
Low-Carbon Tour Route Algorithm of Urban Scenic Water Spots Based on an Improved DIANA Clustering Model


Abstract
:1. Introduction
2. Urban Scenic Water Spot Spatial Clustering Based on the Improved DIANA Algorithm
2.1. The Modeling of the Attribute Quantification Matrix for Scenic Water Spots
- (1)
- The dimensions ofandareand, respectively.
- (2)
- Theandare fully ranked, and the ranks areand, respectively.
- (3)
- Theandare the basic vectors of classification factors and attribute factors, which can be used to create a topological matrix.
- (4)
- When the scenic water spotis confirmed, the elements forandare confirmed, namely, one scenic water spotalways relates to oneand one .
- (1)
- Row rank and column rank:, .
- (2)
- Whenobtains the maximum value, the row meets .
- (3)
- Arbitrary rowalways has one non-zero element; the other elements are 0.
- (4)
- Arbitrary rowsandor arbitrary columnsandare nonlinearly correlated.
2.2. Scenic Water Spot Spatial Clustering Model based on the Improved DIANA Algorithm
- (1)
- Elements in the same cluster have a relatively strong correlation, while elements in different clusters have a weak correlation.
- (2)
- Each cluster is a non-empty set, namely .
- (3)
- Arbitrary element only belongs to one cluster , namely , and only relates to one single combination .
- (4)
- The union of all the clusters is , namely .
- (1)
- The dimension is .
- (2)
- It contains number of elements, in which number of elements are used to store scenic spots , others are used to store 0, .
- (3)
- The row rank is , and column rank is . The matrix should contains at least 2 clusters.
- (4)
- Row sequence is the footnote of cluster , and the column sequence is the footnote of . The footnote is determined by the clustering algorithm.
- (1)
- If there is an scenic spot , its related meets , and then delete and from and , and store into , store into ;
- (2)
- If there is no scenic spot that meets , keep the and elements unchanged.
- (1)
- If there is an scenic spot , its related meets , and then delete and from and , and store into , store into ;
- (2)
- If there is no scenic spot that meets , keep the and elements unchanged.
- (1)
- Take the first element in the steady , calculate the number of objective function values between and number of elements , .
- (2)
- Search the minimum value and its related element and center point . Note the center point as relating to cluster .
- (3)
- Store center point in the first row element of the first column in . Store the element in the second element of the same row. Absorb into .
- (4)
- Connect center point with non-center point , and form the first edge for .
- (1)
- Calculate the number of objective function values between and number of elements ,.
- (2)
- Take the minimum value and its related center point . Make a judgement:
- (i)
- If the center point is , the element belongs to . Store it in the first row element of the third column. Connect the non-center point with and form the second edge .
- (ii)
- If the center point is not . Store it in the second row of the first column element in , and store in the same row’s second column element. Absorb into cluster . Connect the center point with non-center point and form the first edge of .
3. Water Tourism Route Algorithm Based on the Optimal ECER Model
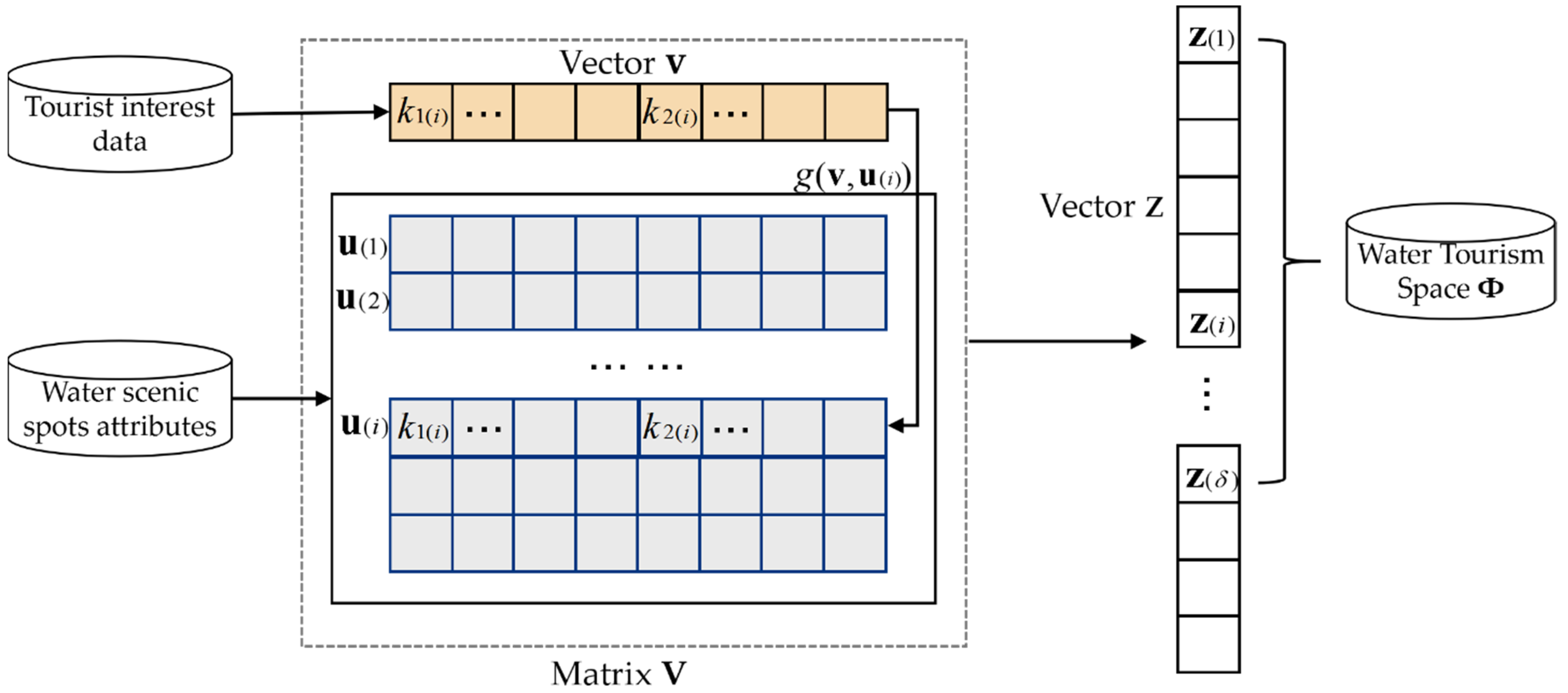
3.1. Water Tourism Space Model Based on Scenic Spot Mining
- (1)
- Its dimension is, in which therepresents thenumber of classifications andrepresentsnumber of attributes, .
- (2)
- The formernumber of elements store the classification labels. The latter number of elements store attribute labels.
- (3)
- This ultimately becomes the fully ranked state, namely .
- (4)
- The element is noted as,, .
- (5)
- As to the formernumber of elements, there is at least one value of 1; other elements have values of 0.
- (1)
- Its dimension is , in which the represents the number of classifications and represents number of attributes, .
- (2)
- The former number of elements store the non-zero elements of the first row in matrix . The latter number of elements store the non-zero elements from the second row in the No. row in matrix .
- (3)
- It must be fully ranked, namely . Each represents the unique label set for each scenic spot. The element of is noted as , , , .
- (4)
- Matrix has rows and columns, and they are both fully ranked, namely , .
- (5)
- Two arbitrary rows are nonlinearly correlated, and two arbitrary columns are also nonlinearly correlated.
- (6)
- As to the former number of elements, there is at least on value of 1; the other elements are values of 0.
- (1)
- The element relates to the value .
- (2)
- The initial state is a zero matrix, and the final state is fully ranked .
- (3)
- The transition state is a dynamic state of value sequencing.
- (1)
- The former number of elements in the first row are the classification factors , , …, , relating to the number of classifications of the vector . The latter number of elements in the first row are the selected attribute factors, relating to the number of attributes , , …, . The latter rows have the same storage mode as the first row.
- (2)
- The second row to the last, No. row, is encoded as , , …, . The function values do not match the code .
- (3)
- The later number of rows do not match the element of vector .
- (1)
- If , keep the element values unchanged.
- (2)
- If , delete the values in and . Store in and store in .
- (1)
- If :
- ①
- If , delete the storage values of and , store in , store in and store in ;
- ②
- If , keep the storage value, delete storage value, store in and store in ;
- ③
- If , keep the and storage value, and store in .
- (2)
- If :
- ①
- If , delete the storage values of and , store in , store in and store in ;
- ②
- If , keep storage value, delete storage value, store in and store in ;
- ③
- If , keep and storage values, and store in .
- (1)
- Tourists have no requirements on cluster . Input the scenic spot quantity , the smart machine searches the former number of elements , and take the related , vector and scenic spot .
- (2)
- Tourists have requirements on cluster . Tourists choose number of and the quantity of scenic spots to be visited in each cluster . Set counter for each cluster as , the initial value is , , , is the total number of cluster .
- ①
- Search the No. 1 element of the vector . Confirm the related , vector and scenic spot :
- (i)
- If , keep , , turn to step ③.
- (ii)
- If , delete.
- ②
- Search the No. element of the vector ,. Confirm the related , vector and scenic spot :
- (i)
- If , keep , , turn to step ③.
- (ii)
- If , delete.
- ③
- Judge the counter :
- (i)
- If , go back to step ② and continue searching the scenic spots for this cluster .
- (ii)
- If and , the algorithm ends. Output scenic spots of each cluster .
3.2. Optimal ECER Tour Route Algorithm Based on the Water Tourism Space
- (1)
- Scenic water spotsare abstracted as the space lattice with longitude and latitude, according to their spatial distribution.
- (2)
- Its dimension is, the row and column’s full ranks are both .
- (3)
- Starting from the first element in the first row and ending at the last element of the No.row, the scenic spotsare stored in spatial sequence.
- (4)
- Empty elements are set as value 0.
- (1)
- Effective intersectionsare abstracted as the space lattice with longitude and latitude, according to their spatial distribution.
- (2)
- Its dimension is, the row and column’s full ranks are both .
- (3)
- Starting from the first element in the first row and ending at the last element of the No.row, the effective intersectionsare stored in spatial sequence.
- (4)
- Empty elements are set as value 0.
- (1)
- It is a connected graph that does not contain a simple loop.
- (2)
- Vertexoris only connected by one edge. Nodemust have two connecting edges.
- (3)
- Any two vertexesandcan only have one connecting edge.
- (4)
- It is a directed graph fromto .
- (5)
- The edge weight of the vertexesandis the spatial distance.
- (1)
- The initial state is shown in Figure 3a. The space lattice is , containing and . The starting point is while the ending point is . Absorb into .
- (2)
- Judge the edge , in which the values are 1, 2, 5, 8 and 9. Confirm the smallest edge weight . Search the and edge of , shown in Figure 3b. Make a judgement: ① If and meet , absorb and into ; ② If and do not meet , delete. Search the other points .
- (3)
- Continue searching the smallest edge weight as in Steps (1)–(2). Find the , and form the edge , as shown in Figure 3c. Judge that it meets , and absorb and into .
- (4)
- Find the , and form the edge , as shown in Figure 3d. Judge that it meets , and absorb and into .
- (5)
- Continue searching; when is found, it forms a loop; then delete . Find and form the edge , shown as Figure 3e. Judge that it meets , and absorb and into .
- (6)
- Find the ending point and absorb it into , as shown in Figure 3f.
- (7)
- Calculate the ECER volume of , and store it into the first element of . Here, the searching process ends.
- (1)
- If , delete and , store in , store in ;
- (2)
- If , keep and .
- (1)
- Vector is fully ranked, namely .
- (2)
- , , if , there is always .
- (1)
- The element is , and it is fully ranked, namely .
- (2)
- Element is used to store the starting point . Elements ~ are used to store the number of scenic spots in the tour sequence.
- (3)
- Element and are the two adjacent scenic spots, and the spatial interval is .
- (4)
- ~ as well as their spatial intervals form a complete tour sequence in the space .
4. Experiment and Result Analysis
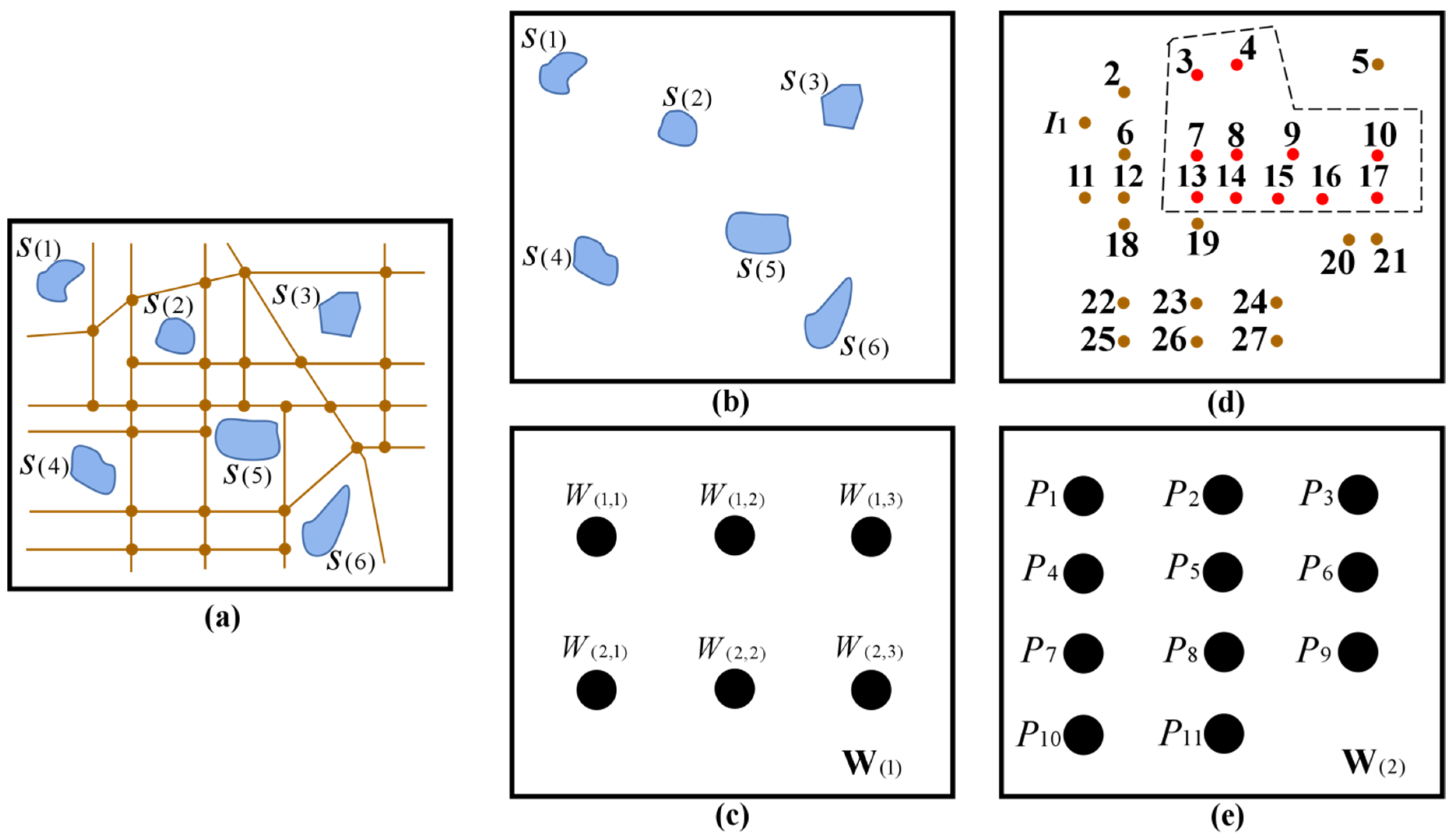
4.1. The Acquisition of the Scenic Water Spots and Calculation Results
4.2. The Results of Scenic Water Spot Clustering and Cluster Visualization
4.3. The Results of the Optimal Scenic Spots and Tour Routes
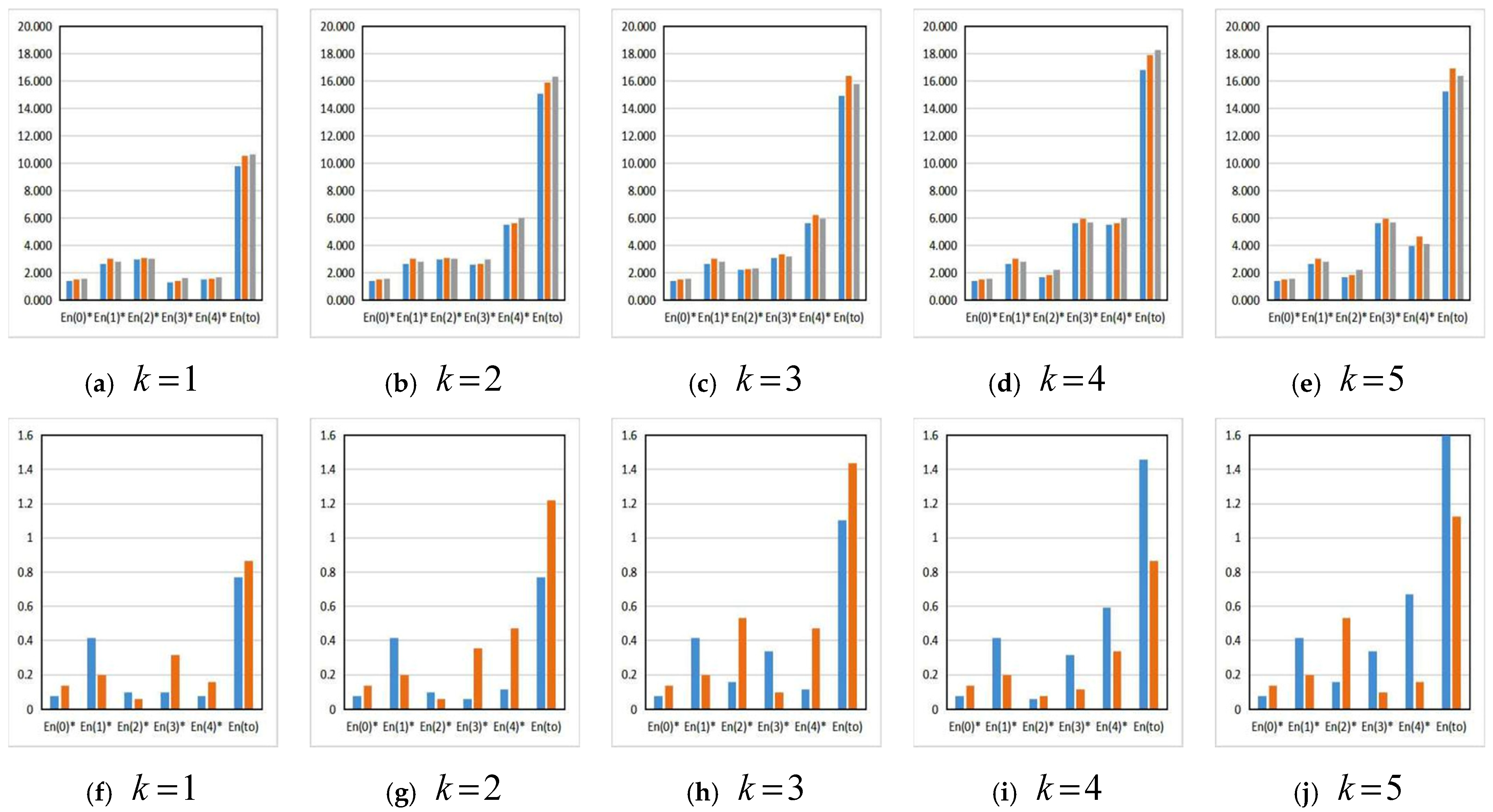
4.4. Comparison of Results
4.5. Experimental Results Analysis
- (1)
- The analysis of the clusters and related visualization results
- (2)
- The analysis of the optimal scenic spots and tour routes results
- (3)
- The analysis of the algorithm comparison results
- (4)
- Discussion of water protection
4.6. Comparison with the Algorithms in the Literature
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Astuti, H.P.; Suryatmojo, H. Water ecosystem services of Merawu Watershed, Banjarnegara, Central Java, Indonesia. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Bangka Belitung, Indonesia, 29–30 September 2021. [Google Scholar]
- Song, S.; Wang, S.; Ye, H.; Guan, Y. Exploratory analysis on the spatial distribution and influencing factors of Beitang landscape in the Shangzhuang Basin. Land 2022, 11, 418. [Google Scholar] [CrossRef]
- Minallah, S.; Steiner, A.L. Analysis of the Atmospheric Water Cycle for the Laurentian Great Lakes Region using CMIP6 models. J. Clim. 2021, 34, 1–47. [Google Scholar] [CrossRef]
- Mata-Carballeira, Ó.; Díaz-Rodríguez, M.; del Campo, I.; Martínez, V. An intelligent system-on-a-chip for a real-time assessment of fuel consumption to promote Eco-driving. Appl. Sci. 2020, 10, 6549. [Google Scholar] [CrossRef]
- Obaid, M.; Torok, A. Macroscopic traffic simulation of autonomous vehicle effects. Vehicles 2021, 3, 187–196. [Google Scholar] [CrossRef]
- Laskowska, M.Z.; Laskowski, P. Emission from internal combustion engines and battery electric vehicles: Case Study for Poland. Atmosphere 2022, 13, 401. [Google Scholar] [CrossRef]
- Li, D.; Shao, C.; Wang, Y. Route and Mechanism study on the development on country water resources. In Proceedings of the 2019 China Urban Planning Annual Conference, Chongqing, China, 19 October 2019. [Google Scholar]
- Zhou, S.F.; Tang, Y.X.; Li, Z.H.; Chen, Q.H.; Deng, M.R. Investigation and Evaluation of Water Tourism Resources in Zhangjiajie Based on AHP. Hunan Agric. Sci. 2019, 3, 49–52. [Google Scholar]
- Xu, X. Research on the development and application on Chizhou city’s water resources. J. Chifeng Univ. 2017, 33, 99–100. [Google Scholar]
- Liu, Q.; Zhou, Y. Development strategy on city water ecotourism of Jintang county, Chengdu city. Tour. Overv. 2018, 2, 112. [Google Scholar]
- Cao, X. Study on the Tourism Exploitation of Urban Water Landscape Based on the Cognition of Tourists and Residents. J. Anhui Agri. Sci. 2008, 36, 11947–11950. [Google Scholar]
- Fan, X.; Wang, L. The value on mining the cultural attributes of water tourism resources in the process of tour planning. J. Leshan Teach. Coll. 2007, 22, 75–78. [Google Scholar]
- Li, H.; Hong, J. Study on the tourism space planning on water resources in megacities—Taking Nanjing for example. In Proceedings of the 2011 Annual Conference of Chinese Society of Landscape Architecture, Nanjing, China, 28 October 2011. [Google Scholar]
- Song, T. Water tourism cultural products and development of Hulun Buir. J. Inn. Mong. Agric. Univ. 2019, 21, 96–100. [Google Scholar]
- Dai, F. Development mode on water sports tourism in the overview of “Health China”, take Hubei province for example. Sport Style 2018, 4, 185–186. [Google Scholar]
- Huang, T.; Tang, Z. The study on the innovation route for low carbon marketing of Heilongjiang tourism industry under the MCN model. ShangYe Jingji 2021, 10, 8–10. [Google Scholar]
- Tao, Y.T.; Tang, Z.; Li, Y.D. Study on tourists’ low carbon traveling activities in the Harbin scenic spots. Tour. Overv. 2021, 16, 1–3. [Google Scholar]
- Tian, Q. Research on the feasibility and strategy on the building of Guilin tourism city. Tour. Overv. 2021, 21, 93–95. [Google Scholar]
- Wang, Z.; Zhang, Q. An empirical study on the endogenous driving mechanism of tourists’ low carbon tourism behavior. Mod. Urban Res. 2020, 10, 105–109. [Google Scholar]
- Ren, J. Study on the transformation Strategy of low carbon tourism for resource exhausted cities, take Tongling city, Anhui province. J. Fuyang Inst. Technol. 2020, 31, 68–71. [Google Scholar]
- Liu, H. Construction and application of low-carbon tourism evaluation system in northern Anhui tourism development. J. Chengdu Technol. Univ. 2020, 23, 73–79. [Google Scholar]
- Sarkar, B.; Debnath, A.; Chiu, A.S.; Ahmed, W. Circular economy-driven two-stage supply chain management for nullifying waste. J. Clean. Prod. 2022, 339, 130513. [Google Scholar] [CrossRef]
- Garai, A.; Sarkar, B. Economically independent reverse logistics of customer-centric closed-loop supply chain for herbal medicines and biofuel. J. Clean. Prod. 2022, 334, 129977. [Google Scholar] [CrossRef]
- Sarkar, B.; Ullah, M.; Sarkar, M. Environmental and economic sustainability through innovative green products by remanufacturing. J. Clean. Prod. 2022, 332, 129813. [Google Scholar] [CrossRef]
- Sarkar, B.; Mridha, B.; Pareek, S. A sustainable smart multi-type biofuel manufacturing with the optimum energy utilization under flexible production. J. Clean. Prod. 2022, 332, 129869. [Google Scholar] [CrossRef]
- Sánchez-Rivero, M.; Rodríguez-Rangel, M.; Fernández-Torres, Y. The Identification of Factors Determining the Probability of Practicing Inland Water Tourism Through Logistic Regression Models: The Case of Extremadura, Spain. Water 2020, 12, 1664. [Google Scholar] [CrossRef]
- Tessema, G.A.; van der Borg, J.; Van Rompaey, A.; Van Passel, S.; Adgo, E.; Minale, A.S.; Asrese, K.; Frankl, A.; Poesen, J. Benefit Segmentation of Tourists to Geosites and Its Implications for Sustainable Development of Geotourism in the Southern Lake Tana Region, Ethiopia. Sustainability 2022, 14, 3411. [Google Scholar] [CrossRef]
- Wang, X.; Choi, T.M.; Liu, H.; Yue, X. Novel ant colony optimization methods for simplifying solution construction in vehicle routing problems. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3132–3141. [Google Scholar] [CrossRef]
- Malyan, S.K.; Singh, O.; Kumar, A.; Anand, G.; Singh, R.; Singh, S.; Yu, Z.; Kumar, J.; Fagodiya, R.K.; Kumar, A. Greenhouse Gases Trade-Off from Ponds: An Overview of Emission Process and Their Driving Factors. Water 2022, 14, 970. [Google Scholar] [CrossRef]
- Yang, B.; Luan, X.; Zhang, Y. A pattern-based approach for matching nodes in heterogeneous urban road networks. Trans. GIS 2014, 18, 718–739. [Google Scholar] [CrossRef]
- Gwon, G.-P.; Hur, W.-S.; Kim, S.-W.; Seo, S.-W. Generation of a precise and efficient lane-level road map for intelligent vehicle systems. IEEE Trans. Veh. Technol. 2017, 66, 4517–4533. [Google Scholar] [CrossRef]
- Kang, S.; Lee, G.; Kim, J.; Park, D. Identifying the spatial structure of tourism attraction system in South Korea using GIS and network analysis: An application of anchor-point theory. J. Destin. Mark. Manag. 2018, 9, 358–370. [Google Scholar]
- Li, J.Q.; Zhou, K.; Zhang, L.; Zhang, W.B. A multimodal trip planning system incorporating the park-and-ride mode and real-time traffic and transit information. Proc. ITS World Congr. 2010, 25, 65–76. [Google Scholar]
- Ciesielski, K.C.; Falcao, A.X.; Miranda, P.A.V. Path-value functions for which Dijkstra’s Algorithm Returns Optimal Mapping. J. Math. Imaging Vis. 2018, 60, 1025–1036. [Google Scholar] [CrossRef]
- Ying, J.J.; Lu, E.H.; Kuo, W.; Tseng, V.S. Urban Point-of-interest Recommendation by Mining User Check-in Behaviors. In Proceedings of the ACM SIGKDD International Workshop on Urban Computing, Beijing, China, 12–16 August 2012; pp. 63–70. [Google Scholar]
- Kato, Y.; Yamamoto, K. A Sightseeing Spot Recommendation System That Takes into Account the Visiting Frequency of Users. ISPRS Int. J. Geo-Inf. 2020, 9, 411. [Google Scholar] [CrossRef]
- Renjith, S.; Sreekumar, A.; Jathavedan, M. An extensive study on the evolution of context-aware personalized travel recommender systems. Inform. Process. Manag. 2020, 57, 102078. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1.00 | 0.00 | 0.00 | 1.00 | 0.36 | 0.00 | 0.20 | 0.14 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.28 | 0.00 | 0.20 | 0.13 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.44 | 0.00 | 0.20 | 0.16 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.25 | 0.00 | 0.15 | 0.15 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.45 | 0.00 | 0.15 | 0.09 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.31 | 0.00 | 0.15 | 0.22 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.28 | 0.00 | 0.15 | 0.08 | |
| 1.00 | 0.00 | 1.00 | 0.00 | 0.68 | 0.50 | 0.20 | 0.06 | |
| 1.00 | 1.00 | 0.00 | 1.00 | 0.72 | 2.30 | 0.20 | 0.05 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.45 | 0.00 | 0.15 | 0.02 | |
| 1.00 | 0.00 | 1.00 | 0.00 | 0.62 | 0.00 | 0.15 | 0.08 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.56 | 0.00 | 0.10 | 0.06 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.38 | 0.00 | 0.15 | 0.33 | |
| 1.00 | 1.00 | 1.00 | 1.00 | 0.72 | 0.00 | 0.20 | 0.05 | |
| 1.00 | 1.00 | 1.00 | 1.00 | 0.70 | 0.00 | 0.20 | 0.06 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.55 | 0.00 | 0.15 | 0.13 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.30 | 0.00 | 0.20 | 0.10 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.30 | 0.00 | 0.20 | 0.14 | |
| 1.00 | 0.00 | 1.00 | 0.00 | 0.25 | 0.35 | 0.20 | 0.15 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.42 | 0.00 | 0.15 | 0.11 | |
| 1.00 | 0.00 | 0.00 | 0.00 | 0.46 | 0.00 | 0.15 | 0.03 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.52 | 0.00 | 0.20 | 0.15 | |
| 1.00 | 0.00 | 0.00 | 1.00 | 0.45 | 0.00 | 0.15 | 0.04 | |
| 1.00 | 1.00 | 0.00 | 1.00 | 0.28 | 0.00 | 0.15 | 0.14 |
| 0.6015 | 0.5970 | 0.5812 | 0.6138 | 0.5773 | 0.6070 | |
| 0.6029 | 1.4168 | 2.4434 | 0.5972 | 1.3556 | 0.6306 | |
| 0.6529 | 1.3824 | 1.3784 | 0.6124 | 0.5912 | 0.5895 | |
| 1.3778 | 0.5723 | 1.1301 | 0.6029 | 0.5892 | 1.1488 |
| Center Point | Cluster Output Result | |
|---|---|---|
| , | : , , , , , , , , , , , | |
| : , , , , , , , , , , , | ||
| , , | : , , , , , , , | |
| : , , , , , , , , , , | ||
| : , , , , | ||
| , , , | : , , , , , , , | |
| : , , | ||
| : , , , , | ||
| : , , , , , , , | ||
| , , , , | : | |
| : , , | ||
| : , , | ||
| : , , , , , , , | ||
| : , , , , , , , , |
| 0.2823 | 0.3490 | 0.2317 | 0.3808 | 0.1749 | 0.3640 | 0.3298 | 1.5042 | |
| 2.5119 | 0.1513 | 1.4166 | 0.0877 | 0.3966 | 1.4211 | 1.4199 | 0.1393 | |
| 0.3202 | 0.3348 | 1.5067 | 0.2110 | 1.0102 | 0.1772 | 0.1552 | 1.0592 |
| PRA | 1.418 | 2.620 | 2.955 | 1.300 | 1.497 | 9.791 | |
| TCA | 1.497 | 3.034 | 3.054 | 1.399 | 1.576 | 10.559 | |
| GDA | 1.556 | 2.817 | 3.014 | 1.615 | 1.655 | 10.658 | |
| PRA | 1.418 | 2.620 | 2.955 | 2.600 | 5.516 | 15.110 | |
| TCA | 1.497 | 3.034 | 3.054 | 2.660 | 5.634 | 15.878 | |
| GDA | 1.556 | 2.817 | 3.014 | 2.955 | 5.989 | 16.331 | |
| PRA | 1.418 | 2.620 | 1.675 | 5.595 | 5.516 | 16.824 | |
| TCA | 1.497 | 3.034 | 1.832 | 5.930 | 5.634 | 17.927 | |
| GDA | 1.556 | 2.817 | 2.206 | 5.693 | 5.989 | 18.262 | |
| PRA | 1.418 | 2.620 | 2.226 | 3.054 | 5.595 | 14.913 | |
| TCA | 1.497 | 3.034 | 2.285 | 3.369 | 6.186 | 16.371 | |
| GDA | 1.556 | 2.817 | 2.305 | 3.172 | 5.930 | 15.780 | |
| PRA | 1.418 | 2.620 | 1.675 | 5.595 | 3.960 | 15.268 | |
| TCA | 1.497 | 3.034 | 1.832 | 5.930 | 4.630 | 16.922 | |
| GDA | 1.556 | 2.817 | 2.206 | 5.693 | 4.117 | 16.390 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Zhang, D.; Tian, J.; Su, M. Low-Carbon Tour Route Algorithm of Urban Scenic Water Spots Based on an Improved DIANA Clustering Model. Water 2022, 14, 1361. https://doi.org/10.3390/w14091361
Zhou X, Zhang D, Tian J, Su M. Low-Carbon Tour Route Algorithm of Urban Scenic Water Spots Based on an Improved DIANA Clustering Model. Water. 2022; 14(9):1361. https://doi.org/10.3390/w14091361
Chicago/Turabian StyleZhou, Xiao, De Zhang, Jiangpeng Tian, and Mingzhan Su. 2022. "Low-Carbon Tour Route Algorithm of Urban Scenic Water Spots Based on an Improved DIANA Clustering Model" Water 14, no. 9: 1361. https://doi.org/10.3390/w14091361
APA StyleZhou, X., Zhang, D., Tian, J., & Su, M. (2022). Low-Carbon Tour Route Algorithm of Urban Scenic Water Spots Based on an Improved DIANA Clustering Model. Water, 14(9), 1361. https://doi.org/10.3390/w14091361