
Clustering Simultaneous Occurrences of the Extreme Floods in the Neckar Catchment


Abstract
:1. Introduction
2. Data and Case Study
2.1. Data
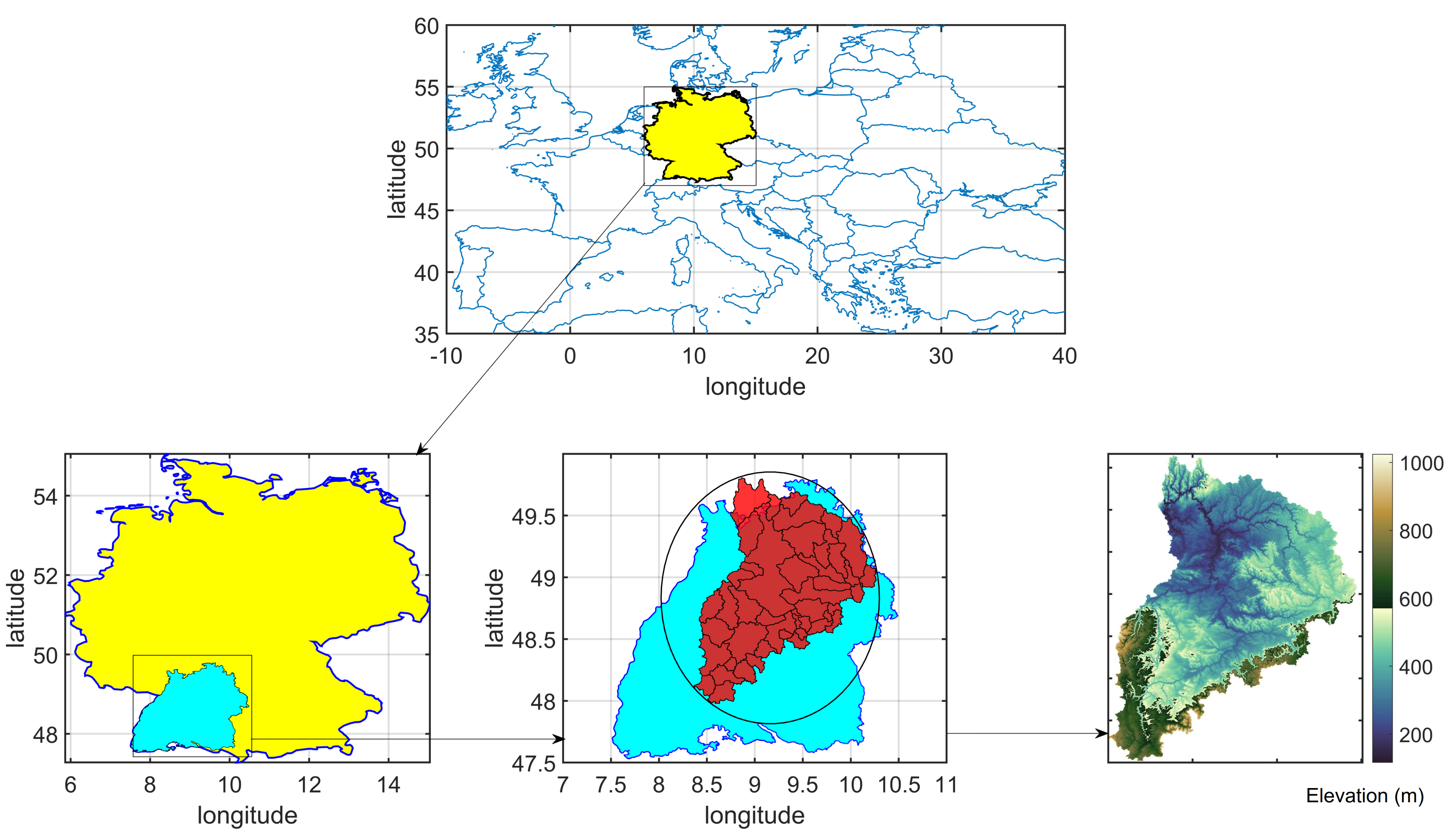
2.2. Case Study
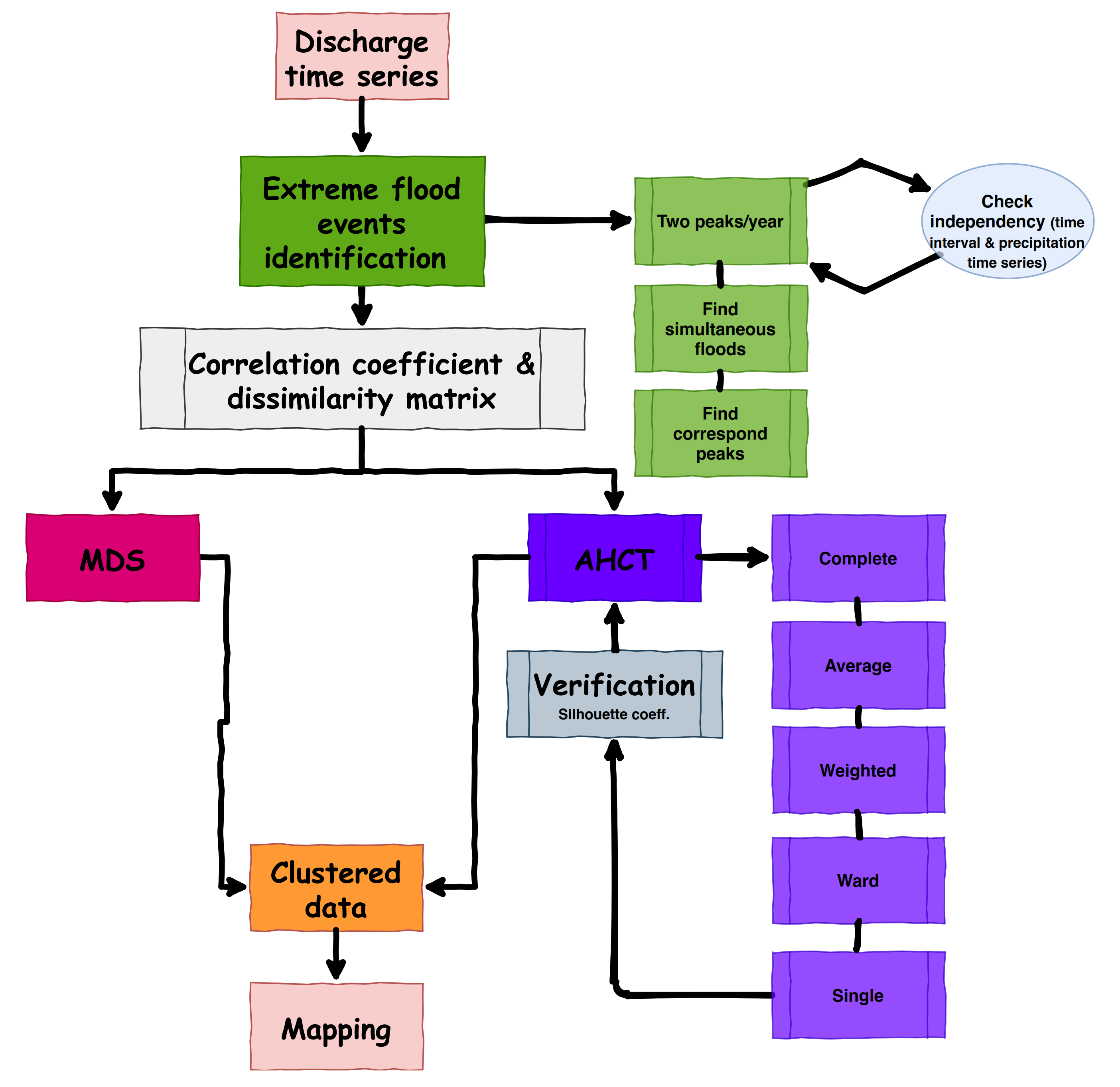
3. Methodology
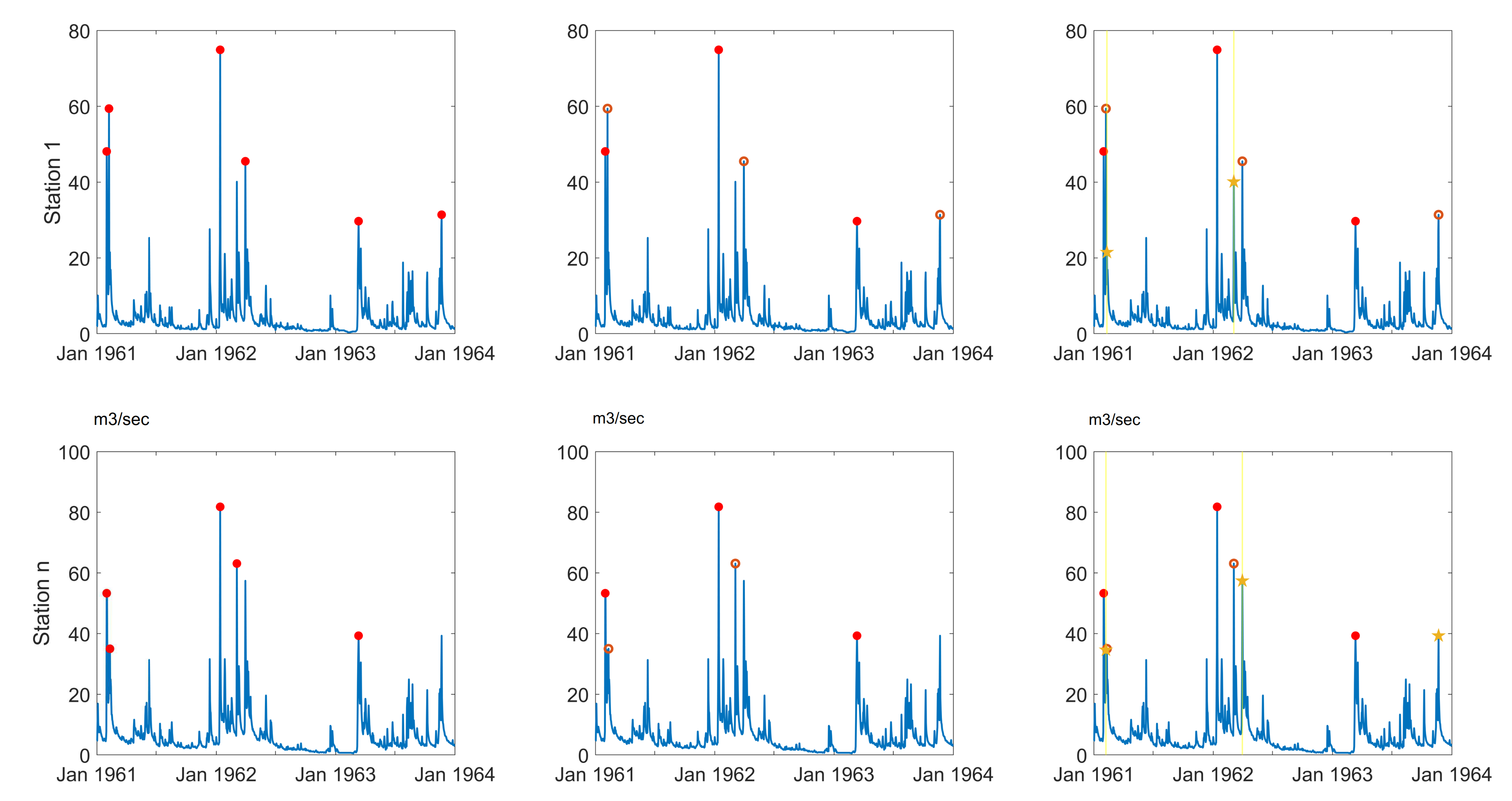
3.1. Flood Events Identification
3.2. Simultaneous Events and Their Corresponding Peaks
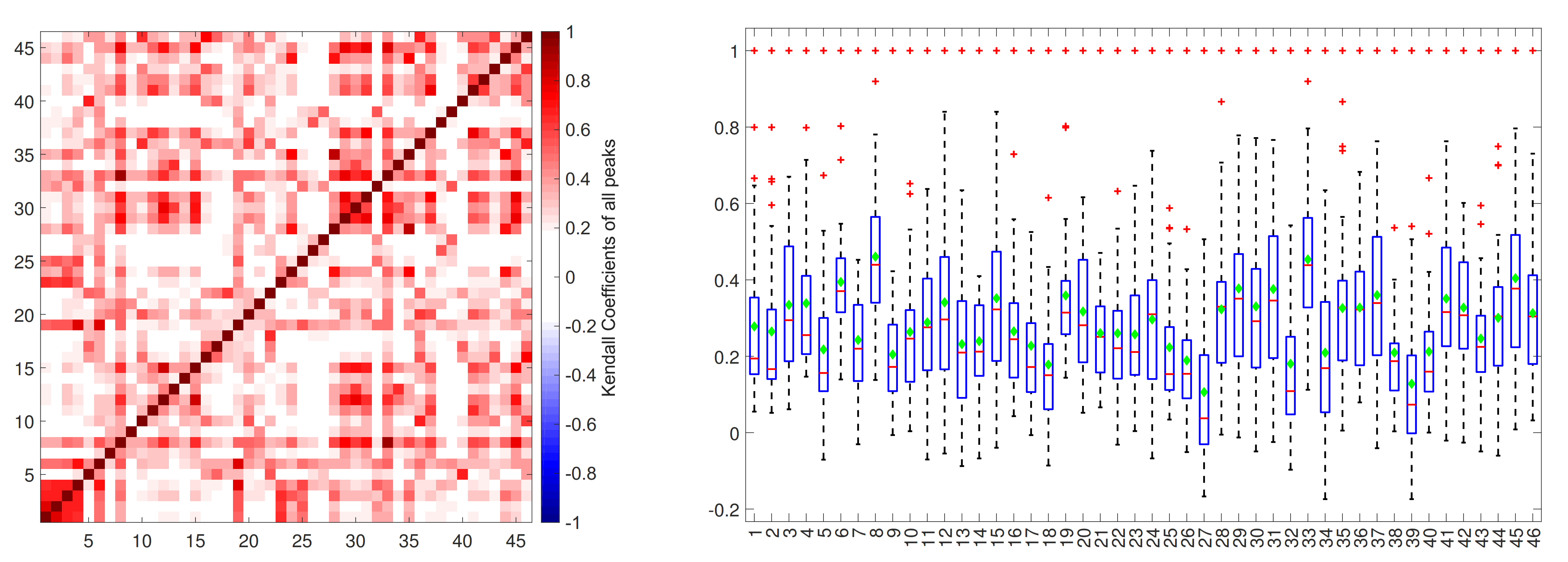
3.3. Investigation of Associations among Simultaneous Flood Series and Distance Matrix
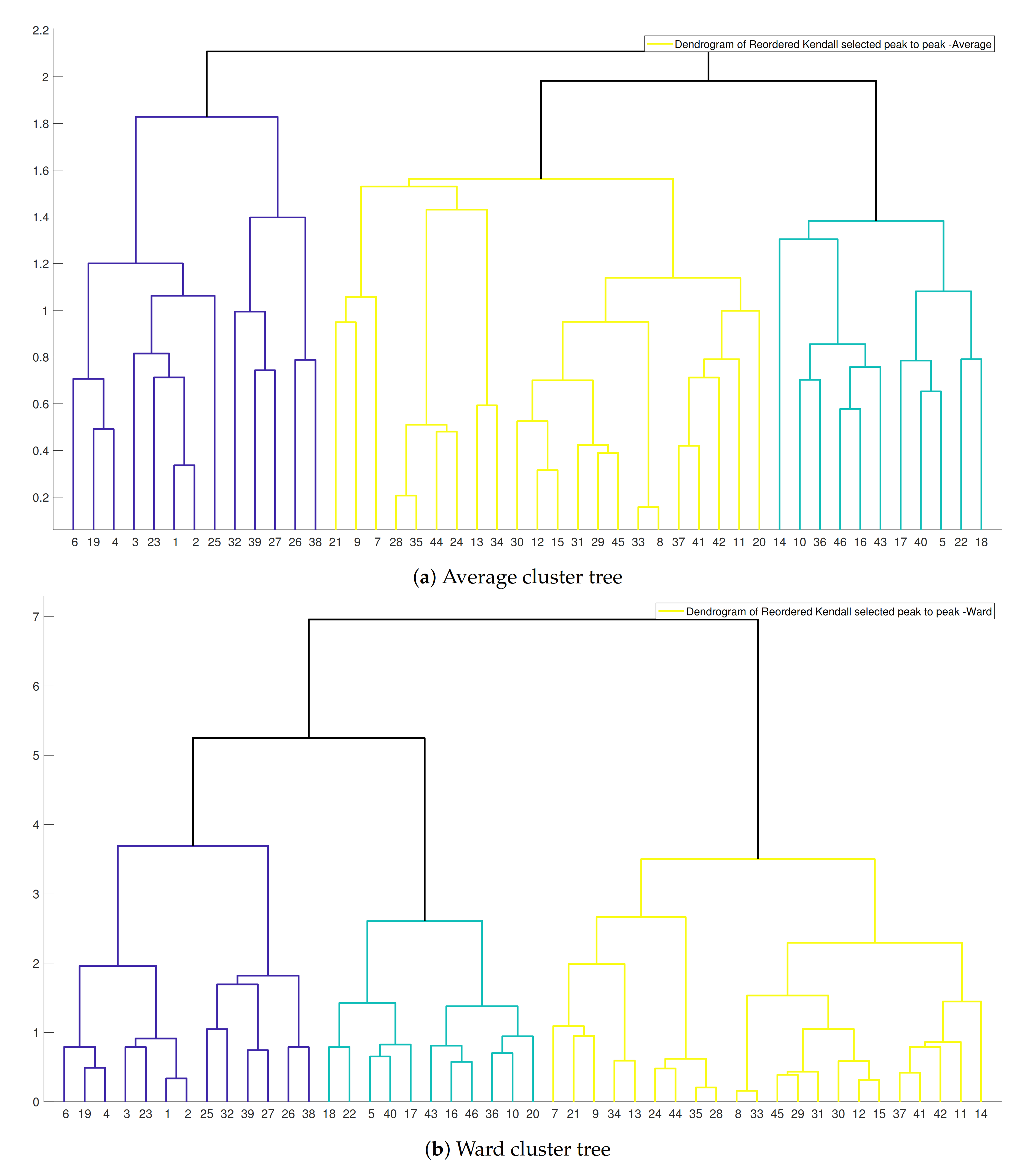
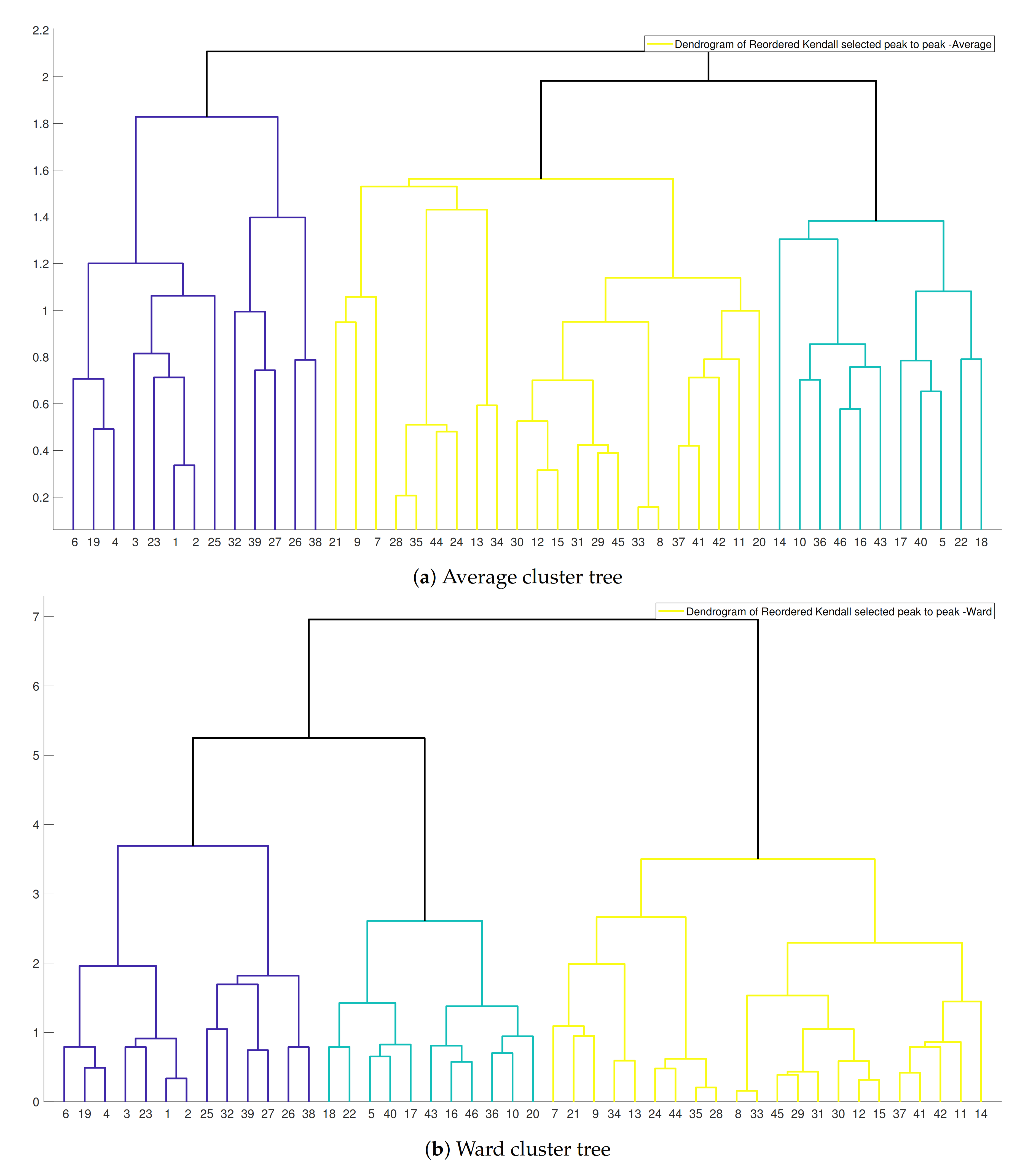
3.4. Hierarchical Cluster Tree
3.4.1. Agglomerative Hierarchical Cluster Tree–AHCT
3.4.2. Construct Agglomerative Clusters for Linkage
3.4.3. Optimal Leaf Tree
3.4.4. Goodness-of-Clustering
Inconsistency Coefficient
Cophenetic Coefficient
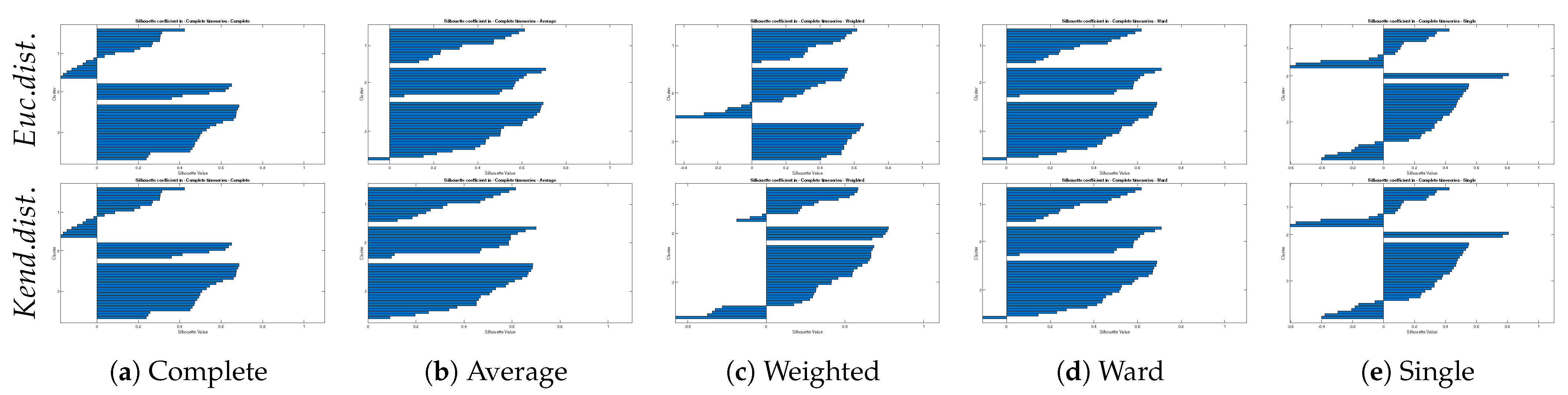
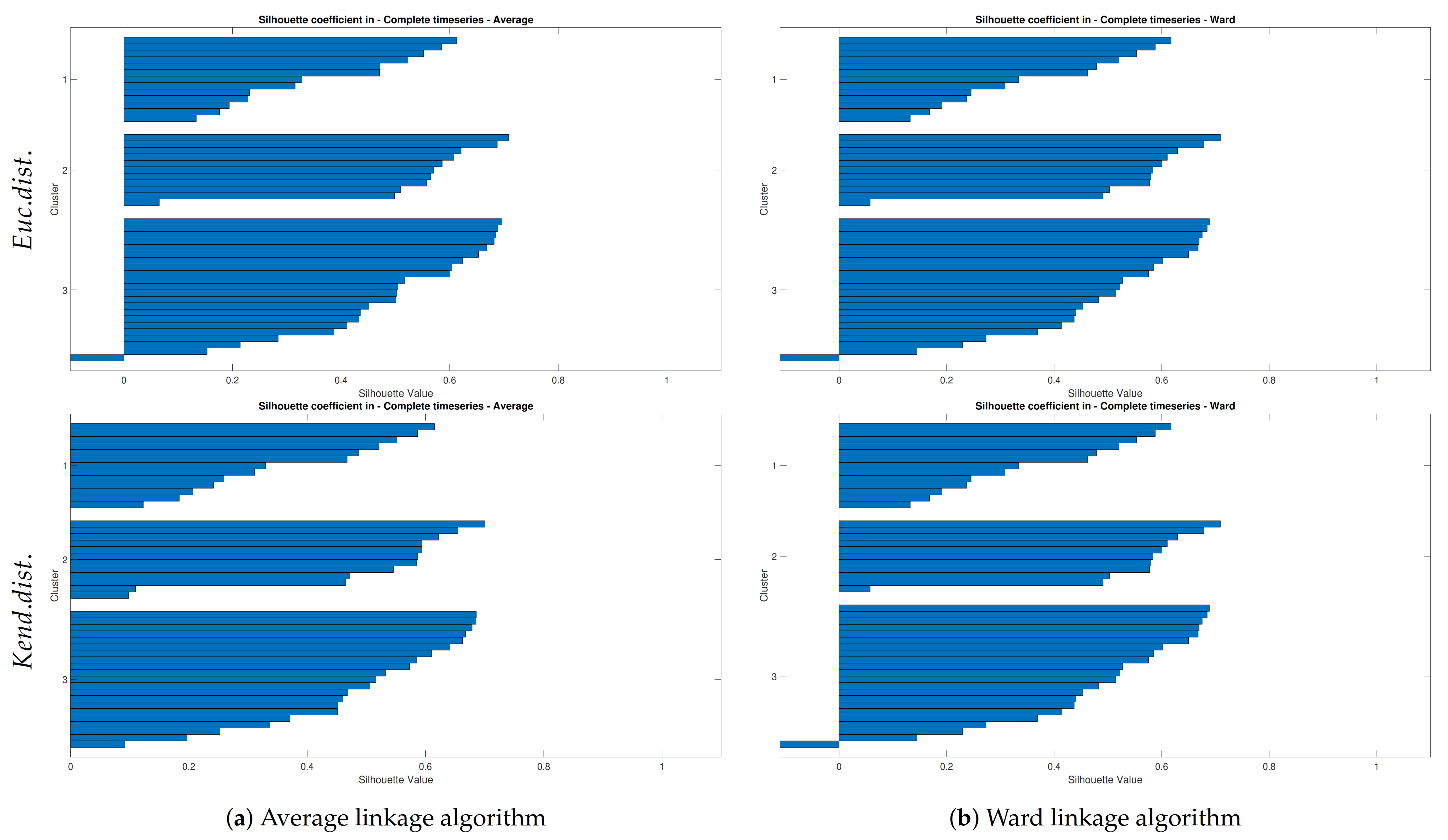
Silhouette Value
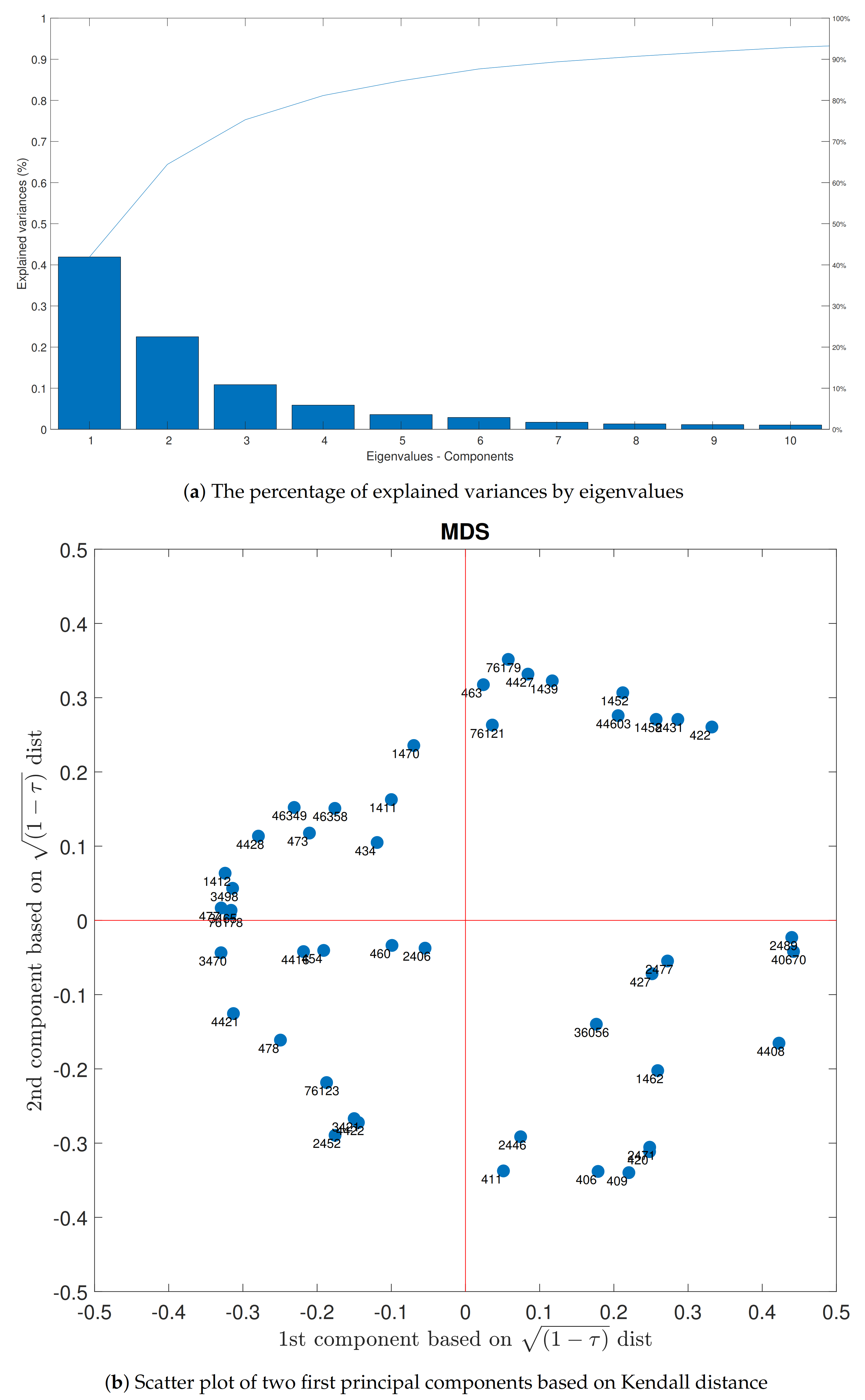
3.5. Multidimensional Scaling
- From D calculate .
- From A calculate , where is the average of all across j.
- Find the p largest eigenvalues of B and corresponding eigenvectors which are normalized so that . (Assumption: p is selected so that the eigenvalues are all relatively large and positive).
- The coordinates of the objects are the rows of L.
4. Result and Discussion
4.1. Investigation of Association and Distance Matrix
4.2. Cluster Analyzing
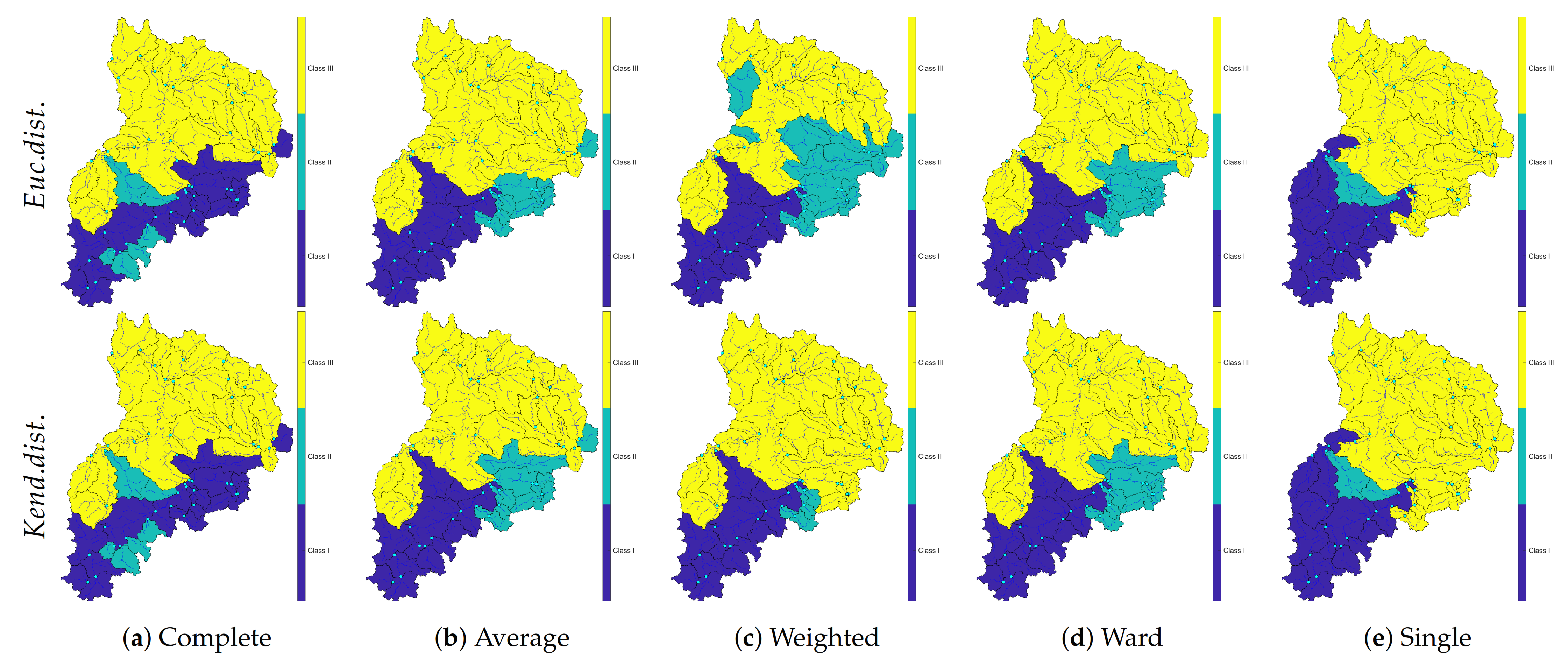
4.2.1. Hierarchical Tree and Verification
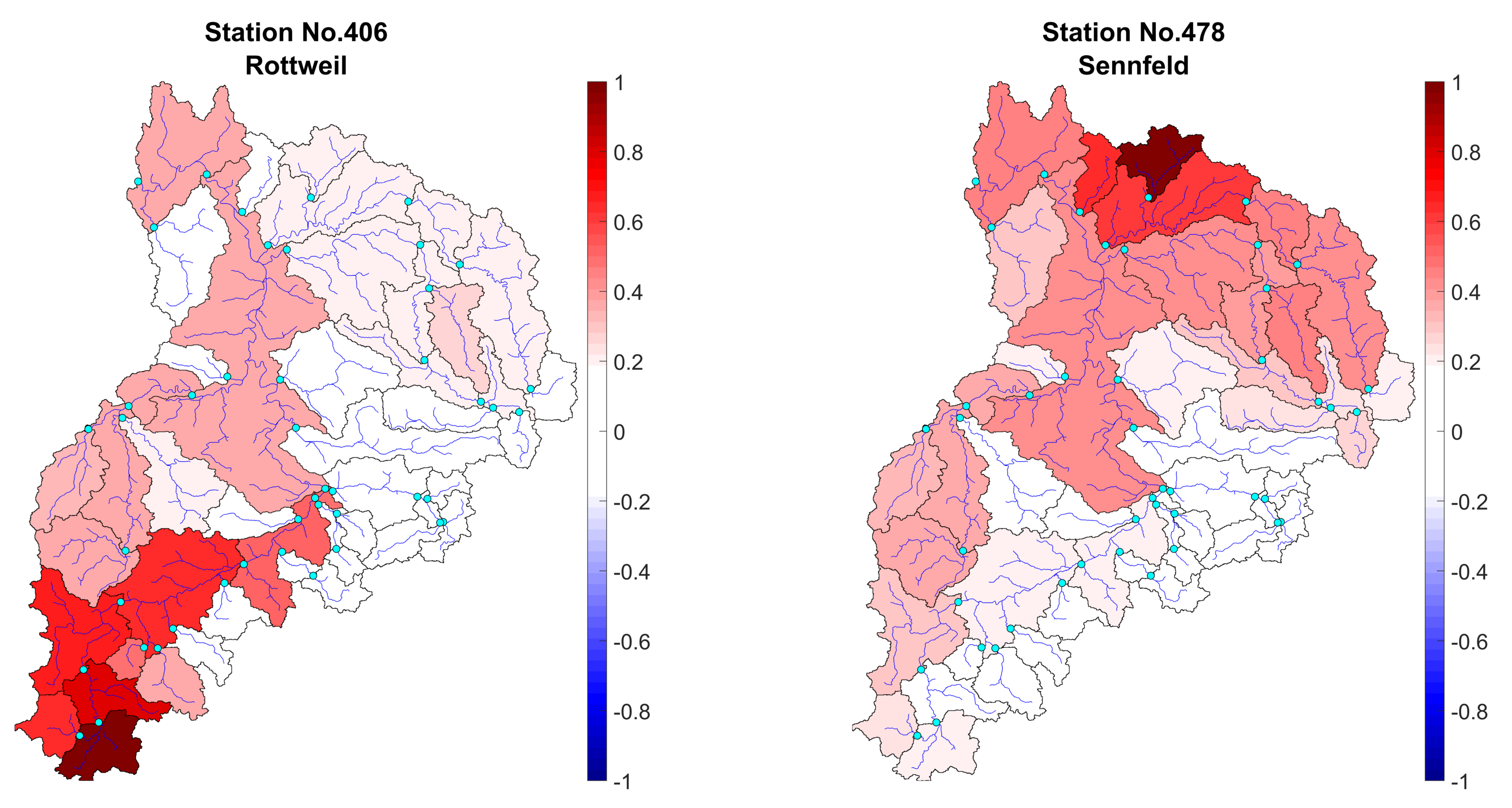
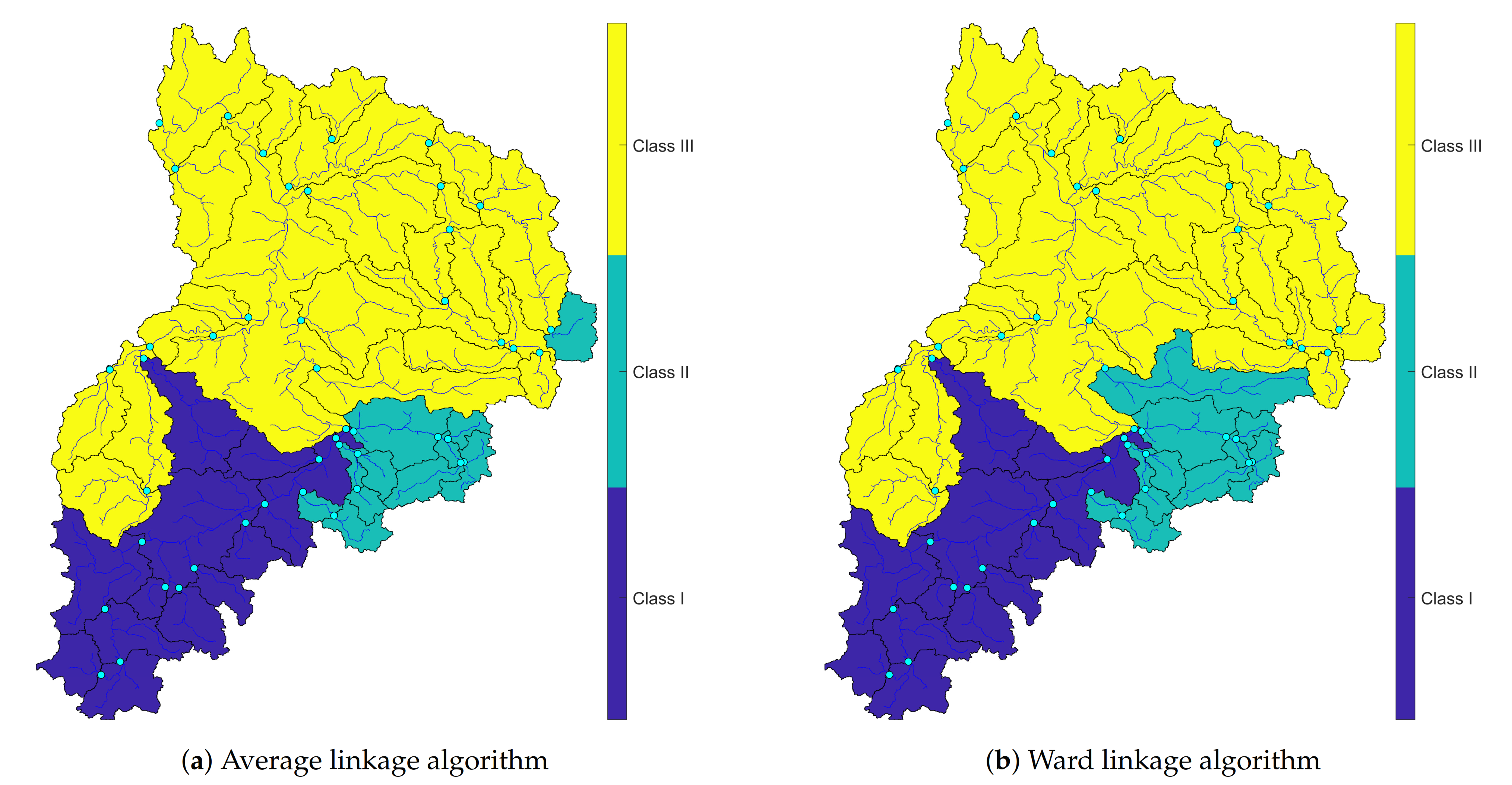
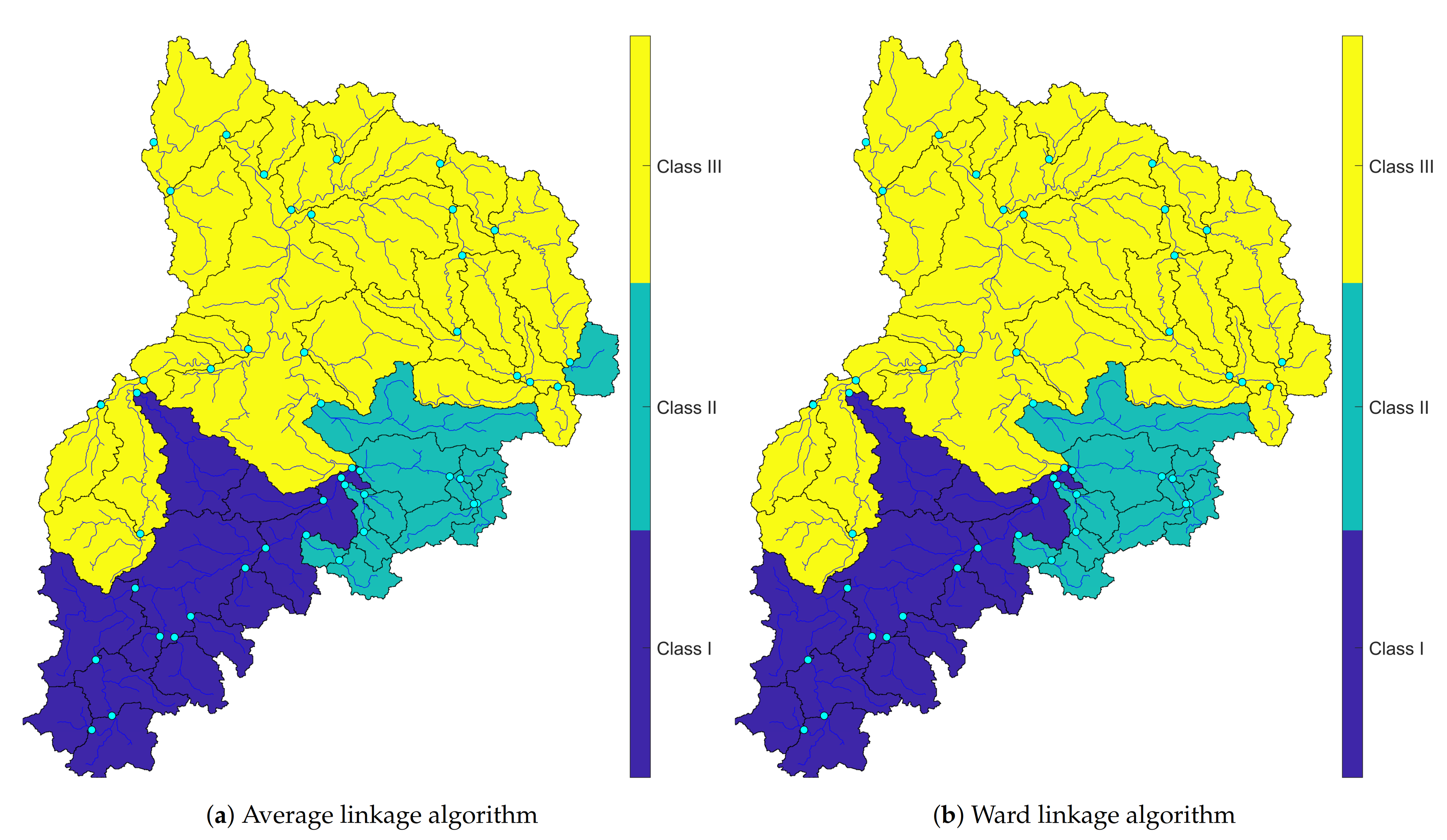
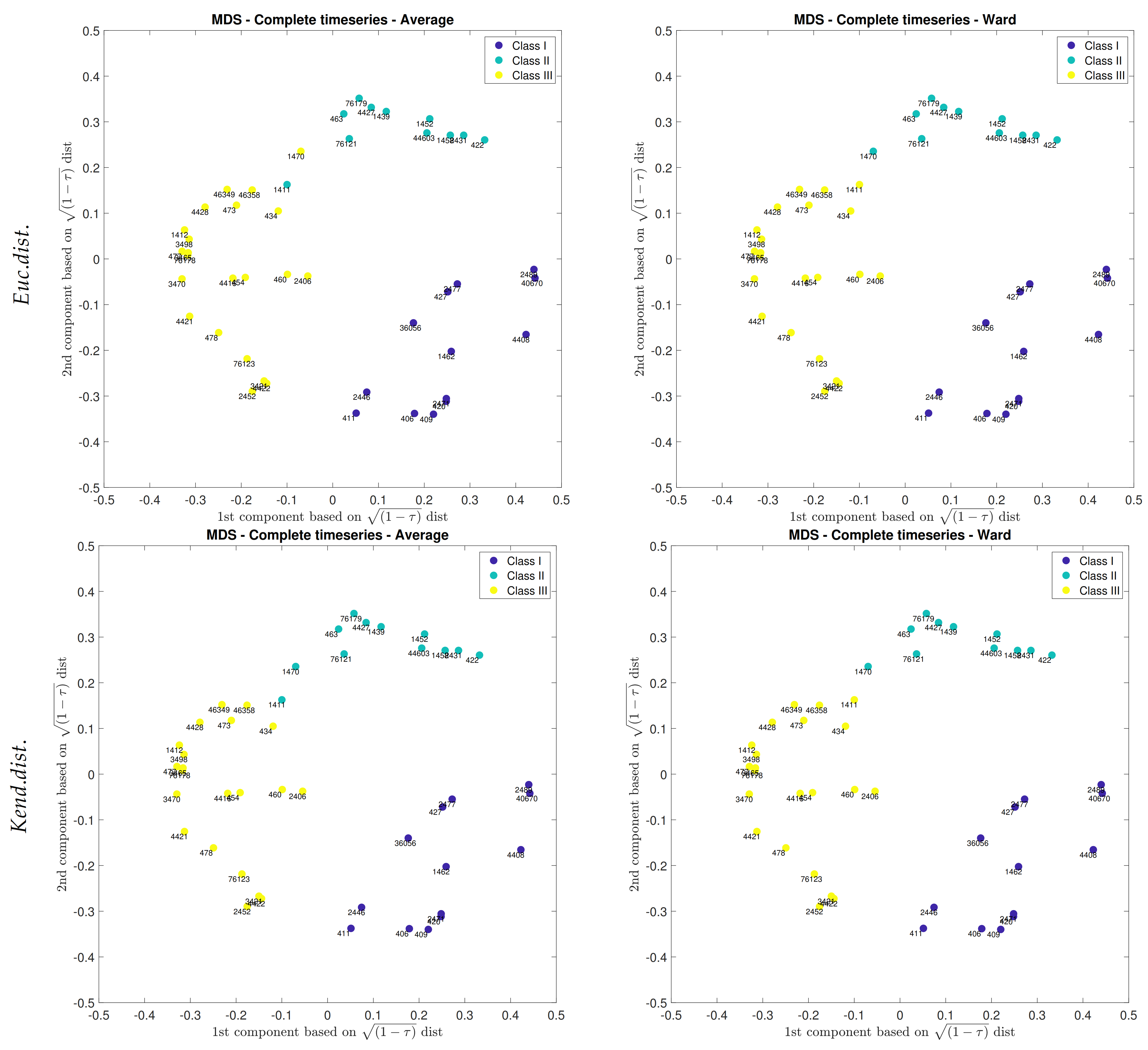
4.2.2. Mapping Clusters
4.3. MDS and AHCT Comparison
5. Conclusions
- The agglomerative hierarchical clustering and multidimensional scaling methods do not need initial assumptions, and they act independently of additional presumptions. The trees were computed based on rank correlation matrices of the highest occurrence of the floods. Both methods are recommended to apply in other case studies.
- The results show that the Average and Ward linkage methods are well-matched and verified in the Neckar basin and the Silhouette coefficient is more robust than other applied verification methods.
- Both Euclidean and Kendall tau distances act mostly the same except in the Average and weighted linkage. Therefore, AHCT is not very sensitive by changing its input distance matrix.
- The results of MDS and AHCT using Ward linkage are perfectly matched each other, which show a constant simultaneous flood occurrence pattern in the Neckar. Thus, we suggest applying the MDS method to have an initial preview of possible clusters to deliver a faster and more robust clustering process.
- The two applied methods result in similar patterns of concurrent flood clustering behavior. Therefore, we propose to employ more than one multivariate clustering method in simultaneous flood analysis to compare the obtained clusters with each other and evaluate their connection with catchment characteristics.
- The results show the simultaneous occurrences of high discharges operating as a function of the topography of the basin and seasonality of the precipitation as the primary input of hydrological analysis. It can be mentioned that a reason for some clustering mismatches might be due to the anthropogenic alterations in this area. Besides, the difference among clusters was observed in the southeast of the Neckar basin, where the geological structure is characterized by a dipping of formation, which could be the reason for the disagreements. Therefore, we suggest taking these factors into clustering consideration.
- The differences between cluster maps of AHCT and MDS have mainly occurred in small size subcatchments. To increase clustering’s robustness, merging some small upstream subcatchments as an area with a bigger size can be an appropriate option.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Baldassarre, G.D.; Viglione, A.; Carr, G.; Kuil, L.; Salinas, J.; Blöschl, G. Socio-hydrology: Conceptualising human-flood interactions. Hydrol. Earth Syst. Sci. 2013, 17, 3295–3303. [Google Scholar] [CrossRef] [Green Version]
- European Environment Agency. Economic Losses from Climate-Related Extremes in Europe (Temporal Coverage 1980–2017); European Environment Agency: Copenhagen, Denmark, 2019. [Google Scholar]
- Schröter, K.; Kunz, M.; Elmer, F.; Mühr, B.; Merz, B. What made the June 2013 flood in Germany an exceptional event? A hydro-meteorological evaluation. Hydrol. Earth Syst. Sci. 2015, 19, 309–327. [Google Scholar] [CrossRef] [Green Version]
- van Oldenborgh, G.J.; Philip, S.; Aalbers, E.; Vautard, R.; Otto, F.; Haustein, K.; Habets, F.; Singh, R.; Cullen, H. Rapid attribution of the May/June 2016 flood-inducing precipitation in France and Germany to climate change. Hydrol. Earth Syst. Sci. Discuss. 2016, 10, 1–23. [Google Scholar]
- MunichRE. Flood/Flash Flood Events in Germany 1980–2018; Technical Report; NatCatSERVICE, Münchener Rückversicherungs-Gesellschaft “Munich RE”: Munich, Germany, 2019. [Google Scholar]
- Thieken, A.H. Floods, Flood Losses and Flood Risk Management in Germany. Ph.D. Thesis, der Universität Potsdam, Potsdam, Germany, 2009. [Google Scholar]
- Glaser, R.; Riemann, D.; Schönbein, J.; Barriendos, M.; Brázdil, R.; Bertolin, C.; Camuffo, D.; Deutsch, M.; Dobrovolnỳ, P.; van Engelen, A.; et al. The variability of European floods since AD 1500. Clim. Chang. 2010, 101, 235–256. [Google Scholar] [CrossRef]
- Hattermann, F.F.; Kundzewicz, Z.W.; Huang, S.; Vetter, T.; Kron, W.; Burghoff, O.; Merz, B.; Bronstert, A.; Krysanova, V.; Gerstengarbe, F.W. Flood Risk from a Holistic Perspective Observed Changes in Germany. In Changes in Flood Risk in Europe; Volume Special Publication No. 10; IAHS Press: Oxfordshire, UK, 2012; Chapter 11. [Google Scholar]
- Blöschl, G.; Hall, J.; Parajka, J.; Perdigão, R.A.; Merz, B.; Arheimer, B.; Aronica, G.T.; Bilibashi, A.; Bonacci, O.; Borga, M.; et al. Changing climate shifts timing of European floods. Science 2017, 357, 588–590. [Google Scholar] [CrossRef] [Green Version]
- Hall, J.; Blöschl, G. Spatial patterns and characteristics of flood seasonality in Europe. Hydrol. Earth Syst. Sci. 2018, 22, 3883–3901. [Google Scholar] [CrossRef] [Green Version]
- Blöschl, G.; Hall, J.; Viglione, A.; Perdigão, R.A.; Parajka, J.; Merz, B.; Lun, D.; Arheimer, B.; Aronica, G.T.; Bilibashi, A.; et al. Changing climate both increases and decreases European river floods. Nature 2019, 573, 1–4. [Google Scholar] [CrossRef]
- Ehmele, F.; Kunz, M. Flood-related extreme precipitation in southwestern Germany: Development of a two-dimensional stochastic precipitation model. Hydrol. Earth Syst. Sci. 2019, 23, 1083–1102. [Google Scholar] [CrossRef] [Green Version]
- Alfieri, L.; Bisselink, B.; Dottori, F.; Naumann, G.; de Roo, A.; Salamon, P.; Wyser, K.; Feyen, L. Global projections of river flood risk in a warmer world. Earth’s Future 2017, 5, 171–182. [Google Scholar] [CrossRef]
- Petrow, T.; Thieken, A.H.; Kreibich, H.; Merz, B.; Bahlburg, C.H. Improvements on flood alleviation in Germany: Lessons learned from the Elbe flood in August 2002. Environ. Manag. 2006, 38, 717–732. [Google Scholar] [CrossRef]
- Diederen, D.; Liu, Y.; Gouldby, B.; Diermanse, F.; Vorogushyn, S. Stochastic generation of spatially coherent river discharge peaks for continental event-based flood risk assessment. Nat. Hazards Earth Syst. Sci. 2019, 19, 1041–1053. [Google Scholar] [CrossRef] [Green Version]
- de Moel, H.; van Alphen, J.; Aerts, J. Flood maps in Europe–Methods, availability and use. Nat. Hazards Earth Syst. Sci. 2009, 9, 289–301. [Google Scholar] [CrossRef] [Green Version]
- Chowdhary, H.; Escobar, L.A.; Singh, V.P. Identification of suitable copulas for bivariate frequency analysis of flood peak and flood volume data. Hydrol. Res. 2011, 42, 193–216. [Google Scholar] [CrossRef]
- Li, J.; Lei, Y.; Tan, S.; Bell, C.D.; Engel, B.A.; Wang, Y. Nonstationary flood frequency analysis for annual flood peak and volume series in both univariate and bivariate domain. Water Resour. Manag. 2018, 32, 4239–4252. [Google Scholar] [CrossRef]
- Wang, C. A joint probability approach for coincidental flood frequency analysis at ungauged basin confluences. Nat. Hazards 2016, 82, 1727–1741. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. Frequency analysis via copulas: Theoretical aspects and applications to hydrological events. Water Resour. Res. 2004, 40. [Google Scholar] [CrossRef]
- Favre, A.C.; El Adlouni, S.; Perreault, L.; Thiémonge, N.; Bobée, B. Multivariate hydrological frequency analysis using Copulas. Water Resour. Res. 2004, 40. [Google Scholar] [CrossRef] [Green Version]
- Heffernan, J.E.; Tawn, J.A. A conditional approach for multivariate extreme values (with discussion). J. R. Stat. Soc. Ser. (Stat. Methodol.) 2004, 66, 497–546. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. Multivariate multiparameter extreme value models and return periods: A copula approach. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Salvadori, G.; Michele, C.D.; Durante, F. On the return period and design in a multivariate framework. Hydrol. Earth Syst. Sci. 2011, 15, 3293–3305. [Google Scholar] [CrossRef] [Green Version]
- Dung, N.V.; Merz, B.; Bárdossy, A.; Apel, H. Handling uncertainty in bivariate quantile estimation—An application to flood hazard analysis in the Mekong Delta. J. Hydrol. 2015, 527, 704–717. [Google Scholar] [CrossRef]
- Falter, D.; Schröter, K.; Dung, N.V.; Vorogushyn, S.; Kreibich, H.; Hundecha, Y.; Apel, H.; Merz, B. Spatially coherent flood risk assessment based on long-term continuous simulation with a coupled model chain. J. Hydrol. 2015, 524, 182–193. [Google Scholar] [CrossRef] [Green Version]
- Merz, B.; Aerts, J.; Arnbjerg-Nielsen, K.; Baldi, M.; Becker, A.; Bichet, A.; Blöschl, G.; Bouwer, L.M.; Brauer, A.; Cioffi, F.; et al. Floods and climate: Emerging perspectives for flood risk assessment and management. Nat. Hazards Earth Syst. Sci. 2014, 14, 1921–1942. [Google Scholar] [CrossRef] [Green Version]
- Merz, B.; Nguyen, V.D.; Vorogushyn, S. Temporal clustering of floods in Germany: Do flood-rich and flood-poor periods exist? J. Hydrol. 2016, 541, 824–838. [Google Scholar] [CrossRef]
- Khare, S.; Bonazzi, A.; Mitas, C.; Jewson, S. Modelling clustering of natural hazard phenomena and the effect on re/insurance loss perspectives. Nat. Hazards Earth Syst. Sci. 2015, 15, 1357–1370. [Google Scholar] [CrossRef] [Green Version]
- Villarini, G.; Smith, J.A.; Vitolo, R.; Stephenson, D.B. On the temporal clustering of US floods and its relationship to climate teleconnection patterns. Int. J. Climatol. 2013, 33, 629–640. [Google Scholar] [CrossRef]
- Vitolo, R.; Stephenson, D.B.; Cook, I.M.; Mitchell-Wallace, K. Serial clustering of intense European storms. Meteorol. Z. 2009, 18, 411–424. [Google Scholar] [CrossRef] [Green Version]
- Mailier, P.J.; Stephenson, D.B.; Ferro, C.A.T.; Hodges, K.I. Serial Clustering of Extratropical Cyclones. Mon. Weather. Rev. 2006, 134, 2224–2240. [Google Scholar] [CrossRef]
- Aubert, A.; Tavenard, R.; Emonet, R.; De Lavenne, A.; Malinowski, S.; Guyet, T.; Quiniou, R.; Odobez, J.M.; Mérot, P.; Gascuel-Odoux, C. Clustering flood events from water quality time series using Latent Dirichlet Allocation model. Water Resour. Res. 2013, 49, 8187–8199. [Google Scholar] [CrossRef]
- Beurton, S.; Thieken, A.H. Seasonality of floods in Germany. Hydrol. Sci. J. 2009, 54, 62–76. [Google Scholar] [CrossRef]
- Mediero, L.; Kjeldsen, T.; Macdonald, N.; Kohnova, S.; Merz, B.; Vorogushyn, S.; Wilson, D.; Alburquerque, T.; Blöschl, G.; Bogdanowicz, E.; et al. Identification of coherent flood regions across Europe by using the longest streamflow records. J. Hydrol. 2015, 528, 341–360. [Google Scholar] [CrossRef] [Green Version]
- Towe, R.; Tawn, J.; Eastoe, E.; Lamb, R. Modelling the clustering of extreme events for short-term risk assessment. J. Agric. Biol. Environ. Stat. 2020, 25, 32–53. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.N.; Chen, X.H.; Shao, Q.X.; Li, Y. Flood indicators and their clustering features in Wujiang River, South China. Ecol. Eng. 2015, 76, 66–74. [Google Scholar] [CrossRef] [Green Version]
- Pappadà, R.; Durante, F.; Salvadori, G.; De Michele, C. Clustering of concurrent flood risks via Hazard Scenarios. Spat. Stat. 2018, 23, 124–142. [Google Scholar] [CrossRef]
- Sahu, N.; Behera, S.K.; Yamashiki, Y.; Takara, K.; Yamagata, T. IOD and ENSO impacts on the extreme stream-flows of Citarum river in Indonesia. Clim. Dyn. 2012, 39, 1673–1680. [Google Scholar] [CrossRef]
- Sahu, N.; Panda, A.; Nayak, S.; Saini, A.; Mishra, M.; Sayama, T.; Sahu, L.; Duan, W.; Avtar, R.; Behera, S. Impact of Indo-Pacific Climate Variability on High Streamflow Events in Mahanadi River Basin, India. Water 2020, 12, 1952. [Google Scholar] [CrossRef]
- LUBW. Landesanstalt für Umwelt, Messungen und Naturschutz Baden-Württemberg. Available online: https://udo.lubw.baden-wuerttemberg.de/public/ (accessed on 15 January 2021).
- DWD. Wetter und Klima–Deutscher Wetterdienst –CDC (Climate Data Center). Available online: https://opendata.dwd.de/climate_environment/CDC/ (accessed on 15 January 2021).
- Bárdossy, A.; Pegram, G. Infilling missing precipitation records—A comparison of a new Copula-based method with other techniques. J. Hydrol. 2014, 519, 1162–1170. [Google Scholar] [CrossRef]
- Emblemsvåg, J. Risk Management for the Future: Theory and Cases; IntechOpen: London, UK, 2012. [Google Scholar]
- Seidel, J.; Dostal, P.; Imbery, F. Analysis of Historical River Floods-A Contribution Towards Modern Flood Risk Management. In Risk Management for the Future-Theory and Cases; Emblemsvåg, J., Ed.; IntechOpen: London, UK, 2012; Chapter 12; pp. 275–294. [Google Scholar]
- Bürger, K.; Dostal, P.; Seidel, J.; Imbery, F.; Barriendos, M.; Mayer, H.; Glaser, R. Hydrometeorological reconstruction of the 1824 flood event in the Neckar River basin (southwest Germany). Hydrol. Sci. J. 2006, 51, 864–877. [Google Scholar] [CrossRef]
- Götzinger, J.; Barthel, R.; Jagelke, J.; Bárdossy, A. The role of groundwater recharge and baseflow in integrated models. In Proceedings of the Symposium IUGG HS1002; IAHS Publication: Perugia, Italy, 2007; Volume 321, pp. 103–109. [Google Scholar] [CrossRef]
- Jagelke, J.; Barthel, R. Conceptualization and implementation of a regional groundwater model for the Neckar catchment in the framework of an integrated regional model. Adv. Geosci. 2005, 5, 105–111. [Google Scholar] [CrossRef] [Green Version]
- Kalweit, H.; Buck, W.; Felkel, k.; Gerhard, H.; Malde, J.; Nippes, K.R.; Ploeger, B.; Schmitz, W. Der Rhein unter der Einwirkung des Menschen: Ausbau, Schiffahrt, Wasserwirtschaft; CHR/KHR: Utrecht, The Netherlands, 1993. [Google Scholar]
- Bormann, H. Runoff regime changes in German rivers due to climate change. Erdkunde 2010, 64, 257–279. [Google Scholar] [CrossRef]
- Kendall, M.G. Rank Correlation Methods.; Charles Griffin & Co. Ltd.: London, UK, 1948. [Google Scholar]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. (CSUR) 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Unal, Y.; Kindap, T.; Karaca, M. Redefining the climate zones of Turkey using cluster analysis. Int. J. Climatol. J. R. Meteorol. Soc. 2003, 23, 1045–1055. [Google Scholar] [CrossRef]
- Lyra, G.B.; Oliveira-Júnior, J.F.; Zeri, M. Cluster analysis applied to the spatial and temporal variability of monthly rainfall in Alagoas state, Northeast of Brazil. Int. J. Climatol. 2014, 34, 3546–3558. [Google Scholar] [CrossRef]
- Corporal-Lodangco, I.L.; Leslie, L.M. Defining Philippine Climate Zones Using Surface and High-Resolution Satellite Data. Procedia Comput. Sci. 2017, 114, 324–332. [Google Scholar] [CrossRef]
- Santos, C.A.G.; Moura, R.; da Silva, R.M.; Costa, S.G.F. Cluster Analysis Applied to Spatiotemporal Variability of Monthly Precipitation over Paraíba State Using Tropical Rainfall Measuring Mission (TRMM) Data. Remote Sens. 2019, 11, 637. [Google Scholar] [CrossRef] [Green Version]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- Davidson, I.; Ravi, S.S. Agglomerative Hierarchical Clustering with Constraints: Theoretical and Empirical Results; Knowledge Discovery in Databases: PKDD 2005; Jorge, A.M., Torgo, L., Brazdil, P., Camacho, R., Gama, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 59–70. [Google Scholar]
- Ward, J.H., Jr. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Murtagh, F.; Legendre, P. Ward’s Hierarchical Agglomerative Clustering Method: Which Algorithms Implement Ward’s Criterion? J. Classif. 2014, 31, 274–295. [Google Scholar] [CrossRef] [Green Version]
- Bar-Joseph, Z.; Gifford, D.K.; Jaakkola, T.S. Fast optimal leaf ordering for hierarchical clustering. Bioinformatics 2001, 17, S22–S29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zahn, C.T. Graph-theoretical methods for detecting and describing gestalt clusters. IEEE Trans. Comput. 1971, 100, 68–86. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice Hall: Englewood Cliffs, NY, USA, 1988. [Google Scholar]
- Sokal, R.R.; Rohlf, F.J. The comparison of dendrograms by objective methods. Taxon 1962, 11, 33–40. [Google Scholar] [CrossRef]
- Farris, J.S. On the cophenetic correlation coefficient. Syst. Zool. 1969, 18, 279–285. [Google Scholar] [CrossRef] [Green Version]
- Holgersson, M. The limited value of cophenetic correlation as a clustering criterion. Pattern Recognit. 1978, 10, 287–295. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Kruskal, J.B.; Wish, M. Multidimensional Scaling (Quantitative Applications in the Social Sciences); Sage Publications, Inc.: Beverly Hills, CA, USA, 1978. [Google Scholar]
- Torgerson, W.S. Multidimensional scaling: I. Theory and method. Psychometrika 1952, 17, 401–419. [Google Scholar] [CrossRef]
- Seber, G. Multivariate Observations; John Wiley & Sons: New York, NY, USA, 1984. [Google Scholar]
- Hintze, J. Multidimensional Scaling, Help Documentation, Chapter 435. NCSS 2019 Statistical Software; NCSS, LLC.: Kaysville, UT, USA, 2019. [Google Scholar]
- Bouguettaya, A. On-line clustering. IEEE Trans. Knowl. Data Eng. 1996, 8, 333–339. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Yu, Q.; Liu, X.; Zhou, X.; Song, A. Efficient agglomerative hierarchical clustering. Expert Syst. Appl. 2015, 42, 2785–2797. [Google Scholar] [CrossRef]
- Day, W.H.E.; Edelsbrunner, H. Efficient algorithms for agglomerative hierarchical clustering methods. J. Classif. 1984, 1, 7–24. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. Methods of Hierarchical Clustering. arXiv 2011, arXiv:1105.0121. [Google Scholar]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- Senthilnath, J.; Rajendra, R.; Suresh, S.; Kulkarni, S.; Benediktsson, J. Hierarchical clustering approaches for flood assessment using multi-sensor satellite images. Int. J. Image Data Fusion 2019, 10, 28–44. [Google Scholar] [CrossRef]
- Li, J.; Hassan, D.; Brewer, S.; Sitzenfrei, R. Is Clustering Time-Series Water Depth Useful? An Exploratory Study for Flooding Detection in Urban Drainage Systems. Water 2020, 12, 2433. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dist. | Complete | Average | Weighted | Ward | Single | |
|---|---|---|---|---|---|---|
| Inconsistency coefficient | Euc. dist. | 0.542 | 0.540 | 0.542 | 0.544 | 0.515 |
| Kend. dist. | 0.524 | 0.543 | 0.561 | 0.537 | 0.513 | |
| Number of zeros | Euc. dist. | 17 | 16 | 16 | 18 | 15 |
| Kend. dist. | 18 | 15 | 15 | 18 | 14 |
| Complete | Average | Weighted | Ward | Single | |
|---|---|---|---|---|---|
| Euclidean distance | 0.725 | 0.787 | 0.676 | 0.730 | 0.630 |
| Kendall distance | 0.672 | 0.784 | 0.786 | 0.649 | 0.710 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Modiri, E.; Bárdossy, A. Clustering Simultaneous Occurrences of the Extreme Floods in the Neckar Catchment. Water 2021, 13, 399. https://doi.org/10.3390/w13040399
Modiri E, Bárdossy A. Clustering Simultaneous Occurrences of the Extreme Floods in the Neckar Catchment. Water. 2021; 13(4):399. https://doi.org/10.3390/w13040399
Chicago/Turabian StyleModiri, Ehsan, and András Bárdossy. 2021. "Clustering Simultaneous Occurrences of the Extreme Floods in the Neckar Catchment" Water 13, no. 4: 399. https://doi.org/10.3390/w13040399
APA StyleModiri, E., & Bárdossy, A. (2021). Clustering Simultaneous Occurrences of the Extreme Floods in the Neckar Catchment. Water, 13(4), 399. https://doi.org/10.3390/w13040399