
A Review of Hydrodynamic and Machine Learning Approaches for Flood Inundation Modeling

 ,
,
Abstract
:1. Introduction
2. Overview of Methods
2.1. Hydrodynamic Models
2.2. Machine Learning Approaches
2.2.1. Classification and Regression
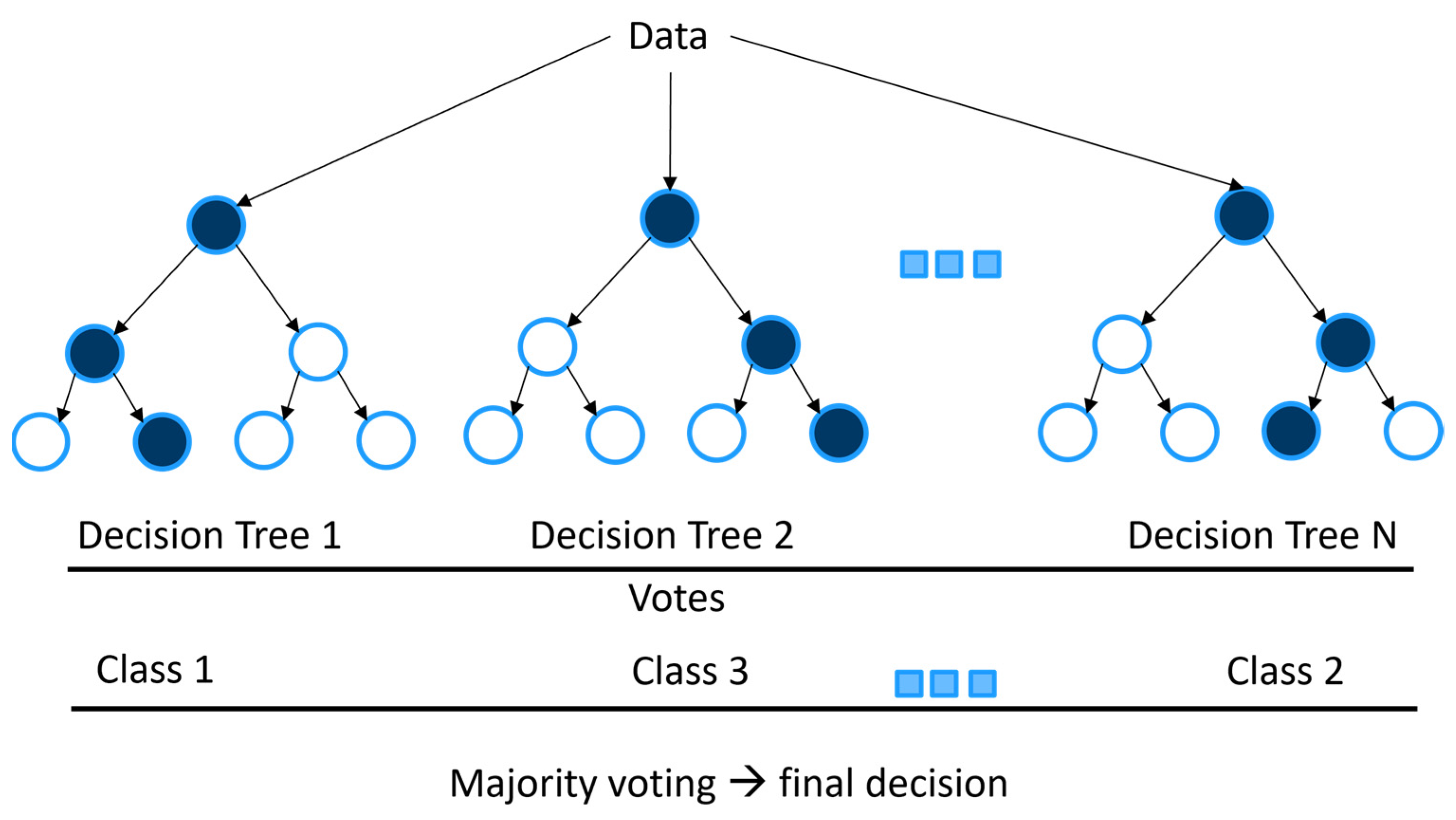
2.2.2. Traditional Machine Learning Models
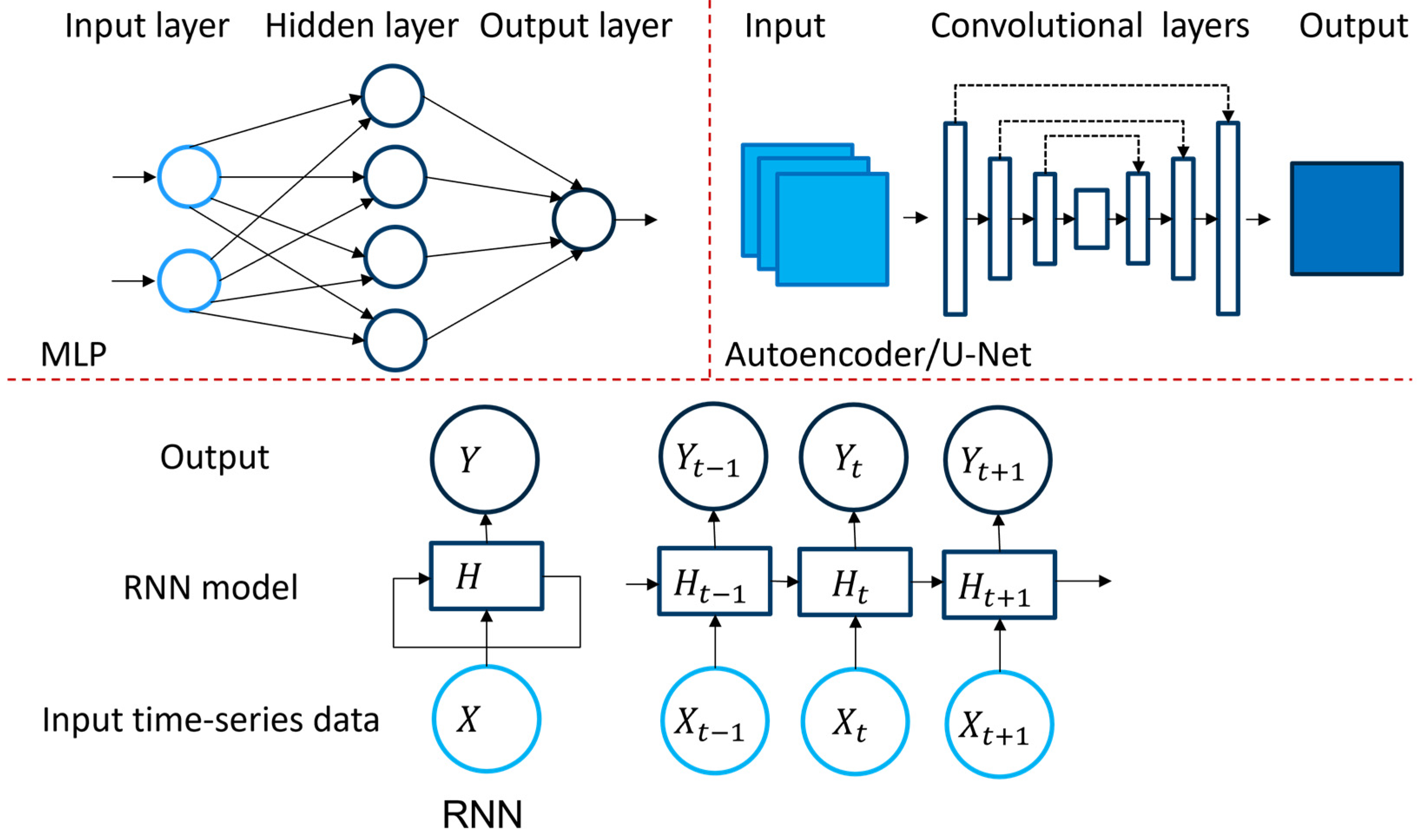
2.2.3. Deep Learning Models
3. Application of Machine Learning for Flood Inundation Modeling
3.1. Traditional Machine Learning Approaches
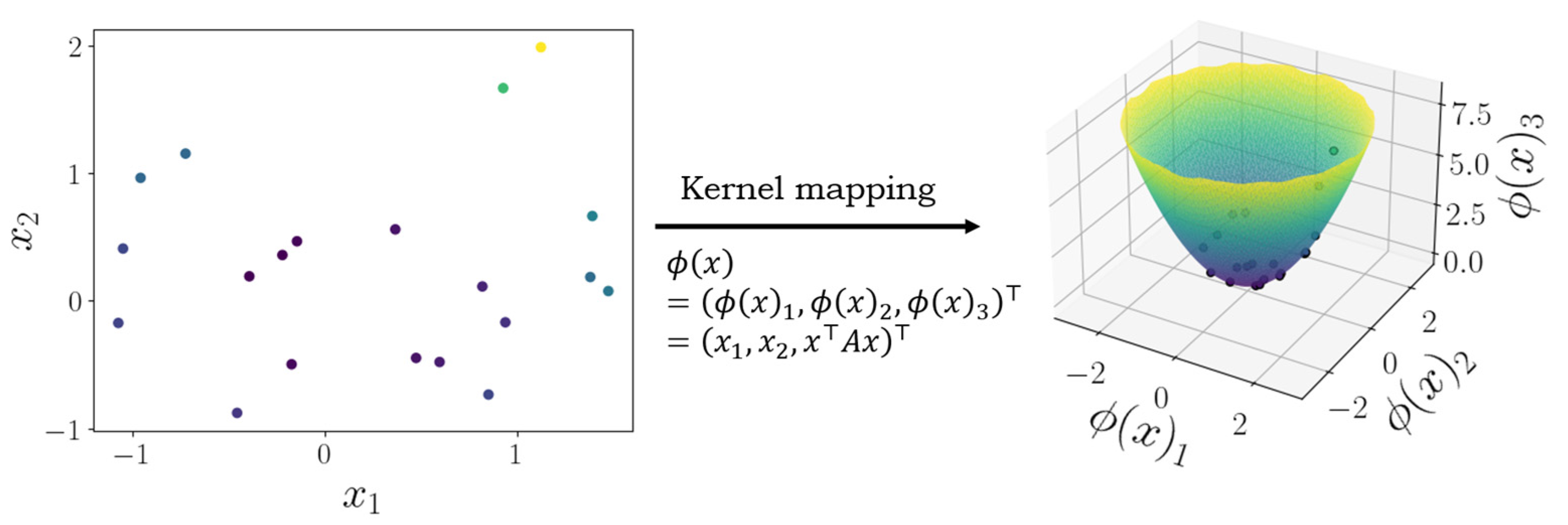
3.1.1. Classification

{kind=link}
{kind=link}
{kind=link}
| Authors | Publication Year | Application | Approach |
|---|---|---|---|
| Avand et al. [48] | 2022 | Effects of DEM resolution | RF, MLP, and GLM |
| Yan et al. [53] | 2021 | Estimating flow depth | MGGP |
| El-Hedad et al. [47] | 2021 | Flood risk assessment | BRT, FDA, GLM, MDA |
| Madhuri et al. [49] | 2021 | Flood risk assessment | Logistic Regression, SVM, KNN |
| Ma et al. [51] | 2021 | Flood risk assessment | XGBoost, LSSVM |
| Hou et al. [54] | 2021 | Urban flooding | RF, KNN |
| Yuan et al. [55] | 2021 | Road flooding | RF, AdaBoost |
| Talukdar et al. [50] | 2021 | Wetland inundation | RF, SVM, MLP |
| Karimi et al. [52] | 2019 | Wetland inundation | RF |
3.1.2. Regression
3.2. Deep Learning Approaches
3.2.1. Multilayer Perceptron (MLP)
3.2.2. Convolutional Neural Networks
3.2.3. Autoencoder Approaches
3.2.4. Adversarial Approaches
3.2.5. Spatio-Temporal Analysis Approaches
| Authors | Publication Year | Application | Approach |
|---|---|---|---|
| Guo et al. [66] | 2021 | Urban flood emulation | Autoencoder |
| Löwe et al. [64] | 2021 | Urban flood depth (pluvial) | U-Net |
| Hosseiny [63] | 2021 | Flood depth | U-Net |
| Hosseiny et al. [59] | 2020 | Flood depth | MLP & RF |
| Wei [69] | 2020 | Flood depth | LSTM |
| Zhou et al. [19] | 2021 | Flood inundation | LSTM |
| Zhu et al. [61] | 2021 | Flood Inundation | MLP |
| Hofman et al. [67] | 2021 | Flood inundation (pluvial) | GAN |
| Tamiru and Wagari [57] | 2021 | Flood inundation | MLP & HEC-RAS [58] |
| Chu et al. [60] | 2020 | Flood inundation | GRNN |
| Kabir et al. [62] | 2020 | Flood inundation (fluvial) | 1-D CNN & SVR |
| Tsakiri et al. [70] | 2018 | Flood inundation | Linear regression, MLP |
| Berkhahn et al. [56] | 2019 | Flood inundation (pluvial) | MLP |
3.3. Datasets
4. Strength and Limitations of ML/DL Models
4.1. Strength
4.2. Limitations and Open Research Challenges
4.2.1. Generalizability
4.2.2. Dataset
4.2.3. Embedding Expert Knowledge
4.2.4. Application of Graph Neural Network and Neural Operators
4.2.5. Explainability
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclatures
| AdaBoost | Adaptive Boosting |
| ANN | Artificial neural network |
| ASTER | Advanced Space-borne Thermal Emission and Reflection Radiometer |
| BRT | Boosted regression tree |
| CNN | Convolutional neural network |
| DL | Deep learning |
| FDA | Functional data analysis |
| FPM | Flood probability map |
| GAN | Generative adversarial network |
| GLM | Generalized linear models |
| GPU | Graphics processing unit |
| GRNN | Generalized regression neural network |
| GRU | Gated recurrent unit |
| HD | Hydrodynamic |
| HEC-RAS | Hydrological Engineering Center—River Analysis System |
| iRIC | International River Interface Cooperative |
| KNN | k-nearest neighbour algorithm |
| KRR | Kernel ridge regression |
| LSSVM | Least squares support vector machine |
| LSTM | Long short-term memory |
| MAE | Mean absolute error |
| MDA | Multivariate discriminant analysis |
| MGGP | Multigene genetic programming |
| MIFNN | Multiple input functional neural network |
| ML | Machine learning |
| MLP | Multilayer perceptron |
| MLR | Multiple linear regression |
| MSE | Mean square error |
| NOAA | National Oceanic and Atmospheric Administration |
| OLS | Ordinary least squares |
| PCA | Principal component analysis |
| REG | Conventional regression |
| RF | Random Forest |
| RKHS | Reproducing Kernel Hilbert Space |
| RMSE | Root mean square error |
| RNN | Recurrent neural network |
| SGD | Stochastic gradient descent |
| SNN | Sequential neural network |
| SVM | Support vector machine |
| SVR | Support vector regression |
| USGS | United States Geological Survey |
| XGBoost | Extreme gradient boosting |
References
- Bentivoglio, R.; Isufi, E.; Jonkman, S.N.; Taormina, R. Deep Learning Methods for Flood Mapping: A Review of Existing Applications and Future Research Directions. Hydrol. Earth Syst. Sci. Discuss. 2022, 26, 4345–4378. [Google Scholar] [CrossRef]
- Sit, M.; Demiray, B.Z.; Xiang, Z.; Ewing, G.J.; Sermet, Y.; Demir, I. A comprehensive review of deep learning applications in hydrology and water resources. Water Sci. Technol. 2020, 82, 2635–2670. [Google Scholar] [CrossRef]
- Mudashiru, R.B.; Sabtu, N.; Abustan, I.; Waheed, B. Flood Hazard Mapping Methods: A Review. J. Hydrol. 2021, 603, 126846. [Google Scholar] [CrossRef]
- Ghorpade, P.; Gadge, A.; Lende, A.; Chordiya, H.; Gosavi, G.; Mishra, A.; Hooli, B.; Ingle, Y.S.; Shaikh, N. Flood Forecasting Using Machine Learning: A Review. In Proceedings of the 2021 8th International Conference on Smart Computing and Communications (ICSCC), Kochi, India, 1–3 July 2021; pp. 32–36. [Google Scholar]
- Mosavi, A.; Ozturk, P.; Chau, K.w. Flood prediction using machine learning models: Literature review. Water 2018, 10, 1536. [Google Scholar] [CrossRef]
- Teng, J.; Jakeman, A.J.; Vaze, J.; Croke, B.F.; Dutta, D.; Kim, S. Flood inundation modelling: A review of methods, recent advances and uncertainty analysis. Environ. Model. Softw. 2017, 90, 201–216. [Google Scholar] [CrossRef]
- Bulti, D.T.; Abebe, B.G. A review of flood modeling methods for urban pluvial flood application. Model. Earth Syst. Environ. 2020, 6, 1293–1302. [Google Scholar] [CrossRef]
- Liu, Q.; Qin, Y.; Zhang, Y.; Li, Z. A coupled 1D–2D hydrodynamic model for flood simulation in flood detention basin. Nat. Hazards 2015, 75, 1303–1325. [Google Scholar] [CrossRef]
- Horritt, M.; Bates, P. Evaluation of 1D and 2D numerical models for predicting river flood inundation. J. Hydrol. 2002, 268, 87–99. [Google Scholar] [CrossRef]
- Leandro, J.; Chen, A.S.; Djordjevic, S.; Savic, D.A. Comparison of 1D/1D and 1D/2D coupled (sewer/surface) hydraulic models for urban flood simulation. J. Hydraul. Eng. 2009, 135, 495–504. [Google Scholar] [CrossRef]
- Bomers, A.; Schielen, R.M.J.; Hulscher, S.J. The influence of grid shape and grid size on hydraulic river modelling performance. Environ. Fluid Mech. 2019, 19, 1273–1294. [Google Scholar] [CrossRef] [Green Version]
- Mackay, C.; Suter, S.; Albert, N.; Morton, S.; Yamagata, K. Large scale flexible mesh 2D modelling of the Lower Namoi Valley. In Floodplain Management Association National Conference; Floodplain Management Australia: Brisbane, Australia, 2015; pp. 1–14. [Google Scholar]
- Noh, S.J.; Lee, J.H.; Lee, S.; Kawaike, K.; Seo, D.J. Hyper-resolution 1D-2D urban flood modelling using LiDAR data and hybrid parallelization. Environ. Model. Softw. 2018, 103, 131–145. [Google Scholar] [CrossRef]
- Kim, B.; Sanders, B.F.; Schubert, J.E.; Famiglietti, J.S. Mesh type tradeoffs in 2D hydrodynamic modeling of flooding with a Godunov-based flow solver. Adv. Water Resour. 2014, 68, 42–61. [Google Scholar] [CrossRef]
- Symonds, A.M.; Vijverberg, T.; Post, S.; Van Der Spek, B.J.; Henrotte, J.; Sokolewicz, M. Comparison between Mike 21 FM, Delft3D and Delft3D FM flow models of western port bay, Australia. Coast. Eng. 2016, 2, 1–12. [Google Scholar] [CrossRef]
- Teng, J.; Vaze, J.; Kim, S.; Dutta, D.; Jakeman, A.; Croke, B. Enhancing the capability of a simple, computationally efficient, conceptual flood inundation model in hydrologically complex terrain. Water Resour. Manag. 2019, 33, 831–845. [Google Scholar] [CrossRef]
- Hoch, J.M.; van Beek, R.; Winsemius, H.C.; Bierkens, M.F. Benchmarking flexible meshes and regular grids for large-scale fluvial inundation modelling. Adv. Water Resour. 2018, 121, 350–360. [Google Scholar] [CrossRef]
- Morales-Hernández, M.; Sharif, M.B.; Kalyanapu, A.; Ghafoor, S.K.; Dullo, T.T.; Gangrade, S.; Kao, S.C.; Norman, M.R.; Evans, K.J. TRITON: A Multi-GPU open source 2D hydrodynamic flood model. Environ. Model. Softw. 2021, 141, 105034. [Google Scholar] [CrossRef]
- Zhou, Y.; Wu, W.; Nathan, R.; Wang, Q.J. A rapid flood inundation modelling framework using deep learning with spatial reduction and reconstruction. Environ. Model. Softw. 2021, 143, 105112. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Faisal, A.A.; Ong, C.S. Mathematics for Machine Learning; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Schölkopf, B.; Herbrich, R.; Smola, A.J. A Generalized Representer Theorem. In International Conference on Computational Learning Theory; Springer: Berlin/Heidelberg, Germany, 2001; pp. 416–426. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1997, 9, 155–161. [Google Scholar]
- Saunders, C.; Gammerman, A.; Vovk, V. Ridge regression learning algorithm in dual variables. In Proceedings of the 15th International Conference on Machine Learning, San Francisco, CA, USA, 24–27 July 1998. [Google Scholar]
- Schölkopf, B.; Smola, A.; Müller, K.R. Kernel principal component analysis. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 1997; pp. 583–588. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- McCullagh, P.; Nelder, J. Generalized Linear Models. In Chapman & Hall/CRC Monographs on Statistics & Applied Probability, 2nd ed.; Taylor & Francis: Oxford, UK, 1989. [Google Scholar]
- Banerjee, A.; Merugu, S.; Dhillon, I.S.; Ghosh, J. Clustering with Bregman Divergences. J. Mach. Learn. Res. 2005, 6, 1705–1749. [Google Scholar]
- Canu, S.; Smola, A. Kernel methods and the exponential family. Neurocomputing 2006, 69, 714–720. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Wiley: Wadsworth, OH, USA, 1984. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 20, 1189–1232. [Google Scholar] [CrossRef]
- Ramsay, J.; Dalzell, C. Some tools for functional data analysis. J. R. Stat. Soc. Ser. B 1991, 53, 539–561. [Google Scholar] [CrossRef]
- Hart, P.E.; Stork, D.G.; Duda, R.O. Pattern Classification; Wiley: Hoboken, NJ, USA, 2000. [Google Scholar]
- Gandomi, A.H.; Alavi, A.H. A new multi-gene genetic programming approach to nonlinear system modeling. Part I: Materials and structural engineering problems. Neural Comput. Appl. 2012, 21, 171–187. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Flat minima. Neural Comput. 1997, 9, 1–42. [Google Scholar] [CrossRef]
- Dinh, L.; Pascanu, R.; Bengio, S.; Bengio, Y. Sharp minima can generalize for deep nets. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1019–1028. [Google Scholar]
- Belkin, M.; Hsu, D.; Ma, S.; Mandal, S. Reconciling modern machine-learning practice and the classical bias–variance trade-off. Proc. Natl. Acad. Sci. USA 2019, 116, 15849–15854. [Google Scholar] [CrossRef]
- Bartlett, P.L.; Long, P.M.; Lugosi, G.; Tsigler, A. Benign overfitting in linear regression. Proc. Natl. Acad. Sci. USA 2020, 117, 30063–30070. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- El-Haddad, B.A.; Youssef, A.M.; Pourghasemi, H.R.; Pradhan, B.; El-Shater, A.H.; El-Khashab, M.H. Flood susceptibility prediction using four machine learning techniques and comparison of their performance at Wadi Qena Basin, Egypt. Nat. Hazards 2021, 105, 83–114. [Google Scholar] [CrossRef]
- Avand, M.; Kuriqi, A.; Khazaei, M.; Ghorbanzadeh, O. DEM resolution effects on machine learning performance for flood probability mapping. J. Hydro-Environ. Res. 2022, 40, 1–16. [Google Scholar] [CrossRef]
- Madhuri, R.; Sistla, S.; Srinivasa Raju, K. Application of machine learning algorithms for flood susceptibility assessment and risk management. J. Water Clim. Change 2021, 12, 2608–2623. [Google Scholar] [CrossRef]
- Talukdar, S.; Mankotia, S.; Shamimuzzaman, M.; Mahato, S. Wetland-inundated area modeling and monitoring using supervised and machine learning classifiers. Adv. Remote Sens. Nat. Resour. Monit. 2021, 346–365. [Google Scholar]
- Ma, M.; Zhao, G.; He, B.; Li, Q.; Dong, H.; Wang, S.; Wang, Z. XGBoost-based method for flash flood risk assessment. J. Hydrol. 2021, 598, 126382. [Google Scholar] [CrossRef]
- Karimi, S.S.; Saintilan, N.; Wen, L.; Valavi, R. Application of machine learning to model wetland inundation patterns across a large semiarid floodplain. Water Resour. Res. 2019, 55, 8765–8778. [Google Scholar] [CrossRef]
- Yan, X.; Mohammadian, A.; Khelifa, A. Modeling spatial distribution of flow depth in fluvial systems using a hybrid two-dimensional hydraulic-multigene genetic programming approach. J. Hydrol. 2021, 600, 126517. [Google Scholar] [CrossRef]
- Hou, J.; Zhou, N.; Chen, G.; Huang, M.; Bai, G. Rapid forecasting of urban flood inundation using multiple machine learning models. Nat. Hazards 2021, 108, 2335–2356. [Google Scholar] [CrossRef]
- Yuan, F.; Mobley, W.; Farahmand, H.; Xu, Y.; Blessing, R.; Dong, S.; Mostafavi, A.; Brody, S.D. Predicting Road Flooding Risk with Machine Learning Approaches Using Crowdsourced Reports and Fine-grained Traffic Data. arXiv 2021, arXiv:2108.13265. [Google Scholar]
- Berkhahn, S.; Fuchs, L.; Neuweiler, I. An ensemble neural network model for real-time prediction of urban floods. J. Hydrol. 2019, 575, 743–754. [Google Scholar] [CrossRef]
- Tamiru, H.; Wagari, M. Machine-learning and HEC-RAS integrated models for flood inundation mapping in Baro River Basin, Ethiopia. Model. Earth Syst. Environ. 2021, 8, 2291–2303. [Google Scholar] [CrossRef]
- Brunner, G.W. HEC-RAS River Analysis System, 2D Modeling Users’ Manual. U.S. Army Corps of Engineer, Institute for Water Resource, Hydrologic Engineering Center. 2016. Available online: https://www.hec.usace.army.mil/software/hec-ras/documentation/HEC-RAS%205.0%202D%20Modeling%20Users%20Manual.pdf (accessed on 28 November 2022).
- Hosseiny, H.; Nazari, F.; Smith, V.; Nataraj, C. A framework for modeling flood depth using a hybrid of hydraulics and machine learning. Sci. Rep. 2020, 10, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Chu, H.; Wu, W.; Wang, Q.; Nathan, R.; Wei, J. An ANN-based emulation modelling framework for flood inundation modelling: Application, challenges and future directions. Environ. Model. Softw. 2020, 124, 104587. [Google Scholar] [CrossRef]
- Zhu, H.; Leandro, J.; Lin, Q. Optimization of Artificial Neural Network (ANN) for Maximum Flood Inundation Forecasts. Water 2021, 13, 2252. [Google Scholar] [CrossRef]
- Kabir, S.; Patidar, S.; Xia, X.; Liang, Q.; Neal, J.; Pender, G. A deep convolutional neural network model for rapid prediction of fluvial flood inundation. J. Hydrol. 2020, 590, 125481. [Google Scholar] [CrossRef]
- Hosseiny, H. A Deep Learning Model for Predicting River Flood Depth and Extent. Environ. Model. Softw. 2021, 145, 105186. [Google Scholar] [CrossRef]
- Löwe, R.; Böhm, J.; Jensen, D.G.; Leandro, J.; Rasmussen, S.H. U-FLOOD–Topographic deep learning for predicting urban pluvial flood water depth. J. Hydrol. 2021, 603, 126898. [Google Scholar] [CrossRef]
- Dodge, Y. The Concise Encyclopedia of Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Guo, Z.; Leitao, J.P.; Simões, N.E.; Moosavi, V. Data-driven flood emulation: Speeding up urban flood predictions by deep convolutional neural networks. J. Flood Risk Manag. 2021, 14, e12684. [Google Scholar] [CrossRef]
- Hofmann, J.; Schüttrumpf, H. floodGAN: Using Deep Adversarial Learning to Predict Pluvial Flooding in Real Time. Water 2021, 13, 2255. [Google Scholar] [CrossRef]
- Jamali, B.; Bach, P.M.; Cunningham, L.; Deletic, A. A Cellular Automata fast flood evaluation (CA-ffé) model. Water Resour. Res. 2019, 55, 4936–4953. [Google Scholar] [CrossRef]
- Wei, C.C. Comparison of river basin water level forecasting methods: Sequential neural networks and multiple-input functional neural networks. Remote Sens. 2020, 12, 4172. [Google Scholar] [CrossRef]
- Tsakiri, K.; Marsellos, A.; Kapetanakis, S. Artificial neural network and multiple linear regression for flood prediction in Mohawk River, New York. Water 2018, 10, 1158. [Google Scholar] [CrossRef]
- Galland, J.C.; Goutal, N.; Hervouet, J.M. TELEMAC: A new numerical model for solving shallow water equations. Adv. Water Resour. 1991, 14, 138–148. [Google Scholar] [CrossRef]
- Darwish, N.; Kaiser, M.; Koch, M.; Gaber, A. Assessing the Accuracy of ALOS/PALSAR-2 and Sentinel-1 Radar Images in Estimating the Land Subsidence of Coastal Areas: A Case Study in Alexandria City, Egypt. Remote Sens. 2021, 13, 1838. [Google Scholar] [CrossRef]
- ASTER Global Digital Elevation Map. Available online: https://asterweb.jpl.nasa.gov/gdem.asp (accessed on 21 September 2022).
- USGS ASTER Data. Available online: https://earthexplorer.usgs.gov/ (accessed on 25 May 2022).
- GEE Google Earth Engine. Available online: https://earthengine.google.com/ (accessed on 25 May 2022).
- HYSTEM-EXTRAN. Available online: https://itwh.de/en/software-products/desktop/hystem-extran/ (accessed on 26 September 2022).
- Huxley, C.; Syme, B. TUFLOW GPU-best practice advice for hydrologic and hydraulic model simulations. In Proceedings of the 37th Hydrology & Water Resources Symposium, Queenstown, New Zealand, 28 November–2 December 2016; pp. 195–203. [Google Scholar]
- DHI. MIKE 21 Flow Model FM: Hydrodynamic Module, Denmark. 2017. Available online: https://manuals.mikepoweredbydhi.help/2019/Coast_and_Sea/MIKE_FM_HD_2D.pdf (accessed on 12 January 2022).
- Guidolin, M.; Chen, A.S.; Ghimire, B.; Keedwell, E.C.; Djordjević, S.; Savić, D.A. A weighted cellular automata 2D inundation model for rapid flood analysis. Environ. Model. Softw. 2016, 84, 378–394. [Google Scholar] [CrossRef] [Green Version]
- Innovyze, InfoWorks ICM. Available online: http://www.innovyze.com/products/infoworks_icm (accessed on 24 May 2022).
- Nelson, J.M.; Shimizu, Y.; Abe, T.; Asahi, K.; Gamou, M.; Inoue, T.; Iwasaki, T.; Kakinuma, T.; Kawamura, S.; Kimura, I.; et al. The international river interface cooperative: Public domain flow and morphodynamics software for education and applications. Adv. Water Resour. 2016, 93, 62–74. [Google Scholar] [CrossRef]
- Bates, P.; De Roo, A. A simple raster-based model for flood inundation simulation. J. Hydrol. 2000, 236, 54–77. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]



| Topic | Reference | ||||||
|---|---|---|---|---|---|---|---|
| [6] | [5] | [2] | [4] | [3] | [1] | Ours | |
| Physical based models | √ | √ | √ | ||||
| Machine learning models | √ | √ | √ | √ | |||
| Deep Learning models | √ | √ | √ | √ | |||
| Extension to real-time response | √ | √ | |||||
| Model interpretation methods | √ | ||||||
| Embedding expert knowledge | √ | ||||||
| Event & Location | Publicly Available | Coverage Data | Type (Real/Synthetic Events) | Data Quantity | Authors |
|---|---|---|---|---|---|
| Inundation, USA | Yes | 3.5 km | Syn | 2100 image | Hosseiny [63] |
| Urban flood, Unknown | No | 96,233 m2 | Syn, real | 9623 cells | Berkhahn et al. [56] |
| Flood inundation, AUS | No | 33,000 km2 | real | 19,448 grid cells | Chu et al. [60] |
| Flood, Ethiopia | Yes | 74,100 km2 | Syn, real | 10 years of data | Tamiru and Wagari [57] |
| Inundation, UK | Yes | 14.5 km2 | Syn, real | 581,061 cells | Kabir et al. [62] |
| Fluvial, Germany | No | 2 × 2 km2 | Syn | 901 samples | Hofman et al. [67] |
| Fluvial, Switzerland, Portugal | No | 10 km2 | Syn | 30,000 samples | Guo et al. [66] |
| Pluvial, Denmark | Yes | 194 km2 | Real | 53 train maps | Löwe et al. [64] |
| Flood, Iran | No | 2185 km2 | Real | 220 flood locations | Avand et al. [48] |
| Flood, Egypt | No | 14.5 km2 | Real | 342 flood locations | El-Haddad et al. [47] |
| Flood, India | No | 625 km2 | Real | 295 flood locations | Madhuri et al. [49] |
| Fluvial, Canada | No | 3.2 × 1.40 km2 | Syn, real | 340,000 | Yan et al. [53] |
| Fluvial, China | No | 2.43 km2 | Real | 180 rainfall events | Hou et al. [54] |
| Flood wetland, Bangladesh | No | 3669.58 km2 | Syn, real | 7 images | Talukdar et al. [50] |
| Flash flood, China | No | 390,000 km2 | Real | two sets of data, 129 counties | Ma et al. [51] |
| Flood plain inundation, AUS | No | 1200 km2 | Real | 10,000 points | Karimi et al. [52] |
| Flood hazard forecasting, USA | No | 240 km | Real | Discharge for 3 gauges for 2005–2013 | Tsakiri et al. [70] |
| Flood depth, Germany | No | 92.7 km2 | Syn, Real | 360 flood events | Zhu et al. [61] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karim, F.; Armin, M.A.; Ahmedt-Aristizabal, D.; Tychsen-Smith, L.; Petersson, L. A Review of Hydrodynamic and Machine Learning Approaches for Flood Inundation Modeling. Water 2023, 15, 566. https://doi.org/10.3390/w15030566
Karim F, Armin MA, Ahmedt-Aristizabal D, Tychsen-Smith L, Petersson L. A Review of Hydrodynamic and Machine Learning Approaches for Flood Inundation Modeling. Water. 2023; 15(3):566. https://doi.org/10.3390/w15030566
Chicago/Turabian StyleKarim, Fazlul, Mohammed Ali Armin, David Ahmedt-Aristizabal, Lachlan Tychsen-Smith, and Lars Petersson. 2023. "A Review of Hydrodynamic and Machine Learning Approaches for Flood Inundation Modeling" Water 15, no. 3: 566. https://doi.org/10.3390/w15030566
APA StyleKarim, F., Armin, M. A., Ahmedt-Aristizabal, D., Tychsen-Smith, L., & Petersson, L. (2023). A Review of Hydrodynamic and Machine Learning Approaches for Flood Inundation Modeling. Water, 15(3), 566. https://doi.org/10.3390/w15030566