1. Introduction
Flooding poses a significant hazard to moving vehicles and causes traffic disruption by placing water flow in the transportation network, resulting in vehicles being swept away, injuries, and the loss of life of passengers. The remote detection of urban flooding over a large area will allow cities to develop flood maps to reduce risk during weather events. Mapping urban flood events is a challenge for three main reasons: the urban environment is highly complex with waterways at submeter resolutions, the flooding will be shallow and ephemeral, and ponding means that the flooding extent will be discontinuous. Hydrologic models that are the conventional approach in flood forecasting struggle with these factors, making the application of these techniques difficult. Attempts have been made to map urban flooding and flood risk with more traditional methods such as [
1]. High resolution hydrologic models are effective at small scales (e.g., a few urban blocks) but the computational resources and highly accurate inputs required to properly model urban flooding at the community scale are not widely available with the current technology. These limiting factors exemplify the need to find methods of mapping or predicting flooding that are less computationally intensive [
2]. The advantage of remote sensing is flood detection for large scale flood mapping without the need for highly accurate inputs and computationally intense processes to advance flood risk management.
While extreme flooding, especially that which falls in the 100-year event category, is well-studied and extensively mapped in the literature, minor flooding is difficult to map and predict. This less severe flooding, known as nuisance flooding or NF, poses less of a hazard to lives and property, but can still be inconvenient or even dangerous, especially to drivers [
3]. Though drier regions such as Southern California may not experience the same extreme, spatially extensive flooding common in other parts of the US, NF remains a problem during the rainy season, especially for aging infrastructure or current systems that are not designed to handle changing climactic patterns. NF is expected to become more of a problem in the future as the climate changes and sea levels rise. Coastal areas such as Southern California are particularly vulnerable to NF [
4]. The techniques developed in this study to detect catastrophic urban flooding may be applied to instances of nuisance flooding in the future and further reduce the risks associated with flooding during heavy rainfall in the urban environment.
Within the field of remote sensing, research has been done in flood detection using methods such as aerial photographs or satellite imagery. A summary of methods such as SAR and LiDAR (Light Detection and Ranging) is given in [
5]. SAR, or Synthetic Aperture Radar, is an especially promising technique. As an active sensor, the radar can detect the Earth’s surface no matter what time of day it is or what cloud conditions prevail. Some notable studies in the detection of flooding with SAR include [
6], which combined SAR imagery from COSMO-SkyMed (Agency Spaziale Italiana, Rome, Italy) and Landsat 8 OLI data (Ball Aerospace and technologies, Boulder, CO, USA) to map flooding along a river in northern China, [
7] which employed RASARSAT-2 SAR images and flood stage data based on the return period for the 2011 Richelieu River flood in Canada, and [
8] which is the culmination of a series of studies using TerraSAR-X in tandem with very high-resolution aerial imagery to map flooding in the River Severn in England. Until fairly recently, SAR data was considered insufficient for mapping flooding in urban zones due to the low resolution and shadow and layover in the complex urban environment [
9].
With more experience and improved methodology, however, there has been some success in using SAR for urban flooding applications, with a combination of better data and innovative image processing techniques. One of the earlier forays into mapping urban flooding with SAR [
10] used TerraSAR-X data and an SAR simulator to remove shadow from buildings and a region growing algorithm. [
9] employed a gamma distribution to recognize the backscatter values of open water and another region-growing approach using open-water seeds for two case studies, while [
8,
11] improved on these aforementioned algorithms by including change detection processing and double-scattering recognition, respectively. Other algorithms have also been used, such as [
6], which employed a counter without edges (C-V) machine learning model to extract flooded areas. Another important method is to use interferometric pairs to compare pre- and post-flooded conditions, with [
12] using another region-growing algorithm and [
13] using Bayesian networks as examples. The current algorithms for machine learning-based algorithms either engaged supervised or unsupervised classification algorithms.
Supervised classification methods have been often used for binary or multivariate classification problems. These methods, such as the K-Nearst Neighbor Classifier [
14], the Random Forest (RF) classifier [
15], and the Support Vector Machine [
16] have been applied to Sentinel 1 SAR images for flood detection. Artificial neural networks (ANN), for example, are a popular machine learning technique which is used in satellite remote sensing and image processing and shows a great potential to detect floods from satellite remote sensing images [
17,
18,
19,
20] applied methods employing ANN techniques to flood detection processes with some degree of success, but there is still work to be done. Moreover, ML-based systems are developed to detect changes between dry and flood images, which pose an advantage of masking out waterbodies and the normal level of water in lakes and rivers. For change detection (CD), at least two images, namely the reference image (pre-event) and the target image (co-event) from the same satellite, orbit track, polarization, and coverage, are required [
13]. For this purpose, estimating the threshold between water and non-water pixels from backscattering images of Sentinel -1 SAR is a critical step to detect the flooded locations. To estimate the threshold and the need for distinguishing flooded areas from other land covers, the Otsu thresholding technique has been commonly used [
21,
22,
23]. In the change detection approach, and where the fuzzy classification system is necessary, classic co-occurrence texture measures mixed with amplitude information can be used for thresholding) [
21,
24]. However, in real-world applications, and due to the shortage of ground truth data, unsupervised change detection methods are preferable for rapid flood mapping [
25]. Unsupervised machine learning algorithms are more robust due to their higher speed, lesser requirements for training data, and computation runtime, and thus offer better computational efficiency.
A review of the literature indicates that Sentinel 1 SAR imagery has significant potential for detecting flooded areas and providing flood-related information. While machine learning approaches have been tested to detect floods from Sentinel 1 SAR images, the inability to establish a critical threshold between water and non-water pixels makes it a challenging task for unsupervised classification methods to analyze the Sentinel 1 image, as well as for supervised classification methods. Three supervised classification algorithms, i.e., Support Vector Machine (SVM), RF and Maximum Likelihood Classifier (MLC) are used and compared in this study. Besides these, an unsupervised classification algorithm which combines Otsu thresholding and fuzzy function is developed in this study for urban flood detection. Thus, this study suggests the combined use of SAR imagery, ground validation points, and machine learning for the purpose of (i) flood mapping using SAR imagery, and (ii) enhancing the current state of knowledge in the use of machine learning for nuisance flood detection in coastal urban systems such as San Diego, California. Moreover, the relative performance of supervised and unsupervised classification algorithms is evaluated and compared in order to develop a robust framework for the flood detections. It is expected that using unsupervised machine learning-based urban flood detection algorithm will be enable faster identification of flooded locations and roads for those that have evaded the attention of transportation authorities.
2. Flood Events in San Diego, CA, USA
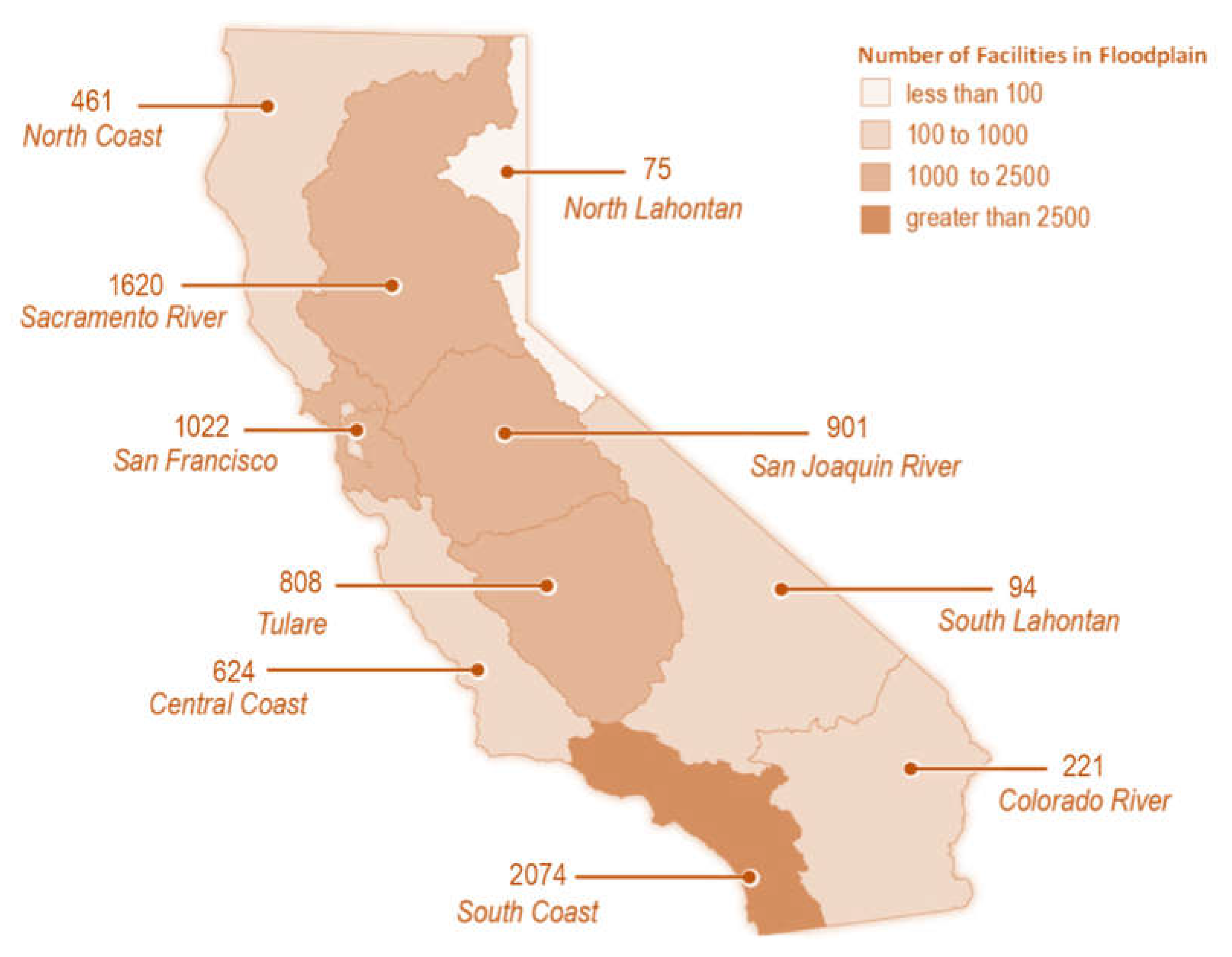
Southern California is particularly at risk for catastrophic flooding from multiple pathways, including flash flooding, stormwater flooding, debris flow flooding, tsunamis, and coastal storms. Coastal storms alone can put 873 miles of California roads at risk [
26]. In addition, around 20% of California’s population lives on a floodplain, making decisions regarding California’s flood risk assessment vital to public safety. Despite the continuous investments in California’s transportation network expansion, the safety of this network is critically vulnerable to flooding. Of particular note is the South Coast hydrologic region (
Figure 1), which has been found to contain over 2000 transportation facilities located within floodplains [
27].
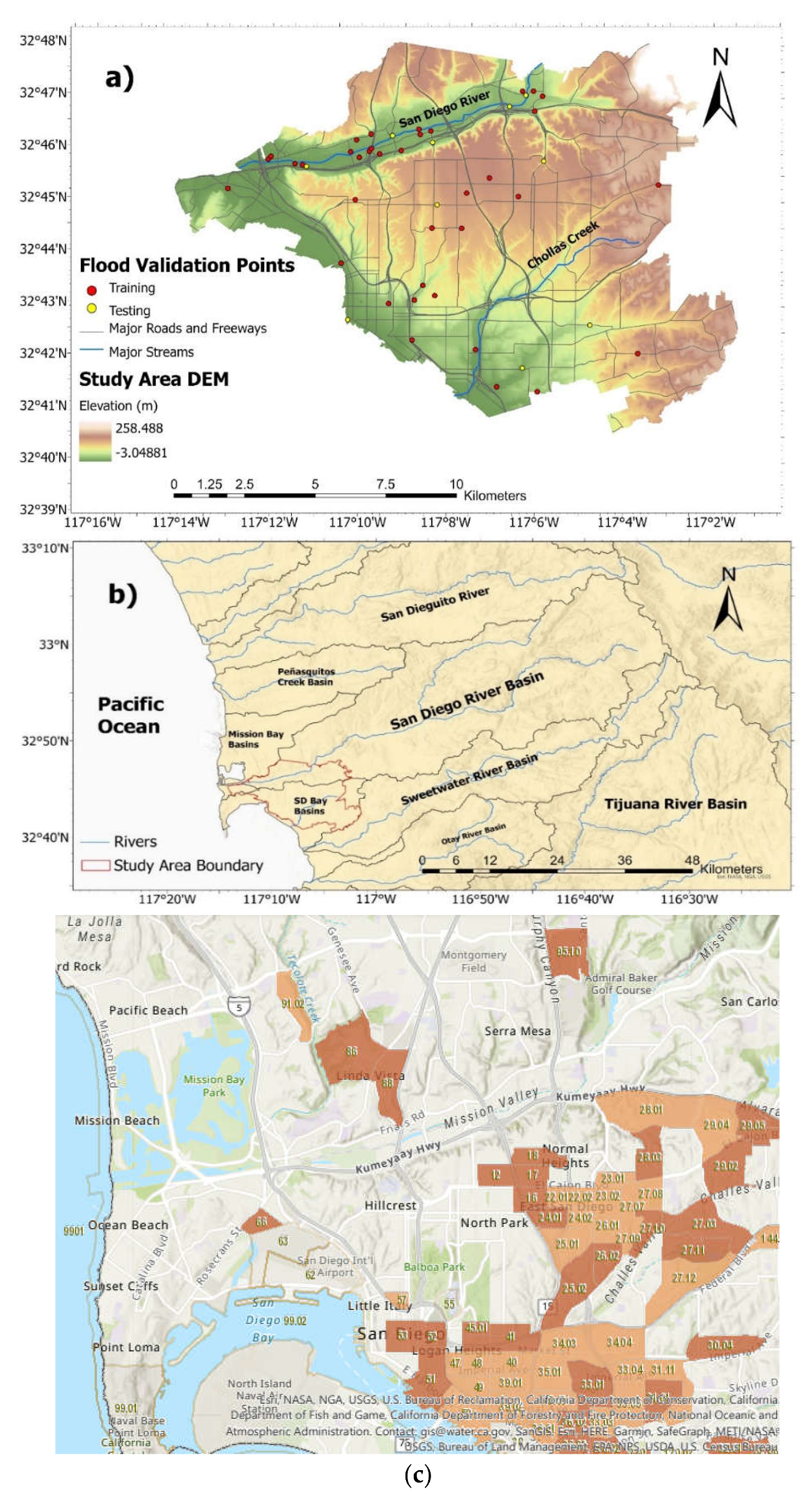
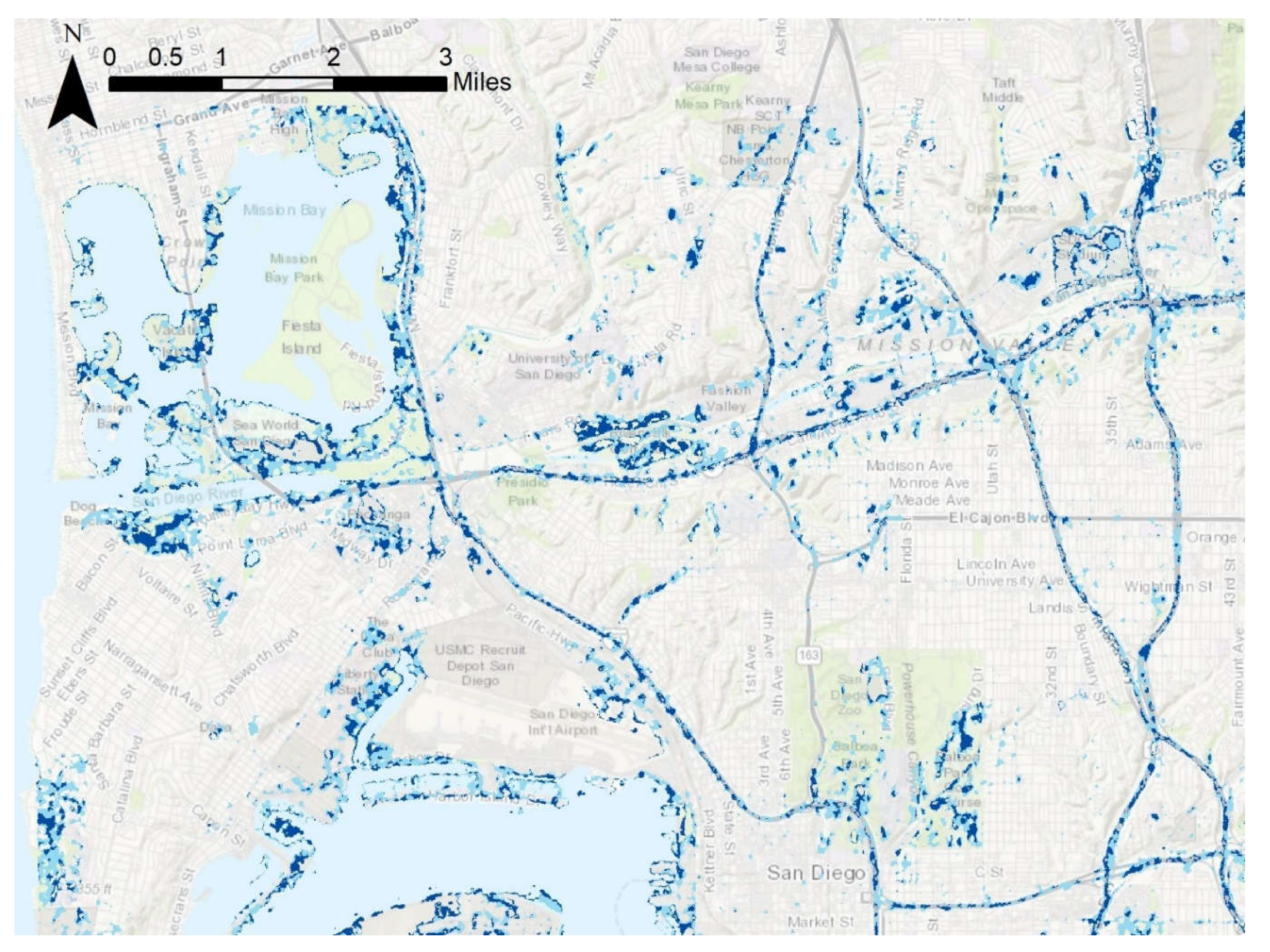
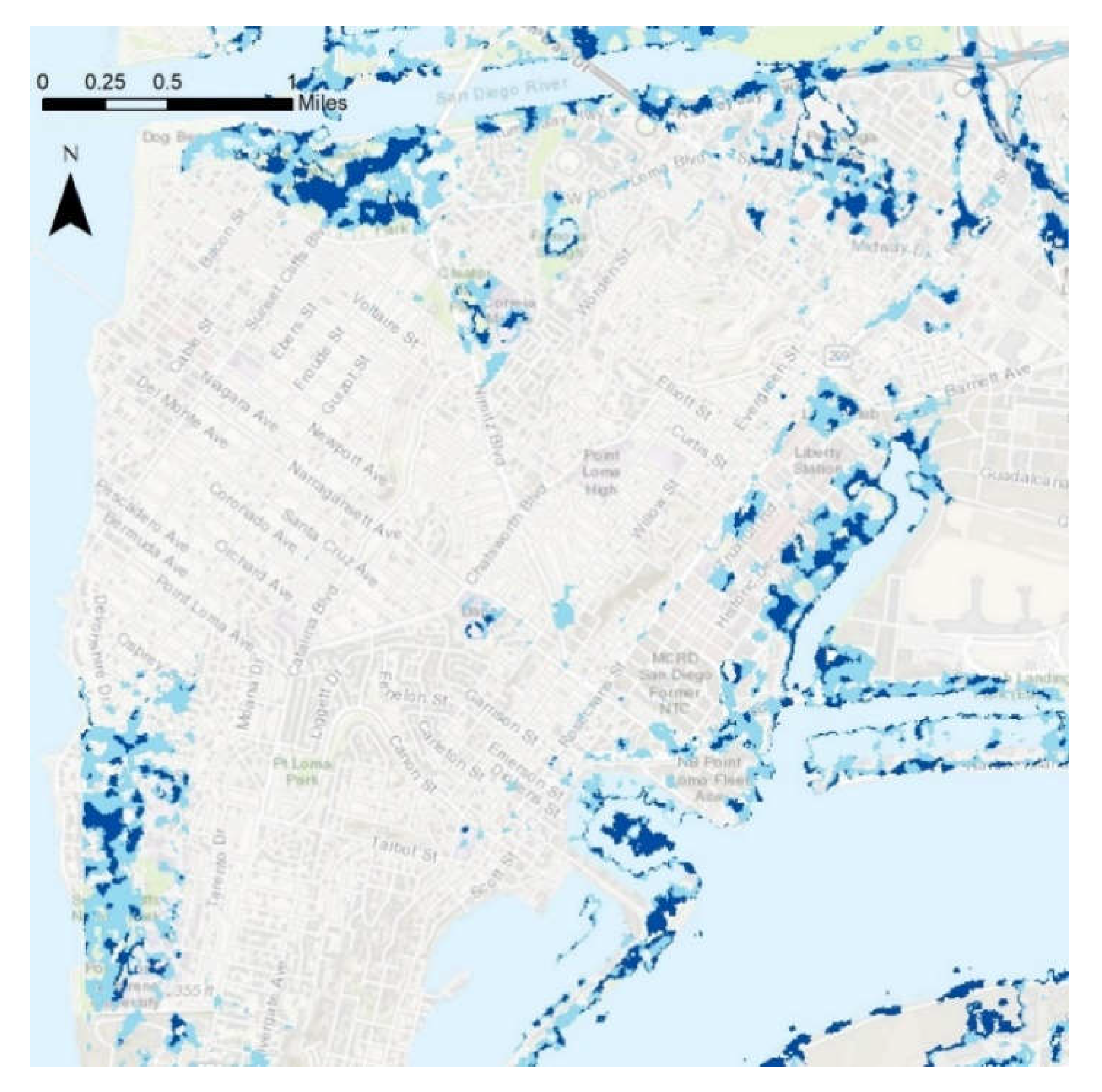
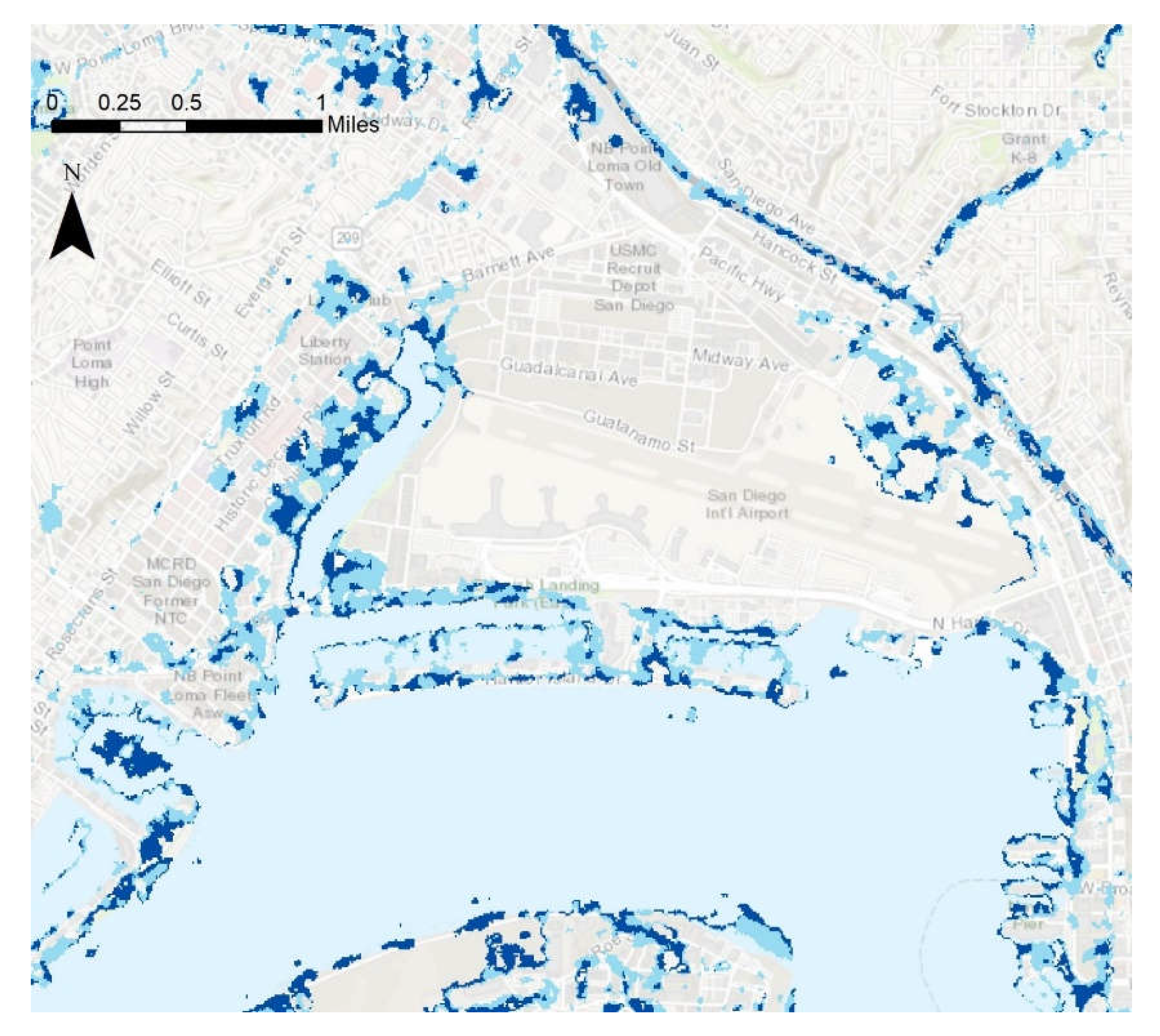
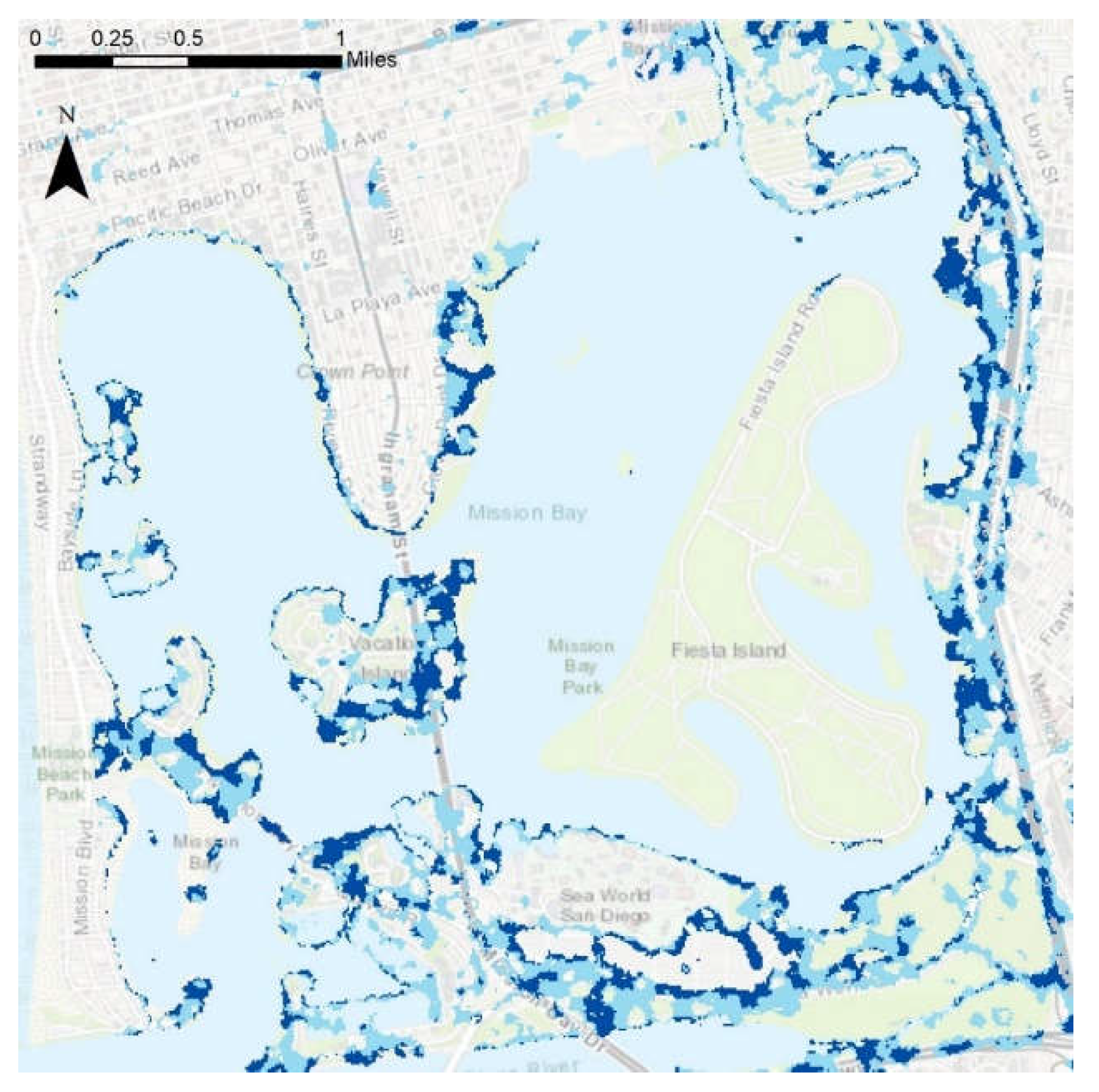
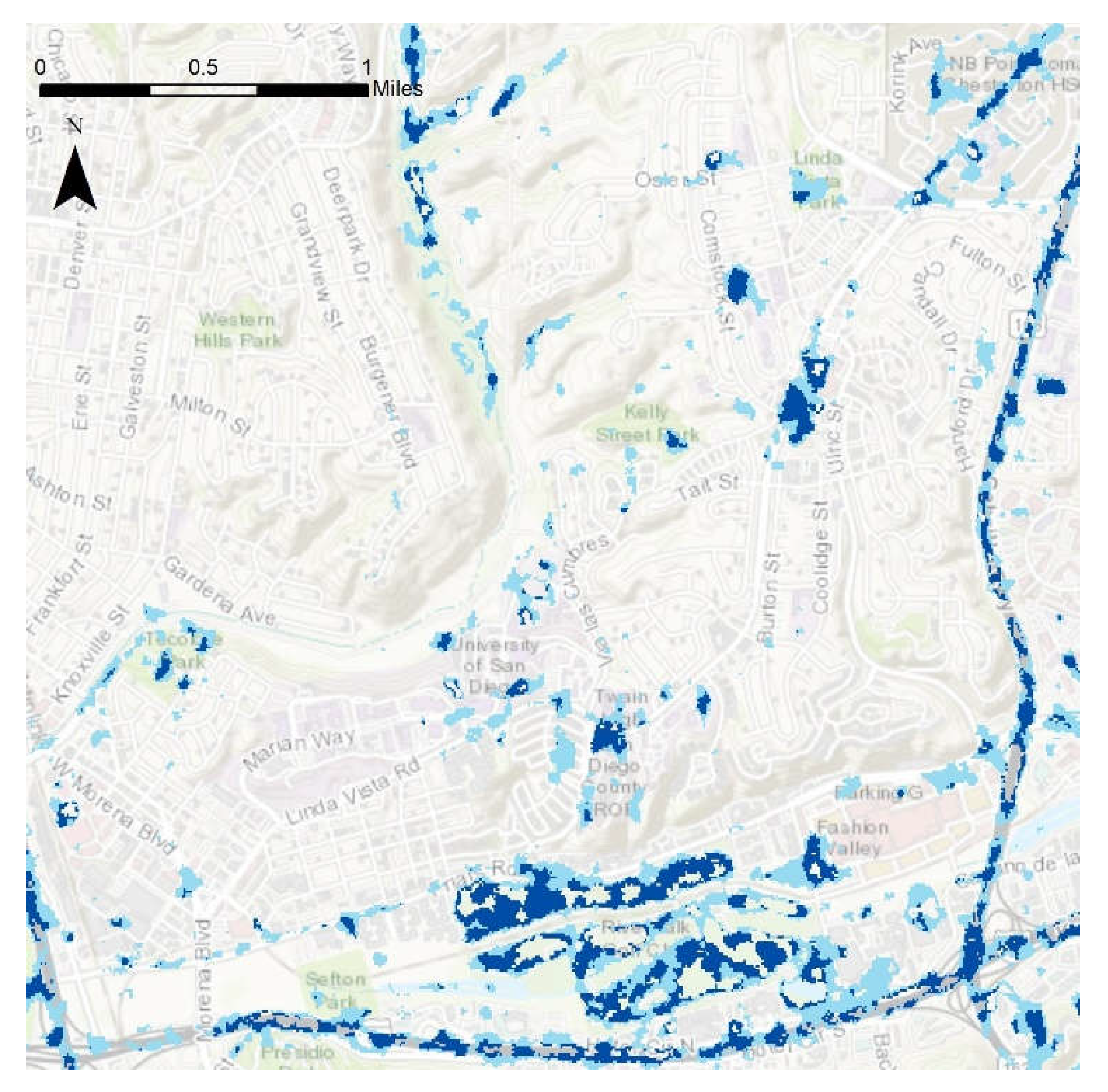
Figure 1 provides broader geographic and infrastructure context for the study area within the San Diego region, and this is shown in detail in
Figure 2. The study area was chosen based on the following parameters: an area entirely within the extent of satellite images taken during times of flooding, an area with the necessary hydrologic data to create a flood risk model, and an area containing enough validation points for statistical significance. The San Diego Bay Basin meets these criteria. The region is entirely within the city of San Diego, covering about 155 mi
2, and includes the flood-vulnerable Mission Valley area as well as disadvantaged neighborhoods such as City Heights and Barrio Logan, as shown in
Figure 2C. The study area is the same for both the flood risk mapping and image classification portions of the study. The climate in the city is semi-arid Mediterranean, with long dry seasons and short wet seasons during the winter months. The climate, measured near the downtown in the south-western corner of the study area, is generally warm and mild, with maximum average monthly temperatures around 25 °C in August and September and average monthly lows in December and January of 14 °C. Precipitation is highly seasonal on both the coast and in the more humid highlands. The average precipitation in the city itself is 9.79 inches a year, with approximately three-quarters of this value falling between December and March.
In addition to carefully selecting the study area, storm events were also required to meet a specific criterion. The selection criteria for a storm we could study were one that occurred recently enough to be imaged by satellites equipped with high-resolution SAR, and one large enough to create enough flooding to be noted by news and police agencies. The selection of the area of interest and weather events for analysis will help to realize our goal of applying detection methods found to be effective for larger-scale flooding to events of a greater magnitude than have been studied previously.
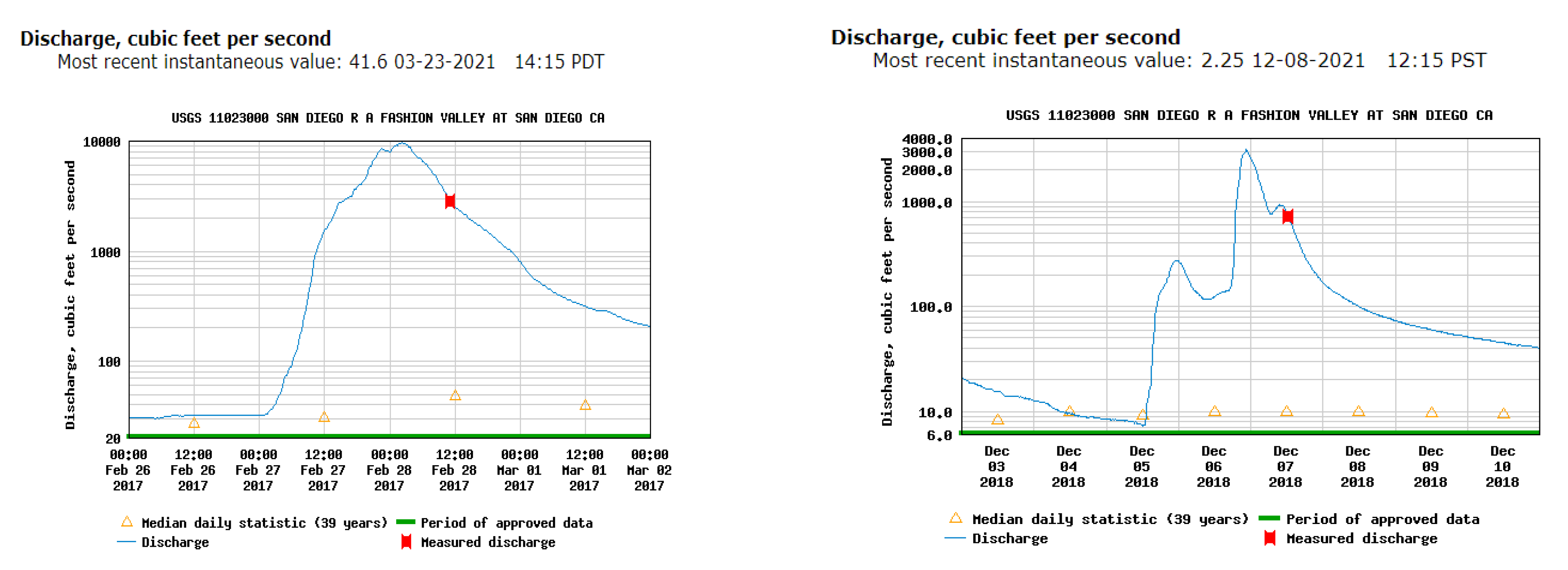
To assess the severity of a storm and the likely extent of flooding, we used rainfall and river stage data. While rainfall is far from homogenous across the San Diego area, we focused on the San Diego River at the Mission Valley community, as this is where most of the reported flooding occurred. Under the reasonable assumption that peak gauge height will correspond to peak flooding, we can use flood gauge data from the United States Geological Survey (USGS) to find peak storms over the past decade when high-resolution SAR sensors have been active. One gauge height peak immediately stands out, that for February of 2017. Closer inspection reveals that the gauge height reached a peak of almost 10,000 cfs at around 1:00 a.m. on 28 February 2017. Rainfall records also reflect a short, intense burst of rainfall that fell around 11:00 p.m. on the 27th—it was likely this high-intensity period of rainfall following steady rain the entire day beforehand that caused the high gauge height and flooding. Flooding for this day can be further verified with other qualitative data. A NOAA report, published in 2017, on heavy flooding through California in February of that year reported an “above-average” flood in Mission Valley on the 27th and 28th, reaching similar levels to historic peaks in 2011 and 1995 (2017). A Times of San Diego article reported enduring flooding on the 28th and evacuations in Lake Hodges and the Mission Valley area, as well as 702 collisions logged by the California Highway Patrol, nearly seven times the fair-weather average [
28]. Roads reported as closed by police on the morning of 28 February 2017 were gathered with road closure data from another storm on 8 December 2018 as another source of data [
29].
3. Methodology
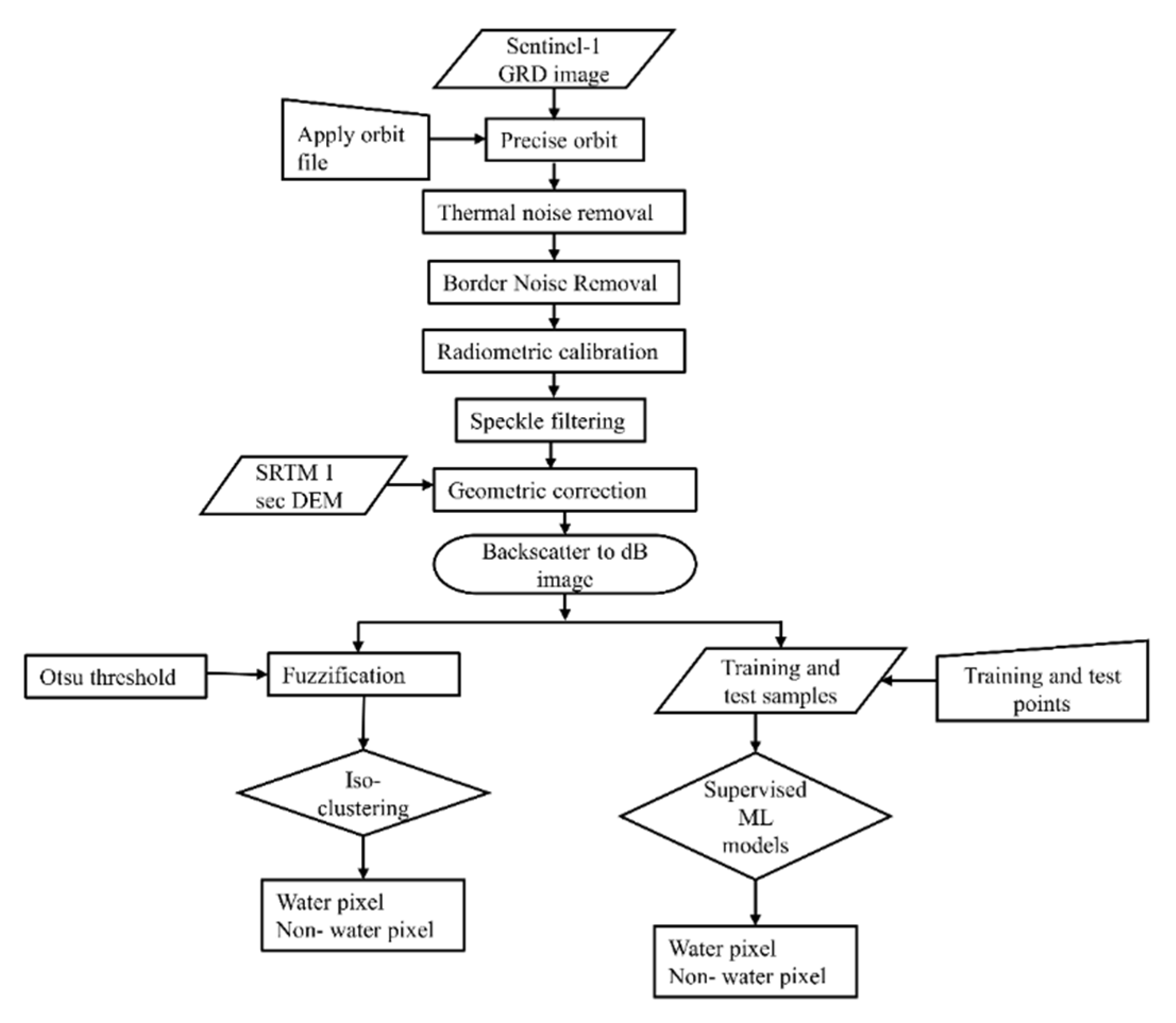
The stepwise image processing in the supervised and unsupervised machine learning method of this research is shown in
Figure 3. Three supervised machine learning methods i.e., SVM, RF and MLC method are engaged. The reason for developing an unsupervised classification algorithm is (1) they are more robust than supervised classification algorithms in their application to early flood detection, and (2) no training datasets are required to set an unsupervised model. In addition to these, an unsupervised classification algorithm is also engaged to classify the flooded area. To obtain the supervised model datasets, first, image pre-processing has been done (
Figure 3) using the European Space Agency Sentinel Application Platform (ESA SNAP) tool [
30]. The purpose of image processing using the SNAP tool is to maintain consistent image properties of model datasets from multiple images. The workflow followed in the machine learning method is shown in
Figure 3, including Sentinel 1 image processing from the raw dataset to backscatter intensity value generation, the unsupervised classification process, and the supervised classification process.
Sentinel-1’s revisit period is about six days, which means there is a significant possibility of missing flood images, and these should be taken during peak of floods. Based on the flood characteristics and timing described in the case study section, the obtained images (
Table 1) from satellite were taken during two flood periods. This is verified by constructing flood hydrographs from streamflow measurements at the USGS gauge at the San Diego River Fashion Valley location [
31] and checking the time these images are taken, which is within the flood periods. Multiple satellite images during both flood events are obtained, and those which better represent the time of flood peak, according to the USGS data, are selected (
Figure 4).
3.1. Sentinel-1 Image Preprocessing Method
Sentinel 1 C band images (
Table 1) are accessed from the Alaska archive. Sentinel 1, C band Interferometric Wide (IW) swath Ground Range Detected (GRD) datasets (
Table 1) are chosen for mapping flooding in San Diego. The image preprocessing is done in a SNAP workflow that consists of seven major steps (1) application of the orbit file, (2) thermal noise removal, (3) border noise removal, (4) radiometric calibration, (5) speckle filtering, (6) geometric correction using Range doppler terrain correction, and (7) band conversion into decibels (dB). The first step of image preprocessing in SNAP is to correctly attribute the orbit state of SAR products [
32]. When Sentinel level 1 products get updated in the archive, it takes several days-to-weeks to update the information about the orbit. Applying the correct information of the orbit file imposes the satellite position and velocity information in image acquisition. The next step of image preprocessing is thermal noise removal from the Sentinel-1 image. This image correction step removes any inter-sub-swath texture that may have been generated from two probable additive noise sources i.e., antenna patterns and scalloping noise [
33]. The Border noise removal resamples the image with any curvature effect during acquisition, and it helps to remove the radiometric artefacts at the image borders caused by the time, azimuth, and range compression withal. The next step is radiometric calibration, which is a procedure of converting the digital numbers to radiometrically calibrated backscatter. It reverts an absolute calibration constant during level-1 product generation. The speckle noises appear in the SAR images as a granular noise that generates from the interaction of out of phase waves reflected from the earth scatterers. Lee speckle filter [
34] at target window size 5 × 5 is applied for the proposed workflow. SAR images are subjected to some distortion by side looking geometry, which happens due to SAR images that are acquired with various viewing angles greater than 0 degrees, as well as with high-rise building structures. These distortions can be restored with orthorectification, which is a process known as terrain correction, e.g., range doppler terrain correction. This process converts the sensor coordinate to a map coordinate in a two-dimensional orthorectification process. The ESA SNAP toolbox is used to handle the Sentinel-1 GRD image preprocessing. The wet period images are obtained from Sentinel 1A GRD for the acquisition periods Feb 2017 and Dec 2018, while for dry period images it is obtained from Sentinel 1B. Sentinel-1A and Sentinel-1B capture images in ascending and descending orbit, respectively, and but they share the same orbit plane, with a 180° orbital phasing difference. Both Sentinel 1A and 1B GRD images have identical spectral properties. When both satellites are operational, Sentinel-1 requires a repeating cycle of about six days to complete a whole cycle for the earth’s observation.
3.2. Flood Mapping with Sentinel-1
A list of supervised and unsupervised machine learning methods which have been applied in this study is shown in
Table 2. The supervised machine learning method considers SVM, RF, and MLC. The unsupervised classification algorithm that is developed in this study consists of Otsu thresholding, fuzzification and iso-clustering.
3.3. Model Datasets for Supervised Classification
The training dataset for the supervised classification model consists of 1000 random samples, including 800 ‘non-water’ and 200 ‘water’ pixels. Pixel information is extracted from the Sentinel-1 VH post-processed backscattering intensity dataset. Pixel information must be taken from a consistent satellite band, here the sentine-1 VH band, to eliminate the effect of temporal difference between dry and wet periods in images. The following steps are taken to extract modeling datasets:
A total of three sentinel-1 images are obtained to extract the modeling datasets. Two images are taken during the wet period, during February 2017 and December 2018, and one image is obtained from a dry period, in March 2017 (
Table 1), to be used for training supervised classification models. The description of modeling datasets is shown in
Table 3.
The Sentinel-1 VH image contains the backscattering intensity information. The SAR images have the advantage of not being covered by clouds in comparison to RGB pixel information in optical satellite images. The purpose of the supervised machine learning model is to classify the sentinel-1 VH band images during the flood event, i.e., classify pixels of images into water (such as waterbodies and flooded streets) and non-water pixels (vegetation, forest, developed area, open spaces and pavement, etc.) (
Table 3).
The input features of the supervised machine learning approach are the backscattering intensity which is extracted from the selected samples. The target variable is the label of a pixel, which can take one of the classes described in
Table 3 depending on its backscattering intensity.
About 800-pixel values from the ‘non-water’ pixel group are extracted to represent the dry period of the ‘March 2017′ image (
Table 1). The pixel information is assigned as open space, vegetation, forest, developed area, or pavement type.
The 200 water pixels consist of waterbodies and flooded street labels (
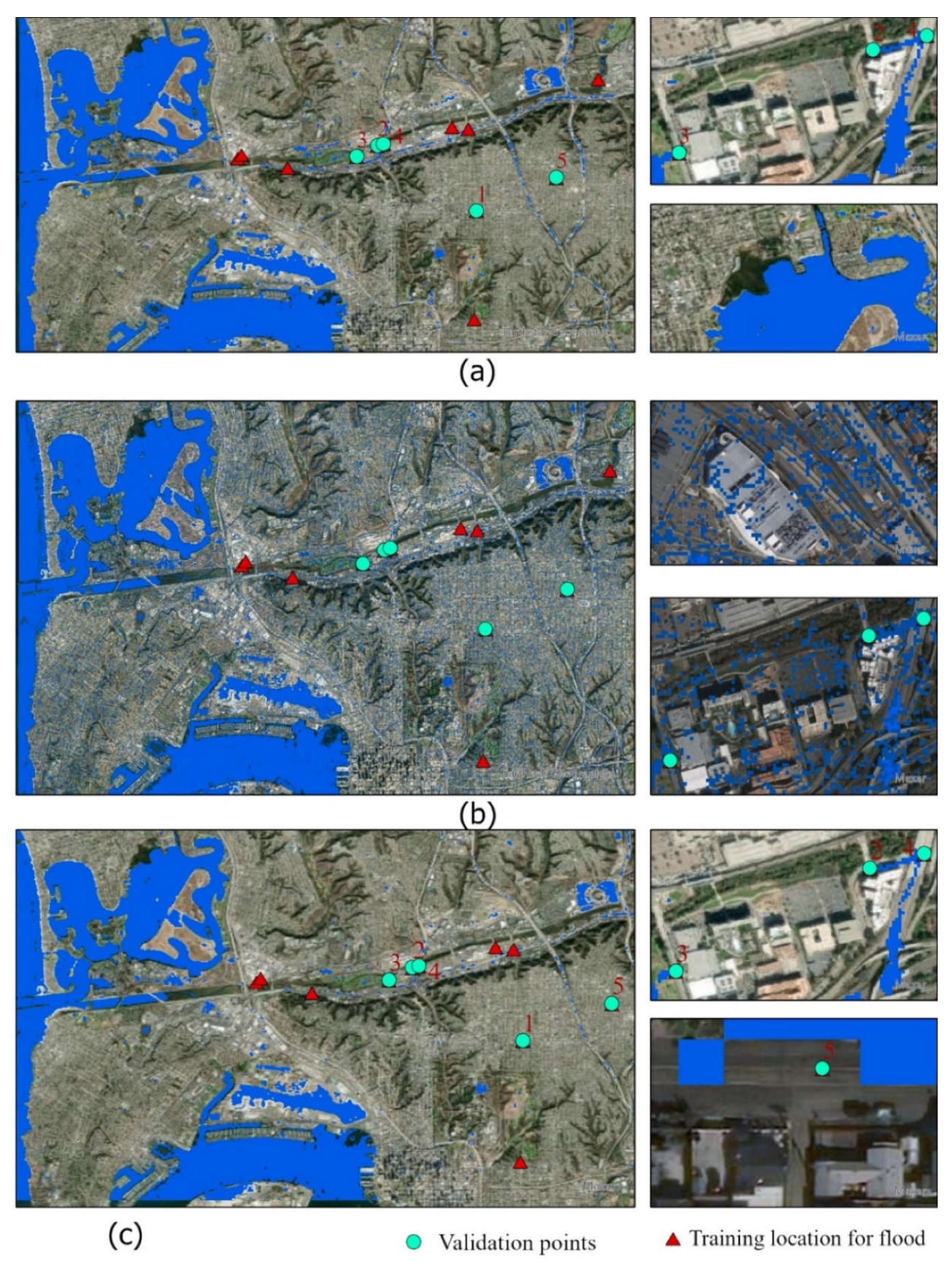
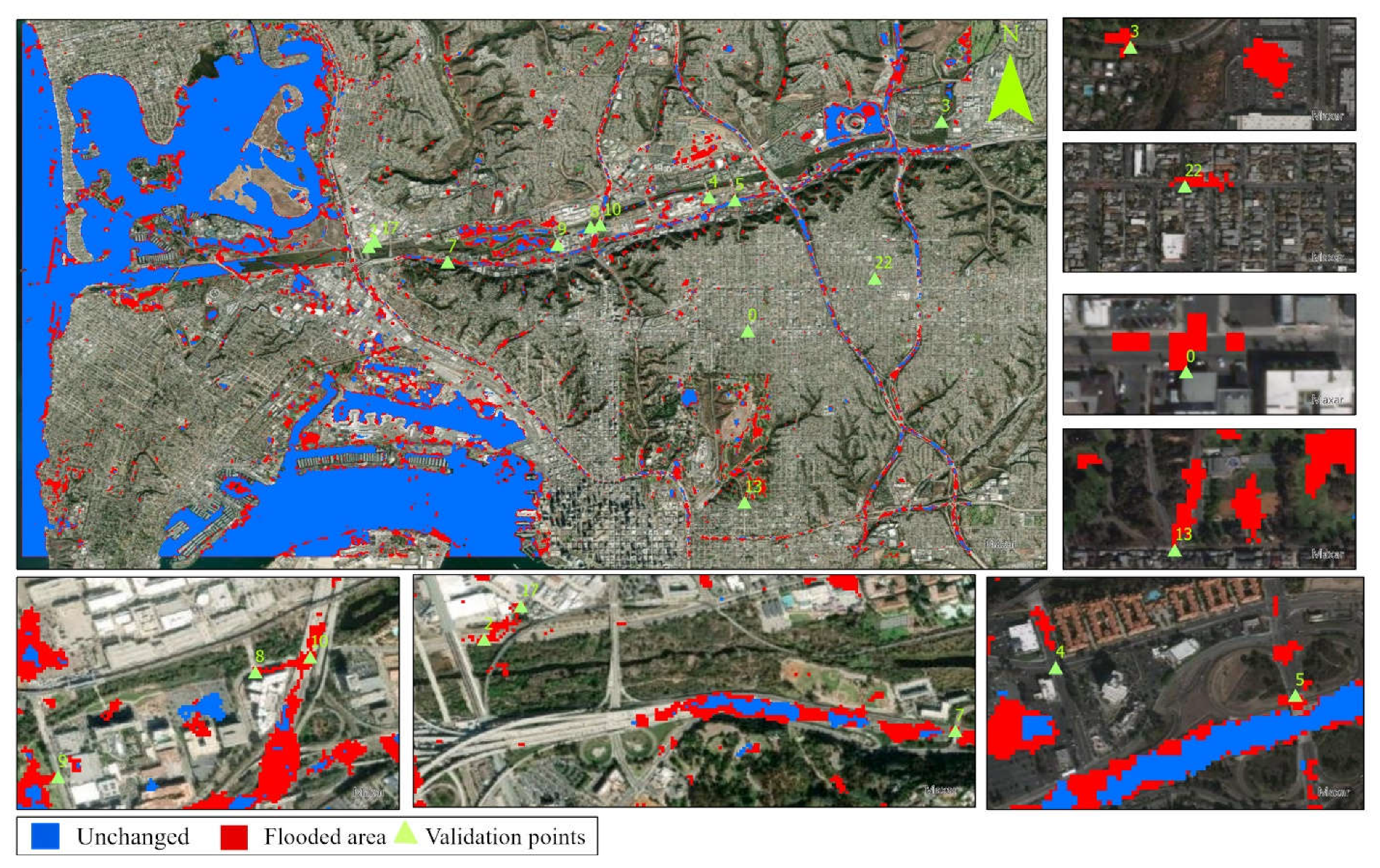
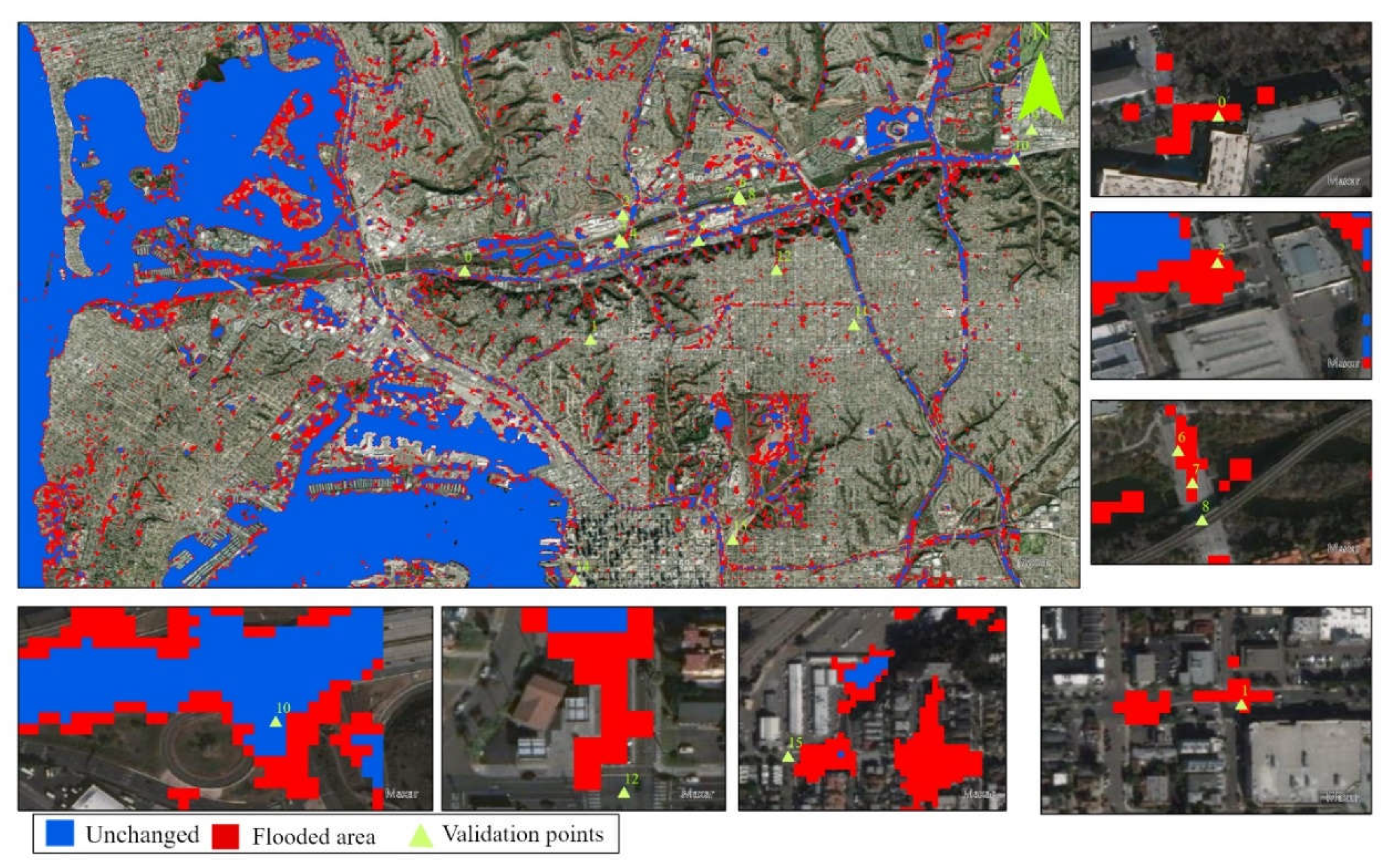
Table 3). The post processed images during the San Diego floods of February 2017 and December 2018 were used to detect flood pixels. The ground truth data sourced from San Diego police road closure reports is used to assign and detect the flood pixels in the wet period images. The information regarding flood pixels were collected for 25 street locations. Since a total of 175 water pixels are represented by waterbodies, about 14 out of the remaining 25 pixels are used for training purposes and 11 pixels are kept for model validation.
For the rest of the pixel types in the datasets, pixels are split into training and testing at the ratio of 80% and 20%, respectively (
Table 3). The testing datasets are used later to verify the models’ prediction performance using accuracy assessment metrics.
3.4. Supervised Classification Method
3.4.1. Random Forest (RF)
In machine learning applications, Random Forest (RF) is an ensemble classification technique that utilizes the decision trees as one single tree in the forest. To create a set of controlled variance decision trees, the RF approach combines bootstrap aggregation (bagging) with random feature sorting. The RF has two parameters, i.e., the number of parameters and the depth of the decision trees that improve the classification accuracy. The depth of decision trees is determined by the number of features used to slice the nodes. The node impurity or the quality of a tree split is evaluated by ‘Gini’ (G), which was defined below in Equation (1) [
35]:
Here,
pi denotes the probability of a pixel classified in water pixel or non-water pixel class. The parameter optimization is done using the ‘GridSearchCV’ method available in scikit learn [
36]. According to the hyperparameter tuning results, the maximum depth of trees found is 10, the minimum number of samples required to beat a leaf node is 3, the minimum number of samples required to split an internal node is 8, and the number of trees were set as 100.
3.4.2. Support Vector Machine
Support Vector Machine (SVM) is a widely used method in machine learning. The SVM method is a supervised classification technique that engages a hyperplane in a data space that divides the sentinel 1 pixel value in water and non-water objects. The SVM method offers several kernel functions including radial basis functions, linear, nonlinear, and polynomial functions. The flood image is classified by choosing the radial basis function, which can be expressed mathematically as Equation (1) [
37]:
where the parameter
controls the spread of the kernel. By tuning the parameter
, the accuracy of the water and non-water pixels is increased. The hyperparameter tuning is done using the ‘GridSearchCV’ method in the sci-kit learn package of python. The model set up is obtained optimally with the radial basis function as a kernel function, with the regularization parameter equal to 10.
3.4.3. Maximum Likelihood Classification
The ArcGIS maximum likelihood classification (MLC) tool is used to classify the Sentinel 1 post processed images. The tool works based on the assumption that the samples assigned under each class are normally distributed. When attributing each cell to one of the classes contained in the signature file, the tool considers both the variances and covariances of the class signatures. The mean vector and the covariance matrix can be applied to identify a class under the assumption that the class sample is normally distributed. The statistical probability for each class is computed using these two features for each cell value to evaluate the cells’ membership in a class. The prior probability weight of each class is set as ‘equal’ for running the MLC tool in ArcGIS (ESRI, Redlands, CA, USA).
3.4.4. Change Detection using Unsupervised Classification Method
The unsupervised classification method engaged in this study utilized the post processed Sentinel 1 image in three steps: (1) determining the Otsu threshold [
23], fuzzification, and iso-clustering. Assume that each pixel in an image is represented by L gray levels (1,2, …, L). Let N denote the total number of pixels, and n
i signify the number of pixels at level
i. The likelihood that level
i will occur is given by
pi = n
i/N. Let us allow a threshold
T to divide a sentinel 1 image pixel into two classes C
0 and C
1. C
0 is made up of pixels with the levels [1, ⋯,
T] and C
1 made up of pixels with the levels [
T + 1, ⋯, L]. Let
P0(
T) and
P1(
T) denote the cumulative probabilities,
μ0(
T) denote the mean levels, and
μ1(
T) denote the variances of the classes C
0 and C
1, respectively. These values are given by:
Let
μ,
, and
denote the image’s mean level, between-class variance, and within-class variance, respectively.
According to Otsu, the threshold determined via maximization of between-class variance is:
This value is the same as the threshold determined by minimizing within-class variances:
Furthermore, the above threshold is identical to the ones determined by maximizing the ratio of between-class to within-class variations [
38]. The threshold obtained following Otsu was later used to apply the fuzzy large function. This threshold selection process maximizes the variance among the water and non-water pixels. This function is used to enhance the class distance between water and non-water pixels, making it easier to distinguish between the two classes in iso-clustering. When the larger input values are more likely to be a member of the set, the fuzzy large transformation function is applied. The following is the definition of the fuzzy large function:
where
x is the raster value of a sentinel 1 image,
f1 and
T are respectively spread and Otsu threshold in raster value distribution. After fuzzification the iso-clustering is done using the Iso Cluster Unsupervised Classification tool in ArcGIS. The Iso Cluster uses an improved iterative optimization procedure of clustering and then fit a maximum likelihood function to transform the pixel cluster in a normally distributed cluster. Thus, the iso-cluster tool extracts the samples that has the unimodal distribution in the sentinel 1 data. Since after fuzzification the class variance between the water and non-water classes are more pronounced, the maximum likelihood function to get two distinct classes is easy to fit by using the iso clustering tool. The functionality of the iso-clustering tool for unsupervised classification is more detailed in ArcGIS (2021).
In order to find the change in water extent during dry and wet periods at first the unsupervised classification is done over the wet image, then the model is re-run over the image acquired during the dry period (March 2017). Based on the difference between the dry and wet period, the change is detected as the inundation extent.
3.4.5. Accuracy Assessment Metrics
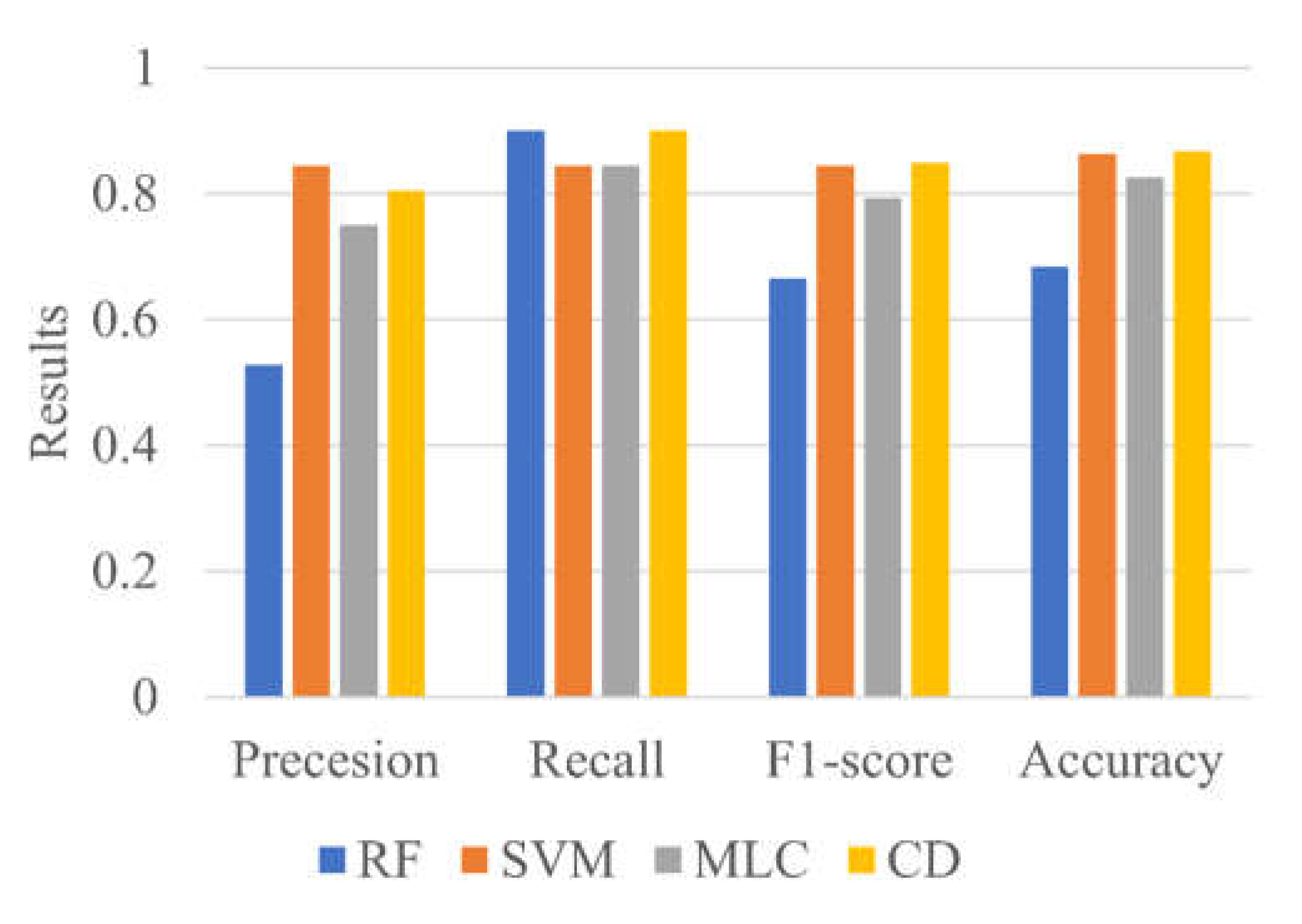
Four machine learning method accuracy metrics i.e., (a) Precision (Equation (13)), (b) Recall (Equation (14)), (c) F1-score (Equation (15)), (d) Accuracy (Equation (16)) are engaged to measure the classification accuracy from the supervised and unsupervised classification in this study [
39]. The ranges of these metrics vary between 0 to 1, and the greater the value of these metrics, the better the model performance. These metrics are required to calculate the true positive (TP), true negative (TN), false positive (FP), and false negative (FN) samples in the testing datasets. The true positive (TP) samples are those pixels in which the machine learning model correctly detects the true classified pixel type as the water pixel in the prediction. The true negative (TN) pixels are non-water pixels in observation correctly detected as non-water pixels in the machine learning prediction. The false positive (FP) samples are incorrectly detected as water pixels, which are non-water pixels in observed datasets. The false negative (FN) samples are the non-water pixels detected by the machine learning model, which are water pixels in the observed datasets.
where, TP, FP, TN, and FN are respectively true positive (TP), true negative (TN), false positive (FP), and false negative (FN) samples.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}