
Evaluation on Development Height of Water-Conduted Fractures on Overburden Roof Based on Nonlinear Algorithm

Abstract
:1. Introduction
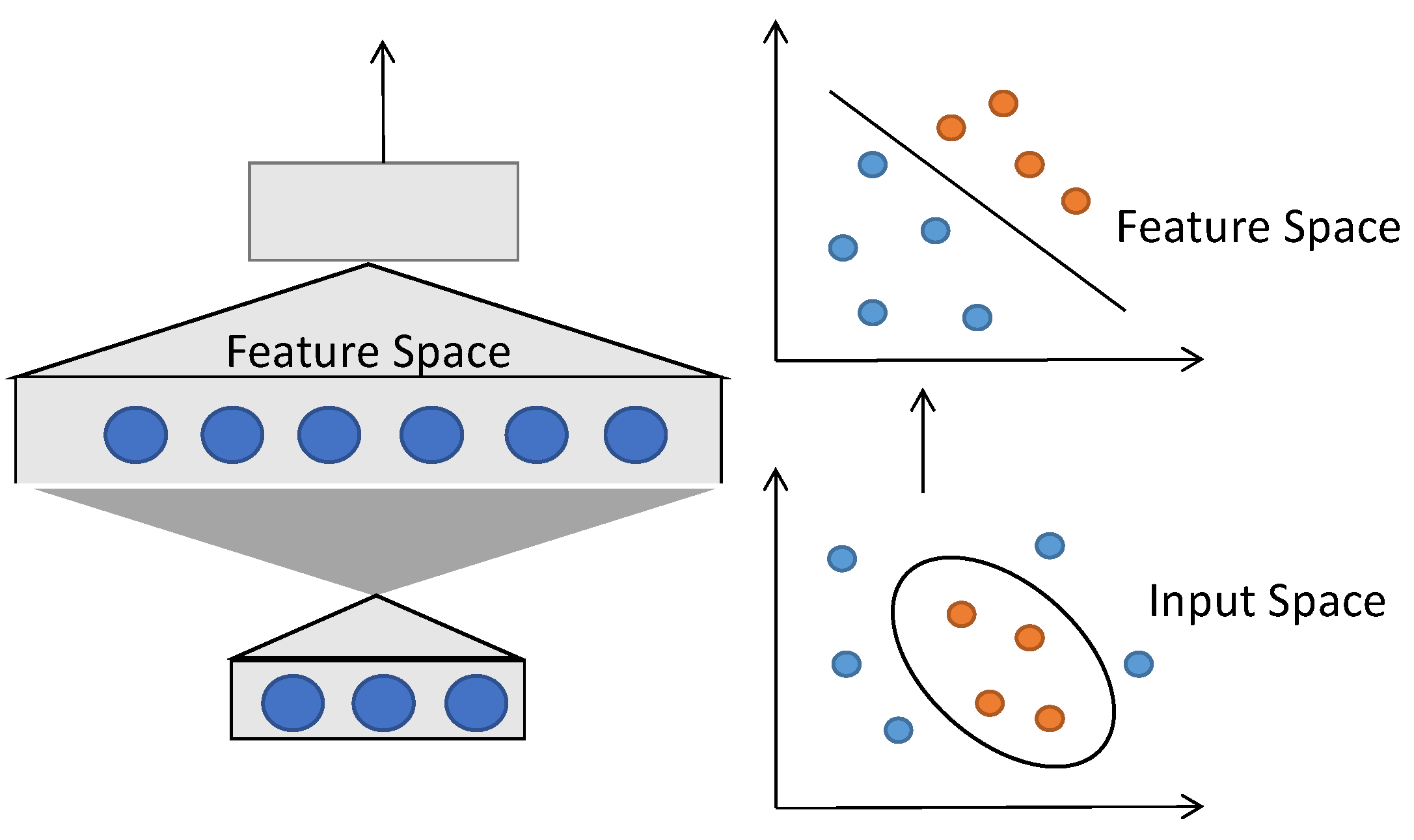
2. Overview of SVM Algorithm
- Universality (can realize internal nesting of various function sets).
- Robustness (no need to fine tune for practical application problems).
- Effectiveness (prediction accuracy and generalization ability meet the needs of different research fields).
- Simple calculation (the Lagrange multiplier is gradually converted to the dual equation for solution and the calculation and optimization are more simplified).
- Theoretical improvement (relying on the framework of the generalization theory of the Vapnik-Chervonenkis Dimension).
2.1. Basic Principles of SVM Algorithm
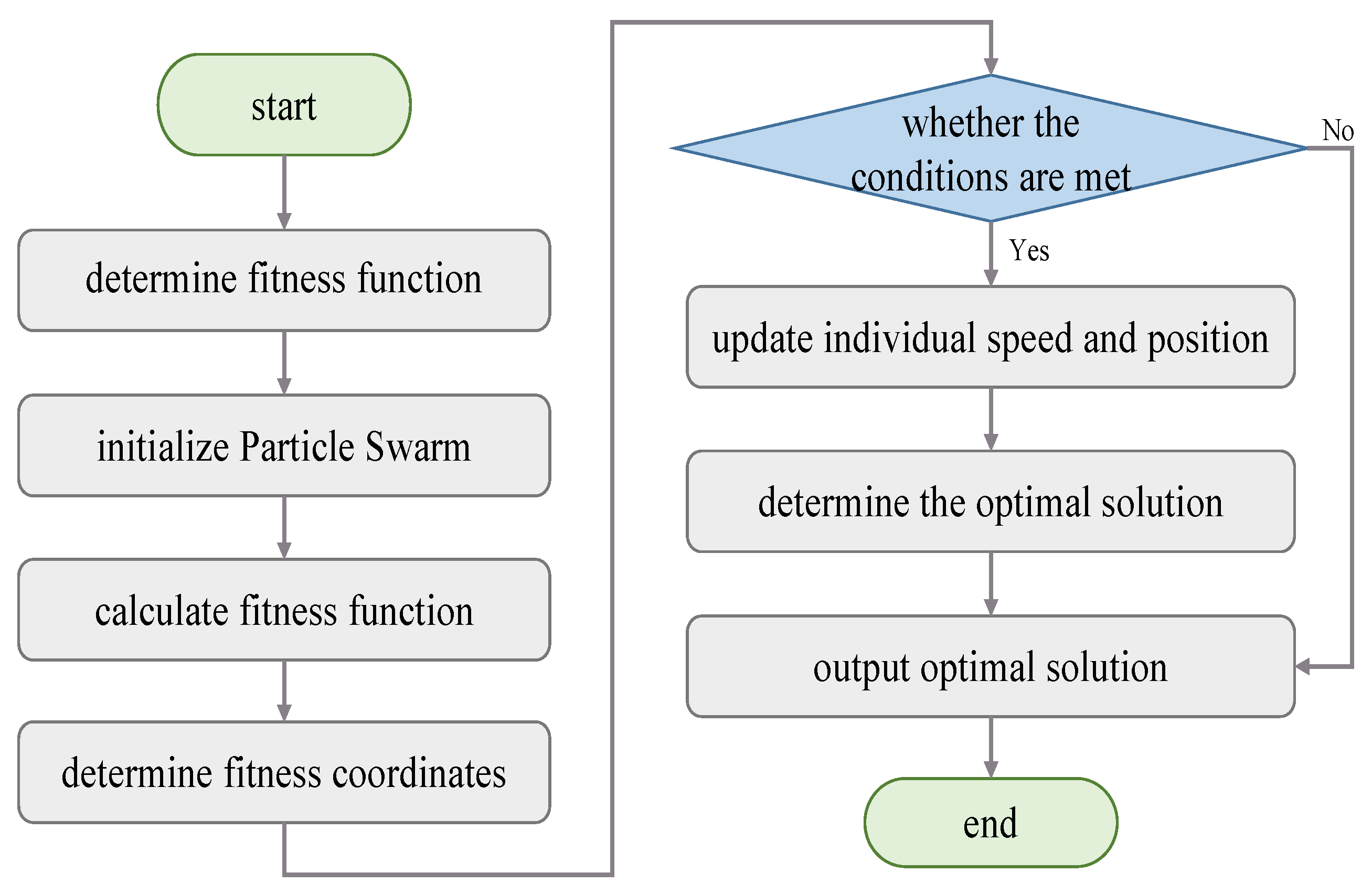
2.2. Solving the Optimal Parameters of the SVM Model
- —inertia weight, i = 1,2,3…, N—the size of the particle population
- k—number of iterations, pi—individual extreme value,
- gi—global extrema c1,c2—learning factor
- vik—The magnitude and direction in the last iteration
- c1r1(pi − xik)—The distance vector between the current and optimal position
- c2r2(gi − xik)—The distance vector between the current and the best neighbor
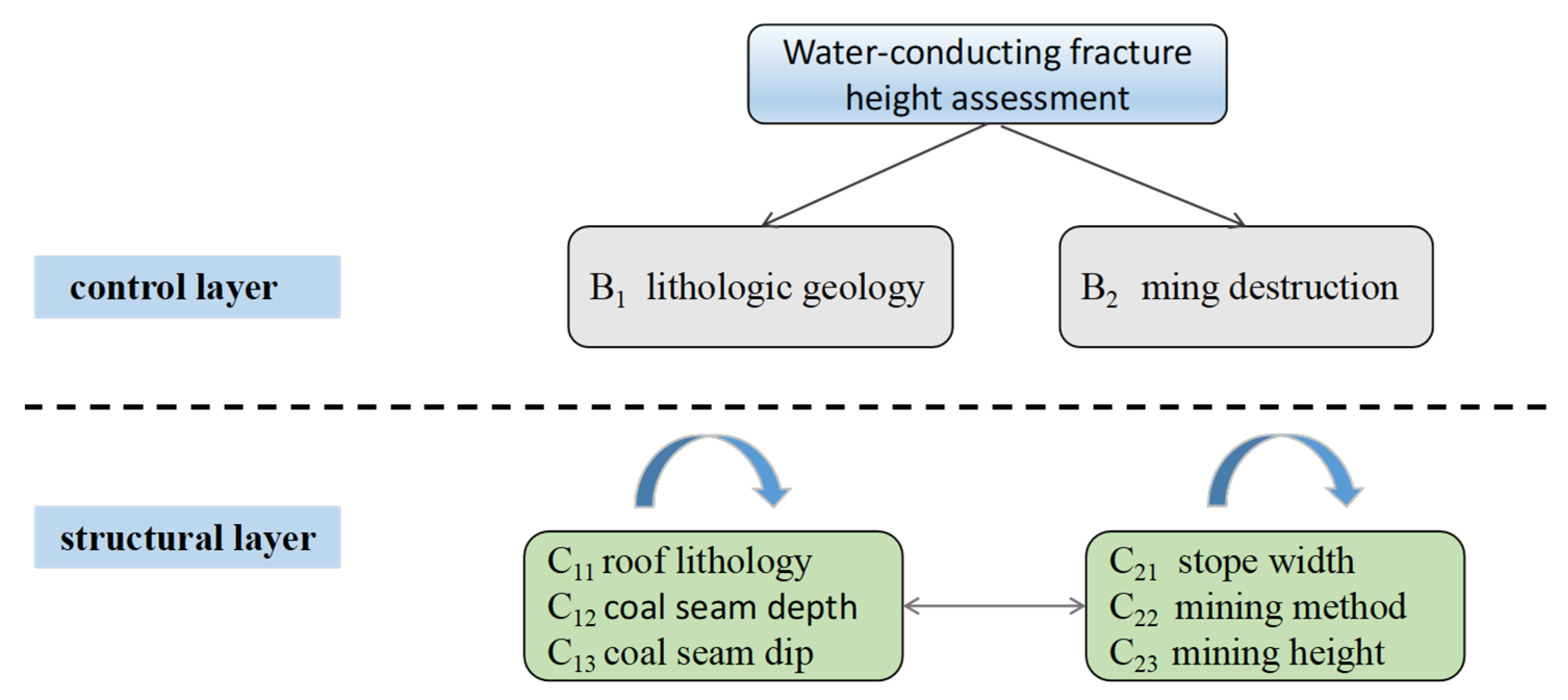
3. Selection of Indicator System
3.1. Research Background
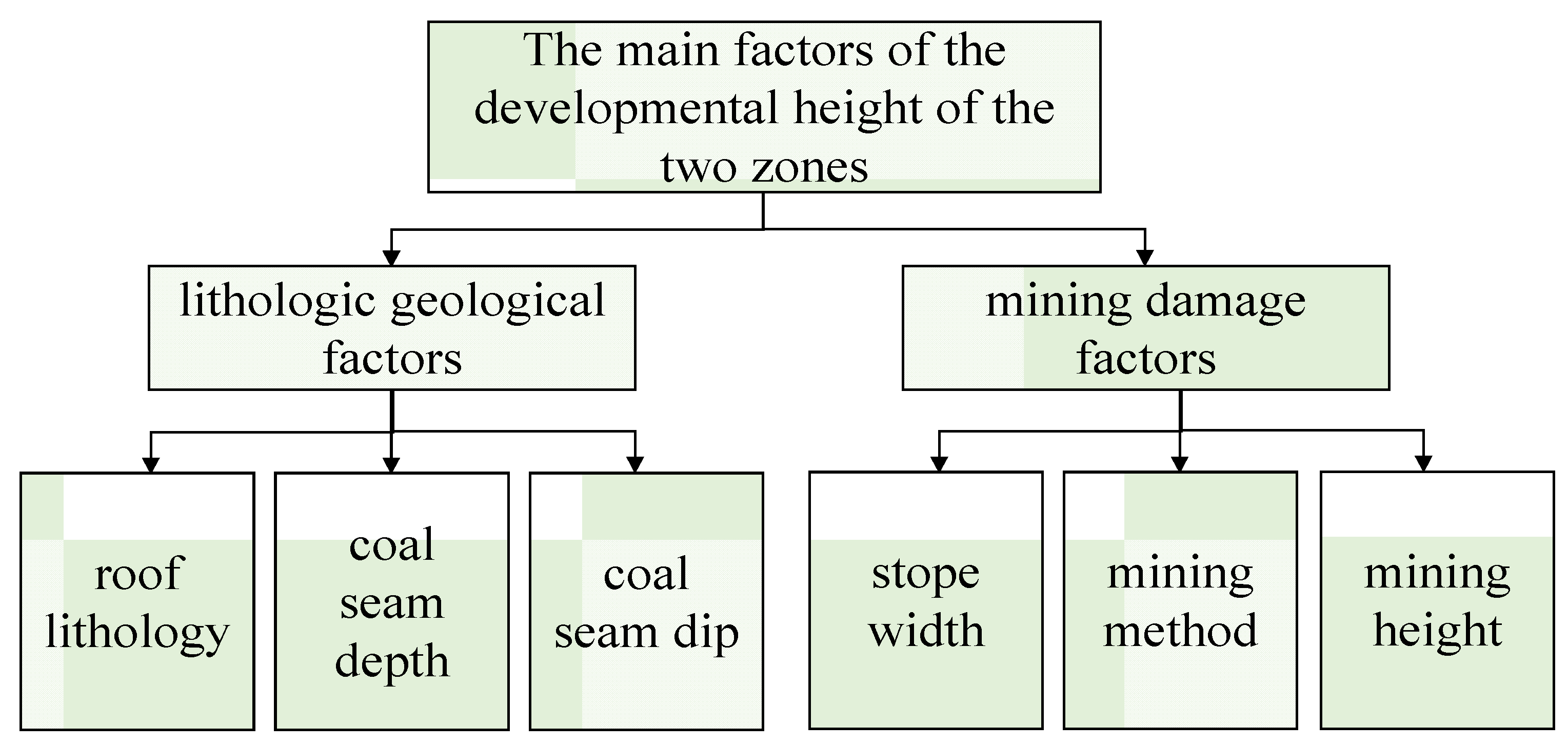
3.2. Factor Primaries
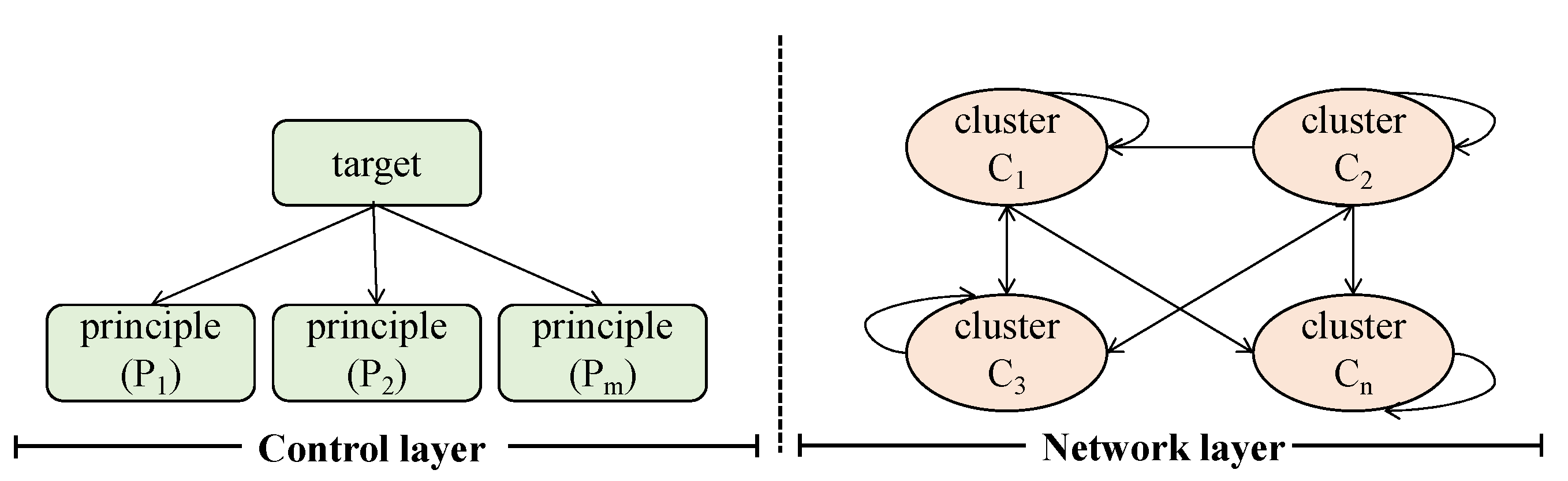
3.3. Feature Dimension Reduction
- Construction of judgment matrix. Taking the elements of the control layer as the criterion and the elements of the network layer as the sub-criteria, and comparing the importance of the elements in the element group on Bij, the construction judgment matrix is obtained:
- 2.
- ANP weighted super-matrix and limit matrix. Combine the sorted vectors of the degree of interaction of network layer elements to obtain the super-matrix under the control element:
4. Establishment and Application of Prediction Model
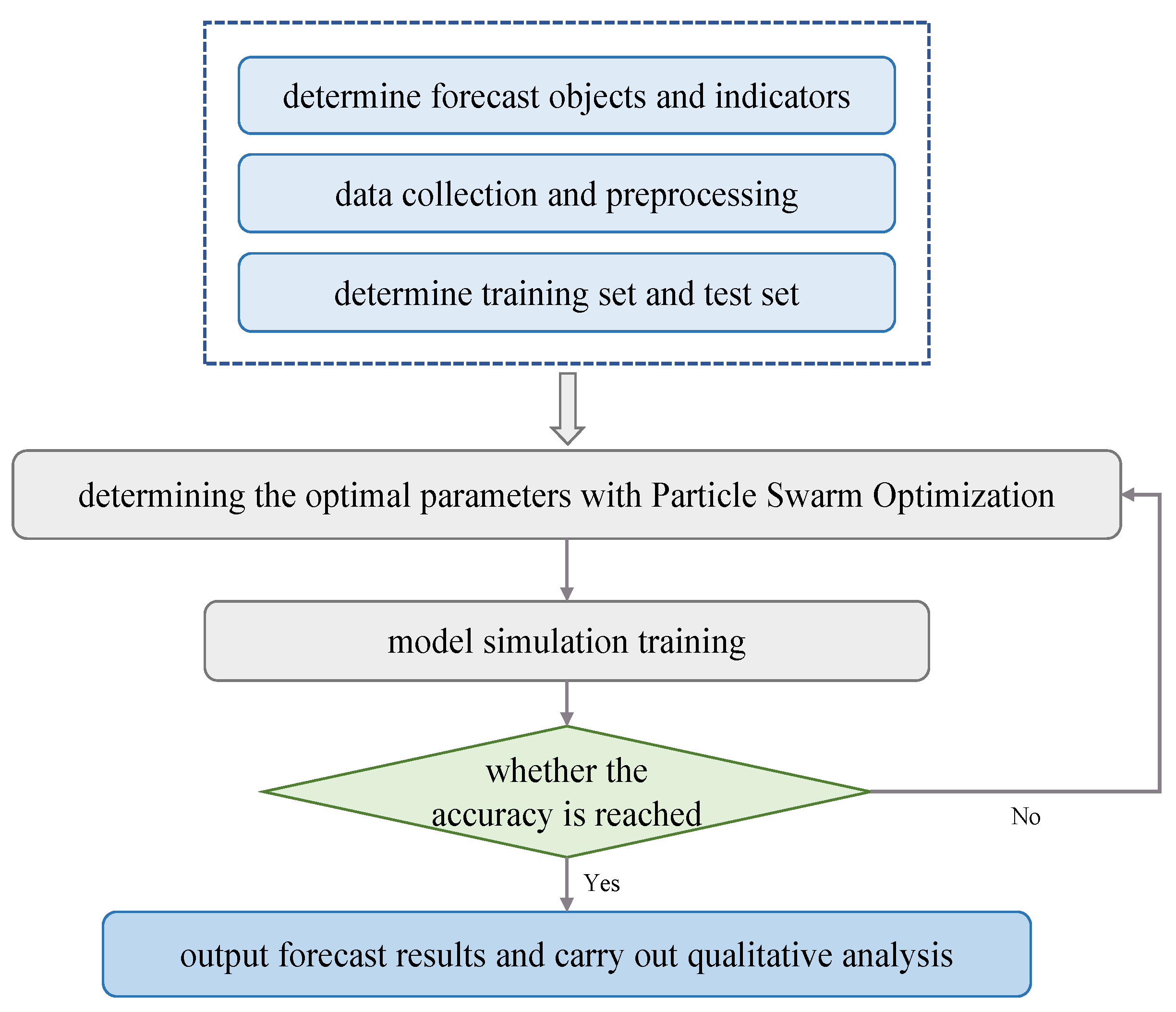
4.1. Model Building
- Collect sample data, complete data cleaning, classification and noise reduction. Normalize or normalize the data and divide the training and test sets.
- The particle swarm optimization algorithm is used to optimize the population parameters, and the smaller the fitness value, the closer to the optimal solution.
- Judging the end condition of the parameter optimization loop, if it meets the set value of the number of iterations or fitness, it will end; otherwise, continue to iterative optimization.
- The optimized optimal parameters c and g are respectively substituted into the SVM regression model to train the sample data.
- Test the PSO-SVM regression prediction performance; if it meets the accuracy requirements, the loop ends, otherwise continue to optimize until the accuracy set value is met.
4.2. Data Processing
- min(Xi)—minimum, max(Xi)—maximum,
- Ni—normalized data, Xi—the quantized value before normalization.
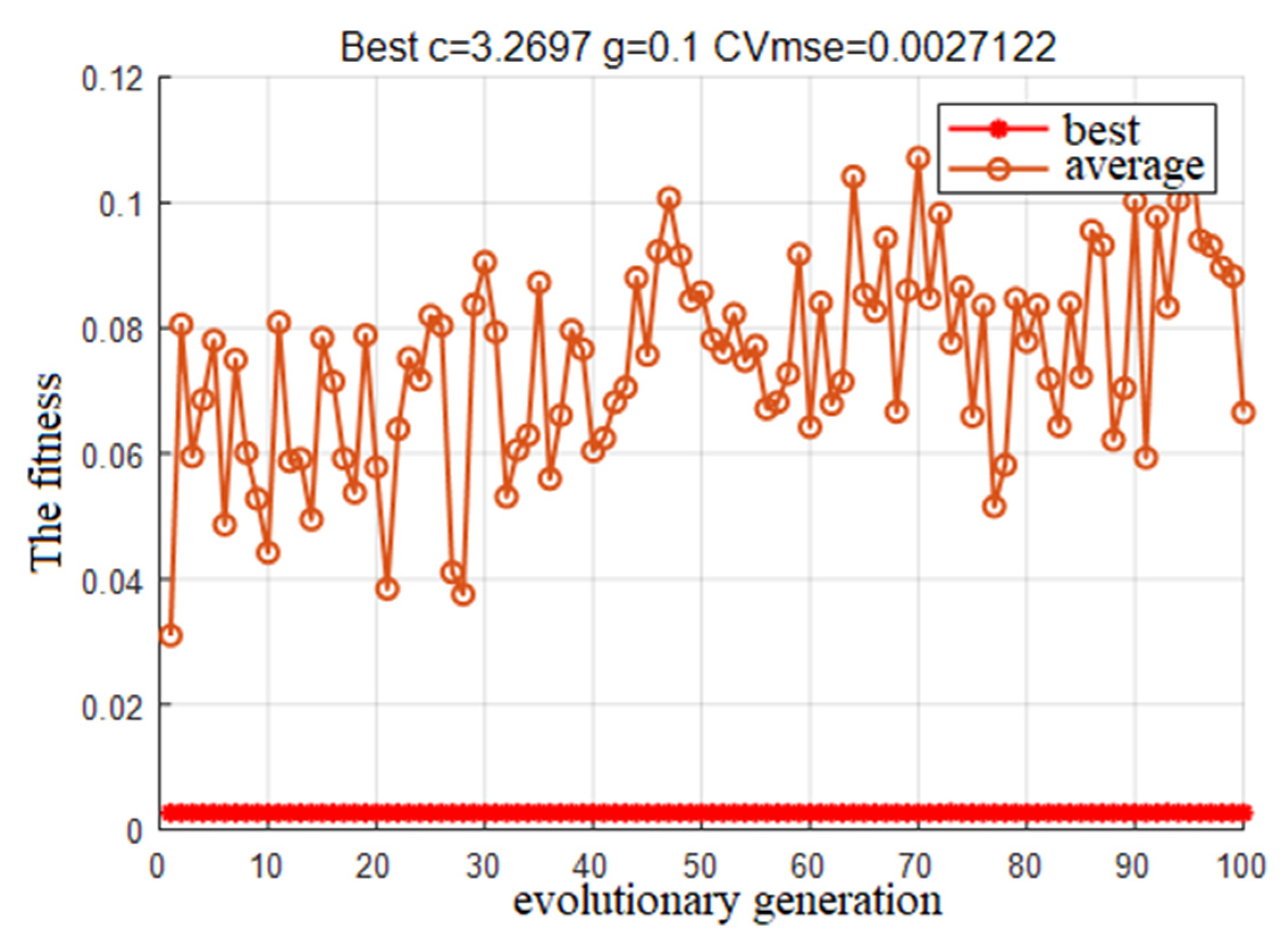
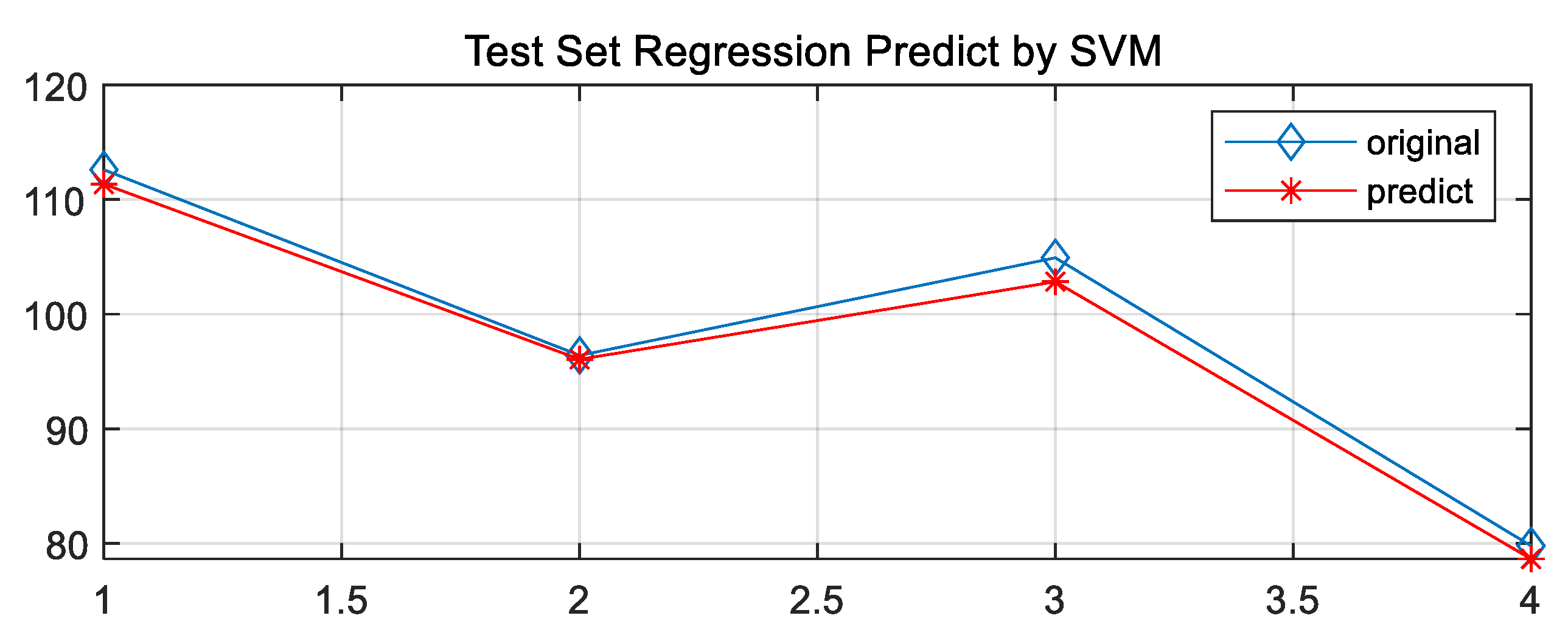
4.3. Parameter Optimization and Model Training
- Mean absolute error (MAE): The mean value of the modulus of the prediction error in the data. The smaller the mean absolute error, the better the prediction and fitting effect of the model. The calculation method is as in formula (16).
- 2.
- Mean Square Error (MSE): The expected error of each observation period in the retrospective forecast value is used as a sample and the mean square error of the sample is calculated. The larger the MSE, the lower the accuracy.
4.4. Water-Conducting Fracture Zone Division
5. Conclusions
- With the hydrogeological structure of the study area as the background, the statistical analysis model was established, the analytic network process method was used for feature dimensionality reduction and the pairwise comparison matrix was constructed to compare the weight distribution of the main control factors according to the scoring by the field technicians and experts, and the two-dimensional factor influence sources of the overburden failure event were identified as the mining height and the stope width of the working face.
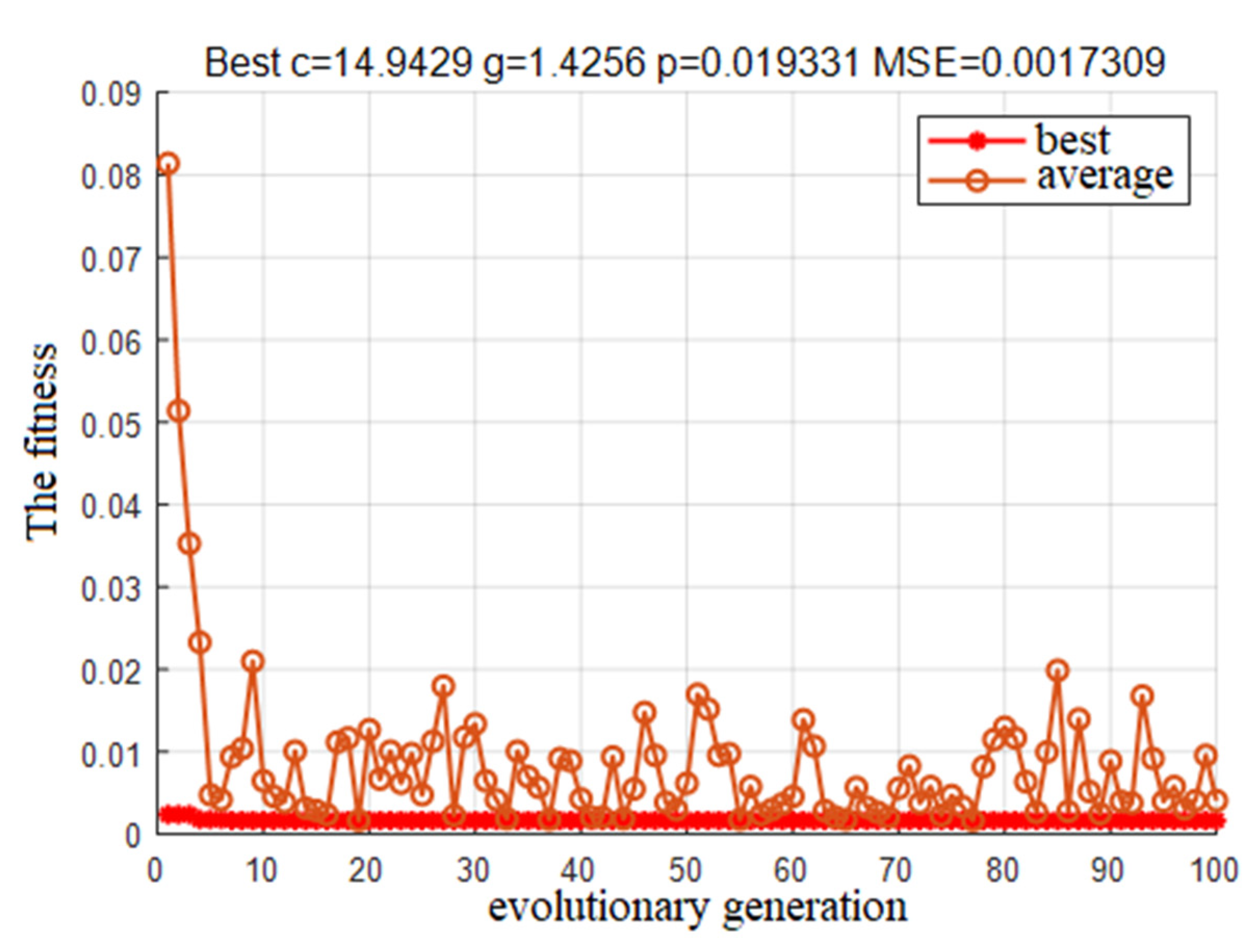
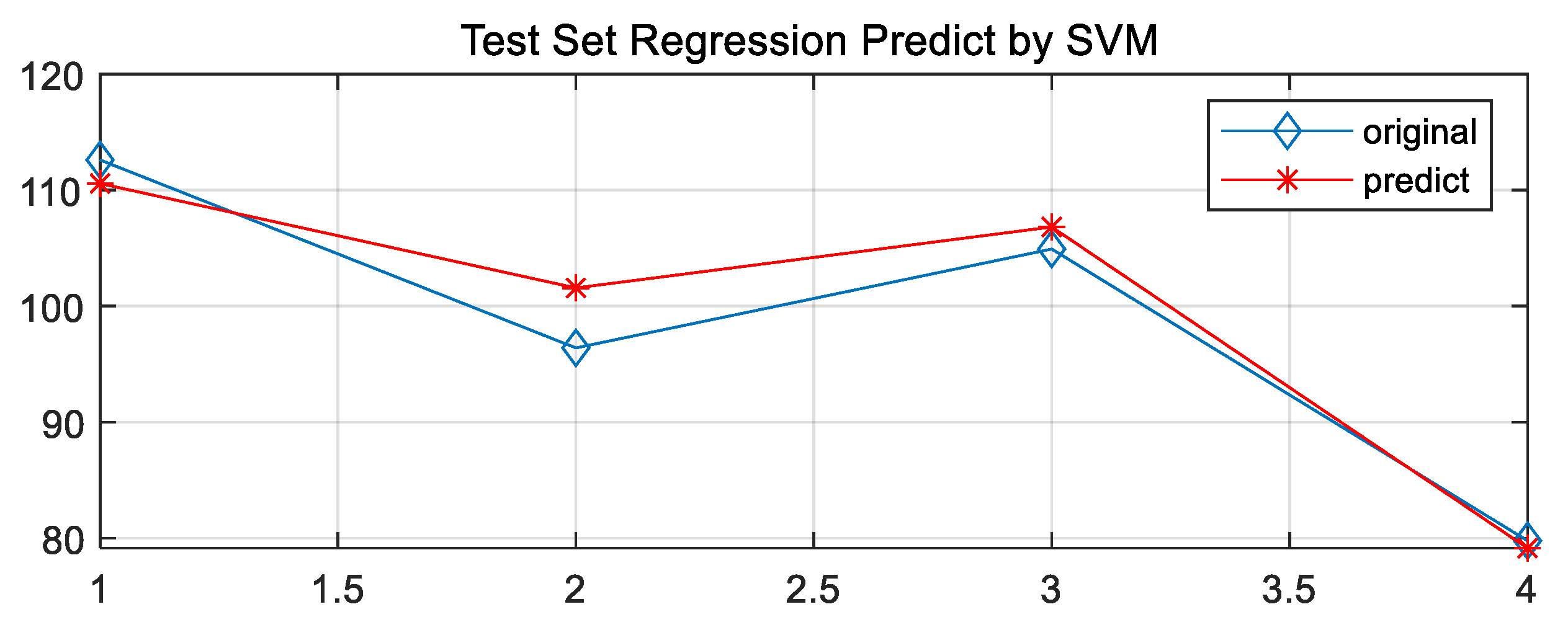
- Based on the LIBSVM toolbox on the MATLAB platform, the PSO-SVM model is extended and compiled to realize the combination of the optimization algorithm and the learning machine. Fit the PSO optimization results, the grid-cg optimization, GA-cg optimization and GA-cgp optimization regression model training results with the actual measurement to obtain the result with the best PSO effect in terms of accuracy, and determine the optimal parameter c as 29.2697, g as 0.1. The prediction model of water-conducting fracture zone based on PSO-SVM is established.
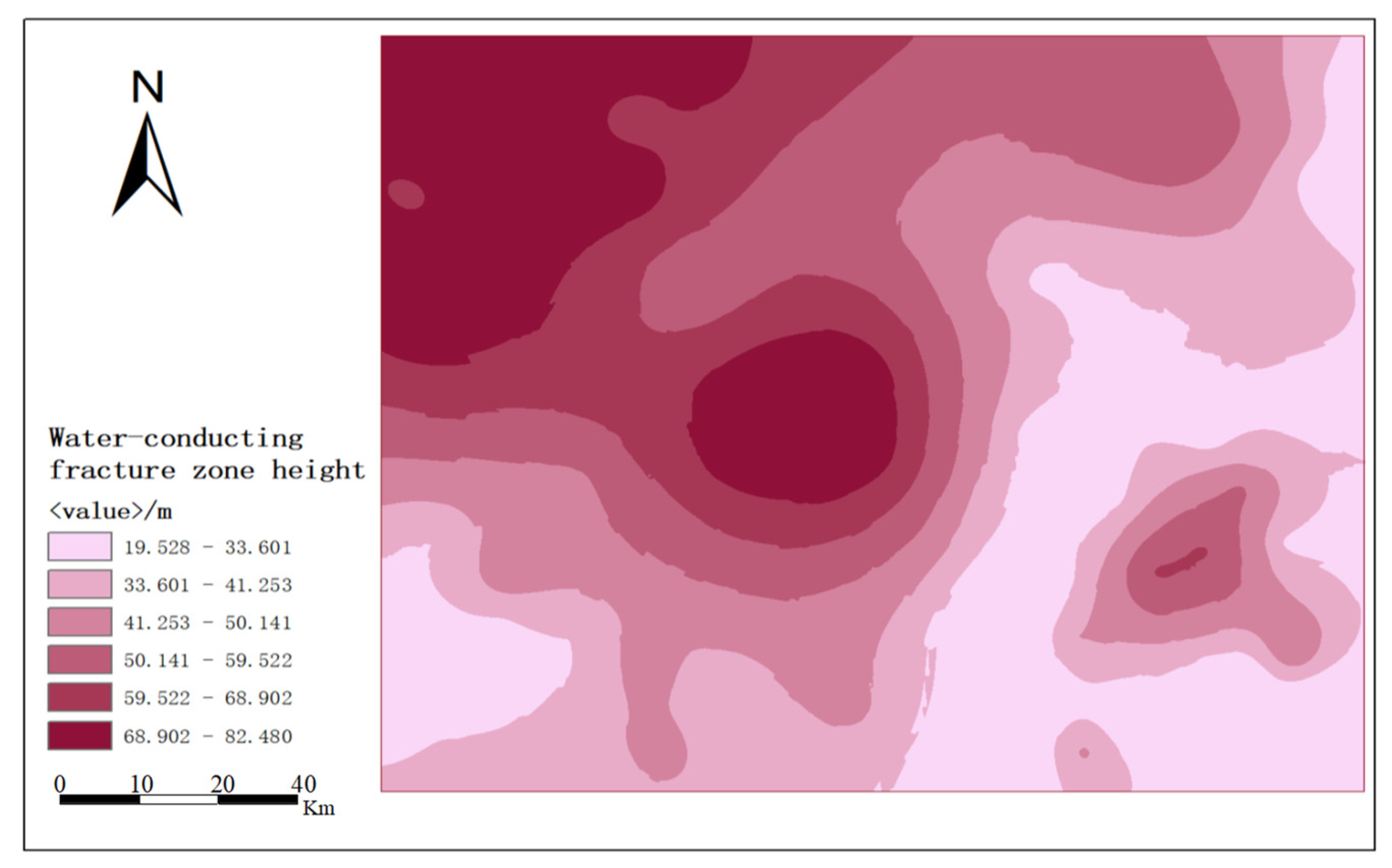
- The PSO-SVM model was used to predict the development height of the two zones in the Yingpanhao mine area and the data were analytically mined, effectively managed and integrated with the help of ArcGIS data spatial analysis function. The unknown geographic information of the study area was evaluated and interpolated by using the Kriging interpolation method, and it can be seen from the figure that the water-conducting channels are more developed in the northwest, which can easily communicate with the upper aquifer in the event of water inrush disaster on the roof.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ministry of Natural Resources, PRC. China Energy Development Report 2021; Geology Press: Beijing, China, 2021.
- Guo, W.B.; Ma, Z.B.; Bai, E.H. Current status and prospect of coal mining technology under buildings, water bodies and railways, and above confined water in China. Coal Sci. Technol. 2020, 48, 16–26. [Google Scholar]
- Bai, X.H.; Zhang, N.; Liu, H. Review on current situation of coal industry in China. Guangdong Chem. Ind. 2018, 45, 84–85. [Google Scholar]
- Liu, T.Q. Current status and prospect of coal mining technology under buildings, water bodies and railways, and above confined water. Coal Sci. Technol. 1995, 1, 5–7. [Google Scholar]
- Gao, Y.F. “Four-zone” model of rockmass movement and back analysis of dynamic displacement. J. China Coal Soc. 1996, 21, 51–56. [Google Scholar]
- Qian, M.G.; Liao, X.X.; Xu, J.L. Resources and environment harmonics (green) mining and its technological system. J. Min. Saf. Eng. 2006, 23, 1–5. [Google Scholar]
- Qian, M.G.; Liao, X.X.; Xu, J.L. Theoretical study of key stratumin ground control. J. China Coal Soc. 1996, 3, 2–7. [Google Scholar]
- Zhou, Y.F.; Deng, K.Z.; Ma, W.M. Mining Subsidence Engineering; China University of Mining and Technology Press: Xuzhou, China, 2003. [Google Scholar]
- Shi, L.Q.; Han, J. Theory and practice of dividing coal mining area floor into four-zone. J. China Univ. Min. Technol. 2005, 34, 8. [Google Scholar]
- Shi, L.Q. Research on the Mechanism and Prediction of Water Inrush from the Floor of Thin Aquifer; Shangdong University of Science and Technology: Qingdao, China, 1999. [Google Scholar]
- Gao, W.; Li, Y.; He, Q. Determination of fractured water-conducting zone height based on microseismic monitoring: A case study in Weiqiang coalmine, Shaanxi, China. Sustainability 2022, 14, 8385. [Google Scholar] [CrossRef]
- Li, X.; Chen, S.; Wang, E.; Li, Z. Rockburst mechanism in coal rock with structural surface and the microseismic (MS) and electromagnetic radiation (EMR) response. Eng. Fail. Anal. 2021, 124, 105396. [Google Scholar] [CrossRef]
- Ikram, R.M.A.; Dai, H.L.; Ewees, A.A.; Shiri, J.; Kisi, O.; Zounemat-Kermani, M. Application of improved version of multi verse optimizer algorithm for modeling solar radiation. Energy Rep. 2022, 8, 12063–12080. [Google Scholar] [CrossRef]
- Di, Z.; Lin, J.; Peng, Q.; Wang, D.; Yang, T.; Sorooshian, S.; Liu, X.; Zhuang, J. Modeling and simulating of reservoir operation using the artificial neural network, support vector regression, deep learning algorithm. J. Hydrol. 2018, 565, 720–736. [Google Scholar]
- Farajzadeh, J.; Alizadeh, F. A hybrid linear–nonlinear approach to predict the monthly rainfall over the urmia lake watershed using wavelet-sarimax-lssvm conjugated model. J. Hydroinformatics 2017, 20, 1–2. [Google Scholar] [CrossRef] [Green Version]
- Noble, W.S. What is a support vector machine. Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe -taylor, J. An Introduction to Support Vector Machines and Other Kernel Based Learning Method; Publishing House of Electronics Industry: Beijing, China, 2014. [Google Scholar]
- Cherkassky, V.; Ma, Y. Practical selection of SVM parameters and noise estimation for SVM regression. Neural Netw. 2004, 17, 113–126. [Google Scholar] [CrossRef] [Green Version]
- Vishwanathan, S.V.M.; Murty, M.N. SSVM: A simple SVM algorithm. In Proceedings of the 2002 International Joint Conference on Neural Networks, Honolulu, HI, USA, 12–17 May 2002; IEEE: Piscataway Township, NJ, USA; Volume 3, pp. 2393–2398. [Google Scholar]
- Marini, F.; Walczak, B. Particle swarm optimization (PSO). A tutorial. Chemom. Intell. Lab. Syst. 2015, 149, 153–165. [Google Scholar] [CrossRef]
- Liu, B.; Wang, L.; Jin, Y.H. An effective PSO-based memetic algorithm for flow shop scheduling. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2007, 37, 18–27. [Google Scholar] [CrossRef]
- Shi, X.H.; Liang, Y.C.; Lee, H.P.; Lu, C.; Wang, L.M. An improved GA and a novel PSO-GA-based hybrid algorithm. Inf. Process. Lett. 2005, 93, 255–261. [Google Scholar] [CrossRef]
- Liu, W.T.; Zheng, Q.S.; Pang, L.; Pang, L.F.; Dou, W.M.; Meng, X.X. Study of roof water inrush forecasting based on EM-FAHP two-factor model. Math. Biosci. Eng. 2021, 18, 4987–5005. [Google Scholar] [CrossRef]
- Yan, B.Q.; Ren, F.H.; Cai, M.F.; Qiao, C. Bayesian model based on Markov chain Monte Carlo for identifying mine water sources in Submarine Gold Mining. J. Clean. Prod. 2020, 253, 120008. [Google Scholar] [CrossRef]
- Jharkharia, S.; Shankar, R. Selection of logistics service provider: An analytic network process (ANP) approach. Omega 2007, 35, 274–289. [Google Scholar] [CrossRef]
- Chung, S.H.; Lee, A.H.I.; Pearn, W.L. Analytic network process (ANP) approach for product mix planning in semiconductor fabricator. Int. J. Prod. Econ. 2005, 96, 15–36. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| C11 | C12 | C13 | C21 | C22 | C23 | |
|---|---|---|---|---|---|---|
| C11 | 0.000 | 0.000 | 0.000 | 0.356 | 0.347 | 0.215 |
| C12 | 0.000 | 0.000 | 0.000 | 0.221 | 0.458 | 0.398 |
| C13 | 0.000 | 0.000 | 0.000 | 0.423 | 0.195 | 0.387 |
| C21 | 0.515 | 0.510 | 0.528 | 0.000 | 0.000 | 0.000 |
| C22 | 0.104 | 0.007 | 0.044 | 0.000 | 0.000 | 0.000 |
| C23 | 0.381 | 0.420 | 0.428 | 0.000 | 0.000 | 0.000 |
| C11 | C12 | C13 | C21 | C22 | C23 | |
|---|---|---|---|---|---|---|
| C11 | 0.000 | 0.000 | 0.000 | 0.407 | 0.265 | 0.265 |
| C12 | 0.000 | 0.000 | 0.000 | 0.328 | 0.407 | 0.407 |
| C13 | 0.000 | 0.000 | 0.000 | 0.265 | 0.328 | 0.328 |
| C21 | 0.495 | 0.300 | 0.588 | 0.000 | 0.000 | 0.000 |
| C22 | 0.099 | 0.100 | 0.089 | 0.000 | 0.000 | 0.000 |
| C23 | 0.407 | 0.600 | 0.323 | 0.000 | 0.000 | 0.000 |
| C11 | C12 | C13 | C21 | C22 | C23 | |
|---|---|---|---|---|---|---|
| C11 | 0.164 | 0.164 | 0.164 | 0.164 | 0.164 | 0.164 |
| C12 | 0.186 | 0.186 | 0.186 | 0.186 | 0.186 | 0.186 |
| C13 | 0.150 | 0.150 | 0.150 | 0.150 | 0.150 | 0.150 |
| C21 | 0.225 | 0.225 | 0.225 | 0.225 | 0.225 | 0.225 |
| C22 | 0.048 | 0.048 | 0.048 | 0.048 | 0.048 | 0.048 |
| C23 | 0.227 | 0.227 | 0.227 | 0.227 | 0.227 | 0.227 |
| Factor | Roof Lithology | Coal Seam Depth | Coal Seam Dip | Stope Width | Mining Method | Mining Height |
|---|---|---|---|---|---|---|
| Weight | 0.164 | 0.186 | 0.150 | 0.225 | 0.048 | 0.227 |
| Serial No. | Mine Name | Working Surface | Stope Width/m | Mining Height/m | Two Zones Height/m | H-T Ratio |
|---|---|---|---|---|---|---|
| 1 | Daliuta Coal Mine | 52,304 | 147.5 | 6.44 | 68.76 | 10.7 |
| 2 | Daliuta Coal Mine | 52,306 | 301 | 7 | 137.32 | 19.6 |
| 3 | SDIC Chahasu Coal Mine | 3103-2 | 300 | 5.1 | 63.1 | 12.4 |
| 4 | Bulianta Coal Mine | 12,511 | 319.1 | 8 | 124.42 | 15.6 |
| 5 | Bulianta Coal Mine | 31,401 | 265 | 5.92 | 147.2 | 24.9 |
| 6 | Tai’an Coal Mine | 6103 | 195 | 6 | 63.4 | 10.6 |
| 7 | Shangwan Coal Mine | 51,201 | 155 | 5.8 | 73 | 12.6 |
| 8 | Burtai Coal Mine | 42,106 | 216 | 6.6 | 80.52 | 12.2 |
| 9 | Zhangjiamao Coal Mine | 15,204 | 300 | 6 | 75.6 | 12.6 |
| 10 | Chenjiagou Coal Mine | 3202 | 98 | 10.79 | 134.98 | 12.5 |
| 11 | Duolun GCL Coal Mine | 1703-1 | 120 | 9.58 | 112 | 11.7 |
| 12 | Jinjitan Coal Mine | 101 | 300 | 5.5 | 108.59 | 19.7 |
| 13 | Hanglai Coal Mine | 30,101 | 300 | 7.5 | 112.6 | 15 |
| 14 | Binchang Coal Mine | 101 | 116 | 7.4 | 96.4 | 13 |
| 15 | Wangpo Coal Mine | 3202 | 180 | 5.89 | 104.92 | 17.8 |
| 16 | Mindong Coal Mine | L3414 | 196 | 7.7 | 79.78 | 10.4 |
| Optimization Algorithm | Error Cost c | Kernel Function Parameters g | MAE% | MSE% |
|---|---|---|---|---|
| PSO-cg | 29.2697 | 0.1 | 9.51 | 14.66 |
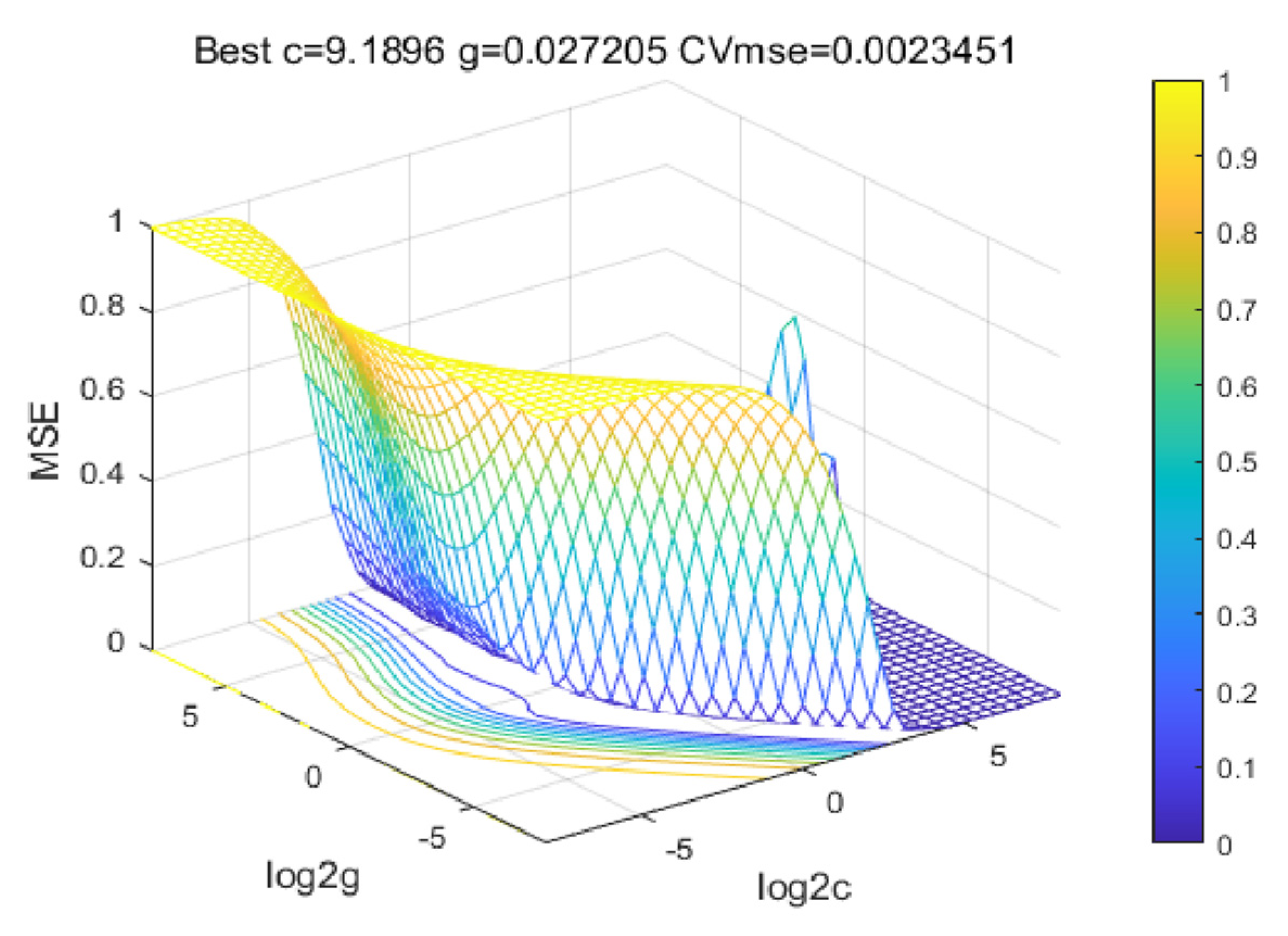
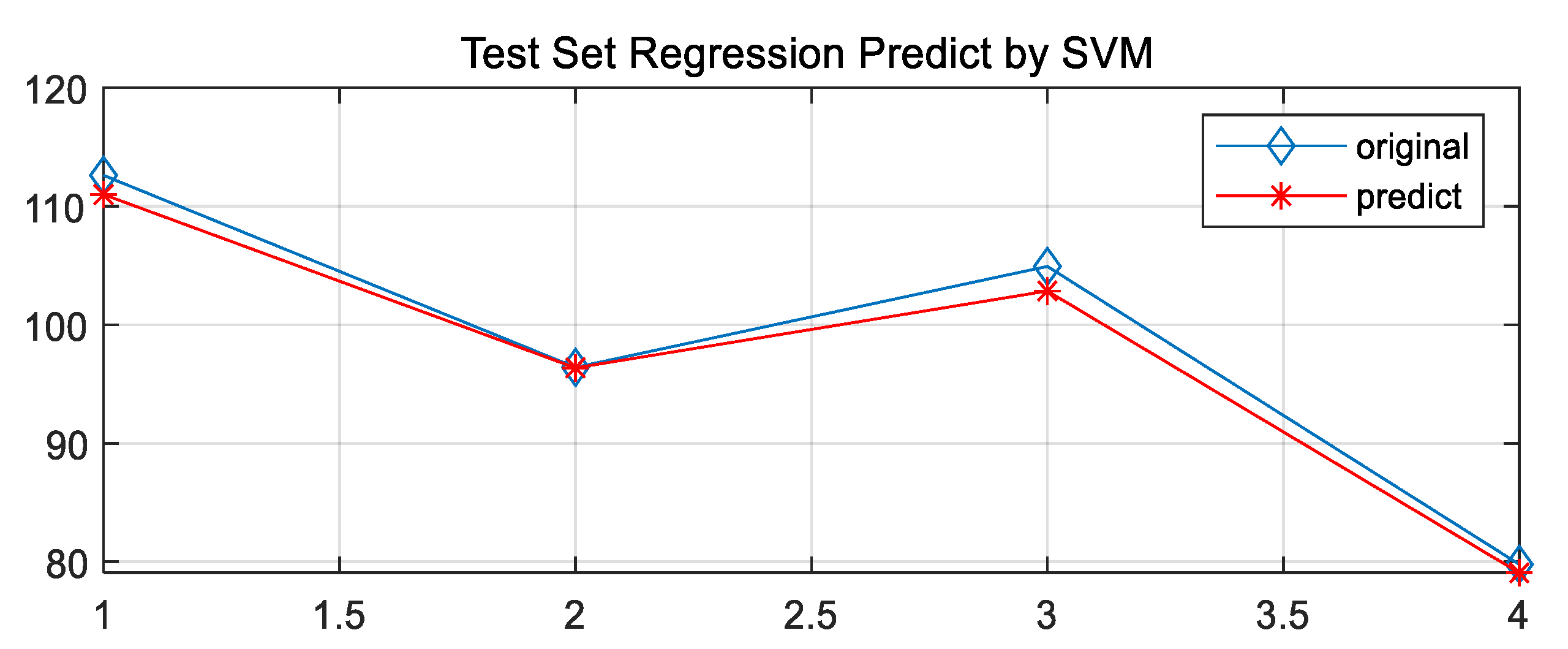
| Grid-cg | 9.1896 | 0.027205 | 16.73 | 19.32 |
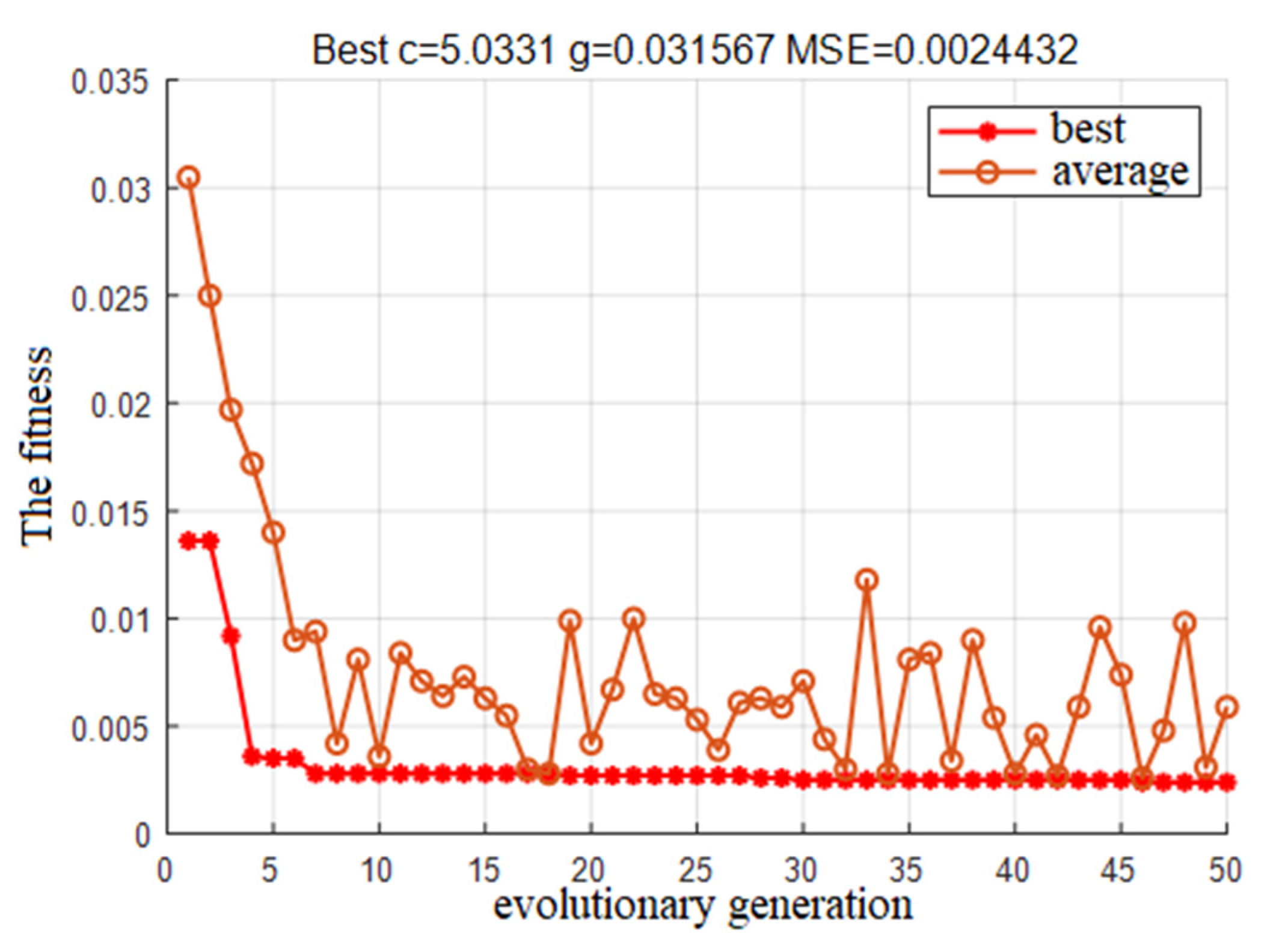
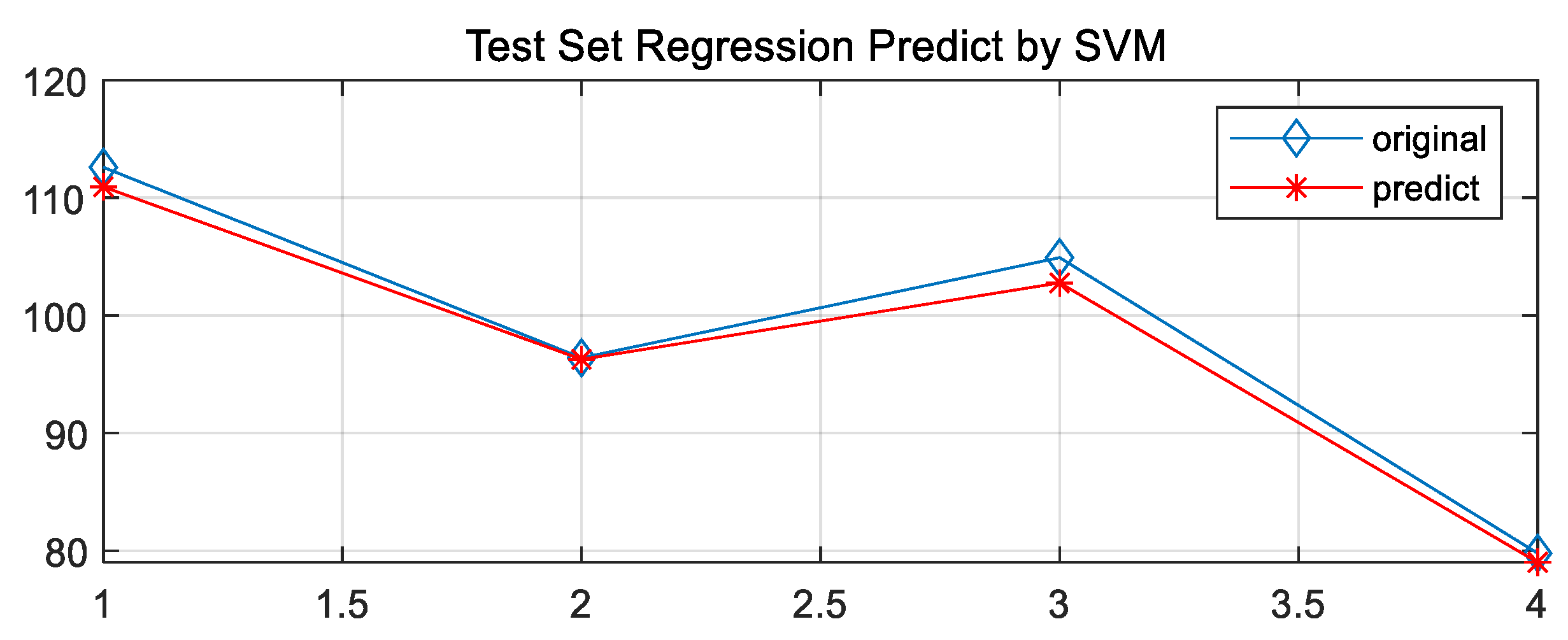
| GA-cg | 5.0331 | 0.031567 | 40.16 | 61.59 |
| GA-cgp | 14.9429 | 1.4256 | 17.26 | 23.85 |
| Drill No. | Mining Height/m | The Two Zones Height/m |
|---|---|---|
| ST-01 | 5.51 | 78.47 |
| ST-02 | 2.32 | 28.51 |
| ST-03 | 5.89 | 65.06 |
| ST-04 | 4.12 | 49.14 |
| ST-05 | 6.11 | 74.18 |
| ST-06 | 5.92 | 67.09 |
| ST-07 | 5.57 | 61.43 |
| ST-08 | 6.72 | 82.95 |
| ST-09 | 4.98 | 55.72 |
| ST-10 | 6.02 | 69.08 |
| ST-11 | 6.43 | 79.11 |
| ST-12 | 4.68 | 52.03 |
| ST-13 | 6.24 | 75.94 |
| ST-14 | 6.72 | 65.32 |
| ST-15 | 6.01 | 67.43 |
| ST-16 | 6.42 | 78.05 |
| ST-17 | 5.86 | 63.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Q.; Wang, C.; Liu, W.; Pang, L. Evaluation on Development Height of Water-Conduted Fractures on Overburden Roof Based on Nonlinear Algorithm. Water 2022, 14, 3853. https://doi.org/10.3390/w14233853
Zheng Q, Wang C, Liu W, Pang L. Evaluation on Development Height of Water-Conduted Fractures on Overburden Roof Based on Nonlinear Algorithm. Water. 2022; 14(23):3853. https://doi.org/10.3390/w14233853
Chicago/Turabian StyleZheng, Qiushuang, Changfeng Wang, Weitao Liu, and Lifu Pang. 2022. "Evaluation on Development Height of Water-Conduted Fractures on Overburden Roof Based on Nonlinear Algorithm" Water 14, no. 23: 3853. https://doi.org/10.3390/w14233853
APA StyleZheng, Q., Wang, C., Liu, W., & Pang, L. (2022). Evaluation on Development Height of Water-Conduted Fractures on Overburden Roof Based on Nonlinear Algorithm. Water, 14(23), 3853. https://doi.org/10.3390/w14233853