholar] [CrossRef]
- Deng, W.; Zhou, J. Approach for feature weighted support vector machine and its application in flood disaster evaluation. Disaster Adv. 2013, 6, 51–58. [Google Scholar]
- Merz, B.; Kreibich, H.; Lall, U. Multi-variate flood damage assessment: A tree-based data-mining approach. Nat. Hazards Earth Syst. Sci. 2013, 13, 53–64. [Google Scholar] [CrossRef]
- Tesfamariam, S.; Liu, Z. Earthquake induced damage classification for reinforced concrete buildings. Struct. Saf. 2010, 32, 154–164. [Google Scholar] [CrossRef]
- Dong, L.J.; Li, X.B.; Peng, K. Prediction of rockburst classification using Random Forest. Trans. Nonferrous Met. Soc. China 2013, 23, 472–477. [Google Scholar] [CrossRef]
- Immitzer, M.; Atzberger, C.; Koukal, T. Tree Species Classification with Random Forest Using Very High Spatial Resolution 8-Band WorldView-2 Satellite Data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef] [Green Version]
- Denga, H.; Runger, G. Gene selection with guided regularized random forest. Pattern. Recognit. 2013, 46, 3483–3489. [Google Scholar] [CrossRef] [Green Version]
- Feng, Q.; Liu, J.; Gong, J. Urban Flood Mapping Based on Unmanned Aerial Vehicle Remote Sensing and Random Forest Classifier—A Case of Yuyao, China. Water 2015, 7, 1437–1455. [Google Scholar] [CrossRef]
- Mihailescu, D.M.; Gui, V.; Toma, C.I.; Popescu, A.; Sporea, I. Computer aided diagnosis method for steatosis rating in ultrasound images using random forests. Med. Ultrason. 2013, 15, 184–190. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Wu, Q. Geemap: A Python package for interactive mapping with Google Earth Engine. J. Open Source Softw. 2020, 5, 2305. [Google Scholar] [CrossRef]
- Zielinski, R.; Chmiel, J. Vertical accuracy assessment of SRTM C-band DEM data for different terrain characteristics. In New Developments and Challenges in Remote Sensin, Bochenek, Z., Ed.; Millpress: Rotterdam, The Netherlands, 2007; pp. 685–693. [Google Scholar]
- Zhang, K.; Gann, D.; Ross, M.; Robertson, Q.; Sarmiento, J.; Santana, S.; Rhome, J.; Fritz, C. Accuracy assessment of ASTER, SRTM, ALOS, and TDX DEMs for Hispaniola and implications for mapping vulnerability to coastal flooding. Remote Sens. Environ. 2019, 225, 290–306. [Google Scholar] [CrossRef]
- Goward, S.N.; Markham, B.; Dye, D.G.; Dulaney, W.; Yang, J. Normalized difference vegetation index measurements from the Advanced Very High Resolution Radiometer. Remote Sens. Environ. 1991, 35, 257–277. [Google Scholar] [CrossRef]
- Avand, M.; Moradi, H.; Ramazanzadeh lasboyee, M. Using Machine Learning Models, Remote Sensing, and GIS to Investigate the Effects of Changing Climates and Land Uses on Flood Probability. J. Hydrol. 2021, 595, 125663. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Lucà, F.; Conforti, M.; Robustelli, G. Comparison of GIS-based gullying susceptibility mapping using bivariate and multivariate statistics: Northern Calabria, South Italy. Geomorphology 2011, 134, 297–308. [Google Scholar] [CrossRef]
- Nachtergaele, F.O.; van Velthuizen, H.T.; Verelst, L. Harmonized World Soil Database; FAO: Rome, Italy; IIASA: Laxenburg; Austria, 2009. [Google Scholar]
- Wang, Z.; Lai, C.; Chen, X.; Yang, B.; Zhao, S.; Bai, X. Flood hazard risk assessment model based on random forest. J. Hydrol. 2015, 527, 1130–1141. [Google Scholar] [CrossRef]
- Youssef, A.M.; Hegab, M.A. Flood-Hazard Assessment Modeling Using Multicriteria Analysis and GIS: A Case Study—Ras Gharib Area, Egypt. In Spatial Modeling in GIS and R for Earth and Environmental Sciences; Elsevier: Amsterdam, The Netherlands, 2019; pp. 229–257. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Yu, P.S.; Yang, T.C.; Chen, S.Y.; Kuo, C.M.; Tseng, H.W. Comparison of random forests and support vector machine for real-time radar-derived rainfall forecasting. J. Hydrol. 2017, 552, 92–104. [Google Scholar] [CrossRef]
- Yeh, C.-C.; Chi, D.-J.; Lin, Y.-R. Going-concern prediction using hybrid random forests and rough set approach. Inf. Sci. 2014, 254, 98–110. [Google Scholar] [CrossRef]
- Ai, F.F.; Bin, J.; Zhang, Z.M.; Huang, J.H.; Wang, J.B.; Liang, Y.Z.; Yu, L.; Yang, Z. Application of random forests to select premium quality vegetable oils by their fatty acid composition. Food Chem. 2014, 143, 472–478. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Pradhan, B. Landslide hazard mapping at Selangor, Malaysia using frequency ratio and logistic regression models. Landslides 2007, 4, 33–41. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Pradhan, B.; Gokceoglu, C. Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat. Hazards 2012, 63, 965–996. [Google Scholar] [CrossRef]
- Emamgholizadeh, S.; Kashi, H.; Marofpoor, I.; Zalaghi, E. Prediction of water quality parameters of Karoon River (Iran) by artificial intelligence-based models. Int. J. Environ. Sci. Technol. 2014, 11, 645–656. [Google Scholar] [CrossRef] [Green Version]
- Aryafar, A.; Khosravi, V.; Hooshfar, F. GIS-based comparative characterization of groundwater quality of Tabas basin using multivariate statistical techniques and computational intelligence. Int. J. Environ. Sci. Technol. 2019, 16, 6277–6290. [Google Scholar] [CrossRef]
- Aryafar, A.; Khosravi, V.; Zarepourfard, H.; Rooki, R. Evolving genetic programming and other AI-based models for estimating groundwater quality parameters of the Khezri plain, Eastern Iran. Environ. Earth Sci. 2019, 78, 69. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, G.; Amankwah, S.O.Y.; Wei, X.; Hu, Y.; Feng, A. Monitoring the summer flooding in the Poyang Lake area of China in 2020 based on Sentinel-1 data and multiple convolutional neural networks. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102400. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite/Sensor | Band Name | Wavelength | Resolution | |
|---|---|---|---|---|
| Landsat 8/OLI | Band-1 | Coastal/Aerosol | 0.43–0.45 | 30 |
| Band-2 | Blue | 0.45–0.51 | 30 | |
| Band-3 | Green | 0.53–0.59 | 30 | |
| Band-4 | Red | 0.64–0.67 | 30 | |
| Band-5 | Near Infrared (NIR) | 0.85–0.88 | 30 | |
| Band-6 | Shortwave Infrared (SWIR) 1 | 1.57–1.65 | 30 | |
| Band-7 | Shortwave Infrared (SWIR) 2 | 2.11–2.29 | 30 | |
| Band-8 | Panchromatic | 0.50–0.68 | 30 | |
| Band-9 | Cirrus | 1.36–1.38 | 30 | |
| Band-10 | Thermal Infrared (TIRS) 1 | 10.6–11.19 | 100 × (30) | |
| Band-11 | Thermal Infrared (TIRS) 2 | 11.5–12.51 | 100 × (30) | |
| Land Use | Forest | Shrub | Herbaceous | Agriculture Land | Cropland | Bare Area | Urban | Water (River) |
|---|---|---|---|---|---|---|---|---|
| Runoff Coefficient | 0.15 | 0.18 | 0.2 | 0.4 | 0.6 | 0.7 | 0.9 | 1 |
| Identification Number of Class | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Type | Alfisols | Entisols | Mollisols |
|---|---|---|---|
| Texture | Silt | Clay | Sandy clay |
| Indentification Number of Class | 6 | 3 | 8 |
| Infiltration Level | Moderate | Low | High |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farhadi, H.; Najafzadeh, M. Flood Risk Mapping by Remote Sensing Data and Random Forest Technique. Water 2021, 13, 3115. https://doi.org/10.3390/w13213115
Farhadi H, Najafzadeh M. Flood Risk Mapping by Remote Sensing Data and Random Forest Technique. Water. 2021; 13(21):3115. https://doi.org/10.3390/w13213115
Chicago/Turabian StyleFarhadi, Hadi, and Mohammad Najafzadeh. 2021. "Flood Risk Mapping by Remote Sensing Data and Random Forest Technique" Water 13, no. 21: 3115. https://doi.org/10.3390/w13213115
APA StyleFarhadi, H., & Najafzadeh, M. (2021). Flood Risk Mapping by Remote Sensing Data and Random Forest Technique. Water, 13(21), 3115. https://doi.org/10.3390/w13213115