1. Introduction
To ensure stable dam operation during the peak season, it is necessary to predict the dam inflow discharge. In the past, the inflow was predicted by approximating the rainfall-runoff relationship in a watershed based on hydraulic and hydrological models. However, recent studies have been conducted using deep learning models, such as the multi-layer perceptron (MLP) model, based on long-term observation data.
Deep learning models use a large amount of data and a specific algorithm to make decisions, predictions, and classifications. Initially, artificial neurons that simulate human brain neurons were proposed as a one-dimensional response model of inputs and outputs [
1]. Based on this artificial neuron theory, a perceptron learning method that outputs a single result from multiple inputs has been proposed [
2]. By adding a hidden layer and an error backpropagation algorithm to existing models, model learning can solve more complex nonlinear problems [
3]. The MLP model is composed of several layers, which become more complex and sophisticated as the number of layers and nodes increases, and therefore requires more computational resources. Various methods to improve the MLP model have been proposed and can be divided into two main types.
The first type is an improvement of the model structure itself, such as a convolutional neural network (CNN) model [
4]. This model combines effective image analysis while significantly reducing the amount of data by applying a filtering technique. Similarly, a recurrent neural network (RNN) model was proposed that can reflect the changes in temporal and spatial antecedents by modifying the forward operation direction to a cyclic structure [
3]. Based on the RNN model, a long short-term memory (LSTM) model with a built-in forget gate was proposed to solve the vanishing gradient problem [
5]. In addition, a gated recurrent unit (GRU) model with improved performance and fewer parameters than the LSTM model has been suggested [
6]. Various methods of model improvement have been made, including a “drop out” method to increase performance by adjusting the degree of connection between nodes and omitting unnecessary information [
7].
The second type of improvement of the internal algorithms includes the “activation function” or “optimizer”, which is used during model training. The rectified linear unit (ReLU) and leaky rectified linear unit (leaky ReLU) are widely known and used in representative studies on the improvement of the activation function [
8,
9,
10]. In the case of optimizer improvement, a resilient backpropagation (RProp) algorithm that updates each of the weights in the network by considering only the signs of partial derivatives was proposed [
11]. An adaptive gradient (AdaGrad) algorithm that reflects the past amount of gradient change was proposed [
12]. To solve the problem of poor learning ability in RProp when learning in mini-batches, the root-mean-square prop (RMSProp) algorithm was proposed, which takes the gradient into account [
13]. Recently, the most widely used optimizer has been adaptive moment estimation (Adam), which combines the advantages of both the AdaGrad and RMSProp algorithms [
14].
Many researchers have performed mathematical and hydrological predictions using deep learning models [
15]. Water level predictions for the Trinity River located in Texas were performed using RNN [
16]. A rainfall-runoff model was built using artificial neural network (ANN) and LSTM, and the water level prediction accuracy was superior to that by the existing physical-based model [
17]. An LSTM rainfall-runoff model that can reflect the retention effect of the watershed [
18], as well as an LSTM model for river-level prediction [
19] was suggested. A method for predicting monthly runoff using LSTM and an ant lion optimizer model was also proposed [
20]. For reservoir operation, a decision-making algorithm using an ANN, support vector regression, and deep learning algorithm was proposed [
21]. Rapid spatiotemporal flood prediction was performed based on the LSTM model [
22]. A method for predicting inflow in a distributed hydrological model using RNN was proposed [
23]. LSTM has been used to predict flooding in a model of the global hydrological context [
24]. LSTM was used to predict the flow of the Brazilianos River basin in Texas [
25]. A rainfall-runoff model that can be used in unmeasured watersheds was suggested using LSTM [
26]. Monthly rainfall was predicted using RNN and LSTM [
27]. Several models and algorithms have been applied to predict hydrological data such as rainfall, water level, and discharge. However, it is necessary to improve the model structure or algorithm rather than simply apply it.
The deep learning algorithm uses a calculation method that reduces loss through a gradient descent calculation and thereby aims to find the global optima more effectively. However, although gradient descent is effective in finding local optima, it lacks the ability to find global optima in complex nonlinear problems. In water resource management, which deals with the complex natural phenomena of rainfall-runoff, many parameters are used to predict flow discharge. Therefore, various studies have been conducted on predictive models combining the MLP model and meta-heuristic optimization. A combined model for rainfall-runoff prediction was suggested by combining the MLP and a genetic algorithm [
28]. A rainfall prediction model was developed by combining an ANN with a genetic algorithm [
29]. A daily rainfall-runoff prediction model that combined an ANN with a genetic algorithm [
30] and a water level prediction model using a hybrid ANN model with a genetic algorithm was suggested [
31]. However, as the hidden layer of the model increases in deep learning, more resources are required for the meta-heuristic algorithm calculations. Therefore, it is necessary to improve the model to ensure the accuracy of the existing deep-learning model and simplify the calculation.
The accuracy of the prediction model is calculated based on the difference between the actual value and the predicted value. In addition, it is an important factor because this error is used as an objective function in the learning process of the model. Studies have been conducted to measure the accuracy of the model in various subjects. An evolutionary model of drag coefficient using genetic programming was developed, and its accuracy was comparatively analyzed [
32]. An algorithm to optimize the shape of labyrinth spillways using meta-heuristic algorithms is presented [
33]. Based on the Muskingum model, reverse flood routing was performed in rivers, and the accuracy was analyzed [
34]. Bayesian network was used to predict the longitudinal dispersion coefficient in natural rivers, and the accuracy was reviewed [
35]. To predict the performance of tunnel boring machines, multi-gene genetic programming was proposed [
36]. In this study, the model accuracy was quantitatively expressed by referring to these papers.
This study aimed to develop a deep learning model to predict inflow into the dam basin from upstream water gauge data. To improve the prediction accuracy of the model, the time series data were divided into “peak season” and “off season”. Then, data normalization was applied to reduce the error due to seasonal discharge fluctuations and the deviation of the measured values. In addition, the revised MLP (RMLP) model, which includes a new learning algorithm, was proposed to improve prediction accuracy. This algorithm adds two random search components, “boundary random ()” and “proportional random ()”, in the weight update step. This prevents the MLP model from being fixed on the local solution and allows the global optima to be obtained simply and effectively. In this study, a daily inflow prediction model was developed for the Soyang Dam Basin. To increase the accuracy of the model, data preprocessing was performed, and an RMLP model with an improved learning algorithm was suggested. For accuracy analysis, test data were applied to the trained model, and the preprocessing and model improvement effects were compared.
2. Methodologies
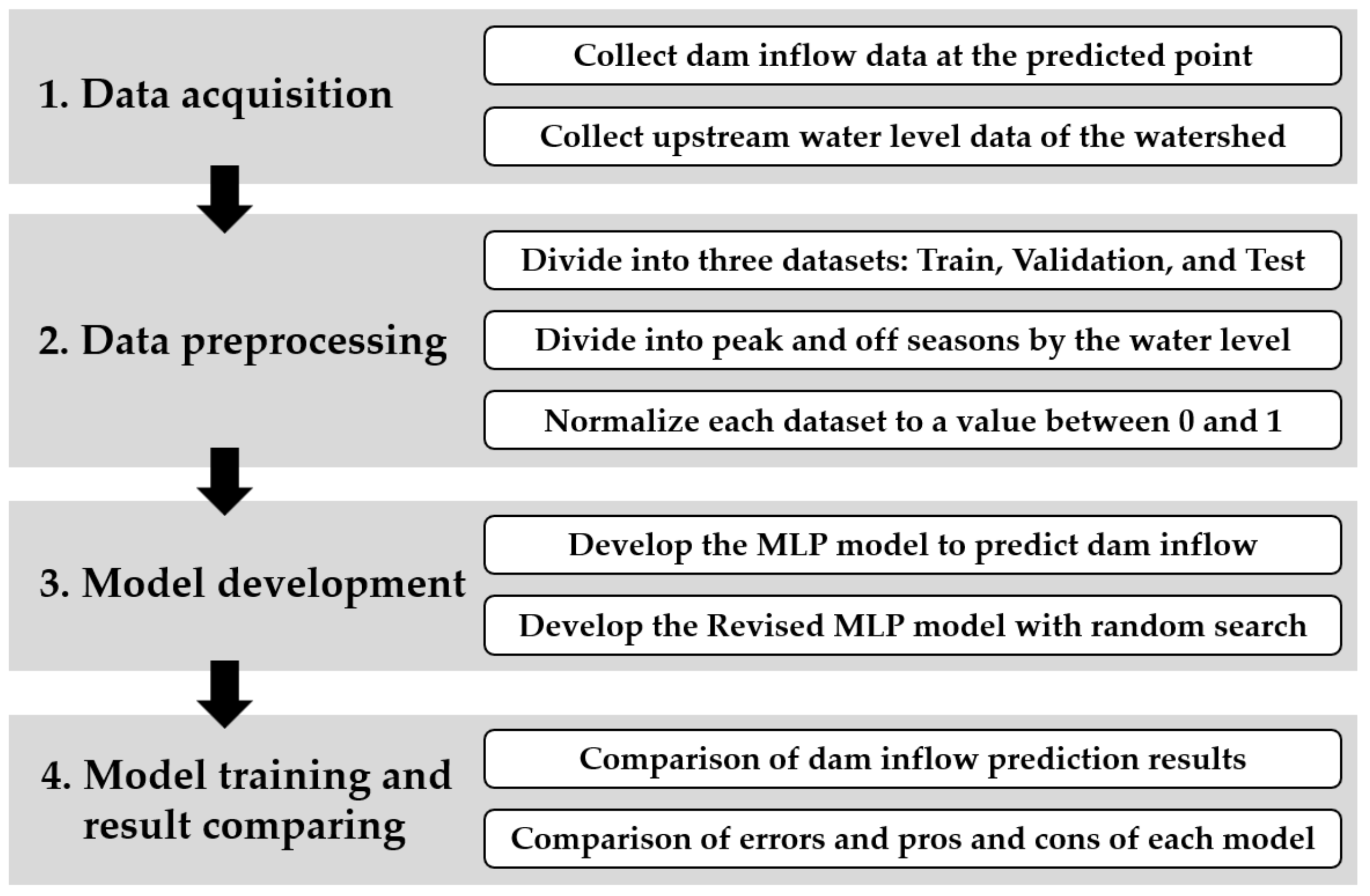
The study comprised four major stages. The first stage was the data-acquisition stage. The status of the target watershed was analyzed, and the required data point and period were selected. The second stage was data preprocessing. The acquired data were divided into training, validation, and test datasets, according to the measurement year. In this stage, two preprocessing steps were performed to improve the performance of the model. (1) Input data were divided into peak and off seasons and above- and below-average based on the water level gauge; (2) Input data were normalized to have a value between zero and one. Seasonal division and normalization were also performed. The third stage involved the construction of the MLP model to predict dam inflow. The analysis was performed for four scenarios: without preprocessing, seasonal division, normalization, and applying combined seasonal division and normalization. Next, an RMLP model with a random search algorithm was developed and analyzed in the same manner. Finally, the prediction results of the test datasets for the preprocessing and model improvement effects were compared.
Figure 1 is a graphical overview representing the methodology of the study.
2.1. Data Preprocessing: Seasonal Division
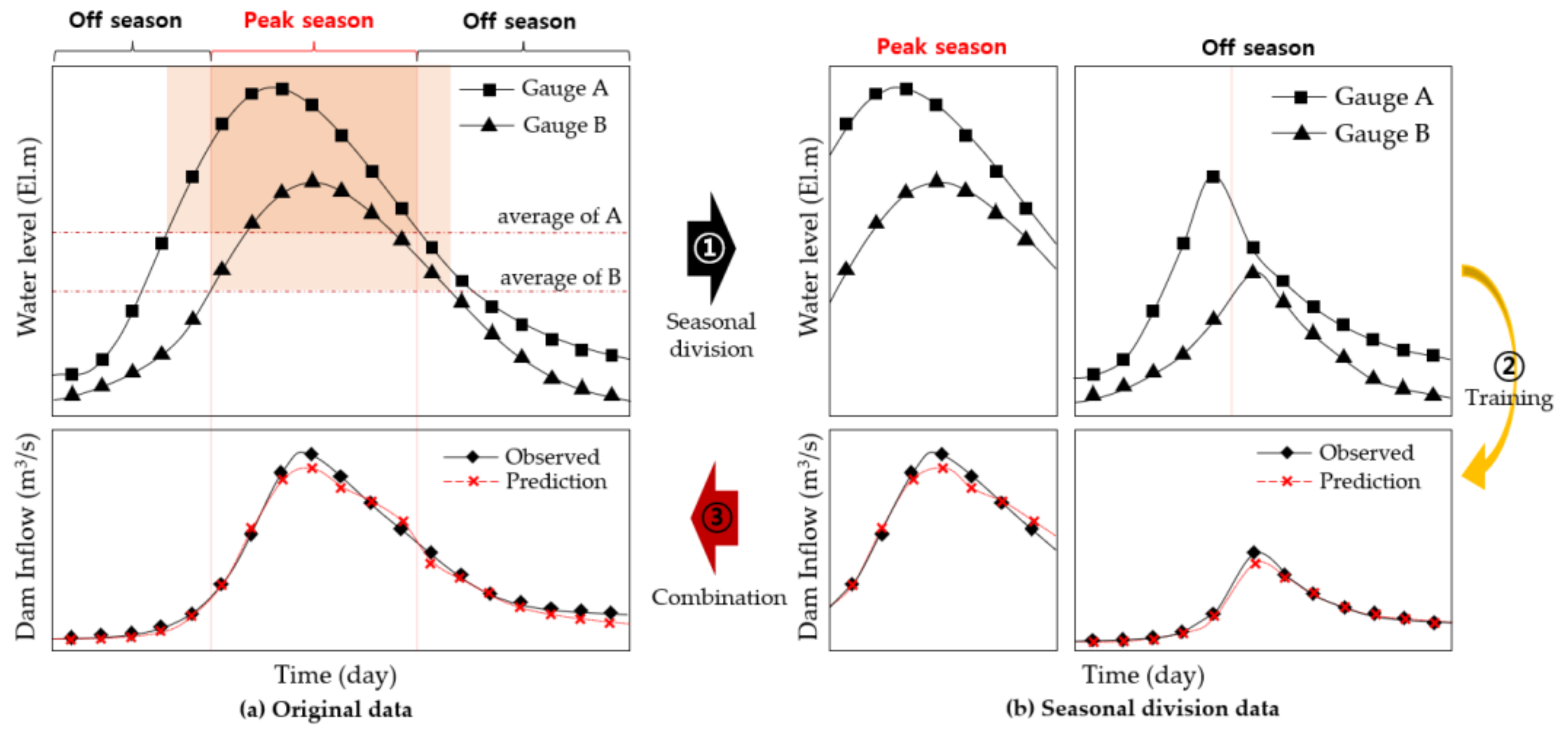
The water level and flow discharge were characterized by significant differences between the peak and off seasons. When rainfall occurred, the water level and flow discharge increased rapidly and then decreased over time. However, when no rainfall occurred, the water level and flow discharge were low because of the small base runoff. In South Korea, rainfall events are concentrated during the rainy season. Therefore, batch training the entire dataset results in a high possibility of decreased prediction accuracy during the peak season. To solve this problem, ① the input data were divided according to the upstream water level. The separation criterion was the average water level at the level gauge. In this study, two data points were used for the upstream water level. Peak season was defined when both water levels exceeded their average height, and all other conditions were defined as the off season, ② Model training was performed in the peak and off seasons, respectively, and ③ the two models were combined after the learning phase was completed. To verify the accuracy of the model, the discharge was predicted by dividing it into peak and off seasons based on the water level of the input data, and the model error and accuracy were calculated by combining the two results. The seasonal division process is briefly represented in
Figure 2.
2.2. Data Preprocessing: Normalization
The data used for model training had different ranges and deviations, depending on the measurement point and type. When biased data were used as inputs to the model, biased results can be obtained during the training process of the model. To prevent this, all water level and discharge data were normalized between zero and one. This process was performed individually for the training, validation, and testing datasets. The data normalization process, called min-max scaling, was calculated using Equation (1).
where
is the normalized data,
is the original data without preprocessing,
and
are the minimum and maximum values, respectively, among the input data
. This process made it possible to remove the bias due to the deviation of the data point characteristics.
2.3. Model Composition
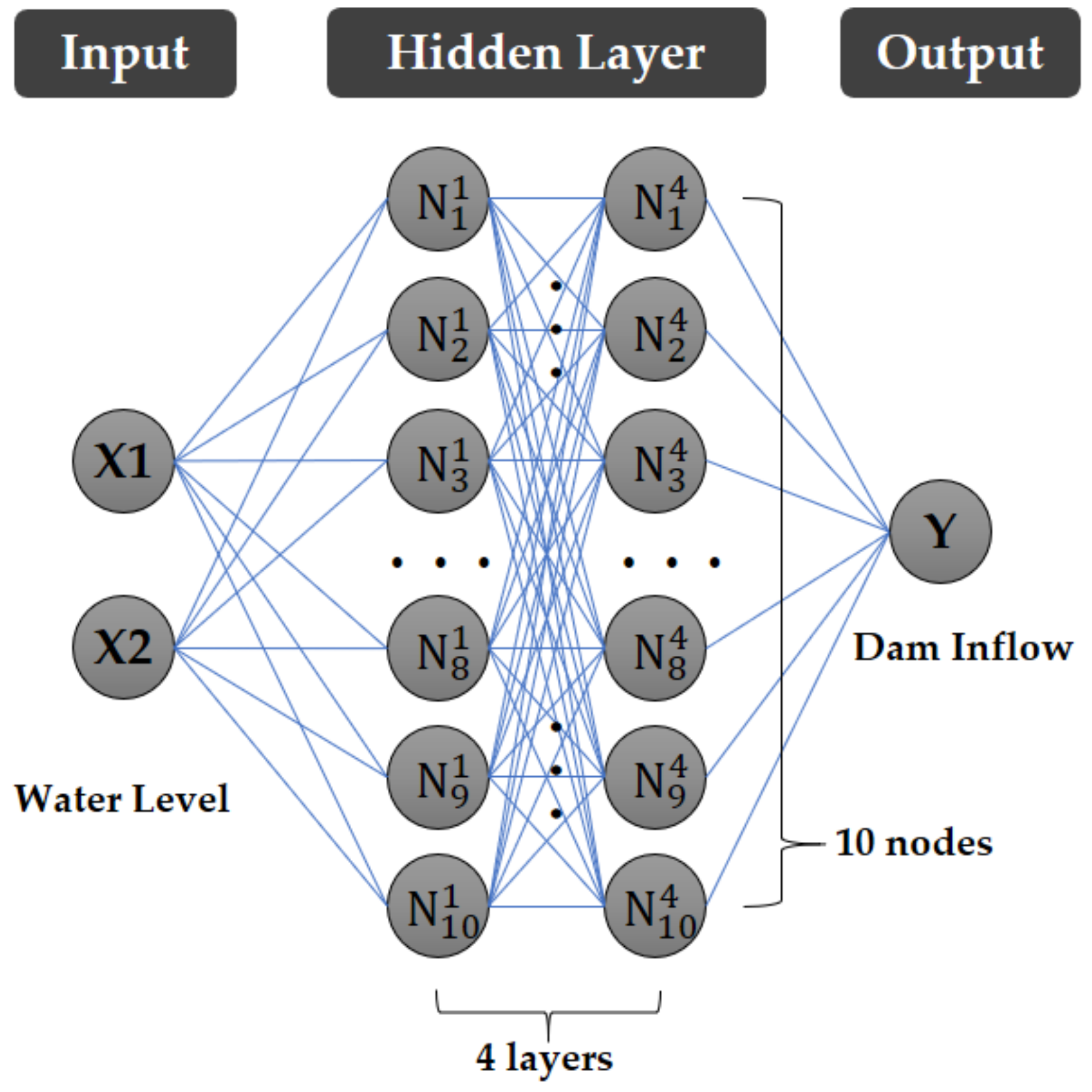
Except for their respective learning algorithm, the MLP and RMLP models have the same model and structure. The MLP model consisted of a dense structure, four hidden layers, and ten nodes per layer. There were two input nodes and one output node because the input data were the water level data of two locations, and the output datum was the predicted dam inflow. The activation function and optimizer of the model were the ReLu and Adam, respectively. The goal of the model training was to predict the average daily inflow of the dam through the upstream water level. Therefore, the daily average data were the temporal resolution. The model was written using Spyder (version 5.1.5), an open-source platform development environment based on the Python (version 3.8.12 64-bit) programming language. The structure of the model is shown in
Figure 3.
Because the goal of this model was to approximate the inflow discharge, the mean squared error (MSE) was selected to calculate the error between the predicted model and the observed data. MSE is the average of the squares of the difference between the predicted and actual values. In general hydrology, the peak discharge during the peak season is more important than that during the off season. Therefore, an MSE that exaggerated the error in the peak discharge was selected. However, it depends on the scale of the data and has a weakness against data noise which is a disadvantage. Therefore, it is necessary to remove noise through data normalization.
2.4. Random Search Algorithm
The current MLP model calculates the gradient and performs weight updates using an optimizer. However, in this study, a new algorithm for updating the model weights is proposed. It adds two random searches (boundary and proportional random) to obtain smaller errors compared to the basic MLP model. The first step of the random search was “boundary random (
)”, which was randomly changed within the range of the initial value of the weight. The random change was performed independently with the probability of the
parameter for all weights in the model. The
was calculated using Equation (2).
where
is
kth weight of the model,
is random value between -one and one,
is an initial boundary of model weight,
is random value between zero and one for
kth weight, and
is the boundary random parameter and a preset value when constructing the model.
The second step was “proportional random (
)”, which changed in proportion to the current weight value. In the
method, the intensity of the weight change was assigned as a learning rate parameter (
). The
was calculated using Equation (3).
where
is the learning rate,
is the proportional random parameter. Both were determined when constructing the model.
A random search was performed with an independent probability for all the weights. If neither nor was selected, the original values were maintained. The sum of the probabilities of the two parameters did not exceed one. Setting the parameter value was important because it affected the analysis results. In this study, parametric sensitivity analysis was performed and = 0.05, = 0.01, and = 0.01 were set as optimal values.
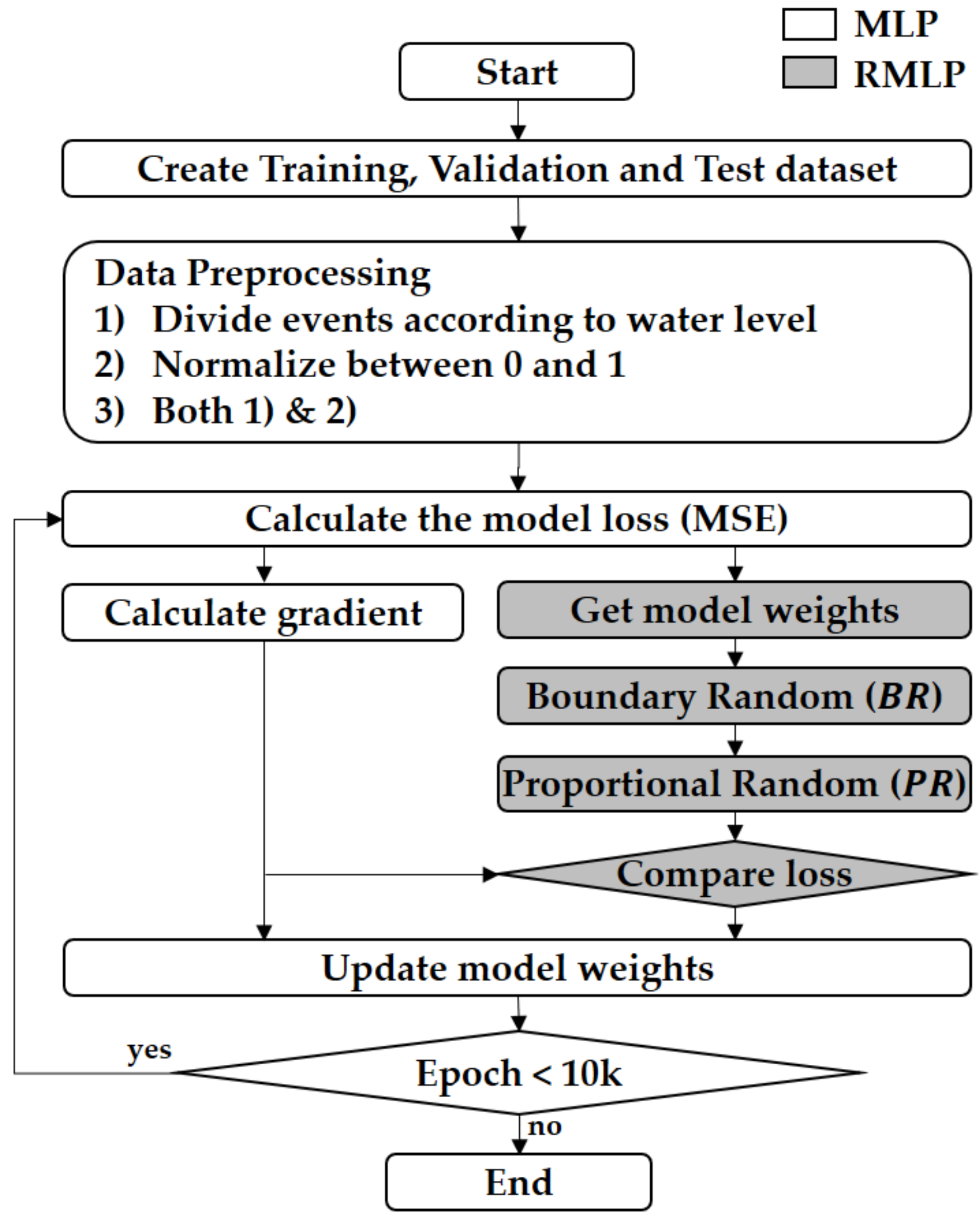
2.5. Model Training Process
In the model training process, the MLP and RMLP followed a similar framework. First, the data were divided into training, validation, and testing datasets. In this study, daily data from 2004 to 2021 were used. Data from 2004 up to 2015 were classified as the training dataset, data from 2016 to 2018 as the validation dataset, and data from 2019 to 2021 as the test dataset. In the data preprocessing stage, based on the value of the upstream water level gauge, the dataset was (1) constructed by dividing it into above-average (peak season) and below-average (off season), (2) normalized to have a value between zero and one through min-max scaling, and (3) analyzed when preprocessing (seasonal division and normalization) was applied. The initial weight of the model also affected the learning performance. In this study, the initial boundary was set to 0.8 through sensitivity analysis. Accordingly, the initial weight of the model was randomly configured within the range of ±0.8. The initial loss for the original model without preprocessing was calculated as MSE, and the weight update was performed by calculating the gradient of the loss. For the weight update, the current method (MLP) and the new algorithm (RMLP) were applied. In RMLP, before updating the weights, the results derived from the random search were compared with the results of MLP using the current optimizer, and the more accurate weights were transferred to the next epoch. If the random search result was worse than the current optimizer result, the next epoch was performed using the current optimizer result. Thus, better alternatives were selected, resulting in more effective results compared to the existing model. This process was repeated from the MSE calculation until the number of epochs exceeded 100,000. The learning process of the model is illustrated in
Figure 4.
In general, the training error continuously decreased as the epoch progressed. However, the validation error may show a different pattern. This problem called overfitting occurred because the model training data are limited. To solve the overfitting problem, the validation error was continuously tracked during the learning process, and the result with the smallest validation error was selected as the final model. In the learning process, the validation error was analyzed by repeating 20 epochs up to 100,000 times.
3. Application and Results
3.1. Target Area
The target watershed was the Soyang Dam Basin, located in Gangwon-do, South Korea, as shown in
Figure 5. The area of the basin was 2694.4 km
2, the basin circumference was 383.6 km
2, the average width of the basin was 16.5 km, and the average watershed slope was 46.0% [
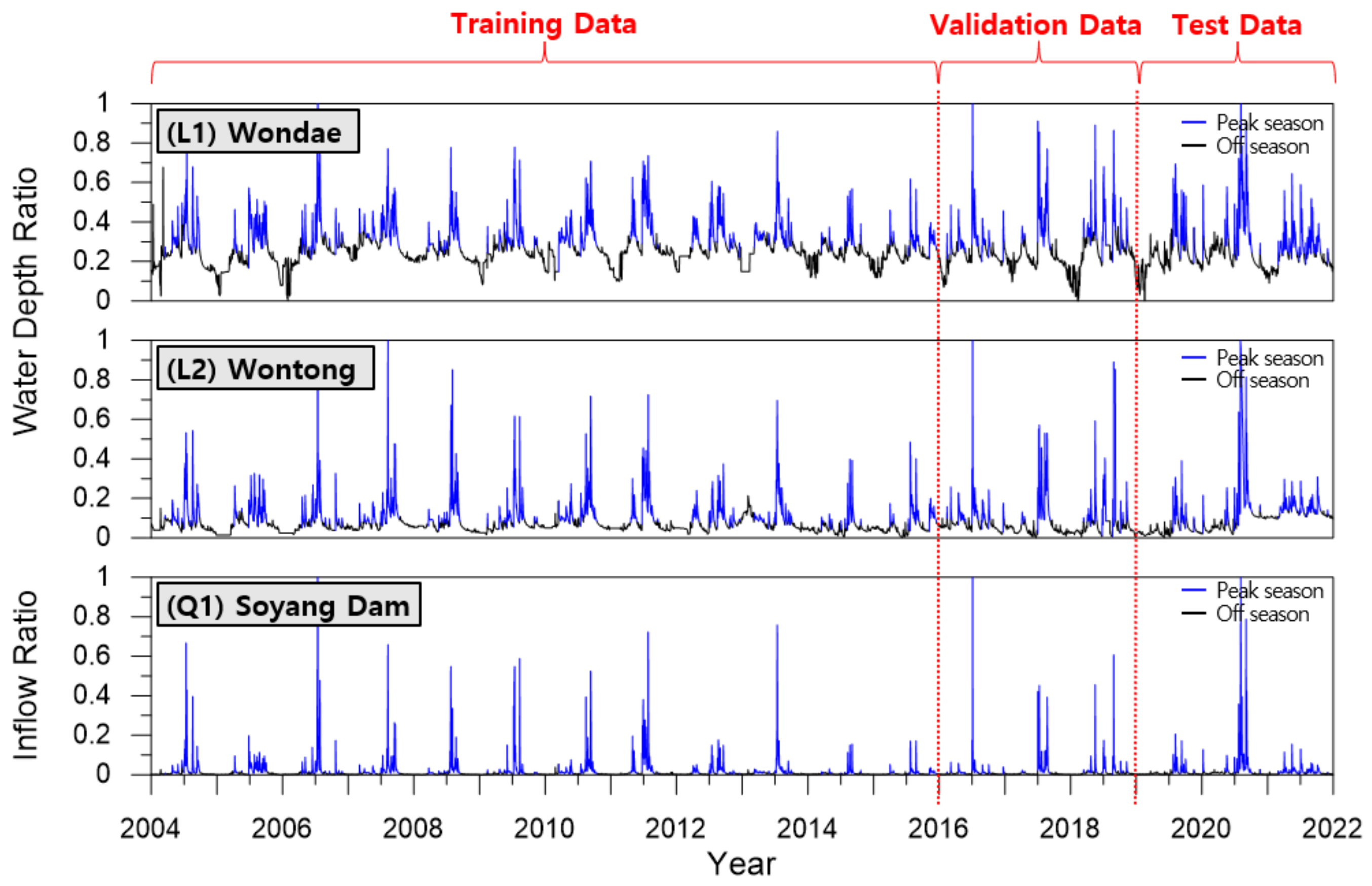
37]. The flow discharge into the Soyang Dam was generated from the Inbukcheon and Soyang rivers. The Soyang Dam was built at the exit of the basin with a storage capacity of 2.9 billion tons. Daily average water level data from 2004 to 2021 were acquired from two water gauges (Wontong and Wondae) installed in Inbukcheon and Soyang rivers, respectively. The daily average dam inflow data for the same period was investigated to determine the water level-inflow discharge time series data.
3.2. Preparation of Input Data
Data from two water gauges located in the middle and upstream of the Soyang Dam Basin and the dam inflow were used as training data for the prediction model. The daily average data from 2004 to 2021 were provided by the Water Resource Management Information System (WAMIS) [
38]. Data preprocessing was performed to build the training, validation, and test models. A total of 4383 data points from 2004 to 2015 were used as the training dataset, 1096 data points from 2016 to 2018 were used as the validation dataset, and the remaining 1096 data points from 2019 to 2021 were used as the test dataset. The cases where both the Wondae and Wontong water levels were above average were classified as the peak season, and the other cases were classified as the off season. The total number of days corresponding to the peak season was 1717, including the 1183 days of training data, 240 days of validation data, and 294 days of test data. The off season was 4858 days long, comprising 3200 days of training data, 856 days of validation data, and 802 days of test data. The number of each dataset and its maximum and minimum values are listed in
Table 1 and
Table 2.
The entire dataset had two sets of water level data and one set of dam inflow data. This was further divided into training, validation, and test data according to the measurement year. The peak season (blue line) and off season (black line) were differentiated according to the water level. Seasonal changes in the water level and inflow discharge were clearly visible. The inflow discharge was closer to zero during the off season and showed a large difference between annual peak seasons. Therefore, more accurate prediction results could be obtained by training the model and dividing the peak and off seasons. The entire input dataset is presented as a time-series graph, as shown in
Figure 6.
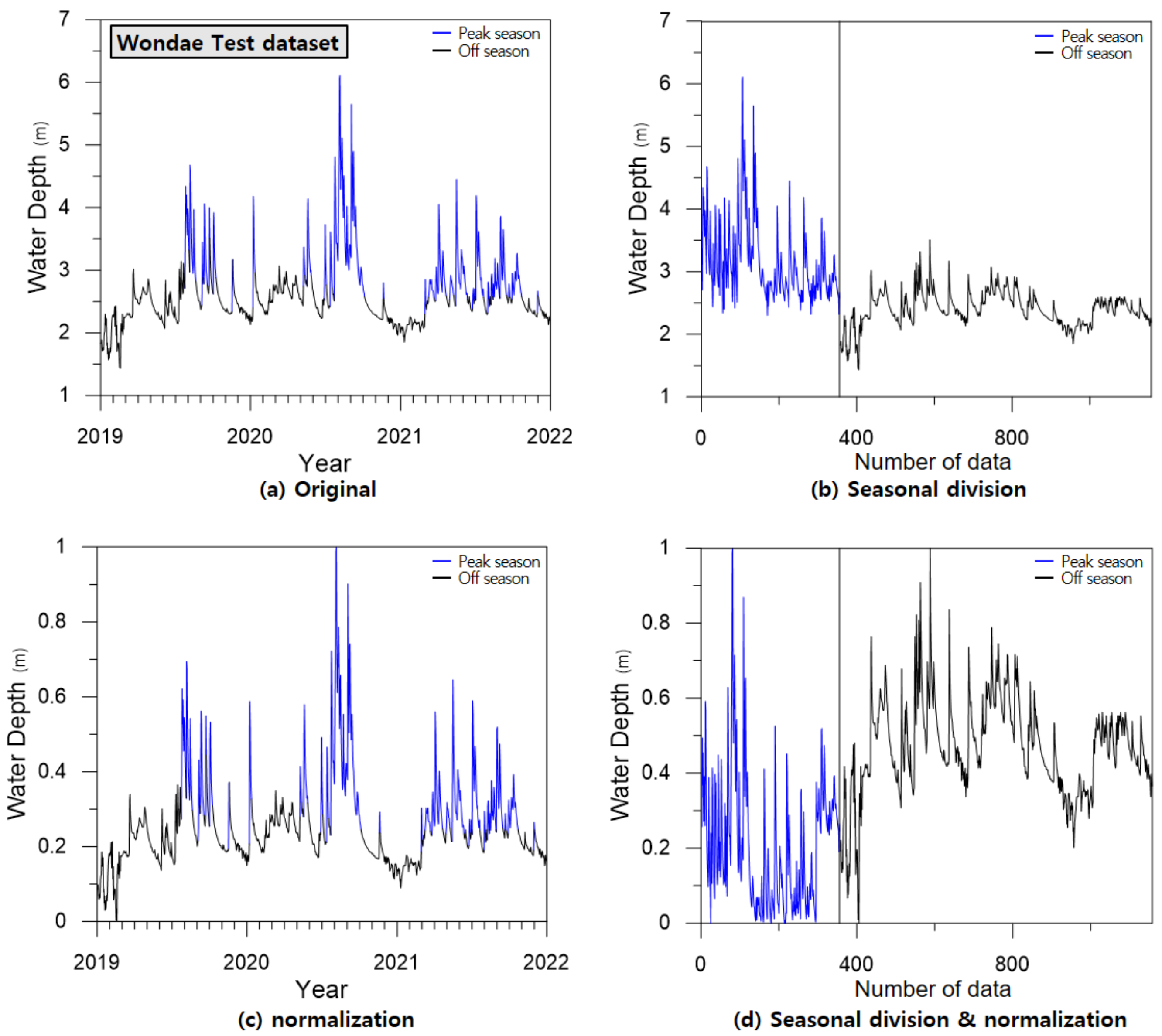
Figure 7 shows the input data separated according to the type of preprocessing, using the Wondae gauge dataset as an example.
Four types of preprocessing methods were applied to the MLP and RMLP models.
Figure 7a shows the original data without preprocessing. The blue line corresponds to the peak season, and the black line corresponds to the off season, which was used as learning data, as shown in
Figure 7b.
Figure 7c shows the data normalized to between zero and one, and
Figure 7d shows the data that applies both seasonal division and normalization.
In this study, eight cases were classified according to the model and preprocessing types. In the MLP model, Case 1 (without preprocessing), Case 2 (seasonal division), Case 3 (data normalization), and Case 4 (both seasonal division and normalization) were applied. Similarly, the RMLP model was classified from Cases 5 to 8. The total cases are presented in
Table 3.
3.3. Model Parameter Estimations for MLP and RMLP
Because model parameters affected the performance of the MLP and RMLP models, it was important to set appropriate values. Each model required different parameters. In the MLP model, the range of the initial weights (
) should be set. This value was used when building the model initially and was not involved in the subsequent learning process. However, in the gradient descent, the initial value was important because it affected the overall learning result. In this study, the model parameters were determined through parameter sensitivity analysis. The results were compared by setting the range of the initial weight in four steps: 0.2, 0.4, 0.6, and 0.8. After training the model, the test dataset was used to compare the MSE with the smallest value. The analysis was repeated ten times, and 10,000 epochs were analyzed during each analysis cycle. The average and minimum values of the test error for each parameter were analyzed, as shown in
Table 4. Finally, the MLP model parameter was determined to be
= 0.8 with the smallest mean and minimum errors.
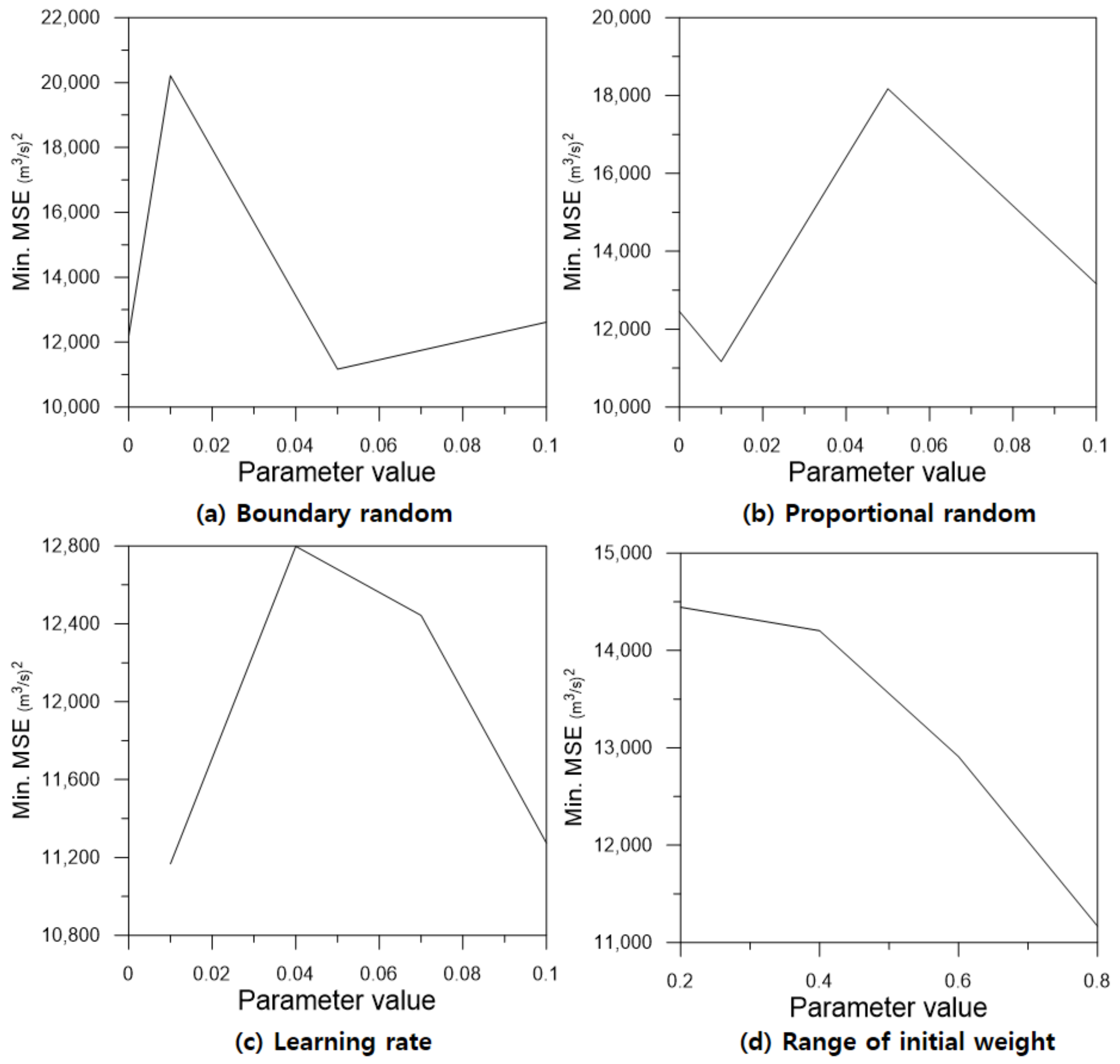
In the RMLP model, four parameters were set. The
and
parameters represented the probability of performing each random search with a value between zero and one. The sum of these two probabilities did not exceed one. A sensitivity analysis of the two parameters was performed for four cases: 0.0, 0.01, 0.05, and 0.1. The learning rate (
) indicated the strength of the existing weight values when
was applied. Sensitivity analysis was performed using four values: 0.01, 0.04, 0.07, and 0.1. Finally, the range of the initial weight was analyzed using four values: 0.2, 0.4, 0.6, and 0.8. Unlike that in MLP, when applying
, the range of the initial weight must be considered continuously. In this study, assuming a small learning rate effect,
was fixed at 0.01, and then the analysis was performed ten times for all 64 cases configurable with the remaining three parameters:
,
, and
. The test error had minimum values at
= 0.05,
= 0.01, and
= 0.8. Subsequently, the three parameters were fixed, and sensitivity analysis of the learning rate was performed to obtain a minimum error at
= 0.01. Finally, the RMLP model parameters were determined as
= 0.05,
= 0.01,
= 0.01, and
= 0.8.
Table 5 presents the sensitivity analysis results for the RMLP model parameters.
As a result, except for the case of zero (without
), the error decreased and then increased in a concave shape and was the smallest at
= 0.05. Conversely,
showed a convex shape and had the highest accuracy at
= 0.01, the minimum value excluding zero (without
). The learning rate showed a convex shape, with a minimum error at
= 0.1. In both MLP and RMLP, the model accuracy improved as the range of initial weight increased. The model accuracy according to the change of each parameter is shown in
Figure 8.
The parameters of the MLP and RMLP models were determined through parameter sensitivity analysis, as shown in
Table 6.
In the MLP model, the range of the initial weight value () was set to 0.8. In the RMLP model, the parameter was 0.05, parameter was 0.01, learning rate () was 0.01, and the range of initial weight () was set to 0.8, the same as in the MLP model.
3.4. Data Preprocessing Results
For the analysis of the preprocessing effect of the input data in the MLP and RMLP models, learning for eight cases was performed using four types of input data and two models. The analysis was repeated 20 times and was performed for up to 10,000 epochs during each cycle. Training and validation errors were calculated for each epoch, and the model with the smallest validation error was selected as the final model. The performance of the model is shown in
Table 7 as MSE for the test data.
In the MLP model, the test error of the inflow prediction result without preprocessing (Case 1) was 11,006. When dividing the peak season and off season (Case 2), it was 14,370, which was an increase of 3364 (30.6%). When data normalization was performed (Case 3), MSE was 8985, which was reduced by 2021 (18.4%) compared to that of Case 1. The result of applying both preprocessing steps (Case 4) was 4511, which decreased by 6495 (59.0%) compared to that of Case 1. All results with normalization showed better results than those of Case 1 because normalization reduced the error caused by the deviation of the training data. In contrast, when only seasonal division was applied, the error increased compared to the original results without preprocessing. Owing to flood characteristics in South Korea, the difference between the peak and off seasons was large, and the low discharge was close to zero. When the discharge was small, the MSE was relatively small, even if an error occurred. When the discharge was large, MSE became large because the square of the deviation increased, while the amount of data was small. The error was the smallest when both preprocessing techniques were applied. Therefore, normalization must be applied with seasonal division. The instability that occurred in the peak season model was reduced through the normalization process. Consequently, the prediction accuracy of the combined peak and off seasons was significantly improved when both preprocessing methods were applied.
The results of the RMLP model analysis showed similar patterns. For the discharge prediction without preprocessing (Case 5), the test error was 11,344. When analyzed by dividing the peak and off seasons (Case 6), the MSE was 12,251, which increased by 907 (8.0%) compared to that in Case 5. After data normalization (Case 7), the MSE decreased from 5978 (52.7%) to 5366. When both preprocessing steps were applied, the MSE was 4368, which is 6976 (61.5%) less than the MSE of Case 5. As with the MLP results, applying both preprocessing methods was more effective than only applying the normalization method.
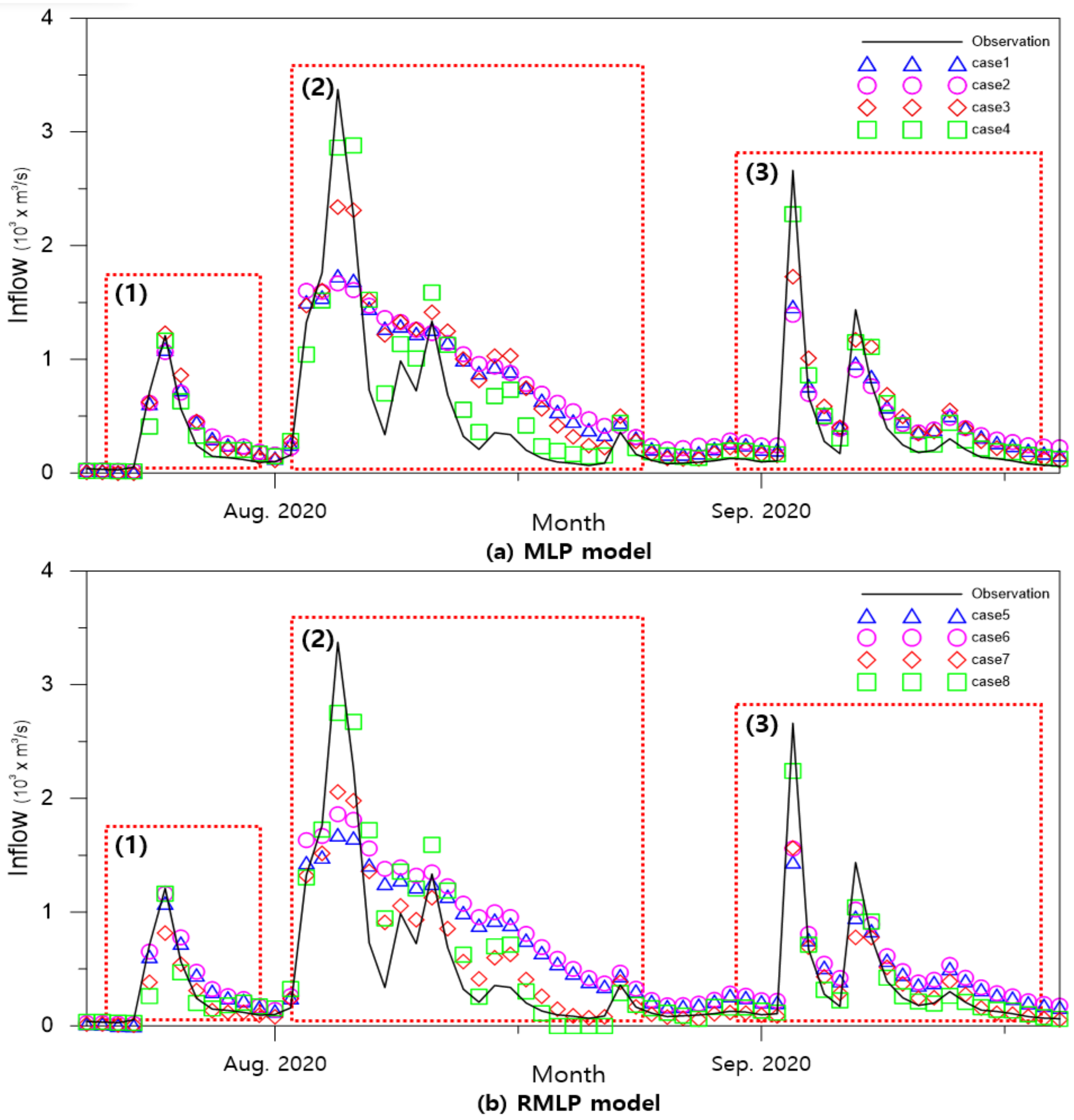
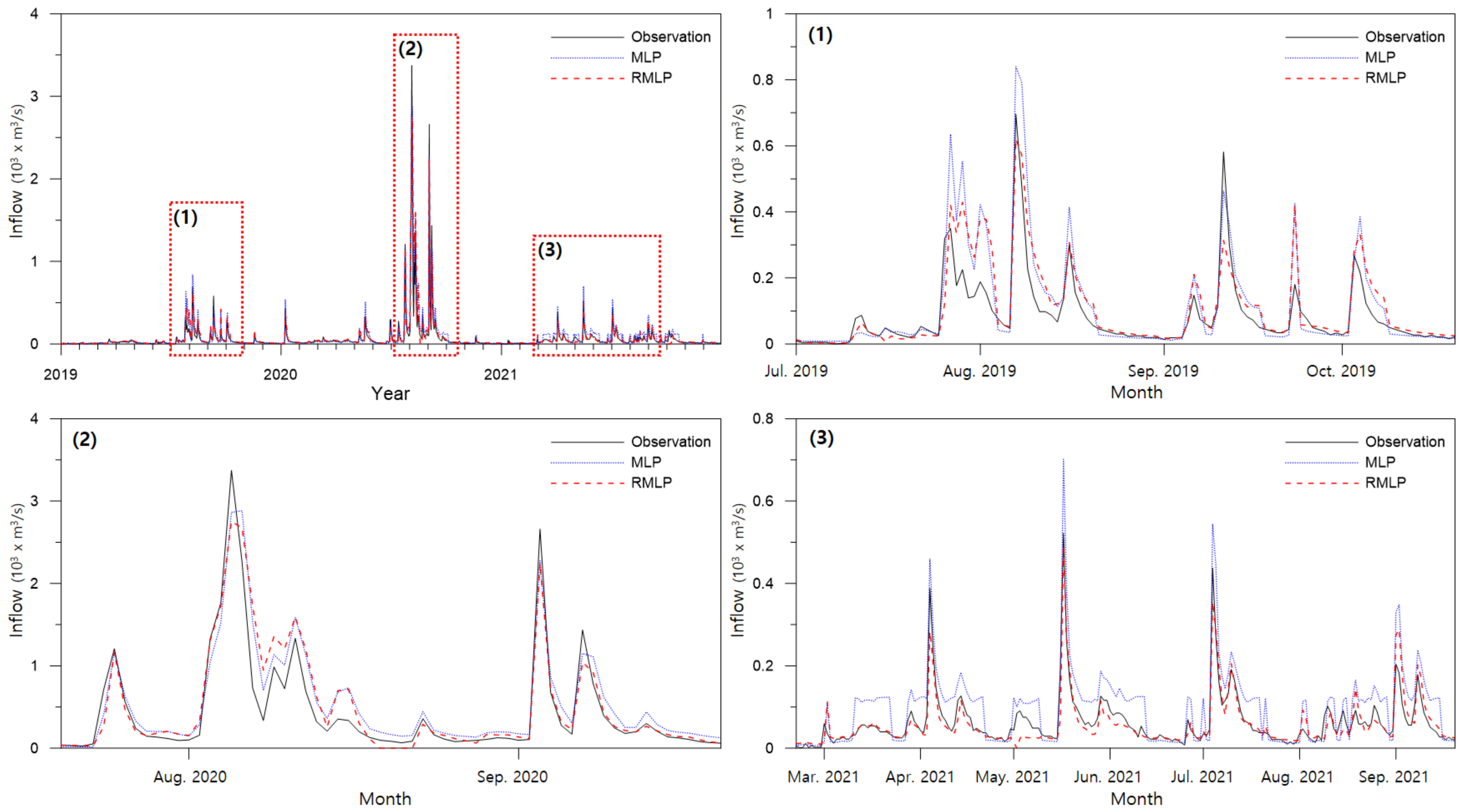
The difference between the measured flow rate and the predicted value was compared using a diagram. The analysis was centered on July–September 2020, when the largest flow occurred among the test datasets.
Figure 9 shows the measured flow discharge and the prediction results of Cases 1–4 using the MLP and Cases 5–8 using the RMLP models.
This graph indicates that three major flood events occurred in 2020. There was a single peak event at (1), multiple smaller peak events, the largest event at (2), and two more peak events at (3). In case (1), the peak discharge was small, and the hydrograph only changed slightly. The preprocessing and model improvement results were not significantly different, and both were predicted relatively accurately. When data preprocessing was not used (Case 1), or only seasonal division was used (Case 2), the peak was underestimated, and the accuracy of the flow reduction curve was poor. The results with normalization (Case 3) predicted a relatively accurate peak discharge, and there was a minor improvement in the low discharge. When applying both seasonal division and normalization (Case 4), peak discharge, flow reduction patterns, and subsequent peaks were predicted accurately. Although the peak discharge was underestimated, the accuracy of the flow-reduction curve was significantly improved. A hydrograph with a rapid increase was observed, with two peaks at (3). Similar to the previous results, there was a slight improvement in the peak prediction for Case 3, and the most accurate peak was the result for Case 4.
The RMLP model predicted the peak and flow reduction curve as well as the MLP at (1). However, it showed a noticeable accuracy improvement at (2), especially in Case 7, compared to Case 3. When only data normalization was applied in Case 7, there was a significant improvement in the prediction accuracy of the flow reduction curve. Consequently, the MSE was smaller in Case 7 than in Case 3. Peak and low discharge predictions were significantly improved in Case 8 in which seasonal division and data preprocessing were applied together. (3) is a hydrograph with a rapid increase and two peaks. Similar to previous results, Case 8 was the most accurate prediction.
As a result of data preprocessing, there was a tendency to underestimate the peak discharge. The reason for this error is the limitation of the error calculation algorithm. Owing to the relatively short duration of peak flooding, the amount of high-flow data was small. In this study, the amount of off season data was more than twice that of the peak season. Therefore, the learning direction was focused on abandoning the peak error and reducing the low flow error, which is a common problem in algorithms that calculate average error. To reduce this error, the peak and off seasons were separated. However, if the discharge were simply separated, the fluctuation in the peak season would still be high. As a result, the error increased, as in Cases 2 and 6. Because the variation in the peak season was larger than that in the off season, data normalization was necessary to improve the accuracy. Data normalization converted the discharge to a value between zero and one, to limit the fluctuation range of the peak season and improve the learning accuracy. Both high and low discharges can be accurately predicted by performing both preprocesses.
3.5. Model Comparison
In this study, the RMLP model was proposed for accurate discharge prediction, which improved the learning algorithm and data preprocessing methods of the model. The RMLP model was more accurate than the MLP model. When using existing data without data preprocessing (a), the test error increased by 338 (3.1%) from 11,006 to 11,344 in the MLP model. However, the difference was not significant because the basic error value was large. Seasonal division (b) decreased by 2119 (14.7%) from 14,370 to 12,251. In both cases, the error increased. This problem occurred because the increase in MSE at high flow was larger than the decrease in MSE at low flow. Because the amount of high flow data was small and the data deviation was large, the MSE result was larger than that of (a). Nevertheless, the error increase rate was relatively small in the case of the RMLP model. To solve this problem, data normalization was required. As a result of data normalization, the MSE decreased by 3619 (40.3%) from 8985 to 5366. There was a relatively low error in Case 7 when only data normalization was used in RMLP, and the model improvement was the most prominent. When both preprocessing steps were performed, the MSE decreased by 142 (3.1%) from 4511 to 4368. Except for Cases 1 and 5, RMLP exhibited better results than MLP. The model improvement effect is quantitatively expressed in
Table 8.
Note that a small test error does not always mean the performance of the learning algorithm is good. In this study, the model showed that the minimum validation MSE was selected during the epochs, as explained in
Section 2.5. Because the RMLP model had a better learning performance than the MLP model, the minimum validation MSE was smaller among the results which were repeated 20 times. However, the training caused an overfitting problem because it only considered the validation data. As new data are input, prediction accuracy may decrease. To solve this problem, prediction performance should be measured using new data. The final MLP and RMLP models were chosen to have the smallest test MSE among the 20 results. However, the test MSE only demonstrated the prediction accuracy of the model and had no effect on the model training performance. Even if the global minimum of the validation MSE was found using a new algorithm with excellent learning ability, the test MSE may be worse than that of the basic MLP model. Therefore, the overall test error can be smaller in RMLP but not always.
To analyze the model improvement effect, the final MLP and RMLP models (Cases 4 and 8, respectively) were compared using a time series graph. Preprocessing method (d) was applied to both models, and the test data were predicted.
Figure 10 compares the measured discharge for the entire test dataset with the predicted values of the two models. During the entire period, major flood events by year are indicated as Events (1) to (3) and expanded using a higher resolution. Event (1) displayed a tendency to overestimate MLP and partially underestimate RMLP in the peak flood forecast based on the 2019 inflow hydrograph analysis. At a low discharge in Event (1), both models provided similar results. Event (2) showed the largest peak value of the hydrologic curve in 2020. The peak prediction tended to be underestimated, and MLP was closest to the observation data, showing a larger peak than RMLP. Event (3) was the case in which low volume rainfall occurred continuously. Again, MLP was overestimated compared to RMLP and showed an unstable overestimation at mid-low discharges. RMLP predicted a more accurate hydrograph at low and medium discharges. Overall, MLP showed a tendency to overestimate discharge, and the accuracy of RMLP was confirmed to be better in the overall hydrograph prediction.
To quantify the difference in peak discharge, the three largest peaks were selected for each year, and the discharge error was compared. In 2020, the largest peak was 3373.1 m
3/s. The MLP model predicted 2862.9 m
3/s, which was underestimated by 510.2 m
3/s (15.1%), and the RMLP model predicted 2752.0 m
3/s, which was 620.7 m
3/s (18.4%). MLP was more accurate when only considering the largest peak value. However, when considering all nine peaks, RMLP showed a smaller error. MLP showed a mean deviation of 237.6 m
3/s (26.3%), and RMLP showed 187.4 m
3/s (12.1%). Again, the MLP tended to overestimate the peak value. In conclusion, the RMLP model can predict the amount of dam inflow more accurately in most cases.
Table 9 shows the forecast results for major peak events by year.
In this study, the model was trained to minimize the validation MSE, and the final model was selected to minimize the test MSE. Because MSE reflects the error of the entire time series, the accuracy of the model cannot be judged only through the difference in several peak flood errors. In
Table 9, the RMLP shows a smaller error when averaging the error of nine peaks, but the MLP shows more accurate results in the largest peak discharge. A decision based on the purpose of the predictive model is necessary. If the model is required to predict the peak flow close to the existing maximum flood, a suitable model learning algorithm is needed. This study only considered the MSE of the model, but results may be derived by additionally considering the error of the peak flow in learning. Future studies may consider multi-purpose model learning, however, the current study focused on improving the model’s learning algorithm and analyzing the preprocessing effect.
4. Discussion
In this study, MSE was used for error calculation in model training. MSE computes the square of the error difference. Therefore, the errors at large values tend to be overestimated. This phenomenon caused a larger error when the model was trained by dividing it into high discharge and low discharge in Cases 2 and 6. As shown in
Table 10, the basic MSE of the RMLP model (Case 5) was 11,344, but the MSE of the seasonal division model during the peak season was 45,417, which increased significantly by 33,773 (297.1%). In the off season, MSE significantly decreased by 11,248 (99.2%) to 96 combined with relatively small fluctuations in discharge. Combining these results, the final MSE was 12,251, which was 907 (8.0%) larger than the original data value. The phenomenon when the error significantly depends on the size of the value can occur even after normalization. The normalization (Case 6) MSE increased by 10,700 (199.4%) from 5366 to 16,066 during the peak season and decreased by 5286 (98.5%) from 5366 to 80 during the off season, resulting in a final MSE of 4368, which decreased by 998 (18.6%). In both cases, the MSE in the peak season increased and the MSE in the off season decreased significantly. However, the error increase without normalization was greater than that of the error-reduction effect. To confirm this difference more intuitively, the mean absolute error (MAE) was calculated and displayed. Similarly, for MAE, it was confirmed that the error in the peak season was large, and the error in the off season was small.
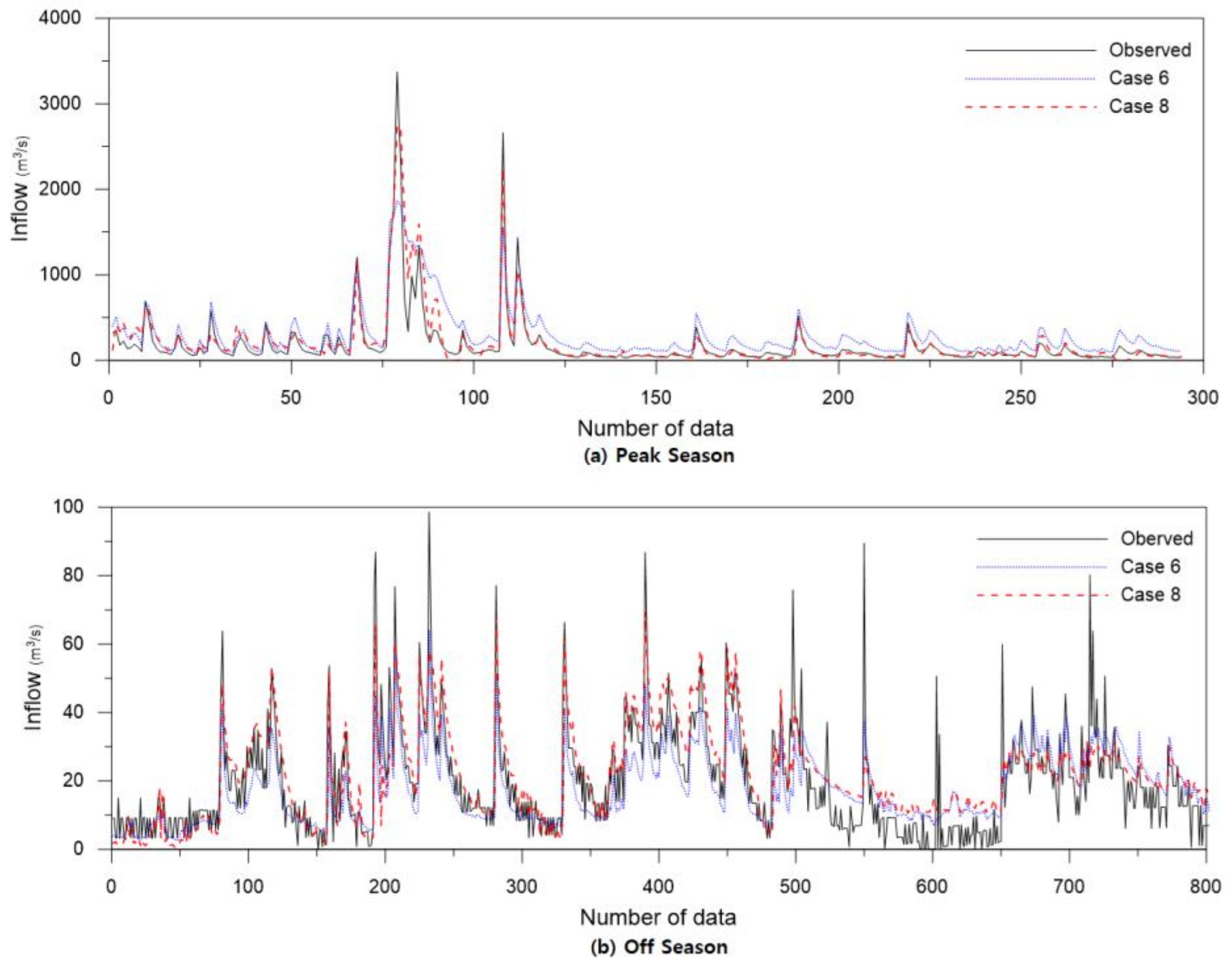
The discharge prediction results in Cases 6 and 8 in which seasonal division was performed, were compared, as shown in
Figure 11. It shows the measured discharge and predicted values on a log scale during the peak (a) and off (b) seasons.
Compared to the measured values, the predicted values in (a) Case 6 were overestimated, and Case 8 was relatively accurate. (b) was the discharge prediction result in the off season and was predicted almost accurately at 10 m3/s or more. There were some inconsistencies in the low discharge values of 10 m3/s or less. However, the MSE was also small because the discharge values and differences were small. As a result, there was still an underestimation error, the MSE of Case 8 in the off season was 80, which was smaller by 16 compared to that of Case 6. When applying seasonal separation, improvement in the prediction accuracy of medium to high flow is important. However, there was no significant difference in the accuracy at low flow rates, even with some errors. Therefore, to improve the accuracy of the high flow prediction model, further study to separate the high flow into two or more stages, such as high, medium high, and low, should be conducted.
Finally, the MSE, root mean squared error (RMSE), MAE, sum of absolute difference (SAD), mean absolute percentage error (MAPE), coefficient of determination (R
2), and coefficient of efficiency (E) were analyzed. Each of the equations is given in
Appendix A. In this study, MSE was used as an error calculation method, but MAE also showed a similar tendency to MSE. However, MAE was not suitable for use as an evaluation index for model learning because it showed fewer error values compared to MSE. In addition, because there was no error weight for the high and low flows, it was easy to obtain a result that was biased toward low flow with a large amount of data. Therefore, for discharge prediction, the MSE is more appropriate than the MAE. The results for all the cases are shown in
Table 11.
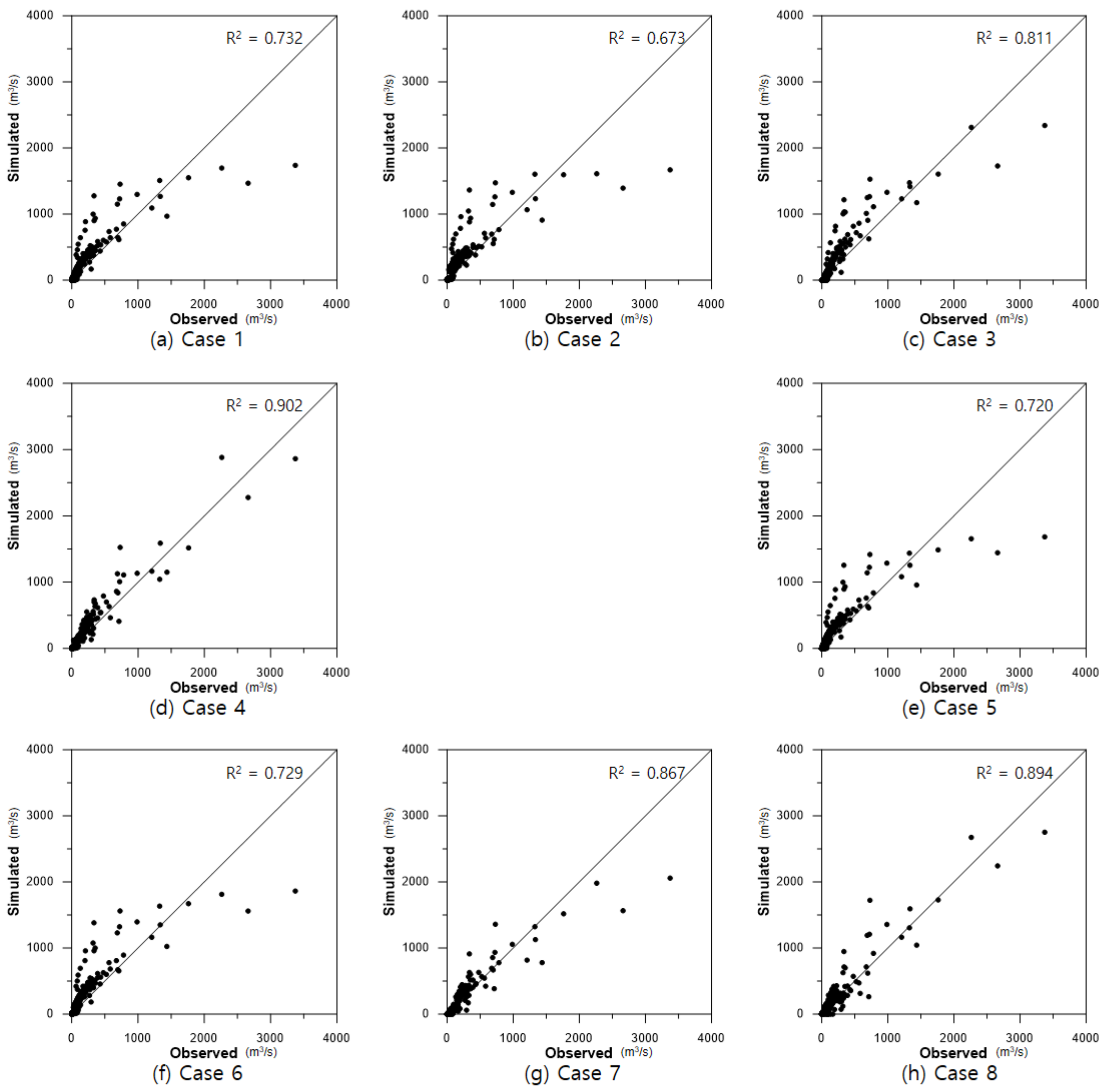
Additionally, without preprocessing or seasonal division alone, R
2 showed an accuracy of approximately 0.7, and the high discharge was underestimated. In cases where only normalization preprocessing was performed, such as in Cases 3 and 7, R
2 was significantly improved. In MLP (Case 3), the medium-low discharge was overestimated, but in RMLP (Case 7), it was significantly improved, and the R
2 also increased from 0.811 to 0.867. Finally, when all preprocessing steps were applied, both MLP (Case 4) and RMLP (Case 8) showed an accuracy close to 90%. The R
2 for the measured and predicted discharges for each model are shown in
Figure 12.
With the dam inflow prediction model developed in this study, it is possible to predict in advance the dam inflow according to the change in the upstream water level. By measuring water stored in the dam and the predicted inflow, it is possible to set an operation rule to secure the water storage during the dry season or to secure the dam reserve by discharging it in advance during the flood season.
5. Conclusions
This study aimed to develop an inflow prediction model for stable dam operation in the Soyang Dam Basin. Inflow prediction was performed using an MLP model. Two approaches were used to increase prediction accuracy. First, the learning accuracy was increased by preprocessing the input data. For preprocessing, two methods were used: Dividing the learning data into the peak and off seasons and normalizing the input data to reduce the deviation of the data. Second, the learning algorithm of the MLP model was improved. A previous MLP used gradient descent to train the model. In this study, a random search algorithm was applied to the existing MLP model such that a wider range of alternatives could be found when the model weight was updated.
The MLP model of the dense structure was used for model construction. Four hidden layers were used with ten nodes per layer. ReLu was used as the activation function, and Adam was used as the optimizer. MSE was used for the error calculation for model training, and MAE and R2 analyses were performed. The input data for model learning were the water level and dam inflow data provided by WAMIS. The study area was the Soyang Dam Basin, and time series data were used for 6575 data points from 2004 to 2021. Training was repeated 20 times every 10,000 epochs to determine the final model weights.
As a result of the model training, it was possible to reduce the error by up to 6976 (61.5%) from MSE of 11,344 to 4368 through data preprocessing. During model training, the error increased when learning by dividing the peak and off seasons. This error occurred excessively owing to the large deviation in the peak data. However, when seasonal division was performed with data normalization, the error owing to the size of the deviation was reduced, enabling high-accuracy learning. The RMLP model showed the greatest improvement effect compared to the MLP model in Case 7, which was reduced by 3619 (40.3%) from 8985 MSE to 5366 MSE. When all preprocessing steps were performed (Case 8), the error reduction rate was small, but an error of 4368 was obtained, which was improved by 142 (3.2%) compared to the MLP error of 4511. Comparing the hydrographs of both models, MLP showed a tendency to overestimate high and intermediate flows, but RMLP predicted the overall hydrograph more accurately. The prediction accuracy of the final RMLP model was MSE 4368, MAE 21.9, peak discharge error 12.1%, and R2 = 0.894.
This model enables high-accuracy inflow forecasting throughout the peak and off seasons and will help in the efficient operation of the dam and ensure safety by predicting the inflow through the upstream water level. A limitation of this study is that it is difficult to guarantee the accuracy of the model when the flooding is greater than the past maximum peak. Therefore, it is essential to continuously measure the data and supplement the model to improve the prediction accuracy, even after the model is derived. In addition, this study was limited to the Soyang dam basin. It is necessary to apply the learning model to different watersheds or apply the learning model to various objects such as the groundwater level, storm water pipe system, and other time series data. In follow-up studies, seasonal divisions will be further subdivided to improve the prediction accuracy at high discharge. In addition, a study to improve the learning algorithm of time-series prediction models such as RNN or LSTM and compare it with MLP will be conducted. It is expected that more accurate prediction models and algorithms can be developed by continuously improving hydraulic and hydrologic prediction models.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}