
Simulation of Pan-Evaporation Using Penman and Hamon Equations and Artificial Intelligence Techniques

 ,
,  ,
,  ,
,  ,
,
Abstract
:1. Introduction
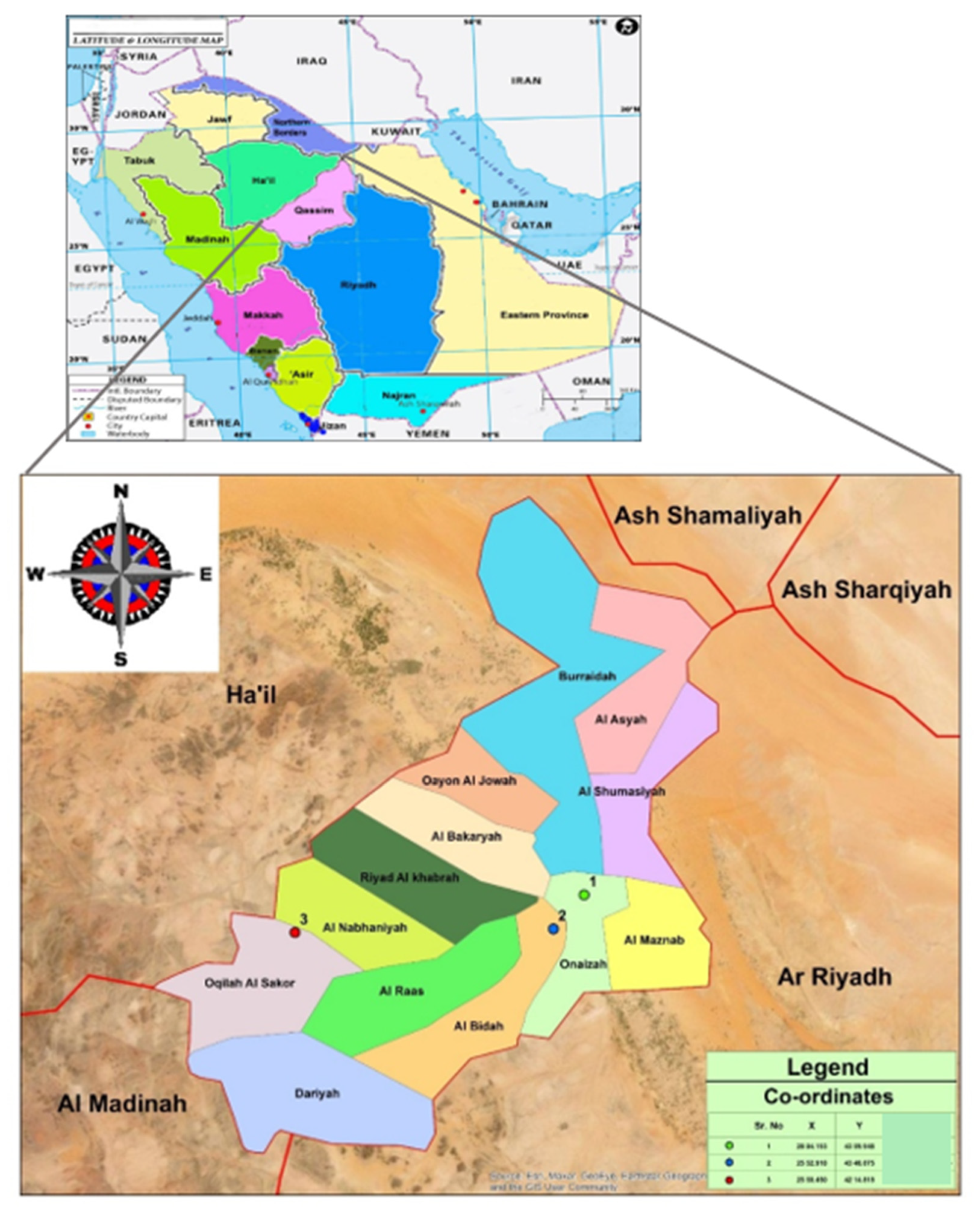
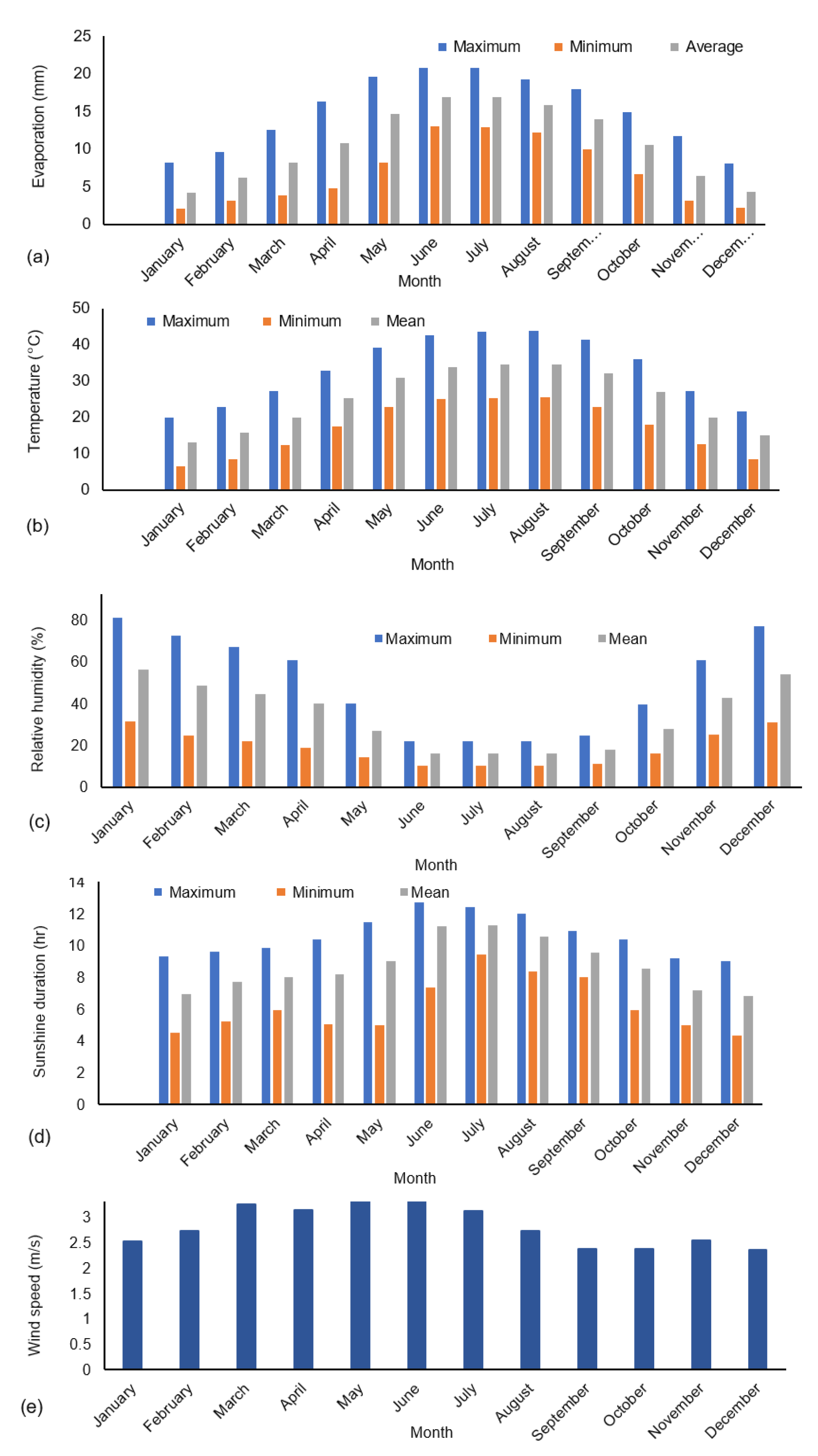
2. Study Area and Baseline Data
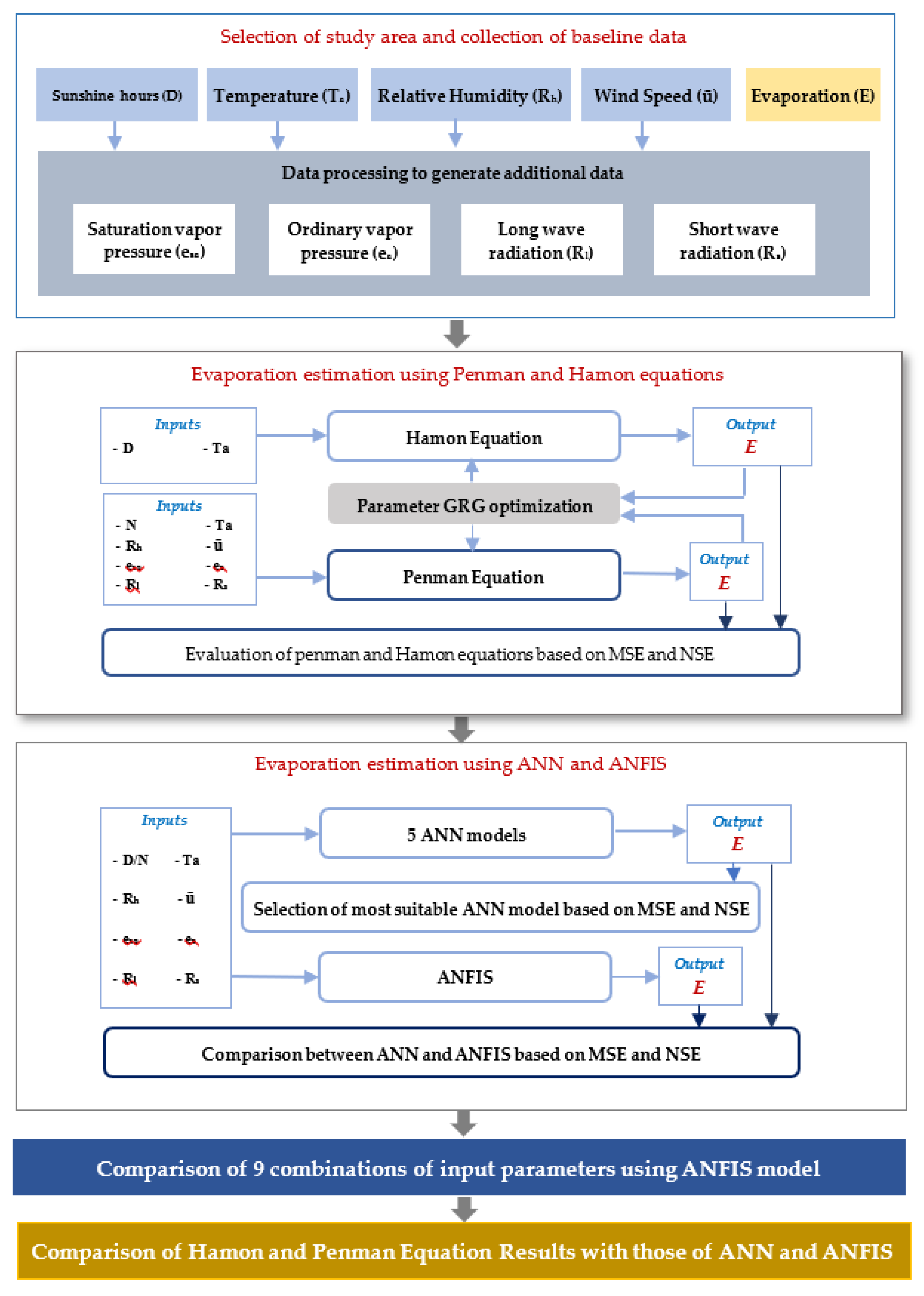
3. Materials and Methods
3.1. Penman Equation
3.2. The Hamon Equation
3.3. Identification of Parameters of Penman and Hamon Equations Using Optimization
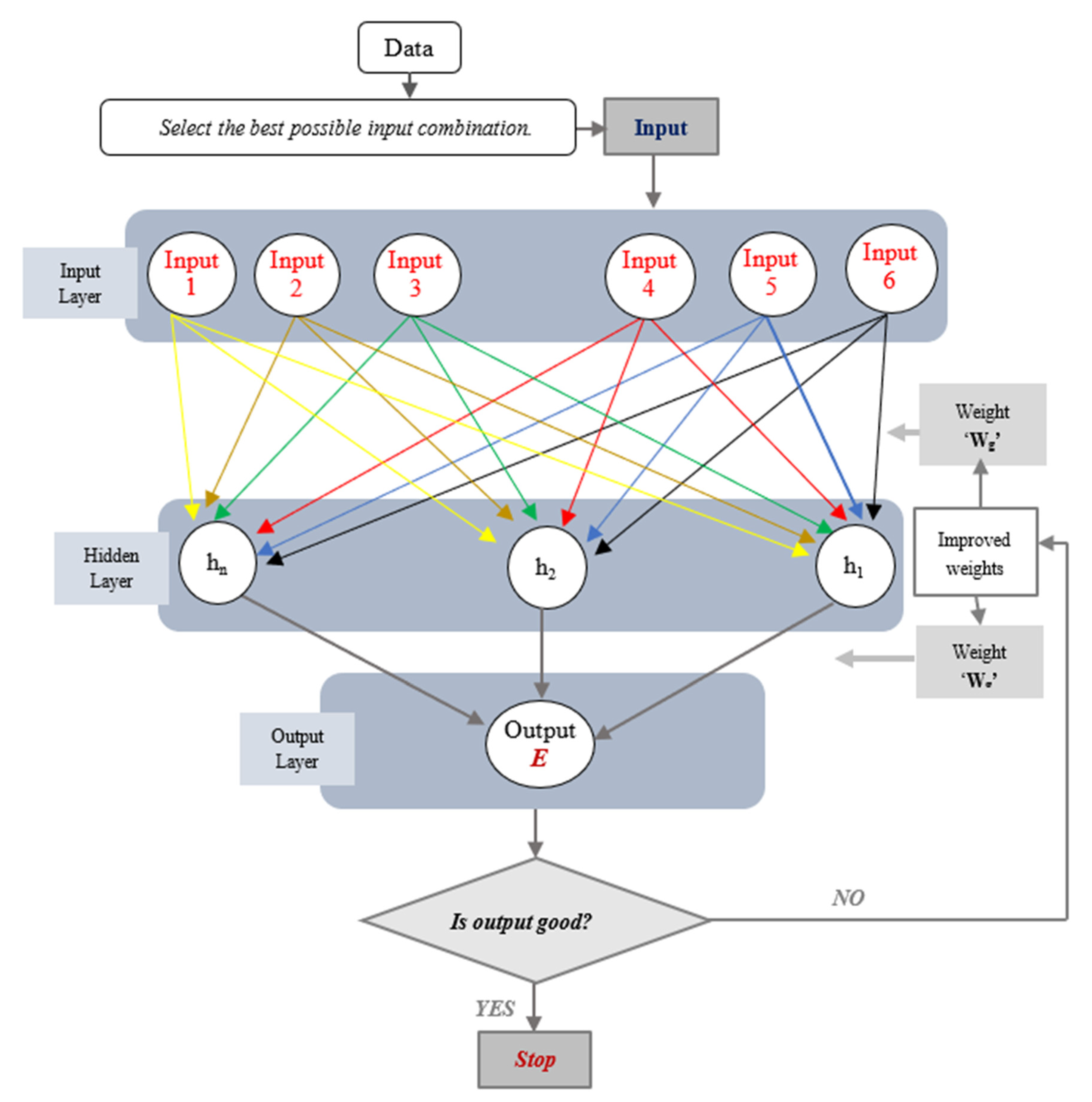
3.4. Artificil Neural Networks
- The network architecture has an input layer and output layer. In the case of multiple hidden layers, it is also known as the Multi-Layer Perceptron (MPL);
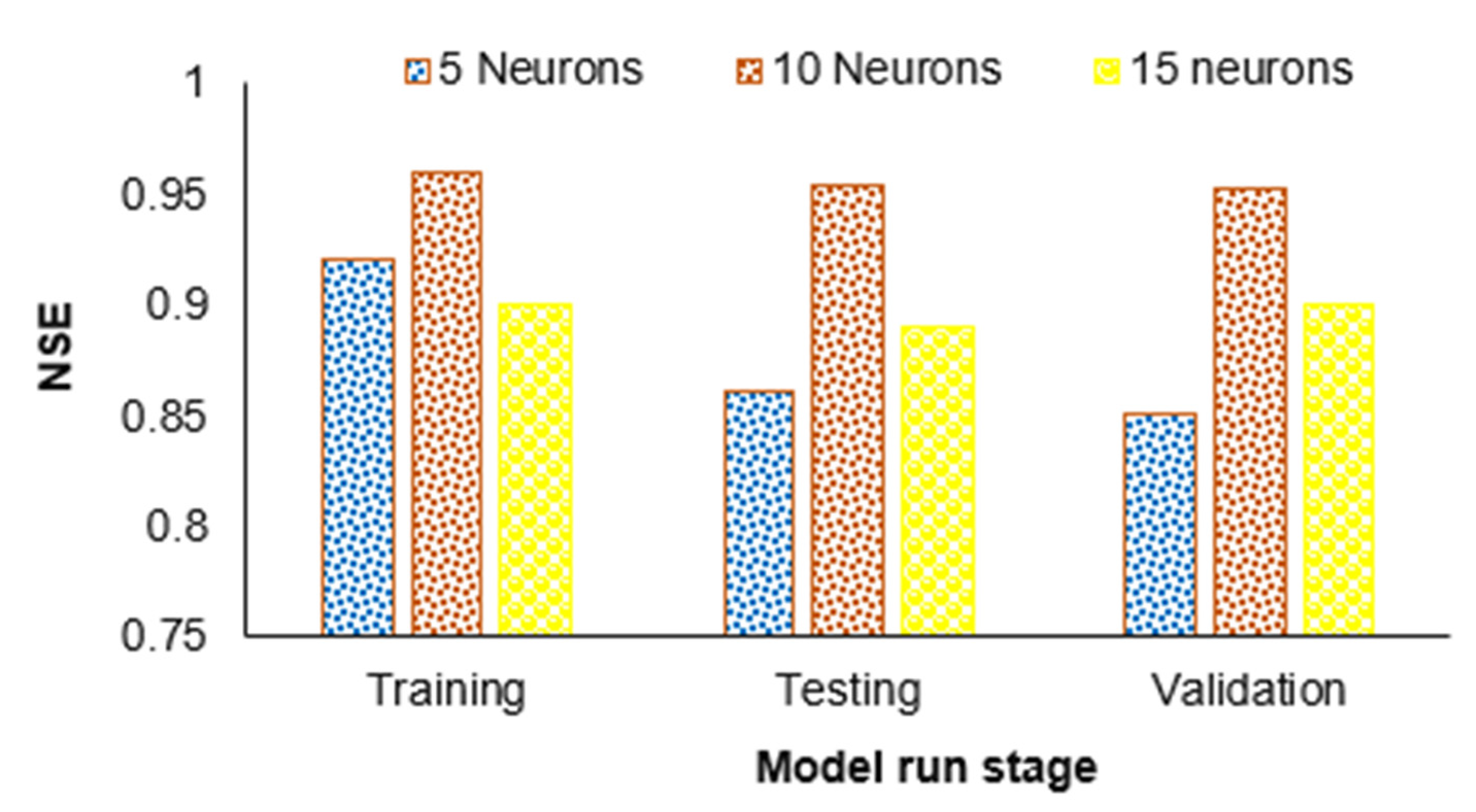
- The hidden layer operates like a “distillation layer” that distills several key patterns from the inputs and forwards them onto the next layer. It enhances the efficiency and speed of the network by identifying the primary information from the inputs and ignores the redundant information. In this research, models with double and triple hidden layers, represented by double layer (DL) and triple layer (TL), were tested. Different numbers of neurons can be chosen in hidden layers. Sheela and Deepa [48] reviewed various methods for selecting the hidden neurons. Some researchers have used a hit and trial approach for selecting the optimal number of neurons in hidden layers; either starting from a lower number (undersized number of hidden neurons) and increasing the number of neurons in every trial to reach an optimal number by reducing the error to the minimum possible or vice versa. The same number of neurons in each type of hidden layer (DL or TL) ANN model or decreasing the number of neurons from a lower to higher hidden layer model have been recommended by many researchers [48,49,50,51]. We investigated an architecture with 5, 10, and 15 neurons in hidden layers in both the cases of DL and TL;
- Two significant purposes of the activation function are that i) it captures the non-linear relationship between the inputs, one by one, and the output, and ii) it helps convert the input into a more useful output.

3.5. Adaptive Neuro-Fuzzy Inference Systems
3.6. Performance Evaluation of Evaporation Models
4. Results
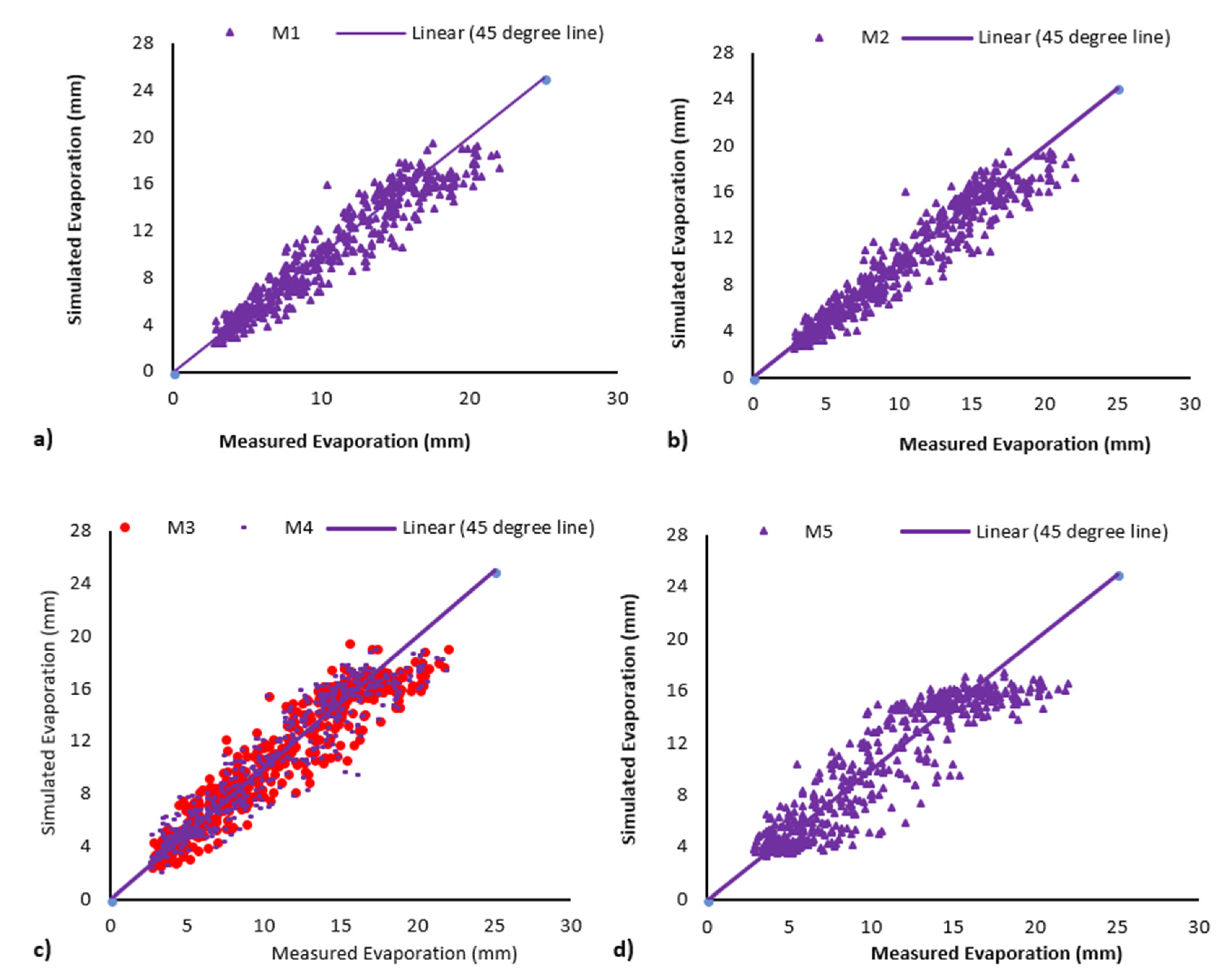
4.1. Comparison of Results of ANN Models with Various Architectures
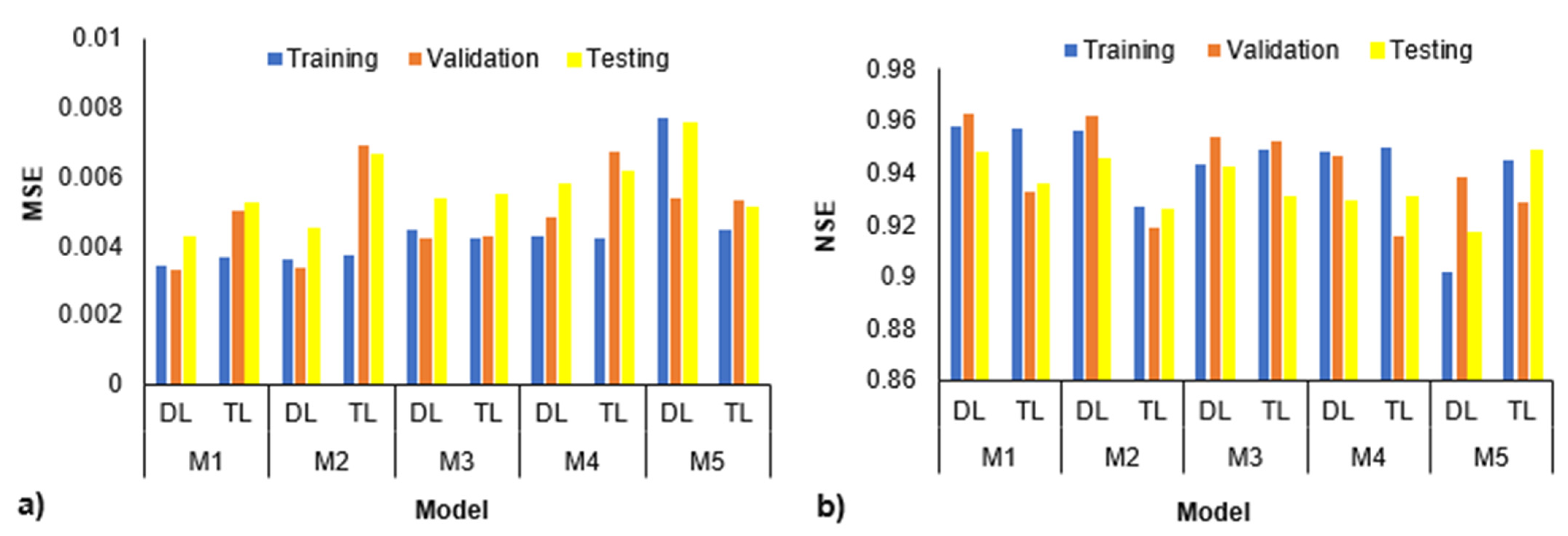
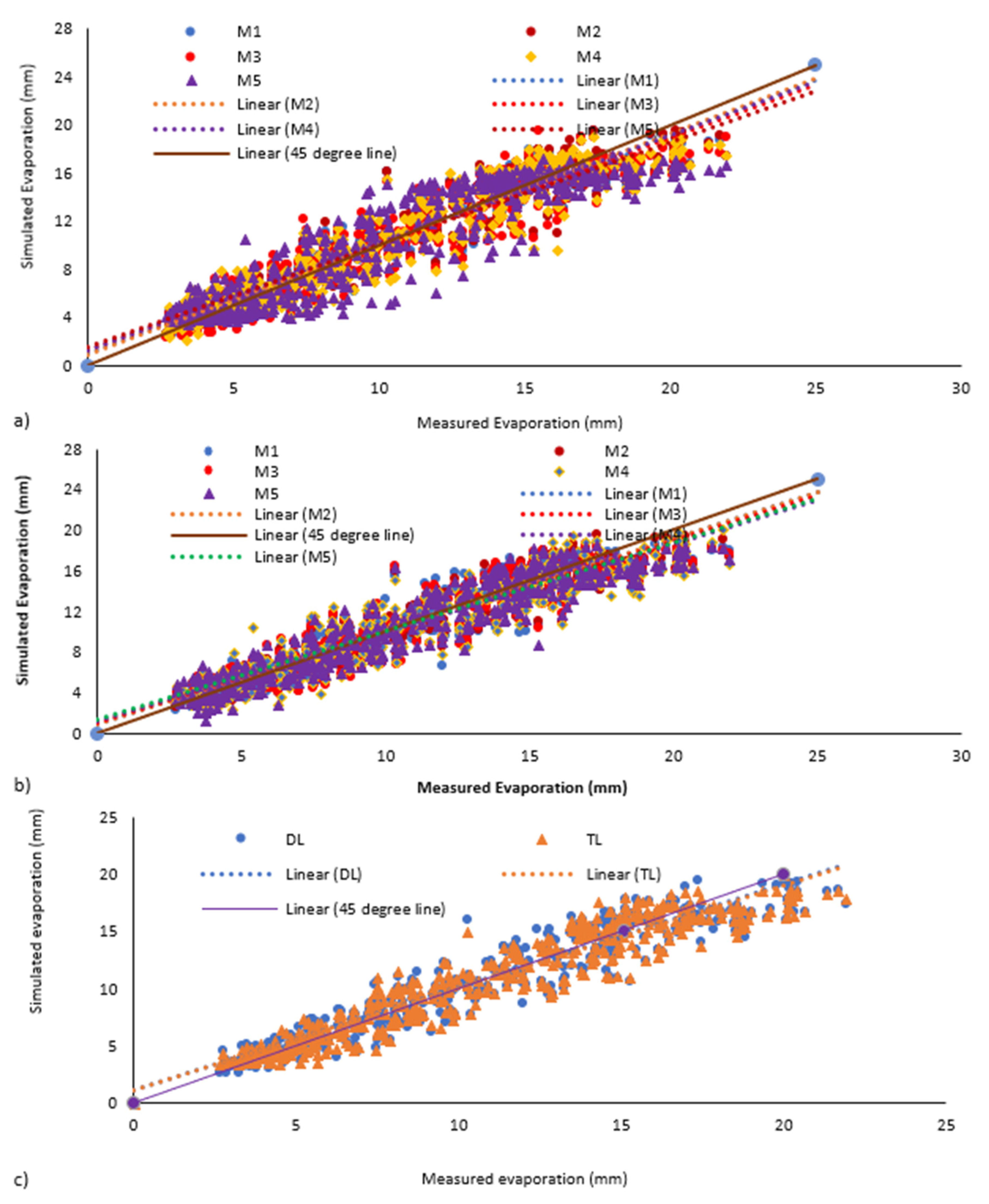
4.2. Comparison of DL- and TL-ANN Models with Five Different Training Functions
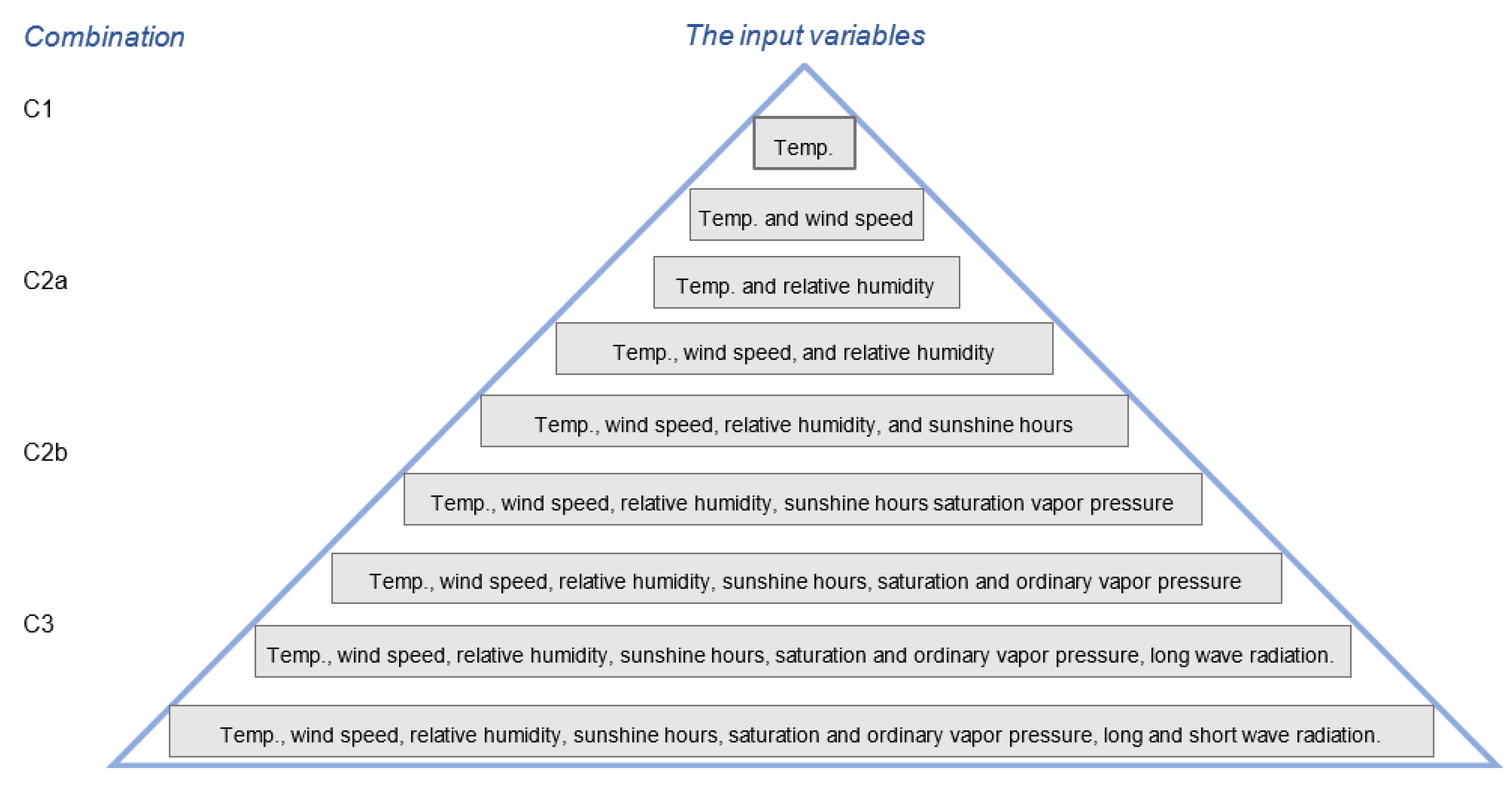
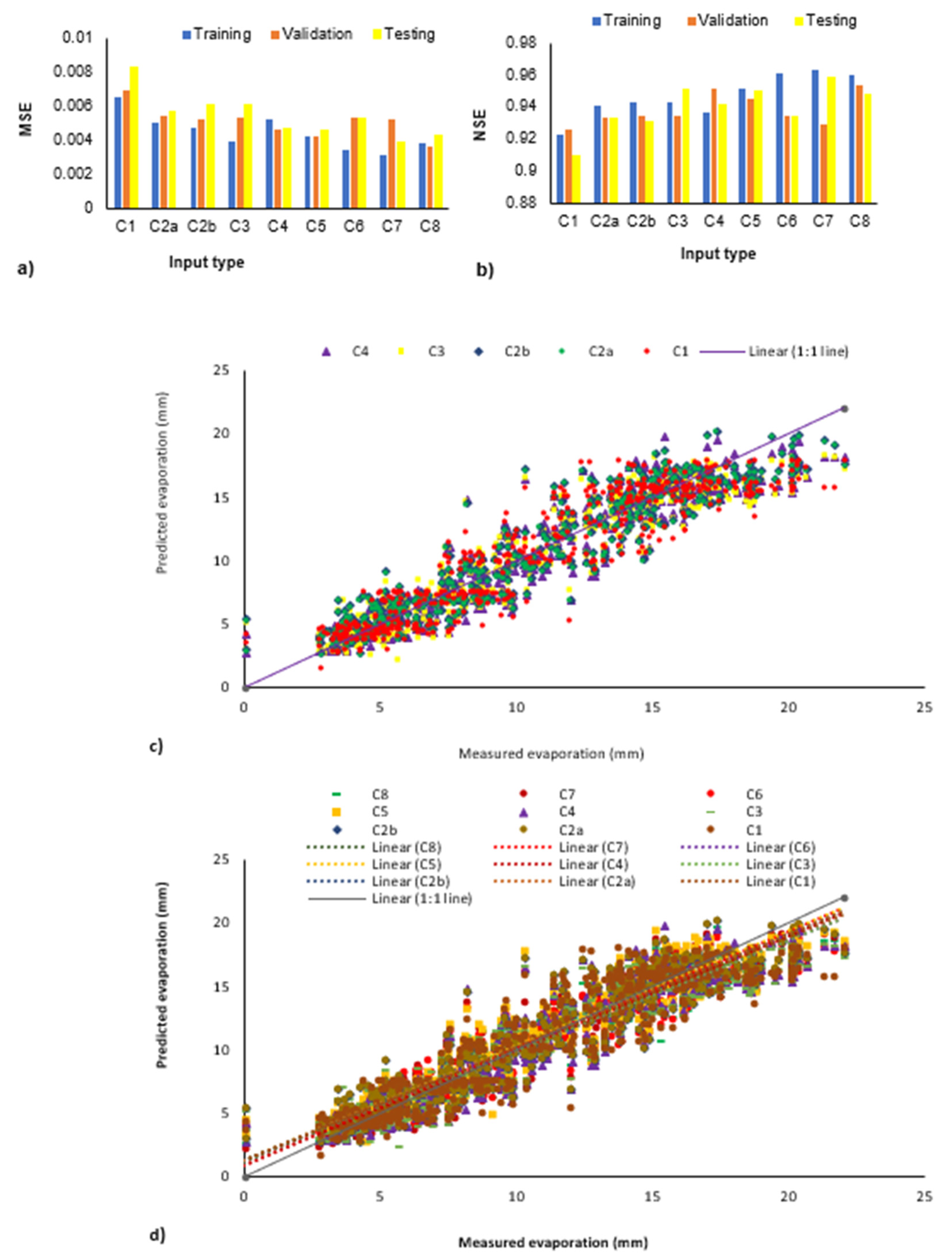
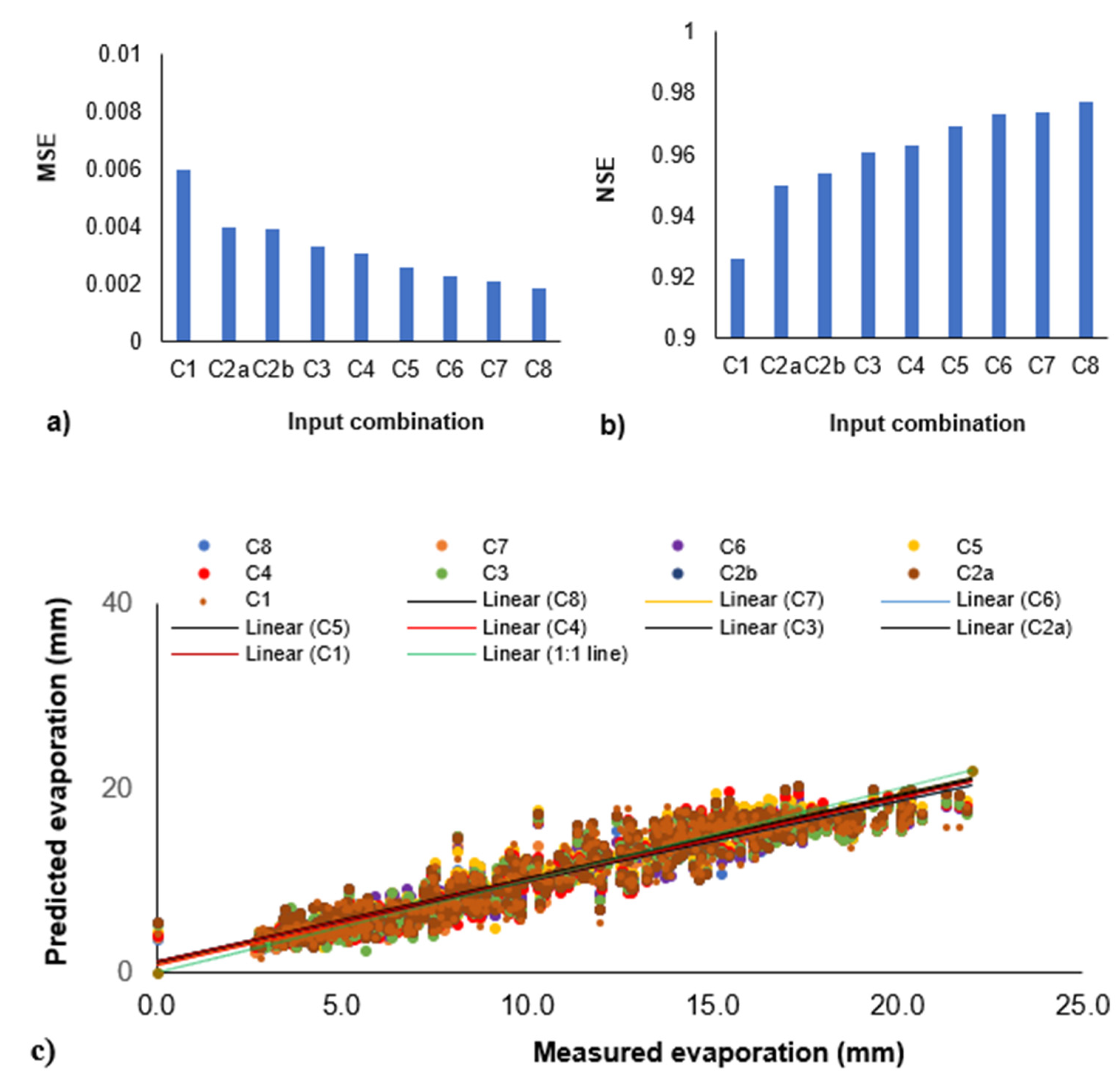
4.3. Impact of the Number of Input Parameters
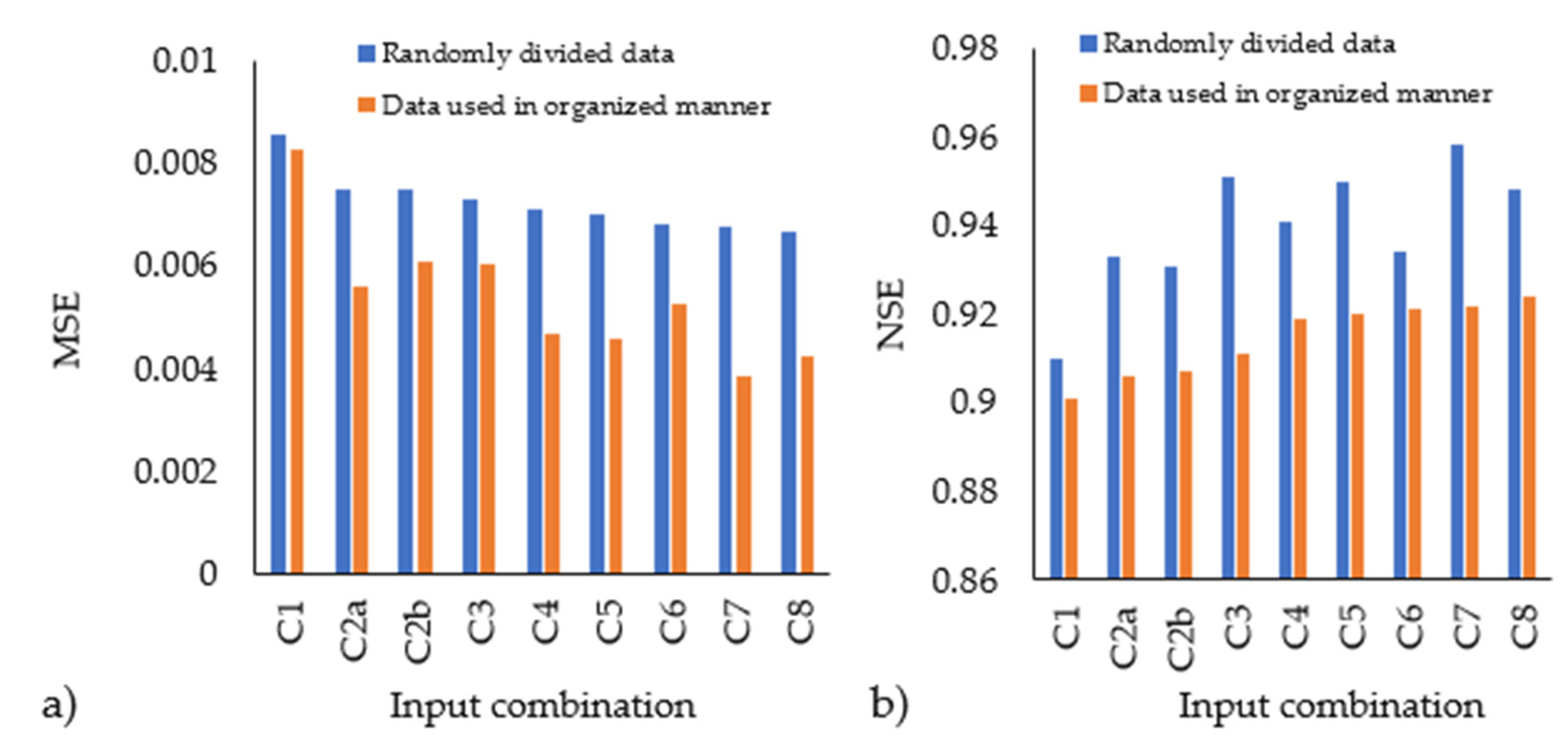
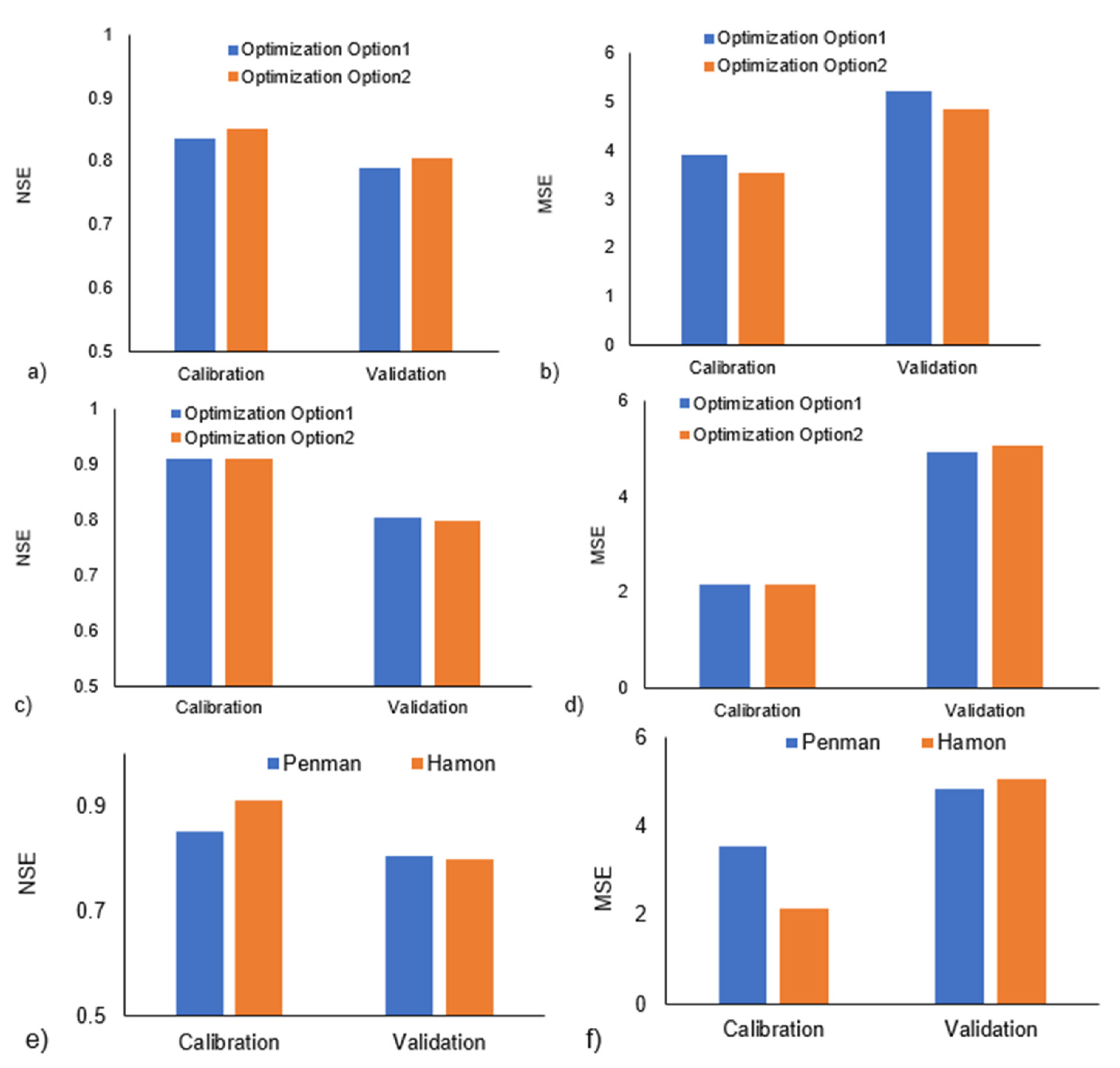
4.4. The Impact Using Various Data Divisions for Training and Testing
4.5. Results of the Prediction of Pan-Evaporation by ANFIS
4.6. Results of the Prediction of Pan-Evaporation by Penman and Hamon’s Equations
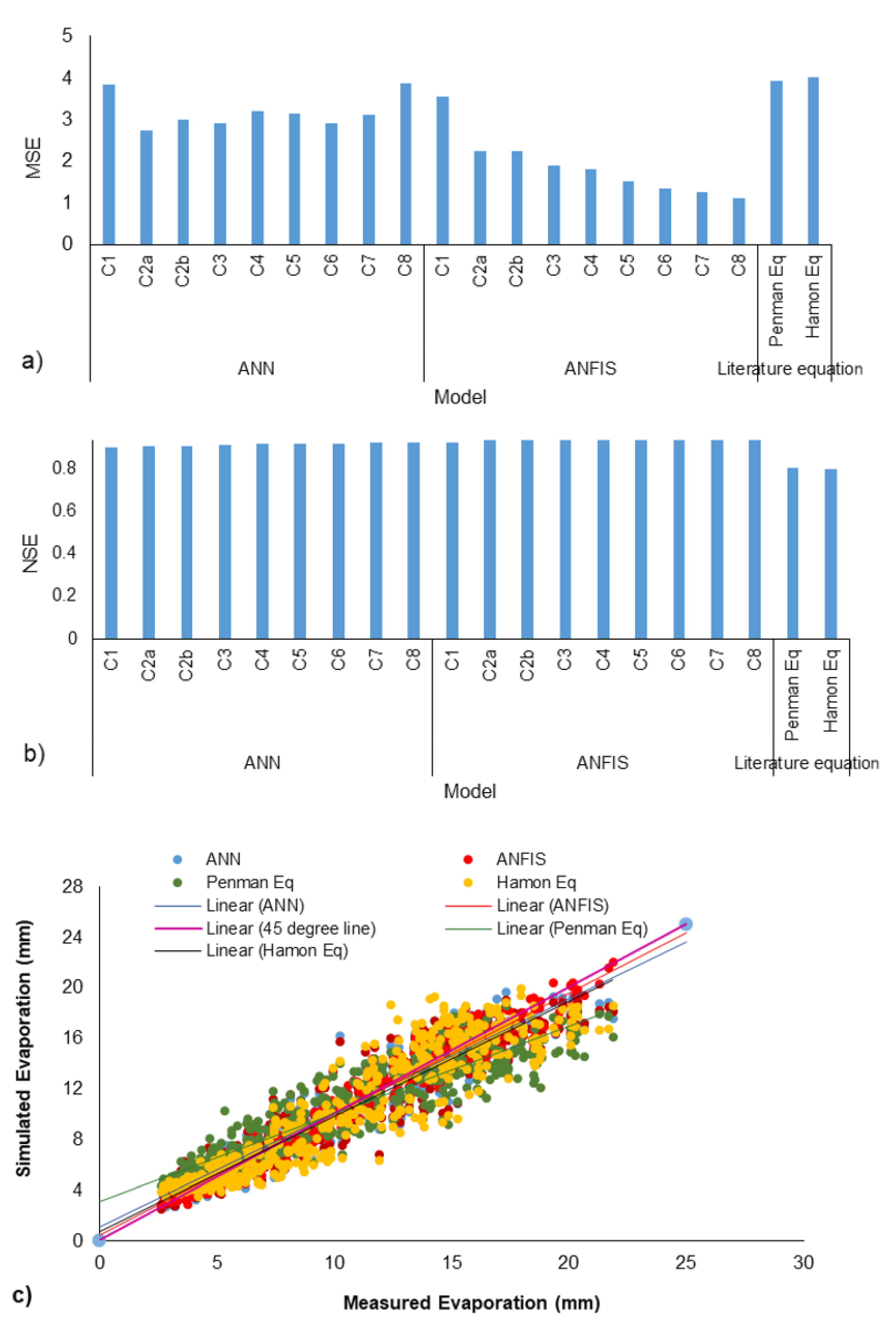
4.7. Comparison of Resuls of Penman and Hamon’s Equations with ANN and ANFIS
5. Discussion
6. Conclusions and Recommendations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tarawneh, Q.Y.; Chowdhury, S. Trends of Climate Change in Saudi Arabia: Implications on Water Resources. Climate 2018, 6, 8. [Google Scholar] [CrossRef] [Green Version]
- Jafari, M.; Dinpashoh, Y.; Asadi, E.; Darbandi, S. Evaluation of Bayesian Network Model for Estimation of Pan Evaporation. Irrig. Sci. Eng. 2020, 43, 93–106. [Google Scholar]
- Kumar, N.; Arakeri, J.H. A fast method to measure the evaporation rate. J. Hydrol. 2020, 125642. [Google Scholar] [CrossRef]
- Li, J.; Wang, C. An Evaporation Correction Approach and Its Characteristics. J. Hydrometeorol. 2020, 21, 519–532. [Google Scholar] [CrossRef]
- Kumar, N.; Arakeri, J.H. Understanding the coupling between the moisture loss and surface temperature in an evaporating leaf-type surface. Dry. Technol. 2020. [Google Scholar] [CrossRef]
- Malik, A.; Kumar, A.; Kim, S.; Kashani, M.H.; Karimi, V.; Sharafati, A.; Ghorbani, M.A.; Al-Ansari, N.; Salih, S.Q.; Yaseen, Z.M.; et al. Modeling monthly pan evaporation process over the Indian central Himalayas: Application of multiple learning artificial intelligence model. Eng. Appl. Comput. Fluid Mech. 2020, 14, 323–338. [Google Scholar] [CrossRef] [Green Version]
- Crago, R.D.; Szilagyi, J.; Qualls, R. Comment on: “A review of the complementary principle of evaporation: From the original linear relationship to generalized nonlinear functions” by Han and Tian (2020). Hydrol. Earth Syst. Sci. 2021, 25, 63–68. [Google Scholar] [CrossRef]
- Weerasinghe, I.; Bastiaanssen, W.; Mul, M.; Jia, L.; van Griensven, A. Can we trust remote sensing evapotranspiration products over Africa? Hydrol. Earth Syst. Sci. 2020, 24, 1565–1586. [Google Scholar] [CrossRef] [Green Version]
- Patle, G.T.; Chettri, M.; Jhajharia, D. Monthly pan evaporation modelling using multiple linear regression and artificial neural network techniques. Water Supply 2020, 20, 800–808. [Google Scholar] [CrossRef]
- Mozny, M.; Trnka, M.; Vlach, V.; Vizina, A.; Potopova, V.; Zahradnicek, P.; Stepanek, P.; Hajkova, L.; Staponites, L.; Zalud, Z. Past (1971–2018) and future (2021–2100) pan evaporation rates in the Czech Republic. J. Hydrol. 2020, 590, 125390. [Google Scholar] [CrossRef]
- Wang, B.; Ma, Y.; Ma, W.; Su, B.; Dong, X. Evaluation of Ten Methods for Estimating Evaporation in a Small High-Elevation Lake on the Tibetan Plateau. Appl. Clim. 2019, 136, 1033–1045. [Google Scholar] [CrossRef]
- Ahmadipour, A.; Shaibani, P.; Mostafavi, S.A. Assessment of Empirical Methods for Estimating Potential Evapotranspiration in Zabol Synoptic Station by REF-ET Model. Medbiotech J. 2019, 3, 1–4. [Google Scholar]
- Zolá, R.P.; Bengtsson, L.; Berndtsson, R.; Martí-Cardona, B.; Satgé, F.; Timouk, F.; Bonnet, M.P.; Mollericon, L.; Gamarra, C.; Pasapera, J. Modelling Lake Titicaca’s Daily and Monthly Evaporation. Hydrol. Earth Syst. Sci. 2019, 23, 657–668. [Google Scholar] [CrossRef] [Green Version]
- Benabdelouahab, T.; Lebrini, Y.; Boudhar, A.; Hadria, R.; Htitiou, A.; Lionboui, H. Monitoring spatial variability and trends of wheat grain yield over the main cereal regions in Morocco: A remote-based tool for planning and adjusting policies. Geocarto Int. 2019. [Google Scholar] [CrossRef]
- Talbot, M. Comparison of Evapotranspiration Estimation Methods and Implications for Water Balance Model Parameterization in the Midwestern United States. Retrieved from the University of Minnesota Digital Conservancy. 2019. Available online: https://hdl.handle.net/11299/211721 (accessed on 26 December 2020).
- Mahmoud, S.H.; Gan, T.Y. Irrigation water management in arid regions of Middle East: Assessing spatio-temporal variation of actual evapotranspiration through remote sensing techniques and meteorological data. Agric. Water Manag. 2019, 212, 35–47. [Google Scholar] [CrossRef]
- Ghumman, A.R.; Ghazaw, Y.M.; Alodah, A.; ur Rauf, A.; Shafiquzzaman, M.; Haider, H. Identification of Parameters of Evaporation Equations Using an Optimization Technique Based on Pan Evaporation. Water 2020, 12, 228. [Google Scholar] [CrossRef] [Green Version]
- Han, S.; Tian, F. A review of the complementary principle of evaporation: From the original linear relationship to generalized nonlinear functions. Hydrol. Earth Syst. Sci. 2020, 24, 2269–2285. [Google Scholar] [CrossRef]
- Hadria, R.; Benabdelouhab, T.; Lionboui, H.; Salhi, A. Comparative assessment of different reference evapotranspiration models towards a fit calibration for arid and semi-arid areas. J. Arid Environ. 2021, 184, 104318. [Google Scholar] [CrossRef] [PubMed]
- Alsumaiei, A.A. Utility of Artificial Neural Networks in Modeling Pan Evaporation in Hyper-Arid Climates. Water 2020, 12, 1508. [Google Scholar] [CrossRef]
- Haghbin, M.; Sharafati, A.; Motta, D.; Al-Ansari, N.; Noghani, M.H.M. Applications of soft computing models for predicting sea surface temperature: A comprehensive review and assessment. Prog. Earth Planet. Sci. 2020, 8, 4. [Google Scholar] [CrossRef]
- Bruton, J.M.; McClendon, R.W.; Hoogenboom, G. Estimating daily pan evaporation with artificial neural networks. Trans. Asae 2000, 43, 491. [Google Scholar] [CrossRef]
- Sudheer, K.P.; Gosain, A.K.; Ramasastri, K.S. Estimating actual evapotranspiration from limited climatic data using neural computing technique. J. Irrig. Drain. Eng. 2003, 129, 214–218. [Google Scholar] [CrossRef]
- Traore, S.; Wang, Y.-M.; Kerh, T. Artificial neural network for modeling reference evapotranspiration complex process in Sudano-Sahelian zone. Agric. Water Manag. 2010, 97, 707–714. [Google Scholar] [CrossRef]
- Qasem, S.N.; Samadianfard, S.; Kheshtgar, S.; Jarhan, S.; Kisi, O.; Shamshirband, S.; Chau, K.-W. Modeling monthly pan evaporation using wavelet support vector regression and wavelet artificial neural networks in arid and humid climates. Eng. Appl. Comput. Fluid Mech. 2019, 13, 177–187. [Google Scholar] [CrossRef] [Green Version]
- Chaudhari, N.; Londhe, S.; Khare, K. Estimation of pan evaporation using soft computing tools. Int. J. Hydrol. Sci. Technol. 2012, 2, 373–390. [Google Scholar] [CrossRef]
- Ghorbani, M.A.; Deo, R.C.; Yaseen, Z.M.; Kashani, M.H.; Mohammadi, B. Pan evaporation prediction using a hybrid multilayer perceptron-firefly algorithm (MLP-FFA) model: A case study in North Iran. Theor. Appl. Climatol. 2018, 133, 1119–1131. [Google Scholar] [CrossRef]
- Majhi, B.; Naidu, D. Pan evaporation modeling in different agro-climatic zones using functional link artificial neural network. Inf. Process. Agric. 2020, 8, 134–147. [Google Scholar] [CrossRef]
- Keskin, M.E.; Terzi, Ö. Artificial neural network models of daily pan evaporation. J. Hydrol. Eng. 2006, 11, 65–70. [Google Scholar] [CrossRef]
- Kumar, M.; Raghuwanshi, N.S.; Singh, R. Artificial neural networks approach in evapotranspiration modeling: A review. Irrig. Sci. 2011, 29, 11–25. [Google Scholar] [CrossRef]
- Zhang, M.; Su, B.; Nazeer, M.; Bilal, M.; Qi, P.; Han, G. Climatic Characteristics and Modeling Evaluation of Pan Evapotranspiration over Henan Province, China. Land 2020, 9, 229. [Google Scholar] [CrossRef]
- Nourani, V.; Elkiran, G.; Abdullahi, J. Multi-station artificial intelligence based ensemble modeling of reference evapotranspiration using pan evaporation measurements. J. Hydrol. 2019, 577, 123958. [Google Scholar] [CrossRef]
- Dou, X.; Yang, Y. Evapotranspiration estimation using four different machine learning approaches in different terrestrial ecosystems. Comput. Electron. Agric. 2018, 148, 95–106. [Google Scholar] [CrossRef]
- Winter, T.C.; Rosenberry, D.O.; Sturrock, A.M. Evaluation of 11 Equations for Determining Evaporation for a Small Lake in The North Central United States. Water Resour. Res. 1995, 31, 983–993. [Google Scholar] [CrossRef]
- Penman, H.L. Natural Evaporation from Open Water, Bare Soil, and Grass. Proc. R. Soc. 1948, 76, 372–383. [Google Scholar]
- Valiantzas, J.D. Simplified Version for The Penman Evaporation Equation Using Routine Weather Data. J. Hydrol. 2006, 331, 690–702. [Google Scholar] [CrossRef]
- Doorenbus, J.; Pruitt, W.O. Guidelines for Predicting Crop Water Requirements, Irrigation and Drainage Paper; Food and Agriculture Organization of the United Nations: Rome, Italy, 1977. [Google Scholar]
- Alazrd, M.; Leduc, C.; Travi, Y.; Boulet, G.; Ben Salem, A. Estimating Evaporation in Semi-Arid Areas Facing Data Scarcity: Examples of the El Haouraeb Dam (Merguellil catchment, Central Tunisia). J. Hydrol. Reg. Stud. 2015, 3, 265–284. [Google Scholar] [CrossRef] [Green Version]
- Souch, C.; Wolfe, C.P.; Susan, C.; Grimmond, B. Wetland Evaporation and Energy Partitioning: Indiana Dunes National Lakeshore. J. Hydrol. 1996, 184, 189–208. [Google Scholar] [CrossRef]
- Yao, H.; Terakawa, A.; Chen, S. Rice Water Use and Response to Potential Climate Changes: Calculation and Application to Jianghan, China. In Proceedings of the International Conference on Water Resources and Environment Research, Kyoto, Japan, 5–9 June 1996; Volume 2, pp. 611–618. [Google Scholar]
- Shuttleworth, W.J. Putting the “Vap” in Evaporation. Hydrol. Earth Syst. Sci. 2007, 11, 210–244. [Google Scholar] [CrossRef] [Green Version]
- Vardavas, I.M. Modeling the Seasonal Radiation of Net All-Wave Radiation Flux and Evaporation in a Tropical Wet-Dry Region. Ecol. Model. 1987, 39, 247–268. [Google Scholar] [CrossRef]
- Vardvas, I.M.; Fountoulakis, A. Estimation of Lake Evaporation from Standard Meteorological Measurements: Application to Four Australian Lakes in Different Climatic Regions. Ecol. Modell. 1996, 84, 139–150. [Google Scholar] [CrossRef]
- Maghrabi, A.H.; Al-Mostafa, Z.A. Estimating surface albedo over Saudi Arabia. Renew. Energy 2009, 34, 1607–1610. [Google Scholar] [CrossRef]
- Hamon, W.R. Estimating Potential Evapotranspiration. J. Hydraul. Div. Proc. Am. Soc. Civ. Eng. 1963, 871, 107–120. [Google Scholar]
- Morton, F.I. Catchment Evaporation and Potential Evaporation Further Development of a Climatological Relationship. J. Hydrol. 1971, 12, 81–99. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, B.; Han, J.; Huang, Y. Robust Linear Programming and Its Application to Water and Environmental Decision-Making under Uncertainty. Sustainability 2019, 11, 33. [Google Scholar] [CrossRef] [Green Version]
- Sheela, K.G.; Deepa, S.N. Review on Methods to Fix Number of Hidden Neurons in Neural Networks. Math. Probl. Eng. 2013, 2013, 425740. [Google Scholar] [CrossRef] [Green Version]
- Peterson, C.; Rognvaldsson, T. An Introduction to Artifical Neuron Network; Departement of Theoretical Physic, Cern School of Computing: Ystad, Sweden, 1991. [Google Scholar]
- Arifin, F.; Robbani, H.; Annisa, T.; Ma’arof, N.N.M.I. Variations in the Number of Layers and the Number of Neurons in Artificial Neural Networks: Case Study of Pattern Recognition. J. Phys. Conf. Ser. 2019, 1413, 012016. [Google Scholar] [CrossRef] [Green Version]
- Ogunbo, J.N.; Alagbe, O.A.; Oladapo, M.I.; Shin, C. N-hidden layer artificial neural network architecture computer code: Geophysical application example. Heliyon 2020, 6, 04108. [Google Scholar] [CrossRef] [PubMed]
- Almuhaylan, M.R.; Ghumman, A.R.; Al-Salamah, I.S.; Ahmad, A.; Ghazaw, Y.M.; Haider, H.; Shafiquzzaman, M. Evaluating the Impacts of Pumping on Aquifer Depletion in Arid Regions Using MODFLOW, ANFIS and ANN. Water 2020, 12, 2297. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River Flow Forecasting Through Conceptual Models, Part I—A Discussion of Principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Liew, V.M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Am. Soc. Agric. Biol. Eng. 2007, 50, 885–900. [Google Scholar]
- Rauf, A.; Ghumman, A.R. Impact Assessment of Rainfall-Runoff Simulations on the Flow Duration Curve of the Upper Indus River—A Comparison of Data-Driven and Hydrologic Models. Water 2018, 10, 876. [Google Scholar] [CrossRef] [Green Version]
- Garces-Jimenez, A.; Castillo-Sequera, J.L.; Corte-Valiente, A.D.; Gómez-Pulido, J.M.; González-Seco, E.P.D. Analysis of Artificial Neural Network Architectures for Modeling Smart Lighting Systems for Energy Savings. IEEE Access 2019, 7, 119881–119891. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Kisi, O.; Piri, J.; Mahdavi-Meymand, A. Assessment of Artificial Intelligence–Based Models and Metaheuristic Algorithms in Modeling Evaporation. J. Hydrol. Eng. 2020, 24, 199886595. [Google Scholar] [CrossRef]
- Tukimat, N.N.A.; Harun, S.; Shahid, S. Comparison of Different Methods in Estimating Potential Evapotranspiration at Muda Irrigation Scheme of Malaysia. J. Agric. Rural Dev. Trop. Subtrop. 2012, 113, 77–85. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Function | Description of Training Function | Model | Function | Description of Training Function |
|---|---|---|---|---|---|
| M1 | trainlm | Levenberg–Marquardt BP | M4 | trainrp | Resilient backpropagation (Rprop) |
| M2 | trainbr | Bayesian regularization | M5 | trainscg | Scaled conjugate gradient BP |
| M3 | trainbfg | BFGS Quasi-Newton BP | - | - | - |
| NSE Range | Performance Level |
|---|---|
| 0.75 to 1.00 | Very Good |
| 0.65 to 0.75 | Good |
| 0.50 to 0.65 | Satisfactory |
| 0.4 to 0.50 | Acceptable |
| ≤0.4 | Unsatisfactory |
| Model Name | Layers | MSE | NSE | ||||
|---|---|---|---|---|---|---|---|
| Training | Validation | Testing | Training | Validation | Testing | ||
| M1 | DL | 0.003406 | 0.003286 | 0.004264 | 0.958 | 0.963 | 0.948 |
| TL | 0.003671 | 0.005014 | 0.005245 | 0.957 | 0.933 | 0.936 | |
| M2 | DL | 0.003586 | 0.003386 | 0.004496 | 0.9565 | 0.9622 | 0.9458 |
| TL | 0.003746 | 0.006913 | 0.006671 | 0.927 | 0.919 | 0.926 | |
| M3 | DL | 0.004448 | 0.004203 | 0.005338 | 0.94361 | 0.95388 | 0.9421 |
| TL | 0.0042 | 0.00426 | 0.005485 | 0.949 | 0.952 | 0.931 | |
| M4 | DL | 0.004272 | 0.004836 | 0.005763 | 0.9479 | 0.9469 | 0.9295 |
| TL | 0.00422 | 0.006738 | 0.006176 | 0.95 | 0.916 | 0.931 | |
| M5 | DL | 0.007715 | 0.005368 | 0.007548 | 0.9018 | 0.93888 | 0.91695 |
| TL | 0.004495 | 0.005339 | 0.005095 | 0.945 | 0.929 | 0.949 | |
| MSE | NSE | |||||
|---|---|---|---|---|---|---|
| Training | Validation | Testing | Training | Validation | Testing | |
| Maximum | 0.0065 | 0.007 | 0.008 | 0.96 | 0.95 | 0.96 |
| Minimum | 0.003 | 0.0036 | 0.004 | 0.92 | 0.92 | 0.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghumman, A.R.; Jamaan, M.; Ahmad, A.; Shafiquzzaman, M.; Haider, H.; Al Salamah, I.S.; Ghazaw, Y.M. Simulation of Pan-Evaporation Using Penman and Hamon Equations and Artificial Intelligence Techniques. Water 2021, 13, 793. https://doi.org/10.3390/w13060793
Ghumman AR, Jamaan M, Ahmad A, Shafiquzzaman M, Haider H, Al Salamah IS, Ghazaw YM. Simulation of Pan-Evaporation Using Penman and Hamon Equations and Artificial Intelligence Techniques. Water. 2021; 13(6):793. https://doi.org/10.3390/w13060793
Chicago/Turabian StyleGhumman, Abdul Razzaq, Mohammed Jamaan, Afaq Ahmad, Md. Shafiquzzaman, Husnain Haider, Ibrahim Saleh Al Salamah, and Yousry Mahmoud Ghazaw. 2021. "Simulation of Pan-Evaporation Using Penman and Hamon Equations and Artificial Intelligence Techniques" Water 13, no. 6: 793. https://doi.org/10.3390/w13060793
APA StyleGhumman, A. R., Jamaan, M., Ahmad, A., Shafiquzzaman, M., Haider, H., Al Salamah, I. S., & Ghazaw, Y. M. (2021). Simulation of Pan-Evaporation Using Penman and Hamon Equations and Artificial Intelligence Techniques. Water, 13(6), 793. https://doi.org/10.3390/w13060793